
Java开发全栈知识体系架构学习 (服务器、微服务、数据库、
2021-03-17 10:15:26 18 举报AI智能生成
2021年从入门到精通java开发全栈知识体系架构学习总结知识脑图(学习使用于项目实战)前端、后台、服务器、Linux、性能优化、集群搭建、微服务、大数据、项目实战等内容
Java
JVM
sql优化
springMVC
spring cloud
模板推荐
作者其他创作
大纲/内容
一、前端技术篇
1、基础知识篇
HTML
CSS
去除a标签默认样式
分支主题
分支主题
如何给盒子设置透明度
使用opacity时,盒子内的内容也会跟着透明
opacity: 0.5;<br>
使用background-color的rgba时,盒子内的内容不会跟着透明
background-color: rgba(0, 0, 0, 0.5);
javascript
jquery
2、框架篇
BOOTSTRAP
Element UI
VUE
项目的创建
3.0之前使用npm init webpackge 项目名创建
3.0之后使用vue create 项目创建
插件卸载
npm uninstall 插件名字
路由的集成和使用
安装命令
npm/cnpm install vue-router --save
创建router文件夹,在文件夹下创建index.js来配制路由
import VueRouter from 'vue-router'
Vue.use(VueRouter)
项目实例
main.js文件中引入插件并且使用
import router from './router'
3、要注意了解的SEO知识
01、合理的title、description、keywords:搜索对着三项的权重逐个减小
title值强调重点即可,重要关键词出现不要超过2次,而且要靠前,不同页面title要有所不同;
description把页面内容高度概括,长度合适,不可过分堆砌关键词,不同页面description有所不同;
keywords列举出重要关键词即可
02、语义化的HTML代码,符合W3C规范:语义化代码让搜索引擎容易理解网页
03、重要内容HTML代码放在最前:搜索引擎抓取HTML顺序是从上到下,有的搜索引擎对抓取长度有限制,保证重要内容一定会被抓取
04、重要内容不要用js输出:爬虫不会执行js获取内容
05、少用iframe:搜索引擎不会抓取iframe中的内容
06、非装饰性图片必须加alt
07、提高网站速度:网站速度是搜索引擎排序的一个重要指标
4、http状态码及其含义
(1)信息状态码
答:100 Continue 继续,一般在发送post请求时,已发送了http header之后服
务端将返回此信息,表示确认,之后发送具体参数信息。
(2)成功状态码
a、200 OK 正常返回信息
b、201 Created 请求成功并且服务器创建了新的资源
c、202 Accepted 服务器已接受请求,但尚未处理
(3)重定向状态码
a、301 Moved Permanently 请求的网页已永久移动到新位置
b、302 Found 临时性重定向
c、303 See Other 临时性重定向,且总是使用 GET 请求新的 URI
d、304 Not Modified 自从上次请求后,请求的网页未修改过。
(4)客户端错误
a、400 Bad Request 服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求
b、401 Unauthorized 请求未授权
c、403 Forbidden 禁止访问
d、404 Not Found 找不到如何与 URI 相匹配的资源
(5)服务器错误
a、500 Internal Server Error 最常见的服务器端错误
b、503 Service Unavailable 服务器端暂时无法处理请求(可能是过载或维护)
5、HTTP的几种方法请求用途
01、GET方法
发送一个请求来取得服务器上的某一资源
02、POST方法
向URL指定的资源提交数据或附加新的数据
03、PUT方法
跟POST方法很像,也是想服务器提交数据。但是,它们之间有不同。PUT指定了资源在服务器上的位置,而POST没有
04、HEAD方法
只请求页面的首部
05、DELETE方法
删除服务器上的某资源
06、OPTIONS方法
它用于获取当前URL所支持的方法。如果请求成功,会有一个Allow的头包含类似“GET,POST”这样的信息
07、TRACE方法
TRACE方法被用于激发一个远程的,应用层的请求消息回路
08、CONNECT方法
把请求连接转换到透明的TCP/IP通道
6、了解前端网站性能的优化
01、优化知识点分类
(1)content方面
减少HTTP请求:合并文件、CSS精灵、inline Image
减少DNS查询:DNS缓存、将资源分布到恰当数量的主机名
减少DOM元素数量
(2)Server方面
使用CDN
配置ETag
对组件使用Gzip压缩
(3)Cookie方面
减小cookie大小
(4)Css方面
将样式表放到页面顶部
不使用CSS表达式
使用<link>不使用@import
(5)Javascript方面
将脚本放到页面底部
将javascript和css从外部引入
压缩javascript和css
删除不需要的脚本
减少DOM访问
(6)图片方面
优化图片:根据实际颜色需要选择色深、压缩
优化css精灵
不要在HTML中拉伸图片
02、常用的优化方法总结
(1)减少http请求次数:CSS Sprites, JS、CSS源码压缩、图片大小控制合适;网页Gzip,CDN托管,data缓存 ,图片服务器。
(2)前端模板 JS+数据,减少由于HTML标签导致的带宽浪费,前端用变量保存AJAX请求结果,每次操作本地变量,不用请求,减少请求次数
(3)用innerHTML代替DOM操作,减少DOM操作次数,优化javascript性能。
(4)当需要设置的样式很多时设置className而不是直接操作style
(5)少用全局变量、缓存DOM节点查找的结果。减少IO读取操作
(6)避免使用CSS Expression(css表达式)又称Dynamic properties(动态属性)
(7)图片预加载,将样式表放在顶部,将脚本放在底部 加上时间戳
(8)避免在页面的主体布局中使用table,table要等其中的内容完全下载之后才会显示出来,显示比div+css布局慢
03、性能优化的注意点
(1)代码层面:避免使用css表达式,避免使用高级选择器,通配选择器
(2)缓存利用:缓存Ajax,使用CDN,使用外部js和css文件以便缓存,添加Expires头,服务端配置Etag,减少DNS查找等
(3)请求数量:合并样式和脚本,使用css图片精灵,初始首屏之外的图片资源按需加载,静态资源延迟加载
(4)请求带宽:压缩文件,开启GZIP
7、vscode工具常用插件介绍
EsLint
语法纠错
Vetur
语法高亮、智能感知、Emmet 等
Auto Close Tag
自动闭合 HTML/XML 标签
Auto Rename Tag
自动完成另一侧标签的同步修改
JavaScript(ES6) code snippets
ES6 语 法 智 能 提 示 以 及 快 速 输 入 , 除 js 外 还 支 持.ts,.jsx,.tsx,.html,.vue,省去了配置其支持各种包含 js 代码文件的时间
HTML CSS Support
让 html 标签上写 class 智能提示当前项目所支持的样式
HTML Snippets
html 快速自动补全
Open in browser
浏览器快速打开
Live Server
以内嵌服务器方式打开
Chinese (Simplified) Language Pack for Visual Studio Code
中文语言包
二、Java技术篇
1、java基础
认识java
1、java的简介
(1)Java 是由 Sun Microsystems 公司于 1995 年 5 月推出的 Java 面向对象程序设计语言和 Java 平台的总称
(2)由 James Gosling和同事们共同研发,并在 1995 年正式推出
(3)后来 Sun 公司被 Oracle (甲骨文)公司收购,Java 也随之成为 Oracle 公司的产品
2、java的三个体系
(1)JavaSE(J2SE)(Java2 Platform Standard Edition,java平台标准版)
JAVA SE:主要用在客户端开发。
(2)JavaEE(J2EE)(Java 2 Platform,Enterprise Edition,java平台企业版)
JAVA EE:主要用在web应用程序开发。
(3)JavaME(J2ME)(Java 2 Platform Micro Edition,java平台微型版)
JAVA ME:主要用在嵌入式应用程序开发。
3、开发环境配制
windows/linux/参考配制地址:https://www.runoob.com/java/java-environment-setup.html
4、什么 是JVM
JVM:java虚拟机,运用硬件或软件手段实现的虚拟的计算机。
java虚拟机包括:寄存器,堆栈、处理器。
5、什么是JDK和JRE
JDK:java development kit:java开发工具包,是开发人员所需要安装的环境。
JRE:java runtime environment:java运行环境,java程序运行所需要安装的环境。
java基础语法
4、Java 基础语法
1)说明:一个 Java 程序可以认为是一系列对象的集合,而这些对象通过调用彼此的方法来协同工作
2)分类
(1)对象:对象是类的一个实例,有状态和行为。例如,一条狗是一个对象,它的状态有:颜色、名字、品种;行为有:摇尾巴、叫、吃等
(2)类:类是一个模板,它描述一类对象的行为和状态
(3)方法:方法就是行为,一个类可以有很多方法。逻辑运算、数据修改以及所有动作都是在方法中完成的
(4)实例变量:每个对象都有独特的实例变量,对象的状态由这些实例变量的值决定
3)基础语法
(1)大小写敏感:Java 是大小写敏感的,这就意味着标识符 Hello 与 hello 是不同的。
(2)类名:对于所有的类来说,类名的首字母应该大写。如果类名由若干单词组成,那么每个单词的首字母应该大写,例如 MyFirstJavaClass
(3)方法名:所有的方法名都应该以小写字母开头。如果方法名含有若干单词,则后面的每个单词首字母大写
(4)源文件名:源文件名必须和类名相同。当保存文件的时候,你应该使用类名作为文件名保存(切记 Java 是大小写敏感的),文件名的后缀为 .java。
(6)主方法入口:所有的 Java 程序由 public static void main(String[] args) 方法开始执行
4)Java 标识符
(1)什么是标识符:由类名、变量名和方法名组成。
(2)所有的标识符都应该以字母(A-Z 或者 a-z),美元符($)、或者下划线(_)开始
(3)首字符之后可以是字母(A-Z 或者 a-z),美元符($)、下划线(_)或数字的任何字符组合
(4)关键字不能用作标识符,并且标识符是大小写敏感的
(5)合法标识符举例:age、$salary、_value、__1_value
(6)非法标识符举例:123abc、-salary
5、Java修饰符
(1)Java可以使用修饰符来修饰类中方法和属性
(2)访问控制修饰符(共4种)
(a)default (默认): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
(b)private(私有的) : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
(c)public (公共的): 对所有类可见。使用对象:类、接口、变量、方法
(d)protected(受保护的) : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
(3)非访问控制修饰符
(a)static 修饰符,用来修饰类方法和类变量。
(b)final 修饰符,用来修饰类、方法和变量
(01)final 修饰的类不能够被继承。
(02)修饰的方法不能被继承类重新定义。
(03)修饰的变量为常量,是不可修改的。
(c)abstract 修饰符,用来创建抽象类和抽象方法。
(d)synchronized 关键字声明的方法同一时间只能被一个线程访问。synchronized 修饰符可以应用于四个访问修饰符。
(e)volatile
答:修饰的成员变量在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。
而且,当成员变量发生变化时,会强制线程将变化值回写到共享内存。这样在任何时刻,
两个不同的线程总是看到某个成员变量的同一个值。
6、java数据类型(2类)
1)内置数据类型
(1)byte 数据类型是8位、有符号的,以二进制补码表示的整数;
(a)最小值是 -128(-2^7);最大值是 127(2^7-1)
(b)默认值是 0;
(2)short 数据类型是 16 位、有符号的以二进制补码表示的整数;
(a)最小值是 -32768(-2^15);最大值是 32767(2^15 - 1);
(b)默认值是 0
(3)int 数据类型是32位、有符号的以二进制补码表示的整数;
(a)最小值是 -2,147,483,648(-2^31);最大值是 2,147,483,647(2^31 - 1)
(b)默认值是 0 ;
(4)long 数据类型是 64 位、有符号的以二进制补码表示的整数;
(a)最小值是 -9,223,372,036,854,775,808(-2^63);最大值是 9,223,372,036,854,775,807(2^63 -1)
(b)默认值是 0L;
(5)float 数据类型是单精度、32位、符合IEEE 754标准的浮点数;
(a)默认值是 0.0f
分支主题
(6)double 数据类型是双精度、64 位、符合IEEE 754标准的浮点数;
(a)最小值:4.9E-324;最大值:1.7976931348623157E308
(b)默认值是 0.0d;
(7)boolean数据类型表示一位的信息;
(a)只有两个取值:true 和 false;
(b)默认值是 false;
(8)char类型是一个单一的 16 位 Unicode 字符;
(a)最小值是 \u0000(即为 0);最大值是 \uffff(即为65、535);
(b)默认值'u0000'
2)引用数据类型
(1)引用类型指向一个对象,指向对象的变量是引用变量。
(2)所有引用类型的默认值都是null。
(3)一个引用变量可以用来引用任何与之兼容的类型。
7、java循环结构
1)while 循环
(1)说明:只要布尔表达式为 true,循环就会一直执行下去。
(3)特点:对于 while 语句而言,如果不满足条件,则不能进入循环。
(2)语法:while( 布尔表达式 ) { //循环内容}
2)do…while 循环
(1)说明:布尔表达式在循环体的后面,所以语句块在检测布尔表达式之前已经执行了。
(2)特点:do…while 循环和 while 循环相似,不同的是,do…while 循环至少会执行一次。
(3)语法:do { //代码语句} while(布尔表达式);
3)普通for 循环
(1)说明:for循环执行的次数是在执行前就确定的。
(2)特点:先初始化一个或多个循环控制变量,接着检测布尔表达式的值,如果为true,继续执行循环,反之循环终止。
(3)语法:for(初始化; 布尔表达式; 更新) { //代码语句}
4)增强 for 循环
(1)声明语句:声明新的局部变量,该变量的类型必须和数组元素的类型匹配。作用域限定在循环语句块。
(2)表达式:表达式是要访问的数组名,或者是返回值为数组的方法。
(3)语法:for(声明语句 : 表达式){ //代码句子}
5)循环中使用到的关键字
(1)break 关键字
(01)作用:break 主要用在循环语句或者 switch 语句中,用来跳出整个语句块。
(02)break 跳出最里层的循环,并且继续执行该循环下面的语句。
(03)语法:break;
(2)continue 关键字
(01)作用:continue 适用于任何循环控制结构中。作用是让程序立刻跳转到下一次循环的迭代。
(02)在 for 循环中,continue 语句使程序立即跳转到更新语句。
(03)在 while 或者 do…while 循环中,程序立即跳转到布尔表达式的判断语句。
(04)语法:continue;
8、java条件控制语句
1)if...else语句
(1)说明:if 语句后面可以跟 else 语句,当 if 语句的布尔表达式值为 false 时,else 语句块会被执行。
(2)语法:if(布尔表达式){ //如果布尔表达式的值为true}else{ //如果布尔表达式的值为false}
2)if...else if...else 语句
(1)说明:if 语句后面可以跟 else if…else 语句,这种语句可以检测到多种可能的情况。
(2)语法:if(布尔表达式 1){}else if(布尔表达式 2){}else {}
(3)注意点:只能有一个else语句,必须在最后,一但一个else if为true则判断结束
3)switch case 语句
java类和方法
1)、java常用类
1)String 类
2)StringBuffer 类
3)StringBuilder 类
4)Scanner 类
2)java方法
1)那么什么是方法呢?
2)使用方法的优点有那些?
(1) 使程序变得更简短而清晰。
(2) 有利于程序维护。
(3)可以提高程序开发的效率。
(4)提高了代码的重用性。
3)方法的命名规则
4)方法的定义
5)方法调用
6)方法的重载
7)方法的重写
8)构造方法
9)finalize() 方法
3)Java中的包装类都是那些
byte:Byte
short:Short
int:Integer
long:Long
float:Float
double:Double
char:Char
boolean:Boolean
4)一个java类中包含那些内容
属性、方法、内部类、构造方法、代码块。
2、java进阶
01、java的对像和类
1)基本概念:多态、继承、封装、抽象、类、对象、实例、方法、重载
2)什么对象:对象是类的一个实例(对象不是找个女朋友),有状态和行为。例如,一条狗是一个对象,它的状态有:颜色、名字、品种;行为有:摇尾巴、叫、吃等。
3)什么是类:类是一个模板,它描述一类对象的行为和状态
4)一个类可以包含那些类型变量
(1)局部变量:在方法、构造方法或者语句块中定义的变量被称为局部变量。变量声明和初始化都是在方法中,方法结束后,变量就会自动销毁。
(2)成员变量:成员变量是定义在类中,方法体之外的变量。这种变量在创建对象的时候实例化。成员变量可以被类中方法、构造方法和特定类的语句块访问。
(3)类变量:类变量也声明在类中,方法体之外,但必须声明为 static 类型
5)什么是构造方法
(1)说明:每个类都有构造方法。如果没有显式地为类定义构造方法,Java 编译器将会为该类提供一个默认构造方法。
(2)在创建一个对象的时候,至少要调用一个构造方法。构造方法的名称必须与类同名,一个类可以有多个构造方法。
6)对象的创建
(1)对象的创建
(a)声明:声明一个对象,包括对象名称和对象类型。
(b)实例化:使用关键字 new 来创建一个对象。
(c)初始化:使用 new 创建对象时,会调用构造方法初始化对象。
02、java的继承、多态、封装(三大特性)
1)继承
(01)继承的概念
继承是java面向对象编程技术的一块基石,因为它允许创建分等级层次的类。
继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。
(02)类的继承格式
class 父类 {}
class 子类 extends 父类 {}
(03)继承的特性
子类拥有父类非 private 的属性、方法。
子类可以拥有自己的属性和方法,即子类可以对父类进行扩展。
子类可以用自己的方式实现父类的方法。
Java 的继承是单继承,但是可以多重继承,单继承就是一个子类只能继承一个父类
提高了类之间的耦合性(继承的缺点,耦合度高就会造成代码之间的联系越紧密,代码独立性越差)
(04)继承关键字
继承可以使用 extends 和 implements 这两个关键字来实现继承
而且所有的类都是继承于 java.lang.Object,当一个类没有继承的两个关键字,则默认继承object
(05)关键字
extends关键字:一个子类只能拥有一个父类,所以 extends 只能继承一个类
implements关键字:使用范围为类继承接口的情况,可以同时继承多个接口(接口跟接口之间采用逗号分隔)。
super关键:可以通过super关键字来实现对父类成员的访问,用来引用当前对象的父类。
this 关键字:指向自己的引用。
final关键字:inal 关键字声明类可以把类定义为不能继承的,即最终类;或者用于修饰方法,该方法不能被子类重写:
(06)构造器
子类是不继承父类的构造器(构造方法或者构造函数)的,它只是调用(隐式或显式)
如果父类的构造器带有参数,则必须在子类的构造器中显式地通过 super 关键字调用父类的构造器并配以适当的参数列表。
如果父类构造器没有参数,则在子类的构造器中不需要使用 super 关键字调用父类构造器,系统会自动调用父类的无参构造器。
2)多态
(01)什么是多态
多态是同一个行为具有多个不同表现形式或形态的能力。
多态就是同一个接口,使用不同的实例而执行不同操作
(02)多态的优点
消除类型之间的耦合关系
可替换性
可扩充性
接口性
灵活性
简化性
(03)多态存在的三个必要条件
继承
重写
父类引用指向子类对象:Parent p = new Child();
3)封装
(1)良好的封装能够减少耦合。
(01)封装(英语:Encapsulation)是指一种将抽象性函式接口的实现细节部分包装、隐藏起来的方法
(02)要访问该类的代码和数据,必须通过严格的接口控制。
(03)封装最主要的功能在于我们能修改自己的实现代码,而不用修改那些调用我们代码的程序片段。
(04)适当的封装可以让程式码更容易理解与维护,也加强了程式码的安全性。
(2)封装的优点
(01)良好的封装能够减少耦合。
(02)类内部的结构可以自由修改。
(03)可以对成员变量进行更精确的控制。
(04)隐藏信息,实现细节。
(3)实现封装的步骤
(01)修改属性的可见性来限制对属性的访问(一般限制为private),
(02)对每个值属性提供对外的公共方法访问,也就是创建一对赋取值方法,用于对私有属性的访问。
03、java的抽象类
1)抽象类总结规定
(1)抽象类不能被实例化(初学者很容易犯的错),如果被实例化,就会报错,编译无法通过。只有抽象类的非抽象子类可以创建对象。
(2)抽象类中不一定包含抽象方法,但是有抽象方法的类必定是抽象类。
(3)抽象类中的抽象方法只是声明,不包含方法体,就是不给出方法的具体实现也就是方法的具体功能。
(4)构造方法,类方法(用 static 修饰的方法)不能声明为抽象方法。
(5)抽象类的子类必须给出抽象类中的抽象方法的具体实现,除非该子类也是抽象类。
04、Java 重写(Override)与重载(Overload)
1)重写(Override)
(1)什么是重写
(01)重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写!
