
2019知识点总结
2022-02-08 20:31:47 0 举报仅支持查看
AI智能生成
2019知识点总结
知识点
模板推荐
作者其他创作
大纲/内容
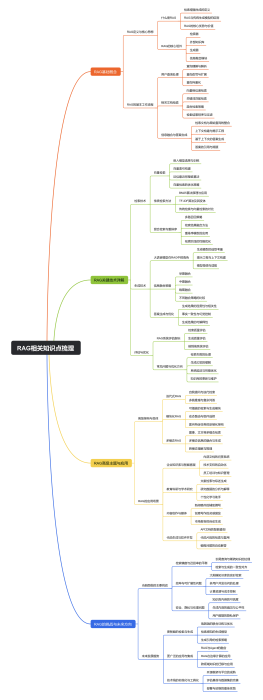
mysql
mysql架构
sql优化
性能优化
索引结构
索引失效情况分析
表设计
null值相关问题
存储引擎对比
https://blog.csdn.net/weixin_39786341/article/details/111276441
myisam为什么比innodb查询快_MyISAM与InnoDB 的区别(9个不同点)<br>1. InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,<br>这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务; <br>2. InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;<br>3. InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。<br>MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。<br> 也就是说:InnoDB的B+树主键索引的叶子节点就是数据文件,辅助索引的叶子节点是主键的值;而MyISAM的B+树主键索引和辅助索引的叶子节点都是数据文件的地址指针<br>4. InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快(注意不能加有任何WHERE条件);<br>那么为什么InnoDB没有了这个变量呢?<br> 因为InnoDB的事务特性,在同一时刻表中的行数对于不同的事务而言是不一样的,因此count统计会计算对于当前事务而言可以统计到的行数,而不是将总行数储存起来方便快速查询。InnoDB会尝试遍历一个尽可能小的索引除非优化器提示使用别的索引。如果二级索引不存在,InnoDB还会尝试去遍历其他聚簇索引。<br> 如果索引并没有完全处于InnoDB维护的缓冲区(Buffer Pool)中,count操作会比较费时。可以建立一个记录总行数的表并让你的程序在INSERT/DELETE时更新对应的数据。和上面提到的问题一样,如果此时存在多个事务的话这种方案也不太好用。如果得到大致的行数值已经足够满足需求可以尝试SHOW TABLE STATUS<br>5. Innodb不支持全文索引,而MyISAM支持全文索引,在涉及全文索引领域的查询效率上MyISAM速度更快高;PS:5.7以后的InnoDB支持全文索引了<br>6. MyISAM表格可以被压缩后进行查询操作<br>7. InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁<br>InnoDB的行锁是实现在索引上的,而不是锁在物理行记录上。潜台词是,如果访问没有命中索引,也无法使用行锁,将要退化为表锁。<br>8、InnoDB表必须有主键(用户没有指定的话会自己找或生产一个主键),而Myisam可以没有<br>9、Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI<br> Innodb:frm是表定义文件,ibd是数据文件<br> Myisam:frm是表定义文件,myd是数据文件,myi是索引文件<br><br><br><br>如何选择:<br> 1. 是否要支持事务,如果要请选择innodb,如果不需要可以考虑MyISAM;<br> 2. 如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读也有写,请使用InnoDB。<br> 3. 系统奔溃后,MyISAM恢复起来更困难,能否接受;<br> 4. MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的,如果你不知道用什么,那就用InnoDB,至少不会差。<br>InnoDB为什么推荐使用自增ID作为主键?<br> 答:自增ID可以保证每次插入时B+索引是从右边扩展的,可以避免B+树和频繁合并和分裂(对比使用UUID)。如果使用字符串主键和随机主键,会使得数据随机插入,效率比较差。<br>innodb引擎的4大特性<br> 插入缓冲(insert buffer),二次写(double write),自适应哈希索引(ahi),预读(read ahead)<br>
tomcat
分库分表
mycat
shardingjdbc
算法
查找
排序
jvm
运行时内存结构
类加载
垃圾回收算法
垃圾收集器
jvm调优
jvm线上故障排查
rpc框架
dubbo
Dubbox
Spring Cloud
gRPC
thrift
Hessian
http
长链接短链接<br>https://www.cnblogs.com/gotodsp/p/6366163.html<br>
select/poll 和 epoll 比较<br>https://www.cnblogs.com/520playboy/p/12743367.html<br>
select:<br><br>查询 fd_set 中,是否有就绪的 fd,可以设定一个超时时间,当有 fd (File descripter) 就绪或超时返回;<br>fd_set 是一个位集合,大小是在编译内核时的常量,默认大小为 1024<br>特点:<br>连接数限制,fd_set 可表示的 fd 数量太小了;<br>线性扫描:判断 fd 是否就绪,需要遍历一边 fd_set;<br>数据复制:用户空间和内核空间,复制连接就绪状态信息<br>poll:<br><br>解决了连接数限制:<br>poll 中将 select 中的 fd_set 替换成了一个 pollfd 数组<br>解决 fd 数量过小的问题<br>数据复制:用户空间和内核空间,复制连接就绪状态信息<br>epoll: event 事件驱动<br><br>事件机制:避免线性扫描<br>为每个 fd,注册一个监听事件<br>fd 变更为就绪时,将 fd 添加到就绪链表<br>fd 数量:无限制(OS 级别的限制,单个进程能打开多少个 fd)<br>select,poll,epoll:<br><br>I/O多路复用的机制;<br>I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。<br>监视多个文件描述符<br>但select,poll,epoll本质上都是同步I/O:<br>用户进程负责读写(从内核空间拷贝到用户空间),读写过程中,用户进程是阻塞的;<br>异步 IO,无需用户进程负责读写,异步IO,会负责从内核空间拷贝到用户空间;
面试题汇总<br>https://mp.weixin.qq.com/s?__biz=MzIyNDU2ODA4OQ==&mid=2247485351&idx=2&sn=214225ab4345f4d9c562900cb42a52ba&chksm=e80db1d1df7a38c741137246bf020a5f8970f74cd03530ccc4cb2258c1ced68e66e600e9e059&scene=21#wechat_redirect<br>
源码分析
设计模式
软件设计原则
开闭原则
(Open-Closed Principle, OCP)是指一个软件实体如类、模块和函数应该对扩展开放,对修改关闭
所谓开闭也是对扩展和修改两个行为的一个原则。强调的是用抽象构建框架,用实现扩展细节。
可以提高软件系统的可复用性、可维护性
开闭原则是面向对象设计中最基础的原则,它知道我们如何构建一个稳定、灵活的系统
案例:<br>课程类定义了基本的---课程名称get方法,价格get方法,idget方法。<br>当我们想要降价java课程时就使用java课程降价类,<br>想涨java课程价格时,<br>就使用java涨价的实体类,实现开闭原则
课程类(抽象类)
java课程
java课程降价
java课程涨价
大数据课程
人工智能课程
代码
public interface ICourse {<br>Integer getId();<br>String getName();<br>Double getPrice();<br>}
public class JavaCourse implements ICourse{<br>private Integer Id;<br>private String name;<br>private Double price;<br>public JavaCourse(Integer id, String name, Double price) {<br>this.Id = id;<br>this.name = name;<br>this.price = price;<br>}<br>public Integer getId() {<br>return this.Id;<br>}<br>public String getName() {<br>return this.name;<br>}<br>public Double getPrice() {<br>return this.price;<br>}<br>}<br>
public class JavaDiscountCourse extends JavaCourse {<br>public JavaDiscountCourse(Integer id, String name, Double price) {<br>super(id, name, price);<br>}<br>public Double getOriginPrice(){<br>return super.getPrice();<br>}<br>public Double getPrice(){<br>return super.getPrice() * 0.61;<br>}<br>}
依赖倒置原则
(Dependence Inversion Principle,DIP)是指设计代码结构时,高层模块不应该依赖于底层模块,二者都应该依赖其抽象。
抽象不应该依赖细节,细节应该依赖抽象
通过依赖倒置可以减少代码的耦合性,提高系统的稳定性,提高代码的可读性和可维护性。并能降低修改程序所造成的风险。
案例分析
原始设计(当继续增加学习项目的代码时候,需要修改原有代码,代码结构发生变化)
public class Tom {<br>public void studyJavaCourse(){<br>System.out.println("Tom 在学习 Java 的课程");<br>}<br>public void studyPythonCourse(){<br>System.out.println("Tom 在学习 Python 的课程");<br>}<br>}
public static void main(String[] args) {<br>Tom tom = new Tom();<br>tom.studyJavaCourse();<br>tom.studyPythonCourse();<br>}
先抽象后细节的设计
定义一个接口<br>public interface ICourse {<br>void study();<br>}<br>
多个类实现对应接口<br>public class JavaCourse implements ICourse {<br>@Override<br>public void study() {<br>System.out.println("Tom 在学习 Java 课程");<br>}<br>}<br>
多个类实现对应接口<br>public class PythonCourse implements ICourse {<br>@Override<br>public void study() {<br>System.out.println("Tom 在学习 Python 课程");<br>}<br>}<br>
public class Tom {<br>public void study(ICourse course){<br>course.study();<br>}}
public static void main(String[] args) {<br>Tom tom = new Tom();<br>tom.study(new JavaCourse());<br>tom.study(new PythonCourse());<br>}
升级tom类<br>public class Tom {<br>private ICourse course;<br>public Tom(ICourse course){<br>this.course = course;<br>}<br>public void study(){<br>course.study();<br>}<br>}<br>
继续改造tom类<br>public class Tom {<br>private ICourse course;<br>public void setCourse(ICourse course) {<br>this.course = course;<br>}<br>public void study(){course.study();}}<br>
最终main类<br>public static void main(String[] args) {<br>Tom tom = new Tom();<br>tom.setCourse(new JavaCourse());<br>tom.study();<br>tom.setCourse(new PythonCourse());<br>tom.study();<br>}<br>
切记:
以抽象为基准比以细节为基准构建的架构要稳定的多。拿到需求后要面向接口编程,先顶层再细节的来设计代码结构
单一职责原则
(Simple Responsibility Pinciple,SRP)不要存在多于一个导致类变更的原因
假设我们有一个 Class 负责两个职责,一旦发生需求变更,修改其中一个职责的逻辑代码,有可能会导致另一个职责的功能发生故障。这样一来,这个 Class 存在两个导<br>致类变更的原因。如何解决这个问题呢?我们就要给两个职责分别用两个 Class 来实现,<br>进行解耦。后期需求变更维护互不影响。这样的设计,可以降低类的复杂度,提高类的<br>可 读 性 , 提 高 系 统 的 可 维 护 性 , 降 低 变 更 引 起 的 风 险 。
总 体 来 说 就 是 一 个<br>Class/Interface/Method 只负责一项职责
案例分析
代码实例,还是用课程举例,我们的课程有直播课和录播课。直播课<br>不能快进和快退,录播可以可以任意的反复观看,功能职责不一样
类层面设计
原始代码
public class Course {<br>public void study(String courseName){<br>if("直播课".equals(courseName)){<br>System.out.println(courseName + "不能快进");<br>}else{<br>System.out.println(courseName + "可以反复回看");<br>}<br>}<br>}
public static void main(String[] args) {<br>Course course = new Course();<br>course.study("直播课");<br>course.study("录播课");<br>}
需求变更:<br>假如,现在要对课程进行加密,那么<br>直播课和录播课的加密逻辑都不一样,必须要修改代码。而修改代码逻辑势必会相互影<br>响容易造成不可控的风险<br>
升级代码
public class LiveCourse {<br>public void study(String courseName){<br>System.out.println(courseName + "可以反复回看");<br>}<br>} <br>
public class ReplayCourse {<br>public void study(String courseName){<br>System.out.println(courseName + "不能快进");<br>}<br>}
public static void main(String[] args) {<br>LiveCourse liveCourse = new LiveCourse();<br>liveCourse.study("直播课");<br>ReplayCourse replayCourse = new ReplayCourse();<br>replayCourse.study("录播课");<br>}
业务继续发展,课程要做权限。没有付费的学员可以获取课程基本信息,已经付费的学<br>员可以获得视频流,即学习权限
再次升级代码
public interface ICourse {<br>//获得基本信息<br>String getCourseName();<br>//获得视频流<br>byte[] getCourseVideo();<br>//学习课程<br>void studyCourse();<br>//退款<br>void refundCourse();<br>}
再次改造
public interface ICourseInfo {<br>String getCourseName();<br>byte[] getCourseVideo();<br>}
public interface ICourseManager {<br>void studyCourse();<br>void refundCourse();<br>}
方法层面设计
原始代码
private void modifyUserInfo(String userName,String address){<br>userName = "Tom";<br>address = "Changsha";<br>}
private void modifyUserInfo(String userName,String... fileds){<br>userName = "Tom";<br>// address = "Changsha";<br>}<br>private void modifyUserInfo(String userName,String address,boolean bool){<br>if(bool){<br>}else{<br>}<br>userName = "Tom";address = "Changsha"}<br>
修改代码
private void modifyUserName(String userName){<br>userName = "Tom";<br>}<br>private void modifyAddress(String address){<br>address = "Changsha";<br>}
显然,上面的 modifyUserInfo()方法中都承担了多个职责,既可以修改 userName,也可<br>以修改 address,甚至更多,明显不符合单一职责。<br>修改之后,开发起来简单,维护起来也容易<br>但是,我们在实际开发中会项目依赖,<br>组合,聚合这些关系,还有还有项目的规模,周期,技术人员的水平,对进度的把控,<br>很多类都不符合单一职责。但是,我们在编写代码的过程,尽可能地让接口和方法保持<br>单一职责,对我们项目后期的维护是有很大帮助的<br>
接口隔离原则
(Interface Segregation Principle, ISP)是指多个专门的接口,<br>而不是单一的总接口,客户端不应该依赖他不需要接口
根据这个原则,指导我们在设计接口时需要注意以下几点:<br>1、一个类对一个类的依赖应该建立在最小的接口之上。<br>2.建立单一接口,不要设计庞大臃肿接口。<br>3.尽量细化接口,接口中的方法尽量少(不是越少越好,一定要适度)
案例分析
旧版
public interface IAnimal {<br>void eat();<br>void fly();<br>void swim();<br>}
public class Bird implements IAnimal {<br>@Override<br>public void eat() {}<br>@Override<br>public void fly() {}<br>@Override<br>public void swim() {}<br>}
