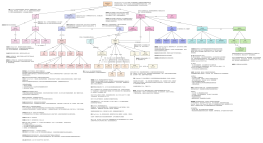
DDD是什么
DDD是一种设计思想,从业务领域视角划分领域边界, 使用通用语言进行高效沟通, 抽象出业务领域模型,解决微服务设计过程中, 边界难以划定的难题
DDD的核心概念
子域
通用域
通用系统,没有企业特点限制如:【认证、权限等】
支撑域
具有企业特性, 具备"定制开发"的特性【消息平台,数据字典平台等】
通用语言
在限界上下文内保证语义的唯一含义,通用性,一致性
限界上下文
领域可以被拆分成多个子领域, 一个领域相当于一个问题域, 拆分的过程就是大问题拆分为小问题的过程. 每个领域模型都有他对应的限界上下文, 理论上限界上下文就是微服务的边界
实体
领域模型中的实体是多个属性, 操作和行为的载体, 拥有唯一标志. 实体和值对象是组成领域模型的基础单元, DDD中采用充血模型构建实体. 使用ID即可判定两实体是否相等
值对象
含义
多个相关联属性,放到一个字段中去表示,值对象也就相当于实体的一个属性
代码形态
如果值对象是单一属性,则直接定义为实体类的属性;这种情况属性和值对象的定义就比较模糊了
如果值对象是属性集合,则把它设计为 Class 类,Class 将具有整体概念的多个属性归集到属性集合,这样的值对象没有 ID,会被实体整体引用
数据库形态
DDD 引入值对象是希望实现从“数据建模为中心”向“领域建模为中心”转变,减少数据库表的数量和表与表之间复杂的依赖关系;尽可能地简化数据库设计,提升数据库性能
在领域建模时,我们可以将部分对象设计为值对象,保留对象的业务涵义,同时又减少了实体的数量;在数据建模时,我们可以将值对象嵌入实体,减少实体表的数量,简化数据库设计
值对象的特点
无 ID,不可变,无生命周期,用完即扔。值对象之间通过属性值判断相等
聚合
领域模型内的实体和值对象就好比个体,而能让实体和值对象协同工作的组织就是聚合,它用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性
聚合在 DDD 分层架构里属于领域层,领域层包含了多个聚合,共同实现核心业务逻辑。
一个微服务可以包含多个聚合,聚合之间的边界是微服务内天然的逻辑边界。有了这个逻辑边界,在微服务架构演进时就可以以聚合为单位进行拆分和组合了,微服务的架构演进也就不再是一件难事了
聚合根
如果把聚合比作组织,那聚合根就是这个组织的负责人。聚合根也称为根实体,它不仅是实体,还是聚合的管理者
首先它作为实体本身,拥有实体的属性和业务行为,实现自身的业务逻辑。
其次它作为聚合的管理者,在聚合内部负责协调实体和值对象按照固定的业务规则协同完成共同的业务逻辑。
最后在聚合之间,它还是聚合对外的接口人,以聚合根 ID 关联的方式接受外部任务和请求,在上下文内实现聚合之间的业务协同。也就是说,聚合之间通过聚合根 ID 关联引用,如果需要访问其它聚合的实体,就要先访问聚合根,再导航到聚合内部实体,外部对象不能直接访问聚合内实体
聚合根是实体,有实体的特点,具有全局唯一标识,有独立的生命周期。一个聚合只有一个聚合根,聚合根在聚合内对实体和值对象采用直接对象引用的方式进行组织和协调,聚合根与聚合根之间通过 ID 关联的方式实现聚合之间的协同
领域事件
场景
发生在微服务内的聚合之间
如果数据的实时性、一致性要求较高
微服务内应用服务,可以在应用层通过跨聚合的服务编排和组合,以服务调用的方式完成跨聚合的访问
如果数据的实时性、一致性要求较不高
通过event事件完成
发生在微服务之间
如果数据的实时性、一致性要求较高
直接调用的方式完成
如果数据的实时性、一致性要求较不高
消息中间件:MQ
事件风暴
梳理用户旅程, 分析业务场景, 领域专家和开发人员头脑风暴的过程, 进而确定 限界上下文, 通用语言,找出实体, 值对象等 依次 进行领域分解, 建立领域模型
注
DDD与微服务的关系
DDD 主要关注
从业务领域视角划分领域边界,构建通用语言进行高效沟通,通过业务抽象,建立领域模型,维持业务和代码的逻辑一致性
微服务主要关注
运行时的进程间通信、容错和故障隔离,实现去中心化数据管理和去中心化服务治理,关注微服务的独立开发、测试、构建和部署
限界上下文和微服务的关系
理论上限界上下文就是微服务的边界。我们将限界上下文内的领域模型映射到微服务,就完成了从问题域到软件的解决方案
DDD、中台和微服务的关系
中台是抽象出来的业务模型,微服务是业务模型的系统实现,DDD作为方法论可以同时指导中台业务建模和微服务建设,三者相辅相成,完美结合
分支主题
仓储
为了解耦应用逻辑和基础资源,在基础层和上层应用逻辑之间会增加一层,这一层就是仓储层。一个聚合对应一个仓储,仓储实现聚合内数据的持久化。聚合内的应用逻辑通过接口来访问基础资源,仓储实现在基础层实现。这样应用逻辑和基础资源的实现逻辑是分离的。如果变更基础资源组件,只需要替换仓储实现就可以了,不会对应用逻辑产生太大的影响,这样就实现了应用逻辑与基础资源的解耦,也就实现了依赖倒置
找不到聚合根时
关于聚合设计过程中的一些原则问题。大部分的业务场景我们都可以通过事件风暴,找到聚合根,建立聚合,划分限界上下文,建立领域模型。但也有部分场景,比如数据计算、统计以及批处理业务场景,所有的实体都是独立无关联的,找不到聚合根,也无法建立领域模型。但是它们之间的业务关系是非常紧密的,在业务上是高内聚的。我们也可以将这类场景作为一个聚合处理,除了不考虑聚合根的设计方法外,其它诸如 DDD 分层架构相关的设计方法都是可以采用的
领域服务的CRUD是不是都是操作聚合根或整个实体对象,比如我只想根据ID判断记录是否存在,或者返回个别字段,需要返回整个实体对象吗?
其实查询类业务可以不必经过聚合根和仓储。传统方法也可以了。
如果聚合数据比较多,会有延迟加载影响性能。聚合根的主要目的是为了保证数据的一致性,这些场景一般在CU的场景。
事务封装在哪一层?
按照业务逻辑来讲,封装到应用层或领域层都是可以的