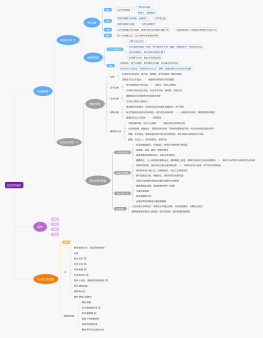
HTTP2
数据传输使用二进制分帧层
多路复用,同一域名只需要创建一个连接
服务端推送
header压缩
应用层的重置连接,可以在不断开连接的前提下取消某个request
请求优先级设置
流量控制
HTTPS
客户端:发送随机数A、协议版本、加密算法
服务端:确定加密算法、数字证书、随机数B
客户端:确认数字证书是否有效、生成随机数C、使用服务器的公钥加密随机数C
根据随机数A、B、C和相同的算法生成对称密钥进行加密通信
TCP
三次握手
客户端发送SYN=1、seq=x,状态:syn-sent
服务端返回SYNC=1、ACK=1、seq=y、ack=x+1 ,状态:syn-rcvd
客户端发送ACK=1、seq=x+1、ack=y+1,状态:establishded
四次挥手
客户端发送FIN=1、seq=u,状态:fin-wait1
服务端返回ACK=1、seq=v,ack=u+1,状态:close-wait
服务端发送FIN=1、ACK=1,seq=w,ack=u+1,客户端状态:fin-wait2
客户端返回ACK=1、seq=u+1,ack=w+1,服务端:closed,客户端:time-wait
客户端等待计时器等待2msl(最长报文段寿命),进入closed
套接字选项
keepalive用于定时检查连接状态
sndbuf发送缓冲区大小
rcvbuf接收缓冲区大小
backlog保存半连接状态的队列
reuseaddr服务端主动关闭进入timewait,可以将端口重新分配
nodelay通过nagle算法得到响应才继续发送下一个数据包
流量控制
基于滑动窗口
接收窗口为0的消息,则启动坚持定时器
坚持定时器每隔一段时间发送一个窗口探测报文
拥塞控制
慢启动算法
由小到大逐渐增加发送数据量
每收到一个报文确认,就加一
拥塞避免算法
维护一个拥塞窗口变量
只要网络不拥塞,就试探着拥塞窗口调大
可靠传输
停止等待协议
每发送一个消息,都需要设置一个定时器
iptables
nat表
prerouting-input(不转发时调用)-forward-output(不转发时或内部进程发出时调用)-postrouting
到本机某进程的报文:PREROUTING --> INPUT
由本机转发的报文:PREROUTING --> FORWARD --> POSTROUTING
由本机的某进程发出报文(通常为响应报文):OUTPUT --> POSTROUTING
表处理优先级
raw-mangle-nat-filter
链
PREROUTING 的规则可以存在于:raw表,mangle表,nat表
INPUT 的规则可以存在于:mangle表,filter表,nat表
FORWARD 的规则可以存在于:mangle表,filter表
OUTPUT 的规则可以存在于:raw表mangle表,nat表,filter表
POSTROUTING 的规则可以存在于:mangle表,nat表
动作
ACCEPT:允许数据包通过。
DROP:直接丢弃数据包,不给任何回应信息,这时候客户端过了超时时间才会有反应。
REJECT:拒绝数据包通过,客户端刚请求就会收到拒绝的信息。
SNAT:源地址转换,解决内网用户用同一个公网地址上网的问题。
MASQUERADE:是SNAT的一种特殊形式,适用于动态的、临时会变的ip上。
DNAT:目标地址转换。
REDIRECT:在本机做端口映射。
LOG:在/var/log/messages文件中记录日志信息,然后将数据包传递给下一条规则,也就是说除了记录以外不对数据包做任何其他操作,仍然让下一条规则去匹配
命令
iptables [-t 表名] <-A|I|D|R> 链名 [规则编号] [-i|o 网卡名称] [-p 协议类型] [-s 源ip|源子网] [--sport 源端口号] [-d 目的IP|目标子网] [--dport 目标端口号] [-j 动作]
参数:-A 增加
-I 插入
-D 删除
-R 替换
虚拟设备
VLAN
将同一网络划分为多个逻辑上的虚拟子网
防止广播报文泛滥
解决同一链路层网络广播域隔离
网桥
二层协议交换设备,可以与其他设备连接,类似于交换机
LVS
NAT模式,调度器通过网络地址转换,调度器重写请求报文的目标地址,根据预设的调度算法,将请求分派给后端的真实服务器,真实服务器的响应报文通过调度器时,报文的原地址被重写,再返回给用户,完成整个负载调度过程
DR模式,通过改写请求报文的目标MAC地址,并将请求发给真实服务器,而真实服务器响应后的处理结果直接返回给客户端用户
IPSec
传输模式,只加密IP头部以上的数据,对IP头部不进行加密
隧道模式,加密原有数据包,再加入新的头部
路由协议
RIP协议
底层是贝尔曼福特算法,它选择路由的度量标准(metric)是跳数,最大跳数是15跳,如果大于15跳,它就会丢弃数据包。
OSPF协议
Open Shortest Path First开放式最短路径优先,底层是迪杰斯特拉算法,是链路状态路由选择协议,它选择路由的度量标准是带宽,延迟
BGP外部网关协议
CRC循环冗余校验码
CRC 算法的基本思想是将传输的数据当做一个位数很长的数。将这个数除以另一个数。得到的余数作为校验数据附加到原数据后面