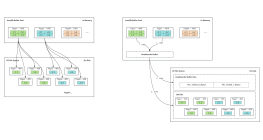
引擎内更新流程
1.加载缓存数据,将更改的数据所在整页加载到缓存中,即buffer pool
2.写undo日志,将旧值写入undo日志,便于回滚
3.修改buffer pool中缓存的值
4.写redo日志到缓存中,重做日志,将修改后的数据记录到redo log buffer中
批量写
5.准备提交事务(将要执行commit操作)将redo log buffer 写入磁盘
6.准备提交事务(将要执行commit操作)写入binlog
7.写入commit标记到redo log 事务提交完成,为标记保证binlog与redo log一致,<br>(此时我们认为事务已经提交完成,但其其实磁盘中数据还未同步)<br>
8.随机时间以页为单位将buffer pool中的数据刷入磁盘
mysql中的增删改查都是基于buffer pool做的(效率问题),<br>buffer pool一般设置为机器内存大小的60%<br>
日志文件的读写为顺序读写,性能极高类似缓存
<b><font color="#f15a23">buffer pool 页链表管理</font></b>
FREE链表
存储没有被使用的buffer块,当free链表里面的数据被使用完的时候,<br>如果再需要申请空间,需要根据LRU淘汰已使用过的数据页
LRU链表
最近最少使用。即最频繁使用的页在LRU链表的前端,<br>最少使用的页在LRU链表的尾端。当缓存池不能存放取到的页时,首先将LRU链表中释放尾端的页。<br>最新读取的页面,并不是放入前端而是放入中间(5:3,插入到5/8),防止热块被新读取的大量数据挤出LRU链表。<br>当LRU里的数据块被修改时,变成脏块,会被添加到FLUSH链表中。
Flush链表
脏块被刷入FLUSH链表,然后会在一定时间落盘。<br>脏块在LRU链表和FLUSH里都存在。LRU链表管理数据块的可用性,<br>FLUSH用于数据块的写入磁盘
页的操作
页面的分配
首先从FREE链表中申请可用的空间。如果FREE链表没有可以使用的空间,<br>那么就要向LRU链表中申请,通过LRU算法。LRU的页面是可以被替换的,条件:
1.页不脏
2.页没有被其他线程使用
页的物理读取
当innodb存储引擎启动后,缓冲池是空的,所有页都在FREE链表中。<br>数据库的读写操作都需要在缓冲池中完成,缓冲池的任务就是将磁盘中的数据读取到缓冲中,<br>即页面的物理读取
页的预读
判断某个区域内的大多数页面是否被访问到,如果被访问到,<br>数据库会进行预读操作。数据库对区域内的数据顺序性读取,提高数据库读取性能<br>
逻辑读取
从缓冲池中读取的页面。如果逻辑读取的页面不在缓冲池,<br>则需要从硬盘加载到内存(物理读取)<br>