
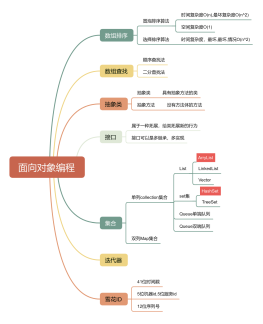
面向功能点开发
2020-01-09 14:51:01 0 举报仅支持查看
AI智能生成
faby-java
java
模板推荐
作者其他创作
大纲/内容
实践业务
支付
扫一扫登录
APP扫码登录
MongoDB
微信扫码登录
登录
权限
单点登录
基础服务
分布式缓存
分布式存储
消息队列
定时任务
配置中心
NoSql
RDBMS
负载均衡
主机集群
数据迁移
我的项目
高速公路综合管理平台app
高速不停车手机支付app
智停云服
工具
接口文档自动生成
uml
qps吞吐量:JMeter
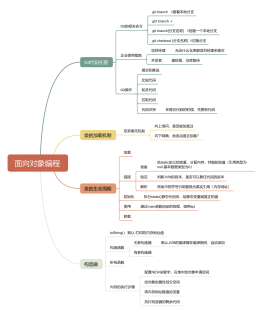
开发
设计模式
模式
创建型
各种工厂模式(Factory、Abstract Factory)
简单工厂和抽象工厂有什么区别?
单例模式(Singleton)
构建器模式(Builder)
原型模式(ProtoType)
结构型
适配器模式(Adapter)
定义:将一个类的接口转换成客户希望的另一个接口。适配器模式让那些接口不兼容的类可以一起工作
uml
桥接模式(Bridge)
装饰者模式(Decorator)
代理模式(Proxy)
组合模式(Composite)
外观模式(Facade)
享元模式(Flyweight)
行为型
迭代器模式(Iterator)
定义:提供一种方法顺序访问一个聚合对象中的各种元素,而又不暴露该对象的内部表示。
使用:容器的迭代foreach,学习和使用的性价比不高,不建议学习
观察者模式(Observer Pattern)
策略模式(Strategy)
解释器模式(Interpreter)
命令模式(Command)
模板方法模式(Template Method)
访问者模式(Visitor)
六个原则
里式替换原则
第一种定义,也是最正宗的定义:如果对每一个类型为S的对象o1,都有类型为T的对象o2,使得以T定义的所有程序P在所有的对象o1都代换成o2 时,程序P的行为没有发生变化,那么类型 S 是类型 T 的子类型。<br>第二种定义:所有引用基类的地方必须能透明地使用其子类的对象。<br>第二个定义是最清晰明确的,通俗点讲,只要父类能出现的地方子类就可以出现,而且替换为子类也不会 产生任何错误或异常,使用者可能根本就不需要知道是父类还是子类。但是,反过来就不行了,有子类出现的地方,父类未必就能适应。
模板模式(Template Pattern)
redis实现避免多人共用一个key、使用模板设计模式生成key前缀
数据结构和算法
时间复杂度
渐进时间复杂度科普
hash
红黑树
保证红黑树是一个平衡二叉树的规则<br>1、节点是红色或黑色<br>2、根节点一定是黑色<br>3、从任一节点到其每个叶子节点的所有路径都包含相同数目的黑色节点<br>4、每个叶节点都是黑色的空节点(NIL节点)<br>5、每个红节点的两个子节点都是黑色的(从每个叶子到跟的所有路径上不能有两个连续的红节点)(即对于层来说除了NIL节点,红黑节点是交替的,第一层是黑节点那么其下一层肯定都是红节点,反之一样)<br>
左旋(右侧过深)或右旋(左侧过深)
二叉查找树
任何节点的值比左孩子大比右孩子小
加密方式
java
java基础
类型转换
继承
类权限
super
1、访问父类的构造函数:可以使用 super() 函数访问父类的构造函数,从而委托父类完成一些初始化的工作。<br>2、访问父类的成员:如果子类重写了父类的某个方法,可以通过使用 super 关键字来引用父类的方法实现。
重写与重载
重写:1、子类方法的访问权限必须大于等于父类方法;<br> 2、子类方法的返回类型必须是父类方法返回类型或为其子类型。<br> 3、子类方法抛出的异常类型必须是父类抛出异常类型或为其子类型。<br> 使用 @Override 注解,可以让编译器帮忙检查是否满足上面的三个限制条件。 <br> 重载:参数类型、个数、顺序至少有一个不同。<br>
抽象类
比较与选择
接口
Object 通用方法
equals()
与null比较
x.equals(null) 结果都为 false
相等与等价
对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。<br>对于引用类型,== 判断两个变量是否引用同一个对象,而 equals() 判断引用的对象是否等价。
hashCode()
hashcode方法返回该对象的哈希码值。<br>equlse()等价的两个对象散列值一定相同,但是散列值相同的两个对象不一定(hash碰撞)equals()等价。<br><span style="font-size: inherit;">在覆盖 equals() 方法时应当总是覆盖 hashCode() 方法,保证等价的两个对象散列值也相等</span><br>
toString()
默认返回 ToStringExample@4554617c 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示。
clone()
clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。应该注意的是,clone() 方法并不是 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了 clone() 方法,就会抛出 CloneNotSupportedException。<br>
浅拷贝:拷贝对象和原始对象的引用类型引用同一个对象。
深拷贝:拷贝对象和原始对象的引用类型引用不同对象。
最好不要用clone()方法
使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换。<br>Effective Java 书上讲到,最好不要去使用 clone(),可以使用拷贝构造函数或者拷贝工厂来拷贝一个对象。
关键字
final
变量
对于基本类型,final 使数值不变;<br>对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
方法
声明方法不能被子类重写。<br>private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,<br>此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
类
声明类不允许被继承。
static
静态变量
