
Java知识总结
2025-10-20 19:18:28 0 举报AI智能生成
jvm,java基础,数据库,mq,框架,ES搜索,系统架构,链路追踪,通信协议,实际问题总结
java基础
数据库
中间件
架构设计
运维
模板推荐
作者其他创作
大纲/内容
jvm
内存
内存溢出
堆内存溢出
内存溢出
堆内存剩余空间小于该对象需要分配的空间
内存泄露
对象一直没有被垃圾回收,造成可用的堆内存越来越少
栈内存溢出
1.栈内存中栈帧过多,栈帧的总内存和超过了当前线程的栈内存大小
2.线程分配过度,导致总的栈内存不足以给下一个线程分配栈内存;
方法区+运行时常量池内存溢出
1.方法区
存储的字节码文件大小超过了方法区内存大小
动态创建了大量java类,这些类需要被存储到方法区,导致方法区内存不够
2.常量池内存溢出
程序中动态的创建了大量的基础数据类型和字符串,导致常量池不够分配新创建的常量
本机内存溢出
频繁调用本地方法,创建对象导致本机直接内存不够分配
对象内存分配原则
对象优先在eden区域分配
对象优先在eden区域分配内存
eden区域内存满了,再存放from suvivor区域
长期存活对象进入老年代
新生代对象经历过一定的垃圾回收次数还存活,就会被放到老年代内存中去;
大对象直接进入老年代
内存大小超过一定大小的对象直接放入老年代
相同年纪大小的对象的内存综合超过survivor区域内存一半,那么大于这个年纪的对象都会放在老年代
内存分配担保原则
新生代每一次gc之后,都有可能把存储不下的对象放在老年代;所以老年代会留出一些空间给这些新生代
老年代每次测量进入老年代对象的年纪大小,去做评估预测,老年代剩余空间是否能足够装下下次进入老年代的新生代对象,如果不够,就会做老年代的垃圾回收
java内存模型
内存模型概述
java是跨平台的,需要同一的内存模型来兼容不同不同的操作系统的差异,硬件差异等等。不能因为操作系统硬件的差异导致相同的程序出现不一样的结果
主内存+工作内存概述
线程都有自己的工作内存;每个线程的工作内存之间都是相互屏蔽;
线程操作变量,都是先通过工作内存,然后复制到主内存;其他线程才能再主内存中访问这个变量;
主内存,是可以被所有的线程访问。
主内存
主内存,是可以被所有的线程访问,公共内存
工作内存
线程都有自己的工作内存
主内存+工作内存之间数据交互
1.交互概述
1.线程的工作内存去访问主内存,获取变量值
2.内存之间的基本操作都是原子操作,不可再分割
8大原子操作
1.lock,表示主内存中变量已经被某个线程占有;
2.unlock,表示主内存中变量已经被某个线程释放,其他线程可以去获取这个变量
3.read,表示从主内存中读取变量到工作内存
4.load,表示主内存中读取的值赋值给工作内存中变量
5.use,表示工作内存中的值传递给工作引擎让工作引擎去做操作;
6.assign,表示工作引擎中计算后的值赋值到工作内存中;
7.store,表示工作内存把变量传递到主内存;
8.write,表示工作内存的值存入到主内存中;
交互原则
所有的操作必须符合前后逻辑关系
操作之前必须要满足前后依赖关系
配对操作之前含有其他操作关系,但是必须保证操作前后逻辑关系
变量被加锁多少次,就要被解锁多少次
内存模型三大特点
有序性
理解
线程内部:线程一定会按照串行的方式去执行指令
线程之间:由于cpu的执行权问题,多线程之间执行的任何代码都可能是交叉进行的,除了volatile,synchronized
原子性
主内存和工作内存之间的基本操作都是原子操作
可见性
共享变量被一个线程操作,操作后的记过能被其他线程直到
java可见性实现
volatile
volatile修饰的变量,修改的之后会立即从工作内存同步到主内存之中;实现其他线程对该变量的可见性
synchronized
解锁之前必须把变量的值从工作内存传递到主内存
final
对象的引用是不变的,所以说对所有线程来说都是可见的
java先行发生原则
解决问题
并发情况下,两个操作是否存在冲突的情况;判断数据是否存在并发问题,以及线程是否安全的重要依据
具体原则
1.锁定规则:同一个锁,只有被释放之后才能被另外一个线程再次占用;
2.读写原则:读写是一对操作,下一的读操作必定在写操作之后;
3.对象终结原则:对象被回收之前必须先要被初始化
4.传递性:a操作优先于b操作,b操作优先于c操作,那么a操作也有限与b操作
运行时数据区域
非堆内存
程序计数器
作用
java的多线程是通过计算机内核线程来回相互切换的,java的线程执行到了某一步,cpu执行权被切换到其他线程上时候,这个程序计数器的作用来了, 就是去记录它所属的线程执行到了哪一步,哪一个指令,执行权再次切换回来的时候,这个计数器就会帮助线程准确无误的接着切换之前的代码接着执行。
特点
1.是线程所独有的
2.生命周期和线程周期相同
3.永远都不会有异常
不存在内存异常的情况
本地方法栈
native方法运行的时候用到的内存空间就是本地方法栈
为java语言调用本地方法,也就是调用native修饰的方法服务的。
方法区
特点
方法区被各个线程所共享
存储内容
也称作永久代,存储的都是,经过虚拟机加载之后的字节码文件,类的信息,常量池,静态变量
运行时常量池,存储了编译期的各种字面量(字面量都是常量池的一部分)
运行时常量池
栈内存
栈帧
特点
线程所独有,存储的都是临时数据
和线程生命周期一样
3.方法在执行的时候栈内存都会去创建这个方法对应的栈帧,栈栈中存储了这个方法的局部变量表,方法返回值,方法出口等等。我们在调用方法的时候通过方法当中嵌套方法,那么栈内存,同样会为这些方法都去创建对应的栈帧,线程去执行这个栈帧(方法),执行完一个栈帧,这个栈帧对应的内存就会被回收,这就是所谓的弹栈。线程永远都只会在栈内存中最上层的栈帧上执行。并且由于前后调用的方法之间存在着返回值的原因,对应的栈内存中的上下两个栈帧之间也并不是完全割裂的,他们需要返回值的传递。每个栈内存最多可以存储1000-2000个栈帧。所以说。
栈内存大小设置
-Xss128k
给栈内存分配128kb
JVM没有设置总的栈内存大小
操作系统会限制线程的数量,从而达到限制总的栈内存大小
JVM 自己用的区域,不属于堆,用于存放元数据、代码、常量池、直接内存等。<br>
堆内存
堆内存区域划分
新生代
eden
from suvivor
to suvivor
老年代
内存比例
默认的新生代:老年代=1:2
默认eden:from suvivor:to suvivor=8:1:1
比例大小可以通过jvm参数调整
堆内存作用
java存储对象的主要区域
永久代说明
堆内存所说的永久代,只是在jdk1.8版本之前有这个概念,1.8就完全摒弃了这个概念,采用本地硬盘的方式来存储这些数据,有效防止了java这个永久代内存溢出。
jdk1.7
永久代也是属于内存,必须制定大小,大小受限制与所分配的内存大小
jdk1.8
存放在磁盘,可以不指定大小,大小受限制与磁盘
存放对象实例,是 GC(垃圾回收)的主要区域。<br>
Java对象在内存中存储
分为三部
对象头
Mark Word
记录内容和锁的状态有关
无锁
对象的hashCode值
分代年纪
锁的标记位
是否偏向
偏向锁
偏向线程的id
偏向锁时间戳
分代年纪
锁的标记位
是否偏向
轻量级锁,重量级锁
指向锁的指针
锁的标记位
Gc标记
标记位
指向类的指针
数组长度
实例数据
对齐填充字节
拷贝
深拷贝
基础数据类型拷贝值, 非基础数据类型,新创建对象,并用老对象给新对象字段赋值;
浅拷贝
基础数据类型拷贝值,非基础数据类型拷贝对应的引用
垃圾回收
垃圾收集算法
判断对象是否存活算法
可达性算法
可达性算法过程
GcRoot对象作为起点,向下搜索,搜索走过的路径称为引用链;一个对象到GcRoot没有任何引用链,那么这个对象就是不可达的。
GcRoot对象
new出来的对象
栈内存中栈帧引用的对象
方法区中引用的对象
本地方法区中引用的对象
软引用,弱引用,虚引用
引用计数算法(被废弃了)
概述
给对象添加一个引用计数器,当程序有地方用到这个对象,计数器+1;引用失效就会-1,任何时候如果引用计数器为0,那么就表示该对象要被回收了
问题
循环依赖,造成内存泄露,最后导致内存溢出
垃圾回收算法
分代收集算法
根据新生代,老年代情况的不同,针对新生代,老年代会有不同的垃圾回收算法;
复制算法(新生代的垃圾回收器都是使用此算法)
复制算法(新生代)
eden区域和一块存有对象的survivor的区域中还存活的对象,会复制到另外一块空闲的survivor区域;如果这块survivor区域内存大小不够,那么还会放在老年代当中;
注意:由于老年代中可以存放新生代的对象,如果此时老年代内存也不够,就会触发老年代的fullgc
新生代使用复制算法原因:新生代的对象存活率比较低,复制起来成本低
复制算法示意图
回收前
回收后
标记-整理算法(老年代)
标记-整理算法(老年代)
老年代不适用复制算法原因:老年代的对象存活率高,如果使用复制算法成本太高
根据可达性算法,把存活的对象会向内存区域的一边做迁移跃动,最后会有一个迁移末端;末端之外的对象就是需要被回收的对象;
标记-整理示意图
回收前
回收后
标记-清除算法示意图
标记-清除算法(老年代)
根据可达性算法需要被回收的对象会被标记,然后堆标记的对象的存错回收;
缺点:
1.标记-清除的效率都不高
2.清除会造成很多内存碎片,有可能导致二级gc;
标记-清除算法示意图
回收前
回收后
三色标记算法
概述
三色标记算法是一种垃圾回收的标记算法
作用
让JVM不发生或仅短时间发生STW(Stop The World),从而达到清除JVM内存垃圾的目的
使用范围
JVM中的CMS、G1垃圾回收器 所使用垃圾回收算法即为三色标记法。
三色标记法过程
黑色:代表该对象以及该对象下的属性全部被标记过了。(程序需要用到的对象,不应该被回收)
灰色:对象被标记了,但是该对象下的属性未被完全标记。(需要在该对象中寻找垃圾)<br>
白色:对象未被标记(需要被清除的垃圾)<br>
三色标记存在问题
并发标记的时候,存在漏标的情况
综合概述:老年代垃圾回收算法还是选择标记-整理算法
垃圾收集器
分代回收器
按照老年代新生代分开回收
新生代垃圾回收器
serial
单线程回收,用户线程需要停止
特点
新生代采用 复制算法(复制存活对象到 Survivor 区)。
回收时需要 Stop-The-World,所有用户线程暂停。
适用场景:
单核 CPU、小内存环境。
例如:客户端应用、小型桌面程序。
PN
多线程回收,用户线程需要停止
ParNew
新生代并行回收,常和 CMS 搭配
特点
新生代采用 复制算法。
可以利用多核 CPU,加快回收速度。
常常和 CMS(老年代收集器) 搭配使用。
适用场景:
多核 CPU 环境。
适合低延迟、对响应时间敏感的场景。
PS
多线程回收,用户线程需要停止
Parallel Scavenge
多线程收集器,目标是提高 CPU 利用率和吞吐量
目标
以高吞吐量标准设计的:应用程序运行时间 / 总时间
:高吞吐量(Throughput),即尽可能让应用线程运行更多时间,GC 占用更少时
特点
新生代采用 复制算法。
提供自适应调节策略(GC Ergonomics),可以根据系统运行情况自动调整 堆大小、Survivor 区比例、晋升阈值
更偏向于提高 整体执行效率,而不是降低停顿时间。
老年代垃圾回收器
serial-old
老年代的单线程垃圾回收,用户线程需停止
算法
标记-整理 (Mark-Compact)。
特点
Serial 的老年代版本,单线程。
适用场景:
单核 CPU、小内存环境。
多用于 客户端模式 或作为 CMS 的“后备方案”(在 CMS 失败时触发)。
PS-old
老年代多线程回收,用户线程需要停止
目标是提高 CPU 利用率和吞吐量。
Parallel Scavenge 的老年代版本,多线程。
算法
标记-整理 (Mark-Compact)。
特点
是 Parallel Scavenge(新生代) 的老年代版本。
注重 吞吐量,适合需要最大化 CPU 利用率的场景。
和 Parallel Scavenge 搭配使用时,叫 吞吐量优先收集器。
CMS
多线程回收,以用户线程暂停时间最短为设计标准
回收的时候,用户线程有一段时间不需要停止
缺点:产生内存碎片,可能会有 “Concurrent Mode Failure”。
算法
标记-清除 (Mark-Sweep)(而不是压缩)。
特点
目标是减少 停顿时间 (Low Latency)。
回收过程分为:初始标记 → 并发标记 → 重新标记 → 并发清除。
优点:
大部分工作并发执行,降低了 STW 停顿时间。
缺点
采用 标记-清除,会产生 内存碎片。
在碎片过多或内存不足时,可能触发 Full GC(Serial Old 作为后备),停顿时间长。
CMS垃圾回收器工作流程图
示意图
整体式垃圾回收器
G1回收器(jdk9)<br>
G1回收器历史
最早出现在jdk7;jdk9以后就是默认的垃圾回收器
特点
垃圾回收的时候几乎没有stop the world 时间
新生代,老年代都可以回收
可将内存分成很多歌大小相同的region区域,根据区域之间使用标记-整理算法,区域内部使用标记复制算法;
可预测垃圾回收时间
很重要的一个特点
对region区域做选择性回收,回收价值高的region区域
垃圾回收过程
1.初始标记:停顿所有的用户线程,标记各个region区域中能被gcroot关联到的对象。
2.并发标记:用户线程和gc线程并行,gc线程根据可达性算法找出存活的对象。
3.最终标记:停顿用户线程,并发执行gc线程去标记刚才用户线程操作引用对象的那部分内存。
4.筛选标记:根据可停顿时间,计算出最优的region区域,并发的对最优的区域进行回收(这个时候用户线程和gc线程是可以并发的)。
垃圾回收过程示意图
示意图
分区region
示意图
region特点
将java的堆内存分成2048个大小相同的region块
region大小特点
每个region 区域的大小都是2的N次幂;即1Mb,2Mb,4MB,
region 区域大小在jvm运行期间都是不会被改变
每个region区域的大小都是相等的
存储特点
每一个region区域只会属于Eden, Survivo,old其中的一种
Eden, Survivo,老年代的区域并不是连续;
新增一种新的内存区域,Humongous内存区域,超过0.5个region对象就会被放Humongous区域
三个过程
Young gc
mixed gc
FGc
G1回收器缺点
G1回收器本身运行垃圾回收程序时相对cms垃圾回收器需要占用更多的系统cpu,内存资源
在内存小于6G时,cms表现优于G1;大于8G,则G1回收器表现更好;6-8G之间,差不多;
相关JVM参数
-XX :G1HeapRegionSize
设定region 区域大小
-XX:+UseG1GC
手动设置G1垃圾回收器;JDK9默认就是G1
-XX:MaxGCPauseMillis
ZGC
ZGC设计目标
停顿时间不超过10ms;
垃圾回收器停顿时间,不会随着活跃对象增加而增加
支持8MB-16TB堆内存
ZGC历史
jdk11引入
JDK15正式发布
ZGC相对以往垃圾回收器特点
已经没有分代收集的概念了
只能运行在64位操作系统上
ZGC内存空间划分
概述
也会像之前的回收器一样,将内存划分成很多个小的块
具体划分
小页面
固定为2MB
用于存放256KB以下的小对象
中页面
固定位32MB
用于存放256KB以上,4MB以下的对象
大页面
大小不固定,但必须是2MB的2次幂的大小
只会存放大于或者等于4MB的大对象,每一个大页面,只会存储一个大对象
示意图
ZGC支持NUMA
内存访问方式
统一内存访问
以前在64位的计算上,内存控制器没有整合进cpu,对内存的访问都必须要通过北桥芯片来控制,任何cpu对内存的访问速度都是一致。
示意图
支持非统一内存访问
cpu都整合到同一个芯片上,各个cpu对于内存的访问会出现争抢,会导致内存访问瓶颈;为了解决这个,将内存和cpu集成在一个单元上,这个就是非统一内存访问
示意图
在NUMA内存访问模式下,cpu访问本地存储器比访问非本地存储器速度快一些;
ZGC支持NUMA,会优先将小页面分配在本地内存,本地内存不够,然后再从远端的内存进行分配。
分配速度很快,收回也很快
中页面,大页面分配不会分配在cpu的本地内存
染色指针?
作用
处理过程
标记阶段
回收阶段
重定位
ZGC垃圾回收
回收策略
小页面优先回收,中页面,大页面尽量不回收
回收过程
回收过程示意图
具体过程
标记阶段
1、多线程并发标记
2、多线程再次并发标记,处理中间并发阶段(用户线程GC线程同时运行)时候,遗漏的对象
转移阶段
1、将原来活跃的对象复制到新的内存空间上,并将原来的内存空间回收;如果发现某一个页全部是垃圾对象,直接全部回收该区域
2、重定位,新的地址值换到原来的对象上面
读屏障
使用场景
当对象的内存地址被转移的时候,刚号在并发阶段应用程序有需要访问这个对象
解释
JVM向应用代码插入一小段代码的技术
相当于有两个操作要一起做的原子操作
过程
1、对已经转移但是还没重定位的对象进行对象的重定位
2、删除对应对象再转发表中的记录的指针的新旧关系
ZGC的GC时机
预热规则
jvm启动预热,如果从未发生过GC,那么就会在堆内存超过10%,20%,30%的时候触发一次GC,来收集GC的数据
基于分配速率的自适应算法
ZGC根据近期对象的分配速度以及GC时间,计算当内存占用达到什么样的阈值的时候出发下一次GC
基于固定时间间隔
流量平稳的时候,自适应需要堆内存占用达到百分之95的时候才会触发
主动触发
和固定时间规则类似。
内存分配不够
内存已经无法再给新的对象分配内存触发
外部触发
代码中直接System.gc()触发
元数据分配触发
元数据区不足时导致触发
ZGC调优
GC触发时机
ZAllocationSpikeTolerance
估算当前的堆内存分配速率,速度估计越快,GC来的越早,速度估算越慢,GC来的越迟
ZCollectionInterval
定 GC 发生的间隔,以秒为单位触发 GC
GC线程
ParallelGCThreads
Stw阶段,GC线程的数量
ConcGCThreads
并发阶段,cpu的数量
Shenandoah
设计目标
将垃圾回收的停顿时间控制在10ms以内
与G1回收器的设计目标一直:低延时为主要目标
历史
jdk12版本以及以后版本
由redhat公司开发
Shenandoah开发使用了很多G1回收器的代码
Shenandoah与G1相同点
基于region的内存布局
标记阶段都是并发标记
Shenandoah与G1不同点
在最终的回收阶段,采用的是并发整理,由于和用户线程并发执行,因此这一过程不会造成STW,这大大缩短了整个垃圾回收过程中系统暂停的时间
默认情况下不使用分代收集,也就是Shenandoah不会专门设计新生代和老年代,因为Shenandoah认为对对象分代的优先级并不高,不是非常有必要实现
采用“连接矩阵”代替记忆集。在G1以及其他经典垃圾回收器中均采用了记忆集来实现跨分区或者跨代引用的问题,每个Region中都维护了一个记忆集,浪费了很多内存,且导致系统负载也更重,「因此在Shenandoah中摒弃了这种实现方式,而是采用连接矩阵来解决跨分区引用的问题」
Epsilon GC<br>
历史
JDK11正式
工作
只负责内存分配,不负责内存回收
使用场景
性能测试
内存压力测试
虚拟机接口测试
极短寿命的工作<br>
极端延迟敏感的应用
参数配置
-XX:+UnlockExperimentalVMOptions<br>
-XX:+UseEpsilonGC<br>
垃圾回收器搭配使用
serial +old serial
新生代
serial
老年代
old serial
响应时间要求比较高
par new + CMS
新生代
par new
老年代
CMS
吐吞量比较高的
PS +PO
新生代
PS
老年代
PO
未设置对应垃圾回收器
默认是: PS + PSo (PS+PO)<br>
垃圾回收器最佳回收内存大小
serial
几十兆
PS
几个G
CMS
20G
G1
上百G
ZGC
4T
垃圾回收器常用参数
Parallel
XX:+UseSerialGc
XX:+SurvivorRatio
XX:+PreTenureSizeThreshold
XX:+SurvivorRatio
XX:+MaxTenuingThreshold
XX:+SurvivorRatio
XX:+ParallelGCThreads
并行回收垃圾线程数量
-XX:+UseApaptiveSizePolicy
自动选择各区大小比例
CMS
XX:+UseConcMarkSweepGC
使用标记清除算法
-XX:ParallelCMSThreads=n
-XX:CMSInitialingOccupancyFraction
设置GC触发阈值,百分比
-XX:+UseCMSCompactAtFullCollection
再Full GC后,进行一次碎片整理
-XX:CMSFullGCsBeforeCompaction=n
设置几次FullGC后进行一次碎片整理
<span style="color:rgb(77, 77, 77); font-family:-apple-system, "SF UI Text", Arial, "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", sans-serif, SimHei, SimSun; font-size:16px;">-XX:+CMSClassUnloadingEnabled</span>
允许对类 元数据进行回收
-XX:CMSInitiatingPermOccupancyFraction=n
当永久区占用达到百分比时,启动CMS回收 (CMS还会根据历史回收情况,判定启动回收不一定会按照百分比阈值)<br>————————————————<br>版权声明:本文为CSDN博主「t0mCl0nes」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。<br>原文链接:https://blog.csdn.net/fly_leopard/article/details/79180783
-XX:+UseCMSinitiatingOccupancyOnly
表示只在达到CMSInitiatingPermOccupancyFraction阈值时,才 进行CMS回收,此时CMS不会根据历史回收情况进行自动回收,只有 达到阈值才会回收
-XX:GCTimeRatio
gc时间占用运行时间比例
-XX:MaxGcPauseMills
停顿时间,是一个建议时间,GC会尝试使用各种手段达到这个时间,比如减小年轻代
G1
-XX:+UseG1GC
-XX:+MaxGCPauseMillis
新生代调整young区域的块的个数达到这个值
新生代回收时间大小
-XX:+MaxGCPauseIntervalMillis
GC间隔时间
-XX:+G1HeapRegionSize
分区大小,size越大,垃圾回收时间越长,GC间隔时间长,也会导致每次GC时间长
1M,2M,4M,8m,16M,32M
-XX:G1NewSizePercent
新生代最小比例,默认5%
-XX:G1MaxNewSizePercent
新生代最大比例,默认60%
-XX:GCTimeRatio
GC时间的建议比例,G1会根据这个值调整整个堆内存大小
-XX:ConcGcThreads
线程数量
-XX:InitiatingHeapOccupancyPercent
启动G1的堆内存占用比例
通用常数
-XX:UseTLAB
使用tlab
-XX:PrintTLAB
打印tlab情况
-XX:TLABSize
设置tlab大小
垃圾回收时间点
线程运行到安全点,安全区域会进行gc信号检查,也就是是否需要做垃圾回收操作;如果需要做,那么线程都会停止在安全点或者安全区域,等待垃圾回收完成;如果不需要垃圾回收,那么就不会停留在安全点,或者安全区域
安全点设置
设置在一些执行时间长的指令上
安全区域设置
相对于安全点来说,就是指令跨度大的安全点;
垃圾回收时间
jdk8及以前版本
当Eden区或者S区不够用了
当老年代空间不够用了
当方法区不够用了
子主题
jdk9开始
根据垃圾回收器的不同,会有所不同
System.gc()(通知jvm进行一次垃圾回收,具体执行还要看JVM,另外在代码中尽量不要用,毕竟GC一次还是很消耗资源的)<br>
GC日志分析
jvm性能调优
调优常见问题
1、jdk1.7,1.8,1.9默认的垃圾回收器是什么?
jdk1.7 默认垃圾收集器PS(新生代)+PO(老年代)
jdk1.8 默认垃圾收集器PS(新生代)+PO(老年代)
jdk9默认G1回收器<br>
2、常见的HotSpot垃圾回收器组合有哪些?
serial +old serial
新生代
serial
老年代
old serial
PN + CMS
新生代
par new
老年代
CMS
PS +PO
新生代
PS
老年代
PO
3、所谓调优,到底是在调什么?
1、提高用户线程吞吐量
PS+PS old<br>
2、提高用户线程响应时间
PN+CMS<br>
4、PN +CMS 怎样才能让系统基本不产生FGC
扩大JVM内存
调整内存比例
加大新生代区间比例
提高去Survivor区域比例
提高新生代到老年代的年纪
避免代码内存泄露
5、PS +PO 怎样才能让系统基本不产生FGC
避免代码内存泄露
6、G1回收器是否分代?G1回收器会产生FGC吗?
不分代收集,在G1回收器概念里面,已经没有新生代,老年代的概念,所有的堆内存区域划分为不同的区域
会发生FGC
7、如果G1回收器发生FGC?
1、扩大内存
2、提高CPU性能(可以提高回收效率)
3、降低MixedGC 触发的阈值,让MixedGc提早发生
8、生产环境可以随随便便dump吗?
小的堆内存影响不大;大的堆内存会有服务器卡顿
9、常见OOM问题有哪些?
栈,堆,方法区直接内存溢出
10、16G内存的服务器,如果设置jvm的内存分配?
如果服务器只跑这一个 JVM 应用,可以分配 12~14GB 给 JVM,一般是分配 70%~80% 物理内存给 JVM
操作系统和基础服务(SSH、日志、监控等)一般需要 2~3GB。
针对不同的服务情况
吞吐量优先(批处理 / 大计算任务)
目标:最大化 CPU 利用率,GC 次数少、停顿时间无所谓。
-Xms12g -Xmx12g # 堆固定 12GB<br>-Xmn4g # 新生代 4GB(1/3 左右)<br>-XX:SurvivorRatio=8 # Eden:Survivor = 8:1:1<br>-XX:+UseParallelGC # 新生代 Parallel Scavenge,老年代 Parallel Old
响应时间优先(Web 服务 / 低延迟系统)
减少 GC 停顿
-Xms12g -Xmx12g # 堆固定 12GB<br>-Xmn3g # 新生代稍小,减少 YGC 停顿<br>-XX:SurvivorRatio=8 <br>-XX:+UseG1GC # 推荐 G1(JDK 8u40+)<br>-XX:MaxGCPauseMillis=200 # 期望最大停顿 200ms
超低延迟(金融 / 实时系统)
目标:GC 停顿 <10ms。
-Xms12g -Xmx12g # 堆固定 12GB<br>-XX:+UseZGC # JDK 11+ 可用
子主题
jvm调优实战
线程
案例1、
CPU经常飙升100%,如何调优
解决步骤
找出哪个进程的CPU高
top 命令
找出该进程中哪个线程cpu高
top -hp命令
导出该线程的堆栈信息
jstack
线程线程占比和垃圾回收线程的占比对比
案例2、
假如100个线程很多线程都在等待,找到持有这把锁的线程
1、找到java的线程,看有哪些线程正在运行,然后拷贝出来运行的线程的唯一标记
2、再去等待线程中,找这些线程等到的是哪个线程,拿出这些线程id和运行的线程对比,,可以找到持有锁的线程;
内存
案例1、
案例1
1、为啥原网站很慢
文档加载斤内存中行程的java对象导致内存不足,频繁GC,导致stw时间过长
2、内存加大之后更卡顿
内存大,然后FGC时间过长,导致用户线程暂停
从PS垃圾回收器,设置成PN+CMS 或者G1回收器
子主题
案例2、
内存消耗不超过10%,频繁发生FGC?
某个分区不足(如 Survivor、老年代、Metaspace) 也会导致 FGC
子主题
案例3、
线程池使用不当,导致OOM
JVM调优的目的
JVM调优的目的
调优前需要明确是以高吞吐量为要求,还是以响应时间低为要求;还是说满足一定的相应时间的情况下,达到多少的吞吐量
垃圾回收器选择
吞吐量优先
PS+PO回收期
场景
数据计算
数据挖掘
追求响应时间
G1回收器
场景
网站
API
JVM 垃圾回收器(GC)调优的目标 就是在 吞吐量优先 和 响应时间优先 之间做取舍。
1、吞吐量
最大化 应用运行时间 / 总时间(应用运行时间 + GC 时间)。
GC 占用的时间越少,吞吐量越高
目标
尽量减少 GC 的开销,让 CPU 大部分时间都在跑业务逻辑。
允许偶尔出现较长的 GC 停顿。
适用场景
批处理、后台计算、大数据任务(Hadoop、Spark、批量 ETL)。
用户不直接等待结果,对响应时间不敏感。
典型 GC 选择
Parallel GC(吞吐量收集器)
新生代:Parallel Scavenge
老年代:Parallel Old
2、响应时间
1、降低单次 stop the world GC 停顿时间,保证应用的 响应速度;即使牺牲部分吞吐量(GC 可能更频繁),也要避免长时间卡顿。
目标
尽量减少单次 GC 停顿时间(比如控制在 100ms 内)。
系统更稳定,用户体验更流畅。
适用场景:
Web 服务、在线交易系统、即时通讯、金融支付系统
用户对响应时间敏感,不能忍受卡顿。
典型 GC 选择:
CMS(并发标记清除)
JDK9+:G1 GC
JDK11+:ZGC、Shenandoah(超低延迟,停顿可控制在 10ms 内)
jvm编译
编译过程
词法解析
token流
语法解析
抽象语法树
语义解析
经过注解的抽象语法树
字节码生成器
字节码文件
指令重排
原因
编译器对代码进行空间复杂度时间复杂度的优化,导致了代码实际的执行顺序和书写的不一样;
现象
程序先执行下面的代码,后执行上面的代码
指令重排原则
重排序的代码没有先后逻辑关系
重排序不影响结果
类加载机制
字节码增强技术
概述
作用
对java的字节码进行修改,增强功能
操作
修改二进制的class文件
目的
减少冗余代码,提高性能,加密代码
实现方式
AspectJ
概述
修改java字节码工具类
作用时间:编译期
Javassist
概述
修改java字节码的工具库
功能
可以直接生成一个类
在已经编译的类里面添加新方法,修改方法
修改时间:运行期
ASM
概述
ASM是一个java字节码操作框架
功能
直接生成class文件
拦截java文件被类加载器加载之前修改类
修改时间:编译期
APT
双亲委派机制
类加载器种类
BootstrapClassLoader
加载java核心库 java.*构建ExtClassLoade,AppClassLoader
ExtClassLoader
加载扩展库,如classpath中的jre ,javax.*
AppClassLoader
加载项目代码所在目录的class文件
自定义加载器
用户自定义的类加载器,可加载指定路径的class文件
加载器的区别
双亲委派机制作用
1.防止类被多个类加载器加载
2.保证核心的class文件不被篡改
双亲委派机制
类加载器需要加载类的时候,会先去让他的父类去加载;父类如果没有加载这个类,也没有权限加载,那么就会子类加载;如果有加载权限,那么就会接着让他的父类再做次判断;
双亲委派机制流程
三个重要判断
当前类是否已经被加载
当前类加载器是否还有父类加载器
当前类加载器是否有权限加载这个类
spi机制
spi
JAVA内置一种服务发现机制
使用场景
根据实际需求替换,扩展框架源码的实现策略
spi实现过程
调用ServiceLoad.load方法,传入接口字节码对象
根据字节码类型到meta-info包下面找到对应的配置文件
读取配置文件中的类全路径
获得类的全路径,通过反射获取到对象
把对象存储到linkedHashMap中
spi优缺点
优点
能够让接口更方便找到拓展的实现类
缺点
不能单独获取这一个实现类,获取了接口的所有实现类,造成了性能消耗
spi配置过程
实现某个想要实现的接口
resource包下配置相关的包路径和文件名
文件中配置类的全路径
spi机制破坏了双亲委派机制
spi机制创建对象的类加载器是classLoad,和传统的类加载器不存在父子关系
对象创建过程
1.将对象的字节码文件加载进内存
2.栈内存给对象分配一个引用变量
3.堆内存开辟一块内存空间
4.给堆内存对象属性做默认初始化赋值
5.给对象属性做显示初始化
6.对代码块进行初始化
1.父类构造代码块
2.当前类的构造代码块
3.父类的构造方法
4.当前类的构造方法
7.将堆内存的地址赋值给栈内存的引用
编译器
jit热点编译
将频繁调用的代码直接加载进内存,无需从硬盘上去加载这些文件
主流编译器
sun公司hotspot
从jdk10之后,JIT有三款
C1
客户端编译器
C2
服务端编译器
Graal 编译器
这三款编译器都是热点编译器,jdk17已经删除了Graal 编译器
还有其他公司开发的,也就是其他有自己开发的openjdk
java基础
核心类库
IO
各种IO模型
IO多路复用
IO多路复用概述
IO多路复用就是通过一个线程可以同事监视多个文件描述符(读就绪或者写接续,也就是可以监视多个IO操作),如果有一个描述符就绪,那么就可以通知程序做相应的读写操作;
本质上还是同步IO;相对于普通的同步IO,多路复用就可以让一个用户线程监视多个IO操作,普通的同步IO,一个用户线程只能只能监听一个IO操作
IO多路复用实现方式
select
概念
调用TCP文件系统的poll函数,不停的查询,直到有一个连接有想要的数据为止
过程
每次调用select函数都需要需要把文件描述符从用户内传递到内核态,内核再不断的去轮询这些文件描述符对应的io操作
缺点
文件描述符数量比较少,只有1024个
poll
概念
和select类似, 也是把用户传入的文件描述符数组复制到内核中,然后中再去不断的去做轮询操作;
优点
没有文件描述符限制
缺点
用户态到内核态的文件描述符的复制
过程
epoll
概念
类似也是让内核去做轮询操作,但是文件描述符只需要从用户空间拷贝到内核空间只拷贝一次
优点
没有最大并发限制,
减少了从内核空间到用户空间的拷贝过程
过程
java-NIO
NIO组件
组件名称
组件功能
NIO工作流程
同步阻塞IO
概念
用户线程调用内核IO操作,需要等IO彻底结束之后才能返回到用户空间,因此IO过程是阻塞的。
调用阻塞直到完成<br>
优缺点
优点
用户线程无延迟,就可以拿到IO之后的数据
缺点
用户线程处于等待之中需要消耗性能;
应用场景
同步非阻塞IO
概念
IO调用后,如果内核这个时候没有把数据准备好,那么就会直接返回一个状态,这个时候用户的IO线程就不会一直等待内核把数据准备好,而是间隔时间一段时间去轮询内核数据是否已经准备好了。最终是内核把数据准备好了,等待下一次用户线程的询问,就把数据从内核复制到用户内存中
优缺点
优点
无需阻塞等待内核准备数据,这个期间可以做其他的事情;
缺点
需要去轮询内核,内核无法以最短的时间把数据复制到用户内存中
应用场景
异步IO(AIO)
概念
用户线程对内核发起了IO操作,用户线程没有任何组阻塞;内核准备好数据并复制到用户内存后,会给用户线程发送一个信号,表明数据IO操作已经完成了;
优缺点
优点
内核会把数据复制到用户内存中,减少了用户线程去复制的过程;
缺点
应用场景
工作模式区别
IO基础概念
阻塞非阻塞
概念
一个线程做io操作,如果数据还没有准备好,线程是直接返回还是继续等待<br>
非阻塞
不等待
阻塞
等待
区别
阻塞,如果内核没有准备好数据,那么线程就会一直阻塞直到有数据返回为止;非阻塞,如果内核没有准备数据,那么就会直接返回,并且还会不断的去轮询内核是否有准备好数据;
现成发起 I/O 请求时是否会被挂起(继续等待还是立即返回)<br>
异步同步
同步
用户线程发起io操作之后,要么阻塞,要么自己不断轮训数据是否准备好<br>
异步
用户线程发起io操作之后,立即返回,不用自己去轮训;io操作完成之后,内核会通知用户线程<br>
描述 I/O 完成通知机制,由谁负责告知结果
IO操作步骤
1.用户代码向操作系统发出IO请求
2.轮询设备是否可以进行操作
3.将数据复制到用户内存之中
集合
ConcurrentHashMap
jdk1.7
数据结构
子主题
外层是segment数组,每个segment对象都是一个ReentrantLock锁
每一个segment 是继承了ReentrantLock 的 一个HashMap,每一个segment就是一把锁,并发度就是segment数组长度<br>
segment 中维护了 HashEntry[] 数组
每一个HashEntry元素可以是一个链表
HashEntry[] table<br> ├── HashEntry(key1, value1, next -> key2)<br> ├── HashEntry(key3, value3, next -> key4 -> key5)<br> ├── null<br> └── ...
读写操作步骤
读操作
步骤
1、根据key,计算出hashCode;
2、根据步骤1计算出的hashCode定位segment,
3、根据hashCode值和hashEntry数组的长度运算,定位到hashEntry数组中具体某一个hashEntry
4、遍历hashEntry,拿到key在链表中做比较<br>
写操作
1、根据key,计算出hashCode;
2、给segement加锁,保证同一时刻只有一个线程修改segement<br>
3、根据hashCode值和hashEntry数组的长度运算,定位到hashEntry数组中具体某一个hashEntry
4、获取到具体的链表,遍历链表查找 key 是否已存在
存在则更新
不存在则在头部插入
5、扩容检查,当前segement中元素的个数是否超过扩容条件
满足,则当前segement进行扩容操作<br>
6、释放锁
扩容条件
当单个Segment元素的数量超过capacity * loadFactor 阈值的时候会进行单个Segment扩容
1.8
数据结构
Node 数组 + 链表 + 红黑树
nodes数组的每一个节点相当一个桶(bucket)<br>
桶里存放的数据结构可能有三种:
单个 Node 节点(只有一个 key-value)
链表(发生哈希冲突时,多个 Node 串起来)
红黑树(链表长度超过 8 时,转成 TreeNode 红黑树)
demo<br>
假设 table.length = 16,插入 3 个 key,哈希分布如下:<br> • key1 → index = 3<br> • key2 → index = 3 (冲突)<br> • key3 → index = 7<br><br>此时数据结构是:
table[3] ──> Node(key1, val1) → Node(key2, val2) (链表)<br>table[7] ──> Node(key3, val3) (单节点)<br>其他 table[i] = null
如果链表长度超过 8,table[3] 会变成:
table[3] ──> TreeNode(key1, val1)<br> ├── left → TreeNode(...)<br> └── right → TreeNode(...)
扩容条件
CAS + synchronized 来保证并发安全
读写操作步骤
读操作
步骤
1、计算 hash,扰动hash值<br>
2、根据hash值桶长度计算桶的位置<br>
3、定位到桶
如果桶为空
返回null<br>
桶是链表
遍历链表,对比key<br>
红黑树
在红黑树里面查找
如果查询到正在扩容
则去新的链表中查找
get 操作是无锁的<br>
写操作
示意图
子主题
步骤
1、针对key做hash算法,扰动hash值<br>
主要目的让后续计算定位hash桶的时候hash值能更加分散<br>
2、初始化 table(懒加载)
如果桶还没有初始化,那么就通过CAS 创建初始容量
3、通过hash值重新计算定位到某一个hash桶<br>
4、写入节点
如果hash桶为空则通 CAS 插入新节点,成功即结束(无锁)。<br>
如果已经有元素:
使用:synchronized锁住桶的头结点<br>
判断是链表还是树
链表
遍历,更新或者是尾部插入
红黑树
走红黑树的插入逻辑
5、检查当前桶是否要做链表转红黑树
如果桶内链表长度大于8,转成红黑树
6、扩容检查
全部的元素个数是否超过扩容阈值,如果超过,则出发多线程扩容
扩容条件
元素总数 size ≥ 扩容阈值 threshold
对比
1.8锁粒度下,针对的每一个桶元素<br>
锁粒度
1.7的锁粒度大,针对是每一个Segment,也就是桶数组(最大也就是16个并发度)<br>
扩容的时候单个segment中的,增加了HashEntry元素个数,扩容只是在segment内部做扩容<br>
1.8的锁粒度小,并发度高,并发度取决于hash桶的数量<br>
扩容的时候是全局扩容,每一次扩容hash桶的数量增加一倍,并发度就咱家一倍;<br>
大量数据插入的情况下,因为1.8的红黑树,以及链表的尾插法,会减少线程对锁的持有时间
扩容
JDK 1.7<br>单个 Segment 元素数 > threshold<br>Segment 级别(局部扩容)<br>分段扩容,减少全表停顿,但可能空间利用率不均匀<br>
Segment中的HashEntry 元素个数增加,只是在sgement内部做扩容<br>
JDK 1.8<br>全局 size >= capacity * loadFactor<br>整表扩容(协作迁移)<br>全局一致性更好,支持多线程并发迁移,避免长时间阻塞<br>
LinkedHashMap
SkipList
LinkedList,ArrayList
LinkedList是双向链表实现的;ArrayList是数组实现的
查询的时候
ArrayList查询的时间复杂度都是O1,LinkedList查询的复杂度是On(因为是从表头或者表位做一个一个遍历查询),
添加删除修改操作
如果都是在尾部添加,那么添加的效率是一样的,
如果都是在头部添加,那么ArrayList效率很低,因为需要有数组元素的复制跃迁;LinkedList集合只是需要把引用之前新的元素就行了。
中间添加,效率都很低,ArrayList需要做数据复制移动;LinkedList需要先遍历查询到具体的位置,然后再前后引用的断开与重新连接;
HashMap
1.HashMap的散列表是什么时候创建的?在第一次put元素的时候创建的,也就是和懒加载机制很像;2.链表转红黑树的前提条件? 链表的长度要达到8,当前散列数组(最外层的数组)长度达到643.hash算法的理解?把任意长度的值转化为固定长度的输出,会有hash冲突,hash冲突是很难避免的。4.为啥要使用红黑树结果?如果hash冲突严重,那么就会导致hash槽下面的数据的链表过长,对于查询数据效率低查询的时间复杂度从 O(n) 变成 O(log)5.扩容规则?也就是扩容之后的容量是扩容之前的两倍6.扩容之后的老数组中的数据怎么往新的数组里面迁移??因为hash槽里面存在四种情况:1.hash槽完全没有数据这个其实没啥说的;2.hash槽里面只有一个数据;根据新计算出来的tableSize,存放过去;3.hash槽里面是链表;4.hash槽里面是红黑树;7.扩容之后的hash槽计算?比如说当前是16个hash,在第1个槽位,在扩容之后,需要迁移的数据就会落在1+16 =17 也就是在第17个槽位上面。
JDK1.7和JDK1.8的区别
1.7的元素是放在单向链表的头部,1.8是放在单向链表的尾部
1.7的存储形式是外层是数组,内层是链表;1.8是外层是数组,内层是链表或者红黑树
1.8元素存储可以转换成红黑树,提高了,元素读取的效率;1.7是没有将链表转成红黑树的功能
1.7外层是Entry数组;1.8外层是Node数组,
1.8重写了Hash方法,降低了hash冲突,提高了Hash表的存,去效率(增加了异或运算,位运算)
1.7扩容后添加元素,1.8扩容前添加元素
因为 1.7 头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环。<br><br>
1.7扩容,需要将元素重新hash然后把数据存放,1.8扩容后不需要重新hash,新位置不变或者新位置是索引+扩容大小
提高扩容效率
1.7的散列函数做了多次位移,异或运算,1.8只做一次
提高hash效率
1.7
数据结构
外层
Entry<K,V>[] table
Entry<K,V>[] table
内层
链表(Entry)
Entry<K,V>
存取过程
存储过程
1、计算 hash
2、根据hash值再次计算定位到桶<br>
3、插入数据<br>
桶为空,直接插入新的entry
桶非空
遍历链表找到key<br>
key存在,做更新<br>
key不存在,插入链表头部<br>
4、扩容检查,如果是超过了阈值,外层table数组元素个数翻倍,重新计算每一个桶的位置,做数据迁移<br>
获取过程
1. 计算哈希值
int hash = hash(key); // 调用扰动函数,减少碰撞
2. 定位桶
Node<K,V> first = table[(n - 1) & hash];
3. 桶判空
如果 first == null → 说明该桶没有数据,直接返回 null。
4. 遍历链表
先比对 hash 值是否相等,再比对 key 是否相等
1.8
数据结构
外层
Node<K,V>[] table
内层
Node 节点(链表节点)
TreeNode 节点(红黑树节点)
存取过程
存储
1. 计算哈希
int hash = hash(key); // 扰动运算:减少 hash 碰撞
2. 定位桶
int i = (n - 1) & hash; // n = table.length,位运算替代取模
3. 插入逻辑
桶为空,直接创建新的Node节点放入数组<br>
桶非空
如果第一个节点就是目标key,直接覆盖<br>
如果首节点是红黑树,按照红黑树的插入逻辑
如果是链表,则遍历链表,存在覆盖,不存在尾部插入
如果插入后链表长度>= 8 且table的容量>=64 链表转红黑树<br>
4.扩容检查
插入后元素总数超过了额定值,则需要扩容
获取
1. 计算 hash 定位桶
int hash = hash(key);<br>Node<K,V> first = table[(n - 1) & hash];
2. 桶判空
如果桶为空 → 返回 null<br>
3.桶首节点检查
如果桶首节点 hash 和 key 相同 → 返回该节点的 value
4.继续查找
如果是 TreeNode → 在红黑树中查找(O(log n))
否则在链表中顺序查找(O(n))
HashMap并发环境下的问题
多线程扩容,引起死锁问题
多线程put的时候可能导致元素丢失
put非null元素后get出来的却是null
1.7和1.8都存在的问题
常见问题
1.HashMap的散列表是什么时候创建?
在第一次put元素的时候创建的,也就是和懒加载机制很像
2.链表转红黑树的前提条件?
1.当前链表的长度大于8;
2.外层Hash桶的数组长度达到64个;
3.为啥要使用红黑树存储?
1.如果hash冲突严重,那么就会导致Hash槽下面的数据的链表长度过长;查询数据的复杂度就是0(n),换成红黑树之后就变成了O(log)
4.扩容相关
扩容之后的hash槽计算?
比如说当前是16个hash槽,扩容之后就会变成32个hash槽;当前第一个槽位中需要被迁移的数据会迁移到第17个槽位上;也就是以此类推,当前第16个槽位的需要被迁移的数据被迁移到第32个上;
什么情况下回触发扩容?
当前实际存储元素的个数超过一定百分比(默认的75%,这个比例可以通过构造函数设置)
扩容之后的老数组中的数据怎么往新的数组里面迁移?
1.hash槽没有数据
也就是没有需要被迁移的数据
2.hash槽里面只有一个数据
根据新计算出来的hash槽位把数据存放过去
3.hash槽里面是链表
4.hash槽里面是红黑树
扩容之后的hash槽计算?比如说当前是16个hash,在第1个槽位,在扩容之后,需要迁移的数据就会落在1+16 =17 也就是在第17个槽位上面。
扩容因子为啥是0.75
假设扩容因子=1,也就是每一次扩容都前集合的元素个数和当前集合的最大容量相同,无形之中就增加了hash碰撞,hash碰撞之后,就会形成对应的链表过长,红黑树高度过高,这样就会导致在查询的时候耗时过高。
如果扩容引子过小,map集合在存储元素的时候,就会经常发生扩容操作,导致添加元素耗时过高。
0.75是经过很多科学计算之后,平衡了添加和查询操作之后,得出来最佳的数值
5.get死循环,put闭环
不安全原因
代码截图
<br>
原因分析
key已经存在,需要修改HashEntry对应的value;<br>
key不存在,在HashEntry中做插入<br>
源码解析
hash方法
1.如果key为null,那么hash值就是为1;
2.如果key不为null
1.获取当前key的hashCode值与value的Code值做异或运算
2.拿到第一步的值,让当前值和当前值的与16做位运算之后的值做异或运算
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h &gt;&gt;&gt; 16);}public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value);}
Put方法解析
1.第一次put的时候,如果散列数组为空,那么就会进行扩容散列操作;
2.如果hash桶只要单个数据,那么先对比数据是否一样,一样就覆盖原来的值;
4.如果hash桶的数据是红黑树,如果key不重复,那么就把数据放在key的末尾;如果key重复了,那么就替代源码的value值;
3.如果hash桶的数据,是链表,如果key不重复,那么就把数据放在key的末尾;如果key重复了,那么就替代源码的value值;
1.8扩容问题
扩容相关参数
capacity
当前数组的长度(桶的数量)
loadFactor
负载因子,默认 0.75
当 size > threshold(capacity*loadFactor) 时,会触发 扩容<br>
扩容条件
都是 size >= threshold
扩容策略
扩容倍数:Java 默认是 2 倍
新数组长度 = 旧数组长度 × 2
阈值也会相应调整 = 新容量 × loadFactor
扩容过程
jdk1.7<br>
扩容后的数组长度是扩容前的两倍
单个元素的保留在原来的桶
如果是链表需要拆分成两个链表,一个保留在低位 的桶,一个保存在高位的桶;
JDK1.7 链表头插法
jdk1.8<br>
扩容后的数组长度是扩容前的两倍
单个元素的保留在原来的桶
如果是链表需要拆分成两个链表,一个保留在低位 的桶,一个保存在高位的桶;
如果是红黑树,拆分红黑树,一个保留在原来索引位置的桶,一个保留在高位的桶(红黑树不会退化成链表)<br>
JDK1.8 尾插法
阻塞队列
概述
阻塞队列也是一种先进先出的队列
特性
线程安全队列
带有阻塞功能
如果队列满,继续入队列时,入队列操作就会阻塞,直到队列不满才能完成入队列
如果队列空,继续出队列时,出队列操作就会阻塞,直到队列不空才能完成出队列
引用场景
生产者消费者模型
代码“解耦合”
“削峰填谷”
阻塞队列概览
AQS
CAS
序列化
java序列化
序列化作用
网络之间传输数据,做持久化;
序列化方式
jdk自带Serializable
json序列化
xml序列化
message pack
Protocol Buffers
Marshalling
设计模式
代理
jdk代理
被代理类必须要实现接口;
底层实现反射
JDK的Proxy类在我们调用方法newProxyInstance时,生成一个代理对象在内存中,该对象根据参数实现了被代理类的接口,重写了接口中的方法。在此方法内,调用了我们创建的InvocationHandler的invoke()方法。实际调用的就是InvocationHandler中我们重写的invoke方法。所以动态代理在运行时会根据我们重写的代码进行增强<br>
cglib代理
ASM
通过cglib包来实现cglib代理,cglib包下最终也是调用的asm,字节码修改技术来相当于生成了一个新的类来替代原有的类执行方法。
单例
策略
设计模式
关键字
synchronized
Synchronized实现
字节码层面
编译后生成了加锁,解锁指令
monitorenter
加锁指令
monitorentexit
解锁指令
JVM层面
jvm调用了操作系统提供的同步方法;
操作系统和硬件
操作系统本身有一些同步的操作
锁对象
锁优化
锁升级
Synchronized 锁升级过程
Synchronize 内部,有一个锁升级的过程;jdk1.6自动打开;1.jvm会偏向第一个执行的线程,给他加上偏向锁;
2.如果这个时候还有其他线程来竞争,这个偏向锁就会升级成轻量级锁,这轻量级锁,多数情况下是自旋锁;
3.如果并发程度高,这个自旋锁会自旋很多次,如果超过十次,还没有拿到锁对象,那么锁又会升级成重量级锁(悲观锁);
详细说明:<br>
线程第一次进入 synchronized 块时,JVM 会把 线程 ID 写入对象头 Mark Word
后续同一线程再进入时,只需检查 Mark Word 是否保存的是自己的线程 ID
锁自旋
线程竞争失败后,不立刻阻塞,而是 循环(自旋)一段时间,反复尝试获取锁:
一般情况:
当线程竞争锁失败时,会被 阻塞,等待操作系统唤醒,这涉及 用户态 → 内核态切换,开销很大。
优点:
避免线程阻塞/唤醒带来的昂贵系统调用
在锁占用时间很短时性能极佳
缺点
自旋期间线程不做有用工作,浪费 CPU 时间
如果锁长期被占用,自旋会一直失败 → 白白消耗 CPU
锁状态转换过程
示意图
锁状态
无锁状态
偏向锁状态<br>
偏向锁:适用于单线程适用锁的情况,如果线程争用激烈,那么应该禁用偏向锁。<br>
轻量级锁状态<br>
轻量级锁:适用于竞争较不激烈的情况(这和乐观锁的使用范围类似)
重量级锁状态
重量级锁:适用于竞争激烈的情况
锁粗化
编译器发现某段代码有连续的加锁解锁操作就会进行锁粗化,将连续的加锁解锁变成一个加锁解锁,提高代码执行效率;
锁消除
编译器发现某段代码不存在多线程竞争共享资源,编译之后就会把锁消除掉,减少加锁解锁的性能消耗
transient
瞬时态
特点
用此修饰符的字段是不会被序列化
使用场景
类中的字段是可以通过其他字段被推导出来,此字段不需要做序列化
一些安全性的信息,一般情况下是不能离开JVM的
需要使用一些类,但是这个类对程序逻辑没有影响,也可以用来修饰
native
本地方法
native 方法就是 本地方法
Java 代码里只声明,不实现
实现部分交给 JNI(Java Native Interface),通常在 .dll(Windows)、.so(Linux)、.dylib(Mac)等动态链接库中
volatile
可见性机制
变量被修改之后,立马从自己的工作内存复制到主内存当中
一致性机制
该关键字修改的变量,在被使用的时候都会先去主内存中获取到该变量的最新值,复制到工作内存当中
使用场景
不存在并发问题但是又被很多地方同时使用。
缺陷
并发环境下使用会有线程安全问题;java的操作并不是原子操作
volatile关键字特点
能够屏蔽指令重排序
保证了 volatile 读写与前后指令之间的 有序性
可见性
一个线程修改了 volatile 变量,其他线程能立即看到
一致性的开销小于锁的开销
实现
字节码层面
给字段加上了ACC_volatile标记
JVM层面
编译后给该字段加上读写屏障
读操作
StoreStoreBarrier
读操作
StoreLoadBarrier
每次读(针对所有线程),都会从主内存中读取,而不是从工作内存中读取<br>
写操作
LoadLoadBarrier
写操作
LoadStoreBarrier
每次写操作,都会将工作内存中的值,刷新到主内存中
操作系统和硬件
翻译成对应的汇编指令,然后给读写加锁
线程
线程池
Executors
newFixedThreadPool
定长线程池,
newWorkStealingPool
newCachedThreadPool
可缓存线程池
特点一个核心线程都没有
newSingleThreadScheduledExecutor
单线程定时任务线程
newScheduledThreadPool
定时任务线程
newSingleThreadExecutor
单线程线程池
ForkJoinPool
ThreadPoolExecutor
ScheduledThreadPoolExecutor
线程池工作过程
1.线程池未达到 核心线程数 → 创建新线程。
除非创建线程池后,调用了prestartAllCoreThreads(),prestartCoreThread(),也就是创建线程池后会创建核心线程数量
2.达到核心线程数 → 任务进入队列。
3.队列满 & 线程数 < 最大线程数 → 创建非核心线程执行任务。
4.队列满 & 线程数 = 最大线程数 → 启动拒绝策略。
工作流程示意图
线程池参数
corePoolSize
核心线程个数
核心线程会一直存活,即使空闲。
当有新任务时,优先使用核心线程执行。
最大线程个数
maximumPoolSize
线程池能容纳的最大线程数。
当任务很多且队列满时,会启用非核心线程,直到达到最大值。
非核心线程多久不做任务就会被回收
keepAliveTime(空闲存活时间)
非核心线程存活时间的单位
unit(存活时间的单位)
工作队列
阻塞队列中传递Runnable
ArrayBlockingQueue
LinkedBlockingQueue
SynchronousQueue
存放等待执行的任务。
线程工厂
线程工厂,主要用来创建线程;
拒绝策略
AbortPolicy
丢弃任务并抛出RejectedExecutionException异常。<br>线程池默认的拒绝策略<br>
DiscardPolicy
丢弃任务,但是不抛出异常。<br>如果线程队列已满,则后续提交的任务都会被丢弃,且是静默丢弃。<br>
CallerRunsPolicy
由调用线程(提交任务的线程)处理该任务
DiscardOldestPolicy
该任务有提交这个任务的线程去执行。<br>
自定义
表示当拒绝处理任务时的策略
线程池状态
线程状态说明
RUNNING
自然运行状态
SHUTDOWN
不接受新任务,执行已添加任务
STOP
不接受新任务,也不执行已添加任务
TIDYING
所有任务已终止,任务数量为0
TERMINATED
线程彻底终止
线程状态扭转
示意图
使用场景
定时生成报表
定时任务处理大量报表信息
外部接口调用
优化接口的时候
数据清理/归档
缓存定期刷新
高并发抢购、秒杀场景
线程
Thread
线程的状态
线程状态转换
示意图
线程各种转态
NEW
新创建的未启动状态的线程
RUNNABLE
线程准备或者运行中
BLOCKED
线程阻塞
发生IO阻塞
发生锁的争用阻塞
WAITING
未指定时间的线程等待
Object.wait,不带超时时间<br>
Object.notify,Object.notifyAll 唤醒线程
Thread.join不带超时时间<br>
等待终止
LockSupport.park<br>
子主题
TIMED_WAITING<br>
指定时间的线程等待
Thread.sleep 方法
指定超时值的 Object.wait 方法
指定超时值的 Thread.join 方法<br>
LockSupport.parkNanos<br>
LockSupport.parkUntil
TEMINATED
线程终止
Thread中的方法
静态方法
sleep
当前线程进行相应时间的休眠,并且不释放锁对象
yield
当前线程放弃cpu执行权,让其他线程去执行,放弃的时间不确定,可能放弃后,又获得了执行权;
currentThread<br>
获取当前执行程序的线程
实例方法
isAlive() 方法的功能是判断当前线程是否处于活动状态
getId() 方法的作用是取得线程的唯一标识
isDaeMon、setDaemon(boolean on) 方法,是否是守护线程,设置守护线程
start()
线程可以开始运行
run()
线程真正执行
getPriority()和setPriority(int newPriority)
设置优先级,获取优先级
interrupt()
中断线程
join()
线程加入,抢占cpu执行权
Runable
开启线程的方式
继承Thread类,重写run方法
实现runnable接口,重写run方法
线程池类
线程调度
抢占式
cpu的执行权由系统去分配
java就是采用的抢占式,可以设置线程的优先级,但是并不会有太好的结果;
协同式
线程在完成某个任务之后通知cpu,进行线程的切换
特殊场景
CountDownLatch
CountDownLatch
Semaphore
线程模型
内核线程实现
线程相当于于一个轻量级进程,一个轻量级进程对应一个内核
线程的切换调度完全依赖内核
用户线程实现
用户实现对线程的创建消耗,和内核没有关系
线程和进程的比例为1:n
用户线程轻量级进程实现
轻量级进程是线程和内核之间沟通的桥梁
线程创建消耗会是由用户来控制
sun公司提供的jdk,使用的线程模型都是内核模型;有的公司提供的方式不是使用内核模型;
线程安全等级
1.final
2.线程绝对安全,类的方法字段做了synchronized同步,调用端单个调用这些的时候是线程安全的;
3.线程相对安全:传统意义上的线程安全,没法保证调用端是线程安全的
4.线程兼容:代码本身不是安全的,通过添加同步方式,保证这块线程是安全的;
5.线程对立:不管是调用方还是被调用方,线程都不安全
概述:线程的安全,需要考虑调用端和被调用端;
锁
锁的分类
锁的性质
java中的锁
jdk新特性
jdk9新特性
http请求是2.0版本
接口可有默认的实现
jdk7
interface IMyInterface {<br> public void test0();<br>}
jdk8
interface IMyInterface {<br> public static void test1 () {<br> System.out.println("静态方法");<br> }<br> default void test2() { // 可以被实现类覆写<br> System.out.println("默认方法");<br> }<br> public void test0();<br>}
jdk9
interface IMyInterface {<br> private void test() {<br> System.out.println("接口中的私有方法");<br> }<br> public static void test1 () {<br> System.out.println("静态方法");<br> }<br> default void test2() {<br> System.out.println("默认方法");<br> }<br> public void test0();<br>}
多版本jar包兼容
在某个版本的java程序运行的时候可以选择不同版本的class版本
模块化
解决的问题
1、jvm启动的需要加载整个jra包,导致不需要使用的类,模块也被加在到内存中,浪费不必要浪费的内存;
在终端开发中尤其明显
不同版本的类库交叉依赖;每个公共类可以被类路径下任何其他的公共类所访问到,会导致使用并不想开放的api;类路径可能重复等
暂时无法理解这些
模块化好处
降低启动所需要的内存,按需加载对应的包
简化类库,方便开发维护
模块化实现
模块化实际上就是包外面在包一层,来管理包。
jshell命令
提供类似python交互式编程环境
可以在dos窗口,终端中进行编程
新增api
多分辨率图像api
mac系统已经支持
暂时还无法看到的api
引入轻量级的JSON API
新的货币api
弃用api
Applet和appletviewer的api都被标记为废弃
主流浏览器已经取消了对java浏览器插件的支持
改进
钻石操作符(泛型)的升级
具体解释
对应的demo
public class DiamondOperatorTest {<br> public static void main(String[] args) {<br> new DiamondOperatorTest().test();;<br> }<br> <br> public void test() {<br> Set<String> set = new HashSet<>(){<br> @Override<br> public boolean add(String s) {<br> return super.add(s + "..");<br> }<br> };<br> <br> <br> set.add("1");<br> set.add("2");<br> set.add("3");<br> set.add("4");<br> <br> <br> for (String s : set) {<br> System.out.println(s);<br> }<br> }<br>}<br>
对应结果
try语句升级
jdk8
传统语句
优化后,jvm自动释放资源
需要将资源的实例化放在try 的小括号里面
jdk9
一次性可以释放多个资源
String实现
jdk8
底层是char 数组
jdk9
底层是byte数组
不同的编码字符集一个字符所需要的字节个数不一致,1-2个
相对于jdk8可以减少字符串内存空间消耗
快速创建只读集合
提高编码效率
所创建的集合都只能是做读取操作,无法做添加删除操作
增强的流api<br>
List<Integer> list = Arrays.asList(11, 32, 44, 29, 52, 72, 82, 64, 4, 19);<br>list.stream().takeWhile(integer -> integer < 50).forEach(System.out::println);
只是做筛选,并不会修改list集合本身元素
List<Integer> list = Arrays.asList(11, 32, 44, 29, 52, 72, 82, 64, 4, 19);<br>list.stream().dropWhile(x -> x < 50).forEach(System.out::println);
只是做筛选,并不会修改list集合本身元素
Stream.ofNullable(null).forEach(System.out::println);
Stream.iterate(0, x -> x < 5, x -> x + 1).forEach(System.out::println);<br>
类似下面代码
for (int i = 0; i < 5; i++) {<br> System.out.println(i);<br>}
Optional.ofNullable(list).stream().forEach(System.out::println);
动态编译器
AOT(Ahead of time)
java引用在jvm启动钱就被编译成二进制代码
jdk9中提出来,jdk10正式发布该新特性
jdk1.9 默认垃圾收集器G1
jdk9版本采用单线程回收
G1回收期新老年代都可以做回收
替换了jdk7,8 Parallel Scavenge(新生代)+Parallel Old(老年代)
jdk10新特性
局部变量类型推断
var 可以作为局部变量
var str = "abc"; // 推断为 字符串类型 <br>var l = 10L; // 推断为long 类型 <br>var flag = true; // 推断为 boolean 类型 <br>var list = new ArrayList<String>(); // 推断为 ArrayList<String> <br>var stream = list.stream(); // 推断为 Stream<String> <br>
但是不可以作为全局变量,还有参数,已经方法返回值
G1引入并行 Full
发生full gc 的时候可以使用多个线程并行回收
jdk9的时候单线程回收
应用程序类数据共享
同一个机器下的多个jvm可以实现数据共享
减少不必要的内存消耗
线程本地握手
ThreadLocal 握手交互。在不进入到全局 JVM 安全点 (Safepoint) 的情况下,对线程执行回调。优化可以只停止单个线程,而不是停全部线程或一个都不停
在备用存储装置上进行堆内存分配
新增加Graal编译器
基于Java的JIT编译器,目前还属于实验阶段
预先把 Java 代码编译成本地代码来提升效能
删除javah工具
javah 用于生成C语言的头文件
JDK8开始,javah的功能已经集成到了javac中。去掉javah工具
新增api
List、Set、Map新增加了一个静态方法 copyOf
class Main {<br> public static void main(String[] args) {<br> List<Integer> list=new ArrayList<Integer>(3);<br> list.add(1);<br> list.add(2);<br> list.add(3);<br> List<Integer> temp = List.copyOf(list);<br> }<br>}<br>
IO
transferTo方法复制文件
JDK10 给 InputStream 和 Reader 类中新增了 transferTo 方法
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("a.txt")));<br> long nums = reader.transferTo(new BufferedWriter(new OutputStreamWriter(new FileOutputStream("b.txt"))));<br> System.out.println("一共复制的字节数量: "+nums);<br><br>
IO流大家族添加Charset参数的方法<br>
ByteArrayOutputStream新增toString方法<br>
JDK10给 ByteArrayOutputStream 新增重载 toString(Charset charset) 方法,通过指定的字符集编码字节,将缓冲区的内容转换为字符串
jdk11新特性
新增api
String类新增方法<br>
判断是否是空白字符串<br>
String s1 = "\t \n";<br>System.out.println(s1.isBlank()); // 判断是否为空白 true
去除首尾空白<br>
s1 = "\t sss\n";<br>System.out.println(s1.trim().length()); // 去除首尾空白,不能去除全角空格<br>System.out.println(s1.strip().length()); // 去除首尾空白,可以去除全角空格<br>System.out.println(s1.stripLeading()); // 去除头部空白<br>System.out.println(s1.stripTrailing()); // 去除尾部空白<br>
lines()<br>
方法可以对字符串每一行进行流式处理
"asc\nccc\nwww".lines().map(str -> str.toUpperCase()).forEach(System.out::println);
ASC<br>CCC<br>WWW
Optional方法增强<br>
System.out.println(Optional.ofNullable(null).orElse("b")); // 如果为空,返回"b"<br>System.out.println(Optional.ofNullable(null).orElseGet(() -> "b")); // 也可以使用函数式接口实现orElse()<br>System.out.println(Optional.ofNullable(null).orElseThrow()); // 如果为空,排除异常
b<br>b<br>Exception in thread "main" java.util.NoSuchElementException: No value present<br> at java.base/java.util.Optional.orElseThrow(Optional.java:382)<br> at com.szc.Main.main(Main.java:42)
transferTo()方法<br>
try (var inputStream = new FileInputStream("D:/test.jar");<br> var outputStream = new FileOutputStream("test2.jar")) {<br> inputStream.transferTo(outputStream);<br>} catch (Exception e) {<br> e.printStackTrace();<br>}
移除废弃api
废弃
jvm参数
-XX:+AggressiveOpts、-XX:UnlockCommercialFeatures、-XX:+LogCommercialFeatures
废弃 Nashorn js引擎,可以考虑使用GraalVM
废弃 pack200和unpack200,这是以前压缩jar包的工具
移除
com.sun.awt.AWTUtilities、sum.misc.Unsafe.defineClass(被java.lang.invoke.MethodHandles.Lookup.defineClass替代)、Thread.destroy()、Thread.stop(Throwable)、sun.nio.disableSystemWideOverlappingFileLockCheck属性、sun.locale.formatasdefault属性、jdk.snmp模块、javafx模块、javaMissionControl等<br>
JavaEE和CORBA模块
更简化的编译运行程序<br>
解释:如果java文件里没有使用别的文件里的自定义类,那么就可以直接使用java就可以编译运行java文件,也不会输出class文件<br>
Unicode编码
Unicode10加入了8518个字符,4个脚本和56个新的emoji表情符号
完全支持linux容器
jdk11以前的java应用程序在docker中运行的性能会下降,但现在此问题在容器控制组(cgroups)的帮助下得以解决,使JVM和docker配合得更加默契
免费的低耗能分析
通过JVMTI的SampledObjectAlloc回调提供一个低开销的堆分析方式
新的加密算法
ChaCha20-Poly1305这种更加高效安全的加密算法,代替RC4;采用新的默认根权限证书集,跟随最新的HTTPS安全协议TLS1.3
Flight Recorder<br>
记录运行过程中发生的一系列事件
Java 层面的事件,如线程事件、锁事件,以及 Java 虚拟机内部的事件,如新建对象,垃圾回收和即时编译事件
启用设置 -XX:StartFilghtRecording
新增垃圾回收器
Epsilon GC<br>
处理内存分配但不负责内存回收的垃圾回收器,堆内存用完,JVM即刻OOM退出
EpsilonGC使用场景
性能测试(过滤GC引起的性能消耗,相当于控制变量)
内存压力测试(看看不回收的情况下,到底能不能消耗指定大小的内存)
执行非常短的任务(GC反而是浪费时间)
VM接口测试、延迟吞吐量的改进等实验性质的调优
ZGC
ZGC是一个并发、基于区域(region)、标记压缩算法的GC
特性
不管堆内存多大,STW 时间不会超过10ms
只在根节点扫描阶段发生stw ,所以停顿事件不会随着堆内存增长和激活对象的增长而增长
启用ZGC的方法:-XX:+UnlockExperimentalVMOptions -XX:+UseZGC<br><br>目前ZGC只能用于64位的linux操作系统下
G1的完全并行GC
jdk12新特性
新增Shenandoah GC
雪兰多收集器使用的内存结构和G1类似,都是将内存划分为区域,整体流程也和G1相似
最大的区别在于雪兰多收集器实现了并发疏散环节,引入的Brooks Forwarding Pointer技术使得GC在移动对象时,对象的引用仍然可以访问,这样就降低了延迟
工作流程
其工作周期如下:<br>1)、初始标记,并启动并发标记阶段<br>2)、并发标记遍历堆阶段<br>3)、并发标记完成阶段<br>4)、并发整理回收无活动区域阶段<br>5)、并发疏散,整理内存区域<br>6)、初始化更新引用阶段<br>7)、并发更新引用<br>8)、完成引用更新阶段<br>9)、并发回收无引用区域阶段<br>
启用方法:<br>XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC
新增一套微基准测试
现有微基准测试的运行和新微基准测试的创建过程
改进
switch表达式
demo
public class Main {<br> public static void main(String[] args) {<br> Fruit f = Fruit.APPLE;<br> <br> <br> switch (f) {<br> case APPLE -> System.out.println(1);<br> case ORANGE, GRAPE -> System.out.println(2);<br> case PEAR, MANGO, WATERMALLON -> System.out.println(3);<br> default -><br> System.out.println("No such fruit");<br> }<br> }<br>}<br> <br> <br>enum Fruit {<br> APPLE, ORANGE, GRAPE, PEAR, MANGO, WATERMALLON<br>}
改进点
简化表达式
可以同时处理多个case
G1回收器
空闲时候G1回收器会自动将java堆内存返回给操作系统
jdk12中的G1将在应用程序不活动期间定期生成或持续循环检测整体的java堆使用情况,以便更及时地将java堆中不使用的内存返回给OS。这一改进带来的优势在云平台的容器环境中更加明显,此时内存利用率的提高会直接降低经济成本
G1 垃圾回收器的回收超过暂停目标,则能中止垃圾回收过程.
