
大数据
2018-11-19 08:47:57 2 举报仅支持查看
AI智能生成
这是学习几个月的大数据的相关笔记
hadoop
hive
hbase
flume
sqoop
模板推荐
作者其他创作
大纲/内容
hadoop总结
有关需要配置存储文件的位置
1.0 配置hadoop(namenode的快照和日志 )临时文件的位置
2.0 除了1.0的配置,还需要配置zookeeper的文件位置<br>设置nn的日志和元数据放在jn上,<font color="#c41230">配置jn的存储文件位置</font>
一共涉及到的配置文件
hadoop-env.sh yarn-env.sh mapred-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
查看有关目录的信息
hdfs dfs 直接按回车帮助
一些必要的启动任务的命令
zkServer.sh start 必须先启动zookeeper
start-all.sh
stop-all.sh
start-dfs.sh 启动 启动nn ,dn ,jn,zkfc
start-yarn.sh 启动nodemanager
yarn-daemon.sh start resourcemanager 启动resourcemanager
HADOOP 生态系统
hdfs
优点 :
高容错性
适合批处理
移动 计算而非数据(计算向数据移动)
适合大数据处理
可构建在廉价的机器
缺点:
不适合小文件存取
低延迟数据访问,用大量的时间用于寻址
一个文件只能 有一个写者,仅支持 append
单个namenode的内存压力过大,内存受限
向hadoop上传文件的时候不需要启动hdfs服务,因为上传文件是在客户端上传(需要一些hadoop的安装包),而hdfs是服务器端;<br>另一种上传的方式 是 写一个java程序,用inputstream读文件,然后用hdfs的filesystem获取输出流对象,输出数据
namenode(NN)
保存文件元数据;单节点
元数据信息包括
静态数据信息
文件的大小,时间,目录结构,还有偏移量
动态数据信息
位置信息 ,每个block快的位置
block每个副本位置
是基于内存存储:不会和磁盘发生交互,但是存储的信息<br>会定时用快照(fsimage)的形式存放在磁盘,做持久化使用
客户端与namenode交互元数据信息
启动过程:
namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。<br>一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不需要SecondaryNameNode)和一个空的编辑日志。 <br>
持久化
依赖于secondnamenode
datanode(DN)
保存文件的block数据
客户端与namenode交互block数据
Block的副本放置策略
第一个副本(这里的源文件就是第一个副本)放置在上传文件的dn,<br>第二个副本放置在与第一个副本不同的机架上,第三个 副本与第二个 副本的机架相同
副本的作用
1.为了解决某个节点的单点故障后,数据不会丢失的问题。<br>副本的数量不能大于集群节点的数量的,并且副本不能与源文件的块放在一个节点上的
2.当并发量大的时候可以并行提供服务,提高集群的性能和处理并发的能力。<br>也就是牺牲存储空间来换取性能和安全。
HDFS的写流程
Client向nameNode发送写数据请求
NameNode节点,记录block信息。并返回可用的DataNode(就近原则)
客户端跟dn交互的时候只个一个dn服务节点交互,然后有这个dn服务与下一个dn服务(备份)建立scoket,<br>在由下一个dn与下下个dn服务建立scoket,这个过程叫pipeline管道模式
HDFS的读流程
client向namenode发送读请求
namenode查看Metadata信息,返回fileA的block的位置
在客户端读取块信息的时候优先选择离自己最近的块信息
SecondaryNameNode(SNN)
作用: 帮助namenode合并edit log 与fsimage<br>(checkpoint操作)
Nn服务器启动的时候会先恢复到fsimage的状态,在根据edits的修改日志进行更新,最终完成nn服务器的修复。<br>当修复好后将会生成一个新的fsimage,和一个空的editslog文件,当集群运行一段时间后,snn将把fsimage和editslog拉走<br>,并合并成一个新的fsimage,和一个空的editslog文件。周而复始。
在哪里进行合并日志
快照 fsimage中值保存静态的元数据信息
snn 设置做快照的条件
snn 会根据配置文件设置最大时间间隔 默认是3600秒
snn 也会根据edit log 的大小 设置最大默认值是64MB
HDFS的启动
配置环境变量
先得配置 hadoop-env.sh mapred-env.sh yarn-env.sh 中的jdk的环境变量
core-site.xml
配置集群的名字
配置 hadoop临时目录的位置
存放快照(镜像文件)和日志
hdfs-site.xml
配置副本的数量和secondnn的位置
slaves
设置datanode的位置
先格式化<br>(只在第一次启动过程中做格式化 )
hdfs namenode -format
<value>/var/neusoft/hadoop/local</value>
<br>格式化前必须确保该目录不存在或者为空。 <br>
目的:格式化就是初始化了目录,并且生成了一个空的fsimage文件,并生成了一个版本信息
创建上传文件的目录
hdfs dfs -mkdir -p /user/root #用递归方式创建目录
上传文件
hdfs dfs -put ./hadoop-2.6.5.tar.gz /user/root/
安全模式
一 : namenode启动的时候,会将映像文件(fsimage)载入内存,并执行log文件中的各项操作<br> 完成后生成新的快照,和日志,此实处于安全模式,namenode对于客户端来说是只读的
二: 当上传文件时,副本数小于最小副本数是,认为是安全模式
处理hdfs文件的类
Filesystem管理文件
hdfs 2.0 背景<br>
历史版本
namenode 单点故障
namenode压力过大,且内存受限,
2.0 版本 由hdfs,mapreduce和yarn构成
解决单点故障
zookeeper
Zookeeper自身也维护了一个目录树的结构,目录树下存放所有的namenode的目录,的这个目录是namenode启动的时候创建,谁先启动谁先创建,也就争抢到了active的锁了,也就成了active的角色了。当active的namenode宕机了会触发zkfc来将zookeeper里的namenode的目录删掉,这个时候就在zookeeper上触发了一个回调事件,会告诉standby的nn,将其角色改为active
zookeeper会设置一个存储数据的目录
zkfc(failovercontroller)
zkfc进程要与nn在同一个物理节点,他又两只手,一只与namenode进行连接,另一只与zookeeper进行连接<br>,同时她还会有 隐藏的第三只手,当另一个zkfc发生宕机时,他会通过zookeeper,控制另一个namenode
journaNades(jn)
作用:存放静态的元数据信息和日志,快照存放在各自的namenode上<br>以达到namenode共享数据
当上传文件时,先通过namenode,再把静态信息存储到jn中
namenode
active namenode
zkfc会实时监测namenode的存活状态
主机也会定是的将快照与日志进行合并
客户端进行 增删改操作与会主namenode进行 交互,并把日志文件共享
standby namenode
实时监测jn中logs的变化,定时将快照与日志文件进行合并,<br>以至于一旦发生主机宕机的现象,备机可以很快恢复主机的状态
standbynn来进行操作日志与快照的合并,并将结果通过http通信传送给activenn
datanode会向主备namenode都发送心跳机制
HA搭建集群
zookeeper
安装过程
配置环境变量
在/etc/profile中配置
自身的环境变量
设置存放数据的目录 dataDir=/var/neusoft/zk<br>在目录中还要设置每个zookeeper的优先级
设置安装 zoo keeper的服务器
hadoop
hdfs-site
设置集群的名字
设置namenode的日志存放在jn及jn所在的服务器
设置jn 存储文件的地址
文件内容包括静态信息和日志
core-site
设置hadoop(namenode)的存储文件的地址
配置集群的名字
指定zookeeper的服务器
启动
启动zookeeper
启动 jn(journalnode)
格式化第一个namenode在、再启动
再同步第二个namenode
初始化zkfc
启动服务
mapreduce
工作原理
split
大量的数据计算需要用mapreduce的切片split来做分片,默认使按一行进行切分
切分的数量(maptask):用文件的大小除以切片的大小
map
map的输入来源于split的切片
map会将 切分的行 设置为键值对的关系,加工数据
shuffer(洗牌)
map计算后会把数据放到一个环型缓冲区(其实是byte 数组),并按照<b>maptask</b>的个数进行分区<br>在分区的过程中进行按key进行排序,因为在内存中做排序的效率很高。<br>当内存一定量是,会发生io溢出,将内容写道磁盘文件;<br>读入磁盘文件,并进行分组,把key值相同的放一起,最后进行key值合并(merger)
具体分为 四个过程
分区
用key'的哈希值取余reduce的个数进行分区
排序(sort)
在进行分区后(溢写前)进行排序,调用 compareto方法
溢写
环形缓冲区(其实是byte数组)有一个阈值(默认使100M),超过阈值就进行溢写<br>而且溢写的过程还能继续进行放入数据,互不影响.溢写的文件是分区且排序
合并
将磁盘上每个文件的相同分区copy到一起,进行merge合并,合并过程也会进行归并排序<br>最终的文件分区且有序,回附带一个索引文件(记录偏移量)
reduce
reduce进行计算value值
环境设置(mapred-site.xml)
设置mapreduce基于yarn进行计算<br>
利用eclipse进行编写自己的map 和reducer时,不能用jdk自带的数据类型<br>因为在序列化时(往文件传输),效率比较低
处理mapreduce任务是需要用到 Fileinputformat 和 Fileoutputformat来获取或者输出内容
通过 context 来连接map与reduce 阶段的输入输出
yarn(资源调度)
JobTracker:因为这个角色是单点运行所以负载过重,<br>并且容易单点故障;相当于rm+applicationmaster
调度的整个过程
客户端首先把计算需求提交给job tracker,<font color="#f1753f">jobtracker</font>与namenode进行交互,<br>取到元信息,之后启动map的task,map根据切片来计算自己的数据,<br>分别统计出自己的分片中所包含refund单词的生成key和value<br>,计算完成后由<font color="#f1753f">jobtracker</font>来触发reducemaster任务。