(02)重写的好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。
(03)重写方法不能抛出新的检查异常或者比被重写方法申明更加宽泛的异常。
(04)例如: 父类的一个方法申明了一个检查异常 IOException,但是在重写个方法的时候不能抛出 Exception 异常,因为 Exception 是 IOException 的父类,只能抛出 IOException 的子类异常
(2)方法的重写规则
(01)参数列表与被重写方法的参数列表必须完全相同。
(02)返回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类(java5 及更早版本返回类型要一样,java7 及更高版本可以不同)。
(03)访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为 public,那么在子类中重写该方法就不能声明为 protected。
(04)父类的成员方法只能被它的子类重写。
(05)声明为 final 的方法不能被重写。
(06)声明为 static 的方法不能被重写,但是能够被再次声明。
(07)子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为 private 和 final 的方法。
(08)子类和父类不在同一个包中,那么子类只能够重写父类的声明为 public 和 protected 的非 final 方法。
(09)重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
(10)构造方法不能被重写。
(11)如果不能继承一个类,则不能重写该类的方法。
(3)Super 关键字的使用
当需要在子类中调用父类的被重写方法时,要使用 super 关键字。
2)重载(Overload)
(1)什么是重载
(01)重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
(02)每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表。
(03)最常用的地方就是构造器的重载。
(2)重载规则
(01)被重载的方法必须改变参数列表(参数个数或类型不一样);
(02)被重载的方法可以改变返回类型;
(03)被重载的方法可以改变访问修饰符;
(04)被重载的方法可以声明新的或更广的检查异常;
(05)方法能够在同一个类中或者在一个子类中被重载。
(06)无法以返回值类型作为重载函数的区分标准。
3)重写与重载的区别
4)重写与重载的总结
(1)方法的重写(Overriding)和重载(Overloading)是java多态性的不同表现,重写是父类与子类之间多态性的一种表现,重载可以理解成多态的具体表现形式。
(2)方法重载是一个类中定义了多个方法名相同,而他们的参数的数量不同或数量相同而类型和次序不同,则称为方法的重载(Overloading)。
(3)方法重写是在子类存在方法与父类的方法的名字相同,而且参数的个数与类型一样,返回值也一样的方法,就称为重写(Overriding)。
(4)方法重载是一个类的多态性表现,而方法重写是子类与父类的一种多态性表现。
05、Java 接口
1)什么是java接口
(1)接口(英文:Interface),在JAVA编程语言中是一个抽象类型,是抽象方法的集合,接口通常以interface来声明。一个类通过继承接口的方式,从而来继承接口的抽象方法。
(2)接口并不是类,编写接口的方式和类很相似,但是它们属于不同的概念。类描述对象的属性和方法。接口则包含类要实现的方法。
(3)除非实现接口的类是抽象类,否则该类要定义接口中的所有方法。
(4)接口无法被实例化,但是可以被实现。一个实现接口的类,必须实现接口内所描述的所有方法,否则就必须声明为抽象类。另外,在 Java 中,
(5)接口类型可用来声明一个变量,他们可以成为一个空指针,或是被绑定在一个以此接口实现的对象
2)接口与类相似点
(1)一个接口可以有多个方法。
(2)接口文件保存在 .java 结尾的文件中,文件名使用接口名。
(3)接口的字节码文件保存在 .class 结尾的文件中。
(4)接口相应的字节码文件必须在与包名称相匹配的目录结构中。
3)接口与类的区别
(1)接口不能用于实例化对象
(2)接口没有构造方法
(3)接口中所有的方法必须是抽象方法
(4)接口不能包含成员变量,除了 static 和 final 变量
(5)接口不是被类继承了,而是要被类实现
(6)接口支持多继承。
4)接口特性
(1)接口中每一个方法也是隐式抽象的,接口中的方法会被隐式的指定为 public abstract(只能是 public abstract,其他修饰符都会报错)。
(2)接口中可以含有变量,但是接口中的变量会被隐式的指定为 public static final 变量(并且只能是 public,用 private 修饰会报编译错误)。
(3)接口中的方法是不能在接口中实现的,只能由实现接口的类来实现接口中的方法
5)抽象类和接口的区别
(1)抽象类中的方法可以有方法体,就是能实现方法的具体功能,但是接口中的方法不行。
(2)抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的
(3)接口中不能含有静态代码块以及静态方法(用 static 修饰的方法),而抽象类是可以有静态代码块和静态方法。
(4)一个类只能继承一个抽象类,而一个类却可以实现多个接口。
6)语法
[可见度] interface 接口名称 [extends 其他的接口名] { // 声明变量 // 抽象方法}
7)接口有以下特性
(1)接口是隐式抽象的,当声明一个接口的时候,不必使用abstract关键字
(2)接口中每一个方法也是隐式抽象的,声明时同样不需要abstract关键字。
(3)接口中的方法都是公有的。
06、java的集合
1)HashMap集合
(1)详细学习地址
(01)详细文章链接地址
(02)学习视屏地址
(2)特点
a、快速存储
b、快速查找(时间复杂度)
3、可伸缩
(3)什么是HashMap
(01)HashMap是基于哈希表的Map接口的非同步实现,是一个用于存储Key-Value键值对的集合,
每一个键值对也叫做Entry。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。
(02)HashMap中元素的key是唯一的,value值可重复。
(03)HashMap中允许使用null值和null键。
(04)HashMap中的元素是无序的。
(05)由于hashMap是非同步实现的,这就意味着它不是线程安全的。
(06)hashMap继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
(4)HashMap的原理是什么
(01)HashMap是基于hash算法实现的,通过put(key,value)存储对象到HashMap中,
也可以通过get(key)从HashMap中获取对象。
(02)当我们使用put的时候,首先HashMap会对key的hashCode()的值进行hash计算,
根据hash值得到这个元素在数组中的位置(即下标),将元素存储在该位置的链表上。
当我们put元素的时候,如果key存在,key不会被覆盖,新的value会代替旧的value,
该方法返回的是旧的value。如果key不存在,该方法返回的是null。
(03)当我们使用get的时候,首先HashMap会对key的hashCode()的值进行hash计算,
根据hash值得到这个元素在数组中的位置,将元素从该位置上的链表中取出。通过key的
equals方法对应 的位置的链表中找到需要的元素。
(5)HashMap常用的接口方法有那些
(01)clear():清空HashMap。它是通过将所有的元素设为null来实现的;
(02)containsKey():判断HashMap是否包含“值为key”的元素;
(03)containsValue():判断HashMap是否包含“值为value”的元素;
(04)entrySet()、values()、keySet():返回“HashMap中所有对应的集合”,它是一个集合;
(05)get(“key值”):获取key对应的value;
(06)put(key,value):对外提供接口,让HashMap对象可以通过put()将“key-value”添加到HashMap中;
(07)putAll():将"m"的全部元素都添加到HashMap中;
(08)remove():删除“键为key”元素。
(6)HashMap有那些构造函数
(01)public HashMap()// 默认构造函数;
(02)public HashMap(int initialCapacity, float loadFactor) / /指定“容量大小”和“加载因子”的构造函数;
(03)public HashMap(int initialCapacity) // 指定“容量大小”的构造函数;
(04)public HashMap(Map<? extends K, ? extends V> m) // 包含“子Map”的
构造函数,将m中的全部元素逐个添加到HashMap中;
(7)在高并发的情况下,为什么hashMap会出现死锁
答:我们知道默认HashMap的初始长度是16,比较小,
每一次push的时候,都会检查当前容量是否超过 预定
的 threshold,如果超过,扩大HashMap容量一倍,
整个表里的所有元素都需要按照新的hash算法被算一
遍,这个代价较大。提到死锁,对于HashMap来说,
貌似只能和链表操作有关。
(8)在java8中,对hashMap有着怎样的优化
答:简单说: java7中 hashMap每个桶中放置的是链表,
这样当hash碰撞严重时,会导致个别位置链表长度过长,
从而影响性能。 java8中,HashMap 每个桶中当链表长
度超过8之后,会将链表转换成红黑树,从而提升增删
改查的速度。
2)HashTable集合
(1)详细学习地址
(01)详细文章链接地址
(02)学习视屏地址
答:hashTable是基于哈希表的map接口的同步实现,它存储的数据都是
(2)什么是Hashtable
键值对(key:value)映射,key和value的不允许存储null值,如遇到null
值时会抛出空指针(NullPointExeeption)异常;key存储是唯一的,
value的值可重复存储;hashTable存储的元素是无序
(3)HashMap常用的接口方法有那些
(01)clear():的作用是清空Hashtable。它是将Hashtable的table数组的值全部设为null;
(02)contains() 和containsValue() 的作用都是判断Hashtable是否包含“值(value)”,
返回true和false,如果值为null,会抛出空指针;来看看源码
(03)containsKey() 的作用是判断Hashtable是否包含key,如果存在则返回true,没有则返回false;
(04)elements() 的作用是返回“所有value”的枚举对象;
(05)get() 的作用就是获取key对应的value,没有的话返回null
(06)put() 的作用是对外提供接口,让Hashtable对象可以通过put()将“key-value”添加到Hashtable中;
(07)remove的作用是就是删除hashtable中键为key的元素;
(08)putAll() 的作用是将“Map(t)”的中全部元素逐一添加到Hashtable中;
(4)Hashtable的成员变量有那些
(01) table:一个Entry[]数组类型,而Entry(在 HashMap 中有讲解过)
就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的
(02)count:Hashtable的大小,它是Hashtable保存的键值对的数量
(03)threshold:Hashtable的阈值,用于判断是否需要调整Hashtable的容
量,threshold的值 = (容量 * 负载因子)
(04)loadFactor:负载因子
(05)dCount:用来实现fail-fast机制的
(5)Hashtable的初始长度是多少
答:hastable的初始长度为11;每一次扩容时,
都是现在的容量*负载因子;负载因子等于0.75;
3)LinkedHashMap集合
详细文章链接地址
4、List集合
07、java的异常
IllegalArgumentException:不合法的参数异常
分支主题
08、阻塞队列
Semaphore
CountDownLatch
CyclicBarrier
09、ThreadPool线程池
例子:MyThreadPoolDemo
为什么用线程池
线程池如何使用
架构说明
编码实现
Executors.newFixedThreadPool(int)
执行长期任务性能好,创建一个线程池,\n一池有N个固定的线程,有固定线程数的线程
Executors.newSingleThreadExecutor()
一个任务一个任务的执行,一池一线程
Executors.newCachedThreadPool()
执行很多短期异步任务,线程池根据需要创建新线程,\n但在先前构建的线程可用时将重用它们。可扩容,遇强则强
ThreadPoolExecutor底层原理
线程池几个重要参数
7大参数
1、corePoolSize:线程池中的常驻核心线程数
2、maximumPoolSize:线程池中能够容纳同时\n执行的最大线程数,此值必须大于等于1
3、keepAliveTime:多余的空闲线程的存活时间\n当前池中线程数量超过corePoolSize时,当空闲时间\n达到keepAliveTime时,多余线程会被销毁直到\n只剩下corePoolSize个线程为止
4、unit:keepAliveTime的单位
5、workQueue:任务队列,被提交但尚未被执行的任务
6、threadFactory:表示生成线程池中工作线程的线程工厂,\n用于创建线程,一般默认的即可
7、handler:拒绝策略,表示当队列满了,并且工作线程大于\n等于线程池的最大线程数(maximumPoolSize)时如何来拒绝\n请求执行的runnable的策略
线程池底层工作原理
线程池用哪个?生产中如设置合理参数
线程池的拒绝策略
是什么
JDK内置的拒绝策略
AbortPolicy(默认):直接抛出RejectedExecutionException异常阻止系统正常运行
CallerRunsPolicy:“调用者运行”一种调节机制,该策略既不会抛弃任务,也不\n会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。
DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加人队列中\n尝试再次提交当前任务。
DiscardPolicy:该策略默默地丢弃无法处理的任务,不予任何处理也不抛出异常。\n如果允许任务丢失,这是最好的一种策略。
以上内置拒绝策略均实现了\nRejectedExecutionHandle接口
在工作中单一的/固定数的/可变的三种创建线程池的方法哪个用的多?超级大坑
答案是一个都不用,我们工作中只能使用自定义的
Executors中JDK已经给你提供了,为什么不用?
在工作中如何使用线程池,是否自定义过线程池
代码
10、java对文件的操作
3、java高级
01、java多线程编程
(1)了解什么是线程
(01)cpu的核心数和线程数的关系
1)核心数:线程数 1:1 超线程技术:1:2
(02)什么是进程和线程
1)进程,程序运行资源分配的最小单位,进程内部有多个线程,会共享这个进程的资源。
2)线程,cpu调度的最小单位
3)进程间不会相互影响,一个线程挂掉将导致整个进程挂掉
4)进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-"互斥锁"
5)进程使用的内存地址可以限定使用量
6)不同进程间数据很难共享
7)同一进程下不同线程间数据很容易共享
8)进程要比线程消耗更多的计算机资源
(2)线程的基础应用
(01)有几种方式启动java线程
1)类Thread(继承)
2)接口Runnable(实现)
3)接口Callable(实现)
(02)线程启动start和run的区别
调用start方法方可启动线程,而run方法只是thread类中的一个普通方法调用,还是在主线程里执行。
(03)如何正确安全停止java的线程
1)正常运行完
2)抛出异常
3)调用stop()、resume()、suspend()线程资源不会释放
4)interrupt()中断一个线程,并不是强行关闭
5)isInterrupted()判断当前线程是否是中断状态
6)interrupted()判断当前线程是滞是中断状态
(04)线程的运行状态和优先级
1)线程的执行状态
(1)新建
(2)就绪
(3)阻塞
(4)执行
(5)结束
(6)死亡
2)线程的优先级
(1)优先级共有10级
(2)设置级别越高,执行的概率越大
(3)线程间的共享理解
(01)线程间的共享
1)synchronized内置锁,使用在类锁、对像锁
2)volatile关键字,只有一个线程写,多个线程读时用。线程不安全
3)ThreadLocal
(02)线程间的协作
1)等待和通知的标准范式
等待方
(1)获取对象的锁;
(2)循环里判断条件是否满足,不满足调用wait方法;
(3)条件满足执行业务逻辑;
通知方
(1)获取对旬的锁;
(2)改变条件;
(3)通知所有等待在对象的线程;
2)线程的通知notify和notifyAll应该使用那一个
应该使用notifyAll,而使用notify通知信息会丢失
3)等待超时
a、假设,等待时间时长为T,当前时间now+T后超时
4)join方法
线程A执行了线程B的join方法,线程A必须要等待线程B执行完成了以后,线程A才能继续执行
5)调用yield()、wait()、notifyAll()、notify()等方法对锁的影响
(1)线程在执行yield()以后,持有的锁是不释放的
(2)sleep()方法被调用后,持有的锁是不释放的
(3)调用方法之前,必须要持有锁,调用wait()方法之后,锁就会被释放
(4)调动方法之前,必须要持有锁,调用notify()方法本身不会释放
(03)守护线程
1)和主线程共生死、try catch不一定执行
2)使用方法:setDaemon(true);需要在start的前面执行
(4)javar的并发工具类
(01)Fork/join体现了"分而治之"
(02)CountDownLatch的作用,应用场景
(1)作用:await用来等待,countDown负责计数器减一
(2)应用场景:是一组线程等待其他的线程完成工作以后在执行,加强版的join方法
用在有几个或者好几个线程中,全部完成在往下走
(03)CyclicBarrier的作用,应用场景
(1)作用:CyclicBarrier(int paries,Runnable barrierAction),屏障开放,barrierAction定义的任务会执行
(2)应用场景:让一组线程达到某个屏障,被阻塞,一直到组内最后一个线程达到屏障时,
屏障开放所有被阻塞的线程会继续运行CyclicBarrier(int parties)
(04)CountDownLatch和CyclicBarrier 的辨析
(1)CountDownLatch放行由第三者控制,CyclicBarrier旅行由一组线程本身控制。
(2)CountDownLatch放行条件>=线程数,CyclicBarrier放行条件等于线程数。
(05)Semaphre的作用,应用场景
(1)作用:控制同时访问某个特定资源的线程数量
(2)应用场景:一般用在流量控制
(06)Callable、Future和FutreTask
(1)任务还没有开始,返回false
(2)任务已经启动,cancel(true),中断正在运行的任务,中断成功,返回true,cancel(false)、不会去中断已经运行的任务
(3)任务已经结束,返回false
(4)isDone,结束:正常还是异常结束,或者自己取消,返回true
(5)isCanelled任务完成前被取消,返回true
(6)cancel(boolean)
业务操作时比较耗时时使用
(07)Exchange的作用
两个线程间的数据交换
02、Java注解和反射
1)注解
1)什么是注解
(1)Annotation是JDK5.0开始引入的新技术
(2)Annotation的作用
不是程序本身,可以对程序做出解释(这一点和注释没有什么区别)
可以被其它程序,比如编译器读取
(3)Annotation的格式
注解以 @注释名 在代码中存在的,还可以添加一些参数值
例如:@SuppressWarnings(value = "unchecked")
(4)Annotation在那里使用?
可以附加在package、class、method、field等上面,相当于给他们添加了额外的辅助信息
通过反射机制变成实现对这些元数据的控制
2)内置注解
(1)@Override:定义在 java.lang.Override中,此注释只适用于修饰方法,表示一个方法声明
打算重写超类中的另一个方法声明
(2)@Deprecated:定义在java.lang.Deprecated中,此注释可以用于修饰方法,属性,类,
表示不鼓励程序员使用这样的元素,通常是因为它很危险,或者存在更好的选择
(3)@SuppressWarnings:定义在java.lang.SuppressWarnings中,用来抑制编译时的
警告信息,与前面的两个注释不同,你需要额外添加一个参数才能正确使用,这些
参数都是已经定义好了的,我们选择性的使用就好了。@SuppressWarnings("all")
3)元注解
(1)元注解的作用就是负责注解其它注解,Java定义了4个标准的meta-annotation类型,他们被用来提供对其它annotation类型作说明。
这些类型和它们所支持的类在 java.lang.annotation包可以找到 @Target 、@Retention、@Documented、@Inherited
(2)@Target:用于描述注解的使用范围,即:被描述的注解可以在什么地方使用
(3)@Retention:表示需要什么保存该注释信息,用于描述注解的生命周期,级别范围:Source < Class < Runtime
(4)@Document:说明该注解被包含在java doc中
4)自定义注解
(1)使用 @interface自定义注解时,自动继承了 java.lang.annotation.Annotation接口<br>@interface 用来声明一个注解,格式:public @interface 注解名 {定义内容其中的每个方法实际上是申明了一个配置参数<br>
(2)方法的名称就是参数的类型
(3)返回值类型就是参数的类型(返回值只能是基本数据类型,Class,String,enum)
(4)通过default来申明参数的默认值
(5)如果只有一个参数成员,一般参数名为 value
(6)注解元素必须要有值,我们定义元素时,经常使用空字符串或者0作为默认值
2)反射
动态语言与静态语言
动态语言
a、动态语言是一类在运行时可以改变其结构的语言:例如x
新的函数,对象,甚至代码可以被引进,已有的函数可x
以被删除或是其它结构上的变化。通俗点说就是在运行
时代码可以根据某些条件改变自身结构
b、主要的动态语言有:Object-c、C#、JavaScript、PHP、Python等
动态语言
a、与动态语言相比,运行时结构不可变的语言就是静态语言。例如Java、C、C++
b、Java不是动态语言,但是Java可以称为“准动态语言”。即Java有一定<br>的动态性,我们可以利用反射机制来获取类似于动态语言的 特性,Java的<br>动态性让编程的时候更加灵活。<br>
什么是反射
Java Reflection:Java反射是Java被视为动态语言的关键<br>反射机制运行程序在执行期借助于Reflection API 去的任何<br>类内部的信息,并能直接操作任意对象的内部属性及方法。<br>
java反射的作用
➢在运行时构造任意--个类的对象
➢在运行时判断任意-一个类所具有的成员变量和方法
➢在运行时获取泛型信息
➢在运行时调用任意一个对象的成员变量和方法
➢在运行时处理注解
➢生成动态代理
java反射相关API
java.lang.reflect.Method:代表类的方法
java.lang.reflect.Field:代表 类的成员变量
java.lang.reflect.Constructor:代表 类的构造器
4、java常见异常
BeansException
分支主题
三、java框架篇
一)Spring
1、初识什么是Spring
1)spring简介
答:Spring是一个开源的轻量级的Java开发框架,由Rod Johnson创建 ,是一个容器框架,用于配制bean并维护bean之间关系的框架,可以管理视图层,业务层,dao层,可以配制各层组件.从简单性,可测试性和松耦合的角度而言,任何java框架的可以从Spring中受益;
2)重要概念
(1)bean(java中任何一种对象):创建对象中需要的对象,同时维护对象之间的关系。
(2)IOC(inverse of control控制反转):将对象的创建和对象间关系的维护放在spring容器中完成。
(3)DI(dependency injection依赖注入):设计者认为di更能体现spring能力。
3)使用步骤
(1)引入 Spring开发包(最小配制spring.jar该包把常用的jar都包括,还要写日志包common-logging.jar)
(2)创建spring核心文件applicationContext.xml,一般放在src下
(3)使用bean,读取spring核心配制文件(加载spring容器)
ApplicationContext ac=new ClassPathXmlApplicationContext("applicationContext.xml");
(4)获取在spring核心配置文件中创建的bean对象,ac.getBean("标签的id值");
(5)传统方式调用和Spring方式的区别,使用Spring无需创建对象,将创建的对象的任务交给Spring,降低耦合
(6)当new ClassPathXmlApplicationContext("applicationContext.xml");执行的时候,spring容器被创建,同时applicationContext.xml中配置的bean就会被创建在内存中,并同时维护了bean与bean之间的关系;
2、Spring的IOC
01、什么是IOC
答:控制反转(inverse of control),就是把创建对象bean和维护对象bean的关系的权利
从程序中转移到spring的容器(applicationContext.xml)中,而程序本身不再维护。
02、使用IOC的目的
为了降低程序的耦合度
03、IOC的底层组成
由xml解析、工厂模式、反射三部份组成
04、Spring提供的IOC容器实现的两种方式
1)BeanFactory接口:IOC容器基本实现是Spring内部接口的使用接口,不提供给开发人
员进行使用(加载配置文件时候不会创建对象,在获取对象时才会创建对象。)
2)ApplicationContext接口:BeanFactory接口的子接口,提供更多更强大的功能,提供
给开发人员使用(加载配置文件时候就会把在配置文件对象进行创建)推荐使用!