静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份。<br>实例变量:每创建一个实例就会产生一个实例变量,它与该实例同生共死。
静态方法
静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法。<br>只能访问所属类的静态字段和静态方法,方法中不能有 this 和 super 关键字<br>
静态语句块
静态语句块在类初始化时运行一次。
静态内部类
非静态内部类依赖于外部类的实例,而静态内部类不需要。<br>静态内部类不能访问外部类的非静态的变量和方法。<br>
初始化顺序
静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
存在继承的情况下,初始化顺序为:<br><br>父类(静态变量、静态语句块)<br>子类(静态变量、静态语句块)<br>父类(实例变量、普通语句块)<br>父类(构造函数)<br>子类(实例变量、普通语句块)<br>子类(构造函数)
switch
值传递
反射<br>
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。<br>类加载相当于 Class 对象的加载,类在第一次使用时才动态加载到 JVM 中,也可以使用 Class.forName("com.mysql.jdbc.Driver") 这种方式来控制类的加载,该方法会返回一个 Class 对象。<br>反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
java.lang.reflect 类库主要包含了以下三个类:<br> Field :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;<br> Method :可以使用 invoke() 方法调用与 Method 对象关联的方法;<br> Constructor :可以用 Constructor 创建新的对象。
优点
可扩展性
应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
类浏览器和可视化开发环境
一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码
调试器和测试工具
调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
缺点
性能开销
反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
安全限制
使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
内部暴露
由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
泛型
类型擦除
泛型是通过类型擦除来实现的,编译器在编译时擦除了所有类型相关的信息,所以在运行时不存在任何类型相关的信息。例如List<String>在运行时仅用一个List来表示。
限定通配符
有两种限定通配符,<br>一种是<? extends T>它通过确保类型必须是T的子类来设定类型的上界,<br>另一种是<? super T>它通过确保类型必须是T的父类来设定类型的下界。
List<? extends T>可以接受任何继承自T的类型的List,<br>而List<? super T>可以接受任何T的父类构成的List。<br>例如List<? extends Number>可以接受List<Integer>或List<Float>。
非限定通配符
<?>表示了非限定通配符,因为<?>可以用任意类型来替代
注解
Java 注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。<br>注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。
Throwable
Error
Exception
受检异常:需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;
非受检异常 :是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。
api树
其他
Java 与 C++ 的区别
Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 为了兼容 C 即支持面向对象也支持面向过程。<br>Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台。<br>Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。<br>Java 支持自动垃圾回收,而 C++ 需要手动回收。<br>Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。<br>Java 不支持操作符重载,虽然可以对两个 String 对象执行加法运算,但是这是语言内置支持的操作,不属于操作符重载,而 C++ 可以。<br>Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。<br>Java 不支持条件编译,C++ 通过 #ifdef #ifndef 等预处理命令从而实现条件编译。
java8
Lambda Expressions<br>Pipelines and Streams<br>Date and Time API<br>Default Methods<br>Type Annotations<br>Nashhorn JavaScript Engine<br>Concurrent Accumulators<br>Parallel operations<br>PermGen Error Removed
java容器
Collection
继承实现关系
Set
TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。<br> 但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。<br>HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。<br>LinkedHashSet:具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。
