
AI+Cloud云原生全栈技术纯享版-持续更新
2026-04-26 10:39:09 1 举报《AI+Cloud云原生全栈技术纯享版》是一套专注于AI与云计算集成的高级技术教程。本系列教程以其全面性、深入性和即时更新性备受技术开发者们的青睐。它深究从基础云架构到高级智能分析算法的全面应用,贯穿了容器化、微服务、自动化部署、人工智能模型等核心云原生技术。
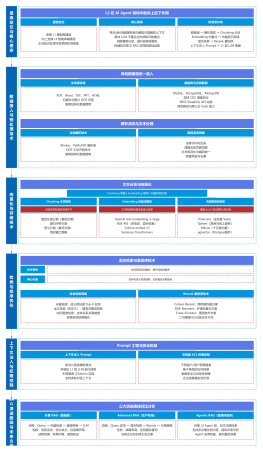
一图看懂AI
AI
云计算
云原生
架构图总览
架构设计
模板推荐
作者其他创作
大纲/内容
阿里平头哥
...资源池
Prompt框架模型:背景、目标、风格、语气、受众、格式
H20+96GBHBM3
训练框架
数据生成获取
多智能体
训推一体
数据安全定级
1.Gang 成组调度2. 拓扑感知调度3.调度策略插件
存储访问协议
2. 指标:训练 / 验证 loss、准确率、显存占用、训练速度(tokens/s);
数据集成
容器网络模型
训练服务
工具反馈观察结果
向量检索
推理服务管理(平台层能力)
微服务管理服务网格、Istio
项目管理、需求跟踪Jira、Trello
交互式分析HetuEngine
B200 SXM+192GBHBM3e
实时流处理
对象存储:对象级存储(OSS/COS)+多副本/ 纠删码 + 智能缓存 + 分层存储
实时加载
数据开发
Agent知识交接子Agent总结汇报给主Agent
演进
腾讯云 TCHouse-P
知识图谱数据库:Neo4j ArangoDB
监控与运维
并行化+投票 (Parallel+voting)
Citation subagent:数据应用Agent1. 避免不必要的引用;2. 引用完整的语义单元;3. 让句子碎片化最小化;4. 避免相邻的冗余引用
硬件防火墙
Agent SkillsAgent工具
数据加速:分布式存储(对象存储、分布式文件系统)DataCache、数据预加载高速读写、小文件优化
A2A(Agent to Agent)
环境沙箱
节点
Self-Discover
Agentic Rag智能体增强 RAG
Multi-Agent 评估
数据源
Factor 8: Own Your Control Flow # 原则8:掌控自己的控制流
单智能体串行:上下文窗口限制,信息有限
即时检索Agentic Search:主动机制:ReAct渐进式披露+元数据梳理优势:即时信息+高信噪比+探索能力
Navie Rag原生 Rag
目标模糊、步骤动态、需要自主决策 / 多工具协作的开放型任务:1. 多轮智能客服(主动理解意图、转接业务、解决非标准化问题)2. 自主数据分析(用户仅提目标,Agent 自主选工具 / 查数据 / 出结论)3. 复杂业务决策辅助(多信息整合、跨任务协作、动态调整策略)4. 开放域问答 + 工具调用(如联网查信息、调用计算器 / API 完成任务)5. 多角色协作任务(如智能助理、自主办公机器人)
MLflow + Kubeflow 协同架构
条件
主数据规范
subagent-1
3. 编译优化模型编译 (AOT/JIT)硬件专属编译优化
流处理引擎Flink SQL
分布式训练技术:数据并行 DP张量并行 TP流水线并行 PP3D 并行 FSDP 完全分片数据并行MoE 专家并行
长期记忆:语义记忆:是什么程序记忆:怎么做情景记忆:何时何地做
存储
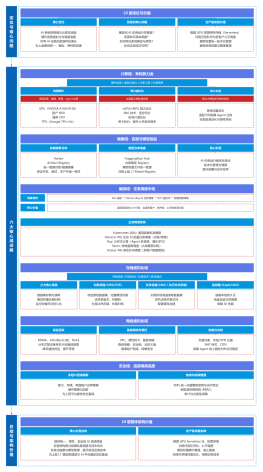
AI Agent解决方案架构师
数据集成数据标准
Token / 成本监控
构建工具、依赖管理Maven/Gradle/npm/Yarn
Kubeflow 流水线触发训练
存储设备
文本结构分割:句子切分段落章节
应用性能管理
消息
模型注册到 MLflow
并行化 (Parallelization)
加速优化(推理核心性能)
Streaming流式输出
存储控制器
模型设计
统一元数据管理&统一权限管理
腾讯云 EMR + TCHouse-D
存储网络分类
隔离
缓存加速(Cache Acceleration)
Text Spliter
发布
数据质量改进
资源池
湖仓一体
半虚拟化
服务器
PyTorch
智能体两种崩溃模式
火山引擎:HiAgent+AgentKit
版本管理
Testing
批量数据接入
Factor 7: Contact Humans with Tool Calls # 原则7:人机协同
开源模型:Qwen-EmbeddingBGE
Memory
Vector Store
腾讯云:Tencent Cloud ADP
语义切分:AI21SemanticTextSplitterBert文本切分
模型训练
Atlas 800T A3
...