05、IOC容器-Bean管理
06、IOC 操作 Bean 管理(基于注解方式)
1)什么是注解
(1)注解是代码特殊标记,格式:@注解名称(属性名称=属性值, 属性名称=属性值…)
(2)使用注解,注解作用在类上面,方法上面,属性上面
(3)使用注解目的:简化 xml 配置
2)Spring 针对 Bean 管理中创建对象提供四种注解创建Bean实例
a、@Component
b、@Service
c、@Controller
d、@Repository
3)基于注解方式实现对象创建
第一步 引入依赖 (引入spring-aop jar包)
第二步 开启组件扫描
<!--开启组件扫描1 如果扫描多个包,多个包使用逗号隔开2 扫描包上层目录-->
<context:component-scan base-package="com.atguigu"></context:component-scan>
第三步 创建类,在类上面添加创建对象注解
//注解等同于XML配置文件:<bean id="userService" class=".."/>
@Component(value = "userService")public class UserService { public void add() {System.out.println("service add......."); }}
4)开启组件扫描细节配置
<!--示例 1use-default-filters="false" 表示现在不使用默认 filter,自己配置 filtercontext:include-filter ,设置扫描哪些内容-->
<context:component-scan base-package="com.atguigu" use-defaultfilters="false"> <context:include-filter type="annotation" expression="org.springframework.stereotype.Controller"><!--代表只扫描Controller注解的类--></context:include-filter></context:component-scan>
<!--示例 2下面配置扫描包所有内容context:exclude-filter: 设置哪些内容不进行扫描-->
<context:component-scan base-package="com.atguigu"> <context:exclude-filter type="annotation"expression="org.springframework.stereotype.Controller"/><!--表示Controller注解的类之外一切都进行扫描--></context:component-scan>
5)基于注解方式实现属性注入
@Autowired:根据属性类型进行自动装配
第一步 把 service 和 dao 对象创建,在 service 和 dao 类添加创建对象注解
第二步 在 service 注入 dao 对象,在 service 类添加 dao 类型属性,在属性上面使用注解
//定义 dao 类型属性 //不需要添加 set 方法 //添加注入属性注解
@Service public class UserService { @Autowired private UserDao userDao; public void add() {\n System.out.println("service add.......");userDao.add(); }}
//Dao实现类//@Repository(value = "userDaoImpl1")
@Repository public class UserDaoImpl implements UserDao { @Override public void add() {\n System.out.println("dao add....."); }}
@Qualifier:根据名称进行注入,这个@Qualifier 注解的使用,和上面@Autowired 一起使用
//定义 dao 类型属性//不需要添加 set 方法//添加注入属性注解@Autowired //根据类型进行注入//根据名称进行注入(目的在于区别同一接口下有多个实现类,根据类型就无法选择,从而出错!)
@Qualifier(value = "userDaoImpl1") private UserDao userDao;
@Resource:可以根据类型注入,也可以根据名称注入(它属于javax包下的注解,不推荐使用!)
//@Resource //根据类型进行注入//@Resource //根据类型进行注入
@Resource(name = "userDaoImpl1") private UserDao userDao;
@Value:注入普通类型属性
@Value(value = "abc") private String name
6、完全注解开发
(1)创建配置类,替代 xml 配置文件
//作为配置类,替代 xml 配置文件
@Configuration @ComponentScan(basePackages = {"com.atguigu"}) public class SpringConfig { }
(2)编写测试类
//加载配置类
@Test public void testService2() { \n ApplicationContext context\n = new AnnotationConfigApplicationContext(SpringConfig.class);\n UserService userService = context.getBean("userService",\nUserService.class);\n System.out.println(userService);\n userService.add();}
3、Spring的AOP
4、给spring容器中添加组件的方法
1)使用包扫描+标注解的方式(@Controller、@Service、@Component、@Repository)
2)@Bean【导入第三包里面的组件】
3)@Import【快速给容器中导入一个组件】
1) 、@Import(要导入到容器中的组件)﹔容器中就会自动注册这个组件,id默认是全类名
2) 、自定义实现 ImportSelector:返回需要导入的组件的全类名数组﹔
@Import({Reds.class,MyImportSelect.class})
4)使用spring的FactoryBean(工厂Bean)
5)bean的生命周期
bean创建---初始化---–销毁的过程
指定初始化和销毁方法;
通过@Bean指定init-method和destroy-method;
2)、通过让Bean实现InitializingBean(定义初始化逻辑)﹐DisposableBean(定义销毁逻辑);
3)、可以使用JSR250;
@Post(oristruct:在bean创建完成并且属性赋值完成;来执行初始化方法
@preDestroy:在容器销毁bean之前通知我们进行清理工作
4)、BeanPostProcessor 【interface】 : bean的后置处理器;
在bean初始化前后进行一些处理工作;
postProcessBeforeInitialization:在初始化之前工作
postProcessAfterInitialization :在初始化之后工作
初始化和销毁源码
BeanPostProcessor.postProcessBeforeInitialization
初始化:对象创建完成,并赋值好,调用初始化方法。。。
BeanPostProcessor.postProcessAfterInitialization销毁:
单实例:容器关闭的时候
多实例:容器不会管理这个bean:容器不会调用销毁方法;
构造(对象创建)
单实例:在容器启动的时候创建对象
多实例:在每次获取的时候创建对象
5、di(dependency injection)
依赖注入,实际上和ioc是同一个概念,spring设计者认为di更能准确体现spring核心技术;
二、mybatis
1、什么是ORM
对象关系映射(ORM Obeject Relational Mapping),ORM模型就是数据库的表与简单Java对象(POJO)的映射模型,它主要解决数据库数据和POJO对象的相互映射;
好处
更加贴合面向对象的编程语意,Java程序员喜欢的姿势;
技术和业务解耦,Java程序员无需对数据库相关的知识深入了解
妈妈再也不用担心我,不释放数据库连接资源了
2、常用接口
sqlSessionFactoryBuilder :读取配置信息创建SqlSessionFactory,建造者模式,方法级别生命周期;
sqlSessionFactory :创建Sqlsession工厂单例模式.存在于程序的整个生命周期;
sqlSession :代表一次数据库连接,可以直接发送SQL执行,也可以通过调用Mapper访问数据库;线程不安全,要保证线程独享(方法级);
SQL Mapper :由一个Java接口和XML文件组成包含了要执行的SQL语句和结果集映射规则。方法级别生命周期;
3、Mybatis配置文件的标签
1、properties
定义配置,配置的属性可以在整个配置文件中其他位置进行引用;
重要,优先使用property配置文件解耦
2、settings
设置,用于指定MyBatis的一些全局配置属性,这些属性非常重要,它们会改变MyBatis的运行时行为;
重要,后面专门说明
3、typeAliases
别名,为Java类型设置一个短的名字,映射时方便使用;分为系统定义别名和自定义别名;
可以通过xml和注解配置
4、typeHandlers
用于jdbcType与javaType之间的转换;
无特殊需求不需要调整;后面专题说明
5、ObjectFactory
MyBatis每次创建结果对象的新实例时,它都会使用对象工厂(ObjectFactory)去构建POJO
大部分场景下无需修改
6、plugins
插件,MyBatis允许你在已映射的语句执行过程中的某一点进行拦截调用;
7、environments
用于配置多个数据源,每个数据源分为数据库源和事务的配置;
在多数据源环境使用
environment元素是配置一个数据源的开始,属性id是它的唯一标识
transactionManager元素配置数据库事务,其中type属性有三种配置方式
jdbc采用jdbc的方式管理事务;
managed,采用容器的方式管理事务,在JNDI数据源中使用;
自定义,自定义数据库事务管理办法;
■dataSource 元素配置数据源连接信息, type属性是连接数据库的方式配置,有四种配置方式
UNPOOLED非连接池方式连接
POOLED使用连接池连接
JNDI使用JNDI数据源
自定义数据源
8、databaseldProvider
MyBatis可以根据不同的数据库厂商执行不同的语句,用于一个系统内多厂商数据源支持。
大部分场景下无需修改
9、mappers
配置引入映射器的方法。可以使用相对于类路径的资源引用、或完全限定资源定位符(包括file:///的URL),或类名和包名等等
10、cacheEnabled
该配置影响的所有映射器中配置的缓存的全局开关
11、lazyLoadingEnabled
延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。特定关联关系中可通过设置fetchType属性来覆盖该项的开关状态
12、aggressiveLazyLoading
当启用时,对任意延迟属性的调用会使带有延迟加载属性的对象完整加载反之,每种属性将会按需加载。
13、multipleResultSetsEnabled
是否允许单一语句返回多结果集(需要兼容驱动)。
14、useColumnLabel
使用列标签代替列名。不同的驱动在这方面会有不同的表现,具体可参考相关驱动文档或通过测试这两种不同的模式来观察所用驱动的结果。
15、useGeneratedKeys
允许JDBC支持自动生成主键,需要驱动兼容。如果设置为 true则这个设置强制使用自动生成主键,尽管-些驱动不能兼容但仍可正常工作(比如Derby).
16、autoMappingBehavior
指定MyBatis应如何自动映射列到字段或属性。NONE 表示取消自动映射; NONE, PAPARTIAL只会自动映射没有定义嵌套结果集映射的结果集。FULL 会自动映射任意复杂的结果集(无论是否嵌套)。
17、defaultExecutorType
配置默认的执行器。SIMPLE 就是普通的执行器; REUSE执行器会重用预处理语句( prepared statements) ; BATCH 执行器将重用语句并执行批量更新。
18、defaultStatementTimeout
设置超时时间,它决定驱动等待数据库响应的秒数。
19、safeRowBoundsEnabled
允许在嵌套语句中使用分页( RowBounds )。
20、mapUnderscoreToCamelCaser
是否开启自动驼峰命名规则( camel case )映射,即从经典数据库列名A COLUMN到经典Jave属性名aColumn的类似映射。
21、localCacheScope
MyBatis利用本地缓存机制( Local Cache )防止循环引用( circular references )和加速重复嵌套查询。默认值为SESSION,这种情况下会缓存一个会话中执行的所有查询。若设置值为STATEMENT本地会话仅用在语句执行上,对相同SqlSession的不同调用将不会共享数据。
22、jdbcTypeForNull
当没有为参数提供特定的JDBC类型时,为空值指定JDBC类型。某些驱动需要指定列的JDBC类型,多数情况直接用一般类型即可,比如NULL. VARCHAR或OTHER。
22、lazyLoadTriggerMethods
指定哪个对象的方法触发一 次延迟加载。
23、callSettersOnNulls
指定当结果集中值为null的时候是否调用映射对象的setter( map对象时为put )方法,这对于有Map.keySet()依赖或null值初始化的时候是有用的。注意基本类型( int. boolean等)是不能设置成null的。
24、logPrefix
指定MyBatis增加到日志名称的前缀。
25、 loglmpl
指定MyBatis所用日志的具体实现,未指定时将自动查找。
26、proxyFactory
指定Mybatis创建具有延迟加载能力的对象所用到的代理工具。
4、基于xml配置的映射器
cache -给定命名空间的缓存配置。
cache-ref -其他命名空间缓存配置的引用。
resultMap- 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。
sql- 可被其他语句引用的可重用语句块。
insert -映射插入语句
update -映射更新语句
delete -映射删除语句
select -映射查询语句
5、select元素
■自动映射
前提: SQL列名和JavaBean的属性是一致的;
自动映射等级autoMappingBehavior设置为PARTIAL ,需要谨慎使用FULL;
使用resultType ;
如果列名和JavaBean不一致,但列名符合单词下划线分割, Java是驼峰命名法则mapUnderscore' ToCamelCase可设置为true ;
■传递多个查询入参
1)使用map传递参数;可读性差,导致可维护性和可扩展性差, 杜绝使用;
2)使用注解传递参数;直观明了,当参数较少般小于5个的时候 ,建议使用;
3)使用Java Bean的方式传递参数;当参数大于5个的时候, 建议使用;
select标签
id
它和Mpper的命名空间组合起来是唯一-的 ,提供给MyBatis调用
如果命名空间和id组合起来不唯一,会抛出异常
parameterType
传入参数的类型 ;可以给出类全名,也可以给出类别名,使用别名必须是MyBatis内部定义或自定义的:基本数据类型: int,String , long , date(不知是sql.date还是util.date)复杂数据类型:类和Map
可以选择JavaBean , Map等复杂的参数类型传递给SQL
resultType
从这条语句中返回的期望类型的类的完全限定名或别名。注意如果是集合情形,那应该是集合可以包含的类型,而不能是集合本身。使用resultType或resultMap,但不能同时使用定义类的全路径,在允许自动匹配的情况下,结果集将通过JavaBean的规范映射;或者定义为int,double,float等参数..也可以使用别名,但是要符合别名规范,不能和resultMap同时使用。
它是我们常用的参数之一 ,比如我们总计总条数就可以把它的值设为int
resultMap
外部resultMap的命名引用。使用resultMap或resultType ,但不能同时使用;它是映射集的引用,将执行强大的映射功能,我们可以使用resultType或者resultMap其中的-个, resultMap可以给予我们自定义映射规则的机会
它是MyBatis最复杂的元素,可以配置映射规则、级联、typeHandler等
flushCache
它的作用是在调用SQL后,是否要求MyBatis清空之前查询的本地缓存和级缓存
true/false,默认为false
useCache
启动级缓存开关,是否要求MyBatis将此次结果缓存
true/false ,默认为true
timeout
设置超时时间.超时之后抛出异常,秒
默认值为数据库厂商提供的JDBC驱动所设置的秒数
fetchSize
获取记录的总条数设定
默认值是数据库厂商提供的JDBC驱动所设条数
6、resultMap元素属性
resultMap元素是MyBatis中最重要最强大的元素。它可以让你从90%的JDBC ResultSets 数据提取代码中解放出来,在对复杂语句进行联合映射的时候,它很可能可以代替数千行的同等功能的代码。
ResultMap的设计思想是,简单的语句不需要明确的结果映射,而复杂一点的语句只需要描述它们的关系就行了。
id
当前命名空间中的一个唯一标识,用于标识一个result map.
type
类的完全限定名,或者一个类型别名(内置的别名可以参考上面的表格).
autoMapping
如果设置这个属性,MyBatis将会为这个ResultMap开启或者关闭自动映射。这个属性会覆盖全局的属性autoMappingBehavior。默认值为:unset。
7、mybatis中使用的符号需要转义
①转义法
大于:><br><br>小于:<<br><br>大于等于:>=<br><br>小于等于:<=<br>
三、spring boot
1、spring boot项目创建
项目的项目报maven configuration problem unkno
解决这是版本问题
在pom文件中设置
<properties>\n <java.version>11</java.version>\n <maven-jar-plugin.version>3.1.1</maven-jar-plugin.version>\n</properties>
在eclipse中安装这个插件
Eclipse > Help > Install New Software > Work with= https://download.eclipse.org/m2e-wtp/signed/mavenarchiver/0.17.4/, <Enter>, m2e extensions= Y > Next...
