Leader
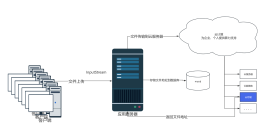
将消息写入本地Log
ACK
Follower从Leader那里Pull数据
发送请求寻找PartitionLeader
Leader收到ISR系统中所有Follower的ACK包后认为该消息已经commit了
Producer
Follower将数据写入本地Log
Topic
Replication机制的引入: 在没有Replication的情况下,一旦某机器宕机或者某个Broker停止工作则会造成整个系统的可用性降低。随着集群规模的增加,整个集群中出现该类异常的几率大大增加,因此对于生产系统而言Replication机制的引入非常重要;引入replica,需要保证同一个Partition的多个Replica之间的数据一致性和有序性。1. Kafka尽量将所有Partition均匀分配到整个集群上。典型的部署方式是一个Topic的Partition数量等于Broker的数量。2. 同时为了提高Kafka的容错恩呢管理,需要将同一个Partition的Replica分散到不同的机器。
Partition 1
Propagate消息时序图:
Replica 3
Replica N
(N =1)
Replica 2
向Topic发送消息时序图
Follower
Push数据到Partition的Replica 3
返回Partition的LeaderReplica 3
Partition
Partition N
ISR列表
ZooKeeper
向Partition的LeaderPush消息
实际方案:
Follower收到消息就立即返回ACK
理论方案:
从Leader执行拷贝sync任务
Replica 1
选 Replica 3为Leader
算法
Replica 3就是被选出和producer及consumer进行交互的partition主分区
Partition 2