
大数据
2021-08-20 13:32:33 3 举报AI智能生成
大数据面试总结
集团数据中台
架构设计
模板推荐
作者其他创作
大纲/内容
Yarn(使用oozie)
服务角色
ResourceManager
YarnScheduler
Applications Manager
资源管理器
处理客户端请求
启动和监控Application Master
监控NodeManager
资源分配与调度
NodeManager
管理节点所有事情
ApplicationMaster
job生命周期内的
管理任务所有事情
Container
调度器
FIFO(一条队列)
Capacity(多条队列,队列内可以嵌入fair)
Fair(资源共享)
提交任务流程
作业提交
job id
作业初始化
MRAppMaster
任务分配
分配Maptask
任务运行
运行Maptask,完成后再申请ReduceTask
其他的任务进度与作业完成
Flume
Agent:核心组件
source 负责数据的产生或搜集
source与channel之间存在拦截器
channel 是一种短暂的存储容器,负责数据的存储持久化,可以理解为flume内部的消息队列(线性安全并且具有事务性)
Memory Channel
读写块,但容量小,依赖内存,服务挂掉会导致数据丢失
File Channel
无数据丢失风险
Kafka Channel
借助kafka做队列功能
sink 负责数据的转发
HDFS Sink
Kafka Sink
启动流程
channel->sink->source
Kafka
写入
写入os cache与磁盘顺序写入
读出
零拷贝技术
架构
子主题
异常
丢数
前中后丢数
使用回调函数写入,带上ack,retries,factor参数;消费手动提交offset以及采用redis set进行辅助存储
重复消费
后期做等幂操作
顺序消费
同用户,同orderi放到同个partition
zookeeper在kafka中的使用
Broker注册
Topic注册
生产者负载均衡
Zookeeper,一个分布式协调服务
数据如何保持一致性?
Zookeeper原子广播
任何时候都需要保证只有一个主进程负责进行事务操作
选主
ZAB协议中多次用到“过半”设计策略 ,该策略是zk在A(可用性)与C(一致性)间做的取舍
选主后的数据同步
paxos
分布式一致性算法
牺牲可用性与一致性
raft
paxos偏向理论,raft偏向实践
拜占庭将军算法
CAP
一致性C
可用性A
分区容错性P
ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能
Znode
持久节点
临时节点
持久顺序节点
临时顺序节点
zab 协议也就是paxos 算法的变种
Zookeeper Watcher 机制
使用场景
管理Kafka原始数据
抽象场景
统一配置管理(例如:统一管理配置文件)
统一命名服务(例如:负载均衡,但nginx的吞吐更好)<br>
分布式锁
细节点
每个znode节点上限1M
最小节点2N+1<br>
分布式协调服务
定位:高可用、高性能,读多写少的场景
Impala
Parquet的列式存储是最优存储方式
MPP SQL
架构
Statestore(发布订阅系统)
在Catalog与impalad之间,做消息传递用,维护impalad进程转态
解耦,提升扩展性
Catalog
元数据服务
Impalad
query planner
query coordinator
query executor
Sql解析,执行计划生产,数据查询,聚合,返回
flink(练习API的同时练习重写source与sink)
flink on yarn
开辟永久flink集群资源(yarn-session.sh)
临时yarn集群,一个job一个flink集群,集群的生命周期就是job的生命周期
架构:Jobmanager与Taskmanager
Jobmanager(包括任务调度,检查点管理,失败恢复)
Actor系统
调度
检查点
保证容错性的核心
Taskmanager
包含多个task slots,<br><div>每个卡槽就是一个executors,</div><div>每个taskmanager就一个jvm,jvm的内存平均分给每个task slot</div><br>
Job Client负责提交任务给Job manager
两大api
DataStream(三大逻辑结构:source、transform、sink)
算子如Dataset
Window
Tumbling window(滚动窗口)
Sliding Windows(滑动窗口)
Session window(会话窗口)
Global window(所有数据放到一个窗口)
窗口函数就是这四个:ReduceFunction,AggregateFunction,FoldFunction,ProcessWindowFunction
WindowAll
DataSet
