线程安全是指,ArrayBlockingQueue内部通过“互斥锁”保护竞争资源,实现了多线程对竞争资源的互斥访问。
而有界,则是指ArrayBlockingQueue对应的数组是有界限的。
阻塞队列,是指多线程访问竞争资源时,当竞争资源已被某线程获取时,其它要获取该资源的线程需要阻塞等待;
而且,ArrayBlockingQueue是按 FIFO(先进先出)原则对元素进行排序,元素都是从尾部插入到队列,从头部开始返回。
原理
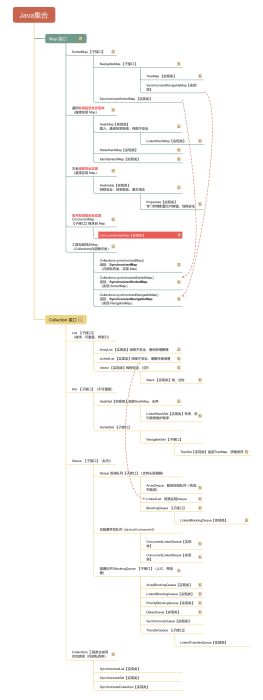
1、ArrayBlockingQueue继承于AbstractQueue,并且它实现了BlockingQueue接口。
2. ArrayBlockingQueue内部是通过Object[]数组保存数据的,也就是说ArrayBlockingQueue本质上是通过数组实现的。ArrayBlockingQueue的大小,即数组的容量是创建ArrayBlockingQueue时指定的。
3. ArrayBlockingQueue与ReentrantLock是组合关系,ArrayBlockingQueue中包含一个ReentrantLock对象(lock)。
ReentrantLock是可重入的互斥锁,ArrayBlockingQueue就是根据该互斥锁实现“多线程对竞争资源的互斥访问”。
而且,ReentrantLock分为公平锁和非公平锁,关于具体使用公平锁还是非公平锁,在创建ArrayBlockingQueue时可以指定;
而且,ArrayBlockingQueue默认会使用非公平锁。
4. ArrayBlockingQueue与Condition是组合关系,ArrayBlockingQueue中包含两个Condition对象(notEmpty和notFull)。
而且,Condition又依赖于ArrayBlockingQueue而存在,通过Condition可以实现对ArrayBlockingQueue的更精确的访问 --
(01)若某线程(线程A)要取数据时,数组正好为空,则该线程会执行notEmpty.await()进行等待;
当其它某个线程(线程B)向数组中插入了数据之后,会调用notEmpty.signal()唤醒“notEmpty上的等待线程”。
此时,线程A会被唤醒从而得以继续运行。
(02)若某线程(线程H)要插入数据时,数组已满,则该线程会执行notFull.await()进行等待;
当其它某个线程(线程I)取出数据之后,会调用notFull.signal()唤醒“notFull上的等待线程”。
此时,线程H就会被唤醒从而得以继续运行。