2.x里面由于使用了ha和联邦机制,<br>既能保证数据安全,又能提升计算效率
resourcemanager
作用: 资源管理的主服务,负责任务调度,客户端提交任务是先交给yarn,resourcemanager,<br>rm与nm之间建立心跳机制resourcemanager根据空闲资源来创建一个application master的临时进程,<br>之后客户端直接与applicationmaster进行交互,之后的一些操作,application回向rm发送请求,申请contain容器<br>rm会返回一个提交资源的路径和jobid,rm内部有一个任务调度队列(application manager),<br>
分配资源的原则::计算向数据移动,也就是说提交的这个任务的数据在哪个节点上,<br>那么任务就提交到哪个服务的节点上,但是并不是任何时候都能有这样的理想状态,<br>假设数据的节点正好没有空闲的资源来开启task任务,这个时候就会有resourcemanager<br>来寻找一个空闲资源的服务节点,将数据移动到空闲的节点上,在将计算任务也调度到这个节点上
nodemanager
作用:实时与resourcemanager进行 心跳 ,回到当前的节点资源情况<br>比如.cpu情况,内存,磁盘信息 等;<br>nodemanager还向resourcemanager实时汇报当前执行的任务<br>负责具体的分配contain容器的任务
放置在与datanode相同的节点上
创建application master
resourcemanager根据空闲资源创建一个application master临时进程,<br>然后 application向resourcemanager申请container资源,开启mapreduce任务 <br>跟踪任务状态及监控各个任务的执行,遇到失败的任务还负责重启它<br>
container 容器:
里面存放mapreduce的任务,也可以存放spark的任务,storm的任务
存放一些程序运行所需要的资源,ram(内存)和vcore(cpu)
环境设置(yarn-site.xml)
设置有关resourcemanager的配置
设置有关zookeeper地址的配置
hive 数据仓库
hive简介
1.Hive是一个数据仓库,不是数据库<br>2.<b>Hive是解释器,编译器,优化器</b><br>3.Hive运行时,元数据存储在关系型数据库中 <br>4.<b>hive最小的处理单元是操作符,每个操作符都是一个MR的作业</b>
作用
数据仓库的主要目的是为了分析数据,或清洗数据。数据仓库所存储的大部分都是历史数据。<br>并且数据库执行的过程是交互式查询,数据仓库是将sql转换成mapreduce了,<br>所以可以认为hive是解释器或者编译器
hive架构
用户接口(连接Driver,<br>一般放在一台服务器)
CLI
Client
可以连接到Hive Server
Hive Web interface
Driver (Compiler,Optimizer,Executor)
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成
会连接 metastore ,hadoop(存储及计算) ,
metastore
作用; 客户端连接meta store服务,meta store再去连接mysql数据库来存取元数据。<br>有了meta store服务,就可以有多个客户端同时连接,而且不需要知道mysql的用户名和密码,只要连接<br>metastore即可
metadata(mysql)<br>使用mysql 关系型数据库<br>
元信息包括表、字段、字段属性、字段长度以及<br>表的数据对应存储在hdfs中的位置信息。
hdfs
存储hive的数据,进行计算的位置
hive的开启方式
1.cli
启动metastoreserver hive -- service metastore 9083
启动客户端 hive
2.hiveJDBC
启动metastore server hiveserver2 10000<br>(开启thrift服务)
客户端 beeline -u jdbc:hive2://node03:10000/数据库名 -n root<br> 或者 beeline 之后 在输入 jdbc:hive2://node03:10000/数据库名 ;auth=nosasl root mima
hive web GUI接口<br>默认端口为9999
将hwi目录进行 打war包
配置hive-site。xml
启动服务
启动metastore
hive --service metastore
启动web的接口 hwi
hive --service hwi
通过网页进入 hive,进行查询
http://node03:9999/hwi
hive的模型图
内嵌(DerBy)模式
客户端,driver,metastort 布置在用一台机器上
本地模式
将metastore Server 和hive服务搭建在一起<br>单独架构一台数据库存储元数据
远程服务器模式
将metastore Server 与hive服务器分开搭建<br>仍然单独架构存储元数据的数据库
配置文件
配置数据的存储目录
<name>hive.metastore.warehouse.dir</name>
<br> <value>/user/hive/warehouse</value> <br>
配置 metastore server 是否与hive 架构在一起
<name>hive.metastore.local</name> <br> <value>false</value> <br>
hive 变量及参数的设置
1. 修改配置文件
hive-site。xml
2.启动hive cli时,通过 -<font color="#924517">-</font><font color="#fdb813"><b>hiveconf</b></font> 的方式进行设置
hive --hiveconf hive.cli.print.current.db=true<br>上面的设置是打印当前数据库 <br>
hive --hiveconf hive.cli.print.header=true<br> 打印出表的字段名
3. 进入cli之后,使用<u><i><b>set命令</b></i></u>设置<br>set设置的作用域为本次会话
例如 set hive.cli.print.header=true;
4.设置自动加载参数
编写文件 <b> .hiverc (宿主 目录下),在启动客户端的时候加载</b><br>配置通用的hive的环境变量
宿主目录下有一个 隐藏文件 .hivehistory 记录曾经的操作
hive 的特殊数据类型
array_type
map_type
struct_type
hql语句
ddl(数据库和表)
desc formatted 表名
查看表的结构信息
创建表
内部表
默认就是创建内部表
创建表的同时,数据存储的目录会根据配置文件建立
外部表
添加关键字 exteranl
需要指定文件数据存储的位置 location
创建外部表,只是把数据放在hdfs中的路径下,<br>hive在并不直接管理该数据,只是引用数据
创建方式
create table 表名 like 另一表名<br>只复制表结构,不复制表数据
create table 表名 as select 。。。<br>创建表的同时插入其它表的数据
删除表
删除内部表
hive删除内部表后,元数据信息被删除, hdfs中也不存在该表数据信息
删除外部表
hive 删除外部表,删除了元数据信息,但hdfs中还存在数据文本
dml(查询和插入)
导入本地数据
load data local inpath ‘位置’ into table 表名
导入非本地数据
load data inpath ‘ hdfs位置’into table 表名
导入数据其实就是文件数据上传到hive'的相关目录下,<br>如果直接将数据拷贝到hive的相关数据目录下,也会被加载为hive数据
插入数据
创建表的时候插入数据
create table 表名 as select 。。。。
实现一表查询,多表插入
from 表名 <br>insert into table 表名<br>select 。。。。。
分区
分区就是目录,目录就是分区,<br>在创建表的同时声明 <b><i>partitioned by</i></b> 字段
字段属性中就是不允许包含分区字段的,字段要么在字段属性中定义,<br>要么在分区中定义,如果字段属性和分区中同时定义的话执行会报错
建立分区的目的是为了提高查询的目录,分区的位置靠左侧的为上级目录,<br>往右依次子集目录。添加分区的时候要将所有的分区全部指定,删除分区<br>的时候可以不全部指定,但是所删除的分区相关的子分区也会一并删除。<br>以上操作的是内部表,内部表删除分区的时候数据会丢失,那么<br>外部表删除分区后,数据不会丢失,只是删除了hive中的相关元数据
特点,好处
会将字段的不同值存放在不同的目录下,便于以后的查询效率
分区的类别
静态分区
一般是将信息导入分区表中
例如 LOAD DATA LOCAL INPATH '/root/data1' INTO TABLE psn2 PARTITION(age=10)
动态分区
需要从其他表导入信息 如 :FROM psn22<br>INSERT overwrite TABLE psn21 <b>partition(sex,age)</b><br>SELECT id,name,likes,address,sex,age <b>distribute by sex,age</b>; <br>
开启支持动态分区 set hive.exec.dynamic.partition=true;
设置非静态分区 set hive.exec.dynamic.partition.mode=nostrict;
优化
设置每一个mr节点上的最大分区数量(100)
set hive.exec.max.dynamic.partitions.pernode;
设置所有的mr节点上的最大数量(1000)
set hive.exec.max.dynamic.partitions;
设置所有的mrjob允许创建的文件的最大数量(100000)
set hive.exec.max.created.files;
分桶
核心思想
将一个数据文件按照列值取哈希值的方式划分为多个数据文件
使用场景
可以对每一个表,分区进行分桶,而且还可以根据多了个列进行分桶
优点
可以进行数据抽样检测
增加了join查询的效率
桶为表加上了额外的结构,Hive在处理有些查询时能利用这个结构。<br>具体而言,连接两个在相同列上划分了桶的表,可以使用Map-side Join的高效实现。
开启分桶
set hive.enforce.bucketing=true;
mr运行时会根据bucket的个数自动分配reduce task的个数<br>一次作业产生的桶(文件数量)和reduce rask的个数一致
创建分桶表
CREATE TABLE psnbucket( id INT, name STRING, age INT)<br><b><i><font color="#0076b3">CLUSTERED BY (age) INTO 4 BUCKETS </font></i></b><br>ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; <br>
加载数据