把回收集分为必须部分和可选部分,优先处理必须部分
必须部分主要包括G1不能递增处理的部分(如年轻代),也可以包含老年代以提高效率
优先处理必须部分时,会维护可选部分的一些数据,但产生的CPU开销不会超过1%,而且会增加本机内存使用率;处理完必须部分后,如果还有时间,就处理可选部分,如果剩下时间不够,就可能只处理可选部分的一个子集。处理完一个子集后,G1会根据剩余时间来决定是否继续收集
参数设置
G1PeriodicGCInterval
G1PeriodicGCSystemLoadThreshold
以上两个参数值都为0表示禁用此功能
G1PeriodicInvokesConcurrent
定期GC的类型,默认是Full GC,如果设置值了,就会继续上一个或启动一个新的并发周期
jdk13新特性
动态CDS档案
支持java应用执行之后进行动态归档,以后执行java程序后一些类就可以直接从这些归档文件中加载了
改进
ZGC提交未使用的堆内存
ZGC在jdk11中引入的收集器,jdk13中使能了向OS提交未使用的堆内存<br>
过程
ZGC中的区域称之为ZPage,当ZGC压缩堆时,ZPage被释放,然后变成ZPageCache,最后使用LRU算法对PageCache区域进行定时清除。时间间隔默认为5分钟,用户自定义时间间隔尚未实现,而如果-Xms和-Xmx相等的话,这个功能就相当于没有
重新实现旧版套接字api
switch表达式中引入yield
文本块
String s = """<br> <html><br> <head><br> <meta charset="utf-8"/><br> </head><br> <body><br> <p>aaa</p><br> </body><br> </html><br> """;
s = """<br> select * from students<br> where id in (12, 13, 14, 15)<br> order by grade desc<br> """;
jdk14新特性
instanceof省去了强制类型转换的过程
jdk14版本之前写法
Object obj = "kuaidi100";<br>if(obj instanceof String){<br> String str = (String) obj;<br>}<br><br>
jdk14版本的写法
Object obj = "kuaidi100";<br>if(obj instanceof String str){<br> //直接使用str<br>}<br>
if (obj instanceof String s) {<br> // can use s here<br>} else {<br> // can't use s here<br>}<br>
垃圾回收器
移除 CMS(Concurrent Mark Sweep)垃圾收集器:删除并发标记清除 (CMS) 垃圾收集器
ZGC
MacOs windows 实现 ZGC
弃用 Parallel Scavenge 和 Serial Old 垃圾回收算法的组合
G1 NUMA感知内存分配:现在尝试跨垃圾收集在年轻一代的同一NUMA节点上分配并保留对象。这类似于并行GC NUMA意识。G1尝试使用<br>严格的交错在所有可用的NUMA节点上均匀分配Humongous和Old区域。从年轻一代复制到老一代的对象的放置是随机的。这些新的NUMA感知<br>内存分配试探法通过使用-XX:+UseNUNMA命令行选项自动启用<br>
NUMA是啥?
这段话怎么理解
更详细的空指针异常<br>
参数-XX:+ShowCodeDetailsInExceptionMessages
更详细地显示空指针异常
Packaging Tool (Incubator)
一个打包工具,可以将java应用直接打包成rpm,dmg或者exe在各自平台可以点击直接运行
改进
JFR Event Streaming JFR事件流
对飞行记录器功能升级
之前是不可以用于实时监控
jdk14之后可以实时获取到JVM的运行情况
弃用
不建议使用线程挂起、删除
涉及的线程挂起Thread的方法已经在jdk14版本种废弃
Thread.suspend(),Thread.<br>resume(),ThreadGroup.suspend(),ThreadGroup.resume(),ThreadGroup.allowThreadSuspension(boolean)这些方法将在<br>将来的版本中删除。<br>
需要验证下对应的版本是否有这个方法?
椭圆曲线:
security-libs / javax.crypto,已过时的旧椭圆曲线去除
jdk15新特性
垃圾回收器
优化G1回收器
默认的堆区域大小计算已更改为默认情况下返回较大的区域,计算仍以2048个区域为目标
两点改进
仅考虑最大堆大小。旧的计算还考虑了初始堆大小,但是当未设置堆大小时,这可能会<br>产生意外的行为<br>
区域大小四舍五入到最接近的2的幂,而不是减小。在最大堆大小不是2的幂的情况下,<br>这将返回更大的区域大小<br>
ZGC可以正式使用
使用-XX:+UseZGC命<br>令行选项启用ZGC<br>
Shenandoah正式使用
一个低暂停时间的垃圾收集器
优化
文本块
简化了编写 Java 程序的任务,同时避免了常见情况下的转义序列
增强 Java 程序中表示用非 Java 语言编写的代码的字符串的可读性。
instanceof
二次优化
弃用
禁用和弃用偏向锁定
移除 Nashorn JavaScript 引擎
弃用 RMI 激活以进行删除
新增API
引入 API 以允许 Java 程序安全有效地访问 Java 堆之外的外部内存<br>
隐藏类
引入隐藏类,即不能被其他类的字节码直接使用的类
隐藏类旨在供在运行时生成类并通过反射间接使用它们的框架使用。隐藏类可以定义为访问控制嵌套的成员,并且可以独立于其他类卸载
密封类(第一版预览)
使用密封的类和接口增强 Java 编程语言。密封的类和接口限制了哪些其他类或接口可以扩展或实现它们。
爱德华兹曲线数字签名算法
jdk16新特性
instanceof
最终版本
Records
最终版本
内存相关
Elastic Metaspace
弹性的元空间
元空间中未使用的 class 元数据内存更及时地返回给操作系统,以减少元空间的内存占用空间
垃圾回收器
ZGC 支持并发栈处理
把 ZGC 中的线程栈处理从安全点移到了并发阶段
不太懂ZGC回收过程?
HotSpot 子系统可以通过该机制延迟处理线程栈
不太懂ZGC回收过程?
对内存操作api
默认对内存的操作的api需要使用强封装的类来调用,提高系统的安全性
好处是
使用统一的api有利于以后对系统化版本的升级
说明
Java 9中,我们通过利用模块来限制对JDK内部元素的访问,从而提高了JDK的安全性和可维护性。模块提供了强封装
模块外部的代码只能访问该模块导出的包的公共和受保护元素
protected 修饰的元素只能由定义它的类已经它的子类访问
强封装适用于编译时和运行时,包括已编译代码试图在运行时通过反射访问元素时。导出包的非公共元素和未导出包的所有元素都被称为是强封装的
jdk17新特性
增强
密封类
在jdk15,16中是预览版本,17正式上线
demo
public abstract sealed class Student<br> permits NameChangeRecordService {<br><br>}<br>
类 Student 被 sealed 修饰,说明它是一个密封类,并且只允许指定的 3 个子类继承
回复严格模式的浮点数定义
伪随机数生成器增强
mac系统平面渲染api更换
新的api Apple Metal
老的api Apple OpenGL
上下文特定反序列化过滤器
通过配置过滤器,通过一个 JVM 范围的过滤器工厂,用来为每个单独的反序列化操作选择一个过滤器。
改进
switch(暂未发布)
老代码写法
static String formatter(Object o) {<br> String formatted = "unknown";<br> if (o instanceof Integer i) {<br> formatted = String.format("int %d", i);<br> } else if (o instanceof Long l) {<br> formatted = String.format("long %d", l);<br> } else if (o instanceof Double d) {<br> formatted = String.format("double %f", d);<br> } else if (o instanceof String s) {<br> formatted = String.format("String %s", s);<br> }<br> return formatted;<br>}
新代码写法
static String formatterPatternSwitch(Object o) {<br> return switch (o) {<br> case Integer i -> String.format("int %d", i);<br> case Long l -> String.format("long %d", l);<br> case Double d -> String.format("double %f", d);<br> case String s -> String.format("String %s", s);<br> default -> o.toString();<br> };<br>}
直接在 switch 上支持 Object 类型,这就等于同时支持多种类型,简化代码
外部函数和内存 API(孵化中)
API 可以调用本地库和处理本地数据,与java环境之外的代码和数据交互
改进14,15引进的一些api
矢量 API(二次孵化中)
增强的 API 允许以一种在运行时,可靠地编译为支持的 CPU 架构上的最佳向量指令的方式表达向量计算
删除
AOT Graal 编译器 移除
删除远程方法调用 (RMI) 激活机制,同时保留 RMI 的其余部分。<br>
弃用
弃用安全管理器
数据库
数据库相关知识点
关系型数据基础知识
范式
第一范式
每个字段都是原子,不可再分割
关系型数据库最基本要求
第二范式
满足第一范式的前提下,每一行的数据只能与其中一列相关,记录需要有唯一标记
第三范式
满足第二范式的前提下,每个字段都是直接与主键过关系,其他字段之间不能存在传递关系
数据存储
mysql
事物
事物隔离级别
读未提交(Read Uncommitted)<br>
一个事物可以读取其他事物没有提交的修改
问题
脏读
一个事务读到另一个事务 未提交 的修改。
读已提交(Read Committed)<br>
一个事物只能读取到其他事物已经提交的数据
关键点:
影响的是 已有记录的内容
发生在 行被修改(UPDATE) 的场景
oracl数据库默认隔离级别<br>
问题
不可重复度
一个事务内 多次读取同一行,结果不同(因为别的事务修改并提交了)。
可重复读(Repeatable Read)<br>
事物在执行期间,获取获取同一行记录,结果都是一样的。
关键点:
影响的是 记录的存在性,不是已有记录的内容
发生在 插入或删除(INSERT/DELETE) 的场景
myslq默认事物隔离级别<br>
问题
幻读
一个事务在某个范围内查询到的记录数 前后不一致(因为别的事务插入/删除了新行)。
串行化(Serializable)<br>
同开启AB事物,A事物没有提交,B事物无法对A事物已经操作的过的任何其他数据进行操作
特点:所有事务 串行执行,通过对读的表加锁实现,最严格。
事物调度
并行
多个事物同时执行
串行
事物必须是一个一个的去执行,不能并发的去执行
并发事物控制
乐观控制
概念
每次访问数据的时候,都认为是查询操作,其他事物也能访问当前事物的数据;造成的数据不一致性,采取的方式是修改数据之后,对修改的数据进行回滚操作
特点
1.读操作过多的情况下,能够显著提高效率
2.采取时候回滚操作来来解决事物冲突问题
具体实现
通过在需要更新的表中设立相关的数据版本号来做操作
MySQL乐观锁使用场景
可在分布式场景下控制多个服务对相同数据的修改是线性执行的;
悲观控制
概念
每次访问数据的时候,都会对数据进行加锁操作
特点
1.采取的是提前预防冲突
2.严格的控制其他事物对当前事物的访问,避免大量的数据回滚
3.其他事物,在某些情况下还是可以访问当前数据
具体实现
通过数据库本身的锁机制来实现悲观控制
mysql悲观锁使用场景
单体服务的时候就实现对并发事物的悲观控制
概述
对并发(交叉)事物的控制的方式;数据本身对并发事物的控制都是悲观控制
ACID
基础概念
原子性
事物中发生多件事情,多件事情要么都成功,要么都失败
场景
A给B转钱,A成功的把钱给了B,B也成功的收到了A的钱
依赖 Undo Log(回滚日志) 实现
如果事务失败,InnoDB 可以根据 Undo Log 恢复数据到事务开始之前的状态。
日志内容
INSERT 操作的 Undo Log
记录如何删除新插入的行。
DELETE 操作的 Undo Log
记录被删除行的完整数据(行的所有列值)。
UPDATE 操作的 Undo Log
记录修改前的旧值。
反向记录sql的操作<br>
一致性
一种状态到另外一种状态必须保证数据逻辑上的一致
场景
A给B转1000块钱,A的账户扣了1000块,B的账户多了1000块
依赖 原子性 + 隔离性 + 持久性 共同保障。
隔离性
当前事物不受其他事物影响
依赖 MVCC(多版本并发控制) + 行级锁 实现。
持久性
数据能够被持久化的存储在磁盘上
事物提交之后,该事物对应的修改数据都会被存储到磁盘上
依赖 Redo Log(重做日志) 实现:
事务提交时,先写 Redo Log,再写入磁盘,保证即使崩溃也能恢复。
日志内容
记录在物理页上面的数据变更
锁
锁的分类
按照粒度划分
库锁
加锁对象:整个数据库实例。
效果:整个库进入只读状态,常用于全库备份。
表锁
表锁是由MySQL本身来实现
表锁具体实现
意向共享锁
给数据行加行级锁之前需要取道该表的意向共享锁
意向排他锁
给数据行家排他锁之前需要取到该表的意向排他锁
概述
意向锁,锁是由innerDB自动添加,无需用户手动添加
行锁(innerDB实现)一个统称
记录锁
锁单条记录<br>
间隙锁
锁范围(两个索引值之间的间隙(不含端点)<br>),防止幻读。<br>
Next-key锁
记录锁 + 前一个间隙<br>
锁分类说明
乐观锁,悲观锁都是在并发事物的一种控制方式,是一种思想,不是实实在在的锁
行锁,表锁也并非实实在在的锁,只是锁的粒度来划分的锁
二阶段锁
概述
关系型数据库的一种加锁原则;把锁的操作划分为两个阶段,加锁阶段,解锁阶段
实际过程
加锁阶段,解锁阶段互不相交,加锁阶段,只加锁,不解锁;解锁阶段,只解锁,不加锁
乐观锁,悲观锁
悲观锁
认为每次对数据库操作都会被并发修改,所以每次操作数据库都会加锁,阻塞其他修改
实现
行锁<br>
SELECT ... FOR UPDATE<br>
加上了排它锁,其他事务无法修改这行,直到事务提交或回滚<br>
共享锁<br>
SELECT ... LOCK IN SHARE MODE<br>
行加共享锁(S锁),其他事务可以读,但不能修改<br>
典型场景
库存扣减、银行转账等对数据安全要求高的场景。
特点
数据访问前加锁,保证安全。
并发性能低,高并发容易阻塞。
乐观锁
思想:假设大多数情况下不会发生冲突,数据操作前不加锁,提交时检查是否有冲突,如果有冲突则重试。
实现
版本号(Version)<br>
在数据表中增加一个 version 字段,每次更新时 WHERE version=旧值,更新成功则 version+1,失败则说明被其他事务修改,重试<br>
时间戳(Timestamp)<br>
在数据表中增加 update_time 字段,更新时检查时间戳是否一致,一致则更新,失败则重试<br>
典型场景
电商商品浏览量统计、点赞、评论等高并发更新。
特点:
数据访问前不加锁,性能高。
适合读多写少的场景。
索引
索引种类
使用方式分类
单列索引
主键索引
根据主键排序做的索引,特殊的唯一索引
唯一索引
强制让表中某个字段值不能重复
普通单列索引
根据某一列字段建立的索引
组合索引
把建立索引的字段值全部兼容在一起组成的索引
聚簇非聚簇
聚簇索引
数据和索引在物理存储上“聚合”在一起。
主键索引就是数据聚簇索引
非聚簇索引
索引和数据分开存储。
非主键索引全部都是属于聚簇索引
分类标准
根据索引的叶子节点中是否存放了整行数据
稀疏密集
稀疏索引
多条数据可以对应一条索引数据
非主键索引和有可能就是稀疏索引
密集索引
数据和索引是一一对应的
主键索引就是密集索引
索引数据结构
B+树
B+树的数据存储结构
数据库引擎不同B+树存储的数据不完全相同
innerDB的的B+树叶子节点存储的是全部的数据或者是主键id;
myisam的B+树叶子节点存储的时候该条数据地址值(不管是主键索引还是其他索引)
B+树和B树区别
B+树的非叶子节点存储的是节点之间的前后指向关系,并不存储实际的数据值;B树的只要是节点不管是叶子节点还是非叶子节点都会存储数据。
B+树的节点存储兄弟节点的地址值,可以直接指向兄弟节点;而B树是不可以的。
在相同数据层级,B+树能够存储更多的数据;而B树存储的数据少很多;
使用场景
myisam和innerDB索引都是使用B+树
hash索引
基于hash算法的散列索引
特点
查询单条数据查询时间的复杂度为01;
范围查询速度比较低
使用场景
memory引擎默认使用该中索引
全文索引
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引;
MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
使用
只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
索引开销
创建和维护索引都需要耗费时间和磁盘空间
修改语句操作的时候,需要对索引进行重新构建
索引相关概念
回表查询
查询的时候根据组合索引去查询,从索引中获取到的数据并未覆盖所需要 查询的全部字段,所以就需要那到索引中的id再回到表中去查询需要的字段,这就是回表
非索引下推
查询的时候,先根据组合索引中最左索引查询,拿到这些查询之后的数据的主键,再回表查询出整条数据,再从整条数据从按照其他条件做筛选;
索引下推
如果查询条件中包含了组合索引,那么就会优先使用组合索引查询,查询满足组合索引中最左索引的值,从这些筛选一遍的数据中再过滤出其他符合条件的数据,不用再次回表查询;
最左匹配原则
组合索引中,如果查询条件中并没有带上组合索引中最左边的索引,那么这个查询是不会先去查询组合索引
覆盖索引
查询的是主键索引字段,也就是查询的数据本身就是索引,直接从索引中拿数据,不需要再去根据主键回表查询其他数据
一次性非锁定读
就是普通的select
读取的是快照版本数据
一次性锁定读
在select 语句后面中加 for update 或者是 lock in share mode
读数据的时候会加锁,保证读取的数据不被其他事物修改
查询需走索引
数据库引擎
innerDB
文件结构
FRM文件
表结构文件
IBD文件
索引数据+表数据
锁
支持行锁,表锁
行锁
记录锁
通过锁定索引记录来实现;锁定某一个索引记录
使用场景
只用通过索引条件查询数据的时候,才会使用到
作用
间隙锁
通过索引记录来实现
对一定返回内数据进行加锁,即使这数据不存在也是会加锁
Select * from emp where empid &gt; 100 for update;会对empid大于100的都加上间隙锁,即使记录不存在也会添加
使用场景
作用
Next-key锁
相当于一个记录锁+间隙锁
使用场景
作用
避免幻读
插入意向锁
插入数据之前,由insert操作设置的一种间隙锁
表锁
意向共享锁
给数据行加行级锁之前需要取道该表的意向共享锁
意向排他锁
给数据行家排他锁之前需要取到该表的意向排他锁
日志
redolog(innerDB引擎独有)
redolog日志类容
记录后事物执行之后的状态,用来记录未写入 datafile 的已成功的事物更新的数据;
记录对数据页的所有写操作,确保在系统崩溃后能够恢复事务的一致性与完整性
日志作用
在MySQL宕机时候,还有数据没有写入磁盘,可以通过重做日志重做,从而达到数据的持久化
日志生成
事物开始的时候就会有日志生成,随着事物的进行的过程中,日志逐渐写入redolog中
日志清理
当某个事物对应的数据写入 datafile中后,redolog的使命已经完成了,重做日志的空间就会被重用
undolog
undolog生成时间
数据库的每一次修改(insert,update,delete)操作,在落到磁盘之前都会先记录到undolog
undolog日志内容
记录信息修改之前数据
undolog日志回滚操作
根据undolog日志做数据库的逆向操作,原来的insert操作变成delete操作,delete变成insert,update变成逆向update
Myisam
文件结构
frm文件
存储的是表结构信息
MYD文件
存储的是数据行记录信息
MYI文件
存储索引对应的数据信息
myisam工作流程
根据索引
锁
支持表锁,不支持行锁
innerDB和Myisam区别
索引数据结构
myisam索引的B+树的叶子节点存储的是该条数据的地址值
innerDB索引的B+树的叶子节点存储的是该条数据的全部字段值(主键索引)
innerDB索引的非主键索引叶子节点存储的是id值(非主键索引)
锁区别
innerDB支持行锁,表锁;myisam支持表锁
事物
innerDB支持事物;myisam不支持事物(原因其实主要是myisam不支持行锁,间接导致不能支持事物)
是否支持全文索引
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引
MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
是否支持外键
innerDB支持外键;myisam不支持外键
主键是否必须
innerDB支持必须有主键;myisam可以没有主键
数据存储不同
innerDB数据存储frm、ibd文件;frm是表定义文件,ibd是数据文件
Myisam是frm、MYD、MYI;frm是表定义文件,myd是数据文件,myi是索引文件
innerDB数据索引数据和表数据是存储在一起;而myisam引擎索引数据和表数据是分开存储在两个文件
是否存储具体行数
innerDB不存储表的具体行数;myisam存储表的具体行数
是否支持表压缩
innerDB不支持表数据压缩;myisam支持表数据压缩,压缩后支持只读,修改操作需要加压才能操作;
memory
锁
支持表锁,不支持行锁
在内存中存在表数据,数据库重启之后,该引擎对应的数据就会消失
默认是使用hash索引
Merge
存储引擎允许将一组使用MyISAM存储引擎的并且表结构相同的数据表合并为一个表,方便了数据的查询
csv
其他存储引擎包括CSV(引用由逗号隔开的用作数据库表的文件)
ARCHIVE
为大量很少引用的历史、归档、或安全审计信息的存储和检索提供了完美的解决方案。
BLACKHOLE
用于临时禁止对数据库的应用程序输入
FEDERATED
能够将多个分离的MySQL服务器链接起来,从多个物理服务器创建一个逻辑数据库。十分适合于分布式环境或数据集市环境。
EXAMPLE
可为快速创建定制的插件式存储引擎提供帮助
BDB
可替代InnoDB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性。
Cluster/NDB
MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性
日志
binlog日志(二进制日志)
binlog日志作用
主从复制;主从复制就是为了读写分离
主从复制过程
1.主机每次完成实事物提交,完成数据更新之前,都会把变更的数据记录在binlog日志中
2.从机开启一个IO线程去从主机的binlog日志中读取数据,记录到自己的中继日志中;
3.从机开启线程,解析中继日志的事件,并执行,来做数据主从复制
数据库基于时间还原数据
读写分离;读写分离的前提就是主从复制
缓存一致性;模拟成从机,拉取binlog日志异步更新到缓存中的数据;
数据多备份
binlog日志格式
5.0之前
statment模式
以mysql事件形式记录的是实际执行的sql语句
5.0之后
row模式
以MySQL事件形式记录字段前后变化的值
binlog日志配置
max_binlog_size
日志文件的大小,默认1G
expire_logs_days
日志保留事件,默认是0,永久保留
记录所有的更新操作
查询日志
记录建立的客户端连接和执行的语句。
只记录查询相关的日志
更新日志
记录更改数据的语句。不赞成使用该日志。
5.1版本之前的日志,5.1版本之后被binlog日志替代
错误日志
记录内容
记录mysql启动关闭,以及运行过程中发生的错误信息
设置
错误日志默认是关闭
慢查询日志
记录内容
记录的是查询时间超过10秒(默认值)的sql语句
设置
慢查询日志默认是关闭
中继日志
场景用在主从复制中从服务器读取到主服务器的二进制日志存储起来就是中继日志,日志格式和二进制日志格式相同,都可以使用相同的binlog解析程序解析
innerDB独有日志<br>
Redo Log(重做日志)
内容:记录的是数据页的物理修改,比如某一页上某个偏移量的数据被更新成了什么值。
使用场景
事务提交后还没把数据写入磁盘,MySQL 崩溃 → 根据 Redo Log 把数据恢复到提交时的状态。
举例
UPDATE user SET balance = balance - 100 WHERE id = 1;
Redo Log 里可能记录:在数据页 #123 偏移量 0x50,把值从 500 改为 400
Undo Log(回滚日志)
内容:记录的是数据的逻辑修改前的值,用于回滚。
使用场景:
回滚事务。
MVCC 读取时,提供历史版本。
举例
UPDATE user SET balance = balance - 100 WHERE id = 1;
Undo Log 里会记录:
balance 从 400 改回 500
MVCC版本控制
MVCC作用
1、解决读写冲突;
2、保证在事物并发条件下的读操作的效率,写操作的准确性。
InnoDB 存储引擎用来实现 高并发读写 + 事务隔离 的核心机制
为什么需要 MVCC?
多个事务并发访问同一行数据时,如果都用加锁,会导致阻塞严重。
MVCC 通过“版本快照”机制,让 读操作不用阻塞写操作,实现 非锁定读。
MVCC的作用<br>
读写不互斥:快照读不加锁,读写可以并行。
避免脏读、不可重复读:靠 ReadView 判断数据可见性。
保证一致性:事务即使长时间运行,也能看到启动时的一致性视图。
MVCC控制分类
快照读
概述
读取记录的可见版本(可能是历史版本,也可能是当前版本)不用加锁
使用场景
不加锁的select操作
当前读
当前读就是读取的最新数据,而且还要保证其他事物不能修改当前数据
场景
加锁的读操作
select * from table where ? for update;
select * from table where ? lock in share mode;
当前写
概述
加锁读取记录的最新版本,保证其他事物不会并发修改这条记录;
使用场景
特殊的读操作
插入/更新/删除
insert into table values (…);
update table set ? where ?;
delete from table where ?;
因为修改操作之前,都是先需要查询到目标记录;
当前读,快照读,Mvcc关系
子主题
MVCC实现原理
undo日志<br>
read view(读视图)
三个隐式字段
什么是mvcc<br>
多数据版本并发控制,通过保存数据的多个版本,不阻塞读写操作。<br>
目标:在高并发环境下,既保证事务的隔离性,又减少锁的开销。
MYSQL架构
server层
概述
所有跨存储引擎的功能都是在server层来实现的;包括存储过程,触发器,视图,函数,binlog日志
其他组件
存储过程
被用户定义的 sql语句的集合
触发器
某个时间所触发的操作;一种特殊的存储过程;
视图
基于基表的一种逻辑表或者虚拟表
五大组件
示意图
子主题
连接器
管理用户对数据库的连接
用户权限管理
优化器
根据语句对sql语句中能够做优化的SQL自动做优化
优化器分类
CBO
基于优化成本来做优化(主流的数据库都是这样)
RBO
基于规则,SQL语句经过分析器之后,会有多种执行方式,程序会判断选择一个效率最高的SQL
分析器
包括词法分析,语法分析
缓存模块
8.0之后就移除缓存模块
移除原因
1.缓存命中率低
2.内存空间宝贵
mysql缓存
mysql缓存查询到的数据永远是最新的数据,如果中件表有发生变化,则该缓存相关的数据就会被清空
缓存命中率比较低,最理想的情况下命中率最高13%
缓存工作
查询必须是完全相同的(逐字节相同)才能被认为是相同的
同样的字符串由于其他原因也可能会被认为是不一样的
缓存相关查询
指定从缓存中查询
SELECT SQL_CACHE id, name FROM customer;<br>
前提是缓存是出于开启的状态
query_cache_type系统变量的值是ON或DEMAND,查询结果被缓存
指定不从缓存中查询
SELECT SQL_NO_CACHE id, name FROM customer;
缓存相关参数
have_query_cache
表示当前是否有使用缓存
query_cache_size
查询缓存大小
如果设置为0,则认为是禁用缓存
query_cache_limit
被缓存的查询结果最大值
默认值1MB
query_cache_min_res_unit
系统变量给查询缓存分配最小值
默认值是4KB
执行器
SQL语句真正的执行者
存储引擎
概述
主要负责数据的读取和存储,采用可替代式插件架构,支持各种数据库引擎。
概述
MySQL主要分为server层和存储引擎层
mysql主从复制
实现原理
mysql的主从复制基于主服务器在二进制日志中跟踪所有对数据库的更改(更新、删除等等)
并且主服务器开启了二进制日志
实现过程
复制过程中有三个线程在执行任务:一个线程在主服务器,负责将二进制日志的内容发送到从服务器(binlog dump线程);
主从复制开始;从服务器上会创建一个io线程,连接主线程并记录二进制日志中的数据到中继日志;中间需要识别binlog dump线程 以获取二进制日志
从服务器会开启一个sql线程(第三个线程),从中继日志中读取日志,并执行日志,以同步数据;
主从复制条件
1、主服务器开启了二进制日志
2、主从服务器的mysql版本之间是可以相互兼容
由于历史原因:
1、二进制日志格式不一样
2、字符集,函数,时区处理不一样
3、主服务器上设置了相应的从服务器
mysql主从数据不一致如何处理?
不一致原因
主从复制延迟
从库在高并发下,压力大,从库比主库慢
复制失败或中断
网络抖动、从库宕机、SQL 冲突,导致部分 binlog 没同步成功。
复制模式不同
异步复制到从库,从库可能还没有更新同步到
半同步复制,只有有一个从库确认复制成功才返回,任然有延迟
全同步复制,全部从库复制成功才返回
常见解决办法
业务层处理
读写分离 + 强制读主
写操作之后强制读主库
场景
下单 → 立刻查订单详情 → 必须走主库。
其他不敏感的数据,走从库
数据库层处理
半同步复制
确保至少一个从库同步到位才返回给客户端,减少丢数据风险。
并行复制(Parallel Replication)
MySQL 5.7+ 支持多线程复制,按库/按表并行,提高同步速度。
架构层优化
监控复制延迟
发现延迟大 → 临时切读主库,或扩容从库。
引入中间件
使用 数据库中间件(如 MyCAT、ShardingSphere、ProxySQL) 自动感知主从延迟,动态路由请求。
避免强依赖从库一致性
对于强一致性要求的场景(支付、下单、库存),直接读主库。
实际落地策略(推荐组合拳)
强一致业务 → 写后强制读主。
弱一致业务 → 读从库 + 容忍延迟。
SQL语句
left join ,inner join ,right join full join<br>
left join ,inner join ,right join 的区别
left join 做关联,以左表为主表,去右表当中匹配,如果左表中的数据未能匹配到右表中的数据,结果集中依旧会将左表的数据展示出来,未能匹配到的字段全部为空
right join 做关联,以右表为主表,去左表当中匹配,如果右表中的数据未能匹配到左表中的数据,结果集中依旧会将右表的数据展示出来,未能匹配到的字段全部为空
inner join 做关联,最明显就是左右两个表中只有关联上的数据才会展示出来,没有关联上的数据不会展示出来;<br>
left join ,inner join ,right join full join 演示<br>
原始数据
子主题
.inner join
子主题
.left join
子主题
.right join
子主题
full join
子主题
mysql模式
性能模式
系统模式
mysql客户端脚本和使用工具
myisampack
压缩MyISAM表以产生更小的只读表
mysql
交互式输入SQL语句或从文件以批处理模式执行它们的命令行工具
mysqlaccess
检查访问主机名、用户名和数据库组合的权限的脚本
mysqladmin
执行管理操作的客户程序,例如创建或删除数据库,重载授权表,将表刷新到硬盘上,以及重新打开日志文件
mysqlbinlog
从二进制日志读取语句的工具。在二进制日志文件中包含的执行过的语句的日志可用来帮助从崩溃中恢复
mysqlcheck
检查、修复、分析以及优化表的表维护客户程序
mysqldump
将MySQL数据库转储到一个文件(例如SQL语句或tab分隔符文本文件)的客户程序
mysqlhotcopy
当服务器在运行时,快速备份MyISAM或ISAM表的工具
mysql import
使用LOAD DATA INFILE将文本文件导入相关表的客户程序
mysqlshow
显示数据库、表、列以及索引相关信息的客户程序
perror
显示系统或MySQL错误代码含义的工具
replace
更改文件中或标准输入中的字符串的实用工具
MYSQL其他知识点
Mysql事件
ReadView
mysql实战问题
mysql主从复制<br>
实现原理
mysql的主从复制基于主服务器在二进制日志中跟踪所有对数据库的更改(更新、删除等等)
并且主服务器开启了二进制日志
实现过程
复制过程中有三个线程在执行任务:一个线程在主服务器,负责将二进制日志的内容发送到从服务器(binlog dump线程);
主从复制开始;从服务器上会创建一个io线程,连接主线程并记录二进制日志中的数据到中继日志;中间需要识别binlog dump线程 以获取二进制日志
从服务器会开启一个sql线程(第三个线程),从中继日志中读取日志,并执行日志,以同步数据;
主从复制条件
1、主服务器开启了二进制日志
2、主从服务器的mysql版本之间是可以相互兼容
由于历史原因:
1、二进制日志格式不一样
2、字符集,函数,时区处理不一样
3、主服务器上设置了相应的从服务器
mysql主从同步延迟解决方案
定义
从库数据落后于主库数据
表现
从库的数据比主库数据旧
读取数据会有延迟
指标
Seconds_Behind_Master(SHOW SLAVE STATUS)从库执行 relay log 相对于主库的时间差(秒)
1、延迟原因
从库硬件水平不行,从库磁盘 IO 瓶颈,CPU 负载高,网络延迟<br>
SQL 执行慢,从库执行复杂 SQL、JOIN 大表、UPDATE 批量操作慢<br>
事务量大,主库高并发写入,binlog 从库处理不过来<br>
锁竞争,从库执行事务时被锁阻塞<br>
子主题
网络延迟,主库 binlog 传输到从库慢<br>
2、解决方案
升级从库硬件
给表加索引,避免大事物一次性执行
分库分表 / 读写分离
增加从库的io线程,sql现成<br>
调整复制策略为异步复制?<br>
主库压力控制
异步复制和半同步复制的区别?
异步复制
主机提交事务后不需要等从机确认拉去到binlog日志,就直接返回到客户端<br>
特点:
高性能:主库提交事务速度快。
数据可靠性低:主库宕机时,从库可能落后,存在数据丢失风险。
半同步
主机提交事务后,至少要等到有一个从机确认拉去到了binlog日志信息,才会返回到客户端,从库再异步执行事务落库<br>
特点:
保证主库事务 binlog 至少被一个从库接收,减少数据丢失风险。
性能略低于异步复制,因为提交要等待从库 ack。
锁
myslq添加索引会不会锁表
肯定是会的
解决方式
前期设计的时候想好设计表的索引
mysql添加表字段会不会锁表
MyISAM 引擎
MyISAM 在执行 ALTER TABLE 时会复制整个表结构 + 数据,期间表是锁住的,读写都阻塞
innerDB<br>
5.6之前版本
1、对原始表加写锁
2、按照原始表和执行语句的定义,重新定义一个空的临时表
3、对临时表进行添加索引(如果有
4、再将原始表中的数据逐条Copy到临时表中
5、当原始表中的所有记录都被Copy临时表后,将原始表进行删除。再将临时表命名为原始表表名
5.6版本以之后版本
1、对原始表加写锁
2、按照原始表和执行语句的定义,重新定义一个空的临时表。并申请rowlog的空间
3、拷贝原表数据到临时表,此时的表数据修改操作(增删改)都会存放在rowlog中。此时该表客户端可以进行操作的
4、原始表数据全部拷贝完成后,会将rowlog中的改动全部同步到临时表,这个过程客户端是不能操作的
5、再将临时表命名为原始表表名
MySQL调优
执行计划详解
id(sql执行顺序)
id相同,从上到下顺序执行
id不同,id值越大执行优先级越高,越先被执行
select_type查询类型
SIMPLE
简单的单表select查询
PRIMARY
子主题 1
SUBQUERY/MATERIALIZED
SUBQUERY
表示select或者是where中含有子查询
MATERIALIZED
表示where后面的in条件有子查询
UNION
被关联查询的语句;也就是关联查询的union中的第二个语句或者是union后面的select语句
UNION RESULT
表示关联查询的结果
table(查询涉及到的表)
直接显示表明
&lt;unionM,N&gt;
由M,N两个表关联产生的结果
&lt;subqueryN&gt;
有N表产生的中间结果集维表
type (重点,查询性能指标)
system
查询的是系统表
const
单表查询直接命中主键查询
demo
CREATE TABLE `user` ( `id` int(11) NOT NULL, `NAME` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into user values(1,&apos;shenjian&apos;);insert into user values(2,&apos;zhangsan&apos;);insert into user values(3,&apos;lisi&apos;);
explain select * from user where id=1;
eq_ref
关联查询用到主键索引做为关联字段
demo
CREATE TABLE `user` ( `id` int(11) NOT NULL, `NAME` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into user values(1,&apos;shenjian&apos;);insert into user values(2,&apos;zhangsan&apos;);insert into user values(3,&apos;lisi&apos;);CREATE TABLE `user_ex` ( `id` int(11) NOT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into user_ex values(1,18);insert into user_ex values(2,20);insert into user_ex values(3,30);insert into user_ex values(4,40);insert into user_ex values(5,50);
EXPLAIN SELECT * FROM USER,user_ex WHERE user.id=user_ex.id;
ref
关联查询用到了非主键索引作为关联字段
demo
EXPLAIN SELECT * FROM USER,user_ex WHERE user.id=user_ex.id;
range
在索引上的范围查询
demo
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into user values(1,&apos;shenjian&apos;);insert into user values(2,&apos;zhangsan&apos;);insert into user values(3,&apos;lisi&apos;);insert into user values(4,&apos;wangwu&apos;);insert into user values(5,&apos;zhaoliu&apos;);
explain select * from user where id between 1 and 4;explain select * from user where id in(1,2,3);explain select * from user where id &gt; 3;
index
查询是在所引述中扫描
demo
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into user values(1,&apos;shenjian&apos;);insert into user values(2,&apos;zhangsan&apos;);insert into user values(3,&apos;lisi&apos;);insert into user values(4,&apos;wangwu&apos;);insert into user values(5,&apos;zhaoliu&apos;);
explain count (*) from user;
ALL
全表扫描
demo
CREATE TABLE `user` ( `id` int(11) DEFAULT NULL, `name` varchar(20) DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into user values(1,&apos;shenjian&apos;);insert into user values(2,&apos;zhangsan&apos;);insert into user values(3,&apos;lisi&apos;);CREATE TABLE `user_ex` ( `id` int(11) DEFAULT NULL, `age` int(11) DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into user_ex values(1,18);insert into user_ex values(2,20);insert into user_ex values(3,30);insert into user_ex values(4,40);insert into user_ex values(5,50);
explain select * from user,user_ex where user.id=user_ex.id;
查询的结果只的好坏顺序system > const > eq_ref > ref > range > index > ALL
CREATE TABLE `user` ( `id` int(11) DEFAULT NULL, `name` varchar(20) DEFAULT NULL, KEY `id` (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into user values(1,&apos;shenjian&apos;);insert into user values(2,&apos;zhangsan&apos;);insert into user values(3,&apos;lisi&apos;);CREATE TABLE `user_ex` ( `id` int(11) DEFAULT NULL, `age` int(11) DEFAULT NULL, KEY `id` (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into user_ex values(1,18);insert into user_ex values(2,20);insert into user_ex values(3,30);insert into user_ex values(4,40);insert into user_ex values(5,50);
possible_key
查询过程中有可能用到的索引
key
实际使用的索引,如果为 NULL ,则没有使用索引
key_len
展示索引字段的实际长度
ref
显示该表的索引字段关联了哪个表的哪个字段
rows
估算查询所需要的记录需要读取的行数
filtered
返回的结果集行数占读取行数的百分比,越大越好
extra
展示其他重要信息
调优方向
1.sql调优
查询尽量覆盖到索引
1.在经常当做查询条件的字段上设置索引
未覆盖到索引情况
1.反向查询,!=,&lt;&gt; ,not in
2.前模糊查询
3.查询语句中在索引字段上做函数操作
4.关联字段虽然都是索引字段,如果数据类型不一致,走不了索引
5.where后面不带有效查询条件
6.建立联合索引,查询的时候不满足最左原则;
7.查询中对索引字段做运算操作
索引建立原则
索引长度限制
在字符串类型的字段上建立索引,需要指定索引的长度,一般10个就够了;
索引建立字段选取
1、必须要有主键索引
2、在经常做为查询条件,排序,分组,关联的字段上建立索引;
表的关联字段建立索引的时候确保两个表的数据类型是一样的
3、索引建立的字段应该是区分度非常高的字段;
索引数量
1、索引的数量不是越多越好,多了会增加索引构建维护成本;
2、不再使用或者使用非常少的索引需要删除索引
3、新建单列索引的时候,考虑和其他字段一起建立联合索引,减少索引个数
查询需要覆盖到索引
2.调整库,表结构
1、表的字段类型,字段长度合理
2、创建高性能的索引
3.系统配置优化
相关操作命令
查询服务器默认缓存区大小
mysqld --verbose --help命令生成所有mysqld选项和可配置变量的列表
SHOW VARIABLES;
查看当前运行的mysql服务器实际运行的值
SHOW STATUS;
运行服务器的统计和状态指标
系统变量和状态信息
mysqladmin variables
mysqladmin extended-status
优化核心参数
key_buffer_size
MYISAM引擎下面的索引缓存所占内存大小
table_cache
mysql同时打开表的数量
read_rnd_buffer_size
线程的缓冲区,注意不是线程的栈内存;
对GROUP BY或ORDER BY读取数据的时候会暂存读取的数据,
max_connections
最大连接数
默认151
可以适当设置大一些
thread_cache_size
线程池线程大小
查询相关
排序缓冲区
sort_buffer_size
默认为2MB
为排序或者分组的线程设置的缓冲区大小,可以提高排序分组的效率
关联查询缓冲区
join_buffer_size
默认为8Mb
为每个链接做联合查询操作的时候缓冲区的大小,提高关联查询效率
表的缓冲区
read_buffer_size
默认64k
每个线程扫描每一个表的锁分配的缓冲区大小
innerDB相关
innodb_buffer_pool_size
innerDB引擎下表和索引的最大缓存
可以缓存表数据还有索引数据
innodb_flush_log_at_trx_commit
innerDB日志刷盘策略
innodb_log_buffer_size
innerDB的失误日志缓冲区
4.硬件优化
数据分散到多个磁盘
提高搜索效率
将数据分布在多个磁盘上,提高单位时间内可以并行搜索磁盘次数
单个磁盘每秒大约1000次搜索
提高读写吞吐量
提高cpu频率
提高cpu缓存大小
概述:以上四个方向,效果最好的是SQL调优,以此往下效果越来越差,成本越来越高
sql优化实战
limit优化
demo
CREATE TABLE `test_news` (`id` int(11) NOT NULL AUTO_INCREMENT,`title` varchar(100) DEFAULT NULL COMMENT &apos;文章标题&apos;,`content` longtext COMMENT &apos;文章内容&apos;,`channel` int(11) DEFAULT NULL COMMENT &apos;文章频道&apos;,`status` int(11) DEFAULT NULL COMMENT &apos;状态,1正常,0关闭&apos;,`create_time` datetime DEFAULT NULL COMMENT &apos;文章发布时间&apos;,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=513 DEFAULT CHARSET=utf8;
原始查询方式
select* from test_news limit 10000,10;
查询每页是10条,查询第10000页的数据;这种查询完全就是没有用到索引;需要扫描到10000条数据,再开始查询
优化方式1
select* from test_news where id &gt;( select id from test_news limit10000,1) limit 10;
解析
1.子查询select id from test_news where limit10000,1;只查询一个id,根据主键就能查询到,不用回表查询;
2.拿到查询出来的id,获取到后面10个id,再用这10个id直接可以直接回表拿到所有的数据;
优化方式2
select* from test_news a join ( select id from test_news limit10000,10) b on a.id = b.id ;
解析
相当于自关联的方式获取到相应的id;
再通过id回表获取所有的数据
分组取前几条
demo
CREATE TABLE `test_news` (`id` int(11) NOT NULL AUTO_INCREMENT,`title` varchar(100) DEFAULT NULL COMMENT &apos;文章标题&apos;,`content` longtext COMMENT &apos;文章内容&apos;,`channel` int(11) DEFAULT NULL COMMENT &apos;文章频道&apos;,`status` int(11) DEFAULT NULL COMMENT &apos;状态,1正常,0关闭&apos;,`create_time` datetime DEFAULT NULL COMMENT &apos;文章发布时间&apos;,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=513 DEFAULT CHARSET=utf8;
SELECT a.id, a.title, a.channel,a.create_time FROM test_news AS a LEFT JOIN test_news AS b ON a.channel = b.channelAND a. STATUS = b. STATUS AND a.id &lt; b.id WHEREa. STATUS = 1 GROUP BY a.channel, a.id HAVINGcount(1) &lt; 5 ORDER BY a.channel ASC, a.id DESC;
having
demo
sELECT CLASS,SUM(TOTAL_SCORES) FROM student_score GROUP BY CLASS HAVING SUM(TOTAL_SCORES)&gt;200;
如何分析并解决 MySQL 慢查询日志中出现的性能瓶颈?
1.需要开启慢查询日志
2.收集慢查询的sql<br>
关注执行时间,扫描行数
3.使用解释器分析执行计划
4.优化索引,sql,表结构,缓存,配置<br>
数据库引擎
MyISAM 和 InnoDB 的区别?
事物
MyISAM:不支持事务。
InnoDB:支持事务(ACID),提供 BEGIN/COMMIT/ROLLBACK。
锁机制
MyISAM:表级锁(读锁、写锁),并发性能较差,适合读多写少的场景。
InnoDB:行级锁(也有表级锁),支持更高的并发,适合读写混合场景。
外键支持
MyISAM:不支持外键。
InnoDB:支持外键约束(FOREIGN KEY)。
崩溃恢复
MyISAM:崩溃后容易损坏,需要 myisamchk 修复,可靠性差。
InnoDB:有 redo log/undo log,支持崩溃恢复,可靠性更好。
存储结构
MyISAM:表文件由三个文件组成:
.frm(表结构)
.MYD(数据)
.MYI(索引)
InnoDB:
.frm(表结构)
数据和索引存储在共享表空间(ibdata)
索引实现
MyISAM:非聚簇索引,索引文件和数据文件分开,索引存放的是数据的物理地址。
InnoDB:聚簇索引(Clustered Index),主键索引和数据存储在一起,辅助索引存储主键值。
全文索引
MyISAM:较早支持全文索引(FULLTEXT)。
InnoDB:MySQL 5.6 之后才支持全文索引。
存储空间
MyISAM:相对较小,数据压缩能力强。
InnoDB:存储空间占用大,维护额外事务和索引开销。
适用场景
MyISAM:以读为主的应用,数据修改不频繁,日志、报表系统。
InnoDB:需要事务、安全性高、并发读写频繁的场景,绝大多数 OLTP 系统。
数据库设计优化
分库分表
分库分表:大规模数据库扩展的常用手段,主要目的是解决单库性能瓶颈、存储容量限制以及高并发问题<br>
分库分表策略分类
垂直拆分
按照不同的业务来拆分库表
方式:
按功能拆表:例如把用户表、订单表、商品表拆到不同的库中。
按字段拆表:把大表的热点列和非热点列拆开,例如把 BLOB 字段单独拆表。
优点:
减少单库表大小,提高查询性能。
不同业务模块独立部署,便于管理。
缺点:
跨库查询复杂(需要应用层或中间件处理)。
水平拆分
按行拆分,把同一张表的数据按某个规则分到不同的库或表中。
方式:
按用户 ID 分库:user_id % 4 → 分到 4 个库
按时间分表:按月份/年份拆分表,如 order_202509, order_202510
优点:
单表行数减少,提高查询和写入性能。
支持数据分布式存储,便于扩展。
缺点:
跨分片查询复杂,需要中间件或应用层聚合。
读写分离
主库写,多个从库读
其他优化点
缓存
查询优化,表结构,mysql系统调参,硬件优化<br>
故障与恢复
数据库宕机如何恢复?
数据库宕机可能是
硬件故障(磁盘坏、服务器死机)
软件异常(MySQL crash、操作系统异常)
误操作(误删表/数据)
解释
宕机 = 数据库不可用
仅仅是物理进程挂掉,也包括:<br> • 数据丢失或不可访问<br> • 大量锁导致响应慢<br> • 系统异常导致无法启动或服务挂起
解决方式
从备份恢复
使用之前做的全量备份恢复数据库
使用日志恢复
利用 redo log / binlog / undo log 恢复事务未提交或丢失的数据
增量恢复
从最近一次备份 + 增量 binlog 恢复
适合恢复到宕机前的最新状态
冷备份与热备份的区别?
冷备份
定义:
在数据库 停止运行的情况下,对整个数据库文件系统进行备份
特点:
数据文件状态静态,备份时无需考虑并发事务
恢复简单,直接复制回原路径即可
缺点<br>
需要停库,业务不可用<br>
热备份
定义:
数据库运行中也可以进行备份,在线备份
实现方式:
MySQL:mysqldump、mysqlpump、Percona XtraBackup
支持增量/全量备份
特点:
业务不停机
需要考虑备份期间的事务一致性
复杂度高,需要 redo/undo 日志或 binlog 协助保证一致性
优点<br>
在线备份,不影响业务<br>
缺点<br>
备份复杂,恢复时可能需要 binlog 回放<br>
备份策略:<br> • 全量备份周期:每日/每周<br> • 增量备份周期:每小时或更频繁<br> • binlog 保留:保证可恢复到任意时间点
在实际情况中,如果发现线上环境mysql的cpu使用率过高,如何处理?
立即
在应用层针对非核心业务做限流和熔断处理
前提是有对应的限流和熔断措施
紧急情况
通过命令找到对应的长sql,然后杀掉长sql
临时
降连接、调参数<br>
过渡<br>
读写分离 / SQL 黑名单<br>
后续<br>
优化 SQL / 索引 / 参数<br>
mysql缓存
mysql缓存查询到的数据永远是最新的数据,如果中件表有发生变化,则该缓存相关的数据就会被清空
缓存命中率比较低,最理想的情况下命中率最高13%
缓存工作
查询必须是完全相同的(逐字节相同)才能被认为是相同的
同样的字符串由于其他原因也可能会被认为是不一样的
缓存相关查询
指定从缓存中查询
SELECT SQL_CACHE id, name FROM customer;<br>
前提是缓存是出于开启的状态
query_cache_type系统变量的值是ON或DEMAND,查询结果被缓存
指定不从缓存中查询
SELECT SQL_NO_CACHE id, name FROM customer;
缓存相关参数
have_query_cache
表示当前是否有使用缓存
query_cache_size
查询缓存大小
如果设置为0,则认为是禁用缓存
query_cache_limit
被缓存的查询结果最大值
默认值1MB
query_cache_min_res_unit
系统变量给查询缓存分配最小值
默认值是4KB
mysql异样工作场景
mysql链式复制
主从复制中,从机又是另外一台的主机;
从服务器本身也可以当做主服务器
MySQL客户端程序和实用工具
数据库中间件
mycat
Mycat 是一个 开源的数据库中间件,主要用于 分库分表、读写分离、SQL 路由。
Mycat 需要单独部署,独立的数据库中间件服务
核心作用
解决单库单表容量瓶颈,实现水平扩展和高可用。
Mycat 的原理
SQL 拦截与路由
客户端发起 SQL 请求 → 连接 Mycat
Mycat 拦截 SQL 并解析语法
根据 配置的分库分表规则,将 SQL 路由到对应物理库/表
Mycat分片策略<br>
水平拆分(Sharding):
按 ID、范围或哈希拆表
垂直拆分(Vertical Sharding)
按业务模块拆库
可以组合使用(垂直 + 水平)
聚合结果
对跨库/跨表查询,Mycat 将结果在中间件层进行聚合、排序、分页,返回给客户端
支持特性
读写分离
分布式事务(XA、柔性事务)
SQL 路由、结果合并
兼容 MySQL 协议,应用无需修改
使用场景
大数据量水平拆分<br>
读写分离<br>
分布式事务<br>
业务模块拆分<br>
Sharding-JDBC
Sharding-JDBC 的定位
轻量级 Java 分库分表中间件,工作在 JDBC 层,无需独立服务
核心功能
分库分表
读写分离
分布式事务(XA/柔性事务)
目标:让应用透明访问分库分表数据库
Sharding-JDBC 原理
SQL 拦截与路由
1. 应用依赖 Sharding-JDBC 的 JDBC 驱动或 DataSource
2. Sharding-JDBC 拦截 SQL
3. 根据配置的 分库分表策略 解析 SQL 的表和字段
4. 将 SQL 路由到对应的物理库/表
分片策略
水平分表(Sharding):按 ID、哈希、范围拆分
垂直分表(垂直拆分):按业务模块拆表
支持组合拆分策略
聚合与分页
对跨库查询结果,Sharding-JDBC 在应用层进行:
结果合并
排序
分页
对应用透明,无需改动 SQL 逻辑
读写分离
配置主库和从库
写操作路由到主库
读操作按权重路由到从库
canal
开源组件,由阿里巴巴开源
支持 MySQL、MariaDB、PostgreSQL 等<br>
需要独立部署
核心作用
解析 MySQL(或其他数据库) Binlog,实现 数据增量同步
常用于
数据库同步到缓存(Redis)
数据库同步到搜索引擎(Elasticsearch)
数据库同步到数据仓库 / 消息队列(Kafka、RocketMQ)
Canal 原理
模拟 mysql从机,连接主机<br>
获取到主机的binlog日志,解析binlog日志<br>
分发增量数据
将解析后的变更数据发送到
消息队列(Kafka / RocketMQ)
下游数据库
搜索引擎(ES)
使用场景
缓存同步
数据库更新 → Canal 捕获 → 同步到 Redis
避免应用层直接操作缓存
搜索引擎同步
数据库更新 → Canal 捕获 → 同步到 Elasticsearch
实现数据库与 ES 实时一致
数据仓库 ETL
Canal 实时捕获变更 → 发送到 Kafka → 数据仓库(Hive / ClickHouse)
微服务异步通信
数据变更事件驱动业务流程
分库分表
sharding-jdbc
oneProxy
mycat
pg
框架
netty
Netty的组件
ServerBootstrap
EventLoop
EventLoopGroup
channel
ChannelPipeline
ChannelContextHandler
netty事件类型
建立连接
连接关闭
收到消息
读完成
channel被注册到EventLoop
channel从EventLoop注销
可写状态改变
出现异常
收到一个用户自定义事件
Netty粘包拆包
粘包拆包原因
粘包拆包解决方式
固定长度的拆包器
行拆包器
分隔符拆包器
基于数据包长度的拆包器
自定义拆包方案
netty线程模型
Reactor单线程模型
Reactor多线程模型
主从Reactor多线程模型
线程池职责
接受客户端请求线程池
处理IO的线程池
netty序列化
Marshalling
Protocol Buffers
message pack
jdk自带
netty零拷贝
子主题 1
netty对象池
netty内存池
rpc
dubbo
支持的通信协议
序列化协议
子主题 3
mybatis
ibatis
缓存
一级缓存
二级缓存
缓存淘汰算法
mybatis-plus
自带雪花算法
实现逻辑
DefaultIdentifierGenerator类
根据时间戳,数据中心,机器标识部分,序列化,做位于运算
图示
子主题
乐观锁插件
mybatis工作流程
详细流程图
<br>
详细步骤
1、读取配置文件
这个文件为mybatis的全局配置文件
构建Configuration保存所有的配置信息
2、加载xml映射文件
也就是sql映射文件
这些文件配置了操作数据库的sql语句
3、创建 SqlSessionFactory 会话工厂
SqlSessionFactory 相当于连接池工厂,负责创建 SqlSession
4、创建sqlSeesion会话对象
由会话工厂SqlSessionFactory对象创建SqlSession
5、创建Mapper 代理对象
通过sqlSeesion会话对象获取Mapper对象<br>
6、执行sql语句;
Excutor执行器根据传入的参数动态生成需要执行
底层还是调用 JDBC:
1. 获取 Connection
2. 预编译 SQL(PreparedStatement)
3. 设置参数
4. 执行 SQL
5. 处理结果集
7、封装结果
结果集交给 ResultSetHandler,映射到 Java 对象;类型可以是map,list类型,实体类,基本数据类型
8、关闭资源
使用完 SqlSession 需要手动关闭,避免资源泄漏。
spring
spring
spring理解
1、是spring整个生态圈的核心基石
2、简化企业级开发
1、基于pojo的轻量级和最小的侵入性编程
2、通过依赖注入还有切面接口实现松耦合
3、通过切面编程减少模板代码
3、ioc,aop的容器框架
spring使用的优势
1、Spring框架之外还存在一个构建在核心框架之上的庞大生态圈
2、低侵入式设计,代码的污染极低
3、独立于各种应用服务器,基于Spring框架的应用,可以真正实现Write Once,Run Anywhere的承诺
4、Spring的loC容器降低了业务对象替换的复杂性,提高了组件之间的解耦
5、Spring的AOP支持允许将一些通用任务如安全、事务、日志等进行集中式处理,从而提供了更好的复用
6、Spring的ORM和DAO提供了与第三方持久层框架的的良好整合,并简化了底层的数据库访问
7、Spring的高度开放性,并不强制应用完全依赖于Spring,开发者可自由选用Spring框架的部分或全部
spring的核心
为了简化项目开发而且有自己生态圈的一个开源框架
核心
IOC(控制反转,Inversion of Control)
由容器负责对象的创建和依赖管理,开发者只关注业务逻辑。
AOP(面向切面编程,Aspect Oriented Programming)
把日志、事务、安全等横切关注点从业务代码中解耦,降低耦合度,提高可维护性。<br>
spring是一个ioc和aop的容器框架
ioc
控制反转
Aop
切面编程
容器
存储bean对象且控制bean生命周期的容器
IOC
IOC的理解
总体回答
容器:存储对象,使用map结构来存储,在spring中一般存在三级缓存,singleionObjects存放完整的bean对象,
IOC原理
Spring 容器通过读取 Bean 定义(BeanDefinition),利用反射创建 Bean 实例,再通过依赖注入(构造器、Setter 或字段注入)注入所需依赖,最后通过初始化方法和后置处理器完成 Bean 生命周期管理
其实就是和bean对象的构建离不开。<br>
IOC的实现
简化流程如下
1. 扫描/注册 BeanDefinition:读取 XML、注解或配置类,保存 Bean 的元数据。<br> 2. 实例化 Bean:通过反射或工厂方法创建对象。<br> 3. 依赖注入(DI):把 Bean 所需依赖注入(构造器、Setter、字段)。<br> 4. 初始化 Bean:调用 @PostConstruct、afterPropertiesSet() 或 XML 配置的 init-method。<br> 5. 后置处理:BeanPostProcessor 对 Bean 做增强(如 AOP)。<br> 6. 加入容器缓存:单例 Bean 放入缓存,原型 Bean 每次获取新实例。<br>
依赖注入
DI:依赖注入,把对应的属性的值注入到具体的对象中,(SJAutowired, populateBean完成属性值的注入
控制反转
控制反转:理论思想,原来的对象是由使用者来进行控制,有了spring之后,可以把整个对象交给spring来帮我们进行管理<br>容器的生命周期<br>
整个bean的生命年期,从创建到使用到销毁的过程全部都是由容器来管理(bean的生命周期)
如何实现一个ioc容器
1、先准备一个基本的容器对象,包含一些map结构的集合,用来方便后续过程中存储具体的对象
2、进行配置文件的读取工作或者注解的解析工作,将需要创建的bean对象都封装成BeanDefinition对象存储在容器中<br>
3、容器将封装好的BeanDefinition对象通过反射的方式进行实例化,完成实例化工作
4、进行对象的初始化操作,也就是给类中的对应属性值就行设置,也就是进行依赖注入,完成整个对象创建一个完整的bean对象,存储在容器的某个map结构中
5、通过容器对象来获取对象,进行对象的获取和逻辑处理工作
6、提供销毁操作,当对象不用或者容器关闭的时候,将无用的对象进行销毁
AOP
AOP的理解
AOP全称叫做Aspect Oriented Programming面向切面编程.它是为解耦而生;
实现原理
Spring AOP 基于代理模式(JDK 动态代理或 CGLIB 动态代理),在方法执行前后织入横切逻辑,实现切面编程
AOP 核心思想
核心机制:通过动态代理,在方法调用的前、后或异常时,执行额外逻辑(Advice)。
AOP(面向切面编程):把事务、日志、安全校验等通用逻辑抽离出来,不和业务代码耦合。
Spring AOP 执行流程
容器启动时,Spring 解析 @Aspect 注解,生成切面信息。
根据切点表达式,找到需要增强的 Bean。
使用 JDK 或 CGLIB 动态代理 创建代理对象。
方法调用时:
进入代理对象 → 匹配切点 → 按顺序执行增强逻辑(Advice) → 调用目标方法。
任何一个系统都是由不同的组件组成的,每个组件负责一块特定的功能,当然会存在很多组件是跟业务无关<br>的,例如日志、事务、权限等核心服务组件,这些核心服务组件经常融入到具体的业务逻辑中,如果我们为每<br>一个具体业务逻辑操作都添加这样的代码,很明显代码冗余太多,因此我们需要将这些公共的代码逻辑抽象出<br>来变成一个切面,然后注入到目标对象(具体业务)中去,AOP正是基于这样的一个思路实现的,通过动态代<br>理的方式,将需要注入切面的对象进行代理,在进行调用的时候,将公共的逻辑直接添加进去,而不需要修改<br>原有业务的逻辑代码,只需要在原来的业务逻辑基础之上做一些增强功能即可。<br>
AOP相关概念
切面( Aspect)
指关注点模块化,这个关注点可能会横切多个对象。事务管理是企业级Java应用中有关横切 [否要开启事物)<br> 正常 J能,开起事物无压力关注点的例子.在Spring AOP中,切面可以使用通用类基于模式的方式(schema-based叩proach) 或者在 ationAfterThrowing 执行普通类中以©Aspect注解(@AspectJ注解方式)来实现<br>
连接点Uoin point)
在程序执行过程中某个特定的点,例如某个方法调用的时间点或者处理异常的时间点。
在Spring AOP中,Y连接点总是代表T方法的执行
通知(Advice)
通知(Advice) :在切面的某个特定的连接点上执行的动作.通知有多种类型,包括忆round", "before" and "afteL等等.通知的类型;许多AOP框架,包括Spring在内,都是以拦截器做通知 模型的,并维护着一个以连接点为中心的拦截器链
切点( Pointcut)
匹配连接点的断言.通知和切点表达式相关联,并在满足这个切点的连接点上运行(例 如,当执行某个特定名称的方法时)。切点表达式如何和连接点匹配是AOP的核心:Spring默认使用Aspect」切点语义。
引入( Introduction
声明额外的方法或者某个类型的字段.Spring^许引入新的接口(以及一个对应的实现)至用田可被通知的对象上.例如,可以使用引入来使bean实现工sModified接口,以便简化缓存机制(在AspectJ社区,引入也被称为内部类型声明 )
目标对象(Target object
被一个或者多个切面所通知的对象.也被称作被通知(advised) 对象。既然 SpringAOP是通过运行时代理实现的,那么这个对象永远是一个被代理( proxied) 的对象。
Aop代理
AOP框架创建的对象,用来实现切面契约(aspect contract) (包括通知方法执行<br>
织人(Weaving):
把切面连接到其它的应用程序类型或者对象上,并创建一个被被通知的对象的过程.这个<br>过程可以在编译时(例如使用AspectJ编译器)、类加载时或运行时中完成.Spring和其他纯Java庆0「框架一<br>样,是在运行时完成织人的<br>
AOP的使用场景
事务、日志
和AspectJ AOP区别
切面的通知类型
1、before
2、after
3、AfterReturning
4、AfterThrowing
5、Around
spring容器
spring容器添加组件
1.包扫描(包下面的类全部都是使用@Controller,@Service,@Respository,@Component注解)
2.@Bean直接给定义bean对象
3.@import相关注解给容器添加组件
1.@Import 导入一个对象
@Import({ 类名.class , 类名.class... })public class TestDemo {}
2.在@Import注解中导入ImportSelector接口的实现类(一次导入多个对象);
步骤1:public class Myclass implements ImportSelector { @Override public String[] selectImports(AnnotationMetadata annotationMetadata) { return new String[]{&quot;com.yc.Test.TestDemo3&quot;}; }}
步骤2:@Import({TestDemo2.class,Myclass.class})public class TestDemo { @Bean public AccountDao2 accountDao2(){ return new AccountDao2(); }}
3.ImportBeanDefinitionRegistrar
步骤1:public class Myclass2 implements ImportBeanDefinitionRegistrar { @Override public void registerBeanDefinitions(AnnotationMetadata annotationMetadata, BeanDefinitionRegistry beanDefinitionRegistry) { //指定bean定义信息(包括bean的类型、作用域...) RootBeanDefinition rootBeanDefinition = new RootBeanDefinition(TestDemo4.class); //注册一个bean指定bean名字(id) beanDefinitionRegistry.registerBeanDefinition(&quot;TestDemo4444&quot;,rootBeanDefinition); }}
步骤2:@Import({TestDemo2.class,Myclass.class,Myclass2.class})public class TestDemo { @Bean public AccountDao2 accountDao222(){ return new AccountDao2(); }}
差异和区别
ImportSelector接口和ImportBeanDefinitionRegistrar最终都是需要使用@Import 来做实现的导入,才能实现对组件的添加
4.使用FactoryBean往工厂里面手动添加bean
后置处理器(BeanFactoryPostProcessor)<br>
后置处理器功能
扩展 Spring 容器功能的关键机制。它们允许在 BeanDefinition 阶段 或 Bean 生命周期阶段 对 Bean 做增强。
后置处理器是什么
后置处理器的处理过程
spring的事物管理
spring的事物传播特性
种类
1、required
requires_new
newsted
support
not_support
never
madatory
场景问题
某一个事务嵌套另一个事务的时候怎么办?<br>
A方法调用B方法,AB方法都有事务,并且传播特性不同,那么A如果有异常,B怎么办,B如果有异常,A怎么办?
