Replication
Write
数据库服务器
Front Server
ID%N=4
DB Slave
Data changes
随着业务规模的拓展,系统变得越来越复杂并且难以维护,开发效率越来越低,并且系统的资源消耗也越来越大,通过硬件提升性能的成本也越来越高。因此系统业务拆分不可避免。每一块业务都使用单独的数据库来进行存储,前端不同的业务访问不同的数据库,这样原本依赖单库的服务变成多个库同时承担压力,吞吐能力自然就提高了。业务拆分不仅提高了系统可拓展性,也带来了开发工作效率的提升。原来一次简单的修改,工程启动和部署可能都需要很长的时间,更别说开发测试了。随着系统的拆分,单个系统复杂度降低,减轻了应用多个分支开发带来的分支合并冲突解决的麻烦,不仅大大提高了开发测试效率,同时也提高了系统稳定性。 随着访问量的不断增加,拆分后的某个库压力越来越大,马上就要达到能力的瓶颈,数据库的架构不得不再次进行变更,这时可以使用数据库的复制策略来对系统进行拓展。通过数据库的复制策略,可将一台数据库服务器中的数据复制到其他数据库服务器上。当各台数据库服务器都包含相同数据时,前端应用通过访问数据库集群中任意一台服务器,都能够读取到相同的数据,这样每台服务器所需承担的负载就会大大降低,从而提高整个系统的承载能力,达到系统拓展的目的。 如下图所示,要实现数据库的复制,需要开启Master服务器端的Binary log。数据复制的过程实际上就是Slave从Master获取Binary log,然后再在本地镜像的执行日志的操作。由于复制过程是异步的,因此Master和Slave之间的数据有可能存在延迟现象,此时只能够保证数据最终的一致性。
Replay
Binary log
DB Master
Read
ID%N=5
分库策略
ID%N=0
Master
ID%N=1
Single_table
SQL Thread
ID%N=3
实际应用场景中,Master与Slave之间的复制架构有可能是这样的,如下图。前端服务器通过Master来执行数据写入的操作,数据的更新通过Binary log同步到Slave集群,而对于数据读取的请求,则交由Slave来处理,这样Slave集群可以分担数据库读的压力,并且读、写分离还保障了数据能够达到最终的一致性。一般而言,大多数站点的读数据库操作要比写数据库更为密集。如果读的压力较大,还可以通过新增Slave来进行系统的拓展,因此,Master-Slave架构能够显著地减轻单库读的压力。毕竟在大多数应用中,读的压力比写的压力大得多。
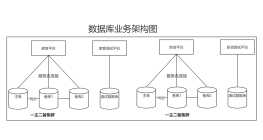
对于大型的互联网应用来说,数据库单表的记录行数可能达到千万级别甚至亿级,并且数据库面临着极高的并发访问。采用Master-Slave复制模式的DB架构,只能对数据库读进行拓展,而对数据库的写入操作还是集中在Master上,并且单个Master挂载的Slave也不可能无限制多,Slave的数量受到Master能力和负载的限制。因此,需要对数据库的吞吐能力进行进一步的拓展,以满足高并发访问与海量数据存储的需要。 对于访问极为频繁且数据量巨大的单表来说,我们首先要做的就是减少单表的记录条数,以便减少数据查询所需要的时间,提高数据库的吞吐,这就是所谓的分表。在分表之前,首先需要适当的分表策略,使得数据能够较为均衡的分布到多张表中,并且不影响正常的查询。具体策略就是用ID取余,然后根据结果操作对应表进行存储。 分表能够解决表单数据量过大带来的查询效率下降的问题,但是,却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库Master服务器无法承载写操作压力时,不管如何拓展Slave服务器,此时都没有意义了。此时需要对数据库进行拆分,这就是分库。如果更进一步提高性能的话,可以进行分库同时分表的策略,原理都是一样的。 这种策略虽然能够提高查询性能和并发处理性能,但也会带来一系列问题。比如原本跨表的事务上升为分布式事务;由于记录被切分到不同库与表,难以进行多表关联查询。
IO Thread
Multi DB
ID%N=2