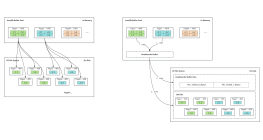
执行过程
FROM <left_table>
对 from 子句的右表执行<font color="#f15a23">笛卡尔积</font>, 产生虚拟表 VT1
ON <join_condition>
对虚拟表VT1 进行on 筛选, 符合 <font color="#c41230" style="font-weight: bold;"><join_condition> </font><font color="#000000" style="">的行插入到虚拟表 VT2</font>
<join_type> JOIN <right_table>
保留未匹配的行, 作为外部行 插入到虚拟表 VT2, 产生虚拟表VT3
如果from 包含多个表,则对上一个连接产生的结果表VT3和下一个表, 重复执行 1,2,3 步骤
WHERE <where_condition> <where_condition></where_condition>
对虚拟表VT3 应用where 过滤条件, 符合条件的数据 记录到虚拟表 VT4
GROUP BY <group_by_list>
根据group by 子句中的列,对VT4 中的记录进行分组操作, 产生VT5
WITH {CUBE|ROLLUP}
对VT5进行 curbe或ROLLUP 操作, 产生VT6
HAVING <having_condition>
SELECT <select_list>
再次进行select 操作, 获取指定列
ORDER BY <order_by_list>
LIMIT <limit_number>
日志
错误日志 error log
记录mysql服务的启停时正确和错误的信息,还记录启动、停止、运行过程中的错误信息
查询日志(general log)
记录建立的客户端连接和执行的语句。
二进制日志(bin log)
记录所有更改数据的语句,可用于数据复制。
慢查询日志(slow log)
记录所有执行时间超过long_query_time的所有查询或不使用索引的查询。
中继日志(relay log)
主从复制时使用的日志
读写分离<br>
并行复制
同一台从库服务器,可以开启多个sql线程,可以保证多个库同时进行
主从延迟
高并发下,导致从库延迟
1000/s, 延迟几毫秒
主库挂掉
数据同步失败
semi-sync
主库写入后,会同时同步从库
从库写入本地relay日志,并返回ack
最少一台从库返回ack,才算写入成功
引擎
MYISAM
优点
增加索引、字段管理
表格锁定、多优化多个并发的读写操作
mysql默认
非聚集索引
查看引擎
show engines
alter table cloud_user engine = InnoDB
选择
InnoDB
可靠性高、要求事务
表更新和查询比较频繁
索引
创建原则
区分度比较大
查询条件
频繁更新不适合做索引
where 和 order by 涉及的列简历索引
索引失效
索引使用了函数
索引列参与计算
前缀模糊
or操作
NULL 查询