innodb引擎
索引
数据模型:B+树
分类
主键索引(聚簇索引):叶子节点存储着一整行数据(也就是说整张表的数据都存在该索引上)
非主键索引(二级索引):叶子节点存储的是主键(意味着若使用二级索引查询,若该查询还需要主键、该索引所存字段之外的其他表字段,则必须在通过主键值在主键索引再查次数据)
一些小知识点:
覆盖索引
前缀索引
索引下推(mysql5.6才有):在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数
设计优化:
主键长度越小,普通索引锁占空间也就越小,所以一般用自增主键(除了空间,还能避免插数据时树结构频繁变更,详细看B+树)
如何优雅地重建主键索引:alter table T engine =InnoDB
事务隔离级别
读未提交(read uncommitted):一个事务还没提交时,它做的变更就能被别的事务看到
读提交(read committed):一个事务提交后,它做的变更才能被其他事务看到(oracle默认隔离级别)
可重复读(repeatable-read):一个事务执行过程中看到的数据,总是跟这个事务启动时看到的数据一致
mysql默认隔离级别
不同时刻启动的事务会有不同的视图,通过MVCC(多版本并发控制)实现
串行化(serializable):对于同一行记录,读会加读锁,写会加写锁,当出现读写锁冲突,后访问的书屋需要等前一个事务执行完成
mvcc
使用场景
读未提交,不能使用它的原因是不能读取符合事物版本的行版本(事务要的一直是最新的数据)
可提交读可以使用
可重复读可以使用
可序列化不能使用,它总是要锁定行。
隔离级别RR下的MVCC知识点
每个事务都有一个唯一的事务id(transaction id),是在事务开始时向Innodb申请的,按申请顺序递增
每行数据是有多个版本的,每次事务更新数据,都会生成一个新的数据版本,并把事务id作为版本号(其实只存储最新版数据,需要旧版数据时再根据undo log 计算出对应旧版本的值)
一个事务中,select语句查到数据一般是事务开始时所记下那个版本号的数据,但如果本事务有更新过,则查询出本事务id版本的数据
一个事务中,update语句则是当前读(当前读,只能读当前(最新版本)的数据)。如果select语句加锁(加for update或lock in share mode),也是当前读
undo log是不会持久化的,如果持久化了,那原本表所占空间会随着数据修改无限膨胀。那么事务怎么快速知道它该读哪个版本数据的?
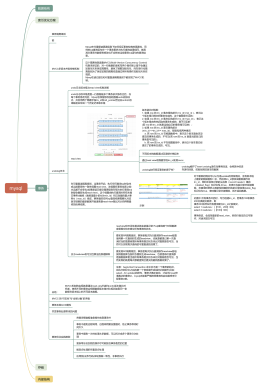
(1)Innodb为每个事务构造了一个存储当前‘活跃’的所有事务id的数组,这里将数组命名为$id_arr(活跃指的是启动了但还没提交)
(2)$id_arr中最小值记为低水位,这里命名为$min_id。最大值再+1,则记为高水位,命名为$max_id
(3)访问一条数据时,快速判断该版本(row trx_id)数据是否可见?row trx_id有几种可能
落在绿色部分,代表是已提交事务或者当前事务自己生成的,数据可见
落在红色部分,代表这版本是由将来启动的事务生成的,数据不可见
落在黄色部分,有俩种情况
row trx_id在$id_arr数组中,表示这个版本是由还没提交的事务生成,不可见
row trx_id不在$id_arr数组中,表示这个版本是已经提交了的事务生成,可见
读提交和可重复读的区别
在可重复读下,只需要在事务开始的时候创建一致性视图
在读提交下,每一个语句执行前都会重新算出一个新的视图来
change buffer
功能:
当更新一条不在内存中的数据时,在不影响数据一致性的前提下,innodb会将更新操作缓存在change buffer中,这样就不需要从磁盘读入数据。下次查询需要访问这个数据页时,将数据页读入缓存,然后执行chang buffer中与这个页有段的操作
使用场景:
无唯一索引
写操作多查询少的(或者说修改完一条数据后,不会马上去查询它)
存储
使用的是buffer pool里的内存,不能无限增大,可通过参数innodb_change_buffer_max_size来控制最多占用buffer pool的百分比
命令:
通过参数innodb_change_buffering来控制change_buffer的是否启用
事务的回滚日志undo log(MVCC就是通过Undo log实现)
定义:每条记录在更新的时候都会同时记录一条回滚日志。记录上的最新值,通过回滚操作可以得到前一状态的值
日志什么时候删除:不同时刻启动的事务会有不同的数据视图,当系统里没有比这个回滚日志更早的数据视图时,回滚就会被删除
尽量不要使用长事务:事务越长,存在的数据视图也就越老,回滚日志就一直不能被删除,会大量占用存储空间
存放:
与redo log存放在日志文件不同,存放在数据库内部的一个特殊段,叫做undo 段(undo segment)
undo 段位于共享表空间,可通过py_innodb_page_info.py工具查看当前undo的数量
如何避免长事务对业务的影响
开发端
set autocommit=1
去除不必要的只读事务
设置每个语句执行的最长时间(SET MAX_EXECUTION_TIME命令)
数据库端