public class Dog implements IAnimal {<br>@Override<br>public void eat() {}<br>@Override<br>public void fly() {}<br>@Override<br>public void swim() {}<br>}
问题及修改方案:<br>Bird 的 swim()方法可能只能空着,Dog 的 fly()方法显然不可能的。这时候,<br>我们针对不同动物行为来设计不同的接口,分别设计 IEatAnimal,IFlyAnimal 和<br>ISwimAnimal 接口<br>
新版
public interface IEatAnimal {<br>void eat();<br>}
public interface IFlyAnimal {<br>void fly();<br>}
public interface ISwimAnimal {<br>void swim();<br>} <br>
public class Dog implements ISwimAnimal,IEatAnimal {<br>@Override<br>public void eat() {}<br>@Override<br>public void swim() {}<br>}
迪米特法则
(Law of Demeter LoD 一个对象应该保持与其他对象最少的了解,<br>又叫最少知道原则(Law of Demeter LoD),<br>尽量降低类与类之间的耦合。<br>
迪米特原则主要强调只和朋友交流,不和陌生人说话。出现在成员变量、方法的输入、输<br>出参数中的类都可以称之为成员朋友类,而出现在方法体内部的类不属于朋友类
案例分析
旧版
public class Course {<br>}
public class TeamLeader {<br>public void checkNumberOfCourses(List<Course> courseList){<br>System.out.println("目前已发布的课程数量是:"+courseList.size());<br>}<br>}
public class Boss {<br>public void commandCheckNumber(TeamLeader teamLeader){<br>//模拟 Boss 一页一页往下翻页,TeamLeader 实时统计<br>List<Course> courseList = new ArrayList<Course>();<br>for (int i= 0; i < 20 ;i ++){<br>courseList.add(new Course());<br>}<br>teamLeader.checkNumberOfCourses(courseList);<br>}<br>}
public static void main(String[] args) {<br>Boss boss = new Boss();<br>TeamLeader teamLeader = new TeamLeader();<br>boss.commandCheckNumber(teamLeader);<br>}
问题:boss和课程类有关联
新版
public class TeamLeader {<br>public void checkNumberOfCourses(){<br>List<Course> courseList = new ArrayList<Course>();<br>for(int i = 0 ;i < 20;i++){<br>courseList.add(new Course());<br>}<br>System.out.println("目前已发布的课程数量是:"+courseList.size());<br>}<br>}
public class Boss {<br>public void commandCheckNumber(TeamLeader teamLeader){<br>teamLeader.checkNumberOfCourses();<br>}<br>}
这样boss只需要知道techer就够了,不用自己关心课程的问题
里氏替换原则
(Liskov Substitution Principle,LSP)A类对象出现的地方,B类对象都可以替换,<br>并且B类对象替换A类对象后不会改变程序的结果,那么B类是A类的子类型
为一个软件实体如果适用一个<br>父类的话,那一定是适用于其子类,所有引用父类的地方必须能透明地使用其子类的对<br>象,子类对象能够替换父类对象,而程序逻辑不变
注意:<br>子类可以扩展父类的功能,但不能改变父类原有的功能<br>1、子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法。<br>2、子类中可以增加自己特有的方法。<br>3、当子类的方法重载父类的方法时,方法的前置条件(即方法的输入/入参)要比父类<br>方法的输入参数更宽松。<br>4、当子类的方法实现父类的方法时(重写/重载或实现抽象方法),方法的后置条件(即<br>方法的输出/返回值)要比父类更严格或相等。<br>
优点:<br>1、约束继承泛滥,开闭原则的一种体现。<br>2、加强程序的健壮性,同时变更时也可以做到非常好的兼容性,提高程序的维护性、扩<br>展性。降低需求变更时引入的风险。<br>
案例分析
旧版
public class Rectangle {<br>private long height;<br>private long width;<br>@Override<br>public long getWidth() {<br>return width;<br>}<br>@Override<br>public long getLength() {<br>return length;<br>}<br>public void setLength(long length) {<br>this.length = length;<br>}<br>public void setWidth(long width) {<br>this.width = width;}}
public class Square extends Rectangle {<br>private long length;<br>public long getLength() {<br>return length;<br>}<br>public void setLength(long length) {<br>this.length = length;<br>}<br>@Override<br>public long getWidth() {<br>return getLength();<br>}<br>@Override<br>public long getHeight() {<br>return getLength();<br>}<br>@Override<br>public void setHeight(long height) {<br>setLength(height);<br>}<br>@Override<br>public void setWidth(long width) {<br>setLength(width);<br>}<br>}
public static void resize(Rectangle rectangle){<br>while (rectangle.getWidth() >= rectangle.getHeight()){<br>rectangle.setHeight(rectangle.getHeight() + 1);<br>System.out.println("width:"+rectangle.getWidth() + ",height:"+rectangle.getHeight());<br>}<br>System.out.println("resize 方法结束" +<br>"\nwidth:"+rectangle.getWidth() + ",height:"+rectangle.getHeight());<br>}
public static void main(String[] args) {<br>Rectangle rectangle = new Rectangle();<br>rectangle.setWidth(20);<br>rectangle.setHeight(10);<br>resize(rectangle);<br>}<br>
问题
把长方形 Rectangle 替换成它的子类正方形 Square,修改测试代码<br>public static void main(String[] args) {<br>Square square = new Square();<br>square.setLength(10);<br>resize(square);<br>}<br>这时候我们运行的时候就出现了死循环,违背了里氏替换原则,将父类替换为子类后,<br>程序运行结果没有达到预期。因此,我们的代码设计是存在一定风险的。里氏替换原则<br>只存在父类与子类之间,约束继承泛滥<br>
新版
抽象四边形 Quadrangle 接口:<br>public interface Quadrangle {<br>long getWidth();<br>long getHeight();<br>}<br>
修改长方形 Rectangle 类:<br>public class Rectangle implements Quadrangle {<br>private long height;<br>private long width;<br>@Override<br>public long getWidth() {<br>return width;<br>}<br>public long getHeight() {<br>return height;<br>}<br>public void setHeight(long height) {<br>this.height = height;<br>}<br>public void setWidth(long width) {<br>this.width = width;<br>}<br>}<br>
修改正方形类 Square 类:<br>public class Square implements Quadrangle {<br>private long length;<br>public long getLength() {<br>return length;<br>}<br>public void setLength(long length) {<br>this.length = length;<br>}<br>@Override<br>public long getWidth() {<br>return length;<br>}<br>@Override<br>public long getHeight() {<br>return length;<br>}<br>}<br>
此时,如果我们把 resize()方法的参数换成四边形 Quadrangle 类,方法内部就会报错。<br>因为正方形 Square 已经没有了 setWidth()和 setHeight()方法了。因此,为了约束继承<br>泛滥,resize()的方法参数只能用 Rectangle 长方形。<br>
合成复用原则
Composite/Aggregate Reuse Principle,CARP <br>是指尽量使用对象组<br>合(has-a)/聚合(contanis-a),而不是继承关系达到软件复用的目的。<br>可以使系统更加灵活,降低类与类之间的耦合度,一个类的变化对其他类造成的影响相对较少<br>
案例分析
旧版
public class DBConnection {<br>public String getConnection(){<br>return "MySQL 数据库连接";<br>}<br>}
public class ProductDao{<br>private DBConnection dbConnection;<br>public void setDbConnection(DBConnection dbConnection) {<br>this.dbConnection = dbConnection;<br>}<br>public void addProduct(){<br>String conn = dbConnection.getConnection();<br>System.out.println("使用"+conn+"增加产品");<br>}<br>}
问题
是一种非常典型的合成复用原则应用场景。但是,目前的设计来说,DBConnection<br>还不是一种抽象,不便于系统扩展。目前的系统支持 MySQL 数据库连接,假设业务发生<br>变化,数据库操作层要支持 Oracle 数据库。当然,我们可以在 DBConnection 中增加对<br>Oracle 数据库支持的方法。但是违背了开闭原则<br>
新版
将 DBConnection 修改为 abstract<br>public abstract class DBConnection {<br>public abstract String getConnection();<br>} <br>
public class MySQLConnection extends DBConnection {<br>@Override<br>public String getConnection() {<br>return "MySQL 数据库连接";<br>}<br>}
public class OracleConnection extends DBConnection {<br>@Override<br>public String getConnection() {<br>return "Oracle 数据库连接";<br>}<br>}
设计模式
创建型
工厂方法
抽象工厂
构建者
原型
单例
结构型
适配器
桥接
组合
装饰器
门面
享元
代理
行为型
设计原则总结
学习设计原则,学习设计模式的基础。在实际开发过程中,并不是一定要求所有代码都<br>遵循设计原则,我们要考虑人力、时间、成本、质量,不是刻意追求完美,要在适当的<br>场景遵循设计原则,体现的是一种平衡取舍,帮助我们设计出更加优雅的代码结构
java集合框架源码
hashmap
arraylist
linkedhashmap
spring源码
springboot启动流程
ioc流程
di流程
aop流程
三级缓存<br>https://www.jianshu.com/p/84fc65f2764b<br><br>https://blog.csdn.net/csdnlijingran/article/details/86617958<br>
能解决的循环依赖
属性注入
不能解决的循环依赖
构造注入
子主题
为什么用三级缓存解决循环依赖
https://www.jianshu.com/p/84fc65f2764b
mybatis源码
架构
tomcat源码
架构
一个请求过来的整个流程
redis
数据类型及底层结构<br>https://zhuanlan.zhihu.com/p/344918922<br>
string
它的底层编码分为三种,int,raw或者embstr<br>简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 作为 Redis的默认字符串表示。<br>底层结构是sds:<br>struct sdshdr{<br> int len;/*字符串长度*/<br> int free;/*未使用的字节长度*/<br> char buf[];/*保存字符串的字节数组*/<br>}<br>
https://www.cnblogs.com/ysocean/p/9080942.html<br>这种数据结构的好处<br>①、常数复杂度获取字符串长度<br> 由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O(1)。而对于 C 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。通过 strlen key 命令可以获取 key 的字符串长度。<br> ②、杜绝缓冲区溢出<br> 我们知道在 C 语言中使用 strcat 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 len 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。<br> ③、减少修改字符串的内存重新分配次数<br> C语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。<br> 而对于SDS,由于len属性和free属性的存在,对于修改字符串SDS实现了空间预分配和惰性空间释放两种策略:<br> 1、空间预分配:对字符串进行空间扩展的时候,扩展的内存比实际需要的多,这样可以减少连续执行字符串增长操作所需的内存重分配次数。如进行字符串拼接操作,这个时候buf数组容量不够的时候,若buf数组小于1MB大小,会对buf数组的容量扩容到原来的两倍,如果大于1MB,那么程序会分配1MB的free空间,这叫做 空间预分配,这样可以大大的减少因为多次空间不足导致的频繁分配空间的情况发生。<br> 2、惰性空间释放:对字符串进行缩短操作时,程序不立即使用内存重新分配来回收缩短后多余的字节,而是使用 free 属性将这些字节的数量记录下来,等待后续使用。(当然SDS也提供了相应的API,当我们有需要时,也可以手动释放这些未使用的空间。)<br> ④、二进制安全<br> 因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而所有 SDS 的API 都是以处理二进制的方式来处理 buf 里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。<br> ⑤、兼容部分 C 字符串函数<br> 虽然 SDS 是二进制安全的,但是一样遵从每个字符串都是以空字符串结尾的惯例,这样可以重用 C 语言库<string.h> 中的一部分函数。<br> ⑥、总结<br><br>
常用命令:<br>set、get、decr、incr、mget 等。<br>
注意:<br>Redis 规定了字符串的长度不得超过 512 MB。<br>
编码区别:<br>int编码:存储整数值(例如:1,2,3),当 int 编码保存的值不再是整数值,又或者值的大小超过了long的范围,会自动转化成raw。例如:(1,2,3)->(a,b,c)<br>embstr编码:存储短字符串。<br>它只分配一次内存空间,redisObject和sds是连续的内存,查询效率会快很多,也正是因为redisObject和sds是连续在一起,伴随了一些缺点:当字符串增加的时候,它长度会增加,这个时候又需要重新分配内存,导致的结果就是整个redisObject和sds都需要重新分配空间,这样是会影响性能的,所以redis用embstr实现一次分配而后,只允许读,如果修改数据,那么它就会转成raw编码,不再用embstr编码了。<br>raw编码:用来存储长字符串。<br>它可以分配两次内存空间,一个是redisObject,一个是sds,二个内存空间不是连续的内存空间。和embstr编码相比,它创建的时候会多分配一次空间,删除时多释放一次空间。<br>版本区别:<br>embstr编码版本之间的区别:在redis3.2版本之前,用来存储39字节以内的数据,在这之后用来存储44字节以内的数据。<br>raw编码版本之间的区别:和embstr相反,redis3.2版本之前,可用来存储超过39字节的数据,3.2版本之后,它可以存储超过44字节的数据。<br>
list(链表)