核心处理逻辑非常简单:<br>1、判断内外方法是否是同一个事务:<br>是:异常统一在外层方法处理.<br>不是:内层方法有可能影响到外层早去,但是外层方法是不会影响内层方法的<br>
实现方式
编程式事务(Programmatic Transaction)
通过代码显式管理事务,使用 TransactionTemplate 或 PlatformTransactionManager。
@Autowired<br>private PlatformTransactionManager transactionManager;<br><br>public void doBusiness() {<br> TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());<br> try {<br> // 业务操作<br> transactionManager.commit(status);<br> } catch (Exception e) {<br> transactionManager.rollback(status);<br> throw e;<br> }<br>}
优点:可控、灵活
缺点:代码侵入性强
声明式事务(Declarative Transaction)
通过 注解或 XML 配置方式定义事务边界,不修改业务逻辑。
@Service<br>public class UserService {<br> @Transactional<br> public void createUser(User user) {<br> userRepository.save(user);<br> // 其他操作<br> }<br>}
优点:侵入性小,业务代码与事务解耦
缺点:底层依赖 AOP 代理
Spring 事务管理器(TransactionManager)
Spring 事务管理是对底层事务的抽象,不同的数据源对应不同实现:
JDBC DataSourceTransactionManager<br>JPA JpaTransactionManager<br>Hibernate HibernateTransactionManager<br>JTA JtaTransactionManager
核心接口:PlatformTransactionManager
核心方法:<br><br>getTransaction(TransactionDefinition definition):开启事务<br><br>commit(TransactionStatus status):提交事务<br><br>rollback(TransactionStatus status):回滚事务
事物的实现
总
由spring aop通过一个TransactionInterceptor实现的
声明式事务实现原理
详细步骤
1、spring 先解析当前事物的属性信息(根据具体的属性判断是否要开启事物)
2、当前需要开启的时候,获取数据库连接,关闭自动提交的功能,开起事物
3、执行具体的sql逻辑
4、在操作过程中,如果执行失败嘞,会通过completeTeanscationAfterThrowing执行回滚操作,然后再通过doRollBack方法来完成具体的事物的回滚操作,最终还是调用的jdbc中的rollbcak方法做回滚操作
5、在操作过程,如果正常,那么通过commitTransactionAfterReturning来完成事物的提交,具体的提交逻辑通过doCommint方法执行实现的时候先获取jdbc链接,然后通过调用jdbc的事物提交方法提交事物;
6、当事物执行完毕之后,需要通过cleanTransactionInfo方法清理事物相关的信息
spring事物失效
bean对象没有被spring容器管理
方法修饰符不是public
方法是本类调用
事物的实现是通过aop实现的,aop的实现是通过代理来实现;如果不能形成其他类的接口调用,那么就无法生效
实际中失效最多的
数据源没有配置事物管理器
数据库不支持事物
数据库本身不支持事物
异常被捕获了
捕获的异常和配置的异常并不一致
spring的事物隔离级别
和当前项目使用的数据的隔离级别是一致的
bean
bean对象属性说明
bean对象作用域
通过配置scope属性值
prototype
多例;每次需要用到的bean的时候就会去创建这个bean,也就是在一个request请求中可能会多次创建bean对象;
singleton
单例,整个容器都会只用这一个对象,作用域就是整个容器
request
同一次请求创建一个对象;bean对象的作用域就在一起请求当中
session
同一次会话创建一个对象;这个Bean对象的作用域就在这次会话当中
global session
懒加载
通过设置lazy-init
true
懒加载
false
非懒加载,也就是提前加载
懒加载概述
懒加载只是针对多例bean才生效;单实例的bean都是提前加载;多实例的bean默认都是懒加载的形式加载,也就是首次需要用到的时候才会加载;
spring默认是提前加载,所以在启动的时候控制台就会有很多对bean对象的加载
懒加载和非懒加载区别
懒加载在第一需要用到这个对象的时候加载;非懒加载就是在环境启动的时候就提前把对象加载;
懒加载可以节约内存,但是不利于提前发现问题;非懒加载,可以提前发现加载的问题;
注意事项:
1.如果懒加载依赖了非懒加载的bean,那么这个懒加载就会失效;
bean注入的注解
1.@AutoWried
注解是spring提供的;
@Component<br>public class UserRepository {}<br><br>@Service<br>public class UserService {<br> @Autowired // 默认按类型注入<br> private UserRepository userRepository;<br>}
根据类型注入从bean容器中找到UserRepository类型的做注入<br>
2.@Resource
注解是JDK提供的
@Component("userRepo")<br>public class UserRepository {}<br><br>@Service<br>public class UserService {<br> @Resource // 默认按名称注入<br> private UserRepository userRepo;<br>}
根据“userRepo” 这个名称从 bean容器中找到 userRepo bean对象注入<br>
相同点不同点
相同点:
1.字段和setter都生效
不同点:
1.一个是spring提供的,一个是JDK提供的
2.注解中的属性不一样;
bean的生命周期
spring bean创建的大致过程<br>
0.实例化spring容器,根据扫描对应的包,把标记是bean对象的类存储在一个Map集合之中;<br>
2.然后在遍历集合中类的对象,把对象的相应的属性都存储到BeanDefintion 中,也就是每一个被遍历的要被构建bean对象的对象都会有一个专属的BeanDefintion 对象;这个BeanDefintion对象存储当前被遍历对象的一切属性,这些属性也是构建bean对象的基础;<br>
3.每一个BeanDefintion 会被存储到 BeanDefintionMap 对象之中;
4.然后还会调用后置处理器去修改增BeanDefintionMap,执行对bean的修改拓展操作(spring内置还有我们自定义的后置处理器)来参与到生命周期的过程;
5.遍历BeanDefintionMap 中BeanDefintion对象,做相关的是否单例,是否抽象,注入模型,循环依赖,是不是懒加载,是不是需要有DepondsOn
6.根据BeanDefintion对象中的信息中的构造方法信息,推断出构造方法;
7.再通过构造方法再去通过反射实例化对象;
11.完成属性注入;
12.回调Aware接口,也就是spring内置的Aware接口(也是修改bean对象的属性)再调用生命周期初始化回调方法(在类中间被@PostConstruct注解修饰,还有实现了InitilizingBean接口的afterPropertiesSet方法,还有xml中配置的afterPropertiesSet方法),执行方法
13.完成aop代理,事件分发,事件监听;
14.生成了Bean,把bean放在单例池;
15.关闭spring容器,那么这些bean对象也会跟着被销毁
bean的实例化过程
bean的作用域
singleton
使用该属性定义Bean时,IOC容器仅创建一个Bean实例,IOC容器每次返回的是同一个Bean实例.
prototype
使用该属性定义Bean时,IOC容器可以创建多个Bean实例,每次返回的都是一个新的实例.
request
该属性仅对HTTP请求产生作用,使用该属性定义Bean时,每次HTTP请求都会创建一个新的Bean,适用于 WebApplicationContexl 环境<br>
session
该属性仅用于HTTP Session,同一个Session共享一个Bean实例.不同Sessio雷用不同的实例.
global-session
该属性仅用于HTTP Session,同session作用域不同的是,所有的Session共享一个Bean实例
bean注入方式
属性注入(最常用的一种方式)
构造器注入
方法上注入
参数上注入
循环依赖
什么是循环依赖
BeanA依赖BeanB;而BeanB又依赖BeanA
spring是怎么解决循环依赖
单例bean是否是线程安全
spring没有对bean对象做多线程处理;bean对象是否安全,主要看定义者怎么定义bean;如果这个bean对象中定义了线程不安全的全局变量,那么这个bean对象就是不安全的;如果定义的对象就是安全,那么这个bean就是安全的;
bean的线程并发问题
定义bean为无状态的bean(对象的时候不要定义全局变量),这样才能再多线程环境下被访问,使用ThreadLoacl来对bean进行线程封闭处理;如果不是无状态的,最好就是把bean定义成多例,每一个线程,或者每一个请求,每一个会话都是一个单独的bean对象
循环依赖创建bean对象过程
具体过程
1、获取ABean对象,从Abean的各级缓存中获取
2发现没有,那么就开始创建bean实例
创建流程
1. 容器创建 A
容器检测 A 不在缓存中 → 开始实例化
实例化对象:调用构造器创建 A(尚未注入 B)
将 A 放入 三级缓存 singletonFactories
提供一个 ObjectFactory,用于获取早期 A 对象
2.容器创建 B<br>
容器检测 B 不在缓存中 → 开始实例化
B 依赖 A → 查找缓存
一级缓存:无
二级缓存:无
三级缓存:有 A 的 ObjectFactory
查三级缓存获取 A 的 ObjectFactory → 提供早期引用
通过 ObjectFactory 获取 早期 A 对象 → 注入 B
3.完成属性注入<br>
1. B 的属性注入完成 → 放入一级缓存
2. 回到 A → 注入 B 完成
3. A 的初始化完成 → 放入一级缓存
4. Bean 初始化完成
BeanPostProcessor 处理前/后置方法
A、B 都可以正常使用
三级缓存
三级缓存各自作用
一级缓存
单例池
使用ConcurrentHashMap
存放构建完成后的完整的bean对象
二级缓存
作用
存放属性还未填充完整的早期暴露出来的bean
特殊说明
也只有处于循环引用中的bean才会被存放在这个二级缓存
三级缓存
作用
存放用于ObjectFactory对象,这个对象是用于来构建bean对象;所以刚刚被创建出来的bean对象都是放在三级缓存
三级缓存流转顺序
有循环依赖
1、反射创建bean实例的时候,将bean对象对应ObjectFactory放在三级缓存
2、有循环依赖时,从三级缓存中获取ObjectFactory实例,然后通过ObjectFactory实例的getObject方法方法来获取早期的bean还没有完全构建完成的bean,且放入二级缓存,从三级缓存中将ObjectFactory实例删除,
3、bean初始化完成,生命周期的相关方法都执行了,就会把bean对象放入一级缓存,然后删除二级缓存;
无循环依赖
1、反射创建bean实例的时候,将bean对象对应ObjectFactory放在三级缓存<br>
3、bean初始化完成,生命周期的相关方法都执行了,就会把bean对象放入一级缓存,然后删除二级缓存;<br>
总结
也就是有循环依赖:三级缓存到二级缓存,再到一级缓存
没有循环依赖就是三级缓存,到一级缓存
循环依赖创建bean对象过程
具体过程
1、获取ABean对象,从Abean的各级缓存中获取
2发现没有,那么就开始创建bean实例
子主题
图片展示
子主题
图片展示
子主题
@Resource和@Autowired
区别
来源不一样<br>
@Resource是jdk提供的注解
@Autowired
注入方式
@Resource默认通过byname注入,也就数已通过名称注入,通过的接口名称来做注入;也可以指定byType注入<br>
@Autowired默认是通过byType(也就是类型注入),也就是默认注入接口的子类;如果接口有多个子类,搭配使用@Qualifier注解指定某一个特定子类<br>
使用差别
如果接口都只有一个子类,那么没有使用上的区别,如果接口有多个实现类,那么只能用@Autowried 搭配@Qualifier 来使用
作用
都可以完成bean对象的注入标识
spring框架组件
核心组件
bean组件(bean对象组件)
封装对象
core组件(核心组件)
发现,构建,维护每一个bean关系所有需要的一些列的关系
context组件(上下文组件)
发现,构建,并且维护每一个bean对象之间依赖关系;可以看成是bean对象的集合,
spring核心类<br>
IOC 容器相关核心类
ApplicationContext
什么是ApplicationContext
BeanFactory 的高级子接口,功能更丰富(国际化、事件发布、AOP 支持)。
FactoryBean
BeanFactory
Spring IOC 容器的顶级接口,定义了 Bean 的获取方式。
BeanDefinition
Bean 的元信息抽象,保存类名、作用域、依赖等。<br>
IOC 容器就是通过 BeanDefinition 来描述和创建 Bean。
BeanWrapper
提供 Bean 的属性访问和修改能力,底层基于 Java 的反射和内省机制。
BeanPostProcessor
Bean 初始化前后提供扩展能力的接口。
比如 AutowiredAnnotationBeanPostProcessor 用来处理 @Autowired 注解。
InstantiationAwareBeanPostProcessor
在 Bean 实例化之前进行扩展(Spring 解决循环依赖时非常关键)。
AOP 相关核心类
ProxyFactoryBean
用来生成代理对象的核心类,基于 JDK 动态代理 / CGLIB。
AdvisedSupport
AOP 配置的核心抽象,包含了切面、通知、目标对象等信息。
MethodInterceptor
方法拦截器,环绕通知的底层接口。
Advisor
切面和通知的组合,封装了 “切点 + 通知”。
上下文与扩展相关
Environment
管理配置文件、属性源(Spring Boot 常用来读取 application.yml)。
ApplicationEvent / ApplicationListener
事件模型,支持事件驱动开发。
Resource / ResourceLoader
Spring 提供的统一资源访问抽象(支持文件、URL、classpath)。
Spring Boot 核心类(扩展了解)
核心注解
引入bean对象
importSelector
import
ImportBeanDefinitionRegistrar
bean对象
@Repository
@Service
@Controller
@Bean
@conditional
@AutoWried
属性值默认是true,一定要被注入;也可以设置成reqiured=false,告诉当前类可以不用注入这个对象;
IOC 相关
@Component
声明一个类交给 Spring 容器管理(通用组件)。
@Controller
Web 层控制器(Spring MVC 专用,语义化 @Component)。
@Service
Service 层业务逻辑类(语义化 @Component)。
@Repository
DAO 层持久化类,语义化 @Component,并支持数据库异常转换。
@Autowired
按 类型 自动注入 Bean。
@Qualifier
配合 @Autowired,指定 Bean 名称,解决多个同类型 Bean 冲突。
@Value
注入配置文件中的属性值。
@Configuration
声明配置类,替代 XML 配置。
@Bean
声明一个方法的返回对象交由 Spring 管理(常用于第三方类注入)。
@Scope
指定 Bean 作用域(singleton/prototype/request/session)。
@Lazy
设置 Bean 延迟加载。
AOP / 事务相关注解
@Aspect
定义切面类。
@Before、@After、@Around、@AfterReturning、@AfterThrowing
定义方法的切入点执行时机。
spring框架设计模式
1、工厂模式
各种BeanFactory,Application创建中都用了
2、模板模式
各种BeanFactory,Application创建中都用到,中间有很多空实现,方便子类去增加方法<br>
3、代理模式
aop的实现用的动态代理
4、策略模式
5、单例模式
bean对象默认都是单利
6、观察者模式
7、适配器模式
8、装饰者模式
实战问题
spring 通过注解开启事物方法<br> 查询某一条数据<br> 更新这条数据<br> 查询这条数据<br><br> 第二次查询获取的数据是咋样的? 读取的事
读取的是更新之后的
原因解释
由于事务未提交,查询还是用 同一个连接,走的是事务内的上下文视图。
所以第二次查询能查到 更新后的值(事务内可见)。
如何实现这个
MySQL InnoDB 支持 MVCC(多版本并发控制):
当前事务的修改自己可见(即使没提交)。
其他事务在你没提交前是看不到的。
springBoot
springBoot优势
1.可以以jar包的形式独立启动
2.内嵌了tomcat/jetty/Undertow服务器。
3.在spring的基础上简化了maven的配置,引入spring-boot-starter-web 依赖;
4.springBoot可以根据类路径中的jar包,类自动配置成bean;
5.有运行时的监控系统
6.快速构建项目,提高开发效率,部署效率;
7.天然与云计算集成;
8.天然的已经整合了很多第三方的框架
spring 和springboot 的区别
Spring 是一个轻量级的企业级开发框架,核心是 IOC 和 AOP,但需要繁琐的配置和依赖管理
Spring Boot 是基于 Spring 的快速开发框架,它通过自动配置、起步依赖和内嵌服务器,简化了 Spring 项目的开发过程
springBoot核心注解
@SpringBootApplication最核心注解<br>
包含以下注解
@SpringBootConfiguration
表示是springboot的配置类
@EnableAutoConfiguration
开启自动配置注解
去mate-info/spring.factiories文件中加载需要被自动注入的java类
@ComponentScan
表示要扫描的当前包以及子包下的所有被标记成spring bean对象的java类
@importResource,@Import
手动给spring添加bean对象,导入一些第三方的配置类
@Indexed
提升@CompontentScan性能的注解
@EnableAsync
开启异步方法
@EnableScheduling
开启定时任务
springBoot自动装配大致过程
详细过程
1、springBoot启动类上面是@SpringBootApplication注解
3、这个注解中又包含了另外一个@Import注解
4、import注解又实现了ImportSelector接口的类型,
5、ImportSelector可以给spring容器中手动添加bean对象
6、所以在spring启动的时候通过ImportSelector中的方法去读取meta/info目录下面的spring.factories文件中需要被自动转配的所有配置类
7、然后再通过meate/info下的springautoconfigure-metadata.properties文件做条件过滤,过滤掉不需要被自动装配的类
8、得到最终需要被装配的类,然后加载到spring容器
1、启动类加载
运行 SpringApplication.run() → 创建 IOC 容器 ApplicationContext。
2、加载自动配置类
@EnableAutoConfiguration → 导入 AutoConfigurationImportSelector。
AutoConfigurationImportSelector 会去 META-INF/spring.factories 里找到所有 xxxAutoConfiguration 类。
3、条件匹配(@Conditional)
每个自动配置类都有条件注解,比如:
@ConditionalOnClass:某个类存在时才生效
@ConditionalOnMissingBean:只有当容器中没有某个 Bean 时才生效
4、注册 Bean
满足条件的 @Configuration 类会向容器中注入 Bean。
比如,DataSourceAutoConfiguration 会帮你自动创建 DataSource,如果你没自己配置数据源的话。
简单过程
Spring Boot 的自动装配是通过 @EnableAutoConfiguration 实现的,它会读取 META-INF/spring.factories 下的自动配置类,再结合 @Conditional 系列注解判断是否生效,最终把符合条件的 Bean 注入到 Spring 容器里,从而实现“约定大于配置,开箱即用”。
springBoot自动装配原理
https://www.bilibili.com/video/BV1TV4y157yz?p=28&vd_source=e6fc2faffd817786a7a38aeaab56c2a1<br>
TODO
springBoot启动方式
1、通过main方法启动
2、达成jar包通过 java -jar的命令启动,或者达成war包掉到web容器中启动
3、使用maven/gradle 插件来运行
springBoot简单介绍
springBoor是基于spring创建的一个上层应用框架,14年发布1.0会比以前那种ssm,给予配置的方式效率高很多
springBoot中starter(启动器)的理解
springBoot启动的时候默认将springBoot自身的bean对象,项目中开发定义的bean对象,以及sptingBoot默认的一些bean对象加载到bean容器
starter会去读取meta-info目录下提供的一个spring.factories文件,将需要默认加载进spring容器的类进行一个读取加载操作
如果第三方的插件组件也需要在启动的时候加载进spring容器,可以自身和spring做一个整合包。但是通常springBoot已经提高了很多整合包了,整合报的命名通常都是 spring-boot-starter-xxx pom依赖
实际开发
如果想引入第三方的配置需要的步骤
1、添加spring-boot-starter-xxx的依赖包到pom文件
2、在配置文件中配置相关的需要的配置
常用的starter包
spring boot-starter-web
提供了SpringMVC+内嵌了Tbmcat容器
spring-boot-starterdata-jpa
提供了 SpringJPA和Hibernate框架整合<br>
sprinq-boot-starter-data-redis
redis数据源整合
spring-boot-starter-solr
solr搜索
mybatis-spring-boot-starter<br>
mybatis-springBoot整合
springBoot需要web容器
一般不需要
spring boot-starter-web
提供了SpringMVC+内嵌了Tbmcat容器
springBoot项目中如何解决跨域问题
解决方式
1、类似通过jsonp类解决跨域问题,但是支持Get方式请求
2、SpringBoot中我们可以通过WebMvcConfigurer重写addCorsMapping方法,在这个方法中添加允许进行跨域的相关请求
什么是跨域问题
1、浏览器的同源策略限制:两个页面的协议,ip地址,端口号必须要是一样的才能请求
还是为了浏览器访问数据安全
跨域就是:协议不一致,ip地址,端口中只要有一个不一致就是跨域
springBoot怎么集成第三方组件
soringBoot项目如何使用log4j
springBoot默认使用的是logback
1、先排除logback的包
2、pom文件中添加log4j依赖
4、配置log4j相关配置
通用方法
1、pom文件中引入springBoot与第三方组件的得整合启动包:spring-boot-starter-redis
2、再在配置文件中引入该组件的必须要配置的配置项
springBoot中bootstrap.yml文件作用
springBoot默认支持的属性文件
application.properties
application.xml<br>
application.yml<br>
application.yaml<br>
springBoot默认是不支持这类配置文件
在springCloud环境下才支持,作用是在springBoot项目启动之前启动一个父容器;
父容器可以在springBoot容器启动之前完成一些加载初始化的操作:比如说加载配置中心的信息
springBoot中Actuator的理解
作用
健康检查(Health):查看应用及依赖服务(数据库、Redis 等)的状态
指标(Metrics):收集 JVM、内存、线程池、请求等指标
信息(Info):应用自定义信息,如版本号、环境等
日志管理(Logging):查看或调整日志级别
审计与追踪(Trace/Httptrace):记录最近请求
端点管理(Endpoint):提供 REST API 来访问以上功能
信息的监控可以在springBoot自带的springBoot admin监控平台上看到;
使用步骤
1、引入依赖
<dependency><br> <groupId>org.springframework.boot</groupId><br> <artifactId>spring-boot-starter-actuator</artifactId><br></dependency>
2、配置路径
# 访问端口<br>management.server.port=8081<br># 根路径<br>management.endpoints.web.base-path=/actuator/z<br># web端允许的路径<br>management.endpoints.web.exposure.include=*
3、请求获取当前可用的统计接口信息
http://127.0.0.1:8081/actuator/z
/actuator/z里还有端口都是配置文件中配置的
可以得到当前所有的统计信息项目
返回请求路径信息
{<br> "_links":{<br> "self":{<br> "href":"http://127.0.0.1:8081/actuator/z",<br> "templated":false<br> },<br> "prometheus":{<br> "href":"http://127.0.0.1:8081/actuator/z/prometheus",<br> "templated":false<br> },<br> "beans":{<br> "href":"http://127.0.0.1:8081/actuator/z/beans",<br> "templated":false<br> },<br> "caches-cache":{<br> "href":"http://127.0.0.1:8081/actuator/z/caches/{cache}",<br> "templated":true<br> },<br> "caches":{<br> "href":"http://127.0.0.1:8081/actuator/z/caches",<br> "templated":false<br> },<br> "health-path":{<br> "href":"http://127.0.0.1:8081/actuator/z/health/{*path}",<br> "templated":true<br> },<br> "health":{<br> "href":"http://127.0.0.1:8081/actuator/z/health",<br> "templated":false<br> },<br> "info":{<br> "href":"http://127.0.0.1:8081/actuator/z/info",<br> "templated":false<br> },<br> "conditions":{<br> "href":"http://127.0.0.1:8081/actuator/z/conditions",<br> "templated":false<br> },<br> "configprops":{<br> "href":"http://127.0.0.1:8081/actuator/z/configprops",<br> "templated":false<br> },<br> "configprops-prefix":{<br> "href":"http://127.0.0.1:8081/actuator/z/configprops/{prefix}",<br> "templated":true<br> },<br> "env":{<br> "href":"http://127.0.0.1:8081/actuator/z/env",<br> "templated":false<br> },<br> "env-toMatch":{<br> "href":"http://127.0.0.1:8081/actuator/z/env/{toMatch}",<br> "templated":true<br> },<br> "loggers":{<br> "href":"http://127.0.0.1:8081/actuator/z/loggers",<br> "templated":false<br> },<br> "loggers-name":{<br> "href":"http://127.0.0.1:8081/actuator/z/loggers/{name}",<br> "templated":true<br> },<br> "heapdump":{<br> "href":"http://127.0.0.1:8081/actuator/z/heapdump",<br> "templated":false<br> },<br> "threaddump":{<br> "href":"http://127.0.0.1:8081/actuator/z/threaddump",<br> "templated":false<br> },<br> "metrics":{<br> "href":"http://127.0.0.1:8081/actuator/z/metrics",<br> "templated":false<br> },<br> "metrics-requiredMetricName":{<br> "href":"http://127.0.0.1:8081/actuator/z/metrics/{requiredMetricName}",<br> "templated":true<br> },<br> "scheduledtasks":{<br> "href":"http://127.0.0.1:8081/actuator/z/scheduledtasks",<br> "templated":false<br> },<br> "mappings":{<br> "href":"http://127.0.0.1:8081/actuator/z/mappings",<br> "templated":false<br> },<br> "refresh":{<br> "href":"http://127.0.0.1:8081/actuator/z/refresh",<br> "templated":false<br> },<br> "features":{<br> "href":"http://127.0.0.1:8081/actuator/z/features",<br> "templated":false<br> }<br> }<br>}
路径
http://127.0.0.1:8081/actuator/z
http://127.0.0.1:8081/actuator/z/prometheus
http://127.0.0.1:8081/actuator/z/beans
当前用哪些bean对象
http://127.0.0.1:8081/actuator/z/health
健康信息
http://127.0.0.1:8081/actuator/z/caches/{cache}
内存信息
http://127.0.0.1:8081/actuator/z/heapdump
当前对内存信息
http://127.0.0.1:8081/actuator/z/threaddump
当前线程内存信息
http://127.0.0.1:8081/actuator/z/metrics
统计信息的具体项目
http://127.0.0.1:8081/actuator/z/scheduledtasks
当前项目有哪些定时任务
<a href="http://127.0.0.1:8081/actuator/z/mappings" target="_blank" class="json_link">http://127.0.0.1:8081/actuator/z/mappings</a>
接口请求路径有哪些
http://127.0.0.1:8081/actuator/z/refresh
http://127.0.0.1:8081/actuator/z/features
springBoot 启动中会去默认加载数据库,redis这些配置吗?
自动配置这些通常都是有条件
@ConditionalOnClass → 当某个类在 classpath 中存在才生效<br> • @ConditionalOnMissingBean → 当容器里没有同类型 Bean 才创建<br> • @ConditionalOnProperty → 根据配置文件中属性决定是否加载
数据库(DataSource)<br> • 条件:<br> 1. classpath 中有 JDBC 驱动或 HikariCP/Tomcat JDBC 等<br> 2. 配置了数据库连接属性,如:
Redis<br> • 条件:<br> 1. classpath 中有 spring-boot-starter-data-redis 或 Jedis/Lettuce 类<br> 2. 配置了 Redis 连接属性,如:
总结
Spring Boot 不会盲目加载数据库或 Redis,它只会:<br> • 当 classpath 有相关依赖<br> • 配置文件中有必要配置<br> • 自动装配条件满足时<br>才去初始化相关 Bean<br> • 优势:开箱即用,但又可通过条件控制关闭(比如 exclude 某些自动配置)
spring开启特殊功能
@EnableAspectJAutoProxy
开启AspectJ自动代理支持
@EnableAsync
开启异步方法
@EnableScheduling
开启定时任务
@EnableWebMvc
开启web mvc配置
@enabletransactionmanagement
开启事物
@EnableRetry
开启方法重试功能
EnableCircuitBreaker
开启方法熔断功能
spring ,springMvc ,springBoot区别
spring和springMvc
1、spring是一个一站式轻量级的java开发框架,核心是控制反转和切面编程,针对web层,业务层,持久层等都提供了多种配置解决方案
2. springMvc是spring基础之上的一个MVC框架,主要处理web开发的路径映射和视图演染,属于spring框架中
springMvc和springBoot
1、springMvc属于一个企业WEB开发的MVC框架,涵盖面包括前端视图开发、文件配置、后台接口逻辑开发<br>等,XML、config等配置相对比较繁琐复杂;
2、springBoot框架相对于springMvc框架来说,更专注于开发微服务后台接口,不开发前端视图,同时遵循默认优于配置,简化了插件配置流程,不需要配置xml,相对springmvc,大大简化了配置流程;<br>
总结
1、Spring框架就像一^家族,有众多衍生产品例如boot、security、jpa等等。但他们的基础都是Spring的ioc. aop等.ioc提供了依赖注入的容器,aop解决了面向横切面编程,然后在此两者的基础上实现了其他延伸产<br>品的高级功能;<br>
2、springMvc主要解决WEB开发的问题,是基于Servlet的fMVC框架,通过XML配置,统T发前端视图和<br>后端逻辑;<br>
3、由于Spring的配置非常复杂,各种XML、JavaConfig、servlet处理起来匕啜繁琐,为了简化开发者的使用,<br>从而创造性地推出了springB。。唯架,默认优于配置,简化了springMvc的配置流程;但区别于springMvc的是,<br>springBoot专注于单体微8艮务接口开发,和前端解耦,虽然springBoot也可以做成springMvc前后台一起开发,<br>但是这就有点不符合springBoot框架的初衷了 ;<br>
spring-cloud
微服务组件
注册中心
注册中心概述
针对于动态数据,对于服务器的加入,或者删除是可以动态感知的;
注册中心核心功能
服务注册
服务提供方想注册中心发送的心跳时间和续约时间
服务发现
服务提供方想注册中心发送的心跳时间和续约时间
动态追踪服务注册信息
自我保护机制
Eureka 的自我保护机制工作
如果15分钟之内超过85%的客户端节点都没有正常的心跳信息,那么Eureka就会认为客户端和注册中心发生了网络故障,那么EURKEA就会自动进入自我保护机制
Eureka 的自我保护机制下Eureka工作情况
不再从注册列表中剔除长时间没有发送心跳的客户端
继续接受新的服务注册和服务查询,但是这些数据都不会被同步到其他的注册中心;
网络稳定之后,Eureka注册信息才会被同步到其他机器上;
Eureka 的自我保护模式是有意义
防止因为分区网络,导致心跳信息没有发送或者没有接受到信条信息,而错误的把一个正常服务的机器从服务注册列表中剔除;
健康检查
通过客户端给服务端间隔一定时间发送心跳还有发送续约信息;
注册中心好处
客户端,服务端ip地址解耦合
实现服务的动态扩容或者动态删除服务
可监控各个服务运行情况
注册中心实现
Zookeeper
eurake
工作流程
1、启动eureka服务集群
2、eureka客户端通过配置的eureka的服务ip,发送ip,端口,还有服务接口信息
3、Eureka Client 会每 30s 向 Eureka Server 发送一次心跳请求,证明客户端服务正常
4、服务调用的时候会向注册中心获取服务列表,然后从服务列表中获取具体信息,发送服务
工作机制
服务注册
服务注册调用示意图
示意图
各个服务启动时,Eureka Client都会将服务注册到Eureka Server,Eureka Server 内部有二层缓存机制来维护整个注册表
作用
Eurake client 想节点提供自身的元数据,比如 IP 地址、端口
服务续约
过程
Eureka Client 会每隔 30 秒会向eurake节点发送一次心跳来续约,告诉节点服务还在正常运行;
重要属性
服务失效时间
默认30秒
子主题
续约间隔时间
如果 Eureka Server 在 90 秒内没有收到 Eureka Client 的续约,Server 端会将实例从其注册表中删除
服务剔除
Eureka Client 和 Eureka Server 不再有心跳时,Eureka Server 会将该服务实例从服务注册列表中删除,即服务剔除
服务下线
服务关闭时候,想eurake节点发送取消请求,然后该客户端对应的注册信息就会在注册列表中被删除
获取注册列表信息
Eureka客户端从eurake服务节点上获取服务注册列表信息,通过ribbon负载均衡进行远程调用,并将服务注册列表信息缓存在本地。
重要属性
开启还是关闭eurake客户端从节点拉取注册信息
拉取注册列表时间间隔
eureka缓存
1.客户端拉服务列表,注册中心会从缓存中拿,并不每次都是从服务注册列表中获取;
服务端,客户端缓存
eureka服务端信息三级缓存
registry
实时更新
readWriteCacheMap
实时更新
readOnlyCacheMap
周期更新
客户端信息缓存
localRegionApps
upServerListZoneMap
缓存相关配置
服务端配置
客户端是从只读缓存还是从读写缓存获取配置信息
读写缓存更新只读缓存
默认30秒
清理未续约节点周期
默认60秒;间隔60秒会去清理不可用的节点信息
清理未续约节点超时时间
默认90秒;
客户端配置
服务续约周期
增量更新周期
负载均衡周期
2.客户端会缓存服务注册列表;
3.负载均衡器也会缓存服务列表
eureka高可用
eureka注册中心本身支持集群化
集群中的每一个节点都是可以堆外提供注册和服务发现功能
这点和zk的差别很大,zk在同一时间点只能是由一个主节点对外提供服务发现注册功能
集群中的每一个节点也是一个微服务,也可以做相互的注册
eureka集群中某一节点挂了,其他节点持续对外提供服务
eureka高可用集群,中注册中心都是对等的,每个注册中心都会把自己的数据同步给其他注册中心;其他注册中心在收到心跳信息的时候会判断是客户端注册信息还是注册中心注册信息,如果是客户端信息那么注册中心就把数据同步到其他注册中心,如果是注册中心的注册信息那么就不做任何操作;
自我保护策略
服务端
默认情况下,注册中心不会剔除已经挂掉的服务;认为挂掉的服务正在尝试连接注册中心
设置
eureka.server.enable-self-preservation=false
关闭该默认机制;确保注册中心可以剔除不可用实例
eureka.server.eviction-interval-timer-in-ms=5000
剔除失效服务的间隔时间
客户端
心跳时间
lease-renewal-interval-in-seconds
每间隔多久发送一次心跳时间,表示当前服务还活着
续约时间
lease-expiration-duration-in-seconds
超过这个时间没有向注册中发送心跳,那么表示我这个服务已经挂了,请把我剔除服务注册列表
子主题 6
eureka架构
zk和eurake区别
zk保证CP(一致性,容错性)
eruake是ap (可用性,容错性)
eurake 每一个节点都是平等都可以对外提供服务注册和发现,而zk只有集群中的主节点才能堆外提供服务注册和发现
nacos
配置中心
概述
系统启动需要的参数和依赖的各类外部信息;
配置中心自动刷新时限
1、配置中心server端承担起配置刷新的职责
2、提交配置出发post请求给server端的bus/refreah接口
3、server端接受到请求并发送给spring cloud bus总线
4、springcloud bus 接收到消息并通知其他连接到总线的客户端
5、其他客户端接收到通知,请求server端获取最新的配置
6、全部客户端均获取到最新的配置
配置中心如何保证数据安全
1、各个环境做到数据配置隔离
2、配置中心所有的配置信息都进行加密处理
具体实现
springCloud config
apollo
apollo由来
是携程架构部门研发的分布式配置中心
特性
1、统一管理不同环境,不同集群的配置
2、配置修改实时生效
热发布,修改配置,客户端可以在1s接收到最新的配置
3、配置版本管理
配置修改都有版本的概念,可以方便回滚到历史某个版本
4、支持灰度发布
支持发布后,配置只对部分客户端实例生效,等观察一段时间再对所有实例生效
5、发布操作审计
配置编辑,发布都有详细的管理机制以及操作日志,方便追踪问题
6、客户端配置信息监控
可以在见面上查看配置被哪些实例使用
7、提供了java和.net原生客户端
8、提供开发平台api
基础概念
配置管理维度
一级维度
应用层级维度
标识配置所属项目应用
二级维度
环境维度
区分一个应用下不同的环境
DEV
FAT
uat
pro
三级维度
集群维度
相同实力的不同分组
比如说,北京分组,上海分组,配置可能不一样
四级维度
namespace维度
类似同一个项目下针对比如说数据库,redis等等不同的配置文件
本地缓存
Apollo客户端会把从服务端获取到的配置在本地文件系统缓存一份,用于在遇到服务不可用,或网络不通的时候,依然能从本地恢复配置,不影响应用正常运行
apollo设计图
配置更新基础示意图
大致工作流程
1、在管理平台上做配置的修改和发布
2、配置中心通知Apollp客户端有配置更新
3、apollpo客户端从配置中心拉去最新配置,更新本地配置并通知都应用
示意图
子主题
配置更新详细示意图
详细工作流程
1、客户端和服务端保持了一个长连接,能第一时间获得配置更新的推送
2、客户端还会定时从 Apollo 配置中心服务端拉取应用的最新配置
这是一个备用机制
客户端定时拉取会上报本地版本,所以一般情况下,对于定时拉取的操作,服务端都会返回 304 - Not Modified
定时频率默认为每 5 分钟拉取一次,客户端也可以通过在运行时指定 apollo.refreshInterval来覆盖,单位为分钟
3、客户端从 Apollo 配置中心服务端获取到应用的最新配置后,会保存在内存中
4、客户端会把从服务端获取到的配置在本地文件系统缓存一份,在遇到服务不可用,或网络不通的时候,依然能从本地恢复配置
5、应用程序从 Apollo 客户端获取最新的配置、订阅配置更新通知
详细工作示意流程图
子主题
apollo整体设计
示意图
<br>
工作流程说明
1、Config Service 提供配置的读取、推送等功能,服务对象是各个微服务
2、Admin Service 提供配置的修改、发布等功能,服务对象是管理界面
3、集群部署
1、Config Service 和 Admin Service 都是多实例、无状态部署,所以需要将自己注册到 Eureka 中并保持心跳
4、服务注册与发现
1、在 Eureka 之上我们架了一层 Meta Server 用于封装Eureka的服务发现接口
2、客户端通过域名访问 Meta Server 获取Config Service服务列表(IP+Port),而后直接通过 IP+Port 访问服务,同时在 Client 侧会做 load balance 错误重试
3、Portal 通过域名访问 Meta Server 获取 Admin Service 服务列表(IP+Port),而后直接通过 IP+Port 访问服务,同时在 Portal 侧会做 load balance、错误重试
apollo相关问题
1、阿波罗如何保证配置实时更新
1、客户端和服务端的长连接保持长连接,能在第一时间获取配置更新的推送
2、客户端还会定时拉取服务端配置是否有更新
2、阿波罗如何保证可用性
1、configservice 集群部署,且都会注册到注册中心
最大程度上保证微服务和服务端配置获取通信畅通
2、admin service 集群部署
配置管理平台和服务端保持配置修改通信畅通
3、客户端会缓存配置信息到本机
当配置中心集群挂了,会从本地读取配置
4、admin sevcie 和conig service 集群工作相互不受对方影响
nacos
实现原理
springBoot 中的@Value是如何读取到 配置中心的数据?
1. 拉取远程配置(在启动时)。
子主题
步骤
1、配置拉取
2、
Apollo
拉取远程配置
启动时从服务端拉配置,写入内存。
apollo将配置信息注入到 Spring Environment。<br>
Apollo 内部会注册 PropertySources,并且对 Environment 做 动态更新:
Spring 的 @Value 注解读取的是 Environment 的实时值,所以再次访问时获取的是最新值。
Nacos
Spring Cloud Config
服务降级熔断
相关概念
服务雪崩
demo解释
当大量的请求请求上层服务,上层服务所依赖的底层服务,在处理请求的时候,无法承受大量的请求,导致底层服务无法快速相应,导致上层服务请求堆积,导致上层服务无法快速处理请求,导致请求堆积,从而导致A服务不可用<br>
解释
由于底层的服务某种原因,导致整个上层服务都不可用,有一种连锁反应
解决方式
服务熔断,服务降级,服务限流
服务限流
解释
单位时间内限制对服务器的访问量
作用
在高并发情况下,保护系统不被大量请求导致服务雪崩
服务熔断
解释
底层服务不可用的时候,上层服务直接不再调用这个底层服务,而直接返回一个结果;
作用
隔离上层和底层服务之间的级联影响,避免系统崩溃
服务降级
解释
服务压力激增的情况下,主动对一些服务不处理或者简单处理,来释放服务器压力,保证服务器核心功能正常运行
作用
保证整个系统核心功能呢个稳定性和可用性
服务熔断,服务降级区别
触发原因
服务熔断是调用链路上的某个服务不可以用引起的;
服务降级从整体负载考虑
目标
熔断是框架层次的处理
降级是业务层次的处理
实现方式
熔断主要是在客户端进行处理,书写兜底处理
降级需要在服务端进行兜底处理
服务降级是对整个系统资源的再次分配(区分核心服务,非核心服务)
服务熔断是服务降级的一种特殊方式,防止服务雪崩而采取的措施;
具体实现
sentinel
sentinel作用
流量控制
熔断降级
系统负载保护
Sentinel概念
资源定义
服务接口
接口中调用的其他服务
熔断降级
某个资源出现不稳定的时候,降低对该资源的调用进行限制并快速失败,避免影响到其他系统造成整个系统雪崩
规则
流量控制规则
熔断降级规则
系统自我保护规则
Sentinel工作机制
1.对资源显示定义,来标记资源
2.提供可修改规则接口
3.对资源适时统计,流量适时监控
熔断降级
熔断策略
平均响应时间
滑动窗口统计中,1秒内的平均响应时间超过了阈值,就会熔断
异常比例
滑动窗口的统计中当资源每秒的请求次数超过5个,且每秒的异常比例超过一定阈值;那么这个方法就会自动返回
异常比例范围 [0.0, 1.0],也就是0%-100%;
异常数
滑动窗口在1分钟的异常数目超过一定的阈值就会进行熔断。
降级策略
线程并发数
线程数量在某个资源上堆积了数量,那么新的请求就会被拒绝;等堆积的线程完成任务后,才开始接受新的请求;
资源相应时间
当依赖的资源出现相应时间过长,那么对该资源的访问都会直接被拒绝,等到一定的时间窗口之后再回复正常访问;
降级规则
熔断-降级区别
熔断就是直接不能访问该接口,该接口直接返回错误的执行方法;降级,一段时间之内不能再次访问这个接口,等高峰期过了才会再次访问该接口;
流量控制
流量控制角度
控制效果
直接限流
冷启动
排队
运行指标
QPS
系统负载
线程池
资源调用关系
概述
一个资源可能调用其他资源,形成一个调用链路,通过调用链路可以衍生出更多的流量控制手段
控制方式
根据调用方限流
根据调用链路入口限流:链路限流
关系资源流量控制
控制方式
保护业务线程不被耗尽,当某个资源超过一定阈值数量的线程排队的时候,对该资源的请求就会直接被拒绝,等到没有排队线程就会接受新的请求
冷启动
系统长期处于低活跃度,短期流量猛增,直接把系统拉大高水位可能直接把系统冲垮;让流量缓慢的增加,给系统一个预热时间,避免系统被冲垮;
均速器
通过漏斗算法严格控制请求通过的间隔时间
直接拒绝
当QPS超过任意规则的阈值,新的请求就会被立即拒绝,拒绝方式抛出FlowException
限流控制规则配置项
resource
限流规则作用对象
count
限流阈值
grade
限流阈值类型(QPS或者并发线程数)
limitApp
是否区分调用来源
strategy
调用关系限流策略
controlBehavior
流控控制效果(直接决绝,冷启动,均速排队)
限流规则统计项目
系统保护
系统保护规则
1.通过网络负载均衡会把本应这台机器承载的流量转发到其它的机器上去
2.让系统的入口流量和系统的负载达到一个平衡,保证在系统能力范围之内处理最多请求;
sentinel和Hystrix对比
不同点
扩展性
sentinel扩展性强Hystrix区别
熔断降级策略
sentinel基于相应时间,异常比例,异常数量熔断降级; Hystrix只能通过异常比例来降级
限流
sentinel基于QPS支持基于调用关系的限流;Hystrix对限流支持比较有限
隔离策略
sentinel通过某一个资源被调用的并发线程数,当线程在某个资源上堆积到了一定程度新请求就会被拒绝; Hystrix每一个资源都会分配相应的线程池,通过资源对应的线程池控制
流量整形
sentinel支持预热模式,匀速器模式,预热排队模式;Hystrix不支持
控制台
sentinel控制台可以查询规则,配置规则,监控情况;Hystrix只能监控查看
系统自适应保护
sentinel支持Hystrix不支持
相同点
实时统计实现
都是通过滑动窗口来做指标统计
动态规则配置
sentinel Hystrix都支持多数据源
注解
sentinel,Hystrix都支持注解开发
hystrix
Hystrix使用<br>
@HystrixCommand
commandKey,groupKey,thread key重点说明
commandKey
代表一类command,代表底层依赖的一个接口
groupKey
代表了某一个底层的依赖服务;这个服务可以有多个接口
逻辑上是组织起一堆的command key的调用,统计信息,成功次数,timeout次数,失败次数,可以看到某一些服务整体的访问情况
如果不配置
threadPoolKey
线程池配置
以上三者实战说明
同时配置了groupKey 和 threadPoolKey,具有相同的threadPoolKey的使用同一个线程池
如果只配置了groupKey ,那么具有相同的groupKey 的使用同一个线程池
总结
一般来说command group 是对应了一个底层服务,多个command key对应这个底层服务的多个接口,这多个接口按照 command group 共享一个线程池
如果想单独给某一个底层接口也就是某一个command key设置线程池,直接配置上threadpool key 就可以
fallbackMethod
回滚的方法名称
报错之后,执行的默认方法
commandProperties
可以配置执行的隔离策略是线程隔离,还是信号量隔离
参数设置
hystrix.command.default.execution.isolation.strategy 隔离策略,默认是Thread, 可选Thread|Semaphore<br>
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds 命令执行超时时间,默认1000ms<br>
hystrix.command.default.execution.timeout.enabled 执行是否启用超时,默认启用true
hystrix.command.default.execution.isolation.thread.interruptOnTimeout 发生超时是是否中断,默认true<br>
hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests 最大并发请求数,默认10,该参数当使用ExecutionIsolationStrategy.SEMAPHORE策略时才有效。如果达到最大并发请求数,请求会被拒绝。理论上选择semaphore size的原则和选择thread size一致,但选用semaphore时每次执行的单元要比较小且执行速度快(ms级别),否则的话应该用thread。
emaphore应该占整个容器(tomcat)的线程池的一小部分。
threadPoolProperties
线程池相关的配置
参数设置
hystrix.threadpool.default.coreSize 并发执行的最大线程数,默认10
hystrix.threadpool.default.maxQueueSize BlockingQueue的最大队列数,当设为-1,会使用SynchronousQueue,值为正时使用LinkedBlcokingQueue。该设置只会在初始化时有效,之后不能修改threadpool的queue size,除非reinitialising thread executor。默认-1。
hystrix.threadpool.default.queueSizeRejectionThreshold 即使maxQueueSize没有达到,达到queueSizeRejectionThreshold该值后,请求也会被拒绝。因为maxQueueSize不能被动态修改,这个参数将允许我们动态设置该值。if maxQueueSize == -1,该字段将不起作用<br>
hystrix.threadpool.default.keepAliveTimeMinutes 如果corePoolSize和maxPoolSize设成一样(默认实现)该设置无效。如果通过plugin(https://github.com/Netflix/Hystrix/wiki/Plugins)使用自定义实现,该设置才有用,默认1.
hystrix.threadpool.default.metrics.rollingStats.timeInMilliseconds 线程池统计指标的时间,默认10000
hystrix.threadpool.default.metrics.rollingStats.numBuckets 将rolling window划分为n个buckets,默认10
ignoreExceptions
忽略一些异常,这些异常不被统计到熔断中
observableExecutionMode
定义hystrix observable command的模式;<br>
raiseHystrixExceptions
任何不可忽略的异常都包含在HystrixRuntimeException中;
defaultFallback
默认的回调函数,该函数的函数体不能有入参,<br> 返回值类型与@HystrixCommand修饰的函数体的返回值一致。如果指定了fallbackMethod,则fallbackMethod优先级更高。<br>
其他参数
hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests 如果并发数达到该设置值,请求会被拒绝和抛出异常并且fallback不会被调用。默认10<br> hystrix.command.default.fallback.enabled 当执行失败或者请求被拒绝,是否会尝试调用hystrixCommand.getFallback() 。默认true<br> Circuit Breaker相关的属性<br> hystrix.command.default.circuitBreaker.enabled 用来跟踪circuit的健康性,如果未达标则让request短路。默认true<br> hystrix.command.default.circuitBreaker.requestVolumeThreshold 一个rolling window内最小的请求数。如果设为20,那么当一个rolling window的时间内(比如说1个rolling window是10秒)收到19个请求,即使19个请求都失败,也不会触发circuit break。默认20<br><br> hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds 触发短路的时间值,当该值设为5000时,则当触发circuit break后的5000毫秒内都会拒绝request,也就是5000毫秒后才会关闭circuit。默认5000<br> hystrix.command.default.circuitBreaker.errorThresholdPercentage错误比率阀值,如果错误率>=该值,circuit会被打开,并短路所有请求触发fallback。默认50<br> hystrix.command.default.circuitBreaker.forceOpen 强制打开熔断器,如果打开这个开关,那么拒绝所有request,默认false<br> hystrix.command.default.circuitBreaker.forceClosed 强制关闭熔断器 如果这个开关打开,circuit将一直关闭且忽略circuitBreaker.errorThresholdPercentage<br> Metrics相关参数<br> hystrix.command.default.metrics.rollingStats.timeInMilliseconds 设置统计的时间窗口值的,毫秒值,circuit break 的打开会根据1个rolling window的统计来计算。若rolling window被设为10000毫秒,则rolling window会被分成n个buckets,每个bucket包含success,failure,timeout,rejection的次数的统计信息。默认10000<br> hystrix.command.default.metrics.rollingStats.numBuckets 设置一个rolling window被划分的数量,若numBuckets=10,rolling window=10000,那么一个bucket的时间即1秒。必须符合rolling window % numberBuckets == 0。默认10<br> hystrix.command.default.metrics.rollingPercentile.enabled 执行时是否enable指标的计算和跟踪,默认true<br>hystrix.command.default.metrics.rollingPercentile.timeInMilliseconds 设置rolling percentile window的时间,默认60000<br> hystrix.command.default.metrics.rollingPercentile.numBuckets 设置rolling percentile window的numberBuckets。逻辑同上。默认6<br> hystrix.command.default.metrics.rollingPercentile.bucketSize 如果bucket size=100,window=10s,若这10s里有500次执行,只有最后100次执行会被统计到bucket里去。增加该值会增加内存开销以及排序的开销。默认100<br> hystrix.command.default.metrics.healthSnapshot.intervalInMilliseconds 记录health 快照(用来统计成功和错误绿)的间隔,默认500ms<br> Request Context 相关参数<br> hystrix.command.default.requestCache.enabled 默认true,需要重载getCacheKey(),返回null时不缓存<br> hystrix.command.default.requestLog.enabled 记录日志到HystrixRequestLog,默认true<br> <br> Collapser Properties 相关参数<br> hystrix.collapser.default.maxRequestsInBatch 单次批处理的最大请求数,达到该数量触发批处理,默认Integer.MAX_VALUE<br> hystrix.collapser.default.timerDelayInMilliseconds 触发批处理的延迟,也可以为创建批处理的时间+该值,默认10<br> hystrix.collapser.default.requestCache.enabled 是否对HystrixCollapser.execute() and HystrixCollapser.queue()的cache,默认true<br>
hystrix设计
hystrix的熔断设计
熔断请求判断机制算法:使用无锁循环队列计数,每个熔断器默认维护10个bucket,每1秒一个bucket,每个blucket记录请求的成功、失败、超时、拒绝的状态,默认错误超过50%且10秒内超过20个请求进行中断拦截。<br>
熔断恢复:对于被熔断的请求,每隔5s允许部分请求通过,若请求都是健康的(RT<250ms)则对请求健康恢复
熔断报警:对于熔断的请求打日志,异常请求超过某些设定则报警
hystrix的隔离设计
线程池隔离
对每一个设置了线程池的资源(理解成一个接口或者一类接口,或者针对某一个底层服务的所有接口),都会开启一个专属的线程池来处理这些资源对应的请求,线程池来处理这些资源对应的请求,堆积的请求也会进入线程池对应的阻塞队列
项目在启动的时候会有一些资源消耗,但是会在大批量的请求到来的时候,可以游刃有余的处理
信号量隔离
信号量来记录当前有多少线程在运行,请求进来的时候先判断是否会超过最大的信号量(最大线程数量),如果超过那么就会丢弃最新的请求,不超过就会让信号量+1,严格控制当前正在执行的线程数量
无法应对大量的请求,大量的请求过来,就是直接放弃执行了,
对比
线程池因为有阻塞队列的原因,所以在一定程度上可以保存一分部请求,慢慢处理;但是信号量就不行,需要严格控制当前执行的线程个数
hystrix的超时机制设置
等待超时
设置任务入列最大时间
判断阻塞队列的头部任务入列时间是否大于超时时间。大于则放弃任务
运行超时
直接可以使用线程池的get方法
hystrix工作流程
熔断流程
1、当出现调用错误的时候,开起一个时间窗口(默认十秒)
2、在这个时间串口内,统计调用次数是否达到最小次数
如果没有达到,则重置统计信息,回到第一步
如果没有达到,即使请求全部失败,也回到第一步
3、如果次数达到了,统计失败占总请求的百分比阈值是否达到
如果没有达到,则重置统计数据,回到第一步
4、如果达到则跳闸
5、开起一个默认时间为5秒的活动窗口,每间隔5秒钟,让一个请求通过去访问已经跳闸的服务;
如果失败,回到第三步继续计算错误百分比
6、如果调用成功,重置断路器
简易工作流程图
流程图
Resillence4j
网关
网关概念
网关工作流程
具体实现
zuul
gateway
限流
负载均衡
熔断
Spring Cloud Gateway 底层使用了高性能的通信框架Netty
负载均衡
负载均衡概念
具体实现
Ribbon
特点
无需部署,直接嵌入客户端做为负载均衡器使用
spring cloud LoadBalance
ribbon
使用
1.调用端引入ribbon的包
注意事项
1.负载均衡默认算法是轮询
2.通过把负载均衡对象定义成bean修改负载均衡算法
负载均衡算法
1、轮询策略
按照一定的顺序依次调用服务实例
2、权重策略
根据每个服务提供者的响应时间分配一个权重,响应时间越长,权重越小,被选中的可能性也就越低
实现
刚开始使用轮询策略并开启一个计时器,每一段时间收集一次所有服务提供者的平均响应时间,然后再给每个服务提供者附上一个权重,权重越高被选中的概率也越大
3、随机策略
从服务提供者的列表中随机选择一个服务实例
4、最小连接数策略
遍历服务提供者列表,选取连接数最小的⼀个服务实例;如果有相同的最小连接数,那么会调用轮询策略进行选取
5、重试策略
可以看做是轮询策略的一种
按照轮询策略来获取服务
如果服务实力失效或者服务实例为null,指定的时间之内不断地进行重试来获取服务,如果超过指定时间依然没获取到服务实例则返回 null
6、可用性敏感策略
可用敏感性策略
先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例
7、区域敏感策略
根据服务所在区域(zone)的性能和服务的可用性来选择服务实例,在没有区域的环境下,该策略和轮询策略类似
工作流程简述
1、ribbon拦截所有的远程调用
2、解析调用路径中的host,获取服务名称
3、根据服务名称获取服务实例列表
1、先从本地获取服务实例列表
2、本地不存在,那么就从注册中心拉去服务列表,缓存本地
4、根据负载均衡策略获取某一个具体的服务ip和端口
3、再通过http请求框架请求服务获取结果
工作流程示意图
示意图
负载均衡实现方式
客户端实现
ribbon
服务端实现
nginx
lvs
F5 硬件实现
客户端服务端负载均衡示意图
子主题
服务端实现负载均衡问题
1、需要服务端有强的流量控制权
2、无法满足不同调用方使用不同的负载均衡策略需求
客户端这边就可以实现这个,避免这个问题;
调用方式
两者的区别联系
区别
feign是ribbon调用方式的封装
联系
子主题
负载均衡
算法种类
轮询
随机
过滤故障,连接数超过一定阈值机器,剩下进行轮询
过滤故障机器,轮询
过滤掉故障机器,选择并发最小访问
根据平均响应时间加权选择服务
根据机器性能,可以用性选择服务
请求重试机制
具体实现
feign
使用
1.调用端引入feign包
2.调用端定义服务接口
3.用定义的服务接口调用
注意事项
1.负载均衡默认算法是轮询
配置文件中定义修改后的负载均衡算法
rest template
open feign
feign理论
简单介绍
http请求调用的轻量级框架
作用
1、简化springcloud 对远程接口开发以及调用
2、整合spring ribbon,hystrix实现接口负载均衡和短路
Feign的HTTP客户端
目前支持
HttpURLConnection
JDK自带
未实现连接池;需要自己手动实现连接池
HttpClient
封装http请求头,参数,内容,响应体,方便开发
自带Http连接池
OKHttp
OKHttp拥有共享Socket,减少对服务器请求次数
自带http连接池
默认使用
HttpURLConnection<br>
feign和openfeign区别
OpenFeign是Spring Cloud 在Feign的基础上支持了Spring MVC的注解
OpenFeign的@FeignClient可以解析SpringMVC的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类做负载均衡和服务调用
feign工作流程
feign接口调用流程
详细流程图
流程图
详细流程
1、本地接口A调用远程接口B
2、通过接口的动态代理实现了接口B
3、接口B读取解析springMvc相关注解,生成http请求
1、解析@FeignClient注解获取服务名称,获取请求路径
2、解析请求路径还有参数信息
3、序列化操作,非必要 ?
4、接口B将请求相关信息交给Ribbon对应的负载均衡器
1、获取去注册中心获取这个服务对应的服务列表
2、根据负载均衡算法从注册列表中选择一个
5、负载均衡器生成最终的请求地址
6、交给http组件发送请求
feign接口启动注册流程
详细流程
1、启动类启动的时候扫描启动类上的注解@EnableFeignClients
2、这个注解中@EnableFeignClients中还有一个@Import注解,这个注解引入了一个FeignClientsRegistrar类
@Retention(RetentionPolicy.RUNTIME)<br>@Target(ElementType.TYPE)<br>@Documented<br>// 引入FeignClientsRegistrar 来扫描@FeignClient注解下的类<br>@Import(FeignClientsRegistrar.class)<br>public @interface EnableFeignClients {<br> ...<br>}
3、这个类实现了ImportBeanDefinitionRegistrar接口,也就是可以想spring容器中手动注入bean对象
**<br> * spring boot 启动时会自动调用 ImportBeanDefinitionRegistrar 入口方法<br> */<br>@Override<br>public void registerBeanDefinitions(AnnotationMetadata metadata<br> , BeanDefinitionRegistry registry) {<br> // 读取 @EnableFeignClients 注解中信息<br> registerDefaultConfiguration(metadata, registry);<br> // 扫描所有@FeignClient注解的类<br> registerFeignClients(metadata, registry);<br>}
4、FeignClientsRegistrar类中有一个方法registerBeanDefinitions ,做bean相关的操作
5、registerDefaultConfiguration方法,会去读取@EnableFeignClients注解;将这些信息注册到一个 BeanDefinitionRegistry 里面去
feign的一些默认配置将通过这里注册的信息中取获取
5、registerFeignClients方法中有registerFeignClients,和扫描所有@FeignClient注解的类
1、先扫描相关包路径
2、通过@FeiginClient注解信息向BeanDefinitionRegistry里面注册bean
registerFeignClients流程图
6、registerFeignClient方法构建bean
1、实际构建的FeignClientFactoryBean
详细流程图
流程图
监控中心
springBoot admin
链路追踪
sleuth
skywalking
pinpoint
微服务架构相关问题
基础概念类
什么是微服务?和单体应用相比有何优缺点?