source算子<br>
fromCollection
readTextFile(文件、目录、压缩文件都可)
Transform
Map
flatMap
mapPartition
filter
reduce
reduceGroup
minBy和maxBy
Aggregate
distinct
first
join
leftOuterJoin
cross
union
rebalance
partitionByHash
partitionByRange
sortPartition
Sink算子
collect
writeAsText
KafkaSink
RedisSink
ElasticsearchSink
自定义Sink
维表Join
广播变量
预加载
热存储
flink的时间有三个:事件时间、接入时间、处理时间;默认是处理时间;接入时间和处理时间都不会出现迟到的数据
概念点
state
checkpoint
watermark
Hudi数据湖(个人理解:整合了列式存储+增量更新);Hadoop Upserts Delete Incrementals
如何做到近实时抽取
如何做到近实时分析
列式存储
两大优势:更新删除、时间漫游
写时复制,读时合并
大数据更新思考
hive更新 ? 答:分区覆盖法 ;Hudi的优势就出来了,可以直接更新(通过写时复制,读时合并)
Hbase更新?答:比较简单,直接覆盖即可
es更新? 答:没什么好办法,查询删除
问题
连续登陆三天以上用户
row_number
海量数据找数据
遍历
hash大文件变小文件
bigmap和布隆过滤器
其他
Hue管理平台
Oozie调度平台
Azkaban
sqoop数据同步工具
datax数据同步工具
Hadoop(最新3.1)
HDFS
<br>NameNode(保存文件目录快照由以下组成,Hadoop1.0由secondaryNamenode定期合并两者数据)
<br>eidt <br>logs编辑日志
<br>fsimage镜像文件
DataNode
<br>定期向NameNode汇报信息
SecondaryNameNode<br>
<br>hadoop2.0以后不在使用这种方法,双namenode随时切换,使用journalNode进行数据同步,同时journalNode记录最近edits
Client
负责将数据切块
读写流程
写入
client请求namenode分配写入地址,client直接流式写入datanode数据块,写完返回给client,client向namenode汇报
读取
client请求namenode获取数据块地址,然后client直接从datanode读取数据
Router-Based Federation 方案
单namenode的解决方案
内存上的影响
Federation
Federation
Router-Based Federation
Federation layer中的router服务对外提供服务,会将block访问引致对应子集群
MapReduce
Split
Map
<br>Shuffle(分map端与reduce端)
输出到环形缓存
环形缓存使用逻辑(equaltor,kvindex,bufferindex)
Spill/Sort(排序并且溢写到磁盘)
合并文件并且Partitioner,将不同数据分到不同reduce(默认hash(key) mod R进行分区)
<br>Reduce
小表关联使用:Distributed Cache
MR会逐步被Spark代替,MR过于笨重,执行DAG(有向无环图)才是大势所趋。但是稳定性能MR还是比较好,数据也存盘
Partitioner
将key分配到不同reduce中,默认是hashParitipner,可以自己实现分区机制,以满足业务或者数据平衡
partitioner分区数量就是reduce数量也是形成文件数据量
combine
本地合并,减少网络传输;本地先来个合并,属于优化操作;比如在做统计的时候,自己本地先合并一次
数据倾斜
mr
combainer、partition、多个mr
hive
hive.map.aggr,嵌套sql,以达到多个mr效果
Hadoop RPC
进程
NameNode
DataNode
ResourceManager
NodeManager
SecondaryNameNode
HistoryServer
JobHistoryServer
任务历史服务器,默认不开启
Spark
Spark RDD两大操作
转换:map, flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey,cros, sortByKey, mapValues
动作:collect, reduce, count, save, lookupKey
弹性分布式数据集,实际运算过程就是有向无环图,惰性求值
RDD依赖
宽依赖
发生shuffle,会进行数据重分区,并以此划分stage,一个stage包含一个或多个task