列表对象的编码有两种,分别是:ziplist、linkedlist。当列表的长度小于 512,并且所有元素的长度都小于 64 字节时,使用ziplist存储;否则使用 linkedlist 存储。<br>Redis中的linkedlist类似于Java中的LinkedList,是一个链表,底层的实现原理也和LinkedList类似。这意味着list的插入和删除操作效率会比较快,时间复杂度是O(1)。<br>底层结构是双向链表:<br>typedef struct listNode{<br> //前置节点<br> struct listNode *prev;<br> //后置节点<br> struct listNode *next;<br> //节点的值<br> void *value; <br>}listNode<br><br>typedef struct list{<br> //表头节点<br> listNode *head;<br> //表尾节点<br> listNode *tail;<br> //链表所包含的节点数量<br> unsigned long len;<br> //节点值赋值函数<br> void (*dup) (void *ptr);<br> //节点值释放函数<br> void (*free) (void *ptr);<br> //节点值对比函数<br> int (*match) (void *ptr,void *key);<br>}list;<br><br>
链表特性:<br> ①、双端:链表具有前置节点和后置节点的引用,获取这两个节点时间复杂度都为O(1)。<br> ②、无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问都是以 NULL 结束。 <br> ③、带链表长度计数器:通过 len 属性获取链表长度的时间复杂度为 O(1)。<br> ④、多态:链表节点使用 void* 指针来保存节点值,可以保存各种不同类型的值。
常用命令:<br>list类型常用的命令有:lpush、rpush、lpop、rpop、lrange等。<br>
hash(字典)
哈希对象的编码有两种,分别是:ziplist、hashtable。<br>当哈希对象保存的键值对数量小于 512,并且所有键值对的长度都小于 64 字节时,使用ziplist(压缩列表)存储;否则使用 hashtable 存储。<br>Redis中的hashtable跟Java中的HashMap类似,都是通过"数组+链表"的实现方式解决部分的哈希冲突。直接看源码定义。<br>typedf struct dict{<br> dictType *type;//类型特定函数,包括一些自定义函数,这些函数使得key和value能够存储<br> void *private;//私有数据<br> dictht ht[2];//两张hash表 <br> int rehashidx;//rehash索引,字典没有进行rehash时,此值为-1<br> unsigned long iterators; //正在迭代的迭代器数量<br>}dict;<br>typedef struct dictht{<br> //哈希表数组<br> dictEntry **table;<br> //哈希表大小<br> unsigned long size;<br> //哈希表大小掩码,用于计算索引值<br> //总是等于 size-1<br> unsigned long sizemask;<br> //该哈希表已有节点的数量<br> unsigned long used; <br>}dictht;<br>typedf struct dictEntry{<br> void *key;//键<br> union{<br> void val;<br> unit64_t u64;<br> int64_t s64;<br> double d;<br> }v;//值<br> struct dictEntry *next;//指向下一个节点的指针<br>}dictEntry;
扩容和收缩的过程:<br><br>1、如果执行扩展操作,会基于原哈希表创建一个大小等于 ht[0].used*2n 的哈希表(也就是每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)。相反如果执行的是收缩操作,每次收缩是根据已使用空间缩小一倍创建一个新的哈希表。<br>2、重新利用哈希算法,计算索引值,然后将键值对放到新的哈希表位置上。<br>3、所有键值对都迁徙完毕后,释放原哈希表的内存空间。<br><br>在redis中执行扩容和收缩的规则是:<br>服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF (持久化)命令,并且负载因子大于等于1。<br>服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF (持久化)命令,并且负载因子大于等于5。<br>负载因子 = 哈希表已保存节点数量 / 哈希表大小。<br>
渐进式rehash:<br><br>什么是渐进式,也就是说扩容和收缩不是一次性,集中式地完成,而是通过多次逐渐地完成的。为什么要采用这种方式呢?如果是几十个键值,那么rehash当然可以瞬间完成,如果是几十万,几百万的键值要一次性进行rehash,势必会导致redis性能严重下降,自然而然地redis开发者就想到采用渐进式rehash。过程如下:<br><br>在rehash时,会使用rehashidx字段保存迁移的进度,rehashidx为0表示迁移开始。<br>在迁移过程中ht[0]和ht[1]会同时保存数据,ht[0]指向旧哈希表,ht[1]指向新哈希表,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]的元素迁移到ht[1]中。<br>随着字典操作的不断执行,最终会在某个时间节点,ht[0]的所有键值都会被迁移到ht[1]中,rehashidx设置为-1,代表迁移完成。如果没有执行字典操作,redis也会通过定时任务去判断rehash是否完成,没有完成则继续rehash。<br>rehash完成后,ht[0]指向的旧表会被释放, 之后会将新表的持有权转交给ht[0], 再重置ht[1]指向NULL。<br>
渐进式rehash的优缺点:<br>优点是把rehash操作分散到每一个字典操作和定时函数上,避免了一次性集中式rehash带来的服务器压力。<br>缺点是在rehash期间需要使用两个hash表,占用内存稍大。<br>
常用命令:<br>hash类型的常用命令有:hget、hset、hgetall 等。<br>
zipList:<br>压缩列表(ziplist)是Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。<br><br> 压缩列表的原理:压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存。<br><br>压缩列表数据结构:<br>①、previous_entry_ength:记录压缩列表前一个字节的长度。previous_entry_ength的长度可能是1个字节或者是5个字节,如果上一个节点的长度小于254,则该节点只需要一个字节就可以表示前一个节点的长度了,如果前一个节点的长度大于等于254,则previous length的第一个字节为254,后面用四个字节表示当前节点前一个节点的长度。利用此原理即当前节点位置减去上一个节点的长度即得到上一个节点的起始位置,压缩列表可以从尾部向头部遍历。这么做很有效地减少了内存的浪费。<br><br> ②、encoding:节点的encoding保存的是节点的content的内容类型以及长度,encoding类型一共有两种,一种字节数组一种是整数,encoding区域长度为1字节、2字节或者5字节长。<br><br> ③、content:content区域用于保存节点的内容,节点内容类型和长度由encoding决定。<br>
set(集合)
set类型的特点很简单,无序,不重复,跟Java的HashSet类似。它的编码有两种,分别是intset和hashtable。如果value可以转成整数值,并且长度不超过512的话就使用intset存储,否则采用hashtable。<br><br>hashtable在前面讲hash类型时已经讲过,这里的set集合采用的hashtable几乎一样,只是哈希表的value都是NULL。这个不难理解,比如用Java中的HashMap实现一个HashSet,我们只用HashMap的key就是了。<br>typedef struct intset{<br> uint32_t encoding;//编码方式<br><br> uint32_t length;//集合包含的元素数量<br><br> int8_t contents[];//保存元素的数组<br>}intset;<br><br>
encoding:<br>分别是INTSET_ENC_INT16、INSET_ENC_INT32、INSET_ENC_INT64,代表着整数值的取值范围。Redis会根据添加进来的元素的大小,选择不同的类型进行存储,可以尽可能地节省内存空间。<br>
length:<br>记录集合有多少个元素,这样获取元素个数的时间复杂度就是O(1)<br>
contents:<br>存储数据的数组,数组按照从小到大有序排列,不包含任何重复项。<br><br>
注意:<br>这里我们可能会提出疑问,如果一开始存的是INTSET_ENC_INT16(范围在-32,768~32,767),如果这时添加了一个40000的数,怎么升级为INSET_ENC_INT32呢?<br>升级过程是这样的:<br>1、根据新元素的类型扩展数组contents的空间。<br>2、从尾部将数据插入。<br>3、根据新的编码格式重置之前的值,因为这时的contents存在着两种编码的值。从插入的数据的位置,也就是尾部,从后到前将之前的数据按照新的编码格式进行移动和设置。从后到前调整是为了防止数据被覆盖。<br><br>
数据类型升级的优缺点:<br>升级的优点在于,根据存储的数据大小选择合适的编码方式,节省了内存。<br>缺点在于,升级会消耗系统资源。而且升级是不可逆的,也就是一旦对数组进行升级,编码就会一直保持升级后的状态。<br><br>
常用的命:<br>set数据类型常用的命令有:sadd、spop、smembers、sunion等等。<br>
应用场景:<br>Redis为set类型提供了求交集,并集,差集的操作,可以非常方便地实现譬如共同关注、共同爱好、共同好友等功能。<br>
zset(有序集合)
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。具有如下性质:<br> 1、由很多层结构组成;<br> 2、每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;<br> 3、最底层的链表包含了所有的元素;<br> 4、如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);<br> 5、链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;
typedef struct zskiplistNode {<br> //层<br> struct zskiplistLevel{<br> //前进指针<br> struct zskiplistNode *forward;<br> //跨度<br> unsigned int span;<br> }level[];<br> <br> //后退指针<br> struct zskiplistNode *backward;<br> //分值<br> double score;<br> //成员对象<br> robj *obj;<br> <br>} zskiplistNode<br><br>typedef struct zskiplist{<br> //表头节点和表尾节点<br> structz skiplistNode *header, *tail;<br> //表中节点的数量<br> unsigned long length;<br> //表中层数最大的节点的层数<br> int level;<br> <br>}zskiplist;<br>
zset是Redis中比较有特色的数据类型,它和set一样是不可重复的,区别在于多了score值,用来代表排序的权重。也就是当你需要一个有序的,不可重复的集合列表时,就可以考虑使用这种数据类型。<br><br>zset的编码有两种,分别是:ziplist、skiplist。当zset的长度小于 128,并且所有元素的长度都小于 64 字节时,使用ziplist存储;否则使用 skiplist 存储。
为什么要设计成这样呢:<br>好处在于查询的时候,可以减少时间复杂度,如果是一个链表,我们要插入并且保持有序的话,那就要从头结点开始遍历,遍历到合适的位置然后插入,如果这样性能肯定是不理想的。<br>所以问题的关键在于能不能像使用二分查找一样定位到插入的点,答案就是使用跳跃表。比如我们要插入38,那么查找的过程就是这样。<br>首先从L4层,查询87,需要查询1次。<br>然后到L3层,查询到在->24->87之间,需要查询2次。<br>然后到L2层,查询->48,需要查询1次。<br>然后到L1层,查询->37->48,查询2次。确定在37->48之间是插入点。<br>有没有发现经过L4,L3,L2层的查询后已经跳过了很多节点,当到了L1层遍历时已经把范围缩小了很多。这就是跳跃表的优势。这种方式有点类似于二分查找,所以他的时间复杂度为O(logN)。<br><br>其实生活中也有这种例子,类似于快递填写的地址是省->市->区->镇->街,当快递公司在送快递时就根据地址层层缩小范围,最终锁定在一个很小的区域去搜索,提高了效率。<br><br>
zet常用的命令有:<br>zadd、zrange、zrem、zcard等<br>
应用场景:<br>zset的特点非常适合应用于开发排行榜的功能,比如三天阅读排行榜,游戏排行榜等等。<br><br>
Redis慢查询
1)典型的一些慢命令,如:save持久化数据化;keys匹配所有的键;hgetall,smembers等大集合的全量操作;<br><br> 2)使用del命令删除一个非常大的集合键,这一点经常被大家忽略;只是删除一个键为什么会慢呢?原因就在于集合键在删除的时候,需要释放每一个元素的内存空间,想想要是集合键包含1000w个元素呢?<br><br> 目前对于集合键的删除,redis提供了异步删除方式,主线程中只是断开了数据库与该键的引用关系,真正的删除动作通过队列异步交由另外的子线程处理。对应的,异步删除需要使用新的删除命令unlink。另外,时间事件循环中也会周期性删除过期键,这里的删除也可以采用异步删除方式,不过需要配置lazyfree-lazy-expire=yes。<br><br> 3)bgsave持久化,虽说是fork子进程执行持久化操作,但有时fork系统调用同样会比较耗时,从而阻塞主线程执行命令请求;<br><br> 4)aof持久化,aof写入是需要磁盘的,如果此时磁盘的负载较高(比如其他进程占用,或者redis进程同时在执行bgsave),同样会阻塞<br>aof的写入,从而影响命令的执行;<br><br> 5)时间事件循环中的周期性删除过期键,在遇到大量键集中过期时,删除过期键同样会比较耗时;另外,如果配置lazyfree-lazy-expire=no,删除大集合键时同样会阻塞该过程;虽说redis保证了周期性删除过期键不会耗费太多时间,根据配置hz计算,比如hz=10时,说明时间事件循环每秒执行10次,限制周期性删除过期键耗时不超过cpu时间的25%,那么执行时间应该不超过1000毫秒 * 25% / 10次 = 25毫秒;显然周期性删除过期键的耗时还是有可能超过redis慢查询门限的。<br><br> 6)快命令被其他慢命令请求阻塞,一来如果是这样前面的慢命令请求也应该有慢查询报警,二来这时候redis server统计的当前命令执行还是非常快的,不会有慢查询日志,只是从客户端角度看来,该请求执行时间较长。
部署模式
主从模式(redis2.8版本之前的模式)<br>
Redis 单节点虽然有通过 RDB 和 AOF 持久化机制能将数据持久化到硬盘上,但数据是存储在一台服务器上的,如果服务器出现硬盘故障等问题,会导致数据不可用,而且读写无法分离,读写都在同一台服务器上,请求量大时会出现 I/O 瓶颈。<br><br>为了避免单点故障 和 读写不分离,Redis 提供了复制(replication)功能实现 master 数据库中的数据更新后,会自动将更新的数据同步到其他 slave 数据库上。<br><br>Redis 主从结构特点:一个 master 可以有多个 slave 节点;slave 节点可以有 slave 节点,从节点是级联结构。<br><br>主从模式优缺点<br>优点: 主从结构具有读写分离,提高效率、数据备份,提供多个副本等优点。<br>不足: 最大的不足就是主从模式不具备自动容错和恢复功能,主节点故障,集群则无法进行工作,可用性比较低,从节点升主节点需要人工手动干预。<br>普通的主从模式,当主数据库崩溃时,需要手动切换从数据库成为主数据库:<br><br>在从数据库中使用 SLAVE NO ONE 命令将从数据库提升成主数据继续服务。<br>启动之前崩溃的主数据库,然后使用 SLAVEOF 命令将其设置成新的主数据库的从数据库,即可同步数据。
哨兵sentinel模式(redis2.8及之后的模式)<br>
哨兵模式是从 Redis 的 2.6 版本开始提供的,但是当时这个版本的模式是不稳定的,直到 Redis 的 2.8 版本以后,这个哨兵模式才稳定下来。<br><br>哨兵模式核心还是主从复制,只不过在相对于主从模式在主节点宕机导致不可写的情况下,多了一个竞选机制:从所有的从节点竞选出新的主节点。竞选机制的实现,是依赖于在系统中启动一个 sentinel 进程。<br><br>哨兵本身也有单点故障的问题,所以在一个一主多从的 Redis 系统中,可以使用多个哨兵进行监控,哨兵不仅会监控主数据库和从数据库,哨兵之间也会相互监控。每一个哨兵都是一个独立的进程,作为进程,它会独立运行。
哨兵模式的作用:<br><br>监控所有服务器是否正常运行:通过发送命令返回监控服务器的运行状态,处理监控主服务器、从服务器外,哨兵之间也相互监控。<br>故障切换:当哨兵监测到 master 宕机,会自动将 slave 切换成 master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换 master。同时那台有问题的旧主也会变为新主的从,也就是说当旧的主即使恢复时,并不会恢复原来的主身份,而是作为新主的一个从。<br>
哨兵实现原理:<br>哨兵在启动进程时,会读取配置文件的内容,通过如下的配置找出需要监控的主数据库:<br>sentinel monitor master-name ip port quorum<br># master-name 是主数据库的名字<br># ip 和 port 是当前主数据库地址和端口号<br># quorum 表示在执行故障切换操作前,需要多少哨兵节点同意。<br>这里之所以只需要连接主节点,是因为通过主节点的 info 命令,获取从节点信息,从而和从节点也建立连接,同时也能通过主节点的 info 信息知道新增从节点的信息。<br><br>一个哨兵节点可以监控多个主节点,但是并不提倡这么做,因为当哨兵节点崩溃时,同时有多个集群切换会发生故障。哨兵启动后,会与主数据库建立两条连接。<br><br>订阅主数据库 _sentinel_:hello 频道以获取同样监控该数据库的哨兵节点信息<br>定期向主数据库发送 info 命令,获取主数据库本身的信息。<br>跟主数据库建立连接后会定时执行以下三个操作:<br><br>每隔 10s 向 master 和 slave 发送 info 命令。作用是获取当前数据库信息,比如发现新增从节点时,会建立连接,并加入到监控列表中,当主从数据库的角色发生变化进行信息更新。<br>每隔 2s 向主数据里和从数据库的 _sentinel_:hello 频道发送自己的信息。作用是将自己的监控数据和哨兵分享。每个哨兵会订阅数据库的_sentinel:hello 频道,当其他哨兵收到消息后,会判断该哨兵是不是新的哨兵,如果是则将其加入哨兵列表,并建立连接。<br>每隔 1s 向所有主从节点和所有哨兵节点发送 ping 命令,作用是监控节点是否存活。<br>
主观下线和客观下线:<br><br>哨兵节点发送 ping 命令时,当超过一定时间(down-after-millisecond)后,如果节点未回复,则哨兵认为主观下线。主观下线表示当前哨兵认为该节点已经下线,如果该节点为主数据库,哨兵会进一步判断是够需要对其进行故障切换,这时候就要发送命令(SENTINEL is-master-down-by-addr)询问其他哨兵节点是否认为该主节点是主观下线,当达到指定数量(quorum)时,哨兵就会认为是客观下线。<br><br>当主节点客观下线时就需要进行主从切换,主从切换的步骤为:<br><br>选出领头哨兵。<br>领头哨兵所有的 slave 选出优先级最高的从数据库。优先级可以通过 slave-priority 选项设置。<br>如果优先级相同,则从复制的命令偏移量越大(即复制同步数据越多,数据越新),越优先。<br>如果以上条件都一样,则选择 run ID 较小的从数据库。<br>选出一个从数据库后,哨兵发送 slave no one 命令升级为主数据库,并发送slaveof 命令将其他从节点的主数据库设置为新的主数据库。<br>
