
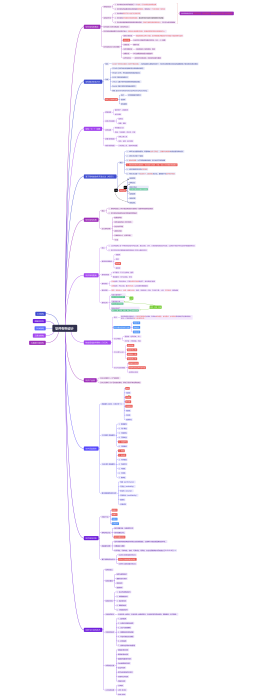
AI Agent解决方案架构设计
2026-04-26 10:38:19 0 举报AI Agent解决方案架构设计:包括Agent架构设计、AI层面的Prompt、Context等
Agent
Prompt
Context
LLM
解决方案
模板推荐
作者其他创作
大纲/内容
1. RLHF(Reinforcement Learning from Human Feedback)算法:PPO(Proximal Policy Optimization)流程:SFT → RM → PPO 用 RM 奖励不断更新模型
2、工具执行沙箱:所有工具执行均在独立沙箱中运行,尤其是 Shell、代码解释器、文件操作等高危工具,实现路径隔离、权限隔离、资源隔离,避免 Agent 越权操作或污染宿主环境。
隔离
目标模糊、步骤动态、需要自主决策 / 多工具协作的开放型任务:1. 多轮智能客服(主动理解意图、转接业务、解决非标准化问题)2. 自主数据分析(用户仅提目标,Agent 自主选工具 / 查数据 / 出结论)3. 复杂业务决策辅助(多信息整合、跨任务协作、动态调整策略)4. 开放域问答 + 工具调用(如联网查信息、调用计算器 / API 完成任务)5. 多角色协作任务(如智能助理、自主办公机器人)
2. 架构层面优化(生产级必用)• RAG 分块检索:不要把整个文档塞入上下文,用 RAG 把文档分块向量化,基于用户问题检索最相关的 Top N 个内容块,只把相关内容放到 Prompt 里,从根源解决长上下文问题;• Map-Reduce 分层摘要:用 Map-Reduce 模式,先让模型并行处理长文档的每个分块,生成块级摘要,再把所有块级摘要汇总生成全局摘要,最后基于全局摘要回答问题;• 模型适配:选择长上下文能力经过真实场景验证的模型,比如 GPT-4o 128K、Claude 3 Opus 200K、通义千问 2 1M,避免纸面参数与实际能力不符。
Reason without observation(REWOO)
Chat Message
并行化 (Parallelization)
Tracing链路跟踪
1. 知识边界强制约束:明确告知模型只能使用提供的上下文知识,禁止使用预训练知识
多模态内容检索
Max Length
知识图谱
Trial(尝试):为了对抗随机性而进行的多次测试(例如运行 10 次),确保结果稳定。
单体式架构模式( Monolithic Architecture Pattern)
Map-reduce
生成策略优化精调、指令微调Answer verification
关键信息筛选提取
Lead Prompt四步思考循环:评估、分类(深度优先、广度优先、直接查询)、计划、执行
通信
双阶段架构
ReAct 模式
评估指标:准确率召回率命中率(Top-p)
3. 少样本格式示例:给 2-3 个完全符合格式要求的输入输出示例,覆盖正常、异常、空值等场景,让模型对齐输出格式;
原生内置了完整的分层记忆体系,解决了传统 AI “会话结束即遗忘” 的痛点,基于SQLite + FTS5全文检索 + LLM摘要实现,跨会话记忆召回准确率达 95% 以上:会话记忆:当前对话的实时上下文,滚动摘要压缩,控制 Token 消耗;持久记忆:跨会话的事实、偏好、项目背景,永久存储,支持全文检索;技能记忆:从经验中沉淀的可复用流程,即结构化技能文档,可随时调用;用户画像记忆:自动学习用户的工作习惯、沟通风格、偏好设置,实现真正的 “越用越懂你”。
• 挑战5:多Agent幻觉消减
结果生成评估指标:Bleu、幻觉率ROUGEBERTScore
1. 角色锚定原则:开头明确给模型定义清晰、具体的角色与权责
全自动化评估体系(LlamaIndex Evals)原生支持 RAG Triad 评估框架,从三个核心维度自动评估 RAG 效果:上下文相关性:检索到的内容是否与用户问题相关答案忠实度:生成的答案是否完全基于检索内容,无幻觉答案有用性:答案是否解决了用户的问题支持批量评估和实时评估生成详细的评估报告,指出问题所在和改进方向支持自定义评估指标和评估模型
工业级高级检索策略Small-to-Big 检索:先检索 50 字符的句子级小块保证精准度,再返回该句子所在的 2000 字符父块提供上下文,准确率提升 22%句子窗口检索:检索到匹配句子后,自动返回前后各 3 个句子的上下文,解决语义断裂问题查询重写:自动将模糊、不完整的用户问题重写为清晰、完整的查询语句,召回率提升 18%递归检索:先检索文档摘要,再检索相关章节,最后检索具体内容,适合长文档和多文档场景
2. 安全合规管控结合:Harness 定义护栏,Context 做双层防护Harness 层定义了 Agent 的安全护栏、合规要求,Context Engineering 则实现了「前置约束 + 后置校验」的双层防护,是 Harness 安全能力的核心落地手段:• 前置约束:Context Engineering 在注入模型的上下文中,固定注入 Harness 定义的合规规则、禁止项、知识边界,从推理前就约束模型的行为;• 后置校验:Context Engineering 把模型生成的内容,和注入的上下文、Harness 的合规规则做交叉校验,拦截无依据、不合规的内容,实现 Harness 的安全兜底;• 审计溯源:Context Engineering 为所有上下文绑定溯源 ID,全链路记录上下文的使用情况,为 Harness 层的合规审计提供完整的 Trace 日志。
解决的核心痛点:Agent 的输出存在幻觉、错误、不符合规范的内容,直接流出到用户或生产系统。
Top_p
Toolkits
起步阶段:从小样本立刻开始(Start Small),做好开头验证,避免潜在问题,后期返工
硬件环境
核心职责:Agent 所有外部能力的标准化封装、注册、调度、执行与回收,是 Agent 突破模型边界的核心载体。
Tools
四、推理引擎与评估闭环:RAG 质量的 \"品控官\":LlamaIndex 在此层解决的是RAG 效果不可控、不可量化、无法持续优化的问题,建立数据驱动的质量保障体系。
一、偏好数据(Preference Data)构建方法人类标注偏好(Human Preference)AI 自动标注(LLM-as-Judge)基于规则 / 关键词的弱监督偏好在线用户行为偏好(Implicit Feedback)
知识图谱数据库:Neo4j ArangoDB
3. 输入输出格式标准化:所有 Agent 的输入输出必须遵循统一的 Schema、通信协议,在 Prompt 中强制规定,确保上下游 Agent 的内容可以无缝对接,不会出现语义歧义、格式不兼容;
架构设计核心要点Checkpoint 断点续传机制:每一步执行完成后,自动将当前状态、上下文、中间结果持久化到状态存储,支持崩溃后 100% 还原执行现场,断点重启,避免长任务从头执行。循环防护机制:内置最大执行轮次、Token 预算管控、超时控制、死循环检测(重复执行相同操作)、上下文腐烂检测,触发阈值后自动熔断或降级。流式执行与进度上报:支持长任务的流式进度输出,实时上报执行状态、当前步骤、剩余预算,解决长任务 “黑盒运行” 的用户体验问题。异常容错机制:每一步执行都内置异常捕获,支持按异常类型配置重试策略、回滚策略、降级策略、人工介入策略,而非直接终止任务。
五、两大企业核心能力
2. 成本与性能优化企业级 RAG 的成本主要来自大模型调用和向量检索,LlamaIndex 提供多种优化手段:多级缓存:查询缓存、检索结果缓存、LLM 响应缓存,缓存命中率可达 60% 以上,成本降低 50%批量处理:支持批量索引和批量查询,提高吞吐量模型蒸馏:用大模型生成的答案微调小模型,用小模型处理简单查询资源监控:实时监控系统的吞吐量、延迟、成本,提供优化建议
条件