窄依赖
父辈RDD只能被一个子RDD相关联,不会发生shuffle
Spark故障恢复
Linage
根据前后关系再执行一遍
Checkpoint
在关键点出进行checkpoint,再执行一遍
DAGScheduler
根据宽分区划分Stage
以action边界生成DAG图,从末端开始以shuffle划分stage
TaskScheduler
把stage里面的taskSet分配到Executor运行,(遵循"计算向数据靠拢")(调度模式可以FIFO,也可以是fair)
框架
Spark Core
Spark SQL
Spark Streaming
消费Kafka保证数据不丢失
数据输入需要可靠的sources和可靠的receivers
应用metadata必须通过应用driver checkpoint
WAL(write ahead log)
receivers与Kafka direct
MLlib
GraphX
Spark的Shuffle
Spark1与Spark2的区别:RDD -->Dataset/DataFrame,Dataset/DataFrame在Spark2中成为了全局API
概念:1.一次action操作会触发RDD的延迟计算,我们把这样的一次计算称作一个Job。2.Spark将宽依赖为划分界限,将Job换分为多个Stage,Stage有TaskSet=多个task
HBase
(数据模型)逻辑结构与物理结构
一个master,多个regionserver
一个regionserver里面有多个region,每个region对应一个表。region会不断切分
一个region里面有一个或者多个Store,每个store表示一个列族
store又memstore与storeFile(小B+树/HFile)组成
HFile结构
HBase读取流程(读写流程基本一致)
zookeeper(meta-region-server)->meta->region->LSM(root表已经取消)
LSM树就是一堆小树,在内存中的小树即memstore,每次flush,内存中的memstore变成磁盘上一个新的storefile,最终Compact也将合并成一棵大树
从ZooKeeper中找到Root region
从Root表找到Meta Region
从Meta表中找到具体Region
HBase写入流程
zookeeper->meta->region->写入HLog,再写入MemStore
MemStore达到一定大小生成StoreFile
当多个StoreFile达到固定大小会合并成一个StoreFile(Compact合并操作),StoreFile过大将会Region拆分
WAL
读写优化
HFile的Bulkload
预分区
建表的时候跟进数据规律提取分开区
散列值
HBase协处理器
zookeeper->meta->region->LSM
Root表与Meta表结构相同,区别在于:当meta大到需要划分region的时候,那么meta表就会存在于不同的两个服务器,遍历复杂,所以就引入root表。默认root表不会超过一个region,确保三次跳转可以定位到region
子主题
LSM(日志结构合并,日志写和B+树的折中,hbase是使用跳跃表组织数据)
B+树,hbase不使用B+树应该是,要旋转树,使其保持平衡
做范围查询时会产生随机读取IO,进而影响效率
随机写也会产生大量写IO,进而影响效率
LSM与B+树的存储引擎一致
通过批量存储避免大量随机读写
多棵小树
https://zhuanlan.zhihu.com/p/181498475
LSM
SSTable
hbase 跳跃表实现有序,空间换时间
https://zhuanlan.zhihu.com/p/98751989
Region Replica
让一个region host在多个regionserver上
数据最终在HDFS上,某一个regionserver的主region挂了,其他region replica启用
RegionServer挂掉,HMaster会重新分配Region到新的RegionServer上
拆分
拆分日志,把各个region日志放在region旁边(recovered.edits目录)
恢复
读取recovered.edits目录进行数据恢复,基于序号ID读取,小于等于就忽略
Region恢复
和es差不多,先恢复region,再恢复log
Region合并
key设计相关
最大长度64KB,实际应用中一般为10~100bytes
子主题
编码
ASCII编码;中文两个字节,英文一个字节
标签存储思考
主ID作为Key
列=标签名称;value=分数值
从Hive层的DW层导入
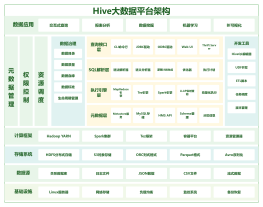
Hive
Hive底层基于MR
Hive元数据服务
Hive Metastore Federation
Hive服务
Hive函数
常规函数
字符函数
数字函数
日期函数
...
