继承
抢锁
NewOutputCollector
datanode3
data4
client
1
mapper
Mapper
溢写时,则锁定已缓冲的数据区,在空的数据区中间相反方向划一刀,分别存取索引跟数据
持有分区器
可有可无
包装
Container
分区数3
持有
拉取数据跟初始化一堆对象
mapper.run()
shuffle数据,这里也会进行combine
索引
数据同步
使用journal日志是为了保证数据在异常宕机时不会丢失。怎么做到的?使用快照(FsImage)跟EditsLog。
map输入文件目录reduce输出文件目录
为了让reduce拿到的数据是内部有序的,降低磁盘读io
Job Submission
new Job
读取配置
zkfc1
input.initialize()
写到缓冲区buffer
context.write()
runNewReducer()
分别为:1、patition 分区2、keyStart key起始位置3、valueStart value起始位置4、valueLength value长度
journal集群,一般3+奇数台
探测
Input PathOutput Path
data5
每个文件会被分成多个块Block,每个块会有多个副本,分别存在不同的datanode上
ReduceTask
data3
Task
达到缓存限制(默认80%),溢写
使用journal
Reducer
input
combine
Partitioner
write()
MapReduce
监听
nextKeyValue()
对溢写数据进行排序
上报块信息
run()
p3
3
根据metadata数据去datanode取数据
内存buffer
拉取
data2
p1
优化点
files metadata
遍历input目录所有文件,获取到文件的块信息,与配置文件设置的minSplits、maxSplits信息进行计算出分区数,也就是map的数量,默认为块block个数
reduce
data1
MapOutputBuffer
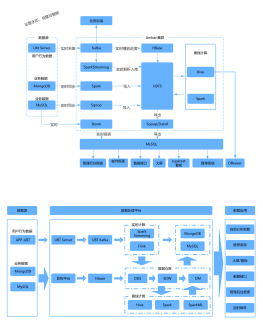
源码执行过程
这里分区有序,且分区内按key也有序
Resource Request
因为这个缓冲区是环形的下一轮溢写会在头尾之间找到合适的位置再切一刀,重复上述步骤
也就是说,每个块读取到最后的时候,都会去下一个块读取完整的一行回来;即使这个块的最后一个字符是\,也会去下一个块读取一行。
zookeeper集群一般3+奇数台
p2
App mstr
MapReduce Status
获取文件metadata数据
MapReduce配置很灵活几乎所有的步骤都能通过配置进行自定义,扩展性极方便。
自己实现的Mapper。可以在run前跟后做些初始化跟清理工作,如:输入原是数据库
每个索引大小固定占用16字节,分为4个int类型
发生溢写
溢写完成
写入文件
MapperTask
2
NodeManager
文合并成一个大文件
MasterNameNode
索引固定大小,排序时只需要排分区,然后按分区取出key再排序
HDFS架构
MapTask
上报node信息
merge
map
zkfc2
计算splits数
每个zkfc都会监听自己的namenode。这里会有几种不同情况的异常:1、网络情况都正常,只有master namenode挂掉。这时zkfc1会通知另一台zkfc2升级为active,然后zkfc2将second namenode升级为active状态,此时zkfc1跟之前的master namenode都为standby状态。2、网络情况都正常只,有zkfc1挂掉。这时zkfc2会抢到zookeeper上的锁,升级为active状态,然后探测master namenode是否存活,存活则将master namenode降级为standby,再将自己监听的second namenode升级为active。3、网络情况异常,master namenode与zkfc1、zkfc2网络断开,但是能正常提供给client服务。此时zkfc1会通知zkfc2,zkfc2也探测不到master namenode,则zkfc2不做任何操作,还是standby状态,zkfc1还是active状态。
调优点
环形缓冲区
上报job信息
p5
这里的inputoutput都是文本
SecondNameNode
主要干了件事就是让计算向数据移动。获取到文件分区信息,将计算程序配置到离读取数据最近的节点上,然后将这些信息上传到hdfs,yarn就知道task需要调度到哪里去。
output
collect()
split分区比较器排序
为什么要有缓冲区?是为了将数据批量写入文件,减少io;同时也为了reduce使用数据时数据是有序的,减少读取磁盘io。
NewTrackingRecordReader
TaskAttemptContextImpl
合并
4
将Job配置文件分发到yarn的各个JobManager
inputsplits
datanode1
上报task信息
请求分配资源
LineRecordReader
分组比较器
上传jar跟配置文件到hdfs
6
Node Status
runNewMapper()
客户端
大小不定
client端会先得到任务在哪些节点跑,然后将这些配置通知resource manager,让其去调度任务。
其他map
datanode2
数据区
LineRecordWriter
NewTrackingRecordWriter
默认200M
资源管理器是主从架构,通过zookeeper选主。Node Manager为每个hdfs的datanode上都会有。App mstr管理map跟reduce过程,上报给resource manager。container为分配到各个节点的计算任务。
p4
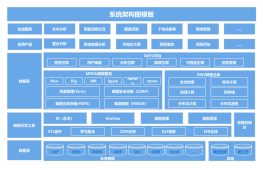
架构图
代码大概执行流程图
获取文件position,读取第一个\行然后抛弃,\后则为position,避免了单词切割问题
自定义mapepr,处理业务
分组比较器比较
初始化一堆对象
yarn架构图
context.nextKey()
5
因为每次溢写是一个新的文件,所以对新文件进行合并,减少shuffle多次文件,降低网络io
谁成功谁是主,谁是active状态则监听的namenode也是active状态
SplitComparator
startSpill()
为什么要这么做?避免溢写时不能写,提高性能。
RawComparator
分区器
设置job name设置job 启动类
reduce.run()
Submit Task
Configuration
ResourceManager