高级JAVA面试总结
2023-08-18 17:50:00 2 举报AI智能生成
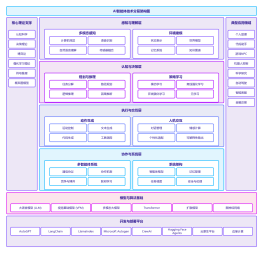
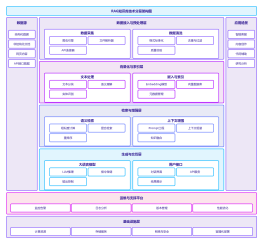
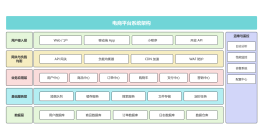
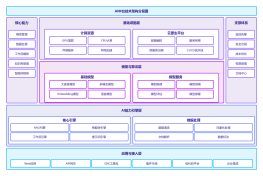
高级Java面试总结的思维导图如下: 思维导图是以中心主题"高级Java面试总结"为中心,分为三个主要分支。 第一个主分支是“核心Java”,其中包含了Java基础和高级特性。Java基础包括数据类型、运算符、控制语句等基本概念,高级特性包括多线程、集合框架、IO操作等。在面试中,核心Java是必不可少的部分, 面试官通常会考察候选人在这方面的知识。 第二个主分支是“框架与技术”,其中包括了Spring框架、Hibernate、MyBatis等常用Java框架;还有Web开发技术如Servlet、JSP、MVC等。对于一个高级Java开发者而言,熟悉并掌握这些框架和技术是非常重要的。 第三个主分支是“面试准备与技巧”,其中包括了准备面试的重要环节如简历中的准备、面试前的准备等;还有面试技巧如面试表现、回答问题的技巧等。这个分支可以帮助候选人提高面试的成功率。 通过这个思维导图,候选人可以全面了解高级Java面试的范围和重点,有针对性地进行准备。同时,这个思维导图也可以帮助候选人整理思路,做到有条不紊地对面试所需的知识进行学习和复习,提高应试能力。
模板推荐
作者其他创作
大纲/内容




0 条评论
下一页