聚合函数
sum
count
avg
max
min
collect_list
collect_set
高阶函数
窗口函数(over)
搭配聚合函数
row_number over(组内排序)(row_number() over(partition by sex order by age desc))
分组组内排序,序号递增(1,2,3)
rank over(组内排序)
排序,比如分数排名的场景;并列第一,有间隔(1,1,3)
dense_rank over(组内排序)
并列第一,无间隔(1,1,2)
LAG,LEAD,FIRST_VALUE,LAST_VALUE
LAG窗口之前N个数
LEAD窗口之后N个数
FIRST_VALUE组内排序第一个
LAST_VALUE组内排序第二个
行转列/列转行
列转行-concat_ws
lateral view explode(split(name,','))(打散功能/行转列)
JSON解析
get_json_object
实现连续3天登录
row_number后,算差值,然后再做group by + having
<br>Hive优化
表设计优化
分区
分桶
Join字段建表的时候定义桶
桶内数据也可以排序(clustered by(id) sorted by (id) into 4 buckets)
实际生产中分桶策略使用频率较低
<br>存储格式
Parquet
ORC
不支持分块
LZO
所以在实际生产中,使用Parquet存储,lzo压缩的方式更为常见;数据量不大可以使用ORC(几个G)
压缩方式
语法与参数的优化
<br>列裁剪
分区裁剪
合并小文件
set hive.merge.mapfiles = true
<br>控制map/reduce数量<br>
join优化
小表放前面
group by 优化
order by 优化
count distinct优化
采用group by代替count(distinct)
一次读取多次插入
<br>启动压缩
hive.groupby.skewindata为true;hive.map.aggr=true
数据倾斜
mr
combainer、partition、多个mr
hive
hive.map.aggr 本地聚合;嵌套sql,以达到多个mr效果;<br>多个mr,hive.groupby.skewindata = true
Join数据倾斜三板斧
过滤异常Key
拆分表减少数据
打散Key分布
如何可以加内存就加内存
数仓分层
DM(data mark)/ADS
DW(按照主题进行建模)
DWM(middle)(中间表)
DWS(service)(轻度汇聚表)
DWD(detail)(数据明细表)
DIM(维度/字典)
ODS(operational data store/不等同于原始数据,要做清洗去噪)<br>
数仓分层依据
流向清晰、减少重复开发
数仓分层依据
清晰的层级,尽可能少交叉,减少重复开发<br>
数据治理
指标治理
流程规范
数据规范以及数据安全
数据质量
实时数仓
不能完全照搬层级
Lambda(离线andT+0的实时)
Kappa,相对于Lambda是移除了离线部分
完全使用flink进行计数,数据全部存储再kafka中
kafka是ods层-》flink sql的清洗是dwd层-》flink sql的聚合得到ads层;ads数据存储到es中
实时OLAP(依赖于引擎来实现)
clickhouse
es
flink小拓展
有界数据
无界数据
架构
JobManager与taskManager组成,client提交数据
Elasticsearch
搜索流程
搜索优化
普通搜索
Filesystem Cache
精简Index,把部分字段存储HBase
数据预热
冷热分离
Document模型设计
避免使用复杂的查询语句(Join 、聚合),就是提前设计好合理doc,利于查询
分页性能优化
不允许深度分页
只支持遍历分页
聚合搜索
查询语句优化
term Query与Filter,filter有缓存,而且不计算相关性
搜索流程
构造分片迭代器,确定搜索策略
构造异步请求action,转发到各个节点
在节点上ShardSearchTransportRequest,进行查询操作
执行查询,确定是否查询缓存
计算文档相关性
Fetch阶段,合并各个分片数据,返回结果给客户端
get是实时的,直接读取tranlog
查询的大部分都在lucene中
删除与更新
都是声明.del文件,查询再过滤
segment合并相关
小segment不断合并
合并过程中会根据del文件内把声明删除数据不进行删除,从而达到删除效果
elasticsearch分片与副本的思考
默认分片是5,副本是1
分片大小最好是50G以内,副本随意
分片数与机器数持平
es内存分配思考
使用聚合
Java head分配更小,6.25%到25%
不使用聚合
Java head分配50%,留给lucene50%<br>
elasticsearch数据类型
核心数据类型
字符串类型
String,5.0版本以后,不在支持String
text与keyword,要分词使用text,不分词使用keyword<br>
数字类型
byte
short