昇腾CCAE(Cluster Computing AI Engine)
ACP智能体通信协议
Rubin 架构(2026,即将发布)
业务库
资源与调度
Plan and Solve
全 K8s 兼容全训推框架支持在离线混部多集群调度(Global)
华为云 FusionInsight MRS 离线计算引擎
数据标准制定
基础设施层(HCS、BMS、容器、专属服务器)
Presence Penalty
流量调度分发:负载均衡
6.高可用架构健康检查、自愈限流、降级、熔断灰度、蓝绿、彩虹
总结/摘要
LLMCompiler
滑动窗口(加载最近 n 轮思考)、状态总结(加载上一步行动与观察结果)、失败复盘(加载所有失败步骤)
简单检索HBASE
镜像市场
提示词攻击:直接注入间接注入越狱提示词泄露训练数据投毒
克隆后可编辑
Tools
数据模型认证
运营运维
存储格式:Parquet、ORC
Router
原则八:并行工具调用极大提升性能
华为云GaussDB(DWS)
寒武纪服务器
AIOps/MLOps
主数据
功能列表:避免两类失败模式,提供清晰任务目标
数据安全
Hopper 架构(2022)
路由 (Routing)
接入 / 汇聚 / 核心交换机
YangtseVPC路由网络
• Grader(阅卷):基于评分规则(Rubric)的打分逻辑脚本,实现自动化判分。
情景:行为规则(系统提示词)程序:few-shot少样本案例(动态提示策略)语义:语义识别和意图识别有效性
数据检索
计算虚拟化
灰度发布
3. Artifacts:自动存储模型 checkpoint、训练日志、配置文件、tokenizer 等,支持对接 S3/MinIO 等分布式存储(适配大模型的超大文件存储)。
数据管理
自动化测试、质量分析JUnit、PyTest、SonarQube
存储虚拟化关键技术
5.高性能网络gRPC / HTTP2RDMA 推理加速无损低时延网络
知识图谱
Chains
网络:Spine-Leaf 拓扑 + 1:1 带宽收敛比 + 无损 RDMA + ECMP 负载均衡
集群调度 / 任务管理
Agent工具技术
SSM(选择性状态空间模型Selective SSM,代表Mamba) 与文件系统的黄金组合
推理 profiling
评估方法
Templates
2. 服务发布与托管一键部署推理服务多版本、灰度发布、流量切分自动扩缩容、缩0(Serverless)
路由控制:路由表
核心构成要素:角色、背景、任务、约束、示例
SAN:FC SAN(Fiber Channel Storage Area Network)和 IP SAN(IP Storage Area Network)
重排序:Top-kcross-encoder深度语义匹配/ms-marco
Jupyter Notebooks
多副本与纠删码(EC)
主数据定义
Transform Chain
多样集市
Blackwell 架构(2024)
单机内网络:NPU 高速互联HCCS 全互联(A2/A3)或 灵衢总线(A5)
云原生、DevSecOps
Models I/O
入湖方案制定
B100 SXM+80GBHBM3e
LangServer
其他数据库:Postgres、RedisMilvus、Mem0
外部记忆系统
核心调度能力
在线模型:OpenAI Embedding智谱AI Embedding
模型管理:checkpoint 保存、断点续训、版本管理
数据地图
输入清晰分类,处理过程和逻辑差异明显
Sequential
分布式存储
控制面(Control Plane)kube-apiserver:认证、授权、准入控制etcd:存储集群关键状态:Pod配置、Service规则、用户权限kube-scheduler:自定义调度策略(亲和性、误点、容忍、资源配额限制)、资源状态、资源需求、动态调整分配逻辑kube-controller-manager: Deployment 控制器、 StatefulSet 控制器、 Node 控制器、Service 控制器cloud-controller-manager:对接云厂商 API、负载均衡、对象存储等控制面辅助组件:HaProxy/NGINX、kube-aggregator
规划
Dorado
1. 通用推理框架容器化、K8s 编排Serverless、Knative 弹性服务网格、流量治理
加速技术:混合精度 / FP8 训练梯度累积、ZeRO 优化算子融合、算子编译、图优化检查点断点续训
分层存储(Tiered Storage)
6. 正式训练(核心执行)前向传播:输入 → 模型 → 输出计算损失:loss反向传播:梯度计算参数更新:优化器更新权重日志与监控:loss、吞吐量、利用率、lr训练阶段:预训练 Pre-training(学语言 / 知识)监督微调 SFT(学任务 / 指令)RLHF/DPO(对齐人类偏好)
云原生大数据计算平台 + 离线数仓引擎
CPU、内存、主板、RAID 卡、HBA 卡、机柜、机架、电源模块、UPS、精密空调、散热风扇
文件
User Request
知识图谱检索:问题-实体相似度识别社区聚类检索
容器
直接交互扩展为外部可交互持久化环境
4. 模型选型与初始化基座选择:开源基座 / 自研从头训结构配置:层数、维度、头数、参数量、上下文长度权重初始化:随机初始化 / 加载已有预训练权重分布式配置:TP/PP/DP/FSDP/MoE 并行策略
可视化可观测Grafana
DevOps生命周期
Client Libraries(客户端库)
流处理引擎
阿里云MaxCompute
云函数 SCF
Language Agent Tree Search (LATS)
控制面
增量进度:一次完成一个任务目标,记录更新完成状态
多租户&队列资源管理
可视化与报告
