AI
推荐
模板社区
专题
登录
免费注册
首页
思维导图
详情
大学必备知识:BeautifulSoup
2025-10-08 15:51:36
0
举报
分享方式
使用 (¥5)
AI智能生成
大学必备知识:BeautifulSoup
知识
模板推荐
作者其他创作
大纲/内容
BeautifulSoup简介
Python库
用于网页解析
提取网页数据
简化HTML/XML文档操作
支持多种解析器
lxml
html.parser
html5lib
应用场景
数据抓取
网络爬虫
数据分析
网页内容提取
文本处理
网页结构分析
安装BeautifulSoup
使用pip安装
pip install beautifulsoup4
确认安装成功
运行简单示例代码
检查是否报错
BeautifulSoup基本使用
导入库
from bs4 import BeautifulSoup
创建BeautifulSoup对象
解析HTML内容
soup = BeautifulSoup(html_content, 39;解析器39;
查找元素
find
查找单个元素
find_all
查找所有匹配元素
选择器
标签选择器
类选择器
ID选择器
获取元素内容
get_text
提取元素文本
.contents
获取元素子节点列表
.string
获取元素的文本内容
遍历文档树
.children
遍历子节点
.descendants
遍历所有后代节点
.parent
获取父节点
.parents
获取所有父节点
修改文档树
修改标签名
.name
修改标签属性
.attrs
修改标签内容
直接赋值
BeautifulSoup进阶技巧
解析嵌套结构
多层嵌套元素的查找
结合find()和find_all
使用CSS选择器
soup.select
通过CSS选择器查找元素
soup.select_one
查找单个元素
处理特殊字符
.encode_contents
编码特殊字符
.decode_contents
解码特殊字符
输出格式化
prettify
美化输出HTML/XML
链式查找
连续调用查找方法
soup.find(39;div39;).find(39;p39;
处理JavaScript生成的内容
需要额外工具
Selenium
Pyppeteer
BeautifulSoup资源与社区
官方文档
学习使用方法
查找函数和参数
示例代码
快速上手
在线教程
视频教程
图文并茂
博客文章
分享实战经验
社区支持
Stack Overflow
解决问题
GitHub
查看源码
提交问题或建议
相关书籍
推荐阅读
深入理解BeautifulSoup
在线电子书
方便快捷学习
BeautifulSoup项目实战
实战项目选择
新闻网站数据抓取
电商产品信息提取
数据清洗与存储
Pandas库
数据处理
数据库存储
SQLite
MySQL
自动化任务
定时任务
使用APScheduler
多线程爬取
提高效率
遵守法律法规
确保合法爬取
不侵犯版权
不违反隐私政策
BeautifulSoup与网络爬虫
结合requests库
获取网页内容
requests.get(url
处理重定向和编码
requests库处理
.ok
.encoding
避免爬虫陷阱
设置请求头
User-Agent
遵守robots.txt
网站爬取规则
异常处理
try-except语句
处理网络请求错误
收藏
立即使用
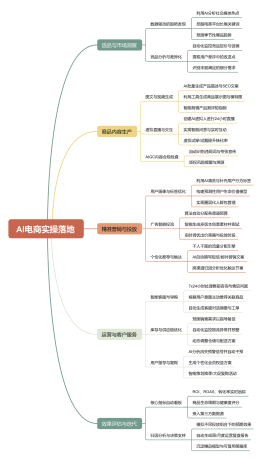
AI电商实操落地
收藏
立即使用
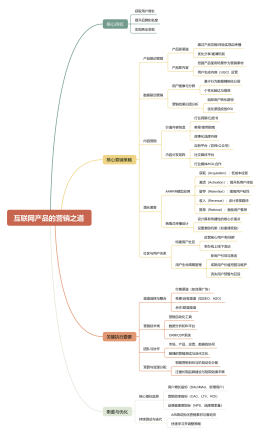
互联网产品的营销之道
收藏
立即使用
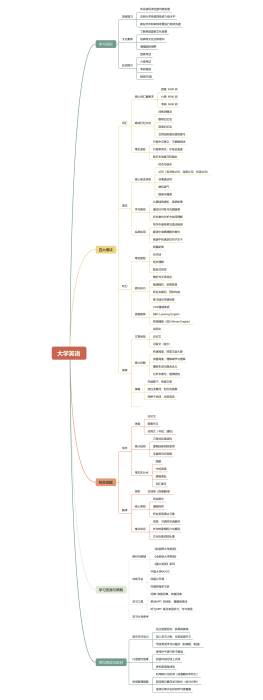
大学英语
收藏
立即使用
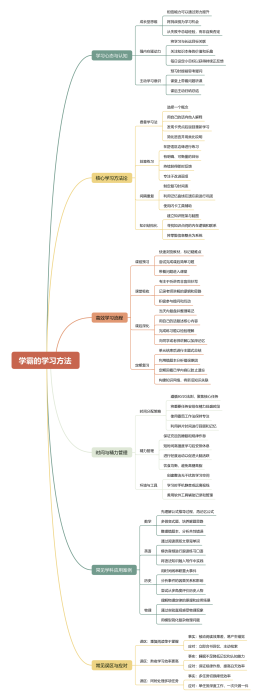
学霸的学习方法
银发书生
职业:本科
去主页
Collect
Get Started
产品经理必备工具
Collect
Get Started
产品经理必备工具1
Collect
Get Started
产品经理必备工具
Collect
Get Started
大学英语
评论
0
条评论
下一页
图形选择
思维导图
主题
补充说明
AI生成
修改AI描述
去编辑
重新生成
提示
关闭后当前内容将不会保存,是否继续?
取消
确定
Document