高可用/高并发/高性能解决方案(3H)
2021-01-15 13:42:34 2 举报AI智能生成
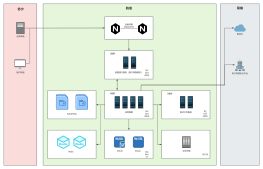
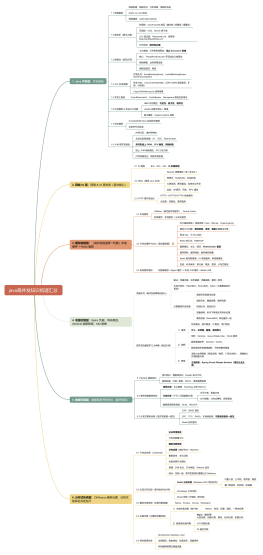
高可用、高并发和高性能是构建现代互联网应用的三大关键要素。高可用性解决方案确保系统在面临故障时仍能保持正常运行,通过数据冗余、负载均衡和故障切换等技术实现服务的持续可用。高并发解决方案则关注如何应对大量用户同时访问,采用分布式架构、缓存技术和异步处理等手段提高系统的处理能力。高性能解决方案致力于优化系统性能,包括硬件升级、代码优化和数据库调优等方面,以满足用户对响应速度和资源利用率的需求。综合运用这三方面的解决方案,可以打造出稳定、高效、可扩展的互联网应用,满足不断增长的业务需求。
模板推荐
作者其他创作
大纲/内容






0 条评论
下一页