缺点
简单
运维复杂、分布式事务难、调用链监控和调试难
详细
服务调用复杂性
网络问题
容错问题
负载问题
高并发问题
事物一致性问题
运维复杂性提高
单体服务只需要维护一个服务;
微服务需要维护很多个服务
测试复杂性提高
微服务调用链路变长了
优点
简单
优点:服务独立部署、技术栈灵活、易于扩展、按需伸缩
详细
1、服务部署灵活性提高
单体架构是每做一次修改,就必须要将单体服务进行全量的重新部署;
微服务是,修改某一块业务只需要部署这某一块业务对应的微服务就可以,发布快捷轻便;
2、技术更加灵活
单体引用对同一类型的技术栈,往往只选择一种技术栈,如果要做多个技术栈选择往往会相互影响;
而微服务可以是针对每一个拆分出来的服务做针对性的技术栈选型,而可以相互不影响;
3、应用性能得到提高
4、简化开发
单体服务
单体服务,就是所有开发都在开发一个单体服务,团队协作,分支合并要求很高;还需要团队的每个成员对整个系统都需要有一定的了解;
团队协作性要求高
每次做修改,都需要沟通团队中的相关其他开发;通知影响范围;
开发上手难度大
需要对整个系统都有一定了解
单体服务包含了各个业务代码,开发,改动起来影响范围更大
微服务
降低对团队协作性要求
一个开发组,只需要开发属于他那一块的微服务,不需要很高的团队协作性;
降低开发上手难度
快速开发只需要熟悉他那块的微服务就可以,不需要对整个系统都很了解;
5、业务边界清晰
单体服务
涉及到复合业务的时候,往往都是在其他的业务中书写相关的业务代码;业务边界,责任不够清晰;
微服务
对同一类型业务会,都已封装成对应的接口,由单独的团队或者开发来负责;业务边界清晰,责任分明
5、代码复用性
微服务还可以提高代码复用性;
单体架构和微服务架构的区别?
单体:一个应用包,所有功能放一起,部署简单但扩展难。
微服务:拆分成多个服务,灵活扩展,但需要治理体系(注册中心、配置中心、网关等)。
微服务之间如何通信?
同步:HTTP REST、gRPC、Dubbo RPC
gRPC
基于 HTTP/2 协议,支持多路复用、双向流、头部压缩。
使用 Protobuf(二进制序列化),性能比 JSON 更高。
用 Protobuf(二进制格式),体积小、性能高,但可读性差。
Dubbo
默认使用 TCP 长连接,结合自定义的二进制协议(Dubbo 协议),也可以支持 HTTP、gRPC。
更加灵活,主要用于 Java 体系。
支持多种序列化方式(Hessian2、Protobuf、JSON 等),默认 Hessian2(二进制格式)。
异步:消息队列(Kafka、RocketMQ、RabbitMQ)
微服务之间通过 HTTP 协议通信,遵循 REST 架构风格,通常使用 JSON 作为数据格式。
REST:是一种 架构风格,告诉你“该怎么设计 API”。
HTTP:才是真正的 通信协议,负责数据在客户端和服务端之间传输。
JSON/XML:是常用的数据格式,用来承载资源的数据。
RPC、gRPC、Thrift 的区别?
RPC(Remote Procedure Call,远程过程调用)
概念
RPC 是一种 通信范式,允许客户端像调用本地方法一样调用远程服务<br><br>本质:封装网络通信,让调用远程服务像本地方法一样透明
特点
可以使用不同协议实现(HTTP、TCP、UDP 等)
序列化方式灵活(JSON、XML、Protobuf 等)
语言无关(取决于具体实现)
gRPC(Google RPC)
gRPC 是 Google 开源的高性能 RPC 框架
基于 HTTP/2 和 Protobuf(默认)
支持 多语言(Java、Go、Python、C++ 等)
Apache Thrift
概念
Thrift 是 Apache 开源的跨语言 RPC 框架
最初由 Facebook 开发
提供 接口定义语言(IDL) + 跨语言序列化/传输协议
微服务如何划分?
按业务领域(DDD 思想)
单一职责,独立部署,避免过度细化
微服务和 SOA 有什么区别?
SOA:面向企业级 系统集成,强调“服务复用 + 中心化”。
微服务:面向互联网 敏捷开发,强调“服务自治 + 去中心化”。
什么情况下不适合上微服务?
系统规模较小
如果是一个 简单的管理后台、企业官网、内部工具,业务逻辑不复杂。
团队规模较小
微服务强调 团队与服务一一对应(Conway 定律)。
业务模型不清晰
业务还在快速变化,领域边界不明确时,如果强行拆分服务,很容易拆错。
技术和运维能力不足
微服务需要 完善的 DevOps、自动化测试、持续集成/部署、容器化、监控告警。
对性能要求极高、延迟敏感
单体应用内部调用是 方法调用,延迟非常低。
事务一致性要求很高
微服务天然是分布式的,事务一致性需要用 分布式事务(TCC、Saga、MQ 补偿) 来保证。
微服务架构特点
一组小的服务
独立的进程
轻量级通信
基于业务能力
独立部署
无集中式管理
服务治理类
为什么需要注册中心?
动态发现服务,避免硬编码 IP/端口
支持扩容/缩容,负载均衡
微服务如何实现服务注册与发现?
通过注册中心(如 Eureka、Nacos、Zookeeper、Consul)。
Provider 启动时注册服务,Consumer 通过注册中心发现可用服务。
微服务调用如何实现负载均衡?
客户端负载均衡:Ribbon、Feign
服务端负载均衡:Nginx、Gateway、K8s Service
Eureka 和 Zookeeper 的区别?
Zookeeper:CP(强一致性,节点挂掉可能不可用)
Eureka:AP(保证可用性,短暂不一致但可继续服务)
日志
如何做 集中日志管理?(ELK、EFK)
总结
集中日志管理 = 采集 (Filebeat/Fluentd) → 传输 (Kafka/直发) → 存储 (Elasticsearch/Loki) → 展示 (Kibana/Grafana) → 告警。
详细步骤
日志采集
每个服务写日志到本地文件(Logback / Log4j2)。
通过 Agent/采集器 收集日志
Filebeat(轻量级日志收集器,常配合 ELK)
Fluentd / Fluent Bit(CNCF 项目,性能更高)
Logstash(功能强大,但资源开销大)
日志传输
采集器将日志发送到消息队列或日志存储:
Kafka(常见缓冲层,削峰填谷)
直接推送到 Elasticsearch / Loki
日志存储
Elasticsearch:全文检索能力强,查询灵活。
日志分析与展示
Kibana(可视化查询,配合 Elasticsearch)。
或者
Grafana + Loki(轻量化日志查询、告警)。
Graylog(开源日志管理平台)。
告警与联动
日志异常 → 触发告警 → 通知(钉钉、企业微信、PagerDuty)。
结合 Prometheus + Alertmanager,实现指标与日志联动。
为什么要集中日志?
微服务部署在不同节点,日志分散。
线上问题要快速定位,单机 grep 不现实。
需要全局视角:查询、聚合、分析、报警。
监控
如何实现服务监控?
Metrics 指标:Prometheus + Grafana
链路追踪:Sleuth + Zipkin / SkyWalking / Jaeger
健康检查:Actuator /health
链路追踪的作用?
跨服务调用时跟踪完整链路,定位性能瓶颈和异常
如何监控微服务的 健康状态
监控微服务的健康状态是 运维和高可用 的核心工作
常见做法包括 主动探测 + 被动监控 + 日志/指标收集
1. 应用层健康检查
目标:判断单个服务是否正常<br>
在每个微服务中提供健康检查接口(常见 /health、/actuator/health)
使用 Spring Boot Actuator,自动提供 /actuator/health,可显示数据库、Redis、消息队列等依赖的健康情况。
可以定制检查逻辑,比如依赖的外部服务是否可用
2. 服务调用链监控
目标:判断微服务之间调用是否正常、是否有瓶颈。
3. 系统指标监控
监控内容
应用级指标:QPS、RT、错误率、线程池情况、队列堆积。
系统级指标:CPU、内存、磁盘、网络带宽。
监控工具
Prometheus + Grafana:常见组合,采集 + 可视化。
Micrometer:Spring Cloud 的指标收集库,支持接入 Prometheus、InfluxDB 等。
4. 日志监控与报警
集中日志管理:ELK(Elasticsearch + Logstash + Kibana)、EFK(Fluentd)。
异常日志报警:接入 告警系统(如钉钉/企业微信/邮件)。
5. 熔断与降级机制(被动容错)
目标:即使监控不到位,微服务也要有 自我保护<br>
Hystrix / Resilience4j:支持熔断、降级、隔离,防止雪崩。
K8s HPA(自动扩容):CPU/请求数过高时自动扩容。
配置
微服务配置中心的作用?
集中管理配置,支持动态刷新、多环境、多租户、灰度发布
配置如何实现 动态刷新?
不同的配置中心有不同的实现方式
Nacos Config
客户端会和 Nacos Server 建立 长轮询 或 推送机制。
当配置变更时,Nacos Server 主动推送变更通知。
Apollo(携程开源)
客户端和 Apollo Server 长轮询。
配置变更时 Apollo Server 主动通知客户端拉取。
常见配置中心有哪些?
Spring Cloud Config、Apollo、Nacos、Consul KV
微服务配置如何管理?
使用配置中心(Spring Cloud Config、Apollo、Nacos)集中管理,支持动态刷新、多环境。
微服务网关
网关在微服务架构中的作用?
统一入口,路由转发
鉴权、限流、熔断、日志、跨域处理
常见实现:Spring Cloud Gateway、Zuul、Kong、Traefik
容错与高可用
微服务如何实现熔断和限流?
熔断:Hystrix、Resilience4j、Sentinel
限流:令牌桶、漏桶算法,或使用网关(Nginx/Gateway)
服务雪崩效应是什么?如何解决?
含义:一个服务不可用,导致调用它的服务也不可用,逐级放大。
解决:熔断、隔离(线程池/信号量隔离)、限流、服务降级。
如何保证微服务的高可用?
多实例部署 + 负载均衡
健康检查和自动剔除不可用节点
配置中心、注册中心的高可用(集群部署)
服务降级(返回兜底数据)
服务熔断(避免雪崩效应)
限流(防止流量突增压垮服务)
异步削峰
熔断和降级,限流区别?
熔断:服务异常/超时过多,直接切断请求
目的
防止下游服务故障或高延迟影响整体系统<br><br>类似电路熔断,遇到故障自动中断请求,防止故障扩散
原理<br><br>状态机:<br><br>闭合(Closed):正常请求,统计错误率<br><br>打开(Open):错误率超过阈值,短时间内拒绝请求<br><br>半开(Half-Open):尝试少量请求,验证服务是否恢复<br><br>当下游恢复正常后,熔断器回到闭合状态
实现方式<br><br>Netflix Hystrix(Java)<br><br>Resilience4j<br><br>Spring Cloud Circuit Breaker
降级:提供备用逻辑或默认响应
目的<br>
当下游服务不可用或响应过慢时,主动降低功能或返回备用结果,保证系统核心功能可用
实现方式
返回默认值 / 缓存值<br><br>比如库存服务不可用时,返回最近一次缓存的库存
简化功能<br><br>比如社交应用动态加载失败,显示文字占位而非图片
静态兜底数据<br><br>提供固定提示或降级内容
限流
目的<br><br>控制系统访问流量,防止过载<br><br>保护下游服务、数据库或资源池不被压垮
实现方式<br><br>固定窗口计数(Fixed Window)<br><br>每个固定时间窗口允许的请求数<br><br>滑动窗口(Sliding Window)<br><br>更平滑统计请求数,防止突发流量<br><br>漏桶算法(Leaky Bucket)<br><br>请求以固定速率流入处理队列,多余请求排队或丢弃<br><br>令牌桶算法(Token Bucket)<br><br>以固定速率生成令牌,请求消耗令牌,超出速率限制流量
具体场景:秒杀系统如何防止流量冲垮服务?
做法
1. 前端限流
目的:在请求到达后端前就做流量削峰。
方式
固定窗口/滑动窗口限流:通过 Nginx、网关或中间件限制每秒请求数。
漏桶/令牌桶算法:平滑流量,防止瞬时峰值冲垮后端。
2. 请求排队 / 异步处理
目的:把瞬时大量请求缓冲,降低后端瞬时压力。
方式
消息队列:将请求放入队列,后端异步消费(Kafka、RabbitMQ、RocketMQ)。
分布式队列:每个商品有一个队列,按顺序处理请求。
好处:秒杀瞬时高峰不会直接压到数据库或库存服务。
3. 库存预减 / 内存标记
目的:减少数据库压力,防止超卖。
方式:
1. Redis 预减库存
2. 内存标记:每个商品在应用内存中维护“是否售罄”标记,售罄直接拒绝请求,避免频繁访问 Redis/DB。
好处:大幅减少 DB 访问,防止库存超卖。
4. 服务熔断与降级
目的:在系统压力过大时,快速拒绝部分请求,保护核心服务。
方式:
使用 Sentinel / Resilience4j 设置熔断规则。
对非核心功能(比如日志统计、排行榜等)进行降级处理。
好处:保证核心秒杀服务可用,不因为非核心请求宕机。
5. 缓存与 CDN
目的:降低数据库压力,提高读取性能。
方式:
秒杀商品信息、库存放入 Redis 缓存。
静态内容可通过 CDN 缓存。
好处:快速返回商品信息,减少 DB 请求量。
6. 数据库优化
分库分表:减轻单表压力。
行级锁/乐观锁:避免超卖。
批量更新:将库存更新操作批量处理,降低事务冲突。
7. 微服务架构配合
网关 + 服务注册发现 + 负载均衡:
网关限流 + 路由请求到多实例。
异步消息 + 秒杀服务 + 库存服务 + 下单服务:
请求异步排队,库存预减,订单异步生成。
监控 & 报警:
Prometheus/Grafana 实时监控 QPS、延迟、库存情况。
微服务 A 调用 B、C 服务时,如何保证调用可靠、可观察?
调用可靠性
重试(Retry)
作用:网络抖动或临时异常时重试,增加成功率
注意:<br><br>配合 指数退避(Exponential Backoff) 避免雪崩<br><br>设置最大重试次数,防止无限循环
限流 / 降级(Rate Limit / Circuit Breaker)
限流:避免下游压力过大<br><br>熔断(Circuit Breaker):下游故障时快速失败,保护系统<br><br>降级:提供默认值或缓存数据,保证服务可用
异步调用 / 消息队列
对于非实时业务,可用 异步消息解耦调用<br><br>优势:<br><br>降低同步调用压力<br><br>可重试、持久化,保证最终一致性
幂等性设计
确保同一个请求重复调用不会产生副作用<br><br>常见方法:<br><br>唯一请求 ID<br><br>数据库唯一约束<br><br>幂等操作接口
可观察性
日志(Logging)
记录调用请求、参数、返回值、异常<br><br>建议使用 结构化日志,便于搜索和分析<br><br>可结合 集中化日志系统(ELK / Loki / Graylog)
指标监控(Metrics)
收集调用次数、成功率、延迟、异常率<br><br>Prometheus + Grafana 是常用组合
分布式追踪(Tracing)
跨服务调用链路可视化<br><br>常用工具:Zipkin、Jaeger、SkyWalking<br><br>利用 Trace ID 追踪请求全链路
健康检查
每个服务提供 /health 接口<br><br>调用方或注册中心定期探测服务健康状态
微服务调用系统中网络延迟、抖动和分区容错处理方法
网络延迟
问题
请求从节点 A 发送到节点 B 的时间不可预测,可能延迟很高
高延迟可能导致服务调用超时、请求堆积
处理方法
超时设置(Timeout)
每个 RPC/HTTP 请求设置合理超时,防止长时间阻塞
设置连接超时时间,读取超时时间
异步调用
异步请求、Future/Promise、消息队列
避免同步阻塞,提高吞吐量
批量请求
将多个请求合并,减少网络往返次数
示例:数据库批量查询、RPC 批量调用
本地缓存 / 最近数据缓存
避免频繁远程调用,降低延迟对业务的影响
网络抖动
问题
网络延迟波动大,导致响应时间不稳定
对高可用系统影响更大,可能触发不必要的重试或熔断
处理方法
指数退避
重试请求时,每次延迟递增,减少对网络的瞬时压力
抖动(Jitter)策略
在退避延迟中增加随机值,避免所有客户端同时重试导致雪崩效应
负载均衡
请求分发到延迟低、负载均衡的节点
常用方式:客户端负载均衡(Ribbon)或服务端负载均衡(K8s Service / Nginx)
分区容错
问题
系统被网络分区(Partition)隔离,节点无法互相通信
CAP 定理表明:在分区发生时,需要在 一致性 和 可用性 之间做权衡
处理方法
副本机制
数据多副本存储,即使部分节点不可达,仍能提供服务
Leader / Follower 选举
利用一致性协议(Raft、Paxos)选出主节点处理写请求
保证在网络分区下仍有单一写入入口
异步写 / 最终一致性
分区时仍允许节点处理请求(可用性优先)
后续通过 副本同步 或 补偿机制 达到最终一致
降级与熔断
分区发生时,拒绝部分请求或返回默认值,保护核心服务
避免雪崩式故障传播
重试与补偿
网络恢复后,对失败请求进行重试
对不可幂等操作使用 补偿事务(TCC / Saga)
数据与事务
微服务如何处理分布式事务?
方案:
2PC(强一致性,但性能差)
TCC(Try-Confirm-Cancel)
Saga(长事务补偿机制)
消息最终一致性(MQ 事务消息)
如何保证不同微服务的数据一致性?
最终一致性(BASE 理论)
事件驱动架构(Event Sourcing)
什么是 最终一致性?
最终一致性是一种 弱一致性模型。
在分布式系统中,当一个数据被更新后,系统允许短时间内各节点数据不一致,但经过一段时间后,所有节点最终会达到一致
实现方式
异步消息/事件
补偿机制
如果一个订单系统和库存系统同时更新,怎么保证数据一致?
网关与安全
微服务网关的作用?
路由转发
统一鉴权与认证(JWT/OAuth2)
限流与熔断
日志收集
常见网关实现有哪些?
Nginx(通用负载均衡)
Spring Cloud Gateway
Kong、Zuul
K8s Ingress
什么是 OAuth2在微服务中如何应用?
OAuth2 是什么?
一种 授权框架(不是协议,也不是具体实现)。
主要解决的问题是:
用户如何把自己在某个系统里的资源,安全地授权给另一个应用访问?
微服务之间的调用也只需要经过一次校验权限
在微服务中的应用
微服务架构下,通常有很多独立的服务(订单、库存、用户、支付...)。如果没有统一的授权机制:
每个服务都得单独管理登录/鉴权,复杂而且不安全。
服务间调用可能会被伪造或越权访问。
用 OAuth2 来做统一的 认证 + 授权中心
1、引入统一的授权服务器(可以用 Keycloak、Auth0、Spring Authorization Server)。
2、用户登录时 → 授权服务器颁发 Access Token(常用 JWT 格式)。
3、前端或 API Gateway 在调用微服务时,把 Token 放到 Authorization: Bearer <token> 请求头里。
4、每个微服务接到请求时
校验 Token 是否有效(签名、过期时间、scope/权限)。
决定是否允许访问该资源。
OAuth2如何实现微服务相互调用权限合法性?<br>
在微服务架构里,所有 Token 都是统一的授权服务器(Authorization Server)发的;这样每个服务只要会验证这个“签发方”的 Token 就行
token传递分为两种场景<br>
转发用户的 Token
前端用户登录后拿到 Access Token(JWT)。
前端调用 订单服务时带上这个 Token。
订单服务再调用 库存服务时,把同一个 Token 转发过去。
库存服务验证、
Token 是否由授权服务器签发(签名验证)。
Token 是否过期。
Token 里的 scope / role / claim 是否允许访问库存 API。
好处:能明确知道“是哪个用户在下单”。
缺点:Token 在多个服务间传来传去,可能会暴露过多权限。
订单服务使用自己的服务 Token
授权服务器事先给每个微服务注册一个 Client ID / Secret。
订单服务调用库存服务时,先用 Client Credentials Flow 去授权服务器换一个 Token。
这个 Token 的权限是“订单服务 → 库存服务”。
库存服务验证这个 Token 的合法性后才返回结果。
好处:粒度清晰,每个服务只拿自己需要的权限。
缺点:如果需要传递用户身份信息,还要额外设计。
验证 Token 合法性的方式
本地验证(常用,性能高)
Access Token 用 JWT 格式,包含签名。
库存服务只要拿到授权服务器公开的 公钥(JWKS endpoint),就能验证签名合法性。
远程验证(集中校验,性能低一些)
库存服务向授权服务器发请求,调用 introspection endpoint(OAuth2 标准接口)。
授权服务器告诉它:这个 Token 是否有效、属于谁、scope 有哪些。
权限服务器是一台单独做权限的服务器吗?
微服务体系里,这个 认证/授权服务器(Authorization Server / Identity Provider) 一般确实是 一个独立的服务,主要负责 身份认证和权限发放,而不会混杂业务逻辑
主要做三件事情
认证(Authentication)
负责“你是谁”。
处理用户的登录、注册、验证密码、多因素认证(MFA)。
授权(Authorization)
负责“你能做什么”。
发放 Access Token / Refresh Token / ID Token。
Token 里会写明用户角色、scope、权限范围。
集中管理账号和权限
统一用户目录(User Directory)。
管理用户 → 角色 → 权限的映射关系。
提供 OAuth2 / OIDC 协议接口给微服务调用。
微服务部署与容器化
微服务一般如何部署?
Docker 容器化 + Kubernetes 编排
配合 CI/CD 流水线自动发布
基础概念
容器
封装微服务运行环境。
Docker容器只是容器实现的其中的一种方式
Docker
流行的容器引擎
功能
打包应用(build 镜像)。
运行容器(run)。
提供镜像仓库(Docker Hub)。
Kubernetes(K8s)
容器编排平台
功能:
管理成百上千个容器的部署、扩容、滚动更新。
提供服务发现、负载均衡。
监控容器健康状态,挂掉了自动拉起来。
pod<br>
Pod 是 Kubernetes(K8s)中最小的调度单位
换句话说,K8s 在集群里分配资源、调度运行的最小对象就是 Pod。
一个 Pod 可以包含 一个或多个容器,但这些容器共享网络和存储,并且生命周期绑定在一起。
一般情况下会有一个微服务应用以及日志收集服务;不会存在两个微服务
Service
概念
Service 提供 Pod 的稳定访问入口
在 K8s 中,Pod 是 短暂的、会随调度变化而重建的
Service 通过标签选择器(Selector)将请求转发到对应 Pod 集合
Deployment
Deployment 用于 声明式管理 Pod 副本(Replica)
负责:<br><br>创建 Pod 副本<br><br>版本升级(Rolling Update)<br><br>回滚历史版本<br><br>扩缩容(scale up/down)
特点<br><br>Pod 是 Deployment 的实例,Deployment 管理 Pod 的生命周期<br><br>保证 Pod 数量满足副本数(Replica)<br><br>支持滚动更新、蓝绿发布等策略
Kubernetes 在微服务中的作用?
服务发现
负载均衡
如何实现负载均衡
K8s 自带基本负载均衡(Pod 间流量分发)。
给同一个服务的不同pod会标记成一个组<br>
当请求打到 Service 时,K8s 会自动在组中的 Pod 之间做 负载均衡(通常是轮询)。
自动弹性伸缩
弹性伸缩的层次
Pod 级别
作用:根据应用负载动态调整 Pod 副本数。
节点级别
作用:Pod 扩容需要更多计算资源时,自动增加节点;节点闲置时自动回收。
扩缩容的是“运行 Pod 的机器”
容器资源调整
作用:动态调整 Pod 容器的 CPU / 内存请求与限制。
弹性伸缩流程
监控:HPA/VPA/CA 监控指标(CPU、内存、请求量、自定义指标)。
判断:指标超阈值 → 触发扩容,低于阈值 → 触发缩容。
执行:
HPA:增加或减少 Pod 副本数。
VPA:调整 Pod 内容器资源。
CA:增加或减少节点数量。
调度:K8s Scheduler 把新 Pod 调度到可用节点。
demo<br>
用户访问量高峰 → CPU 使用率超过 70% → HPA 扩容 Pod 数量 3 → 5
节点资源不够 → Cluster Autoscaler 自动添加节点
高峰结束 → CPU 使用率下降 → HPA 缩容 Pod 数量 5 → 2
空闲节点 → Cluster Autoscaler 回收节点
如何实现 蓝绿发布、灰度发布、滚动更新?
滚动更新
概念
默认的 K8s Deployment 更新方式。
逐步替换 Pod:旧版本 Pod 被新版本 Pod 替换,但始终保持服务可用。
工作原理
Deployment 更新镜像或配置。
K8s 按配置(maxUnavailable、maxSurge)逐个或逐批替换 Pod
旧 Pod 健康检查通过后被删除,新 Pod 替换完成。
特点
无停机,平滑更新。
配置灵活:可以控制更新速度和并发数量。
蓝绿发布
概念
同时运行 两套环境:
蓝色:当前线上版本
绿色:新版本
流量切换一次性从蓝色切到绿色。
工作原理
部署绿色环境(新版本 Pod),与蓝色环境并行。
测试新版本健康状态。
切换流量(Service/Ingress 指向绿色 Pod)。
蓝色环境可以保留一段时间作为回滚。
特点
切换瞬间完成,停机时间几乎为 0。
回滚简单:只需切回旧版本 Service。
需要更多资源(同时保留两套环境)。
灰度发布
概念
逐步放量:新版本先分配一小部分流量,验证稳定后再逐步增加。
工作原理
部署少量新版本 Pod(Canary Pod)。
配置流量分配策略(Ingress、Service Mesh、Istio、NGINX 等)。
监控指标(错误率、响应时间)。
如果稳定 → 逐步增加新版本流量,最终替换旧版本。
出问题 → 回滚到旧版本。
特点
风险最小,适合复杂业务。
可以结合 A/B 测试。
配置复杂,需要支持流量路由的工具(Service Mesh、Ingress Controller)。
k8s 如何让微服务如何实现自动化部署?
微服务自动化部署目标
快速交付:代码提交 → 自动构建 → 测试 → 部署
稳定可靠:标准化流程,减少人为错误
零停机:通过滚动更新、蓝绿或灰度发布
弹性伸缩:部署后自动适应流量
Kubernetes 下自动化部署流程
源码管理
每个微服务单独 Git 仓库(或 mono repo)
代码 Push 或 Merge Request → 触发 CI/CD
持续集成(CI)
构建镜像
编译代码 → 单元测试 → Docker 镜像打包
推送到镜像仓库(Harbor、Docker Hub 等)
自动化测试
单元测试、集成测试、静态扫描、漏洞扫描
持续部署(CD)
更新 K8s 配置
Deployment / StatefulSet / Service / Ingress 的 YAML 或 Helm Chart
镜像版本号更新(image tag)
部署策略
滚动更新(Rolling Update)
蓝绿发布(Blue-Green Deployment)
灰度发布(Canary Deployment)
自动回滚
Deployment 健康检查失败 → 回滚到上一版本
监控与告警
热点进阶问题
CAP 理论是什么?在微服务里怎么理解?
C(一致性)、A(可用性)、P(分区容忍性),三者不可同时满足。
微服务一般选择 AP 或 CP,通过 BASE 理论(最终一致性)解决强一致性问题。<br>
CAP 定理在微服务中的应用?
分布式系统无法同时满足一致性(C)、可用性(A)、分区容忍性(P)
注册中心选型时要权衡:
Zookeeper 偏向 CP
Eureka 偏向 AP
你在项目中如何落地微服务架构?
注册中心(Nacos/Eureka)
配置中心(Apollo/Nacos)
网关(Gateway/Nginx)
熔断/限流(Sentinel/Resilience4j)
监控(Prometheus + Grafana + Zipkin)
部署(Docker + K8s)
微服务实用性
引入微服务的时间点
什么样的组织结构更适合微服务架构
中台战略
分层
IAAS
paas层
应用
核心业务层
渠道接入
业务前台
业务中台
业务后台
服务发现模式
传统lb模式
依赖外接的负载均衡器(F5,NGINX)
主机内lb模式
在每主机上部署一个负载均衡器
进程内lb模式
负载均衡移动到应用服务内
性能好,
zuul网关
前置路由过滤器
路由过滤器
后置路由过滤器
可动态插拔
网关上设计防爬虫
路由发现体现
服务分层
服务网关
服务之间是怎么相互发现
外面流量怎么通过网关访问微服务
服务
基础服务
相互之间同步路由表
聚合服务
服务调用方式
RPC
REST
服务治理
配置集成
文档
统一异常处理
代码生成
自动生产服务端客户端
序列化
REST/RPC
安全访问控制
限流熔断
调用链埋点
Metrics
日志
负载路由
服务注册发现
后台服务集成,DB,MQ,CACHE
微服务监控系统分层监控架构
日志监控
健康检查
调用链监控
告警系统
metrics监控
子主题 6
ELK -- log监控
nagios
调用链监控选型
CAT
ZIPKIN
PINPOINT
字节码增强的方式做
子主题 4
容器
解决的问题
环境一致性问题
镜像部署问题
容器集群调度平台
容器发布
发布体系
k8s集群
微服务业务拆分维度和原则
维度(拆分方式)
1、功能维度<br>
按照系统业务功能进行划分,例如对于电商系统,按功能维度咱们能够拆分为商品中心,订单中心,用户中心,购物车,结算等功能模块
2、状态维度
功能模块如果能够按照不一样的业务状态再进行划分,就好比电商中的优惠券,可以分成建立优惠券,领券,使用优惠券,优惠券失效
相同的业务从开始到结束的不同状态的区分
3、读写维度
按照读写压力拆分
商品中心读压力大,那么就将商品读写分成两个服务,以提高系统安全性,可用性<br>
4、纵深维度
按照业务纵深维度,最底层的业务模块和上层的业务模块拆分开
比如说:订单需要用到商品,用户,等信息;但是用户模块,商品模块是不会用到订单信息;此时商品模块和用户模块就是相当于订单模块就是下层模块
5、AOP维度
根据访问特征,按照aop拆分
商品详情页能够分为CDN、页面渲染模块等。而CDN就是一个AOP
AKF拆分原则
概述
也就是服务拆分的一个总的指向原则
Availability(可用性)
系统要保证高可用,避免单点故障。
在拆分服务时,要确保即使某个服务不可用,其他服务依然可以正常运行。
常用方法:冗余、负载均衡、服务隔离。
K-factor(增长因子 / 可扩展性)
“K”代表可扩展性,关注如何水平扩展系统来应对用户增长。
拆分服务时,需要考虑不同模块的负载和增长模式,确保可以独立扩展。
例如:用户服务、订单服务、支付服务可以分别水平扩展。
Failure isolation(故障隔离)
当系统某部分发生故障时,要限制影响范围,不让整个系统瘫痪。
设计原则:单个服务出问题不影响其他服务(类似微服务的理念)。
微服务应用架构原则
2、前后端分离
3、无状态服务
不能在服务本地内存中缓存数据
4、无状态通讯原则
降低服务之间通讯协议沟通成本
一、服务设计原则
单一职责原则 (Single Responsibility)
每个微服务只聚焦一个清晰的业务能力,例如订单服务、库存服务、支付服务。
避免“大而全”的服务,降低耦合。
高内聚,低耦合
服务内部紧密围绕某一业务目标组织,外部依赖尽可能少。
避免跨服务强耦合、循环调用。
自治性 (Autonomy)
服务应当可以独立开发、部署、扩展、运维。
个服务升级不应强制影响其他服务。
小而轻量 (Size & Scope)
微服务不追求越小越好,而是“业务边界清晰”。
避免过度拆分,增加管理复杂度。
二、接口与通信原则
API 优先 / 契约优先 (API First / Contract First)
服务之间的通信必须通过明确的接口契约(REST/gRPC/GraphQL 等)。
避免共享数据库、绕过 API 直接访问内部数据。
无状态 (Stateless)
服务调用尽量无状态,用户状态存储在外部(Redis/Session 服务/Token)。
方便水平扩展与负载均衡。
异步优先
在可能的情况下,使用事件驱动、消息队列降低耦合,提高吞吐。
同步调用仅用于强一致或强实时需求。
三、数据与存储原则
每个服务独立数据存储 (Database per Service)
不同服务不共享数据库表,保证自治和解耦。
需要一致性时,通过 API、消息事件实现。
最终一致性优先
在分布式系统中,牺牲部分强一致性,采用补偿/对账机制保证最终一致。
避免大范围分布式事务。
四、部署与运维原则
独立部署 (Independent Deployment)
每个服务可以单独构建、发布、回滚。
配合 CI/CD 流水线实现快速上线。
自动化与容器化
服务应能在容器(Docker、K8s)中独立运行,便于扩缩容。
配置中心、服务发现、注册中心等支撑组件必不可少。
可观测性 (Observability)
服务必须具备日志、指标、链路追踪能力(Logging / Metrics / Tracing)。
方便故障定位与监控。
五、组织与团队原则
按业务能力划分团队 (Conway’s Law)
团队和服务边界对应,每个团队负责一个或多个完整的业务能力。
避免跨团队依赖过多。
DevOps 文化
团队对服务全生命周期负责(开发、测试、运维、监控)。
强调自治与快速迭代。
六、演进与治理原则
演进式架构 (Evolutionary Architecture)
微服务拆分/合并应当可以演进,不是一拆到底。
支持灰度发布、AB 测试、蓝绿部署。
容错与弹性 (Resilience)
超时、重试、限流、熔断、降级必须设计在服务调用中。
系统要能在部分失败时继续提供核心功能。
治理与标准化
统一的 API 规范、认证授权、安全策略。
服务注册发现、配置管理、版本控制要有统一机制。
微服务概论
微服务产生
微服务是有一个martin fowler大师提出来的,是一种架构风格,通过将大型单体应用划分成较小服务单元,从而降低整个系统复杂度
springCloud和springCloudalibaba都有哪些组件
spring cloud netflix
配置中心
Spring Cloud Config
注册中心
Eureka<br>
提供了一个服务注册中心、服务发现的客户端,还有一个方便的查看所有注册的服务的界面。 所有的服务使用Eureka的服务发现客户端来将自己注册到Eureka的服务器上
远程调用
Feign
服务客户端,服务之间如果需要相互访问,可以使用RestTemplate,也可以使用Feign客户端访问
负载均衡
Ribbon
熔断降级
Hystrix
Hystrix Dashboard
提供可视化界面,监控各个服务上服务调用所花费的时间
监控和断路器
通过快速的失败,降低服务的级联报错
网关
Zuul
客户端的请求都需要先通过网关后,再请求后台服务,通过配置的路由来判断请求需要访问哪个问题,再从注册中心获取注册服务来转发请求
监控
Turbine
聚合监控平台
可以查看所有的服务实力,都聚集到统一的一个地方查看;
springCloud alibaba
注册中心-配置中心
nacos
负载均衡
Ribbon
服务调用
Feign
熔断降级
Sentinel
网关
Gateway
调用链路监控
Sleuth
分布式事物处理
Seata
springCloud
提供了构建微服务系统所需要的一组通用开发模式;以及一系列快速实现这些开发模式的工具
通常说的springCloud是指的是springCloud netflix;和springcloud cloud alibaba都是springcloud这一系列开发模式的具体实现
springcloud和dubbo区别
dubbo开始只是一个rpc调用框架,核心是解决服务调用问题,侧重也是服务调用,没有springcloud功能全面;springcloud 是一个大而且全的框架,提供了一些列的解决方案;dub
dubbo数据传输直接使用传输层的二进制传输,对象直接转成二进制数据
spring cloud 是使用应用层http协议进行传输,数据最终会转成二进制,中件会有性能消耗
soa,分布式,微服务之间的关系和区别
SOA
SOA历史
上世纪90年代出现的一个面向服务的体系结构
SOA缺点
ESB(服务总线)是单体结构,很容易出现单点故障<br>
SOA不能解决部署速度
SOA很容易出现功能直接相互依赖
soa和微服务
soa是一种架构设计风格,是为了将单体服务拆分成一些具有特定业务目标的较小模块
微服务也是soa架构思想的一种形式
两者区别
服务通讯方式
SOA依赖消息传递协议在服务之间进行通信
数据存储
SOA类似单体服务,通常都是共享使用一个数据库
微服务,每一个微服务都有自己业务的服务
规模和范围
虽然都是较小服务组成,但是SOA服务的粒度比较粗,微服务粒度比较小
通信
微服务之间是通过与语言无关的http协议通信
SOA通过SOA上层的ESB,通过消息传递协议进行服务之间通信
松耦合和高内聚
微服务的耦合性更低
SOA耦合性更高
SOA,和微服务架构图
左边是SOA,右边是微服务
分布式和微服务
两者区别
部署方式
分布式架构,将打的系统分为多个业务模块,部署到不同机器上,通过接口进行数据交互;
微服务可以部署在同一台机器上也可以分散部署到不同的机器上
两者联系
微服务架构也算是分布式架构的一种
三者之间的联系
SOA架构,微服务架构都可以看做是分布式架构思想的一种表现
spring生态
spring-生态
springframework<br>
springframework 是spring 里面的一个基础开源框架
spring data
提供对各种数据源操作的封装
Spring Cloud Data Flow
Spring Cloud Data Flow是用于构建数据集成和实时数据处理管道的工具包
Spring for GraphQL
spring 对图数据结构的处理
spring-cloud生态
Azure
spring cloud 为项目部署提供的一套环境
项目发布的云平台
可以为项目提供生命周期管理,监控诊断,配置管理,服务发现,CI/CD集成,蓝绿部署
Spring Cloud Alibaba
提供一整套分布式项目的各种技术解决的框架
<font color="#ffffff">Spring Cloud netflux</font>
<font color="#ffffff">提供一整套分布式项目的各种技术解决的框架</font>
Spring Cloud for Amazon Web Services<br>
可简化与托管Amazon Web Services的集成
spring cloud bus
用于实现微服务之间的通信<br>
spring cloud bus整合 java的事件处理机制和消息中间件消息的发送和接受,主要由发送端、接收端和事件组成
Spring Boot Cloud CLI
该工具为Spring Boot CLI提供了一组命令行增强功能,有助于进一步抽象和简化Spring Cloud部署
Spring Cloud Cloud Foundry
Spring Cloud for Cloudfoundry可以轻松地在Cloud Foundry(平台即服务)中运行Spring Cloud应用程序。 Cloud Foundry具有“服务”的概念,即“绑定”到应用程序的中间件,实质上为其提供包含凭据的环境变量(例如,用于服务的位置和用户名)
Spring Cloud - Cloud Foundry Service Broker<br>
Spring Cloud Cluster<br>
Spring Cloud Cluster提供了一组用于在分布式系统中构建“集群”功能的功能。 例如领导选举,集群状态的一致存储,全局锁和一次性令牌。<br>
Spring Cloud Commons
Spring Cloud Commons模块是为了对微服务中的服务注册与发现、负载均衡、熔断器等功能提供一个抽象层代码,可以自定义相关基础组件的实现
Spring Cloud Config
spring的配置中心
统一管理微服务配置的一个组件,具有集中管理、不同环境不同配置、运行期间动态调整配置参数、自动刷新等功能。
参考文档
https://blog.csdn.net/u011066470/article/details/106741430
Spring Cloud Connectors
简化了云平台(如Cloud Foundry和Heroku)中连接服务和获取操作环境感知的过程,尤其适用于Spring应用程序
它是为可扩展性而设计的:您可以使用提供的云连接器之一或为您的云平台编写一个,并且您可以使用内置支持常用服务(关系数据库,MongoDB,Redis,RabbitMQ)或扩展Spring 云连接器可与您自己的服务配合使用。
SpringCloud Consul
Consul是一套开源的分布式服务发现和配置管理系统
提供了微服务系统中的服务治理、配置中心、控制总线等功能。这些功能中的每一个都可以根据需要单独使用,也可以一起使用以构建全方位的服务网格,总之Consul提供了一种完整的服务网格解决方案
Spring Cloud Contract
为通过CDC(Customer Driven Contracts)开发基于JVM的应用提供了支持。它为TDD(测试驱动开发)提供了一种新的测试方式 - 基于接口
传统自测
示意图
<font color="#ffffff">Spring Cloud Contract</font>
示意图
Spring Cloud Function<br>
通过函数促进业务逻辑的实现
将业务逻辑的开发生命周期与任何特定运行时目标分离,以便相同的代码可以作为Web端点,流处理器或任务运行<br>
支持无服务器提供商之间的统一编程模型,以及独立运行(本地或PaaS)的能力<br>
在无服务器提供商上启用Spring Boot功能(自动配置,依赖注入,指标)<br>
就像Spring一直在推广基于普通java对象(POJO)的编程模型一样,Spring Cloud Function也基于普通的函数来推广编程模型。我们指的是java.util.function包中定义的核心接口:Function,Consumer和Supplier。<br>
Spring Cloud Gateway
网关
Spring Cloud GCP<br>
Spring 数据是用于在众多存储技术中存储和检索 POJO 的抽象。 Spring Cloud GCP 在数据存储模式下为Google Cloud Firestore添加了 Spring Data 支持。<br>
与谷歌的数据处理的整合
Spring Cloud Open Service Broker
Spring Cloud Open Service Broker 是一个框架,用于构建实现Open Service Broker API 的Spring Boot应用程序。<br>
Spring Cloud Pipelines<br>
该项目试图解决以下问题:<br><br> 创建公共部署管道<br> 传播良好的测试和部署实践<br> 加快将功能部署到生产所需的时间
Schema Registry
对不同的项目统一数据编码格式
Spring Cloud Security<br>
权限
Spring Cloud Skipper
Skipper是一种工具,允许您在多个云平台上发现应用程序并管理其生命周期。<br>
Skipper是一个工具,允许您发现Spring Boot应用程序并管理其在多个云平台上的生命周期。您可以单独使用Skipper或将其与Continuous Integration管道集成,以帮助实现应用程序的持续部署。<br>
Spring Cloud Sleuth
链路追踪
Spring Cloud Sleuth是对Zipkin的一个封装
Spring Cloud Stream
微服务应用构建消息驱动能力的框架
简化了消息队列的开发上手难度
目前只支持 RabbitMQ ,Kafka
Spring Cloud Task<br>
SpringBoot应用程序提供创建短运行定时任务
Task中,我们可以灵活地动态运行任何任务,按需分配资源并在任务完成后检索结果。Tasks是Spring Cloud Data Flow中的一个基础项目,允许用户将几乎任何SpringBoot应用程序作为一个短期任务执行。
Spring Cloud Task App Starters
Spring Cloud Task Application Starters是独立的可执行应用程序,可用于按需用例,例如数据库迁移,机器学习和计划操作
特性<br> 独立运行作为Spring Boot应用程序<br> 编排为短暂的数据微服务<br> 将数据微服务应用程序用作maven或docker工件<br> 通过命令行,环境变量或YAML文件覆盖配置参数<br> 提供基础架构以单独测试应用程序<br> 从此版本的Spring Initializr下载为初学者
Spring Cloud Vault
辅助spting boot程序保护一些敏感配置信息
SpringCloud——Zookeeper
注册中心
Spring Cloud App Broker
Spring Cloud App Broker是一个用于构建Spring Boot应用程序的框架,该应用程序实现Open Service Broker API以将应用程序部署到平台。<br>
Open Service Broker API项目允许开发人员为云本地平台(如Cloud Foundry,Kubernetes和OpenShift)中运行的应用程序提供服务。 Spring Cloud App Broker提供了一个基于Spring Boot的框架,使您能够快速创建服务代理,在配置托管服务时将应用程序和服务部署到平台。<br>
Spring Cloud Circuit Breaker<br>
熔断
Spring Cloud Kubernetes
Spring Cloud Kubernetes提供使用Kubernetes原生服务的Spring Cloud公共接口实现。此代码仓库中提供的项目是促进在Kubernetes中运行的Spring Cloud和Spring Boot应用程序的集成
Kubernetes就是帮助大家更快的搭建使用Kubernetes原生服务的微服务项目,并与Spring Cloud集成
Spring Cloud Kubernetes意味着我们想要将服务部署到Kubernetes集群,Spring Cloud Kubernetes为我们实现了Spring Cloud的一些接口,让我们可以快速搭建Spring Cloud微服务项目框架,并能使用Kubernetes云原生服务。<br><br>Kubernetes提供服务注册和发现、以及配置中心的实现,我们完全没有必要再自己部署一套注册中心、配置中心,因此Spring Cloud Kubernetes为我们提供使用这些原生服务的接口实现。除注册中心和配置中心之外,如果我们还想使用istio,Spring Cloud Kubernetes也提供了支持,这些无非就是解释文章开头的那句话“Spring Cloud Kubernetes提供使用Kubernetes原生服务的Spring Cloud公共接口实现”
参考文档
https://www.likecs.com/show-203352078.html#sc=586
Spring Cloud OpenFeign
基于http请求的接口调用
redis
数据结构
基本数据类型
string
1.存储普通字符串
2.存储数字类型字符串,让数字做自增(可以用作全局唯一ID,计数器)
实现方式
long类型整数
long范围内的数据就做此类型存储
embstr,编码简单动态字符串
长度小于44个字节的字符串
raw 简单动态字符串
长达大于44个字节的字符串
长度限制
最大512M
使用场景
incr
自增命令
使用场景
全局唯一ID
计数器
sentx
分布式锁
赋值命令
hash
特性:一个key,可以对应多个field字段,每个字段都可以存储不同的数据,可以缓存数据库行数据
实现方式
压缩列表
hashtable表
使用压缩列表条件满足
列表保存元素个数小于512个
每个元素长度小于64字节
使用场景
导入mysql数据库的表
表的字段如下: id,name ,age,sex
使用hash数据结构,key就设置成表的唯一字段;value可以存放多个字段和对应的值
如下:key 设计成user:1 value 设计成 name fankuai age 28 sex name 这样就ok了
list
使用场景
利用list双向链表的性质,可以实现栈,队列,阻塞队列数据结构
子主题
实现方式
双向链表
压缩列表
使用压缩列表条件满足
1、列表保存元素个数小于512个
2、每个元素长度小于64字节
使用场景
消息队列
利用对应的api从头部添加,从尾部获取数据的api
可以模仿一切队列使用到的场景
set
使用场景
用于抽奖
集合的并集,交集,差集(社交网站的关注模型)
常见api
SADD KEY {ID}
所有的id 都放在一个集合中
SRANDMEMBER key [数量]
这个随机选择几个,并且不从集合里面删除;
SRANDMEMBER SPOP key [数量]
随机选择几个,从集合里面删除掉;
实现方式
intset
存储整数集合
hashTable
使用intset实现方式条件满足
1、集合中所有的元素都必须是整数
2、集合中所有的元素不超过512个
使用场景
抽奖
添加抽奖者
sadd sku01 1001 1002 1003 1004
查看抽奖者用户
smembers sku01
查询参与抽奖的人数
scard sku01
抽取2人获奖
srandmember sku01 2
spop sku01 2
点赞,收藏,标签
用户添加商品收藏
sadd user1 sku1001 sku1002 sku1003 sku1004
用户取消收藏
sadd user1 sku1001
检查是否收藏
sismember user1 sku1001
查询用户的收藏列表
smembers user1
获取用户收藏数量
scard user1
关注模型
关注的人
sadd user1 元素1 元素2 元素3
共同关注的人
Sinter user1 user2
两个集合取交集
zset
使用场景
一些需要做排序的数据;
实现方式
压缩列表
HashTable和SkipList
HashMap存储的分数
skipList存储的是所有成员
使用压缩列表的需要满足条件
保存元素数量小于128个
保存的所有元素长度小于64个字节
使用场景
各种排行榜
主要是用的score 分数的排序功能
zadd key score1 member1 score2 member2
key对应的value中有两个元素,并且这两个元素对应的分数是score1, score2
数据结构实际应用场景
hash
zset
数据排序
数据如下: 88分 ,小明; 99分,小红
使用set命令存储的时候排序:key 为 chengjipaixu ; value为 99,小红 88 小明
实战
限流
用户消息时间线timeline
消息队列
商品标签
商品筛选
高级数据类型
bitMap
hyperLogLog
Geo
实战问题
缓存相关问题
缓存穿透
概述
大量的请求在redis缓存中没有拿到数据,直接请求数据库,数据库也没有拿到数据;大量的请求直接怼到了数据库,给数据库造成了巨大压力
分支主题
解决方式
1.Redis缓存从数据库也没有查询到的空数据
分支主题
2.在业务系统和缓存之间使用布隆过滤器,直接过滤掉一些缓存以及数据库都没有的请求,直接返回null
分支主题
布隆过滤器,guav提供的。
缓存击穿
概述
Redis缓存的是失效时间到了或者是Redis服务挂了,同一时间大量的请求过来,就会访问数据库,从数据库里面获取数据,这样对数据库的压力太大了
分支主题
解决方式
在Redis和数据库之间再做一层中间缓存;
通过定时job,给快要失效的缓存数据做一个再次续期的操作;
redis和数据库之前的代码中自己手动做限流措施
缓存雪崩
概述
大量的缓存数据在同一时间过期,引起大量的数据直接访问数据库,引起数据压力过大甚至宕机
解决方式
错开缓存的过期时间
搭建高可用redis集群
做好熔断操作
缓存击穿缓存穿透区别
缓存穿透,就是访问了根本就不存在的数据;缓存击穿,缓存中不存在,但是数据库存在;
缓存数据一致性
缓存更新时间节点
1、更新完数据库, 再更新缓存
缓存更新失败,导致缓存未被更新,从缓存中获取的数据还是更新之前的老数据
2、更新完缓存,再更新数据库
缓存更新成功,数据库更新失败,数据库中的数据是老数据;缓存失效之后,再去读取数据库老数据,覆盖到缓存,造成数据还是老数据
存在问题
1、针对缓存或者数据库更新失败的解决方式
子主题
1、更新失败导致缓存不一致
解决方案
1、采用先更新数据库,后更新缓存的做法
2、更新缓存失败后,捕捉失败的异常,然后发送消息队列,消息队列的消费方做缓存数据的再次更新,并且更新后,将缓存数据和需要被更新的数据做对比,是否保持一致;
使用场景
并发量非常低
2、多线程并发修改,造成数据的不一致
不一致原因示意图
示意图1
示意图2
解决方案
分布式锁
将数据库数据的更新还有缓存数据封装在一起,使用分布式锁来操作;
以被更新的目标数据的id为key;
数据倾斜问题
数据倾斜解释
在redis集群模式下,数据会按照一定的分布规则分散到不同的实例上;如果由于业务数据特殊性,按照指定的分布规则,可能导致不同的实例上数据分布不均匀
数据倾斜分类
数据量倾斜
在集群中的各个实例上数据类大小不一致
示意图
子主题
数据访问倾斜
对集群中某些实例的访问频率大大超过了其他实例
示意图
子主题
数据量倾斜
原因
存在大key
大key导致占据的缓存空间过大,实际上可能这些大key并没有多少;
解决方式
将大key拆分成其他缓存
业务层面避免大key创建
solt分配不均
某些实例分配到的槽位到,相应的得到数据量也会多
解决方式
初始分配的时候,将槽位分配均匀
如果已经造成,则可以进行实例之间的数据迁移
hashTag使用不当
在hash设置key的时候不要带上画括号
数据访问倾斜
主要原因
存在热key
并发问题
redis本身执行读写操作命令式单线程执行的,但是从调用redis的客户端来说,使用的时候会存在线程安全问题
比如说:扣库存操作,读取库存和扣减库存,不是一个原子操作
redis也有自增自减的api,将两个不是原子操作的操作合并成一个原子操作;
解决此类由客户端导致的并发问题方式
1、客户端加锁
2、客户端使用单线程执行
3、将客户端的逻辑放在lua脚本中执行
好处
ua脚本的开销非常低
缺点
Lua脚本只能保证原子性,不保证事务性,当Lua脚本遇到异常时,已经执行过的逻辑是不会回滚的
redis为什么快<br>
基于内存存储
采用单线程避免锁竞争,结合 I/O 多路复用模型
高效的数据结构和内存分配器优化,使其在处理高并发、小数据量请求时能达到极高的性能
分布式锁
Redis 分布式锁依赖以下特点:
1. 原子操作
使用 SET key value NX PX ttl 命令保证 锁的原子获取:
NX → 只有 key 不存在时才设置,保证互斥
PX ttl → 设置锁过期时间,防止死锁
2. 自动过期
避免客户端崩溃或忘记释放锁导致死锁
TTL 时间应该略大于业务执行时间
3. 唯一标识
每个客户端在加锁时生成一个随机 value
解锁时检查 value 是否匹配,防止误删其他客户端的锁
集群脑裂
集群脑裂概述
集群中由于网络分区或节点故障,集群的不同部分相互失联,触发了从节点升为主节点机制,从而产生多个“主节点”的现象
Redis 中,这主要发生在:
Redis Sentinel + 主从架构
Redis Cluster 模式
Redis 脑裂的表现
多个节点同时是主节点(Master)
客户端写入不同主节点,数据冲突
从节点可能无法及时同步数据
系统可能出现不可预测的异常
集群脑裂问题
新的master节点就不会同步原来老master节点的数据;当网络原因解决之后,原来的主节点就会变成从节点,新的master节点由于没有同步数据,就会造成缓存数据的丢失;
解决方式
网络可靠性
避免网络分区,减少主从节点之间的延迟和断连。
哨兵模式
严格配置哨兵选举规则<br>
保证哨兵数量奇数,超过半数才能提升主节点。
分片集群
Cluster 模式下注意节点分布
保证每个主节点至少有部分从节点和投票节点在线。
使用多数派(quorum)机制
只有大多数节点确认主节点挂掉,才允许从节点提升。
hash分片<br>
Redis Cluster 如何处理数据倾斜?
数据倾斜的原因
slot 分配不均
每一个master节点分配到的槽位数量不同,有的多,有的少<br>
解决方式
将每一个master节点槽位分配均匀<br>
增加节点,迁移槽位
存在热点数据
某些 key 被频繁访问(例如 user:123)
解决方式
对key中的{}中的内容计算 slot,将热点数据分散<br>
将热点数据拆分成多个key,分散开<br>
业务设计问题
key 命名模式不均匀,到时在hash算法计算槽位的时候偏向某些范围的槽位<br>
缓存分片hash问题
一致性hash
解决的问题
1.普通hash算法的伸缩性差,解决了分布式系统中机器的加入和退出
2.解决了数据倾斜问题
增设了很多虚拟节点
hash槽
jedis已经支持了hash槽位的计算
redis默认的缓存分片是hash槽位,槽位的最大个数是16384个。每一个主节点都会分配到相应的槽位;根据计算key的对16384取模计算,当前的key应该属于哪个槽位。就知道落在了哪个节点
每一master节点对应的槽位是连续的吗?
可以连续,可以不连续,取决于实际操作
热key<br>
如何监控热点数据?
热点数据的定义
Hot Key:访问频率远高于其他 key 的数据
Hot Slot:某个 slot 被频繁访问的情况(适用于 Redis Cluster)
表现为:
单节点 QPS 占总流量的很大比例
CPU/内存消耗异常高
单 key TTL 短或数据量大
原理
MONITOR 命令,可以统计每个 key 的访问次数,可用脚本收集频率,发现热点 key<br>
看每一个master节点的QPS数据量,如果存在异常,极有可能存在热点key<br>
实现
Redis Exporter + Prometheus 做到可视化<br>
Redis Exporter 可以收集:
每个命令调用次数(keyspace_hits, keyspace_misses)
每个 DB 的 key 数量
配合 Prometheus/Grafana:
绘制 key 或 slot 热点图
配置告警(单 key 访问量过高)
热点数据有什么危害?
单节点压力过大
延迟和响应不稳定
数据不均衡(Cluster 场景)
内存压力
持久化与复制压力
高可用风险
如何保证缓存中的数据都是热键数据
使用LFU算法
最小使用频率做缓存数据的淘汰
实现
记录了最近访问的时间
记录了请求访问的次数
相对其他算法
不设置任何淘汰机制
这种肯定不行
随机淘汰
这种也不行
生命周期淘汰
这种也不行,如果是一个高频使用的缓存,缓存周期到了也被淘汰了
最近最少使用算法
不能够完全说明这个问题;短期之内使用的比较少,但是整个周期内使用的次数比较多,这种也会被淘汰
最终选择LFU
热key优化?<br>
将热点 key 拆分成多个 key
和对大key的处理方式一样<br>
子key分散到多个槽位上<br>
使用过期 / TTL 策略
对热点 key 设置 短期 TTL
避免长期占用内存和单节点负载
主从读写分离
不适用分片集群的时候可以优化
限流 / 队列削峰
大key<br>
如何监控大key<br>
MEMORY USAGE命令
查询单个 key 占用内存:
可结合脚本扫描所有 key,统计大于阈值的 key
实现
编写脚本使用MEMORY USAGE命令扫描各个 Master 节点
获取到每一个节点的key排行榜,最后汇总<br>
可视化监控
Redis Exporter + Prometheus
收集 key 的统计信息(按前缀或类型)
可以设置告警:
单 key 内存占用超过阈值
集合长度超过阈值
大 key 告警
告警实现
在Prometheus 配置规则
key_memory_bytes > 阈值 → 告警
内存超过阈值 → 警告
单 key 访问耗时超过阈值 → 警告
热点大 key → CPU/延迟告警
优化策略
拆分 key
List / Set / ZSet → 按分页或哈希拆分
限制写入
避免一次性 push/insert 大量数据
设置 TTL
避免长期占用大量内存
本地缓存或外部存储
超大对象存储在对象存储或数据库,Redis 缓存部分数据
Redis 的一致性保证?为什么不是强一致性?
Redis 的一致性模型
单节点
操作是原子性的,客户端每次写操作立即生效,读取也能马上看到最新值 → 强一致性
哨兵或集群模式
主从复制延迟:主节点写入后,从节点异步复制 → 从节点可能暂时读不到最新数据
为什么不是强一致性
Redis 选择了 优先可用(AP)或最终一致性
主节点挂掉 → 自动切换新主节点
某些从节点可能落后 → 数据不完全同步
确保系统可用性,而非严格同步所有节点
一致性保证的机制
单节点模式
强一致性,写操作立即生效
主从复制(异步)
主节点写 → 异步复制到从节点
从节点可能滞后 → 弱一致性/最终一致性
哨兵模式
自动故障切换 → 数据可能丢失或落后
避免脑裂,需要多数哨兵确认 ODOWN
一致性是最终一致性
Cluster 模式
主节点宕机 → 从节点提升为新主节点
异步复制导致短期内部分节点数据不同步
通过投票机制 + quorum 保证多数节点数据可靠
最终一致性得到保证
Redis 如何做延时队列?
如何保证 Redis 高并发下的性能?
数据分片
分片(Sharding)
把数据按 Key 哈希到多个 Redis 实例,避免单节点瓶颈。
集群化
集群模式
Redis Cluster 可以水平扩展,多个 Master+Slave 节点共享数据
主从架构
Master 写入,Slave 提供读服务,提高并发读能力
缓存策略优化
添加本地缓存
过期策略
LRU/LFU 等策略淘汰冷数据,保证热点数据命中率
异步与批量处理
Pipeline:一次发送多个命令,减少往返时间
Lua 脚本:在 Redis 内部执行复杂逻辑,减少客户端多次请求
基础原理类
redis为啥快
1.数据存储在内存
2.数据结构简单
3.单线程不存在锁
4.io多路复用
Redis 为什么是单线程的?
- 避免上下文切换、内存操作快,多核可通过分片/多实例利用。
Redis 常见的使用场景?
缓存、分布式锁、计数器
数据结构类
1.Redis 常见的数据结构?底层实现是什么?
String(SDS)
Redis 自己实现的动态字符串
特点:
存储长度、已用空间、预分配空间 → 减少频繁 realloc
支持二进制安全(可存储 \0)
高性能拼接和扩容
List(双端链表/压缩列表)
有序集合
底层实现:
1. ziplist(压缩列表)
小量数据和短字符串优化
内存紧凑,但随机访问慢
2. 双向链表(linkedlist)
数据量大或元素较长时使用
支持快速头尾插入/删除
Hash(哈希表/ziplist)
无序集合,不允许重复,常用去重
底层实现
intset(整数集合)
全是整数且数量少时使用
内存紧凑,支持快速查找
哈希表(dict)
元素多或者包含非整数时
提供 O(1) 查找、添加、删除
Redis 会自动在 intset 和哈希表之间转换
Set(哈希表/intset)
键值对集合,用于对象存储
底层实现:
ziplist(压缩列表)
小量字段,短字符串
哈希表(dict)
字段多或者字符串长时
支持 O(1) 查找、添加、删除
Sorted Set(跳表+哈希表)
带 score 的集合
子主题
底层实现:
ziplist(压缩列表)
元素少且短字符串时使用
跳表(skiplist) + 哈希表
大量元素或字符串长时使用
哈希表存成员到 score 的映射 → 快速查找
跳表保证按 score 排序 → 支持范围查询
Bitmap / Bitfield
位操作,如签到、布隆过滤器、计数器
底层实现:
使用字符串(String)存储二进制位
操作通过 位运算,非常高效
HyperLogLog
用途:基数统计(去重计数)
底层实现:
压缩算法 + 估算算法
内存固定(~12KB)
精确度允许一定误差(~0.81%)
3.Redis 为什么用跳表而不用红黑树?
4.Redis 的 HyperLogLog、Bitmap、GEO 是做什么的?
工作机制
缓存淘汰机制
缓存淘汰类型
不设置任何淘汰机制
noeviction
不做任何处理,写入超过限制后,会返回操作错误;读操作还是可以正常进行
默认淘汰策略
LRU最近最少使用淘汰
volatile-lru
设置了过期时间,清除最近最少使用的键值对
allkeys-lru
未设置过期时间,清除最近最少的键值对
存在问题
1、需要存储缓存数据之外额外的时间数据
2、可能会删除热key
解决方案
设置每一次要被淘汰的key的个数,个数如果=10比较,对热键数据影响比较小
实现
缓存对象中会存储这个缓存最近被访问的时间戳
淘汰的时候会根据当前的时间戳-缓存对象中的时间戳,差值最大的就被淘汰
LFU最小使用频率淘汰
volatile-lfu
设置了过期时间,清除某段时间内使用次数最少的键值对
allkeys-lfu
未设置过期时间,清除某段时间使用次数最少的键值对
TTL生命周期结束淘汰
volatile-ttl
设置了过期时间,清除过期时间最早的键值对
random随机淘汰
allkeys-random
未设置过期时间,随机清除键值对
volatile-random
设置了过期时间,随机清除键值对
缓存淘汰机制选择
1.如果缓存有明显的热点分部,那么就选择lru算法
2.如果缓存没有明显热点分部,那么就选择随机
触发内存淘汰时间点
1.Redis的每一次命令处理的时候,都会去判断当前redis是否已经达到最大缓存极限,如果达到极限,就会启用相应算法去处理需要清除的键值对;
2.过期key的回收
定期删除
Redis启动时候的定时时间,默认是每100毫秒的检测过期的key,过期就清理;
惰性删除
访问key的时候,key是否过期,过期就删除;
实际执行策略
Redis 惰性删除 + 定期删除同时启用
访问时删除 → 确保访问的 key 立即生效
后台扫描删除 → 确保不访问的 key 也能最终被回收
事件通知机制
事件通知概述
redis数据集改动事件之后对客户端的一种通知行为
事件通知类别
键空间通知
键事件通知
通知类型
删除,设置过期时间,重命名等一些和数据类型无关的操作的通知
字符串命令通知
列表命令通知
集合命令通知
哈希命令通知
有序集合命令通知
过期事件通知
缓存驱逐事件通知
不管发生什么事件都通知
事件通知使用
该功能默认是关闭;需要在config配置文件中开启该功能
配置形式:notify-keyspace-events +事件通知类别和通知类型;notify-keyspace-events &quot;Ex&quot;表示对过期事件进行通知发送
事件订阅缺陷
事件通知是不可靠的,服务器采用的是发送即忘,如果当订阅事件发生的时候;客户端掉线了,那么这个事件就不会通知到客户端,所有事件订阅是不可靠的
持久化机制
AOF
机制说明
1.记录每一个redis的写命令以日志的形式进行存储
2.AOF刷盘时间间隔
1.有命令就刷盘一次
2.一秒刷盘一次(推荐,也是默认的)
3.由系统决定刷盘时间间隔
3.为啥需要设置刷盘时间:持久化的目的是把数据记录在磁盘上,所以当数据在内存中的时候,就需要把内存中的数据放到磁盘上,放到磁盘上的时间间隔就是刷盘时间;
优缺点
优点
1.持久化实时性比较高(可以设置间隔多少秒追加一次日志,也就是间隔时间越短,丢失的数据就是越少)
缺点
1.AOF文件的体积通常大于RDB
2.数据恢复比rdb慢
AOF机制
1.当AOF文件过大时,后台会去优化AOF文件;
当AOF文件出错(以下两者方式都是可以解决AOF文件出错了,数据该怎么恢复的问题,最终还是需要重启redis服务器去载入AOF文件)
1.可以使用修复程序修改AOF文件;
2.为AOF文件创建一个备份文件
RDB(默认方式)
机制说明:就是以内存快照的形式缓存内存中的数据
缺点:1.实时性比较低,单独使用该持久化机制,服务器宕机导致数据丢失较多;
优缺点
缺点
1.实时性比较低,单独使用该持久化机制,容易导致数据丢失;
2.从主进程fork子进程的时候会被阻塞,
优点
1.rdb文件大小紧凑;可以设置间隔时间备份,还原到不同历史时期的数据状态
2.持久化的时候可以由子进程去完成所有的数据保存工作;父进程无需任何的io操作;
3.数据恢复比AOF快
数据存储:存储在dump.rdb文件中
RDB 的触发机制主要有两类:自动触发和手动触发
Redis 可以根据配置自动触发 RDB 快照,配置在 redis.conf 中以 save 指令定义
save 900 1 # 900秒内如果至少1个key发生变化,则触发RDB<br>save 300 10 # 300秒内如果至少10个key发生变化,则触发RDB<br>save 60 10000 # 60秒内如果至少10000个key发生变化,则触发RDB
Redis 也支持管理员手动触发 RDB 快照:
优点:确保 RDB 完成后返回
持久化机制
1.可以在不重启的情况下切换RDB到AOF模式
2.当RDB,AOF都打开的时候,程序默认使用AOF方式持久化
容灾措施
1.定期的把RDB文件备份到其他位置
Redis 持久化如何避免数据丢失?