2、spring boot的配置
各种配置的拥有默认值
默认配置最终都是映射到MultipartProperties
配置文件的值最终会绑定每个类上,这个类会在容器中创建对象·
按需加载所有自动配置项
非常多的starter
引入了哪些场景这个场景的自动配置才会开启
SpringBoot所有的自动配置功能都在spring-boot-autoconfigure包里面
3、注解详解
1、@Configuration(proxyBeanNjthods = true)配置组件
//告诉SpringBoot这是一个配置类==配置文件
1、配置类里面使用@Bean标注在方法上给容器注册组件,默认也是单实例的*
2、配置类本身也是组件
3、proxyBeanMethods : 代理bean 的方法
2、@Import
给容器中导入组件
3、@Conditional
当满足条件时在注入,条件装配注解
4、配制文件
yml
基本语法
● key: value; kv之间有空格
● 大小写敏感
● 使用缩进表示层级关系
● 缩进不允许使用tab,只允许空格
● 缩进的空格数不重要,只要相同层级的元素左对齐即可
● '#'表示注释
●“与"”表示字符串内容会被转义/不转义
四、数据库篇
一)结构化数据库:postgres、mysql
(一)postgres数据库
1、postgres 安装
a、Linux(centos7)以上安装
b、windows安装
c、集群安装
2、数据类型
a、说明:数据类型,数据类型是我们在创建表的时候为每个字段设置的。
b、分类(18类)
(1)数据类型
说明:数值类型由 2 字节、4 字节或 8 字节的整数以及 4 字节或 8 字节的浮点数和可选精度的十进制数组成
名称:smallint、integer、bigint、decimal、numeric、real、double precision 、smallserial、serial、bigserial
(2)货币类型
说明:money 类型存储带有固定小数精度的货币金额。不建议使用浮点数来存储,因为会存在四舍五入错误问题
名称:money
(3)字符类型
说明:下面的列出来的postgres数据库支持的字符类型
名称:character varying(n), varchar(n):变长,有长度限制;character(n), char(n):f定长,不足补空白;text:变长,无长度限制
(4)日期/时间类型
说明:下面是支持的日期和时间格式
名称:timestamp、date、time、interval
(5)布尔类型
说明:boolean 有"true"(真)或"false"(假)两个状态, 第三种"unknown"(未知)状态,用 NULL 表示。
名称:boolean
(6)枚举类型
说明:枚举类型是一个包含静态和值的有序集合的数据类型,不同的是要使用如下sql创建
名称:CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
(7)几何类型
说明:几何数据类型表示二维的平面物体
名称:point、line、lseg、box、path、polygon、circle
(8)网络地址类型
说明:用于存储 IPv4 、IPv6 、MAC 地址的数据类型
名称:cidr:IPv4或IPv6网络、inet:IPv4或IPv6主机和网络、macaddr:MAC地址
(9)位串类型
说明:位串就是一串 1 和 0 的字符串
名称:bit(n) 和bit varying(n)
(10)文本搜索类型
说明:全文检索即通过自然语言文档的集合来找到那些匹配一个查询的检索
名称:tsvector、tsquery
(11)其他
UUID 类型、XML 类型、JSON 类型、数组类型、复合类型、范围类型、对象标识符类型和伪类型共8种
3、增、删、查、改语法
1)增加:INSERT INTO TABLE_NAME (column1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN);
2)删除:DELETE FROM table_name WHERE [condition];
3)查询:SELECT column1, column2,...columnN FROM table_name;
4)修改:UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
4、条件语句
1)where子句:当我们需要根据指定条件从单张表或者多张表中查询数据时,就可以在 SELECT 语句中添加 WHERE 子句,从而过滤掉我们不需要数据。
2)and和or:AND 和 OR 也叫连接运算符,在查询数据时用于缩小查询范围,我们可以用 AND 或者 OR 指定一个或多个查询条件。
3)like语句:如果要获取包含某些字符的数据,可以使用 LIKE 子句。
4)limit子句:limit 子句用于限制 SELECT 语句中查询的数据的数量。
5)odery by子句:用于对一列或者多列数据进行升序(ASC)或者降序(DESC)排列。
6)group by子句:GROUP BY 语句和 SELECT 语句一起使用,用来对相同的数据进行分组。放在where后面,order by前面。
5、视图
a、什么是视图:视图相当于一张虚拟表,根据用户的业务需求对已有的表进行组合生成的查询SQL语句,视图不能对数据增加、删除、修改。,
b、创建视图的SQL:CREATE VIEW 视图名 as 查询SQL集合语句
c、视图的删除:DROP VIEW 视图名称;
d、视图的特点
(1)用户或用户组认为更自然或直观查找结构数据的方式
(2)限制数据访问,用户只能看到有限的数据,而不是完整的表
(3)汇总各种表中的数据,用于生成报告
6、索引
1)什么是索引:索引是加速搜索引擎检索数据的一种特殊表查询。简单地说,索引是一个指向表中数据的指针。一个数据库中的索引与一本书的索引目录是非常相似的
2)优缺点:索引有助于加快 SELECT 查询和 WHERE 子句,但它会减慢使用 UPDATE 和 INSERT 语句时的数据输入。索引可以创建或删除,但不会影响数据。
3)特点:使用 CREATE INDEX 语句创建索引,它允许命名索引,指定表及要索引的一列或多列,并指示索引是升序排列还是降序排列。
4)语法:CREATE INDEX index_name ON table_name;
5)索引分类(共5种)
1)单列索引
(1)说明:单列索引是一个只基于表的一个列上创建的索引
(2)语法:CREATE INDEX index_name ON table_name (column_name);
2)组合索引
(1)说明:组合索引是基于表的多列上创建的索引
(2)语法:CREATE INDEX index_name ON table_name (column1_name, column2_name);
3)唯一索引
(1)说明:唯一索引不允许任何重复的值插入到表中
(2)语法:CREATE UNIQUE INDEX index_nameon table_name (column_name);
4)局部索引
(1)说明:局部索引 是在表的子集上构建的索引;子集由一个条件表达式上定义。索引只包含满足条件的行
(2)语法:CREATE INDEX index_nameon table_name (conditional_expression);
5)隐式索引
(1)说明:隐式索引 是在创建对象时,由数据库服务器自动创建的索引。索引自动创建为主键约束和唯一约束。
(2)语法:CREATE INDEX salary_index ON COMPANY (salary);
6)删除索引
(1)说明:一个索引可以使用 PostgreSQL 的 DROP 命令删除
(2)语法:DROP INDEX index_name;
7)什么情况下要避免使用索引
(1)索引不应该使用在较小的表上
(2)索引不应该使用在有频繁的大批量的更新或插入操作的表上。
(3)索引不应该使用在含有大量的 NULL 值的列上
(4)索引不应该使用在频繁操作的列上
7、pgsql修改表名和修改字段
(01)添加表字段:ALTER TABLE 表名 ADD 字段名 字段类型(字段长度);
(02)给字段添加注释:COMMENT ON COLUMN "表名"."字段名" IS '注释内容';
(03)修改表名:alter table table_name(表名) rename to new_table_name(新表名);
(04)修改字段名称:ALTER TABLE "表名" alter COLUMN 字段名 type 字段类型(长度) ;
(05)详细内容请查阅
工作常用
1、查询客户端连接情况SQL
SELECT * FROM pg_stat_activity;
SELECT count(*) FROM (SELECT pg_stat_get_backend_idset() AS backendid) AS ConCount;
(二)mysql数据库
1、mysql安装
2、视图
3、索引
4、修改mysql大小写敏感
在配置文件 /etc/mysql/mysql.conf.d/mysqld.cnf 中添加
lower_case_table_names=1
5、删除mysql中未提交的事务
使用命令查询3秒内未来加提交的事务<br>
SELECT <br>p.ID AS conn_id,<br>P.USER AS login_user,<br>P.HOST AS login_host,<br>p.DB AS database_name,<br>P.TIME AS trx_sleep_seconds,<br>TIME_TO_SEC(TIMEDIFF(NOW(),T.trx_started)) AS trx_open_seconds,<br>T.trx_started,<br>T.trx_isolation_level,<br>T.trx_tables_locked,<br>T.trx_rows_locked,<br>t.trx_state,<br>p.COMMAND AS process_state<br>FROM `information_schema`.`INNODB_TRX` t<br>INNER JOIN `information_schema`.`PROCESSLIST` p<br>ON t.trx_mysql_thread_id=p.id<br>WHERE t.trx_state='RUNNING'<br>AND p.COMMAND='Sleep'<br>AND P.TIME>3<br>ORDER BY T.trx_started ASC;
查询未提交的事务
select t.trx_mysql_thread_id from information_schema.innodb_trx t
删除你想要删除的事务
kill 7487<br>
7)事务的基本要素(ACID)
1、原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
2、一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。其实一致性也是因为原子性的一种表现
3、隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。串行化
4、持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
二)非结构化数据库:FastDfs、HDFS
1、HDFS文件服务器
2、FastDfs文件服务器
01、安装的FastDfs文件服务器配置访问
使用Nginx配置访问
常用命令
校验整合FastDfs集群的情况
/usr/bin/fdfs_monitor /etc/fdfs/storage.conf
启动storaged
/etc/init.d/fdfs_storaged start
停止storaged
/etc/init.d/fdfs_storaged stop<br>
查询fastdfs的配置文件
/etc/fdfs/mod_fastdfs.conf
三)缓存数据库:redis、Nosql
1、redis缓存数据<br>
01、redis的基础操作
redis启动(进入redis安装目录)
指定配制文件启动
./redis-server redis.conf
默认启动
./redis-server
02、redis数据类型使用场景
String
比如说 ,我想知道什么时候封锁一个IP地址。Incrby命令
Hash
存储用户信息【id,name,age】
Hset(key,field,value)
Hset(userKey,id,101)
Hset(userKey,name,admin)
Hset(userKey,age,23)
----修改案例----
Hget(userKey,id)
Hset(userKey,id,102)
为什么不使用String 类型来存储
Set(userKey,用信息的字符串)
Get(userKey)
不建议使用String 类型
List
实现最新消息的排行,还可以利用List的push命令,将任务存在list集合中,同时使
用另一个命令,将任务从集合中取出[pop]。Redis—list数据类型来模拟消息队列。
【电商中的秒杀就可以采用这种方式来完成一个秒杀活动】
Set
特殊之处:可以自动排重。比如说微博中将每个人的好友存在集合(Set)中,
这样求两个人的共通好友的操作。我们只需要求交集即可。
Zset
以某一个条件为权重,进行排序。
京东:商品详情的时候,都会有一个综合排名,还可以按照价格进行排名
03、高并发下缓存失效问题
缓存穿透<br>
描述<br>
指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的null写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义<br>
风险<br>
利用不存在的数据进行攻击,数据库瞬时压力增大,最终导致崩溃<br>
解决<br>
null结果缓存,并加入短暂过期时间<br>
做好参数校验,包括前端和后端,尽量在系统上有对无效参数进行过滤。<br>
缓存击穿<br>
描述<br>
• 对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常高“热点”的数据。如果这个key在大量请求同时进来前正好失效,那么所有对这个key的数据查询都落到db,我们称为缓存击穿。<br>
解决<br>
加锁<br>
大量并发只让一个去查,其他人等待,查到以后释放锁,其他人获取到锁,先查缓存,就会有数据,不用去db查<br>
缓存雪崩<br>
描述<br>
缓存雪崩是指在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。<br>
解决<br>
(01)原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。<br>
(02)使用熔断组件,进行降级处理,返回默认数据库或其他页面。<br>
(03)使用限流组件,在流量达到一定值之后,对请求直接返回失败信息。<br>
04、持久化机制(快照RDB,追加文件AOF)
默认使用RDB<br>
配置:save 900 1 900秒之后至少有1个key发生变化则保存快照<br>
save 300 10 300秒之后至少有10个key发生变化则保存快照<br>
save 60 10000 60秒之后至少有10000个key发生变化则保存快照<br>
优缺点:生成文件比较小,适合全量复制场景,可能会造成数据丢失,在做快照时对系统资源消耗比较大。<br>
AOF<br>
1、配置:appendonly yes 开启<br>
appendfsync everysec 每秒同步一次,可以兼顾数据和写入性能,宕机后只会丢失一秒内的数据。<br>
2、优缺点:因为要记录所有操作所以文件比较大(可能会对一个值进行多次操作),但丢失数据会少一些。<br>
AOF重写:是产生一个压缩的AOF文件,代替之前的AOF文件。开辟一个子线程对<br>
内存中所有的key进行遍历,转换成一些列redis操作,再将操作期间发生的增量的AOF日志,添加到文件尾部,替换掉之前的文件。<br>
05、redis过期键删除策略<br>
(1)定时删除<br>
(01)Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。<br>
(02)立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,<br>
其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的<br>
时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成<br>
额外的压力,让CPU心累,时时需要删除,忙死。。<br>
(03)这会产生大量的性能消耗,同时也会影响数据的读取操作。<br>
总结:对CPU不友好,用处理器性能换取存储空间(拿时间换空间)<br>
(2)惰性删除<br>
(01)数据到达过期时间,不做处理。等下次访问该数据时,<br>
(02)如果未过期,返回数据; .发现已过期,删除,返回不存在。.<br>
(03)惰性删除策略的缺点是,它对内存是最不友好的。<br>
(04)如果一个键已经过期,而这个键又仍然保留在数据库中,那么只要这个过期键不被删除,它所占用的内存就不会释放。<br>
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一一种内存泄漏-无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息<br>
总结:对memory不友好,用存储空间换取处理器性能(拿空间换时间)<br>
(3)定期删除<br>
(01)定期删除策略是前两种策略的折中:<br>
(2)定期删除策略每隔--段时间执行--次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。<br>
(3)周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度<br>
特点1: CPU性能占用设置有峰值,检测频度可自定义设置<br>
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理<br>
总结:周期性抽查存储空间( 随机抽查,重点抽查)<br>
举例:
a、 redis默认每个100ms检查, 是否有过期的key, 有过期key则删除。注意: redis不是每隔100ms将所有的key检查一 次而是随机抽取进<br>
行检查(如果每隔100ms,全部key进行检查,redis直接进去ICU)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
b、定期删除策略的难点是确定删除操作执行的时长和频率:如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化
成定时删除策略,以至于将CPU时间过多地消耗在删除过期键上面。如果删除操作执行得太少,或者执行的时间太短,定期删除策略
又会和惰性删除策略--样,出现浪费内存的情况。因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的
执行时长和执行频率。
06、6种缓存淘汰机制
noeviction:不会驱逐任何key
allkeys-lru:对所有key使用LRU算法进行删除,从所有key中选最近最少使用的进行淘汰。
volatile-lru:对所有设置了过期时间的key使用LRU算法进行删除,从已设置过期时间的数据集中选最近最少使用的进行淘汰
allkeys-random:对所有key随机删除
volatile-random:对所有设置了过期时间的key|随机删除,从已设置过期时间的数据集中选任意数据删除
volatile-ttl: 删除马上要过期的key .从已设置过期时间的数据集中选将要过期的。
allkeys-lfu:对所有key使用LFU算法进行删除
volatle-lfu:对所有设置了过期时间的key使用LFU算法进行删除.
总结:一般生产中使用allkeys-lru
07、redis集群
1)主从复制
(1)解释:主要是为了备份数据,防止数据丢失
(2)过程
(1)slave向master发起tcp连接。
(2)master与client建立tcp连接。
(3)master发送ping请求,确认对方是一个redis实例。
(4)slave返回pong。
(5)发送SYNC命令进行同步(master开始执行SYNC命令准备数据)
(6)master将RDB文件发送给slave
(3)命令:SYNC命令
主服务器器执行BGSAVE命令来生成RDB文件,消耗大量资源
master发送数据占用大量网络资源
slave接收时会阻塞无法处理其他命令。
(4)改进的:PSYNC命令
全量复制:将全部数据复制
部分复制:网络中断后,只将网络中断期间的数据进行发送。
Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后
2) 哨兵
(1)哨兵节点:哨兵系统由一个或多个哨兵节点组成,是一个特殊的redis节点,不存数据。
(2)数据节点:主从节点构成
架构图
(3)功能
(01)监控,心跳检测。
(02)自动故障转移,主节点宕机时,升级一个从节点成为主节点。
(03)配置提供者,客户端初始化时,通过哨兵来获取主从节点信息。
(04)通知,将故障转移结果发送给客户端。
(4)如何选择主节点
(01)淘汰ping命令大于5秒的或已经断线的从节点
(02)淘汰与失效主服务器断开时间过长的从节点
(03)两次淘汰后选择复制偏移量最大的从节点
(这么多操作都是为了找到一个从节点,这个从节点的数据和失效主服务器的数据最接近)
3)redis集群
(1)主要作用
(01)将数据分区:增大redis容量上限
(02)高可用,支持主从复制和自动故障转移
(2)分区的方法
(01)哈希值%节点数:计算hash,对节点数量进行取余,但是在新增或删除节点时要全部重新计算
(02)一致性哈希分区:一致性哈希算法,是将整个哈希值空间组织成一个虚拟闭环,
对每个数据进行hash运算,计算出在环上的位置,然后顺时针向前走,找到第一个服务
器即可。缺点:当节点较少时,增删节点时,对单个节点的流量影响较大。
(03)带有虚拟节点的哈希分区,优点:解耦了数据和实际节点之间的关系。
08、配置redis密码登录
第一种方式:在配置文件中配置requirepass
在配置文件中添加如下语句重启即可生效
requirepass 201314
第二种方式:在命令界面设置密码<br>
config set requirepass 201314
注:如果没有在配置文件中配置 requirepass,redis重启后密码将失效
09、登录有密码的redis
第一种方式:在登录的时候的时候输入密码
redis-cli -p 6379 -a 201314<br><br>
第二种方式:先登陆后验证
redis-cli -p 6379
auth 201314
2、Nosql
1、概述
五、系统软件服务篇:Linux、vagrant
1)linux(centos)服务器
1、Centos系统安装
虚拟机安装
U盘安装
2、Linux系统基本结构
01、linux系统的目录结构详解
常用目录
/tmp
临时文件
/root
管理员的家目录(一般情况下不要使用管理员用户登录系统)
/home/USERNAME
普通用户家目录
LSB,FHS(FileSystem Meirache Standard)
一级子目录:/etc /usr /var /root /home /dev
根文件系统(rootfs)
root filesystem
系统相关目录
/proc
用于输出内核与进程信息相关的虚拟文件系统
/srv
系统上运行的服务用到的数据
/lib64
专用于x86_64系统上的辅助共享库文件存放位置
/sbin
管理类的基本命令,不能关联至独立分区,OS启动即会用到的程序
供所有用户使用的基本命令,不能关联到独立分区,OS启动即会用到的程序
/bin
/sys
用于输出当前系统上硬件设备相关信息的虚拟文件系统
/lib
基本共享库文件,以及内核模块文件(/lib/modules)
必须了解目录
/var varlable data files
cache 应用程序缴存数据目录
lib 应用程序状态信息数据
local 专用于为/usr/local下的应用程序存储可变数据
lock 锁文件
log 日志目录及文件
opt 专用于为/opt下的应用程序存储可变数据
run 运行中的进程相关的数据,通常用于存储进程的pid文件
spool 应用程序数据池
tmp 保存系统两次重启之间产生的临时数据
/usr
universal shared read-only data
bin 保证系统拥有完整功能而提供的应用程序
sbin
lib
lib64
include C程序的头文件(header files)
share 结构化独立的数据 例如:doc man等
local 第一方应用程序的安装位置 可以关联到一个完全的分区上去
bin sbin lib lib64 etc share
/opt
第三方应用程序的安装位置
/etc
配制文件目录(纯文本文件)
/selinux securlty enhanced linux selinux
相关的安全策略信息的存储位置
磁盘操作相关目录
/mnt
临时文件系统的挂载点
/dev
设备文件及特殊文件存储位置
b:block devlce 随机访问
c:character devlce 线性访问
/boot
引导文件存放目录,内核文件(vmlinuz),引导加载器(bootloader,grub),都存放此目录。
/media
便捷式移动设备挂载点
cdrom usb
02、linux上的应用程序的组成部分
二进制程序 /bin /sbin /usr/bin /usr/sbin /usr/local/bin /usr/local/sbin
库文件: /lib /lib64 /usr/lib /usr/lib64 /usr/local/lib /usr/local/lib64
配置文件: /etc /etc/DIRECTORY /usr/local/etc
帮助文件: /usr/share/man /usr/share/doc /usr/local/share/man /usr/local/share/doc
03、Linux下的文件类型
- (f) 普通文件
d 目录文件
b 块设置
c 字符设置
l 符号链接文件 软链接
p 管道文件
s 套接字文件 socket
7、Linux系统进程管理
4、Linux系统权限管理
01、用户和组管理
(1)资源分派
(01)Authentication 认证
(02)Authorization 授权
(03)Accouting 审计:Audition
(04)token identity(username/password)
02、Linux用户分类:Username/UID
(1)管理员: root 0
(2)普通用户: 除了root用户的用户都是普通用户 1-65535
系统用户: 1-499
守护进程获取资源进行权限分配
登录用户: 500+
交互式登录
03、Linux用户组:Groupname/GID
(1)管理员组 root 0
(2)普通组
系统组: 1-499
管理组 : 500+
04、Linux安全上下文(运行中的程序: 进程(process))
(1)以进程发起者的身份运行(root: cat tom: cat )
(2)进程所能够访问的所有资源的权限取决于进程发起者的身份。
05、Linux组的类别
(1)用户的基本组(主组)(组名同用户名,且仅包含一个用户,私有组)
(2)用户的附加组(额外组)
06、Linux用户和组相关的配置文件
/etc/passwd 保存及其属性信息(名称、UID、基本组ID等)
usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin
用户名:密码:UID:GID:GECOS:主目录:默认/sbin/nologin
/etc/group 组及其属性信息
group_name:password:GID:user_list
组名:组密码:GID:以当前组为附加组的用户列表(分隔符为逗号 )
/etc/shadow 用户密码及其相关属性
用户名:加密了的密码:最近一次更改密码的日期:密码的最小使用期限:最大密码使用期限:密码警告时间段:密码禁用期:账户过期日期:保留字段分支主题
加密机制:
加密:明文——————>密文
解密:密文------------------>明文
单向加密: 提取数据指纹
雪风效应:初始的条件的微小改变,将会引起结果的巨大改变
定长输出
/etc/gshadow 组密码及其相关属性
07、用户和组相关的管理命令
用户创建: useradd
useradd [options] LOGIN
-u UID: [UID_MIN,UID_MAX],定义在/etc/login.defs
-g GID:指明用户所属基本组,可为组名,也可以GID
-c "COMMENT" 用户的注释信息
-d /PATH/TO/SOMETHING 以指定的路径为家目录
-s SHELL 指定用户的默认的默认shell程序,可用列表在/etc/shells文件中
-G GROUP1[,GROUP2,......[,GROUPN]]] 为用户指明附加组,组必须事先存在
-r 创建系统用户
CentOS 6 id<500
CentOS7 id<1000
默认值设定: /etc/default/useradd文件中
useradd -D
-s SHELL
groupadd [options] group
组创建:groupadd
-g GID 指明GID号 【GID_MIN,GID_MAX】
-r 创建系统组
CentOS 6 id<500
CentOS7 id<1000
用户属性修改:usermod
语法: usermod [options] LOGIN
-u UID 新UID
-g GID 新GID
-G GROUP1[,GROUP2,......[,GROUPN]]] 新附加组,原来的附加组将会被覆盖,若保留原有,则要同时使用-a选项,表示append
-s Shell 新的默认shell
-c 'COMMANT' 新的注释信息
-d Home 新的家目录
-l login_name 新的名字
-L lock指定用户
-U unlock指定用户
-e YYYY-MM-DD 指明用户账号过期日期
-f INACTIVE 设定非活动期限
给用户添加密码:passwd
passwd UserName 修改指定用户的密码,仅root用户有权限
passwd 修改自己的密码
常用选项
-l 锁定指定用户
-u 解锁指定用户
-n 指定最短使用期限
-x 最大使用期限
-w 提前多少天开始警告
--i 非活动期限
--stdin 从标准输入修改用户密码
Note: /dev/null bit buckets
删除用户:userdel
语法:userdel [options] LOGIN
-r 删除用户家目录
组属性修改: groupmod
语法:groupmod [options] GROUP
-n group_name 新名字
-g GID 新的GID
组删除:groupdel
groupdel GROUP
组密码:gpasswd
gpasswd [option] group
-a user 将user添加至指定组中
-d user 删除用户user的以当前级为组名的附加组
-A user1,user2 设置有管理权限的用户列表
newgrp命令:临时切换基本组
如果用户本不属于此组,则需要组密码;
pwck 检查密码文件的有效性
修改用户属性:chage
-d LAST_NAY
8)权限管理操作
文件的权限主要针对三类对象进行定义
owner 属主 u
group 属组 g
outher 其他 o
每个文件针对每类访问者都 定义了三种权限
r Readable
w Writable
x eXcutable
文件
r 可使用文件查看类工具获取其内容
w 可修改其内容
x 可以把此文件提请内核启动为一个进程
目录
r 可以使用ls查看此目录中文件列表
w 可在此目录中创建文件,也可删除此目录中的文件
x 可以使用ls -l 查看此目录中文件列表,可以cd进入此目录
权限参数说明(重要)
--- 000 0
--x 001 1
-wx 011 3
r-- 100 4
r-x 101 5
rw- 110 6
rwx 111 7
实例:
640 rw-r----
rwxr-xr-x 755
修改文件权限: chmod
作用:任何用户的可以使用
语法
chmod [OPTION]... MODE[,MODE]... FILE...
