
技术之内
2021-12-30 17:27:33 4 举报AI智能生成
Java架构师道路上的学习笔记
java
架构
笔记
学习笔记
知识管理
模板推荐
作者其他创作
大纲/内容
计算机科学基础
计算机科学导论
数据结构和算法
数组
有序数组
二分查找
存储对象的数组
算法复杂度分析
链表
单链表
双端链表
有序链表
双向链表
迭代器
递归
递归与迭代
三角数字
阶乘和变位字
二分查找
汉诺塔问题
消除递归
栈
应用
队列
优先级队列
树
二叉树
红黑树
B树
B+树
哈希表
堆
堆排序
图
图搜索
最小生成树
有向图和拓扑排序
带权图-最小生成树
带权图-最短路径问题
排序
冒泡排序
选择排序
插入排序
对象的插入排序
希尔排序
归并排序
快速排序
基数排序
查找
操作系统
计算机组成原理
计算机网络
网络技术与应用
其他编程语言
Kotlin
Python
Clang
Golang
https://github.com/snail007/goproxy
python
持续学习
<h2 style="padding-left:18px;">利用开源代码和读相关论文来提高写代码能力</h2>
开源代码
熟悉
阅读文档,熟悉基本概念
常用文档 Read List
官方文档:常用的开源代码都有其公开的网站。
wiki:对应github仓库的wiki文档。
系统对应的发表论文:比如Bigtable、Zookeeper、Kafka等都有论文发表。
以Storm源码阅读为例
文档中,storm提出了一些新的概念,spouts,bolts,详细阅读这些名词背后所表述的含义以及在系统中担任的职责。
文档内容需要反复的读,每次读都会有不同的新的认识
实践使用
具体实践活动
按官方文档部署相关软件,准备运行环境。
写一个hello world的demo运行起来:开发包中一般存在文件夹名包含starter 和example字眼的文件夹,该文件夹下会有许多官方使用例子。
修改demo实现自己的业务逻辑。
构建数据流图
storm数据流图
子主题
为什么要花时间构建这样一个图呢?
理解概念,了解系统的运行机制。
逼迫自己去思考,比如模块之间如何交互,数据流怎么流动。脑海里有越多的问题,看源码的动力就越足。
随着对系统的逐渐了解,可以一步步完善,添加一些具体的实现细节,比如task如何知道输出结果应该发往那个task呢,其地址是多少呢?
遇到问题时,可以依照该图猜测问题可能出在哪个模块,迅速找到切入点。
在分析系统时,可以从<strong>数据流动</strong>的角度来思考这个问题。
阅读
准备阶段
切入阶段<br>
如何选择切入点
(1)从熟悉的基础依赖库入手,查看它在代码中是如何使用的。
(2)从使用过程中遇到的bug入手,依赖错误日志的上下文来查看代码。
(3)从概念模型中提到的概念模块入手
(4)从问题出发,查看相应的技术文章,进一步缩小范围,查看相关代码。
(5)从demo代码开始一步步debug。
深入阶段
忽略ifelse分支,和异常代码,先看主线流程
整理阶段
应用实践
概念模型和命名
开源基础库的使用
部分代码的copy
论文<br>
阅读<br>
论文的选择
(1)在阅读开源代码的时候,有些代码注释会标注其涉及到的论文
(2)比较出名的开源系统(kafka,zookeeper,disruptor等)都会有相对应的论文。对于想学习分布式系统的同学,有网友已经总结了一些好的论文<a href="https://github.com/ty4z2008/Qix/blob/master/ds.md">readlist</a>,有兴趣的可以看下。
阅读方法
着重花时间在论文的<strong>introduction</strong>部分,并试着翻译成中文记录下来
应用实践
阅读论文是为了更好的解决实际遇到的问题。有些论文描述了解决思路和方法,在遇到问题提出解决方案时会有一定的指导作用。有些论文则会具体论述其实现细节,比如一篇论文<a href="http://web.stanford.edu/~ouster/cgi-bin/papers/rifl.pdf">Implementing Linearizability at Large Scale and Low Latency</a>
可以利用业余时间,动手做个小项目,从论文到工程实现,提高自己的代码能力。
总结
开发代码就如搭积木,每个开源工具就好比每个积木快,论文和具体开源代码的实现思路则是搭积木的粘合剂。只要有正确的指导思想,再配备正确高效的基础工具,代码开发真的可以做到如奶茶般润滑。但是这个过程是<strong>极其漫长的</strong>,需要长期的积累,才会在工作中潜移默化的提高自己的能力,送大家一句,以共勉。
在成功的道路上都是艰辛而且孤独的。
最后,每个人都有自己的学习方法体系,欢迎提出自己的意见积极讨论,谢谢大家!!
如何学习分布式系统
概念
分布式系统
节点
异常
CAP理论
CAP 理论指出,无法设计一种分布式协议同时完全具备CAP属性
AP还是CP?
数据存储系统<br>
数据分布方式<br>
<strong>哈希方式</strong>
优点<br>
不需要存储数据和server映射关系的meta信息,只需记录serverId和server ip映射关系即可。
缺点<br>
可扩展性不高,当集群规模需要扩展时,集群中所有的数据需要迁移,即使在最优情况下——集群规模成倍扩展,仍然需要迁移集群一半的数据(这个问题有时间可以考虑一下,为啥只需要迁移一半?);另一个问题:数据通过某种hash计算后都落在某台服务器上,造成数据倾斜(data<br> skew)问题
应用例子
ElasticSearch数据分布就是hash方式,根据routingId取模映射到对应到不同node上。
<strong>数据范围分布</strong>
优点
数据区间可以自由分割,当出现数据倾斜时,即某一个区间的数据量非常大,则可以将该区间split然后将数据进行重分配;集群方便扩展,当添加新的节点,只需将数据量多的节点数据迁移到新节点即可。
缺点<br>
需要存储大量的元信息(数据区间和server的对应关系)
应用例子
Hbase的数据分布则是利用data的rowkey进行区间划分到不同的region server,而且支持region的split
<strong>数据量分布</strong>
优点<br>
不会有数据倾斜的问题,而且数据迁移时速度非常快(因为一个文件由多个block组成,block在不同的server上,迁移一个文件可以多个server并行复制这些block)。
缺点
需要存储大量的meta信息(文件和block的对应关系,block和server的对应关系)。
应用例子
Hdfs的文件存储按数据量block分布。
<strong>一致性哈希</strong>
优点
集群可扩展性好,当增加删除节点,只影响相邻的数据节点。
缺点
上面的优点同时也是缺点,当一个节点挂掉时,将压力全部转移到相邻节点,有可能将相邻节点压垮。
应用例子
Cassandra数据分布使用的是一致性hash,只不过使用的是一致性hash改良版:虚拟节点的一致性hash(有兴趣的可以研究下)。
分区容错的解决:副本
primary-secondary副本控制模型
子主题
主从(primary-secondary )模型是一种常见的副本更新读取模型,这种模型相对来说简单,所有的副本相关控制都由中心节点控制,数据的并发修改同样都由主节点控制,这样问题就可以简化成单机问题,极大的简化系统复杂性。
注:常用的副本更新读取架构有两种:主从(primary-secondary)和去中心化(decentralized)结构,其中主从结构较为常见,而去中心化结构常采用paxos、raft、vector time等协议,这里由于本人能力有限,就不再这儿叙述了,有兴趣可以自己学习,欢迎补充。
主从副本操作
副本的更新
副本的读取
副本的切换
当系统中某个副本不可用时,需要从剩余的副本之中选取一个作为primary副本来保证后续系统的正常执行。这儿涉及到两个问题:
副本状态的确定以及防止brain split问题:一般方法是利用zookeeper中的sesstion以及临时节点,其基本原理则是lease协议和定期heartbeat。Lease协议可以简单理解成参与双方达成一个承诺,针对zookeeper,这个承诺就是在session有效时间内,我认为你的节点状态是活的是可用的,如果发生session timeout,认为副本所在的服务已经不可用,无论误判还是服务真的宕掉了,通过这种机制可以防止脑裂的发生。但这样会引起另外一个问题:当在session timeout期间,primary 副本服务挂掉了,这样会造成一段时间内的服务不可用。
primary副本的确定:这个问题和副本读取最新数据其实是一个问题,可以利用quoram以及全局版本号确定primary副本。zookeeper在leader选举的过程中其实利用了quoram以及全局事务id——zxid确定primary副本。
存储架构模型
中心化的节点membership管理架构
子主题
去中心化的节点membership管理架构
子主题
数据计算处理系统
数据投递策略
如何做到exactly once, 需要在数据处理各个阶段做些保证:
数据接收:由不同的数据源保证。
数据传输:数据传输可以保证exactly once。
数据输出:根据数据输出的类型确定,如果数据的输出操作对于同样的数据输入保证幂等性,这样就很简单(比如可以把kafka的offset作为输出mysql的id),如果不是,要提供额外的分布式事务机制如两阶段提交等等。
异常任务的处理
其中任务恢复策略有以下几种:
简单暴力,重启任务重新计算相关数据,典型应用:storm,当某个数据执行超时或失败,则将该数据从源头开始在拓扑中重新计算。
根据checkpoint重试出错的任务,典型应用:mapreduce,一个完整的数据处理是分多个阶段完成的,每个阶段(map 或者reduce)的输出结果都会保存到相应的存储中,只要重启任务重新读取上一阶段的输出结果即可继续开始运行,不必从开始重新执行该任务。
背压——Backpressure
数据处理通用架构
storm
子主题
yarn
子主题
总结
数据存储
持久化
MySQL
高级
<span>1.mysql的架构介绍</span>
<span>MySQL介绍</span>
<span>MySQL linux版安装</span>
<span>MySQL的配置文件</span>
<span>MySQL逻辑架构介绍</span>
<span>MySQL存储引擎</span>
<span>2.索引优化分析</span>
<span>性能下降SQL慢</span>
<span>3.查询截取分析</span>
<span>4.MySQL锁机制</span>
<span>5.主从复制</span>
分库分表
mycat
sharding jdbc<br>
SQL优化
imooc<br>
数据库面试题
存储过程
什么是?
优点
缺点
三范式
第一范式
表中字段不可再分
第二范式
满足第一范式,表中字段必须依赖全部主键
第三范式
满足第二范式,表中非主键字段不能其他表的非主属性
视图
使用场景
回收站
drop、delete与truncate分别在什么场景之下使用?
drop table
truncate table
delete from
索引
什么是索引
rowid
索引的特点
什么时候建
什么时候不建
优缺点
索引分类
事务
什么是事务
事务的ACID
什么是悲观锁乐观锁
超键、候选键、主键、外键分别是什么?
SQL 约束有哪几种?
数据库运行于哪种状态下可以防止数据的丢失?
mysql的存储引擎
Innodb
nnodb引擎提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束。它的设计的目标就是处理大数据容量的数据库系统。
MyIASM
不提供事务的支持,也不支持行级锁和外键。
MEMORY引擎
所有的数据都在内存中,数据的处理速度快,但是安全性不高。
对比
MyIASM和Innodb两种引擎所使用的索引的数据结构是什么?
mysql有关权限的表都有哪几个
数据表损坏的修复方式有哪些?
MySQL中InnoDB引擎的行锁是通过加在什么上完成
sql优化
选择最有效率的表名顺序
WHERE子句中的连接顺序
SELECT子句中避免使用*号
删除表的所有记录使用TRUNCATE替代DELETE
多使用内部函数提高SQL效率
SQL大写
避免在索引列上使用NOT
避免在索引列上使用计算
用 >= 替代 >
用IN替代OR
总是使用索引的第一个列
数据库结构优化
sql练习题
Oracle和Mysql的区别
MySQL 优化原理
逻辑架构
查询过程
MySQL查询过程
客户端/服务端通信协议
半双工
尽量避免不必要的结果返回,不用select *
查询缓存
只有当缓存带来的资源节约大于其本身消耗的资源时,才会给系统带来性能提升。
不要轻易打开查询缓存,特别是写密集型应用
语法解析和预处理
查询优化
其他
子查询中慎用group by
Oracle
看懂Oracle执行计划
oracle分页
oracle错误异常处理
ORA-12505
Oracle性能优化求生指南
数据库逻辑设计和物理设计
sql<br>
多对多查询
多对多查询内容
oracle分页
基于rownum
rownum和rowid的区别
自定义函数strsplit
MySQL里实现类似SPLIT的分割字符串的函数
查询内容中case when的使用
to_char、to_number、to_date的互相转换和使用
max、min函数的使用场景
substr的使用
nvl的使用
NVL2
Oracle在NVL函数的功能上扩展,提供了NVL2函数。<br>NVL2(E1, E2, E3)的功能为:如果E1为NULL,则函数返回E3,若E1不为null,则返回E2。
TRUNC函数的使用
coalesce函数
oracle mybatis insert 序列
exists在查询条件中的使用
instr的使用
文件服务器
FastDFS
nosql
HBase
MongoDB
redis
基础
数据结构
发布订阅
事务
脚本<br>
数据备份与恢复
安全
管道技术
分区
集群容错
分布式锁
中间件
消息队列
Kafka
高吞吐量
RocketMQ
支持消息持久化
RabbitMQ
分布式协调服务
Zookeeper
zab协议
etcd
raft协议
pingCap
TiDB
RockDB
LSM-tree
Raft
GTS
服务化
Spring boot
服务注册和发现
Consul
Dubbo
Zuul
Eureka
Service mesh
topic
分布式数据库原理与实践
事务
事务的简介(什么是事务)
事务的核心
锁
并发
优势和逆势
优势
比传统的锁和并发更容易理解
逆势
性能较低
不存在完美的东西
容易理解的模型性能不好,性能好的模型不容易理解
单个事务单元
ACID保证事务的完整性
原子性
一致性
不存在中间状态
隔离性
隔离级别
可序列化
可重复读
对于读写锁,读是并行的,在读锁未释放时,要能保证我每次读的的状态是一致的
读已提交
读不加锁,如果多个客户端读取同一份资源的时候,此时有写入请求,可以执行写请求,达到读写并行
可能出现幻读
读未提交
持久性
只要资源状态被线程访问到,必须是持久的,状态不能回退
只要资源状态被线程访问到,必须是持久的,状态不能回退
事务单元举例
商品要建立一个基于GMT_Modified的索引
从数据库读取一行记录
向数据库写入一行记录,同时更新这行记录的所有索引
删除整张表
基本上所有对数据的一个操作都是事务
一组事务单元
事务单元之间的Happen-before关系
读写
写读
读读
写写
如何能够以最快的速度完成?又能保证上面四种操作的逻辑顺序
1 排队法,全部顺序
序列化读写
不会冲突,不会死锁
但是如果有一个慢速设备消费慢,会导致后面的事务受影响,性能差
1 排队法就是使用排他锁(独占资源)
并行执行没有共享资源的事务单元
对共享资源加锁
2 读写锁
分离写锁和读锁,具体的,编码的时候将写方法和读方法独立开来,解耦读和写
读读并行
进一步提升读多写少的应用的并行度
3 MVCC(多版本并发控制)
本质
copy on write
针对写读的优化,写不阻塞读,写的时候是可以读的
现在主流数据库事务实现的原理
可以维持一个大的并发事务
实现复杂度高
针对读多写少的场景优化
事务处理常见问题
多个事务,谁先谁后
自增号
逻辑时间戳
物理时间戳
时钟
如何故障恢复
数据回滚,从当前事务开始反向操作
碰到死锁怎么办
死锁产生的三个必要条件
两个线程
不同方向
相同资源
死锁的解决方案
尽可能不死锁,减少线程相互等待的可能性
尽可能降低隔离级别,不加读锁
碰撞检测
申请锁之前,在内存中记录某个事务维持的锁,以及该事务等待的锁
终止一边的事务
等锁超时
需要按照业务设置合理的时间
深入单机事务
事务的ACID
原子性
事务要么全部成功,要么就全部失败,不存在中间状态。要回滚到事务的初始状态
原子性,只是记录undo日志,保证可以回滚到事务的初始状态
一致性
核心
Can(happen before)
事务单元的中间状态的处理
<b><font color="#f384ae">一个事务单元,只要保证事务全部执行成功,就是一致的</font></b>。保证能看到系统内的所有更改
子主题
强一致性
事务单元开始时加锁
happen before,相当于排队
就是将锁下推到每个数据之上,是一种锁分离
隔离性
以性能为理由,对一致性的破坏
隔离级别
排他锁
<font color="#f15a23">4 序列化读写</font>
用排他锁,单位时间内只能有一个事务进来访问资源
读写锁
<font color="#f15a23">3 可重复读</font>
读锁不能被写锁升级
读读才可以并行
性能并不是特别理想
读写锁
<font color="#f15a23">2 读已提交</font>
读锁可以被写锁升级,正在读的时候,有写请求进来,可以将读锁升级为写锁
读读并行,读写并行(写读不行)
读的数据版本可能会不同,出现了幻读,即这个级别不可重复读
读的数据版本可能会不同,出现了幻读,即这个级别不可重复读
读写锁
快照隔离级别
MVCC(多版本并发控制)
适合读写比率高的场景
copy on write+ 无锁编程
读回滚段(存的是初始版本),在新的版本上写
读到一致性的同时,实现读未提交
可以保证读写和写读并行
不同于SQL92标准,快照读映射到读已提交和读未提交
标准也不一定是对的,只是相对对的
因为业务应用的发展已经远远超过对传统意义上事物的认识
思考
写写有可能并行吗
乐观锁
比较版本,让版本低的并发更新回滚
悲观锁
认为锁竞争严重,一开始就给写加锁
事务就是将多个命令组装起来执行
数据库在持久化数据的时候,为了让数据不丢失,会记录日志,这样会带来性能问题,怎么办?怎么提高并行度
读写锁
<font color="#f15a23">1 读未提交</font>
只加写锁,读不加锁
读读,读写,写读并行
写的时候,可以读到中间状态,出现脏读
持久性
定义:事务完成后,该事务对数据库所做的更改便持久的保存在数据库之中
如何才能保证数据不丢
传统做法
RAID的持久性
RAID控制器保证数据同时存到多个磁盘中。
1 提交请求到内存后返回,即直接写入内存的时候,就对客户端说完成了存储操作
优点:IOPS高
缺点:可能丢失数据
磁盘是块存储,一行行存储反而慢
2 将内存的数据打包到磁盘,group commit
优点:保证系统的持久性和吞吐量
缺点:进一步提高延迟
吞吐量和性能(Input/output operations per second)也是一对矛盾
他们的比值是一个经验值,针对不同的业务系统而不同
快速设备和慢速设备的协调问题
包括CPU和内存也要处理这样的问题
具体多少数据的时候打包成块呢
磁盘损坏
内存中的数据掉电会丢失
每一次Commit,如果都要fsync到磁盘上,会导致系统性能下降
持久性和延迟之间的矛盾,如何均衡
ACID核心目的:提升并行度
计算机没有魔法,就是打字机
单机事务的典型异常应对策略
业务属性不匹配时,需要回滚,如何回滚
什么是业务属性不匹配
比如Smith账户不存在,所以需要判断业务对象存在否
加锁,保证单位时间其他事务不会在判断的时候写数据
系统Down机
Lock bob and smith
打字机
提高并行度,多线程去做,但是又不要影响数据的一致性
事务的原子性操作只有一个标记commit,commit完成时,之后的请求必须正常的完成
每次执行事务前,先记录操作log(其实就是一组操作命令),这样down机后,先读取操作log,分析哪些操作是完成的,已经完成的事务继续,没有提交的事务单元回滚,recovery过程系统不可访问
recovery时,也要记录日志,而且也是原子性的,不开端口,不让外部访问
事务的调优原则
在不影响业务应用的前提下
减少锁的覆盖范围
Myisam表锁 -> Innodb行锁
大锁拆小
原位锁 -> MVCC多版本
增加锁上可并行的线程数
读写锁分离、允许并行读取数据
多线程并行读取
允许多人读取
选择正确的锁类型
操作系统内部概念
悲观锁
线程加锁后直接进入blocking状态,cpu不会调度该线程
通知信息ok的状态切换回等待状态
换入换出
适合并发争抢严重的场景
乐观锁
适合并发争抢不严重的场景
死锁的扩展——U锁(Update)
可能出现的死锁情况:对于先读后写的场景,如果多个先读后写的事务操作同一份数据,可能会产生死锁。因为先读的话,通常的想法就是先加读锁,由于是读锁,另外一个事务的读也可以访问资源,此时如果第一个获取读锁的事务现在写数据,那么他要等另一个事务的读锁释放,同样的,另一个事务需要写,让自己的读锁升级为写锁,同样需要等待第一个事务的读锁释放
解决方案:对于一个先读后写的事务,读的时候就会申请写锁,阻塞后续的读后写
只要一个事务有更新操作,那么就会立刻申请一个写锁,即使需要先读数据
分布式事务
分布式事务面临的问题
分布式事务
单机事务的ACID
无限扩展
分布式事务对于以上两点不能同时满足
只能和单机数据库并存
Google Spanner的创新与代价
DRDS/TDDL的实践
大纲
分布式事务与单机事务,相同与不同
分布式事务的主要难题
传统数据库的分布式事务
新兴互联网行业的分布式事务尝试
Google Spanner赏析
阿里的分布式事务模型
DRDS/TDDL实战
分库分表<br>
shardingjdbc
mycat
DEVOPS
Linux
内核
常用命令
字体安装
安装jdk<br>
安装oracle<br>
虚拟化
容器
Docker
容器编排
Kubernetes
KVM
Jekins
Git
Maven
nginx
Mac上安装nginx
设计模式
软件模式
根据用途分类
<span>创建型(Creational)</span>
<span>主要用于描述如何创建对象</span>
<span>结构型(Structural)</span>
<span>主要用于描述如何实现类或对象的组合</span>
<span>行为型(Behavioral)</span>
<span>主要用于描述类或对象怎样交互以及怎样分配职责</span>
学习设计模式有什么用?
总结
面向对象设计原则
<span>单一职责原则 (Single Responsibility Principle, SRP)</span>
<font color="#c41230">一个类只负责一个功能领域中的相应职责。<br>就一个类而言,应该只有一个引起它变化的原因</font>。<br>用于控制类的粒度大小
实现高内聚低耦合的指导方针
实现难度
需要设计人员发现类的不同职责并将其分离,而发现类的多重职责需要设计人员具有较强的分析设计能力和相关实践经验。如何拆分系统,从哪些维度拆分?
需要设计人员发现类的不同职责并将其分离,而发现类的多重职责需要设计人员具有较强的分析设计能力和相关实践经验。如何拆分系统,从哪些维度拆分?