Redis 的 持久化机制本身是为了解决内存数据丢失问题,但不同持久化方式的可靠性不同
1. 高性能型场景(对数据丢失可容忍)
用途:缓存型场景,例如热点数据、会话数据、排行榜
方案:
RDB 快照即可,默认配置 save 900 1 等
不启用 AOF 或 AOF everysec
特点:
快速启动、性能高
宕机时可能丢失最近几分钟的数据,但业务可以容忍
2. 数据安全型场景(对数据丢失敏感)<br>
用途:需要较高可靠性的业务,如消息队列、计数器、交易系统缓存
方案:
AOF + RDB 混合持久化
AOF 推荐 appendfsync everysec(性能和安全折中)
定期 RDB 快照作为备份
可结合 主从复制,保证高可用
特点:
数据丢失窗口最小(一般 ≤ 1 秒)
启动稍慢,因为需要加载 AOF 文件
3. 超高可靠场景(金融、电商核心数据)
用途:绝对不能丢失的数据
方案:
AOF always + RDB + 主从复制 + Sentinel/Cluster 高可用
定期异地备份
特点:
性能稍差,但几乎保证不丢数据
启动时间最长(需要重放 AOF)
多路复用机制
epoll模式的多路复用
多线程
单线程性能瓶颈
网络IO
多线程只是用来处理网络数据读写和协议的解析,执行Redis命令依旧是单线程去执行
事物机制
事物本质
一组命令的集合,要么所有的命令都执行成功,要么都执行失败
特点
命令队列化:事务内命令先入队,不立即执行
一次性执行:执行 EXEC 时按顺序执行队列中的命令
错误处理:
语法错误:命令不会入队
运行错误(如操作类型错误):事务仍继续执行,不回滚
只能保证原子性
原子性:事务中的命令要么全部执行,要么都不执行(在执行期间不会被其他客户端命令打断)
隔离性弱:事务执行期间,其他客户端可以看到数据库状态,但不会插入事务内的命令
一致性和持久性:依赖 Redis 本身的数据模型和持久化机制
事物执行过程
一个事物所有的命令都会放在队列中缓存,执行的时候会去串行执行队列中的命令
事物相关命令
MULTI
开启一个事物
EXEC
执行这个事物的所有命令
discard
取消事物
watch
监视某些key
unwatch
放弃监视某些key
watch命令特别说明
配置事物一起使用,只有被监视的key没有发生任务数据变化的时候,事物才会被执行,否则是不会被执行
使用方式:在事物开始之前监听某些key
事物中的错误类型
入队时候的语法错误
2.6.5之前版本,忽略入队失败的命令,可以继续执行事物
2.6.5开始版本,入队失败,执行事物的时候会自动放弃执行该事物
执行事物调用之后错误;比如说错误的用string数据结构的命令操作list数据结构的数据
exec事物开始执行的命令开始了,事物队列中某条或者某些命令执行失败了,Redis依旧会接着执行命令,不会放弃执行命令
redis事物与数据库事物最大差别
不支持回滚,即使事物队列开始执行后,有命令执行失败了也不会回滚
主从复制机制
复制分类
全量复制
作用:把从服务器数据的状态更新到和主服务器状态一致;=
使用场景:一般都刚刚搭建服从服务的时候
缺点
1.数据量较大时候,主从节点的网络开销很大
增量复制
作用
1.当主服务器收到写命令的时候,为了保持从服务器与主服务器的数据一致;就会让从服务器也去执行主服务器的命令;这个过程就是增量赋值的过程
2.对全量复制方式的工作方式弥补,当主从断开了连接,就不需要做全量复制,只需要执行断开期间主服务器的写命令
概述:复制分为全量复制,增量复制,也就是对应着同步操作,命令行操作;
心跳检测
1.各自彼此都模拟成对方的客户端发送心跳信息
2.主节点默认间隔10秒给从节点 发送链接信息
3.从节点默认间隔1秒给主节点发送偏移量
主从复制过程
1. Slave 重连时发送 PSYNC 请求,告诉 Master 上次同步的 偏移量(offset)。
2. Master 检查偏移量是否在缓冲区内:
如果在 → 直接发送缓冲区中未同步的命令(增量复制)。
Slave 执行 Master 发送的命令,补齐数据
如果不在 → 需要进行全量复制。
Master 生成 RDB 快照,将快照传递给从机;从机获取快照数据加载进内存
主机缓存这段时间之内的命令,在从机降快照加载完成之后,传递缓存之中的命令,从机再执行换从之中的命令;之后都是增量复制了。
复制原理
1.主节点处理完命令之后,会把命令字节长度累加记录起来,一个记录在命令表,一个记录在偏移量表
2.从节点收到主节点的命令,也会累计自身节点的复制的偏移量;
3.从节点每秒钟把自己的偏移量发送给主节点,主节点对比偏移量,
4.主节点就知道从节点的数据是否和主节点数据一致;
复制注意事项
1.从服务器在同步时,会清空所有数据
2.Redis不支持主主复制
3.主从复制不会阻塞master
4.主节点的处理完写命令就会直接给客户端返回,然后异步将命令传递给从服务器
Pipeline
客户端批量发送多条命令 → Redis 按顺序执行 → 客户端一次性读取返回
核心优化:减少每条命令的网络往返时间
特点:
不保证原子性
批量命令提高吞吐量
常用于批量写入或获取大量数据
redis集群
主从模式
特点
1.一主一备,主机写,从机读;主机挂了不影响从机读
2.主机挂了,系统还能提供读服务,并不能提供写服务,从机不会变成主机
缺点
Master 挂掉后,无法自动切换,需人工干预。
哨兵模式
特点
1.建立在主从模式之上,哨兵节点本身不做数据存储;
2.主节点挂了,哨兵节点就会从所有从节点中选取一个节点做为主节点;
3.挂掉的主节点重启之后,就作为从节点;
工作机制
1.客户端连接的是哨兵节点,由哨兵节点来提供Redis的各种服务
特点:
实现了 高可用(HA)。
运维简单,适合中小型项目。
缺点:写请求仍然集中在 Master,容量受单机限制。
分片集群
概述
哨兵模式就能保证高可用了,但是如果数据量过大,一台服务器存不下所有数据,就需要搭建高可以用集群
分片集群 自带高可用机制
特点
分片集群(Cluster) → 最少 6 节点(3 主 + 3 从)。
可在线添加,删除节点
既能保证高可用,又能实现水平扩展。
节点间自动分片,使用 **16384 个槽位(slot)**分布数据。
支持节点间的自动发现、自动故障转移。
数据存储特点:
数据按照 槽位(slot)哈希分布存储在不同节点。
每个节点有自己的 Master,通常也有 Slave 做备份。
客户端可直接根据 key 找到对应的 slot -> 节点,进行访问。
如果集群中一个master挂了,会怎们样?<br>
正常情况(有 Slave 备份)
其他 Master 不受影响,因为它们负责的槽位独立。
会从这个master从节点从选一个节点作为主节点<br>
客户端会被告知新的 Master 地址(MOVED 或 ASK 重定向)
最终结果:集群整体可用,数据不会丢失(可能丢失少量主从未同步的数据)
异常情况 1(Master 没有 Slave)
这个 Master 负责的槽位(hash slots)不可用。
整个 Redis Cluster 会认为 集群处于 FAIL 状态(不可用)。
客户端访问任何 key 时,可能都会报错(即使 key 在别的 Master 上)。
原因:Redis Cluster 必须保证 槽位全集完整,否则视为集群故障。
异常情况 2(网络分区 / 少数节点故障)
如果 Master 节点挂了,但由于网络原因,集群无法达成多数派投票(quorum),那么故障转移不会发生。
这时,挂掉的 Master 负责的槽位依旧不可用,客户端请求会超时或失败。
影响范围
影响范围:只有挂掉的那个 Master 的槽位数据暂时不可用,几秒钟内自动恢复
投票过程说明
只有 Master 节点 有投票权;Slave 节点没有投票权,它们只负责竞选成为新的 Master。
故障检测流程(两阶段)
主节点之间相互发送心跳,如果超过半数节点,发现有一个节点没有发送心跳信息给自己,就会被标记下线了
挂掉的主节点对应的从节点会发起选举,其他正常的主节点会根据从节点的(发起请求、数据同步最新、延迟最小),来选择谁作为新的主节点当超过半数的时候会成为新的主节点。<br>
为什么可以在线加节点?
所有的master节点的数据都是在分部在16384 个哈希槽(hash slots)<br>
新增 Master 节点时,可以把已有 Master 上的一部分槽位迁移到新节点
槽位迁移时,客户端访问会被 ASK 重定向到新节点,保证在线过程不中断。
Redis配置文件说明
内存相关
maxmemory
Redis最大存储大小
为0的时候表示可以无限制使用redis内存
maxmemory-policy
配置内存清理策略
maxmemory-samples
作为LRU,LFU,TTL内存回收策略,检查数量的key
redis命令
数据类型操作
String
在来的字符串后面追加拼接
APPEND myphone &quot;nokia&quot;
返回指定字符串的值中间几位对应的字符串
GETRANGE greeting 0 4
重新设置key的值返回老的key的值
GETSET db mongodb
把key为db 的数据的值设置成 mongodb,返回老的值
自增自减
DECR failure_times
failure_times对应的数值自减1
DECRBY count 20
count对应的数值指定自减的数量
INCR page_view
page_view的值自增1;
INCRBY rank 20
rank对应的数据自增20
INCRBYFLOAT mykey 0.1
mykey对应的值自鞥指定的浮点数值
位图操作
Hash表操作
设置值
HSET website google &quot;www.g.cn&quot;
key为website
value中field为Google,value为&quot;www.g.cn&quot;
获取指定value指定field对应的值
HGET site redis
获取key的所有field的值
HGETALL people
获取people所有field和值
删除指定key的指定的field的值
HDEL abbr a
指定field是否存在
HEXISTS phone myphone
自增自减
HINCRBY counter page_view 200
对key 为counter 中field字段难为page_view的自增200
HINCRBYFLOAT mykey field 0.1
返回所有的field
HKEYS website
HMSET website google www.google.com yahoo www.yahoo.com OK
操作结果
1) &quot;google&quot;2) &quot;yahoo&quot;
返回所有的域的值
HVALS website
1) &quot;www.google.com&quot;2) &quot;www.yahoo.com&quot;
List操作
往列表中添加
LPUSH languages python
可以重复添加
LPUSHX greet &quot;hello&quot;
往列表的表头添加
RPUSH languages c
往列表的表尾添加
LINSERT mylist BEFORE &quot;World&quot; &quot;There&quot;
指定key中在指定元素的前面或者后面添加元素
从列表中获取
LPOP course
获取表头元素并删除
RPOP mylist
获取表尾元素并删除
blpop key timeout
获取表头元素,如果没有元素就会阻塞,阻塞的时间为指定时间
brpop key timeout
获取表尾元素,如果没有元素就会阻塞,阻塞的时间为指定时间
LRANGE fp-language 0 1
返回list中指定某个索引位置的数据
LINDEX mylist 3
返回对应索引位置的值
删除
lrem key count value
根据key中value的值删除指定个数
ltrim key start stop
删除指定区间的值
Set
存储
添加单个
SADD bbs &quot;discuz.net&quot;
不能被重复添加
hmset
批量存储hash
移除
单个移除
SREM languages ruby
移除 languages 中的ruby元素
SMEMBERS not_exists_key
移除key的所有元素
删除集合并随机返回一个元素
SPOP db
获取
获取集合长度
SCARD tool
获取tool集合长度
获取集合中所有元素
SMEMBERS db
返回两个集合的交集
SINTER group_1 group_2
返回两个集合的并集
SUNION songs my_songs
返回两个集合的差集
SDIFF peter&apos;s_movies joe&apos;s_movies
判断
判断某个元素是不是当前set集合的元素
SISMEMBER joe&apos;s_movies &quot;bet man&quot;
判断key为 joe&apos;s_movies 中是否含有&quot;bet man&quot;
Zset
添加
添加单个元素
ZADD page_rank 10 google.com
往key为page_rank集合中添加数值为10 的google.com 元素
添加多个元素
ZADD page_rank 9 baidu.com 8 bing.com
给指定的元素添加分数
ZINCRBY salary 2000 tom
移除
移除一个或者对个元素
ZREM page_rank google.com
ZREM page_rank baidu.com bing.com
移除按照排名指定区间的数据
ZREMRANGEBYRANK salary 0 1
移除指定索引区间的值
ZREMRANGEBYSCORE salary 1500 3500
移除指定分数区间的值
获取
获取集合长度
ZCARD salary
获取salary集合长度
返回指定区间的元素
ZRANGE salary 200000 3000000 WITHSCORES
正序从小到大
ZRANGE salary 0 -1 WITHSCORES
整个集合从小到大排序
ZREVRANGE salary 0 -1 WITHSCORES
递减排列
获取指定分数区间的元素个数
ZCOUNT salary 2000 5000
获取salary集合中分数在2000到5000之间的分数
获取指定元素的分数
ZSCORE salary peter
获取salary集合 peter对应的分数
指定分数区间分页查询
zrevrangebyscore key max min [WITHSCORES] [LIMIT offset count]
排序获取元素排名
zrank key member
排序按照分数从小到大
zrevrank key member
排序按照分数从大到小
相同操作
设置
字符串
setnx key value
setex key seconds value
hash
HSETNX nosql key-value-store redis
重新设置 nosql 中指定field对应的数据
移动元素到另外集合
set集合
SMOVE songs my_songs &quot;Believe Me&quot;
将songs 集合中的&quot;Believe Me&quot;元素移动到my_songs
list
rpoplpush source destination
把 source的list集合尾部元素添加到 目标元素的头部;并把值返回给客户端
brpoplpush source destination timeout
上一个命令的阻塞版本
批量操作
批量存储
字符串
MSET date &quot;2012.3.30&quot; time &quot;11:00 a.m.&quot; weather &quot;sunny&quot; OK
Hash
HMSET website google www.google.com yahoo www.yahoo.com OK
批量获取
字符串
MGET date time weather
Hash
HMGET pet dog cat fake_pet
获取key 为pet中对应的field对应的数据
批量设置
字符串
MSETNX rmdbs &quot;MySQL&quot; nosql &quot;MongoDB&quot; key-value-store &quot;redis&quot;
返回长度
字符串
STRLEN mykey
返回mykey对应的value的长度
hash
hlen key
返回key对应的field的个数
list
LLEN job
list集合对应的长度
key操作
存活时间
获取key存活还有多少存活时间
TTL key
-1
没有设置存活时间
10084
还存活 10084秒
PTTL key
返回值是key存活的毫秒值
设置生存时间
EXPIRE cache_page 30000
设置的时间为毫秒值
PEXPIRE mykey 1500
生存时间为1500毫秒值
PERSIST mykey
移除key的生存时间
删除key
DEL name
指定key删除
FLUSHDB
清除整个redis的数据
判断key是否存在
EXISTS phone
模糊匹配获取key
先批量设置key,value MSETone1two2three3four4
KEYS *o*
返回值 four,two,one
KEYS t??
&quot;two&quot;
KEYS t[w]*
KEYS t[w]*
随机返回一个key
RANDOMKEY
返回值为随机的一个key
移动key到其他数据库
MOVE song 1
把key为song 的值移动到数据库1里面;Redis默认的存放在第一个数据库
重命名key
RENAME message greeting
0,key不存在
1,成功
renamenx key newkey
新的key不存在的时候才会成功
根据key获取value的数据类型
TYPE weather
排序
SORT
返回指定list,有序集合,无需集合拍过排序之后的结果
排序方式按照 数字大小,字母的自然排序
序列,反序列key
DUMP
RESTORE
特殊命令
分页查询操作
Zset
List
说明,只有Zset和List支持分页查询;
计算地理位置
获取经纬度的geoHash值
Redis与MemCache的区别
线程操作
redis数据处理是单线程,memcache是多线程处理
数据结构
Redis支持更多更复杂的数据结构,memcache只支持keyvalue的字符串数据;
数据安全性
Redis支持数据的持久化,会把数据同步到磁盘上;memcache不支持数据的持久化
数据备份
Redis支持数据备份,需要开启主从模式;memcache不支持数据备份
过期策略
REDIS支持更多的过期策略;memcache支持的过期策略少
开发模式
jedis
redisson
springBoot+整合redis
本质还是springBoot整合了jedis
MQ
RabbitMQ
通信协议
基于AMQP协议
基础概念
消费者消息获取方式
(默认的方式)轮询poll的方式拉取消息
生产者推送消息给消费者
RabbitMq书写语言:erlang
基础概念
VirtualHost
:从主机中虚拟出来的一个虚拟主机;每个虚拟主机都是一个相对独立的rabbitmq服务器
一个虚拟主机里面可以有多个不同的交换机和不同的队列
exchange
概念:1.数据从生产者到消费者之间的数据转换层;2.隔离了一个虚拟主机下面不同数据之间的推送;3.生产者消费者隔离;
交换机种类
Headers Exchange默认交换机
不绑定route-key;交换机和queue名称一样
Fanout Exchange广播交换机
把消息发送到绑定了该交换机的所有队列上
不需要指定routeing-key
Direct Exchange直连交换机
数据会被发送到指定路由的queue上去
Topic Exchange主题交换机
消息会被转发到所有满足route-key的队列,以及bingkey模糊匹配到的队列
Queue
消息队列,实际存储消息数据
参数配置
name
交换机名称
Durability
是否持久化,true持久化
值集True flase
Auto-delete
所有的消费者完成消费后自动删除
ture,所有的消费者消费完成之后,自动删除
值集True flase
Arguments(拓展参数)
Message TTL
消息生存时间
时间单位毫秒
消息在被抛弃前可以存活多久
Auto expire
队列生存时间
时间单位是毫秒
队列在指定时间内没有被使用,就会自动被删除
Max length
队列容纳的消息的最大条数
超过设定条数就会默认放弃队列头部数据
Max length byte
队列可容纳最大字节数量
超过设定的长度的数据,那么就会默认放弃头部消息
Broker:
消息中间件的服务节点。
Connection
生产端消费端都需要和服务端建立Connection连接,也就是tcp连接
Channel
消息通道,在客户端的每个Connection连接里,可建立多个channel.
Channel是轻量级的Connection,减少了tcp频繁连接断开的开销
Channel实际上就是Tcp的连接复用
mandatory标志
表示作用
标记当消息发送出去,找不到路由的处理方式
处理方式
true:消息返回给服务端,服务端可以做后续的处理
false:消息返回服务端,服务端直接删除
队列工作模式
简单模式
生产者消费者一对一
work模式
生产者消费一对多;每个消费者获取的消息都是唯一
订阅模式
生产者消费者一对多,同样的消息会被订阅的消费者都消费到
路由模式
生产者指定发给一个消费者
主题模式
生产者指定发送给某一类消费者
工作流程
子主题
消息队列设计机制
消息确认机制
发送端-服务端
return消息机制
发送端把消息发送到服务器,结果找不到对应的交换机,路由队列;return消息机制就是应对这种情况
发送消息时候给Channel参数manDetory设置为true;消费就会返回到发送端可以做后续处理;如果为false,服务端就会直接把该条消息删除
事物消息机制
实现原理:AMQP协议
服务端
confirm消息机制
发送端把消息发送个服务端,服务端接收到消息并且把消息持持久化到磁盘就会给发送端一个异步的confirm应答
confirm种类
单条应答
批量应答
服务端-消费端
ack消息机制
ack种类模式
不确认
消费端发生异常或者无响应,都会通知服务端消费成功
自动确认
自动确认,如果发生异常,就会给服务端发送不确认信息;那么消费就会回到消息队列尾部
手动确认
针对个性化处理,针对默写异常是否需要做ack,或者做noack处理;
消息重试机制
消息重试目的
消费者异常的情况下,能够让生产者重新发送该消息;保证消息的最大程度被正常消费
消息重试配置说明:以springBoot整合RabbitMQ说明
enabled
开启重试机制
max-attempts
最大重试次数
initial-interval
重试间隔时间
max-interval
最大间隔时间(不能超过这个时间间隔)
multiplier
间隔时间乘法数(重试的时间间隔在上一次的倍数)
重试机制原理
消息被消费的时候会被监听,当抛出异常的时候,就会执行补偿机制;
实现的原理还是建立在消费端的ack机制之上
消息拒绝机制
消费端手动拒绝
单条拒绝
多条拒绝
消息被拒绝后可以再次回到队列中
消息重新入队机制
消息路由不成功的消息,可以配置相关的死信队列;消息可以发送到死信队列
批量消息发送机制
此机制需要开发做拓展
消息持久化
持久化的对象
交换机
把交换机的属性持久化;在宕机或者重启之后服务器可以自动的去创建交换机,避免手动或者跑程序创建
设置durable=true
队列
把队列的属性持久化,在宕机或者重启之后可以自动的去创建队列,避免手动创建
设置durable=true
消息
消息的持久化是建立在队列的持久化之上,如果队列没有持久化,那么消息也不能持久化
设置 deliveryMode =2 ; deliveryMode =1 是不进行持久化
概述
并不能完全解决消息丢失问题
持久化会降低rabbtimq性能
持久化过程
持久化概述
所有队列的消息都会写入到磁盘的中间中去;当写入的数据大小超过了文件大小,那么就会关闭此文件,再新建一个文件存储;
持久化时间节点
消息本身推送到消费端的时候在服务端需要存入磁盘
内存资源少,需要把队列中的数据存入磁盘
消息刷盘条件
消息并不是来一条消息就往磁盘上存储一条,而是先把消息都放入到一个缓冲池;等一定的条件才会缓存的消息写入磁盘
1.缓冲池缓冲的数据大小超过缓冲池本身
2.超过固定的刷盘时间25ms,不管缓冲池是否满了,都会刷盘
3.消息写入缓冲区后,没有其他后续请求写入,那么也会刷盘
读取持久化数据过程
根据消息ID,找到消息所在文件,根据消息在文件中的偏移量,找到该消息;
持久化消息删除
删除说明
收到消费者的ack消息的时候,并不是马上去删除消息,而是先给消息做一个删除的标记
删除过程
后台进程检车到垃圾数据比例超过50%,并且文件不少于3个,的时候就会触发持久化数据的垃圾回收;找到符合要求的左右两个文件,先整理左文件中的有效数据,然后再把有文件中有消息数据复制到左文件;再把又文件删除;
删除条件
1.所有文件中垃圾数据达到50%的比例;
2.存储的文件必须至少有三个;
RabbitMq队列问题+解决方案
消息延迟发送
RabbitMq本身并没有延迟队列;
解决方案
设置消息的存活时间
消费在队列中存活时间;当时间超过了消息就会被抛弃;设置死信交换机,被抛弃的消息就会落入到死信交换机;
核心点
1.不设置消费者,就可以让消息一直堆积,直到超过存活时间
具体解步骤
1.创建死信交换机
2.创建死信路由
3.新建消费者队列绑定死信路由
特别说明
1.死信交换机就是普通交换机
2.死信交换机被动接受其他交换机或者无法消费的消息
3.创建生产的交换机的时候就需要设置对应的死信交换机
消息丢失
消息丢失类型
生产者发送消息-服务端
丢失原因
1.由于网络原因导致数据丢包
2.交换机的路由没有被队列绑定,消息直接丢失
解决方案
针对1:
1.事物消息机制
发送端开启一个事物,再推送消息,如果投递失败;进行事物回滚,然后重新发送消息;如果服务端收到消息,发送端就提交事务。
缺点:事物消息造成发送端阻塞,发送端只有等到服务端回应之后,才会发送下一条数据;生产者的消息吞吐量大大降低;
2.confirm消息机制
发送端把消息发送个服务端,服务端接收到消息并且把消息持持久化到磁盘就会给发送端一个异步的confirm应答
确认方式
1.串行确认
发送一条确认一条;服务器返回flase,会重新发送
缺点:效率比较低
2.批量确认
发送端每发送一批,才会确认
缺点:重新发送消息的时候需要把同一批消息再次发送
3.异步确认
服务端接受到了一条或者多条之后,会异步回调发送端的异步确认方法;
发送端发送完消息,可以接着发送其他消息,不会阻塞;
整体流程
任何一种确认方式,服务端接受到消息之后不是立马给发送端确认;而是需要等待批量数据持久化之后再发送确认消息;
在发送消息之前把消息用排序的Map集合保存起来;如果消息发送失败,那么就会从map集合中读取消息再次发送
针对2:
1.设置mandatory 设置true
交换机找不到相应的队列就会把消息返回被生产者
2.alternate-exchange设置备用交换机
交换机找不到消息,消息会发给备用的交换机
服务端丢失
丢失原因
丢失原因:客户端在处理消息的时候突然机器挂了,导致消息丢失了;
解决方案
服务端设置交换机,队列,数据的持久化;服务器宕机后,重启会读取磁盘上的持久化的数据;
问题:由于消息的持久化是一批的持久化,可能宕机了,这一批数据还持久化到磁盘
消息的持久化
1、服务端收到生产者发送过来的消息,会做消息的持久化
2、当服务宕机后, 会从磁盘当中读取相应的消息,最大程度上保证消息不在服务节点上丢失
消费端丢失
丢失原因
1.消费者在处理消息的时候出现异常了,那么这条消息就是没有被正常的消费;如果不采取措施,那么这个消息就会丢失
解决方案
ack机制
ack机制概述
消息只有正常消费后,反馈给服务端;服务端才会从队列里面把该条消息删除
ack机制三种模式
不确认
不会发送ack确认消息
自动确认
服务端发送完消息就自动认为该消息被成功消费
缺点:由于网络原因,造成数据从服务端发送到消费者消息丢失
手动确认
消费者消费成功之后,显示的给服务端ack信号;服务端只有收到该信号才会把数据从队列里面删除
设置手动ack,尽可能减少消费端的数据丢失问题;正常就是发送ack,异常就记录日志,然后发送nack
ack机制弊端
内存泄露
如果消费者异常没法发ack消息,服务端会认为这些数据都是没有被正常消费;就会堆积在队列当中,造成内存没法回收,内存泄露;
内存泄露解决方案
1.设置手动应答,如果异常,捕获异常记录日志,给服务端发送正常消费;
2.设置重试次数(默认是3次,三次不消费成功就会放入到默认的死信队列)
ack机制默认打开,而且是自动确认
消息堆积
消息堆积的本质
消费者的消费速度低于生产者生产的速度
堆积的实际原因
生产者原因
生产者突然发送大量信息
消费者原因
消费者消费失败
消费者出现性能瓶颈
消费者直接挂掉
消息堆积后果
队列溢出,新消息无法进入队列
消息无法被消费
阻塞时间超过消息存活时间
等待消费时间超过业务时间
消息堆积解决方案
优化消费者消费参数
设置多个线程同时处理消费消息
默认是单线程消费
设置一次从服务端拉取多条消息
默认是每次拉取一条消息
取消消费端ack确认机制
新增生产这队列,把消息推送另外的机器上
排查性能瓶颈,针对性改造
顺序消费
顺序错乱场景
1.生产者消费者一对多
2.生产者消费者一对一,消费者多线程消费
解决方案
针对1
生产者拆分成多个,让生产者和消费者一对一生产消费(消费者内部可以开多线程消费)
针对2
开启多个消费者,把前后有关联的数据往同一个消费者发送
消息重复消费
消息重复消费原因
1.消费端异常没有给服务端发送消息成功消费的标记;
2.服务端没有接收到消费端发送的消费成功的标记;
只要是服务端没有接收到消费成功的标记,服务端都会再次给消费端发送消息;
解决方案
1.在消费端做幂等性判断
1.全局消息id做幂等性判断
2.全局业务id做幂等性判断
2.消费端代码做限制,无论如何都会发送消费确认消息
RabbitMQ集群
集群模式:
1.主备模式
特点:
1.一主一备;也可以是一主多备
2.主节点提供读写,从节点备份主节点数据
3.主节点挂了,从节点就会变成主节点;原来的从节点回复之后,就会变成备用节点
使用场景
1.并发和数据量不高的情况下;
搭建过程
1.需要使用haproxy作为中间件
2.远程模式
概述:数据进行复制,跨地域让两个MQ集群复制和通信;如果当前集群MQ服务超过设定的阈值,那么消息就会被转移到远程的MQ上做分担处理;
说明:需要使用到shovel插件,让跨地域的集群通信
3.镜像模式
概述:集群模式,一般2-3个节点实现数据同,主节点收到发送过来的数据,然后同步到其他节点上。
需要搭配haProxy做高可用负载均衡器
4.多活模式
概述:多中心模式,多套数据中心部署相同的MQ集群;一个集群中通过负载均衡器使得只有一个节点接受消息
各个中心需要配置插件 federation,可以使一个集群节点与另外一个集群节点做通信
死信队列
死信队列定义
未被正常消费的消息存放的队列;
死信队列数据来源
1.拒绝消息
拒绝一条消息
拒绝多条消息
2.超时消息
超过消息本身设置的存活时间还没有被消息
超过消息发送时候队列设置的存活时间还没有被消息
3.溢出消息
超过队列的最大长度
超过了队列的最大容量
死信队列使用场景
延时操作
kafka
基础概念
topic
区分不同类别信息别称
broker
kafka服务器或者服务集群
副本
TODO
每个主题在创建时会要求制定它的副本数(默认1)
partition(分区)
特点
分区也就是让kafka相同的topic在不同机器,也就是同一个消息可以在不同的kafka节点上;这样就天然的让kafka变成队列集群
概述
同一个topic会有不同的分区,分区可在不同的机器
同一个topic可以有一个或者多个分区
所以一个节点上面可以有来自多个topic对应的分区
分区工作机制
每一个分区都是一个有序队列,分区中的消息都会被分配上一个有序的id(偏移量)
分区策略
message
生产者向某个topic发送的消息
offest偏移量
消息在日志文件中存储的位置
Segment
日志分段
Consumer
消费者
Consumer Group
消费者组
kafka消息核心api
生产者api
消费这api
stream-api
connectior-api
admin-api
管理台对应的api
ISR(InSyncRepli)、OSR(OutSyncRepli)、AR(AllRepli)
ISR
速率和leader相差低于10秒的follower的集合
kafka中与leader副本保持一定同步程度的副本(包括leader)组成ISR
OSR
速率和leader相差大于10秒的follower
AR
全部分区的follower
HW、LEO
HW:高水位,指消费者只能拉取到这个offset之前的数据
LEO:标识当前日志文件中下一条待写入的消息的offset
工作机制
零拷贝
零拷贝的实现
概述
DMA直接内存访问;现代计算机就是允许硬件之间直接进行数据交互;DMA将一个地址空间复制到另外一个地址空间,然后数据的传输是DMA设置之间完成
DMA
直接内存访问
DMA设备
能够不经过cpu直接相互直接就能进行数据交互的硬件设备
两种实现方式
mmap
概述(kafka就是mmap实现方式)
用户态直接应用内核态的文件句柄
mmap方式,用户态和内核态共享内核态数据缓冲区,数据不需要从内核态复制到用户态空间;用户态发送数据的时候,就直接应用内核态的文件句柄就行(无需把数据从内核态拷贝到用户态,再从用户态拷贝到socket套接字的内核空间);
sendfile
数据不需要经历从内核态拷贝用户态;数据直接从DMA设备直接发送对应的做网络传输的DMA设备,由这个设备直接传输数据
Kafka零拷贝
概述
Kafka的零拷贝并不是说完全不存在拷贝,而是避免不必要的拷贝
零拷贝过程
从磁盘把数据拷贝到内核空间;
从内核空间中直接把数据发送到网卡;
传统拷贝方式步骤
1.从磁盘去读到内核空间缓存页;
2.应用从内核缓存页读取到用户空间缓存区;
3.应用程序将用户缓冲区的数据放入socket缓冲区;
4.操作系统将socket里面的数据复制到网卡接口,发送数据;
零拷贝和传统拷贝方式对比
1.kafka的零拷贝从获取数据到最终把数据发送出去只需要经历一次拷贝;
2.传统拷贝方式从获取数据到最终把数据发送出去,需要经历4次拷贝;
kafka的拷贝方式大大降低了数据在不同的内存空间中复制的次数,提高了系统io效率
kafka持久化机制
消息持久化原理
概述
基于磁盘的线性的读写(操作系统做了大量的IO技术优化),甚至会被随机的内存读写更快
io优化技术
read-ahead
write-behind
和其他数据缓存的差异
kafka是直接把数据写入日志文件;其他几乎都是先把数据缓存在内存中然后再间隔刷盘
持久化读写
读写操作
写操作
将数据顺序追加到文件末尾
文件写入超过一定大小会被滚动到新的文件中
写操作参数设置
操作系统积累多少条数据就一定要被刷到磁盘
操作系统积累了多少秒的数据就一定要被刷到磁盘
关于日志丢失
也就是根据设置最多丢失多少秒或者多少条数据
读操作
从文件中读取
读操作参数设置
最大消息大小
缓冲区大小
读取过程
1.缓冲区大小大于消息大小就可以直接读取成功
2.如果缓冲区大小小于消息大小,那么就会读取失败,缓冲区大小翻倍知道成功读取完整条消息;
读写概述
读写都是顺序写入顺序消费,能保持较高的效率
好处
1.读操作不会组阻塞写操作
2.不受内存大小限制
3.线性的读取速度依旧很快
4.相对于内存保存时间更长
删除
删除策略
删除策略是可以配置
常见删除策略
超过一定时常
保留最近多少磁盘大小文件
删除内容
日志文件中的消息和日志文件本身都会被删除
删除操作阻塞读操作
读操作读取的是要被删除文件的副本
持久化文件构成
日志文件
日志文件特点
1.topic的每一个分区都会专属的append-only日志文件;
3.每条消息在文件的位置称之为offset(偏移量)
2.属于分区的消息会被追加到日志文件的末尾
日志条目
概述
日志文件由日志条目组成
日志条目内容
消息头(4字节整形数,表示消息体有多长)
消息体
包含消息内容
消息偏移量(用来表示消息的起始位置)
日志文件名称
该文件第一条数据偏移量+.kafka
索引文件
记录每一个segment下包含的日志条目偏移量范围
日志清理
消息有效期
在消息有效期内,是允许消费者重复消费;
日志清理两种方式
日志删除
根据保留策略删除日志分段
参数配置log.cleanup.policy = delete
日志删除策略
基于时间
log.retention.hours、log.retention.minutes、log.retention.ms
最长时间7天
基于日志大小
log.segment.bytes,每个日志分段大小
og.retention.bytes ,总的日志大小
扫描,某个分段超过日志分段大小,那么就删除;如果总的文件大小超过了设定,那么就删除时间距离现在最久的日志
基于日志起始偏移量
logStartOffset;删除偏移量小于这个设定的偏移量大小的日志
日志压缩
根据消息的key进行压缩,相同的key的消息,只会保留一个副本;这个key就是业务消息中的key,需要去手动指定这个key对应的是业务中的那个字段
参数设定
log.cleanup.policy = compact
log.cleaner.enable = true
压缩过程
压缩线程会根据日志分段中需要被清理压缩的占比最高的日志分段开始压缩清理;根据业务中的key去做删除,相同的key只会保留一条消息;
log.cleaner.min.cleanable.ratio ,设置当需要被压缩的数据超过百分之多少的比例的时候,就进行压缩;
队列工作方式
消息发送/消费方式assign
消息发送方式
1.消息可以指定分区发送
2.消息可以通过负载均衡方式发送到不同的分区
3.通过指定key进行hash运算后确定让哪个分区发送
消息消费方式
消费者集群的各个消费者只能消费不同的分区
一个topic消息可以发送给多个消费者集群
一个消费者可以消费多个集群的消息
多个消费者集群可以消费一个topic下面的消息
订阅队列模式设置subscribe
设置多个消费者消费一个分区的消息-订阅
一个消费组中的一个消费者只订阅一个分区的消息-点对点
kafka集群
zk的作用
注册中心服务治理
注册服务节点
同一管理所有的服务器
注册topic
记录topic的分区信息与对应的服务器节点对应关系
注册消费者
消费者启动的时候,都会去zk创建自己的节点
负载均衡
生产者负载均衡
可以通过zk的配置文件动态感受来自服务器节点的新增减少,来实现相应的负载均衡
消费者负载均衡
zk动态感受消费者新增减少,来合理的实现负载均衡
记录数据
记录分区与消费者关系
将分区和消费者id绑定记录到临时节点上
记录消费中的偏移量
记录每个分区中消费者消费的偏移量会发送给zk,方便在消费者重启之后,或者是重新分配消息分区,能够继续之前的消费
负载均衡
四层负载均衡
此负载均衡是kafka自带的
缺点是无法动态感知服务器节点的新增减少,从而在服务器新增减少的时候,不能根据服务器做负载均衡
kafka事务
事务场景
生产者发送的多条消息需要组成事物,对所有消费者同时可见,或者同时不可见
生产者发给多个topic,多个分区发送消息,要么都成功,要么都失败
子主题 3
子主题 4
leader选取策略
策略
OfflinePartition Leader
有新的分区上线就重新选leader
ReassignPartition Leader
运行重新分区命令,重新选择leader
PreferredReplicaPartition Leader
运行重新选择leader命令
ControlledShutdownPartition Leader
服务正常关闭之后,重启重新选择leader
子主题
不支持读写分离
主要原因
数据一致性问题
leader副本的数据和其他副本数据都不一致,读写分离容易导致数据不一致
延时问题
leader副本数据到从副本数据有数据延迟;
消费者是pull(拉)还是push(推)
producer 将消息推送到 broker
consumer 从broker 拉取消息
如果是kafka节点向消费这push消息,可能会造成消费者消费积压,或者是消费者性能浪费
zookeeper对于kafka的作用
1、存储kafka元数据
2、集群不同节点之间通信
3、leader 检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等。
kafka判断一个节点还活着的有那两个条件
1、节点和zk之间心跳检测正常
2、follow节点可以即时同步leader的写操作,且不能延时过高
ack 的三种机制
0
生产者不需要等到kafka节点的ack;
1
kafka节点上的leader副本收到消息就发送ack;
不需要等所有follow副本确认
-1
kafka所有的follow副本接收到消息,leader服务才会发送ack
kafka高性能原因
1、0拷贝
1、索引和日志文件读写
2、数据传输
2、对log文件进行分段处理,且分段数据会简历索引文件
3、本身就是天然的分布式
4、页缓存
对下一页数据的读取是从缓存中读取
5、对磁盘的写入顺序写入
6、消费采取pull模式
能够让消费者处于消费者机器自身资源相符的消费速度
leader副本和Follow副本区别
读写都是从leader副本操作的
follow副本的数据都是从lader服务同步
实际开发
引用场景
日志收集
同一日志同一收集,然后以同一服务的形式发放给各种消费者
消息系统(削峰,异步处理)
用户日活跟踪
运营指标
收集生产者各种生产数据,同一做报表处理
流式处理
和flink,spark,strom做流计算处理
实际的开发方式
1.需要导哪些包
2.有哪些核心API
消息队列实际问题
重复消费
消息重复消费原因
概述:
主要原因就是消息消费时候提交的偏移量,服务器并不知情
具体情况分类
1.强行杀掉线程,导致偏移量没有提交
2.消费了,还没有提交偏移量,分区就掉线了,触发重平衡,然后消息就会重复消费
3.消费者重新分配分区,导致消费者数据重新消费
4.消息消费时间过长,让zk觉得机器宕机了,触发了重平衡
解决方式
最稳定的方式就是在代码中根据消息唯一id做幂等性判断
消息一致性
概述
kafka消息一致性指的是分区中的leader和多个副本的消息数据保持一致性;
消息一致性解决方式
ISR机制
副本同步leader数据
同步参数
rerplica.lag.time.max.ms=10000
根据一定的时间间隔副本同步leader数据
rerplica.lag.max.messages=4000
当副本数据和leader数据查了多少条也会同步数据
ACK=all机制,生产者给服务器发送消息的时候,直到所有的副本都收到消息才会通知生产者,服务端这边已经收到消息
消息延迟消费
时间轮
延迟消息的实现
消息有序性
消息乱序原因
1.消息重试机制会导致消息乱序(一个分区对应一个消费者)
2.多个分区对应多个消费者, 需要顺序消费的数据被分配到了不同的消费者
解决方案
针对1:max.in.flight.requests.per.connection=1禁止生产者想服务器响应前再次发送请求,也就是消息的重试必须是在上次失败之后,里面发起重试
针对2:
可以设置一个topic只有一个分区,只有一个消费者
生产者把需要顺序消费的消息发送到指定的分区上
消息丢失
消息丢失情况分类
生产者发送消息给节点丢失
消息丢失原因
发送消息的程序异常,导致消息压根没有发送出去
消息发送了,由于中间网络原因,以及服务器接收原因,导致数据服务器没有正常接收到数据
节点保存消息丢失
消息丢失原因
ACk设置=1,主机拿到了数据,从机还没有同步主机数据,这时候主机挂了,从机无法同步主机数据
主机拿到数据,主机就挂了,没有设置相应的从节点,来备份数据;
主机挂了,从机被选为主机,主机中还有部分数据没有被同步到从机
消费者丢失消息
消息丢失原因
消息在消费的时候,消息消费的自动确认提交偏移量;如果批量的消息有20条,消费到10条消息的时候异常了,那么就会自动提交消息的偏移量是20,也就是会导致后面10条消息是没有被正常消费,也相当于消息丢失;
针对不同丢失情况对策
生产者发送丢失
消息确认机制
消息确认机制
消息确认等级
ACK =0
ACK=1
ACK=all
消息确认相应机制
ACK=1(默认设置),只要分区的leader副本接受到了消息,就会给生产者发送消息接受成功(其他副本再回去同步leader的数据)。
设计上是比较折中的在一定程度上能够保证消息的不丢失,也能保证一定的吞吐量
ACK=0,生产者给服务端发送消息,不等服务端是否有接收到消息,发送完了就认为消息到被服务端接受了;而实际情况是,消息会生产者的缓冲池中待一段时间然后才会被发送到服务端,生产者就不知道消息具体在啥时候发送到服务端;
缺点:网络宕机的时候,消息会丢失
优点:满足大吞吐量的数据发送;
ACK=all,消息的分区leader还有所有的副本都接受到消息,才会给生产者发送消息已经被接受了。
优点:最大程度上保证服务器节点接受到消息;
缺点:极度影响性能,导致数据的吞吐量低
消息重试机制
概述
生产者发送消息异常,然后会重新给服务器发送消息
消息重试前提条件(两者同时满足才能重试)
1.重试的次数小于retries指定的次数
也就是当重试的次数超过了设定次数,那么也不会发送的;
2.异常的类型是RetriableException或者事务管理器允许重新发送
消息重试机制参数设置
retries
消息重试次数,默认次数为int的最大值
retry.backoff.ms
重试的间隔时间
消息确认机制和重试机制区别
消息确认机制主要是针对消息发送到服务器正常接收这个过程的处理
消息重试机制,主要是针对消息发送之前生产者内部自己发送消息异常的兜底处理
节点数据丢失
1.ACK=all,让所有的服务器节点都获取到数据;
2.合理的设置从机的个数,设置数据的备份
参数设置:min.insync.replica
3.禁止主机挂掉,选从机作为新的主机
参数设置:unclean.leader.election.enable=false 本身默认就是flase
消费者消费数据丢失
设置消息消费提交偏移量为手动提交偏移量,通过代码在finnaly里面手动设置消息异常的那个前一条的偏移量做提交;
消息积压
积压原因
消费者消费能力不足
消费者处理不及时
解决方式
针对1
添加分区个数和消费者个数
针对2
合理增大每次拉取的消息数量
死信队列
不支持死信队列
消息如何控制只被消费群组中一个消费者消费
原则
kafka的一个分区的数据只会被消费者组中的一个消费者消费;
一个消费者可以消费来自多个分区的数据;
详细说明
分区数量- 3,消费者数量- 3<br><br>Kafka 将一个分区分配给一个使用者。除非某些使用者发生故障并且发生使用者重新平衡(将分区重新分配给使用者),否则所有使用者都将映射到其分区,并按顺序使用这些分区的事件。<br><br>分区数量 - 1,使用者 - 3<br><br>如果消费者多于分区数量,Kafka就没有足够的分区来分配消费者。因此,该组中的一个消费者被分配给分区,而该组中的其他消费者将处于闲置状态。<br><br>分区- 4,消费者- 3<br><br>在此方案中,其中一个使用者获得 2 个分区,而在使用者重新平衡期间,另一个使用者可能会获得 2 个分区。<br>
kafka参数设置
1.服务器配置
1.节点自身属性设置
broker.id
broker在集群中的标识
默认值-1
listeners
监听的服务地址(多个用,隔开)
无默认值
2.连接zk配置
zookeeper.connect
连接的zookeeper地址(多个地址用,隔开)
zookeeper.connection.timeout.ms
连接zookeeper超时时间(毫秒)
无默认超时时间
zookeeper.session.timeout.ms
连接ZK会话超时时间
zookeeper.sync.time.ms
zk的从机落后zk主机的最长时间
zookeeper.max.in.flight.requests
消费者有多少个未确认的消息,才会导致阻塞
3.日志配置
log.dirs
日志存放目录(有多个目录分布时使用,隔开)
无默认值
log.dir
日志存放目录(当log.dirs为null时)
默认值/tmp/kafka-logs
log.flush.interval.messages
将消息刷新到磁盘之前,日志分区上累计的消息数量
默认值:9223372036854775807
log.flush.interval.ms
刷盘前在内存中最长存在时间
log.retention.bytes
日志文件的最大容量
默认值-1,也就是可以无穷大
日志保存时间
log.retention.hours
日志文件保存的最长时间
默认是1周时间
log.retention.minutes
日志保存的最长分钟
默认为null
log.retention.ms
日志保存的最长分钟
默认为null
日志分区
log.roll.hours
新分区产生时间,以小时为单位
默认一周
log.roll.ms
子主题 1
子主题 2
log.segment.bytes
分区最大容量
默认1g
log.segment.delete.delay.ms
分区等待删除时间
默认60000ms
消息配置
message.max.bytes
拉取的批量消息的最大内存大小
默认值:0.9M
子主题 2
主题相关配置
auto.create.topics.enable
第一次发动消息时,自动创建topic。
默认值:true;
delete.topic.enable
是否可以删除topic
默认值:true
如果为Flase,那么管理工具将不能删除主题
auto.leader.rebalance.enable
rebalance配置
auto.leader.rebalance.enable
leader.imbalance.check.interval.seconds
分区重平衡检查的频率
leader.imbalance.per.broker.percentage
触发重平衡比例
默认值100%
线程配置
background.threads
后台处理线程个数
默认值10;
num.io.threads
处理请求线程数量
默认值:8
num.network.threads
处理网络请求网络相应线程数量
默认值3
num.recovery.threads.per.data.dir
日志恢复和日志关闭时刷新的线程数
默认值1
num.replica.alter.log.dirs.threads
日志之间移动副本线程数
无默认值
num.replica.fetchers
主节点数据复制到副本的线程数
偏移量
offset.metadata.max.bytes
与偏移量提交管道的元数据最大大小
offsets.commit.timeout.ms
偏移量超时时间
offsets.topic.num.partitions
偏移量提交主题分区的数量
offsets.topic.replication.factor
子主题 1
offsets.topic.segment.bytes
日志索引文件大小
默认值100M
子主题 6
unclean.leader.election.enable
leader挂了,是否会选举其他副本作为leader
默认值;false
压缩
compression.type
按照给定的压缩方式压缩数据
值集:“gzip”、“snappy”、“lz4”、“zstd”
事物
transaction.max.timeout.ms
事务执行最长时间,超时则抛出异常
900000ms
2.生产者配置
1.连接配置
bootstrap.servers
服务器节点配置
2.消息相关配置
buffer.memory
消息缓冲区大小
默认值:33554432 =32M
生产者最大可以用缓存;生产者可以用来缓冲等待发送到服务器的记录的总内存字节
消息序列化
key.serializer
指定消息的key的序列化类(需要实现Serializer接口)
无默认值
value.serializer
指定消息内容的序列化类(需要实现Serializer接口)
无默认值
消息发送
消息发送条件
batch.size
批量发送的最大容量
默认值16384 =16k;缓存到本地内存批量发送大小;每当消息的数据量达到16k才会把数据发送给服务器
作用
消息不是一条一条的发送,而是积累到一定量才会发送
linger.ms
生产者将请求传输之间到达的任何记录组合到一个批处理请求中的时间
默认值0
作用
消息发送延迟时间,也就是在一个延迟时间内所有的消息都是被同一批次的发送出去;
batch.size和liger.size只要满足一个,消息就会被发送
消息发送阻塞
max.block.ms
消息发送到具体分区的阻塞时间
默认值:60000ms,一分钟
阻塞原因:缓冲池已经满了,或者是系统元数据不可用,导致这个问题;
消息请求阻塞时间
request.timeout.ms
生产者请求发出后,获取相应的最长时间,如果超过了该时间,那么客户端就会重新发送
默认值:30000 ,30秒
消息发送大小
max.request.size:
生产者发送最大直接数量
默认值:1M
消息确认
acks
生产者要求领导者在考虑完成请求之前收到的确认数量
默认值1
用途:
配置消息发送发到服务的消息确认机制
值集
0:表示producer无需等待leader的确认;
1:代表需要leader确认写入它的本地log并立即确认;
-1(all):代表所有的备份都完成后确认
delivery.timeout.ms
生产者发送完消息,接受服务器消息确认的时间
默认值120000ms,120秒
消息重试
retries
消息发送失败消息重试次数
默认值是int的最大值
retry.backoff.ms
消息重新发送中间间隔时间
默认值100ms
消息压缩
compression.type
消息以怎么的压缩格式进行压缩
值集:“gzip”、“snappy”、“lz4”、“zstd”
和服务器连接
connections.max.idle.ms
关闭空闲连接时间(生产者和服务器最大失联时间)
默认540000
max.in.flight.requests.per.connection:
单个连接,可接受的最大未确认数量
默认值5;也就是消息发送需要服务端确认,这个就是在发送消息之前需要确认发送如果没有确认的消息大于等于该参数,那么就会发送失败。
自定义操作类
metric.reporters
参数修改之后发送通知的类
interceptor.classes
消息拦截器
发送消息之前消息会被拦截,消息还可以做相应的处理
数据传输设置
receive.buffer.bytes
TCP连接接受方缓冲区大小
默认值:32K
send.buffer.bytes
TCP连接发送方缓冲区大小
默认值:128
3.事物消息相关配置
transactional.id
事务ID(当有多个生产者时,标识哪个生产者的事务,可用于消息幂等)
transaction.timeout.ms
事务超时时间
3.消费者配置
1.连接配置
bootstrap.servers
服务器连接地址
2.消费者本身配置
group.id
消费者组的ID
client.id
消费者ID
3.消息配置
auto.offset.reset
初始偏移量当前偏移量不存在的时候,消费者消费的起始点
值集
earliest
自动到最早的偏移量位置
latest
自动把偏移量充值为最新偏移量
none
如果没有找到以前的偏移量,那么就会抛出异常
anything else
直接抛出异常
默认值
earliest
exclude.internal.topics
是否公开topic内部的元数据信息
默认值:true;
事物
isolation.level
隔离级别
生产者数据拉取配置
max.poll.records
自动拉取消息的个数
默认值:500
max.poll.interval.ms
自动拉取消息的频率
默认值:5分钟
fetch.max.bytes
拉取消息的最大数据量
默认值:50M
fetch.min.bytes
拉取最小字节数
默认值:1字节
如果服务器没有数据,那么就会阻塞,直到服务器有数据才会相应
fetch.max.wait.ms
拉取消息阻塞时间
默认值:500ms
生产者自动提交配置
enable.auto.commit
消费者是否是自动提交偏移量
auto.commit.interval.ms
消费者自动提交偏移量的间隔时间
生产者序列化配置
key.deserializer
指定消息的key的反序列化类(需要实现Deserializer接口)
value.deserializer
指定消息内容的反序列化类(需要实现Deserializer接口)
生产者连接配置
connections.max.idle.ms
超过多久关闭服务器和消费者的连接
默认值:540000
request.timeout.ms
消费者给服务端发送请求超时时间
默认值:30秒
session.timeout.ms
心跳发送相应超时时间
说明:消费者是会主动向服务器发送心跳,以此来正面自己是存活的
heartbeat.interval.ms
心跳时间:消费者心跳消息发送到消费者协调器的期望时间
默认值:3秒,设置必须是小于session超时时间的三分之一
kafka监控平台
kafka缺点
对于mqtt协议不支持
不支持物联网传感数据直接接入
仅支持统一分区内消息有序,无法实现全局消息有序
可以通过代码控制顺序
监控不完善,需要安装插件
依赖zookeeper进行元数据管理
kafka最全面试题
https://zhuanlan.zhihu.com/p/109814155
http://events.jianshu.io/p/869464e66cfb
RocketMQ
RocketMQ通信方式
示意图
基础概念
生产发送消息类型<br>
消息种类划分
同步消息
最大程度上确保消息的不丢失
使用场景
重要的消息通知
短信通知
异步消息
使用场景
对业务的效应时间非常敏感的业务
单向消息
使用场景
不是特别关注发送结果的场景
日志发送
优缺点
同步消息,异步消息会有消息的重新发送,单向消息消息发送失败不会重新发送
同步消息,异步消息发送的时候需要服务器节点返回消息接收的确认信息,而单向消息没有
消费方式
拉取式消费
消费者从服务节点上拉取消息消费
默认的消费方式,但是实时性不高,但是不会造成消息消费堆积
推动式消费
服务器节点主动给消费者推送消息消费
优点
消息消费实时性高
缺点
消费者来不及消费过多消息,容易造成消费者消息堆积
本质
消息推送本质上还是消息拉取
基本概念解释
Name Server
功能
1、服务器路由提供者,
2、生产者,消费者能够通过名称服务查询各主题的相应元数据信息
工作模式
1、多个Name Serve 组成集群
2、集群中各个Name Server相互独立,没有信息交互
生产者组
同一类Producer的集合,生产者发送消息逻辑一致
消费者组
同一类Consumer的集合,这类Consumer通常消费同一类消息且消费逻辑一致
集群消费
集群消费模式下,相同的消费者组,每一个消费者平摊消息;
广播消费
消费者集群中的每一个消费者,都是都会受到消息;
普通顺序消费
工作特性
1、消费者通过同一个消息队列(topic分区)收到的消息是有序的
2、不同的消息队列收到的消息可能是无序的
优缺点
优点
生产者发送消息快速
缺点
同一个消费者消费的不同队列之间的消息,是无序的
使用场景
对程序性能要求高,但是顺序消费要求不高
严格顺序消费
消费者收到的所有消息均是有顺序的
优缺点
优点
最大程度上确保了消息的有序性
缺点
消息发送的吞吐量大大降低
使用场景
对消费有顺序要求,且对程序性能要求不高
RocketMQ消息特性
消息顺序
全局顺序消费(严格顺序消费)
某个Topic下的所有消息都要保证顺序
分区顺序消费(普通顺序消费)
部分顺序消息只要保证每一组消息被顺序消费即可
消息过滤
发送消息的时候设置tag,消费的时候根据对应的tag做相关的过滤处理
消息可靠性
影响消息可靠性几种情况
1、节点非正常关闭
2、节点宕机
3、节点所在服务宕机
4、服务器断电,但是能立即供电
5、机器无法开机
6、磁盘设备损坏
影响范围
1、前四种可以立即回复,可能会有少量的数据丢失
2、后面两种,如果服务器是单点,那么消息将全部丢失,如果不是单点,消息还可以恢复绝大部分消息
至少一次
Consumer先Pull消息到本地,消费完成后,才向服务器返回ack,如果没有消费一定不会ack消息
消息回溯
工作机制
按照特定时间回溯到具体的历史时间点,重新消费消息
事物消息
应用本地事务和发送消息操作可以被定义到全局事务中,要么同时成功,要么同时失败
定时消息
指消息发送到broker后,不会立即被消费,等待特定时间投递给真正的topic
消息重试
工作机制
1、消费者消费消息失败后,令消息再消费一次;
消费失败后的消息会进入消息重试队列
消息消费失败原因
1、消息反序列化失败
2、程序异常
2、消费者依赖的校友服务不可用
消息重投
工作机制
1、生产者发送消息时,同步消息,异步消息的发送如果失败了,生产者会重新发送
2、单向发送发送失败,生产者无法重新发送消息;
流量控制
生产者流量控制
生产这发送消息过多,服务器节点处理这些消息达到性能瓶颈
控制副作用
消息不会重投
消费者流量控制
消费者这边接收到的消息,消息处理不过来达到性能瓶颈
控制副作用
降低拉取频率
作用
降低服务器节点压力,降低消费者节点压力
死信队列
消息重试达到最大次数后,依旧无法正常消费,死信队列就会接受到该消息;
可以通过RocketMQ的控制台,对死信队列中的数据重新消费;
接受不能被处理的消息,放在以后再做处理
Rocket消息问题
消息消费问题
消息堆积
消息堆积的原因
Producer原因
生产者生产速度过快,超过了broker写入能力<br>
短时间的业务高峰期;
Broker消息堆积
主从复制延迟
消息存储过多,ConsumeQueue/CommitLog 查询变慢
Consumer原因
消费者消费速度过慢(业务逻辑过长,线程数少)<br>
顺序消费模式导致队列单线程被消息,吞吐量受限
消费者宕机,无法正常消费数据
解决方式
Producer原因
消息降级 / 延迟处理
非核心消息设置延时消费,或者延迟队列
对老消息,可批量迁移到 备份 Topic,降低压力
削峰处理
异步处理
Broker消息堆积
调整刷盘策略为异步
扩容
增加主节点个数,分散消息存储压力和消费压力
调整 队列数量(MessageQueue),增加分区并行消费能力。
Consumer
扩容
增加 消费线程数,提高并发度
消费者组增加消费者实例数量
对顺序消费场景,可考虑 业务分区优化,降低单线程瓶颈。
优化消费者逻辑
异步处理消息,批量处理消息 ,缓存优化。
设置数据开关,开关打开消息直接放入数据库,或者直接返回,最大程度上降低消费者程序时间
使用 幂等性 + 并发安全设计,允许多线程并行消费。
判断MQ是否存在消息堆积场景方式
Producer发送消息的速率监控
Consumer消费消息的速率监控
Producer发送消息的最大偏移量(maxOffset)与Consumer消费消息的当前偏移量(currOffset)
的差别值与给定的消息堆积数值告警值对比,若是差别 值大于数据告警值,则存在消息堆积,不然不存在消息堆积
消息堆积场景
差别值呈现增大趋势
producer消息的发送速度大于consumer的消息消费速度
处理方式
1、消费者进行扩容操作
2、提高消费者消费速度;
3、对生产者限流操作;
producer的生产速率无明显增长,consumer的消费速率无明显增长
处理方式
这种状况基本上是能够肯定是RocketMQ自己的故障造成的,需要提高Broken节点自身的服务器配置,和相关参数;
producer生产速率正常,RocketMQ服务器性能正常,consumer消费速率下降
差别值呈现平稳趋势或者降低趋势
最佳工作模式:RocketMQ自己的服务性能,必要的时候能够对RocketMQ 进行扩容,提升消息堆积能力。
消息顺序消费
问题出现原因
某些特殊场景下,发送出去的消息,消费者需要按照顺序来消费
顺序消费的前提
发送出去的多条消息,都是走的同一个topic发送
问题具体场景
大多数业务场景不需要考虑消息的顺序性
不需要考虑消费顺序
具体实现
生产端
通过自定义队列选择器(MessageQueueSelector),将需要顺序消费的消息消息固定路由到同一个队列(MessageQueue)。
Broker
单个队列内部,消息是按照写入的物理顺序存储的,天然有序。
消费端
消费者使用 MessageListenerOrderly(顺序监听器)保证同一个时刻是有一个线程去消费这一个队列的消息
RocketMQ 消费消息是多线程还是单线程?
非顺序消息 → 多线程并发消费(线程池处理)。
顺序消息
每一个队列只有一个线程去消费,保证队列内的消息是顺序消费
一个topic是有多个队列,每一个队列都会对应一个消费的线程<br>
还是多线程
消息重复消费(消息幂等)
问题原因
网络问题,导致消息消费的确认消息,rocketMQ节点没有收到
1、消费者没有发出
2、网络原因导致数据丢失
3、rocketMQ节点没有收到
解决方式
1、代码层面
消费者代码逻辑中保持幂等性
2、消息消费层面
通过每条消息的唯一编号来保证
消费者记录消费过的消息的唯一id,接收到消息的时候,发现有此id已经消费,那么就不做处理
唯一编号
msgId
消息设置的key
消息体重的唯一标记
分布式锁控制
对同一条业务 Key 加锁(如订单号),在锁内只执行一次消费逻辑。
3、重复消息不处理
有些业务场景,重复接受到消息,也不会影响到业务,所以不处理也行
消息丢失
消息丢失场景
主要有三种场景
1、生产者发送到队列节点消息丢失
网络抖动导致消息丢失
2、RocketMQ节点消息未能持久化到磁盘
消息还未持久化到磁盘,节点宕机
已经持久化到磁盘,磁盘损坏,但是没有备份
3、RoekctMq节点消费者丢失
消息还未消费完成,就通知节点消息已经消费完了,此时消费者宕机,导致当前正在消费消息丢失;
处理方式
针对场景1处理
消息重投机制,消息投递失败,会再次投递=
支持三种发送方式:
同步发送(send):发送后等待 Broker 返回结果 → 最可靠。
异步发送(sendAsync):回调确认,适合高并发。
单向发送(sendOneway):不关心结果,可能丢失。
失败重试
Producer 如果发送失败,会自动重试(默认 2 次,可配置)。
可以切换到其他 Broker 再发,降低单点风险。
针对场景2处理
1、刷盘策略
同步刷盘:消息必须写入磁盘成功才返回。
异步刷盘:写入 PageCache 即返回,后台线程再刷盘。
可根据业务选择:金融业务多用 同步刷盘。
2、RocketMQ采用主从机构
Broker Master 写消息,Slave 异步或同步复制。
同步刷盘 + 同步复制:消息写入内存 & 磁盘成功,且复制到 Slave 才算成功 → 最可靠。
针对场景3处理
消费确认机制(ACK)
ack机制,设置消息成功消费之后,再通知节点消息已经成功消费
消息重试 & 死信队列(DLQ)
消费失败重试
超过最大重试次数进入死信队列,人工处理
处理方式带来的问题
导致问题
性能和吞吐量也将大幅下降
优化机制
使用事务机制传输消息
1、耗费性能,导致消息发送速率降低
同步刷盘
刷盘操作更为频繁,导致刷盘效率低下
主从机制
主机需要把数据同步到从机,消耗主机网络io,和cpu
消费完再通知节点
消费者消费消息速度降低
基础概念
核心组件有哪些
Producer(生产者)
负责 发送消息 到 Broker。
特点:
可同步、异步、单向发送
可以指定 Topic、Tag 或消息 Key
Consumer(消费者)
作用:从 Broker 消费消息。
模式:
集群(Clustering):同组内消息均摊
广播(Broadcasting):每个实例都消费全部消息
特点:
支持顺序消费(每个 Queue 顺序)
支持事务消息回查
Broker
作用:
存储消息(CommitLog + ConsumeQueue + IndexFile)
提供消息读写服务
特点:
支持主从复制(同步/异步)
可水平扩展
类型:
Master(主节点)
Slave(从节点)
NameServer
作用:
提供 路由注册与发现服务
Producer/Consumer 通过 NameServer 获取 Broker 信息
特点:
无状态,可多节点部署
类似于服务注册中心
部署方式
单独部署或者Broker节点部署一起<br>
Topic
作用:消息的分类标签
消费组消费 Topic 中的消息时,实际上是消费它的各个队列
Message Queue(消息队列)
作用:
Topic 内的物理队列
保证顺序消息的分区顺序
特点:
每个 Queue 可以被多个消费者均摊消费(集群模式)
顺序消息需保证同一 Key 消息进入同一 Queue
队列数量由创建 Topic 时指定(或者通过 Broker 配置的默认值)
类型
写队列
用于 生产者向 Topic 写入消息时的队列数量
决定了 并发写入能力
读队列
用于 消费者从 Topic 读取消息时的队列数量
决定了 消费端可以并行消费的队列数量
注意:
写队列是消息存储的物理队列
读队列是消费端并行读取队列的逻辑分配
消费者消费的是 Broker 上的写队列消息
<br>
RocketMQ 消息类型有哪些?