就像动态分区一样,需要中间表导入数据
insert into table bucket_table select columns from tbl;
应用
数据抽样
主要是使用到了函数 tablesample(bucket x out of y on 字段)<br>x :从第几个桶开始 y:步长 抽样的个数=桶的个数/y;
select id, name, age from psnbucket tablesample(bucket 2 out of 4 on age);
map-join 关联
两个关联表的分桶个数要么相同,要么成倍数
自定义函数
UDF(一进一出)
例如 :时间函数,trim函数 ,
自定义的脱敏函数
自定义java代码
添加jar文件
add jar 路径
创建函数
CREATE TEMPORARY FUNCTION tm AS 'com.neusoft.hive.TuoMin';
函数的使用
UDAF(多进一出)
count,sum,max,min,avg 等函数
UDTF(一进多出)
一般处理数组,map等
函数 explode () <br>(一般与split 配合使用,将结果变成多行)
hive lateral view
作用: 用于跟UDTF函数(explode split)结合使用<br>主要是将udtf函数拆分成的多行结果组合成<i style=""><b><font color="#fdb813">一个支持别名的虚拟表</font></b></i>
主要解决的问题: 在select使用UDTF做查询过程中,查询只能包含单个UDTF,不能包含其他字段、以及多个UDTF的问题
语法规则: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)<br> udtf函数 字段名 拆分后定义的表名 拆分的字段名
select count(distinct(myCol1)), count(distinct(myCol2)) from psn2 <br>LATERAL VIEW explode(likes) myTable1 AS myCol1 <br>LATERAL VIEW explode(address) myTable2 AS myCol2, myCol3; <br>
视图
hive支持视图,但不支持物化视图(存储查询的结果),只能存查询语句,是虚表;<br><b>只能查询,不能做加载数据操作;</b>
hive视图中保存的是一份元数据,mysql视图中保存的是as 后面的sql语句执行的结果
创建视图
create view as select ......;
删除视图
drop view 视图名
索引
目的 :优化查询以及检索性能
索引机制
在指定列上建立索引,<b>会产生一张索引表(Hive的一张物理表)</b>,里面的字段包括,<b>索引列的值</b>、<b>该值对应的HDFS文件路径</b>、<b>该值在文件中的偏移量</b>;<br>在执行索引字段查询时候,首先额外生成一个MR job,根据对索引列的过滤条件,从索引表中过滤出索引列的值对应的hdfs文件路径及偏移量,输出到hdfs上的一个文件中,然后根据这些文件中的hdfs路径和偏移量,筛选原始input文件,生成新的split,作为整个job的split,这样就达到不用全表扫描的目的。
缺点:
每次查询都会先用一个job扫描索引表,如果索引列的值比较稀疏,那么索引表本身就会非常大
索引表不会自动rebuild,如果有数据新增或者删除,必须手动rebuild索引表数据
创建: create index 索引名 on table 表名(字段名) <br>as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild<br>in table 索引表名;<br> as 是指定索引器;in table 是把引用存放在索引表,不指定会默认生成
创建索引后不直接生效,需要重新生成索引信息
<p><b><i>ALTER INDEX t1_index ON psn2 REBUILD;</i></b></p>
索引表的信息
索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量;
查询索引
show index on 表名
删除索引
drop index if exists 索引名 on 表名
hive的运行方式
cli客户端运行
需要开启metastore和客户端 hive
web GUI接口运行
需要开启metastore和web服务hwi
hiveserver 运行(默认端口10000)
开启metastore,和hiveserver2,客户端 beeline
脚本运行
在linux下运行 hive 命令
hive -e “sql语句”
hive -e “ sql语句” >文件民 将输出结果重定向到文件
hive -e -S“ sql语句” >文件民 静默输出,将输出结果重定向到文件
hive -f file 运行文件中的sql语句,执行完还在linux端
hive -i file 上同,执行完会进入hive客户端状态
交互式运行
在hive上查看hdfs的内容,也可以运行linux命令
source file (在hive中运行文件)
dfs -ls / (查看hdfs内容)
运行linux 命令 !pwd
hive权限管理
基于存储进行授权
基于sql标准的hive授权
完全兼容SQL的授权模型,推荐使用该模式。<br>就是基于sql授权,grant的授权方式。
public
普通用户登录都有public权限
admin
管理员权限
权限验证
启动权限认证后,dfs, add, delete, compile, and reset等命令被禁用
添加、删除函数以及宏的操作,仅为具有admin的用户开放
transform 功能被禁用
hive默认授权
预防好人做坏事,不是放置坏人做坏事
hive优化
核心思想
把hive sql当作mapreduce程序区做优化,最终都是mapreduce任务来执行
执行计划
explain sql语句; 查看计划
explain extended sql语句; 查看计划的继承
运行方式
本地模式
开启 : set hive.exec.mode.local.auto=true;
设置文件的最大值 : hive.exec.mode.local.auto.inputbytes.max默认值为128M<br>当超过文件的最大值,仍以集群模式运行
本地模式一般应用于小表,数据量不大或者开发模式的应用
集群模式
当开启本地模式设置后,如果计算的表数据超过最大限制的话也还是以集群方式运行。
<br>hive.exec.mode.local.auto.inputbytes.max默认值为128M <br>
并行计算
开启并行计算 :set hive.exec.parallel=true;
最大允许job个数 :set hive.exec.parallel.thread.number<br>默认个数为8个,可自行设置
子查询之间没有任何依赖关系,适用于使用并行计算
严格模式
开启方式
set hive.mapred.mode=strict;
<br>(默认为:nonstrict非严格模式) <br>
查询限制
1、对于分区表,必须添加where对于分区字段的条件过滤;<br>2、order by语句必须包含limit输出限制;<br>3、限制执行笛卡尔积的查询。 (可以加where条件)<br>
目的;
不是优化查询,是为了避免发生误操作
hive 排序
order by
对于查询结果做全排序,只允许有一个reduce处理
<br>(当数据量较大时,应慎用。严格模式下,必须结合limit来使用) <br>
sort by
对于单个reduce(单个分区)的数据进行排序
distribute by
针对map进行分区,保证相同的key在同一分区
cluster by
相当于 Sort By + Distribute By
<br>(Cluster By不能通过asc、desc的方式指定排序规则;
<br>可通过 distribute by column sort by column asc|desc 的方式 <br>
join关联
join计算时,将小表放在join的左边,减少内存的使用
mapjoin 实现方式
1.sql方式,添加maphoin标记(mapjoin hint)
2. 开启自动的majoin
set hive.auto.convert.join = true;<br>(该参数为true时,Hive自动对左边的表统计量,<br>如果是小表就加入内存,即对小表使用Map join) <br>
注意事项
map-side 聚合
是开启在map端的聚合,省略了suffer和ruduce的过程,<br>在map聚合会提升 很大的效率
相关的一些参数设置
设置
可能会出现数据倾斜
常用的单词的重复率非常高,生僻的单词重复率非常低,这样做聚合的过程中就会产生数据倾斜
相关设置
hive.groupby.skewindata
<br>是否对GroupBy产生的数据倾斜做优化,默认为false <br>
解决方案
将原理默认的一个mapreduce转换成两个mapreduce任务,<br>第一个mapreduce的map输出是随机分发给reduce,不是相同<br>的key放到一组了,这样相对来说每个reduce所得到的数据相对比较均匀了,<br>这个时候每个reduce再做局部聚合,第二个mapreduce从第一个mapreduce获取到局部聚合后的数据再做完全聚合。
控制map以及reduce 的数量
相关设置
jvm重用
使用场景
小文件过多
task个数过多
频繁的申请资源-释放资源,造成资源的浪费,大部分时间都浪费在申请和释放资源过程
思路:
先预申请n个jvm资源,当需要新的资源的时候直接在这n个资源里获取,<br>当资源使用结束后在归还资源,不用释放资源,这个思路有点想关系型数据库的连接池的思想。<br><br>通过 set mapred.job.reuse.jvm.num.tasks=n; 来设置 <br>
缺点;
设置开启之后,task插槽会一直占用资源,不论是否有task运行,<br>直到所有的task即整个job全部执行完成时,才会释放所有的task插槽资源
优化的关键:
设置jvm资源的个数
Hbase 非关系型数据库
hbase简介
Hbase database,是一个高可靠行,高性能,面向列,可伸缩,实时读取的分布式数据库,<br>利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量<br>数据,利用Zookeeper作为其分布式协同服务,主要用来存储非结构化和半结构化的松散数据
目的
主要用来存储非结构化和半结构化的松散数据(列存 NoSQL 数据库),列存储,<br>关系型数据库是行式数据库其实就关系型数据库,非关系型数据库空值就不开辟内存和磁盘空间,<br>可以大大节省数据库的资源。
数据的存储
hbase最终会把持久化的数据存储在hdfs上,具体的存储在哪一个datenode,节点大小,副本数不用知道,但是会产生疑惑,hbase读取数据从哪读取<br>
其实,regionserver有自己的存储机制,Region Server运行的时间越长,那么数据的存储地点就越稳定,每个Region Server就能保证它要管理的数据在本地就有一份拷贝。这样无论是Scan还是MapReduce都能达到效率的最优化。
架构分析
zookeeper
分布式协调工具
作用
保证任何时候集群中只有一个master,通过zookeeper连接master