反例
一个类承担职责过多,各个类耦合在一起,其中一个职责变化,会影响其他职责的运作,所以需要将不同的职责封装在不同的类中
一个特殊的反例<br>
<font color="#c41230">如果多个职责总是同时发生改变则可将它们封装在同一类中</font>
个人总结:<br>
开发中经常遇到一些类里面写的非常大,仔细分析业务,应该能够拆分的更细,但是也存在风险,改过之后,需要大量时间测试
<span>开闭原则 (Open-Closed Principle, OCP)</span>
<span>软件实体应对扩展开放,而对修改关闭</span>
<span>面向对象设计的目标</span>
<span>里氏代换原则 (Liskov Substitution Principle, LSP)</span>
<span>所有引用基类对象的地方能够透明地使用其子类的对象</span>
<span>里氏代换原则是实现开闭原则的重要方式之一</span>
<span>依赖倒转原则 (Dependence Inversion Principle, DIP)</span>
<span>抽象不应该依赖于细节,细节应该依赖于抽象</span>
<span>面向对象设计的主要实现机制之一</span>
依赖注入
<span>构造注入</span>
<span>设值注入(Setter注入)</span>
接口注入
<span>接口隔离原则 (Interface Segregation Principle, ISP)</span>
<span>使用多个专门的接口,而不使用单一的总接口</span>
接口的含义
<span>一个类型所具有的方法特征的集合,仅仅是一种逻辑上的抽象</span>
<span>某种语言具体的“接口”定义,有严格的定义和结构,比如Java语言中的interface</span>
<span>合成复用原则 (Composite Reuse Principle, CRP)</span>
<span>尽量使用对象组合,而不是继承来达到复用的目的</span>
<span>迪米特法则 (Law of Demeter, LoD)</span>
<span>一个软件实体应当尽可能少地与其他实体发生相互作用</span>
中介者模式<br>
六个创建型模式
简单工厂模式
创建对象和使用对象分离
符合单一职责原则
提高可维护性
提高可重用性
防止用来实例化一个类的数据和代码在多个类中到处都是,可以将有关创建的知识搬移到一个工厂类中
<span>以一种更加可读、易懂的方式来创建对象,因为通过构造函数创建对象,只能以参数区分</span>
什么时候需要用工厂模式创建对象
类的创建比较复杂,或者创建代价比较大,比如JDBCFactory,BeanFactory,创建的过程涉及到更细粒度的步骤,变数比较多,需要的配置项比较多
String类的创建就不需要用工厂模式,否则只会增加复杂度
工厂方法
抽象工厂
单例
原型
建造者
七个结构型模式
适配器
桥接
组合
装饰
外观
享元
代理
十一个行为模式
职责链
请求的链式处理
命令
解释器
迭代器
中介者
备忘录
观察者<br>
状态<br>
策略
模板方法
访问者
Java-Interview
架构师之路<br>
面试题<br>
linux
sprinboot
spring
springmvc中request线程安全问题
try-finally大法,百战百胜!(一定要在finally里清空ThreadLocal)
因为线程资源宝贵,经常被复用,如果为线程set了threadlocal,没有及时remove,会导致一些逻辑性错误,时间长了会导致OOM
使用参考Spring中的使用
Spring中的线程安全性
Spring与线程安全
Spring并没有保证这些对象的线程安全,需要由开发者自己编写解决线程安全问题的代码。
Spring对每个bean提供了一个scope属性来表示该bean的作用域。
每个单例的无状态对象都是线程安全的(也可以说<font color="#c41230">只要是无状态的对象,<br>不管单例多例都是线程安全的</font>,不过单例毕竟节省了不断创建对象与GC的开销)
无状态最明显的编码体现,就是<font color="#c41230">不要使用全局变量,使用局部变量</font>
局部变量是在方法栈中的,而且方法栈本身就是线程私有的内存区域,所以不存在线程安全问题
无状态的对象即是自身没有状态的对象,自然也就不会因为多个线程的交替调度而破坏自身状态导致线程安全问题。
如果要<font color="#c41230">使用全局变量(类变量/实例变量),需要用到ThreadLocal</font>
锁更强调的是如何同步多个线程去正确地共享一个变量,ThreadLocal则是为了解决同一个变量如何不被多个线程共享
可参见XmlBeanDefinitionReader.loadBeanDefinitions方法中对ThreadLocal的使用
聊一聊Spring中的线程安全性
Spring事务的传播行为本质上是在传递threalocal中的JDBC Connection
如果是required new 就保存当前的Connection,新建一个Connection
如果是默认的required,有事务连接就用事务连接,否则新建一个Connection
SpringMVC拦截器原理
分布式事务
TCC
面试大纲<br>
成长感悟
面试感悟
一个学渣的阿里之路
蚂蚁金服网商
能力
解决问题的能力
来源于经验的积累和学习的总结
思维方法
正向,逆向
局部,总体
试错
思考方式
学习能力
社交
自我管理
情绪控制
时间管理
生活管理
杂谈
人不成熟的5个特征
1 立即要回报<br>
2 不自律<br>
3 经常被情绪左右<br>
4 不愿意学习,自以为是,没有空杯的心态<br>
5 做事不靠信念,靠人言<br>
JDK源码及其他框架源码解析
Java基础
谈谈多态
什么是多态
<font color="#f15a23">不同类的对象对同一消息作出不同的响应就叫做多态</font>。就像上课铃响了<br>,上体育课的学生跑到操场上站好,上语文课的学生在教室里坐好一样。
引用基类的对象也可以引用子类(里氏代换原则)
父类的引用可以指向不同子类的对象,子类的实现各不一样
多态的作用
简单讲就是<font color="#f15a23">解耦</font>。再详细点讲就是,多态是设计模式的基础,<br>不能说所有的设计模式都使用到了多态,但是23种中的很大一部分,都是基于多态的。
多态存在的三个条件
有继承关系
子类重写父类方法
以下三种类型的方法是没有办法表现出多态特性的(因为不能被重写)
static方法,因为被static修饰的方法是属于类的,而不是属于实例的
final方法,因为被final修饰的方法无法被子类重写
private方法和protected方法,前者是因为被private修饰的方法对子类不可见,后者是因为尽管被protected修饰的方法可以被子类见到,<br>也可以被子类重写,但是它是无法被外部所引用的,一个不能被外部引用的方法,怎么能谈多态呢
父类引用指向子类对象
多态的分类
编译时多态,即方法的重载,从JVM的角度来讲,这是一种静态分派(static dispatch)
运行时多态,即方法的重写,从JVM的角度来讲,这是一种动态分派(dynamic dispatch)
使用细节
我们有一个父类Father,有一个子类Children
向上转型是自动的。即Father f = new Children()是自动的,不需要强转
向下转型要强转。即Children c = new Father()是无法编译通过的,<br>必须要Children c = (Children)new Father(),让父类知道它要转成具体哪个子类
父类引用指向子类对象,子类重写了父类的方法,调用父类的方法,实际调用的是子类重写了的父类的该方法。<br>即Father f = new Children(),f.toString()实际上调用的是Children中的toString()方法
谈谈final的作用
final关键字的作用
被final修饰的类不可以被继承
被final修饰的方法不可以被重写
被final修饰的变量的地址(引用)不可以被改变
被final修饰不可变的是变量的<font color="#c41230">引用</font>,而不是引用指向的内容,引用指向的<font color="#c41230">内容是可以改变的</font>。
用final修饰数组是没有意义的
因为内容是可以改变的
总结
被final修饰的变量,不管变量是哪种变量,切记<font color="#c41230">不可变的是变量的引用而非引用指向对象的内容</font>。
被final修饰的方法,JVM会尝试为之寻求内联,这对于提升Java的效率是非常重要的。<br>因此,假如能确定方法不会被继承,那么尽量将方法定义为final的,具体参见运行期优化技术的方法内联部分
被final修饰的常量,在编译阶段会存入调用类的常量池中,具体参见类加载机制最后部分和Java内存区域
static关键字作用总结
用法
被static修饰的变量属于类变量,可以通过类名.变量名直接引用,而不需要new出一个类来
被static修饰的方法属于类方法,可以通过类名.方法名直接引用,而不需要new出一个类来
被static修饰的变量、被static修饰的方法统一属于类的静态资源,是类实例之间共享的,<br>换言之,一处变、处处变。JDK把不同的静态资源放在了不同的类中而不把所有静态资源放在一个类里面
不同的类有自己的静态资源,这可以实现静态资源分类。比如和数学相关的静态资源放在java.lang.Math中,<br>和日历相关的静态资源放在java.util.Calendar中,这样就很清晰了
避免重名。不同的类之间有重名的静态变量名、静态方法名也是很正常的,<br>如果所有的都放在一起不可避免的一个问题就是名字重复,这时候怎么办?分类放置就好了。
避免静态资源类无限膨胀,这很好理解。
静态方法能不能引用非静态资源?静态方法里面能不能引用静态资源?非静态方法里面能不能引用静态资源?
静态方法能不能引用非静态资源?
<font color="#c41230">不能,静态方法是在类加载初始化的,而非静态资源是new出来的,发生时机比静态资源产生晚</font>
静态方法里面能不能引用静态资源?可以,因为都是类初始化的时候加载的,大家相互都认识。
非静态方法里面能不能引用静态资源?可以,非静态方法就是实例方法,那是new之后才产生的,那么属于类的内容它都认识。
静态块
和静态变量、静态方法一样,<font color="#c41230">静态块里面的代码只执行一次,且只在初始化类的时候执行</font>。
三个细节
静态资源的加载顺序是严格按照静态资源的定义顺序来加载的
示例代码
输出<br>
静态代码块对于定义在它之后的静态变量,可以赋值,但是不能访问。
示例代码<br>
会报异常Cannot reference a field before it is defined
静态代码块是严格按照父类静态代码块->子类静态代码块的顺序加载的,且只加载一次。
示例代码
输出
static修饰类
静态内部类
import static
简化了一些操作,比如静态导入Math下的所有静态资源,在频繁使用Math类下静态资源的地方,可以少些很多“Math.”
降低了代码的可读性
建议在某些场景下导入特定的静态资源,不建议使用“.*”的导入方式。
不重要<br>
Java语法糖
可变长参数
可以使用遍历数组的方式去遍历可变参数
可变参数是利用<font color="#c41230">数组</font>实现的
可变长度参数必须作为方法参数列表中的的最后一个参数且方法参数列表中只能有一个可变长度参数。
foreach循环原理
示例代码
反编译
javap -verbose TestMain.class
反编译后的字节码
查看反编译后的字节码的最后两行可知<br>
在编译的时候编译器会<font color="#c41230">自动将对for这个关键字的使用转化为对目标的迭代器的使用</font>
结论
ArrayList之所以能使用foreach循环遍历,是因为ArrayList所有的List都是Collection的子接口,而Collection是Iterable的子接口,ArrayList的父类AbstractList正确地实现了Iterable接口的iterator方法
任何一个集合,无论是JDK提供的还是自己写的,只要想使用foreach循环遍历,就必须正确地实现Iterable接口
相关设计模式:迭代器模式
foreach遍历数组的原理
Java将对于数组的foreach循环转换为对于这个数组每一个的循环引用。
反编译后会生成goto指令
自动装箱和自动拆箱
测试代码
反编译后的字节码指令<br>
自动装箱的时候,Java虚拟机会自动调用Integer的<font color="#c41230">valueOf</font>方法;在自动拆箱的时候,Java虚拟机会自动调用Integer的<font color="#c41230">intValue</font>方法。这就是自动拆箱和自动装箱的原理。
小心空指针异常
示例代码<br>
这种使用场景很常见,我们把一个int数值放在session或者request中,<br>取出来的时候就是一个类似上面的场景了。所以,小心自动拆箱时候的空指针异常。
小陷阱
示例代码1
输出结果
示例代码2
输出结果<br>
产生这样的结果的原因是:Byte、Short、Integer、Long、Char这几个装箱类的valueOf()方法<br>是以128位分界线做了<font color="#c41230">缓存</font>的,假如是128以下且-128以上的值是会取缓存里面的引用的
以Integer为例,其valueOf(int i)的源代码为
<font color="#c41230">-128~127之间的数是从缓存中取</font>的,其他的会new Integer对象<br>
而Float、Double则不会,原因也很简单,因为byte、Short、integer、long、char在某个范围内的整数个数是有限的,但是float、double这两个浮点数却不是,他们是实数。
结论
不重要,除了面试考察求职者对于知识的掌握程度,没多大用
要有缓存这个概念,缓存对于提高程序运行效率、节省内存空间是有很大帮助的
泛型
好处
类型安全
类型错误现在在编译期间就被捕获到了,而不是在运行时当作java.lang.ClassCastException展示出来,<br>将类型检查从运行时挪到编译时有助于开发者更容易找到错误,并提高程序的可靠性
消除了代码中许多的强制类型转换,增强了代码的可读性
为较大的优化带来了可能
getClass()相同
示例代码
执行结果<br>
结论
泛型是什么并不会对一个对象实例是什么类型的造成影响
所以,通过改变泛型的方式试图定义不同的重载方法也是不可以的
使用精确的类型定义泛型,不要使用接口或者父类
否则set不同的子类进去后,get出来的要根据实际类型强转,失去了泛型的意义
<!--?--><?>是类型通配符,表示是任何泛型的父类型
使用类型通配符,只能从中检索元素,不能添加元素。
泛型方法
示例代码
不用显式告诉编译器,想要T什么值:编译器只知道这些T都必须相同
静态资源不认识泛型
个人理解:静态资源在类加载时需要确定存储空间,不指定类型无法知道初始化多少内存<br>
泛型约束
定义class的时候只能使用extends关键字且不能用通配符"?"
示例代码
TestMain类的泛型只能传B的子类,也就是C。"new TestMain<A>()"、"public class TestMain<? extends B>"、"public class TestMain<T super B>"都是错误的写法
作为方法的参数
泛型可以使用"? extends B"或者"? super B",前者表示实际类型只可以是B的子类,后者表示实际类型只可以是B的父类
示例代码1<br>
示例代码2
作为局部变量的参数
泛型可以使用"? extends B"或者"? super B",不过前者好像没什么意义,后者表示只可以传以B为父类的对象
示例代码<br>
不要写"list.add(new A())",JDK将会认为这是类型不匹配的。
泛型应用
Collections.copy()
内部类
成员内部类
示例代码
成员内部类是依附其外部类而存在的,如果要产生一个成员内部类,必须有一个其外部类的实例
成员内部类中不可以定义静态的方法或者变量属性
成员内部类可以声明为private的,声明为private的成员内部类对外不可见,外部不能调用私有成员内部类的public方法
成员内部类可以声明为public的,声明为public的成员内部类对外可见,外部也可以调用共有成员内部类的public方法
成员内部类可以访问其外部类的私有属性,如果成员内部类的属性和其外部类的属性重名,则以成员内部类的属性值为准
局部内部类
示例代码
局部内部类没有访问修饰符
局部内部类要访问外部的变量或者对象,该变量或对象的引用必须是用<font color="#f15a23">final</font>修饰的
why
匿名内部类
唯一没有构造器的类
一般都用于继承抽象类或实现接口(注意只能继承抽象类,不能继承普通类)
匿名内部类Java自动为之起名为XXX$1.classs
匿名内部类使用的外部变量必须声明为final<br>
静态内部类
示例代码
静态内部类中可以有静态方法,也可以有非静态方法
静态内部类只能访问其外部类的静态成员与静态方法
和普通的类一样,要访问静态内部类的静态方法,可以直接"."出来不需要一个类实例;要访问静态内部类的非静态方法,必须拿到一个静态内部类的实例对象
注意一下实例化成员内部类和实例化静态内部类这两种不同的内部类时写法上的差别
成员内部类:外部类.内部类 XXX = 外部类.new 内部类();
静态内部类:外部类.内部类 XXX = new 外部类.内部类();
局部内部类和匿名内部类只能访问final局部变量的原因
先理清楚两点
匿名内部类是唯一没有构造器的类
局部内部类有构造器,通过构造器把外部的变量传入局部内部类再使用是完全可以的
那万一局部内部类中没有定义构造器传入局部变量怎么办呢?这时候Java想了一个办法,把局部变量修饰为final就好了,被final修饰的变量相当于是一个常量,编译时就可以确定并放入常量池。这样即使匿名内部类没有构造器、局部内部类没有定义有参构造器,也无所谓,反正要用到的变量编译时候就已经确定了,到时候去常量池里面拿一下就好了。既然上面说到了"去常量池里面拿一下就好了",那么把局部内部类、匿名内部类里面要用到的局部变量设定为static的也是可以的(不过static不可以修饰局部变量,可以放在方法外),可以自己试一下
使用内部类的好处
Java允许实现多个接口,但不允许继承多个类,使用成员内部类可以解决Java不允许继承多个类的问题。在一个类的内部写一个成员内部类,可以让这个成员内部类继承某个原有的类,这个成员内部类又可以直接访问其外部类中的所有属性与方法,是不是相当于多继承了呢?
成员内部类可以直接访问其外部类的private属性,而新起一个外部类则必须通过setter/getter访问类的private属性
有些类明明知道程序中除了某个固定地方都不会再有别的地方用这个类了,为这个只用一次的类定义一个外部类显然没必要,所以可以定义一个局部内部类或者成员内部类,写一段代码用用就好了
使用内部类可以让类与类之间的逻辑上的联系更加紧密,如果一个类只和当前类有联系,就可以定义为当前类的内部类,充分隐藏内部类,明确访问界限
Java对象表示方式(序列化)
序列化、反序列化和transient关键字的作用<br>
什么是序列化和反序列化<br>
序列化
将一个对象转换成一串二进制表示的字节数组,通过保存或转移这些字节数据来达到持久化的目的。
反序列化
将字节数组重新构造成对象。
示例代码<br>
分析序列化后的二进制文件(见文章)
结论
序列化之后保存的是对象的信息
被声明为transient的属性不会被序列化,这就是transient关键字的作用
被声明为static的属性不会被序列化,这个问题可以这么理解,<br><font color="#c41230">序列化保存的是对象的状态</font>,但是static修饰的变量是属于类的而不是属于对象的,因此序列化的时候不会序列化它
运行结果
结果分析
因为str1是一个transient类型的变量,没有被序列化,因此反序列化出来也是没有任何内容的,显示的null。
手动指定序列化过程
手动指定序列化方式的规则
进行序列化、反序列化时,虚拟机会首先试图调用对象里的<font color="#f15a23">writeObject和readObject</font>方法,进行用户自定义的序列化和反序列化。
如果没有这样的方法,那么默认调用的是<font color="#f15a23">ObjectOutputStream的defaultWriteObject</font>以及<font color="#f15a23">ObjectInputStream的defaultReadObject</font>方法。
利用自定义的writeObject方法和readObject方法,用户可以自己控制序列化和反序列化的过程。
自定义序列化过程的场景举例
有些场景下,某些字段我们并不想要使用Java提供给我们的序列化方式,而是想要以自定义的方式去序列化它,比如ArrayList的elementData、HashMap的table(至于为什么在之后写这两个类的时候会解释原因),就可以通过将这些字段声明为transient,然后在writeObject和readObject中去使用自己想要的方式去序列化它们
因为<font color="#c41230">序列化并不安全</font>,因此有些场景下我们需要对一些敏感字段进行加密再序列化,然后再反序列化的时候按照同样的方式进行解密,就在一定程度上保证了安全性了。要这么做,就必须自己写writeObject和readObject,writeObject方法在序列化前对字段加密,readObject方法在序列化之后对字段解密
示例:尝试将上面的示例代码中的transient修饰的变量序列化
示例代码
运行结果
通过常看序列化后的二进制文件总结一下writeObject和readObject的通常用法
先通过defaultWriteObject和defaultReadObject方法序列化、反序列化对象,<br>然后在文件结尾追加需要额外序列化的内容/从文件的结尾读取额外需要读取的内容。
复杂序列化情况总结
当父类继承Serializable接口时,所有子类都可以被序列化
子类实现了Serializable接口,父类没有,父类中的属性不能序列化(不报错,数据丢失),但是在子类中属性仍能正确序列化
如果序列化的属性是对象,则这个对象也必须实现Serializable接口,否则会报错
反序列化时,如果对象的属性有修改或删减,则修改的部分属性会丢失,但不会报错
反序列化时,如果serialVersionUID被修改,则反序列化时会失败
XStream实现对对象的XML化
Java原生支持的序列化方式缺点
无法跨语言
占用的字节数比较大,而且序列化、反序列化效率也不高
json
protobuf
thrift
自己实现一个Native方法的调用(JNI)
基本上用的很少,了解即可<br>
JNI实现了Java和本地代码间的双向交互。
JNI允许Java代码使用以其他语言编写的代码和代码库,本地程序中的函数也可以调用Java层的函数
native关键字
被Native关键字声明的方法说明该方法不是以Java语言实现的,而是以本地语言实现的,Java可以直接拿来用。
本地语言,可以和操作系统直接交互的语言,通常指ANSI C,<br>标准C语言是为开发UNIX操作系统而诞生的,操作系统的系统调用基本上都是封装在C语言函数中,系统调用(system call)是用来操作内核的系统指令的封装
System.load(String filename)和System.loadLibrary(String libname)的区别
两种加载类库的方式
了解即可
工作中遇到有个印象,可以从这里开始研究
从为什么String=String谈到StringBuilder和StringBuffer
常量池中的数据是那些<font color="#c41230">在编译期间被确定</font>,并被保存在已编译的.class文件中的一些数据。除了包含所有的8种基本数据类型(char、byte、short、int、long、float、double、boolean)外,还有String及其数组的常量值,另外还有一些以文本形式出现的符号引用。
常量池中数据创建的一般性步骤:<font color="#f15a23">先看常量池中有没有要创建的数据,有就返回数据的地址,没有就创建一个</font>
Java栈的特点是存取速度快(比堆块),但是空间小,数据生命周期固定,只能生存到方法结束。
==用来判断对象的引用(地址)是否相等
Java虚拟机的解释器每遇到一个new关键字,都会在堆内存中开辟一块内存来存放一个String对象,所以str2、str3指向的堆内存中虽然存储的是相等的"234",但是由于是两块不同的堆内存,因此str2 == str3返回的仍然是false
为什么要使用StringBuilder和StringBuffer拼接字符串?
例子代码
找到编译后的StringTest.class文件,使用"<font color="#c41230">javap -verbose StringTest</font>"<br>或者"<font color="#c41230">javap -c StringTest</font>"都可以,反编译一下class获取到对应的字节码
反编译后的字节码
编译器每次碰到"+"的时候,会new一个StringBuilder出来,接着调用append方法,在调用toString方法,生成新字符串。
String的concat方法
通过两次字符串的拷贝,产生一个新的字符数组buf[],再根据字符数组buf[],new一个新的String对象出来,这意味着concat方法调用N次,将发生N*2次数组拷贝以及new出N个String对象,无论对于时间还是空间都是一种浪费
StringBuffer和StringBuilder
底层维护了一个char数组,每次append的时候就往char数组里面放字符而已,在最终sb.toString()的时候,用一个new String()方法把char数组里面的内容都转成String,这样,整个过程中只产生了一个StringBuilder对象与一个String对象,非常节省空间
性能缺失
char数组不够的时候需要进行扩容,扩容需要进行数组拷贝
使用建议
初始化时如果能估算出字符串长度,使用带长度的构造函数初始化
StringBuffer是线程安全的,它对所有方法都做了同步,StringBuilder是线程非安全的,所以在不涉及线程安全的场景,比如方法内部,尽量使用StringBuilder,避免同步带来的消耗。
讲讲HashCode的作用
Hash是散列的意思,就是把任意长度的输入,通过散列算法变换成固定长度的输出,该输出就是散列值。
关于散列的结论<br>
如果散列表中存在和散列原始输入K相等的记录,那么K必定在f(K)的存储位置上
不同关键字经过散列算法变换后可能得到同一个散列地址,这种现象称为<font color="#c41230">碰撞</font>
如果两个Hash值不同(前提是同一Hash算法),那么这两个Hash值对应的原始输入必定不同
HashCode,总结几个关键点
HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的
如果两个对象equals相等,那么这两个对象的HashCode一定也相同
如果对象的equals方法被重写,那么对象的HashCode方法也尽量重写
如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
HashCode有什么用
好的Hash函数,可以生成一个重复率低的hashcode,查询和存储都根据hashcode选择位置,效率高
自定义一个类加载器
一个功能健全的Web服务器,要解决如下几个问题
部署在同一个服务器上的两个Web应用程序所使用的Java类库可以实现相互隔离。这是最基本的要求,两个不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求一个类库在一个服务器中只有一份,服务器应当保证两个应用程序的类库可以互相使用
部署在同一个服务器上的两个Web应用程序所使用的Java类库可以相互共享。这个需求也很常见,比如相同的Spring类库10个应用程序在用不可能分别存放在各个应用程序的隔离目录中
支持热替换,我们知道JSP文件最终要编译成.class文件才能由虚拟机执行,但JSP文件由于其纯文本存储特性,运行时修改的概率远远大于第三方类库或自身.class文件,而且JSP这种网页应用也把修改后无须重启作为一个很大的优势看待
TomcatClassLoader架构
图
JDK中的ClassLoader
所使用jdk是1.8.0_192<br>
synchronized (getClassLoadingLock(name))
getClassLoadingLock
默认使用当前的ClassLoader作为锁对象,比如AppClassLoader
判断是否当前的ClassLoader支持并行加载<br>
if (parallelLockMap != null)
使用的是ConcurrentHashMap
如果支持,new一个Object对象作为锁对象<br>
Object newLock = new Object();
建立当前ClassLoader到上面new的Object对象锁的映射关系,<br>赋值给lock变量,同时lock变量和当前ClassLoader引用关系断开
parallelLockMap是ConcurrentHashMap类型
lock = parallelLockMap.putIfAbsent(className, newLock);
如果上一步的lock不为空,即要加载的className在parallelLockMap中可以找到一个对应的lock,<br>即当前这个className没被加载过,就返回当前设置的newLock
如果上一步lock为空,即当前传入的className第一次加载,使用new Object作为锁对象<br>
总结
1.7以上支持并行加载字节码
其他相关例子和解析
检查类是不是已经被加载
Class<?> c = findLoadedClass(name);
最终调用native方法
如果没有被加载过,就去找父类加载器去加载,父类加载器会调用loalClass方法,这里是个<font color="#c41230">递归调用</font>,直到找到Bootstrap类加载器加载
如果父类加载器被设置为空,会直接调用Bootstrap类加载器加载
加载成功就返回一个java.lang.Class,加载不成功就抛出一个ClassNotFoundException,给子加载器去加载
如果要解析这个.class文件的话,就解析一下,解析的作用类加载的文章里面也写了,主要就是将符号引用替换为直接引用的过程
结论
<font color="#c41230">如果不想打破双亲委派模型,那么只需要重写findClass方法即可</font>
<font color="#c41230">如果想打破双亲委派模型,那么就重写整个loadClass方法</font>
ClassLoader.getResourceAsStream(String name)方法作用
用来读入指定的资源的输入流,并将该输入流返回给用户用
Class的getResourceAsStream(String name)方法,参数不以"/"开头则默认从此类对应的.class文件所在的packge下取资源,<br>以"/"开头则从CLASSPATH下获取
Class的getResourceAsStream(String name)方法,只是将传入的name进行解析一下而已,<br>最终调用的还是ClassLoader的getResourceAsStream(String name)
ClassLoader的getResourceAsStream(String name)方法,默认就是从CLASSPATH下获取资源,参数不可以以"/"开头
.class和getClass()的区别
.class用于类名,getClass()是一个final native的方法,因此用于类实例
.class在编译期间就确定了一个类的java.lang.Class对象,但是getClass()方法在运行期间确定一个类实例的java.lang.Class对象
Comparable和Comparator的区别
Comparable
内比较器,实现了Comparable接口的类有一个特点,就是这些类是可以和自己比较的
和另一个实现了Comparable接口的类如何比较,则依赖compareTo方法的实现,compareTo方法也被称为自然比较方法
compareTo方法的返回值是int,有三种情况
比较者大于被比较者(也就是compareTo方法里面的对象),那么返回正整数
比较者等于被比较者,那么返回0
比较者小于被比较者,那么返回负整数
示例代码
泛型未必就一定要是Domain,将泛型指定为String或者指定为其他任何任何类型都可以----只要开发者指定了具体的比较算法就行
Comparator
外比较器<br>
一个对象不支持自己和自己比较(没有实现Comparable接口),但是又想对两个对象进行比较
一个对象实现了Comparable接口,但是开发者认为compareTo方法中的比较方式并不是自己想要的那种比较方式
Comparator接口里面有一个compare方法,方法有两个参数T o1和T o2,是泛型的表示方式,<br>分别表示待比较的两个对象,方法返回值和Comparable接口一样是int,有三种情况
o1大于o2,返回正整数
o1等于o2,返回0
o1小于o3,返回负整数
因为泛型指定死了,所以实现Comparator接口的实现类只能是两个相同的对象(不能一个Domain、一个String)进行比较了,<br>因此实现Comparator接口的实现类一般都会以"待比较的实体类+Comparator"来命名
总结
Comparator是可以理解为给JDK使用者、Java开发人员用来自定义比较算法和逻辑的
Comparator是JDK源码一些带比较功能的类使用的
Comparator是相对于自然排序,比如一般的数字是可排序的,字母可以排序这种使用Comparable
两者语义不一样,Comparable是这个类本身是可比较的,而Comparator是为自己的类写比较器,自定义比较
JDBC学习1:详解JDBC使用
什么是JDBC
JDBC做了三件事
与数据库建立连接
发送操作数据库的语句
处理结果
JDBC编码
加载JDBC驱动类
根据数据库配置获取数据库连接<br>
使用连接创建一个PreparedStatement
使用PreparedStatement 设置占位符上的参数值
执行查询获取结果集
增删改用的是executeUpdate()方法,因为增删改认为都是对数据库的更新
查询用的是executeQuery()方法,看名字就知道了"Query"
遍历结果集,设置JavaBean<br>
关闭连接
为什么要使用占位符"?"
防止SQL注入攻击<br>
JDBC事务
默认是开启事务自动提交
事务控制
抛异常的时候利用rollback()方法回滚掉事物。
JDBC学习2:为什么要写Class.forName("XXX")?
JDBC是23种模式中的桥接模式的典型应用
Class.forName(String className)的作用
CLASSPATH下指定名字的.class文件加载到Java虚拟机内存中
初始化这个类
初始化做了什么?
