失败记录
⑧ 补偿提交
Labs集群HDFS
通过FTP上传到Lab01
纳税人
HDFS路径:1. 清洗结果:hdfs:/user/yimr/YiMR/workflow/1106_719daede3fc5666fcd21e01a312901bf/10590_8cad76a95bd2757ee5d13a65cfb7dd40/output/20160413_05002. 统计结果hdfs:/user/yimr/YiMR/workflow/1106_719daede3fc5666fcd21e01a312901bf/10587_62156e279098a1ce69a9e580114bb841/output/20160413_0500数据处理周期:1小时文件名样例:part-00001文件内容样例(lab01):/home/work/ANHUI_DATA_PROCESS_SAMPLE/3_anhui_hdfs_process_output
STEP 3
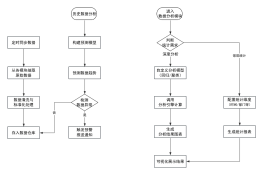
核心征管提交
申报征收应用
申报服务
End
①
公用分发库
④
申报提交
专用分发库
核心征管
流程规则服务
STEP MAIN
金税三期
安徽数据处理整体流程
安徽FTP数据源
超出重试限制
HDFS路径:1. 标签统计结果hdfs://hadoopmaster:21030/anhuiwap/fav-stat2. spider待抓取列表hdfs://hadoopmaster:21030/anhuiwap/to-spider3. 用户标签结果hdfs://hadoopmaster:21030/anhuiwap/userprofile4. 用户URL访问集hdfs://hadoopmaster:21030/anhuiwap/userurl数据处理周期:1天文件名样例:part-00001文件内容样例(lab01):/home/work/ANHUI_DATA_PROCESS_SAMPLE/7_labs_hdfs_spider_and_stat
Web/APP
③ 查询
已收妥
⑥ 申报提交阶段2(提交)
⑦ 补偿判断
STEP 6
STEP 1
状态锁定
申报失败
主体处理步骤:52步主体处理流程:具体处理流程见流程图数据处理周期:1天
征管提交服务
数据处理分类主体流程
失败
OGG
FTP地址:ftp://yanjiuyuan@192.168.50.249/http/all数据下载周期:1小时文件名样例:009_00_0002_201606021050_1.dat.gz文件内容样例(lab01):/home/work/ANHUI_DATA_PROCESS_SAMPLE/1_anhui_ftp_datasource_sample
HDFS路径:1. url分类结果hdfs://hadoopmaster:21030/anhuiwap/classified/20160603/06/src-feature-all2. proapp分类结果hdfs://hadoopmaster:21030/anhuiwap/classified/20160603/06/src-proapp-all3. 带抓取结果hdfs://hadoopmaster:21030/anhuiwap/classified/20160603/06/src-scrap-all数据处理周期:1天文件名样例:part-00001文件内容样例(lab01):/home/work/ANHUI_DATA_PROCESS_SAMPLE/6_labs_hdfs_clfprocess_output
⑤ 申报提交阶段1(暂存)
⑤ 申报提交
状态解锁
安徽集群清洗后结果
②
中间存储区
STEP 5
结果文件
补偿提交
STEP 7
重新申报
开始
⑥ 补偿
入库和服务
路径:1. 标签入库HBASE2. 喜好查询服务lab30:8002数据处理周期:1天文件名样例:HBase::user_profileSpark:: SparkServer文件内容样例(lab01):/home/work/ANHUI_DATA_PROCESS_SAMPLE/8_labs_hbase_userprofile
抓取和统计
HDFS路径:/user/yimr/YiMR/workflow/1106_719daede3fc5666fcd21e01a312901bf/10584_55f7645d714dc121bfc5467d90c06292/output/20160418_1000/数据处理周期:1小时文件名样例:009_00_0002_201606021050_1.dat.gz文件内容样例(lab01):/home/work/ANHUI_DATA_PROCESS_SAMPLE/2_anhui_hdfs_process_input
申报成功
STEP 2
Start
STEP 4
重试
FS路径:1.清洗结果lab01:/home/work/var/upload/anhui/clean-result2. 统计结果lab01:/home/work/var/upload/anhui/stat-result数据处理周期:1小时文件名样例:part-merge-1.gz文件内容样例(lab01):/home/work/ANHUI_DATA_PROCESS_SAMPLE/4_labs_upload_data_sample
时序队列拉取
成功
超时
STEP 8
HDFS路径:hdfs:/user/yimr/YiMR/datasource/84_2fca26d65fe14eeec93245ca625036f9/output数据处理周期:1小时文件名样例:part-merge-1.gz文件内容样例(lab01):/home/work/ANHUI_DATA_PROCESS_SAMPLE/5_labs_hdfs_clfprocess_input
安徽集群数据清洗和统计