run
receiveBlock
在NameNode创建得时候会启动这个线程 2s检查一小时都没续约得,
第一个异常:创建管道异常?申请新块和管道
是否是最后的一个空packet
1、创建新的 LocatedBlockLocatedBlock = dfsClient.namenode.getAdditionalDatanode
create返回的是 FSDataOutputStream,然后封装成 HdfsDataOutputStream
如果第一个节点都没有超过一小时,直接return
packet (127个)64K
dataQueue是否为空并且判断hasError
mkdir
while重试10次
DataStreamer
没有数据要写入
第二步:写入本地磁盘 out.write
1、nextBlockOutputStream()2、initDataStreaming
blk_0002_checksum
基于输出流,向DataNode发送请求 Sender
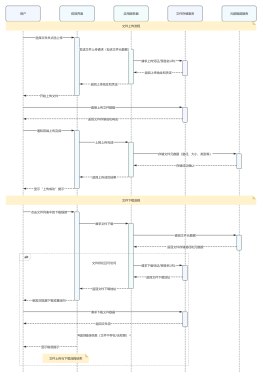
向NameNode发送创建文件请求
lastUpdate
从in流中获取下一个packet
extends
是空的packet
获取DataNode返回数据initDataStreaming
FSOutputSummer
FSDataOutputStream
发送 send
否
DFSPacket 移除
失败
发送RPC调用
INodeDirectory
LocatedBlock
获取lease中所有path释放契约、移除lease
BlockConstructionStage.PIPELINE_SETUP_APPEND
WRITE_BLOCK
第二个异常:写第一个datanode异常
DatanodeInfo[]筛选出来的DataNode
setPipeline(nextBlockOutputStream()) ;申请block、并创建数据管道
是
设置管道状态PIPELINE_CLOSE
获取所有的client ArrayList
契约管理 LeaseManager
blk_0001
成功
如果租赁软限制时间到期,请恢复租赁
本地上传文件
加入管理
endBlock()关闭流、释放资源、重置各种状注意此时就会重置数据管道
封装 INodeFile
这里是一个线程,边写这边在边删除ack
DataXceiverServerDataXceiverServer
1
Packet
移除
写入的数据的剩余内容大于或等于 buf 的大小 ---这里避免多余一次复制
newStreamForCreate
返回的是 FSDataOutputStream
加入add
第二个异常不确定是不是这里也算?
创建 DFSOutputStream 输出流
chunk512字节
for循环client
判断是否需要添加新的DataNode1、副本数量 < 32、当前节点总数小于副本数除以2
需要判断一下
封装创建 new DataStreamerstage = BlockConstructionStage.PIPELINE_SETUP_CREATE
Sender(out).writeBlock
DistributedFileSystem
1秒一次
从 blockReplyStream 获取请求状态
DFSPacket
写入
优点:其实这里就是不用全部遍历了,我只用遍历第一个最久的,是否超过一小时,如果最久的都没有,那后面的肯定也就不会了。 * 这个是不是可以用在注册中心的那个租约上,那样我们也就不用遍历所有的了
第三个异常:DN节点传输数据异常
namenode.renewLease(clientName)
因为传递过来时,说明和下游的DataNode通信失败,所以需要把之前维护的block和文件的对应信息都删除
2.1 关闭各种流2.2 将ACKqueue中数据,重新加入到dataQueue2.3 清空ACKqueue2.4 重置数据流管道
dataQueue (LinkedList)
TreeSet<String>
Lease
封装返回消息BlockOpResponseProto
创建一个新的block
write
DFSClient
opWriteBlock(in)
FSNamesystem
申请block locateFollowingBlock
RPC
上一次续约得一个时间戳
返回
blockReceivedAndDeleted
失败,重试三次
NameNode
加入契约管理
本地下载文件
success = createBlockOutputStream
生成校验和 chunkSum
do locateFollowingBlock while(3次)
blk_0001_checksum
abandonBlock
BlockOpResponseProto
create
wait 等待 ackQueue中的消息消费完成
通过client获取契约 Lease
Block blockid自增
bloc (2048个packet)128M
NameNodeRpcServerNameNodeRpcServerNameNodeRpcServerNameNodeRpcServerNameNodeRpcServerNameNodeRpcServerNameNodeRpcServer
把当前这个包转发给下游DataNode
当前客户端针对哪些文件持有契约
创建输出流new DFSOutputStream
使用流上传文件
创建输出流 HdfsDataOutputStream
这里实际上是开启这个client 得 续约操作,因为在创建文件的过程中,在NameNode的create中,已经开启了一个契约如果超过一小时都没发送,那在NameNode那端得线程,就会定时检查Lease,超过一小时未续约,进行删除
传递过来是client
updateBlockForPipeline
一个block对应一个 BlockReceiver
2、processDatanodeError(
添加
移除文件 、 移除租约
public class HdfsText01 { public static void main(String[] args) throws Exception { //1 创建连接 Configuration conf = new Configuration(); //2 连接端口 conf.set(\"fs.defaultFS\