测试
FG
双阶段架构
LakeFormation
短期记忆实时处理
系统Prompt
Gaea华为云高性能网络节点
安全资源池
DBService
GUI-Agent
日志服务ELK
Multi-Agent拆分原则
Raid磁盘阵列
云防火墙、WAF、微分段、ACL 访问控制、流量清洗
按需索引
Lead Prompt四步思考循环:评估、分类(深度优先、广度优先、直接查询)、计划、执行
提示词追踪
长期记忆持久化
统一命名空间(Unified Namespace)
运维工具
定时加载
Monitoring
VMware VMM(ESXi/Workstation)
监控、日志、追踪Prometheus/Grafana/ELK
异构资源池
4. API 网关 & 协议HTTP/gRPC/REST API兼容 OpenAI 接口规范流式输出(Stream)支持
任务串行化接力:Workflow进行接力,状态和信息传递
TensorFlow / Keras
统一数据服务设计规范
Prompt Engineering
专题集市
实时同步
React
持计划与结构化
海光服务器
特征存储
1. 串行 workflow:步骤按顺序执行2.独立LLM调用:非单次 prompt 内完成所有步骤3. 显式信息流:上一步输出作为下一步输入
昇腾服务器
训练关键技术(框架核心)
• Suite(题库):一组 Task 的集合,例如客服场景下的测试题集。
7.可观测体系指标监控调用日志 & 链路追踪自动告警、异常检测
Corrective Rag纠错型Rag
演进阶段:注意多智能体的涌现行为,警惕系统 “涌现行为”,评估协作模式合理性。
FC协议:FC是光纤通道(Fiber Channel)
顶级集成工具:MarkerMinerUMarkitdown
4. 调度优化动态批处理(Dynamic Batching)多请求复用、迭代级调度资源超配、QoS 保证
在线:爬虫(Scrapy)Wikipedia、Github、Bilibili、网页
弹性容器服务 EKS
数据治理体系
治理价值体现
数据质量标准
MLFlow GenAI
Workflow
Serving
文件即上下文:文件+日志解决失忆和信息不足问题
单点打磨:围绕同一个结果反复修改而非横向选优标准驱动:根据精确标注提供反馈;闭环迭代:满足标准或达成停止条件
实时宽表分析ClickHouse
脚本、作业开发
英伟达服务器
Knative框架(Serverless)
3. 硬件专属推理引擎TensorRT(NVIDIA)MindIE(昇腾)ONNX RuntimeOpenVINO(Intel)
离线数据湖
3. 环境与资源准备算力集群:GPU/NPU 服务器、无收敛叶脊网络存储:对象存储 /文件存储/存数据/ checkpoint框架环境:PyTorch / MindSpore + 分布式通信库(NCCL/HCCL)容器镜像:统一依赖、CUDA/CANN、加速库
训练服务过程
数据服务生命周期管理
虚拟 NUMA(vNUMA)
实现业务上线有数据的快速传递共享,提升业务运作效率
Outcome(结果):最终的评估标准,是判断 Agent 表现的核心依据。
知识库选择
二层Spine-Leaf架构
数据质量
硬件环境
英伟达 DCGM + NGC + Base Command Manager + NVIDIA AI Enterprise 运维套件
Exporters(导出器)
技术元数据
Oozie
文件资源池
并行召回(向量搜索即语义检索、关键词搜索、知识图谱)、Agentic Search、重排序
数据飞轮
静态路由、动态路由、路由策略、子网路由隔离
模型评估
7. Volcano 调度集成(资源调度中枢)
主数据识别
数据治理价值
边
Multi-Agent 提示词工程八条原则
时序IoTDB
H100 PCIe+80GB HBM3
通知、备份管理
镜像Image
阿里云湖仓一体:Delta Lake、ADB
有效的数据质量监控
原则二:教会指挥官如何授权
原则五:让智能体参与自我改进
总结对话历史:提取任务概览、关键抉择
异构算力精细化调度
Hudi
Paralllelization并行执行多任务
短期记忆草稿纸(Scratpad)
腾讯云:语义感知 +VStation优先级调度 + 全局优化
CPU:4 × 鲲鹏 920(新一代)NPU:8 × Atlas 300I A5(昇腾 910B5/910C,更高能效)算力:INT8 1400+ TOPS,能效比提升 30%+网络:200GE/400GE 灵活配置
Frameworks for Training • Chainer • MPI • MXNet • PyTorch • TensorFlow
动态上下文:感知外部实时信息推理前检索Rag+即时检索Agentic Search
瞬时记忆:未加工原始信息任务结束淘汰
SCSI协议:小型计算机系统接口
Storm
全量、增量集成
Retriever
批处理引擎Spark
治理诉求
Action
User
vCPU(云厂商技术)
MLflow Projects
监控
数据版本控制
标签分类管理
部署
Workflow设计模型
函数计算 FC
数据安全访问控制
物理路由器
分离 “思考” 与 “执行”:沙箱是 “状态化环境”,隔离 “真实环境的状态”
Paln and Execute
结果生成评估指标:Bleu、幻觉率ROUGEBERTScore
数据存储
Factor 9: Compact Errors into Context Window # 原则9:将错误压缩进上下文窗口
openAI Function
数据探查/画像
云原生网络
阿里云 AnalyticDB(ADB)
分布式训练 profiling