--R 递归修改权限
chmod [OPTION]... OCTAL-MODE FILE...
修改一类用户的所有权限
u=
g=
o=
ug=
a=
u=,g=
chmod [OPTION]... --reference=RFILE FILE...
修改一类用户某位或某些位权限
u+
u-
修改文件的属主和属组
仅root可用
修改文件的属主 chown
chown [OPTION]... [OWNER][:[GROUP]] FILE...
用法
OWNER
OWNER:GROUP
GROUP
Note: 命令中的冒号可以用,替换
-R递归
修改文件的属组 chgrp
chgrp [OPTION]... GROUP FILE...
chgrp [OPTION]... --reference=RFILE FILE...
-R递归
Note: 如果某类的用户的权限减得的结果中存在x权限,则将其权限+1
文件或目录创建时的啁罩码 umask
FILE: 666-umask
DIR: 777-umask
5、Linux磁盘存储管理
6、Linux文件系统管理
8、centos系统防火墙实操总结大全
centos6和7版本的区别
1)、Centos6 使用的是iptables,iptables 用于过滤数据包,属于网络层防火墙
2)、Centos7 使用的是filewall,firewall 能够允许哪些服务可用,那些端口可用,属于更高一层的防火墙。
基本操作命令
1)、查询防火墙的状态命令:
systemctl status firewalld.service<br>
firewall-cmd --state<br>
2)、重启防火墙命令:
systemctl restart firewalld.service
3)、停止防火墙:
systemctl stop firewalld.service
4)、启动防火墙:
systemctl start firewalld.service<br>
如果启动报Failed to start firewalld.service: Unit is masked,请执行这个命令
systemctl unmask firewalld<br>
5)、查询某个端口是否开放:
firewall-cmd --query-port=9527/tcp<br>
6)、查看开放的防火墙端口:
firewall-cmd --list-all<br>
firewall-cmd --zone=public --list-ports
7)、添加端口到防火墙:
firewall-cmd --zone=public --add-port=6379/tcp --permanent<br>
8)、重载生效添加的端口
firewall-cmd --reload<br>
9)、开机禁用
systemctl disable firewalld
10)、开机启动
systemctl enable firewalld
11)、查看服务是否开机启动
systemctl is-enabled firewalld.service
12)、查看已启动的服务列表
systemctl list-unit-files|grep enabled
13)、查看防火墙版本
firewall-cmd --version
14)、给指定的ip添加访问权限
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="10.60.104.83" port protocol="tcp" port="5432" accept"<br>
https://www.cnblogs.com/faithH/p/11811286.html
3、Linux常用命令
01、目录和文件管理命令
1)cd命令:进入目录命令,例: cd /data/
2)ls命令:用于显示指定工作目录下之内容;例:ls [-alrtAFR] [name...]
a、-a 显示所有文件及目录 (. 开头的隐藏文件也会列出)
b、-l 除文件名称外,亦将文件型态、权限、拥有者、文件大小等资讯详细列出
c、-r 将文件以相反次序显示(原定依英文字母次序)
d、-t 将文件依建立时间之先后次序列出
e、-A 同 -a ,但不列出 "." (目前目录) 及 ".." (父目录)
f、-F 在列出的文件名称后加一符号;例如可执行档则加 "*", 目录则加 "/"
g、-R 若目录下有文件,则以下之文件亦皆依序列出
3)pwd命令:显示当前工作的目录;例:执行 pwd 指令可立刻得知您目前所在的工作目录的绝对路径名3)
4)mkdir命令
(1)创建目录;例:mkdir 目录名称
(2)-p 存在于不报错,且可自动创建所需的各目录
(3)-v 显示详细信息
(4)-m MOOE 创建目录时直接指定权限
5)tree命令
-d 只显示 目录
-l level 指定显示的层级数目
-P pattern 只显示由指定pattern匹配到的路径
6)rmdir命令
删除空目录
-v 显示过程
7)toucn命令
语法:touch [OPTION]... FILE...
参数
-a only atime
-m only mtime
-t STAMP
-c 如果文件 不存在,则不予创建
8)文件的时间戳
文件: metadata data
查盾文件状态 stat
三个时间戳
access time 访问时间 简写为atime
modify time 修改时间 mtime 改变文件内容(数据)
chage time 改变时间 ctime 元数据发生改变
02、文件下载管理命令
1)、wget命令:下载文件命令;例:wget http://cn.wordpress.org/wordpress-4.9.4-zh_CN.tar.gz
03、用户管理类命令
1)、su命令:切换用户或以其他用户身份执行命令
语法: su [options...] [-] [user [args...]]
切换用户的方式
su UserName 非登录切换,即不会读取目标用户的配置文件
su - UserName 登录式切换,会读取目标用户的配置文件,完全切换
Note: root su至其他用户无须密码,非root用户切换时需要密码
换个身份执行命令
su [-] UserName -c 'COMMAND'
2)、ID命令:查看用户相关的id信息
id [OPTION]... [USER]
-u: UID
-g GID
-G Group
-n Name
04、软件安装相关命令
rpm
yum
apt-get
05、修改主机名和建立ssh信任
1)修改主机名
(1)编辑hosts文件
vim /etc/hosts
(2)配置示例
10.60.104.78 zhl-sv
(3)配置完成执行命令
hostnamectl set-hostname zhl-sv<br>
(4)验证配置
su -
2)配置ssh信任
(1)创建key的命令
ssh-keygen
注意:执行时一直默认就行
(2)将密钥复制到子节点命令
ssh-copy-id root@主机名
注意:按提示完成配置
(3)验证配置
ssh 配置的主机名
注意:有多少个节点就在多少个节点上做现样的操作
3)ssh服务查询与操作
(1)查看ssh服务状态
systemctl status sshd.service
(2)启动ssh服务
systemctl start sshd.service
(3)重启ssh服务
systemctl retart sshd.service
3)详细内容阅读查询地址
06、查询IO占用情况
命令
iostat -xdk 2 4
命令表示每两秒执行一次,每一次显示4行数据
磁盘块设备分布
rkB/s每秒读取数据量kB;
wkB/s每秒写入数据量kB;
svctm I/O请求的平均服务时间,单位毫秒;
await I/O请求的平均等待时间,单位毫秒:值越小,性能越好;
util一秒中有百分几的时间用于I/O操作。接近100%时,表示磁盘带宽跑满,需要优化程序或者增加磁盘;
svctm的值与await的值很接近,表示几乎没有I/O等待,磁盘性能好,
rkB/s、wkB/s 根据系统应用不同会有不同的值,但有规律遵循:长期、超大数据读写,肯定不正常,需要优化程序读取。
如果await的值远高于svctm的值,则表示I/O队列等待太长,需要优化程序或更换更快磁盘。
07、SCP拷贝文件
对拷文件夹下所有文件 (不包括文件夹本身)<br>
scp /home/helpteach/project/mallupload/* wasadmin@10.127.40.25:/home/test
对拷文件夹 (包括文件夹本身)
scp -r /home/helpteach/project/mallupload/ wasadmin@10.127.40.25:/home/test
对拷文件并重命名
scp /home/helpteach/project/mallupload/1509681299449.png wasadmin@10.127.40.25:/home/test/test.png
2)vagrant
常用命令集
vagrant up
启动一个容器
vagrant plugin list
查询plugin的版本信息、0.29.0这个版本有点问题
vagrnaat plugin uninstall vagrant-vbguest
卸载plugin插件
vagrant plugin install vagrant-vbguestst --plugin-version 0.21
安装指定版本的plugin插件
vagrant ssh
连接已安装的虚拟机
六、服务器篇:docker、nginx
一)docker
1、了解docker的架构和基本概念
01、Docker简介
1)Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。<br>它基于 Google 公司推出的 Go 语言实现。 项目后来加入了 Linux 基金会,遵从了 Apache 2.0协议,项目代码在 GitHub 上进行维护。<br>
2)Docker 项目的目标是实现轻量级的操作系统虚拟化解决方案。 Docker 的基础是 Linux 容器(LXC)等技术。
3)背景,云计算兴起后,服务器硬件扩展非常便利,软件服务部署成为了瓶颈,docker趁势而兴。
4)Docker 支持 CentOS6 及以后的版本
02、为什么用Docker
1)容器的启动可以在秒级实现,比传统的虚拟机方式要快得多
2)对系统资源的利用率很高,一台主机上可以同时运行数千个Docker 容器
3)docker的出现,让开发/测试/线上的环境部署,成为便利一条龙。
4)更简单的管理,使用Docker,只需要小小的修改,就可以替代以往大量的更新工作。
所有的修改都以增量的方式被分发和更新,从而实现自动化并且高效的管理。
5)更轻松的迁移和扩展,Docker 容器几乎可以在任意的平台上运行,包括物理机、
虚拟机、公有云、私有云、个人电脑、服务器等。这种兼容性可以让用户把一个应用
程序从一个平台直接迁移到另外一个。
03、Docker基本概念
1)Docker架构
分支主题
2)Docker 镜像
(1)Docker 镜像就是一个只读的模板
(2)镜像可以用来创建Docker 容器。
(3)Docker 提供了一个很简单的机制来创建镜像或者更新现有的镜像,用户甚至可以直
接从其他人那里下载一个已经做好的镜像来直接使用。
(4)例如:一个镜像可以包含一个完整的ubuntu 操作系统环境,里面仅安装了 Apache
或用户需要的其它应用程序
3)Docker 容器
(1)Docker 利用容器来运行应用。
(2)容器是从镜像创建的运行实例。它可以被启动、开始、停止、删除。每个容器都是相互隔离的、保证安全的平台。
(3)可以把容器看做是一个简易版的Linux 环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在
其中的应用程序。
4)Docker 仓库
(1)仓库是集中存放镜像文件的场所。有时候会把仓库和仓库注册服务器(Registry)混为一谈,并不严格区分。实
际上,仓库注册服务器上往往存放着多个仓库,每个仓库中又包含了多个镜像,每个镜像有不同的标签(tag)。
(2)仓库分为公开仓库(Public)和私有仓库(Private)两种形式。
(3)最大的公开仓库是Docker Hub存放了数量庞大的镜像供用户下载。国内的公开仓库包括Docker Pool等,可以
提供大陆用户更稳定快速的访问。
(4)当然,用户也可以在本地网络内创建一个私有仓库。
(5)当用户创建了自己的镜像之后就可以使用push 命令将它上传到公有或者私有仓库,这样下次在另外一台机器上
使用这个镜像时候,只需要从仓库上pull 下来就可以了。
2、docker的安装和基础应用
01、安装Docker
1)查询安装过的包
yum list installed | grep docker<br>
2)删除安装的软件包
yum -y remove docker-engine.x86_64<br>
3)删除镜像/容器等
rm -rf /var/lib/docker<br>
4)直接安装(不是最新版的)
yum install docker<br>
5)启动docker
service docker start<br>
systemctl start docker
6)配置随系统启动
chkconfig docker on
systemctl enable docker<br>
7)查询安装的版本信息
docker version<br>
docker info
02、docker的基本操作
1)容器操作
(1)docker [run|start|stop|restart|kill|rm|pause|unpause]
docker [if !supportLists]· [endif]run/create[镜像名]:创建一个新的容器并运行一个命令
docker start/stop/restart[容器名]:启动/停止/重启一个容器
docker kill [容器名]: 直接杀掉容器,不给进程响应时间
docker rm[容器名]:删除已经停止的容器
docker pause/unpause[容器名]:暂停/恢复容器中的进程
(2)docker [ps|inspect|exec|logs|export|import]
ps:查看容器列表(默认查看正在运行的容器,-a查看所有容器)
inspect[容器名]:查看容器配置元数据
exec -it [容器名] /bin/bash:进入容器环境中交互操作
logs --since="2019-02-01" -f --tail=10 [容器名]:查看容器日志
cp path1 [容器名]:path 容器与主机之间的数据拷贝
export -o test.tar [容器名] / docker export [容器名]>test.tar : 文件系统作为一个tar归档文件
import test.tar [镜像名:版本号]:导入归档文件,成为一个镜像
2)镜像操作
(1)docker images|rmi|tag|build|history|save|load]
images:列出本地镜像列表
rmi [镜像名:版本]:删除镜像
tag [镜像名:版本] [仓库]/[镜像名:版本]:标记本地镜像,将其归入某一仓库
build -t [镜像名:版本] [path]:Dockerfile 创建镜像
history [镜像名:版本]: 查看指定镜像的创建历史
save -o xxx.tar [镜像名:版本] / save [镜像名:版本]>xxx.tar : 将镜像保存成 tar 归档文件
load --input xx.tar / docker load<xxx.tar : 从归档文件加载镜像
03、镜像与容器原理及用法
history命令查看镜像层
例:docker history hello-world
显示镜像hello-world分三层,其中两个空层
查看镜像文件
镜像存放在imagedb里
一般在image/overlay2/imagedb/content/sha256下
层文件在layerdb里
ll /var/lib/docker/image/overlay2/layerdb/sha256
04、镜像与容器总结
1)总结描述内容
(1)一个镜像就是一层层的layer层文件,盖楼而成,上层文件叠于下层文件上,
若上层文件有与下层文件重复的,则覆盖掉下层文件重复的部分。
(2)初始挂载时读写层为空。
(3)当需要修改镜像内的某个文件时,只对处于最上方的读写层进行了变动,不复写
下层已有文件系统的内容,已有文件在只读层中的原始版本仍然存在,但会被读
写层中的新版本文件所隐藏,当 docker commit 这个修改过的容器文件系统为
一个新的镜像时,保存的内容仅为最上层读写文件系统中被更新过的文件。
(4)联合挂载是用于将多个镜像层的文件系统挂载到一个挂载点来实现一个统一文
件系统视图的途径,是下层存储驱动(aufs、overlay等) 实现分层合并的方式。
2)创建容器详解
交互式创建容器并进入
docker run -it --name centos centos /bin/bash
exit退出也关闭容器; Ctrl+P+Q退出不关闭容器
后台启动容器
docker run -dit --name centos centos
进入已运行的容器
docker exec -it nginx /bin/bash
查看容器的元数据:docker inspect nginx
绑定容器端口到主机
docker run -d -p 8080:80 --name nginx nginx:latest
挂载主机文件目录到容器内
docker run -dit -v /root/peter_dir/:/pdir --name cent centos
复制主机文件到容器内
docker cp anaconda-ks.cfg cent:/var
3)docker先删除容器再删除镜像
05、docker镜像加速
创建目录
mkdir -p /etc/docker
3、docker的进阶学习、创建私有仓库
仓库使用
docker官方仓库
命令使用
Docker pull/search/login/push/tag
tag [镜像名:版本] [仓库]/[镜像名:版本]:标记本地镜像,将其归入某一仓库
Push [仓库]/[镜像名:版本]: 推送镜像到仓库 --需要登陆
Search [镜像名]:在仓库中查询镜像 – 无法查询到tag版本
Pull [镜像名:版本]: 下载镜像到本地
Login:登陆仓库
私有仓库
搭建、下载registry镜像
docker pull registry
可配置加速器加速下载
vim /etc/docker//daemon.json
https://registry.docker-cn.com
启动
docker run -d --name reg -p 5000:5000 registry
然后可以通过restful接口查看仓库中的镜像(当前仓库是空的)
配置http传输
私服默认只能使用https,需要配置开放http
配置完毕重启下docker服务
配置路径一般在:vim /etc/docker/daemon.json
systemctl daemon-reload
systemctl restart docker
私服仓库推送镜像
docker tag hello-world http://192.168.244.7:5000/hello-world
docker push 192.168.244.7:5000/hello-world
查询镜像:http://192.168.244.5:5000/v2/_catalog
查询hello版本:http://192.168.244.5:5000/v2/hello/tags/list
commit镜像并上传仓库
数据管理
理解
docker容器运行,产生一些数据/文件/等等持久化的东西,不应该放在容器内部。
应当以挂载的形式存在主机文件系统中
docker的文件系统
镜像与容器读写层,通过联合文件系统,组成系统文件视角
容器服务运行中,一定会生成数据
容器只是运行态的服务器,是瞬时的,不承载数据的持久功能
volume文件挂载的探究
volume参数创建容器数据卷
查看容器元数据,可看到挂载信息
docker inspect data
在容器端添加一个文件
cd /opt/data/
volumes-from引用数据卷
新启一容器,引入上一步的data容器目录
备份/恢复数据卷
备份
docker run --rm --volumes-from data -v $(pwd):/backup centos tar cvf /backup/data.tar /opt/data
恢复
docker run --rm --volumes-from data -v $(pwd):/backup centos tar xvf /backup/data.tar -C
删除数据卷
docker rm -v data
4、docker的高级学习
Dockerfile使用
dockerfile方式创建容器
dockerfile基本要素
dockerfile指令
5、docker常用命令集
查询docker中所有的容器
docker ps -a
启动已有的容器
docker start 容器名/容器ID
重启已启动的容器
docker restart 容器名/容器ID
停止已启动的容器
docker stop 容器名/容器ID
删除容器
docker rm 容器名/容器ID
删除镜像
docker rmi 镜像名
查看容器状态
docker ps –a
查询docker容器运行的状态
docker stats
重启docker服务
systemctl restart docker
5、docker安装软件实战篇
01、docker安装postgres
https://blog.csdn.net/qq_28245087/article/details/112766451?spm=1001.2014.3001.5502
02、docker安装Mysql
https://blog.csdn.net/qq_28245087/article/details/112788703?spm=1001.2014.3001.5502
03、docker安装oracle
https://blog.csdn.net/qq_28245087/article/details/115053269?spm=1001.2014.3001.5502
04、docker安装nginx
https://www.cnblogs.com/qiqiloved/p/13470064.html
二)nginx
1、nginx安装
a、使用docker安装
b、使用yum安装
c、使用编译安装
2、nginx核心配置文件
nginx.conf
upstream nginx
server
3、正向代理与反向代理
正向代理:如科学上网,隐藏客户端信息
反向代理:屏蔽内网服务器信息,负载均衡访问
4、常见的负载均衡算法
01、轮询
为第一个请求选择健康池中的第一个后端服务器,然后按顺序往后依次选择,直到最后一个,然后循环。
02、最小连接
优先选择连接数最少,也就是压力最小的后端服务器,在会话较长的情况下 可以考虑采取这种方式。
03、散列