实时监测regionserver ,进行心跳检查机制,发生问题,实时通知master
保存表的结构信息(schema)和表的元数据(包括表,列族之类的)
存储所有的region的寻址入口,会通过保存root表位置,再通过root表找到相应的meta表,在找到region<br>(root表与meta表都存在region上,但是root表只有一个)
zookeeper还会保存经常用到的数据地址(数据缓存在regionserver上)
Hmaster
作用
为regionserver 分配region,
负责regionserver的负载均衡
发现regionserver失效后,重新分配region到其他的regionserver,并将hlog文件进行拆分,分达到不同的regionserver
管理用户对table的增删改操作
当合并storefile 时,会对垃圾数据进行处理
Regionserver
一般跟datenode存储在同一节点上,可以实现数据的 本地化,便于查询
每个regionserver都会共享一个hlog文件,访问发生错误时可以恢复数据
作用
维护region,处理对region的io请求
负责切分在运行过程中变得过大的region
内存分配
一个blockcache
用来保存经常读取的数据,第一次读数据时,先去memstore,再去blockcache,最后去storefile<br>第二次读数据 ,就直接去blockcache(有阈值,达到0.85时 淘汰最老的数据)
多个 memstore (一个region中一个)
写数据时,先往hlog中写,然后往memstore中写,
Region
每个region会保存一个表里面某段连续的数据(因为rowkey是按字典序排序的)
region是分布式存储和负载均衡的最小单元,但不是存储的最小单元。region相当于行
每个region是由多个store来组成的,store是由storefile和memstore组成
当一个region越来越大时,就会被split为两个新的region,并有hmaster分配到相应的regionserver
Hlog
key: hlogkkey记录数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是” 写入时间”
value : HBase的KeyValue对象,即对应HFile中的KeyValue
hlog是一个实现write ahead log的类,每次写入memstore的同时,也会写一份数据到hlog文件中,<br>hlog文件会定期滚动出新的,并删除旧的文件(已经持久化到storefile的数据)
当hregionserver意外中之后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的 HLog文件,<br>将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配<br>,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,<br>因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复
Memstore与 storefile
store(保存列族)包括位于一个内存中的memstore和多个位于磁盘的storefile
写数据时,先检查memstore有相同的数据,没有,则先写入hlog,再写入memstore,<br>当memstore的数据达到阈值(0.9)时,regionserver启动flash ,将数据写入store file。<br>
storefile 当store file文件的数量增长到一定阈值后,会进行合并。合并后的store file文件的大小<br>和数量超过一定阈值是,会把storefile切分split ,并 把当前的region分为两个,并由<br>hmaster分配到相应的regionserver,实现符在均衡
hbase环境的配置
安装 ntp(网络时间协议),同步时间
配置 hbase与hdfs交互的方式
安装hbase时,会自动安装一个zookeeper,在进行设置集群提交任务时,要设置禁用自带的zookeeper
设置 hbase-site.xml
集群的名字,是否启用分布式,zookeeper的位置
设置 regionservers
一般跟datenode保存在相同的节点上,便于数据查询
设置备用的master
hbase基本的命令设置
启动服务 start-hbase.sh 服务的端口 60010
单独启动hmaster hbase-daemon.sh start master<br>主master发生宕机重启后,不会再回到主
对表的操作
创建表
create ‘表名’,‘列族’
删除表
先查看表是否被禁用 is-disabled '表名'
禁用表 disable ‘表名’
删除表 drop ‘表名’
查看表结构
desc ‘表名’
查看所有的表
list
插入数据
<b>Put ‘表名’,’rowkey’,’列族:列’,’’列值’</b>
查看表数据
get ‘表名’,‘rowkey’,‘列族:列’
scan ‘表名’ 全表扫描 ,慎用
删除表中数据
删除某一列
delete <table>, <rowkey>, <family:column> , <timestamp>,必须指定列名
删除一行
deleteall ‘表名’,‘rowkey’
删除表中所有数据
truncate ‘表名’
删除表中的 数据,并不是直接删除,而是对相应的数据做一个标记,只能在进行storefile合并时进行删除
hbase中数据存储的时候真正的数据value 占用的空间很小,<br>key占用了大部分的空间,<br>存储结构不合理。可以使用 <b> Protobuf</b> 来进行整合
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。<br>它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、<br>可扩展的序列化结构数据格式。
写数据请求
1. client 通过zookeeper的调度,向regionserver发出写数据请求,在region中写数据
2. 先将操作记录写入hlog中,再把数据被写入region的memstore,直到memstore达到预设的阈值(0.9)
3.memestore中的数据被flush成一个storefile
4.storefile文件的不断增多,其数量增长到一定阈值,触发compact 合并操作,<br>将多个storefile合并为一个storefile,同时进行版本合并和数据删除
5.storefile 通过不断的compact合并操作,逐步形成越来越大的storefile(底层实现是hfile)
6. 单个storefile大小超过一定阈值后,触发split操作,将当前的region split为两个新的region<br>,父region会下线,新的region被hmaster分配到相应的regionsrever上,使得原先一个region的<br>压力分流到两个region上
读数据请求
1. 客户端访问zookeeper,查找-root-表,获取。meta表信息
2. 从。meta表查找,获取存去目标数据的region信息,从而找到对应的regionserver
3.通过regionserver获取 需要查找的数据
4.regionserver 内存分为memstore和blockcache两部分,memstore主要用于 写数据,blockcache主要用于<br>读数据。读请求先到memstore中查数据,查不到就去blockcache(0.85)中查,在查不到就去storefile上查找,<br>最后把查到的结果放入blockcache(整个regionserver就一个blockcache,多个memstore(每个region就一个))
第一次读数据就像上面所说的那样,但是第二次读数据 就会直接去blockcache读取数据,blockcache中没有数据,<br>就去memstore中读取,在找不到就去storefile中找
hbase 性能优化
Pr-create regions
Rowkey设置
检索方式
单个rowkey进行访问
通过rowkey的rang进行scan
全表扫描
设计rowkey
越小越好,最大十六字节
要根据实际的业务来进行设置
rowkey的设置要具有散列行<br>(散列行的分布在不同的节点上,避免数据倾斜<br>但是散列行会增加查询的压力)
取反
hash取模
Cloumn-Family设置
一般不超过2-3个
当一个store的memstore在做溢写的时候会触发临近列族的meestore也进行溢写,<br>列族过多时,且有些列族memstore的数量还不是很多的时候,溢写会导致storefile文件零碎过多,<br>文件合并的效率也会降低。
compact&split 设置
blockcache设置
常用的类与用法
HBaseAdmin
作用:提供接口关系管理HBase 数据库中的表信息<br>用法:HBaseAdmin admin = new HBaseAdmin(config);
HBaseConfiguration
作用:通过此类可以对HBase进行配置信息<br>用法实例: Configuration config = HBaseConfiguration.create();
HTable
<b>作用:HTable 和 HBase 的表通信</b><br>用法:HTable tab = new HTable(config,Bytes.toBytes(tablename));<br> ResultScanner sc = tab.getScanner(Bytes.toBytes(“familyName”));
HTableDescriptor
作用:HTableDescriptor 包含了hbase中表格的详细信息,包括表中的列族,该表的类型<br>用法:HTableDescriptor htd =new HTableDescriptor(tablename);<br> Htd.addFamily(new HColumnDescriptor(“myFamily”));
HColumnDescriptor
作用:HColumnDescriptor 维护列族的详细信息,包括列族的版本号,压缩设置等<br>用法:HTableDescriptor htd =new HTableDescriptor(tablename);<br> Htd.addFamily(new HColumnDescriptor(“myFamily”));
.Get
作用:获取单个行的数据<br>用法:HTable table = new HTable(config,Bytes.toBytes(tablename));<br> Get get = new Get(Bytes.toBytes(row));<br> Result result = table.get(get);
.Put
作用:用于向单元格中插入信息<br>用法:HTable table = new HTable(config,Bytes.toBytes(tablename));<br> Put put = new Put(row);<br> p.add(family,qualifier,value);
result
用于存放 get或者scan操作后的查询结果
將hdfs中的数据经过maprudece处理,放入到hbase中所用到的类