integer
long
float
double
half_float
scaled_float<br>
日期类型
布尔类型
二进制类型
范围类型
复杂数据类型
数组类型
对象类型
嵌套类型
地理数据类型
地理点类型
地理形状类型
专门数据类型
IP类型
计数数据类型
写入流程(写入流程至关重要)
分布式的写流程:一主多副,直到最后一个副本写完才算成功
client
c_node(route)(协调节点)
p_shard
replica
具体写入与优化
写入内存buffer同时写入translog(每5s fsync刷新到磁盘)--->1s后refresh刷入segment(segment会定时合并)--->30分钟后会把数据flush从os cache持久化到 disk。数据库先写log再写内存,es是先写内存再写log。es内存里面的东西每1秒(最低可为300ms)转换成segment,这时才会被搜索到。
RestController会绑定所有action,所有就走到了RestBulkAction(guice绑定这个),然后通过nodeclient转发到Transport层(TransportAction对应的具体对象是TransportBulkAction)--TransportShardBulkAction--indexShard--engine(InternalEngine)--最终调用到(实现从es到Lucene的转变)--Lucene的IndexWriter<br>
假如要求极高可靠性,那就要把translog每次有请求都需要刷新到磁盘
删除操作
拿到内存中加锁操作,最后写入segment的时候将之前的同id数据删除掉
es去重
合并字段后使用agg,大于1就是重复
其他优化
使用G1垃圾收集(相比CMS更加容易控制GC停顿时间。 另外G1不会像CMS那样产生内存碎片,对于大堆回收垃圾的效率更高)
对于时间段细微变化的查询,缓存是累赘。1.要么更改时间,不要太多细微2.要么修改源码去除缓存
GC算法改为G1或者ZGC
JVM堆内存不要分配超过31G
关闭linux交换分区<br>
配置专门的协调节点
三种缓存
filter cache/query cache<br>
查询子语句缓存,以便下次同样的查询语句直接取缓存数据
request cache<br>
1.dsl的缓存2.分片级别缓存 3.默认不开启 4.分片有改变的情况下很快失效(默认情况下1s失效)(Request Cache缓存失效是自动的,当索引refresh时就会失效)5.缓存大小为jvm1% ,对于实时应用基本没有什么优化余地
fielddata cache与doc_values正排索引用于聚合排序<br>
fielddata cache
JVM 内存堆
使用于analyzed的String分词字段
doc_values
是倒排索引的一种补充
除了analyzed的String字段都是默认支持doc_value,不需要聚合或者排序的可"doc_values": false
聚合,排序、脚本、子父文档关系
使用堆外内存
因为 Doc Values 不是由 JVM 来管理,而是由操作系统的内存来管理
之前,我们会建议分配机器内存的 50% 来给 JVM Heap。但是对于 Doc Values,这样可能不是最合适的方案了。 以 64gb 内存的机器为例,可能给 Heap 分配 4-16gb 的内存更合适,而不是 32gb
列式存储压缩
script访问doc属性
Global Ordinals(映射结构)
各种方法缩小数据,以便可以放到内存里面进行计算
桶(bucket)和指标(metric)
前面两种的聚合原理:
group by源码解析
elasticsearch script(做些特殊需求,搜索聚合满足不了的需求)
疑问总结
在ElasticSearch里面有filter cache这个过滤器缓存,大部分使用filter这个查询的语句都会缓存下来。但是在index不断增大的时候,缓存就会无用?那如何解决?答:Segment合并或者被删除时,缓存失效
一般多少次查询会构建缓存,有2次的,5次的,4次的,详情看源码UsageTrackingQueryCachingPolicy<br>
分片恢复:先对比meta,meta不同进行segment的对比。将不同的segment发送到待恢复节点,第二阶段发送tranlog到目标节点
(ES 6.4.3)分片恢复造成的分布式死锁
通用线程池用满,增删操作卡死
分片恢复并发数配置过高造成占用线程过多(node_concurrent_recoveries )
lucene
全文检索原理
主要内容:索引与检索
相识度评分算法
TF/IDF
BM25
elasticsearch存储结构<br>
逻辑结构:index-》type-》docment-》fieid
物理结构:index-》分片-》segment;请求将doc写入index buffer与tranlog此时不能搜索,然后写入file cache(以segment段形式存在)可以搜索,然后写入磁盘并删除tranlog
一个ES index包含多个分片,每个分片也是一个lucene索引,一个分片里面有很多分段(segment)。默认每秒生成一个segment<br>
