10_具身机器人Neo4j数据库
2025-10-15 15:54:38 0 举报AI智能生成
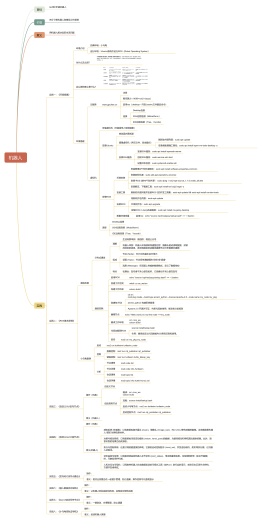
由于10_具身机器人Neo4j数据库的具体内容未知,我将提供一个虚构的描述示例: 本次提交的文件是一个详细记录了具身机器人研究与开发情况的Neo4j图数据库。该数据库以图形的形式展示了各种数据实体和它们之间复杂关系,方便进行高效的查询和分析。其中包括机器人的设计参数、零件和组件、功能与性能指标,以及机器人与环境中其他物体互动的相关数据。数据库使用了多种修饰语来丰富节点属性,如“高速”、“自适应”、“无线控制”等,以更精确地标识不同的机器人特征。通过这种方式,可以迅速检索并理解机器人项目的核心内容以及它们之间的联系,进而指导新的研究方向和开发工作。文档最终以.gdf格式保存,确保了信息的结构化存储和容易导入其他支持Neo4j图形数据模型的软件中。
模板推荐
作者其他创作
大纲/内容





Collect

Collect

Collect

Collect
0 条评论
下一页

