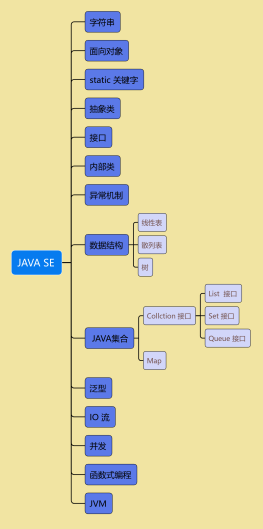
BIO(Blocking I/O)<br>
<b><font color="#0000ff">BIO 属于同步阻塞 IO 模型 。</font></b>
同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。<br>
在客户端连接数量不高的情况下,是没问题的。但是,当面对十万甚至百万级连接的时候,传统<br>的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。<br>
NIO(Non-blocking/New I/O)
Java 中的 NIO 于 Java 1.4 中引入,对应 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,<br>不单纯是 New。它是支持面向缓冲的,基于通道的 I/O 操作方法。 对于高负载、高并发的(网络)应用,应使用 NIO 。<br>
Java 中的 NIO 可以看作是 <b><font color="#0000ff">I/O 多路复用模型</font></b>。也有很多人认为,Java 中的 NIO 属于同步非阻塞 IO 模型。<br>
跟着我的思路往下看看,相信你会得到答案!<br>
我们先来看看 <b><font color="#0000ff">同步非阻塞 IO 模型</font></b>。<br>
同步非阻塞 IO 模型中,应用程序会一直发起 read 调用,等待数据从内核空间拷贝<br>到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。<br>
相比于同步阻塞 IO 模型,同步非阻塞 IO 模型确实有了很大改进。通过轮询操作,避免了一直阻塞。<br>
但是,这种 IO 模型同样存在问题:<b><font color="#0000ff">应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的</font></b>。<br>
这个时候,<b><font color="#0000ff">I/O 多路复用模型</font></b> 就上场了。<br>
IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,<b><font color="#0000ff">等内核把数据准备好了,<br>用户线程再发起 read 调用</font></b>。<b><font color="#0000ff">read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的</font></b>。<br>
目前支持 IO 多路复用的系统调用,有 select,epoll 等等。select 系统调用,目前几乎在所有的操作系统上都有支持。<br><br><ul><li>select 调用 :内核提供的系统调用,它支持一次查询多个系统调用的可用状态。几乎所有的操作系统都支持。</li><li>epoll 调用 :linux 2.6 内核,属于 select 调用的增强版本,优化了 IO 的执行效率。</li></ul>
<b><font color="#0000ff">IO 多路复用模型,通过减少无效的系统调用,减少了对 CPU 资源的消耗。</font></b><br>
Java 中的 NIO ,有一个非常重要的 <b><font color="#0000ff">选择器 ( Selector ) </font></b>的概念,也可以被称为 <b><font color="#0000ff">多路复用器</font></b>。<br>通过它只需要一个线程便可以管理多个客户端连接。当客户端数据到了之后,才会为其服务。<br>
AIO(Asynchronous I/O)
AIO 也就是 NIO 2。Java 7 中引入了 NIO 的改进版 NIO 2,它是 <b><font color="#0000ff">异步 IO 模型</font></b>。
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。<br>
目前来说 AIO 的应用还不是很广泛。Netty 之前也尝试使用过 AIO,不过又放弃了。<br>这是因为,Netty 使用了 AIO 之后,在 Linux 系统上的性能并没有多少提升。
最后,来一张图,简单总结一下 Java 中的 BIO、NIO、AIO。<br>
BIO:<br><ul><li>同步阻塞 IO,一个连接一个线程;</li><li>发起请求一直阻塞,一般通过线程池改善;</li></ul>
NIO:<br><ul><li>同步非阻塞 IO,一个请求一个线程;</li><li>多个连接多路复用一个线程;</li></ul>
AIO:<br><ul><li>异步非阻塞 IO,一个有效请求一个线程;</li><li>IO 请求立即返回,操作结束后,回调通知;</li></ul>