...
1.*.*
二测
v1.2.0
AB
FFN4
周三之前全部上线
FFN3
周一预发布
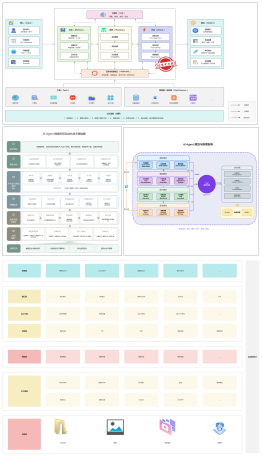
产品版本
v1.1.1
hotfix_1.1.0 分支
图像编码器(基于ResNet或ViT架构)
假设:发版日固定为周二每 2 周发一次版本
0208
04 生成对抗网络(GAN)
0218
一测分支(develop)
二测分支(master)
试运行
0215
从快照拉取分支临时修复
0219
JIRA-3 分支期望 02.20 上线
master 分支(JIRA-1 & JIRA-2 & hotfix)
Hidden layers
AB+C
周二晚上灰度
小C
拉取
修复上线后确保二测分支最新
残差连接和归一层
创建快照
一测
0216
合并可能需要解决冲突
0227
修复上线后确保一测分支最新
编码
输出(右位移)
开发分支(Jira)
1.1.0
develop 分支(JIRA-1 & JIRA-2)
创建
02...
I₁·T₃
对比学习(构建相似性矩阵)
小B
微调训练
v1.1.0
紧急需求(Jira)
Iₙ·T₁
小A
03 CLIP多模态模型
I₂·T₂
紧急补丁(hotfix)
0207
#afe3e6
合并
AB+
tag 生产版本
测试通过直接从开发分支合并
I₁
JIRA-2 分支
Parameters
εθ(Xtspan style=\"font-size:31px; color:#000000; letter-spacing:0px;\
输入嵌入
Softmax 层
0220
输出概率
测试通过直接从开发分支合并可能需要解决冲突
I₁·Tₙ
I₂·Tₙ
0213
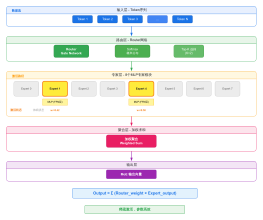
MoE 模型的典型架构(参考自:Google 的 Switch Transformers)
(Switching FFN Layer)
输出嵌入
I₂·T₃
文本编码器(基于Transformer模型)
Input layer
Iₙ·T₃
T₃
随机噪声
Router
master 分支(JIRA-1 & JIRA-2)
master 分支(JIRA-1 & JIRA-2 & hotfix & JIRA-3)
GConv-2
上一轮
I₁·T₂
v1.0.0
掩码多头自注意力
I₃·T₁
多头自注意力
T₁
02..
Diffusion 扩散模型图
1.0.0
0217
位置编码
GAN 生成对抗网络模型图
Time Representation
y1
GCN(Graph Convolutional Network) 的经典模型架构图
生成假样本
Iₙ
该MoE (Mixture of Experts) 架构:将 Transformer 中的前馈网络 (FFN) 层替换为由门控网络和多个专家组成的 MoE 层。
#ffcccc
Tₙ
I₃
FFN2
I₃·T₂
x2
ABC
I₂
p=0.65
0201
配色参数参考
JIRA-1 分支
创建Tag紧急上线
y2
#fad8ad
Fully-connected Layers
线性层
生成器Generator
Output layer
真/假?
Nx
y
位置嵌入
自注意力
Iₙ·Tₙ
I₃·Tₙ
GConv-1
该架构是 GCN 在半监督节点分类中的典型应用,通过图卷积操作融合节点自身特征与邻域结构信息,最终完成分类任务。
CLIP(Contrastive Language-Image Pre-training)模型是一种多模态预训练神经网络,训练分为三个阶段:Contrastive pre-training:预训练阶段,使用图片-文本对进行对比学习训练;【本图中展示的】Create dataset classifier from label text:提取预测类别文本特征;Use for zero-shot predictiion:进行零样本推理预测。
输入处理(分别提取文本、图像特征向量)
02 混合专家模型(MoE)
T₂
FFN1
Iₙ·T₂
前馈层
I₁·T₁
05 图卷积网络(GCN)
01 Transformer
CLIP 模型结构图(预训练阶段的)
#cfcee3
Xt
判别器Discriminator
#d6e9d5
ImageEncoder
Softmax
x
x1
真实样本x
隐空间
p=0.8
动态切换的前馈网络层
I₂·T₁
TextEncoder
More
06 扩散模型(Diffusion)
I₃·T₃
t
输入
pepper the aussie pup