TableMapReduceUtil
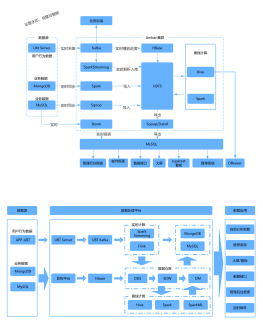
Flume 日志收集
作用
日志收集
配置文件
还需要配置环境变量
/etc/profile
flume 的环境变量
flume-env.sh
架构 设计
source
可以监听的数据来源
netcat tcp
netcat是一个用于TCP/UDP连接和监听的linux工具, 主要用于网络传输及调试领域
avro
一般用于整合多态flume ,上面的输出作为下一台flume的输入
exec(文件)
用于检测文件的变化,如果以日志形式输出,会显示添加的内容
(spooling)directory (目录)
用于检测目录,会把处理过的文件添加后缀 .completed
kafka
channel
管道,用来整理输入和输出的信息
jdbc
kafka
file channel (文件管道)
sink
可以输出到
hdfs
将输出的内容输出到hdfs上
将检测的文件夹中或者文件中变化的文件的内容存储到hdfs的日志中<br>hdfs生成新目录,新文件将会按照配置来走
avro
输出到另一层flume
logger
以日志的形式输出
kafka
hive
hbase
elasticsearch
http
启动命令
flume-ng agent -n a1 -f option1 -Dflume.root.logger=INFO,console
详解 : flume-ng agent 是启动服务, -n agent的名字 , - f 配置文件<br>最后是日志输出级别,这里配置的是控制台输出
用到的网络命令
telnet ---远程登录
telnet 主机 端口 <br>telnet node02 44444
运行原理
Source监听127.0.0.1:44444的地址,当Telnet发送消息后source将收到的<br>消息发送到channel管道,内存,然后sink以日志的方式到管道内存获取,并以日志的形式输出到前台。 <br>
结合 netcat 进行数据的输入,利用telnet协议往netcat里发送数据
sqoop 数据迁移
目的 : 数据迁移,是一个用来将hadoop和关系型数据库中的数据进行交互转移的工具
sqoop的导入导出数据都是基于hdfs进行的
对sqoop进行配置时 ,要用到与mysql数据库进行连接 ,必须将mysql连接的jar包导入到lib下
sqoop的运行方式;
一 直接命令接参数的形式
比如 : sqoop list-databases -connect jdbc:mysql://node01:3306/ -username -password
二 命令接配置文件的形式
sqoop --options-file /.. /.. (配置文件的地址)
到数据的方式
将mysql中的数据导入到hdfs上
在配置文件中指定 导入的目录,还有导出的表的名字,字段
将MySQL中的数据导入到hive中
首先将hive 安装在hive所在的客户端上,并进行配置
编写配置文件
往hive中导入数据时,不能 直接导入,需要生成一个临时文件。然后在往hive中导入<br>(之前往hive导入数据就是从liunx本地或者hdfs上,所以要先生成hdfs临时目录,导入完成后删除)
使用 --query 作为查询条件的话 必须加上where (查询字段,可以没有)+$conditions
将hdfs上的数据导出到MySQL
配置好导出的文件,导入的表 ,字段
整合 hive与hbase
创建表的要点:
hive建内部表的时候直接将表的映射建立到了hbase中了。因为是hive内部表,<br>所以建表有hive来建立hbase表,但是如果hive建立外部表,当然就要先有hbase表,<br>在创建hive的外部表并映射到hbase表。
hive创建表的时候要指定存储方式
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
指定要与hbase的映射关系
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
环境的配置
1.hive与hbase配置文件中都需要 jar包 hive-hbase-handle。jar
2.将hbase的相关jar包全部拷贝到hive服务器端的lib'包下
3.在 hive中配置hbase的入口(配置zookeeper)
优点: 1.Hive方便地提供了Hive QL的接口来简化MapReduce的使用,而HBase提供了低延迟的数据库访问。如果两者结合,可以利用MapReduce的优势针对HBase存储的大量内容进行离线的计算和分析
缺点: 性能的损失,速度慢
storm 流式处理
storm简介
是一个纯实时的在线分析工具,是一种流式处理,数据的处理不会经过磁盘,是直接在内存中进行处理的<br>
storm 特性
实时的,分布式以及具备高容错的计算系统
进程常驻内存,运算速度比较快
数据不经过磁盘,直接在内存中进行处理
可维护性,
stormui图形化监控接口与
storm架构
storm的架构设计
nimbus(主节点)
作用:接受jar包,接受任务,分配任务,资源调度;<br>不管提交的任务从哪个节点提交,最终都会把任务上传到nimbus上
zookeeper 分布式资源协调工具
Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。<br>Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。两者之间的调度器。<br>nimbus和supervisor的所有状态信息都会存放在zookeeper中来管理
supervisor(从节点)
真正做具体任务的服务,用来接收nimbus分配的任务,启动,停止自己管理的worker进程
worker (工作进程)
运行具体处理运算组件的进程(每个Worker对应执行一个Topology的子集)
executor(线程)
executor即worker JVM进程中的一个java线程,一般默认每个executor负责执行一个task任务
task(任务)
spout/bolt
Bolt可以执行过滤、函数操作、合并、写数据库等任何操作
在一个topology中产生源数据流的组件。通常情况下spout会从外部数据源中读取数据,<br>然后转换为topology内部的源数据。内部有一个函数nexttuple函数,会源源不断地创造数据
编程模型
storm采用的是DAG(topology)有向无环图,因此,在storm提交的程序称为topology<br>
storm所处理的最小的单元是tuple(是一个任意对象的数组,如果是自定义的对象 需要进行序列化)
spout理解为数据的来源,bolt是数据的具体处理单元
数据传输
ZeroMQ开源的消息传递框架,并不是一个MessageQueue
Netty 是基于NIO(同步非阻塞)的网络框架,效率更加高效
计算模型
storm提交的程序成为topology,--DAG 有向无环图的实现,他处理的最小的消息单元是tuple(任意对象的数组)
从spout中源源不断的传递数据给bolt,以及传递给其他的bolt,形成的数据通道交stream
stream在声明是需要给其指定一个id(默认是default)
生命周期: 拓扑只要启动就会一直在集群中运行 ,直到手动将其kill,否则不会停止。mapreduce执行完就会结束
spout :数据源 ,一般从外部获取数据, 可以发送多个数据流,需要通过declare方法声明不同的数据流,<br>发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去<br> spout中最核心的方法是nextTuple()方法,该方法不断的被线程调用,通过emit()将数据生成Tuple发送出去
bolt:数据流处理组件 ,对接受的数据进行处理,<br> 最核心的方法是execute方法,负责接受一个元组Tuple数据,真正实现核心的业务逻辑<br> 也可以实现多个数据流的发送
目录结构
zookeeper的目录结构u
nimbus ,supervisor,work 的目录结构
通信机制
work进程间的数据通信,依赖与数据传输,如上
对于每一个worker进程来说,都有一个独立的接收线程和发送线程,负责从网络上发送和接受消息
每个executor线程有自己的incoming-queue和outgoing-queue
worker的接收线程将受到的消息通过task编号传送给对应的executor的incoming-queue<br>executor处理数据,将结果放入outgong-queue,达到一定阈值,传输给发送线程
worker内部的数据通信
内部通信或在同一个节点的不同worker的thread通信使用LMAX Disruptor来完成。
Disruptor实现了“队列”的功能。可以理解为一种事件监听或者消息处理机制,<br>即在队列当中一边由生产者放入消息数据,另一边消费者并行取出消息数据处理
storm环境的搭建
storm.yaml 配置文件
启动服务的命令
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &<br>2>&1 意思是将错误的结果传递给1输出通道,&1表示1 输出通道(标准输出)<br>
storm提交任务的流程
client
提交jar包
nimbus
a.会把提交的jar包放到nimbus所在服务器的nimbus/inbox目录下<br> b.submitTopology方法会负责topology的处理;包括检查集群是否有active节点、配置文件是否正确、是否有重复的topology名称、各个bolt/spout名是否使用相同的id等。<br> c.建立topology的本地目录,nimbus/stormdist/topology-uuid<br> 该目录包括三个文件:<br> stormjar.jar --从nimbus/inbox目录拷贝<br> stormcode.ser --此topology对象的序列化<br> stormconf.ser --此topology的配置文件序列化<br> d.nimbus任务分配,<b>根据topology中的定义,给spout/bolt设置task的数目,并分配对应的task-id,最后把分配好的信息写入到zookeeper的../task目录。</b><br> e.nimbus在zookeeper上创建taskbeats目录,要求每个task定时向nimbus汇报<br> f.<b>将分配好的任务写入到zookeeper,此时任务提交完毕</b>。zk上的目录为assignments/topology-uuid<br> g.将topology信息写入到zookeeper/storms目录<br>
zookeeper
Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。<br>Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。两者之间的调度器。<br>nimbus和supervisor的所有状态信息都会存放在zookeeper中来管理
supervisor
a.定期扫描zookeeper上的storms目录,看看是否有新的任务,有就下载。<br> b.删除本地不需要的topology<br> c.根据nimbus指定的任务信息启动worker
worker
