AI
推荐
模板社区
专题
登录
免费注册
首页
流程图
详情
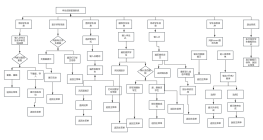
爬虫抓取内容信息流程图
2016-08-02 15:06:44
0
举报
分享方式
仅支持查看
爬虫流程图
爬虫
流程图
模板推荐
作者其他创作
大纲/内容
配置定时任务,定时检索数据库,筛选出待清洗数据
No
爬虫爬取内容信息流程图
根据规则,抓取待爬取页面
更新数据内容和时间
问题和追问合并,去掉【补充提问:】,【病情描述等】一行字去掉
Yes
插入或更新提问内容
是否匹配疾病库
插入或更新医生回复数据
将结果存储在db中,标记状态【未清洗】
医生回复【指导意见”、“问题分析”、“意见建议”】等去掉,内容用空格合并
标记原数据为失效
对需要分页的url,获取最大页,将分页url加入到待爬取页面队列
更新疾病标签
是否已匹配疾病库
结束
爬虫
插入数据内容
标记原数据已清洗
过滤掉/question的url
调用疾病库接口,查看疾病是否在疾病库中存在
抓取目标页面,根据规则收集信息
是否匹配疾病映射库
校验url是否已经抓取过
疾病库接口
清洗
收藏
立即使用
系统结构
收藏
立即使用
AWS
收藏
立即使用
爬虫抓取内容信息流程图
sugar8763
职业:数据分析师
去主页
Collect
Get Started
信息流
Collect
Get Started
c语言学生信息流程图
Collect
Get Started
地址信息流程图
Collect
Get Started
文本内容流程图
评论
0
条评论
下一页
Document