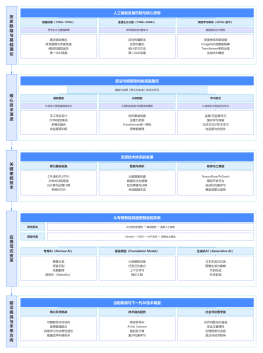
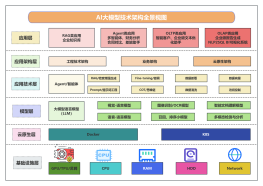
抓取架构演进
2017-03-11 12:43:58 0 举报随着互联网的发展,抓取架构也在不断演进。最初的抓取架构通常是基于静态网页的,使用正则表达式或XPath等技术进行解析和提取。但是,随着动态网页的出现,这种架构已经无法满足需求。因此,人们开始使用模拟浏览器行为的爬虫来抓取数据。此外,分布式抓取也成为了一种新的趋势,它可以将抓取任务分配到多台计算机上并行执行,从而提高抓取效率。同时,为了应对反爬虫策略,一些高级的抓取架构还采用了代理IP、验证码识别等技术来保证抓取的稳定性和可靠性。总之,抓取架构的演进是一个不断适应变化的过程,它将继续发展以满足不断变化的需求。
模板推荐
作者其他创作
大纲/内容



0 条评论
下一页