hive工作原理
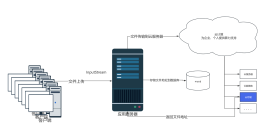
2016-11-25 14:18:35 0 举报Hive是基于Hadoop的一个数据仓库工具,可以将复杂的MapReduce任务转化为简单的SQL查询语句,从而实现数据的快速查询和分析。其工作原理是将HiveQL语句解析成一系列MapReduce任务,并将这些任务提交给Hadoop集群执行。在执行过程中,Hive会将原始数据存储在HDFS中,并根据用户指定的表结构和分区方式进行组织和管理。同时,Hive还提供了一些优化机制,如数据压缩、内存缓存等,以提高查询性能和效率。总之,Hive通过将大数据处理与SQL查询相结合的方式,为用户提供了一种简单易用、高效灵活的大数据分析工具。
模板推荐
作者其他创作
大纲/内容







0 条评论
下一页