大模型推理加速技术架构图
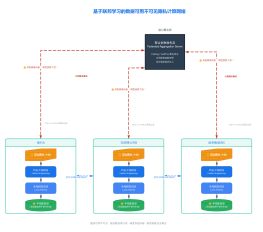
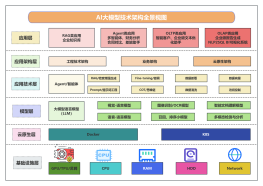
2026-03-11 22:25:13 0 举报本图展示了vLLM大模型推理加速技术架构。流程从用户请求队列开始,经请求调度器、Continuous Batching动态批处理、PagedAttention分页注意力机制及量化计算,最终实现流式Token生成。图表详细解析了KV Cache显存管理的Block Pool机制,并通过数据对比展示了优化后显存利用率提升及吞吐量24倍的性能增益,适合后端工程师参考。
模板推荐
作者其他创作
大纲/内容
Collect

Collect
Collect
Collect
0 条评论
下一页