Factor 6: Launch/Pause/Resume with Simple APIs#原则6:使用简单的API启动/暂停/恢复
Agent工具技术
Paralllelization并行执行多任务
Templates
5. CPO / Safety Preference Alignment专门做安全对齐、无害性偏好对:安全回答 > 不安全回答常用于风控、合规、拒绝危险请求。
防范策略:提示层防御 (Prompt-Level):• 分隔符 (Delimiters)、• XML 标签加固、• 防御性指令架构层防御 (Architectural):• 独立审核模型、• 沙盒隔离、• 输出清洗流程层防御 (Process):• 最小特权原则、• 人机协作
原则八:并行工具调用极大提升性能
记忆类型
稳态智能体上线文工程实践
生产中,80% 的幻觉问题可以通过「RAG+Prompt 知识边界约束 + 强制溯源」解决;金融、医疗等高严谨性场景,必须加交叉校验环节,同时 Temperature 必须低于 0.3,绝对不能用高随机性参数。
Prompt 核心设计原则
Out Response
ANP智能体网络协议
Factor 7: Contact Humans with Tool Calls # 原则7:人机协同
多模态混合索引体系:最佳实践:生产环境必须使用向量 + 关键词 + 图谱三重混合索引,综合召回准确率可达 94% 以上,比纯向量检索提升 25%。
4. 上下文处理与组装:根据当前任务需求,完成上下文的检索、筛选、分块、压缩、去重、优先级排序,按模型要求的格式组装成最终的推理上下文;
实现了「执行 - 评估 - 优化 - 沉淀」的完整学习闭环自动技能生成:当 Agent 完成涉及 5 步以上工具调用的复杂任务后,会自动从执行经验中提取核心流程,生成符合agentskills.io开放标准的结构化技能文档,无需人工编写代码或 Prompt;技能持续优化:技能在后续使用中,会根据执行结果自动迭代、优化流程,提升执行成功率;社区生态共享:官方推出了技能市场,用户可分享、安装社区优质技能,目前已收录 200 + 开箱即用的技能。
训练采集器模型:分类模型处理压缩
Prompt框架模型:背景、目标、风格、语气、受众、格式
3. 滑动窗口策略:只保留最近的 N 轮对话 / 内容片段,超出窗口的旧内容直接截断,适合临时短对话、无长程依赖的轻量场景,优点是零成本实现,缺点是会丢失早期核心信息;
通用工具:PyPDFLlamaIndexLangChain
2. 全局目标强绑定:每个 Agent 的 Prompt 开头,必须明确全局业务目标,以及该角色对全局目标的贡献,让每个 Agent 的行为都围绕全局目标展开,避免局部最优导致全局最差;
奖励模型(RM)+ 偏好数据
原则四:工具设计与选择至关重要
1. 生命周期管控结合:Harness 定义规则,Context 落地执行Harness 层定义了 Agent 的角色权责、行为边界、安全规则、生命周期流程,而 Context Engineering 则把这些规则,转化为每一次模型推理的上下文内容:• Harness 层定义了 Agent 的角色与权限,Context Engineering 则在上下文中固定注入角色定义、权限边界、合规规则,同时在上下文路由时,严格遵循 Harness 的权限管控,只给 Agent 加载权限范围内的上下文;• Harness 层定义了 Agent 的任务执行流程,Context Engineering 则基于任务进度,动态加载对应步骤所需的上下文,实现 Harness 定义的分步执行逻辑;• Harness 层定义了 Agent 的失败重试、兜底策略,Context Engineering 则在重试时,补充对应的错误上下文、优化检索策略,帮助 Agent 完成重试。
• 挑战9:多Agent联合学习与经验积累
subagent-1
解决方案
mission-control:多 Agent 管理面板,支持小团队多 Agent 的统一管控与监控。全链路可观测:完整的执行 Trace 日志、审计记录,支持全流程回放、调试、问题排查。
Outcome(结果):最终的评估标准,是判断 Agent 表现的核心依据。
问题:用户问题模糊不清,传统 RAG 无法理解用户真实意图,导致答非所问解决方案:使用 LlamaIndex 的意图路由 + 查询重写 + 反问机制,当问题模糊时自动反问用户澄清,直到获取足够信息
外部记忆系统
3. 格式强制原则:明确规定输出的结构化格式(JSON/Markdown/XML),用 Schema、标签约束输出,避免格式不稳定导致下游系统解析失败;
1. 上下文建模:定义业务场景的上下文结构、分层规则、本体模型,明确哪些信息需要纳入上下文、信息的优先级、权限边界;
扩展阶段:LLM 裁判的规模化(Auto Eval),五维评分量规实现规模化验证
评估工具:Rag ASLangSmithLLM-as-a-Judge
第二组:题目与判卷(Static Definition)
7. 分步执行原则:复杂任务用 CoT 拆解为多步执行,强制模型分步完成,避免逻辑跳跃;
3、熵减闭环
Prompt分类:系统提示词和动态提示词
Factor 2: Own Your Prompts #掌控好你的提示词
Agent设计模式
核心原理:强制模型在每一步推理中都必须遵循预定义的结构化思维模板,而非自由发挥,将 ReAct 范式做了标准化、工程化落地;核心能力:维护任务状态机、协调工具调用、管理记忆读写、异常自动重试与兜底,保证复杂多步任务的执行稳定性。
Frequency Penalty:按 token 的出现频率动态施加惩罚,出现次数越多,惩罚越强,核心解决「车轱辘话反复说、同一个词 / 句子重复出现」的问题,降低文本重复度。
5. 子 Agent 分治策略(复杂任务场景):主 Agent 把超长任务拆分为多个子任务,分派给不同的子 Agent,每个子 Agent 在独立的上下文窗口中完成专项任务,仅向主 Agent 返回精炼的结果摘要,避免主上下文被污染;
有限资源下进行良好的管理和调度
5. 角色能力与模型匹配:不同角色的 Agent,在 Prompt 中绑定适配的模型、参数,比如复杂推理的 Agent 用强模型、高 Temperature,简单执行的 Agent 用轻量化模型、低 Temperature,平衡效果与成本;
Agentic Rag智能体增强 RAG
上下文工程与 Harness Engineering 如何结合落地
指令确定目标
推理池化管理:实现模型推理请求的池化、排队、批量处理,提升推理吞吐量;支持模型的预热、保活,降低推理延迟;支持推理请求的超时控制、重试机制。
RAG 技术全景图(设计模式)
Example Selector
以上下文为中心进行拆分
初始化智能体:使用相同系统提示词、工具集、控制框架
Chains
边
知识图谱检索:问题-实体相似度识别社区聚类检索
工具反馈观察结果
压缩
单点打磨:围绕同一个结果反复修改而非横向选优标准驱动:根据精确标注提供反馈;闭环迭代:满足标准或达成停止条件
3、治理与迭代体系:内置任务失败复盘、异常根因分析、执行效果评估能力;支持基于历史执行数据,自动优化提示词、工具调用策略、循环规则,实现 Agent 的自迭代。
Retrieval
词向量化
一套配置即可接入 14 + 主流消息平台,部署一次即可实现全渠道可用:原生支持:CLI、Telegram、Discord、Slack、WhatsApp、Signal、SMS 等;社区适配:飞书、企业微信、微信等国内平台的第三方适配;核心特性:跨平台对话连续性、语音备忘录转录、多端消息同步。
核心职责:负责所有 Agent 任务的全生命周期管理,是业务需求与 Agent 执行之间的桥梁。核心能力:任务拆解与 DAG 编排、优先级调度、依赖管理、子任务分发、多 Agent 协同调度、任务状态追踪、终止与回滚控制。生产级特性:支持任务的定时执行、周期执行、事件触发执行;支持复杂任务的 T-DAG(有向无环图)编排,实现子任务的并行、串行、依赖执行;支持任务的暂停、恢复、终止、回滚操作。