2.低时延高吞吐调度Dynamic BatchingContinuous BatchingPagedAttention迭代级调度
Pipelines:• Python SDK• DSL compiler• Pipeline Web Server• Pipeline Service• Kubernetes Resources• Machine Learning • Metadata Service• Artifact Storage• Orchestration Controllers
多机集群网络:RDMA 网络:InfiniBand (IB)或RoCEv2(以太网 RDMA)
AI Agent架构
JAX(google)
大页内存(Huge Pages)
预训练 Pre-training(学语言 / 知识)
词向量化
SmallFS
数据质量政策
英伟达GPU
数据层
训练模型:Jupyter
多模态处理
精细化监控
关键信息筛选提取
Planning
全栈监控
Atlas 800 A5
HDFS
提升数据准备读,为业务运作提供可信的足量的数据支撑
事件总线能力
OBS
数据仓库
数据标准
Document Loader
Flume
Multi-Tenancy in Kubeflow:Kubeflow的多租户
Customized Chain
闪存阵列
网络架构
块资源池
虚拟化技术
训练阶段
挖掘建模
故障自愈与数据重建
实时数据接入
计算芯片与零件
统一调度
快照与克隆(Snapshot/Clone)
DataOps
Factor 2: Own Your Prompts #掌控好你的提示词
存储、网络优化
云DNS
IPsec VPN、物理专线、VPC Peering、跨AZ互联
MLflow Model Registry
示例Few-shot
Overlay 虚拟化、SDN、弹性网卡虚拟化、子网隔离
Agent
运维
SATA SSD/HDD
图片信息切分:图片解析+文档单独切分图片链接+文档单独切分
分布式训练支持:DP/MP/PP/FSDP/MoE
启动命令
数据开发规范
Context Engineering(范式转移:从提示工程(战术优化)到上下文设计(架构设计))
工具集选择
构建知识图谱:实体识别关系判别实体聚类
数据分片与分布式一致性
数据湖统一存储
SparkStreaming
对象资源池
数据质量管控
软件栈:HCCL + CANN ≥6.0 + RDMA 配置
第一组:动态执行(Dynamic Execution)
虚拟机池
滚动升级
挑战:成本与复杂性
版本控制、代码审查Git/GitHub/GitLab
阿里云 ACK:Terway
初始化智能体:使用相同系统提示词、工具集、控制框架
Agent Tolling
编码
原则七:引导思维过程
容灾
3. 流量与调度负载均衡、流量控制、限流熔断多实例调度、GPU/NPU 调度多区域 / 多可用区分发
请求队列管理
逻辑数据湖
subagent-2
Kafka
文档分割
华为云:Flexus+Kunpeng-V硬件加速 + 双模式调度
阿里云
公网访问 / 出口公网: IP、NAT 网关、CDN
计算
Research subagent:流程:研究规划、工具选择、研究循环(调整、决策、行动)
原则六:先宽后窄的搜索策略
MLflow Tracking
2. 推理引擎优化图优化、算子融合内存优化、连续 Batch动态 Batch、异步推理
云原生数据湖
数据面(Data Plane)Kublete:Pod生命周期管理、健康检查机制(存活探针、就绪探针)、监控Pod状态kub-proxy:负载均衡和网络规则转发:iptables、ipvsContainer Runtime:容器资源隔离机制、镜像管理、与kubelet通信CNI插件:容器网络连通(容器网络模型)CSI插件:存储对接(创建、挂载、扩容、快照等)Ingress Controller:反向代理服务器(如 Nginx)、HTTPS解密、路径重写、负载均衡、访问控制
subagent-n
核心功能
南大通用 GBase
推理前检索(RAG):检索机制:混合检索(关键词检索+向量检索)优势:速度快+成本低+流程成熟
H800 SXM+80GB HBM3
磁带库(归档存储)
模型版本管理
操作系统
交互式分析跨湖查询HetuEngine
事件过滤
SAS SSD/HDD
影子页表(Shadow Page Tables)
构建
分布式SDI网关
CPU:4 × 鲲鹏 920NPU:8 × 昇腾 910/910C算力:FP16 6.0 PFLOPS,INT8 12.0 POPS互联:灵衢总线,双向 784GB/s,1:1 无收敛集群:单机 8 卡,多机可扩至 384 卡超节点
NoF网络:NVMe(Non-Volatile Memory express
原则一:像智能体一样思考,理解智能体逻辑
故障自愈
Pipelines
4. 分布式 KV 缓存(性能倍增器)
数据资产
Playground
Fallbacks失败回退机制
Annotation
大数据资源池
DevOps
优先选 Workflow五大模式适配
专题分析
数据元接入
故障诊断 / 自愈
IaaSCloud Infra
8.模型评估与导出:验证集评估:困惑度 PPL、loss、准确率;benchmark 评测;人工评估:流畅度、安全性、业务效果;模型格式转换、导出、上线推理;
业务元数据
硬件层 profiling
7.断点续训、容错与扩缩容异常断训后从最新 checkpoint 恢复多机故障自动替换节点弹性增减卡、重排分布式组
SAS协议:(Serial Attached SCSI)
阿里云:神龙架构硬件加速 + 双模式调度
Prometheus
Prompt进阶:思维连CoT、少样本提示(Few-shot Prompting)、负向约束....
