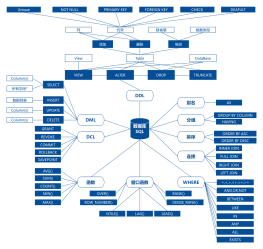
SQL语句优化
数据量很大,分页查询
避免在 where 子句中使用 or 来连接条件, 否则将导致引擎放弃使用索引而进行全表扫描, 可以使用union all 或union合并查询
避免在 where 子句中对字段进行表达式操作、函数操作
关于 in 和 exist,如果查询的俩个表大小一致则性能差别可忽略,如果子查询表大用 exist,否则使用 in,比如:select num from a where num in(select num from b).用下面的语句替换:select num from a where exists(select 1 from b where num=a.num)<br>select in 会被改写为exists,造成查询缓慢,可改成关联join查询<br>
where条件中(比如在IN后面值的列表),将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数
当有一批处理的插入或更新时,用批量插入或批量更新,绝不会一条条记录的去更新
当只要一行数据时使用 LIMIT 1
推荐使用group by, 因为distinct会导致全表扫描
join时 尽量将条件内嵌,先过滤后join
使用索引
建立复合索引时
走索引不一定都快,区分度不够的索引可用考虑用复合索引,把区分度最高的字段放在最左侧
explain 中的 type 至少要达到 range,要求为 ref
表结构优化
优化表存储结构,降低IO 操作次数,提升性能
适当使用冗余字段
尽量少用text,非用不可最好分表
应尽量避免在 where 子句中对字段进行 NULL值判断,因为NULL 极大影响整个索引的效率,创建表时NULL是默认值,但大多数时候应该使用NOT NULL,或者使用一个特殊的值,如0,-1作为默 认值
数据类型选择
数字类型:非万不得已不要使用DOUBLE
字符类型:定长字段,建议使用 CHAR 类型(char查询快,但是耗存储空间,可用于用户名、密码等长度变化不大的字段);<br>不定长字段尽量使用 VARCHAR,且仅仅设定适当的最大长度<br>
时间类型:尽量使用TIMESTAMP类型,因为其存储空间只需要DATETIME 类型的一半;<br>对于只需要精确到某一天的数据类型,建议使用DATE类型<br>
字符编码——使用合适的字符集
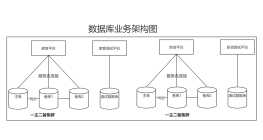
数据库架构优化
负载均衡
高可用性负载均衡集群,具备读写分离,一般只对读进行负载均衡
读写分离
对数据库读和写的操作分开对应不同的数据库服务器,这样能有效地减轻数据库压力,也能减轻io压力
参数配置优化
硬件三件套(CPU、内存、磁盘)