给静态资源赋值以及执行静态代码块,所以,反编译一下"mysql-connector-java-5.1.20-bin.jar"这个jar包,查看一下Driver类
Class.forName("com.mysql.jdbc.Driver")的作用实际上就是调用DriverManager的registerDriver方法注册一个mysql的JDBC驱动(Driver)
Driver继承NonRegisteringDriver.java,NonRegisteringDriver.java实现了JDK提供的Driver接口,这个Driver提供了若干数据库连接的方法,每个不同的数据库连接类都必须实现它,并重写和具体的数据库连接的算法。
DriverManager也是JDK中的类
底层利用了一个CopyOnWriteArrayList作为容器(这是一个线程安全的容器,不过每次add的时候都会对底层数组进行一次新的复制,所以在读远多于写的时候建议可以使用这个),放那些注册进去的DriverInfo。
最终getConnection(...)的时候就拿registerDrivers里面注册进去的具体的某个数据库的DriverInfo(像MySql的Driver就在DriverInfo里面)去连接具体的数据库。
总结<br>
JDK不负责和数据库连接打交道,也没必要,只提供一个具体的接口Driver,告诉所有第三方,要连接数据库,就去实现这个接口,然后通过DriverManager注册一下,到时候连接某个数据库的时候,你已经在我这里注册了,我会调用你注册进来的Driver里面的方法去对指定数据库进行连接的。然后Mysql就实现自己的Driver,Oracle就实现自己的Driver,通过static块注册一下
和classLoader的区别
classLoader只会加载.class文件,不会初始化,不执行static代码块、方法
为什么不直接new?
为什么删除Class.forName("com.mysql.jdbc.Driver")还是可以运行?
历史原因这么写
说说WeakReference弱引用
用来描述非必需的对象,比如缓存<br>
垃圾收集时,无论内存是否充足,弱引用引用的对象都会被回收
GC后回收了软引用引用的对象后,有继续使用软引用对象的地方不就会报NPE吗?继续使用说明是强引用?
软引用关联的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行二次回收,如果这次回收没有足够的内存才抛出内存溢出异常
怎么探测将要发生内存溢出的?
GC时,内存没有溢出,就不会回收软引用<br>
WeakReference的父类Reference中有一个变量queue,是ReferenceQueue类型的。WeakReference中的构造函数中有一个两个参数的构造函数,其中第二个参数就是这个ReferenceQueue,表示在WeakReference指向的对象被回收之后,可以利用ReferenceQueue来保存被回收的对象
示例<br>
在JDK的WeakHashMap中,很好的应用了弱引用,其中Entry继承了WeakReference,<br>如果一个entry对象,一旦没有指向key的强引用,WeakHashMap在GC后会自动删除相关的entry。
Cloneable接口和Object的clone()方法
原型模式<br>
深拷贝
浅拷贝
应用场景
反射<br>
反射的作用
Java反射描述的是,在运行状态中
对于任意一个类,都能够知道这个类的所有属性和方法
对于任意一个类,都能够调用它的任意一个属性和方法
不仅仅可以获知类的属性、方法,还可以获知类的父类、接口、包等信息
反射的原理
一个类在加载的时候,会在内存中生成一个代表这个.class文件的java.lang.Class对象,.classs文件里面就包含了描述这个类的信息的一切内容。
常用API举例
Class<?> c = Class.forName("reflection.Reflection");
通过类的全限定名加载类,返回一个Class对象,代表该类的字节码在内存中的存在
Class.newInstance()
根据Class实例化出一个类实例来,默认调用无参构造方法
Class.getPackage();
获取包的抽象,返回类的Package对象
Class.getField("b");
指定属性名,获取类的public属性抽象,返回类的Field对象
Class.getDeclaredField("d");
指定属性名,获取类的任意访问权限的属性
Class.getFields();
获取类的所有public属性
Class.getDeclaredFields();
获取类的所有属性
f0.getName() // 获取字段名
f0.getType() // 获取类的类型
f0.getBoolean(r) // 获取某个实例对象该Field的值,什么类型的Field就是getXXX(Object obj)
f0.getModifiers() // 以整数形式返回此Field对象的Java语言修饰符,如public、static、final等
f0.isAccessible() // 返回Field的访问权限,对private的Field赋值,必须要将accessible设置为true
f1.setAccessible(true);
使可以访问private权限的属性<br>
f1.setDouble(r, 1.1);
设置属性值
Constructor<?> constructor = c.getConstructor(String.class);
获取参数为String的构造函数
Constructor<?>[] constructors = c.getConstructors();
获取所有构造函数
constructor.getParameterTypes()[0] // 获取Constructor的参数类型,是个数组
constructor.getModifiers() // 获取以整数形式返回的此Constructor对象的Java语言修饰符,如public、static、final等
constructor.isVarArgs() // 获取此Constructor中是否带了可变数量的参数,即例如"String... str"类型的参数
Reflection r = (Reflection)constructor.newInstance("123"); // 根据指定的构造方法实例化出一个类的实例来,重要
Method md0 = c.getMethod("publicMethod", int.class, double.class, List.class);
根据方法名和参数列表获取指定的public方法
Method md1 = c.getDeclaredMethod("privateMethod", new Class[0]);
根据方法名和参数列表获取指定的任意访问权限的方法,但不包括继承的方法
Method[] ms0 = c.getMethods();
获取此类包括其父类中所有的public方法
Method[] ms1 = c.getDeclaredMethods();
返回此类中所有的方法(无访问权限限制),但不包括继承的方法
md0.isVarArgs() // 获取方法是否带有可变数量的参数
md0.getReturnType())// 获取方法的返回类型
md0.getParameterTypes()[0] + ", " + md0.getParameterTypes()[1] + ", " + md0.getParameterTypes()[2]; // 获取方法的参数类型,数组形式,注意一下和下面的方法的区别
md0.getGenericParameterTypes()[0] + ", " + md0.getGenericParameterTypes()[1] + ", " + md0.getGenericParameterTypes()[2]; // 获取方法的参数化(带泛型)类型,数组形式
md0.invoke(r, 1, 2.2, new ArrayList<String>()); // 反射调用方法,重要
Field、Constructor、Method中都有getModifiers()方法,返回的是表示此对象的Java语言修饰符,详细看下每个修饰符对应的枚举值
枚举值
也就是说如果一个方法是"public static final synchronized"的,那么这个方法的getModifiers()返回的应该是1 + 8 + 16 + 32 = 57
那如果反过来,我有一个值是X,如何通过X知道它是哪种访问权限的呢?
其他参考
Java异常
异常继承层次图
异常继承层次图
Throwable
Exception
Checked Exception<br>
IOException
一定要编写异常处理的程序代码才行,它通常用来处理输入/输出相关的操作,如对文件的访问、网络的连接等。
RuntimeException
Error
当异常发生时,发生异常的语句代码会抛出一个异常类的实例化对象,之后此对象与catch语句中的类的类型进行匹配,然后在相应的catch中进行处理。
Java默认的异常处理机制做处理
只能输出异常信息,接着便终止程序的运行
自行编写try-catch-finally块来捕捉异常
可以灵活操控程序的流程且可做出最适当的处理
try语句块中是要检查异常的语句,不要写不相关的语句
finally表示无论catch内部写了什么,即使是return,也都会运行到的语句,可省略。
finally常用于对某段待检查的代码做扫尾工作,比如ReentrantLock的unlock()、IO的close()
throw表示抛出一个类的<font color="#f15a23">实例</font>,注意实例二字,实例意味着throw出去的是一个实例化的异常对象。
注意,throw关键字可以写在任何地方,并不强制必须写在catch块中,运行到throw所在的行,打印异常并立即退出当前方法
throws用于方法声明,表示如果方法内的程序代码可能会发生异常,且方法内又没有使用try-charch的代码块来捕捉这些异常时,则必须在声明方法时一并指明所有可能发生的异常,以便让调用此方法的程序得以做好准备来捕捉异常。比如"方法名称(参数...) throws 异常类1, 异常类2, 异常类3...",也可以不这么麻烦,Exception是所有异常的父类,因此也可以直接"方法名称(参数...) throws Exception"
异常场景汇总
接口方法可以throws异常,但必须throws一个具体的异常,不能直接throws出去Exception
示例代码
接口方法throws异常,其实现类实现该方法的时候不强制必须抛出该异常,也可以任意抛出异常
示例代码1
示例代码2<br>
catch块内如果捕获到了异常并且throw出去了e,那么方法之后的代码都不会再运行了(编译不通过);catch块内如果捕获到了异常,但是没有throw出去e,也没有任何导致程序终止的语句,那么try...catch...finally之后的语句仍然可以继续运行
示例代码
捕获异常不可以先catch (Exception e){...}再catch (NullPointerException e)
因为先处理了Exception,就不会处理其他异常了,cache NPE的代码不可达<br>
方法A声明throws异常,则调用方法A的代码必须try...catch...该异常
方法A声明throws出Exception,调用方法A的代码必须try...catch...该异常,如果:
有匹配异常的catch块,则优先走匹配异常的catch块
如果没有匹配异常的catch块,但是有catch (Exception e){...},则走catch (Exception e){...}
如果没有匹配的catch块,则调用方法A的地方throw异常,方法终止
如果方法中没有try...catch异常而该方法发生了异常,且方法声明中有throws,那么发生的该异常可以被抛到调用方法的代码中
如果方法中对某个代码块做了try...catch并且想把catch到的异常抛给调用方法的地方,那么
只有在catch块中throw捕获到的异常并且在方法声明的地方throws异常,才可以将一个异常正确地抛给调用方法的地方
枚举
一般用法
示例代码
EnumDay枚举类继承自java.lang.Enum类,每个枚举对象都是static final的类对象
枚举类型符合通用模式Class Enum<E extends Enum<E>>,E表示的就是枚举类型的名称
枚举类型的每一个值都将映射到protected Enum<String name, int ordinal>构造函数中
每个枚举值都是一个泛型为EnumDay的Enum
遍历枚举类型及枚举方法
为枚举类型中的枚举值定义数值----自定义属性和方法
示例代码<br>
可以为枚举类型自定义方法,也可以自定义属性,也可以重写父类中的方法(如果不自定义方法的话,只有toString()方法可以重写,<br>因为只有它不是final的),枚举类型是Enum<e extends="" enum<e="">>,所以EnumDay也可以继承类,实现接口,定义更多的方法。</e>
EnumSet、EnumMap
示例代码
都是线程非安全的
枚举的本质<br>
Java的枚举类型也是语法糖
从字节码层面弄明白Java是怎么实现枚举的,顺便了解字节码指令,可以分析所有的类似问题
接口和抽象类
接口interface的作用(<font color="#c41230">使用面向接口编程的思维写代码,使用面向对象的思维建模</font>)
接口限制命名规范,帮助理清楚业务
示例代码
弥补了Java类单继承的不足
接口也可以多继承
实现类就是所有父接口的子类。
降低代码的耦合性。
由于Java多态的特性,接口的引用是可以接受子类对象的,用实现的子类实例化声明的接口后,就可以通过接口调用子类重写的方法。也就是说<font color="#f15a23">调用接口的地方,和实现接口的地方是无关的</font>,增加或者删除了接口,都不需要去改动调用接口的地方,这就大大缩减了代码量、增加了代码的扩展性、灵活性
示例代码<br>
接口比抽象类还抽象,最纯粹的抽象
接口和抽象类的区别
接口和抽象类的概念是不一样的。接口是对动作的抽象,表示的是<font color="#f15a23">这个对象能做什么</font>,比如人可以吃东西、狗也可以吃东西,只要有相同的行为;<br>抽象类是对根源的抽象,表示的是<font color="#f15a23">这个对象是什么</font>,比如男人是人、女人也是人
可以实现多个接口,只能继承一个抽象类
接口中只能定义抽象方法,抽象类中可以有普通方法
接口中只能有静态的不能被改变的数据成员,抽象类可以有普通的数据成员
接口可以有静态方法,不能有静态代码块
领域建模初识
比如设计一个Door,有close和open方法。现在想给门添加一个alarm方法,怎么加
示例代码
表示is a的关系,Door可以抽象为一个类。
我们对AlarmDoor的认知是,其本质一个Door。AlarmDoor具有报警功能,但是本质是一个门,门最基础的行为是开关,但是报警功能不一定有。但是这是基于对业务领域认知的建模
Java中类继承、接口实现的一些细节
接口A有void C()方法,接口B有int C()方法,则无法同时实现这两个接口
示例代码
子主题
个人理解,两个接口有同样的方法抽象,说明业务规范冗余<br>
A是接口,B实现A,C继承B,则C也是A的子类
父子类中有同名属性,不会覆盖
示例代码
一个实现类继承自一个抽象类并且实现了多个接口,那么必须实现所有未被实现的抽象方法
示例代码<br>
Java代码优化
<font color="#c41230">避免未知的错误</font>
在写代码的时候,从源头开始注意各种细节,权衡并使用最优的选择,将会很大程度上避免出现未知的错误,从长远看也极大的降低了工作量。
代码优化的目标是
减小代码的体积
提高代码运行的效率
StringBuilder替换StringBuffer
尽量指定类、方法的final修饰符
编译期会尽量对final修饰的方法进行内联优化
尽量重用对象
尽可能使用局部变量
保存在栈中速度快,生命周期短,不需要垃圾回收
及时关闭流
尽量减少对变量的重复计算
性能隐患代码
优化后代码<br>
在list.size()很大的时候,就减少了很多的消耗
尽量采用懒加载的策略,即在需要的时候才创建
慎用异常。异常只能用于错误处理,不应该用来控制程序流程。
异常对性能不利。抛出异常首先要创建一个新的对象,Throwable接口的构造函数调用名为fillInStackTrace()的本地同步方法,fillInStackTrace()方法检查堆栈,收集调用跟踪信息。只要有异常被抛出,Java虚拟机就必须调整调用堆栈,因为在处理过程中创建了一个新的对象。
如果能估计到待添加的内容长度,为底层以数组方式实现的集合、工具类指定初始长度
比如ArrayList、LinkedLlist、StringBuilder、StringBuffer、HashMap、HashSet等等
像HashMap这种是以数组+链表实现的集合,别把初始大小和你估计的大小设置得一样,因为一个table上只连接一个对象的可能性几乎为0。初始大小建议设置为2的N次幂,如果能估计到有200个元素,设置成new HashMap(128)、new HashMap(256)都可以。
当复制大量数据时,使用System.arraycopy()命令
乘法和除法使用移位操作
移位操作虽然快,但是可能会使代码不太好理解,因此最好加上相应的注释。
<font color="#f15a23">循环内不要不断创建对象引用</font>
low代码
优化后代码
这样的话,内存中只有一份Object对象引用,每次new Object()的时候,Object对象引用指向不同的Object罢了,<br>但是内存中只有一份,这样就大大节省了内存空间了。
基于效率和类型检查的考虑,应该尽可能使用array,无法确定数组大小时才使用ArrayList
尽量使用HashMap、ArrayList、StringBuilder,除非线程安全需要,否则不推荐使用Hashtable、Vector、StringBuffer,<br>后三者由于使用同步机制而导致了性能开销
不要将数组声明为public static final
因为这毫无意义,这样只是定义了引用为static final,数组的内容还是可以随意改变的,<br>将数组声明为public更是一个安全漏洞,这意味着这个数组可以被外部类所改变
尽量在合适的场合使用单例
使用单例可以减轻加载的负担、缩短加载的时间、提高加载的效率,但并不是所有地方都适用于单例
单例的适合场景
控制资源的使用,通过线程同步来控制资源的并发访问
控制实例的产生,以达到节约资源的目的
控制数据的共享,在不建立直接关联的条件下,让多个不相关的进程或线程之间实现通信
尽量避免随意使用静态变量
当某个对象被定义为static的变量所引用,那么gc通常是不会回收这个对象所占有的堆内存的
此时静态变量b的生命周期与A类相同,如果A类不被卸载,那么引用B指向的B对象会常驻内存,直到程序终止
及时清除不再需要的会话
实现RandomAccess接口的集合比如ArrayList,应当使用最普通的for循环而不是foreach循环来遍历
随机访问的,使用普通for循环效率将高于使用foreach循环;反过来,如果是顺序访问的,则使用Iterator会效率更高
foreach循环的底层实现原理就是迭代器Iterator
示例代码<br>
使用同步代码块替代同步方法
避免对那些不需要进行同步的代码也进行了同步,影响了代码执行效率。
减小锁的粒度
将常量声明为static final,并以大写命名
这样在编译期间就可以把这些内容放入常量池中,避免运行期间计算生成常量的值。另外,将常量的名字以大写命名也可以方便区分出常量与变量
不要创建一些不使用的对象,不要导入一些不使用的类
理由:无意义
程序运行过程中避免使用反射
如果确实有必要,一种建议性的做法是将那些需要通过反射加载的类在项目启动的时候通过反射实例化出一个对象并放入内存----用户只关心和对端交互的时候获取最快的响应速度,并不关心对端的项目启动花多久时间。
使用数据库连接池和线程池
这两个池都是用于重用对象的,前者可以避免频繁地打开和关闭连接,后者可以避免频繁地创建和销毁线程
使用带缓冲的输入输出流进行IO操作
带缓冲的输入输出流,即BufferedReader、BufferedWriter、BufferedInputStream、BufferedOutputStream,这可以极大地提升IO效率
顺序插入和随机访问比较多的场景使用ArrayList,元素删除和中间插入比较多的场景使用LinkedList
不要让public方法中有太多的形参,形参多封装成传输对象DTO
字符串变量和字符串常量equals的时候将字符串常量写在前面
公用的集合类中不使用的数据一定要及时remove掉
把一个基本数据类型转为字符串,基本数据类型.toString()是最快的方式、String.valueOf(数据)次之、数据+""最慢
使用最有效率的方式去遍历Map
遍历Key和value<br>
遍历key
对资源的close()建议分开操作
对于ThreadLocal使用前或者使用后一定要先remove
线程池中的线程会被复用,线程不销毁意味着上条线程set的ThreadLocal.ThreadLocalMap中的数据依然存在,<br>那么在下一条线程重用这个Thread的时候,很可能get到的是上条线程set的数据而不是自己想要的内容。
以常量定义魔法数字
字符串是否以常量定义并不总是必须的,视情况而为
long或者Long初始赋值时,使用大写的L而不是小写的l,因为字母l极易与数字1混淆,这个点非常细节,值得注意
所有重写的方法必须保留@Override注解
清楚地可以知道这个方法由父类继承而来
getObject()和get0bject()方法,前者第四个字母是"O",后者第四个子母是"0",加了@Override注解可以马上判断是否重写成功
在抽象类中对方法签名进行修改,实现类会马上报出编译错误
推荐使用JDK7中新引入的Objects工具类来进行对象的equals比较,直接a.equals(b),有空指针异常的风险
循环体内不要使用"+"进行字符串拼接,而直接使用StringBuilder不断append
使用+编译器编译后还是会new StringBuilder,这样循环中会new很多StringBuilder对象 <br>
不捕获Java类库中定义的继承自RuntimeException的运行时异常类
避免Random实例被多线程使用,虽然共享该实例是线程安全的,但会因竞争同一seed 导致的性能下降,<br>JDK7之后,可以使用ThreadLocalRandom来获取随机数
静态类、单例类、工厂类将它们的构造函数置为private
动态代理
可以结合自己的博客复习,有讲到动态代理和Cglib原理
我们把对于待生成代理的接口方法的调用,变成了对于InvocationHandler接口实现类的invoke方法的调用
Thread.sleep(XXX)方法消耗CPU吗?
Thread.sleep(1000)的意思是:代码执行到这儿,1秒钟之内我休息一下,就不参与CPU竞争了,1秒钟之后我再过来参与CPU竞争。
sleep和wait的区别
seelp不释放锁,wait释放锁。在同步代码块中,wait如果后面有代码,执行wait会立即释放锁,wait的后面的代码的线程安全无法得到保障
Thread.sleep(0)的作用
线程调度指的是系统为线程分配处理器使用权的过程,主要调度方式有两种
协同式线程调度
抢占式线程调度
总结<br>
CPU分出来的时间片,可以竞争的线程都是会去竞争获取的
调用了Thread.sleep(XXX)方法的线程,意味着在XXX毫秒的时间内,该线程不参与CPU时间片的竞争
Thread.sleep(0)的作用
<font color="#f15a23">强制操作系统触发一次CPU计算优先级并分配时间片的动作。</font>比如线程A获得了5毫秒的CPU执行时间,如果在执行了2毫秒的时候遇到了Thread.sleep(0)语句,那么后面的3毫秒的时间片就不运行了,操作系统重新计算一次优先级,并分配下一个CPU时间片给哪个线程。
好处
避免了某一线程长时间占用CPU资源,我们知道在Java中比如开了两个非守护线程,线程优先级为10的线程A与线程优先级为5的线程B同时执行,这意味着操作系统基本上绝大多数时间都在运行线程A,基本不会把CPU控制权交给线程B
避免了系统假死
让线程有比较平均的机会获得CPU资源
总结
不过Thread.sleep(0)虽然好,但是不要去滥用它。一个系统CPU占用率高是好事情,这意味着CPU在做事情,没有闲着。但是CPU占用率高还得保证CPU做的事情是<font color="#f15a23">应该做的事情</font>,比如CPU占用率高,但是在死循环,有意义吗?这就是代码写得有问题。Thread.sleep(0)也一样,这句语句触发了操作系统计算优先级、分配时间片的动作,势必占用CPU的时间,如果在很多线程里面都滥用这个方法的话,CPU使用率是上去了,但大多数时间做的都是无意义的事情。我认为这个动作的<font color="#f15a23">目的更多是为了优化系统,而不是代码必须执行的一部分</font>。
可变对象(immutable)和不可变对象(mutable)
String为什么是不可变的
字符数组容器是final修饰
但是只是引用不可变,内容依然可变,光final修饰无法保证不可变
不可变对象就是那些一旦被创建,它们的状态就不能被改变的对象,<font color="#f15a23">每次对它们的改变都是产生了新的对象</font>
可变对象就是那些创建后,状态依然可以被改变的对象
不可变的对象对比可变对象有两点优势:
保证对象的状态不被改变
不使用锁机制就能被其他线程共享
不可变对象举例
实际上JDK本身就自带了一些不可变类,比如String、Integer、Float以及其他的包装类,判断的方式就是看它们真正的那个对象是不是final的就好了。
创建不可变对象应该遵循几个原则
不可变对象的状态在创建之后就不能发生改变,任何对它的改变都应该产生一个新的对象
不可变对象的所有属性应该都是final的
对象必须被正确地创建,比如对象引用在创建过程中不能泄露
?
对象应该是final的,以此来限制子类继承父类,以避免子类改变了父类的不可变特性
使用不可变类的好处
不可变类是线程安全的,可以不被synchronized修饰就在并发环境中共享
不可变对象简化了程序开发,因为它无需使用额外的锁机制就可以在线程之间共享
不可变对象提高了程序的性能,因为它减少了synchronized的使用
不可变对象时可以被重复利用的,你可以将它们缓存起来,就像字符串字面量和整型数值一样,可以使用静态工厂方法来提供类似于valueOf这样的方法,<br>它可以从缓存中返回一个已经存在的不可变对象,而不是重新创建一个
不可变对象的坏处
每次修改都创建新的对象,给垃圾收集带来压力
字符串保存密码不要保存明文,要用密文,否则明文的字符串使用后常驻内存,任何可以访问内存的手段都可以访问到明文密码
计算密集型任务和IO密集型任务
计算密集型
顾名思义就是应用程序需要非常多的CPU计算资源,在多核CPU时代,我们要让每一个CPU核心都参与计算,将CPU性能充分利用起来,这样才算是没有浪费服务器配置,如果在非常好的服务器配置上还运行着单线程程序那将是多么大的浪费。
对于计算密集型的应用,完全是靠CPU的核数来工作的,所以为了让它的优势完全发挥出来,避免过多的上下文切换,比较理想的方案是两种
(1)线程数 = CPU核数 + 1
(2)线程数 = CPU核数 * 2
IO密集型
对于IO密集型的应用,就很好理解了,我们现在做的大部分开发都是WEB应用,涉及到大量的网络传输,不仅如此,与数据库、与缓存之间的交互也涉及IO,一旦发生IO,线程就会处于等待状态,当IO结束,数据准备好之后,线程才会继续执行。
对于IO密集型的应用,我们可以多设置一些线程池中的线程数量,这样就能让在等待IO的这段时间内,线程可以去做其他事情,提供并发处理效率。但是这个线程池的线程数量也不是可以随意增大,因为线程上下文切换是有代价的,对于IO密集型的应用,线程数的计算有一个公式
线程数 = CPU核心数 / (1 - 阻塞系数)
作者的验证过程记一下
Reactor模式
将所有要处理的IO时间注册到一个中心IO多路复用器上,同时主线程阻塞在多路复用器上,一旦有IO时间到来或是准备就绪,多路复用器返回并将相应IO时间分发到对应的处理器当中,这就是一种典型的事件驱动机制。Reactor模式是编写高性能网络服务器的必备技术之一
优点<br>
响应快,不必为同步单个时间所阻塞,虽然Reactor本身依然是同步的
编程相对简单,可以最大程度地避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销
可扩展性好,可以方便地通过增加Reactor实例个数来充分利用CPU资源
可复用性好,Reactor框架本身与具体事件处理逻辑无关
Unsafe与CAS
Unsafe
提供了硬件级别的原子操作。
方法举例
public native long staticFieldOffset(Field paramField);
public native int arrayBaseOffset(Class paramClass);<br>public native int arrayIndexScale(Class paramClass);
public native long allocateMemory(long paramLong);<br>public native long reallocateMemory(long paramLong1, long paramLong2);<br>public native void freeMemory(long paramLong);
CAS
CAS有三个操作数:内存值V、旧的预期值A、要修改的值B,当且仅当预期值A和内存值V相同时,<br>将内存值修改为B并返回true,否则什么都不做并返回false。
可以看AbstractQueuedSynchronizer中的应用
由CAS分析AtomicInteger原理
示例代码
valueOffset表示的是变量值在内存中的偏移地址,因为Unsafe就是根据内存偏移地址获取数据的原值的
value是用volatile修饰的,这是非常关键的
addAndGet
<font color="#c41230">分析</font><br>
CAS的缺点
ABA问题
ABA问题的解决和讨论<br>
扩展阅读及更多<br>
sun.misc.Unsafe的各种神技Unsafe
Java Magic. Part 4: sun.misc.Unsafe
线程进阶:多任务处理(17)——Java中的锁(Unsafe基础)
通过反射和Unsafe可以打破单例模式,生成多例<br>
40个Java多线程问题总结
CPU执行代码,执行的不是Java代码,这点很关键,一定得记住。Java代码最终是被翻译成机器码执行的,机器码才是真正可以和硬件电路交互的代码。即使你看到Java代码只有一行,甚至你看到Java代码编译之后生成的字节码也只有一行,也不意味着对于底层来说这句语句的操作只有一个。一句"return count"假设被翻译成了三句汇编语句执行,一句汇编语句和其机器码做对应,完全可能执行完第一句,线程就切换了。
锁粗化<br>
高并发、任务执行时间短的业务怎样使用线程池?并发不高、任务执行时间长的业务怎样使用线程池?并发高、业务执行时间长的业务怎样使用线程池?