灾备
软件栈:NCCL+NVLink/RDMA (IB/RoCE/GPUDirect RDMA)
评估器 - 优化器 Evaluator-Optimizer
DAS(Direct Attached Storage 直接连接存储)
事件路由
ICAN容器隧道网络
1. 需求与目标定义:确定模型类型:LLM、多模态、CV、ASR确定规模:基座 / 微调 / 领域小模型确定指标:loss、困惑度、准确率、业务效果
Knative 弹性伸缩
LangSmith
IaaS中间层
结构化功能任务清单:结构化Schema+Todo List
统一调度与生态兼容
Chains as Rest APIS
HyDE Rag假设性文档嵌入
网络资源池
分布式存储节点
raid 0、1、5、10
知识提供依据
单体式架构模式( Monolithic Architecture Pattern)
盲目自信:上下文腐烂,未测试,信息缺失导致幻觉
文件系统即为外部长期记忆
网路虚拟化
硬件辅助内存虚拟化(EPT/NPT)
Agent 技术十大挑战
KVM
2. 数据准备(训练成败核心)数据采集、爬取、购买、业务数据接入数据清洗:去重、去噪、过滤低质、敏感信息清洗数据预处理:分词、token 化、格式标准化、分桶数据构建:预训练语料 / SFT 指令数据 / 偏好数据(RLHF)数据集划分:训练集、验证集、测试集
全栈智能可观测平台
定义运行环境
TKE Serverless
Conversation Summary Memory
物联网IoT
2. 大模型专用推理框架vLLM(最主流)Text Generation Inference(TGI)TensorRT-LLM(英伟达)MindSpeed(昇腾)LightLLM、FastLLM、Qwen-Server
应用引擎 SAE
数据准备
Embedding Model
安全与访问
图GES
多智能体并行:决策冲突和灾难性合并
Prompts
可观测链路
文件即上下文
1. 模型管理模型上传、版本管理模型格式转换、打包模型生命周期管理
模型验证:Katib
X86(海光、Intel)
硬件辅助虚拟化
核心冲突
集中式存储
VLAN/VxLAN
导出可部署的推理服务
光纤、网线、PON 设备、专线接入硬件
网络
记忆类型
Alertmanager(告警管理器)
模型服务上线:Serving
1. 通用推理框架TorchServeTriton Inference Server(行业标准)TensorFlow ServingONNX Runtime
数据治理框架
Yarn
复杂搜索ES
数据字典发布
可信的数据源
AI Agent
华为云
异构算力资源
批处理引擎Hive
Atlas 800T A2
自动扩缩容
5. 可观测性QPS、时延、错误率、吞吐量硬件利用率(GPU/NPU/CPU)日志、调用链、告警
Lead Agent(Orchestrator)Tools:Rag+MCP+Memory+ run_subagent+complete_task
PaddlePaddle
Hyperparameter Tuning:Katib
Grafana(可视化)
Conversational
运行时状态对象
Operator:TF-OperatorPyTorch-OperatorCaffe2-OperatorMPI-OperatorMXNet-Operator
元数据采集
CPU:4 × 鲲鹏 920NPU:8 × 昇腾 910/910B/910C算力:FP16 约 3.2 PFLOPS,INT8 约 6.4 POPS
算力调度
Community
1. 模型优化量化:INT8/FP8/FP16/BF16剪枝、蒸馏、结构优化KV Cache 优化、PagedAttention
实验管理
CDL
EIP 、SNAT/DNAT、端口映射、就近接入
iSCSI协议:互联网小型计算机系统接口
Eventing
MindSpore
腾讯云 湖仓一体:Iceberg、Spark
容器网络类型桥接网络(Bridge Network)/主机网络(Host Network)/无网络(None Network)/自定义网络(Custom Network)
测试评估:Agent测试评估标准
• Agent Harness:将 LLM 包装成 Agent 的代码脚手架,是运行 Agent 的基础框架。
Fairing:打包构建image
Toolkits
Reflexion
1. 参数:学习率、批次大小、模型参数量、GPU 数量、分布式策略(如 DeepSpeed ZeRO 级别);
