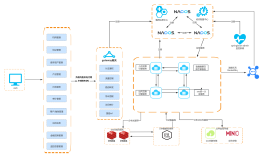
启动
-server : 定义agent运行在server模式
-bootstrap-expect :在一个datacenter中期望提供的server节点数目,当该值提供的时候,consul一直等到达到指定sever数目的时候才会引导整个集群,该标记不能和bootstrap共用
-bind:该地址用来在集群内部的通讯,集群内的所有节点到地址都必须是可达的,默认是0.0.0.0
-node:节点在集群中的名称,在一个集群中必须是唯一的,默认是该节点的主机名
-ui-dir: 提供存放web ui资源的路径,该目录必须是可读的
-rejoin:使consul忽略先前的离开,在再次启动后仍旧尝试加入集群中
-config-dir:配置文件目录,里面所有以.json结尾的文件都会被加载
-client:consul服务侦听地址,这个地址提供HTTP、DNS、RPC等服务,默认是127.0.0.1所以不对外提供服务,如果你要对外提供服务改成0.0.0.0
-join :加入到集群中
-data-dir 指定agent储存状态的数据目,对于server尤其重要,因为他们必须持久化集群的状态
存储K/V
设置key value
consul kv put user/config/connections 5
根据key获取value
kv get -detailed user/config/connections
服务
注册服务
配置文件方式
编辑 /etc/consul.d/jetty.json
重启consul,并将配置文件的路径给consul(指定参数:-config-dir /etc/consul.d)
{
"service":{
"id": "jetty",
"name": "jetty",
"address": "192.168.1.200",
"port": 8080,
"tags": ["dev"],
"checks": [
{
"http": "http://192.168.1.200:8080/health",
"interval": "5s"
}
]
}
}
HTTP API接口方式
直接调用/v1/agent/service/register接口注册即可,需要注意的是:http method为PUT提交方式
curl -X PUT -d '{"id": "jetty","name": "jetty","address": "192.168.1.200","port": 8080,"tags": ["dev"],"checks": [{"http": "http://192.168.1.104:9020/health","interval": "5s"}]}' http://192.168.1.100:8500/v1/agent/service/register
发现服务
curl http://172.17.0.4:8500/v1/catalog/service/userService
返回值
[
{
"Address": "172.17.0.4",
"CreateIndex": 880,
"ID": "e6e9a8cb-c47e-4be9-b13e-a24a1582e825",
"ModifyIndex": 880,
"Node": "node3",
"NodeMeta": {},
"ServiceAddress": "127.0.0.1",
"ServiceEnableTagOverride": false,
"ServiceID": "userServiceId",
"ServiceName": "userService",
"ServicePort": 8000,
"ServiceTags": [
"primary",
"v1"
],
"TaggedAddresses": {
"lan": "172.17.0.4",
"wan": "172.17.0.4"
}
}
]