Java Socket
什么是Socket
网络上运行的两个程序间双向通讯的一端,既可以接收请求,也可以发送请求,利用它可以较为方便地编写网络上数据的传递。
Socket之间的连接过程可以分为几步
服务器监听
服务器端Socket并不定位具体的客户端Socket,而是处于等待连接的状态,实时监控网络状态
客户端请求
客户端Socket发出连接请求,要连接的目标是服务端Socket。为此,客户端Socket必须首先描述它要连接的服务端Socket,指出服务端Socket的地址和端口号,然后就向服务端Socket提出连接请求
连接确认
当服务端Socket监听到或者说是接收到客户端Socket的连接请求,它就响应客户端Socket的请求,建立一个新的线程,把服务端Socket的描述发给客户端,一旦客户端确认了此描述,连接就好了。而服务端Socket继续处于监听状态,继续接收其他客户端套接字的连接请求
TCP/IP、HTTP、Socket的区别
TCP/IP讲的其实是两个东西:TCP和IP。IP是一种网络层的协议,用于路由选择、网络互连
TCP是一种传输层协议,用于建立、维护和拆除传送连接,在系统之间提供可靠的透明的数据传送
HTTP是一种应用层协议,提供OSI用户服务,例如事物处理程序、文件传送协议和网络管理等,其目的最终是为了实现应用进程之间的信息交换
Socket,它只是TCP/IP网络的API而已,Socket接口定义了许多函数,用以开发TCP/IP网络上的应用程序,组织数据,以符合指定的协议。
Socket的两种模式
面向连接
无连接
传统的一请求一应答通信模型,也就是Blocking IO模型即BIO,不适合高并发场景
多线程上下文切换
上下文切换次数查看
vmstat查看cs(Context Switch)
如果要查看上下文切换的时长,可以利用Lmbench3,这是一个性能分析工具。
如何减少上下文切换
无锁并发编程
多线程竞争时,会引起上下文切换,所以多线程处理数据时,可以用一些办法来避免使用锁,<br>如将数据的ID按照Hash取模分段,不同的线程处理不同段的数据
CAS算法
Java的Atomic包使用CAS算法来更新数据,而不需要加锁
使用最少线程
避免创建不需要的线程,比如任务很少,但是创建了很多线程来处理,这样会造成大量线程都处于等待状态
协程
在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换
切勿用普通for循环遍历LinkedList
Java回调机制解读
模块间调用
同步调用
这种调用方式适用于方法b()执行时间不长的情况
异步调用
异步调用是为了解决同步调用可能出现阻塞,导致整个流程卡住而产生的一种调用方式。<font color="#f15a23">类A的方法方法a()通过新起线程的方式调用类B的方法b()</font>,代码接着直接往下执行,这样无论方法b()执行时间多久,都不会阻塞住方法a()的执行。但是这种方式,由于方法a()不等待方法b()的执行完成,在方法a()需要方法b()执行结果的情况下(视具体业务而定,有些业务比如启异步线程发个微信通知、刷新一个缓存这种就没必要),必须通过一定的方式对方法b()的执行结果进行监听。在Java中,可以使用Future+Callable的方式做到这一点
回调
类A的a()方法调用类B的b()方法
类B的b()方法执行完毕主动调用类A的callback()方法
代码实现
回调的核心就是回调方将本身即this传递给调用方
同步回调与异步回调
有多种数据需要处理且数据有主次之分,使用回调会是一种更加合适的选择,优先处理的数据放在回调方法中先处理掉。
Cglib及其基本使用
使用Cglib定义不同的拦截策略
在JVM中执行程序并不一定非要写Java代码----只要你能生成Java字节码,JVM并不关心字节码的来源
程序最终如何运行,也不是只看java代码,或者编译后的字节码,有的时候要看最后转化的机器码是什么样,<br>不过大部分的程序代码执行过程不会隐藏的那么深,但是要掌握查看字节码甚至机器码的方法
构造函数不拦截方法
我们为什么要使用AOP?
AOP使用场景举例
MyBatis事务自动提交
权限控制
日志记录
特殊的注解解析
Java日志框架:slf4j作用及其实现原理
slf4j的作用:只要所有代码都使用门面对象slf4j,我们就不需要关心其具体实现,最终所有地方使用一种具体实现即可,更换、维护都非常方便。
Logger logger = LoggerFactory.getLogger(Object.class);
getLogger的时候会去classpath下找STATIC_LOGGER_BINDER_PATH,STATIC_LOGGER_BINDER_PATH值为"org/slf4j/impl/StaticLoggerBinder.class",即所有slf4j的实现,在提供的jar包路径下,一定是有"org/slf4j/impl/StaticLoggerBinder.class"存在的
Java日志框架:logback详解
记一次synchronized锁字符串引发的坑兼再谈Java字符串
分布式
集合<br>
Arraylist
特征:动态数组
如何实现的动态数组,如何扩容
默认容量是10
private static final int DEFAULT_CAPACITY = 10;
主要属性
transient Object[] elementData;
private int size;
插入
add(E e)
向数组末尾添加数据项<br>
ensureCapacityInternal
calculateCapacity
如果存储的内容为空,就返回默认存储空间大小和实际存储数据长度的最大值
ensureExplicitCapacity
modcount是统计结构变化的次数,比如扩容了几次
if判断,是判断实际存储的数据比ArrayList长度要大,就扩容
grow
先将容量扩为:原数组大小+原数组大小/2
上面的长度仍然比这次添加的长度小,新的数组长度就是这次添加的长度
如果新的长度比Integer最大值-8大,就去判断当前的实际长度是不是大于Integer的最大值-8,大于,就返回Integer的最大值,否则返回Integer最大值-8
最后得到的扩容长度,使用System.arraycopy复制原有内容到一个新的长度的数组中
elementData[size++] = e;
public void add(int index, E element)
在指定位置插入数据项,总是会进行数组拷贝,需要移动指定位置后面的数据
删除
public E remove(int index)
根据下标删除
如果要删除的位置不是末位,都需要把要删除位置后面的数据项迁移一位,用到数组拷贝方法<br>
最后一位空了出来,设置为null,让GC去回收,不设置为null,被删除的数据项只是逻辑删除,实际上仍然存在一个引用
public boolean remove(Object o)
根据数据项删除,由于ArrayList中的数据是可以重复的,这种删除会删除第一个匹配的数据项
测试代码
测试的时候一开始误以为会无论如何多进行一次数据拷贝,浪费时间,<br>然而并不是这样的,如果是最后一项,不需要进行数组拷贝
查询
由于内部使用数组作为基本的容器存储,所以查询支持根据索引随机访问
支持排序、迭代、随机访问
优缺点
根据索引查询数据项很快,复杂度O(1)<br>
添加元素
末尾添加,O(1)
其他位置添加,最坏复杂度O(n)
删除
同添加
ArrayList是非线程安全的,如果想使用的线程安全的,怎么用
Collections.synchronizedList(List<T> list)
CopyOnWriteArrayList
为什么ArrayList的elementData是用transient修饰的?
因为序列化ArrayList的时候,ArrayList里面的elementData未必是满的,ArrayList中重写了writeObject方法
LinkedList
双向链表
主要属性
transient int size = 0;
transient Node<e> first;</e>
transient Node<E> last;
主要特征:<br>
允许空
允许重复
有序
非线程安全
添加
add(E e)
linkLast(E e)
last赋值给l,l拥有last的原始数据
构造一个新节点
新节点赋值给last<br>
如果l保存的last原始内容为null,说明该LinkedList原本的最后一个节点为null,<br>说明该LinkedList为空,新节点赋值给first,表示第一个节点,此时first和last都指向这个新节点<br>
否则将新节点赋值给l.next
size++;
modCount++;
addLast(E e)
linkLast(E e)
addFirst(E e)
linkFirst(e);
first保存的内容首先赋值给f
构造新节点
新节点赋值给first<br>
如果f保存的原始首节点内容为空,说明当前加入的是第一个节点,新节点也赋值给last,此时,first和last都指向这第一个节点<br>
否则,last节点赋值给f.prev,说明原始的first指向一个元素,在这个元素插入这个新节点
size++;
modCount++;
add(int index, E element)
在指定位置插入新数据项<br>
checkPositionIndex(index);
越界检查,快速试错
如果是插入到链表最后
使用尾插法linkLast(element);
否则linkBefore(element, node(index));
node(index)
返回给定索引对应的数据项
根据链表长度折半遍历查找<br>
如果要查的索引在链表的前半部分,从首节点向后逐个查找
如果要查的索引在链表的后半部分,从尾结点向前逐个查找
linkBefore(E e, Node<e> succ)</e>
将根据索引定位到的原数据项的前驱节点保存,赋值给pred
构造新节点new Node<>(pred, e, succ);
将新节点通过原索引位置节点的prev指针链接到原位置的前面<br>
如果原先该索引位置的前驱节点为空,说明当前加的是链表的第一个数据项
否则将新节点赋值给原索引位置的前驱节点的next
size++;
modCount++;
set(int index, E element)
设置某个索引位置的数据项,只改内容,前驱后继不用管
addAll(Collection<!--? extends E--> c)
offer(E e)
调用linkLast
offerFirst(E e)
调用addFirst(e);
offerLast(E e)
调用addLast(e);
push(E e)
调用addFirst(e);
删除
removeFirst()
unlinkFirst(f)
保存首节点数据项<br>
保存首节点next指向,因为这个首节点要被移除,next指针也需要解除<br>
清空原首节点数据项
原首节点next指针清空
原首节点的next节点赋值给first<br>
如果原首节点的next指向为空,说明原来链表中只有一个元素,last赋值为null
否则,说明节点中数据项大于1个,原首节点的后继节点成为新的首节点,现在把这个新节点的prev指针指向null
size--;
modCount++;
remove()
调用removeFirst();
removeLast()
unlinkLast(l)
过程和unlinkFirst类似<br>
remove(Object o)
由于允许存储null,所以会先定位有没有存储null,如果有,调用unlink方法<br>
unlink
保存要删除的数据项引用
保存要删除的数据项next引用
保存要删除的数据项prev引用
如果原数据项前驱为空,说明是链表中原来的首节点,把该节点的next设置为首节点
如果原数据项前驱引用不为空,原数据项的前驱节点的后继引用设置为原数据项的后继节点,原数据项的前驱引用设置为null
如果原数据项的next指向为null,说明是链表的尾节点,原数据项的前驱设置为last
如果原数据项的后继不为空,原数据项后继的前驱引用设置为原数据项的前驱节点,原数据项的后继引用设置为null
原数据项设置为null
size--;
modCount++;
非空数据项逐个遍历,使用equals
remove(int index)
checkElementIndex(index);
越界检查,快速试错
unlink(node(index))
node(index)
clear()
poll()
同removeFirst
pollFirst
同removeFirst
pollLast
同removeLast
pop()
调用removeFirst()
removeLastOccurrence(Object o)
removeFirstOccurrence
调用remove(o)
查询
getFirst()
getLast()
contains(Object o)
indexOf(o) != -1;
运行存储null为数据项
size()
get(int index)
获取指定位置的数据项,使用到node方法
indexOf(Object o)
返回索引位置,从前向后逐个遍历
lastIndexOf(Object o)
返回索引位置,从后向前逐个遍历
peek()
获取头结点
element()
同getFirst()
peekFirst
同getFirst()
peekLast
同getLast()
切勿用普通for循环遍历LinkedList
LinkedList在get任何一个位置的数据的时候,都会把前面的数据走一遍,复杂度O(N^2)
get方法调用node方法遍历
遍历LinkedList使用foreach或者迭代器(foreach是编译期提供的语法糖,编译后还是会使用迭代器)
使用foreach循环时,编译期插入的迭代器使用的是ListItr,可以看下LinkedList内部的ListItr的next方法
为什么会调用ListItr迭代器,可以debug看一下list.iterator()
LinkedList并没有重写iterator方法,而是在其父类AbstractSequentialList.iterator()
内部调用listIterator方法
AbstractSequentialList中的listIterator方法需要子类实现,即最终会调用LinkedList中的listIterator
HashMap
特征:
key和value都可以空
key重复会覆盖,value允许重复
无序<br>
非线程安全
单向链表,只有后继;默认容量是16,Node数组长度为16<br>
添加
public V put(K key, V value)
hash(key)
key允许null值,如果是null,这次rehash返回0
对key的hashCode做了一次rehash,key的hashCode的高16位和低16位异或运算,提高hash的随机性
putVal(hash(key), key, value, false, true);
如果HashMap的table为空,调用resize方法扩容,扩容后的Node数组赋值给tab,并返回扩容后的数组长度给n
通过(n - 1) & hash获取hash桶的位置,将这个位置上的数赋值给p,判断这个数是不是null,<br>是null说明该位置没有内容,调用newNode方法构造节点赋值给这个计算的位置
如果通过取余长度n得到的的位置上的值不为null
判断两个key的hash和key本身是否相等
判断这个定位到的节点是不是TreeNode
如果是TreeNode,调用putTreeVal
如果key既不相同,节点也不是TreeNode,遍历链表
如果该桶位置的next指针指向null,说明是链表的目前只有一个节点,将新定位到的这个值赋值给p.next,即使用尾插法
如果链表长度>=8,调用treeifyBin(tab, hash);
如果e不等于null,说明这个桶上的key和现在要put的key相同,准备处理对应的value,是使用新的value还是旧的value
++modCount;
如果实际存储长度大于阈值,调用resize
afterNodeInsertion(evict);
为子类服务
++modCount;
为迭代时fail-fast服务
如果实际长度>阈值,扩容
afterNodeInsertion(evict);
这个是为子类服务的,比如LinkedHashMap<br>
删除
public V remove(Object key)
首先调用hash方法对key的hashcode进行rehash
removeNode(hash(key), key, null, false, true))
如果Node不为空,并且哈希桶长度>0,并且通过hash取余数组长度<br>获得的索引位置上的节点不为空,开始remove逻辑
如果这个定位到的节点的hash值等于要移除元素的hash<br>并且这个节点的key等于要移除元素的key,就把p赋值给node
如果这个节点的next指针不为空,判断是不是树节点,<br>是树节点调用getTreeNode从树节点找,否则遍历链表找,找到的元素都赋值给node
如果找到这个待删除的节点,<br>开始删除逻辑,依然分三种情况
如果是树节点,调用removeTreeNode
如果是数组节点,当前位置设置为要删除节点的下一个节点
如果是单链表节点,将要删除节点的上一个节点的next指针指向删除节点的next,<br>这里的p已经因为上面的链表遍历而成为要删除的上一个节点,因为每次循环都会p = e;
++modCount;
--size;
afterNodeRemoval(node);
子类实现逻辑
return node;
查询
get
hash(key)
getNode(int hash, Object key)
如果table不为空,并且table的长度>0,并且hash取余数组长度<br>定位到的元素不为null(定位到桶的位置),开始处理查询逻辑
如果通过rehash后的hashcode取余数组长度,定位到的元素的hash和<br>现在传入的key的hash相同,并且两个key本身(==或者equals)相同,直接返回
如果定位到的位置,key不同,说明这个位置上有冲突链存在,<br>处理链表查询逻辑,如果first.next不为空,有后继,开始处理
如果first node是一个TreeNode,调用getTreeNode处理红黑树的查询
否则遍历链表查找<br>
resize
分析调用resize的地方就可以知道扩容时机是什么
将table赋值给oldTab
oldCap存储哈希表长度
threshold赋值给oldThr
threshold会在初始化时确定
如果使用无参构造实例化HashMap,默认值是0
如果使用有参构造函数实例化HashMap,会通过tableSizeFor获取一个比初始容量-1大的二次幂的数
为什么一定是二次幂?为了hash能够让key的hashcode更加的分散,减少冲突,提高效率
int newCap, newThr = 0;
如果不是第一次put调用resize,
如果oldCap已经大于最大容量MAXIMUM_CAPACITY
阈值设置为Integer的最大值,oldTab直接返回
否则将OldCap*2赋值给newCap,这个时候newCap如果小于最大容量MAXIMUM_CAPACITY,并且oldCap>=默认值DEFAULT_INITIAL_CAPACITY
将阈值也扩容为原来的两倍
如果是第一次put的时候调用resize
如果oldCap<=0并且oldThr>0
将新的容量设置为oldThr
如果newThr==0,算出新的阈值
如果算出的新阈值和新的容量都<最大容量,设置新阈值为这个算出的,否则设置为Integer的最大值
如果是<font color="#c41230">第一次调用无参构造实例化HashMap</font><br>
容量为默认值16
阈值为16*0.75=12
threshold = newThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
用上面得到的新容量实例化数组
table = newTab;
如果oldTab不为空,开始遍历赋值老数据到新的哈希表中
e = oldTab[j],下面都是对e操作,当前节点已经赋值给e
oldTab[j] = null;
当前节点设置为null<br>
判断当前节点上有没有冲突链
如果没有,当前节点的hash取余新的容量大小,即取余数组长度大小
key为null始终在第一位,即下标为0
如果是树节点,调用split
如果是链表节点
如果(e.hash & oldCap) == 0成立,即当前节点hash取余原来的容量等于0,会被放置到lo
lo的头结点会被放置到哈希桶的原来位置
否则在hi,<font color="#c41230">lo和hi各自构成新的链表</font><br>
hi的头结点会被放置到哈希桶的原来位置+oldCap的位置
putTreeVal
treeifyBin(tab, hash);
这个方法是在<font color="#c41230">冲突链表长度大于8的时候调用的,当哈希表长度小于64,会调用resize扩容</font>,不是立即构造红黑树。<br>也就是说,<font color="#c41230">构造红黑树的条件是:冲突链表长度>=8,并且哈希表总长度>=64</font>
否则,构造红黑树
getTreeNode
从根节点找
split
当前节点的hash按位与oldCap如果==0
放入lo,比链表的分区多了++lc,这个统计是为了将树变为链表
否则放入hi<br>
如果上面的统计值lc<=6,调用untreeify方法将树节点变为链表节点,否则调用treeify构造红黑树,头结点或者root节点依然在原先的位置上
untreeify
treeify
如果hc<=6,调用untreeify方法将树节点变为链表节点,否则调用treeify构造红黑树,头结点或者root节点依然在原先的位置上
遍历<br>
EntrySet
遍历示例
foreach循环是编译期提供的语法糖,从反编译看就可以清楚的知道真正的循环执行逻辑
HashMap.entrySet返回Set,调用Set的Iterator获取到迭代器
下面就是常规的先用迭代器的hasNext判断,再用next拿值
HashMap.entrySet()
HashMap中的entrySet属性
类型是Set,泛型是Map.Entry<k,v></k,v>
Map.Entry其实就是Node,这个是继承自HashMap父接口的Map.Entry
看一下Node的类声明<br>
entrySet属性什么时候被赋值的?
size
size是实际长度,包括冲突链表或者冲突树上的节点,++size在put方法最后可知这一点
HashMap作为实例变量在多线程环境下使用,会在扩容时发生死循环<br>
代码
LinkedHashMap
特征
Key和Value都允许空
Key重复会覆盖、Value允许重复
有序
非线程安全
继承自hashmap
Entry继承自Hashmap的Node,添加了before和after节点的引用
主要属性<br>
由于继承了HashMap,所以HashMap的public和default属性都能继承(HashMap中只有序列化Id是private)<br>
head
tail
accessOrder
false,所有的Entry按照插入的顺序排列
true,所有的Entry按照访问的顺序排列
利用LinkedHashMap实现LRU算法缓存
什么是LRU
LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据。比方说数据a,1天前访问了;数据b,2天前访问了,缓存满了,优先会淘汰数据b。
LRU(Least Recently Used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
内部实现原理
如果有1 2 3这3个Entry,那么访问了1,就把1移到尾部去,即2 3 1。每次访问都把访问的那个数据移到双向队列的尾部去,那么每次要淘汰数据的时候,双向队列最头的那个数据不就是最不常访问的那个数据了吗?换句话说,双向链表最头的那个数据就是要淘汰的数据。
put,没有重写put方法,put逻辑和HashMap相同
和HashMap不同的是构造新节点时,LinkedHashMap重写了newNode方法,<br>假如插入了一个新节点,此时newNode调用的是LinkedHashMap重写的newNode方法
HashMap中调用newNode<br>
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
这个方法是<font color="#c41230">将新加的节点始终插入到链表尾部</font>
put方法返回前会调用afterNodeInsertion(evict);,afterNodeInsertion是在LinkedHashMap中实现的
removeEldestEntry(first)默认返回false,不会删除任何节点
如果想要实现LRU缓存,可以去实现这个方法
get
首先进行非空判断,边界检查,如果查询不到这个key,就返回null
查询逻辑是HashMap的查询逻辑,根据rehash后的hashcode取余size得到该key所在的桶的位置索引,判断索引上的值是否为空
如果accessOrder为true,调用afterNodeAccess(e);
void afterNodeAccess(Node<k,v> e)</k,v>
满足条件就把访问的节点移到map最后
accessOrder是true
当前节点不是尾节点,尾节点已经在最后,不需要移动
否则返回key对应的value
总结:
put的时候,如果实现了afterNodeInsertion,满足afterNodeInsertion中的条件,就把map中第一个节点删除
get的时候,如果满足afterNodeAccess调用条件,调用afterNodeAccess方法,将访问的节点移到map最后
HashSet
使用HashMap实现,利用key不重复的特点
JUC
CopyOnWriteArrayList
JUC下的包,为并发而设计
主要特征
允许空<br>
允许重复
有序
线程安全<br>
主要属性
final transient ReentrantLock lock = new ReentrantLock();
可重入锁,用来实现互斥和同步的基本组件
private transient volatile Object[] array;
存储容器,真正用来存数据的数据结构是数组
添加
add(E e)
加锁
得到原数组,默认构造器初始化的是一个长度为0的Object数组<br>
扩容,得到一个原数组长度+1的新数组,需要将原数组内容拷贝<br>
添加新元素到新数组中<br>
设置内部数组的引用为这个新的数组<br>
解锁
返回true
添加方法,每次都会进行数组拷贝,优点也是缺点,视具体的问题场景使用,适合读多写少
优点
多线程环境下读写是线程安全的
缺点
<font color="#c41230">每个写都需要拷贝数组,耗费时间和空间</font>
体现的分布式设计思想
读写分离
<font color="#c41230">读取的是CopyOnWriteArrayList中的Object[] array</font>
<font color="#c41230">修改的时候,操作的是一个新的Object[] array</font>
适合读多写少的场景,如果极端的情况,都是写写,由于写写加锁,会严重影响性能
最终一致
最终一致对于分布式系统也非常重要,它通过容忍一定时间的数据不一致,提升整个分布式系统的可用性与分区容错性。当然,最终一致并不是任何场景都适用的,像火车站售票这种系统用户对于数据的实时性要求非常非常高,就必须做成强一致性的。
删除
查询
遍历
和查询一样,都是原数组内容
CopyOnWriteArraySet
ReentrantLock
公平锁和非公平锁,默认是非公平锁
公平锁和非公平锁都是继承自AbstractQueuedSynchronizer
AbstractQueuedSynchronizer提供了模板方法,是模板模式的典型应用
获取锁资源的操作都是使用CAS自旋来保证线程安全,在子操作逻辑里都需要考虑线程进入的可能性,<br>
AbstractQueuedSynchronizer
Node
这个内部类的作用:多个线程并发获取锁资源,竞争失败的线程通过cas加入等待队列尾部,并且从队列中获取线程节点<br>
双向链表实现的队列
ConditionObject
单链表实现的队列
模板方法<br>
tryAcquire
tryRelease
tryAcquireShared
tryReleaseShared
isHeldExclusively
IO
IO流的基础File
RandomAccessFile
特征
支持<font color="#c41230">随机访问</font>,可以<font color="#c41230">跳转到文件的任意位置处读写数据</font>。要访问一个文件的时候,不想把文件从头读到尾,而是希望像访问一个数据库一样地访问一个文本文件,使用RandomAccessFile类是最佳选择。
RandomAccessFile对象类中有个<font color="#c41230">位置指示器</font>,指向当前读写处的位置,当读写n个字节后,文件指示器将指向这n个字节后的下一个字节处。刚打开文件时,文件指示器指向文件的开头处,可以移动文件指示器到新的位置,随后的读写将从新的位置开始。
RandomAccessFile类在文件随机(相对于顺序)读取时有很大的优势,但该类仅限于<font color="#c41230">操作文件</font>,不能访问其他得IO设备,如网络、内存映像等。
主要的构造方法
RandomAccessFile(File file, String mode)
rw:打开以便读取和写入,如果该文件尚不存在,则尝试创建该文件
Java并不强求指定的路径下一定存在某个文件,假如文件不存在,会自动创建
主要方法
读<br>
写
skipBytes(int n)
跳出指定字节,将文件指针移到指定位置,相对于当前位置<br>
seek(long pos)
将文件指针移到某个字节长度的位置,相对于文件开始,比如seek(0),代表移到文件开始位置处
字节流
概述