1)根据请求源的 IP 的散列(hash)来选择要转发的服务器。这种方式可以一定程度上保证特定用户能连接到相同的服务器。
2)如果你的应用需要处理状态而要求用户能连接到和之前相同的服务器,可以考虑采取这种方式。
5、常用命令集
启动
/usr/local/nginx/sbin/nginx
停止
/usr/local/nginx/sbin/nginx -s stop
重启
/usr/local/nginx/sbin/nginx -s reload
检查配置文件是否配置正确
/usr/local/nginx/sbin/nginx -t
6、nginx配置https
1、到各大平台申请注册域名和获取https证书
2、打开配置文件:nginx.conf
3、配置示例:
a、配置虚拟主机监听80端口、主要是域名配置
# 虚拟主机配置<br> server {<br> # 监听端口<br> listen 80;<br> # 监听地址<br> server_name bar.huimayun.com;<br> # 重定向<br> rewrite ^(.*)$ https://$host$1 permanent;<br> }
b、配置监听443端口
server {<br> listen 443 ssl;<br> server_name huimayun.com www.huimayun.com;<br><br> # SSL证书配置<br> ssl_certificate /home/project-server/certificate/4024682_huimayun.com.pem;<br> ssl_certificate_key /home/project-server/certificate/4024682_huimayun.com.key;<br> ssl_session_timeout 5m;<br> ssl_protocols TLSv1 TLSv1.1 TLSv1.2;<br> ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;<br> ssl_prefer_server_ciphers on;<br><br> # 配置页面访问路径<br> location / {<br> root /home/project-server/huimayun-www;<br> #root /home/project-server/yoga;<br> }<br>}<br>
4、参数讲解
a、证书配置目录
ssl_certificate
ssl_certificate_key
b、配置监听的端口
listen
c、配置主机的服务名
server_name
一般为主机的域名或者IP
d、本地要访问的内容
location
可配置静态访问页面或者后台服务器的地址
7、nginux配置访问后台反向代理
location /huimayun-authorization/ {<br> proxy_pass http://localhost:10002/huimayun-authorization/;<br> proxy_set_header Host $host;<br> proxy_set_header X-Real-IP $remote_addr;<br> proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;<br> proxy_set_header X-Forwarded-Proto $scheme;<br> }
如果location后面配置的路径不加"/",那么他会拼接到下面访问的路径上
8、nginx配置上传文件大小限制
根据代码
client_max_body_size 1024M;<br>
配置示例
9、查询nginx使用的配置文件
1、首先查找到nginx的启动路径
第一种方法
1. 查看nginx的PID,以常用的80端口为例:
netstat -anop | grep 0.0.0.0:80
2. 通过相应的进程ID(比如:4562)查询当前运行的nginx路径:<br>
ll /proc/4562/exe
第二种方法
Which查找命令<br>
Which命令是通过 PATH环境变量查找可执行文件路径,用于查找指向这个命令所在的文件夹
which nginx
第三种方法
Whereis命令和find类似,不过不同的是whereis是通过本地架构好的数据库索引查找会比较快。如果没有更新到数据库里面的文件或命令则无法查找到信息
whereis nginx
第四种方法
通过rpm查看
查看软件是否安装。首先我们需要查看软件是否已经安装,或者说查看安装的软件包名称。如查找是否安装mysql
rpm -qa | grep nginx<br>
第五方法
yum查找
除了rpm 查询还可以通过yum search 查找对应可以安装的软件包
yum search nginx<br>
2、获取到nginx的执行路径后,使用-t参数即可获取该进程对应的配置文件路径
/data/sunsheen/soft/nginx/sbin/nginx -t
10、nginx指定配置文件启动
1、验证配置文件
/usr/local/nginx/sbin/nginx -tc /usr/local/nginx/conf/nginx.conf<br>
/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.conf<br>
2、指定配置文件启动
/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf<br>
3、指定配置文件重启
/usr/local/nginx/sbin/nginx -s reload -c /usr/local/nginx/conf/nginx.conf<br>
注:/usr/local/nginx/ 目录视自己的安装情况而定。配置文件同样根据自己的命名习惯指定
业务系统启动
/data/sunsheen/soft/nginx/sbin/nginx -s reload -c /data/nginx/conf/nginx.conf
11、负载均衡
https://www.runoob.com/w3cnote/nginx-proxy-balancing.html
七、性能优化篇
1、Jvm原理学习与性能调优
01、初始JVM
1)为什么要学习Java虚拟机
首先是高新工作的面试需要(BAT、TMD、PKQ等面试都爱问)。
再是中高级程序员必备技能,也是项目管理、调优的需要。
最后是追求极客的精神,比如:垃圾回收算法、JIT、底层原理等。
java虚拟机的垃圾收集机制为我们打理了很多繁琐的工作,大大提高了开发的效率,但是,垃圾收集也不是万能的,懂得JVM内部的内存结构、工作机制,才是设计高扩展性应用和诊断运行时问题的基础,也是Java工程师进阶的必备能力。
2)什么是Java虚拟机
虚拟机是一种抽象化的计算机,通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机有自己完善的硬体架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。Java虚拟机屏蔽了与具体操作系统平台相关的信息,使得Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行,其实是因为不同的操作系统的开发了相应的Java虚拟机才能使Java编写好的程序能在不同的机器上运行。
Java虚拟机(Java Virtual Machine 简称JVM)是运行所有Java程序的抽象计算机,是Java语言开发的程序的运行环境。
Java虚拟机就是二进制字节码的运行环境,负责装载字节码到其内部,解释/编译为对应平台上的机器指令执行。每一.条Java指令,Java虚拟机规范中都有详细定义,如怎么取操作数,怎么处理操作数,处理结果放在哪里。
jvm运行在系统之上的,它与硬件没有直接交互<br>
4)什么是虚拟机
所谓虚拟机(Virtual Machine),就是一台虚拟的计算机。和程序虚拟机。它是一款软件,用来执行一系列虚拟讲得机指令。大体上,虚拟机可以分为系统虚拟机和程序虚拟机。
➢大名鼎鼎的Visual Box, VMware就属于系统虚拟机,它们完全是对:物理计算机的仿真,提供了一个可运行完整操作系统的软件平台。
➢程序虚拟机的典型代表就是Java虚拟机,它专门为执行单个计算机程序而设计,在Java虚拟机中执行的指令我们称为Java字节码指令。
➢无论是系统虚拟机还是程序虚拟机,在上面运行的软件都被限制于虛拟机提供的资源中。
02、Jvm的内部结构<br>
1)Jvm的在系统上的位置
2)Jvm架构模型<br>
Java编译器输入的指令流基本上是一种基于栈的指令集架构,另外一种指令集架构则是基于寄存器的指令集架构。<br>
具体来说:这两种架构之间的区别:
●基于栈式架构的特点<br>
➢设计和实现更简单,适用于资源受限的系统;<br>
➢避开了寄存器的分配难题:使用零地址指令方式分配。<br>
➢指令流中的指令大部分是零地址指令,其执行过程依赖于操作栈。指令集更小,编译器容易实现。<br>
➢不需要硬件支持,可移植性更好,更好实现跨平台<br>
●基于寄存器架构的特点<br>
➢典型的应用是x86的二进制指令集:比如传统的PC以及Android的Davlik虛拟机。<br>
➢指令集架构则完全依赖硬件,可移植性差<br>
➢性能优秀和执行更高效;<br>
➢花费更少的指令去完成一项操作。<br>
➢在大部分情况下,基于寄存器架构的指令集往往都以一-地址指令、二地址指令和三地址指令为主,而基于栈式架构的指令集却是以零地址指令为主。方难学的技<br>
总结
由于跨平台性的设计,Java的指令都是根据栈来设计的。不同平台CPU架构不同,所以不能设计为基于寄存器的。优点是跨平台, 指令集小,编译器容易实现,缺点是性能下降,实现同样的功能需要更多的指令。<br>
该是HotSpotVM的宿主环境已经不局限于嵌入式平台了),那么为什么不将该是HotSpotVM的宿主环境已经不局限于嵌入式平台了),那么为什么不将架构更换为基于寄存器的架构呢?<br>
3)Jvm的生命周期
虚拟机的启动<br>
Java,虚拟机的启动是通过引导类加载器(bootstrap class loader) 创建-一个初始类(initial class) 来完成的,这个类是由虚拟机的具体实现指定的。<br>
虚拟机的执行<br>
一个运行中的Java虚拟机有着- -个清晰的任务:执行Java程序。<br>
程序开始执行时他才运行,程序结束时他就停止。<br>
执行一个所谓的Java程序的时候,真真正正在执行的是一个叫做Java虚拟机的进程。<br>
虚拟机的退出的情况<br>
程序正常执行结束<br>
程序在执行过程中遇到了异常或错误而异常终止<br>
由于操作系统出现错误而导致Java虚拟机进程终止<br>
某线程调用Runtime类或System类的exit方法,或Runt ime类的halt方法,并且Javal安全管理器也允许这次exit或halt操作。<br>
除此之外,JNI ( Java Native Interface) 规范描述了用JNIInvocation API来加载或卸载Java虚拟机时,Java 虛拟机的退出情况。<br>
03、类加载子系统<br>
类加载子系统的作用<br>
●类加载器子系统负责从文件系统或者网络中加载Class文件,class文件在文件开头有特定的文件标识。<br>
●ClassLoader只负责class文件 的加载,至于它是否可以运行,则由Execution Engine决定。<br>
●加载的类信息存放于一块称为方法区的内存空间。除了类的信息外,方法区中还会存放运行时常量池信息,可能还包括字符串字面量和数字常量(这部分常量信息是.Class文件中常量池部分的内存映射)<br>
类加载器ClassLoader角色<br>
1. class file存在于本地硬盘上,可以理解为设计师画在纸上的模板,而最终这个模板在执行的时候是要加载到JVM当中来根据这个文件实例化出n个--模一样的实例。<br>
2. class file 加载到JVM中,被称为DNA元数据模板,放在方法区。<br>
3.在.class文件-> JVM ->最终成为元数据模板,此过程就要-一个运输工具(类装载器Class Loader) ,扮演一个快递员的角色。<br>
类的加载过程<br>
加载:<br>
1.通过一个类的全限定名获取定义此类的二进制字 节流<br>
2.将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构<br>
3.在内存中生成-一 个代表这个类的java. lang.Class对象,作为方法区这个类的各种数据的访问入口<br>
补充:加载.class文件的方式
从本地系统中直接加载
通过网络获取,典型场景: Web Applet
从zip压缩包中读取,成为日后jar、war格式的基础
运行时计算生成,使用最多的是:动态代理技术
由其他文件生成,典型场景: JSP应用
从专有数据库中提取. class文件,比较少见
从加密文件中获取,典型的防Class文件被反编译的保护措施
2、Tomcat性能优化
3、posgtesSQL优化
4、MySql优化
01、MySQL的架构和存储引擎
1)sql优化衡量指标
(1)什么是TPS
(01)每秒传输的事物处理个数。
(02)这是指服务器每秒处理的事物数支持事务的存储引擎如InnoDB等特有的一个性能指标。
(03)计算公式:TPS=(COM_COMMIT+COM_ROLLBACK)/UPTIME
(2)什么是QPS
(01)每秒查询处理量。
(02)同时适用于InnoDB和MyISAM引擎等待时间,执行SQL等待返回结果之间的等待时间。
(03)计算公式:QPS=QUESTIONS/UPTIME
(3)响应时间
2)MySql压力测试工具
(1)工具名:MySqlSlap
(2)目的:测试MySql服务器的瓶颈
(3)工具使用
3)MySql逻辑架构层
(1)连接层
(01)当mysql启动(mysql服务器就是一个进程),等待客户端连接,
(02)每一个客户端连接请求,服务会新建一个线程处理(如果是线程池的话,
(03)则昌分配一个空的线程),每个线程独立拥有各自的内存处理空间,
(04)但是,如果这个请求只是查询,没有关系,但是若是修改数据,很显然,当两个线程修改同一块内存是会引发数据同步问题的。
(05)当连接到服务器时需要对其进行验证权限,如连接成功验证所需要操作的权限(查询、修改)等
(2)服务层
(3)引擎层
(4)存储层
4)了解MySql的缓存
(1)查询是否开启
show VARIABLES like '%query_cache_type%'
(2)查询缓存大小
show VARIABLES like '%query_cache_size%'
(3)设置缓存大小的值
set GLOBAL query_cache_size = 113443112;
(4)如果没有开启,修改配置文件开启,如果在生产环境中,建议使用其他的缓存框架实现
5)了解mysql的执行计划
(1)解析查询语句,执行优化
6)MySql存储引擎
(1)查询数据库有多少存储引擎
show engines;
(2)查看当前默认的存储引擎
show variables like '%storage_engine%';
(3)查询某张表使用了什么引擎
show create table table_name;
show table status from db_name where name='table_name';
(4)查询数据库文件的存储地址
show VARIABLES like '%datadir%'
(5)MyISAM引擎
(01)适用场景
a、非事物型应用(数据仓库、报表、日志等)
b、只读场景、空闲类应用(空间函数、、坐标)
(02)MyISAM特性
a、支持全文检索
b、支持数据压缩
c、并发性与锁级别-表级锁
(6)InnoDB引擎
(01)适用场景:Innodb适用于大多数OLTP应用
(02)版本5.6之前默认是系统表空间
(03)系统表空间
a、系统表空间无法简单的收缩文件大小
b、系统表空间会产生IO瓶颈
c、设置系统空间:set GLOBAL innodb_file_per_table = off
(04)独立表空间
a、独立表空间可以使用optimize table 表名来收缩系统文件
b、可以同时向多个文件刷新数据
c、设置独立空间:set GLOBAL innodb_file_per_table = off
(05)InnoDB特点
a、InnoDB是一种事物性存储引擎
b、完全支持事后的ACID特性
c、InnoDB支持等级锁(并发程度更高)
d、Redo log和Undo log
(7)MyISAM和innoDB的区别
(01)MyISAM
a、不支持主外键
b、不支持事物
c、表空间比较小
d、比较注重性能
e、只缓存索引,不缓存数据
f、支持表锁,就算操作一条数据也会锁住整个表、不适合高并发的操作
(02)InnoDB
a、主外键支持
b、事物支持
c、表空间比较大
d、比较注重事物
e、不但缓存索引,还要缓存数据,对内存要求太高,而且内存大小对性能有决定性影响
f、支持行锁,操作时只锁某一行,不对其他行影响,适合高并发操作
(8)CSV引擎
(01)组成
a、数据以文本方式存储在文件
b、.csv文件存储内容
c、.csm 文件存储表的元数据;如表的状态和数据量
d、.frm文件存储表结构
(02)特点
a、所有的列的不能为null的
b、不支持索引(不适合大表和在线处理)
c、可以直接对数据文件进行编辑(保存文本文件内容)
(9)Memory存储引擎
(01)系统使用临时表,未超过限制的Memory临时表
(02)创建临时表语法
CREATE TEMPORARY TABLE 表名{字段}
(03)重启时,临时表里的数据消失,因为是存在内存中的
(10)FEDERATED引擎
(01)特点
(a)提供访问远程mysql服务器上的表的方法
(b)本地不存储数据、数据全部放到远程服务器上
(c)本地需要保存表结构信息和远程服务器的连接信息
(2)应用场景
偶尔的统计分析及手工查询
(3)如何使用
默认是禁止的,启用时需要在启动时增加FEDERATED参数
8)事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据,与表中最终的实际数据不一致
<span style="font-size: inherit;">2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。读取结果与上次结果不一致</span><br>
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。修改过来了但又被改了,导致结果和预期不一样
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
02、业务设计
1)锁
(1)什么是锁
(01)锁是计算机协调多个进程 或线程并发访问某一资源的机制
(02)在数据库中,数据也是一种供许多用户共享的资源
(03)锁对数据库而言显得尤其重要,也更加复杂
(2)锁机制
(01)MyISAM和Memory采用的是表级锁
(02)InnoDB支持表级锁和行级锁
(03)不同的存储引擎采用不同的锁
(3)锁分类
(01)表级锁
开销小、加锁快;不会出现死锁,锁定粒度大,发生锁冲突的概率最高,并发度最低
(02)行级锁
开销小,加锁慢;会出现死锁,锁定粒度最小,发生锁冲突的概率最低,并发度也最高
(03)页面锁
开销和加锁时间界于表锁和行锁之间,会出现死锁;锁定粒度界于表锁和行销之间,并发度一般
(4)锁的应用场景
(01)表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用
(02)行级锁则更适合于有大师按索引条件并发更新少量不同数据,同时又有并发查询的应用
(5)MyISAM表锁的两种形式
(01)表共享读锁(Table Read Lock)同一个session中读时不能写,也不能更新,不同的session中写会等待
(02)表锁占写锁(Table Write Lock) 写时不能读
(03)加锁的语法:lock table 表名 read
(04)解除锁的语法:unlock tables
(05)总结
(a)对MyISAM表的读操作,不会阻塞其他用户对同- -表的读请求,但会阻塞对同-表的写请求◆对MyISAM表的读操作,\n不会阻塞当前session对表读,当对表进行修改会报错
(b)一个session使用LOCK TABLE命令给表f加了读锁,这个session可以查 询锁定表中的记录,但更新或访问其他表都会提示错误:
(c)读锁情况,另外一个session可 以查询表中的记录,但更新就会出现锁等待
(d)对MyISAM表的写操作,则会阻塞其他用户对同一表的读和写操作:
(c)MyISAM表的写操作,当前session可以对本表做CRUD,但对其他表进行操作会报错
(6)InnoDB锁
(01)共享锁又称:读锁。当一个事务对某几行上读锁时,允许其他事务对这几行进行读操作,但不允许其进行写操作,\n也不允许其他事务给这几行上排它锁,但允许上读锁
(02)排它锁又称:写锁。当一个事务对某几个上写锁时,不允许其他事务写,但允许读。更不允许其他事务给这几行上任何锁。包括写锁。
(7)实战:怎么修改超在表的物理结构
(01)先建立一张表和业务表一样的表结构
(02)把业务表的数据同步到新建立的表里
(03)在业务表上建立触发器同步新插入业务数据表的数据
(04)新表修改完成后,对原业务表进行表锁,将新表的表名改为业务表的表名即可完成
2)事务
(01)什么是事务
(a)现在的很多软件都是多用户,多程序,多线程的,对同一个表可能同时有很多人在用,为保持数据的一致性,所以提出了事务的概念
(b)A给B要划钱,A的账户-1000元,B 的账户就要+1000元,这两个update语句必须作为- -个整体来执行,不然A扣钱了,B没有加钱这种情况很难处理。
(02)事务的特点
(a)事务应该具有4个属性:原子性、一致性、 隔离性、持久性。这四个属性通常称为ACID特性。
(b)原子性(atomicity)
-一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
(c)一致性 (consistency)
事务必须是使数据库从一个一 致性状态变到另 一个一致性状态。一致性与原子性是密切相关的。
(d)隔离性(isolation)
一个事务的执行不能被其他事务干扰。即-一个事务内部的操作及使用的数据对 并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰
(e)持久性(durability)
持久性也称永久性( permanence),指一一个事务一旦提交, 它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
(03)事务的特性
(a)隔离性(isolation) ;隔离性要求一一个 事务对数据库中数据的修改,在未提交完成前对于其他事务是不可见的
(b)未提交读( READ UNCOMMITED)脏读.
