垂直大模型微调学习计划
2025-12-10 10:40:14 6 举报AI智能生成
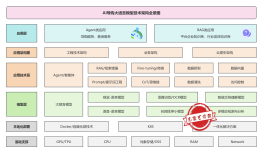
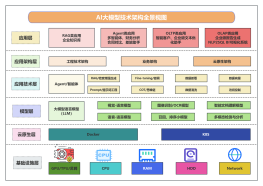
本学习计划围绕"垂直大模型微调"主题展开,旨在深入剖析并教授在特定领域中对大型语言模型进行微调的技能。学员将通过本课程掌握模型微调的关键技术和方法论,以便将其应用于诸如医疗、金融、教育等特定垂直行业。课程内容将着重传授模型评估、优化算法以及如何结合领域知识实现高效微调。学员完成课程后,将具备根据行业需求进行定制化模型调整的能力,并能够根据业务场景编写和实施微调方案。培训形式结合理论讲解与实践演练,通过实战项目让学员将所学知识应用到具体的微调任务中,实现知识内化。此外,本计划注重资源分享,提供必要的编程脚本、预训练模型和调试工具,为学员提供全面的学习资源支撑。
模板推荐
作者其他创作
大纲/内容


Collect

Collect
Collect

Collect
0 条评论
下一页