Java的流式输入/输出是建立在四个抽象类的基础上的:InputStream、OutputStream、Reader、Writer。它们用来创建具体的流式子类。尽管程序通过具体子类执行输入/输出操作,但顶层类定义了所有流类的基本通用功能。
InputStream和OutputStream为字节流设计,Reader和Writer为字符流设计,字节流和字符流形成分离的层次结构。一般来说,处理字符或字符串使用字符流类,处理字节或二进制对象使用字节流。
操作文件流时,不管是字符流还是字节流,都可以按照以下方式进行:
1、使用File类找到一个对象
2、通过File类的对象去实例化字节流或字符流的子类
3、进行字节(字符)的读、写操作
4、关闭文件流
OutputStream(字节输出流)
close()
flush()
刷新此输入流并强制写出所有缓冲的输出字节
write(int b)
写指定数量的流到输出流
write(byte b[])
将字节数组写入到输出流
write(byte b[], int off, int len)
将一个字节数组的指定范围的数据写入到输出流
FileOutputStream(文件字节输出流)
FileOutputStream(File file)
FileOutputStream(File file, boolean append)
append如果设置为true,文件则以搜索路径模式打开。FileOutputStream的创建不依赖于文件是否存在,<br>在创建对象时,FileOutputStream会在打开输出文件之前就创建它。
示例代码
文件内容会被覆盖
InputStream(字节输入流)
int available()
返回当前可读的字节数
void close()
关闭此输入流并释放与该流关联的所有系统资源,关闭之后再读取会产生IOException
int mark(int readlimit)
在输入流中放置一个标记,该流在读取N个Bytes字节前都保持有效
boolean markSupported()
如果调用的流支持mark()/reset()就返回true
int read(byte b[], int off, int len)
三个read方法,在输入数据可用、检测到流末尾或者抛出异常前,此方法将一直阻塞
void reset()
重新设置输入指针到先前设置的标记处
long skip(long n)
跳过和丢弃此输入流中数据的n个字节
FileInputStream(文件字节输入流)
FileInputStream(File file)
示例代码<br>
read(byte b[])方法之前讲明了,表示"试图读取buffer.length个字节到buffer中,并返回实际读取的字节数",返回的是实际字节的大小。不要误以为"Hello World!!!"是14个字符即28个字节,字节流底层是以byte为单位的,因此文件里面只有14个字节罢了,至于返回的是20,还是因为"字节对齐"的问题。
OutputStream的作用是将内容由Java内存输出到文件中、InputStream是将内容由文件输入到Java内存中。
字符编码(了解即可)
字符集和字符编码
字符集(charset)
字符编码(encoding)
ASCII码
Java与字符编码
Java中的字符使用的都是Unicode字符集,编码方式为UTF-16,Java技术在通过Unicode保证跨平台特性的前提下也支持了全扩展的本地平台字符集,而显示输出和键盘输入都是采用的本地编码。因此,免不了二者的转化问题。
Java中的String都是Unicode字符集的
从Java源代码到输入文件正确的内容,要经过"Java源代码->Java字节码->虚拟机->文件"几个步骤,<br>在上述过程中的每一步都必须正确地处理汉字的编码,才能够使最终有我们期望的结果。
"Java源代码->Java字节码",标准的Java编译器Javac使用的字符集是系统默认的字符集,比如在中文Windows操作系统上就是GBK(上面GBK的部分已经说明过了),而在Linux操作系统上就是ISO8859-1,所以大家会发现Linux操作系统上编译的类中源文件中的中文字符都出现了问题,解决办法就是在编译的时候添加encoding参数,这样才能够与平台无关,用法是:javac -encoding GBK。
"Java字节码->虚拟机->文件",Java运行环境(JRE)分英文版和国际版,但只有国际版才支持非英文字符。Java开发工具包(JDK)肯定支持多国字符,但并非所有的计算机用户都安装了JDK。很多操作系统应用软件为了能够更好地支持Java,都内嵌了JRE的国际版本,为支持自己多国字符提供了方便。
小结
<font color="#c41230">不要使用操作系统的默认编码</font>,因为这样会使你的应用程序的编码格式和运行时环境绑定起来,这样在跨环境时很可能出现乱码问题。
字符流
字节流不可以直接操作Unicode字符,一个Unicode字符占用2个字节,而字节流一次只能操作一个字节
Reader
Writer
FileReader和FileWriter
FileWriter(String fileName, boolean append)
如果append为true,那么输出是追加到文件结尾的。FileWriter类的创建不依赖文件是否存在
示例代码
<font color="#c41230">不推荐用,而是用带缓冲区的字符流</font><br>
<font color="#c41230">字符流和字节流的转化<br></font>
字符流本身就是一种特殊的字节流
InputStreamReader
将一个字节流中的字节解码成字符
OutputStreamWriter
将写入的字符编码成字节后写入一个字节流。
建议指定Charset编码格式,否则将使用本地环境中的默认字符集
<font color="#c41230">FileReader是InputStreamReader的子类,调用FileReader的构造方法会调用InputStreamReader的构造方法</font>
<font color="#c41230">FileWriter是OutputStreamWriter的子类,调用FileWrite的构造方法会调用OutputStreamWriter的构造方法</font>
BufferedWriter、BufferedReader
在<font color="#c41230">关闭字符流时会强制性地将缓冲区中的内容进行输出</font>,但是如果没有关闭,缓冲区中的内容是无法输出的。<br>如果<font color="#c41230">不想在关闭时再输出字符流的内容,使用Writer的flush()方法</font>。
为了达到最高的效率,避免频繁地进行字符与字节之间的相互转换,<font color="#c41230">最好不要直接使用FileReader和FileWriter这两个类进行读写,而使用BufferedWriter包装OutputStreamWriter,使用BufferedReader包装InputStreamReader。</font>
示例代码
管道流、对象流
管道流
管道流主要用于连接两个线程的通信。
关键类
PipedInputStream
向管道中读数据
int length = in.read(b0);
PipedOutputStream
向管道中写数据
out.write(str.getBytes());
关键方法
out.connect(in)
对象流
关键类
ObjectInputStream
readObject()
ObjectOutputStream
writeObject(Object obj)
要求读写或存储的对象必须实现了Serializable接口
transient修饰的不能被序列化
小结
File是一些文件/文件夹操作的源头,File代表的就是文件/文件夹本身,因此无论如何,使用IO的第一步是建议开发者根据路径实例化出一个File
操作文本一般使用字符流,即Reader和Writer;操作字节文件使用字节流,即InputStream和OutputStream
把内容从文件读入Java内存使用输入流,即Reader和InputStream;把内容从Java内存读到文件使用输出流,即Writer和OutputStream
字符串使用带缓冲的BufferedReader和BufferedWriter,可以包装FileReader和FileWriter,或者包装InputStreamReader和OutputStreamWriter
个人观点:流在输出前最好使用flush方法,虽然close方法会强制流刷新缓冲区<br>
JavaIO是装饰器模式的典型应用
NIO
I/O模型概述
I/O模型
用户空间和内核空间
程序只能使用用户空间的内存
所有I/O都直接或间接通过内核空间
进程执行I/O操作的步骤
同步和异步、阻塞和非阻塞
同步和异步,关注的是消息通信机制
同步
在发出一个"调用请求"时,在没有得到结果之前,该"调用请求"就不返回,调用者需要等待
异步
"调用"发出之后,这个调用就直接返回了,所有没有返回结果。
当一个异步调用请求发出之后,调用者不会立刻得到结果,因此异步调用适用于那些对数据一致性要求不是很高的场景
阻塞和非阻塞,关注的是程序在等待调用结果时的状态。
阻塞
调用结果返回之前,当前线程会被挂起,调用线程只有在得到结果之后才会返回。
非阻塞
在不能立即得到结果之前,该调用不会阻塞当前线程。
Linux网络I/O模型
阻塞I/O模型
阻塞I/O模型就是最常用的I/O模型,缺省情况下所有的文件操作都是阻塞的,以Socket来讲解此模型:<font color="#c41230">在用户空间中调用recvfrom,其系统调用直到数据包到达且被复制到应用进程的缓冲区或者发生错误时才返回</font>,在此期间会一直等待,进程在从调用recvfrom开始到它返回的整段时间内都是被阻塞的,因此被称为阻塞I/O。
非阻塞I/O模型
<font color="#c41230">recvfrom从用户空间到内核空间的时候,如果该缓冲区没有数据的话,就直接返回一个EWOULDBOCK错误</font>,一般都对非阻塞I/O模型进行轮询检查这个状态,看内核空间是不是有数据到来,有数据到来则从内核空间复制数据到用户空间。
I/O复用模型
Linux提供select/poll,进程通过将一个或者多个fd传递给select或poll系统调用,<font color="#c41230">阻塞在select操作上</font>,这样select/poll可以帮助我们侦测多个fd是否处于就绪状态。<font color="#c41230">select/poll是顺序扫描fd是否就绪,而且支持的fd数量有限,因此它的使用受到了一些制约</font>。Linux还提供了一个epoll系统调用,<font color="#c41230">epoll使用基于事件驱动方式替代顺序扫描</font>,因此性能更高。当有fd就绪时,立即会调函数callback。
信号驱动I/O模型
首先开启Socket信号驱动I/O功能,并通过系统调用sigaction执行一个信号处理函数(此系统调用立即返回,进程继续工作,它是非阻塞的)。当数据准备就绪时,就为进程生成一个SIGIO信号,通过信号会掉通知应用程序调用recvfrom来读取数据,并通知主循环函数来处理数据。
异步I/O
告知内核启动某个操作,并让内核在整个操作完成后(包括将数据从内核复制到用户自己的缓冲区)通知开发者。这种模型与信号驱动I/O模型的主要区别是:信号驱动I/O模型由内核通知开发者何时可以开始一个I/O操作,<font color="#c41230">异步I/O模型由内核通知开发者I/O操作何时已经完成</font>。
再谈BIO与NIO
当一个连接建立之后,有两个步骤要做:
1、接受完客户端发过来的所有数据
2、服务端处理完请求业务之后返回Response给客户端
在BIO中,<font color="#c41230">等待客户端发送数据这个过程是阻塞的,这就造成了一个线程只能处理一个请求的情况,而机器能支持的最大线程数是有限的</font>,这就是为什么BIO不能支持高并发的原因
在NIO中,<font color="#c41230">当一个Socket建立好之后,Thread并不会去阻塞接收这个Socket,而是将这个请求交给Selector</font>,Selector会判断哪个Socket建立完成,然后通知对应线程,对应线程处理完数据再返回给客户端,这样就可以让一个线程处理更多的请求了在NIO上,我们看到了主要是使用Selector使得一条线程可以处理多个Socket,接着我们来理解一下Selector。
Selector原理
Selector做的事情
以单条线程监视多Socket I/O的状态,空闲时阻塞当前线程,当有一个或者多个Socket有I/O事件时就从阻塞状态中醒来
epoll函数是第三个阶段,它改进了select与poll的所有缺点,epoll将select与poll分为了三个部分
1、epoll_ecreate()建立一个epoll对象
2、epoll_ctl<font color="#c41230">向epoll对象中添加socket套接字</font>顺便<font color="#c41230">给内核中断处理程序注册一个callback</font>,高速内核,当<font color="#c41230">文件描述符上有事件到达(或者中断)的时候就调用这个callback</font>
3、调用epoll_wait收集发生事件的链接
实现上epoll()的三个核心点
1、使用<font color="#c41230">mmap</font>共享内存,即用户空间和内核空间共享的一块物理地址,这样当内核空间要对文件描述符上的事件进行检查时就不需要来回拷贝数据了
2、<font color="#c41230">红黑树</font>,用于存储文件描述符,<font color="#c41230">当内核初始化epoll时,会开辟出一块内核高速cache区,这块区域用于存储我们需要监管的所有Socket描述符</font>,由于红黑树的数据结构,对文件描述符增删查效率大为提高
<font color="#c41230">3、rdlist,就绪描述符链表区</font>,这是一个双向链表,epoll_wait()函数返回的也就是这个就绪链表,上面的epoll_ctl说了添加对象的时候会注册一个callback,这个callbakc的作用实际就是将描述符放入rdlist中,所以当一个socket上的数据到达的时候内核就会把网卡上的数据复制到内核,然后把socket描述符插入到就绪链表rdlist中
缓冲区
什么是缓冲区
<font color="#c41230">一个缓冲区对象是固定数量的数据的容器</font>,其作用是一个存储器,或者分段运输区,在这里数据可被存储并在之后用于检索。缓冲区像前篇文章讨论的那样被写满和释放,对于每个非布尔原始数据类型都有一个缓冲区类,尽管缓冲区作用于它们存储的原始数据类型,但缓冲区十分倾向于处理字节,非字节缓冲区可以再后台执行从字节或到字节的转换,这取决于缓冲区是如何创建的。
<font color="#c41230">缓冲区的工作与通道紧密联系。</font>通道是I/O传输发生时通过的入口,而缓冲区是这些数据传输的来源或目标。对于离开缓冲区的传输,待传递出去的数据被置于一个缓冲区,被传送到通道;待传回的缓冲区的传输,一个通道将数据放置在所提供的缓冲区中。这种在协同对象之间进行的缓冲区数据传递时高效数据处理的关键。
Buffer的类层次
缓冲区基础
缓冲区的使用数组来存储数据,大多数Buffer的子类都有hb这个属性
Buffer
属性
capacity
容量,指缓冲区能够容纳的数据元素的最大数量,这一容量在缓冲区创建时被设定,并且永远不能被改变
limit
缓冲区中现存元素的计数
position
指下一个要被读或写的元素的索引,位置会自动由相应的get()和put()函数更新
mark
标记,指一个备忘位置,调用mark()来设定mark=position,调用reset()来设定postion=mark,标记未设定前是未定义的
方法
Object array()
返回此缓冲区的底层实现数组
int arrayOffset()
返回缓冲区数组的第一个偏移量
int capacity()
返回此缓冲区的容量
Buffer clear()
清除此缓冲区
Buffer flip()
反转此缓冲区
boolean hasArray()
告知此缓冲区是否具有可访问的底层实现数组
boolean isDirect()
告知此缓冲区是否为直接缓冲区
boolean isReadOnly()
告知此缓冲区是否为只读缓存
int limit()
返回此缓冲区的上界
Buffer limit(int newLimit)
设置此缓冲区的上界
Buffer mark()
在此缓冲区的位置设置标记
int position()
返回此缓冲区的位置
Buffer position(int newPosition)
设置此缓冲区的位置
int remaining()
返回当前位置与上界之间的元素数
Buffer reset()
将此缓冲区的位置重置为以前标记的位置
Buffer rewind()
倒带此缓冲区
使用,示例使用get和put无参方法,只能一个元素一个元素的移动,<br>实际使用中建议使用批量移动的API
实例化buffer子类
通过allocate方法,实例化Heap*Buffer,比如示例代码实例化了HeapCharBuffer
缓冲区比较
个人理解:position到limit之间的数组上的数据相等即两个缓冲区相等
批量移动数据
API
CharBuffer put(char[] src, int offset, int length)
第一个参数是要读取的源
第二个是要读的开始位置
第三个是要读的长度或者结束的位置
字节缓冲区ByteBuffer和DirectByteBuffer
通道只接收ByteBuffer作为参数。
通道最好和直接缓冲区搭配使用,如果向通道传递一个非直接缓冲对象,也会被jvm转换成一个临时的直接缓冲对象,这时候会有一个将非直接缓冲对象的数据拷贝到临时直接缓冲对象的操作,这个对象很大的时候,是很耗费时间和性能的,所以管道和直接缓冲对象搭配使用<br>
DirectByteBuffer的访问级别是<font color="#c41230">包级别的,在java.nio包下</font>,就<font color="#c41230">只能是这个包下的其他类可以访问到</font>,<br>一般通过<font color="#c41230">ByteBuffer.allocateDirect</font>方法申请直接缓冲对象
class DirectByteBuffer <br>extends MappedByteBuffer <br>implements DirectBuffer
MappedByteBuffer 内存映射的buffer
重要属性
unsafe
Unsafe.getUnsafe();
使用操作系统底层去操作数据,方法一般是native修饰
内部类Deallocator
在实例化DirectByteBuffer时调用Cleaner.create(this, new Deallocator(base, size, cap));<br>加入到Cleaner内部的引用队列
Cleaner是一个继承自PhantomReference的类
Phantom Reference的唯一作用是在对象被回收时收到通知,这样可以做一些后续操作,比如这里当DirectByteBuffer对象被回收时,<br>调用DirectByteBuffer的内部类Deallocator的run方法回收堆外内存
通道(Channel)和文件通道
Channel的作用
Channel用于在字节缓冲区和位于通道另一侧的实体(通常是一个文件或套接字)之间有效地传输数据
通道是一种途径,借助该途径,可以用最小的总开销来访问操作系统本身的I/O服务。缓冲区则是通道内部用来发送和接收数据的端点,
Channel接口的主要方法
isOpen()
close()
Channel的类层次图
图
通道可以是单向的也可以是双向的。
一个Channel类可能实现定义read()方法的ReadableByteChannel接口,而另一个Channel类也许实现WritableByteChannel接口以提供write()方法。实现这两种接口其中之一的类都是单向的,只能在一个方向上传输数据。如果一个类同时实现这两个接口,那么它是双向的,可以双向传输数据,就像上面的ByteChannel。
通道可以以阻塞(blocking)或非阻塞(nonblocking)模式运行
非阻塞模式的通道永远不会让调用的线程休眠,请求的操作要么立即完成,要么返回一个结果表明未进行任何操作。<br><font color="#c41230">只有面向流的(stream-oriented)的通道,如sockets和pipes才能使用非阻塞模式。</font>
SocketChannel
从SelectableChannel类引申而来,从SelectableChannel引申而来的类可以和支持有条件的选择的选择器(Selectors)一起使用。<br>将非阻塞I/O和选择器组合起来可以使开发者的程序利用多路复用I/O
分类
I/O可以分为广义的两大类
File I/O
Stream I/O
通道也有两种类型
File
FileChannel
文件通道总是阻塞式的
FileChannel对象是线程安全的
这种事底层操作系统来保证,比如改变文件大小这样的操作是单线程
代码实例
向通道写数据示例<br>
Socket
SocketChannel
ServerSocketChannel
DatagramChannel
Socket通道
三个特征<br>
NIO的Socket通道类可以运行于非阻塞模式并且是可选择的,这两个性能可以激活大程序(如网络服务器和中间件组件)巨大的可伸缩性和灵活性,因此,再也没有为每个Socket连接使用一个线程的必要了。这一特性避免了管理大量线程所需的上下文交换总开销,借助NIO类,一个或几个线程就可以管理成百上千的活动Socket连接了并且只有很少甚至没有性能损失
全部Socket通道类(DatagramChannel、SocketChannel和ServerSocketChannel)在被实例化时都会创建一个对应的Socket对象,就是我们所熟悉的来自java.net的类(Socket、ServerSocket和DatagramSocket),这些Socket可以通过调用socket()方法从通道类获取,此外,这三个java.net类现在都有getChannel()方法
每个Socket通道(在java.nio.channels包中)都有一个关联的java.net.socket对象,反之却不是如此,如果使用传统方式(直接实例化)创建了一个Socket对象,它就不会有关联的SocketChannel并且它的getChannel()方法将总是返回null概括地讲,这就是Socket通道所要掌握的知识点知识点,不难,记住并通过自己写代码/查看JDK源码来加深理解。
非阻塞
SelectableChannel
configureBlocking(true)
isBlocking()
blockngLock()
用来作为同步configureBlocking()方法和register方法的对象锁,防止多线程的时候并发修改阻塞模式
Socket通道服务端程序
示例代码
Socket通道客户端程序
示例代码
选择器Selector
理论
关键类
Selector
keys()
已注册的所有key
selectedKeys()
已注册的key中被相应channel选择的key
selectNow()
调用selectNow()方法执行就绪检查过程,但不阻塞,如果当前没有通道就绪,立刻返回0.
wakeup()
调用wakeup()方法将使得选择器上的第一个还没有返回的选择操作立即返回,如果当前没有正在进行中的选择,<br>那么下一次对select()方法的一种形式的调用将立即返回,后续的选择操作将正常进行。
AbstractSelector
private final Set cancelledKeys = new HashSet();
已注册的key中被调用了cancel方法的key<br>
deregister(AbstractSelectionKey key)
注销key
SelectableChannel
SelectionKey register(Selector sel, int ops, Object att)
SelectionKey
选择过程
实验
Selector可以简化用单线程同时管理多个可选择通道的实现。
单核CPU<br>
效率很高,没有线程上下文切换开销,CPU也被充分利用
多核<br>
对所有的可选择通道使用同一个选择器,并将对就绪选择通道的服务委托给其他线程。<br>开发者只使用一个线程监控通道的就绪状态,至于通道处于就绪状态之后又如何做,有两种可行的做法
使用一个协调好的工作线程池来处理接收到的数据,当然线程池的大小是可以调整的
通道根据功能由不同的工作线程来处理,它们可能是日志线程、命令/控制线程、状态请求线程等
Java多线程
不要改变同步代码块锁住的对象,<font color="#c41230">防止使用动态的String内容作为锁对象</font>,<br>如果不使用inter方法加入常量池,会有线程不安全的风险
运行时使用动态生成字符串的API一般都会返回一个new String,比如StringBuffer或者StringBuilder的toString方法<br>
更不要直接使用new String<br>
直接使用字符串字面量的形式定义的字符串可以作为锁对象,因为在编译期就已经加入到常量池,能够<font color="#c41230">保证多线程访问的是同一个对象锁</font>
Java多线程1:进程与线程概述
进程<br>
线程
Java中创建线程的方式
extends Thread<br>
单继承,Thread类本身也是实现了Runnable
implements Runnable<br>
可以多继承<br>
线程的状态
NEW
RUNNABLE
BLOCKED
WAITING
超时等待TIMED_WAITING
TERMINATED
Java多线程2:Thread中的实例方法
Thread类中的方法调用方式:
this.XXX()
这种调用方式表示的线程是线程实例本身
Thread.currentThread.XXX()或Thread.XXX()
正在执行Thread.currentThread.XXX()所在代码块的线程
Thread类中的实例方法
start()
CPU执行哪个线程的代码具有不确定性
调用start()方法的顺序不代表线程启动的顺序,线程启动顺序具有不确定性。
run()
线程开始执行,虚拟机调用的是线程run()方法中的内容。
调用run方法不能启动线程,启动线程调用start<br>
isAlive()
getId()
getName()
getPriority()和setPriority(int newPriority)
isDaeMon、setDaemon(boolean on)
interrupt()
isInterrupted()
join()
sleep(2000)不释放锁,join(2000)释放锁
join()方法内部使用的是wait()
官方Javadoc上对这类的注释说,不建议在线程实例上使用wait, notify, or notifyAll
join无参方法会调用参数为0的有参方法,0代表一直等待,join本身有超时机制。
Java多线程3:Thread中的静态方法
Thread类中的静态方法
currentThread()
线程类的构造方法、静态块是被main线程调用的,而线程类的run()方法才是应用线程自己调用的。
当前执行的Thread未必就是Thread本身
sleep(long millis)
yield()
interrupted()
Java多线程4:synchronized锁机制
A线程持有Object对象的Lock锁,B线程可以以异步方式调用Object对象中的非synchronized类型的方法
A线程持有Object对象的Lock锁,B线程如果在这时调用Object对象中的synchronized类型的方法则需要等待,也就是同步
synchronized锁重入
当一个线程得到一个对象锁后,再次请求此对象锁时时可以再次得到该对象的锁的
支持在父子类继承的环境中
异常自动释放锁
Java多线程5:synchronized锁方法块
两个synchronized块之间具有互斥性
如果线程1访问了一个对象A方法的synchronized块,那么线程B对同一对象B方法的synchronized块的访问将被阻塞
synchronized块获得的是一个对象锁,换句话说,synchronized块锁定的是整个对象。
synchronized块和synchronized方法
synchronized同步方法
对其他synchronized同步方法或synchronized(this)同步代码块呈阻塞状态
同一时间只有一个线程可以执行synchronized同步方法中的代码
synchronized同步代码块
对其他synchronized同步方法或synchronized(this)同步代码块呈阻塞状态
同一时间只有一个线程可以执行synchronized(this)同步代码块中的代码
多个线程<font color="#c41230">持有"对象监视器"为同一个对象</font>的前提下,同一时间只能有一个线程可以执行synchronized(非this对象x)代码块中的代码。
synchronized(非this对象x),这个对象如果是实例变量的话,指的是对象的引用,只要对象的引用不变,即使改变了对象的属性,运行结果依然是同步的。
Java多线程6:synchronized锁定类方法、volatile关键字及其他
同步静态方法
对当前.java文件对应的Class类加锁
volatile关键字
volatile只保证可见性,原子类在使用的时候也不一定就能保证原子性,使用不当依然不行
比如两个原子操作组成一个事务,虽然单个是原子性的,但是这整个事务如果不加锁,依然不能保证原子性
synchronized除了保障了原子性外,其实也保障了可见性。
原子类也无法保证线程安全
Java多线程7:死锁
什么情况产生死锁
如果线程A持有锁L并且想获得锁M,线程B持有锁M并且想获得锁L,那么这两个线程将永远等待下去
数据库如果监测到了一组事务发生了死锁时,将选择一个牺牲者并放弃这个事务
如何进行死锁检测
类似CAS,检查版本号?