大小无限制
概念漂移
CDL实时集成引擎
Kubernetes ASK
湖内分析
后处理工具反馈检索数据后预处理提取核心要点
硬件负载均衡
Volcano(底层算力调度引擎)
优炫数据库 UXDB
数据质量的持续提升减少纠错成本,降低运营风险,提升业务服务满意度
起步阶段:从小样本立刻开始(Start Small),做好开头验证,避免潜在问题,后期返工
文件存储:NAS+缓存+配额管理
内存共享与去(KSM/KVM Shared Memory)
数据接入与数据服务
训推一体 / 服务编排
一键部署
监控运维层
国产新兴:OceanBaseGaussDB
数据安全访问日志审计
鲲鹏服务器
CoT
AI 芯片调度与虚拟化资源配额、隔离、超配GPU动态切分、共享
R200 SXM+128GB HBM4
Trial(尝试):为了对抗随机性而进行的多次测试(例如运行 10 次),确保结果稳定。
向图检索
Language Model
OLAP集市Doris
集中式网关
Max Length
Out Response
网路虚拟化关键技术
Agent设计模式
多模态内容检索
长期记忆
多模态处理:单独处理图片、视频文本+多模态序列混合统一处理
Evaluation
Prometheus Server
数据条带化(Striping)
稳态智能体上线文工程实践
协作
星环科技 TDH
MCPModel Context Protocol
高质量方法:结构化Schema
Istiod管理面、Linkerd Control Plane、Consul Connect• 服务发现;• 配置下发;• 证书管理;• 可观测性集成
AG-UI(Agent to UI)
推理平台
系统级profiling
训练采集器模型:分类模型处理压缩
Central Dashboard
Hybird Rag混合检索Rag
容器引擎/编排工具/配置管理Docker/K8S/Nacos...
Prompt压缩
上线文窗口限制拆解成离散会话,新会话失忆,Session记忆高墙,遗失工作状态和细节
AIBrix云原生编排平台
SDN:OpenFlow协议
大任务拆分独立的子任务,无依赖无传递中间结果
模型构建:Fairing
通用文本类型:PDF、Word、CSV、Markdown、Html、txt...
Metadata
5. 缓存优化KV Cache 复用、Cache 预分配多层缓存(GPU / 内存 / 磁盘)
环境管理
检索过程优化:Embedding模型优化混合检索与加权重排多查询扩展
容器网络接口CNI
血缘关系
备份与容灾
Temperature
Serverless NPU
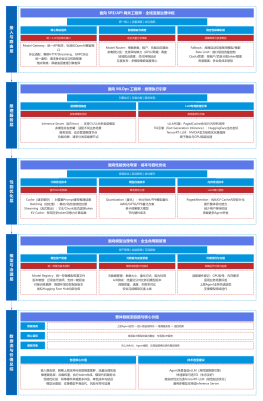
KubeFlow(AI 训练全生命周期平台)
华为云 FusionInsight:自研湖仓引擎
RAG(Retrieval Adanced Generation)
MLflow 跟踪实验
流处理引擎Flink
用户交互
Factor 1:Natural Language to Tool Calls #自然语言到工具调用
气球内存(Ballooning) 动态内存调度方案
管理中心
Agent之间隔离:主Agent做Planing和任务拆解主与子Agent隔离,子Agent之间上下文隔离主Agent避免海量细节导致灾难性遗忘
实时数据湖
模型效果
Kubeflow 部署推理
辅助当前决策
AI分析
Prompt:角色职责限制
数据清洗
上下文拼接策略优化分块摘要拼接动态窗口拼接
存储架构分类
算子 / 模型层 profiling
MLFlow
Serving:• TFServing• KFServing• Seldon
第三组:基础设施(System Environment)下发指令并行运行测试,收集记录并汇总
阶段管理
多机集群网络:200G/400G RoCEv2 + RDMA + 无收敛叶脊
Prompt LLM参数调优
数据加速
Nsight Systems + Nsight Compute + DCGM Profiler
优先选 Agent
大模型
任务执行多次独立运行,聚合多轮运行结果,投票机制提升置信度 + 鲁棒性
容器池
资源调度与编排
规则分割:字数切分Token分割滑动窗口切分
昇腾 Profiling:全栈性能分析工具
调度与编排:KubernetesVolcano / YARN / Slurm任务队列、优先级调度、弹性训练
云监控服务
规则过滤
单机内网络:NVLink / NVSwitch(必须!)