持计划与结构化
AG-UI(Agent to UI)
Community
整合总结:多 Agent 场景的 Prompt,先设计全局的协同契约、统一的输入输出 Schema,再基于契约编写每个 Agent 的 Prompt,确保所有 Agent 的行为都在全局契约的约束内;同时,每个 Agent 的 Prompt 都包含失败兜底、异常上报的规则,避免单个 Agent 的故障导致整个协同链路崩溃,完全对齐 Harness Engineering 的全生命周期管控理念。
语义切分:AI21SemanticTextSplitterBert文本切分
openAI Function
ProcessON
Agent的角色(包括名称、职责、描述等)定义,周期长且难以适应动态任务需求
短期记忆草稿纸(Scratpad)
多智能体架构模式( Multi-Agent Architecture Pattern)
上下文拼接策略优化分块摘要拼接动态窗口拼接
安全沙箱与工具系统
模型微调:对比学习标注回归
Navie Rag原生 Rag
大模型的幻觉问题--Prompt层面解决方案
Language Model
Workflow设计模型
AgentTestOps Agent评估工程
Factor 8: Own Your Control Flow # 原则8:掌控自己的控制流
辅助当前决策
硬编码启发式:滑动窗口设定规则
Vector Store
6. 异常重试机制:格式校验失败时,自动给模型返回错误提示,让模型重新输出符合要求的内容,最多重试 2-3 次,避免无限循环。
Agent之间隔离:主Agent做Planing和任务拆解主与子Agent隔离,子Agent之间上下文隔离主Agent避免海量细节导致灾难性遗忘
专业词向量数据库:ChromaFaissQdrant
RAG(Retrieval Adanced Generation)
3. 权限管控模块
评估器 - 优化器 Evaluator-Optimizer
3. IPO / KTO / SLiC / ORPO 等新一代对齐方法IPO(Iterative Preference Optimization)更稳定,抑制模式崩溃KTO(Kalman Filtering-based...):支持单点偏好,不一定非要成对ORPO(Odds Ratio Preference Optimization):把 SFT + DPO 合并一步训完,SFT + 对齐一步到位SLiC、SPIN:自迭代蒸馏类偏好对齐
2. 核心主观评估指标(人工专家评估)• 业务贴合度:输出内容是否符合业务场景要求、行业规范;• 逻辑连贯性:推理过程是否清晰、无逻辑跳跃、无矛盾;• 可读性 / 用户体验:输出内容是否通顺、易懂、符合用户需求;• 合规性:是否符合行业合规要求、安全规范,无违规内容。
2、自我验证闭环
2、全链路日志与追踪体系:基于 TraceID,实现从用户请求→任务拆解→每一次 Loop 执行→每一次模型调用→每一次工具调用→最终结果交付的全链路日志追踪,所有日志不可篡改,支持执行过程的 100% 复现。
3、参数校验与结果清洗:工具调用前,Harness 自动校验入参的合法性、合规性、权限范围,拒绝非法参数;工具执行后,自动清洗结果中的敏感信息、冗余内容,格式化后注入上下文,避免无效内容占用上下文窗口。
总结对话历史:提取任务概览、关键抉择
长上下文场景,LLM注意力衰减,如何优化
Factor 4: Tools Are Just Structured Outputs # 工具必须结构化输出
Max Length:限制模型输出的最大 token 数量,精准控制回复篇幅,同时管控 API 调用成本(绝大多数大模型按 token 计费)。
长期记忆持久化
多层防护体系:输入层防护:用户请求的敏感词检测、注入攻击检测、恶意指令识别、合规校验,拒绝非法请求。推理层防护:模型 Prompt 注入防护、系统提示词防篡改、模型输出的合规校验、敏感信息过滤、幻觉识别。执行层防护:高危操作拦截、违规行为识别、越权操作阻断、执行结果的安全扫描。输出层防护:最终交付内容的合规校验、敏感信息脱敏、格式规范校验。
架构设计核心要点上下文智能路由:摒弃全量上下文注入的粗放模式,基于当前执行步骤、任务目标,智能筛选、压缩、召回相关上下文,最大化保留有效信息,最小化上下文窗口占用,解决上下文腐烂问题。记忆生命周期管理:内置记忆的过期清理、脱敏归档、GC 机制,避免记忆无限膨胀,同时满足合规要求。结构化状态存储:将任务进度、子任务完成情况、依赖关系等结构化状态,独立存储在关系型数据库中,而非纯文本上下文,支持精准的任务调度与状态回溯。
高质量方法:结构化Schema
1、主体权限管理:为不同 Agent、不同用户、不同业务场景,分配独立的权限主体,实现权限的隔离。
• 挑战3:Agent角色自动生成与优化
4. RLAIF(RL from AI Feedback)用 LLM-as-Judge 替代人类标注流程:AI 打分 → RM → PPO/DPO
LLM
• 挑战1:多模型协同与智能路由
Batching批处理输入数据
HEX(Hermes Execution) 结构化推理引擎(核心执行底座)
长期记忆
核心职责:解决 Agent 的黑盒运行问题,实现全链路可观测、可追溯、可复现、可优化。
短期记忆实时处理
• 挑战2:Agent推理资源竞争与高效调度
Conversational
全链路Trace与可观测系统(审计、监控、调试)
Action
二、结构化索引与存储管理:企业知识的 \"逻辑架构师\":LlamaIndex 在此层解决的是纯向量检索的上下文碎片化和语义丢失问题,将企业的非结构化数据转化为有逻辑、可推理的知识体系。
数据飞轮
1. 核心客观量化指标(可自动化统计)• 任务成功率:输出结果符合业务要求的比例,是核心指标,比如客服场景的问题解决率、代码生成的可运行率、JSON 格式的合规率;• 准确率:输出内容的事实准确性、无幻觉比例,通过和标准答案比对、事实校验工具自动统计;• 格式合规率:输出格式符合要求的比例,能否被下游系统正常解析;• 召回率 / 精确率:针对分类、信息提取场景,统计正确提取的信息占比;• 推理耗时 / Token 消耗:单次请求的平均耗时、Token 消耗量,评估成本和效率;• 异常率:输出违规内容、格式错误、无意义内容的比例。
即时检索Agentic Search:主动机制:ReAct渐进式披露+元数据梳理优势:即时信息+高信噪比+探索能力
流水线架构模式(Pipeline-Based Architecture Pattern)
华为云:AgentArts(Versatile)
Prompt压缩
4. 模型原生能力适配:使用模型原生支持的格式约束能力,比如 GPT-4o、Claude 3 支持的 JSON Mode、Structured Outputs,从模型层面强制输出符合 Schema 的内容,这是最稳定的方案;
Annotation
我用老师教学生写作文这个生活场景,把 7 种 LLM 微调方法一次性讲明白,保证看完就懂、不记公式。
LlamaIndex 全解析:2026 年最主流的 RAG 开发框架
Factor 3: Own Your Context Window #掌控号你的上线文窗口
User
Monitoring
• 如何高效表示多样化领域知识• 如何提升垂域任务规划准确性• 如何增强推理过程的可解释性
1、标准化工具注册中心:支持工具的元数据注册、可用性探活、版本管理、动态上下线,兼容 OpenAPI、MCP、Function Call 等主流协议,实现工具的一次注册、全平台复用。
结构化隔离 Agent 内部状态Schema 设计预先定义信息边界和访问权限“隔离” 定义信息边界,“选择” 在边界内活动。
大小无限制
