transformer精简
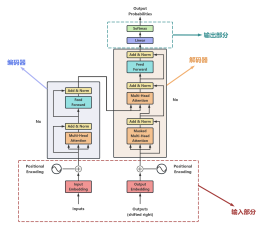
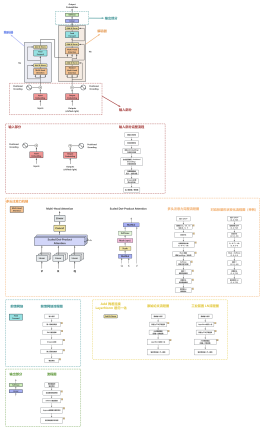
2022-03-26 13:41:37 12 举报Transformer是一种基于自注意力机制的深度学习模型,它在自然语言处理领域取得了巨大的成功。它的主要特点是能够并行处理输入序列的所有位置,从而大大提高了训练效率。此外,Transformer还引入了多头注意力机制和残差连接,进一步提高了模型的性能。然而,由于Transformer的复杂度较高,计算量较大,因此在实际应用中需要进行精简。这可以通过减少模型的层数、隐藏单元数或者使用更小的词嵌入等方式来实现。总之,Transformer是一种强大的深度学习模型,但在使用过程中需要根据具体任务进行适当的精简。
模板推荐
作者其他创作
大纲/内容




Collect

Collect
Collect

Collect
0 条评论
下一页