普通消息(Normal Message)
没有特殊属性,直接发送、存储、消费。
顺序消息(Ordered Message)
局部顺序(同一个业务的key的消息进入到同一个队列中)<br>
实现方式
消息进入队列之前,会经过队列选择器,队列选择器根据key路由,相同的key会进去到同一个队列中<br>
消费者设置顺序,保证消息是按照发送时候的前后顺序来被消费的。
机制:
一个 MessageQueue(分区)只会分配给一个线程消费;
该线程会按照消息在队列里的存储顺序,一条一条地拉取、处理;
在消费完成前,这个队列不会被别的线程抢走。
延时消息(Delayed Message)
消息不会马上投递,而是等到指定的时间点后才可被消费。
RocketMQ 内部是通过 定时轮询机制 + 延时等级(level) 来实现的(默认支持 18 个固定延时等级,比如 1s、5s、10s、30s、1m、2m、…、2h)。
应用场景:
订单 30 分钟未支付则取消
用户注册后 1 小时发送提醒邮件
事务消息(Transactional Message)
用于分布式事务场景。
RocketMQ 提供 两阶段提交:
先发送一条 半消息(Half Message),消费者不可见。
执行本地事务逻辑。
根据事务结果提交/回滚消息(如果超时未确认,Broker 会回查生产者)。
批量消息(Batch Message)
生产者可以一次发送一批消息,减少网络开销,提高吞吐量
rocketMq 消费群组中,多台服务器消费消息,还是一台服务器消费消息?
看 消费模式 和 消费组(Consumer Group) 的配置
集群模式
消费者组内有多个服务实例,消费同一个topic的消息<br>
特点
同一个消息只会被组内的一个服务实例消费
多台服务器之间实现 负载均衡,消息被均摊。
子主题
广播模式
消费者组内的每一个实例会消费topic的每一条消息<br>
特点:
同一个消费组的每条消息 每个实例都会消费一次
不做负载均衡,每个实例都收到完整消息
集群模式下消费的负载均衡是如何实现的?<br>
每个消费者组中的消费实例只会去消费某些队列
每个队列在同一个消费组中只会被一个实例消费
队列分配策略
RocketMQ 内置了几种队列分配策略,最常用的是 平均分配
示例:
Topic 有 4 个队列:Q0、Q1、Q2、Q3
消费组有 2 个消费者:C1、C2
分配结果:
消费者<br>分配队列<br>C1<br>Q0、Q1<br>C2<br>Q2、Q3<br>
RocketMQ 消息存储机制<br>
存储文件结构
RocketMQ 所有消息都存储在 Broker 的磁盘上
核心文件
CommitLog(消息日志)
内容
按照顺序存储所有的消息
每条消息内容
topic,队列,消息体,属性<br>
默认文件大小为1GB,写满之后,新建一个消息日志继续写<br>
ConsumeQueue(消费队列)
特点
每一个MessageQueue对应一个ConsumeQueue 文件
内容
记录消息在消息日志中的物理偏移量
消息大小
Tag 的 hash 值(用于消息过滤)
IndexFile(索引文件)
提供按 Key 查询消息的能力,前提是消息发送时候设置了key<br>
消息写入机制
步骤
生产者发消息到broker节点,节点接受到消息写入commitlog中<br>
写入commitlog的时候是按照顺序写入,然后ConsumeQueue去记录该条消息在commitlog中的物理位置偏移量
如果有设置消息 Key,还会写入 IndexFile。
消息消费机制
消费者会他对应的ConsumeQueue 找到消息的物理位置偏移量,再去commiLog中找到具体的消息内容,获取到消息之后,根根据tag过滤<br>
刷盘策略(持久化)
RocketMQ 写 CommitLog 时,有两种刷盘方式
同步刷盘:消息必须写入磁盘成功才返回 → 高可靠。
异步刷盘:写入 PageCache(内存中) 就返回,后台线程再批量写盘 → 高性能。<br>
存储机制特点
顺序写 CommitLog,读取的时候是随机读
多级文件结构(CommitLog + ConsumeQueue + IndexFile) → 兼顾写入性能和检索性能。
PageCache + mmap → 减少系统调用,提高磁盘 I/O 效率。
刷盘 + 主从复制 → 保证消息可靠性。
RocketMQ 消息拉取模型和推送模型?
拉取模型(Pull Consumer)
机制:Consumer 主动向 Broker 发起请求,拉取消息。
Consumer 需要自己管理:
拉取的起始位置(偏移量)
是否有新消息
轮询频率
优点:
消费者完全掌握主动权,能灵活控制速率。
适合定时批量拉取、低实时性场景。
缺点:
需要自己写轮询逻辑。
实时性差,可能“拉不到”消息。
推送模型(Push Consumer)
机制:RocketMQ SDK 封装了拉取逻辑,表现为 Broker 向 Consumer “推送”消息。
实际上,Push Consumer 底层还是 Pull,只是客户端 SDK 帮你轮询 Broker、拉取消息,再回调到 MessageListener
优点:
使用简单,开发者只需要写回调逻辑。
实时性好,消息几乎一到 Broker 就会被消费。
缺点:
速率由 Broker 控制,Consumer 可能被“推爆”,需要消费端限流。
RocketMQ 的特点
本质都是 Pull 模型:Broker 不会主动往 Consumer 发消息。
Push 是 SDK 封装的 Pull:SDK 内部起一个线程循环拉取消息,再“推送”给业务代码。
所以 RocketMQ 既能支持高实时(Push),也能支持按需批量(Pull)。
延迟消息实现?
等时间到了才会把消息转发给真正的topic,和queue中,消息才能被拉取到<br>
延时等级
1s 5s 10s 30s <br>1m 2m 3m 4m 5m 6m 7m 8m 9m 10m <br>20m 30m <br>1h 2h
过程
1.生产者给消息设置一个延时等级,消息会被存储在特殊的延时队列中,
2.定时任务每100ms执行一次,看有没有延时消息,存在就会把延时topic上的消息写入到真正的topic和Commitlog中<br>
3.然后 Consumer 才能拉取到消息,正常消费。
rocketMq事物消息?
事务消息的整体流程
发送半消息
先把消息发送broker节点上,存储为半消息,消费者对半消息不可见<br>
执行本地事务
生产者端执行本地业务逻辑,事物完成之后给broker发送事物状态是成功了,还是需要回滚<br>
成功,则半消息会转成正常消息投递给消费者
失败,则broker删除半消息,不投递<br>
事务回查机制
broker长时间得不到生产者发送的事物消息状态,则会回查生产者该事物消息的状态。<br>
典型应用场景
电商下单:写订单表 + 发送“订单创建成功”消息
金融转账:扣减账户余额 + 发送转账成功消息
库存扣减:扣库存 + 发送库存更新消息
RokectMQ Broker 主从复制
节点类型
主节点
负责接收生产者发送的消息,储存消息,提供给消费者消费
从节点
同步主机的数据,可用于高可用,负载分担消息
一个主节点可以有多个从节点,组成一个集群
nameServer会保存主节点和从节点的对应关系<br>
复制模式
同步复制
流程
1.生产者把消息推给主节点,主节点写入commitLog,<br>
2.等待消息被同步到从机,且从机同步成功,<br>
3.主节点才会返回ack到生产者
优点:保证消息 不丢失(Master 挂掉,Slave 也有完整数据)。
缺点:性能较低,写入延迟高,因为要等 Slave 完成同步。
异步复制
流程
2.主节点直接返回ack给生产者<br>
3.消息再异步同步给从机
缺点
Slave 可能缺少部分消息。
优点:吞吐量高,写入延迟低。
RocketMQ NameServer 多节点无状态
功能
轻量级服务发现和路由中心
注册 Broker
Broker 启动时向 NameServer 注册自己的地址和 Topic 信息。
路由查询
Producer/Consumer 启动或发送/拉取消息时,从 NameServer 查询 Broker 的路由信息。
无状态(Stateless)
NameServer 不保存消息,不参与消息存储或投递。
内部只缓存路由表信息,可以丢失,不影响 Broker 和消息。
Producer/Consumer 查询路由信息后可以直接访问 Broker。
支持多节点部署
集群模式下推荐至少部署两台
Producer/Consumer 可以同时连接多个 NameServer,轮询使用
NameServer 挂掉一台不影响集群运行
轻量级、高可用
无状态意味着无需复杂的主备切换或数据同步。
高可用性靠多节点部署实现。
RocketMq集群中从机的作用?
从机的作用
数据冗余和可靠性
从机会复制主机的消息,备份主机的消息,保证消息不丢失
消费容错
除了顺序消费,普通消息是可以从从机拉取消费,提高系统可用性
高可用架构
主机宕机,从机可以切换成主机,保证服务可用
消费者访问 Slave
消费者默认是从主机拉取消息,可以设置从从机拉取消息
为啥在实际的技术选型中Kafka常用作日志数据的收集,而rocketMq常用作业务场景?
消息可靠性
kafka即使开启副本和ack机制依旧会有数据丢失<br>
rocketMq在设计上对消息的可靠性,幂等性,事物消息 能够更贴切实际的业务场景<br>
设计初衷不同
Kafka强调高吞吐,批量处理,允许有数据丢失
RocketMQ起源于阿里双十一交易系统,定位是高可靠、严格顺序、金融级别保障
MQ对比
性能对比
示意图
各自优缺点
Kafka
优点
性能卓越,单机写入TPS约在百万条/秒,最大的优点,就是吞吐量高。<br>时效性:ms级<br>可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用<br>消费者采用Pull方式获取消息, 消息有序, 通过控制能够保证所有消息被消费且仅被消费一次;<br>有优秀的第三方Kafka Web管理界面Kafka-Manager;<br>在日志领域比较成熟,被多家公司和多个开源项目使用;<br>功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用<br>
缺点
Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长<br>使用短轮询方式,实时性取决于轮询间隔时间;<br>消费失败不支持重试;<br>支持消息顺序,但是一台代理宕机后,就会产生消息乱序;<br>社区更新较慢;<br>
RabbitMQ
优点
由于erlang语言的特性,mq 性能较好,高并发;<br>吞吐量到万级,MQ功能比较完备<br>健壮、稳定、易用、跨平台、支持多种语言、文档齐全;<br>开源提供的管理界面非常棒,用起来很好用<br>社区活跃度高;<br>
缺点
erlang开发,很难去看懂源码,基本职能依赖于开源社区的快速维护和修复bug,不利于做二次开发和维护。<br>RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。<br>需要学习比较复杂的接口和协议,学习和维护成本较高<br>
RocketMQ
优点
单机吞吐量:十万级<br>可用性:非常高,分布式架构<br>消息可靠性:经过参数优化配置,消息可以做到0丢失<br>功能支持:MQ功能较为完善,还是分布式的,扩展性好<br>支持10亿级别的消息堆积,不会因为堆积导致性能下降<br>源码是java,我们可以自己阅读源码,定制自己公司的MQ,可以掌控<br>
缺点
支持的客户端语言不多,目前是java及c++,其中c++不成熟;<br>社区活跃度一般<br>没有在 mq 核心中去实现JMS等接口,有些系统要迁移需要修改大量代码<br>
技术选型
Kafka
日志收集和传输
RocketMQ
RoketMQ在稳定性上可能更值得信赖,业务有并发场景,建议可以选择RocketMQ
RabbitMQ
数据量没有那么大,小公司优先选择功能比较完备的RabbitMQ
子主题
分布式
理论
分布式和微服务区别?
微服务是一种分布式架构的实现形式
微服务天然就是分布式,因为服务可能部署在多台服务器上,通过网络调用通信。
但分布式系统不一定是微服务,例如分布式缓存、分布式数据库、分布式计算集群。
分布式关注的是系统层面的问题
负载均衡、容错、网络分区、节点通信、分布式事务。
微服务关注的是业务层面的问题
服务拆分、模块化、自治服务、独立部署、持续交付、DevOps 支持。
<br>
分布式系统的特点有哪些?
多节点协作
系统由 多台计算机或服务器组成
节点之间通过 网络通信协作完成任务
资源可以共享:计算、存储、数据库、服务
透明性(Transparency)
分布式系统对用户和开发者应该表现为单一系统:
可扩展性(Scalability)
系统可以通过 增加节点扩展处理能力
多节点协作、透明性、可扩展性、容错性、高并发以及一致性挑战,同时系统复杂性高,需要通过架构设计和中间件解决
什么是 CAP 定理?
在一个分布式系统中,**一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)**三者不能同时完全满足,只能同时满足两个
Consistency(一致性)
所有节点在同一时间看到的数据是一致的,即 同一数据的读操作总是返回最新写入结果。
Availability(可用性)
系统始终对外提供服务,每个请求都能得到响应(可能不是最新数据)。
Partition Tolerance(分区容错性)
系统可以在网络分区(节点之间无法通信)情况下继续运行
重点:在网络分区发生时,只能选择 一致性和可用性其中一个。
BASE 理论?
BASE 理论是 分布式系统中对数据一致性的一种设计理念
BASE 理论是 CAP 定理在 系统可用性优先 时的设计思想,BASE 是 “可用性优先、最终一致性” 的实践策略
B(基本可用)
S(最终一致性)
A(软状态)
强一致性、最终一致性、可用性优先
强一致性(Strong Consistency)
任何时刻,所有节点对同一数据的读写结果都是一致的
特点
数据同步严格,读写操作通常是同步阻塞
场景
金融交易系统
库存扣减系统
对数据一致性要求极高的业务
最终一致性(Eventual Consistency)
系统允许短时间内 数据状态不一致,但经过一段时间后,所有节点的数据最终会 收敛到一致
特点
写操作快速返回,提高可用性
节点之间通过异步同步或消息队列保证最终一致
临时的不一致可能导致读到旧数据或冲突
场景
社交媒体动态、点赞计数
缓存系统
大规模分布式存储(Dynamo、Cassandra)
可用性优先
在系统发生 网络分区或节点故障 时,仍然尽量提供服务
特点
系统高度可用,不会因为少数节点故障而完全不可用;
数据可能暂时不一致,需要通过最终一致性或补偿来修正
场景
秒杀或高并发访问的电商系统
海量日志、监控、统计系统
实战
分布式事物
什么是分布式事务
在 多个独立节点或服务上执行的一组操作,要么全部成功,要么全部回滚,以保证系统数据一致性。
特点
涉及 多个数据库或微服务
操作分布在不同 物理节点
系统需要保证 ACID 特性(原子性、一致性、隔离性、持久性)
分布式事物解决方案
XA
XA事物理论基础
同一个服务中操作多个数据库
2PC协议
协议定义
一种原子承诺协议,一种分布式算法,协调参与分布式事物的所有应用提交事物,或者回滚事物
2PC协议过程
阶段1:准备阶段
1、协调者向所有事物参与者发送事物内容,并等待所有参与者执行的结果答复
2、各参与者执行事物操作,并且记录事物日志,但是不提交事物;
3、参与者向协调者反馈事物执行的结果;
阶段2:提交阶段(回滚阶段)
提交事物
1、协调者向所有参与者发送事物提交消息;
2、参与者提交事物,释放事物锁定期间的资源;
3、参与者向协调者反馈事物执行成功消息
4、协调者收到各个参与者执行成功的消息,事物就成功
回滚事物
1、协调者向所有参与者发送事物回滚消息;
2、参与者做回滚操作,释放事物锁定期间的资源;
3、参与者向协调者反馈事物执行成功消息
4、协调者收到各个参与者执行成功的消息,事物就中断
2PC协议示意图
阶段1:
阶段2:
2PC协议问题
最大问题
同步阻塞问题
参与者向协调者反馈事物执行的情况,直到等到协调者反馈,是做提交还是回滚操作;之间的时间参与者都是处于阻塞状态;
数据不一致问题
如果参与者或者协调者,一方不可以用,导致事物数据不一致;
解决方式
依赖于数据库支持XA事物模型
主流数据库:mysql、oracle、sqlserver、postgre都是支持XA事物
备注:主要是这些数据库都遵守2PC协议
XA事物解决方案
Atomikos
特点
简单方便,无需搭载服务器
使用范围
单体应用多个数据库数据源之间跨库事物处理;
理论可行:XA 可以跨服务数据库
实际不推荐:高并发、跨网络、服务自治受限 → 性能差、阻塞风险大
XA模式优缺点
XA模式是分布式强一致性的解决方案;
简单易理解,开发较容易
对资源进行了长时间的锁定,并发度低
TCC
TCC事物理论基础
最早是由 Pat Helland 于 2007 年发表的一篇名为《Life beyond Distributed Transactions:an Apostate’s Opinion》的论文提出
TCC补充说明<br>
TCC 不是数据库自动事务,是业务层分布式事务模式
TCC 的核心就是通过业务代码手动实现跨服务事务的三段逻辑,以保证最终一致性
适合微服务和高并发场景
关键点在于:
Try 阶段锁定资源
Confirm/Cancel 阶段业务逻辑明确
幂等性设计 + 异常重试
三个阶段概述
Try 阶段
尝试执行,完成所有业务检查(一致性), 预留必须业务资源(准隔离性)
Confirm 阶段
确认执行真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作要求具备幂等设计,Confirm 失败后需要进行重试。
Cancel 阶段
取消执行,释放 Try 阶段预留的业务资源。Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致,要求满足幂等设计
TCC解决方案
seata
TCC事物特点
并发度较高,无长期锁定事物资源
开发量较大,需要自己提供try,confirm,cancel接口
一致性好
TCC适用于订单类业务,对中间状态有约束
TCC事物流程图
流程图
3PC协议
背景来源
主要是为了解决2PC中同步阻塞问题;
特点:
非阻塞协议,在实体提交或者终止之前增加一种超时机制,当超过这个时间上线事物还未提交,就会把该事物绑定的资源释放
3PC过程
阶段1:投票
1、协调者接收到事务请求后,向所有参与者发送能否提交请求,等待参与者返回信息
备注:如果协调者在接收事务请求时出现故障或者不可用,协调者将直接中止事务
2、参与者接收到协调者的的是否提交事物请求后,发送是否可以提交事物请求
阶段2:预提交
1、协调者,在超时时间内收到了各个参与者返回的可以提交按钮
备注:如果参与者都同意后会向协调者回复yes消息并进入准备状态,如果参与者获取资源失败或者出现不可用会回复no中止事务
2、协调者,向各个参与者发送预提交消息,参与者执行事物,并且记录日志,但是不做提交操作,并将执行结果返回给协调者;
阶段3:提交或者回滚
1、协调者接受到各个参与者发送回来的消息;
2、根据消息,做出是提交事物,还是回滚事物的决定,然后将将消息发送给各个参与者;各个参与者再根据协调者发送的消息,做回滚或者提交,并释放事物资源,向协调者反馈消息;
事物回滚情况
1、阶段1如果有返回不能提交事物
2、阶段2事物执行失败
3、预提交阶段中,协调者超时未收到消息
自动提交事物
阶段3参与者未收到协调者发送出来的提交或者回滚消息,那么就会自动提交事物
3PC问题
阶段3参与者未收到协调者发送出来的事物回滚的消息,那么参与者都是自动提交,就会造成事物不一致的情况;
AT
AT事物
一种自动化的分布式事务实现模式
核心思想是通过 自动记录操作前后的数据状态(Undo/Redo),在分布式环境中实现事务的 原子性和一致性,无需手动拆分三段逻辑(Try/Confirm/Cancel)
协议
数据库层的补偿事务协议
使用特点
单服务多数据源的 AT
核心:每个数据源都在本地事务中执行
系统通过 Undo/Redo 日志 拦截数据库操作
事务协调器(TC) 只需要指挥本地事务提交或回滚
这种场景非常适合 AT,回滚机制简单、自动
多服务情况下不适合
AT事物特点
业务无需编写各类补偿操作,回滚由框架自动完成
AT事物解决方案
seata
AT事物示意图
示意图
saga
saga事物理论基础
一种面向微服务的分布式事务模式,通过 将全局事务拆分为一系列本地事务,并为每个本地事务定义 补偿操作(Compensation),保证最终一致性
协议性质:属于 补偿事务协议,但更偏流程编排
核心思想:
不依赖数据库底层事务
不阻塞资源
通过顺序执行本地事务 + 补偿回滚实现分布式事务一致性
saga事物特点
优点
事物并发度高,不会长时间锁定资源
缺点
需要定义补偿相关操作,代码量大
一致性弱,采用补偿机制实现事物一致性
Saga 模式的补偿操作
同步执行、异步消息驱动、定时任务方式实现,但都必须保证幂等性和逆向操作,保证全局事务最终一致性。
具体实现
同步补偿
特点:当某个事务失败时,立即同步调用已执行事务的补偿操作<br><br>优点:补偿及时,数据最终一致性快<br><br>缺点:阻塞当前事务流程,如果补偿操作耗时或失败,需要重试处理
T1: 创建订单 → 成功<br>T2: 扣减库存 → 失败<br>立即调用 T1 补偿:<br>T1: 取消订单 → 同步执行
异步补偿(消息驱动)
特点:失败时将需要补偿的操作发送到消息队列,由异步服务处理<br><br>优点:非阻塞,提高系统吞吐量<br><br>缺点:短时间内系统可能不一致,需要设计重试机制<br><br>常用技术:RabbitMQ、Kafka、RocketMQ 等消息队列
T1: 创建订单 → 成功<br>T2: 扣减库存 → 失败<br>T1 补偿消息发送到队列 → 异步服务消费并取消订单
定时补偿 / 补偿任务
特点:失败事务将补偿任务写入数据库或任务表,由后台定时任务扫描执行<br><br>优点:系统高可用,适合网络波动或服务宕机场景<br><br>缺点:补偿有延迟,可能造成短时间不一致
T1 补偿操作写入任务表:status=pending<br>后台任务扫描任务表执行补偿<br>执行完成后更新 status=done
幂等补偿
说明:无论补偿操作被调用多少次,结果都是相同的
必要性:消息重试、网络失败、重复消费等场景必须保证幂等性,否则可能造成二次扣减或重复操作
取消订单操作:<br>if (order.status != CANCELLED) {<br> order.status = CANCELLED<br> refundPayment()<br>}
补偿操作设计原则
逆向操作
补偿操作应该逆转原操作的效果<br><br>如库存扣减 → 库存回滚
可幂等
确保多次执行不会破坏系统状态
异步 + 重试
尽量通过消息或定时任务实现异步补偿<br><br>异常情况要支持多次重试
可观察性
补偿操作要有日志、监控和报警,方便排查异常
saga事物解决方案
方案差别
1、思路不一样
最大努力通知型,消息通知方需要不断的通知消息发送方,来保证最终一致性
可靠消息一致性,实用通知方保证把消息发送出去,一致性是由消息发送方来保证的;
2、技术解决方向不同
最大努力通知,解决的是消息接收到了之后的一致性;
可靠消息,解决的是消息发出到接收的一致性;
3、使用场景不一样
最大努力通知型,关注的交易后的通知事物;
可靠消息一致性,关注的整个交易过程的事物;
具体实现方案
最大努力通知型
1、中间事物参与者提供查询事物是否成功接口;2、后续事物参与者调用该接口,获取事物是否成功消息
特点
利用接口查询做补偿
事物流程图
流程图
消息最终一致型
1、中间事物参与者发送事物成功或者失败的消息;2后续事物参与者订阅消息完成最终事物
特点
利用消息队列来通知消息
事物流程图
流程图
Saga事物示意图
示意图
Saga模式使用场景
事物流程比较长
对中间过程不敏感的业务
本地消息表 / Outbox Pattern
不算严格的分布式事务,而是 利用消息队列保证最终一致性。
侧重点是“先把消息和业务操作写在一个本地事务里”,再异步投递消息。
可靠消息 + 最终一致性
属于 Outbox 的“标准化升级版”,依赖支持事务消息的 MQ。
也是 最终一致性方案,但不是数据库级分布式事务。
对账 / 补偿机制
不是分布式事务协议,而是 事后弥补不一致 的手段。
适合高吞吐、允许临时不一致的系统(电商订单、积分、库存校对)。
解决方案技术选型
单体服务,跨数据
XA
AT<br>
单服务多数据源XA,AT模式的区别
XA:严格 2PC,每个库都锁住资源,强一致但性能低
AT:基于 undo/redo 日志,事务本地提交,出现异常可回滚,高性能、柔性一致
跨服务,数据实时性高
TCC<br>
跨服务,数据实时性低
saga<br>
分布式系统中用户注册、下单、支付流程如何保证一致性?
1.用户注册一致性
场景:注册时需要写入用户表,同时可能需要初始化账户、发放优惠券、发送注册消息等。
常见方案:
本地事务 + 事件驱动:
本地事务
用户服务先写用户表(本地事务保证一致)。
事件驱动
通过消息队列(Kafka/RabbitMQ/Redis Stream)异步通知账户服务、优惠券服务,有新的用户注册了
在同一事务里写入 “注册成功事件” 到消息表。
保证:即使下游失败,消息会重试,最终达到一致。
幂等处理:下游系统处理事件要支持幂等(防止重复扣减或重复发券)。
2. 下单一致性
场景:用户下单,需要写订单库,同时扣减库存。
挑战:订单和库存不是一个数据库,不能直接用传统事务。
常见方案:
TCC(Try-Confirm-Cancel):
Try:冻结库存(不是直接扣减),订单状态为“待确认”。
Confirm:下单成功后确认扣减库存,订单状态更新“已创建”。
Cancel:失败时释放冻结的库存,订单状态更新“取消”。
子主题
本地消息表 / Outbox Pattern:
订单服务本地事务写订单表 + 订单消息。
订单消息发送给库存服务,扣减库存。
如果消息丢失,库存服务通过定时任务扫描未处理订单。
可靠消息 + 最终一致性:
订单成功 → 发送扣库存消息。
库存扣减成功 → 回调或再发消息确认订单。
失败则补偿。
3.支付一致性
场景:支付涉及订单服务、支付服务(可能还有第三方支付平台,如支付宝/微信)、库存服务。
挑战:第三方支付结果通知是异步的,可能延迟或丢失。
常见方案:
支付状态机:
订单初始为 “待支付”。
支付服务收到支付请求 → 调用第三方。
第三方异步回调支付结果 → 更新支付服务状态。
支付服务再通知订单服务,更新订单为“已支付”。
对账 / 补偿机制:
定时对账:定时从第三方拉取支付状态,修正本地状态。
确保最终一致。
幂等性:订单更新“已支付”时要保证幂等,避免重复更新。
4. 整体一致性设计思路
避免分布式强一致事务:因为性能差、可用性低。
采用最终一致性:通过消息队列、补偿机制、定时对账来兜底。
保证幂等性:所有跨服务调用、消息消费都要保证幂等。
异常场景处理:
注册消息丢失 → 消息队列重试。
下单库存不足 → 回滚订单状态。
支付通知丢失 → 定时对账。
分布式锁
什么是分布式锁?
分布式锁(Distributed Lock)是一种在 分布式系统中控制共享资源访问的机制
目的
保证同一时刻只有一个节点/进程访问某个资源
实现方式
基于数据库实现
思路
思路:通过数据库表记录锁状态(如 lock_table),利用事务或唯一索引实现互斥
示例:
CREATE TABLE lock_table (<br> lock_key VARCHAR(64) NOT NULL,<br> owner_id VARCHAR(64) NOT NULL,<br> created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,<br> PRIMARY KEY (lock_key)<br>);
INSERT INTO lock_table (lock_key, owner_id) VALUES ('order:123', 'client1');<br>-- 如果插入成功,则获取锁;失败表示锁被占用
优点:简单,容易实现
缺点:数据库压力大,性能低,不适合高并发
Redis分布式锁
使用redisson连接方式
操作步骤
1.在try catch外面获取锁
通过RedisClient对象获取到RedissionLock对象
2.在try catch中加锁
通过RedissionLock对象进行加锁
分支主题
3.在finally里面解锁(防止死锁,解不了锁)
原理
因为redis的crud都是单线程的,通过想Redis中设置key,value的方式
设置成功,说明当前就获取到了Redis的锁
设置失败,说明其他请求已经向Redis中设置过了当前值,其他线程获取到了锁,当前线程会阻塞等待获取锁;
Redis的SETNX命令给向reids中添加键值对,key不存在就是添加成功,key存在就添加失败
1、添加成功相当于获取到redis锁
2、添加失败相当于未获取到redis锁
3、redis删除该key,相当于释放了锁
Lua脚本加锁过程
1.先判断key是否存在,不存在才会加锁;
2.如果key存在,那么通过lua脚本判断,获取锁的客户端id是否和当前客户端的id相同,也就是进行可重入判断;
3.如果客户端id也不一样,那么会返回一个当前获取锁需要等待的时间,并且进入while死循环中等待获取锁;
设计需要注意的点
适时释放锁
1、锁的释放操作需要放在finnaly代码中;
未设置,程序异常,导致当前代码永远死锁
2、给key设置超时时间;(相当于设置锁的有效期时常)
防止获取到锁的程序,由于某种原因一直不释放锁,阻塞后续线程执行
确保sentx命令还有设置超时命令是同一个原子操作;
该操作由redis提供相关的操作命令
防止sentx命令执行完成,再去执行设置超时时间中间,reids宕机;
加锁,解锁两个操作都是同一个线程
防止,自己设置的锁被其他业务误删;
锁需要具备可重入性
子主题
锁需要具备阻塞和非阻塞特性
原因
获取不到锁的线程,需要让这些线程做获取的锁的等待从而可以执行锁中间的代码,而不是直接返回到客户端
解决方式
死循环不断的尝试获取锁操作,获取到锁操作后,跳出死循环;
锁失效
原因
锁失效后,其他线程可以直接获取到锁对象,两个线程同时执行锁中间的代码,无法保证串行执行;
解决方式
需要给锁有效期续命
高并发分布式锁设计
核心思想
分而治之,类ConcurrentHashMap种的分段锁
将需要被并发访问的数据拆分成多份,每一份数据对应设置一个分布式锁
案例
高并发下秒杀商品,商品库存有1000个,将商品库存缓存到10个key,value中,每一个key value的缓存只有100个,这样并发度就是原来的10倍
特别注意:
当获取的key对应的库存数据为0时候,需要释放当前锁,且需要再次获取其他库存不为0的锁;
分布式锁使用场景
1、批量操作防止重复操作
背景说明
运营后台需要针对线下商品的批量操作,一个商品可以绑定200-300个门店,批量100个商品就会有2W-3W条数据更新
2W-3W条数据,使得程序响应过慢,运用以为操作失败,然后接着继续狂点,导致服务器内存溢出宕机;
解决方式
方式1
1、获取到批量操作的商品id,按照大小排序,获取对应的uuid值,作为key,也就是redis的锁
2、后面重复操进来的数据,发现锁已经被获取,就放弃执行当前操作,显示已经在执行中;
2、显示抢购商品秒杀活动
背景说明
以鸡蛋,大白菜,食盐等商品做1毛钱秒杀活动,达到线上引流目的
解决方式
1、初始化分段锁信息
key为商品id,value为hash表,hash表中的字段就是各个子锁key,值为库存数据
2、用原子类的Long记录请求请求数量
3、对请求数量按照锁的个数取模,以此来确定需要访问具体的是哪个子锁
4、尝试sentx操作,key为子锁key,为第三步中获取的value为库存
5、获取到锁之后,执行业务代码,然后在最后更新hash表中的库存数据,也更新当前子锁对应库存数据
6、最后解锁
7、未获取到锁的线程,在做死循环自旋的时候,每次sentx操作之前都是需要获取hash表中库存数据;确保获取的库存数据是最新数据
ZK分布式锁
操作步骤
1.通过zkClient对象创建临时节点,作为加锁
2.通过zkClient对象删除临时节点,作为解锁
原理
1.zk是不允许创建相同的临时节点
2.如果zkclient对象发现已经相同的临时节点已经存在了,那么就会阻塞被阻塞;
3.阻塞实际上就是等待创建了这个节点的客户端去删除这个临时节点;
4.阻塞结束之后,创建临时节点,就获取到了锁
本质
zk不允许重复创建临时节点
有创建临时节点,就会客户端就会被阻塞
优点:可靠性高、自动失效
缺点:实现复杂,对 Zookeeper 依赖强
全局唯一id生成
分布式Id要求
全局唯一
全局业务中必须要是唯一
趋势递增
这个id最好是能递增
高性能
高可用
接入方便
全局唯一id生成方式
UUID
优点
简单
无网路消耗
缺点
无业务意义
不是递增
存储消息空间大
UUID作为数据库主键,性能低下
使用场景
数据库实现方式
数据库自增id
方式概述
获取数据库自增的主键作为全局ID
优点
实现简单
id是递增
数值类型查询速度快
缺点
如果数据是单节点,无法完全保证数据的高可以用
数据库多主模式
方式概述
给几台数据库服务器自增时候设置相应的步长(比如说,自增3,自增4),获取到自增id
优点
解决单节点,并不能高可用问题
缺点
不利于后续扩容
号段模式
方式概述
从数据库批量获取自增ID
优点
批量减少数据库压力
号段方式是推荐的使用方式
ZK
实现概述
通过node节点版本生成序列号
可以生成32位,64位
redis
实现概述
利用的incr命令实现原子的自增
雪花算法
实现概述
正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
百度uid-generator
和雪花算法类似
优点
可自定义时间戳,机器ID,序列号
美团Leaf
同时支持号段模式,雪花算法模式,可以切换
滴滴(Tinyid)
号段模式的实现
分布式缓存
分布式缓存常见策略:LRU、FIFO、LFU、TTL,应用场景?
LRU(Least Recently Used,最近最少使用)
原理
淘汰 最长时间没有被访问过 的数据。
实现方式
双向链表 + 哈希表(O(1) 时间复杂度)
应用场景
热点数据频繁访问
demo<br>
电商商品详情、用户会话缓存
优势:高命中率,适合访问模式变化频繁
劣势:实现略复杂,需要维护访问顺序
FIFO(First In First Out,先进先出)
原理
淘汰 最早放入缓存的数据
实现方式
队列(Queue)管理缓存顺序
应用场景
数据访问比较均匀,没有明显热点
临时缓存、批处理数据
优势:实现简单
劣势:可能淘汰仍热的数据,命中率低
LFU(Least Frequently Used,最不经常使用)
原理
淘汰 历史访问次数最少 的数据。
实现方式
哈希表 + 计数器,记录每个 key 的访问次数
应用场景
高频热点数据固定且访问频率差距大
视频播放量统计、排行榜缓存
优势:热点数据长期保留,命中率高
劣势:需要维护访问频率,计数器可能随时间膨胀,需要衰减策略
TTL(Time To Live,过期时间)
原理
为缓存数据设置 过期时间,超过时间自动删除
实现方式
Redis 每个 key 可设置 EXPIRE 时间
应用场景
数据本身有时效性,例如:
会话信息(Session)
验证码
秒杀活动库存缓存
优势:简单、保证数据不过期
劣势:无法保证热点数据长期存在,需要结合 LRU/LFU
选择方案(组合使用)<br>
热点数据 + 时效性数据
LRU + TTL
访问频率差异大且长期热点
LFU + TTL
简单缓存且均匀访问
FIFO + TTL
Redis与MemCache的区别
线程操作
redis数据处理是单线程,memcache是多线程处理
数据结构
Redis支持更多更复杂的数据结构,memcache只支持keyvalue的字符串数据;
数据安全性
Redis支持数据的持久化,会把数据同步到磁盘上;memcache不支持数据的持久化
数据备份
Redis支持数据备份,需要开启主从模式;memcache不支持数据备份
过期策略
REDIS支持更多的过期策略;memcache支持的过期策略少
设计分布式缓存架构,如何保证缓存一致性?
Redis / Zookeeper 在分布式场景中的作用?
Redis常见用途
分布式锁
分布式缓存
计数器 / 限流
Zookeeper常见用途
服务注册与发现
节点临时注册,客户端可感知服务上下线
分布式锁 / 选主
分布式定时任务
主要解决问题
微服务的分布式定时任务核心就是保证同一任务在集群中只执行一次
场景问题
重复执行:同一任务被多个实例同时执行
任务丢失:某个实例宕机,任务无法执行
负载不均:任务无法均匀分布到不同实例
所以需要 分布式定时任务调度 来保证任务只执行一次,并可容错和扩展。
分布式定时任务设计要点
任务幂等:任务执行可能重复,业务逻辑需要幂等
容错处理:任务失败可重试、迁移到其他实例
任务分片:大任务可分片执行,均衡负载
监控和报警:任务延迟、失败、执行次数异常需报警
XXL-JOB如何支持分布式调度、任务分片?
分布式调度实现
任务调度
任务注册:Executor 启动时向 Admin 注册自己(IP + port)
任务触发:Admin 根据 Cron 或触发规则生成调度列表
分配任务:
查询活跃 Executor 列表
根据任务分片策略或负载均衡策略,把任务派发给特定 Executor
心跳监控:
Executor 定期心跳 → Admin 判断健康状态
如果某 Executor 挂掉 → 重新分配任务给其他 Executor
分布式锁保障单机执行
Admin 调度任务时,使用数据库或内存锁,确保同一分片任务在集群中只执行一次
Executor 执行前再次校验任务状态,避免重复执行
任务分片机制
把一类任务拆成 N 份,由不同 Executor 执行,减少单机压力
分配规则:Admin 根据分片总数、活跃 Executor 数量,均匀分配
分片参数传递:
Executor 执行任务时,会带上 shardingIndex 和 shardingTotalCount
任务逻辑内部根据分片参数处理对应的数据
优点:
大任务拆分成多份并行执行
集群扩容后,分片重新分配,支持弹性伸缩
比如说我需要根据一个表里面的数据来做定时任务,XXL-JOB是如何分片?
demo<br>
背景场景
假设有一个大表 order,每天需要处理数百万条数据
单机执行容易压力过大 → 需要分片并行处理
目标:每个 Executor 只处理表的一部分数据,并行完成任务
分片参数
每个分片会传递两个核心参数给 Executor:<br><br>参数 含义<br>shardingIndex 当前分片的序号(0 开始)<br>shardingTotalCount 总分片数<br><br>比如 shardingTotalCount=4,shardingIndex=0~3,表示任务被拆成 4 份
分片数量来源
用户在任务配置时指定
用户在任务配置时指定在 XXL-JOB 管理后台创建任务时,可以设置:
总分片数(Sharding Total Count)<br><br>分片参数(Sharding Item Parameters)
策略驱动(可选)
XXL-JOB 默认分片策略是 平均分配<br><br>可自定义分片策略,如:<br><br>按节点权重分配<br><br>按业务数据量分配
分片执行逻辑
Admin 在触发任务时,根据活跃 Executor 数量和任务配置生成分片列表
每个 Executor 接收到分片参数后,在任务逻辑中通过 分片参数计算处理的数据范围
分片执行完成 → Admin 收集状态 → 标记任务完成
分片优点
并行执行:大表任务拆分成多片,提高效率
Executor 弹性:Executor 扩容后,Admin 重新分配分片
容错:某 Executor 异常 → 其他 Executor 可接管未完成的分片
简单易控:通过 shardingIndex + shardingTotalCount 控制数据划分
单点登录实现
设计一个秒杀系统,如何保证高并发下库存不超卖?
java诊断与链路追踪监控
链路追踪
链路追踪工具
cat
产品定位
CAT(Central Application Tracking)是一个实时和接近全量的监控系统<br>
侧重于Java应用的监控<br>
应用场景
mvc框架
rpc框架
持久层框架
分布式缓存框架
提供各项性能监控,健康检查,自动报警
cat系统的设计要求
实时处理
时间越久,监控的信息价值会锐减
全量数据
监控的是所有的请求数据
高可用
应用服务挂了,监控还在,可以辅助排查定位问题
高吞吐
全量数据的接收和处理能力
故障容忍
监控本身的故障不会影响业务代码的正常运行
可扩展
支持分布式,跨IDC部署,横向扩展的监控系统
不保证可靠
cat监控系统的可靠性可以做到四个九
cat整体设计
主要分为三个模块
CAT-client
应用应用埋点的底层sdk,的客户端
CAT-consumer
实时消费,处理客户端提供的数据
CAT-home
给用户展示的控制端平台
结构展示
<br>
客户端信息收集
1、为每一个线程创建一个ThreadLocal(线程局部变量);
2、执行业务逻辑的时候,就把请求对应的监控信息存储在线程的局部变量中
请求对应的上下文其实是一个监控树的结构
3、业务线程执行结束之后,将监控对象放入一个异步内存队列中;
4、cat会有一个消费线程将异步队列中的信息发送给服务端;
核心监控对象
Transaction
一段代码运行时间,次数
Event
一行代码的执行次数
Heartbeat
jvm内部的一些状态信息,Memory.Thread等
Metric
一个请求调用的链路统计
序列化和通信设计
序列化
cat序列化协议是cat自己自定义的协议
通信
netty来实现nio
存储设计
cat报表数据
cat原始logview数据
整体架构设计图
设计图
子主题
流程说明
1、客户端向服务端发送消息基于netty-nio实现
2、服务端接受消息放入内存队列,开起一个线程消费来分发这个内存队列中的消息
3、消息解析完成站会,存入本地磁盘,然后再异步上传到HDFS
实时分析
总个数
总和
均值
最大,最小
吞吐
95线,99线,999线
诊断工具
arthas-阿尔萨斯<br>
产品自我定位
线上监控诊断产品
大大提升线上问题排查效率
新名词学习
Perf
性能剖析(performance profiling)和代码优化
指标参数说明参考文档
https://blog.csdn.net/web18224617243/article/details/123953692
https://blog.csdn.net/Cr1556648487/article/details/126816451
https://docs.oracle.com/javase/8/docs/platform/jvmti/jvmti.html
https://arthas.aliyun.com/doc/getstatic.html
统计指标项目学习
java.ci.totalTime
jit编译花费的总时间
命令列表
常用命令
查看 logger 信息,更新 logger level<br>
logger
logger<br>
<br>
查看当前 JVM 的 Perf Counter 信息<br>
perfcounter
子主题
生成发放火焰图
profiler
<br>
内存相关
下载当前内存信息
heapdump
heapdump /tmp/dump.hprof
下载当前内存信息到某个目录下
子主题
查看jvm当前内存信息
jvm
jvm
查看当前 JVM 信息<br>
查看 JVM 内存信息<br>
memory
memory
<br>
查看当前线程信息,查看线程的堆栈<br>
最忙的几个
子主题
所有
子主题
编译文件相关
dump 已加载类的 bytecode 到特定目录<br>
子主题
dump
反编译指定已加载类的源码
子主题
编译.java文件生成.class
子主题
查看 JVM 已加载的类信息
sc
子主题
查看已加载类的方法信息
sm
子主题
vmtool 利用JVMTI接口,实现查询内存对象,强制 GC 等功能。<br>
子主题
方法监控
方法执行监控
monitor
<br>
输出当前方法被调用的调用路径
stack
<br>
方法内部调用路径,并输出方法路径上的每个节点上耗时<br>
trace
<br>
方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
tt
<br>
函数执行数据观测
watch
<br>
参数查看
查看当前 JVM 的环境属性
子主题
查看当前 JVM 的系统属性
子主题
查看,更新 VM 诊断相关的参数<br>
vmoption
子主题
查看指定参数
<br>
更新指定的 option
子主题
子主题
预览命令
当前系统的实时数据面板
dashboard
dashboard
子主题
当前系统的实时数据面板,按 ctrl+c 退出
查看当前类静态属性
getstatic
预览
子主题
查看 classloader 的继承树,urls,类加载信息<br>
输出当前目标 Java 进程所加载的 Arthas 版本号<br>
<br>
文件相关
打印文件内容,和 linux 里的 cat 命令类似
子主题
打印命令历史
history
实现原理
cpu 使用率是如何统计出来的?
一段采样间隔时间内,当前 JVM 里各个线程的增量 cpu 时间与采样间隔时间的比例
和linux系统类似
具体步骤
首先第一次采样,获取所有线程的 CPU 时间(调用的是java.lang.management.ThreadMXBean#getThreadCpuTime()及sun.management.HotspotThreadMBean.getInternalThreadCpuTimes()接口)
然后睡眠等待一个间隔时间(默认为 200ms,可以通过-i指定间隔时间)
再次第二次采样,获取所有线程的 CPU 时间,对比两次采样数据,计算出每个线程的增量 CPU 时间<br>
线程 CPU 使用率 = 线程增量 CPU 时间 / 采样间隔时间 * 100%<br>
注意事项
命令本身也是需要消耗时间的,会对结果有一定干扰
把统计的时间拉长可以降低命令本身执行的时间损耗
功能概述
1:查看应用 load、内存、gc、线程的状态信息
2:可在不修改应用代码的情况下,对业务问题进行诊断
查看方法调用的出入参
查看方法异常
监测方法执行耗时
类加载信息
监控系统
监控系统的要求
1、快速发现故障
2、快速定位故障
3、辅助进行程序性能优化
监控维度
一、基础资源监控
1. 主机/容器资源
CPU、内存、磁盘、网络IO
容器层:Docker Stats、cAdvisor
2. 节点健康
节点是否在线、负载情况
K8s:Node Condition、Pod 状态
3. 存储和数据库
存储和数据库指标
1. 性能指标
查询响应时间(Query Latency)<br>
单条 SQL 或事务平均耗时,慢查询监控<br>
每秒查询数(QPS/Queries Per Second)<br>
SQL 执行频率<br>
并发连接数<br>
当前活跃连接数 vs 最大连接数<br>
事务吞吐量(TPS/Transactions Per Second)<br>
每秒事务提交/回滚数<br>
锁等待<br>
死锁、行锁/表锁等待情况<br>
缓存命中率<br>
缓存层(如 MySQL InnoDB Buffer Pool、Redis)命中率<br>
事务回滚率<br>
反映异常或错误事务比例<br>
2. 资源指标
CPU 使用率<br>
数据库进程的 CPU 占用<br>
内存使用<br>
数据库缓存、buffer pool、连接缓存等内存使用<br>
磁盘 I/O<br>
读写吞吐量、延迟<br>
网络 I/O<br>
数据库与应用通信流量<br>
数据库空间<br>
数据文件/日志文件大小,剩余容量<br>
3. 健康状态指标
数据库实例是否可用(Ping/Heartbeat)
子主题
主从复制延迟(MySQL、PostgreSQL 等)
数据库错误日志中的异常条数
进程数量/线程池状态
4. 业务指标(可选)
订单数量、支付事务量等业务层面的 DB 指标
这些指标有助于理解数据库负载和业务压力的关系
数据库指标获取(以mysql为例)<br>
数据源
mysql内置监控工具<br>
global_status<br>
QPS、TPS、连接数、慢查询数等<br>
global_variables<br>
配置参数,缓存大小、线程数等<br>
info_schema.*<br>
表大小、索引、行数、锁等待等<br>
perf_schema.*<br>
SQL 执行时间分布、表锁/死锁等<br>
慢查询日志 → 找到耗时长的 SQL
错误日志 → 监控异常事件、死锁、连接失败
数据传输
Prometheus + mysqld_exporter
通过 MySQL 提供的状态信息(主要是系统表和状态变量)采集,再以 Prometheus 可抓取的格式暴露
连接数据库,查询mysql的系统信息和信息表,将这些信息转成Prometheus 格式,通过http接口暴露给Prometheus<br>
二、服务运行监控
1. 服务可用性(Availability)
服务实例是否存活(Health Check)
接口是否可访问(HTTP 200/500 状态码统计)
2. 请求指标监控
接口相关
调用总数
接口调用
错误数
最慢
最快
999线
95线
99线
平均耗时
总耗时
最大并发
平均QPS
错误率(Error Rate)、超时率
QPS(每秒请求数)、TPS(事务数)、延迟(Latency)
Exception监控
异常类型
异常方法:
异常时间
异常数量
堆栈信息
3. 资源消耗
服务容器 CPU/内存使用、线程数、GC频率
4. 容量与伸缩
当前实例数 vs 压力 vs 自动扩缩容阈值
数据库连接池监控
数据库连接池监控指标
连接池使用情况
活跃连接数(Active Connections / Used Connections)
当前正在使用的连接数
空闲连接数(Idle Connections)
可立即使用的空闲连接数
最大连接数(Max Connections)
连接池允许的最大连接数
等待获取连接数 / 阻塞数
当所有连接都被占用时,新的请求等待的数量
连接池性能指标
连接获取时间
获取连接的平均/最大耗时
连接池拒绝请求数
当连接池满时,拒绝的请求或抛出的异常
连接池初始化/关闭事件
监控池生命周期异常
其他辅助指标
连接池泄漏
长时间不释放的连接
数据库端活跃连接数
与应用端连接池使用情况对比
数据库连接池监控指标参数获取
通过连接池自身暴露的监控接口
大多数 Java 连接池都提供内置监控接口
HikariCP<br>HikariDataSource.getHikariPoolMXBean() → 获取活跃连接、空闲连接、等待数、连接获取耗时<br>Druid<br>Druid 提供 StatViewServlet 和 DruidDataSource.getStat() → 全面监控连接池状态<br>Tomcat JDBC Pool<br>org.apache.tomcat.jdbc.pool.jmx.ConnectionPoolMBean → JMX 方式暴露指标<br>C3P0<br>ComboPooledDataSource.getNumBusyConnections() / getNumIdleConnections() / JMX 支持<br>
集成到应用监控系统
实现方式
Spring Boot + Micrometer
直接采集这些数据;暴露在 /actuator/metrics 或 Prometheus 格式接口
Prometheus
通过 Micrometer 或自定义 exporter 拉取连接池指标,转成Prometheus格式,提供http接口给Prometheus调用<br>
没有现成的针对连接池的exporter工具
jvm监控<br>
jvm监控指标
1. 堆内存(Heap)
Eden / Survivor / Old Generation
Eden区:新对象分配区,频繁GC
Survivor区:短暂存活对象
Old区:长寿命对象,Full GC 发生在这里
指标:
已用 vs 总容量
GC 次数与时间
堆使用趋势
2. 非堆内存(Non-Heap)
方法区/元空间(Metaspace)
存放类元数据和静态信息
指标:
已用 vs 总容量
Metaspace 内存泄漏监控
3. GC 性能
指标:
Minor GC / Major GC 次数
GC 暂停时间(Stop-the-world)
GC 时间占比
4. 线程与类加载
活跃线程数、线程池状态
已加载/卸载类数量
5. JVM 其他指标(可选)
堆外内存(Direct Memory)使用情况
文件句柄、Socket 连接等
常用监控工具
Prometheus + JMX Exporter + Grafana
通过 JMX 获取 JVM 内存、GC、线程等指标。
2. Spring Boot Actuator + Micrometer
简单易集成,指标直接暴露 HTTP 接口。
jvm内存监控参数获取
JMX
概述
全称Java Management Extensions,jdk5引进的技术
java.management包下提供接口
接口功能
ClassLoadingMXBean
获取类装载信息,已装载、已卸载量<br>
CompilationMXBean
获取编译器信息
GarbageCollectionMXBean
获取GC信息,但他仅仅提供了GC的次数和GC花费总时间
MemoryManagerMXBean
提供了内存管理和内存池的名字信息
MemoryMXBean
提供整个虚拟机中内存的使用情况
MemoryPoolMXBean
提供获取各个内存池的使用信息
OperatingSystemMXBean
提供操作系统的简单信息
RuntimeMXBean
提供运行时当前JVM的详细信息<br>
ThreadMXBean
提供对线程使用的状态信息<br>
Java Management API 是 JMX 的 Java 内置实现和封装,使开发者无需手动操作 MBean 就能获取 JVM 指标<br>
JMX架构
分层
资源层
包含 MBean 及其可管理的资源
提供了实现 JMX 技术可管理资源的规范
代理层
充当 MBean 和应用程序之间的中介
远程管理层
为远程程序提供Connector 和 Adapter访问 MBean Server
架构图
核心功能
实现对运行时应用程序动态资源查询
修改对运行时应用程序动态资源配置
利用JMX创建javaBean规则
JMX创建javaBean规则
具体规则
1、创建需要被存入进程的对象;
2、对象必须是接口,且必须以MBean结尾
demo
创建接口
public interface BlackListMBean {<br> // 获取黑名单列表<br> public String[] getBlackList();<br> // 在黑名单列表中添加一个用户<br> public void addBlackItem(String uid);<br> // 判断某个用户是否在黑名单中<br> public boolean contains(String uid);<br> // 获取黑名单大小<br> public int getBlackListSize();<br>}<br>
实现接口
public class BlackList implements BlackListMBean {<br> private Set<String> uidSet = new HashSet<>();<br> @Override<br> public String[] getBlackList() {<br> return uidSet.toArray(new String[0]);<br> }<br> @Override<br> public void addBlackItem(String uid) {<br> uidSet.add(uid);<br> }<br> @Override<br> public boolean contains(String uid) {<br> return uidSet.contains(uid);<br> }<br> @Override<br> public int getBlackListSize() {<br> return uidSet.size();<br> }<br>}<br>
MBean 注册到 MBeanServer
// 获取 MBean Server<br>MBeanServer platformMBeanServer = ManagementFactory.getPlatformMBeanServer();<br><br>// 创建 MBean 初始黑名单用户为 a 和 b<br>BlackList blackList = new BlackList();<br>blackList.addBlackItem("a");<br>blackList.addBlackItem("b");<br><br>// 注册<br>ObjectName objectName = new ObjectName("com.common.example.jmx:type=BlackList, name=BlackListMBean");<br>platformMBeanServer.registerMBean(blackList, objectName);<br>
演示
String hostname = "localhost";<br>int port = 9000;<br>// 循环接收<br>while (true) {<br> // 简单从 Socket 接收字符串模拟接收到的用户Id<br> try (Socket socket = new Socket()) {<br> socket.connect(new InetSocketAddress(hostname, port), 0);<br> try (BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()))) {<br> char[] buffer = new char[8012];<br> int bytes;<br> while ((bytes = reader.read(buffer)) != -1) {<br> String result = new String(buffer, 0, bytes);<br> String uid = result;<br> // 去掉换行符<br> if (result.endsWith("\n")) {<br> uid = result.substring(0, result.length() - 1);<br> }<br> if (blackList.contains(uid)) {<br> System.out.println("[INFO] uid " + uid + " is in black list");<br> } else {<br> System.out.println("[INFO] uid " + uid + " is not in black list");<br> }<br> }<br> }<br> }<br> Thread.sleep(3000);<br> System.out.println("[INFO] 休眠 3s ..............");<br>}<br>
添加jvm配置
-Dcom.sun.management.jmxremote.port=8888 --表示远程jmx的端口<br>-Dcom.sun.management.jmxremote.authenticate=false --是否要使用用户名和口令验证<br>-Dcom.sun.management.jmxremote.ssl=false --是否使用安全socket<br>
开通远程接口调用权限
登录远程jvm
已经实现的应用
jconsole
Java内置的实现监控工具 jconsole
消息中间件监控
rabbitMq监控
监控指标
基础设施和核心指标
CPU状态(user、system、iowait&idle percentages
内存使用率(used、buffered、cached & free percentages)
虚拟内存统计信息(dirty page flushes, writeback volume)
磁盘I/O(operations & amount of data transferred per unit time, time to service operations)
装载上用于节点数据目录的可用磁盘空间
beam.smp使用的文件描述符与最大系统限制
按状态列出的TCP连接(ESTABLISHED,CLOSE_WAIT,TIME_WATT)
网络吞吐量(bytes received,bytes sent) & 最大网络吞吐量
网络延迟(集群中所有RabbitMQ节点之间以及客户端之间)
集群监控指标
集群信息获取
集群指标获取
请求集群中的任意节点获取
该节点在声场响应之前,需要收集组合来自其他节点的数据
集群指标
集群名称
cluster_name
集群范围的消息速率
message_stats
总连接数量
生产者,消费者和服务端的链接数量
object_totals.connections
总消息通道数量
消息通道是轻量级的连接
object_totals.channels
总队列数量
object_totals.queues
总的消费者数量
object_totals.consumers
消息总数(ready+unacked)
queue_totals.messages
准备交付的消息数量
queue_totals.messages_ready<br>
未确认消息总量
queue_totals.messages_unacknowledged
最近发送消息数量
message_stats.publish
消息发布的速度
message_stats.publish_details.rate
最近给消费者消息数量
message_stats.deliver_get
消息发送速度
message_stats.deliver_get.rate
Other message stats
节点指标获取
可以对任意节点请求获取统计指标
节点指标
总的内存使用大小
mem_used
Memory usage high watermark
内存使用大小的最高水位
统计历史
内存使用阈值
以上两种理解?如何选择
当内存使用超过阈值时将触发报警memory alarm
Is a memory alarm in effect?
mem_alarm
剩余磁盘空间阈值
disk_free_limit
当空闲磁盘空间低于配置的限制时,将触发报警
可用文件描述符总数
已经使用的文件描述符大小
尝试打开的文件描述符数量
socket 系统连接最大值
socket 连接已经使用数量
Message store disk reads
?
Message store disk writes
?
Inter-node communication links
垃圾回收次数
垃圾回收内存大小
erlang 最大进程数量
已经使用的erlang 进程数量
正在运行的队列
单个队列指标获取
队列指标
内存大小
消息总数(ready+unacknowledged)
准备交付的消息数量
总的消息大小
准备传送的消息数量
未确认的消息数量
最近发布的消息数量
消息发布速度
最近交付的消息数量
消息传送速度
Other message stats
本质都是通过RabbitMq提供的Http api接口获取
GET /api/overview
返回集群范围的指标
GET /api/nodes/{node}
返回单个节点的状态
GET /api/nodes
返回所有集群成员节点的状态
GET /api/queues/{vhost}/{qname}
单个队列的指标
应用程序级指标
监控的rabbitMq系统本身指标
应用程序跟踪的指标可以是特定于系统
客户端库和框架提供了注册指标收集器或收集现成指标的方法
RabbitMQ Java客户端和Spring AMQP就是两个例子。其它开发人员必须跟踪应用程序代码中的指标。
监听堵塞消息
可以在MQ中专门创建一个监控的队列,定时的发送和消费队列中的消息,并且通过的如下的代码去监控队列是否已经堵塞,如果监听到队列已经堵塞,就立即发送告警的短信和邮件
监控检测
集群中是否有资源报警
rabbitMq是否正常运行
当前节点是否有报警
监控频率
生产系统建议收集间隔30秒-60秒<br>
频率太高,容易对系统产生负面影响
数据采集
Management Plugin
Management Plugin 是一个官方插件,旨在为 RabbitMQ 提供图形化管理界面、HTTP API 和命令行工具,方便用户进行监控、配置和管理
RabbitMQ Exporter 采集通过 Management Plugin 采集到数据封装成Prometheus的格式,提供http接口给Prometheus<br>
监控工具实现
RabbitMq自带管理平台
公开了节点、连接、队列、消息速率等的RabbitMQ指标
限制
监控系统与被监控系统交织在一起
占用系统一定的开销
它只存储最近的数据(最多一天,不是几天天或几个月)
它有一个基本的用户界面
它的设计强调易用性,而不是最佳可用性
管理UI访问通过RabbitMQ权限标记系统(或JWT令牌作用域的约定)进行控制
rabbitmqctl命令
后端命令行工具
REST API
Http接口
监控工具
Prometheus & Grafana
优点
监控系统与被监控系统分离
降低服务开销
长期存储指标
方便关联聚合对比各个相关指标
更强大和可定制的用户界面
易于分享的指标数据
更健全的访问权限
针对不同节点的数据收集更具弹性
RabbitMQ自带的(Management插件
Rocketmq监控
rocketMq参数采集和获取
Broker 内置 metrics → 可通过 Prometheus Exporter 或管理控制台获取<br>
监控工具
1、官方提供的一个console web监控工具
本质依赖的是rokcetMq mqadmin命令行工具
2、Prometheus
将rockeMq的数据源导入到Prometheus上做相关监控
大体步骤
1、系统rocketMq服务
大致流程
1、通过 RocketMQ Exporter 工具从rokcetMq 上获取到相关的指标数据;
2、配置Prometheus 从RocketMQ Exporter 获取到对应的指标数据
kafka监控
监控实现原理
jmx
kafka官方也是提倡使用jmx并且提供了jmx的调用给用户以监控kafka.