Multi-Agent 评估
文件即上下文:文件+日志解决失忆和信息不足问题
Hermes Agent
原则六:先宽后窄的搜索策略
国产新兴:OceanBaseGaussDB
Document Loader
3. 上下文存储与管理:通过向量数据库、关系型数据库、KV 存储、图数据库,实现上下文的持久化、版本控制、权限管控、生命周期管理;
工具集选择
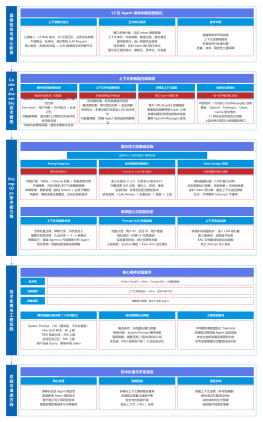
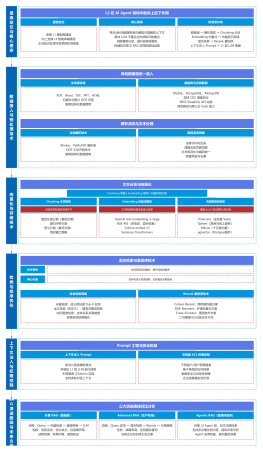
AI Agent
Transform Chain
1. 权责边界绝对清晰:每个 Agent 的 Prompt 必须明确、唯一的角色定位、RACI 权责矩阵、任务边界,绝对不能出现职责重叠、责任真空,比如 “你是专属的代码开发 Agent,只负责根据产品需求编写 Python 代码,不负责需求分析、测试用例编写,禁止超出职责范围的输出”,避免多 Agent 抢活、推诿;
CoT
盲目自信:上下文腐烂,未测试,信息缺失导致幻觉
数据生成获取
文本结构分割:句子切分段落章节
第三组:基础设施(System Environment)下发指令并行运行测试,收集记录并汇总
GUI-Agent
• 系统稳定性与可扩展性• 协作式探索与任务分配• 动态优化与反馈机制
8. 可维护性原则:Prompt 分模块编写,加清晰的注释,方便后续迭代优化,避免写一大段无结构的文本。
• 决策权重比例分配• 流程可引导性• 消除Agent偏见
Research subagent:流程:研究规划、工具选择、研究循环(调整、决策、行动)
Prompt进阶:思维连CoT、少样本提示(Few-shot Prompting)、负向约束....
Multi-Agent 提示词工程八条原则
意图感知与智能路由支持 6 种以上意图分类:事实查询、总结查询、分析查询、计算查询、多文档对比、操作指令动态路由到最合适的索引和检索策略:事实查询 → 关键词索引 + 向量索引总结查询 → 树状索引分析查询 → GraphRAG 索引计算查询 → SQL 索引
通用文本类型:PDF、Word、CSV、Markdown、Html、txt...
写入
原则三:根据任务复杂度匹配投入力度
HyDE Rag假设性文档嵌入
提示链 (Prompt Chaining)
知识
LangServer
Prompt:角色职责限制
Stop Sequences:设定模型停止生成的触发词 / 符号,当模型生成的内容匹配设定的停止序列时,会立即终止输出,精准控制生成的边界和格式。模型是逐 token 生成内容的,一旦输出内容匹配你设定的停止序列,就立刻停止,不会继续生成额外内容。
完全模型无关,支持 200 + 主流大模型,一键切换,无需修改业务逻辑:支持商用模型:OpenAI、Claude、Gemini、DeepSeek、通义千问、文心一言等;支持开源模型:通过 Ollama、OpenRouter、Nous Portal 接入本地部署的大模型;核心特性:自动模型路由、失败自动降级、Token 消耗统计与优化。
核心职责:实现 Agent 实例、模型资源、算力资源的统一调度与管理,支撑 Agent 的规模化部署与水平扩展。
企业级推理引擎:多模型路由:自动根据问题复杂度选择最合适的大模型,简单问题用小模型,复杂问题用大模型,成本降低 70%上下文管理:自动管理多轮对话上下文,支持超长上下文(100K+ tokens),自动压缩和裁剪无关内容提示词工程平台:内置企业级提示词模板库,支持提示词版本控制、A/B 测试和灰度发布引用溯源:自动为答案中的每个事实添加引用来源,点击可跳转到原始文档的对应位置
大模型
Agent 技术十大挑战
Factor 5: Unify Execution State and Business State #统一执行状态和业务状态
静态上下文:出厂设置(身份角色、能力、行为准则)
数据元接入
解决的核心痛点:Agent 在长周期、多轮次执行中,输出质量逐渐下降,累积技术债务、冗余内容、逻辑偏差,最终偏离任务目标。
系统Prompt
智能体两种崩溃模式
上下文缓存
Agent 构建12条原则Factor
Chains as Rest APIS
• Agent Harness:将 LLM 包装成 Agent 的代码脚手架,是运行 Agent 的基础框架。
全模型兼容层
Conversation Summary Memory
1. 按需检索策略(生产级首选):不把全量内容塞入上下文,而是通过 RAG 把全量内容向量化存储,用户提问时仅检索最相关的 Top N 个内容片段放入上下文,从根源解决窗口溢出问题;
• 挑战4:异构Agent间通信
Storm
AI Agent架构
4. 协同规则明确化:在 Prompt 中明确该 Agent 的上下游协同对象、通信规则、异常上报流程、升级策略,比如 “如果需求不明确,必须向产品经理 Agent 发起澄清,禁止自行假设需求;如果执行失败,立即向总管 Agent 上报,附带失败原因”;
执行平面是 Harness 管控规则的落地载体,是 Agent 执行任务的核心链路,所有模块的行为均受控于管控平面。标准执行范式(增强 ReAct 状态机)生产级 Harness 摒弃了原生 ReAct 的无边界循环,采用有限状态机(FSM) 固化执行流程,所有状态流转必须经过 Harness 校验:初始化 → 感知(Observe)→ 推理(Think)→ 决策校验(Harness拦截)→ 执行(Act)→ 结果验证 → 状态持久化 → 循环/终止
Vector Store-backed Memory
编排器 - 工作者 Orchestrator-Workers
2. 强制事实溯源:要求模型输出的每个结论,都必须标注对应的知识来源
Text Spliter
• 挑战8:多Agent记忆共享
Agent
2. 上下文获取:从多源异构数据源(文档、数据库、API、对话历史、工具返回结果)提取、清洗、标准化上下文信息,包括 RAG、实时数据接入等;
6. 模型切换策略(兜底方案):切换到更大上下文窗口的模型,仅作为临时兜底,不推荐作为常规方案,因为会带来成本的指数级上升。
演进
Harness 架构三大核心闭环(架构精髓:将 LLM 的非确定性转化为确定性,这是 Demo 级 Agent 与生产级 Agent 的核心差距。)
Multi-Agent
Agent Tolling
贪多嚼不烂:一次会话完成所有任务目标
评估
3、实时鉴权机制:每一次工具调用、资源访问,都必须经过 Harness 的实时鉴权,鉴权不通过直接拦截,禁止预授权的全局权限。
闭环自进化学习系统(核心差异化竞争力)
Paln and Execute
Agent 平台
原则二:教会指挥官如何授权
核心特性:支持规则的动态更新、灰度发布;支持违规行为的分级处置(告警、拦截、熔断、人工介入);支持等保、GDPR、行业合规要求的定制化规则。
示例Few-shot
Memory
技术挑战
环境管理
1. 安全合规与访问控制数据脱敏:自动识别并脱敏身份证号、手机号、银行卡号等敏感信息细粒度访问控制:基于角色的权限管理(RBAC),支持文档级、段落级、实体级的权限控制审计日志:记录所有用户的查询、检索、生成操作,支持审计和追溯国产化支持:完美适配国产大模型(通义千问、文心一言、智谱清言)、国产向量库(Milvus、NebulaGraph)和国产硬件(昇腾、昆仑芯)私有化部署:支持完全私有化部署,数据不出企业内网
企业级数据治理能力:增量同步:自动监控数据源变化,仅同步新增和修改的内容,避免全量重新索引,更新延迟 < 5 分钟数据版本控制:保留文档的所有历史版本,支持回滚到任意时间点的索引状态自动去重:基于语义相似度的全局去重,避免同一内容在多个数据源重复存储,索引体积减少 40% 以上数据清洗流水线:内置敏感信息识别、垃圾内容过滤、格式标准化等预处理节点,可自定义清洗规则
...