哨兵模式的优缺点:<br><br>优点:哨兵模式是基于主从模式的,解决可主从模式中master故障不可以自动切换故障的问题。<br><br>缺点:<br><br>是一种中心化的集群实现方案:始终只有一个 Redis 主机来接收和处理写请求,写操作受单机瓶颈影响。<br>集群里所有节点保存的都是全量数据,浪费内存空间,没有真正实现分布式存储。数据量过大时,主从同步严重影响 master 的性能。<br>Redis 主机宕机后,哨兵模式正在投票选举的情况之外,因为投票选举结束之前,谁也不知道主机和从机是谁,此时 Redis 也会开启保护机制,禁止写操作,直到选举出了新的 Redis 主机。<br>主从模式或哨兵模式每个节点存储的数据都是全量的数据,数据量过大时,就需要对存储的数据进行分片后存储到多个 Redis 实例上。此时就要用到 Redis Sharding 技术。<br><br>
分片
客户端分片
客户端分片是把分片的逻辑放在 Redis 客户端实现,(比如:jedis 已支持 Redis Sharding 功能,即 ShardedJedis),通过 Redis 客户端预先定义好的路由规则(使用一致性哈希),把对 Key 的访问转发到不同的 Redis 实例中,查询数据时把返回结果汇集。<br><br>一致性哈希算法:<br><br>是分布式系统中常用的算法。比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的 hash 方法,将数据映射到具体的节点上,如 mod(key,d),key 是数据的 key,d 是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了。<br><br>一致性哈希算法解决了普通余数 Hash 算法伸缩性差的问题,可以保证在上线、下线服务器的情况下尽量有多的请求命中原来路由到的服务器。<br><br>一致性哈希算法实现方式:一致性 hash 算法,比如 MURMUR_HASH 散列算法、ketamahash 算法。比如 Jedis 的 Redis Sharding 实现,采用一致性哈希算法(consistent hashing),将 key 和节点 name 同时 hashing,然后进行映射匹配,采用的算法是 MURMUR_HASH。<br><br>采用一致性哈希而不是采用简单类似哈希求模映射的主要原因是当增加或减少节点时,不会产生由于重新匹配造成的 rehashing。一致性哈希只影响相邻节点 key 分配,影响量小。
客户端分片的优缺点:<br><br>优点:客户端 sharding 技术使用 hash 一致性算法分片的好处是所有的逻辑都是可控的,不依赖于第三方分布式中间件。服务端的 Redis 实例彼此独立,相互无关联,每个 Redis 实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强。开发人员清楚怎么实现分片、路由的规则,不用担心踩坑。<br><br>缺点:<br><br>这是一种静态的分片方案,需要增加或者减少 Redis 实例的数量,需要手工调整分片的程序。<br>运维成本比较高,集群的数据出了任何问题都需要运维人员和开发人员一起合作,减缓了解决问题的速度,增加了跨部门沟通的成本。<br>在不同的客户端程序中,维护相同的路由分片逻辑成本巨大。比如:java 项目、PHP 项目里共用一套 Redis 集群,路由分片逻辑分别需要写两套一样的逻辑,以后维护也是两套。<br>客户端分片有一个最大的问题就是,服务端 Redis 实例群拓扑结构有变化时,每个客户端都需要更新调整。如果能把客户端分片模块单独拎出来,形成一个单独的模块(中间件),作为客户端 和 服务端连接的桥梁就能解决这个问题了,此时代理分片就出现了。<br>
代理分片
Redis 代理分片用得最多的就是 Twemproxy,由 Twitter 开源的 Redis 代理,其基本原理是:通过中间件的形式,Redis 客户端把请求发送到 Twemproxy,Twemproxy 根据路由规则发送到正确的 Redis 实例,最后 Twemproxy 把结果汇集返回给客户端。<br><br>Twemproxy 通过引入一个代理层,将多个 Redis 实例进行统一管理,使 Redis 客户端只需要在 Twemproxy 上进行操作,而不需要关心后面有多少个 Redis 实例,从而实现了 Redis 集群。
codis
redis cluster模式(redis3.0版本之后)
出现原因:<br><br>Redis 的哨兵模式虽然已经可以实现高可用,读写分离 ,但是存在几个方面的不足:<br><br>哨兵模式下每台 Redis 服务器都存储相同的数据,很浪费内存空间;数据量太大,主从同步时严重影响了 master 性能。<br>哨兵模式是中心化的集群实现方案,每个从机和主机的耦合度很高,master 宕机到 slave 选举 master 恢复期间服务不可用。<br>哨兵模式始终只有一个 Redis 主机来接收和处理写请求,写操作还是受单机瓶颈影响,没有实现真正的分布式架构。<br>
Redis 在 3.0 上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的数据。cluster 模式为了解决单机 Redis 容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS 不受限于单机,可受益于分布式集群高扩展性。Redis Cluster 是一种服务器 Sharding 技术(分片和路由都是在服务端实现),采用多主多从,每一个分区都是由一个 Redis 主机和多个从机组成,片区和片区之间是相互平行的。Redis Cluster 集群采用了 P2P 的模式,完全去中心化。
Redis Cluster 集群特点:<br><br>集群完全去中心化,采用多主多从;所有的 redis 节点彼此互联(PING-PONG 机制),内部使用二进制协议优化传输速度和带宽。<br>客户端与 Redis 节点直连,不需要中间代理层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。<br>每一个分区都是由一个 Redis 主机和多个从机组成,分片和分片之间是相互平行的。<br>每一个 master 节点负责维护一部分槽,以及槽所映射的键值数据;集群中每个节点都有全量的槽信息,通过槽每个 node 都知道具体数据存储到哪个 node 上。<br>
注意:<br><br>Redis cluster 主要是针对海量数据 + 高并发 + 高可用的场景,海量数据,如果你的数据量很大,那么建议就用 Redis cluster,数据量不是很大时,使用 sentinel 就够了。Redis cluster 的性能和高可用性均优于哨兵模式。<br><br>Redis Cluster 采用虚拟哈希槽分区而非一致性 hash 算法,预先分配一些卡槽,所有的键根据哈希函数映射到这些槽内,每一个分区内的 master 节点负责维护一部分槽以及槽所映射的键值数据。<br>
Proxy模式对比cluster
1. cluster模式<br>优点:<br>客户端(Jedis)直连redis节点,性能会更好<br>缺点:<br> 1. 客户端(Jedis)直连redis节点,意味着客户端就需要保存集群所有节点信息,当集群比较大100-200个master节点时,这个数据量会比较大<br> 2. 当集群规模比较大,100-200个master节点时,算上从节点,要到200-400个节点,互相ping pong的健康检查网络开销会非常大<br><br>2. proxy模式<br>优点:<br> 1. 客户端(Jedis)直连有限的proxy节点,会比较轻量和简单<br> 2. 集群规模理论上可以非常大,因为proxy对外隐藏了集群规模<br>缺点:<br> 1. 多了一层proxy访问,性能会有影响<br> 2. 需要第三方的proxy实现,集群水平扩容时proxy要想平滑动态更新集群配置,需要开发工具支持<br>3. 方案<br> 1. 采用 twemproxy做为代理,去zk获取集群配置<br> 2. 集群通过sentinel保证高可用<br>4. 水平扩容<br> 1. 开发工具,伪装成集群的slave节点,从而拿到RDB文件和增量更新数据,路由到新的集群(此处的路由算法要保证和twemproxy实际实现的一致)<br> 2. 当开发工具评估两个集群基本一致(实时更新数据较小、偏移量追平等因素综合考虑),更新新的集群配置到zk<br> 3. zk会动态通知twemproxy,由于twemproxy的路由算法跟4.1步骤相同,基本就可以保证平滑迁移
redismaster选举机制
当从节点发现自己的主节点变为fail状态时,便尝试进行failover,以期成为新的主节点。由于挂掉的主节点可能会有多个从节点,从而存在多个从节点竞争成为主节点的过程,其过程如下:<br><br>1.从节点发现自己的主节点变为fail。<br><br>2.将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST信息。<br><br>3.其他节点收到该信息,只有主节点响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack。<br><br>4.尝试failover的从节点收集其他主节点返回的FAILOVER_AUTH_ACK。<br><br>5.从节点收到超过半数主节点的ack后变成新主节点(这里解释了集群为什么至少需要三个主节点,如果只有两个,当其中一个挂了,只剩一个主节点是不能选举成功的)<br><br>6.从节点广播pong消息通知其他集群节点,从节点并不是在主节点一进入fail状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待fail状态在集群中传播,从节点如果立即尝试选举,其它主节点尚未意识到fail状态,可能会拒绝投票。<br><br>延迟计算公式:DELAY = 500ms + random(0~500ms)+SALVE_RANK*1000ms<br>SALVE_RANK表示此从节点从主节点复制数据的总量的rank。rank越小代表已复制的数据越新。这种方式下,持有最新数据的从节点将会首先发起选举。
哨兵leader选举流程
当一个主节点服务器被某哨兵视为下线状态后,该哨兵会与其他哨兵协商选出哨兵的leader进行故障转移工作。每个发现主节点下线的哨兵都可以要求其他哨兵选自己为哨兵的leader,选举是先到先得。每个哨兵每次选举都会自增选举周期,每个周期中只会选择一个哨兵作为的leader。如果所有超过一半的哨兵选举某哨兵作为leader。之后该哨兵进行故障转移操作,在存活的从节点中选举出新的主节点,这个选举过程跟集群的主节点选举很类似。<br><br>哨兵集群哪怕只有一个哨兵节点,在主节点下线时也能正常选举出新的主节点,当然那唯一一个哨兵节点就作为leader选举新的主节点。不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个主节点类似。
分布式锁
Redisson方式<br>https://zhuanlan.zhihu.com/p/150602212<br>
Redis分布式锁的底层原理:<br>加锁机制<br> 某个客户端要加锁。如果该客户端面对的是一个Redis Cluster集群,它首先会根据hash节点选择一台机器,这里注意,仅仅只是选择一台机器。紧接着就会发送一段lua脚本到redis上,lua脚本如下所示:<br>使用lua脚本,可以把一大堆业务逻辑通过封装在lua脚本发送给redis,保证这段赋值业务逻辑执行的原子性。在这段脚本中,这里KEYS[1]代表的是你加锁的那个key,比如说:RLock lock = redisson.getLock(“myLock”);这里你自己设置了加锁的那个锁key就是“myLock”。<br><br> ARGV[1]代表的就是锁key的默认生存时间,默认30秒。ARGV[2]代表的是加锁的客户端的ID,类似于下面这样:8743c9c0-0795-4907-87fd-6c719a6b4586:1。<br> 脚本的意思大概是:第一段if判断语句,就是用“exists myLock”命令判断一下,如果你要加锁的那个key不存在,就可以进行加锁。加锁就是用“hset myLock 8743c9c0-0795-4907-87fd-6c719a6b4586:1 1”命令。通过这个命令设置一个hash数据结构,这个命令执行后,会出现一个类似下面的数据结构:<br><br>上述就代表“8743c9c0-0795-4907-87fd-6c719a6b4586:1”这个客户端对“myLock”这个锁key完成了加锁。接着会执行“pexpire myLock 30000”命令,设置myLock这个锁key的生存时间是30秒。好了,到此为止,ok,加锁完成了。<br><br>锁互斥机制<br> 如果这个时候客户端B来尝试加锁,执行了同样的一段lua脚本。第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在。接着第二个if判断,判断myLock锁key的hash数据结构中,是否包含客户端B的ID,但明显没有,那么客户端B会获取到pttl myLock返回的一个数字,代表myLock这个锁key的剩余生存时间。此时客户端B会进入一个while循环,不听的尝试加锁。<br><br>watch dog自动延期机制<br> 客户端A加锁的锁key默认生存时间只有30秒,如果超过了30秒,客户端A还想一直持有这把锁,怎么办?其实只要客户端A一旦加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果客户端A还持有锁key,那么就会不断的延长锁key的生存时间。<br><br>可重入加锁机制<br> 客户端A已经持有锁了,然后可重入加锁,如下代码所示:<br>这个时候lua脚本是这样执行的:第一个if判断不成立,“exists myLock”会显示锁key已经存在了。第二个if判断会成立,因为myLock的hash数据结构中包含的那个ID,就是客户端A的ID,此时就会执行可重入加锁的逻辑,它会用“incrby myLock 8743c9c0-0795-4907-87fd-6c71a6b4586:1 1 ”这个命令对客户端A的加锁次数,累加1,此时myLock的数据结构变成下面这样:<br>即myLock的hash数据结构中的那个客户端ID,就对应着加锁的次数。<br><br>释放锁机制<br> 执行lock.unlock(),就可以释放分布式锁。释放逻辑是:每次对myLock数据结构中的那个加锁次数减1,如果加锁次数为0了,说明客户端已经不再持有锁了,此时就会用“del MyLock”命令,从redis里删除了这个key。然后另外的客户端B就可以尝试完成加锁了。<br>
Redis分布式锁的缺点:<br><br>如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例,但是这个过程中如果发送redis master宕机,主备切换,redis slave变为了redis master。<br><br> 这就会导致客户端B来尝试加锁的时候,在新的redis master上完成了加锁,而客户端A也以为自己成功加了锁,此时就会导致多个客户端对一个分布式锁完成了加锁。这时就会导致各种脏数据的产生。<br><br> 所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。<br>
setnex方式
原理:<br>加锁设置key对应的value,加上失效时间<br>返回1则加锁成功<br>解锁先判断是否为指定key,相等则删除;<br>加锁期间若业务代码超时,可以使用线程池自动刷新机制,刷新加锁时间
package com.xiaoju.manhattan.financing.base.redis;<br><br>import com.google.common.collect.Lists;<br><br>import com.xiaoju.manhattan.financing.base.log.FinLogger;<br>import com.xiaoju.manhattan.financing.base.util.Inspections;<br>import java.util.UUID;<br>import java.util.concurrent.Executors;<br>import java.util.concurrent.ScheduledExecutorService;<br>import java.util.concurrent.TimeUnit;<br>import org.apache.commons.codec.digest.DigestUtils;<br>import org.apache.commons.lang3.StringUtils;<br>import org.springframework.data.redis.connection.RedisStringCommands.SetOption;<br>import org.springframework.data.redis.core.RedisCallback;<br>import org.springframework.data.redis.core.StringRedisTemplate;<br>import org.springframework.data.redis.core.script.RedisScript;<br>import org.springframework.data.redis.core.types.Expiration;<br><br>/**<br> * 基于redis的简单的分布式锁,可重入。<br> *<br> * 在下面描述的极端情况下,在释放锁以后,锁还会存在 lifeSeconds 秒。<br> *<br> * 假设主线程名称为"主",过期时间刷新线程名称为"刷",那么上述情况为: 1. 刷:执行了一次过期时间刷新 2. 主:设置了刷新线程的stop标记为true 3. 主:由于未知原因而挂掉。<br> */<br>public class RedisLock {<br><br> private static final FinLogger log = FinLogger.create();<br><br> private StringRedisTemplate redis;<br> private String lockKey;<br> private String lockValue;<br> private RedisLockRefresher refresher;<br><br> /**<br> * redis key 的 过期时间,单位秒<br> */<br> private int lifeSeconds;<br><br> /**<br> * redis key 的 过期时间的最小边界,实际lifeSeconds必须大于该值。<br> *<br> * 同时,过期时间刷新线程的间隔为:lifeSeconds - LIFE_SECONDS_FLOOR<br> *<br> * 单位:秒<br> */<br> static final int LIFE_SECONDS_FLOOR = 3;<br><br> /**<br> * 是否自动刷新<br> */<br> private boolean autoRefresh;<br><br> /**<br> * Redis分布式锁。lifetime时间过后自动解锁。