提供 Topic、Partition、Producer/Consumer、Broker 指标<br>
实现过程
Kafka JMX Exporter连接kafka,获取到核心参数,转换成Prometheus的格式,提供http接口给Prometheus调用<br>
监控指标
资源类型监控
实例监控
实例消息生产流量(bytes/s)
实例消息消费流量(bytes/s)
实例磁盘使用率(%)-实例各节点中磁盘使用率的最大值
topic
Topic 消息生产流量(bytes/s)
Topic 消息消费流量(bytes/s)
group监控
Group 未消费消息总数(个)
Broker 指标
Kafka-emitted 指标
未复制的分区数
UnderReplicatedPartitions(可用性)kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions
在运行正常集群中,同步副本(ISR)数量应等于副本总数。如果分区副本远远落后于 Leader,则从 ISR 池中删除这个 follower。如果代理不可用,则 UnderReplicatedPartitions 指标急剧增加。Tips:UnderReplicatedPartitions 较长时间内大于零,需要进行排查。
同步副本(ISR)池缩小/扩展的速率
IsrShrinksPerSec / IsrExpandsPerSec(可用性)kafka.server:type=ReplicaManager,name=IsrShrinksPerSec
如果某副本在一段时间内未联系 Leader 或者 follower 的 offset 远远落后于 Leader,则将其从 ISR 池中删除。因此,需要关注 IsrShrinksPerSec / IsrExpandsPerSec 的相关波动。IsrShrinksPerSec 增加,不应该造成 IsrExpandsPerSec 增加。在扩展 Brokers 集群或删除分区等特殊情况以外,特定分区同步副本(ISR)数量应保持相对稳定。
离线分区数(仅控制器)
OfflinePartitionsCount(可用性)kafka.controller:type=KafkaController,name=OfflinePartitionsCount
主要统计没有活跃 Leader 的分区数。Tips:由于所有读写操作仅在分区引导程序上执行,因此该指标出现非零值,就需要进行关注,防止服务中断。
集群中活动控制器的数量
ActiveControllerCount(可用性)kafka.server:type=ReplicaManager,name=IsrShrinksPerSec
所有 brokers 中 ActiveControllerCount 总和始终等于 1,如出现波动应及时告警。Kafka 集群中启动的第一个节点将自动成为Controller且只有一个。Kafka 集群中的Controller负责维护分区 Leader 列表,并协调 Leader 变更(比如某分区 leader 不可用)。
每秒 UncleanLeader 选举次数
UncleanLeaderElectionsPerSec(可用性)kafka.controller:type=ControllerStats,name=UncleanLeaderElectionsPerSec
在可用性和一致性之间,Kafka 默选了可用性。当 Kafka Brokers 的分区 Leader 不可用时,就会发生 unclean 的 leader 选举。当作为分区 Leader 的代理脱机时,将从该分区的 ISR 集中选举出新的 Leader。Tips:UncleanLeaderElectionsPerSec 代表着数据丢失,因此需要进行告警。
特定请求(生产/提取)用时
TotalTimeMs 作为一个指标族,用来衡量服务请求(包括生产请求,获取消费者请求或获取跟随者请求)的用时,其中涵盖在请求队列中等待所花费的时间 Queue,处理所花费的时间 Local,等待消费者响应所花费的时间 Remote(仅当时requests.required.acks=-1)发送回复的时间 Response。
传入/传出字节率
每秒请求数
Host 基础指标 & JVM 垃圾收集指标
消耗磁盘空间消耗与可用磁盘空间
页面缓存读取与磁盘读取的比率
CPU 使用率
网络字节发送/接收
JVM 执行垃圾回收进程总数
JVM 执行垃圾收集进程用时
Producer 指标
每秒收到的平均响应数
每秒发送的平均请求数
平均请求等待时长
每秒平均传出/传入字节数
I / O 线程等待的平均时长
每个分区每个请求发送的平均字节数
Consumer 指标
Consumer 在此分区上滞后于 Producer 的消息数
特定 Topic 每秒平均消耗的字节数
特定 Topic 每秒平均消耗的记录数
Consumer 每秒获取的请求数
监控工具
Kafka Manager
Kafka Eagle
Logi-KafkaManager
消息中间件监控核心指标
1. 服务运行时监控(核心部分)
消息吞吐和延迟
消息生产速率、消费速率
队列长度/堆积量
消息延迟/滞留时间
消息可靠性
消息确认状态(ack/nack)
重试次数、失败率
客户端/连接状态
活跃消费者数
客户端连接数
集群/Broker 状态
节点存活、Leader/Partition 状态
副本同步状态、消息复制延迟
2. 基础资源监控(辅助部分)
系统资源使用
CPU、内存、磁盘 I/O、网络 I/O
Broker 进程相关
文件句柄、线程数
缓存监控
redis监控
监控指标数据来源
redis自带的info命令和monitor命令的相关信息
INFO 命令
Redis 内置命令,提供全量的服务器状态信息
数据类型
Server:Redis 版本、运行时间、进程 ID
Clients:客户端连接数、阻塞连接数
Memory:已用内存、内存碎片率、内存峰值
Persistence:RDB/AOF 状态、最后一次保存时间
Stats:命令执行次数、QPS、慢查询数量、缓存命中率
Replication:主从复制状态、延迟
CPU:Redis 进程 CPU 使用情况
Cluster:集群节点状态、槽分布
MONITOR 命令
作用:实时打印 Redis 收到的每条命令
用途:分析慢命令、异常操作,但会增加 CPU 开销,不适合生产环境持续使用
SLOWLOG 命令
作用:获取慢查询日志
用途:分析执行时间过长的命令,优化 Redis 配置和数据结构
客户端统计
Redis 客户端(Jedis、Spring Data Redis)可以采集:
请求/响应时间
错误率
重试次数
通过 自定义指标暴露给监控系统
监控采集过程
集成到Prometheus + redis_exporter
redis_exporter 连接redis获取指标,封装成Prometheus格式,再提供http接口给Prometheus<br>
集成到 Spring Boot / Micrometer
Spring Boot 应用可通过 Micrometer Redis 模块采集 Redis 指标
数据会暴露在 /actuator/metrics,可被 Prometheus 拉取
redis监控指标
连接检测
连接失败检测
客户端连接数
执行 info clients 命令获取 connected_clients 就是客户端连接数
吞吐量监控
info stats
此命令可以查询吞吐量相关的监控项
具体指标
总执行命令数量
从 Redis 启动以来总计处理的命令数,可以通过前后两次监控组件获取的差值除以时间差,以得到 QPS
total_commands_processed
当前 Redis 实例的 OPS
instantaneous_ops_per_sec
网络总入量
total_net_input_bytes
网络总出量
total_net_output_bytes
每秒输入量,单位是kb/s
instantaneous_input_kbps
每秒输出量,单位是kb/s
instantaneous_output_kbps
内存监控
已使用内存大小
used_memory
通过 info memory 获取,表示 Redis 真实使用的内存
最大内存大小
maxmemory
通过 config get maxmemory 获取。
内存碎片
计算方式:used_memory_rss/used_memory
两个参数均通过 info memory 获取
大于 1 表示有内存碎片,越大表示越多;小于 1 表示正在使用虚拟内存,虚拟内存其实就是硬盘,性能会下降很多。一般内存碎片率在 1 - 1.5 之间比较健康。
持久化监控
持久化可以防止数据丢失
相关参数均为执行完 info Persistence 的结果
上一次 RDB 持久化状态
rdb_last_bgsave_status
上一次 RDB 持久化的持续时间
rdb_last_bgsave_time_sec
查看 AOF 文件大小
aof_current_size
key监控
大key
什么是大key
指单个 key 存储的数据量过大(比如一个 Hash 里有几百万字段,或者一个字符串值大小几十 MB)。
危害
单次读取或写入耗时长
阻塞 Redis 单线程
影响主从复制和 AOF 持久化性能
监控方式
如何监控大key(最优解)<br>
MEMORY USAGE命令
查询单个 key 占用内存:
可结合脚本扫描所有 key,统计大于阈值的 key
实现
编写脚本使用MEMORY USAGE命令扫描各个 Master 节点
获取到每一个节点的key排行榜,最后汇总<br>
可视化监控
Redis Exporter + Prometheus
收集 key 的统计信息(按前缀或类型)
可以设置告警:
单 key 内存占用超过阈值
集合长度超过阈值
redis自带的redis-cli --bigkeys
作用
可以找出五种数据类型中各自最大的key;
缺点
只能显示每种类型的最大 key,不提供全部排行<br>
一般不适用该种方式监控
通过脚本或者命令扫描所有的key
缺点
结果的准确性不高,集合类型的扫描只能扫描出集合的长度,而不是value的大小
还会阻塞redis正常的执行
解析rdb文件
通过解析工具解析rdb文件,获取大key
常用解析工具
很多第三方的解析工具
通过代码aop的方式,异步每一次key的大小
大 key 告警
告警实现
在Prometheus 配置规则
key_memory_bytes > 阈值 → 告警
内存超过阈值 → 警告
单 key 访问耗时超过阈值 → 警告
热点大 key → CPU/延迟告警
优化策略
拆分 key
List / Set / ZSet → 按分页或哈希拆分
限制写入
避免一次性 push/insert 大量数据
设置 TTL
避免长期占用大量内存
本地缓存或外部存储
超大对象存储在对象存储或数据库,Redis 缓存部分数据
热key
热点数据的定义
Hot Key:访问频率远高于其他 key 的数据
Hot Slot:某个 slot 被频繁访问的情况(适用于 Redis Cluster)
表现为:
单节点 QPS 占总流量的很大比例
CPU/内存消耗异常高
单 key TTL 短或数据量大
原理
MONITOR 命令,可以统计每个 key 的访问次数,可用脚本收集频率,发现热点 key<br>
看每一个master节点的QPS数据量,如果存在异常,极有可能存在热点key<br>
自建对热key监控
可视化监控(最优解)<br>
Redis Exporter + Prometheus 做到可视化<br>
Redis Exporter 可以收集:
每个命令调用次数(keyspace_hits, keyspace_misses)
每个 DB 的 key 数量
配合 Prometheus/Grafana:
绘制 key 或 slot 热点图
配置告警(单 key 访问量过高)
机器
监控示意图
四种方式优缺点对比
客户端监控
每一个链接redis的客户端,都做相应的热key监控
代理端监控
监控示意图
子主题
服务端监控
监控示意图
子主题
原理
利用monitor命令的结果就可以统计出一段时间内的热点<br>key排行榜、命令排行榜、客户端分布
缺点
monitor命令的执行影响正常的reids命令的执行
只能统计单机的热key
子主题
慢查询监控
慢查询涉及参数
执行时间超过了多久,会被记录到慢查询日志中
slowlog-log-slower-than
默认10000微妙
慢日志的长度
当慢查询日志达到最大条数时,如果有新的慢查询,会移除最大的慢查询。
slowlog-max-len
具体命令
slowlog get
查询所有慢查询
slowlog get 1
显示最新的一条慢查询
集群监控
具体指标
集群状态
cluster_state
hash槽状态
cluster_slots_fail
节点数量
cluster_known_nodes
具体命令
cluster info 命令中可以获取集群的状态
缓存命中率
HitRate = keyspace_hits / (keyspace_hits + keyspace_misses)
keyspace_hits 表示 Redis 请求键被命中的次数<br>
keyspace_misses 表示 Redis 请求键未被命中的次数<br>
info stats 可以获取两个指标
建议缓存命中率不要低于90%,越高越好
命中率越低,导致越多的缓存穿透,对mysql容易造成影响
线程池监控
线程池自带查询当前线程状态的方法
线程池中正在执行任务的线程数量
getActiveCount()
线程池已完成的任务数量,该值小于等于taskCount<br>
getCompletedTaskCount()
线程池的核心线程数量
getCorePoolSize()
线程池曾经创建过的最大线程数量。通过这个数据可以知道线程池是否满过,也就是达到了maximumPoolSize
getLargestPoolSize
线程池的最大线程数量
getMaximumPoolSize
线程池当前的线程数量
getPoolSize
线程池已经执行的和未执行的任务总数
getTaskCount
线程池动态修改参数
具体可修改参数
核心线程数<br>
ThreadPoolExecutor的api setCorePoolSize(int corePoolSize)
最大线程数
ThreadPoolExecutor的api setMaximumPoolSize(int maximumPoolSize)
等待队列大小
自定一个阻塞队列继承阻塞队类,然后在队列长度字段设置可以做修改。此队列作为线程池的阻塞队列
是否自动扩容
?
都是需要在县城的运行期做相关的操作进行修改
监控任务
任务分类
执行任务前后全量统计任务排队时间和执行时间
定时任务,定时获取活跃线程数,队列中的任务数,核心线程数,最大线程数等数据
线程池告警
告警指标
任务超时时间告警阈值
任务执行超时时间告警阈值
等待队列排队数量告警阈值
线程池定时监控时间间隔
告警实现
1、ThreadPoolExecutor线程池中beforeExecute和afterExecute方法是空实现
2、自定义线程池继承线程池类,实现beforeExecute和afterExecute方法
3、通过线程池的beforeExecute和afterExecute方法队线程池相关可查询参数进行监控
4、当相关的监控参数达到了告警阈值,那么就做出相关的告警操作;
三、日志监控
1. 集中式日志
收集微服务日志(应用日志、请求日志、错误日志)
统一存储和查询(ELK/EFK:Elasticsearch + Logstash/Fluentd + Kibana)
2. 日志分析
异常日志告警、错误聚合
请求追踪日志,辅助性能分析
如何做 集中日志管理?(ELK、EFK)
总结
集中日志管理 = 采集 (Filebeat/Fluentd) → 传输 (Kafka/直发) → 存储 (Elasticsearch/Loki) → 展示 (Kibana/Grafana) → 告警。
详细步骤
日志采集
每个服务写日志到本地文件(Logback / Log4j2)。
通过 Agent/采集器 收集日志
Filebeat(轻量级日志收集器,常配合 ELK)
Fluentd / Fluent Bit(CNCF 项目,性能更高)
Logstash(功能强大,但资源开销大)
日志传输
采集器将日志发送到消息队列或日志存储:
Kafka(常见缓冲层,削峰填谷)
直接推送到 Elasticsearch / Loki
日志存储
Elasticsearch:全文检索能力强,查询灵活。
日志分析与展示
Kibana(可视化查询,配合 Elasticsearch)。
或者
Grafana + Loki(轻量化日志查询、告警)。
Graylog(开源日志管理平台)。
告警与联动
日志异常 → 触发告警 → 通知(钉钉、企业微信、PagerDuty)。
结合 Prometheus + Alertmanager,实现指标与日志联动。
四、分布式追踪(Tracing)
1. 调用链跟踪
跟踪每个请求在各微服务间的调用情况
记录延迟、错误发生节点
2. 常用工具
Zipkin、SkyWalking、CAT
子主题
五、告警与自动化响应
1. 告警策略
需要自己设置告警策略
2. 告警渠道
邮件、钉钉、Slack、PagerDuty 等
3. 自动化响应
K8s 自动扩容
服务自动重启、流量熔断
六、业务指标监控
业务自定义
订单数量,支持成功数,点击次数,下载次数
监控方案设计
1、每个应用自监控或者统一上报监控?
自监控
应用自监控,就是每个应用实例的监控数据存放在应用本身,比如一个Map。然后通过JMX或者其他方式暴露出去。然后开发人员可以通过JConsole或者API(一般是Web界面)得到这些监控数据。比如Druid就是这种做法。访问: hk01-xxxx-mob03.hk01:8090/druid/index.html 得到hk01-xxxx-mob03.hk01:8090这个应用的监控数据。
统一监控
统一上报监控方式,就是所有的应用监控数据都上报到监控中心,由监控中心负责接收、分析、合并、存储、可视化查询、报警等逻辑。这种方式是瘦客户端模型,客户端的职责就是埋点上报监控数据。所有的监控逻辑都在中心处理
结论
自监控的话实现起来简单,并且没有与监控中心的网络交互,性能也会好很多。但是缺点就是缺乏全局的统计和监控。从实用角度来说还是集中式监控好一些。
2、监控中心与客户端应用之间要不要通过本地Agent上报?
agent上报
一个物理机上的多台服务器通过一个统一的agent向监控中心上报监控数据
独立上报
一个物理机上的多台服务器各自向监控中心上报统计数据
结论
网络通常的情况下,直接独立上报
3、存储最终状态还是事件序列
最终状态
经过业务逻辑的处理,得到相关的统计数据,然后再做储存
事件序列
直接就存储上报的统计信息本身的数据
结论
最终状态还是弱了一些,事件序列会好一些,存储可以采用HBase这样的分布式存储系统,性能问题可以采用预聚合等方式解决
4、数据存储
因为Events或者Metrics的特殊性,一般都会采用一种专门的存储结构——Distributed time series database
RRD(round-robin-database): RRDtool使用的底层存储。C语言编写的。性能比较高
whisper: Graphite底层的存储,Python写的<br>
prometheus: An open-source service monitoring system and time series database. 目前只有单机版本。<br>
InfluxDB: 开源distributed time series, metrics, and events database。Go语言编写, 不依赖于其他外部服务。底层支持多种存储引擎,目前是LevelDB, RocksDB, HyberLevelDB和LMDB(0.9之后将只支持Bolt)。<br>
OpenTSDB: 基于HBase编写的Time Series Database<br>
结论
如果要存储事件序列,那么InfluexDB和OpenTSDB是个非常不错的选择。都是可扩展,分布式存储,文档很详细,还是开源的。 influexDB 0.9.0之后支持tag,使用风格跟Google Cloud Monitor很相似,而且支持String类型。并且最重要的是不需要额外搭建HBase(Thus Hadoop & Zookeeper),看起来非常值得期待,不过截至今天0.9.0还是RC阶段(非Stable)。OpenTSDBvalue不支持String类型,这意味着日志不能上报到OpenTSDB,需要另外处理。
5、如果服务器挂掉了,统计数据怎么处理?缓存本地,等服务器起来再发送?还是丢弃?
前期可以先丢弃,后续要缓存起来。受影响比较大的是counter接口。
存储的话,可以考虑使用本地存储在RRD文件或者BDB中,或者消息队列中(RabbitMQ, ie.),最后再异步批量上报给中心的TSDB。<br>
6、网络通信和协议
如何高性能的接收大量客户端的上报请求。以及使用什么通讯协议
有几种选择:<br><br>HTTP<br><br>TCP<br><br>UDP: fire and forget, 主要需要注意MTU问题。
同时要考虑同步和异步接口
开源监控系统
Prometheus
Prometheus相关介绍
概述
Prometheus是一个开源的系统监控和警报工具包
历史
最初由SoundCloud构建。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户社区。它现在是一个独立的开源项目,独立于任何公司进行维护
Prometheus于2016年加入了云原生计算基金会,成为Kubernetes之后的第二个托管项目
特点
1、一个多维数据模型,其时间序列数据由度量名称和键/值对标识
2、有自己独有的的查询语言,PromQL
3、不依赖分布式存储;单个服务器节点是自治的
但是可以把采集到的数据再次被同步到其他平台,或者数据存储库
Prometheus有具体的接口可以提供查询指标数据
对应的第三方的支持将数据导入到第三方
4、(统计指标)收集通过HTTP上的拉模型进行
5、通过中间网关支持推送(统计指标)时间序列
6、被采集的服务是通过服务发现或者静态配置的
7、支持多种模式的图形化和仪表板
架构
具体组件
1、主服务器,用于采集存储统计指标数据
2、搭载在各种客户端库数据采集器
3、数据推送网关
4、各种导出组件
5、告警组件
6、支持各种第三方工具
架构图
使用场景
1、以机器为核心的监控
2、多维度手机和查询数据
3、可靠性
不适合的场景
1、需要百分之百保证数据准确性
Prometheus收集到的数据并不是非常详细完整
Prometheus统计指标
Prometheus客户端库提供了四种核心指标类型
总和 Counter
计数器是一种累积度量,表示一个单调递增的计数器,其值只能在重新启动时增加或重置为零
例如,您可以使用计数器来表示服务的请求、完成的任务或错误的数量
Gauge
度量是指表示单个数值的度量,该数值可以任意上下波动
内存使用的最大子,最小值
Histogram
直方图对观测值进行采样(通常是请求持续时间或响应大小),并将它们计数在可配置的桶中
Summary
与直方图类似,摘要对观察结果进行抽样(通常是请求持续时间和响应大小)。虽然它也提供了观测的总数和所有观测值的总和,但它可以在滑动时间窗口上计算可配置的分位数。
Prometheus监控
Exporter
广义上讲所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter,Exporter的一个实例称为target
数据导出器
导出器来源
社区
用户自定义
需要根据基于Prometheus提供的Client Library创建自己的Exporter程序
Promthues社区官方提供了对以下编程语言的支持:Go、Java/Scala、Python、Ruby
导出器的运行方式
独立使用
需要独立部署的
MySQL Exporter、Redis Exporter等都是通过这种方式实现
集成到应用中
为了能够更好的监控系统的内部运行状态,有些开源项目如Kubernetes,ETCD等直接在代码中使用了Prometheus的Client Library,提供了对Prometheus的直接支持。这种方式打破的监控的界限,让应用程序可以直接将内部的运行状态暴露给Prometheus,适合于一些需要更多自定义监控指标需求的项目。<br>
自定义export
需要在自定义的程序中引入prometheus的依赖包,且需要和prometheus定义通讯连接
Prometheus 监控 Java 应用
监控方式
使用官方提供的jar包,然后嵌入到应用中
这种方式一般都是新项目
prometheus的jmx_exporter
具体监控实施文档
https://blog.csdn.net/qq_25934401/article/details/82185236
https://blog.csdn.net/penngo/article/details/126982183
监控容器
cAdvisor
介绍
CAdvisor是Google开源的一款用于展示和分析容器运行状态的可视化工具
通过在主机上运行CAdvisor用户可以轻松的获取到当前主机上容器的运行统计信息,并以图表的形式向用户展示
CAdvisor默认只保存2分钟的监控数据
CAdvisor已经内置了对Prometheus的支持
相对于docker命令行工具
用户不用再登录到服务器中即可以可视化图表的形式查看主机上所有容器的运行状态
典型指标
container_cpu_load_average_10s gauge 过去10秒容器CPU的平均负载<br>container_cpu_usage_seconds_total counter 容器在每个CPU内核上的累积占用时间 (单位:秒)<br>container_cpu_system_seconds_total counter System CPU累积占用时间(单位:秒)<br>container_cpu_user_seconds_total counter User CPU累积占用时间(单位:秒)<br>container_fs_usage_bytes gauge 容器中文件系统的使用量(单位:字节)<br>container_fs_limit_bytes gauge 容器可以使用的文件系统总量(单位:字节)<br>container_fs_reads_bytes_total counter 容器累积读取数据的总量(单位:字节)<br>container_fs_writes_bytes_total counter 容器累积写入数据的总量(单位:字节)<br>container_memory_max_usage_bytes gauge 容器的最大内存使用量(单位:字节)<br>container_memory_usage_bytes gauge 容器当前的内存使用量(单位:字节<br>container_spec_memory_limit_bytes gauge 容器的内存使用量限制<br>machine_memory_bytes gauge 当前主机的内存总量<br>container_network_receive_bytes_total counter 容器网络累积接收数据总量(单位:字节)<br>container_network_transmit_bytes_total counter 容器网络累积传输数据总量(单位:字节)
和Prometheus集成
先启动cadvisor
Prometheus配置文件中配置cadvisor的ip地址和端口
然后启动Prometheus
监控mysql数据库
监控步骤
1、先部署MySQL_Exporter
该引用并不是和mysql整合在一起
2、在Prometheus配置MySQL_Exporter的IP和端口
redis监控
同mysql监控类似,通过redis_export
Prometheus数据存储
本地存储
将2小时作为一个时间窗口产生的数据放在一个数据块里面,保存在本地磁盘上
单个Prometheus Server基本上能够应对大部分用户监控规模的需求。
Prometheus数据序列数据库设计
核心设计思想:内置了一个本地数据序列数据库
优缺点
优点
1、可降低部署和管理复杂性
2、减少高可用带来的复杂性
缺点
本地存储无法将数据持久化,无法存储大量的数据,无法做到灵活扩展和迁移
远程存储
Prometheus定义两个标准接口(读写),让用户基于这两个接口保存到任意第三方存储服务,这就是远程存储
解决数据无法持久化问题
读写
远程写
远程读
联邦集群
特点
数据的采集和数据存储是分开的
利用数据是做远程存储,可以在每一个数据监控中安装一个监控实例,这个监控实例从公用的远程存储中心获取数据。
一个实例已经处理处理上千规模的集群
原理
1、在每一个数据监控中心部署一个实例
2、由中心的实力负责聚合多个数据中心的监控数据
示意图
数据可视化
概述
prometheus本身有自己的大盘数据,但是不太好用,一般是与grafana集成在一起
grafana
Grafana官方提供了对:Graphite, InfluxDB, OpenTSDB, Prometheus, Elasticsearch, CloudWatch的支持
所以prometheus可以将数据导入到grafana大盘中
Promthues高可用部署
基本HA:服务可用性
示意图
子主题
概述
1、部署多台服务器
2、多台服务器都会向同样的一批被监控的应用或者服务采集数据
3、数据展示的时候通过nginx负载均衡后从其中一台服务器拉取数据
优缺点
优点
确保Promthues服务的可用性问题
缺点
Prometheus Server之间的数据一致性问题
持久化问题(数据丢失后无法恢复)
无法进行动态的扩展
适用场景
适合监控规模不大
Promthues Server也不会频繁发生迁移的情况
保存短周期监控数据
基本HA + 远程存储
示意图
子主题
概述
相对于基础的服务可用性,此种部署方式,让数据在远程
优缺点
优点
确保了数据持久化,增加了系统可扩展性
Promthues宕机后,可以快速回复
可进行数据迁移
适用场景
用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues Server的可迁移性的场景
基本HA + 远程存储 + 联邦集群<br>
示意图
子主题
概述
将不同的采集任务划分到不同的Promthues
使用场景
场景一:单数据中心 + 大量的采集任务
场景二:多数据中心
按照实例进行功能分区
示意图
子主题
概述
极端情况下,采集的目标数量过大,通过联邦集群进行功能分区,也无法有效处理,考虑按照被采集的对象的级别,进行区分采集
Promthues服务发现
Promthues服务发现概述
服务注册中心存储所有监控目标的访问信息,Promthues只需要去访问服务注册中心就知道需要对那些目标进行监控,这种模式成为服务发现
为什么需要有服务发现注册
很多云平台的服务,可以创建销毁应用,在这个过程被监控的对象的信息都是在变化中,但是Promthues无法动态感知到这些信息的变化,需要有一个外部注册中心来感知这个,然后Promthues通过统一的调用注册中心的信息得到这些变化的信息;
示意图
子主题
注册中心
不同的场景下,会有不同的东西来扮演注册中心
注册中心举例
平台级别的公有云
AWS公有云平台
平台级别的私有云
OpenStack的私有云平台
容易云
Kubernetes容器管理平台
文件
DNS解析
服务发现实战
基于文件的服务发现
Promthues通过读取文件中的被监控者的信息,来动态更新监控对象的信息
可以不依赖第三方的平台
基于Consul的服务发现
Consul本身是一个支持多数据中心的分布式服务发现和键值对存储服务的开源软件
被监控的服务的信息会被注册到Consul
Promthues去Consul拉取对应的被监控的信息
服务发现与Relabeling
通过自定义标签,来区分不同环境的被监控对象的信息
Nagios
Zabbix
各种应用监控
数据库监控
mysql监控
java监听Mysql数据变化
具体步骤
1、修改配置
log-bin=mysql-bin #[必须]启用二-进制日志<br>server-id=100 #[必须]服务器唯一ID,如果是用于多台MySQL,ID不要重复就行<br>binlog-format = ROW
binlog-format = ROW,binlog_format 设置为 ROW可以保证数据的一致, 因为在 STATEMENT 或 MIXED 模式下, Binlog 只会记录和传输 SQL 语句(以减少日志大小),而不包含具体数据,我们也就无法保存了。
2、引入依赖包
<dependency><br> <groupId>com.zendesk</groupId><br> <artifactId>mysql-binlog-connector-java</artifactId><br> <version>0.27.1</version> <!--2022.09.17版的--><br> </dependency><br>
3、具体代码demo
//为什么甚至路径都一样,还是com.github.shyiko.***,<br>// 因为com.zendesk这个包,里面包了个com.github.shyiko.***这玩意,我怀疑是收购关系<br>import com.github.shyiko.mysql.binlog.BinaryLogClient;<br>import com.github.shyiko.mysql.binlog.event.*;<br>import org.springframework.boot.ApplicationArguments;<br>import org.springframework.boot.ApplicationRunner;<br>import org.springframework.stereotype.Component;<br>import lombok.extern.slf4j.Slf4j;<br><br>import java.io.IOException;<br><br>//此类可以监控MySQL库数据的增删改<br>@Component<br>@Slf4j //用于打印日志<br>//在SpringBoot中,提供了一个接口:ApplicationRunner。<br>//该接口中,只有一个run方法,他执行的时机是:spring容器启动完成之后,就会紧接着执行这个接口实现类的run方法。<br>public class MysqlBinLogClient implements ApplicationRunner {<br><br> @Override<br> public void run(ApplicationArguments args) throws Exception {<br> //项目启动完成连接bin-log<br> new Thread(() -> {<br> connectMysqlBinLog();<br> }).start();<br><br> }<br><br> /**<br> * 连接mysqlBinLog<br> */<br> public void connectMysqlBinLog() {<br> log.info("监控BinLog服务已启动");<br><br> //自己MySQL的信息。host,port,username,password<br> BinaryLogClient client = new BinaryLogClient("localhost", 3306, "root", "root");<br> /**因为binlog不是以数据库为单位划分的,所以监控binglog不是监控的单个的数据库,而是整个当前所设置连接的MySQL,<br> *其中任何一个库发生数据增删改,这里都能检测到,<br> *所以不用设置所监控的数据库的名字(我也不知道怎么设置,没发现有包含这个形参的构造函数)<br> *如果需要只监控指定的数据库,可以看后面代码,可以获取到当前发生变更的数据库名称。可以根据名称来决定是否监控<br> **/<br><br> client.setServerId(100); //和自己之前设置的server-id保持一致,但是我不知道为什么不一致也能成功<br><br>//下面直接照抄就行<br> client.registerEventListener(event -> {<br> EventData data = event.getData();<br> if (data instanceof TableMapEventData) {<br> //只要连接的MySQL发生的增删改的操作,则都会进入这里,无论哪个数据库<br><br> TableMapEventData tableMapEventData = (TableMapEventData) data;<br><br> //可以通过转成TableMapEventData类实例的tableMapEventData来获取当前发生变更的数据库<br> System.out.println("发生变更的数据库:"+tableMapEventData.getDatabase());<br><br> System.out.print("TableID:");<br> //表ID<br> System.out.println(tableMapEventData.getTableId());<br> System.out.print("TableName:");<br> //表名字<br> System.out.println(tableMapEventData.getTable());<br> }<br> //表数据发生修改时触发<br> if (data instanceof UpdateRowsEventData) {<br> System.out.println("Update:");<br> System.out.println(data.toString());<br> //表数据发生插入时触发<br> } else if (data instanceof WriteRowsEventData) {<br> System.out.println("Insert:");<br> System.out.println(data.toString());<br> //表数据发生删除后触发<br> } else if (data instanceof DeleteRowsEventData) {<br> System.out.println("Delete:");<br> System.out.println(data.toString());<br> }<br> });<br><br> try {<br> client.connect();<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br><br> }<br>}<br>
参考文档
https://blog.csdn.net/qq_45821251/article/details/127490460
https://blog.csdn.net/chengsw1993/article/details/119328869
监控工具
SigNoz
Prometheus
MySQL Enterprise Monitor
MySQL 企业版附带了 MySQL 企业级监视器
特性
基于云的远程监控
查询分析可视化
支持 MySQL 集群监控
实时健康状态上报、可用性监控
易于配置
Paessler PRTG Network Monitor
Sematext
Solarwinds
配置中心
Apollo
基础概念
Apollo 是什么?
Apollo(阿波罗)是 携程开源的一个分布式配置中心
主要用户集中化管理应用的配置,支持实时推送,灰度发布,权限管理,版本回滚
注册中心(如 Nacos、Eureka)的区别?
Apollo主要是解决分布式服务的配置问题<br>
Nacos、Eureka 主要解决分布式服务注册和发现问题
和注册中心(如 Nacos、Eureka)的区别?
配置推送与加载
Apollo 的架构
Portal
管理界面,提供配置管理、权限、审计等功能。
Admin Service
提供配置修改接口。
Config Service
提供配置读取接口,支持长连接推送。
子主题
Meta Server/Eureka
负责服务发现(Config/Admin 的注册与发现)。
Client
接入应用,通过 SDK 获取配置,并监听变更。
项目结合问题
dubbo调用是如何实现负载均衡的?
服务启动之后,服务提供方会把自己的服务信息注册到注册中心
消费者自己会从注册中心拉取服务列表,并在本地维护一份服务列表
当需要调用接口的时候,消费者根据配置的负载均衡算法(随机,轮训,最少活跃,一致性hash)来选一个来调用。<br>
清结算项目中的重点和难点问题?<br>
清结算项目的主要流程
初始化
通过监听合同状态为已签约状态:装修合同到已签约状态就会进入到决算系统中,匹配合同对应的费率规则,装修类型对应的费率规则<br>
交易数据采集
从交易系统、支付网关、第三方支付渠道拉取交易明细。
决算服务
从交易中心获取合同对应的已支付的各项费用信息(已经支付的各种费用)<br>
项目经理会在他负责的工地,来操作对应的费用的购买。
各项费用的区分都是按照对应的商品code编码信息<br>
从合同中心获取合同对应的各项预算费用信息
从装修管理中心获取各项决算费用(实际每一项需要支付的费用)<br>
清分(Clearing)
按商户、渠道、产品、结算规则等维度进行分类和汇总。
生成应收、应付金额,计算手续费、分润。
决算服务
从交易中心得到各项费用信息,合计统计对应,人工管,管理费,税金,设计费,单项安装费等等
根据基础的费用信息,以及对应的配置的费率信息来计算分给项目经理的,工人的,公司的各种费用明细。
结算(Settlement)
各种费用明细以及费率信息生成对应的结算单
对账(Reconciliation)
决算服务
各种已缴纳的费用和实际费用对比;
实际支付的费用和最新交易流水记录计算的到的数据再做对比
项目中的重点
清分规则引擎
高并发批量处理
数据一致性
资金安全
对账与差错处理
幂等与防重
安全与合规
项目中的难点
大数据量处理
如何保证 亿级交易清算的性能(批量并行处理、异步化、流式计算)。
决算系统
根据分片的规则中传递的总数,对目标数据进行分区,按照每一个分片执行其中一个分区的任务信息。<br>
分布式事务
清分、结算、出款涉及多个系统,如何保证跨系统一致性?
常见方案:本地消息表 / 可靠消息最终一致性 / 补偿机制。
决算系统
因为系统对数据一致性要求低,所以都是及财务最终一致型的解决方案<br>
决算完成之后会发起异步消息通知,且提供根据合同号维度来查询的决算状态的接口;
财务系统分布式事物:<br>
推送财务凭证生成之前,对财务凭证的数据尽心,满足是否发起财务凭的条件(校验是否已经发起过生成财务凭证操作,关键指标,和最新的实时数据计算是否匹配上);<br>
推送的财务凭证后获取财务系统返回的财务凭证id(这个id是唯一),且财务系统有一个根据合同维度的财务凭证查询接口(推送财务凭证发起失败之后,重复发起的时候会先去查询一下是否真正失败,真正失败才需要推送财务凭证,假失败不需要生成财务凭证;或者是在推送超时之后,查询是否财务推送是否成功)。<br>
T+N 结算模式
银行一般是 T+1/T+N 结算,如何对账、调账。
涉及账期管理(结算周期 vs 实际到账)。
决算系统
每月20号推送财务凭证;
差错处理复杂
可能出现多对多关系(如一笔支付对应多笔渠道流水),差错处理逻辑复杂。
工人决算中,同一个合同同一个里程碑同一个工人工号来做区分,
灵活性与可扩展性
新增一个商户结算规则时,如何不改代码? → 规则配置化。
新增一种装修类型的时候,对应的费率就是不一样,将装修类型和对应的费率信息记录在表中。在初始化决算信息的时候将合同和对应的费率信息绑定,在计算中获取到对应的费率信息,按照对应的费率信息做处理。
面试常问问题
你们清结算系统的数据量有多大?是如何处理高并发批量任务的?
demo<br>
背景场景
假设有一个大表 order,每天需要处理数百万条数据
单机执行容易压力过大 → 需要分片并行处理
目标:每个 Executor 只处理表的一部分数据,并行完成任务
分片参数
每个分片会传递两个核心参数给 Executor:<br><br>参数 含义<br>shardingIndex 当前分片的序号(0 开始)<br>shardingTotalCount 总分片数<br><br>比如 shardingTotalCount=4,shardingIndex=0~3,表示任务被拆成 4 份
分片数量来源
用户在任务配置时指定
用户在任务配置时指定在 XXL-JOB 管理后台创建任务时,可以设置:
总分片数(Sharding Total Count)<br><br>分片参数(Sharding Item Parameters)
策略驱动(可选)
XXL-JOB 默认分片策略是 平均分配<br><br>可自定义分片策略,如:<br><br>按节点权重分配<br><br>按业务数据量分配
分片执行逻辑
Admin 在触发任务时,根据活跃 Executor 数量和任务配置生成分片列表
每个 Executor 接收到分片参数后,在任务逻辑中通过 分片参数计算处理的数据范围
分片执行完成 → Admin 收集状态 → 标记任务完成
决算系统
每月的财务凭证大约有10万条;
如何保证资金结算的 准确性 和 幂等性?
准确性
对账机制
结算前
系统会对比实际产生的各种费用和实际支付的各种费用是否一致
目的就是确认各项分类费用是否存在问题
财务凭证生成时
生成财务凭证的时候和当前最新的交易流水记录中的各项费用来对比(出现过已经决算之后,还产生费用的情况)按照计算比例之后的费用来做对比。如果金额不一致,则不会生成财务凭证,在看具体的情况,必要的时候人工手动介入。<br>
推送财务凭证时
推送财务凭证的时候和当前最新的交易流水记录中的各项费用来对比(出现过已经决算之后,还产生费用的情况)按照计算比例之后的费用来做对比。如果金额不一致,则不会生成财务凭证,在看具体的情况,必要的时候人工手动介入。<br>
且操作员也会在推送前根据该合同的交易流水信息中的数据来核算对应的金额,当然这个本来就是靠不住的
每日对账
未推送的财务凭证信息,会在晚上执行定时任务,和最新的交易信息中的各项费用进行对比,来确保和实际费用能对上。
人工对账
决算员会对比新老系统的数据,来看对应的账目是否准确。
资金划拨必须基于清算结果
财务系统的资金划拨必须要根据正确的财务凭证信息。
幂等性
全局唯一流水号
设计
合同号+对应的财务凭证类型编号+项目经理工号(或者工人工号)<br>
核心点,确保不能重复推送财务凭证给财务
在每一次推送之前去判断决算系统这个凭证是否已经做过推送且还需要查询财务系统是否已经推送过。
财务凭证表会有一个状态标记
加密
发送给财务的财务凭证信息需要做加密操作
如果银行代付接口超时了,你们如何避免重复打款?
决算系统
推送财务凭证,财务接口超时,如何避免重复推送?<br>
决算系统
在每次推送财务凭证之前,都会先根据对应的唯一标记字段查询是否已经推送过;
接口如果超时,此时将推送状态设置为推送失败
定时任务间隔5分钟执行一次,根据唯一标记字段查询财务接口是否已经推送过,如果已经推送则把状态设置为成功,如果是没有推送过,则重新推送<br>
财务系统
每次推送过去的财务凭证会根据唯一字段来校验是否已经推送过。
对账发现差错时,如何处理?(自动调账 / 人工处理)
自动对账
结算前
对比实际产生的各项费用和实际支付的费用是否一致,一直需要两边的账目相等才能结算<br>
如果是实际支付的费用大于实际产生的费用,提示让管理员给用户退钱
如果是实际支付的费用小于实际产生的费用,提示让管理员购买对应的费用
定时任务
晚上也会执行这个定时任务
如果不满足平账信息,会让在系统中给管理员发送待处理任务。
财务凭证生成和推送
生成财务凭证的时候和当前最新交易流水记录计算出来的数据来做对比,如果不一致,则财务凭证设置为驳回,需要人工介入
推送的时候还会再次去和当前的最新的数据计算的到的来对比,如果不一致,则财务凭证设置为驳回,需要人工介入
并行阶段
新来系统数据对比
并行阶段的时候,拉取老系统的数据来自动化对比新系统的数据;
人工对账
发现数据不对,将财务凭证驳回,对于被驳回的财务凭证,可以通过页面再次生成的按钮,重新生成对应的财务凭证。
数据计算错误,已经生成了财务凭证,这个时候如何避免错误打款?<br>
如果是还没有推送财务凭证
手动驳回有问题财务凭证,然后再次按照最新数据生成财务凭证
如果再次生成财务凭证还有问题
如果数据财务凭证误差的数据量很小,容易修正,直接上sql,修改凭证表的里面的数据<br>
排查这个错误本身,影响的范围有多大
如果范围比较大,错误数据较多,则需要将老的凭证数据做逻辑删除;回归到上一个流程,然后重新生成财务凭证;
目前通过定时任务,可以在定时任务里面传入对应的合同号信息,重新批量生成新的财务凭证;
已推送的财务凭证
未完成打款
需要财务那边配合,删除错误的财务凭证<br>
决算系统,按照重新生成正确的财务凭证,并推送到财务那边
已完成的打款
多打款的
从项目经理的质保金里面扣除,将这部分多打的钱作为项目经理的质保金;如果质保交满了,则在下一次打款的时候扣除相应部分;
少打款的
再下一次打款的时候,生成财务凭证的时候,手动修改财务凭证中的打款金额加上应该要多打的。
系统如何支持多商户、多渠道的结算规则?
决算系统
费率配置
费率配置有一个对应的管理平台
费率配置维度
基础规则
辅料内购
公司对项目经理,在施工过程中,需要购买一定量的辅料金额,按照完成百分比,来对项目经理考核(也就是扣钱,或者奖励)<br>
辅料内购完成率对应的不同的 扣除金额或者扣钱比例(项目经理佣金)<br>
拖期考核
如果施工的工期超过了计划的工期,会对项目经理考核(也就是扣钱)<br>
拖期天数对应的不同的 扣除金额或者扣钱比例(项目经理佣金)
铁面巡检
公司有专门对工地巡检的工作人员,对工地巡检的时候,会对工地施工情况打分,也是对项目经理考核(扣钱)<br>
不同的巡检评分对应的不同的 扣除金额或者扣钱比例(项目经理佣金)
客户评价
客户的评分也会影响到项目经理考核(扣钱)<br>
客户不同的评价对应的不同的 扣除金额或者扣钱比例(项目经理佣金)
施工质量考评
公司对项目经理最后施工完成的工地也有一个考评
不同的考评对应的不同的扣除金额和扣钱比例(项目经理佣金)<br>
门店,城市
费率配置详情
针对不同的装修类型也有对应的费率配置
针对门店,和城市维度有对应的费率配置
具体费用类别
人工管理费比例,或者金额<br>
局装基础人工管理费比例,或者金额
劳务费比例,或者金额
保险费比例,或者金额
公司强制给每一个工地缴纳的保险费
质保金比例,或者金额
每一个项目进入到公司,需要向公司缴纳一笔质保金(防止项目经理飞单,或者跑路);这个质保金是从项目经理的每一个合同对应的佣金里面来做扣除,这个就是设置每次项目经理应该缴纳的质保金的金额<br>
各种费用比例+基础规则<br>
配置的时候:将具体费用比例和基础规则的code管理储存<br>
加盟店
只按照门店维度来配置对应的费率
配置对应的基础规则:辅料内购,拖期考核,铁面巡检,客户评价,施工质量考评,工地奖惩<br>
各种费用比例+基础规则<br>
配置的时候:将具体费用比例和基础规则的code管理储存<br>
在决算数据初始化的时候
合同与对应的加盟店规则(城市,门店规则)绑定,存储在一起。<br>
新增门店
通过读取配置表的数据来控制
也就是在监听已签约的合同,获取合同信息中的门店信息,判断是否需要做新的决算操作。门店都是一部分一部分切换到新的决算系统,不是全量的切
决算系统切换问题
主要合同之前走老的决算系统,现在要走新的决算系统,在数据切换到新的决算系统之后,如何确保数据没有问题?<br>
在切换到新系统之后:老系统和新系统实行一段时间的双写操作,新老系统对比一段时间,看下新系统的数据计算是否有问题,没有问题的数据直接通过新的系统发起决算(给老系统推送mq消息告知在老系统不要做决算,决算在新系统做),生成财务凭证,老的系统中就不生成也不推送财务凭证;有问题的数据分析具体问题,看是否可以快速解决,如果不能快速解决还是通过老的系统来推送财务凭证。<br>
运行一段时间之后,发现已经不存在新老系统的数据不一致的情况,这个时候全部切换成新系统。
新老系统切换,如何保证平滑切换?
双写
如何确保双写成功?<br>
老系统的写入肯定是正常
新系统监听消息状态;且根据接口查询自检应该写入但是没有写入的数据,做写入操作;
新系统做决算的时候mq消息通知老的系统老系统不要做财务凭证推送,且提供接口给老的系统让老的系统在推送前校验是否要做推送。<br>
将新系统的数据对比老系统数据,校验其正确性
存量数据如何处理?<br>
进入到新系统的数据在新系统中完成决算
进入老系统的数据,如果还没有完成决算,在新系统中也完成决算操作
可以控制老的系统不做财务凭证推送
老系统的报表数据如何处理
数据安全问题
推送的财务凭证信息加密
财务凭证操作权限控制
特定权限的人才会有财务凭证推送和重新生成
查看数据对敏感信息会有脱敏处理
银行卡
手机号码
财务凭证操作日志记录
会记录财务凭证重新生成这个操作,记录其更新前后的具体数据,方便数据回滚
其他的一些更新操作也会去记录日志,记录其逆向操作的信息
运营那边是怎么对账的?<br>
运营那边,通过新老系统的数据来做对比
为啥财务凭证要提前生成而不是在推送的时候生成?<br>
就是为了在推送财务凭证之前操作员能够看到每一笔财务凭证中的具体的账单金额信息。
遇到的一些问题?<br>
决算系统的数据计算流程长,数据来源广,数据的计算错误比较难弄清除是在哪一步出现错误。正常的情况下只能是一步一步的排查这个计算的错误,问题定位排查非常慢
针对数据计算每一步计算结果都做数据跟踪,按照合同维度来记录到计算链路表中,出现问题直接翻看是哪一步的数据记录有问题
链路表的数据有
合同号
类名,方法名
入参,回参
方法调用时长
方法调用成功失败标记,失败的大致信息
财务凭证生成数量自检
redis在项目中的哪些场景下使用到了?
热点数据缓存
在团购项目中会用到
减少数据库压力,提升响应速度。
电商项目:缓存商品详情页数据(如价格、库存、描述),避免每次请求都查询数据库。
分布式会话管理
案例:用户登录状态存储(如Session ID),解决集群环境下Session共享问题。<br>
决算项目,其实基本分布式项目都会有
页面静态化缓存
案例:CMS(内容管理系统)生成的HTML页面,通过Redis缓存整页内容。
实现:使用Hash结构存储页面片段,结合Lua脚本实现原子性更新。
之前在site项目中会用到<br>
分布式锁
多进程/线程同时操作共享资源时避免冲突。
保证数据一致性。
秒杀系统:防止超卖,通过 Redis 锁控制库存扣减。
实现方式:使用 SETNX(或 Redlock 算法)实现锁机制,结合过期时间防止死锁。
redis实现分布式锁的时候需要注意哪些事项?
锁的唯一性:避免误删其他客户端的锁
设置合理的过期时间
确保锁的释放是无误的
锁的粒度尽量降低
锁的监控与告警
子主题
计数器与统计
实时统计数据(如点赞数、浏览量、订单数)。
高性能计数,支持原子性增减。
电商系统
实现
原子操作命令
INCR/DECR:原子递增/递减计数器(如INCR page_views:home_page)。
INCRBY/DECRBY:按指定步长增减(如INCRBY user_points:123 10)。
原子性保障:单命令执行保证并发安全,无需锁机制。
需要设置过期时间的场景
临时性统计数据
短期活动统计(如限时促销的点击量)
每日/每小时的指标(如“今日订单量”)
原因:
避免历史数据无限堆积,节省内存。
不需要设置过期时间的场景
场景:全站总访问量、用户累计积分、系统核心指标(如“注册用户总数”)。
原因:
数据需长期保留,作为业务分析的基础。
限流与降级
控制接口访问频率,防止系统过载。
保护后端服务。
API 限流:限制用户每秒请求次数。
秒杀系统:防止短时间内大量请求击垮数据库。
实现方式:使用 Incr + 过期时间统计请求数,或 令牌桶算法。
地理位置服务
场景:存储和查询地理位置信息(如附近的人、店铺搜索)。
作用:支持基于地理位置的查询。
团购,显示附近的团购点
实现
redsi数据是否需要和mysql数据保持一致?<br>
无需同步到MySQL的场景
临时性或实时性要求高的场景
实时监控
限流计数
会话状态跟踪
数据可重建或容忍丢失
用户在线状态、页面浏览量(PV)、广告点击量
高并发写入且查询简单
需要同步到MySQL的场景
业务要求强一致性
金融交易计数、订单状态统计、库存扣减等涉及资金或资源变更的场景
需要复杂查询或历史分析
用户行为分析、多维度报表、时间序列趋势查询。
数据持久化要求高
用户积分、等级、成就等需长期保留的数据。
分布式系统下的最终一致性
如何保证redis和mysql数据的一致性?
一致性级别选择
强一致性
要求Redis和MySQL数据实时同步(如金融交易),但性能开销大。
最终一致性
允许短暂不一致,通过异步机制最终同步(如社交媒体点赞数),性能更高。
核心解决方案
旁路缓存
读多写少,允许短暂不一致。
在实际情况中,如果发现线上环境mysql的cpu使用率过高,如何处理?
立即
在应用层针对非核心业务做限流和熔断处理
前提是有对应的限流和熔断措施
紧急情况
通过命令找到对应的长sql,然后杀掉长sql
临时
降连接、调参数<br>
过渡<br>
读写分离 / SQL 黑名单<br>
后续<br>
优化 SQL / 索引 / 参数<br>
运维
常用命令
k8s命令
1、模糊查询节点
kubectl get pods -nsite -owide | grep social
模糊查询 节点名称中带有 socail的节点详细信息
得到的信息
microservice-payment-server-59cdc58dcc-fd7sw 1/1 Running 0 40m 10.39.0.51 k8s-test-worker-84 <none> <none>
可以看到对应的ip信息,运行状态
k8s命令操作docker
k8s是在docker基础上又封装了一层
k8s命令操作
常用linux命令
1、查看日志命令
1、查看所有日志
tail -f 日志文件名称
2、精确搜索查询日志
cat default.log | grep 'my name'
查询日志信息中带有my name信息的日志
default log 是日志文件名称呢过
zcat default.log.2022-12-07_00.0.gz | grep 'my name'
从日志的压缩文件中查询带有my name信息的日志
default.log.2022-12-07_00.0.gz 日志压缩文件
3、生成文件命令
touch test.log
test.log 新建文件名称
docker常用命令
docker iamges
查看当前所有的镜像
docker search 镜像名
搜索镜像
docker ps
查看当前docker容器下运行了哪些镜像
拉取镜像
docker pull mysql
默认会拉取最新的镜像
docker pull mysql:5.7.30
指定拉取版本
运行镜像
docker run mysql
docker run mysql:tag
指定运行的镜像版本
删除镜像
docker rmi -f 镜像名/镜像id
命令参考文档
https://blog.csdn.net/leilei1366615/article/details/106267225
docker
基础
仓库dockerhub
docker远程仓库,类似于maven仓库,所有的docker软件的下载都是通过从远程的docker下载
dockerhub可以类似于maven一样构建自己私有的dokcer仓库
dockerhub可以将自己的包上传到dockerbub上,所有人都可以下载使用
如何上传本地包到docker仓库?
镜像 images
docker 镜像可以理解成maven的本地仓库,所有的从dockerhub上下载的软件都是存放在本地docker 镜像仓库
通过images 中的镜像文件来创建docker容器运行环境
image 存储位置
存储位置取决于images文件的保存形式
images有四种保存形式
远程镜像仓库保存
本地保存
此种方式,images保存在本地
镜像时保存方式
容器运行时保存方式
容器 container
docker从物理机上虚拟化出来的一个程序运行环境,容器与容器之间是相互隔离的
dokcer有势
docker compose技术
docker容器编排技术
解决的痛点问题
生产环境中的每一次的发布都需要拉取镜像,启动容器,如果需要启动很多歌容器,那么就是一个非常费时费力的事情,所以就诞生了docker compose技术,
通过compoase,可以使用YML文件配置中创建并启动所有的服务
compose实现的快速编排站在项目角度将一组相关的容器整合在一起,对这组容器按照指定顺序进行启动,也让项目使用到的容器组合更加清晰,方便不同服务器之间的迁移部署
k8s
k8s自动化部署扩展管理运维多个跨机器docker程序的集群<br>
k8s核心特性
自动装箱
自动根据物理机的资源环境来配置容器相关的运行环境
自我修复
容器失败会自动重启
部署节点有问题时候,会对容器进行重新部署和重新调度
当容器未通过监控检查时,会关闭此容器直到容器正常运行时,才会对外提供服务。
水平扩展
通过简单的命令、用户UI界面或基于CPU等资源使用情况,对应用容器进行规模扩大或规模裁剪
服务发现
用户不需要使用额外的服务发现机制,就能够基于k8s自身能力实现服务发现和负载均衡
基于service这个统一入口对外提供服务、完成服务,实现服务发现和pod内部的负载均衡
滚动更新
可以根据应用的变化,对应用容器运行的应用进行一次性或批量式更新
等应用更新的时候会先检测之前更新是否成功,成功则进行下一个应用的更新
版本回退
可以根据应用部署情况,对应用容器运行的应用,进行历史版本即时回退
密钥和配置管理
在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署
存储编排
自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要。存储系统可以来自于本地目录、网络存储(NFS、Cluster、Ceph等)、公共云存储服务
批处理
提供一次性任务、定时任务;满足批量数据处理和分析的场景
系统架构
数据库架构
出于灾难备份目的,数据库都会建设两个或者多个数据中心
数据中心之间关系
热备
主数据中心承担用户业务,备数据中心对主数据中心进行备份
主数据中心挂了,备数据中心接管主数据中心业务
冷备
主数据中心承担用户业务,备数据中心不会对主数据中心进行实时备份,可能周期性备份,或者干脆不备份
如果主数据中心挂了,用户业务也会断掉
双活
主备两个数据中心同时承担用户业务,数据相互为备份,且主数据中心承担大多数业务。
两地三中心
两地
本地+异地
三中心
本地中心+本地容灰中信+异地备份中心
主数据中心/灾备数据中心,
双运营数据中心
双活数据中心
缓存架构设计
概述
缓存本身就是一个内存io密集型应用
缓存是通过牺牲强一致性来提高性能的
80%的缓存命中率就算很高了。
缓存使用原则
如果业务允许不是很实事的数据情况下,可以使用缓存解决
设计重点
1、提高缓存命中率
2、缓存时间周期
过长,缓存长期没有被访问,浪费内存
过段,需要不断将缓存数据从数据库添加到内存
3、缓存淘汰算法
需要匹配当前系统的最佳的缓存淘汰策略
4、设计缓存管理系统
与程序的缓存系统分开,但是可以控制程序的缓存数据情况
此情况相当于是在紧急情况下给缓存添加的一个后门操作
缓存架构的问题
缓存穿透
缓存击穿
缓存雪崩
热点缓存
并发更新-数据一致性
项目设计
业务数据统计
统一处理
全局异常统一处理
管理系统
全局修改操作记录到日志表
系统业务数据自检
针对已上线的业务数据是否正常 做一个核心业务数据的一个自动检测
平台建设
平台化出现原因
子主题
平台化优点
复用性强
研发效率高
降低复杂性
稳定性
平台化建设方式
嵌入式
接口依赖式
中台式
平台化建设常用模式
DSL领域特性语言
Specification规约模式
异构
统一存储
常见操作平台
自动化发布系统
自动回滚
测试环境可部署多套环境
依赖包版本控制
mysql操作平台
数据表结构变更,从测试环境,自动变更到预发布环境,自动变更到线上环境
权限控制
生产环境禁止使用delete,update操作
配置中心操作平台
自动化将低环境配置同步到高环境中去
redis操作平台
rocketMq ,kafka操作平台
流计算操作平台
大数据计算平台
ES-kibana操作平台
日志搜索平台
链路追踪
cat
skyWalking
对各个操作平台的系统权限控制平台
saas erp crm 系统
SaaS
通过互联网提供,用户只需开通账号即可使用,不必自己部署、运维
SaaS 模式下,ERP 和 CRM 常常融合:
CRM 负责“找客户、促销售”
ERP 负责“接订单、管库存、算财务”
ERP
管理企业内部资源(财务、采购、库存、生产、人力)
ERP 偏重内部管理
子主题
CRM
管理客户关系(销售机会、客户信息、营销活动、售后服务)。
CRM 偏重外部关系
ES搜索
数据类型
字符串
keyword
字段不会被分词
text
字段会被分词
系统参数说明
number_of_replicas 是数据备份数,如果只有一台机器,设置为0<br>
number_of_shards 是数据分片数,默认为5,有时候设置为3<br>
ES查询
ES查询语句
term
keyword
条件不会被分词,表中字段也不会被分词;
需要条件和表中字段数据完全匹配才会有结果
text
条件不会被分词,表中字段会被分词;
查询条件必须和是表中字段分词后的某一个字段相同才会获取到数据;
match
keyword
条件会被分词,表中字段不会被分词
条件和表中字段完全一致,才会查询到数据
text
条件会被分词,表中字段也会被分词
条件的分词和表中字段的分词有匹配的就会被查询出来
match_phrase
短语查询-词组查询
GET /test/student/_search<br>{<br> "query": {<br> "match_phrase": {<br> "description": "He is"<br> }<br> }<br>}<br>
会去匹配出包含He is的数据,并且顺序要是一致,且中间没有其他词汇
keyword
条件会被分词,表中字段不会被分词
条件和表中数据一致,才会查询出数据
text
条件会被分词,表中字段也会被分词
必须要条件的词组顺序和表中字段该词组顺序一致才会查询出来
query_string
子主题
multi_match
DSL语句
update语句
条件更新
POST idx_hippo_sku_statistics_index/_update_by_query<br>{<br> "script": {<br> "source": "ctx._source['distributionChannel']=1" <br> },<br> "query": {<br> "term":{<br> "cityId":138<br> }<br> }<br>}
全部覆盖更新
PUT /idx_product-fat/doc/10006145<br>{<br>"minPrice": 1,<br>"price": 30<br>}<br>
根据id更新某些字段
POST idx_product-fat/doc/100101/_update<br> {<br> "doc" : {<br> "minPrice" : 3,<br> "price" : 2<br> }<br> }
delete语句
删除某一个索引
DELETE idx_hippo_sku_statistics_index<br>
根据id删除某条数据
Delete /idx_product-fat/doc/10006306 <br>
条件删除
<br>POST idx_hippo_sku_statistics_index/_delete_by_query<br>{<br><br> "query": {<br> <br> "term": {<br> "skuId": {<br> "value": 10005956<br> }<br> <br> }<br>}<br>}
insert语句
新增数据-不指定id
POST idx_hippo_shop_sku_index/shop_sku_index/<br>{<br>"title":"java架构师",<br>"salary_min":30000,<br>"city":"上海",<br>"name":"美团",<br>"publish_date":"2017-4-16",<br>"comments":20<br>}
新增数据-指定id
POST idx_hippo_shop_sku_index/shop_sku_index/3<br>{<br>"title":"java架构师",<br>"salary_min":30000,<br>"city":"上海",<br>"name":"美团",<br>"publish_date":"2017-4-16",<br>"comments":20<br>}
select语句
条件查询
范围+in查询
GET /idx_hippo_sku_statistics_index/sku_statistics_index/_search<br>{<br> "from" : 0,<br> "size" : 100,<br> "query" : {<br>"bool" : {<br> "must":[ <br> {<br> "range" : {<br> "salePrice" : {<br> "from" : 1.9,<br> "to" : 2.1,<br> "include_lower": true,<br> "include_upper": true<br> }<br> }<br> }<br> ,<br> {<br> "bool": {<br> "must": {<br> "terms": {<br> "cityId": [136]<br> }<br> }<br> }<br> }<br> <br> ]<br>}<br>},<br>"sort": [<br> {<br> "salePrice": "asc"<br> }<br> <br>],<br>"_source": ["productName","salePrice"]<br>}
排序
GET /idx_hippo_sku_statistics_index/sku_statistics_index/_search<br>{<br><br> "query": {<br>"term": {<br> "cityId": {<br> "value": 136<br> }<br>}<br> },<br>"sort": [ { "salePrice": "asc" }<br><br>]<br>}
按照某个字段去重查询
DSL语句
POST idx_hippo_shop_sku_index/shop_sku_index/_search<br>{<br> "query" : {<br> "bool" : {<br> "filter" : [<br> {<br> "term" : {<br> "shopId" : {<br> "value" : 10000051<br> }<br> }<br> }<br> ]<br> }<br> },<br> <br> "collapse":{<br> <br> "field":"categoryId1"<br> }<br> ,<br> "_source": ["categoryId1"]<br>}<br><br><br>
java代码
CollapseBuilder collapseBuilder = new CollapseBuilder(EsQueryConstants.THIRD_CATEGORY_ID);<br>sourceBuilder.collapse(collapseBuilder);<br><br>EsQueryConstants.THIRD_CATEGORY_ID 需要被去重的字段的对应的字符串;
范围+精确+排序+固定字段返回
GET /idx_hippo_sku_statistics_index/sku_statistics_index/_search<br>{<br>"from" : 0,<br> "size" : 100,<br>"query" : {<br>"bool" : {<br> "must":[ <br> {<br> "range" : {<br> "salePrice" : {<br> "from" : 1.9,<br> "to" : 2.1,<br> "include_lower": true,<br> "include_upper": true<br> }<br> }<br> }<br> ,<br> {<br> "bool": {<br> "must": {<br> "term": {<br> "cityId": 136<br> }<br> }<br> }<br> }<br> <br> ]<br>}<br>},<br>"sort": [<br> {<br> "salePrice": "asc"<br> }<br> <br>],<br>"_source": ["productName","salePrice"]<br>}
范围查询+精确匹配+排序
GET /idx_hippo_sku_statistics_index/sku_statistics_index/_search<br>{<br>"from" : 0,<br>"size" : 100,<br>"query" : {<br>"bool" : {<br> "must":[ <br> {<br> "range" : {<br> "salePrice" : {<br> "from" : 1.9,<br> "to" : 2.1,<br> "include_lower": true,<br> "include_upper": true<br> }<br> }<br> }<br> ,<br> {<br> "bool": {<br> "must": {<br> "term": {<br> "cityId": 136<br> }<br> }<br> }<br> }<br> <br> ]<br>}<br>},<br>"sort": [<br> {<br> "salePrice": "asc"<br> }<br> <br>]<br><br>}<br>
查询所有数据<br>
方式1
GET /idx_hippo_shop_sku_index/shop_sku_index<br>{<br>"query":{"match_all":{}}<br>}<br>
方式2
GET /idx_hippo_shop_sku_index/_search<br>
多条件查询
DEMO1
GET /idx_hippo_shop_sku_index/shop_sku_index/_search<br>{<br>"query": {<br> "bool": {<br> "must": [<br> {<br> "match": {<br> "city": "上海"<br> }<br> },<br> {<br> "match": {<br> "name": "美团"<br> }<br> }<br> ]<br> }<br>}<br>}<br>
DEMO2
GET /idx_hippo_sku_statistics_index/sku_statistics_index/_search<br>{<br> "from" : 0,<br> "size" : 100,<br>"query" : {<br> "bool" : {<br> "filter" : [<br> {<br> "term" : {<br> "cityId" : {<br> "value" : 136,<br> "boost" : 1.0<br> }<br> }<br> },<br> {<br> "term" : {<br> "saleArea" : {<br> "value" : 1,<br> "boost" : 1.0<br> }<br> }<br> },<br> {<br> "terms" : {<br> "skuCode" : [<br> "2013001000146186085"<br> ],<br> "boost" : 1.0<br> }<br> }<br> ],<br> "disable_coord" : false,<br> "adjust_pure_negative" : true,<br> "boost" : 1.0<br>}<br> }<br>}
单条件查询
GET /idx_hippo_shop_sku_index/shop_sku_index/_search<br>{<br>"query":{<br> "match":{<br> "name":"美团"<br> }<br>}<br>}
GET /idx_hippo_sku_statistics_index/sku_statistics_index/_search<br>{<br><br> "query": {<br> "term": {<br> "cityId": {<br> "value": 136<br> }<br> }<br>}<br>}
根据id查询
GET /idx_hippo_shop_sku_index/shop_sku_index/1<br>
查询某个字段存在
GET index/type/_search<br>{<br> "query": {<br> "bool": {<br> "must": {<br> "exists": {<br> "field": "字段名"<br> }<br> }<br> }<br> }<br>}
查询某个字段不存在
方式1
GET index/type/_search<br>{<br> "query": {<br> "bool": {<br> "must_not": {<br> "exists": {<br> "field": "字段名"<br> }<br> }<br> }<br> }<br>}
方式2
GET /my_index/posts/_search<br>{<br> "query" : {<br> "constant_score" : {<br> "filter": {<br> "missing" : { "field" : "tags" }<br> }<br> }<br> }<br>}<br>
or条件查询
DSL语句
POST /idx_hippo_shop_sku_index_fat/shop_sku_index/_search<br>{<br> "from":0,<br> "size":1,<br> "query" : {<br> "bool" : {<br> "should" : [<br> {<br> "bool" : {<br> "must" : [<br> {<br> "terms" : {<br> "categoryId1" : [<br> 30,<br> 79<br> ]<br> }<br> }<br> ]<br> }<br> },<br> {<br> "bool" : {<br> "must" : [<br> {<br> "terms" : {<br> "categoryId2" : [<br> 30,<br> 79<br> ]<br> }<br> }<br> ]<br> }<br> },<br> {<br> "bool" : {<br> "must" : [<br> {<br> "terms" : {<br> "categoryId3" : [<br> 30,<br> 79<br> ]<br> }<br> }<br> ]<br> }<br> }<br> ]<br> }<br> },<br> "_source" : {<br> "includes" : [<br> "skuId"<br> ],<br> "excludes" : [ ]<br> }<br>}<br>
对应java代码
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();<br> BoolQueryBuilder shouldBuilder = QueryBuilders.boolQuery();<br><br> //or 条件<br> BoolQueryBuilder categoryId1BoolBuilder = QueryBuilders.boolQuery().must(QueryBuilders.termsQuery(EsQueryConstants.FIRST_CATEGORY_ID,categoryIdList));<br> BoolQueryBuilder categoryId2BoolBuilder = QueryBuilders.boolQuery().must(QueryBuilders.termsQuery(EsQueryConstants.SECOND_CATEGORY_ID,categoryIdList));<br> BoolQueryBuilder categoryId3BoolBuilder = QueryBuilders.boolQuery().must(QueryBuilders.termsQuery(EsQueryConstants.THIRD_CATEGORY_ID,categoryIdList));<br><br> shouldBuilder.should(categoryId1BoolBuilder).should(categoryId2BoolBuilder).should(categoryId3BoolBuilder);<br> sourceBuilder.query(shouldBuilder);
嵌套条件
GET /my-index-000001/_search?from=40&size=20<br>{<br> "query": {<br> "term": {<br> "user.id": "kimchy"<br> }<br> }<br>}<br>
聚合查询
去重查询
DSL语句
POST /idx_hippo_shop_sku_index_fat/shop_sku_index/_search<br>{<br> "from":0,<br> "size":1,<br> "query" : {<br> "bool" : {<br> "should" : [<br> {<br> "bool" : {<br> "must" : [<br> {<br> "terms" : {<br> "categoryId1" : [<br> 30,<br> 79<br> ]<br> }<br> }<br> ]<br> }<br> }<br> ]<br> }<br> },<br> "_source" : {<br> "includes" : [<br> "skuId"<br> ],<br> "excludes" : [ ]<br> },<br> "aggregations" : {<br> "skuIdGroup" : {<br> "terms" : {<br> "field" : "skuId",<br> "size" : 1000,<br> "min_doc_count" : 1,<br> "shard_min_doc_count" : 0,<br> "show_term_doc_count_error" : false,<br> "order" : [<br> {<br> "_count" : "desc"<br> },<br> {<br> "_term" : "asc"<br> }<br> ]<br> }<br> }<br> }<br>}
JAVA代码
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();<br><br><br>TermsAggregationBuilder agg = AggregationBuilders.terms(StringConstant.SKU_ID_GROUP).field(EsQueryConstants.SKU_ID).size(1000);<br>sourceBuilder.aggregation(agg);<br><br>指定EsQueryConstants.SKU_ID 对应的字段分组,且查询后结果集的别名是StringConstant.SKU_ID_GROUP<br><br>去重后条数结构集的获取;<br>SearchResponse responseResult = restHighLevelClient.search(searchRequest);<br>//解析聚合函数的结果集<br>Aggregations aggregations = responseResult.getAggregations();<br>Map<String, Aggregation> asMap = aggregations.getAsMap();<br>ParsedLongTerms aggregation = (ParsedLongTerms)asMap.get(StringConstant.SKU_ID_GROUP);<br>List<? extends Terms.Bucket> buckets = aggregation.getBuckets();<br>Integer count = buckets.size();
system-select语句
查询索引下面文档数量
GET my_index/_count
获取索引字段信息
GET /idx_hippo_sku_statistics_index<br>
DDL语句
创建索引
PUT idx_hippo_shop_sku_index<br>{<br>"mappings": {<br>"shop_sku_index": {<br> "properties": {<br> "text": { <br> "id": "string",<br> "poolId": "long",<br> "shopId":"long",<br> "skuId":"long",<br> "productId":"long",<br> "price":"string",<br> "categoryId1":"long",<br> "categoryId2":"long",<br> "categoryId3":"long",<br> "mainImage":"string",<br> "headImages":"string",<br> "title":"string",<br> "titleLetter":"string",<br> "standard":"string",<br> "skuCode":"string",<br> "dimensionValues":"string",<br> "stock":"string",<br> "salesNum":"string"<br> }<br> }<br> }<br>}<br>}<br>
添加字段
PUT idx_hippo_shop_sku_index/_mapping/shop_sku_index<br>{<br>"properties": {<br>"poolId": { <br> "type": "long"<br>},<br>"productId": { <br> "type": "long"<br>}<br> }<br>}
语法解析
must与filter区别
分词查询:<br>//组合查询对象,//如搜索条件为“小米手机”这里must会分词为“小米”和“手机”这两个词是or关系<br>//加operator(Operator.AND)可以把or改为and关系<br>BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();<br>boolQueryBuilder.must(QueryBuilders.matchQuery("name",searchmap.get("keywords")).operator(Operator.AND));
//组合查询对象<br>BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();<br>//filter指不分词查询<br>boolQueryBuilder.filter(QueryBuilders.termQuery("brandName",searchmap.get("brand")));<br>
不分词查询:must和 filter 的效果一样;
ES分析器
分析器种类
标准分析器
适合字母语言
简单分析器
使用了将所有大写转小写的分词器
空白分析器
按照空白来分割
停用分析器
能够过滤停用词
关键词分析器
字段不做分词
模拟分析器
允许指定分词切分模式
语言分析器
按照特定语言分词
雪球分析器
子主题
分词器
过滤器
倒排索引
倒排索引历史来源
实际应用中需要根据属性的值来查找记录
倒排索引概念
索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引
倒排索引核心思想
对文本内容进行分词(tokenization),记录每一个分词对应的文档id;<br>
搜索的时候根据得到分词,获取分词获取到对应的文档id,再通过文档id获取整个文档信息<br>
类似于书本的“关键词索引”:书后列出某个词出现在哪些页。
正排索引和倒排索引区别
存储方向<br>
正排索引<br>
文档 → 内容
倒排索引<br>
词 → 文档<br>
查询效率<br>
正排索引<br>
全文搜索慢,需要扫描每个文档<br>
倒排索引<br>
搜索快,直接通过词找到文档<br>
用途<br>
正排索引<br>
用于展示、回溯、存储原始文档<br>
倒排索引<br>
用于全文检索、快速匹配查询<br>
典型场景<br>
正排索引<br>
数据仓库、传统数据库<br>
倒排索引<br>
搜索引擎、ElasticSearch、Lucene<br>
相关基础概念
Term
字段分词后的单个词语,单词
Term Dictionary
对当前分词字段上所有的Term做排序,构建成B+树数据结构;
B+树
Term index
针对Term Dictionary做前缀提取,通过Term Index可以快速定位到Term Dictionary中某一个term的具体存储位置;
字典树
Posting List
存储符合某个term(分词)的所有文档id;
倒排索引数据结构示意图
整体示意图
字典树/前缀树示意图
实战问题
为什么 Elasticsearch 适合做全文检索?