死锁的触发
避免死锁的方式
使用超时机制
Java多线程8:wait()和notify()/notifyAll()
wait和notify必须在同步方法或者同步代码块中使用
wait()方法可以使调用该线程的方法释放共享资源的锁,然后从运行状态退出,进入等待队列,直到再次被唤醒。
notify()方法可以随机唤醒等待队列中等待同一共享资源的一个线程,并使得该线程退出等待状态,进入可运行状态
notifyAll()方法可以使所有正在等待队列中等待<font color="#c41230">同一共享资源的全部线程</font>从等待状态退出,进入可运行状态
wait()释放锁以及notify()不释放锁
interrupt()方法的作用不是中断线程,而是在线程阻塞的时候给线程一个中断标识,表示该线程中断。wait()就是"阻塞的一种场景"
Java多线程9:ThreadLocal源码剖析
关于ThreadLocal
每个线程都有一个自己的ThreadLocal.ThreadLocalMap对象
每一个ThreadLocal对象都有一个循环计数器
ThreadLocal.get()取值,就是根据当前的线程,获取线程中自己的ThreadLocal.ThreadLocalMap,然后在这个Map中根据第二点中循环计数器取得一个特定value值
当table的位置上有数据的时候,ThreadLocal采取的是办法是找最近的一个空的位置设置数据。
ThreadLocal不是用来解决共享对象的多线程访问问题的
ThreadLocal不是集合,它不存储任何内容,真正存储数据的集合在Thread中。<br>ThreadLocal只是一个工具,一个往各个线程的ThreadLocal.ThreadLocalMap中table的某一位置set一个值的工具而已
同步与ThreadLocal是解决多线程中数据访问问题的两种思路,前者是数据共享的思路,后者是数据隔离的思路
同步是一种以时间换空间的思想,ThreadLocal是一种空间换时间的思想
ThreadLocal与线程有关,只在一次请求中有效,对比request
ThreadLocal只能存一个值,一个Request由于是Map形式的,可以用key-value形式存多个值
ThreadLocal一般用在框架,Request一般用在表示层、Action、Servlet
Java多线程11:ReentrantLock的使用和Condition
ReentrantLock,一个可重入的互斥锁,它具有与使用synchronized方法和语句所访问的隐式监视器锁相同的一些基本行为和语义,但功能更强大。
ReentrantLock持有的是对象监视器
ReentrantLock和synchronized持有的对象监视器不同
Condition
一个Lock里面可以创建多个Condition实例,实现多路通知
ReentrantLock结合Condition可以实现有选择性地通知
Condition的await()方法是释放锁
如果想单独唤醒部分线程该怎么办呢?new出多个Condition就可以了,这样也有助于提升程序运行的效率。<br>使用多个Condition的场景是很常见的,像ArrayBlockingQueue里就有。
Java多线程12:ReentrantLock中的方法
可以指定锁是公平锁还是非公平锁
默认是非公平锁<br>
getHoldCount()
ReentrantLock和synchronized一样,锁都是可重入的,同一线程的同一个ReentrantLock的lock()方法被调用了多少次,getHoldCount()方法就返回多少
getQueueLength()
isFair()
hasQueuedThread()
hasQueuedThreads()
isHeldByCurrentThread()
isLocked()
tryLock()
tryLock(long timeout, TimeUnit unit)
getWaitQueueLength(Condition condition)
hasWaiters(Condition condition)
lockInterruptibly()
getWaitingThreads(Condition condition)
Java多线程13:读写锁和两种同步方式的对比
读写锁ReentrantReadWriteLock概述
多个Thread可以同时进行读取操作,但是同一时刻只允许一个Thread进行写入操作。
读读共享,读写,写写互斥
synchronized和ReentrantLock的对比
synchronized是关键字,synchronized获取锁以及释放锁都是Java虚拟机帮助用户完成的。ReentrantLock是类层面的实现,因此锁的获取以及锁的释放都需要用户自己去操作。特别再次提醒,ReentrantLock在lock()完了,一定要手动unlock()
synchronized简单,简单意味着不灵活,而ReentrantLock的锁机制给用户的使用提供了极大的灵活性。这点在Hashtable和ConcurrentHashMap中体现得淋漓尽致。synchronized一锁就锁整个Hash表,而ConcurrentHashMap则利用ReentrantLock实现了锁分离,锁的只是segment而不是整个Hash表
Java中的锁是对象锁,意味着,同一个类的不同方法使用同一个锁的时候,锁的是同一个对象,访问A方法的同步代码的时候,其他的线程也不能访问B方法的同步代码,但是如果有这样的需求,希望线程1在访问A方法的同步代码的同时,运行其他线程访问B方法的同步代码呢?这个时候可以对A和B方法使用不同的锁对象监视器,即所谓的<font color="#c41230">锁分离</font>思想,例子:ConcurrentHashMap和HashTable的区别。
synchronized是不公平锁,而ReentrantLock可以指定锁是公平的还是非公平的
synchronized实现等待/通知机制通知的线程是随机的,ReentrantLock实现等待/通知机制可以有选择性地通知
和synchronized相比,ReentrantLock提供给用户多种方法用于锁信息的获取,比如可以知道lock是否被当前线程获取、lock被同一个线程调用了几次、lock是否被任意线程获取等等。ReentrantLock比synchronized更强大
如果只需要锁定简单的方法、简单的代码块,那么考虑使用synchronized,复杂的多线程处理场景下可以考虑使用ReentrantLock
1.5以后JDK对synchronized进行了多项优化,性能和ReentrantLock差不多。
<font color="#c41230">具体哪些优化,优化思路?</font>
加入了偏向锁、锁膨胀升级逻辑<br>
Java多线程14:生产者/消费者模型
自己的理解:特别适合数据积压场景,比如秒杀场景中的发货,面对大量的订单,使用消息队列做一个缓冲
一种重要的模型,基于等待/通知机制。生产者/消费者模型描述的是有一块<font color="#c41230">缓冲区</font>作为仓库,<br>生产者可将产品放入仓库,消费者可以从仓库中取出产品,生产者/消费者模型关注的是以下几个点
生产者生产的时候消费者不能消费
消费者消费的时候生产者不能生产
缓冲区空时消费者不能消费
缓冲区满时生产者不能生产
优点
<font color="#c41230">解耦。</font>因为多了一个缓冲区,所以生产者和消费者并不直接相互调用,这一点很容易想到,这样生产者和消费者的代码发生变化,都不会对对方产生影响,这样其实就把生产者和消费者之间的强耦合解开,变为了生产者和缓冲区/消费者和缓冲区之间的弱耦合
<font color="#c41230">通过平衡生产者和消费者的处理能力来提高整体处理数据的速度</font>,这是生产者/消费者模型最重要的一个优点。如果消费者直接从生产者这里拿数据,如果生产者生产的速度很慢,但消费者消费的速度很快,那消费者就得占用CPU的时间片白白等在那边。有了生产者/消费者模型,生产者和消费者就是两个独立的并发体,生产者把生产出来的数据往缓冲区一丢就好了,不必管消费者;消费者也是,从缓冲区去拿数据就好了,也不必管生产者,缓冲区满了就不生产,缓冲区空了就不消费,使生产者/消费者的处理能力达到一个动态的平衡
小心多生产者和多消费者场景的假死
假死出现的原因是因为notify的是同类,所以非单生产者/单消费者的场景,可以采取两种方法解决这个问题
synchronized用notifyAll()唤醒所有线程、ReentrantLock用signalAll()唤醒所有线程
用ReentrantLock定义两个Condition,一个表示生产者的Condition,一个表示消费者的Condition,唤醒的时候调用相应的Condition的signal()方法就可以了
原文例子中的生产者和消费者写在同一个类中,使用一个锁对象上的condition,而实际业务中,生产者和消费者不可能在同一个实例中,生产消费逻辑本身不会耦合在一个类中。
一般会把生产和消费的对象抽出来单独的共享类,这个类中实例化lock和condition,让生产者和消费者公用同一个lock和condition。生产者和消费者类各自维护一个共享类的引用,客户端使用的时候为生产者和消费者类传入同一个共享类。
Java多线程15:Queue、BlockingQueue以及利用BlockingQueue实现生产者/消费者模型
Queue是什么
Queue通常不允许插入Null,尽管某些实现(比如LinkedList)是允许的,但是也不建议。
BlockingQueue
可以用来实现消费者生产者
BlockingQueue中的方法
void put(E e) throws InterruptedException
void take() throws InterruptedException
int drainTo(Collection<? super E> c, int maxElements)
ArrayBlockingQueue
LinkedBlockingQueue
SynchronousQueue
公平模式
非公平模式
Java多线程16:线程组
线程组的作用是:可以批量管理线程或线程组对象,有效地对线程或线程组对象进行组织。
线程必须启动后才能归到指定线程组中
线程组自动归属特性
根线程组
Java多线程17:中断机制
概述<br>
interrupt()
设置标志位
isInterrupted()
是测试线程是否已经中断,中断标识位的状态并不受到该方法的影响
interrupted()
测试当前线程是否已经中断,线程的中断标识位由该方法清除。换句话说,连续两次调用该方法的返回值必定是false
中断处理时机
像sleep、wait、notify、join,这些方法遇到中断必须有对应的措施,可以直接在catch块中处理,也可以抛给上一层。
Java多线程18:线程池
线程池的作用
减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务
可以根据系统的承受能力,调整线程池中工作线程的数据,防止因为消耗过多的内存导致服务器崩溃
线程池类结构
最顶级的接口是Executor,不过Executor严格意义上来说并不是一个线程池而只是提供了一种任务如何运行的机制而已
ExecutorService才可以认为是真正的线程池接口,接口提供了管理线程池的方法
下面两个分支,AbstractExecutorService分支就是普通的线程池分支,ScheduledExecutorService是用来创建定时任务的
ThreadPoolExecutor六个核心参数
corePoolSize
maximumPoolSize
keepAliveTime
unit
workQueue
threadFactory
handler
corePoolSize与maximumPoolSize举例理解
池中线程数小于corePoolSize,新任务都不排队而是直接添加新线程
池中线程数大于等于corePoolSize,workQueue未满,首选将新任务加入workQueue而不是添加新线程
池中线程数大于等于corePoolSize,workQueue已满,但是线程数小于maximumPoolSize,添加新的线程来处理被添加的任务
池中线程数大于大于corePoolSize,workQueue已满,并且线程数大于等于maximumPoolSize,新任务被拒绝,使用handler处理被拒绝的任务
强烈建议程序员使用较为方便的Executors工厂方法Executors.newCachedThreadPool()(无界线程池,可以进行线程自动回收)、Executors.newFixedThreadPool(int)(固定大小线程池)和Executors.newSingleThreadExecutor()(单个后台线程),它们均为大多数使用场景预定义了设置。
Executors
线程池的重点
在合适的场景下使用合适的线程池,所谓"合适的线程池"的意思就是,ThreadPoolExecutor的构造方法传入不同的参数,<br>构造出不同的线程池,以满足使用的需要
newSingleThreadExecutos() 单线程线程池
无界队列
newFixedThreadPool(int nThreads) 固定大小线程池
无界队列
newCachedThreadPool() 无界线程池
不管多少任务提交进来,都直接运行
只要60秒没有被用到的线程都会被直接移除
workQueue
当前线程大于corePoolSize时,线程以什么样的方式排队等待被运行。排队有三种策略:直接提交、有界队列、无界队列。
有界队列相对于无界队列的缺点
四种拒绝策略
Java多线程19:定时器Timer
Timer的schedule(TimeTask task, Date time)
执行任务的时间晚于当前时间:未来执行
计划时间早于当前时间:立即执行
多个TimerTask任务执行
Task是以队列的方式一个一个被顺序执行的,所以执行的时间有可能和预期的时间不一致,<br>因为前面的任务可能消耗过长,后面任务的运行时间也有可能被延迟。
Timer的schedule(TimerTask task, Date firstTime, long period)
在指定的日期之后,按指定的间隔周期性地无限循环地执行某一任务
TimerTask的cancel()方法
将自身从任务队列中清除
Timer的cancel()方法
schedule(TimerTask task, long delay)
以当前时间为参考,在此时间基础上延迟指定的毫秒数后执行一次TimerTask任务
schedule(TimerTask task, long delay, long period)
以当前时间为参考,在此时间基础上延迟指定的毫秒数后,以period为循环周期,循环执行TimerTask任务
scheduleAtFixedRate(TimerTask task, Date firstTime, long period)
Java多线程20:多线程下的其他组件之CountDownLatch、Semaphore、Exchanger
CountDownLatch
使用场景
如果有类似这样的场景:3、2、1,跑。
Semaphore
信号量为1的时候相当于互斥锁,只能被1个线程执行<br>
信号量为多个,说明运行多个线程同时运行
控制并发数
可以配置公平非公平锁
acquire方法和release方法是可以有参数的,表示获取/返还的信号量个数
Exchanger
Java多线程21:多线程下的其他组件之CyclicBarrier、Callable、Future和FutureTask
CyclicBarrier
Callable、Future和FutureTask
Callable可以返回结果
Future
判断任务是否完成
中断任务
获取任务执行结果
使用方法
主要的好处:异步执行任务时,API完善
Java虚拟机
web技术
分布式
JCSprout
Java进阶
Synchronize关键字原理
对象的创建与内存分配
<span style="color: rgb(34, 34, 34); font-family: Consolas, "Lucida Console", "Courier New", monospace; font-size: 12px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: pre-wrap; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">Distributed Tools</span>
算法
树型结构
树型结构的基本概念
结点的度
结点所拥有的子树的个数称之为结点的度
分支结点
度不为0的结点,也叫作非终端结点或内部结点
结点的层次
从根节点到树中某结点所经路径上的分支树称为该结点的层次,根节点的层次规定为1,其余结点的层次等于其父亲结点的层次+1
连接线的个数+1
树的深度
树中结点的最大层次数
<font color="#c41230">树的高度决定树的时间复杂度</font>
二叉树
每个结点都不能有多于两个子树。
二叉查找树深度的平均值是O(logN),查找较快
缺点
不平衡,最坏情况树的深度大到了N-1
二叉查找树
对于树中的每个结点X,它的左子树中所有项的值小于X,而它的右子树中所有项的值大于X,这意味着该树所有的元素可以用某种一致的方式排序。
平衡树
AVL树
平衡条件
空树
每个结点的左子树和右子树深度最多差1
红黑树
条件
每个结点都只能是红色或者黑色
根节点是黑色
每片叶子都是黑色的
如果一个结点是红色的,则它的两个子节点都是黑色的,也就是说在一条路径上不能出现相邻的两个红色结点
从任意一个结点到其每个叶子的所有路径都包含着相同数目的黑色结点
ssm
done +1
JavaGuide
CS-Notes
思维导图
服务化<br>
分布式Unique ID的生成方法一览
Leaf——美团点评分布式ID生成系统
限流
兼容性与版本号
负载均衡与路由的设计
谈谈服务化体系中的异步(上)
Java 领域从传统行业向互联网转型你必须知道的事儿<br>
非技术因素<br>
责任心
团队精神
主动性
性格
年龄
期待
职业规划<br>
工作业绩
技术攻关
应急
创新
分享<br>
项目管理
程序开发案例<br>
项目设计案例
SSH
Struts
Spring
AOP
IOC
Spring MVC<br>
Spring Boot<br>
Spring Security<br>
Hibernate/mybatis
分布式<br>
负载均衡
水平伸缩
集群
分片
key-hash
一致性hash
异步
消峰
分库分表
锁
悲观锁
乐观锁
行级锁
分布式锁
分区排队
一致性
一致性算法
paxos
zab
raft
nwr
gossip
2pc
3pc
4pc
柔性事务(TCC)
一致性原理
CAP
BASE
中间件<br>
数据库
mysql
存储引擎
索引<br>
锁
oracle
db2
缓存
Redis
数据结构
持久化
复制
cas
单线程
memcache
tair
消息队列<br>
JMS
queue
topic
kafka
持久
复制
partition
stream
rocketMQ
rabbitMQ
activeMQ<br>
设计和架构<br>
设计模式
架构方法论
设计案例
UML
数据结构<br>
查找
二分
二叉树
平衡查找树<br>
散列表
二分
排序<br>
选择
冒泡
插入
快速
归并
堆
桶排序
基数
高级算法
贪婪
回溯
剪枝
动态规划<br>
大数据算法
hash分桶,统计
网络
TCP/IP
HTTP
日志框架<br>
老框架
common logging<br>
log4j
jdk logger<br>
新框架
slf4j
logback
测试框架<br>
新
testing<br>
mockito
老<br>
junit
easymock
开发工具
IDE
eclipse
vscode
IDEA
cvs
svn
git
开发流程
code review<br>
hotfix流程
性能优化<br>
分层优化
系统级别
中间件级别
JVM级别
代码级别
分段优化
前端
后端
资源
大数据和nosql
zookeeper
hadoop
hbase
mongodb
cassandra
yarn
Java语言
语言
异常
类继承
泛型
内部类
反射
序列化
对象类
字符串类
引用
强引用
弱引用
软引用
幻影引用
类库<br>
集合
IO
网络
JUC
流
第三方类库
netty
guava
等等
JVM
多线程与并发
GC
GC收集器类型
算法
复制
标记清理
标记整理
分区
新生代
eden
survivor
老年代
永久带
GC收集器类型
串行
CMS
分配担保失败
并行
G1
IO/NIO
IO类型
同步阻塞
同步非阻塞
基于信号
多路复用
异步IO
类加载
双亲委派
破坏双亲委派
OSGI
Java基础的学习
注重对自己能力的培养
1 编码能力
2 面向对象分析能力
3 内存底层和源码分析的习惯
4 调试和排错能力
学习路径
基础能力培养
1 环境搭建,完成第一个程序
2 编程能力培养
1 数据类型和变量
2 控制语句
3 方法
3 面向对象基础
1 类和对象
2 内存分析和垃圾回收机制
3 this、static
4 package、import
4 面向对象进阶
1 三大特征
继承
封装
多态
2 Object类
3 super和继承树追溯
4 抽象类
5 接口
6 设计模式入门(单例、工厂、组合)
5 其他知识<br>
final
遗忘点<br>
final修饰方法时,和private关键字作用一样,使得子类不能复写该方法
修饰基本数据类型时,值初始化后不可变
修饰引用类型,引用不可变,但是内容可变
内部类
广义上的<br>
成员内部类
通过反编译后的字节码可以看出,成员内部类的默认构造器持有一个外部类的引用,所以可以访问外部类的成员变量
局部内部类
<span style="color: rgb(0, 0, 0); font-family: Verdana, Arial, Helvetica, sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">为什么方法中的局部变量和形参都必须用final进行限定</span>
匿名内部类
<span style="color: rgb(0, 0, 0); font-family: Verdana, Arial, Helvetica, sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">为什么方法中的局部变量和形参都必须用final进行限定</span>
因为外部类局部变量和形参的生命周期可能比内部类的生命周期短,考虑到这种情况,设计的时候使用过值拷贝的方式,将外部类局部变量拷贝到内部类中,这样有两份拷贝,可能导致数据不一致,编译器要求这个局部变量必须是final。
静态内部类<br>
<span style="color: rgb(0, 0, 0); font-family: Verdana, Arial, Helvetica, sans-serif; font-size: 14px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial; display: inline !important; float: none;">静态内部类是不依赖于外部类的,也就说可以在不创建外部类对象的情况下创建内部类的对象。另外,静态内部类是不持有指向外部类对象的引用的,这个读者可以自己尝试反编译class文件看一下就知道了,是没有Outter this&0引用的。</span>
面向对象编程深化
1 异常机制
1 异常基本概念
Throwable
Exception
RuntimeException
NullPointerException
IllegalStateException
IllegalArgumentException
NumberFormatException
checked exception
FileNotFoundException
Error
2 异常处理机制
3 自定义异常
4 常见异常如何处理
2 数组
1 数组的本质
2 数组的初始化和遍历
3 多维数组
4 算法(冒泡排序、排序优化、二分法)
3 常用类
1 包装类
2 字符串相关类
3 时间相关类
4 容器(集合)
1 泛型
2 容器本质
3 List
4 Set
5 Map
6 Iterator迭代器
5 IO流(与外部数据交互)
1 流的基本操作
2 流的分类
3 相关工具(Apache IO)
nio
6 多线程技术
多线程基础
1 多线程相关基本概念
2 创建线程类
3 线程的状态
4 线程通讯和协作
多线程高级
JUC
Disruptor
7 网络编程
网络编程基础
1 TCP和IP基本概念
2 socket通讯经典代码
3 socket通讯结合多线程
4 UDP通讯入门
网络编程高级
Netty网络编程
8 反射,代理
常用框架和工具内部原理
Spring源码解读
Spring可以做些什么,提供的功能
三个核心组件
Core
主要类
Resource
定义了资源的访问方式
屏蔽了文件类型的不同,屏蔽资源使用者
继承了 InputStreamSource 接口,屏蔽了资源提供者
ResourceLoader,屏蔽资源加载方式
DefaultResourceLoader
ResourcePatternResolver
Context资源的加载、解析和描述工作给了该类去做
Context
org.springframework.context
作用就是给Spring 提供一个运行时的环境,用以保存各个对象的状态
顶级父类
ApplicationContext
相关类结构图
类结构图
ApplicationContext 继承了 BeanFactory,这也说明了 Spring 容器中运行的主体对象是 Bean
ApplicationContext 继承了 ResourceLoader 接口,使得 ApplicationContext 可以访问到任何外部资源
主要子类
ConfigurableApplicationContext 表示该 Context 是可修改的
WebApplicationContext
可以直接访问到 ServletContext
这个接口通常使用的少
Bean
org.springframework.beans
Bean 的定义
Bean 的定义主要由BeanDefinition 描述
Bean 的创建
使用者唯一需要关心的
工厂模式
顶级接口是 BeanFactory
主要的子接口
ListableBeanFactory
HierarchicalBeanFactory
AutowireCapableBeanFactory
DefaultListableBeanFactory
这四个接口共同定义了 Bean 的集合、Bean 之间的关系、以及 Bean 行为。
对 Bean 的解析
Bean 的解析主要就是对 Spring 配置文件的解析。
主要接口
BeanDefinitionReader
BeanDefinitionDocumentReader
三个组件的关系
图2
子主题
设计目标
使用Spring创建的Java对象都是低耦合的
单一职责原则
核心功能
操作对象的创建,管理对象的依赖关系
Ioc 容器如何工作
如何创建 BeanFactory 工厂
AbstractApplicationContext.refresh
如何创建 Bean 实例并构建 Bean 的关系网
Bean 的实例化代码,是从 finishBeanFactoryInitialization 方法开始的。
DefaultListableBeanFactory.preInstantiateSingletons
Ioc 容器的扩展点
BeanFactoryPostProcessor
bean定义加载完,bean实例化之前
PropertyPlaceholderConfigurer就是间接实现该接口,<br>完成功能扩展,可以将属性配置文件的属性注入到beanDefinition
BeanPostProcessor
前置方法postProcessBeforeInitialization
InitializingBean
属性设置后afterPropertiesSet<br>
后置方法postProcessAfterInitialization
AOP
DisposableBean
销毁<br>
AOP
代理的目的是调用目标方法时我们可以转而执行 InvocationHandler 类的 invoke 方法
AOP有哪些实现方式?各自优缺点?(解决什么问题,适合什么场景)
JDK动态代理
目标类必须实现接口
CGLIB
可以直接代理目标类,目标类不需要实现接口,且支持自定义拦截方法
如何实现自定义拦截的?
AspectJ
Spring源码分析
Bean加载流程概览
入口<br>
AbstractApplicationContext.refresh()
方法是加锁的,这么做的原因是<font color="#f15a23">避免多线程同时刷新Spring上下文</font>
尽管加锁可以看到是针对整个方法体的,但是没有在方法前加synchronized关键字,而使用了对象锁<font color="#f15a23">startUpShutdownMonitor</font>,这样做有两个好处
refresh()方法和close()方法都使用了startUpShutdownMonitor对象锁加锁,<br>这就保证了<font color="#f15a23">在调用refresh()方法的时候无法调用close()方法</font>,反之亦然,<font color="#f15a23">避免了冲突</font>
使用对象锁可以减小同步的范围,只对不能并发的代码块进行加锁,<br>提高了整体代码运行的效率(这里主要是出于业务逻辑的考虑,避免refresh方法和close方法冲突)
方法里面使用了每个子方法定义了整个refresh()方法的流程,使得整个方法流程清晰易懂。
扩展性
可读性
可维护性
refresh中的方法分析
prepareRefresh方法
设置一下刷新Spring上下文的开始时间
将active标识位设置为true
obtainFreshBeanFactory方法
主要做的事:获取刷新Spring上下文的Bean工厂,这个Bean工厂保存了BeanDefinition信息
细节:配置文件读取及bean definition加载<br>
refreshBeanFactory
createBeanFactory()返回核心的beanfactory,<br>后面会反复对这个beanfactory操作,包括配置设置和保存bean定义<br>
loadBeanDefinitions(beanFactory)
其中的核心类是XmlBeanDefinitionReader
关键方法是loadBeanDefinitions(beanDefinitionReader)
reader.loadBeanDefinitions(configResources);
XmlBeanDefinitionReader.loadBeanDefinitions
关键方法doLoadBeanDefinitions
doLoadDocument(inputSource, resource)负责将内存中的xml二进制流数据转化为Dom树
registerBeanDefinitions(doc, resource)负责将dom树转化为bean definition并注册到DefaultListableBeanFactory<br>
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
this.delegate = createDelegate(getReaderContext(), root, parent);
将<beans>标签下的default-lazy-init、default_merge、default_autowire、default-dependency-check、default-autowire-candidates、default-init-method、default-destroy-method这几个属性取出来,设置到DocumentDefaultsDefinition即defaults中,后面的解析属性时,如果用户没有配置一些属性,会用到这里的默认值</beans>
delegate.initDefaults(root, parentDelegate);
populateDefaults(this.defaults, (parent != null ? parent.defaults : null), root);
parseBeanDefinitions(root, this.delegate);
parseCustomElement
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
从spring.handlers文件加载处理不同namespace的处理器<br>
aop
context
NamespaceHandlerSupport.parse(Element element, ParserContext parserContext)
BeanDefinitionParser parser = findParserForElement(element, parserContext);
ComponentScanBeanDefinitionParser.parse(element, parserContext)
Perform a scan within the specified base packages,returning the registered bean definitions.
findCandidateComponents(basePackage);
Scan the class path for candidate components.
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
getMetadataReader
super.getMetadataReader(resource);
classReader.accept(visitor, ClassReader.SKIP_DEBUG);
通过基于asm工具访问class文件结构。查看了部分源码,注释很多,<br>对了解class文件结构很有帮助,后续研究下。目前由于主要对Spring进行源码研究,先不深入到三方工具
determine whether the given class does not match any exclude filter and does match at least one include filter.
this.scopeMetadataResolver.resolveScopeMetadata(candidate);
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
checkCandidate(beanName, candidate)
registerBeanDefinition(definitionHolder, this.registry);
发送组件注册的事件,非主要,默认实现是空的
ConfigBeanDefinitionParser.parse(Element element, ParserContext parserContext)
configureAutoProxyCreator(parserContext, element);
AopNamespaceUtils.registerAspectJAutoProxyCreatorIfNecessary
AopConfigUtils.registerAspectJAutoProxyCreatorIfNecessary
包装AspectJAwareAdvisorAutoProxyCreator为RootBeanDefinition,优先级最高
向BeanFactory注册org.springframework.aop.config.internalAutoProxyCreator
可以自定义,也可以使用Spring提供的(根据优先级来)
默认提供的是org.springframework.aop.aspectj.autoproxy.AspectJAwareAdvisorAutoProxyCreator
useClassProxyingIfNecessary(parserContext.getRegistry(), sourceElement);
根据配置proxy-target-class和expose-proxy,设置是否使用CGLIB进行代理以及是否暴露最终的代理
发布组件注册事件<br>
获取aop:config命名空间下的子元素,遍历子元素逐个解析
pointcut
advisor
aspect
开始解析aop:aspect下的子节点,判断满足if (isAdviceNode(node, parserContext))才解析
Return true if the supplied node describes an advice type. <br>May be one of: 'before', 'after', 'after-returning', 'after-throwing' or 'around'.
调用parseAdvice解析,解析后,将advisor注册到BeanFactory<br>
parseAdvice
create the method factory bean
create instance factory definition
createAdviceDefinition
getAdviceClass(adviceElement, parserContext)
Gets the advice implementation class corresponding to the supplied Element.
不同的切入方式对应不同的Class
before对应AspectJMethodBeforeAdvice
After对应AspectJAfterAdvice
after-returning对应AspectJAfterReturningAdvice
after-throwing对应AspectJAfterThrowingAdvice
around对应AspectJAroundAdvice
configure the advisor
将adviceDef包装为advisorDefinition,包装类型是org.springframework.aop.aspectj.AspectJPointcutAdvisor
判断<aop:aspect>标签中有没有"order"属性的,有就设置一下,"order"属性是用来控制切入方法优先级的
register the final advisor
获取注册的名字BeanName,和<bean>的注册差不多,使用的是Class全路径+"#"+全局计数器的方式,其中的Class全路径为org.springframework.aop.aspectj.AspectJPointcutAdvisor,依次类推,每一个BeanName应当为org.springframework.aop.aspectj.AspectJPointcutAdvisor#0、org.springframework.aop.aspectj.AspectJPointcutAdvisor#1、org.springframework.aop.aspectj.AspectJPointcutAdvisor#2这样下去。
如果内部解析到pointcut节点,调用parsePointcut解析
获取<aop:pointcut>标签下的"id"属性与"expression"属性</aop:pointcut>
获取切点表达式
将id包装成PointcutEntry推至栈顶,表示Spring上下文正在解析这个Pointcut标签
createPointcutDefinition
把切点表达式包装成一个RootBeanDefinition,具体类型为AspectJExpressionPointcut
<aop:pointcut>标签对应的Bean是prototype即原型的
注册切点的BeanDefinition到BeanFactory
id配置不为空,就使用id作为key注册
否则就按指定规则生成beanname<br>
pointcutBeanName=org.springframework.aop.aspectj.AspectJExpressionPointcut#序号(从0开始累加)
向解析工具上下文中注册一个Pointcut组件定义
切点解析出栈,表示对这个切点解析完毕
parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate)
processBeanDefinition
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele)
获取BeanName
checkNameUniqueness用于确保BeanName的唯一性
真正的解析逻辑parseBeanDefinitionElement
this.parseState.push(new BeanEntry(beanName));
一个用Linkedlist实现的栈,用于记录解析的位置<br>
从xml节点属性获取class属性和parent属性的值<br>
利用上一步获取的两个值创建AbstractBeanDefinition
设置scope、lazy-init、abstract、autowire、depends-on、autowire-candidate、primary、init-method、destroy-method、factory-method、factory-bean等属性,如果用户没有配置,设置默认值
getAutowireMode(autowire)获取注入的方式
这是一个deprecation方法,新的判断注入方法的逻辑滞后到getBean
设置description属性
设置meta属性
如果配置了lookup-method属性,还需要向bean definition设置子元素复写的方法<br>
如果配置了replaced-method属性,还需要向bean definition设置子元素复写的方法
如果配置了constructor-arg属性,解析
解析property属性
解析qualifier属性
设置操作deanDefinition的上下文环境
设置bean definition元数据的配置资源
this.parseState.pop();
节点解析完毕。finally中将当前节点从栈顶推出
生成bean name<br>
Inner bean: generate identity hashcode suffix.