(c)已提交读( READ COMMITED)不可重复读
(d)可重复读( REPEATABLE READ) mysql默认
(e)可串行化( SERIALIZABLE)
(f)设置和事务的级别
set SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
(04)事务的语法
(a)开始:begin或start transaction
(b)begin work
(c)事务回滚:rollback
(d)事务提交:commit
(05)事务隔离级别(总结)
(a)事务隔高级别为可重复读时,如果有索引(包括主键索引)的时候,以索引列为条件更新数据,会存在间隙锁间、行锁、页锁的问题,从而锁住一些行: 如果没有索引,更新数据时会锁住整张表
(c)隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大,对于多数应用程序,可以优先考忠把数据库系统的隔离级别设为ReadComited,它能够避免脏读取,而且具有较好的并发性能。
(b)事务隔高级别为串行化时,读写数据都会锁住整张表
3)数据库范式
(01)数据库的三大范式
(a)第一范式(确保每列保持原子性):所有字段值都是不可分解的原子值
(b)第二范式(确保表中的每列都和主键相关):也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中
(c)第三范式(确保每列都和主键列直接相关,而不是间接相关):每一列数据都和主键直接相关,而不能间接相关
(02)数据库的反范式
a、什么是反范式
反范式化是针对范式化而言得,在前面介绍了数据库设计得范式
所谓得反范式化就是为了性能和读取效率得考虑而适当得对数据库设计范式得要求进行违反
允许存在少量得冗金,换句话来说反范式化就是使用空间来换取时间
b、反范式的优点
可以减少表的关联
可以更好的进行索引优化
c、反范式的缺点
存在数据冗余及数据维护异常
对数据的修改需要更多的成本
4)物理设计
(01)定义数据库、表及字段的命名规范
(02)教据库、表、字段的命名要遵守可读性原则
使用大小写来格式化的库对象名字以获得良好的可读性
例如:使用custAddress而i不是custaddress水提高可读性
(03)数据库、表、字段的命名要遵守表意性原则
对象的名字应该能够描述它所表示的对象
例如:对于表,表的名称应该能够体现表中存储的数据内容;对于存储过程存储过程应该能够体现存储过程的功能。
(04)数据库、表、宁段的命名要遵守长名原则,尽可能少使用或者不使用缩写
(05)为表中的字段选择合适的数据类型
(06)当一个列可以选择多种数据类型时
优先考虑数字类型
其次是日期、时间类型
最后是字符类型
对于相同级别的数据类型,应该优先选择占用空间小的数据类型
(07)注意事项:timestarmp和时区有关,而datatime和时区无关
03、查询以及优化、执行计划
1)慢查询
(1)什么是慢查询、定义与作用
慢查询日志,顾名思义,就是查询慢的日志,是指mysql记录所有执行超过long. _query_ _time参数设定的时间阈值的SQL语句的日志。
该日志能为SQL语句的优化带来很好的帮助。默认情况下,慢查询日志是关闭的,要使用慢查询日志功能,首先要开启慢查询日志功能
(1)慢查询的配制
slow_ query_ log启动停止技术慢查询日志
slow_ _query_ log. file指定慢查询日志得存储路径及文件(默认和数据文件放一起)
long_query_time 指定记录慢查询日志SQL执行时间得伐值(单位:秒,默认10秒)
log_ queries_ not_ using_ indexes 是否记录未使用索引的SQL
log_ output日志存放的地方[TABLE] [FILE] [FILE,TABL
记录符合条件得SQL
查询语句
数据修改语句
已经回滚得SQL
(2)慢查询分析
(01)慢查询分析工具[mysqldumpslow]
汇总除查询条件外其他完全相同的SQL,并将分析结果按照参数中所指定的顺序输出。
语法
mysqldumpslow -S r -t 10 slow-mysql.log
参数说明:-s order (,t,r,at,al,ar)
c:总次数
t:总时间
l:锁的时间
r:总数据行
at,al,ar :t,I,r平均数[ 例如: at =总时间/总次数]
-t top指定取前面几天作为结果输出
(02)慢查询分析工具[pt_ query_ _digest]
语法
pt-query-digest --explain h=127.0.0.1, u=root, p=password slow-mysql.log
汇总的信息[总的查询时间]、[ 总的锁定时间]、[ 总的获取数据量]、[扫描的数据量] 、[查询大小]
2)索引
(1)什么是索引
a、MySQL官方对索引的定义为:索引(Index) 是帮助MySQL高效获取数据的数据结构。
b、可以得到索引的本质:索引是数据结构。
(2)InnoDB默认的索引
mysql默认存储引擎innodb只显式支持B-Tree(从技术,上来说是B+ Tree)索引
(3)索引的分类
a、普通索引: “即一个索引只包含单个列,一个表可以有多个单列索引
b、唯一索引:索引列的值必须唯一,但允许有空值
c、复合索引:即一个索引包含多个列
d、聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行。
e、非聚簇索引:不是聚簇索引,就是非聚簇索引
(4)基础语法
3)执行计划
(1)什么是执行计划
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈
(2)语法
Explain + SQL语句
(3)执行计划的作用
a、数据读取操作的操作类型
b、哪些索引可以使用
c、哪些索引被实际使用
d、表之间的引用
e、每张表有多少行被优化器查询
(4)执行计划的列
id
id相同:从上住下读取
id不同:数字大的优先级高,相同的从上往下读
作用:用于获取select子句的操作表顺序
select_type
SIMPLE:简单的select查询查询中不包含子查询或者UNION
PRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为
SUBQUERY:在SELECT或WHERE列表中包含了子查询
DERIVED:在FROM列表中包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询,把结果放在临时表里。
UNION:若第二个SELECT出现在UNION之后,则被标记为UNION; ;若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED
UNION RESULT:从UNION表获取结果 的SELECT
table
显示这一行是关于那张表的
type
说明:type显示的是访问类型,是较为重要的一-个指标,结果值从最好到最坏依次是
顺序
system>const>eq__ref>ref> range>index>ALL
system:表只有一行记录 (等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计
const:表示通过索引一次就找到了,
const用于比较primary key或者unique索引。
因为只匹配一行数据,所以很快如将主键置于where列表中,MySQL就能 将该查询转换为一个常量
eq_ref:唯一性索引扫描, 对于每个索引键,表中只有一条记录与之匹配。 常见于主键或唯一索引列
ref:非唯一性索引扫描,返回匹配某个单独值的所有行
本质上也是一种索引访问,它返回所有匹配某个单独值的行
然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体
range:只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引
一般就是在你的where语句中出现了between、<、>、in等 的查询
这种范围扫描索引扫描比全表扫描要好,
因为它只需要开始于索引的某-点,而结束语另一点,不用扫描全部索引。
index:当查询的结构全为索引列的时候
all:Full Table Scan,将遍历全表以找到匹配的行
possible_key<br>
预计会用到的索引
key
实际使用的索引。如果为NULL,则没有使用索引
查询中若使用了覆盖索引,则该索引和查询的select字段重叠
key_ len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下.长度越短越好
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key, _len是根据表定义计算而得,不是通过表内检索出的
注意:根据底层使用的不同存储引擎,受影响的行数这个指标可能是一个估计值,也可能是一个精确值。即使受影响的行数是-一个估计值(例如当使用InnoDB存储引擎管理表存储时),通常情况下这个估计值也足以使优化器做出一个有充分依据的决定.
key_ len表示索引使用的字节数.
根据这个值,就可以判断索引使用情况,特别是在组合索引的时候,判断所有的索引字段是否都被查询用到。
char和varchar跟字符编码也有密切的联系,
latin1占用1个字节,gbk占用2个字节,utf8占用3个字节。 (不同字符编码占用的存储空间不同)
整数/浮点数/时间类型的索引长度,NOT NULL=字段本身的字段长度
NULL=字段本身的字段长度+1(因为需要有是否为空的标记,这个标记需要占用1个字节)
datetime类型在5.6中字段长度是5个字节,datetime类 型在5.5中字段长度是8个字节
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值
rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
Extra
1、包含不适合在其他列中显示但十分重要的额外信息
2、Using filesort
说明mysq|会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。
MySQL中无法利用索引完成的排序操作称为“文件排序"
3、Using temporary
使了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序order by和分组查询group by。
4、USING index
是否用了覆盖索引
5、Using where
表明使用了where过滤
6、Using join buffer
使用了连接缓存:
7、Impossible where
where子句的值总是false,不能用来获取任何元组
8、Using filesort
说明mysq|会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成的排序操作称为“文件排序"
9、Using temporary
使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序order by询group by。
10、USING index
表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据
如果同时出现using where,表明索引被用来执行索引键值的查找;
如果没有同时出现using where,表明索引用来读取数据而非执行查找动作。
4)Sql优化
(01)查询优化
策略1:尽量全值配制
策略2:最佳左前缀原则,让索引不失效的一个策略,法则
策略3:不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
策略4:范围条件放最后,存储引擎不能使用索引中范围条件右边的列,如果使用了范围查询,会导致范围查询以后的索引失效
策略5:覆盖索引尽量用,尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)), 减少select
策略6:不等于要甚用.,mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
策略7:Null/Not有影响注意null/not nll对索引的可能影响
策略8:Like查询要当心,like以通配符开头(%abc... )mysq|l索引失效会变成全表扫描的
策略9:字符类型加引号,字符串不加单引号索引失效
策略10:ORTUNIONXXE
(02)insert语句优化
a、提交前关闭自动提交
b、尽量使用批量insert语句
c、可以使用MyISAM存储引擎
5)实例:大批量数据导入
(01)LOAD DATA INFLIE
(02)使用LOAD DATA INFLIE;比一般的insert语句快20倍
(03)select * into OUTFILE 'D:lproduct.txt' from product info;
(04)load data INFILE 'D:product.txt' into table product info;
5、SQL优化的重点
01、程序设计优化
1)应用流程的优化,避免不必要的流程
2)代码层的优化,代码逻辑改写,简化
3)接口间的相互调用是否可以简化
4)一些状态数据是否可以利用缓存来避免多次访问数据库
5)数据的最少化查询会返回
6)柔和数据的分类展示
02、SQL物理层优化
1)表结构的调正是否可以调整为更优的结构
2)分表,充分利用多主机的计算能力
03、SQL层优化
1)SQL的执行计划都否都是最优的
2)常用的SQL功能可以优化封装成函数
3)对慢查询SQL进行分批次的逐步优化
4)长时间范围的查询结果集是否可以分为多次小范围的查询
小总结
业务操作需要调用三个服务来完成。此时每个服务内部的数据一致性由本地事务来保证,但是全局的数据一致性问题没法保证。
八、微服务(Could)架构篇
服务注册中心
Eureka
Zookeeper<br>
Consul<br>
Nacos
服务调用<br>
Ribbon
LoadBalancer
Feign
如何使用
只需要写一个【接口】在接口上添加【注解】就可以完成【客户端】的服务调用通过添加注解给接口生成动态代理,然后去调用方法的时候会生成http协议格式的请求feign集成封装了ribbon,通过轮询实现了客户端的负载均衡,使服务调用更加简单
能做什么
Feign旨在使编写Java Http客户端变得更容易。
前面在使用Ribbon+ RestTemplate时,利用RestTemplate对http请求的封装处理,形成了-套模版化的调用方法。但是在实际开发中,由于对服务依赖的调用可能不止一处,往往- -个接会被多处调用,所以通常都会针对每个微服务自行封装一些客户端类来包装这些依赖服务的调用。所以,Feign在此基础上做了进一步封装, 由他来帮助我们定义和实现依赖服务接口的定义。在Feign的实现下,我们只需创建一个接口并使用注解的方式来配置它(以前是Dao接口 上面标注Mapper注解现在是一个微服务接口. 上面标注一个Feign注解即可),即可完成对服务提供方的接C门绑定,简化了使用Spring cloud Ribbon时,自动封装服务调用客户端的开发量。
Feign集成了Ribbon:利用Ribbon维护了Payment的服务列表信息,并且通过轮询实现了客户端的负载均衡。而与Ribbon不同的是,通过feign只需要定义服务绑定接口且以声明式的方法,优雅而简单的实现了服务调用
OpenFeign
OpenFeign是什么
1、Feign是一个声明式WebService客户端。 使用Feign能让编写Web Service客户端更加简单。
2、它的使用方法是定义一个服务接口然后在上面添加注解。Feign也支 持可拔插式的编码器和解码器。Spring Cloud对Feign进行了封装,使其支持了Spring MVC标准注解和HttpMessageConverters。Feign可以与Eureka和Ribbon组合使用以支持负载均衡
官网地址:https://cloud.spring.io/spring-cloud-static/Hoxton.SR1/reference/htmlsingle/#spring-cldud-%20openfeign
Feign和OpenFeign的区别
使用步骤
接口+注解
微服务调用接口+ @FeignClient
新建cloud- consumer -feign- order80
Feign用在消费端<br>
POM
<!--openfeign--><dependency><groupId>org . springframework. cloud</ groupId><artifactId>spring-cloud- starter- openfeign</artifactId></dependency><br>
YML
主启动
业务类
测试
服务调用<br>
在接口上添加注解FeignClient(value="服务名"),将服务端Controller中
的方法头拷贝到接口中,在客户端Controller中注入接口实例,完成调用
超时控制
openfeign底层是ribbon,客户端默认等待1秒钟
在application.yml中设置ribbon的超时等待时间
日志增强<br>
Feign提供了日志打印功能,可以调整日志级别,对接口的调用情况进行监控
日志级别
NONE:【默认】不显示任何日志
BASIC:仅记录请求方法、URL、响应状态码及执行时间
HEADERS:除了BASIC中定义的信息之外,还有请求和响应的头信息
FULL:除了BASIC中定义的信息之外,还有请求和响应的正文及元数据
代码实现
创建配置类
@Configuration
public class FeignConfig{
@Bean
Logger.Level feignLoggerLevel(){
return Logger.Level.FULL;
}
配置application.yml
配置Feign日志以什么级别监控哪个接口<br>logging:<br> level:<br> com.cherry.springcloud.service.PaymentFeignService: debug<br><br>
服务降级
Hystrix<br>
概述
分布式系统面临的问题
复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。.
服务雪崩:多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的"扇出。如果扇出的链路.上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引|起系统崩溃,所谓的“雪崩效应"
是什么<br>
Hystrix是一个用于处理分布式系统的延迟和容错的开源库, 在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下, 不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
"断路器”本身是-种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回-个符合预期的、可处理的备选响应(FallBack) ,而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
能干嘛<br>
服务降级
服务熔断<br>
接近实时监控
。。。。。
官网资料
https://github.com/Netflix/Hystrix/wiki/How-To-Use
<font color="#ff99cc">Hystrix停更进维</font><br>
Hystrix重要概念
服务降级
服务器忙,请稍后再试,不让客户端等待并立刻返回一个友好提示,fallback
那些情况会触发服务降级<br>
程序运行异常
超时<br>
服务熔断触发服务降级
线程池/信号量打满也会导致服务降级<br>
服务熔断<br>
类比保险丝达到最大服务访问后,直接拒绝访问,拉闸限电,然后调用服务降级的方法并返回友好提示
就是保险丝
服务的降级->进而熔断->恢复调用链路
服务限流
秒杀高并发等操作,严禁一窝蜂的过来拥挤,大家排队,一秒钟N个,有序进行
Hystrix案例
构建
新建cloud-provider-hystrix-payment8001
POM
YML
主启动
业务类
service
controller
正常测试
启动eureka7001
启动cloud-provider-hystrix-payment8001
访问
上述module均OK
以上述为根基平台,从正确->错误->降级熔断->恢复
高并发测试
上述在非高并发情形下,还能勉强满足,but......
Jmeter压测测试
开启Jmeter,来20000个并发压死80Q1,20000个请求都去访问paymentInfo_ Tim
再来一个访问
两个都在自己转圈圈
为什么会被卡死A
看演示结果
tomcat的默认的工作线程数被打满了,没有多余的线程来分解压力和处理。
Jmeter压测结论
上面还是服务提供者8001自己测试,假如此时外部的消费者80也来访问,那消费者只能干等,最终导致消费端80不满意,服务端8001直接被拖死
看热闹不嫌弃事大,80新建加入
cloud- consumer-feign- hystrix-order80
新建
POM
POM
主启动
业务类
正常测试
高并发测试
故障现象和导致原因
8001同一层次的其它接口服务被困死,因为tomcat线程池里面的工作线程已经被挤占完毕
80此时调用8001,客户端访问响应缓慢,转圈圈
上诉结论
正因为有.上述故障或不佳表现
才有我们的降级/容错/限流等技术诞生
如何解决?解决的要求<br>
超时导致服务器变慢(转圈)
超时不在等待
出错(宕机或程序运行出错)
出错要有兜底
解决
对方服务(8001)超时了,调用者(80)不能一-直 卡死等待,必须有服务降级
对方服务(8001)down机了,调用者(80)不能一-直 卡死等待,必须有服务降级
对方服务(8001)OK,调用者(80)自己出故障或有自我要求(自己的等待时间小于服务提供者),自己处理降级
服务阶级
降级配置
@HystrixCommand
8001先从自身找问题
设置自身调用超时时间的峰值,峰值内可以正常运行,
超过了需要有兜底的方法处理,作服务降级fallback
8001fallback<br>
业务类使用
@ HystrixCommand报异常后如何处理
一旦调用服务方法失败并抛出了错误信息后,会自动调用@HystrixCommand标注好的fallbackMethod调用类中的指定方法
图示
主启动类激活
添加新注解@ EnableCircuitBreaker
80fallback
80订单微服务,也可以更好的保护自己,自己也依样画葫芦进行客户端降级保护
题外话,切记
YML
feign:<br> hystrix;<br> enabled: true<br>
主启动
业务类
目前问题<br>
每个业务方法对应- -个兜底的方法,代码膨胀
和自定义的分开
解决问题<br>
每个方法配置一个? ? ?膨胀
feign接口系列
@DefaultProperties(defaultFallback= "")
说明
@DefaultProperties(defaultallback =")
1: 1每个方法配置一个服务降级方法,技术上可以,实际上傻X
1: 1每个方法配置一个服务降级方法,技术上可以,实际上傻X
通用的和独享的各自分开,避免了代码膨胀,合理减少了代码量, 0(∩∩)O哈哈~
controller配置
和业务逻辑混一起???混乱
服务降级,客户端去调用服务端,碰. 上服务端宕机或关闭
本次案例服务降级处理是在客户端80实现完成的,与服务端8001没有关系只需要为Feign客户端定义的接口添加一个服务降级处理的实现类即可实现解耦
未来我们要面对的异常
再看我们的业务类PaymentController
修改cloud-consumer-feign-hystrix-order80
根据cloud-consumer-feign-hystrix- order80已经有的PaymentHystrixService接口,重新新建一个类(PaymentFallbackService)实现该接口, 统一为接口里面的方法进行异常处理
PaymentFalbackService类实现PaymentFeignClientService接口
YML圓
PaymentFeignClientService接口
测试
单个eureka先启动7001
PaymentHystrixMain8001启动.
正常访问测试
故意关闭微服务8001
客户端自己调用提示
此时服务端provider已经down'了,但是我们做了服务降级处理,让客户端在服务端不可用时也会获得提示信息而不会挂起耗死服务器
服务熔断
断路器
熔断是什么
大神论文
https://martinfowler.com/bliki/CircuitBreaker.html
实操
修改cloud- provider- hystrix- payment8001
PaymentService
why配置这些参数
PaymentController享
测试
原理(小总结)
服务限流
Resilience4j<br>
Sentinel<br>
熔断和降级
什么是熔断和降级
描述
答:在微服务架构中,微服务之间通过网络进行通信,存在相互依赖,当其中一个服务不可用时,
有可能会造成雪崩效应。要防止这样的情况,必须要有容错机制来保护服务。
服务熔断
答:设置服务的超时,当被调用的服务经常失败到达某个阈值,我们可以开
启断路保护机制,后来的请求不再去调用这个服务。本地直接返回默认
的数据
服务降级
答:在运维期间,当系统处于高峰期,系统资源紧张,我们可以让非核心业
务降级运行。降级:某些服务不处理,或者简单处理【抛异常、返回 NULL、
调用 Mock 数据、调用 Fallback 处理逻辑】。
服务降级是在服务器压力陡增的情况下,利用有限资源,根据当前业务情况,关闭某些服务接口或者页面,以此释放服务器资源以保证核心任务的正常运行。
为什么要使用熔断和降级
在一个分布式系统里,一个服务依赖多个服务,可能存在某个服务调用失败,比如超时、异常等,需要保证在一个依赖出问题的情况下,不会导致整体服务失败。
sentinel 熔断和降级
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel是面向分布式服务架构的流量控制组件,主要以流量为切入点,从流量控制、熔断降级、系统自适应保护等多个维度来帮助您保障微服务的稳定性。
服务网关
Zuul
概述简介
路由基本配置<br>
路由访问映射规则
查看路由信息
过滤器
Zuul2
Gateway<br>
其他理解
什么是服务网关
API Gateway(APIGW / API 网关),顾名思义,是系统对外的唯一入口。API网关封装了系统内部架构,为每个客户端提供定制的API。 近几年来移动应用与企业间互联需求的兴起。从以前单一的Web应用,扩展到多种使用场景,且每种使用场景对后台服务的要求都不尽相同。 这不仅增加了后台服务的响应量,还增加了后台服务的复杂性。随着微服务架构概念的提出,API网关成为了微服务架构的一个标配组件。
描述
Spring Cloud Gateway是基于Spring生态系统之上构建的API网关,包括:Spring 5.x,Spring Boot 2.x和Project Reactor。Spring Cloud Gateway旨在提供一种简单而有效的方法来路由到API,并为它们提供跨领域的关注点,例如:安全性,监视/指标,限流等。
为什么要使用网关
微服务的应用可能部署在不同机房,不同地区,不同域名下。此时客户端(浏览器/手机/软件工具)想 要请求对应的服务,都需要知道机器的具体 IP 或者域名 URL,当微服务实例众多时,这是非常难以记忆的,对 于客户端来说也太复杂难以维护。此时就有了网关,客户端相关的请求直接发送到网关,由网关根据请求标识 解析判断出具体的微服务地址,再把请求转发到微服务实例。这其中的记忆功能就全部交由网关来操作了。
核心概念
路由(Route):路由是网关最基础的部分,路由信息由 ID、目标 URI、一组断言和一组过滤器组成。如果断言 路由为真,则说明请求的 URI 和配置匹配。
断言(Predicate):Java8 中的断言函数。Spring Cloud Gateway 中的断言函数输入类型是 Spring 5.0 框架中 的 ServerWebExchange。Spring Cloud Gateway 中的断言函数允许开发者去定义匹配来自于 Http Request 中的任 何信息,比如请求头和参数等。
过滤器(Filter):一个标准的 Spring Web Filter。Spring Cloud Gateway 中的 Filter 分为两种类型,分别是 Gateway Filter 和 Global Filter。过滤器将会对请求和响应进行处理。
概述简介
官网
上一-代zuul 1.X
https://github.com/Netflix/zuul/wiki
当前gateway
https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/
是什么
SpringCloud Gateway是Spring Cloud的一个全新项目, 基纡Spring 5.0+Spring Boot 2.0和Project Reactor等技术开发的网关,它旨在为微服务架构提供-种简单有效的统一 的API路由管理方式。
SpringCloud Gateway作为Spring Cloud生态系统中的网关,目标是替代Zuul,在Spring Cloud 2.0以上版本中,没有对新版本的Zuul 2.0以上最新高性能版本进行集成,仍然还是使用的Zuul 1.x非Reactor模式的老版本。而为了提升网关的性能,SpringCloud Gateway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。
Spring Cloud Gateway的目标提供统- 的路由方式且基于Filter链的方式提供了网关基本的功能,例如:安全,监控/指标,和限流。
Gateway是在Spring生态系统之上构建的API网关服务,基于Spring 5, Spring Boot 2和Project Reactor等技术。
Gateway旨在提供-种简单而有效的方式来对API进行路由,以及提供一些强大的过滤器功能, 例如:熔断、限流、重试等
一句话
SpringCloud Gateway使用的Webflux中的reactor- netty响应式编程组件,底层使用了Netty通讯框架。
能做什么
反向代理<br>
鉴权<br>
流量控制<br>
熔断
日志监控
。。。。。。
微服务架构中的网关在那里<br>
有了zuul,为何双出来geteway
为什么选择
1. neflix不太靠谱, zyl2.0一直跳票,迟迟不发布
一方面因为Zuul1.0已经进入了维护阶段,而且Gateway是SpringCloud团队研发的, 儿子产品,值得信赖。而且很多功能Zuul都没有用起来也非常的简单便捷。
Gateway是基于异步非阻塞模型上进行开发的,性能方面不需要担心。虽然Netflix早就发布了最新的Zuul 2.x,但Spring Cloud貌似没有整合计划。而且Netflix相关组件 都宣布进入维护期;不知前景如何?