ACP智能体通信协议
• 任务复杂度量化• 动态路由策略设计
Async异步执行
优先选 Agent
持续学习闭环自动收集用户反馈(点赞、点踩、修改建议)定期分析用户反馈和评估结果,识别常见问题自动优化检索策略、提示词模板和分块参数形成 \"数据→索引→检索→生成→评估→优化\" 的完整闭环
2. 工具与能力管理模块(Agent 的手脚)
原则一:像智能体一样思考,理解智能体逻辑
2. 分层摘要策略(长文档通用最优):采用 Map-Reduce 模式,先把超长内容分块,并行生成每个块的核心摘要,再把所有块摘要汇总生成全局摘要,基于全局摘要完成推理;
多Agent联合学习与经验积累的核心在于• 协作式探索• 经验共享• 动态优化
Prompt全流程管控输出
• 挑战7:多Agent关系拓扑自动生成与优化
上线文管理四大核心操作
• Eval Harness:负责发起、并行测试和汇总分数的 “考场系统”。
1. Prompt 层面核心优化手段• 关键信息首尾前置:把核心任务要求、输出格式、关键约束、核心问题,放在 Prompt 的最开头和最结尾,避免被长文本淹没,模型对首尾内容的敏感度最高;• 强制分步检索:不要让模型一次性读完长文档,先让模型拆解问题,列出需要的关键信息点,再让模型逐段检索文档提取对应信息,最后汇总回答,比如 “第一步:列出回答问题需要的 3 个核心信息点;第二步:从文档中找到每个信息点的原文内容;第三步:基于提取的内容汇总回答”;• 长文本分块摘要:先让模型把长文档按章节分块,生成每一块的核心摘要,标注关键信息位置,再基于摘要回答问题,需要详细信息时再召回对应原文块;• 注意力引导:在 Prompt 中明确告诉模型 “必须基于文档中的所有相关内容回答,重点关注文档中关于 XX 的章节,不要忽略中间内容”,强制模型关注长文本中间部分;• 任务拆解分步执行:不要让模型在长上下文里同时完成多个任务,拆分为「信息提取→分析→生成报告」等多个单任务,分步执行。
React
1.模型分化加剧;2.任务需求分化;3.资源约束加剧
选择
• 通信协议的通用性• 通信性能优化• 安全性与可靠性
7. AdaLoRA 自适应 LoRA生活案例:给学生配一副 “智能自动调焦眼镜”• 普通 LoRA 眼镜度数固定。• AdaLoRA:看重点内容时度数加深,看不重要内容度数变浅,自动分配精力。• 同样一副眼镜,** smarter、效果更好 **。• 对应微调:不同层自适应分配秩大小,同样参数量,效果比普通 LoRA 更强。
Testing
提示词攻击:直接注入间接注入越狱提示词泄露训练数据投毒
输入清晰分类,处理过程和逻辑差异明显
MCPModel Context Protocol
直接交互扩展为外部可交互持久化环境
闭环实现:Harness 内置后台校验进程,在 Agent 执行过程中,定期扫描当前的执行状态、输出内容、中间结果。2. 基于预设的规范、规则、目标,识别冗余内容、技术债务、逻辑偏差、规范不符点。3. 自动发起重构、清理、修正操作,或向 Agent 注入明确的优化指令,强制 Agent 修正偏差。4. 任务完成后,自动复盘整个执行过程,沉淀优化规则,更新到全局规则库,实现长期的质量稳定。
Prompt Engineering
Lead Agent(Orchestrator)Tools:Rag+MCP+Memory+ run_subagent+complete_task
测试评估:Agent测试评估标准
4. 少样本示例原则:给 2-5 个高质量的输入输出示例,覆盖正常场景、边界场景、异常情况,对齐输出标准;
6. 降低模型随机性:调低 Temperature 参数(建议 0-0.3)、Top_P 参数,减少模型的创造性输出,让模型更聚焦于给定的知识,减少随机编造;
知识库选择
推理成本管控:内置 Token 消耗的统计、预算管控、限流策略;支持模型的智能路由(简单任务用小模型,复杂任务用大模型),在保证效果的前提下,最大化降低推理成本。
Factor 12: Make Your Agent a Stateless Reducer # 原则12:无状态
三、高级检索与动态工作流编排:RAG 系统的 \"智能指挥官LlamaIndex 在此层将 RAG 从 **\"检索 - 生成\" 的线性链路升级为\"会思考、能自愈\" 的智能系统 **,解决传统 RAG\"检索什么就生成什么\" 的机械性问题。
结构化功能任务清单:结构化Schema+Todo List
裁剪
Transcript(轨迹):完整的思考与调用日志,作为评估的过程证据。
优先选 Workflow五大模式适配
多智能体并行:决策冲突和灾难性合并
后处理工具反馈检索数据后预处理提取核心要点
规则分割:字数切分Token分割滑动窗口切分
Agent间不同接口、编程语言、运行环境、功能特性,支持持通信接口与协议
重排序:Top-kcross-encoder深度语义匹配/ms-marco
挑战
• Grader(阅卷):基于评分规则(Rubric)的打分逻辑脚本,实现自动化判分。
运行时状态对象
Language Agent Tree Search (LATS)
Retriever
• Suite(题库):一组 Task 的集合,例如客服场景下的测试题集。
Citation subagent:数据应用Agent1. 避免不必要的引用;2. 引用完整的语义单元;3. 让句子碎片化最小化;4. 避免相邻的冗余引用
上下文管理三类信息
4. Prompt Tuning 提示微调生活案例:只在作文开头给一句引导语• 学生完全不变,只在最开始给一句提示:“请写一篇关于春天的记叙文”• 不教新东西,不改变习惯,只靠开头一句话引导。• 对应微调:只训练输入层的软提示,参数极少、极省显存,但大模型才好用。
工具Tools
4. 否定性指令强化:明确禁止模型编造内容、猜测不确定的信息
构建知识图谱:实体识别关系判别实体聚类
Top_p:和 Temperature 协同控制生成多样性,但逻辑完全不同:通过累计概率阈值,划定 token 采样的候选池边界。关键提示:Temperature 和 Top_p 建议固定一个、只调另一个,不要同时大幅修改,避免效果失控。
Hybird Rag混合检索Rag
超过模型的上下文窗口时,主流处理策略有哪些
A2A(Agent to Agent)
任务执行多次独立运行,聚合多轮运行结果,投票机制提升置信度 + 鲁棒性
在线:爬虫(Scrapy)Wikipedia、Github、Bilibili、网页
Memory:Context Window+外部文件主智能体在 Think plan 后执行 Save Plan 动作,将宏观战略写入外部记忆存储
• 如何生成调用外部工具、执行代码等能力更强的Agent?• 如何让生成的Agent根据任务场景自主选择协作模式?