Top-level bean: use plain class name with unique suffix if necessary.
假如不是innerBean,使用【类全路径+#+数字】的格式来命名Bean,其中数字指的是,同一个Bean出现1次,只要该Bean没有id,就从0开始依次向上累加,比如a.b.c#0、a.b.c#1、a.b.c#2
返回new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
将加载的bean definition设置到DefaultListableFactory的内部数据结构中<br>
Map、List、Set<br>
重置缓存的Bean<br>
Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
处理默认的namespace beans下的其它标签:import、alias、beans<br>
xml解析成Document,这里的解析使用的是JDK自带的DocumentBuilder,<br>DocumentBuilder处理xml文件输入流,发现两个中定义的id重复即会抛出XNIException异常,<br>最终将导致Spring容器启动失败。Spring不允许两个<bean>定义相同的id。</bean>
prepareBeanFactory(beanFactory);
Tell the internal bean factory to use the context's class loader etc.
Configure the bean factory with context callbacks.
BeanFactory interface not registered as resolvable type in a plain factory.<br>MessageSource registered (and found for autowiring) as a bean.
Register early post-processor for detecting inner beans as ApplicationListeners.
Detect a LoadTimeWeaver and prepare for weaving, if found.
Register default environment beans.
postProcessBeanFactory(beanFactory);
默认实现内容是空的,如果是web应用,实现类是AbstractRefreshableWebApplicationContext
Register request/session scopes, a ServletContextAwareProcessor, etc.
invokeBeanFactoryPostProcessors(beanFactory);
Instantiate and invoke all registered BeanFactoryPostProcessor beans,respecting explicit order if given.<br class="Apple-interchange-newline"><div id="inner-editor"></div>实例化并调用所有已注册的BeanFactoryPostProcessor bean,如果有顺序遵从顺序调用。
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
PropertyPlaceholderConfigurer
.properties文件读取及占位符${...}替换
在bean definition加载后,bean实例化前<br>
PropertyResourceConfigurer.postProcessBeanFactory
mergeProperties();
PropertiesLoaderSupport.loadProperties(result);
PropertiesLoaderUtils.fillProperties
DefaultPropertiesPersister.load(props, stream);
props.load(is);
convertProperties(mergedProps);
默认是实现没有任何转化,直接返回了值
processProperties(beanFactory, mergedProps);
new PlaceholderResolvingStringValueResolver(props);
doProcessProperties(beanFactoryToProcess, valueResolver);
遍历beanFactory中的BeanDefinitions
PropertyPlaceholderConfigurer本身不会去解析占位符"${...}"
!(curName.equals(this.beanName)
BeanDefinitionVisitor.visitBeanDefinition(bd);
轮番访问<bean>bean定义中的parent、class、factory-bean、factory-method、scope、property、constructor-arg属性,但凡遇到需要"..."就进行解析</bean>
<bean>parent</bean>
class
factory-bean
factory-method
scope
property
BeanDefinitionVisitor.visitPropertyValues(beanDefinition.getPropertyValues());
BeanDefinitionVisitor.resolveValue
BeanDefinitionVisitor.resolveStringValue
this.valueResolver.resolveStringValue(strVal);
PropertyPlaceholderHelper.parseStringValue
constructor-arg
Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
invoke the postProcessBeanFactory callback of all processors handled so far.
Separate between BeanFactoryPostProcessors that implement PriorityOrdered, Ordered, and the rest.
First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.
Next, invoke the BeanFactoryPostProcessors that implement Ordered.
Finally, invoke all other BeanFactoryPostProcessors.
Detect a LoadTimeWeaver and prepare for weaving, if found in the meantime
initMessageSource();初始化国际化资源
没有国际化资源就设置空的messageSource
initApplicationEventMulticaster();
Initialize the ApplicationEventMulticaster.Uses SimpleApplicationEventMulticaster if none defined in the context.
onRefresh();
Initialize other special beans in specific context subclasses.
这是一个模板方法,默认实现是空的
registerListeners();
Add beans that implement ApplicationListener as listeners.<br>Doesn't affect other listeners, which can be added without being beans.
Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
Instantiate all remaining (non-lazy-init) singletons.
beanFactory.preInstantiateSingletons();
Return a merged RootBeanDefinition, traversing the parent bean definition.<br>if the specified bean corresponds to a child bean definition.
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
Bean定义公共的抽象类是AbstractBeanDefinition,普通的Bean在Spring加载Bean定义的时候,实例化出来的是GenericBeanDefinition,而Spring上下文包括实例化所有Bean用的AbstractBeanDefinition是RootBeanDefinition,这时候就使用getMergedLocalBeanDefinition方法做了一次转化,将非RootBeanDefinition转换为RootBeanDefinition以供后续操作
由于此方法实例化的是所有非懒加载的单例Bean,因此要实例化Bean,<br>必须满足三个定义:(1)不是抽象的(2)必须是单例的(3)必须是非懒加载的
判断一下Bean是否FactoryBean的实现
if (isFactoryBean(beanName))
工厂Bean有一个前缀&
getBean(beanName);
检查缓存中是否已经加载过bean,有直接用,<br>这里一些基础设施的bean比如工厂bean总会被优先加载,因为需要用它来实例化其他的bean<br>
Last step: publish corresponding event.
AbstractBeanFactory.doGetBean
创建bean实例的方法入口,不管是哪个scope的bean都是从这里开始创建
final String beanName = transformedBeanName(name);
根据别名获取规范的beanname<br>
Object sharedInstance = getSingleton(beanName);
如果是单例,会获取到实例化的单例对象<br>
Object singletonObject = this.singletonObjects.get(beanName);
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
如果beanName以&开头却不是FactoryBean,抛异常
如果beanName不是bean factory或者以&开头,返回这个单例bean
如果是bean factory.需要从这个bean factory获取真正的Bean对象<br>
FactoryBeanRegistrySupport.getObjectFromFactoryBean
if (factory.isSingleton() && containsSingleton(beanName))
先从缓存中获取,没有获取到,调用doGetObjectFromFactoryBean获取后放入缓存
不是单例就直接创建
Object object = doGetObjectFromFactoryBean(factory, beanName);
接着调用factory.getObject();
而getObject()内部做的是createBean
如果sharedInstance为空,说明是一个从未实例化的类,开始实例化步骤。<br>AbstractAutowireCapableBeanFactory.createBean
Guarantee initialization of beans that the current bean depends on.
创建当前Bean实例之前先解决这个类的依赖问题,先实例化依赖,这里是递归调用getBean<br>
Create bean instance.开始创建Bean实例。<br>AbstractAutowireCapableBeanFactory.doCreateBean
<font color="#c41230">不管哪个scope的Bean实例化,都要调用createBean方法</font>
singleton
DefaultSingletonBeanRegistry.getSingleton
先从singletonObjects获取,如果有直接返回,没有调用createBean创建单例
prototype
createBean前后会调用回调方法
bean在创建前要把当前beanName设置到ThreadLocal中去,其目的是保证多线程不会同时创建同一个bean
创建后把beanName从ThreadLocal中移除
createBean是AbstractAutowireCapableBeanFactory这个类的中心方法:创建一个bean实例,填充bean实例,应用后处理器等。
关键方法Object beanInstance = <font color="#c41230">doCreateBean</font>(beanName, mbdToUse, args);
Create a new instance for the specified bean, using an appropriate instantiation strategy:<br>factory method, constructor autowiring, or simple instantiation.
使用适当的实例化策略为指定的bean创建新实例: 工厂方法,构造函数自动装配或简单实例化。
如果工厂方法不为空,使用工厂方法实例化<br>
ConstructorResolver.instantiateUsingFactoryMethod
beanInstance = this.beanFactory.getInstantiationStrategy().instantiate( mbd, beanName, this.beanFactory, factoryBean, factoryMethodToUse, argsToUse);
如果是使用工厂方法,通过反射匹配到工厂方法名,然后通过反射调用工厂方法实例化bean
实际上创建指定的bean。 此时已经发生了预创建处理,例如 检查postProcessBeforeInstantiation回调。<br>和默认bean实例化不同的是,使用工厂方法和自动装配构造函数。
Allow post-processors to modify the merged bean definition.
Eagerly cache singletons to be able to resolve circular referenceseven when triggered by lifecycle interfaces like BeanFactoryAware.
Initialize the bean instance.
填充bean instance<br>
AbstractAutowireCapableBeanFactory.populateBean
byName与byType
autowireByName
获取不是SimpleProperties的属性,主要是为了获取用户创建的对象属性
BeanUtils.isSimpleProperty(pd.getPropertyType())
Check if the given type represents a "simple" property: a primitive, a String or other CharSequence, a Number, a Date, a URI, a URL, a Locale, a Class, or a corresponding array.Used to determine properties to check for a "simple" dependency-check.
遍历需要注入的属性<br>
判断是否在BeanFactory中,如果在,调用getBean
注册到依赖的bean里,销毁的时候先销毁依赖<br>
autowireByType
PropertyDescriptor pd = bw.getPropertyDescriptor(propertyName);
获取PropertyName对应的属性描述
不要尝试自动装配Object类型,这没有任何意义,即使从技术角度看它是一个非简单的对象属性。
if (Object.class != pd.getPropertyType())
resolveDependency
判断注入的依赖属性的类型,选择合适处理方式<br>
java.util.Optional
return new OptionalDependencyFactory().createOptionalDependency(descriptor, requestingBeanName);
ObjectFactory或者ObjectProvider
return new DependencyObjectProvider(descriptor, requestingBeanName);
javax.inject.Provider
return new Jsr330ProviderFactory().createDependencyProvider(descriptor, requestingBeanName);
其他类型
如果使用了Lazy注解,创建代理的依赖对象,根据委托对象是否实现了接口选择jdk动态代理或者Cglib代理生成子类
buildLazyResolutionProxy
没有使用Lazy注解,调用doResolveDependency
ConstructorResolver.setCurrentInjectionPoint(descriptor);
使用ThreadLocal保证多线程不会创建相同的Bean
resolveShortcut
不是很理解,没有用过shortcut
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
处理属性的值注解,返回转换后的值(但是定义的属性值一般不就是基本数据类型吗,怎么会走到这个代码块?)<br>
resolveMultipleBeans
处理注入的Array、Collection、Map类型装配
其实就是处理属性值和当前Bean是一对多的情况<br>
主要的方法:findAutowireCandidates
找一下所有的Bean定义中指定Type的实现类或者子类
判断要自动装配的类型是不是要自动装配的纠正类型,如果要自动装配的类型是纠正类型,<br>比如是一个ResourceLoader,那么就会为该类型生成一个代理实例
AutowireUtils.resolveAutowiringValue(autowiringValue, requiredType);
正常来说都是逐个判断查找一下beanName对应的BeanDefinition,判断一下是不是自动装配候选者,默认都是的,如果<bean>的autowire-candidate属性设置为false就不是这样,拿到所有待装配对象的实现类或者子类的候选者,组成一个Map,Key为beanName,Value为具体的Bean。</bean>
如果拿到的matchingBeans是空,抛异常
如果拿到的Map中有多个候选对象,判断其中是否有<bean>中属性配置为"primary=true"的,没有就抛异常</bean>
如果拿到的Map中只有一个候选对象,直接拿到那个
注册到依赖的bean里,销毁的时候先销毁依赖
AbstractPropertyAccessor.setPropertyValues
AbstractNestablePropertyAccessor.setPropertyValue(pv);
BeanWrapperImpl.setValue
writeMethod.invoke(getWrappedInstance(), value);
可以看到最后也是通过反射设置属性,填充bean instance<br>
Initialize the given bean instance, applying factory callbacks as well as init methods and bean post processors.Called from createBean for traditionally defined beans, and from initializeBean for existing bean instances.<font color="#c41230">开始真正的实例化</font>
调用初始化前后的扩展点<br>
invokeAwareMethods
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
i<font color="#c41230">nvokeInitMethods</font>(beanName, wrappedBean, mbd);<br>使用反射调用init方法
((<font color="#c41230">InitializingBean</font>) bean).<font color="#c41230">afterPropertiesSet</font>();
invokeCustomInitMethod(beanName, bean, mbd);
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
<font color="#c41230">AOP代理生成原理</font>
AbstractAutoProxyCreator.postProcessAfterInitialization
wrapIfNecessary
一些不需要生成代理的场景判断
判断为哪些bean生成代理
AbstractAdvisorAutoProxyCreator.getAdvicesAndAdvisorsForBean
findEligibleAdvisors
BeanFactoryAdvisorRetrievalHelper.findAdvisorBeans
从BeanFactory获取advisors,beanFactory中的advisor bean definition是解析的时候生成并注册的<br>
findAdvisorsThatCanApply
ProxyCreationContext.setCurrentProxiedBeanName(beanName);
使用ThreadLocal保证多线程访问下面的方法,每个线程只会在自己的线程空间内写
AopUtils.findAdvisorsThatCanApply(candidateAdvisors, beanClass);
canApply
目标类必须满足expression的匹配规则,不满足返回false
如果有一个方法满足直接返回true
考虑Introduction的方法匹配
匹配类中的其他方法
ProxyCreationContext.setCurrentProxiedBeanName(null);
extendAdvisors(eligibleAdvisors);
Adds an ExposeInvocationInterceptor to the beginning of the advice chain. These additional advices are needed when using AspectJ expression pointcuts and when using AspectJ-style advice.
排序advice chain<br>
createProxy
如果当前的beanFactory是ConfigurableListableBeanFactory的实现,exposeTargetClass
创建ProxyFactory<br>
判断proxy-target-class属性,设置到ProxyFactory的不同属性中,方便后面创建代理的时候使用
if (!proxyFactory.isProxyTargetClass())
是否直接代理目标类以及任何接口。false进入代码块
if (shouldProxyTargetClass(beanClass, beanName))
确定给定的bean是否应该使用其目标类而不是其接口进行代理。
如果强制使用类代理,设置属性proxyFactory.setProxyTargetClass(true);
否则将要代理的接口设置到ProxyFactory属性中
evaluateProxyInterfaces(beanClass, proxyFactory);
其他在创建代理前为ProxyFactory准备的属性设置
return proxyFactory.getProxy(getProxyClassLoader());
createAopProxy().getProxy(classLoader);
ProxyCreatorSupport.createAopProxy()
getAopProxyFactory().createAopProxy(this);
DefaultAopProxyFactory.createAopProxy
使用Cglib代理
如果满足三种情况之一使用Cglib代理
isOptimize方法为true,这表示让Spring自己去优化而不是用户指定
isProxyTargetClass方法为true,这表示配置了proxy-target-class="true"
hasNoUserSuppliedProxyInterfaces方法执行结果为true,这表示<bean>对象没有实现任何接口或者实现的接口是SpringProxy接口
其他情况使用JDK动态代理
总结
proxy-target-class没有配置或者proxy-target-class="false",返回JdkDynamicAopProxy
proxy-target-class="true"或者<bean>对象没有实现任何接口或者只实现了SpringProxy接口,返回Cglib2AopProxy
getProxy(classLoader)
Cglib代理实现
JDK动态代理实现
JdkDynamicAopProxy.invoke
equals方法与hashCode方法即使满足expression规则,也不会为之产生代理内容,调用的是JdkDynamicAopProxy的equals方法与hashCode方法
方法所属的Class是一个接口并且方法所属的Class是AdvisedSupport的父类或者父接口,直接通过反射调用该方法。
判断是否将代理暴露出去的,由<aop:config>标签中的expose-proxy="true/false"配置。
获取AdvisedSupport中的所有拦截器和动态拦截器列表,用于拦截方法
ExposeInvocationInterceptor
默认的拦截器,对应的原Advisor为DefaultPointcutAdvisor
MethodBeforeAdviceInterceptor
用于在实际方法调用之前的拦截,对应的原Advisor为AspectJMethodBeforeAdvice
AspectJAfterAdvice
用于在实际方法调用之后的处理
注册到依赖的bean里,销毁的时候先销毁依赖<br>
如果拦截器列表为空,很正常,因为某个类/接口下的某个方法可能不满足expression的匹配规则,因此此时通过反射直接调用该方法。
如果拦截器列表不为空,按照注释的意思,需要一个ReflectiveMethodInvocation,并通过proceed方法对原方法进行拦截,proceed方法感兴趣的朋友可以去看一下,里面使用到了递归的思想对chain中的Object进行了层层的调用。
Register bean as disposable.
如果是单例,this.disposableBeans.put(beanName, bean);
Spring MVC源码解读<br>
Spring事务原理
基于AOP
AOP是基于Spring扩展点BeanPostProcessor.postProcessAfterInitailization
SpringBoot
SpringBootApplication注解
SpringBootConfiguration注解
ComponentScan注解
Inherited注解表示被注解类是否继承其父类的注解
EnableAutoConfiguration注解,使用了该注解就启动自动注解
SpringBoot做的事,就是进一步简化配置,将多个注解整合到一个注解,完成配置
RestController注解
Controller注解,修饰class,用来创建处理http请求的对象
ResponseBody注解,默认响应json数据
整合JPA
引入data-jpa依赖和mybatis连接依赖
实体类上加注解@Entity,@Table(name="表名")
id属性的注解,@Id,@Column(name="id"),@GeneratedValue(strategy=GenerationType.identity)
其他字段使用@Column(name="列名")
dao接口继承JpaRepository<要操作的实体类,实体类对应表的主键类型>,dao接口加上注解@Repository("dao名字")
application.properties文件中配置jpa相关配置
整合reids
引入依赖
在启动类上加注解@EnableCaching
在业务层代码,要使用缓存的方法上加上注解Cacheble(value="存入redis数据库的key")
整合junit
引入依赖
在单元测试类加上@RunWith(SpringJUnit4ClassRunner.class)注解和@SpringBootTest(Classes=启动类.class)
读取配置文件
使用Environment.getProperty
整合rabbitMQ
引入spring-boot-starter-amqp依赖
在application.properties中配置关于RabbitMQ的连接和用户信息,用户可以回到上面的安装内容,在管理页面中创建用户。
创建消息生产者Sender。通过<font color="#c41230">注入AmqpTemplate接口</font>的实例来实现消息的发送,AmqpTemplate接口定义了一套针对AMQP协议的基础操作。在Spring Boot中会根据配置来注入其具体实现。在该生产者,我们会产生一个字符串,并发送到名为hello的队列中。
创建消息消费者Receiver。通过<font color="#c41230">@RabbitListener注解定义该类对hello队列的监听</font>,并用<font color="#c41230">@RabbitHandler注解来指定对消息的处理方法</font>。所以,该消费者实现了对hello队列的消费,消费操作为输出消息的字符串内容。
创建RabbitMQ的<font color="#c41230">配置类RabbitConfig,用来配置队列、交换器、路由等高级信息</font>。这里我们以入门为主,先以最小化的配置来定义,以完成一个基本的生产和消费过程。
Mybatis源码解读
使用<br>
基本使用
配置config.xml
typeAliases
environments
你可以配置多种环境,但你只能为每个SqlSessionFactory实例选择一个
如果你想连接两个数据库,那么就需要创建两个SqlSessionFactory实例
环境元素<br>
transactionManager
JDBC
这个配置直接简单使用了JDBC的提交和回滚设置,它依赖于数据源得到的连接来管理事物范围
MANAGED
这个配置几乎不做什么。它从来不提交或回滚一个连接,而它会让容器来管理事物的整个生命周期(比如Spring或J2EE应用服务器的上下文)
dataSource
三种内建的数据源类型(也就是type="XXX")
UNPOOLED
POOLED
JNDI
initial_context
data_source
mappers
告诉Mybatis找映射语句
settings
配置student.xml
导包,mybatis包和数据库驱动包<br>
编写父类,封装SqlSessionFactory、Reader
reader = Resources.getResourceAsReader("config.xml");
ssf = new SqlSessionFactoryBuilder().build(reader);
创建子类StudentOperator,单例
SqlSession ss = ssf.openSession();
student = ss.selectOne("com.xrq.StudentMapper.selectStudentById", 1);
sql映射
为什么要使用CDATA?
><和xml标签冲突导致无法解析
select
使用"#"最重要的作用就是防止SQL注入
#是占位符,$是字符串拼接
查询多个结果
属性含义<br>
resultType如果是集合,值应该是集合的类型,而不是集合本身
使用resultMap来接收查询结果
resultType的方式是有前提的,那就是假定列名和Java Bean中的属性名存在对应关系,否则就要用resultMap
resultMap定义中主键要使用id
resultMap和resultType不可以同时使用
insert
MySQL本身的语法,主键字段在insert的时候传入null
MyBatis支持的生成主键方式,useGeneratedKeys表示让数据库自动生成主键,keyProperty表示生成主键的列
有一个问题,这个我回头还得再看一下。照理说设置了transactionManager的type为JDBC,对事物的处理应该和底层JDBC是一致的,JDBC默认事物是自动提交的,这里事物却得手动提交,抛异常了得手动回滚才行。
修改、删除元素
update<br>
delete
SQL代码段
使用场景<br>
代码重用,查询总数和count的条件一般是一样的,不需要写两遍,可以用sql代码片段
定义
使用<br>
动态SQL
基于OGNL的表达式
if
test里面可以判断字符串、整型、浮点型,大胆地写判断条件吧。如果属性是复合类型,则可以使用A.B的方式去获取复合类型中的属性来进行比较。
choose、when、otherwise
不想应用所有的应用条件,相反我们想选择很多情况下的一种
两个when只能满足一个,都不满足则走other。还是注意一下这里的"<![CDATA[ ... ]]>",不可以包围整个语句。
trim、where、set
where 1=1<br>
where子元素
trim
prefixOverrides中填入的是字符串,用于精确匹配,不能忽略空格
set
set元素会动态前置set关键字,而且也会消除任意无关的逗号
foreach
只能遍历集合类元素(数组、map、list、set),而不是纯字符串,比如"xiao,ming,ai,xiao,hua"就不能按照逗号分割遍历
MyBatis集成Spring事务管理(上篇)
企业级开发<br>
定义和实现分开
分层开发,通常情况下为Dao-->Service-->Controller,不排除根据具体情况多一层/几层或少一层
使用Spring管理MyBatis事务
除了Spring必要的模块beans、context、core、expression、commons-logging之外,还需要
(1)MyBatis-Spring-1.x.0.jar,这个是Spring集成MyBatis必要的jar包
(2)数据库连接池,dbcp、c3p0都可以使用,我这里使用的是阿里的druid
(3)jdbc、tx、aop,jdbc是基本的不多说,用到tx和aop是因为Spring对MyBatis事务管理的支持是通过aop来实现的
(4)aopalliance.jar,这个是使用Spring AOP必要的一个jar包
MyBatis的配置文件config.xml里面,关于jdbc连接的部分可以都去掉,只保留typeAliases的部分
sql映射文件student_mapper.xml不需要改动
Spring的配置文件
SqlSessionFactory
configLocation
配置文件的位置
mapperLocations
映射文件的位置
java代码
继承MyBatis-Spring-1.x.0.jar自带的SqlSessionDaoSupport.java
@Repository,这个注解和@Component、@Controller<br>和我们最常见的@Service注解是一个作用,都可以将一个类声明为一个Spring的Bean
@Repository注解,对应的是持久层即Dao层,其作用是直接和数据库交互,通常来说一个方法对应一条具体的Sql语句
@Service注解,对应的是服务层即Service层,其作用是对单条/多条Sql语句进行组合处理,当然如果简单的话就直接调用Dao层的某个方法了
@Controller注解,对应的是控制层即MVC设计模式中的控制层,其作用是接收用户请求,<br>根据请求调用不同的Service取数据,并根据需求对数据进行组合、包装返回给前端
@Component注解,这个更多对应的是一个组件的概念,如果一个Bean不知道属于拿个层,可以使用@Component注解标注
@Resource,这个注解和@Autowired注解是一个意思,都可以自动注入属性属性。
整个过程中没有任何的commit、rollback,全部都是由Spring帮助我们实现的,这就是利用Spring对MyBatis进行事务管理
MyBatis集成Spring事物管理(下篇)
多数据的事物处理
单表多数据的事物处理
多库/多表多数据的事物处理
实例演示<br>
建立一个Teacher相关的表及类
表
teacher_mapper.xml
Teacher.java
推荐重写toString()方法,打印关键属性
在config.xml里面给Teacher.java声明一个别名
TeacherDao.java接口
实现类TeacherDaoImpl.java
单表事物管理
在同一张表里面,我想批量插入100条数据,但是由于这100条数据之间存在一定的相关性,<br>只要其中任何一条事物的插入失败,之前插入成功的数据就全部回滚,这应当如何实现?
使用MyBatis的批量插入功能
使用MyBatis的批量插入功能,只需要发起一次数据库的连接,这100次的插入操作在MyBatis看来是一个整体,<br>其中任何一个插入的失败都将导致整体插入操作的失败,即:要么全部成功,要么全部失败。
具体实现<br>
sql映射文件
StudentDao.java
StudentDaoImpl.java
实际上这并没有用到事物管理,而是使用MyBatis批量操作数据的做法,目的是为了减少和数据库的交互次数。
底层不是事务管理?怎么控制事务的?越说越玄乎<br>
这个是sql的批量插入吧,并不是mybatis的内容<br>
使用Spring管理事物,任何一条数据插入失败
每插入一条数据就要发起一次数据库连接,即使使用了数据库连接池,但在性能上依然有一定程度的损失
多库/多表事物管理
要对单库/多库的两张表(Student表、Teacher表)同时插入一条数据,要么全部成功,要么全部失败,该如何处理?
