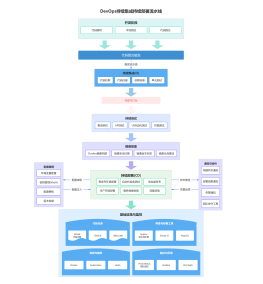
DevOps CI
2018-08-28 14:44:21 0 举报jenkins+docker
模板推荐
作者其他创作
大纲/内容



Collect

Collect
Collect

Collect
0 条评论
下一页