User Request
图片信息切分:图片解析+文档单独切分图片链接+文档单独切分
Conversation Buffer(Context Window)
全格式无损解析:文档类:原生支持带复杂排版的 PDF(扫描件 + 可编辑)、Word、Excel、PPT、Markdown、HTML,表格解析准确率达 92%(比传统工具高 35%),可保留单元格合并、公式、图表标题等语义信息多模态类:内置 OCR 引擎支持手写体识别、印章识别、流程图解析;支持音频 / 视频自动转文字并对齐时间戳;支持 CAD 图纸、医学影像等专业格式解析结构化类:直接对接 MySQL、PostgreSQL、Oracle、MongoDB 等 20 + 种企业数据库,支持增量同步和 CDC 实时更新办公协作类:原生集成飞书、钉钉、企业微信、Slack、Notion、Confluence 等 15 + 种办公平台,支持实时同步聊天记录、会议纪要、文档变更
动态选择策略(Agent Skills):固定工具集+工具检索工具选择:按需加载,以任务为核心,精准能力治理
Router
Factor 9: Compact Errors into Context Window # 原则9:将错误压缩进上下文窗口
Planning
大任务拆分独立的子任务,无依赖无传递中间结果
开源模型:Qwen-EmbeddingBGE
优化方法
增量进度:一次完成一个任务目标,记录更新完成状态
• 挑战6:多Agent集体决策优化
Multimodel Rag多模态Rag
解决的核心痛点:Agent 经常误判任务完成状态,提前终止任务,交付半成品。
GraphRAG 2.0 企业级增强:自动实体提取:支持中文实体和关系识别,准确率达 85% 以上社区检测:使用 Leiden 算法自动将知识图谱划分为主题社区,提升多跳推理效率动态更新:支持增量更新知识图谱,无需全量重建可视化:内置图谱可视化工具,可直观查看实体和关系
Workflow
Multi-Agent拆分原则
单智能体串行:上下文窗口限制,信息有限
未克隆,请勿搬运,尊重版权知识成果,谢谢
Frequency Penalty
环境沙箱
5. LoRA 低秩适配(目前最主流)生活案例:给学生加一副 “作文专用隐形眼镜”• 学生本身完全不动。• 戴上一副轻薄眼镜,只修正看世界的角度,不改变大脑。• 写完作文,眼镜可以摘掉、换一副、存起来。• 推理时:眼镜直接融到眼睛里,看不出区别,速度不变。• 对应微调:只训练低秩小矩阵,效果接近全量,无推理延迟,工业标配。
多模态处理:单独处理图片、视频文本+多模态序列混合统一处理
1. 任务管控模块
• 角色定义的精准生成• 动态优化能力• 多目标权衡
数据存储
Agent知识交接子Agent总结汇报给主Agent
Composition:任务组合
Agent SkillsAgent工具
10
Graph Rag知识图谱Rag
7. 多角色交叉校验:用多个 Agent 交叉校验,比如一个 Agent 生成答案,另一个 Agent 专门校验答案的事实准确性、是否有幻觉,发现问题直接打回重写。
Temperature
Agent上下文限制
技术背景
多平台统一消息网关
4、权限审计与动态变更:所有权限的申请、变更、使用,都记录在审计系统中;支持权限的临时授权、过期自动回收。
4. 闭环优化结合:Context 反馈效果,Harness 迭代策略Harness 层负责 Agent 的整体策略优化,Context Engineering 负责提供效果反馈数据,二者结合形成完整的自优化闭环:• Context Engineering 收集上下文的检索效果、生成结果、用户反馈,同步到 Harness 层的优化模块;• Harness 层基于反馈数据,优化上下文的检索策略、分块规则、组装逻辑、权限管控规则,再通过 Context Engineering 落地执行;• 二者结合,实现 “执行 - 反馈 - 优化 - 执行” 的完整闭环,让 Agent 系统越用越准,无需人工频繁迭代。
Models I/O
Presence Penalty:只要 token 在已生成内容里出现过,就施加固定惩罚,和出现次数无关,核心鼓励模型生成新的话题、新的概念,拓展内容的广度,避免翻来覆去只讲一个点。
6. QLoRA 量化 LoRA(单卡神器)生活案例:给学生戴 超薄超轻折叠眼镜 + 简化课本• 在 LoRA 眼镜基础上:把课本内容压缩成迷你版,不影响理解,但超级省空间、省力气。• 原本要搬大书包,现在口袋书就能学。• 对应微调:4bit 量化模型 + LoRA,消费级显卡也能训 70B 大模型,效果几乎不掉。
3. 分步推理 + 自我校验:用 CoT 让模型先拆解问题,再检索对应知识,再生成结论,最后自我校验
5. 后处理兜底校验:用代码做最终的格式校验、清洗、修复,比如用正则提取 JSON 内容,过滤掉额外的文本,用 JSON 库解析,解析失败时触发重试或兜底逻辑;
上下文工程的核心生命周期 / 全流程阶段有哪些
Sequential
1. 前置强制格式约束:在 Prompt 最开头,明确告知输出格式要求,比如 “你必须严格输出标准 JSON 格式,禁止输出任何 JSON 之外的解释、说明、备注、markdown 格式,否则会导致系统解析失败”;
1. 全量微调 Full Fine-Tuning生活案例:把学生重新回炉重造一遍• 原来的学生:基础很好,但写作文不太会。• 做法:从三观、习惯、知识全部重新教一遍,连写字姿势、说话逻辑都改。• 结果:作文写得超级好,但代价极大、很累、容易把以前会的东西忘掉。• 对应微调:更新模型全部参数,效果最好,但费卡、费时间、容易遗忘。
一、数据处理层
SSM(选择性状态空间模型Selective SSM,代表Mamba) 与文件系统的黄金组合
• Task(题目):单道题目具体的测试用例,包含输入和成功判定标准。
7 种SFT(有监督微调 Supervised Fine-Tuning)核心微调方法
二、奖励模型 RM(Reward Model)训练方法1. Pairwise Ranking RM(成对排序,最经典)2. Pointwise RM(单点打分)3. Bradley-Terry / Plackett-Luce 多排序 RM
向量检索
6. 安全护栏原则:明确禁止项、合规要求、兜底策略
3. Prefix Tuning 前缀微调生活案例:给学生发一张 “作文专用小纸条”,每写一句都看一眼• 学生本人不动,知识不动。• 纸条上写:“先开头→再举例→最后总结”• 每一层思考都偷偷看这张纸条,引导思路,但不改脑子。• 对应微调:给每一层注意力加可训练前缀向量,不改动模型权重,适合生成任务。
搜索算法:相似度评估 Similarity Measures(FLAT)局部敏感哈希(LSH)Local Sensitive Hashing(LSH)倒排索引文件(IVF)Invert Index File(IVF)乘积量化 Product Quantization(PQ)分层可导航小世界(HNSW)
Customized Chain
Prompt 的效果?有哪些核心指标?