<br> */<br> RedisLock(StringRedisTemplate redis, String lockKey, int lifeSeconds, boolean autoRefresh) {<br> this.redis = redis;<br> this.lockKey = lockKey;<br> this.lifeSeconds = lifeSeconds;<br> this.lockValue = UUID.randomUUID().toString();<br> this.autoRefresh = autoRefresh;<br> refresher = new RedisLockRefresher();<br><br> }<br><br> public boolean tryLock() {<br> // 为了保证 set value 和 set expire 两个操作的原子性,使用下面的方式<br> redis.execute((RedisCallback<String>) conn -> {<br> conn.set(<br> redis.getStringSerializer().serialize(lockKey),<br> redis.getStringSerializer().serialize(lockValue),<br> Expiration.seconds(lifeSeconds),<br> SetOption.SET_IF_ABSENT);<br> return "";<br> });<br> // 验证是否设置成功。即使这次没有执行成功,但是只要redis中的value和lockValue相同,则认为加锁成功<br> if (this.hasLock()) {<br> if (autoRefresh) {<br> refresher.run(); // 设置redis过期时间,并设置定时任务进行刷新过期时间<br> }<br><br> return true;<br> } else {<br> return false;<br> }<br> }<br><br> public boolean unLock() {<br> // 先停止刷新线程<br> refresher.terminate();<br><br> // 利用lua脚本保证这次操作的原子性,删除之前先判断redis值是否一致<br> Long del = redis.execute(new RedisScript<Long>() {<br><br> private String script = "if redis.call('get', KEYS[1]) == ARGV[1] "<br> + "then return redis.call('del', KEYS[1]) "<br> + "else "<br> + "return 0 end";<br><br> @Override<br> public String getSha1() {<br> return DigestUtils.sha1Hex(script);<br> }<br><br> @Override<br> public Class<Long> getResultType() {<br> return Long.class;<br> }<br><br> @Override<br> public String getScriptAsString() {<br> return script;<br> }<br> }, Lists.newArrayList(this.lockKey), this.lockValue);<br><br> return del != null && del > 0;<br> }<br><br> public boolean hasLock() {<br> String curValue = redis.opsForValue().get(lockKey);<br> return Inspections.isNotBlank(curValue) && curValue.equals(lockValue);<br> }<br><br> private static ScheduledExecutorService refresherExecutor = Executors.newScheduledThreadPool(1,<br> r -> new Thread(r, "RedisLockRefresher"));<br><br> /**<br> * 用来在释放锁之前自动刷新redis的过期时间<br> */<br> private class RedisLockRefresher implements Runnable {<br><br> /**<br> * 表示该刷新器是否被停止<br> */<br> volatile boolean stop = false;<br><br> /**<br> * 为了防止terminate操作和刷新expire时间操作同时执行,影响锁的正常释放,这里用锁控制<br> */<br> @Override<br> public synchronized void run() {<br> if (stop) {<br> log.debug("RedisLockRefresher of key[{}] stop.", lockKey);<br> } else {<br> log.debug("RedisLockRefresher of key[{}] refreshing.", lockKey);<br> if (!redis.hasKey(lockKey)) {<br> log.debug("RedisLockRefresher of key[{}] refreshing. lockKey not exist,not fresher",<br> lockKey);<br> return;<br> }<br> redis.opsForValue().set(lockKey, lockValue, lifeSeconds, TimeUnit.SECONDS);<br> refresherExecutor.schedule(this, lifeSeconds - LIFE_SECONDS_FLOOR, TimeUnit.SECONDS);<br> }<br> }<br><br> /***<br> * 为了防止terminate操作和刷新expire时间操作同时执行,影响锁的正常释放,这里用锁控制<br> */<br> private synchronized void terminate() {<br> this.stop = true;<br> }<br> }<br><br> /**<br> * 判断该redis是否被锁定<br> */<br> public boolean isLocked() {<br> return Inspections.isNotBlank(redis.opsForValue().get(lockKey));<br> }<br><br>}<br>
使用SETNX完成同步锁的流程及事项如下:<br><br>使用SETNX命令获取锁,若返回0(key已存在,锁已存在)则获取失败,反之获取成功<br><br>为了防止获取锁后程序出现异常,导致其他线程/进程调用SETNX命令总是返回0而进入死锁状态,需要为该key设置一个“合理”的过期时间<br><br>释放锁,使用DEL命令将锁数据删除
主从复制<br>https://www.cnblogs.com/daofaziran/p/10978628.html<br>
全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下: <br>- 从服务器连接主服务器,发送SYNC命令; <br>- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令; <br>- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令; <br>- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照; <br>- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令; <br>- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;<br>完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。<br><br>
增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。 <br>增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。<br>
Redis主从同步策略<br>
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
注意点
如果多个Slave断线了,需要重启的时候,因为只要Slave启动,就会发送sync请求和主机全量同步,当多个同时出现的时候,可能会导致Master IO剧增宕机。<br><br>Redis主从复制的配置十分简单,它可以使从服务器是主服务器的完全拷贝。需要清除Redis主从复制的几点重要内容:<br>1)Redis使用异步复制。但从Redis 2.8开始,从服务器会周期性的应答从复制流中处理的数据量。<br>2)一个主服务器可以有多个从服务器。<br>3)从服务器也可以接受其他从服务器的连接。除了多个从服务器连接到一个主服务器之外,多个从服务器也可以连接到一个从服务器上,形成一个<br> 图状结构。<br>4)Redis主从复制不阻塞主服务器端。也就是说当若干个从服务器在进行初始同步时,主服务器仍然可以处理请求。<br>5)主从复制也不阻塞从服务器端。当从服务器进行初始同步时,它使用旧版本的数据来应对查询请求,假设你在redis.conf配置文件是这么配置的。<br> 否则的话,你可以配置当复制流关闭时让从服务器给客户端返回一个错误。但是,当初始同步完成后,需要删除旧的数据集和加载新的数据集,在<br> 这个短暂的时间内,从服务器会阻塞连接进来的请求。<br>6)主从复制可以用来增强扩展性,使用多个从服务器来处理只读的请求(比如,繁重的排序操作可以放到从服务器去做),也可以简单的用来做数据冗余。<br>7)使用主从复制可以为主服务器免除把数据写入磁盘的消耗:在主服务器的redis.conf文件中配置“避免保存”(注释掉所有“保存“命令),然后连接一个配<br> 置为“进行保存”的从服务器即可。但是这个配置要确保主服务器不会自动重启(要获得更多信息请阅读下一段)<br>
主从复制的一些特点:<br>
1)采用异步复制;<br>2)一个主redis可以含有多个从redis;<br>3)每个从redis可以接收来自其他从redis服务器的连接;<br>4)主从复制对于主redis服务器来说是非阻塞的,这意味着当从服务器在进行主从复制同步过程中,主redis仍然可以处理外界的访问请求;<br>5)主从复制对于从redis服务器来说也是非阻塞的,这意味着,即使从redis在进行主从复制过程中也可以接受外界的查询请求,只不过这时候从redis返回的是以前老的数据,<br> 如果你不想这样,那么在启动redis时,可以在配置文件中进行设置,那么从redis在复制同步过程中来自外界的查询请求都会返回错误给客户端;(虽然说主从复制过程中<br> 对于从redis是非阻塞的,但是当从redis从主redis同步过来最新的数据后还需要将新数据加载到内存中,在加载到内存的过程中是阻塞的,在这段时间内的请求将会被阻,<br> 但是即使对于大数据集,加载到内存的时间也是比较多的);<br>6)主从复制提高了redis服务的扩展性,避免单个redis服务器的读写访问压力过大的问题,同时也可以给为数据备份及冗余提供一种解决方案;<br>7)为了编码主redis服务器写磁盘压力带来的开销,可以配置让主redis不在将数据持久化到磁盘,而是通过连接让一个配置的从redis服务器及时的将相关数据持久化到磁盘,<br> 不过这样会存在一个问题,就是主redis服务器一旦重启,因为主redis服务器数据为空,这时候通过主从同步可能导致从redis服务器上的数据也被清空;<br>
Redis大概主从同步是怎么实现的?<br><br>
全量同步:<br>master服务器会开启一个后台进程用于将redis中的数据生成一个rdb文件,与此同时,服务器会缓存所有接收到的来自客户端的写命令(包含增、删、改),当后台保存进程<br>处理完毕后,会将该rdb文件传递给slave服务器,而slave服务器会将rdb文件保存在磁盘并通过读取该文件将数据加载到内存,在此之后master服务器会将在此期间缓存的<br>命令通过redis传输协议发送给slave服务器,然后slave服务器将这些命令依次作用于自己本地的数据集上最终达到数据的一致性。<br> <br>部分同步:<br>从redis 2.8版本以前,并不支持部分同步,当主从服务器之间的连接断掉之后,master服务器和slave服务器之间都是进行全量数据同步,但是从redis 2.8开<br>始,即使主从连接中途断掉,也不需要进行全量同步,因为从这个版本开始融入了部分同步的概念。部分同步的实现依赖于在master服务器内存中给每个slave服务器维护了<br>一份同步日志和同步标识,每个slave服务器在跟master服务器进行同步时都会携带自己的同步标识和上次同步的最后位置。当主从连接断掉之后,slave服务器隔断时间<br>(默认1s)主动尝试和master服务器进行连接,如果从服务器携带的偏移量标识还在master服务器上的同步备份日志中,那么就从slave发送的偏移量开始继续上次的同步<br>操作,如果slave发送的偏移量已经不再master的同步备份日志中(可能由于主从之间断掉的时间比较长或者在断掉的短暂时间内master服务器接收到大量的写操作),则<br>必须进行一次全量更新。在部分同步过程中,master会将本地记录的同步备份日志中记录的指令依次发送给slave服务器从而达到数据一致。
主从同步中需要注意几个问题<br>
1)在上面的全量同步过程中,master会将数据保存在rdb文件中然后发送给slave服务器,但是如果master上的磁盘空间有效怎么办呢?那么此时全部同步对于master来说<br>将是一份十分有压力的操作了。此时可以通过无盘复制来达到目的,由master直接开启一个socket将rdb文件发送给slave服务器。(无盘复制一般应用在磁盘空间有限但是网<br>络状态良好的情况下)<br> <br>2)主从复制结构,一般slave服务器不能进行写操作,但是这不是死的,之所以这样是为了更容易的保证主和各个从之间数据的一致性,如果slave服务器上数据进行了修改,<br>那么要保证所有主从服务器都能一致,可能在结构上和处理逻辑上更为负责。不过你也可以通过配置文件让从服务器支持写操作。(不过所带来的影响还得自己承担哦。。。)<br> <br>3)主从服务器之间会定期进行通话,但是如果master上设置了密码,那么如果不给slave设置密码就会导致slave不能跟master进行任何操作,所以如果你的master服务器<br>上有密码,那么也给slave相应的设置一下密码吧(通过设置配置文件中的masterauth);<br> <br>4)关于slave服务器上过期键的处理,由master服务器负责键的过期删除处理,然后将相关删除命令已数据同步的方式同步给slave服务器,slave服务器根据删除命令删除<br>本地的key。
数据持久化方式及数据恢复
aof
2)AOF方式<br>默认情况下Redis没有开启AOF(append only file)方式的持久化,可以在redis.conf中通过appendonly参数开启:<br>appendonly yes<br>在启动时Redis会逐个执行AOF文件中的命令来将硬盘中的数据载入到内存中,载入的速度相较RDB会慢一些<br> <br>开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof,可以通过appendfilename参数修改:<br>appendfilename appendonly.aof<br>配置redis自动重写AOF文件的条件<br> <br>auto-aof-rewrite-percentage 100 # 当目前的AOF文件大小超过上一次重写时的AOF文件大小的百分之多少时会再次进行重写,如果之前没有重写过,则以启动时的AOF文件大小为依据<br> <br>auto-aof-rewrite-min-size 64mb # 允许重写的最小AOF文件大小<br>配置写入AOF文件后,要求系统刷新硬盘缓存的机制<br> <br># appendfsync always # 每次执行写入都会执行同步,最安全也最慢<br>appendfsync everysec # 每秒执行一次同步操作<br><br># appendfsync no # 不主动进行同步操作,而是完全交由操作系统来做(即每30秒一次),最快也最不安全<br> <br>Redis允许同时开启AOF和RDB,既保证了数据安全又使得进行备份等操作十分容易。此时重新启动Redis后Redis会使用AOF文件来恢复数据,因为AOF方式的持久化可能丢失的数据更少
rdb(默认)
RDB方式(默认)<br>RDB方式的持久化是通过快照(snapshotting)完成的,当符合一定条件时Redis会自动将内存中的所有数据进行快照并存储在硬盘上。进行快照的条件可以由用户在配置文件中自定义,由两个参数构成:时间和改动的键的个数。当在指定的时间内被更改的键的个数大于指定的数值时就会进行快照。RDB是redis默认采用的持久化方式,在配置文件中已经预置了3个条件:<br>save 900 1 #900秒内有至少1个键被更改则进行快照<br>save 300 10 #300秒内有至少10个键被更改则进行快照<br>save 60 10000 #60秒内有至少10000个键被更改则进行快照<br> <br>可以存在多个条件,条件之间是"或"的关系,只要满足其中一个条件,就会进行快照。 如果想要禁用自动快照,只需要将所有的save参数删除即可。<br>Redis默认会将快照文件存储在当前目录(可CONFIG GET dir来查看)的dump.rdb文件中,可以通过配置dir和dbfilename两个参数分别指定快照文件的存储路径和文件名
Redis实现快照的过程<br>- Redis使用fork函数复制一份当前进程(父进程)的副本(子进程);<br>- 父进程继续接收并处理客户端发来的命令,而子进程开始将内存中的数据写入硬盘中的临时文件;<br>- 当子进程写入完所有数据后会用该临时文件替换旧的RDB文件,至此一次快照操作完成。<br>- 在执行fork的时候操作系统(类Unix操作系统)会使用写时复制(copy-on-write)策略,即fork函数发生的一刻父子进程共享同一内存数据,当父进程要更改其中某片数据时(如执行一个写命令 ),操作系统会将该片数据复制一份以保证子进程的数据不受影响,所以新的RDB文件存储的是执行fork一刻的内存数据。<br> <br>Redis在进行快照的过程中不会修改RDB文件,只有快照结束后才会将旧的文件替换成新的,也就是说任何时候RDB文件都是完整的。这使得我们可以通过定时备份RDB文件来实 现Redis数据库备份。RDB文件是经过压缩(可以配置rdbcompression参数以禁用压缩节省CPU占用)的二进制格式,所以占用的空间会小于内存中的数据大小,更加利于传输。<br> <br>除了自动快照,还可以手动发送SAVE或BGSAVE命令让Redis执行快照,两个命令的区别在于,前者是由主进程进行快照操作,会阻塞住其他请求,后者会通过fork子进程进行快照操作。 Redis启动后会读取RDB快照文件,将数据从硬盘载入到内存。根据数据量大小与结构和服务器性能不同,这个时间也不同。通常将一个记录一千万个字符串类型键、大小为1GB的快照文件载入到内 存中需要花费20~30秒钟。 通过RDB方式实现持久化,一旦Redis异常退出,就会丢失最后一次快照以后更改的所有数据。这就需要开发者根据具体的应用场合,通过组合设置自动快照条件的方式来将可能发生的数据损失控制在能够接受的范围。如果数据很重要以至于无法承受任何损失,则可以考虑使用AOF方式进行持久化。
缓存淘汰策略
> - allkeys-lru: 所有的key都用LRU进行淘汰。<br>> - volatile-lru: LRU策略淘汰已经设置过过期时间的键。<br>> - allkeys-random:随机淘汰使用的。<br>> - key volatile-random:随机淘汰已设置过过期时间的key<br>> - volatile-ttl:只回收设置了过期时间的key
Redis线程模型<br>
