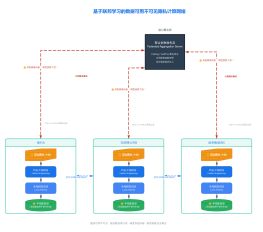
多模态大模型视觉编码器处理架构图
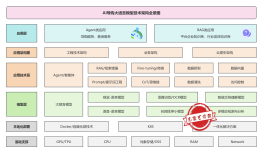
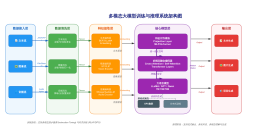
2026-03-23 23:12:21 10 举报该图表详细展示了多模态大模型视觉编码器的处理架构。流程从输入层的图像与文本提示开始,经过编码层的Patch切分、线性投影及Tokenization处理,生成Visual Tokens与Text Tokens。随后在对齐层进行Embedding空间融合,输入Transformer Blocks模型层(含Self-Attention与FFN),最终在输出层生成文本描述。
模板推荐
作者其他创作
大纲/内容

Collect
Collect
Collect
Collect
0 条评论
下一页