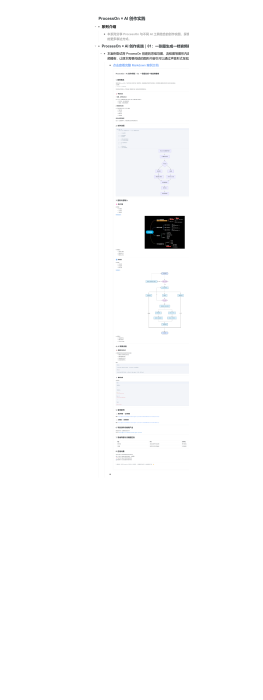
AI爬虫抓取潜客名单
2025-07-17 14:02:16 0 举报AI智能生成
AI爬虫抓取潜客名单
模板推荐
作者其他创作
大纲/内容
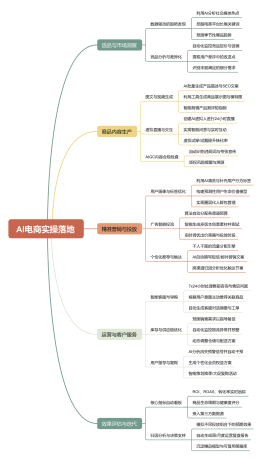
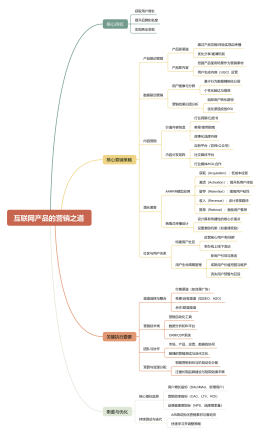
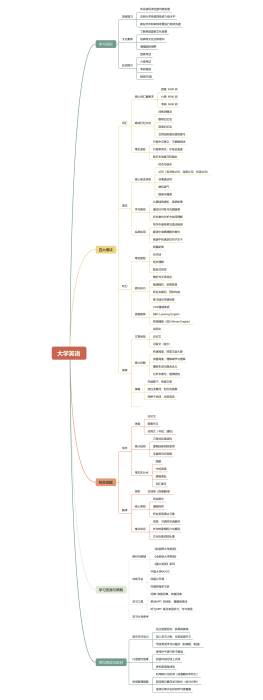
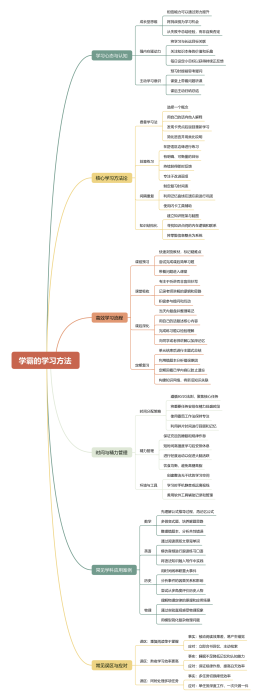



0 条评论
下一页

