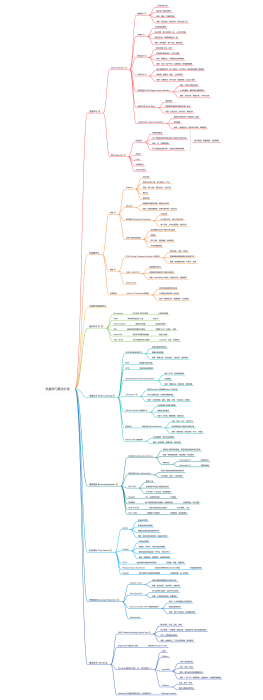
步骤简述
1.数据集的下载
2.确定好输入数据的格式(矩阵)
3.构建神经网络
conv-->pooling-->conv-->pooling-->平坦化-->全连接-->dropout-->全连接
4.使用softmax分类和交叉熵计算出loss,然后用梯度下降反向传播来优化参数
5.神经网络的输出结果与标签真实值进行比较,计算出准确率
6.设置超参数,将训练数据集的train和label传到占位符输入到神经网络去训练<br>再用测试集的train和label去检测准确率
设置x,y占位符, x-->train, y-->label,要注意占位符设置的类型是float32
# x = [-1, 28 * 28]<br># y = [-1, 10], one_hot 编码
改变输入图片x的形状
input_x_images = tf.reshape(input_x, [-1, 28, 28, 1]) <br># x = [-1, 28, 28, 1], 2维矩阵
<font color="#c41230">开始构建神经网络:<br>构建卷积层 conv</font>,使用 <font color="#31a8e0">tf.layers.conv2d </font>这个方法<br>
参数:<br><ol><li><font color="#c41230">inputs</font>=input_x_images, # 输入形状 [28, 28, 1]<br></li><li><font color="#c41230">filters</font>=32, # 32 个过滤器, 输出的深度 (depth) 是 32<br></li><li><font color="#c41230">kernel_size</font>=[5, 5], # 过滤器在二维的大小是(5 * 5)<br></li><li><font color="#c41230">strides</font>=1, # 步长是 1<br></li><li><font color="#c41230">padding</font>='same', # same 表示输出的大小不变, 因此需要在外围补零 2 圈<br></li><li><font color="#c41230">activation</font>=tf.nn.relu # 激活函数是 Relu<br></li></ol>
<font color="#c41230">构建池化层</font>,使用<font color="#31a8e0"> tf.layers.max_pooling2d</font>
参数<br><ol><li><font color="#c41230">inputs</font>=conv_shape # 输入形状是卷积后的矩阵<br></li><li><font color="#c41230">kernel_size</font>=(2, 2) # 亚采用矩阵的大小<br></li><li><font color="#c41230">strides</font>=(2, 2) # 步幅<br></li></ol>
<font color="#fdb813">卷积池化2~3层后</font>,进行<font color="#c41230">平坦化</font><font color="#000000">,</font><font color="#0076b3">将二维矩阵摊平成零位矩阵</font><font color="#c41230">(直接使用 tf.reshape 改变它的形状)</font><br>
tf.reshape(x, [-1, ??]) # 将 x reshape 成 [-1, ??]的矩阵
平坦化后,进行<font color="#c41230">全连接,使用 tf.layers.dense</font>
参数<br><ol><li><font color="#c41230">inputs</font>=pooding_shape, # 上一层的输出矩阵<br></li><li><font color="#c41230">units</font>=1024, # 卷积完后的神经元个数<br></li><li><font color="#c41230">activation</font>=tf.nn.relu # 使用的激活函数<br></li></ol>
全连接后抛弃一部分连接,使用tf.layers.dropout
dropout = tf.layers.dropout(inputs=dense, rate=0.5)<br><font color="#c41230"># rate = 0.5 每个循环,随机给50%的神经元带上面具,让他们不能连接</font>
再进行一次<font color="#c41230">全连接</font>,<font color="#c41230">输出10个神经元</font>,对应one_hot编码~
logits = tf.layers.dense(x, 10)
以上就是全部的神经网络,接下来要对网络输出的结果与label真实值进行对比预测
softmax函数和交叉熵函数,我们可以使用tensorflow封装好的函数<br>——<font color="#31a8e0">tf.losses.sparse_softmax_cross_entropy(labels=y, logit=y_)</font>
softmax的意义:比如神经网络最终输出的是[2, 4.0, 6.5....],softmax函数会把他们<font color="#c41230">转成对应的概率值[0.1, 0.15, 0.23....],概率全部相加等于1</font>。<br>
交叉熵函数(cross_entropy)通过交叉熵,能够计算出一个 loss 值,这个loss值越小证明预测出来的值准确率越高
<font color="#c41230">优化器optimize</font><font color="#000000">,这是十分重要的一个东西,它将上面计算好的loss值,</font><font color="#c41230">通过梯度下降进<br>行求导反向传播,从而改变W权重的参数</font><font color="#000000">,也就是所谓的“</font><font color="#c41230">调参</font><font color="#000000">”,不断优化网络的参数,<br>这里我们使用梯度下降的一个进化版,</font><font color="#31a8e0">AdamOptimizer(动量梯度下降)</font>
tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)<br># learing_rate 学习率,minmize 要优化的对象是以减小的方向进行优化
<font color="#c41230">比较预测值和实际标签label的匹配程度</font>,求平均值时<br>候要转成<font color="#c41230">tf.float64,求百分比</font><font color="#000000">,使用的函数右边所示</font>
<ol><li>predict = tf.argmax(y_, 1)<br></li><li>correct_values = tf.argmax(label, 1)<br></li><li>correct_prediction = tf.equal(predict, correct_values)<br></li><li>accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float64)) <br></li></ol>
<font color="#c41230">创建Session</font>,启动神经网络!!!~
<font color="#c41230">注意:启动前要激活所有的变量</font>,使用<br><font color="#31a8e0">init = tf.global_variables_initializer()<br>sess.run(init)</font>
设置<font color="#c41230">超参数,</font>Epoch,minibatch<br>
Epochs=20<br>batch_size=128<br><br><font color="#c41230">for epoch in range(Epochs):<br> for ites in range(input_size / batch_size):<br></font> <font color="#c41230"> batch_x, batch_y_ = mnist.train.next_batch(batch_size)</font><br># input_size 就是输入的数据集大小,意思是要经过ites次遍历才能跑完一次完整的数据集(epoch)<br># <b><font color="#c41230">每一次迭代都将更新一次权重参数</font></b><br># mnist.train.next_batch是mnist数据集自带的,<font color="#c41230">返回的是匹配的图片和标签</font>
将数据集读写进神经网络!!!之前的占位符就是为了这个用的!!!
batch_x, batch_y_ = mnist.train.next_batch(batch_size) # 读取训练数据集,上面一步有解释<br>loss_val, acc_val, _ = sess.run([loss, accuracy, train_op], <br> feed_dict={x: batch_data, y: batch_labels}) # <font color="#c41230">这里的 train_op 就是优化器,虽然没有赋值进去,但是一定要用 run 启动它!!!不然没办法进行梯度下降反向传播!</font><br>
1.每隔一个batch_size就打印一次训练集的准确率和loss值<br>2.每隔一个batch就打印一次测试集的准确率和loss值,输入数据的方式和上一步相同
mnist数据集下载
# 下载并载入 MNIST 手写数字库 (55000 * 28 * 28) 55000张训练图像<br># mnist = [-1, 28 *28], -1表示输入图片的张数
详细步骤