DataNode DataNode DataNode DataNode DataNode DataNode
数据上传过程中,出现了错误
返回 HdfsFileStatus
1、关闭ResponseProcessor响应线程
PacketReceiver用于DataNode之间写数据
ACKqueue
receivePacket 读取packet
是否最后一个包
write 数据写入
写入内存后判断是否需要进行 刷盘
没地方画了,画在最上面的容错
根据需要判断是否需要进行刷盘的操作
将chunk、checksum写入
wait 等待 ackQueue中的消息消费完成
//hdfs文件复制到本地(流)FSDataInputStream in = fs.open(new Path(\"/output\"));FileOutputStream out = new FileOutputStream(\"E:/mm.txt\
createRbwFile
循环读取
获取发送过来请求类型OP
TreeSet<Lease> sortedLeases 通过续约时间排序得集合
addBlock
磁盘文件
将block加入BlocksMap BlockManager
BlockReceivernew 创建核心组件
checksum
getAdditionalDatanode
哪个客户端持有得契约,client
while循环
INodeFile
1、通过之前的管道发送数据,block不变2、initDataStreaming
针对DataNode创建Socket链接createBlockOutputStream
blockReplyStream
1、从 BlockManager 中移除2、取消当前block和元数据文件的关联3、写日志、供standby同步
dfsClient.namenode.abandonBlock
datanode写数据失败副本数不足时调用
catch 异常
DdataNode之间传输失败的标识
while (receivePacket() >= 0)
hasError 如果报错的话,这里的的while循环也会退出
获取分配的DataNode
不是
Packet 添加
DataBlockScanner 线程会进行磁盘上的block进行扫描检查
移除 ACKqueue头
ACKqueue (LinkedList)
感觉这里应该是一个标识,这个空的packet就标识这个block写满了
是否是block中最后的一个空packet
2
请求是否成功
HdfsDataOutputStream
getEditLog().logSync()查看04 Mkdir创建过程
接收DataNode汇报block得信息写入block完成、删除block等
peerServer.accept() 阻塞等待连接
报错外层设置 catch hasError = true;
FsVolumeImpl创建文件
DataNode
3
异常时:失败重试
dir.addFile添加到文件目录树
renewLease
key:client名称
DataXceiverServer线程是以数据流的方式,为client提供block的数据流上传、数据流下载通信方式:SocketDataXceiverServer
createRbw
Socket
此时会把DdataNode连接失败的节点加入excute集合
第一步: NameNode 端创建一个 file 文件 ,文件名blk_00001
注意此时会把DdataNode不通的节点传递过去,告诉NameNode,下次不要把这个节点给我
重新获取block、重置管道如果这里发生错误,失败重试3次
报错
Socket 创建
大概看了一下,如果是在datanode同步数据的时候出错,此时好像会停止这个数据的线程写入,然后给client返回对应的异常信息,然后client端的 hasError 就会设置成true,然后会再重进行block的选择等
循环遍历所有DataNode返回的写入状态
这个异常应该是第二次循环才会改过来有的
参考一下 04 图 ,创建路径
TreeSet<Lease> sortedLeases
HdfsDataOutputStream
private void endBlock() { if(DFSClient.LOG.isDebugEnabled()) { DFSClient.LOG.debug(\"Closing old block \" + block); } this.setName(\"DataStreamer for file \
启动这个流 out.start()
无限while 循环
创建文件的操作,包括目录树和editlog的操作
初始化一个 ResponseProcessor处理响应请求的
线程 run
此时会告诉NameNode,这个DataNode节点不通
DataStreamer是一个核心线程,主要负责数据上传到 DataNode,他是负责通过一个数据管道(pipeline) 将数据包 (packets)发送到DataNode
一个FsVolume可以理解成一个本地磁盘的一个文件组,包含一堆的block文件,DataNode上包含了多个FsVolume
getNewBlockTargets
获取 第一个 lease
blk_0003_checksum
packetReceiver.mirrorPacketTo第一步: 首先将数据包写入镜像
关闭各种流 finalizeBlock完成block的写入
这里会有一个心跳包的判断,这个代码应该在创建block的时候发了一个测试的心跳packetisHeartbeatPacket
1、向NameNode报备2、记录异常Node3、重试
blk_0002
设置 mirrorError = true
2.41、移除那个坏的datanode节点2、重置数据流管道setPipeline
从dataQueue中获取数据getFirst()
获取 BPOfferService
是否是新的block 创建管道
返回 LocatedBlock
for (BPServiceActor actor : bpServices)可以i理解成就是循环向active namenode 和standby namenode发送通知
DFSOutputStream.