监控information_schema.Innodb_trx表,设置长事务阈值,超过就报警或kill
Percona的pt-kill工具(百度:监控mysql链接,自动kill有问题的链接)
业务测试阶段输出general_log,分析日志提前发现问题(该日志会记录所有到达server的sql)
mysql 5.6或更高版本:innodb_undo_tablespaces设置成2或更大的值(该参数设置构成rollback segment文件的数量)
误解
容易理解成:undo log 用于将数据库物理地恢复到执行语句或事务之前的样子
事实:undo log是逻辑日志,因此只是将数据库逻辑地恢复到原来的样子,所有的修改都被逻辑地取消了(因为会有多事务并发)
造成主从延迟的几种情况
1.主库DML语句并发大,从库qps高
2.从库服务器配置差或一台服务器上几台从库(资源竞争激烈,特别是IO)
3.主库和从库参数配置不一样
4.大事务(例如一次性delete了大量数据),或者大表DDL
5.从库上再进行备份操作
6.表上无主件
7.设置的是延迟备库
8.备库空间不足
redo log(重做日志)
特点
引擎层,且innodb特有
物理日志,记录的是:数据页的修改、以及change buffer新写入的信息
循环写,空间固定,会用完,用完就需要把日志里的操作持久化到磁盘(不一定是用完才持久化),然后清理
可通过参数innodb_flush_log_at_trx_commit设置每次事务都持久化到磁盘
为0时,每次都只是把redo log留在redo log buffer
为1时,每次事务提交都把日志持久化到磁盘(即执行了flush)
为2时,每次事务提交都把日志存到page cache
日志是按数据页(主键索引数据页)来存储的(binlog则是按顺序存储的)
功能描述:当有一条记录需要更新时,先把记录写到redo log,并更新内存。适当的时候,引擎再将操作记录更新到磁盘
小知识点:
redo log的存储空间可以想象成是一个环
checkpoint: 当前mysql同步redo log的刻度点,即checkpoint之后的redo log都还没写进磁盘
writepoint :当前mysql写redo log写日志的刻度点
redo log buffer
作用:这是一块用于临时存储redo log的内存,在事务未commit时,redo log是不会"主动"写进log文件的,以减少不必要的的IO消耗
WAL技术(write-ahead logging):就是redo log和磁盘表数据配合的整个过程。关键点:先写日志,再写磁盘
crash-safe:有了redo log ,InnoDB就可以保证技术数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe
脏页
Innodb_buffer_pool_pages_dirty:当前脏页数
Innodb_buffer_pool_pages_total:内存总页数。
脏页比例是通过 Innodb_buffer_pool_page_dirty/Innodb_buffer_pool_pages_total得到的<br>
select VARIABLE_VALUE into @a from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty';<br>select VARIABLE_VALUE into @b from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_total';<br>select @a/@b;<br>
innodb_max_dirty_pages_pct:脏页比例上限,默认为75%。到达这个上限后,必须开始刷脏页
innodb_io_capacity:刷脏页时,用于告诉InnoDB你的磁盘能力,作者建议设置成磁盘的IOPS。
设置不当的问题
过小,mysql写入速度很慢,但服务器io压力不大
过大,影响其他服务的IO
redo log buffer持久化
每一秒轮询
innodb_log_buffer_size使用到了一半
并行事务,顺带把redo log buffer持久化到磁盘
目标:节省随机<b>写</b>磁盘的IO消耗(注意是写)
为什么偶尔sql语句执行变慢了?(flush,刷脏页)
变慢原因:当时mysql在刷脏页进磁盘
发生flush的四个场景
redo log写满了
当write point要追上check point时,mysql会将check point往后移,移的过程中会把redo log里的操作更新到磁盘
内存不够用了
mysql要淘汰一些内存页,如果淘汰的是脏页,就要先将脏页写到磁盘。(不是直接淘汰)
拓展点:
脏页里所做操作在redo log里不一定是连续的,所以有其他机制来保证redo log进行“重放”时,识别出这个数据页已经刷过了,然后跳过
不直接淘汰脏页是为了性能,保证每个数据页有两种状态(疑问:change buffer呢?数据文件上有,但不是对的)
内存里存在,内存里的肯定是正确的结果,直接返回(个人理解这里包括change buffer)
内存没数据,数据文件上是正确的结果,读入内存后返回
mysql空闲时
mysql正常关闭时
innodb刷脏页的控制策略