Plan and Solve
LangGraph
4. 可观测与治理模块
节点
动态上下文:感知外部实时信息推理前检索Rag+即时检索Agentic Search
核心职责:解决 LLM 原生的上下文窗口限制、失忆问题、上下文腐烂问题,实现 Agent 的跨会话、长周期、结构化记忆。
5. 资源调度模块
检索方法:向量检索关键词检索(BM25)混合检索
演进阶段:注意多智能体的涌现行为,警惕系统 “涌现行为”,评估协作模式合理性。
本地存储:对象存储、文件存储、块存储
滑动窗口(加载最近 n 轮思考)、状态总结(加载上一步行动与观察结果)、失败复盘(加载所有失败步骤)
多Agent之间的记忆共享和协同学习能力
在线模型:OpenAI Embedding智谱AI Embedding
Self-Discover
Prompts
数据检索
文件即上下文
文档分割
subagent-2
长期记忆:语义记忆:是什么程序记忆:怎么做情景记忆:何时何地做
Streaming流式输出
Core LCEL(LangChain Expression Language
架构价值:将错误闭环在 Harness 内部,避免错误流出到生产环境,大幅提升 Agent 输出的稳定性与可靠性。
Harness Engineering 理念深度结合,多 Agent 场景下,Prompt核心设计原则有 6 条
1、监控指标体系:核心指标包括任务成功率、平均执行耗时、Token 消耗、工具调用成功率、异常率、熔断次数、SLA 达标率,支持实时大盘、告警通知。
推理前检索(RAG):检索机制:混合检索(关键词检索+向量检索)优势:速度快+成本低+流程成熟
核心职责:基于零信任架构,实现 Agent 的细粒度权限管控,是企业级 Agent 的核心准入门槛。
瞬时记忆:未加工原始信息任务结束淘汰
文档解析
向图检索
• 现有基准测试的局限性• 多Agent系统的复杂性• 场景适用性与任务准确性
LLMCompiler
混合架构模式(Hybrid Architecture Pattern)
• 记忆存储与检索• 记忆的动态增长与多样性• 安全性与隐私保护
目标明确、步骤固定、规则可量化的标准化任务1. 合规审核、内容安全检测(Voting 模式)2. 固定步骤的数据分析、报告生成Chaining+Parallelism3. 按类型分发的客服工单、任务分配(Routing 模式)4. 单点结果的迭代优化(Optimizer 模式)5. 高风险、对鲁棒性要求极高的确定性判断任务
路由 (Routing)
3. 生产级评估方法• 自动化测试集:构建覆盖正常、边界、异常场景的标准化测试集,每次 Prompt 迭代都自动跑全量用例,输出量化指标;• A/B 测试:线上灰度发布不同版本的 Prompt,对比核心业务指标(用户满意度、问题解决率、人工转接率);• 持续监控:线上实时监控格式合规率、异常率、Token 消耗,指标劣化自动告警;• 专家抽检:定期对线上输出做人工抽检,评估主观指标,发现潜在问题。
主流的多Agent框架多由开发者根据任务场景预先定义好Agent之间的协作模式,增加了开发工作量
文件系统即为外部长期记忆
并行化+投票 (Parallel+voting)
5. 上下文注入与执行:将组装好的上下文注入模型 / Agent,完成推理执行,同时全链路记录上下文的使用情况、效果反馈;
任务串行化接力:Workflow进行接力,状态和信息传递
请求的优先级调度和资源分配切换时保证上下文不丢失• 异构Agent任务多样性和复杂性
按需索引
2. DPO(Direct Preference Optimization)直接用偏好数据训练,不需要 RM!把偏好优化变成分类任务:p(好回答) > p(坏回答)
总结/摘要
顶级集成工具:MarkerMinerUMarkitdown
Basic Reflection
Adaptive Rag自适应
短期记忆:上线文窗口滑动窗口/对话摘要受限于LLM容量上限
架构价值:确保任务交付的完整性,杜绝模型自主终止导致的半成品交付,100% 对齐用户的原始需求。
6. 上下文优化与闭环:基于推理结果、用户反馈、业务指标,持续优化上下文的建模、检索、组装策略,实现 “越用越准” 的自优化闭环。
基于 RM 的对齐算法:RLHF 家族、DPO 家族
二、执行平面三大核心模块(Harness 的执行载体)
2. 明确 JSON Schema 定义:在 Prompt 中给出完整的 JSON 结构定义,包括每个字段的名称、类型、含义、取值范围,避免模型随意增减字段;
挑战:成本与复杂性
前级Agent产生的幻觉被后续Agent逐级处理,从而产生幻觉放大的问题。
1. 核心执行引擎模块(Agent 的心脏)
幻觉增强事实校验溯源标注
检索过程优化:Embedding模型优化混合检索与加权重排多查询扩展
阿里云:PAI-LangStudio
企业级存储管理分布式索引:支持将大索引分片存储在多个节点上,支持水平扩展冷热数据分离:将高频访问的热数据存储在高性能向量库(如 Milvus),低频访问的冷数据存储在低成本对象存储,存储成本降低 60%多租户隔离:支持逻辑隔离和物理隔离两种模式,确保不同租户的数据完全隔离备份与恢复:支持自动备份和一键恢复,RPO<1 小时,RTO<4 小时
LangSmith
一、推理平面三大核心模块(Harness 的底层支撑)
2. 指令清晰原则:用祈使句明确任务目标、输出要求、禁止项,拆分复杂任务为多个子指令,避免模糊、歧义的表述;
攻击&防范
多模态处理
Fallbacks失败回退机制
Feedback
4. 滚动摘要策略(多轮对话场景):对话超出窗口时,让模型把早期对话压缩成核心摘要,用「摘要 + 最近对话」替代全量历史,既保留核心信息,又控制 Token 消耗,是智能客服、长对话场景的工业界标准方案;
Agent和Workflow核心维度对比
6. GRPO(Group Relative Policy Optimization,分组相对策略优化)Deepseek新一代大模型偏好对齐算法,属于 RLHF 简化版。核心是去掉 Critic / 价值网络、用组内相对奖励做 PPO,训练更稳、显存更低、适合长文本 / 推理任务。GRPO:PPO 简化版 → 保留策略梯度优势,但砍掉 Critic→ 用 同 Prompt 多输出分组(Group) → 组内算相对优势 → 更稳更快
评估方法
4、熔断与限流:内置工具调用的熔断机制,当工具调用失败率超过阈值时,自动熔断;针对高频调用工具,内置限流策略,避免打爆下游系统。
闭环实现:Agent 生成内容 / 执行操作后,结果先提交到 Harness,而非直接输出。Harness 调用独立的验证模块(可基于规则、小模型、测试用例),对结果进行多维度校验:正确性校验、格式校验、合规校验、安全校验。校验不通过:打回 Agent,明确指出错误点,要求重新生成 / 修正,同时记录错误次数,触发阈值后熔断。校验通过:结果放行,进入下一步执行或最终交付。
Temperature:控制模型生成内容的随机性、创造性与发散程度,是最常用的调参项,本质是调节 token(模型最小处理单位)概率分布的平滑度。
Context Engineering(范式转移:从提示工程(战术优化)到上下文设计(架构设计))