a.查看需要执行的任务,根据任务id分辨出spout/bolt任务<br> b.计算出所代表的spout/bolt会给哪些task发送信息<br> c.执行spout任务或者blot任务
storm提交任务的方式
本地提交
LocalCluster cluster=new LocalCluster();<br> cluster.submitTopology("wc", new Config(), builder.createTopology()); <br>
集群提交
//集群提交<br> StormSubmitter.submitTopology(args[0], config, builder.createTopology()); //args[0]是传递的参数,别名 <br>
数据分发策略
shuffle grouping --随机分组 ,随机分发,但保证了每<br>个bolt分发的数量大致相同,类似于轮循,平均分配
builder.setBolt("bolt", new MyBolt(), 2).shuffleGrouping("spout");
fields grouping --字段分组 。相同的字段分组
builder.setBolt("bolt", new MyBolt(), 2).fieldsGrouping("spout", new Fields("session_id"))
all grouping -- 广播分组 ,所有的bolt都会接受tuple
global grouping --全局分组 ,把tuple分给taskid最低的task
builder.setBolt("bolt", new MyBolt(), 2).globalGrouping("spout");<br><br>
none grouping --不分组,真的是随机分
builder.setBolt("bolt", new MyBolt(), 2).noneGrouping("spout");
direct grouping --制定型分组 ,指定有哪个bolt来处理消息
local or shuffle grouping --本地或随机分组
并发机制
worker 进程
一个拓扑会包含一个或者多个worker,每个worker进程只属于一个 topology<br>这些worker并行运行在不同的服务器上
进程数的设置
Config.setnumworkers(n)
executor 线程
一个worker中有多个线程,一个线程 中可以执行一个或者多个task任务<br>(但是默认一个线程运行一个task),每个task任务对应着同一个组件(spout,bolt)
线程数的设置
setSpout(id,spout,parallelism_hint) parallelism_hint就是线程数
task 任务
task是执行数据处理的最小单元,每个task即为一个spout或者一个bolt
task数量在整个topology生命周期中保持不变,executor的数量可以调整
task数量的设置
ComponentConfigurationDeclarer.setNumTasks(Number val)
rebalance 再平衡机制
动态设置拓扑的worker进程数量,以及executor线程数量
设置的代码 : [storm rebalance topology-name [-w wait-time-secs] [-n new-num-workers] [-e component=parallelism]*]
容错机制
架构容错
nimbus与supervisor都是无状态信息和快速启动的,他们的状态信息都保存在zookeeper上
worker挂掉时
Supervisor会重新启动这个进程。如果启动过程中仍然一直失败,并且无法向zookeeper发送心跳,<br>Nimbus会将该Worker重新分配到其他服务器上 nimbus会检测work的心跳
nimbus挂掉
nimbus的状态信息都保存在zookeeper上,所以不会有大影响
已经存在的拓扑可以继续正常运行,但是不能提交新拓扑
正在运行的 worker 进程仍然可以继续工作。而且当 worker 挂掉,supervisor 会<br>一直重启 worker
失败的任务不会被分配到其他机器(是 Nimbus 的职责)上了
supervisor发生失误时,nimbus不能进行重新分配
nimbus属于单点故障吗
Nimbus 在“某种程度”上属于单点故障的。在实际中,这种情况没什么<br>大不了的,因为当 Nimbus 进程挂掉,不会有灾难性的事情发生
supervisor挂掉
会与zookeeper失去心跳,zookeeper会将该从节点的故障通告给主节点,<br>同时主节点会把从节点上的任务分配到其他节点上
数据容错(保证数据的完整性)
ack机制 ,不能继承baserichspout,要实现irichspout,还要重写 ack与fail方法
配置 storm 的 tuple 的超时时间 – 超过这个时间的 tuple 被认为处理失败了。这<br>个设置的默认设置是 30 秒
ack机制中
spout 作用
在使用emit时添加一个Msgid,,以便于tuple被正确或者发生错误时调用方法
在spout中会出现两个缓存map,一个用来缓存发送过的tuple,一个用来换尺寸发送失败的tuple
发送成功时,ack ()从缓存中删除执行过的tuple(数据),发送失败时,fail()在缓存中添加tuple及次数,<br>超过三次就从map中删除
如果处理的tuple一致失败的话,spout作为消息的发送源,在没有收到该tuple来至左右bolt的返回信息前,<br>是不会删除的,那么如果消息一直失败,就会导致spout节点存储的tuple数据越来越多,导致内存溢出
bolt作用
在进行emit时进行 锚定,指定父节点与发送的tuple<br>要显示的回调 ack (一般放在try代码块中)<br>或者fail(一般放在catch代码块中)
ack原理
首先对于每一个生成的tuple,都带有 ----[root id (根据msgId生成的spout tuple id)、 tuple id]
每次都用tuple id 进行异或运算,如果最终的结果为零,表明数据处理成功。
ack机制可能引发的问题
重复消费
ack机制可以保证数据被正确处理,但是不保证只被正确处理一次,可能会出现重复消费的问题 <br>也就是说第一次发送完整数据,但中国过程出现了偏差,需要在重新发送一次全部的数据,但之前已经处理过一部分数据
storm还提供了一种事务机制,来保证数据只被处理一次,采用的是强一致性的方式
storm的运行模式
流式处理(异步)
客户端提交数据进行结算,并不会等待数据计算结果
消息是逐条处理
实时请求应答服务(同步)
客户端提交数据请求后,立刻取得计算结果并返回客户端
同步处理可以看出是有多个bolt单元并行计算,并行计算性能更好,效率更高
使用到了 DRPC 分布式远程过程调用
drpc server 负责接受rpc 的请求,并将该请求发送到storm中运行<br>topology,最后将结果返回给发送请求的客户端
drpc的设计 是为了充分利用storm的计算能力实现高密度的并行实时计算
客户端发送 消息时,发送一个 request-id(标志客户端),args(消息),return-info(返回的消息)
定义拓扑
一: 通过 LinearDRPCTopologyBuilder ,该方法自动为我们设置spout,并结果传送给drpcserver
二: 通过普通的拓扑 topologybuilder 来创建drpc拓扑<br>需要手动设置开始的DRPCSpout和结束的ReturnResult
kafka 消息队列
简介
kafka是一个分布式的消息队列系统(messagequeue),kafka集群有多个Broker服务器组成
kafka的配置
将kafka的目录移动到各个集群
配置broker服务节点的id,以及zookeeper的位置
kafka中重要的角色
producers(生产者)
创建的命令
kafka-console-producer.sh --broker-list node01:9092 .. --topic test
生产者的创建要与broker相连
consumers(消费者)
创建的命令
kafka-console-consume.sh --zookeeper node01:2181 .... --from-beginning --topic test
消费者的创建要与zookeeper相连
每一个消费之在zookeeper中每个唯一保存的元数据信息就是消费者当前消费日志的位移位置。<br>位移位置是由消费者控制,即、消费者可以通过修改偏移量读取任何位置的数据。
同一个消费组里面的consumer一次不能够去消费同一个Topic的Partition
broker(集群服务节点)
topic(主题,相当于表)
每个类型的消息成为topic,同一个topic内部的消息按照一定<br>key和算法备份去存储在不同的broker上
topic 在kafka中可以由多个消费者,订阅消费
创建话题 kafka-topics.sh --zookeeper node02:2181,node03:2181,node04:2181 --create --replication-factor 2 --partitions 3 --topic test<br> replication 代表分区的复制个数,默认为一 partition为分区的个数,默认为一 topic 为名字
分区
每一个分区(partition)都是一个顺序的、不可变的消息队列,并且可以持续的添加,<br>分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的<br>分区默认保留七天的数据,只需要支持顺序读写文件
分区的方式
根据消息的hashcode值进行取模分区个数运行,也就是RoundRobin strategy(轮询的消费策略)
第二个分区方式 ;Range Startegy(根据范围消费)<br>用总的分区数/消费者线程总数=每个消费者线程应该消费的分区数<br>
分区的组成
index 文件 (.index)存储在内存中
存储大量的元数据,索引文件中元数据指向对应数据文件中message的物理偏移地址。
存储内容为; 相对offset 与 position(Message在数据文件中的绝对位置)
index文件的命名为 每一段分区的起始偏移量.index -------可以通过起始偏移量来查询index文件
data 文件(.log)
存储大量的数据
分区的目的
一是可以处理更多的消息,不受单台服务器的限制。
第二,分区可以作为并行处理的单元
读取数据的方法
1.先通过二分查找找到对应的index文件
2.通过二分查找到对应的相对偏移量对应的物理位置
3.打开数据文件,从查找到的位置的那个地方开始顺序扫描直到找到需要的那条Message。
分区的复制因子
replication-factor,如果不进行设置,默认为一。
每个partition都有一个server为"leader";leader负责所有的读写操作,如果leader失效,<br>那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader跟进,<br>同步消息即可..由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,<br>有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,<br>来确保整体的性能稳定.
