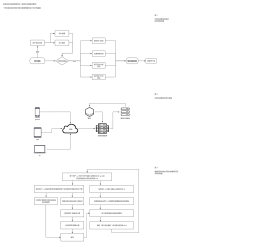
矢量量化方法 (VQ)vector quantization,核心定义为: 空间划分 - 将高维向量空间用一个有限离散子集来进行编码表示。
<br>
常见算法
聚类都是一种矢量量化方法。而在 ANN 搜索问题中,向量量化方法VQ又以乘积量化(PQ, Product Quantization)最为典型。
索引算法
设有 N 个 D=128 维的向量需要索引,考虑引入参数 M,C 来对向量分段,和使用 Clustering 来计算分段向量空间的簇心。<br>
在 Pretrain 的时候,如有 M=4 向量将被分成4段,在 C=256 时所有N向量做4次聚类,计算每段的256个簇心。<br>
簇心应该是 M=4, C=256 的矩阵 centers.shape = (4, 256, 32),然后可以Assign各个向量<br>
然后 Add 把原来的 N 维的向量映射到 M 个数字,然后对于每一段向量 D=128 维的向量就变成了一个由 M=4 个ID组成的向量<br>
比如的库里的某个向量被量化成了 [124, 56, 132, 222], vectors.shape = (N, 4)<br>
最后 Search 的时候,先把128维也分成 M 段向量,然后计算每一段向量与之前预训练好的簇心 C=256 的距离,得到一个4*256 的表<br>
4组和256个簇心的距离,query.shape = (256, 4)<br>
查表得到查询向量第一段子向量与其ID为124的簇心的距离,然后再查表得到查询向量第二段子向量与其ID为56的簇心的距离。。。最后就可以得到四个距离d1、d2、d3、d4,查询向量跟库里向量的距离d = d1+d2+d3+d4。
潜在特点
保持向量结构,但损失向量内部细节
PQ优化了向量距离计算的过程,但是假如库里面的向量特别多,依然逃不了一个遍历整个库 N 个向量的过程<br>