Evaluation
Agent深度推理强化学习+记忆等多种技术能力协同思考与规划的过程。
Factor 1:Natural Language to Tool Calls #自然语言到工具调用
核心职责:构建 Agent 的全链路安全护栏,确保 Agent 的所有行为符合业务规范、法律法规、企业安全要求。
情景:行为规则(系统提示词)程序:few-shot少样本案例(动态提示策略)语义:语义识别和意图识别有效性
并行召回(向量搜索即语义检索、关键词搜索、知识图谱)、Agentic Search、重排序
Reflexion
核心冲突
第一组:动态执行(Dynamic Execution)
• 挑战10:多Agent系统评估与基准测试
5. 少样本反例引导:在示例中加入错误的幻觉示例,标注错误原因,告诉模型正确的回答方式,强化模型的合规认知;
2. Adapter Tuning 适配器微调生活案例:给学生戴一个 “作文专用小耳机”• 学生本身完全不动,脑子、知识都不变。• 耳朵里塞一个小适配器,只教它怎么写作文。• 写别的科目时,摘掉耳机;写作文戴上。• 对应微调:冻结大模型,只训练插入的小网络,不影响原能力,多任务可切换,但推理稍微慢一点。
Playground
原则五:让智能体参与自我改进
多模态内容识别:大模型多模态功能VL专业大模型MonkeyOCR、DS-OCR
Output parsers
上线文窗口限制拆解成离散会话,新会话失忆,Session记忆高墙,遗失工作状态和细节
核心能力:Agent 实例池化管理、弹性扩缩容、模型推理流量调度、算力资源的配额管理、多租户资源隔离、故障实例的自动迁移与恢复。生产级特性:兼容 K8s 容器化部署,支持多集群、多可用区部署;支持多租户的资源配额与隔离,满足企业级多业务线的复用需求;支持故障自动转移,实现高可用部署。
兜底阶段:人类评估捕捉盲区(Human Eval),人类介入捕捉自动化裁判的 “信源偏见” 和 “幻觉”;
Prompt LLM参数调优
模型网关:统一的模型调用入口,支持多模型厂商、多模型版本的兼容,实现模型的动态切换、故障转移、流量分发;内置 Prompt 的标准化、防篡改、敏感信息过滤。
知识提供依据
原生内置 40 + 开箱即用的工具,同时提供 6 种隔离执行环境,兼顾灵活性与安全性,完全符合 Harness Engineering 的最小权限原则:内置工具:网页搜索、文件操作、终端命令、多模态视觉、图像生成、TTS、浏览器控制等;执行环境:本地、Docker、SSH、Daytona、Singularity、Modal,所有工具调用都在沙箱中隔离执行,避免越权操作与系统风险;兼容标准:原生支持 MCP(Model Context Protocol)协议,可接入海量第三方 MCP 工具。
PPO:老前辈,效果强但难训、容易崩DPO:现在最常用,简单、稳、不用折腾 RM 和 RLGRPO:想比 DPO 更强、尤其做数学 / 代码 / 长文本KTO:数据不好凑不成对,单点标注就行ORPO:不想分 SFT 和对齐两步,想一步训完
5. 知识边界原则:明确告知模型可用的知识范围、禁止使用的知识
核心构成要素:角色、背景、任务、约束、示例
LangChain Universe
事件驱动的动态工作流(Workflows)支持异步执行、并行分支、错误重试、超时控制支持状态管理和断点续跑提供可视化工作流编辑器,无需编码即可构建复杂流程
多智能体
Embedding Model
四层持久化记忆引擎(Context 工程落地)
解决无法提前拆分任务时的并行提效问题。中心 Orchestrator 在任务执行过程中动态拆解子任务给多个 worker 并行完成,最后汇总结果。、子任务非提前定义,而是运行中动态规划拆分。
闭环实现:Agent 向 Harness 发起任务终止请求,声明任务完成。Harness 立即拦截终止请求,不直接放行。读取原始任务目标、交付要求、验收标准,自动校验交付物的完整性、合规性、正确性。校验不通过:驳回终止请求,强制 Agent 继续执行,同时注入明确的优化方向。校验通过:放行终止请求,完成任务归档。
协作
subagent-n
三、管控平面五大核心模块(Harness 的灵魂)
6. 安全护栏统一化:所有 Agent 的 Prompt 都必须包含统一的合规规则、安全护栏、权限边界,同时每个角色根据自身职责,补充专属的权限约束,比如财务 Agent 只能读取财务数据,不能修改代码,避免越权操作。
生产级 Harness 标准架构(三大平面 + 七大核心模块)
3. 记忆与上下文管理模块(Agent 大脑记忆)
ReAct/CoT
腾讯云:Tencent Cloud ADP
其他数据库:Postgres、RedisMilvus、Mem0
1、终止拦截闭环(Ralph Loop)
原则七:引导思维过程
Corrective Rag纠错型Rag
离散会话失忆
1. 串行 workflow:步骤按顺序执行2.独立LLM调用:非单次 prompt 内完成所有步骤3. 显式信息流:上一步输出作为下一步输入
2. 安全合规模块(Guardrails)
Presence Penalty
2、细粒度操作权限:针对工具、API、数据、资源,实现操作级的权限管控(如文件只读 / 读写、API 的 GET/POST 权限、数据库的查询 / 修改权限)。
Agent Harness Engineering(生产级Agent = (LLM推理内核 + 能力组件)× Harness管控系统)
处理任务多样性和通用基准测试多轮交互交互场景至关重要•多Agent系统的效率如何度量。
功能列表:避免两类失败模式,提供清晰任务目标
3. 可观测性结合:Context 提供数据,Harness 实现管控Harness 层负责 Agent 全流程的可观测、可监控、可告警,而 Context Engineering 则为 Harness 层提供全链路的上下文数据提供核心数据来源:• Context Engineering 记录上下文的检索、处理、注入、使用的全链路 Trace 数据,同步到 Harness 层的可观测系统,实现上下文全流程的可视化监控;• Harness 层基于 Context Engineering 提供的指标(检索准确率、上下文信噪比、Token 消耗),设置告警阈值,出现异常自动触发熔断、告警;• 当 Agent 执行失败时,Harness 层可通过 Context Engineering 的全链路 Trace 数据,快速定位是上下文供给问题,还是模型推理问题,实现根因分析。
架构价值:确保 Agent 在长周期、复杂任务中,始终保持输出质量稳定,不偏离目标,实现长期的熵减,而非熵增。
Fuction Calling
分离 “思考” 与 “执行”:沙箱是 “状态化环境”,隔离 “真实环境的状态”
用户交互
规则过滤
语义摘要
Stop Sequences
火山引擎:HiAgent+AgentKit
信息熵度量

收藏
立即使用

收藏
立即使用
收藏
立即使用
收藏
立即使用

Collect
Get Started

Collect
Get Started

Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页