动态选择策略(Agent Skills):固定工具集+工具检索工具选择:按需加载,以任务为核心,精准能力治理
Adaptive Rag自适应
CI/CD 平台、部署工具Jenkins、GitLab CI
Overlay 网络:Flannel/Calico/Weave Net(跨云、加密)/CiliumUnderlay网络:IPvlan/Macvlan/SR-IOV
模型部署层
Graph Rag知识图谱Rag
Tools for Serving:• KFServing• Seldon Core Serving• TensorFlow Serving(TFJob)• NVIDIA Triton Inference Server• TensorFlow Batch Prediction
数据接入
贪多嚼不烂:一次会话完成所有任务目标
上下文管理三类信息
自助分析
大屏展示
• Eval Harness:负责发起、并行测试和汇总分数的 “考场系统”。
Frequency Penalty
解决无法提前拆分任务时的并行提效问题。中心 Orchestrator 在任务执行过程中动态拆解子任务给多个 worker 并行完成,最后汇总结果。、子任务非提前定义,而是运行中动态规划拆分。
原则三:根据任务复杂度匹配投入力度
硬编码启发式:滑动窗口设定规则
算子 / 内核级profiling
Multimodel Rag多模态Rag
优化方法
6. 高可用&容错健康检查、自动重启故障隔离、滚动更新多副本、跨节点部署
工具Tools
成本与权限
ReAct 模式
业务对象识别
数据湖B
5. 训练配置与超参设定优化器:AdamW、 Lion学习率:warmup、衰减策略批次:batch size、梯度累积精度:FP16/BF16/FP8 混合精度正则:dropout、权重衰减并行策略、checkpoint 保存策略
Fuction Calling
PaaS(大数据)
数据面
4.分布式推理张量并行 TP流水线并行 PP多机推理协同
统一资源调度
容灾备份
数据飘逸
标准化模型打包格式
K8S
数据服务
BI
5. 分布式推理编排(大规模引擎)
金仓数据仓库(KingbaseDW)
作业、实例运维
Retrieval
数仓资源池
生成策略优化精调、指令微调Answer verification
数据务组织、流程、政策、平台与工具
VolcanoJob(VcJob)增强型批量作业PodGroup容错与自愈作业流编排
高效的数据共享
增强型交换机网关
NVME
语义摘要
大规模训练:TFJob
网络互通连接:VPN 网关、专线、对等连接
GB200 Grace-Blackwell384GB HBM3e(2×B200)
专业词向量数据库:ChromaFaissQdrant
监控:Prometheus
AgentTestOps Agent评估工程
模型开发层
以上下文为中心进行拆分
1. LLM 网关与智能路由(流量大脑)
机器学习
Basic Reflection
Prompt分类:系统提示词和动态提示词
Tracing链路跟踪
原生支撑事件驱动的 Serverless 开发模式
Manager
无缝对接 Knative
• Task(题目):单道题目具体的测试用例,包含输入和成功判定标准。
RAG 技术全景图(设计模式)
Vector Store-backed Memory
Agent和Workflow核心维度对比
海光信息
KubeFlow流程图
存储格式:Parquet、ORC、Hudi
集群管理
编排器 - 工作者 Orchestrator-Workers
Async异步执行
ReAct/CoT
多模态内容识别:大模型多模态功能VL专业大模型MonkeyOCR、DS-OCR
Top_p
Chat Message
裁剪
检索方法:向量检索关键词检索(BM25)混合检索
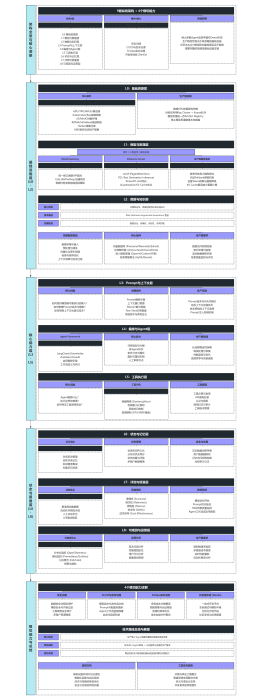
AI体系
网络设备
Flink
解决方案
Agent上下文限制
存储虚拟化
模型性能
Stop Sequences
一致的数据标准
IaaS(云原生)
混合架构模式(Hybrid Architecture Pattern)
Feedback
Factor 6: Launch/Pause/Resume with Simple APIs#原则6:使用简单的API启动/暂停/恢复
容器存储容器存储接口(CSI)动态存储供应声明式API与控制循环
压缩
指令确定目标
训练平台
防范策略:提示层防御 (Prompt-Level):• 分隔符 (Delimiters)、• XML 标签加固、• 防御性指令架构层防御 (Architectural):• 独立审核模型、• 沙盒隔离、• 输出清洗流程层防御 (Process):• 最小特权原则、• 人机协作
静态上下文:出厂设置(身份角色、能力、行为准则)
资源调度
昇腾NPU
Superrior
基础设施平台
Envoy:Istio数据面/Linkerd 默认、HAProxy、Nginx• 流量代理:◦ 负载均衡算法;◦ 路由匹配• 安全通信:◦ 自动加密;◦ 身份认证;• 故障恢复:◦ 熔断;◦ 重试;◦ 超时控制• 数据收集:◦ 指标收集;◦ 日志收集;◦ 调用链追踪
选择
封装为标准化项目
容器引擎(Container)Docker、Containerd、CRI-O、Podman、runc...