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器(file event handler)。它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。<br><br>文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字, 并根据套接字目前执行的任务来为套接字关联不同的事件处理器。<br><br>当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时, 与操作相对应的文件事件就会产生, 这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。<br><br>虽然文件事件处理器以单线程方式运行, 但通过使用 I/O 多路复用程序来监听多个套接字, 文件事件处理器既实现了高性能的网络通信模型, 又可以很好地与 redis 服务器中其他同样以单线程方式运行的模块进行对接, 这保持了 Redis 内部单线程设计的简单性。
redis面试题https://www.cnblogs.com/javazhiyin/p/13839357.html
缓存异常
缓存雪崩
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。<br><br>解决方案<br><br>缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。<br><br>一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。<br><br>给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。<br><br>解决方案<br><br>接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;<br><br>从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击<br><br>采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力
隆过滤器
对于空间的利用到达了一种极致,那就是Bitmap和布隆过滤器(Bloom Filter)。<br><br>Bitmap:典型的就是哈希表<br><br>缺点是,Bitmap对于每个元素只能记录1bit信息,如果还想完成额外的功能,恐怕只能靠牺牲更多的空间、时间来完成了。<br><br>布隆过滤器(推荐)<br><br>就是引入了k(k>1)k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。<br><br>它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。<br><br>Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲突”。<br><br>Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是Bloom-Filter的基本思想。<br><br>Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。<br><br>解决方案<br><br>设置热点数据永远不过期。<br><br>加互斥锁,互斥锁
缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!<br><br>解决方案<br><br>直接写个缓存刷新页面,上线时手工操作一下;<br>数据量不大,可以在项目启动的时候自动进行加载;<br>定时刷新缓存;
缓存降级<br>
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。<br><br>缓存降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。<br><br>在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:<br><br>一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;<br><br>警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;<br><br>错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;<br><br>严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。<br><br>服务降级的目的,是为了防止Redis服务故障,导致数据库跟着一起发生雪崩问题。因此,对于不重要的缓存数据,可以采取服务降级策略,例如一个比较常见的做法就是,Redis出现问题,不去数据库查询,而是直接返回默认值给用户。
热点数据和冷数据
热点数据,缓存才有价值<br><br>对于冷数据而言,大部分数据可能还没有再次访问到就已经被挤出内存,不仅占用内存,而且价值不大。频繁修改的数据,看情况考虑使用缓存<br><br>对于热点数据,比如我们的某IM产品,生日祝福模块,当天的寿星列表,缓存以后可能读取数十万次。再举个例子,某导航产品,我们将导航信息,缓存以后可能读取数百万次。<br><br>数据更新前至少读取两次,缓存才有意义。这个是最基本的策略,如果缓存还没有起作用就失效了,那就没有太大价值了。<br><br>那存不存在,修改频率很高,但是又不得不考虑缓存的场景呢?有!比如,这个读取接口对数据库的压力很大,但是又是热点数据,这个时候就需要考虑通过缓存手段,减少数据库的压力,比如我们的某助手产品的,点赞数,收藏数,分享数等是非常典型的热点数据,但是又不断变化,此时就需要将数据同步保存到Redis缓存,减少数据库压力。
缓存热点key
缓存中的一个Key(比如一个促销商品),在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。<br>解决方案<br><br>对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询<br>
cap模型属于哪个?
一致性(Consistency):读操作总是能读取到之前完成的写操作结果,系统每时每刻每个节点上的同一份数据都是一致<br>可用性(Availability):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)<br>分区可容忍性(Partition tolerance):大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition);分区可容忍性:系统节点无法通信,系统依旧可以运行<br><br>可用性和分区容忍性区别:<br>可用性是指节点故障,如主、从redis宕机,剩下的从redis依旧可以提供服务,该系统有可用性<br>分区容忍性是指节点间无法通信,如主从redis无法通信,系统依旧可用<br><br>Redis是保证AP不保证C:系统要不管何时系统都能够响应读写请求<br><br>
并发
volatile
synchronized
aqs
线程
线程池
jmmjava内存模型
mq
kafaka
https://www.cnblogs.com/kx33389/p/11182082.html
https://blog.csdn.net/qq_34668848/article/details/105611546
架构<br>https://blog.csdn.net/Computer_hello/article/details/109549542<br>
https://zhuanlan.zhihu.com/p/94412266<br>1)Producer :消息生产者,就是向kafka broker发消息的客户端;<br><br>2)Consumer :消息消费者,向kafka broker取消息的客户端;<br><br>3)Consumer Group (CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。<br><br>4)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。<br><br>5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic;<br><br>6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;<br><br>7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。<br><br>8)leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。<br><br>9)follower:每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的follower。
topic
在kafka中,topic只是存储消息的一个逻辑的概念,他并没有实际的文件存在磁盘上,可以认为是某一类型的消息的集合。所有发送到kafka上的消息都一个类型,这个类型就是他的topic。在物理上来说,不同的topic的消息是分开存储的。同时,一个topic可以有多个producer和多个consumer。
partition
每个topic下面可以有多个分区,每一个topic至少会有一个partition,相同的topic下面,不同的partition他的消息内容是不一样的。每一个消息在被分配到partition都会有一个offset(偏移量),表示当前消息的位置,所有的消息都是追加到partition后面的。每个分区partition的offset都是从0开始的,每个partition的消息都是由顺序的,不同的partition的消息的顺序是不保证有序的 ,每一消息发送broker之后,broker会根据partition的规则分配到不同的partition里面。<br><br>
kafka中topic和partition的存储
(1)我们创建一个有三个分区的topic先,创建语句如下:<br>./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic quanTest<br>(2)partition是以文件的形式存储在文件系统里面的。<br>
消息的分发到partition的原理<br>
1.首先消息是我们kafka最基本的数据单元,每一个消息都是由key–>value组成的,在发送消息时,我们可以指定key,我们的生产者producer会根据key和partition的规则来确认这一个消息应该分发到哪一个partition里面。<br><br>2.我们消息分发到partition的默认的规则:当我们的key不为空的时候,我们的分区数为key的哈希值取模运算值。当我们的key为空的时候,他会随机发送,但是这个随机数是在这个参数”metadata.max.age.ms”的时间范围内随机选择一个,这个metadata.max.age.ms的值每十分钟会刷新一次。<br><br>3.当然,我们也可以自己定义消息分发到partition的规则
消息的消费原理
1.简要说明:在真实的生产环境中,我们都是有多个partition的,使用多个partition的好处在于能有效的对broker上面的数据进行分片,减少io性能问题。同时为了提高消费能力,我们会有多个consumer对数据进行消费。在多个consumer,多个partition的消费策略有时什么?我们有分组group的概念,我们知道相同topic下的同一个partition只能被一个consumer消费。组内的所有consumer订阅这个topic下的所有的消息。<br><br>2.对于consumer消费端而言他的分区分配策略是:<br>(1)默认是范围分区:Range:他会先对所有的分区按照序号进行排序,所有的consumer按字母进行排序,然后将partitions的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。弊端是:当有多个topic是这样的情况的时候,会出现某一个consumer的压力会很大。<br>(2)第二种就是轮询分区策略(RoundRobin strategy)<br>轮询分区策略就是先把所有的partition和所有的consumer都列出来,然后进行hashCode,根据hash值排序,然后根据轮询算法,把partition分配给consumer消费。如果所有consumer实例的订阅是相同的,那么partition会均匀分布。 <br><br>使用轮询分区策略必须满足两个条件<br>(1)每个主题的消费者实例具有相同数量的流<br>(2) 每个消费者订阅的主题必须是相同的<br><br>3.partition与partition的数量关系:<br>(1)消费者数量多于partition的数量的时候,会有消费者消费不到数据的情况<br>(2)消费者数量少于partition的数量的时候,会有消费者消费多个partition<br>(3)一般partition是consumer的整数倍 <br>
kafka consumer的rebalance机制
简要的说明:kafka consumer的rebalance机制规定了同一个group下的consumer如何达成一致来消费订阅各个分区的消息,具体的策略是范围策略,或者轮询策略。<br>1.什么时候会触发kafka consumer的rebalance<br>(1) 同一个consumer group内新增了消费者<br>(2)消费者离开当前所属的consumer group,比如主动停机或者宕机<br>(3)topic新增或者减少了分区<br><br>2.如何管理rebalance,以及整个过程是怎么样的?<br>(1)首先我们会确定的一个coordinate角色,当启动第一个consumer的时候我们就会确定为coordinate,之后所有的consumer都会与这个coordinate保持通信。而我们的coordinate就是对consumer group进行管理。<br><br>(2)如何确定coordinate:<br>消费者向kafka集群中的任意一个broker发送一个GroupCoordinatorRequest请求,服务端会返回一个负载最小的broker节点的id,并将该broker设置为coordinator<br><br>(3)接着,我们会进行第一阶段joinGroup(选举leader)的过程:所有的消费者都会向consumer发送joinGroup的请求,当所有的consumer都发送了请求之后,我们的coordinate就会在选举出一个consumer来作为leader,而且会把订阅消息,组成员信息反馈回去。 <br>简要的文字说明:所有的consumer都来了的时候,coordinate会选出一个leader<br><br>(4)接着再继续,我们会进入第二阶段Synchronizing Group State(同步leader的分区分配方案),这个过程简单来说就是leader把分区分配方案发送给coordinate,然后,coordinate再把这个分区发送给各个consumer。 <br>简要说明:第二阶段就是把leader的分区分配方案,发送到coordinate,然后通过coordinate同步到组内的所有的consumer<br>
offset
(1)什么是offset:每一个消息进入partition的时候,他都会有一个偏移量,就是offset,他代表这个消息在这个partition上面的位置,他只保证在同一个partition上面是有顺序的。<br>(2)我们是如何确保同一个分组consumer不会去重复消费同一个消息?<br>我们通过一个叫consumer_offset_*的topic来保存已经消费的各个组的信息,commit之后,他就会保存在对应的consumer_offset分区里面,consumer_offset默认有50个分区,具体是落在哪一个分区使用过:Math.abs(“groupid”.hashCode())%50来计算得到的。 <br>
消息的存储
1)我们的kafka的消息都是日志消息(log),他不是直接存放在磁盘上面的,而是存放在对应的topic_partitionNum目录下面<br>2)在多个broker和多个partition,他是这样分配的:<br>总结:他就是partition按照broker顺序一个一个轮着来分配下去<br>3)我们写入的方式是顺序写入<br>
消息的性能问题<br>
1)我们的kafka是零拷贝的。他大概的过程是磁盘上的数据,读到内存里面,内存里面的数据再通过socket发送到消费者<br>通过“零拷贝”技术,可以去掉这些没必要的数据复制操作,同时也会减少上下文切换次数<br>传统的是磁盘-内核空间-用户空间--socketbuffer-网卡buffer<br>零拷贝是磁盘-内核空间-网卡buffer<br>只需要一次拷贝就行,允许操作系统将数据直接从页缓存发送到网络上<br>
详细介绍及Spring集成<br>https://blog.csdn.net/james_xiaojun/article/details/103380297
分区包含java代码<br>https://blog.csdn.net/Computer_hello/article/details/109549542<br>
面试题<br>https://blog.csdn.net/qq_34668848/article/details/105611546<br>
1、Kafka的用途有哪些?使用场景如何?<br>
1、日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如Hadoop、Hbase、Solr等<br>2、消息系统:解耦和生产者和消费者、缓存消息等<br>3、用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到Hadoop、数据仓库中做离线分析和挖掘<br>4、运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告<br>5、流式处理:比如spark streaming和storm<br>6、事件源
2、 Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么<br>
1、分区中的所有副本统称为AR(Assigned Repllicas)。所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。与leader副本同步滞后过多的副本(不包括leader)副本,组成OSR(Out-Sync Relipcas),由此可见:AR=ISR+OSR。<br>2、ISR集合的副本必须满足:<br> 副本所在节点必须维持着与zookeeper的连接;<br> 副本最后一条消息的offset与leader副本最后一条消息的offset之间的差值不能超出指定的阈值<br>3、每个分区的leader副本都会维护此分区的ISR集合,写请求首先由leader副本处理,之后follower副本会从leader副本上拉取写入的消息,这个过程会有一定的延迟,导致follower副本中保存的消息略少于leader副本,只要未超出阈值都是可以容忍的<br>4、ISR的伸缩指的是Kafka在启动的时候会开启两个与ISR相关的定时任务,名称分别为“isr-expiration"和”isr-change-propagation".。isr-expiration任务会周期性的检测每个分区是否需要缩减其ISR集合。<br>
3 Kafka中的HW、LEO、LSO、LW等分别代表什么?
1、HW是High Watermak的缩写,俗称高水位,它表示了一个特定消息的偏移量(offset),消费之只能拉取到这个offset之前的消息。<br>2、LEO是Log End Offset的缩写,它表示了当前日志文件中下一条待写入消息的offset。<br>3、LSO特指LastStableOffset。它具体与kafka的事物有关。消费端参数——isolation.level,这个参数用来配置消费者事务的隔离级别。字符串类型,“read_uncommitted”和“read_committed”。<br>4、 LW是Low Watermark的缩写,俗称“低水位”,代表AR集合中最小的logStartOffset值,副本的拉取请求(FetchRequest)和删除请求(DeleteRecordRequest)都可能促使LW的增长。
4、Kafka中是怎么体现消息顺序性的?