Segment info,filed name,term dic<br>
https://lucene.apache.org/core/7_3_0/core/org/apache/lucene/codecs/lucene70/package-summary.html
Segment有哪些文件,都可以在这找到
子主题
其中有一个.tip文件就是FST文件
segment合并策略
tiered
log_byte_size
log_doc
ES的heap是如何被瓜分掉的
segment memory
filter cache
field data cache
bulk queue
indexing buffer
state buffer
超大搜索聚合结果集的fetch
对高cardinality字段做terms aggregation
https://www.jianshu.com/p/4a99886ba785
框架
lucene原理
基本概念
倒排索引
图片二
Sequence Number(DocId)
DocId实际上并不在Index内唯一,而是Segment内唯一,所有Segment的DocId都是从0开始取值,如何做到index唯一呢?答案:会根据所在Segment进行一次二次转换,这样做,每个Segment内的Docid基本一样(除非删除导致差异),方便压缩优化。但取值的时候会进行转换变为唯一
查询原理
倒排索引的模型
核心就是基于term的反向链表
term非常多的时候,如何定位到term呢?(解决办法:term的查找定位从二分查找-->hashmap-->FST)
term的查找定位从二分查找-->hashmap-->FST
使用FST和SkipList实现了底层存储:FST前缀搜索和压缩率都有优势,SkipList则用空间换取时间
FST
共用前缀
SkipList做多层索引,减少对比次数
使用FST定位到term反向链表后,反向链表内部使用跳跃表(SkipList)存储数据
FST慢于HashMap
FST在ES7中存储在了堆外内存
倒排合并
理解跳跃表的前提下,做倒排合并
二重for循环法,X
拉链法
水平分桶,X
bitmap,X
跳表
BKDTree:用于范围查询
类似LSM树
segment合并的过程类似HBase StoreFile合并
KDB-Tree实际是一棵特殊的多维度B+Tree
Doc'Value
列式存储
利于做聚合统计和排序等,不利于事务类型操作,属于OLAP
便于压缩存储
global ordinals
映射表将数据尽可能映射小,然后方便做聚合
1.最小公约数2.小于255对应表,3.做差值
IndexWriter
IndexWriterConfig
核心的增删查改操作+flush+commit+merge
数据路径
并发模型
add & update
delete
索引结构(1)
索引结构(2)
elasticsearch功能
数据模型
写入
查询
elasticsearch主要模块
cluster<br>
allocation
discovery
gateway
indices<br>
http
transport
engine
集群启动流程
选举主节点
选举集群元数据<br>
选举主分片与副分片
index recovery(恢复)<br>
选主流程
bully选举算法<br>
Discovery<br>
elasticsearch架构
分布式一致性原理:node
分布式一致性原理:meta
分布式一致性原理:data
分布式选举\共识算法:Raft
简化版拜占庭将军问题
3个将军都有一个随机倒计时( 150ms 到 300ms),前面倒计时结束的将军封自己为大将军候选人,并且通知询问其他人可否当选(多数赞成即可)。当选后,定期发送心跳重置TimeOut维持现状
Paxos
分片恢复
根据metadata确定是否需要恢复,先复制差异的segment,在复制tratranlog
源码分析
segments merge 流程分析
segment如何使用堆外内存
源码架构
Lucene
ClickHouse
主流趋势:es迁移到clickhouse,es优势是倒排索引,docvalue的列式存储相对于clickhouse反而是鸡肋。分析型还是需要使用分析类数据库clickhouse(OLAP)
聚合分析使用clickhouse
多维搜索/全文检索使用es
整体架构
写入流程
查询流程
ClickHouse快的原因
列式存储(Clickhouse存储和查询数据的核心基础)
{column_name}.bin文件
primary.idx
{column_name}.mrk2
数据分块压缩(列式存储中,数据是分块的,一个bin中是有多个压缩块)
压缩块中的元数据
CompressionMethod_CompressedSize_UncompressedSize
压缩块中的压缩数据
64KB~1MB
数据已排序
LZ4和ZSTD
数据块索引
LSM


Collect
Get Started

Collect
Get Started
Collect
Get Started

Collect
Get Started
评论
0 条评论
下一页