和对应的INodeFile绑定之误认为是添加到树,其实我感觉应该是Block和对应的File文件节点绑定
处理请求processOp(op)
响应结果
重要
success = createBlockOutputStream此处流程就和前面是一样的了,参照获取block时得图
INodeDirectory
addDatanode2ExistingPipeline
blockReceiver.receiveBlock
是否是最后一个空packet
发生异常
holder
再次获取 LocatedBlock向NameNode发送RPC请求
1、移除 dataQueue 2、添加 ACKqueue
删除ACKqueue中第一个节点,说明写入成功
buf = chunk*9 = 512字节 * 9 buf初始化的大小是chunk*9的大小,chunk默认是512字节
写数据
NIO
机架感知 BlockPlacementPolicy
接收packet的核心逻辑 :接收并处理数据包
2、重置数据管道 setPipeline(lb)
renew(); 续约
超过
判断是否需要添加新的DataNode
getEditLog().logOpenFile写入内存Editslog
创建通信管道 Pipeline
开启文件的续约操作
第三步:写入对应的校验和文件checksumOut.write
应该是开始直接写数据了
//流上传文件 FileInputStream in=new FileInputStream(\"E://haha.txt\");//读取本地文件 FSDataOutputStream out = fs.create(new Path(\"/output2\
FsDatasetImpl
创建接收DataNode的返回数据流 (输入流)
此时其实传递过来得是一个空得block
读取第一个
写入的数据的剩余内容 < buf 的大小 -- 规避了数组越界问题
excludedNodes.put 记录异常DataNode
startFileInternal
如果此时NameNode正在启动中,则休眠五秒
return false不休眠,继续处理,就是跳出 while
执行完之后,也走上面方法
3、重新和新的DataNode创建连接,发送请求 TRANSFER_BLOCK注意此时的发送类型
success是否成功
PacketResponder
写满的packet放入 dataQueue
休眠1s
等待消费完成之后再移除添加
创建block
Lease 两个客户端得排序主要是,先通过最后一次续约得时间,如果时间一样的话,再通holder,也就是client name得顺序
好像不是向NameNode发送请求,但是是notify什么、还没看懂
这个while里面的每一步报错,都会设置 hasError = true;
return DFSOutputStream
创建一个Socket把当前这个包转发给下游DataNode
packet
添加契约管理LeaseManager
文件是否被覆写
logOpenFile
尝试收回租约时可能记录了交易。即使抛出异常,也需要对其进行同步。
创建FsVolumeReference
在文件目录树中添加了文件的目录结构
如果写入的数据== blockSize
DFSOutputStream
blk_0003
DataStreamer 核心线程
创建一个空的packet放入 dataQueue
chunk
契约管理器 LeaseManager
waitForAckHead获取ack中的头数据
写入的长度read > buf
startFile
DataXceiver 创建核心线程
创建 PacketResponder ,开启线程,暂时没懂、
读取下游ACK
写满放入
INodeDirectory 目录
超过十次
addLease
key:文件path
这里应该会通知namenode,然后需要注意的是,这里会通知到集群中所有NameNode
建立连接
1、从 sortedLeases 移除契约2、更新一下lastUpdate为当前时间3、再次添加契约到 sortedLeases
应该是Namenode更新block时间戳,这样异常DataNode过期数据块会被删除
读取发送过来数据
猜测这里应该是一个统一返回吧,就是返回所有datanode的写入状态,成功失败
1、创建多少个副本2、每个副本都在哪台DataNode上
writeChecksumChunks
未超过
向上游DataNode发送一个ACK消息
switch(op)
FileSystem # copyFromLocalFile
one.writeTo(blockStream)写数据
return
while 无限循环
循环while从头开始,重新写
checksum4字节
参考一下 06 图 ,write写数据HdfsDataOutputStream
判断是否超过1小时
发送RPC
如果写入数据长度大于缓冲区长度(4608),将其直接发送到底层流(packet)
将 chunk 和chunck写入currentPacket
DataNode
直接return,就不会进行写磁盘了
向上游DataNode发送一个ACK消息(不知道为啥又一次)
在写完一个block之后,其实这里就会重置 PIPELINE_SETUP_CREATE具体代码看最下面的 engBlock
当前packet为空,新建一个packet
ResponseProcessor响应处理器
BlockConstructionStage.PIPELINE_SETUP_CREATE
currentPacket
dfsClient.namenode.create
数据写入失败时得处理方式
需要注意的是:此时只是修改了一个状态值,也就是 readyToSend = true然后这个值得true得引用实际上是在 sendImmediately() 方法中,然后这个方法其实是 BPServiceActor 线程中,如果 readyToSend = true 为 true得时候,此时 就会调用 ibrManager.sendIBRs 方法,里面会通知namenode对应03图得最下面 (心跳)
计算数据包得大小computePacketChunkSize
如果不足一个chunk,就缓存到本地buffer,如果还有下一次写入,就填充这个chunk,满一个chunk再flush