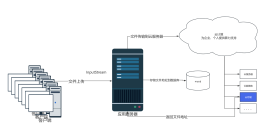
sparkStreaming原理图
2017-02-22 09:59:33 0 举报Spark Streaming是Spark核心API的扩展,它支持高吞吐量、可容错的实时数据流处理。其原理图主要包括以下部分:数据输入源(如Kafka、Flume等),接收到的数据会被分成小批次进行处理;然后通过Spark的转换操作(如map、filter等)对数据进行预处理;接着使用Spark的输出操作(如print、saveAsTextFile等)将处理结果输出;最后,通过监控状态和更新信息的持久化存储,实现故障恢复和状态管理。整个流程在Spark集群上并行执行,保证了数据处理的高吞吐量和低延迟。
模板推荐
作者其他创作
大纲/内容






0 条评论
下一页