倒排索引
可以通过关键词快速定位到具体文档
分词(Analyzer)
根据输入的文本,进行关键词分词
相关性打分
会有文档和相关检索词的关联性打分排序
丰富查询能力
不仅能查词,还能做模糊搜索、短语搜索、范围搜索、聚合统计、自动补全、推荐
分布式架构
并行查询,性能高
近实时(NRT, Near Real-Time)
新写入的数据会很快(默认 1 秒内)对外可见,既支持实时索引,也支持快速搜索。
ES 搜索为啥快?和哪些有关系?
底层数据结构:倒排索引
对词的搜索的时间复杂度
O(1) 或 O(log n)
缓存机制
操作系统缓存 + Elasticsearch 内存缓存(如 filter cache、fielddata cache)
热数据尽量在内存中,提高访问速度。
分片(Sharding)和副本(Replica)
读写分离
支持快速排序和聚合
列式存储和压缩
减少io次数<br>
内存与并发优化
ES 利用 线程池 + 异步 I/O,多线程处理查询请求。
ES 缓存<br>
ES 是如何统计热点数据的?
ES 内部 统计每个 filter 被访问的次数。
使用 LRU(最近最少使用)策略管理缓存
被频繁访问的 filter → 保留在缓存 → 热点。
很少访问的 filter → 淘汰 → 冷数据。
ES 记录 字段加载和访问次数。
被频繁使用的字段 → 保留在内存 → 热点字段。
很少使用的字段 → 淘汰 → 冷字段。
缓存每个文档访问计数。
使用 LRU 策略淘汰不常用条目。
缓存内容
Filter
缓存过滤条件对应的文档id<br>
Field Data
字段列数据
Shard Request Cache
分片级别的查询结果
OS 文件系统缓存
Lucene segment 文件页
Elasticsearch 底层是如何工作的?
写入过程
1. 文档写入
用户写入的文档根据路由算法定位到具体的哪个主分区
2. 分词(Analyzer)
对写入的文档进行分词
3. 构建倒排索引
将分词和对应的文档id存储起来<br>
具体存储在 Lucene 的 Segment 文件里
4.刷新文档状态为可查询<br>
5. 副本同步
查询流程
查询阶段
1. 用户输入搜索词
2. 对搜索词进行分词
3. 针对每一个分词通过倒排索引获取到对应的文档id<br>
4.获取到的文档再做交并集计算
用户输入搜索词的时候有条件查询,in,or ,not in ,and 这些计算的<br>
5. 相关性打分
结果合并排序
取回阶段
协调节点根据文档 ID 去对应的分片请求数据
各分片把文档内容返回给协调节点
协调节点把结果组装好,返回给用户。
分词器
中文分词如何实现?
基于词典
核心思路:将一段文本与词典进行匹配,尽量找出最长的词(最大匹配原则)。
基于统计
概率语言模型(如 n-gram、HMM、CRF、深度学习)判断一个分词组合出现的概率
混合分词
先用词典做初步切分,再用统计模型做优化。
自定义词典
可以将业务专有词(如“苹果手机壳”、“鸿蒙系统”)加入到自定义词典,保证不会被错误切分。
停用词(Stopwords)过滤
支持定义停用词表(如“的”、“了”、“啊”),在搜索和索引时去掉这些无意义的词,提高效率。
IK 分词器的原理
ik_max_word(细粒度切分)
尽可能多地切分出词语,适合 召回率优先 场景(搜索尽量不要漏掉相关结果)。
ik_smart(智能切分)
只保留最合理的一种切分,适合 精确度优先 场景。
存储
分词,倒排索引,还有文档本身存在在哪里?
分词
存储在 Lucene 的 Segment 文件里
.tim(term dictionary)、.doc(posting list)、.pos(位置)文件
倒排索引
Lucene 的 Segment 文件
文档本身
原始 JSON 文档,默认会存储在磁盘上
本质都是在磁盘上,只不过是Lucene Segment:为了“查得快”存的结构化索引,_source:为了“还原原文”存的压缩 JSON。
为什么 ES 删除数据后,磁盘空间不会立刻释放?如何手动回收?
删除只是在segement中给文档做了删除标记,在系统自动合merge的segement的时候才会把标记删除的文档做删除,回收物理空间<br>
或者是在删除之后立马手动操作合并segement操作<br>
Elasticsearch 在 CAP 理论中是如何取舍的?
AP ,近实时性<br>
ES搜索问题<br>
term 查询和 match 查询的区别?
term 查询
term 查询是精确匹配查询,不会对输入的内容做分词。
match 查询
match 查询会先把查询字符串用 分词器(Analyzer) 分词,再去倒排索引里查。
Elasticsearch 如何做高亮搜索?
搜索的时候有对应的高亮参数设置
pre_tags / post_tags:设置高亮包裹标签(比如 <em>)
fragment_size:高亮片段的长度(默认 100)
number_of_fragments:返回多少个高亮片段
require_field_match:是否只在匹配字段上高亮(默认 true)
写入 Elasticsearch 的数据为什么不是立刻可见?
内存刷新过程
1. 写入内存缓冲区(Indexing Buffer)
写入的数据是先进入内存buffer,这个时候搜索是无法搜索到<br>
2. 定期 refresh(刷新)
把数据刷到系统内存中的 segement中,这个时候查询是可以查询得到<br>
数据写入和数据可见之间有 ~1 秒的延迟,这就是“近实时(NRT)”。
如果想立马查询到数据,手动执行refresh操作<br>
持久化过程
flush 机制会把系统内存中的segement中的数据真正写入到磁盘里面。<br>
总结
ES是近实时查询的,写入后1s内可见<br>
写刷新到系统内存中的sgement中,再flush到磁盘上<br>
性能优化
如何解决 Elasticsearch 的写入性能瓶颈?
索引设计优化
减少 _source 字段存储
_source 默认存储完整 JSON,会占用磁盘和 I/O。
如果不需要返回原始文档,可以通过 _source: false 或只存部分字段。
选择合适的字段类型
对于不需要全文检索的字段,使用 keyword 类型而不是 text。
避免对大文本字段做不必要的倒排索引。
控制索引分片数
分片太多 → 写入需要更新多个分片 → I/O 竞争
分片太少 → 单分片压力大
推荐:根据节点数量 + 磁盘大小 + 写入吞吐量合理规划分片数。
减少索引刷新频率
默认 refresh_interval=1s,会每秒生成新的 segment,频繁刷新会影响吞吐量。
写入密集场景可延长刷新间隔(如 30s),批量写入后再刷新。
写入方式优化
批量写入
每批大小一般控制在 5~15MB 或 1000~5000 条文档,根据集群性能调节。
异步写入
避免频繁更新
更新操作会产生 delete + insert,开销大。
调整刷新和合并策略
refresh_interval:适当延长刷新间隔,减少 segment 生成次数。
集群配置优化
副本分片策略
写入时,每条数据要写到主分片 + 副本分片 → 写放大
写入密集场景可暂时把副本数设置为 0,然后批量写入完成再增加副本。
磁盘和硬件优化
SSD 可以显著提升写入性能。
避免单节点磁盘 I/O 成为瓶颈。
并发线程和队列
如何优化搜索性能?
索引设计优化
使用合适的字段类型
text 类型:用于全文检索,支持分词和评分。
keyword 类型:用于精确匹配、排序和聚合。
DocValues:对排序、聚合、脚本计算字段开启。
减少倒排索引大小
不必要的字段不要开启索引
使用 index: false 禁止索引字段
对大文本字段,如果只搜索部分内容,可以使用 index_options 限制(比如只存 term 不存位置)。
合理规划分片
分片过多 → 查询会被广播到很多分片,协调节点合并成本高。
分片过少 → 单分片压力大。
一般建议 每个分片 ≤ 50GB,根据节点数量平衡分片。
使用索引模板或预处理
对于高频查询的字段,可以做 预分词/Edge N-gram,优化前缀和模糊查询。
查询策略优化
避免低效查询
避免通配符,模糊查询
使用过滤器(Filter)
Filter 是布尔查询中 must_not 或 filter 部分,不计算相关性评分(score),性能更高
使用 stored_fields / _source 控制返回字段
分页优化
深分页(from + size 很大) 会性能差 → 用 search_after 或 scroll 查询大数据量。
利用缓存
Filter Cache:布尔过滤器会缓存,重复查询速度快。
Query Cache:静态或热点查询可以启用缓存。
集群配置优化
读负载均衡
查询请求可以分发到多个节点。
副本分片可以提升并发查询能力。
协调节点(Coordinating Node)优化
查询会在协调节点汇总分片结果 → 协调节点负载过高也会影响搜索速度。
高并发查询可以增加协调节点或分散请求。
硬件优化
SSD 提升 I/O 性能。
足够内存 → 缓存热词倒排索引,提高查询速度。
高级优化
预聚合 → 对热点数据提前做聚合或计数,避免实时聚合压力大。
冷热数据分层 → 冷数据放低性能节点,热数据放高性能节点,提高查询速度。
合并优化 → 减少 segment 数量,避免查询时扫描太多小 segment。
使用搜索建议器(Suggester) → 前缀、自动补全搜索无需扫描全文倒排索引。
如何避免大字段、大文档对 ES 的影响?
存储角度出发
避免在倒排索引里存大字段
原因
大字段(如长文本、JSON blob)建立倒排索引会生成大量 term → 倒排索引膨胀
解决方法
分拆大字段
只存储必要字段索引
控制 _source 大小
_source 默认存储原始 JSON 文档,用于返回和重建索引
解决方法
部分存储 _source
压缩 _source
冷热数据分离在 Elasticsearch 中如何实现?
在集群设置中设置冷热节点;
设置索引从热节点迁移冷节点的规则
查询时控制冷热节点统一访问
用户无需感觉冷热
冷热节点的硬件配置
热节点
高性能节点(SSD、更多内存和 CPU)<br>
冷节点
性价比节点(HDD、较少内存)<br>
Elasticsearch 如何防止雪崩(大查询导致集群负载过高)?
查询限制
限制返回结果数
优化方式:<br> • 使用 search_after(基于上一次结果的游标)。<br> • 使用 scroll(滚动查询,适合导出)。
限制字段加载
使用 _source filtering 只取必要字段:
禁止或严格限制 expensive query
通配符(wildcard)、正则(regexp)、前缀查询(prefix)都很危险。
限制聚合大小
例如 terms 聚合不要设置 size: 100000,容易 OOM。
优化方式:用 composite 聚合分批拿结果。
深度分页问题
为什么 from + size 深分页性能差?
假设我们要取第 100000 页,每页 10 条:
ES 的执行流程是这样的:
1. 各个分片执行查询,返回排序结果。
2. 每个分片都必须收集 (from + size) 条结果(这里是 1000010 条)。
3. 协调节点(coordinating node)对这些结果做全局排序,再丢掉前 1000000 条,只保留最后 10 条。
也就是说,虽然你只要 10 条数据,ES 却要扫描和排序 100 万条数据,性能自然急剧下降。<br>这是 深度分页 O(n) 的代价
为什么 search_after 对深度分页效率高?
search_after 的原理
search_after 的思路是:基于上一次查询的排序值,接着往后查,避免扫描和丢弃前面的数据
机制
必须 指定排序字段(通常是时间戳 + 唯一ID)。
ES 会记住上一次最后一条文档的 sort 值(这里是时间戳和 _id)。
下一次查询直接从该位置继续,不需要从头扫描。
优点:
避免了前面数据的排序/丢弃,效率高。
适合 基于时间/ID 顺序的深度分页(比如日志流、数据导出)。
缺点:
不能跳页(只能一页一页往后翻)。
依赖稳定的排序字段,否则结果不确定。
scroll深度分页
scroll 用于 大规模数据导出/遍历,不是普通分页查询。<br>
机制:
第一次查询时,ES 固定住快照(snapshot),把符合条件的所有文档锁定住(不会被新数据打乱)。
返回第一页数据,并附带一个 scroll_id。
之后的请求带上 scroll_id,ES 就在快照里继续往下取。
优点:
避免重复扫描,直接顺序返回所有数据。
适合 全量导出 / 批量处理。
缺点:
会占用集群资源(快照在内存中保持,直到 scroll 超时或清除)。
不适合实时搜索(因为结果快照不会更新)。
ES集群<br>
Elasticsearch 集群的 Master 节点作用是什么?
维护整个集群的元数据,配置修改,节点管理,索引管理,分片管理<br>
一般不处理搜索和写入请求
整个集群中只有 一个节点是真正的主节点,一般还会设置三个备用主节点(主节点挂了,做选举为主节点)<br>
主节点故障
新 master 节点选举完成之前,集群无法进行索引创建、删除、分片调度等操作
数据查询一般不受影响(只要原来的数据节点还在线)
Master 节点选举
集群启动或当前 master 挂掉时,剩余 备用主节点选举新 master
为保证集群高可用,通常至少有 3 个 备用节点
Elasticsearch 集群 Data 节点<br>
存储索引数据、执行搜索和写入<br>
Elasticsearch 集群 协调节点
路由请求、聚合分片结果<br>
不存数据、不参与分片分配<br>
一个ES 集群至少有多少个节点?
一个节点也能工作,但是没有高可用性和稳定性
最佳实践
至少 3 个 Master-eligible 节点(奇数)
防止脑裂产生多个主节点
Data 节点:数量根据数据量、分片数和查询吞吐决定
协调节点
根据查询并发量和吞吐量
高并发、大量聚合查询 → 需要更多协调节点
查询压力低 → 1~2 个协调节点足够
数据节点也可以作为协调节点
集群规模<br>
小型(少于 5 Data 节点)<br>
0~1 个专用协调节点(Data 节点兼任)<br>
中型(5~20 Data 节点)<br>
1~2 个专用协调节点<br>
大型(>20 Data 节点)<br>
2~3+ 专用协调节点,根据并发可扩展<br>
ES 集群脑裂问题是什么?如何避免?
当网络分区或节点挂掉,Master 节点无法联系到多数节点时
原 Master 或其他 Master-eligible 节点可能以为自己应该成为 Master
集群分裂成两个部分,各自认为自己是 Master → 数据冲突
影响
写入可能同时发生在两个分裂的部分
集群状态混乱
数据可能丢失或索引不一致
产生脑裂的典型场景
单 Master-eligible 节点或偶数节点
例如 2 个 Master-eligible 节点,1 个挂掉 → 剩下的节点无法达成多数
可能两个节点都认为自己是 Master
网络分区
网络分区导致节点间通信中断
两个分区各自选举 Master
节点频繁重启或延迟高
Master 节点被短暂隔离 → 触发新 Master 选举
避免脑裂的策略
保证奇数个 Master-eligible 节点
设置选举投票超过一般才能成master节点<br>
如果一个分片丢失了怎么办?
ES分片<br>
ES为什么分片数一旦确定不能更改?
每个分片是独立的 Lucene 索引
一旦分片确定之后,每一个分片的数据结构都是固定了,想要修改分片,只能是重建索引
分布式存储和路由机制
分片的路由也是确认的,新增分片无法被路由到
如果需要修改分片数怎么办?
创建一个新的索引,指定新的分片数量
将旧索引的数据重新索引到新索引
主副分片的作用
主分片(Primary Shard)
存储索引的原始数据
负责处理写入请求
副本分片(Replica Shard)
主分片的备份
可用于搜索请求,提高查询吞吐
在主分片丢失时可以被提升为新的主分片
大规模数据量下,如何设计索引分片?
关键指标:
每个分片的大小 → 推荐 30~50GB,过大单分片会影响搜索和恢复性能。
分片数量 → 过多分片会导致集群协调开销高,过少分片写入压力大。
设计思路
根据数据量和增长预测分片数
估算数据量:
计算分片数:
demo<br>
举例:每天写入 200GB,保留 30 天 → 总量 6TB
推荐分片数:6TB / 50GB ≈ 120 个分片
根据查询模式调整分片
高并发查询 → 分片数可以适当多一些,利用更多节点并行
热点写入 → 避免分片过少造成单分片压力过大
深分页/聚合 → 避免单分片太大,减少内存压力
使用时间序列索引(索引按天/周/月切分)
日志、监控、IoT 数据等场景常用:
新数据写入新索引(Hot phase)
新数据写入新索引(Hot phase)
好处:
分片数固定,可预测
老索引只读 → 减少写入竞争
支持 ILM 自动管理生命周期
副本数和分片分布
每个索引主分片数 + 副本数 = 集群总分片数
核心思想
分片数 = 预估总数据量 ÷ 单分片合理大小,同时结合 写入模式、查询并发、冷热分离策略 做动态调整。
节点和分片的关系
节点是物理/逻辑实例,分片是数据存储的逻辑单元
一个节点可以存储多个分片(来自不同索引的)
分片是数据切分的维度,节点是资源调度的维度
每个分片独立维护:
倒排索引
正排存储(DocValues)
段(Segment)文件
分片丢失的常见场景
节点宕机或磁盘损坏 → 分片所在节点不可用
索引损坏或硬件故障 → 分片文件丢失
分片丢失如何处理
主分片丢失<br>
副本提升为新主分片,重新分配副本<br>
副本分片丢失<br>
集群自动创建新的副本分片<br>
使用快照恢复或重新索引<br>
防止丢失<br>
配置副本分片 + 分布节点 + 定期快照<br>
ES监控<br>
ES的健康指标有哪些?<br>
集群健康状态
status(集群健康状态):
green:所有主分片和副本分片都可用
yellow:主分片可用,但部分副本分片不可用(常见于单节点集群)
red:部分主分片不可用,可能导致数据丢失
节点健康状态
资源使用
CPU 使用率:过高时会导致查询/写入延迟增加
内存使用率:JVM heap 使用率 > 75% 可能触发频繁 GC
磁盘使用率:
ES 默认在磁盘使用 > 85% 时限制写入
90% 时禁止写入
索引与分片
分片数量:过多的小分片会带来内存和管理开销
段(Segment)数量:段过多时需要优化合并(merge)
分片情况
看未分配分片、分片数量是否过多
性能级
ES健康指标数据来源<br>
数据源都是通过ES提供的api<br>
集群整体状态
_cluster/health
节点信息
_nodes/stats
请求速率:indexing rate / search rate
请求延迟:index latency / query latency
倒排索引中是如何处理同义词的?
什么是同义词
就比如搜索 iphone ,其实含有苹果手机文档也应该被搜索出来。<br>
同义词处理的时机
索引时扩展
分词过程中,同义词词典会把一个词扩展成多个词,全部写入倒排索引。
也就是:分词中含有iphone 的时候,会把同义词苹果手机和iphone 都构建索引<br>
查询过程
用户搜索 "iPhone" → 查询倒排索引 iPhone → 命中 doc1
用户搜索 "苹果手机" → 查询倒排索引 苹果手机 → 命中 doc1
查询时 只查用户输入的词,不需要额外做同义词扩展。
优点:查询时快,因为倒排里已经有扩展好的词。
缺点:索引变大,后续如果修改同义词词典,需要 重建索引。
查询时扩展
存储时只保存原始分词,不做同义词扩展。
查询时,把查询词扩展成多个同义词,再查倒排。
demo<br>
用户搜索 “iPhone”,查询阶段扩展为 ["iPhone", "苹果手机"],再去倒排查。
查询的时候会变成 iphone or 苹果手机 来查询<br>
优点:索引体积小,修改词典后立刻生效。
缺点:查询开销大,因为每次都要扩展。
实际应用中的考虑
通常用 查询时扩展,因为灵活,改词典立即生效。
ES技术概念
index
类似mysql 的库
每个索引都有一个唯一名字。
type(ES6.0之后被废弃,es7中完全删除)
类似mysql的表
document
类似于mysql的行
ES存储的最小单元,相关于数据库的一行记录<br>
field(可以再进行拆分成更小的字段)
类似mysql的clounm
分片(Shard)
定义:索引在底层的物理存储单位,一个分片本质上就是一个 Lucene 实例。
类型:
主分片
负责写入原始数据
副本分片
主分片的拷贝,用于高可用和读负载均衡
作用
水平扩展:分片可以分布在不同节点上,提升存储能力和查询性能。
容错:当主分片所在节点宕机时,副本分片可以被提升为主分片。
使用过程中遇到的一些坑?<br>
写入
批量写入未控制
实际问题解决
场景类
CPU突然飙升,系统反应慢,怎么排查?
导致cpu使用率飙升的原因
1、cpu上线文切换过多
1、在同一个时刻,每个cpu核心只能运行一个线程,如果有多个线程需要执行,cpu只能是通过上线文切花的方式来执行不同的线程
cpu上下文切换做的事情
记录线程执行的状态
让处于等待中的线程执行
过多的上下文切换,占用了过多的cpu资源,导致无法去执行用户进程中的cpu指令,导致用户进程中cpu相应速度过慢
上下文切换过多的场景
1、文件io操作
2、网络io
3、锁等待
4、线程阻塞
解决方式
多查询一些线程,是否处于阻塞状态中
如果是io导致,不管是网络,还是文件,
统一给这些io设置线程池,不让他们占用过多的系统资源
2、cpu资源过度消耗
过度消耗原因
1、创建了大量线程
2、有线程一直占用cpu资源,死循环
解决方式
linux系统解决
1、通过linux系统的top命令来找到cpu利用率过高的进程
2、ps -mp 进程号
查询进程信息,查看线程
2、shirt +H来找到进程中CPU消耗过高的线程
出现两种情况
cpu消耗过高的是同一个线程
通过jsatck工具根据线程id去下载线程的dump日志,然后定位到具体的代码
cpu消耗过高的是不同的线程
说明线程创建的比较多,拿几个线程id去下载线程的dump日志,
结果1、程序正常,在cpu飙高那一刻,用户访问量增大
结果2、也有可能程序不正常,线程池的创建相关有问题。
做针对性调整
docker
docker stats
1、查看docker的cpu占用率:<br>
docker exec -it 容器编号 /bin/bash
2、进入cpu占用高的docker容器
查看容器中具体进程cpu占用率,执行top
查看进程中线程cpu占用率:top -H -p 进程号
将异常线程号转化为16进制: printf “%x\n” 线程号
查看线程异常的日志信息:jstack 进程号|grep 16进制异常线程号 -A90
各种监控系统辅助我们排查
<i>线上服务内存溢出如何定位排查</i>
排查问题方式
1、先获取堆内存快照文件
1、通过设置jvm参数
让jvm发生内存溢出的时候自动生成dump文件,并且存放在某个固定路径下面
2、通过执行dump命令来获取当前jvm的内存快照
2、通过mat工具分析dump文件
dump文件分析工具
1、mat工具
专门用来分析dump文件的
2、jprpfile工具
3、解析dump文件,得到内存统计信息总览
4、点击dominator Tree
dump文件中内存占用情况
5、获取到内存占用最高的类
6、然后再查看这个类中相信的内存占用情况
根据代码的情况惊醒调整
count(*)和count(1) 谁快
1、如果是innerdb 数据库引擎
两者一样快,两者最终执行的时候语句是一样的。但是比count(列名)快
直接遍历索引来查询;
2、myisam数据库引擎
count(*)快于或者等于count(1), myisam存储了表的总行数,可以直接获取总条数;
count(1)如果是第一列不为null,也是直接可以获取总条数,如果可以为null,那么就需要统计不为空的条数
count(列名)只统计不为null的数据,需要遍历整个表
技术通用相似点总结
数据
数据存储
刷盘策略
子主题
通信
多路复用
redis
netty
零拷贝
netty
kafka
心跳检测
eurake
eurake和各个微服务之间通过心跳检测,检查微服务是否还在线
nacos
eurake和各个微服务之间通过心跳检测,检查微服务是否还在线
zk
主从节点之间的心跳
pull数据
kafka
rocketMq
rabbitMq
共同问题
消息队列
消息丢失
消息顺序消费
消息重复消费
消息积压
集群部署
redis集群
数据库
消息队列
系统优化问题
如果这个系统本身使用java写的,肯定需要从jvm优化方面可以入手
从这个系统的本身所在机器的cpu,内存,磁盘io,等硬件优化
系统本身的某个重点功能的性能瓶颈点,寻找优化突破,代码优化,
可视化管理平台
springboot
提供admin管理平台
springCloud组件
eurake
查看注册中心有哪些服务已经注册
hystrix
有对应的监控平台
消息队列
kakfa
有admin平台
各种参数设置
rabbitMq
队列管理平台
各种参数设置<br>
rocketMq
队列管理平台
各种参数设置<br>
操作平台
k8s可视化操作平台
linux可视化操作平台
猜想一个简化软件开发的思路
各种需要进行命令进行操作的组件或者引用开发对应的可视化平台
对应的问题
界面如何和对应的服务做相关的命令数据交互
系统级别接口
springBoot提供查询当前服务运行各项指标接口
猜想
spring是否也有
各种dao层框架是否也有
jvm也提供系统系统级别的接口
unsafe类
对系统内存操作类
MBean-jvm层级监控
mysql对外暴露接口
猜想,为啥可以去拉取mysql的二进制日志,是否也是mysql提供了对外暴露接口
可视化操作平台也表明了对应的引用是否也提供了对外暴露的系统级别的接口?
消息队列
kafka提供也提供当前系统查询指标接口
rabbitMq 也提供了相关接口
rokcetMq 提供了mqadmin 命令行工具来操作
新技术
领域渠道设计
实践
比如说一个商品的信息储存
一般设计
需要把商品相关的属性都放在一个表
DDD设计
将商品的价格对应的信息,商品物流相关的信息,分别放在不同的业务实体模型中去;
子主题
子主题
和一般开发区别
一般开发都是由下至上的开发
先设计表,
DDD开发都是从上至下
<br>
云原生
云原生应用
跨编程语言使用整合成同一套微服务架构<br>
将不同的语言的应用整理成像spring cloud 那样的微服务架构
k8s+service mesh
Service mesh
服务网格
实际问题
性能调优
系统调优
SQL调优
JVM调优
redis缓存
数据存入缓存
首页
banner
List集合
三个豆腐块
List集合
为你推荐条件
List集合
竞拍大厅
筛选条件
骨架星级
Hash表
注册地
Hash表
车龄
Hash表
里程
Hash表
车辆级别
Hash表
排放标准
Hash表
车源属性
Hash表
燃料类型
Hash表
查询条件
场次
Hash表
拍场模式
Hash表
所有品牌车系
List集合
热门品牌
Hash表
业务城市数据
List集合
查询结果集
为你推荐
通过zset排序用户出价的品牌车系;每次出价的时候异步去更新redis的记录以及数据库
心愿单
心愿单的查询条件
车源id存放在Zset缓存,从缓存中拿到车源id;再去ES中获取数据;
我的出价
一个月前未中标
车源id存放在Zset缓存,从缓存中拿到车源id;再去ES中获取数据;
近一个月未中标
车源id存放在Zset缓存,从缓存中拿到车源id;再去ES中获取数据;
交易失败
车源id存放在Zset缓存,从缓存中拿到车源id;再去ES中获取数据;
交易成功
车源id存放在Zset缓存,从缓存中拿到车源id;再去ES中获取数据;
我的账户
账户余额
String
保证金
String
出价次数
String
INCR
做自增操作
关注次数
String
INCR
做自增操作
加密算法
不可逆加密
加密方式
MD5
概述
信息摘要算法5
特点
单向不可逆,无法解密
产生一个固定长度的散列码
使用场景
密码存储
信息完成性校验
HMAC系列
概述
散列消息鉴别码
特点
SHA系列
特点
单向不可逆,无法解密
产生一个固定长度的散列码
使用场景
密码存储
信息完成性校验
不可逆特点
单向不可逆,无法解密
产生一个固定长度的散列码
可逆加密
非对称加密
概述
公钥加密,私钥解密
非对称加密方式
RSA
DSA/DSS
特点
1.比对称加密更加安全可靠;
2.加密解密比对称加密慢很多
使用场景
HTTPS建立SSL连接中有一个步骤就是,将服务端的公钥加密用于对称加密的密钥;也就是把数据传输的对称加密的密钥发送给服务端,这样客户端和服务端都知道了实际做数据传输的对称密钥了
对称加密
概述
加密解密都是用的同一个密钥
对称加密方式
DES
3DES
AES
特点
1.加密解密速度快;
2.适用于大量数据加密
3.由于需要把密钥传递给需要用的对接方,在传递的密钥的过程中容易被人抓包,造成数据不安全;
场景
HTTPS建立SSL连接之后,客户端和服务端使用的就是对称加密来传输数据;主要就是利用对称加密解密速度快的优势
对称/非对称加密区别
性能
对称加密性能高于非对称加密
安全性
非对称加密安全性比对称加密安全性高
加密解密方式
对称加密,加密解密都是用的同一个密钥;非对称加密,加密解密密钥是分开的;
可逆/不可逆区别
可逆:可以通过解密的密钥获取到加密之前的数据;不可逆:数据是没有办法做解密操作,无法拿到解密之前的数据;
加密盐
作用
增加数据被破解的难度
让相同的数据在被加密之后显示的数据是不一样的;
接口幂等性
查询和修改操作都是幂等;添加和删除不是幂等
分布式环境下怎么保证接口的幂等性
幂等性概述
1.用户对于同一操作发起的一次请求或者多次请求结果都是一样。
具体操作
查询操作
天然幂等的
删除操作
删除一次和删除多次可能返回的数据不是一样
更新操作
如果把某个字段的值设置为1,那么不管多少次都是幂等
如果把某个字段值加1,那么就不是幂等
添加操作
重复提交会有幂等性问题
幂等性解决方案
1.通过代码逻辑判断实现
一般场景:代码中通过代码逻辑判断
支付场景:通过唯一的订单id来判断重复
2.使用token机制实现
支付场景:页面跳转的时候获取全局唯一的token,把token缓存起来;等到提交到后台的时候,再校验token是否存在,第一次提交成功就会删除token
使用场景:分布式环境
3.乐观锁
分布式环境中,做重复校验,直接用乐观锁实现
使用场景:分布式环境
分布式系统问题
单点登录
全局唯一id生成
分布式Id要求
全局唯一
全局业务中必须要是唯一
趋势递增
这个id最好是能递增
高性能
高可用
接入方便
全局唯一id生成方式
UUID
优点
简单
无网路消耗
缺点
无业务意义
不是递增
存储消息空间大
UUID作为数据库主键,性能低下
使用场景
数据库实现方式
数据库自增id
方式概述
获取数据库自增的主键作为全局ID
优点
实现简单
id是递增
数值类型查询速度快
缺点
如果数据是单节点,无法完全保证数据的高可以用
数据库多主模式
方式概述
给几台数据库服务器自增时候设置相应的步长(比如说,自增3,自增4),获取到自增id
优点
解决单节点,并不能高可用问题
缺点
不利于后续扩容
号段模式
方式概述
从数据库批量获取自增ID
优点
批量减少数据库压力
号段方式是推荐的使用方式
ZK
实现概述
通过node节点版本生成序列号
可以生成32位,64位
redis
实现概述
利用的incr命令实现原子的自增
雪花算法
实现概述
正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
百度uid-generator
和雪花算法类似
优点
可自定义时间戳,机器ID,序列号
美团Leaf
同时支持号段模式,雪花算法模式,可以切换
滴滴(Tinyid)
号段模式的实现
分布式锁
数据库乐观锁
操作步骤
1.先去查询数据是否存在
2.在做更新的时候对比当前数据的版本是否和第一次查询的时候版本号一致,一致才更新;
原理
基于第一次查询和第二次做修改时候查询的数据来判断中间的数据有没有被修改过
Redis分布式锁
使用redisson连接方式
操作步骤
1.在try catch外面获取锁
通过RedisClient对象获取到RedissionLock对象
2.在try catch中加锁
通过RedissionLock对象进行加锁
分支主题
3.在finally里面解锁(防止死锁,解不了锁)
原理
因为redis的crud都是单线程的,通过想Redis中设置key,value的方式
设置成功,说明当前就获取到了Redis的锁
设置失败,说明其他请求已经向Redis中设置过了当前值,其他线程获取到了锁,当前线程会阻塞等待获取锁;
Lua脚本加锁过程
1.先判断key是否存在,不存在才会加锁;
2.如果key存在,那么通过lua脚本判断,获取锁的客户端id是否和当前客户端的id相同,也就是进行可重入判断;
3.如果客户端id也不一样,那么会返回一个当前获取锁需要等待的时间,并且进入while死循环中等待获取锁;
ZK分布式锁
操作步骤
1.通过zkClient对象创建临时节点,作为加锁
2.通过zkClient对象删除临时节点,作为解锁
原理
1.zk是不允许创建相同的临时节点
2.如果zkclient对象发现已经相同的临时节点已经存在了,那么就会阻塞被阻塞;
3.阻塞实际上就是等待创建了这个节点的客户端去删除这个临时节点;
4.阻塞结束之后,创建临时节点,就获取到了锁
本质
zk不允许重复创建临时节点
有创建临时节点,就会客户端就会被阻塞
分布式事物
分布式事物概述
CAP
Consistency
强一致性
Availability
可用性
Partition tolerance
分区容错性
CAP只能保证两点
这个理论中的一致性指强一致性,而不是弱一致性
CAP选择
一般情况下保证AP和最终一致性
金融业,CA,强一致性+可用性
seata解决方案
集成了4中分布式事物解决方案
AT 模式、TCC 模式、Saga 模式和 XA 模式
分布式事物模型
AT模式
AT模式概述
对代码无侵入性的分布式解决方案
使用场景
同一项目调用两个处于不同服务上的微服务修改接口
特点
事物的第一阶段其实已经提交了;事物的回滚操作是在原来正向操作的基础上做的一个逆向操作,这个逆向操作seata已经帮你做了;
原来的一个insert操作变成delete操作;delete操作变成insert操作;update修改操作会修改回来;
解决方案
seata
TCC模式
TCC概述
事物3个操作
Try
预留业务资源
Confirm
确认执行提交事物
Cancel
执行事物回滚
TCC可以分成两个阶段
资源预留阶段
事物提交阶段/事物回滚阶段
TCC事物实现方式
Hmily轻量级分布式事务的框架, 无需搭建Hmily服务器
需要标记Try,confirm,cancel方法
Seata
ByteTCC
EasvTransaction
Saga模式
使用场景
流程比较长且只需要保证事物最终一致性的长事物解决方案
事物的参与者是其他公司的服务
特点
每个事物都有其正向的操作和逆向的事物回滚操作
正向服务,逆向补偿服务都是开发者来实现的,对业务造成了很大的侵入性
优缺点
优点
第一阶段已经提交了事物,性能比较高;
事物回滚操作基于时间异步执行,效率高;
逆向补偿服务,易于理解,易于实现;
缺点
事物在第一阶段已经提交了,也就是没有预留动作保证隔离性。
实现方式
最大努力通知
使用场景
给调用提供一个接口给被调用方回调,用来不断的通知调用方,被调用者这边是否执行结果
消息队列通知
使用场景
公司内部系统直接相互推送某个事物是否执行成功;相当于给其他系统通知这个事物是否成功。
finnally里面做事物回滚
使用场景
当前系统调用了内部的多个数据库,或者是多个服务,在调用方这边直接做数据回滚;
XA模式
理论基础
2PC协议
第一阶段每个事物完成预提交并通知把结果告诉事物协调器;事物协调器等所有分支事物都操作完成,预提交之后;第二阶段协调器通知每个事物进行逐步的提交或者是逐步的回滚操作;
二阶段详细过程
准备阶段
事物协调器向所有的事物发起者询问是否可以执行提交操作,并等待各个参与者节点的响应
参与者节点执行询问发起为止的所有事物操作,并记录到redo,undo日志中;
事物的各个参与者对事务管理器响应自己的事物是执行成功还是执行失败;
提交阶段
协调者只要收到一个事物失败或者超时,那么就会给每一个参与者发送回滚消息否则发送提交消息;
实现原理
mysql oracle等关系型数据都是支持两阶段提交协议的,也就是有一个支持多个多个事物的接口;
两阶段提交主要保证了分布式事务的原子性:即所有结点要么全做要么全不做)
使用场景
同一项目中直连两个数据库,做修改操作
解决方案
AtomMikos
使用方式
springBoot整合atomikos
&lt;!-- atomikos 多数据源管理 --&gt;&lt;dependency&gt;&lt;groupId&gt;org.springframework.boot&lt;/groupId&gt;&lt;artifactId&gt;spring-boot-starter-jta-atomikos&lt;/artifactId&gt;&lt;/dependency&gt;
spring整合atomikos
&lt;dependency&gt;&lt;groupId&gt;com.atomikos&lt;/groupId&gt;&lt;artifactId&gt;transactions-jdbc&lt;/artifactId&gt;&lt;version&gt;4.0.6&lt;/version&gt;&lt;/dependency&gt;
无整合开发
&lt;dependency&gt;&lt;groupId&gt;com.atomikos&lt;/groupId&gt;&lt;artifactId&gt;transactions-jdbc&lt;/artifactId&gt;&lt;version&gt;4.0.6&lt;/version&gt;&lt;/dependency&gt;
事物过程
第一阶段每个事物完成预提交并通知把结果告诉事物协调器;事物协调器等所有分支事物都操作完成,预提交之后;第二阶段协调器通知每个事物进行逐步的提交或者是逐步的回滚操作;
特点
事物粒度大,高并发环境下,系统可用性比较低
分布式缓存
Redis与MemCache的区别
线程操作
redis数据处理是单线程,memcache是多线程处理
数据结构
Redis支持更多更复杂的数据结构,memcache只支持keyvalue的字符串数据;
数据安全性
Redis支持数据的持久化,会把数据同步到磁盘上;memcache不支持数据的持久化
数据备份
Redis支持数据备份,需要开启主从模式;memcache不支持数据备份
过期策略
REDIS支持更多的过期策略;memcache支持的过期策略少
分布式定时任务
微服务项目
模块拆分方式
1.按照不同的业务划分不同的项目
2.同一业务下不同的功能划分
Job
同一业务下的定时任务模块
获取本业务数据
直接查询属于本业务的库
直接调用本业务的原子微服务
直接调用本服务的非原子微服务
获取其他业务数据
1.调用其他原子的微服务
2.调用其他服务的非原子微服务
MQ
同一业务下消息队列模块
获取本业务数据
直接查询属于本业务的库
直接调用本业务的原子微服务
直接调用本服务的非原子微服务
获取其他业务数据
1.调用其他原子的微服务
2.调用其他服务的非原子微服务
web
同一业务下pc端接口
获取本业务数据
直接查询属于本业务的库
直接调用本业务的原子微服务
直接调用本服务的非原子微服务
获取其他业务数据
1.调用其他原子的微服务
2.调用其他服务的非原子微服务
App
同一业务下对APP接口
获取本业务数据
直接查询属于本业务的库
直接调用本业务的原子微服务
直接调用本服务的非原子微服务
获取其他业务数据
1.调用其他原子的微服务
2.调用其他服务的非原子微服务
Ms
同一业务下原子的微服务接口
Api
同一业务下非原子的微服务接口
可以聚合其他业务的原子的微服务接口
延时任务
redis
实现方式
通过Redis的key的事件通知机制
缺点
Redis的事件通知,消息只会发送一次,不管客户端是否有收到(无消息确认机制)
使用场景
需要对某些key的改变做监控
消息队列
RocketMQ
RocketMQ设置固定延时时间发送消息
缺点
延时的消息时间只能是十几个固定的延时时间
使用场景
RabbitMQ
实现方式
1.正常队列不设置消费者,给单个消息设置超时时间;
2.设置死信队列和死信队列的消费者,把超时未发送的消息发送到死信队列;
使用场景
kafka
实现方式
时间轮定时任务
使用场景
定时任务
实现方式
先对数据先进行落库,再对数据库进行定时轮询
缺点
对数据库压力大
使用场景
java延时队列
实现方式
实现Java的延时队列,这是固定的延时时间;
高并发问题
接口限流
限流方式
验证码
使用场景
容器限流
NGINX
Tomcat
队列
手动控制某些接口访问
gateway
使用场景
服务器限流
Semaphore类控制并发访问数量
任务线程池控制方式
锁
限流算法
令牌桶
实现
使用场景
漏斗桶
实现
使用场景
滑动窗口
实现
使用场景
计数器
实现
使用场景
子主题 5
流量计算方式
滑动窗口
子主题 2
子主题 3
秒杀系统设计
秒杀系统的特点及对应解决方式
1.读多写少
缓存
2.高并发
限流
负载均衡
缓存
异步
队列
3.资源访问冲突
不同层级对应解决方案
应用层
控制方式
按钮控制
点击之后,一段时间之后才能再次被点击
验证码控制
需要收到验证码才能点击
控制目的
降低用户秒杀系统的点击频率
网络层
CDN
负载层
负载均衡,反向代理,限流
降低服务器访问压力
服务层
缓存,异步,队列,限流,原子操作
降低对数据库的压力
数据库
乐观锁,悲观锁
CDN作用
lua脚本为啥可以原子性执行
中间件
zookeeper
zk的作用
数据发布/订阅
负载均衡
命名服务
Master 选举
集群管理
分布式协调/通知
分布式队列
znode数据结构
分布式锁
持久化
持久化本质
持久化方式
事物日志
快照数据
watcher
watcher过程
watcher特点
只会触发一次
通知需要封装成事件发送给服务端
时间通知是异步从服务端发送到客户端
概述
zk的数据结构
选举
初始化选举
中期选举
健康检查
健康检查指标
haProxy
作用
特点
使用场景
nginx
功能
代理
正向代理
客户端先给自己NGINX服务发送请求,NGINX再把请求转发给目标服务器
反向代理
客户端发送的请求到服务器,是先经过服务端的代理服务器NGINX,然后再转发给实际提供服务的服务器
正反代理区别
1.正向代理:客户端和代理服务器在同一个网络中;反向代理:实际的服务器和代理服务器数据一个网络
2.正向代理,服务器是透明的,知道具体的服务器地址;反向代理,服务器是不透明的,不知道代理服务器请求的是具体哪台服务器
动静分离
NGINX本身也是一个静态资源服务器,请求可以获取到NGINX上的静态资源,所以可以做静态资源服务器
负载均衡
NGINX自带负载均衡算法
(默认)轮询算法:请求一台一台的给机器分发
根据IP地址做hash
权重算法
第三方插件负载均衡算法
根据相应时间长短来分配,相应时间短的请求可以获取到更多的请求
根据URL做hash路由,特定的请求会路由到特定的服务器上
NGINX工作方式
NGINX工作模式
单工作进程
工作进程是单线程
多工作进程
工作进程是多线程
工作特点
1.接受用户请求异步,无需长连接
2.接受一定了的请求,再全部一次转发给相应的服务器,减少连接消耗;
3.接受数据和发送请求给具体服务器可以同时进行
进程
主进程
主进程是管理工作进程;
工作进程
单工作进程
多工作进程
nginx.conf的worker_ processes 可以配置工作进程个数
多进程
多进程概述
主进程会按照配置fork出相应个数的工作进程,工作进程至少会有一个;
工作进程连接池
1.每个工作进程都会有自己独立的连接池(连接池中最大连接个数就是worker_connections)
2.连接池中连接存储的空闲连接链表,需要用到连接的时候从链表中获取这些连接
NGINX连接数说明
最大连接数量=工作进程数*worker_connections
最大并发数量=进程数*worker_connections/2(因为NGINX是客户端和实际服务器的桥梁,一个请求会占用两个连接)
master,work进程通信
通信方式
主进程和工作进程之间是单向通信,只有主进程给工作进程发送消息;工作进程是无法给主进程发送消息;
通信类容
工作进程的编号;工作进程的进程索引;文件描述符
多进程好处
1.多个进程之间是相互独立,一个进程挂了不会影响其他进程工作;
2.进程绑定了CPU,减少CPU切换造成的时间消耗;
3.热启动,修改配置,无需重启NGINX服务器
1.master进程接到命令,重新加载配置文件;
2.建立新的进程,再停掉所有的老进程;
3.老的进程在停掉之前会把已接受的请求处理完再退出;
多进程工作
所有的工作进程都是从主进程中fork出来,所有的工作进程都会去监听相同的服务器;所有的工作进程在获取请求的时候都会有一个共享锁,只有一个进程会获取到这个请求;
处理请求
处理请求过程
1.启动的时候解析配置文件,监听对应的服务IP,端口;
2.在主进程中初始化对被监听机器的socket连接;
3.fork出多个子进程,用于处理客户端发送的请求(客户端也是需要经历三次握手才能与NGINX服务器建立连接);
4.子进程竞争到了请求之后,就开始对socket连接进行封装,设置处理函数,读写事件来与客户端进行数据交互;
5.NGINX服务器或者客户端主动关闭连接,一个连接就结束
处理请求特点
异步,时间驱动方式处理连接
线程池
epoll
数据库中间件
mycat
oneProxy
canal
大数据
flink
flink开发方式
ProcessFunction
DataStream API
SQL
窗口
窗口概念
窗口分类
滚动窗口
滑动窗口
时间窗口
会话窗口
全局窗口
count窗口
窗口函数
ProcessWindowFunction
AggregateFunction
ReduceFunction
区别
算子
计算过程
tomcat
Tomcat组件
Tomcat核心参数说明
minProcessors
最小空闲连接线程数,用于提高系统处理性能
默认值为 10
maxProcessors
能够处理的最大并发请求数量
默认值75;
acceptCount
TCP三次握手结束后就绪的的最大允许连接数量;如果超过该连接数量,那么连接就会被放弃
默认100;
MaxConnections
最大连接数
超过这个连接
server.xml配置文件
connector
基础配置
port
端口号,根据实际情况设置应用服务的端口号
protocol
应用层通讯协议
IO模型默认是BIO
可以设置成NIO
connectionTimeOut
连接超时时间
redirectPort
重定向的通讯端口
当用户以HTTP请求方式去请求HTTPS资源的时候;这个时候Tomcat就会重定向以该端口重新发送HTTPS请求
UriEncoding
服务器以何种编码方式接收客户端的请求数据
线程配置
maxThreads
最大线程个数,如果Executor标签配置了线程池;那么该配置就失效
子主题 2
子主题 3
Executor线程池
属于非必须配置标签;该配置可以不用配置;
属性值
maxThreads
最大线程个数
实际处理请求的最大线程数量
允许客户端连接的最大线程数
默认值200
minSpareThreads
初始时创建的线程个数;随着后面的请求增多,线程也会慢慢增多
默认值4;
maxIdleTime
线程空闲时间;空闲的线程超过了这个时间,就会被销毁
默认值:1分钟
maxQueueSize
请求被执行前,最大排队数目
默认值为int最大值
prestartminSpareThreads
线程池是否开启最小线程数量配置;也就是minSpareThreads配置是否生效
threadPriority
线程池中线程优先级
默认值为5,值从1到10
className
线程池实现类,可以指定线程池实现类
如果没有指定实现类:默认是org.apache.catalina.core.StandardThreadExecutor
connector和线程池关系
connector是服务器负责与客户端建立连接的管理者;
线程池是连接器接受了客户端的请求,之后就会从线程池中拿一个线程去服务这些连接;
子主题 5
子主题 6
子主题 8
tomcat运行模式
bio
默认的工作模式,性能低下,没有经过任何优化
nio
比bio新能更高
apr
解决大量异步IO问题
tomcat性能优化
性能优化指标
降低相应时间
提高服务吞吐量
提高服务可用性
优化原则
具体情况具体分析
积少成多
性能优化工具
JCONSOLE
JMETER
Tomcat优化方式
内存优化
设置Tomcat有所运行的jvm的内存配置
Tomcat本省就是Java语言写的,运行在JVM之上,所以也可以从Tomcat本身所运行JVM上优化
针对不同操作系统
Windows
catalina.bat
设置JVM的垃圾回收参数
Linux
catalina.sh
设置JVM的垃圾回收参数
配置优化
connector优化
protocol
设置成nio形式
//NIO protocol=&quot;org.apache.coyote.http11.Http11NioProtocol&quot; //NIO2 protocol=&quot;org.apache.coyote.http11.Http11Nio2Protocol&quot;
设置ARP
protocol=&quot;org.apache.coyote.http11.Http11AprProtocol&quot;
compression
是否启用gzip压缩
compressionMinSize
启用压缩后,输出的内容大小,默认2kb
compressableMimeType
压缩类型
监听器优化
线程池优化
合理设置线程池参数
IO方式优化
修改IO方式为NIO,或者APR
只处理动态资源
大量的静态资源会占用内存空间,导致GC;
组件优化
使用APR组件
server
不建议优化
service组件
不建议优化
Engine
不建议优化
Connector连接器优化
修改不同的io方式
设定自己的线程池大小
Host
自动部署,如果包有更新,就会自动部署
Context
协议
应用层协议
HTTP
HTTP1.1特点
默认都是长连接
HTTP2.0特点
1.数据都是二进制传输
2.多路复用:多个请求可以复用一个TCP连接
3.请求头压缩
4.服务器可以给客户端推送消息
5.HTTP2.0对安全协议做了升级,数据传输更加安全
http1.1,2.0版本区别
请求头压缩
HTTP2.0服务器客户端都会维护一个请求头索引表;对于之前出现过的请求头,再次发送的时候会直接传递请求头的索引键;HTTP2.0没有请求头压缩
服务端推送
http2.0服务器可以主动给客户端推送数据;
HTTP2.0之前服务器是不能主动给客户端推送数据;
传输格式不同
Http2.0之前都是文本直接传输,文本的格式有很多种;
HTTP2.0之后内容都是转成2进制进行传输
头阻塞问题
Http1.1所有请求都是串行执行;如果前面的请求阻塞了,那么后面的请求也是跟着阻塞,这就是头阻塞问题。Http2.0多路复用也就是多个请求可以在同一个链接上并行执行,根据数据的帧就知道对应某个请求;某个任务阻塞或者是资源消耗大不会影响其他任务
安全性更高
HTTP2.0升级了很多安全协议,使数据传输更加安全
Http1.0和Http1.1区别
HTTP1.0一次http请求就需要建立一次链接,请求完成链接断开
http1.1默认的是长连接,传输层的一次连接可以做多次HTTP请求
报文数据结构
请求报文
请求行
内容
请求方法
路径
协议版本
换行符
回车符+换行符
请求头结束之后会有一空行和请求正文隔开
请求头
请求头字段名称以及对应的值(一个键值对占一行)
换行符
回车符+换行符
请求正文
相应报文
状态行
内容
协议版本
状态码
状态码描述符
换行符
回车符+换行符
响应头部
请求头字段名称以及对应的值(一个键值对占一行)
常见头部
换行符
回车符+换行符
响应正文
http协议弊端
HTTP的消息冗长繁琐
有太多的无用的请求头数据
容易遭到黑客攻击
http复用
一个客户端的多个Http请求复用一个tcp连接
与Tcp复用的区别:tcp复用是多个客户端的请求复用一个tcp连接:http复用是一个客户端的多个http请求复用一个tcp连接;
http内容缓存
把热点图片,静态页面等数据缓存在负载均衡服务器上;
Http压缩
客户端服务端都支持压缩,服务端把数据压缩,再发送给客户端,客户端再解压;
优点:减少了数据包在网络传输的大小
注意事项:一般情况下都是使用负载均衡服务器来做数据的压缩处理,减少web服务器压力;
Http获取数据方式
轮询polling
特点:客户端定时给服务器发送请求,不管是否有数据,都会立即相应
缺点:会浪费大量的请求资源,而获取不到数据
长轮询 long polling
特点:客户端给服务器发送HTTP请求,直到服务端有数据才会相应
HTTP重要头信息
HTTP请求头
Connection:keep-alive
标记请求方式为长连接
Upgrade-lnsecure-Requests
升级为https请求
Content-Length
表示请求消息正文的长度
Accept-Charset
浏览器可接受的字符集
HTTP响应头
Allow
允许的请求方法
Content-Encoding
文档的编码(Encode)方法
Content-Length
表示内容长度
HTTP请求方式
种类
GET
向特定的资源发出请求
PSOT
向指定资源提交数据进行处理请求
DELETE
请求服务器删除Request-URL所标识的资源
PUT
向指定资源位置上传其最新内容
CONNECT
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
HEAD
向服务器索与GET请求相一致的响应,只不过响应体将不会被返回
OPTIONS
返回服务器针对特定资源所支持的HTTP请求方法
TARCE
回显服务器收到的请求,主要用于测试或诊断
post/get区别
从语义角度说get请求获取数据;post请求是提交数据
get请求回退的时候无害,也就是再获取一次数据;post请求就会重新提交一次表单
get请求会被浏览器主动缓存;post请求不会被主动缓存;
get请求只能进行URL编码;post请求支持多种编码方式
get请求的请求参数有长度限制;post请求参数没有长度限制;
get请求相对post请求来说不安全,get请求把请求参数拼接在请求路径中;post请求是把参数request body 里面;
get请求,post请求都有各自特定的请求头和响应头
HTTPS
SSL
概述
SSL协议是web浏览器与web服务器之间进行信息交换的协议
SSL协议特点
保密:在握手协议中定义了会话密钥后,所有的消息都被加密。
鉴别:可选的客户端认证,和强制的服务器端认证。
完整性:传送的消息包括消息完整性检查(使用MAC)。
TSL
在SSL基础之上做了优化,弥补了安全漏洞;
工作流程
1.客户端请求建立SSL连接,把自己支持的加密方式发送给服务器
2.网站把自己的公钥和证书发送给客户端
3.客户端把检查证书是否合法;
4.客户端随机生成一个数字作为之后数据交互的密钥;
5.用服务器发送过来的公钥加密生成的密钥,并发送给服务器
6.服务器用客户端生成发送过去的密钥加密发送内容;
7.客户端收到数据类容,然后用生成的密钥解密
HTTPS工程概述
1.用非对称的方式加密数据传输的密钥
2.用对称加密的方式加密传输的数据
SSL加速器
负载均衡服务器上SSL加速芯片专门来处理SSL加密信息;节省了大量的服务器资源
WebSocket
websocket特点
1.只需要一次握手就可以建立持久化的通信
2.客户端和服务器完成连接之后;数据传输不需要再经过中间的代理服务器
3.服务器可以主动给客户端推送数据
推送数据实现方式,回调客户端
webSocket协议使用
利用HTTP建立连接
请求头设置
Upgrade: websocket
告诉服务器应用层服务器换成了websocket协议
Connection: Upgrade
告诉中间代理服务器,建立连接之后,数据传输不需要在经过代理服务器,直接发送给客户端
websocket+http协议关系
1.同属于应用层协议;都是基于tcp,udp传输协议
websocket协议建立连接和断开连接的时候都是依赖于HTTP协议;中间的数据传输与HTTP协议已经没有关系;
Http,tcp,Socket关系
Http和tcp关系
TCP是传输层协议,HTTP是应用层协议;应用层协议是需要依赖传输层协议传输数据
tcp和Socket关系
socket通信是传输层协议的一种实现;
socket通信的时候可以设置参数
传输层协议是TCP/UDP协议
通信的同步异步
同步
客户端发送请求只会必须等到服务器响应才能发送下一个请求
异步
客户端发送请求,比不等到响应,就可以发送下一个请求
数据读写阻塞非阻塞
阻塞
客户端发送请求,直到服务端有数据才会返回,否则就会一直阻塞在网路读取
非阻塞
客户端发送请求,即使得不到结果,也哦度会都直接返回;
Http和socket关系
socket连接是传输层协议的一种实现;HTTP协议是需要建立在传输层实现之上。
传输协议
udp相对于TCP的优势
1.传输协议简单;
2.传输速度快;
3.网络拥塞少;
tcp/udp区别
1.TCP传输需要建立稳定的连接,消耗系统资源多;udp不需要简历稳定连接,消耗系统资源少
2.TCP数据传输可靠,避免数据丢失,数据重复问题;udp是尽最大努力交付,不能避免数据乱序丢失
3.UDP更适合做高速传输和实时性强的通信;UDP传输速度大于TCP传输
4.TCP只能是一对一通信;UDP可以是一对一,多对一,一对多通信
tcp保证消息可靠性
防丢失:
1.数据包会被拆分成合适大小的数据块发送
3.消息接收方有消息接收确认机制
2.发送超时,发送丢失会重新发送
防阻塞
1.拥塞机制:减少数据量的发送
2.滑动窗口流量控制,接收方来不及接收数据,会让发送方降低发送的速度
3.停止等待协议:发送方发送完一组数据之后,会停下来等到接收方确认消息再发送
防篡改
1.校验和,确认数据在传输过程中没有被篡改
确保消息顺序性
1.发送方发送消息会有一个包的编号,通过包的编号排序,确保消息顺序性
tcp粘包/拆包
粘包拆包原因概述:
TCP协议数据传输没有消息保护边界;UDP是由消息边界保护,所以TCP会存在粘包,拆包问题
粘包
粘包原因
每次数据的发送都必须先发送到固定大小的缓冲池,如果发送的消息大小小于缓冲池大小,那么就会是多条消息集中一起直到缓冲池满了,才发送出去,这样就是一次数据传输发送了多条消息,就是粘包了
发送端粘包
接收方就必须要要学会怎么拆包才能获取到目标数据
拆包
拆包原因
每次数据的发送都必须先发送到固定大小的缓冲池,如果数据包大于缓冲池大小,那么数据包就会被拆分成多个,分词发送,这样就会造成拆包
发送端拆包
接受方就必须要知道怎么粘包来获取一个完整的数据
粘包拆包解决方式
解决思路:通过应用层协议的设置解决
具体解决方式
1.固定每次发送数据包的大小,客户端每次只按照长度读取;
2.设置消息边界,在消息末尾设置特殊标记字符,表示消息结束;
把消息拆成消息头和消息体,在消息头里面设置消息的长度大小
tcp三次握手/四次挥手
三次握手
1.客户端先发送Tcp的 syn (synchronize 标示)的数据包 已经一个初始化seq 序列号 给 服务端;
2.服务端接受到了 syn (synchronize) 数据包 和序列号数据包后,会给客户端把刚刚发送过来的syn(synchronize 同步) 标示的数据包,以及ack(acknowledement回函) 数据包,确认号 seq+1 ,自己初始化的seq 序列号 这些数据发送给客户端。
3.客户端收到所有的数据之后,把客户端发送过来的 ack acknowledement(回函) 数据包 ;服务端发送给客户端的回函 作为序列号 ;服务端发送给客户端的序列号 + 作为回函 发送给客户端
四次挥手
挥手步骤
1.客户端给 服务端发送 Fin (finish结束) 标示 的数据, 以及一个seq序列号数据发送给服务端;此时客户端是 Fin-wait -1 状态
2.服务端接收 到数据后, 给客户端发送,ACK(回函,Fin 的数据作为ack的数据),以及回函号 = seq+1,以及自身的 seq服务端回去通知应用进程,服务端的状态编程 close-wait状态;在这个中间,服务器如果还有一些数据没有发送给客户端,服务器还是可以给客户端发送数据的。
3.服务端没有数据要发送给客户端的时候,服务端会发出, Fin ,ACK 数据, ack 的编号为之前发过的编号,以及一个序列号给客户端,此时客户端状态编程 Fin-wait -2 状态;
4.客户端收到服务端发送的信息之后,会回复 服务员, ACK= 服务端发送的ACK数据,序列号为 服务端的 ack 编号,以及自己的一个序列号;此时,客户端还会延迟 一个两倍 的报文寿命时间,再结束,服务端收到了数据后,再会结束;
为啥需要四次
保证数据的传输的完整性
tcp连接复用
概述
客户端的多个http请求的数据传输是建立在通过一个tcp连接上
实现方式
一个客户端和代理服务器连接,代理服务器再去请求真实服务器;此时代理服务器会和真实服务器建立长连接,其他客户端发送到代理服务器的请求,直接复用这个长连接和真实服务器数据交互;
tcp缓冲
解决的问题:后端服务器网速与客户端网速不匹配,造成服务端资源浪费。客户端网速慢,后端网速快,客户端的慢网速请求,容易拖垮后端服务器;
把客户端的tcp请求全部缓冲在负载均衡服务器里面;将客户端与服务器的一个tcp连接变成了两个tcp连接,分别来适应客户端,服务端的不同的网速;
tcp冷热连接
冷连接
每次Http请求,都是先建立tcp连接,用完就断开连接;下次请求再建立连接;这样一个tcp连接只是为一个http请求服务,不能复用,就是冷连接;
热连接
多个http请求复用一个tcp连接,这就是热连接;Http复用,tcp复用的tcp连接都是热连接;
tcp长连接短连接
短连接
服务器和客户端之间完成一次请求操作客户端或者服务器都可以断开TCP连接
优点
存在连接都是有用连接,不需要额外的控制手段
缺点
需要频繁的建立连接,销毁连接
长连接
服务器和客户端之间完成一次请求之后不会主动断开连接,之后的读写操作都可以复用这个连接
长连接保活
服务器会提供报货功能,当客户端已经消失且连接没有断开,服务端会保留一个半连接,永远等待客户端的数据。
优点
避免频繁的建立连接,断开连接,造成性能好时间的消耗
缺点
建立过多的长连接对服务器的资源也是一种消耗,长连接越多,服务器资源消耗也越大;
协议常见问题
1.建立TCP连接后是否会在一个 HTTP 请求完成后断开?
http1.1之后一个TCP链接可以复用,发送多个http请求
HTTP1.1之前是一个http请求需要对应一个TCP链接
2.一个 TCP 连接可以对应几个 HTTP 请求?
HTTP1.1之前是一个TCP对应一个HTTP;HTTP1.1之后默认是长连接,一个TCP可以用多个HTTP请求
3.一个 TCP 连接中多个HTTP 请求发送是否可以一起发送?
HTTP2.0一个Tcp连接可以处理多个请求,多路复用且不阻塞;HTTP1.1也可以,请求都是线性去执行的,会存在头阻塞问题;
4.HTTP/1.1 时代,浏览器是如何提高页面加载效率的?
1.使用长连接
2.一个页面建立多个连接
5.为什么有的时候刷新页面不需要重新建立 SSL 连接
因为TCP可以是不断开的,所以就不需要重新建立SSL连接
6.浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
谷歌浏览器默认一个host最多建立6个TCP连接;
可以建立多个连接,不同的浏览器有不同的最大限制个数;
其他协议
2c协议
AMQP协议
ZAB协议
概述
ZAB协议是paxos协议的简化版本
实现的功能
确保已经在leader服务器上提交的失误最终被所有的服务器提交
确保再leader重启之后继续同步之前没有完成的数据
实现了leader选举
实现了在最快速度同步到半数节点,并会尽快的把数据同步到所有节点
子主题





Collect
Get Started

Collect
Get Started
Collect
Get Started
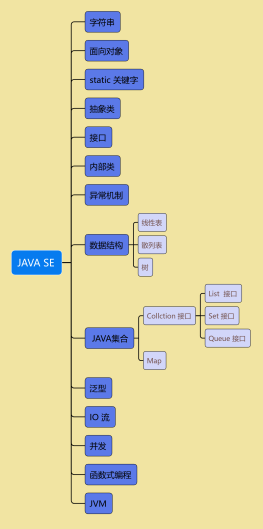
Collect
Get Started
评论
0 条评论
下一页