zookeeper
Zookeer和Producer没有建立关系,<b>只和Brokers、Consumers建立关系以实现负载均衡,</b><br>即同一个ConsumerGroup中的Consumers可以实现负载均衡(因为Producer是瞬态的,可以发送后关闭,无需直接等待)
Broker端使用zookeeper用来注册并保存相关的元数据(topic,partition信息等)更新。
Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,<br>同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息.
scala语言
特性
1.java和scala可以混编,是姊妹语言
2.类型推测(自动推测类型)
3.并发和分布式
4.特质,特征trait(类似于java中的interfaces和abstract结合)
5.模式匹配match(类似java switch ,支持的类型有 char byte short int 枚举 string)
6.高阶函数 返回值和形参都可以是函数
数据类型
与java中的八种基本数据类型,首字母大写
Unit : 标识无值 相当于 void
Null : 空值或者空引用
Any : 所有类型的超类,但是Any是java中object的子类
AnyRef :所有引用类型的超类
AnyVal : 所有值类型的超类
Nothing : (Trait ,)所有类型的子类,没有实例
None : Option的两个子类之一,另一个是some,用于安全的函数返回值
定义变量 var <br>定义常量 val
object与class 的区别
object里所有的方法和变量都是静态并且单利的,class默认的访问级别是公共的,还有一个私有的
class可以传递参数,object不可以传递参数,不提供构造器
重写构造函数要先调用原来的构造函数 方式为 :def this(x:string,y:string){this() ; this.x=x }
在scala中的 类
有主构造函数的概念,其他派生的构造函数,就必须直接或者间接的调用主构造函数,<br>而且调用的时候必须通过关键字this来操作,而且派生构造函数的名字必须是this。
在类中,除了def定义的成员函数外的所有操作,都可以看作是构造函数的行为组成部分,<br>不管是变量赋值还是函数调用,与java中的class有区别
在scala中,若有继承关系,只有主构造函数才能将参数的值传递到父类的构造函数中去
单例模式
类与object的名称可以相同都叫person,但是不可以两个class同名,<br>如果object和class同名的话这个类叫做对象的伴生类
类与伴生对象,他们直接可以相互访问私有变量
函数
函数的要求
1.有返回值的函数定义在大括号前必须有等号,不能省略
2.如果函数想要返回值,不要以赋值语句作为最后一条语句
函数的写法
def max(参数):={函数体 }<br><b>简写 : def max(参数)= 函数体</b>
匿名函数的写法
写法 : ()=>{}
匿名函数的调用需要将匿名函数赋值 如 var f= ()=>{}<br>调用时直接调用 f()
匿名函数 在 高阶函数中 的 写法 ()=>int 返回值类型
偏应用函数
先定义一个普通函数,如果说函数的某个变量参数不变,可以给这个函数做包装,<br>让某些参数固定,发生变化的参数继续变化
例子: val fun=showLot(date, _:String) <br> 原来的函数 date是不变的参数 变化的参数用占位符
高阶函数
参数是函数
将一个函数当作参数传入
写法 : def fun(ff:(int,int )=>int ,a:string)={函数体}
返回值是函数
将函数的返回值设置为函数
写法:def fun(a:int,b:int):(string,string)=>string ={def fun1(s1:string,s2:string)={函数体} fun1}
参数和返回值都是函数
结合上面两个
遍历
for循环
for循环中写多个条件,相当于嵌套循环
例如:for(i<-1 to 10 ;j<- 1 to 10 ) { } 相当于嵌套循环
foreach循环
a.foreach { x=>{println(x)}}<br>a.foreach{ println(_)}<br>a.freach { println}
数组
数组的定义
var arr=Array(1,2,3,4)
var arr=new Array[Int](3) 3代表数数组的长度 <br> 数组元素赋值 arr(0)=2 arr(1)=5
二维数组的定义
var arr=Array[Array[string]]
var array=Array[Array[String]](<br> Array[String]("a","b","c"), <br> Array[String]("d","e","f")<br> ) <br>
集合
list
定义 : var list=List(1,2,3)<br> val list=List("hello neu","hello soft","hello edu","hello dr")<br>
<b>list.map 为每一个输入进行指定的操作,然后为每一条输入返回一个对象,最终输出对象组成的集合</b>
<b>在scala语言中,map可以用来进行键值组队,也可以用来对数据进行批处理<br>在java语言中,用maptopair进行键值组队</b>
<b>list.flatmap </b> 扁平化的map ,对元素进行切分,返回的list 就是单个元素组成的集合<br> <b> 其实是在map的基础上,对所有的对象合并为一个对象</b>
<b>list.filter {x =>x.equals(" ")} 返回的是过滤之后的元素集合</b>
list.count 返回的是 int类型
set
定义方式 : var set=Set(1,2,3,4)
两个重要方法
intersect 交集 val rs1=set.intersect(set1)
diff 差集 val rs2=set.diff(set1)
map
定义方式 : var map=Map(1->'a',2->'c',(3,'c'),(4,'d') ) 两种写法都一样
遍历map集合元素,相当于得到了 二元组,可以使用(x._1)(x._2) 获取key与value
map 也具有 得到所有的keys或者values
map.keys | map.values
两个map集合相加 ,有相同的key ,先进去的value 留下
tuple 元组
元组的定义方式
var t=new Tuple(1,2,3)
var t=Tuple(1,2,3,4)
var t=(1,2,3,4)
如果是二元组的话 ,元素的位置可以交换, 函数 swap
获取某一位置上的元素 (i._n)
遍历元素 可以使用迭代器 <br>(实现iterable接口,才能返回iterator)
var it=t.productIterator
trait 特性
trait相当于java中的接口,但是可以定义属性和方法的具体实现,也可以定义抽象的方法
一般情况下 scala中的类只能继承单一的父类,但是trait的话可以继承多个trait
构造函数
在Scala中,trait也是有构造代码的,也就是trait中的,不包含在任何方法中的代码<br>// 而继承了trait的类的构造机制如下:1、父类的构造函数执行;<br>2、trait的构造代码执行,多个trait从左到右依次执行;<br>3、构造trait时会先构造父trait,如果多个trait继承同一个父trait,则父trait只会构造一次;<br>4、所有trait构造完毕之后,子类的构造函数执行 <br>
写法 :在Scala中,trait是没有接收参数的构造函数的,这是trait与class的唯一区别<br> 所以 一般是 trait Logger { println("Logger's constructor!") } <br>
子类重写了父类的非抽象方法是必须用override修饰<br>子类重写了父类的属性是,用override修饰
case 样例类
<b>样例类就是用case修饰的类,样例类不用定义类体</b>
<b>样例类创建对象时,不用使用关键字new</b>
写法 ; case class person(name:string)
var p1=person(“xiaoming”)<br>var p2=person("xiaozhang")<br> <b>p1==p2 </b>
返回的是true ,因为比较的是内容,不是内存地址。<br>样例类重写了equal,tostring,hashcode 等方法
match 模式匹配
类似于java中的switch case
写法是 x match {case i:string=> ....<br> case j :int =>...<br> case _ => ...}
scala 通信模型
通信模型类似于thread多线程,spark1.6之前节点之间用的通信用的是akka,akka的底层就actor,<br>1.6之后用netty ,基于 nio(同步非阻塞式通信)的网络框架
actor通信
使用receive 来接受消息(其实还有react ,receiveWithin(5000),reactWithin(5000))
receive 经常与case 来进行匹配对应的消息
使用 avtor! 来发送消息
actor通信 类似于线程,通过start 来开启通信
小案例
期间使用了样例类
spark计算框架
spark体系
sparkcore
spark简介
Spark是一个计算框架,类似于mapreduce,但是运行和读写速度要明显高于mapreduce
环境搭建
配置文件
slaves.template 改名为slaves (配置worker)
<b>spark-env.sh.template 改名为 spark.env.sh </b><br>(配置单个master节点,端口号,cpu的核数)
配置master 的高可用
集群中只有一个master,如果挂了,就无法提交程序,需要配置高可用,
zookeeper有选举和存储功能,存储master的元数据信息(worker信息,driver信息,提交的任务信息),<br>当 alivemaster挂掉时,zookeeper通知standbymaster切换为alivemaster
配置
在spark-env.sh 中添加
启动服务
start-all.sh
提交任务的方式
基于yarn
基于 standalone
spark角色分析