多方面综合考虑Gateway是很理想的网关选择。
2. SpringCloud Gateway具有如下特性
Spring Cloud Gateway具有如下特性:
基于Spring Framework 5, Project Reactor和Spring Boot 2.0进行构建;
动态路由:能够匹配任何请求属性;
可以对路由指定Predicate (断言)和Filter (过滤器) ;
集成Hystrix的断路器功能;
集成Spring Cloud服务发现功能;
易于编写的Predicate (断言)和Filter (过滤器) ;
请求限流功能;
支持路径重写。
3. SpringCloud Gateway与Zuul的区别
Spring Cloud Gateway与Zuul的区别,在SpringCloud Finchley正式版之前, Spring Cloud推荐的网关是Netflix提供的Zuul:
1、Zuul 1.x, 是一个基于阻塞I/ 0的API Gateway
2、Zuul 1.x基于Servlet 2. 5使用阻塞架构它不支持任何长连接(如WebSocket) Zuul的设计模式和Nginx较像,每次I/ 0操作都是从工作线程中选择一个执行,请求线程被阻塞到工作线程完成,但是差别是Nginx用C++实现,Zuul 用Java实现,而JVM本身会有第一次加载较慢的情况, 使得Zuul的性能相对较差。
3、Zuul 2.x理念更先进,想基于Netty非阻塞和支持长连接,但SpringCloud目前还没有整合。Zuul 2.x的性能较Zuul 1.x有较大提升, 在性能方面,根据官方提供的基准测试, Spring Cloud Gateway的RPS (每秒请求数)是Zuul的1.6倍。
4、Spring Cloud Gateway建立在Spring Framework 5、Project Reactor和Spring Boot2之上,使用非阻塞API。
5、Spring Cloud Gateway还支持WebSocket,并诅与Spring紧密集成拥有更好的开发体验
zuul1.0的模型
Springcloud中所集成的Zuul版本,采用的是Tomcat熔器,使用的是传统的Servlet I0处理模型。<br>
Servlet的生命周期?servlet由servlet container进行生命周期管理。container启动时构造servlet对象并调用servlet init(进行初始化;container运行时接受请求,并为每个请求分配一个线程(一般从线程池中获取空闲线程) 然后调用service()。container关闭时调用servlet destory0销毁servlet;
上述模式的缺点:
servlet堤一个简单的网络IO模型, 当请求进入servlet container时,servlet container就会为其绑定一个线程, 在并发不高的场景下这种模型是适用的。但是- -旦高并发(此如抽风用jemeter压),线程数量就会.上涨,而线程资源代价是昂贵的(上线文切换,内存消耗大)严重影响请求的处理时间。在一些简单业务场景下, 不希望为每个request分配一个线程, 只需要1个或几个线程就能应对极大并发的请求,这种业务场景下servlet模型没有优势
所以Zuul 1.X是基于servlet之上的一个阻塞式处理模型,即spring实现了 处理所有request请求的一个servlet (DispatcherServlet) 并由该servlet阻塞式处理处理。所以Springcloud Zuul无法摆脱servlet模型的弊端
geteway模型
webflux是什么<br>
传统的Web框架,比如说: struts2, springmvd等 都是基于Servlet API与Servlet容器基础之上运行的。但是在Servlet3.1之后有了异步非阻塞的支持。而WebFlux是- -个典型非阻塞异步的框架,它的核心是基于Reactor的相关API实现的。相对于传统的web框架来说,它可以运行在诸如Netty, Undertow及 支持Servlet3.1的容器上。非阻塞式+函数式编程(Spring5必须让你使用java8)
Spring WebFlux是Spring 5.0引入的新的响应式框架,区别于Spring MVC,它不需要依赖Servlet API,它是完全异步非阻塞的,并且基于Reactor来实现响应式流规范。
三大核心概念<br>
Route(路由)<br>
路由是构建网关的基本模块,它由ID, 目标URI, - -系列的断言和过滤器组成,如果断言为true则匹配该路由
Predicate(断言)<br>
参考的是Java8的java.util.function.Predicate
开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由
Filter(过滤)
指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
总体
web请求,通过一些匹配条件, 定位到真正的服务节点。并在这个转发过程的前后,进行些精细化控制。
predicate就是我们的匹配条件:而filter, 就可以理解为个无所不能的拦截器。有了这两个元素,再加上目标uri,就可以实现个具体的路由了
geteway的工作流程
官网介绍
客户端向Spring Cloud Gateway发出请求。然后在Gateway Handler Mapping中找到与请求相匹配的路由,将其发送到Gateway Web Handler。Handler再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回。过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前( "pre” )或之后( "post" )执行业务逻辑。
核心逻辑<br>
路由㔹发+执行过滤器<br>
入门配置
新建model
pom
yml
spring:application:name: C loud- gateway<br>
业务类
无
主启动类
YML新增网关配置
测试
配置说明
通过微服务设置动态路由<br>
predicate的使用<br>
是什么
启动我们的gateway9527
Route Predicate Factories这个是什么东东?<br>
Spring Cloud Gateway将路由匹配作为Spring WebFlux HandlerMapping基础架构的一部分。Spring Cloud Gateway包括许多内置的Route Predicate工厂。所有这些Predicate都 与HTTP请求的不同属性匹配。多个RoutePredicate工厂可以进行组合。
Spring Cloud Gateway创建Route对象时,使用 RoutePredicateFactory创建Predicate对象,Predicate 对象可以赋值给Route。Spring Cloud Gateway包含许多内置的Route Predicate Factories。
所有这些谓词都匹配HTTP请求的不同属性。多种谓词工厂可以组合,并通过逻辑and。
常用的Route Predicate
filter的使用<br>
服务配置
Config
Nacos
服务总线
Bus
Nacos
分布式事务
SpringCloud Alibaba seata处理布式事务
分布式事务问题
分布式事务之前
单机单库没有这个问题
分布式事务之后
单体应用被拆分成微服务应用,原来的三个模块被拆分成三个独立的应用,分别使用三个独立的数据源,
一句话
一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务问题
Seata简介
是什么
Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事。
官网地址
http://seata.io/zh-cn/
能干什么
一个典型的分布式事务过程
分布式事务处理过程的 ID+三组件模型
Transaction lD XID
全局唯一的事务ID
3组件概念
Transaction Coordinator (Tc)
事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚;
Transaction Manager (TM)
事务管理器:控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
Resource Manager (RM)
资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
处理过程
1.TM向TC申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的XID;
2. XID在微服务调用链路的上下文中传播;
3. RM向TC注册分支事务,将其纳入XID对应全局事务的管辖;
4.TM向TC发起针对XID的全局提交或回滚决议;
5. TC调度XID下管辖的全部分支事务完成提交或回滚请求。
去那下
https://github.com/seata/seata/releases
怎么玩
本地@Transactional
全局@GlobalTransactional
SEATA的分布式交易解决方案
Seata服务的安装
1、官网
2.下载版本
3.seata-server-0.9.0.zip解压到指定目录并修改conf目录下的file.conf配置文件
先备份原始file.conf文件
主要修改:自定义事务组名称+事务日志存储模式为db+数据库连接信息
file.conf
service模块
service {
vgroup_mapping.my_test_tx_group = "fsp_tx_gropp"
default.grouplist = "127.0.0.1:8091"
enableDegrade = false
disable = false
max.commit.retry.timeout = "-1"max.rollback.retry.timeout = "-1”}
store模块
从文件存储修改为db存储,也就是数据库存储,接着修改数据库的连接信息
4.mysql5.7数据库新建库seata
5.在seata库里建表
建表db store.sql在\seata-server-0.9.0\seata\conf目录里面
db_store.sql
sQL
6.修改seata-server-0.9.0\seata\conf目录下的registry.conf配置文件
目的是:指明注册中心为nacos,及修改nacos连接信息
7.先启动Nacos端口号8848
8.再启动seata-server
九、消息中间件篇
消息中间件的理解
消息中间件(MQ)的定义
其实并没有标准定义。一般认为,消息中间件属于分布式系统中一个子系统,关注于数据的发送和接收,利用高效可靠的异步消息传递机制对分布式系统中的其余各个子系统进行集成。
JMS规范
JMS对象模型
连接工厂:连接工厂负责创建一个JMS连接。
JMS连接:JMS连接(Connection)表示JMS客户端和服务器端之间的一个活动的连接,是由客户端通过调用连接工厂的方法建立的。
JMS会话:JMS会话(Session)表示JMS客户与JMS服务器之间的会话状态。JMS会话建立在JMS连接上,表示客户与服务器之间的一个会话线程。
JMS目的/ Broker:客户用来指定它生产的消息的目标和它消费的消息的来源的对象,一个消息中间件的实例。
JMS生产者和消费者:生产者(Message Producer)和消费者(Message Consumer)对象由Session对象创建,用于发送和接收消息。
消息的消费方式
同步消费。通过调用 消费者的receive 方法从目的地中显式提取消息。receive 方法可以一直阻塞到消息到达。
异步消费。客户可以为消费者注册一个消息监听器,以定义在消息到达时所采取的动作。
JMS规范中的消息
JMS 消息由以下三部分组成
消息头。每个消息头字段都有相应的getter 和setter 方法。
消息属性。如果需要除消息头字段以外的值,那么可以使用消息属性。
消息体。JMS 定义的消息类型有TextMessage、MapMessage、
BytesMessage、StreamMessage 和 ObjectMessage。ActiveMQ也有对应的实现
JMS规范模型包含这几个要素<br>
连接工厂
JMS连接
JMS会话
JMS目的/Broker<br>
JMS消费者
JMS生产者<br>
ActiveMQ
RabbitMQ
RocketMQ
kafka
十、大数据篇
分布式计算
Hadoop
spark
storm
Apache Flink
云计算
云服务
IaaS(nfrastructure-as-a- Service):基础设施即服务
消费者通过Internet可以从完善的计算机基础设施获得服务。
SaaS(Software-as-a- Service):软件即服务
它是一种通过Internet提供软件的模式,用户无需购买软件,而是向提供商租用基于Web的软件,来管理企业经营活动。
PaaS(Platform-as-a- Service):平台即服务
PaaS实际上是指将软件研发的平台作为一种服务,以SaaS的模式提交给用户。
因此,PaaS也是SaaS模式的一种应用。但是,PaaS的出现可以加快SaaS的发展,尤其是加快SaaS应用的开发速度。
Openstack
OpenStack是一个开源的云计算管理平台项目,是一系列软件开源项目的组合。
算法
机器学习
一致性
数据结构
常用算法
数据分析工具
R语言
SAS
matlab
十一、项目开发(云城购物)
1、云城购物管理系统实战篇
01、需求功能设计
02、数据库架构设计
03、技术选型
服务器
linux Centos7版本以上
docker
nginx
数据库选择
PostgresSQL分布式数据库
Redis缓存服务器
后台框架选择
SpringBoot
SpringCloud
MyBatis
消息中间件
前端框架选择
Vue
Element UI
小程序
Uniapp
04、框架搭建
05、业务开发
06、软件测试
业务测试
性能测试
安全测试
GUI测试
易用性测试
容错性测试
备份测试
配置测试
测试内容:包括软件配置和硬件配置。
测试目的:通过对被测系统软件与硬件环境的修改,分析每个环境组合对系统性能影响的程度,最后确定系统各项资源的最优分配原则
07、上线试运行
2、小程序开发(uniapp)
3、微信公众号开发
十二、设计模式
设计模式的七大原则
1) 单一职责原则
描述
对类来说的,即一个类应该只负责一项职责。如类 A 负责两个不同职责:职责 1,职责 2。
当职责 1 需求变更而改变 A 时,可能造成职责 2 执行错误,所以需要将类 A 的粒度分解为 A1,A2
使用注意
1) 降低类的复杂度,一个类只负责一项职责。
2) 提高类的可读性,可维护性
3) 降低变更引起的风险
4) 通常情况下,我们应当遵守单一职责原则,只有逻辑足够简单,才可以在代码级违反
单一职责原则;只有类中方法数量足够少,可以在方法级别保持单一职责原则
2)接口隔离原则
描述
1) 客户端不应该依赖它不需要的接口,即一个类对另一个类的依赖应该建立在最小的接口上
3)依赖倒转原则
4)里氏替换原则
5)开闭原则ocp
6)迪米特法则
7)合成复用原则
23种设计模式
单例设计模式
工厂设计模式
适配器设计模式
十三、测试篇
1、压力测试
压力测试的作用
(1)压力测试考察当前软硬件环境下系统所能承受的最大负荷并帮助找出系统瓶颈所在。
压测都 是为了系统在线上的处理能力和稳定性维持在一个标准范围内,做到心中有数
使用压力测试,我们有希望找到很多种用其他测试方法更难发现的错误。有两种错误类型是:
内存泄漏,并发与同步。
(2)有效的压力测试系统将应用以下这些关键条件:重复,并发,量级,随机变化。
性能指标
响应时间(Response Time: RT)
响应时间指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回的响 应结束,整个过程所耗费的时间。
HPS(Hits Per Second)
每秒点击次数,单位是次/秒。
TPS(Transaction per Second)
系统每秒处理交易数,单位是笔/秒。
QPS(Query per Second)
系统每秒处理查询次数,单位是次/秒。
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么 TPS=QPS=HPS,
一 般情况下用 TPS 来衡量整个业务流程,用 QPS 来衡量接口查询次数,用 HPS 来表 示对服务器单击请求。
最大响应时间(Max Response Time)
指用户发出请求或者指令到系统做出反应(响应) 的最大时间。
最少响应时间(Mininum ResponseTime)
指用户发出请求或者指令到系统做出反应(响 应)的最少时间
90%响应时间(90% Response Time)
是指所有用户的响应时间进行排序,第 90%的响应时间。
无论 TPS、QPS、HPS,此指标是衡量系统处理能力非常重要的指标,越大越好
从外部看
性能测试主要关注如下三个指标
吞吐量:每秒钟系统能够处理的请求数、任务数。
响应时间:服务处理一个请求或一个任务的耗时。
错误率:一批请求中结果出错的请求所占比例。
压测工具
JMeter
下载地址
十四、常用API地址和操作篇
1、Java8SE_API下载地址
https://www.oracle.com/java/technologies/javase-jdk8-doc-downloads.html
2、Java8SE_API在线地址
https://docs.oracle.com/javase/8/docs/api/index.html
3、程序员大礼包
https://www.programmer-box.com/
4、Gighub使用
搜索范围
公式
xxx关键词in:name或description或readme
XXX in:name XXX in:name
xxx in:description项目描述包含xx的
xxx in:readme项目的readme文件中包含xx的
组合使用
搜索项目名或者readme中包含秒杀的项目
seckill in:name,readme
精确查找
公式
xxx关键词stars 通配符
:> .或者:>=
springboot stars:>=5000
查找stars数大于等于5000的springboot项目
查找forks数大于500的springcloud项目
springboot forks:>=5000
组合使用
springboot forks:100..2000 stars:100..50000
awesome加强搜索
公式
awesome 关键字
awesome系列一般是用来收集学习、工具、框架相关的栏目
搜索优秀的redis相关的项目,包括框架、教程等
示例
awesome redis
高亮显示代码
公式
一行
地址后面紧跟#L数字+
多行
地址后面紧跟#L数字-L数字2
单行显示
https://github.com/nginx/nginx/blob/master/conf/fastcgi.conf#L12
多行显示
https://github.com/nginx/nginx/blob/master/conf/fastcgi.conf#L12-L18
项目内搜索
项目内搜索输入小写t
搜索某个地区的大佬
公式
location:地区
language:语言
地区北京的Java方向的用户
location:guiyang language:java
5、git
https://git-scm.com/
6、idea破解地址
https://www.exception.site/essay/how-to-free-use-intellij-idea-2019-3
7、微信支付APIf地址
微信支付申请地址
微信支付开发文档
微信商户开发文档
微信公众号官网
公众号开发文档
8、微软全家桶
https://msdn.itellyou.cn/
9、java面试资料大全
https://blog.csdn.net/qq_36894974/article/details/115505102?utm_medium=distribute.pc_category.none-task-blog-hot-5.nonecase&dist_request_id=1330147.33050.16182038011106813&depth_1-utm_source=distribute.pc_category.none-task-blog-hot-5.nonecase
10、百度echarts
https://echarts.apache.org/examples/zh/index.html
11、工作中的地址集
1、气象云平台
http://10.203.64.50:8088/cmadaas//home/jumpPage.action?pageName=homespace
2、cimiss气象服务平台
http://10.203.89.55/cimissapiweb/apidataclassdefine_list.action
3、smos地址
http://10.204.35.210:8080/
12、uniapp前端铺子
https://gitee.com/kevin_chou/front-end-pu-zi#%E9%A1%B9%E7%9B%AE%E4%BF%A1%E6%81%AF
13、Maven Jar查找网站
https://mvnrepository.com/artifact/com.google.zxing/core
14、墨刀
https://v6.modao.cc/dashboard/me
15、uniapp开发激励广告功能API
https://uniapp.dcloud.io/api/a-d/rewarded-video
https://github.com/miyuesc/bpmn-process-designer
十五、bug查找解决篇
1、服务器
1、服务器cpu占用过高分析与定位
1)通过top命令找出有问题的进程
2)使用ps -mp 进程号 -o THREAD,tid,time命令来查询有问题的线程
-m显示所有线程
-p pid 进程使用cpu的时间<br>
-o 该参数后是用户自定义格式
ps -mp 进程号 -o THREAD,tid,time
3)将需要的线程ID转换为16进制格式(英文小写格式),命令为<font style="font-weight: normal;" color="#ffcce6">printf "%x\n" 线程id</font><br>
printf "%x\n" 线程id<br>
4)jstack 进程ID | grep tid(16进制线程ID小写英文) -A60<br>
打印线程的前60行记录
2、linux查询服务器的启动的服务路径
1、找到服务的端口号<br>
netstat -ntlp<br>
ps -ef | grep 服务名
2、使用命令
netstat -anop | grep 0.0.0.0:80
3、在执行命令即可看到<br>
ll /proc/pid/exe<br>
ll /proc/服务的pid号/exe
3、linux使用cat命令搜索文件中的关键字,并显示出来
cat 文件名 | grep -C 20 '关键字' 显示文件里匹配关键字那行以及上下20行
cat 文件名 | grep -B 20 '关键字' 显示关键字及前20行
cat 文件名 | grep -A 20 '关键字' 显示关键字及后20行
2、数据库
1、删除mysql中未提交的事务
使用命令查询3秒内未来加提交的事务<br>
SELECT <br>p.ID AS conn_id,<br>P.USER AS login_user,<br>P.HOST AS login_host,<br>p.DB AS database_name,<br>P.TIME AS trx_sleep_seconds,<br>TIME_TO_SEC(TIMEDIFF(NOW(),T.trx_started)) AS trx_open_seconds,<br>T.trx_started,<br>T.trx_isolation_level,<br>T.trx_tables_locked,<br>T.trx_rows_locked,<br>t.trx_state,<br>p.COMMAND AS process_state<br>FROM `information_schema`.`INNODB_TRX` t<br>INNER JOIN `information_schema`.`PROCESSLIST` p<br>ON t.trx_mysql_thread_id=p.id<br>WHERE t.trx_state='RUNNING'<br>AND p.COMMAND='Sleep'<br>AND P.TIME>3<br>ORDER BY T.trx_started ASC;
查询未提交的事务
select t.trx_mysql_thread_id from information_schema.innodb_trx t<br>
删除你想要删除的事务
kill 7487<br>
2、pgSQL时间加减
select now() + interval '2 years';<br>
3、pgsql查询连接月份SQL
3、后台框架
4、前端框架
1、css设置div不可点击
pointer-events:none;<br>cursor:default;<br>
2、url请求时字符编码与解码
1、js进行编码
encodeURIComponent(要进行编码的内容)
2、js时行解码
decodeURIComponent(要解码的内容);
5、windows
1、windows查询端口占用和关闭
使用命令Netstat –ano|findstr “<端口号>”
杀掉windows的进程号:taskkill /PID 进程号 -F -T<br>






Collect
Get Started
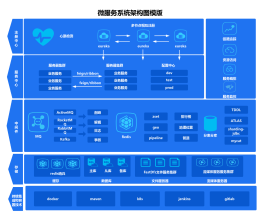
Collect
Get Started

Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页