1、一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。<br>2、写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
5、Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?<br>
拦截器 -> 序列化器 -> 分区器<br><br>补充:Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。Intercetpor的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor。实现下面四个方法<br><br> 1)、configure(configs):获取配置信息和初始化数据时调用<br><br> 2)、onSend(ProducerRecord):用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的topic和分 区,否则会影响目标分区的计算<br><br> 3)、onAcknowledgement(RecordMetadata, Exception):该方法会在消息被应答或消息发送失败时调用<br><br> 4)、close:关闭interceptor,主要用于执行一些资源清理工作
6、Kafka生产者客户端的整体结构是什么样子的?
子主题
有哪些情形会造成重复消费?<br>
消费者消费后没有commit offset(程序崩溃/强行kill/消费耗时/自动提交偏移情况下unscrible) <br><br>
那些情景下会造成消息漏消费?<br>
先提交offset,后消费,有可能造成数据的重复 <br><br>
rocketmq
架构图
负载均衡
pruducer
1)producer发送消息的负载均衡:默认会轮询向Topic的所有queue发送消息,以达到消息平均落到不同的queue上;而由于queue可以落在不同的broker上,就可以发到不同broker上(当然也可以指定发送到某个特定的queue上)<br>
consumer
2)consumer订阅消息的负载均衡:假设有5个队列,两个消费者,则第一个消费者消费3个队列,第二个则消费2个队列,以达到平均消费的效果。而需要注意的是,当consumer的数量大于队列的数量的话,根据rocketMq的机制,多出来的队列不会去消费数据,因此建议consumer的数量小于或者等于queue的数量,避免不必要的浪费
面试题
https://www.wwwbuild.net/huangtalkit/23928.html
01.为什么要用RocketMq?<br>吞吐量高:单机吞吐量可达十万级<br>可用性高:分布式架构<br>消息可靠性高:经过参数优化配置,消息可以做到0丢失<br>功能支持完善:MQ功能较为完善,还是分布式的,扩展性好<br>支持10亿级别的消息堆积:不会因为堆积导致性能下降<br>源码是java:方便我们查看源码了解它的每个环节的实现逻辑,并针对不同的业务场景进行扩展<br>可靠性高:天生为金融互联网领域而生,对于要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况<br>
02.RocketMq的部署架构了解吗?<br>包含了四个主要部分:NameServer集群,Producer集群,Cosumer集群以及Broker集群<br>NameServer 担任路由消息的提供者。生产者或消费者能够通过NameServer查找各Topic相应的Broker IP列表分别进行发送消息和消费消息。nameServer由多个无状态的节点构成,节点之间无任何信息同步<br><br>broker会定期向NameServer以发送心跳包的方式,轮询向所有NameServer注册以下元数据信息:<br><br>1)broker的基本信息(ip port等)<br>2)主题topic的地址信息<br>3)broker集群信息<br>4)存活的broker信息<br>5)filter 过滤器<br>也就是说,每个NameServer注册的信息都是一样的,而且是当前系统中的所有broker的元数据信息<br>Producer负责生产消息,一般由业务系统负责生产消息。一个消息生产者会把业务应用系统里产生的消息发送到broker服务器。RocketMQ提供多种发送方式,同步发送、异步发送、顺序发送、单向发送。同步和异步方式均需要Broker返回确认信息,单向发送不需要<br>Broker,消息中转角色,负责存储消息、转发消息。在RocketMQ系统中负责接收从生产者发送来的消息并存储、同时为消费者的拉取请求作准备<br>Consumer负责消费消息,一般是后台系统负责异步消费。一个消息消费者会从Broker服务器拉取消息、并将其提供给应用程序。从用户应用的角度而言提供了两种消费形式:拉取式消费、推动式消费<br>
03.它有哪几种部署类型?分别有什么特点?<br>RocketMQ有4种部署类型<br>1)单Master<br>单机模式, 即只有一个Broker, 如果Broker宕机了, 会导致RocketMQ服务不可用, 不推荐使用<br><br>2)多Master模式<br>组成一个集群, 集群每个节点都是Master节点, 配置简单, 性能也是最高, 某节点宕机重启不会影响RocketMQ服务<br>缺点:如果某个节点宕机了, 会导致该节点存在未被消费的消息在节点恢复之前不能被消费<br><br>3)多Master多Slave模式,异步复制<br>每个Master配置一个Slave, 多对Master-Slave, Master与Slave消息采用异步复制方式, 主从消息一致只会有毫秒级的延迟<br>优点是弥补了多Master模式(无slave)下节点宕机后在恢复前不可订阅的问题。在Master宕机后, 消费者还可以从Slave节点进行消费。采用异步模式复制,提升了一定的吞吐量。总结一句就是,采用<br>多Master多Slave模式,异步复制模式进行部署,系统将会有较低的延迟和较高的吞吐量<br>缺点就是如果Master宕机, 磁盘损坏的情况下, 如果没有及时将消息复制到Slave, 会导致有少量消息丢失<br><br>4)多Master多Slave模式,同步双写<br>与多Master多Slave模式,异步复制方式基本一致,唯一不同的是消息复制采用同步方式,只有master和slave都写成功以后,才会向客户端返回成功<br>优点:数据与服务都无单点,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高<br>缺点就是会降低消息写入的效率,并影响系统的吞吐量<br>实际部署中,一般会根据业务场景的所需要的性能和消息可靠性等方面来选择后两种<br>
05.rocketmq如何保证高可用性?<br>1)集群化部署NameServer。Broker集群会将所有的broker基本信息、topic信息以及两者之间的映射关系,轮询存储在每个NameServer中(也就是说每个NameServer存储的信息完全一样)。因此,NameServer集群化,不会因为其中的一两台服务器挂掉,而影响整个架构的消息发送与接收;<br><br>2)集群化部署多broker。producer发送消息到broker的master,若当前的master挂掉,则会自动切换到其他的master<br>cosumer默认会访问broker的master节点获取消息,那么master节点挂了之后,该怎么办呢?它就会自动切换到同一个broker组的slave节点进行消费<br>那么你肯定会想到会有这样一个问题:consumer要是直接消费slave节点,那master在宕机前没有来得及把消息同步到slave节点,那这个时候,不就会出现消费者不就取不到消息的情况了?<br>这样,就引出了下一个措施,来保证消息的高可用性<br><br>3)设置同步复制<br>前面已经提到,消息发送到broker的master节点上,master需要将消息复制到slave节点上,rocketmq提供两种复制方式:同步复制和异步复制<br>异步复制,就是消息发送到master节点,只要master写成功,就直接向客户端返回成功,后续再异步写入slave节点<br>同步复制,就是等master和slave都成功写入内存之后,才会向客户端返回成功<br>那么,要保证高可用性,就需要将复制方式配置成同步复制,这样即使master节点挂了,slave上也有当前master的所有备份数据,那么不仅保证消费者消费到的消息是完整的,并且当master节点恢复之后,也容易恢复消息数据<br>在master的配置文件中直接配置brokerRole:SYNC_MASTER即可<br>
06.rocketmq的工作流程是怎样的?<br>RocketMq的工作流程如下:<br><br>1)首先启动NameServer。NameServer启动后监听端口,等待Broker、Producer以及Consumer连上来<br>2)启动Broker。启动之后,会跟所有的NameServer建立并保持一个长连接,定时发送心跳包。心跳包中包含当前Broker信息(ip、port等)、Topic信息以及Borker与Topic的映射关系<br>3)创建Topic。创建时需要指定该Topic要存储在哪些Broker上,也可以在发送消息时自动创建Topic<br>4)Producer发送消息。启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取当前发送的Topic所在的Broker;然后从队列列表中轮询选择一个队列,与队列所在的Broker建立长连接,进行消息的发送<br>5)Consumer消费消息。跟其中一台NameServer建立长连接,获取当前订阅Topic存在哪些Broker上,然后直接跟Broker建立连接通道,进行消息的消费<br>
07.RocketMq使用哪种方式消费消息,pull还是push?<br>RocketMq提供两种方式:pull和push进行消息的消费<br>而RocketMq的push方式,本质上也是采用pull的方式进行实现的。也就是说这两种方式本质上都是采用consumer轮询从broker拉取消息的<br>push方式里,consumer把轮询过程封装了一层,并注册了MessageListener监听器。当轮询取到消息后,便唤醒MessageListener的consumeMessage()来消费,对用户而言,感觉好像消息是被推送过来的<br>其实想想,消息统一都发到了broker,而broker又不会主动去push消息,那么消息肯定都是需要消费者主动去拉的喽~<br>
08.RocketMq如何负载均衡?<br>1)producer发送消息的负载均衡:默认会轮询向Topic的所有queue发送消息,以达到消息平均落到不同的queue上;而由于queue可以落在不同的broker上,就可以发到不同broker上(当然也可以指定发送到某个特定的queue上)<br><br>2)consumer订阅消息的负载均衡:假设有5个队列,两个消费者,则第一个消费者消费3个队列,第二个则消费2个队列,以达到平均消费的效果。而需要注意的是,当consumer的数量大于队列的数量的话,根据rocketMq的机制,多出来的队列不会去消费数据,因此建议consumer的数量小于或者等于queue的数量,避免不必要的浪费<br>
09.RocketMq的存储机制了解吗?<br>RocketMq采用文件系统进行消息的存储,相对于ActiveMq采用关系型数据库进行存储的方式就更直接,性能更高了<br><br>RocketMq与Kafka在写消息与发送消息上,继续沿用了Kafka的这两个方面:顺序写和零拷贝<br><br>1)顺序写<br>我们知道,操作系统每次从磁盘读写数据的时候,都需要找到数据在磁盘上的地址,再进行读写。而如果是机械硬盘,寻址需要的时间往往会比较长<br>而一般来说,如果把数据存储在内存上面,少了寻址的过程,性能会好很多;但Kafka 的数据存储在磁盘上面,依然性能很好,这是为什么呢?<br>这是因为,rocketmq采用的是顺序写,直接追加数据到末尾。实际上,磁盘顺序写的性能极高,在磁盘个数一定,转数一定的情况下,基本和内存速度一致<br>因此,磁盘的顺序写这一机制,极大地保证了Kafka本身的性能<br>2)零拷贝<br>比如:读取文件,再用socket发送出去这一过程<br><br><br>buffer = File.read<br>Socket.send(buffer)<br><br>传统方式实现:<br>先读取、再发送,实际会经过以下四次复制<br>1、将磁盘文件,读取到操作系统内核缓冲区Read Buffer<br>2、将内核缓冲区的数据,复制到应用程序缓冲区Application Buffer<br>3、将应用程序缓冲区Application Buffer中的数据,复制到socket网络发送缓冲区<br>4、将Socket buffer的数据,复制到网卡,由网卡进行网络传输<br><br>传统方式,读取磁盘文件并进行网络发送,经过的四次数据copy是非常繁琐的<br>重新思考传统IO方式,会注意到在读取磁盘文件后,不需要做其他处理,直接用网络发送出去的这种场景下,第二次和第三次数据的复制过程,不仅没有任何帮助,反而带来了巨大的开销。那么这里使用了零拷贝,也就是说,直接由内核缓冲区Read Buffer将数据复制到网卡,省去第二步和第三步的复制。<br><br>那么采用零拷贝的方式发送消息,必定会大大减少读取的开销,使得RocketMq读取消息的性能有一个质的提升<br><br>此外,还需要再提一点,零拷贝技术采用了MappedByteBuffer内存映射技术,采用这种技术有一些限制,其中有一条就是传输的文件不能超过2G,这也就是为什么RocketMq的存储消息的文件CommitLog的大小规定为1G的原因<br><br>小结:RocketMq采用文件系统存储消息,并采用顺序写写入消息,使用零拷贝发送消息,极大得保证了RocketMq的性能<br>
子主题
子主题
子主题
10.RocketMq的存储结构是怎样的?<br>如图所示,消息生产者发送消息到broker,都是会按照顺序存储在CommitLog文件中,每个commitLog文件的大小为1G<br>CommitLog-存储所有的消息元数据,包括Topic、QueueId以及message<br>CosumerQueue-消费逻辑队列:存储消息在CommitLog的offset<br>IndexFile-索引文件:存储消息的key和时间戳等信息,使得RocketMq可以采用key和时间区间来查询消息<br>也就是说,rocketMq将消息均存储在CommitLog中,并分别提供了CosumerQueue和IndexFile两个索引,来快速检索消息<br>
11.RocketMq如何进行消息的去重?<br>我们知道,只要通过网络交换数据,就无法避免因为网络不可靠而造成的消息重复这个问题。比如说RocketMq中,当consumer消费完消息后,因为网络问题未及时发送ack到broker,broker就不会删掉当前已经消费过的消息,那么,该消息将会被重复投递给消费者去消费<br><br>虽然rocketMq保证了同一个消费组只能消费一次,但会被不同的消费组重复消费,因此这种重复消费的情况不可避免<br>RocketMq本身并不保证消息不重复,这样肯定会因为每次的判断,导致性能打折扣,所以它将去重操作直接放在了消费端:<br>1)消费端处理消息的业务逻辑保持幂等性。那么不管来多少条重复消息,可以实现处理的结果都一样<br>2)还可以建立一张日志表,使用消息主键作为表的主键,在处理消息前,先insert表,再做消息处理。这样可以避免消息重复消费<br>
12.RocketMq性能比较高的原因?<br>就是前面在文件存储机制中所提到的:RocketMq采用文件系统存储消息,采用顺序写的方式写入消息,使用零拷贝发送消息,这三者的结合极大地保证了RocketMq的性能<br>