建立一个SchoolService接口
SchoolServiceImpl
@Service注解
@Transactional注解
这个注解用于开启事物管理,注意@Transactional注解的使用前提是该方法所在的类是一个Spring Bean,因此上面的@Service注解是必须的。
假如你给方法加了@Transactional注解却没有给类加@Service、@Repository、@Controller、<br>@Component四个注解其中之一将类声明为一个Spring的Bean,那么对方法的事物管理,是不会起作用的。
@Transactional注解
如果不是使用@Transactional注解,使用配置文件的做法进行声明式事务管理,没有注解方便
可以精细到具体的类甚至具体的方法上(区别是同一个类,对方法的事物管理配置会覆盖对类的事务管理配置)
事务属性配置
@Transactional(propagation = Propagation.REQUIRED)
propagation属性表示的是事物的传播特性,传播行为
Propagation.REQUIRED
方法运行时如果已经处在一个事物中,那么就加入到这个事物中,否则自己新建一个事物,REQUIRED是默认的事物传播特性
Propagation.NOT_SUPPORTED
如果方法没有关联到一个事物,容器不会为它开启一个事物,如果方法在一个事物中被调用,该事物会被挂起直到方法调用结束再继续执行
Propagation.REQUIRES_NEW
不管是否存在事物,该方法总会为自己发起一个新的事物,如果方法已经运行在一个事物中,则原有事物挂起,新的事物被创建
Propagation.MANDATORY
该方法只能在一个已经存在的事物中执行,业务方法不能发起自己的事物,如果在没有事物的环境下被调用,容器抛出异常
Propagation.SUPPORTS
该方法在某个事物范围内被调用,则方法成为该事物的一部分,如果方法在该事物范围内被调用,该方法就在没有事物的环境下执行
Propagation.NEVER
该方法绝对不能在事物范围内执行,如果在就抛出异常,只有该方法没有关联到任何事物,才正常执行
Propagation.NESTED
如果一个活动的事物存在,则运行在一个嵌套的事物中。如果没有活动事物,则按REQUIRED属性执行,<br>它只对DataSourceTransactionManager事物管理器有效
分析事务代码执行逻辑<br>
1、由于没有指定propagation属性,因此事物传播特性为默认的REQUIRED
2、StudentDao的insertStudent方法先运行,此时没有事物,因此新建一个事物
3、TeacherDao的insertTeacher方法接着运行,此时由于StudentDao的insertStudent方法已经开启了一个事物,insertTeacher方法加入到这个事物中
4、StudentDao的insertStudent方法和TeacherDao的insertTeacher方法组成了一个事物,两个方法要么同时执行成功,要么同时执行失败
@Transactional(isolation = Isolation.DEFAULT)
事物隔离级别
@Transactional(readOnly = true)
该事物是否为一个只读事物,配置这个属性可以提高方法执行效率。
@Transactional(rollbackFor = {ArrayIndexOutOfBoundsException.class, NullPointerException.class})
遇到方法抛出ArrayIndexOutOfBoundsException、NullPointerException两种异常会回滚数据,仅支持RuntimeException的子类。
@Transactional(noRollbackFor = {ArrayIndexOutOfBoundsException.class, NullPointerException.class})
遇到ArrayIndexOutOfBoundsException、NullPointerException两种异常不会回滚数据,同样也是仅支持RuntimeException的子类。
NPE举例
@Transactional(rollbackForClassName = {"NullPointerException"})、@Transactional(noRollbackForClassName = {"NullPointerException"})
@Transactional(timeout = 30)
事物超时时间,单位为秒。
@Transactional(value = "tran_1")
value这个属性主要就是给某个事物一个名字而已,这样在别的地方就可以使用这个事物的配置
使用声明式事务还是注解事务?<br>
原理都是基于AOP<br>
声明式事务可以按照拦截规则配置哪些包下的哪些方法开启事务,如果是其他包的方法或者同包下的其他方法,需要另外配置拦截规则,同样的事务配置下的多个拦截规则逗号隔开
注解事务,使用简单,写方法时需要为应该开启事务的方法加上注解和对应的事务配置。方法多需要一个个配,也不是很方便
实际项目中用声明式事务多一点
MyBatis插件及示例----打印每条SQL语句及其执行时间
Plugins
需求:打印每条真正执行的SQL语句及其执行的时间。
MyBatis本身的日志可以记录SQL,但是有以下几个问题
需求实现:实现Interceptor接口
源码分析
配置文件解析成inputstream
使用classLoader.getResourceAsStream(resource);
以解析为输入流的Reader为入参,通过SqlSessionFactoryBuilder构建SqlSessionFactory
在实例化XMLConfigBuilder做了一些初始化的操作
new XMLMapperEntityResolver()
初始化mybatisxml文件的约束dtd
new XPathParser(reader, true, props, new XMLMapperEntityResolver())
注入基本的参数,构造XPathParser
XPathFactory factory = XPathFactory.newInstance();
从本地环境中找到http://java.sun.com/jaxp/xpath/dom
先从构造的javax.xml.xpath.XPathFactory:http://java.sun.com/jaxp/xpath/dom系统属性中找,<br>找不到再从java.home下找,仍然没有,实例化JdkXmlFeatures
this.xpath = factory.newXPath();
将输入流转化为dom文档结构<br>
使用的DocumentBuilder是com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl
DocumentBuilder builder = factory.newDocumentBuilder();
解析为Dom结构的具体实现在com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument、scanStartElement等方法
do while循环,内部使用switch逐个处理各个节点以及空格和换行<br>
实例化Configuration类<br>
将dom结构文档按节点解析成具体的数据存储到Configuration类中,关键方法:org.apache.ibatis.builder.xml.XMLConfigBuilder.parseConfiguration
通过看每个配置节点的解析,可以更清楚的知道Mybatis的配置使用
解析plugin配置
通过class.forname反射获取插件类的class,然后调用newInstance实例化插件类对象,设置属性
添加到configuration类中
addInterceptor
pinterceptorChain在configuration类加载时实例化
InterceptorChain类很简单,可以看一下
内部用一个ArrayList,存放用户配置的插件
pluginAll会在扩展点处被调用
解析environments配置,涉及到事务工厂和数据源的解析和配置,比较陌生,值得看
transactionManagerElement,在 MyBatis 中有两种类型的事务管理器(也就是 type=”[JDBC|MANAGED]”),<br>整合Spring还有一个SpringManagedTransactionFactory
org.apache.ibatis.transaction.jdbc.JdbcTransactionFactory
这个配置就是直接使用了 JDBC 的提交和回滚设置,它依赖于从数据源得到的连接来管理事务作用域。
org.apache.ibatis.transaction.managed.ManagedTransactionFactory
基本不用
整合Spring后,不需要配置,默认使用org.mybatis.spring.transaction.SpringManagedTransactionFactory
参见org.mybatis.spring.SqlSessionFactoryBean.buildSqlSessionFactory,<br>buildSqlSessionFactory方法会在InitializingBean.afterPropertiesSet扩展点调用
dataSourceElement
org.apache.ibatis.datasource.pooled.PooledDataSourceFactory
org.apache.ibatis.datasource.unpooled.UnpooledDataSourceFactory
org.apache.ibatis.datasource.jndi.JndiDataSourceFactory
数据库厂商标识databaseIdProviderElement,具体可参见官网wiki
MyBatis 可以根据不同的数据库厂商执行不同的语句,这种多厂商的支持是基于映射语句中的 databaseId 属性。 MyBatis 会加载不带 databaseId 属性和带有匹配当前数据库 databaseId 属性的所有语句。 如果同时找到带有 databaseId 和不带 databaseId 的相同语句,则后者会被舍弃。
处理mapper映射文件,调用mapperElement
mapper的配置
for循环逐个解析和配置
这里的关键类是XMLMapperBuilder
XMLMapperEntityResolver,初始化mapper文件的约束等
实例化XPathParser,和解析配置文件逻辑一致
parse方法内部调用configurationElement,依次配置mapper映射文件中的各个节点
如果看cacheElement,就可以看到关于cache的一系列配置,更清楚的使用
通过sqlSessionFactory打开session
org.apache.ibatis.session.defaults.DefaultSqlSessionFactory.openSessionFromDataSource
从configuration中拿事务工厂
从事务工厂获取事务
实例化执行器
如果开启了缓存,包装为CachingExecutor
调用插件拦截方法,如果拦截了执行器的执行,就生成执行器的代理返回
返回一个DefaultSqlSession,包装了配置、事务、数据源、执行器等
查询
selectList
根据namespace.statementid从Configuration中获取语句内容的抽象模型MappedStatement
使用执行器查询
MappedStatement.getBoundSql(parameterObject)
createCacheKey一级缓存
更新
Shiro
Activiti Workflow<br>
Dubbo
Dubbo有几种配置方式
XML配置
注解配置
源码分析,基于2.7.1
<br><br> 通过 @EnableDubbo 可以在指定的包名下(通过 scanBasePackages 属性),或者指定的类中(通过 scanBasePackageClasses 属性)扫描 Dubbo 的服务提供者(以 @Service 注解)以及 Dubbo 的服务消费者(以 @Reference 注解)。<br><br> 扫描到 Dubbo 的服务提供方和消费者之后,对其做相应的组装并初始化,并最终完成服务暴露或者引用的工作。 <br>
属性配置
Java API配置
外部化配置
Dubbo如何Spring Boot整合
Dubbo框架的分层设计
分层设计图
Dubbo调用流程
Dubbo调用是同步的吗
默认是
谈谈对 Dubbo 的异常处理机制?
Dubbo 异常处理机制涉及的内容比较多,核心在于 Provider 的 异常过滤器 ExceptionFilter 对调用结果的各种情况的处理。
Netty在dubbo中的使用
Dubbo SPI
实现了按需加载接口实现类
测试代码
源码分析
getExtension
关键方法createExtension
getExtensionClasses()
loadExtensionClasses()
loadDirectory
loadResource
loadClass
injectExtension(Dubbo IOC)
尚硅谷dubbo教程
RPC
核心模块
通讯
序列化
有哪些RPC框架
dubbo、gRPC、Thrift、HSF
注册中心说一下?
Zookeeper
默认端口2181
树形目录服务
启动
./bin/zkServer.sh start-foreground
启动控制台(必须先启动ZK)
java -jar dubbo-admin-0.0.1-SNAPSHOT.jar
Dubbo如何使用说一下?
1、抽取公用包:将<font color="#c41230">接口、异常、bean</font>放入单独的API项目,需要依赖的项目引入
2、引入依赖:在provider和consumer都引入API项目依赖,引入dubbo依赖,引入zk的客户端依赖
2.6以前是zkclient,2.6以后是curator
3、如何配置provider和consumer
provider主要配置
application:应用名
registry:<font color="#c41230">注册中心</font>
protocol:指定<font color="#c41230">协议名称和通信端口号</font>
service:<font color="#c41230">暴露服务</font>,指定interface和真正实现ref
consumer主要配置
application:应用名
registry:注册中心
reference:声明需要调用远程服务的接口,生成远程服务代理
监控中心monitor
provider和consumer都需要配置monitor
dubbo.properties及覆盖策略
java -D优先级最高
xml和application.properties
dubbo.properties优先级最低,一般为公共配置
启动时检查,及早发现错误
配置comsumer统一规则
check="false",默认是true
超时和配置覆盖关系
防止阻塞
timeout
不同粒度配置的覆盖关系
<font color="#c41230">方法级优先,接口级次之,全局配置再次之。</font>
<font color="#c41230">如果级别一样,则消费方优先,提供方次之。</font>
总结:精确优先,消费者优先,精确优先于消费者
建议由<font color="#000000">服务</font><font color="#c41230">提供方设置超时</font>,因为一个方法需要执行多长时间,服务提供方更清楚,如果一个消费方同时引用多个服务,就不需要关心每个服务的超时设置
重试次数
整数,不包含第一次调用
retries
如果多个提供者,会逐个重试
幂等方法设置重试次数
查询天然幂等
一个方法不管调用多少次,结果都是一样的
删除和修改也要设置幂等
不幂等不设置重试次数
新值就不需要重试,或者重试的时候进行业务判断,查询是不是已经插入
设置为0表示不重试,出错就出错
用过多版本?什么场景用的?
灰度发布
当一个接口实现出现不兼容升级时,考虑使用这个功能
先让一部分服务上新
提供者提供多版本实现,消费方声明调用的版本
version="*"是随机调用版本
本地存根
stub
在客户端做验证、缓存之类的
SpringBoot与Dubbo整合的三种方式
导入dubbostarter,在application.properties配置属性,使用@Service暴露服务,使用@Reference引用服务
在启动类上配置EnableDubbo注解,这个注解就是配置包扫描
导入dubbo-starter,使用@ImportResource导入dubbo配置文件
使用Java注解API
说一下如何使用Dubbo做服务的高可用?
zookeeper宕机
消费者和提供者可以使用本地缓存调用服务
提供者全部宕掉,消费者应用无法使用,无线重连直到提供者恢复
Dubbo直连,直接在Reference注解中添加提供者url属性
集群模式下<font color="#c41230">负载均衡</font>配置
基于权重的随机负载(默认)
某一个服务的负载率为该服务的权重值/所有服务权重值和
基于权重的轮训负载
最少活跃数
一致性哈希
LoadBalance接口
<font color="#c41230">服务降级</font>
屏蔽非关键业务服务
比如广告
屏蔽
不调用提供者直接返回空
容错
调用失败返回空
<font color="#c41230">集群容错</font>,设置cluster属性
缺省failover模式
失败自动切换,失败重试。通常用于读操作,但重试会带来更长延迟。可通过retries="2"来设置重试次数(不含第一次)
failfast模式
快速失败,只发起一次调用,失败立即报错。通常用于非幂等写操作,比如新增
failsafe
出现异常,直接忽略,通常用于写入审计日志等操作。
failback
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知
forking
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过forks="2"来设置最大并行数
broadcast
广播调用所有提供者,逐个调用,任意一台报错则报错,通常用于通知所有提供者更新缓存或日志等本地资源信息。
整合Hystrix
Hystrix具有回退机制和断路器功能的线程和信号隔离,请求缓存和请求打包,以及监控和配置功能
导入spring-cloud-starter-netflix-hystrix,在启动类上加EnableHystrix注解
为可能出现异常的方法加上HystrixCommand注解,出现异常后,会由Hystrix代理容错
消费者也需要在需要容错的方法上加HystrixCommand注解,需要提供一个属性fallbackMethod="方法名",提供一个出错时调用的方法
Dubbo原理
RPC原理和Netty原理
RPC原理
1、消费方调用以本地调用方式调用服务
2、client stub接收到调用后负责将方法、参数等组装成能够进行网路传输的消息体
3、client stub找到服务地址,并将消息发送到服务端
4、server stub收到消息后进行解码
5、server stub根据解码结果调用本地服务
6、本地服务执行并将结果返回给server stub
7、server stub将返回结果打包成消息并发送至消费方
8、client stub接收到消息,并进行解码
9、服务消费方得到最终结果
Netty原理
基于NIO
Buffer
Selector
多路复用器
Channel
NioServerSocketChannel注册到Selector,监听事件,Connect、Accept、Read、Write
Netty线程模型
ServerBootstrap.bind
初始化NioServerSocketChannel
注册channel到selector
轮询accept事件
accept事件触发建立连接,selectionkey.channel().accept()返回一个SocketChannel
再将socketChannel注册到另一个selector上,专门监听read、write事件
read、write事件触发后,使用handler业务处理线程处理read、write
框架设计
config
proxy
registry
cluster
monitor
protocol
exchange
transport
serialize
标签解析
DubboBeanDefinitionParser是具体的解析类
DubboNamespaceHandler中注册解析器要解析的接口实现
服务暴露流程
ServiceBean
实现了InitializingBean接口的afterPropertiesSet,在所有属性设置完可以做一些事情
将配置中配置的provider、protocol、registry、monitor等等设置到ServiceBean中
实现了ApplicationListener的onApplicationEvent,监听ContextRefreshedEvent事件
满足不是延迟并且没有暴露,就调用export方法暴露
doExport()
doExportUrls();
doExportUrlsFor1Protocol
protocol.export(invoker);
private static final Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
DubboProtocol.export
openServer()
createServer(URL url)
server = Exchangers.bind(url, requestHandler);
getExchanger(url).bind(url, handler);
Transporters.bind
getTransporter().bind(url, handler)
new NettyServer(url, listener);
doOpen方法中就是Dubbo的线程模型
RegistryProtocol.export
doLocalExport,启动netty服务器,监听消费者的请求连接事件
ProviderConsumerRegTable.registerProvider(originInvoker, registryUrl, registedProviderUrl);//保存提供者和消费者信息到注册表,缓存远程调用
register,向注册中心注册提供者服务,除了注册,还有容错、订阅
如果注册中心没有启动,会使用FailbackRegistry容错策略,定时重试;否则就往对应的注册中心添加提供者
doRegister
registry.subscribe(overrideSubscribeUrl, overrideSubscribeListener);
ZookeeperRegistry.doSubscribe
notify
doNotify
服务引用流程
ReferenceBean
同样,实现InitializingBean接口的afterPropertiesSet,在引用的Bean的所有属性设置完后,将配置中配置的consumer、application、module、registry、monitor等等设置到ServiceBean中
还实现了FactoryBean
ReferenceConfig.get()
ReferenceConfig.init()
createProxy(map)
invoker = refprotocol.refer(interfaceClass, urls.get(0));
RegistryProtocol.refer
doRefer,调用zk客户端订阅目录服务,拿到提供者列表,将invoker注册到注册表,返回invoker
DubboProtocol.refer
使用netty客户端调用服务端
服务调用流程
AbstractInvoker.doInvoker
DubboInvoker
调用netty客户端和提供者交互
Redis
Quartz定时任务
Rabbit MQ
Nginx
Oracle
Mysql
Freemarker
Linux操作系统编程
先修课程<br>
C语言程序设计
C/C++参考书
数据结构与算法
操作系统原理
目标
熟悉linux操作系统基础知识,理解Linux操作系统部分重要的设计思想
熟悉Linux应用程式开发环境<br>
掌握Linux环境原生应用设计方法
学习使用LinuxAPI(POSIX API,C库函数),重点包括文件系统管理、进程与线程管理、线程同步以及进程间通信等方面,掌握文件IO、目录操作、进程创建、线程同步重要API的使用方法
从程序员视角看计算机系统(四个层次)
Shell、其他开发库或中间件、C/C++库
应用开发工程师也可以基于这一层开发程序、本课程关注重点
API层
应用开发工程师基于API开发程序、本课程关注重点
操作系统
硬件设备
第一章 操作系统基本知识
第二章 文件与目录操作<br>
第三章 进程与线程<br>
第四章 线程同步和进程间通信<br>
实验<br>
简历模板
https://lzl1521230945.gitee.io/myresume/2018/12/17/resume/
项目实战<br>
Java生产环境下性能监控与调优详解
2、基于JDK命令行工具的监控
JVM的参数类型
标准参数
-help
-server -client<br>
-version -showversion<br>
-cp -classpath<br>
X参数<br>
-Xint:解释执行
-Xcomp:第一次使用就编译成本地代码
-Xmixed:混合模式,JVM自己来决定是否编译成本地代码
XX参数
-XX:+UseConcMarkSweepGC<br>
-XX:+UseG1GC
-XX:MaxGCPauseMillis=500
-XX:GCTimeRatio=19
-Xms等价于-XX:InitialHeapSize
-Xmx等价于-XX:MaxHeapSize
-xss等价于-XX:ThreadStackSize
jinfo查看参数值大小
jinfo -flag MaxHeapSize pid<br>
jinfo -flag ThreadStackSize pid<br>
运行时JVM参数查看
查看初始值<br>
-XX:+PrintFlagsInitial
java -XX:+PrintFlagsFinal -version
=表示默认值
:=表示被用户或者JVM修改后的值
查看最终值<br>
-XX:+PrintFlagsFinal
解锁实验参数
-XX:+UnlockExperimentalVMOptions
解锁诊断参数<br>
-XX:+UnlockDiagnosticVMOptions
打印命令行参数<br>
-XX:+PrintCommandLineFlags
jps
查看java进程,主要用来获取pid
jps -l<br>
查看详细的类名
jinfo
jinfo flags pid<br>
查看已经修改过的jvm参数值
jinfo flag 参数名 pid<br>
查看参数值
jinfo -flag UseConcMarkSweepGC pid<br>
jinfo -flag UseG1GC pid<br>
jinfo -flag UseParallelGC pid<br>
jstat查看虚拟机统计信息
可以查看的信息
类装载
-class<br>
jstat -class pid 1000 10<br>
1000代表1秒
10表示要打印几个结果,即总共打印几次
最终会每秒打印一次,总共打印10次
time表示类装载和卸载掉耗时
垃圾收集
-gc
jstat -gc 1544 1000 3
输出结果<br>
JIT编译
-compiler
jstat -compiler 1544 1000 3
JVM内存结构<br>
jmap+MAT实战内存溢出
jstack实战死循环与死锁
Java并发编程入门与高并发面试
准备<br>
并发与高并发
JMM
Activiti6.0工作流引擎深度解析与实战
工作流入门
源码初探
引擎配置
核心API
数据设计与模型映射
BPMN2.0规范
集成Spring Boot2.0<br>
搭建工作流平台
如何设计一个秒杀系统
剑指Java面试
计算机网络面试核心
OSI开放互联参考模型
物理层
传输原始比特流,转化为电流强弱传输,到达后再转化成比特流,数模转换和模数转换
TCP/IP四层协议
TCP三次握手
TCP四次挥手
算法面试通过·40讲
如何事半功倍地学习数据结构和算法
精通一个领域
切碎知识点
数据结构
数据结构和算法
刻意练习
刻意练习
<font color="#c41230">练习缺点、弱点的地方</font>
有这种感觉:<font color="#c41230">不舒服、不爽、枯燥</font>,才是正确的感觉
生活中的例子:乒乓球、台球、游戏
获得反馈
即时反馈
主动型反馈(自己去找)
高手代码(Github,LeetCode,etc.)
第一视角直播
被动式反馈(高手给你指点)
code review
教练看你打,给你反馈
切题四件套
Clarification明确题目意思
Possible solutions,列出尽可能多的解,并取最适合的解
compare(time/space)
optimal(加强)
Coding(多写)
Test cases
如何计算算法的复杂度
大O
O(n)、O(n^2)
其他复杂度
复杂度趋势直观
求和
斐波拉契数列
主定理
二分查找O(logn)
二叉树遍历
O(n)
排序二维查找
O(n)
归并排序
O(nlogn)
链表的常见面试题
题目
算法
《算法之美》
前言、从今天起,跨过“数据结构与算法”这道坎
微服务接口限流的设计与思考
作为面试官,我是怎么快速判断程序员能力的?
算法学习需要不断积累,最好是写博客或者github,因为你可能有一段时间理解的非常深入,但是时间长了,就会忘了<br>
学习数据结构和算法可以锻炼编程能力和逻辑思维能力
01 | 为什么要学习数据结构和算法?
不需要自己实现,并不代表什么都不需要了解
掌握数据结构和算法,不管对于阅读框架源码,还是理解其背后的设计思想,都是非常有用的。
基础架构研发工程师,写出达到开源水平的框架才是你的目标!
掌握了数据结构与算法,你看待问题的深度,解决问题的角度就会完全不一样
大量n次加工的知识,对底层的封装,导致现在的程序员越来越"懒"了,他们认为这些工具的便利是理所当然。潜意识的认知里认为就是这样的存在,关底层什么事?你问他们底层,他们会说,我依然用的很好,为什么要了解底层?可以说这些便利的框架,更多的使大部分人很晚才觉悟到底层原理的重要性,扼杀了人们创新的动力,使人们工作的方式越来越像机器。觉悟的早晚取决于你工作的强度和工作的领域使用技术的深度,越强越深,你就会遇到越多的问题,在解决这些问题的时候,又不得不引着你去了解和学习底层知识原理。
掌握学习的方法,学习的重点,不走马观花,要么花时间看,要看就看的仔细,抓重点,做笔记。否则就不看,出去玩好了
一定要动手写,动手记导图
做技术就是不要浮躁。要耐得住寂寞。沉得下心。长期坚持,不要三天打鱼两天晒网
不做一个没有追求的码农,那些说过了35就不行的码农大部分都是不求上进的人。
数据结构与算法是基本功,基本功的作用就是,打个比方:篮球运动员只有每天坚持练基本功,才可能在球场上充分发挥,不被人虐
如果工作不满意 不顺心 更要卧薪尝胆 提高能力 沉淀自己。总有一天 机会会到来 你做好充分的抓住它的准备就好。<br>人在职场中 只要抓住一两次大的机会 就能做到很高的职位 就怕的是机会来了我们也抓不住
oom这种问题看似很遥远 实际上我还真遇到过很多次 多数是从数据库捞数据时 一不小心捞了太多的数据到内存 就oom了 而且这种情况用mat等工具也无法分析 因为这种oom是一过性的 heap dump的时候可能数据已经不可达 而mat这些工具只能分析可达对象
操作系统 计算机网络 编译原理 这些是比较基础的计算机课程
你要自己做些benchmark,然后再benchmark的基础上做优化,否则,再换个解决思路,你也不知道是不是更好了。要有数据比对,才能知道哪个更好。
02 | 如何抓住重点,系统高效地学习数据结构与算法?
小组学习,输出学习,错题学习,常用点难点学习,有重点的学
新技术和基础的学习要权衡投入精力 不然基础知识的不足很快就会成为你成长为大牛的拦路虎
具体措施:<br>
小组学习
有疑问多提多搜,没有疑问,也要搜使用场景,算法利弊
输出学习
将所学所想记录到博客里<br>
用Java实现算法<br>
错题学习
将容易犯错的地方记录到博客,多总结归纳错误的根源,针对性的学习<br>
常用点难点学习
网上搜索使用场景和案例,比如,别人怎么用的,别的开源项目怎么用,面试怎么考察
有重点学习
从始至终需要有这个意识,不要因为枯燥导致机械的走马观花,提醒自己要有重点的学习
如何衡量自己是否真正掌握了某一数据结构或者算法?
如果能掌握特点 应用场景。遇到问题能想的具体的解决算法 就说明掌握的很好了 并不要求都能手撸代码
先从看懂我写的代码 理解之后自己默写一遍 开始
03 | 复杂度分析(上):如何分析、统计算法的执行效率和资源消耗?
复杂度分析是整个算法学习的精髓,只要掌握了它,数据结构和算法的内容基本上就掌握了一半
看不懂别慌,也别忙着总结,先读五遍文章先,无他,唯手熟尔

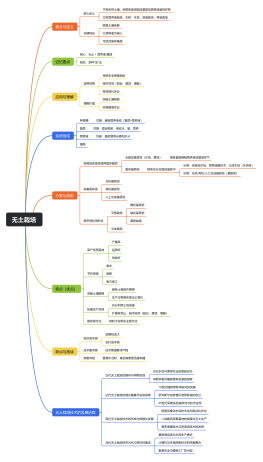


评论
0 条评论
下一页