application: 基于spark的用户程序,包含了driver程序和运行在集群上的executor程序
executor:是worker上的某一进程,负责运行任务,并且负责将数据存在内存或者磁盘上,executor中有 线程池<br>线程池就是用来接受stage发送的task
job: 包含很多task任务,可以看作和action算子对应
stage : 一个job拆分为多个 stage
task: 相当于线程,被送到某个executor上的工作单元
spark运行模式
local 本地模式
多用于本地测试运行
Mesos 资源调度框架
mesos是spark的计算框架,但是基于内存,不常用
Standalone spark
standalone提交任务流程<br>任务的提交通过 <b>spark-submit </b>
client方式提交
在standalone集群启动的时候work向master汇报资源
客户端提交任务的时候会启动一个driver进程,driver向master申请资源
master根据worker回报的资源分配给client的driver进程
driver在向worker发送task任务,并且回收worker上的result结果
产生的问题
在客户端产生大量的driver,driver与集群有大量的通信,会造成客户端网卡流量激增<br>严重情况会导致客户端正常的任务被卡掉
cluster方式提交
<b>客户端基于cluster提交任务的时候,先向master申请启动driver,<br>master随机在一台worker上启动driver</b>
随后driver在进行一系列的申请资源,发送task任务,以及回收结果
cluster提交的好处
如果在客户端提交任务,driver是随机的启动在worker节点上,<br>客户端看不到任务执行情况和结果,在webui可以看到,<br>而且单节点网卡流量激增问题也被分散到不同的worker上
Yarn 基于hadoop的yarn
基于yarn提交任务<br>提交任务也通过 <b>spark-submit<br></b>
client方式提交
客户端开启时启动driver进程,然后向resourcemanager申请applicationmaster
resourcemanager根据nodemanager的资源汇报在一台nm上开启applicationmaster
applicationmaster向resourcemanager申请资源启动executor
resourcemanager找到一批nodemanager,applicationmaster去启动executor
executor反响注册driver,driver会发送task给exector,也会回收结果
存在的问题
也容易出现单节点网卡流量激增问题
cluster方式提交
<b>客户端提交任务后向resourcemanager申请applicationmaster,rm在nodemanager上启动applicationmaster,<br>appplicationmaster也担任driver的角色</b>
am申请资源开启executor,executor要反向注册给applicationmaster(driver)
applicationmaster(driver)发送task任务并且接受结果
好处: 解决了单节点网卡流量激增 问题。但是客户端看不到结果。需要去集群中查看结果
rdd
产生rdd的两种方式
读取文件产生 textfile(),返回一行一行的数据
通过将集合转化为rdd
parallelize 并行化创建rdd
parallelizepairs(也是将集合转化为rdd,但几何中的元素是元组形式)
makerdd
rdd的定义
rdd叫做弹性分布式数据集,是spark中基本的数据抽象,他代表了一个<br>不可变,可分区,里面的元素可并行计算的集合<br>RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,<br>
存储内容: RDD其实不存储真是的数据,只存获取数据的方法,以及分区的方法,还有就是数据的类型。
rdd只能向上依赖,记录自己来源于谁,
初代rdd:处于血统的顶层,存储的是任务所需的数据的分区信息,还有单个分区数据读取的方法
子代rdd: 处于血统的下层,存储的东西是 初代rdd到底干了什么会产生自己,还有初代rdd的引用
读取数据发生在运行的task中
rdd产生的原因
mapreduce是一种基于数据集的工作模式,面向数据,,数据更多的面临一次性处理
有些学习是基于数据集,或者数据集的衍生数据反复查询,反复操作,mr不适合
rdd是基于工作集的工作模式,更多的是面向工作流,支持迭代和有效数据共享
rdd的特点
基于血统的搞笑容错机制: 当某一个RDD失效的时候,<br>可以通过重新计算上游的RDD来重新生成丢失的RDD数据。
如果任务失败会自动进行特定次数的重新计算,默认次数为4
rdd可以通过持久化存储在内存或者磁盘上,可以加快计算的效率
rdd之间的依赖关系
宽依赖
父rdd与子rdd partition之间的关系是一对多的存在
宽依赖会产生shuffle<br>shuffle会落地磁盘
产生shuffle的原因: 数据量特别大,在内存里计算不过来<br> 这时候效率会低
窄依赖
父rdd与子rdd partition之间的关系是一对一,或者父rdd与子rdd partition是多对一的关系
不会产生shuffle
stage的切割规则
spark任务会根据rdd之间的依赖关系,形成一个dag有向无环图,dagscheduler会把dag<br>会的dag划分为相互依赖的多个stage,划分依据就是宽依赖
切割规则: 从后往前,遇到宽依赖就切割为stage,stage是由一组并行的task组成
<b>Stage的task并行度是由stage的最后一个RDD的分区数来决定的 。</b>
算子
定义: 对rdd进行操作的方法叫做算子(方法或者函数)
类型
tranaformations(转化算子)
特点
会延迟执行,会将rdd类型 转化为rdd类型,
必须有执行算子的触发才会生效
常用的算子
map
为每一个输入的对象进行指定的操作,为每一条输入返回一个对象
flatmap
在map的基础上,对所有的对象形成的集合进行合并
reducebykey
按照key'值,将value进行相加
groupbykey
根据key值进行分组
sample
三个参数 ;是否重复取样,抽象比例,抽象种子号
join
如数据库中的join类似,会对有相同字段的进行合并<br>(RDD[(K,V)],RDD[(K,W)])=>RDD[K,(V,W)]
如果进行分区,分区的数量以两个分区中最多的分区为准
union
对具有相同类型的数据进行联合,union不会去重复<br>如果有分区,分区的数量为两个分区之和
在mysql中,union默认会去重,使用unionall不去重
intersection
交集算子,如果有分区,分区数以最大的为准
subtract
差集算子,如果有分区数,谁进行操作,分区数为谁的个数
mappartitions
map是对每一个进来的对象进行处理,如果一个一个处理,会非常消耗资源
mappartition是将每一个分区的一个个数据封装到一个集合中,批处理数据
distinct
对重复的数据进行清除
cogroup
关联合并算子,是对两个集合中拥有相同key的元素全部合并到一起<br>( RDD[K,V],RDD[K,W] )=>RDD[ ( K, ( Seq[v],Seq[w]))]
action(执行算子)
特点
是触发执行的算子,会将 rdd 类型转化为非 rdd类型
常用的算子
count
计算结果的个数
collect
对结果进行收集,driver向work发送task,将work计算后的结果拉回到driver
数据量打的时候尽量不要用collect,容易造成driver端溢出
reduce
将rdd类型转化为rdd的结果类型,可以用来计算所有的单词个数
scala : var t =rs.reduce(( rs1:(string,int),rs2:(string,int) )=>("dancigeshu",rs1._2+rs2._2))
take
返回的是结果的集合
first
实际上还是调用了take(1)
foreach
一个一个遍历元素
foreachpartition
如果一个一个遍历元素也会造成数据的浪费,<br>如果将一个分区的数据放在一个集合中<br>遍历输出,会减少数据库的连接
持久化
目的
转化算子是懒加载,只有action触发以后才会执行转化算子,但是转化算子的执行<br>是一步一步向上调用,如果说每次执行转化算子都要执行一遍,会增加开销,浪费时间,<br>所以如果多次调用行动算子的时候,最好将前面的rdd进行持久化,以后只需要计算rdd上<br>的最终结果即可,可以增加运算的效率
方式
cache
将转化算子的计算结果持久化内存中,下次直接调用<br>默认是没有缓存的
cache可以看作是persist的一种简写方式
Persist和cache都是懒执行,需要有action算子触发。
persist
可以手动执行持久化级别
级别
持久化到磁盘
持久化到内存
如果内存不足会,会使用最近最少未使用原则,将原先的数据删除,用来存储最新的数据
持久化到堆外内存
不使用序列化(序列化可以节省空间但是读取的时候要增加一个反序列化的过程)<br>还是放到内存中
memory_and_disk不是内存和磁盘各放一份,而是内存放不下的时候将剩余的内容放到磁盘。
checkpoint
这个持久化的不仅可以将计算结果持久化到磁盘,还能将之前的rdd切断<br>以至于之前的rdd父类依赖关系全都销毁,下次调用直接从检查点开始计算
实现方式
localrddcheckpointdate 是没有设置临时存储地址,就存储在本地executor的磁盘和内存上
reliablerddcheckpointdata 设置了存储路径,存储在外部可靠的存储上(如hdfs)
清除缓存
rdd.unpersist
spark 任务流程
集群中有三个重要节点
Driver
用来向集群中提交任务的,给worker发出tasks任务,并回收result结果<br>运⾏main函数并且新建SparkContext的程序<br>
master
主节点,用来分配application到worker节点,维护worker节点,driver,application的状态
worker
负责具体的业务执行,运行executor
sparkstream
sparksql

Collect
Get Started

Collect
Get Started
Collect
Get Started
Collect
Get Started
评论
0 条评论
下一页