kafaka消息积压解决方案
消费者消费单个topic
案例分享:<br>5个topic,前4个数量很小,第5个数量多,每次消费的时候,前4个消费数量很少,但是很耗时间,<br>于是把第5个分为一个单独的消费之进行消费,后面解决了消费慢的问题
消费者拉去数量控制offset设置
消费者拉取消息的时间间隔设置
代码层面可以使用多线程解决速度问题
拉取消息的大小设置
消费单条数据时间过长,可以修改拉取数量由500条修改为50条<br>props.put("session.timeout.ms", "30000");<br>30000/500=60ms,60ms处理一次数据库更新操作显然有点难,因此考虑修改消费批次大小:<br>props.put("max.poll.records", "50");<br>之前没有出现问题是因为这是一个低频操作,每一批只有一条或几条数据更新。<br>这次问题出现的原因为Broker宕机,导致堆积的消息过多,每一批达到500条消息,导致poll之后消费的时间过长,session超时。服务注册中心zookeeper以为客户端失效进行Rebalance,因此连接到另外一台消费服务器,然而另外一台服务器也出现超时,又进行Rebalance...如此循环,才出现了两台服务器都进行消费,并且一直重复消费。<br><br>找到问题的所在就比较好解决了,加大超时时间、减少拉取条数或者异步进行业务处理,如果消息量比较大的话还可以增加消费线程等。<br>起初认为Kafka对于poll的实现也太坑了,为什么心跳机制会隐藏在poll()方法中实现,好在新的版本有新的实现方式。不过后来这也是因为我们在使用Api的过程中不熟悉其实现原理导致的。所以在以后的开发中,一定要知其然,还要只其所以然。 <br>
消息积压问题原因及解决方案
1.实时/消费任务挂掉<br>比如,我们写的实时应用因为某种原因挂掉了,并且这个任务没有被监控程序监控发现通知相关负责人,负责人又没有写自动拉起任务的脚本进行重启。<br>那么在我们重新启动这个实时应用进行消费之前,这段时间的消息就会被滞后处理,如果数据量很大,可就不是简单重启应用直接消费就能解决的。<br><br>解决方案:<br>a.任务重新启动后直接消费最新的消息,对于"滞后"的历史数据采用离线程序进行"补漏"。<br>此外,建议将任务纳入监控体系,当任务出现问题时,及时通知相关负责人处理。当然任务重启脚本也是要有的,还要求实时框架异常处理能力要强,避免数据不规范导致的不能重新拉起任务。<br>b.任务启动从上次提交offset处开始消费处理<br>如果积压的数据量很大,需要增加任务的处理能力,比如增加资源,让任务能尽可能的快速消费处理,并赶上消费最新的消息<br><br>
2.Kafka分区数设置的不合理(太少)和消费者"消费能力"不足<br>Kafka单分区生产消息的速度qps通常很高,如果消费者因为某些原因(比如受业务逻辑复杂度影响,消费时间会有所不同),就会出现消费滞后的情况。<br>此外,Kafka分区数是Kafka并行度调优的最小单元,如果Kafka分区数设置的太少,会影响Kafka consumer消费的吞吐量。<br><br>解决方案:<br>如果数据量很大,合理的增加Kafka分区数是关键。如果利用的是Spark流和Kafka direct approach方式,也可以对KafkaRDD进行repartition重分区,增加并行度处理。<br>
3.Kafka消息的key不均匀,导致分区间数据不均衡<br>在使用Kafka producer消息时,可以为消息指定key,但是要求key要均匀,否则会出现Kafka分区间数据不均衡。<br><br>解决方案:<br>可以在Kafka producer处,给key加随机后缀,使其均衡。<br><br>
多个topic读取消息如何保证顺序性
可以分类,每个类型的topic存放到不同分区,这样可以保证存数据的顺序性,<br>每个消费者消费不同分区就会是有序的消费
mq对比
1、我们可以对比下kafka和rocketMq在协调节点选择上的差异,kafka通过zookeeper来进行协调,而rocketMq通过自身的namesrv进行协调。<br><br> 2、kafka在具备选举功能,在Kafka里面,Master/Slave的选举,有2步:第1步,先通过ZK在所有机器中,选举出一个KafkaController;第2步,再由这个Controller,决定每个partition的Master是谁,Slave是谁。因为有了选举功能,所以kafka某个partition的master挂了,该partition对应的某个slave会升级为主对外提供服务。<br><br> 3、rocketMQ不具备选举,Master/Slave的角色也是固定的。当一个Master挂了之后,你可以写到其他Master上,但不能让一个Slave切换成Master。那么rocketMq是如何实现高可用的呢,其实很简单,rocketMq的所有broker节点的角色都是一样,上面分配的topic和对应的queue的数量也是一样的,Mq只能保证当一个broker挂了,把原本写到这个broker的请求迁移到其他broker上面,而并不是这个broker对应的slave升级为主。<br><br> 4、rocketMq在协调节点的设计上显得更加轻量,用了另外一种方式解决高可用的问题,思路也是可以借鉴的。<br><br>作者:晴天哥_王志<br>链接:https://www.jianshu.com/p/c474ca9f9430<br>来源:简书<br>著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
关于吞吐量<br>1、首先说明下面的几张图片来自于互联网共享,也就是我后面参考文章里面的列出的文章。<br><br>2、kafka在消息存储过程中会根据topic和partition的数量创建物理文件,也就是说我们创建一个topic并指定了3个partition,那么就会有3个物理文件目录,也就说说partition的数量和对应的物理文件是一一对应的。<br><br>3、rocketMq在消息存储方式就一个物流问题,也就说传说中的commitLog,rocketMq的queue的数量其实是在consumeQueue里面体现的,在真正存储消息的commitLog其实就只有一个物理文件。<br><br>4、kafka的多文件并发写入 VS rocketMq的单文件写入,性能差异kafka完胜可想而知。<br><br>5、kafka的大量文件存储会导致一个问题,也就说在partition特别多的时候,磁盘的访问会发生很大的瓶颈,毕竟单个文件看着是append操作,但是多个文件之间必然会导致磁盘的寻道。<br><br><br><br>作者:晴天哥_王志<br>链接:https://www.jianshu.com/p/c474ca9f9430<br>来源:简书<br>著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://blog.csdn.net/damacheng/article/details/42846549<br><br>数据可靠性<br>RocketMQ支持异步实时刷盘,同步刷盘,同步Replication,异步Replication<br>Kafka使用异步刷盘方式,异步Replication<br>总结:RocketMQ的同步刷盘在单机可靠性上比Kafka更高,不会因为操作系统Crash,导致数据丢失。 同时同步Replication也比Kafka异步Replication更可靠,数据完全无单点。另外Kafka的Replication以topic为单位,支持主机宕机,备机自动切换,但是这里有个问题,由于是异步Replication,那么切换后会有数据丢失,同时Leader如果重启后,会与已经存在的Leader产生数据冲突。开源版本的RocketMQ不支持Master宕机,Slave自动切换为Master,阿里云版本的RocketMQ支持自动切换特性。<br><br>性能对比<br>Kafka单机写入TPS约在百万条/秒,消息大小10个字节<br>RocketMQ单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节<br>总结:Kafka的TPS跑到单机百万,主要是由于Producer端将多个小消息合并,批量发向Broker。<br><br>RocketMQ为什么没有这么做?<br><br>Producer通常使用Java语言,缓存过多消息,GC是个很严重的问题<br>Producer调用发送消息接口,消息未发送到Broker,向业务返回成功,此时Producer宕机,会导致消息丢失,业务出错<br>Producer通常为分布式系统,且每台机器都是多线程发送,我们认为线上的系统单个Producer每秒产生的数据量有限,不可能上万。<br>缓存的功能完全可以由上层业务完成。<br>单机支持的队列数<br>Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长<br>RocketMQ单机支持最高5万个队列,Load不会发生明显变化<br>队列多有什么好处?<br><br>单机可以创建更多Topic,因为每个Topic都是由一批队列组成<br>Consumer的集群规模和队列数成正比,队列越多,Consumer集群可以越大<br>消息投递实时性<br>Kafka使用短轮询方式,实时性取决于轮询间隔时间<br>RocketMQ使用长轮询,同Push方式实时性一致,消息的投递延时通常在几个毫秒。<br>消费失败重试<br>Kafka消费失败不支持重试<br>RocketMQ消费失败支持定时重试,每次重试间隔时间顺延<br>总结:例如充值类应用,当前时刻调用运营商网关,充值失败,可能是对方压力过多,稍后在调用就会成功,如支付宝到银行扣款也是类似需求。<br><br>这里的重试需要可靠的重试,即失败重试的消息不因为Consumer宕机导致丢失。<br><br>严格的消息顺序<br>Kafka支持消息顺序,但是一台Broker宕机后,就会产生消息乱序<br>RocketMQ支持严格的消息顺序,在顺序消息场景下,一台Broker宕机后,发送消息会失败,但是不会乱序<br>Mysql Binlog分发需要严格的消息顺序<br><br>定时消息<br>Kafka不支持定时消息<br>RocketMQ支持两类定时消息<br>开源版本RocketMQ仅支持定时Level<br>阿里云ONS支持定时Level,以及指定的毫秒级别的延时时间<br>分布式事务消息<br>Kafka不支持分布式事务消息<br>阿里云ONS支持分布式定时消息,未来开源版本的RocketMQ也有计划支持分布式事务消息<br>消息查询<br>Kafka不支持消息查询<br>RocketMQ支持根据Message Id查询消息,也支持根据消息内容查询消息(发送消息时指定一个Message Key,任意字符串,例如指定为订单Id)<br>总结:消息查询对于定位消息丢失问题非常有帮助,例如某个订单处理失败,是消息没收到还是收到处理出错了。<br><br>消息回溯<br>Kafka理论上可以按照Offset来回溯消息<br>RocketMQ支持按照时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息<br>总结:典型业务场景如consumer做订单分析,但是由于程序逻辑或者依赖的系统发生故障等原因,导致今天消费的消息全部无效,需要重新从昨天零点开始消费,那么以时间为起点的消息重放功能对于业务非常有帮助。<br><br>消费并行度<br>Kafka的消费并行度依赖Topic配置的分区数,如分区数为10,那么最多10台机器来并行消费(每台机器只能开启一个线程),或者一台机器消费(10个线程并行消费)。即消费并行度和分区数一致。<br><br>RocketMQ消费并行度分两种情况<br><br>顺序消费方式并行度同Kafka完全一致<br>乱序方式并行度取决于Consumer的线程数,如Topic配置10个队列,10台机器消费,每台机器100个线程,那么并行度为1000。<br>消息轨迹<br>Kafka不支持消息轨迹<br>阿里云ONS支持消息轨迹<br>开发语言友好性<br>Kafka采用Scala编写<br>RocketMQ采用Java语言编写<br>Broker端消息过滤<br>Kafka不支持Broker端的消息过滤<br>RocketMQ支持两种Broker端消息过滤方式<br>根据Message Tag来过滤,相当于子topic概念<br>向服务器上传一段Java代码,可以对消息做任意形式的过滤,甚至可以做Message Body的过滤拆分。<br>消息堆积能力<br>理论上Kafka要比RocketMQ的堆积能力更强,不过RocketMQ单机也可以支持亿级的消息堆积能力,我们认为这个堆积能力已经完全可以满足业务需求。<br><br>开源社区活跃度<br>Kafka社区更新较慢<br>RocketMQ的github社区有250个个人、公司用户登记了联系方式,QQ群超过1000人。<br>商业支持<br>Kafka原开发团队成立新公司,目前暂没有相关产品看到<br>RocketMQ在阿里云上已经开放公测近半年,目前以云服务形式免费供大家商用,并向用户承诺99.99%的可靠性,同时彻底解决了用户自己搭建MQ产品的运维复杂性问题<br>成熟度<br>Kafka在日志领域比较成熟<br>RocketMQ在阿里集团内部有大量的应用在使用,每天都产生海量的消息,并且顺利支持了多次天猫双十一海量消息考验,是数据削峰填谷的利器。
zookeeper
选举机制
每个节点启动是会发送一个投票,默认投票是投自己为leader,发送vote(myid,zxid,epoch)到集群中的所有节点,每个节点同时在监听并接收着2181端口,接收到其他节点的vote后和自己进行对比,大于自己则把自己的vote改为大于自己的节点,并重新发送出去,若不大于自己,则不处理.重新发送自己的节点;后续判断投票数量是否已经超过一半,若超过则设置leader节点;再次检查leader选举结果是否有变更,若没有则结束.同时设置自己的节点为leader或者follower
leader-follower数据同步
1、leader 接受到消息请求后,将消息赋予给一个全局唯一的64位自增id,叫:zxid,通过zxid的代销比较即可以实现因果有序的这个特征<br>2、leader 为每个follower 准备了一个FIFO队列(通过TCP协议来实现,以实现了全局有序这个特点)将带有zxid的消息作为一个提案(proposal)分发给所有的follower<br>3、当follower接受到proposal,先把proposal写到磁盘,写入成功以后再向leader恢复一个ack<br>4、当leader 接受到合法数量(超过半数节点)的 ack,leader 就会向这些follower发送commit命令,同时会在本地执行该消息<br>5、当follower接受到消息的commit命令以后,就会提交该消息<br>————————————————<br>版权声明:本文为CSDN博主「菜鸟编程98K」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。<br>原文链接:https://blog.csdn.net/qq_39938758/article/details/105754198
分布式锁
通过创建临时有序节点,各个zookeeper节点对比自己的节点大小,按照最小的开始获取分布式锁,每个节点监听自己的上一个节点的删除事件,上一个节点使用完成分布式锁之后断开连接,下个节点接收到通知,获取指定节点下的所有节点,对比自己是否是最小节点,是则获取分布式锁,不是则监听自己的上一个节点的删除事件.直到获取分布式锁
限流
限流算法





Collect
Get Started
Collect
Get Started
Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页