Serverless(FaaS 函数计算、Serverless 容器服务)
统一数据服务实现规范
权限管控
信息熵度量
Factor 5: Unify Execution State and Business State #统一执行状态和业务状态
容器隔离机制Namespace(环境隔离)+Cgroups(资源限制)
集群 / 分布式 profiling
数据湖A
流水线架构模式(Pipeline-Based Architecture Pattern)
短期记忆:上线文窗口滑动窗口/对话摘要受限于LLM容量上限
Pushgateway
H200 SXM+141GB HBMe3
监督微调 SFT(学任务 / 指令)
文档解析
结构化隔离 Agent 内部状态Schema 设计预先定义信息边界和访问权限“隔离” 定义信息边界,“选择” 在边界内活动。
Conversation Buffer(Context Window)
Output parsers
Agent 构建12条原则Factor
Batching批处理输入数据
幻觉增强事实校验溯源标注
弹性伸缩
LangGraph
ANP智能体网络协议
块存储:LUN+Ceph+分层存储
容器网络
提示链 (Prompt Chaining)
飞腾服务器
原则四:工具设计与选择至关重要
ARM(鲲鹏、泰山等)
云块存储
流量拆分
Factor 12: Make Your Agent a Stateless Reducer # 原则12:无状态
数据质量目标
知识
3. 高密度 LoRA 管理(多租户引擎)
扩展阶段:LLM 裁判的规模化(Auto Eval),五维评分量规实现规模化验证
本地存储:对象存储、文件存储、块存储
上线文管理四大核心操作
评估
硬件监控
Hyper-V、Xen 等
批量作业全生命周期管理
Example Selector
Reason without observation(REWOO)
阿里云:PAI-LangStudio
镜像与环境管理:PyTorch、CUDA、CANN、依赖库
评估指标:准确率召回率命中率(Top-p)
Multi-Agent
Composition:任务组合
LangChain Universe
华为云:AgentArts(Versatile)
攻击&防范
搜索算法:相似度评估 Similarity Measures(FLAT)局部敏感哈希(LSH)Local Sensitive Hashing(LSH)倒排索引文件(IVF)Invert Index File(IVF)乘积量化 Product Quantization(PQ)分层可导航小世界(HNSW)
腾讯云
6. 统一 AI 运行时(标准化底座)
通用工具:PyPDFLlamaIndexLangChain
Factor 4: Tools Are Just Structured Outputs # 工具必须结构化输出
火山云ByteHouse
KMS
Hypervisor(虚拟机监控器 / VMM)
RLHF/DPO/GRPO(对齐人类偏好)
内存虚拟化技术
3.模型编译与加速图编译、算子融合量化引擎(INT8/FP8)硬件专属优化(CUDA/CANN)
数据源认证
多级队列资源借用 / 回收 / 抢占多租户强隔离
物理机池
智算资源池
Map-reduce
Transcript(轨迹):完整的思考与调用日志,作为评估的过程证据。
网络安全:安全组、云防火墙
腾讯云TKE:VPC-CNI
X86服务器
监控、日志、告警:(算力利用率、loss、学习率、吞吐量)
离散会话失忆
CCI
Factor 3: Own Your Context Window #掌控号你的上线文窗口
兜底阶段:人类评估捕捉盲区(Human Eval),人类介入捕捉自动化裁判的 “信源偏见” 和 “幻觉”;
Ranger
原创作品,尊重产权,请勿抄袭
通信
Memory:Context Window+外部文件主智能体在 Think plan 后执行 Save Plan 动作,将宏观战略写入外部记忆存储
多智能体架构模式( Multi-Agent Architecture Pattern)
4/7 层转发、会话保持、健康检查、集群负载调度
10
传统三层网络架构
Core LCEL(LangChain Expression Language
仓库Repository
写入
服务网格(Service Mesh)
上下文缓存
LUN 虚拟化(逻辑单元抽象)
R100 SXM+128GB HBM4
第二组:题目与判卷(Static Definition)
事件源接入
基础网络资源:VPC、弹性网卡
2. LLM 专属自动扩缩容 (APA)(弹性心脏)
安全层
LLM
数据治理
模型微调:对比学习标注回归
任务管理
数据安全等级定义
按需加载
评估工具:Rag ASLangSmithLLM-as-a-Judge
数据湖、数据仓库
NAS(Network Attached Storage 网络附加存储)
目标明确、步骤固定、规则可量化的标准化任务1. 合规审核、内容安全检测(Voting 模式)2. 固定步骤的数据分析、报告生成Chaining+Parallelism3. 按类型分发的客服工单、任务分配(Routing 模式)4. 单点结果的迭代优化(Optimizer 模式)5. 高风险、对鲁棒性要求极高的确定性判断任务
数据校验工具
IaaS(云计算)
全虚拟化
收藏
立即使用
收藏
立即使用
收藏
立即使用


Collect
Get Started

Collect
Get Started

Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页