源码分析
List
ArrayList:基于动态数组实现,支持随机访问。<br>Vector:和 ArrayList 类似,但它是线程安全的。<br>LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
源码分析
ArrayList
因为 ArrayList 是基于数组实现的,所以支持快速随机访问。RandomAccess 接口标识着该类支持快速随机访问
数组的默认大小为 10。
扩容: 添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。<br>扩容操作需要调用 Arrays.copyOf() 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
删除元素: 需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),可以看出 ArrayList 删除元素的代价是非常高的。
Vector
它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。
与 ArrayList 的比较: 1、Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;<br>2、Vector 每次扩容请求其大小的 2 倍空间,而 ArrayList 是 1.5 倍。<br>
得到一个线程安全的 ArrayList
可以使用 Collections.synchronizedList();
也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类
CopyOnWriteArrayList
读写分离
写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。<br>写操作需要加锁,防止并发写入时导致写入数据丢失。<br>写操作结束之后需要把原始数组指向新的复制数组。
适用场景
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。<br>但是 CopyOnWriteArrayList 有其缺陷:<br> 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;<br> 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。<br>所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
LinkedList
基于双向链表实现,使用 Node 存储链表节点信息。
每个链表存储了 first 和 last 指针:
与 ArrayList 的比较
ArrayList 基于动态数组实现,LinkedList 基于双向链表实现;<br>ArrayList 支持随机访问,LinkedList 不支持;<br>LinkedList 在任意位置添加删除元素更快。
Queue
LinkedList:可以用它来实现双向队列。<br>PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
源码分析
Map
特点比较
HashMap:数组+链表+红黑树(JDK1.8)
允许一条记录的键为null
非线程安全
即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。<br>如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
很快的访问速度,但遍历顺序却是不确定的
它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的
子类:LinkedHashMap
LinkedHashMap是HashMap的一个子类,使用双向链表来维护元素的顺序保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序
Hashtable(美团淘汰)
线程安全
任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。<br>Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
TreeMap:基于红黑树
TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
Comparable:所有可以 “排序” 的类都实现了java.lang.Comparable接口,接口中只有一个方法,public int compareTo(Object obj) ;
源码分析
HashMap 1.8
先分析几个值
内部包含了一个 Entry 类型的数组 table
Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。<br>即数组中的每个位置被当成一个桶,一个桶存放一个链表。<br>HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
负载因子(loadFactor=0.75f)<br>
为什么是0.75f ? <br>这是一个均衡值,权衡“哈希冲突”与“空间利用率”<br>
拉链法的工作原理
put 操作
取key的hashCode值、高位运算、取模运算
扩容
方法是使用一个新的数组代替已有的容量小的数组<br>扩容后的HashMap容量是之前容量的两倍<br>
从 JDK 1.8 开始,一个桶存储的链表长度大于 8 时会将链表转换为红黑树。
容器中的设计模式
迭代器模式:Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
适配器模式
java.util.Arrays#asList() 可以把数组类型转换为 List 类型。<br>
java集合框架图
java并发
一、线程状态转换
新建(New):创建后尚未启动。
可运行(Runnable):可能正在运行,也可能正在等待 CPU 时间片。
阻塞(Blocked):等待获取一个排它锁,如果其线程释放了锁就会结束此状态。
无限期等待(Waiting):等待其它线程显式地唤醒,否则不会被分配 CPU 时间片。
进入方法 退出方法<br>没有设置 Timeout 参数的 Object.wait() 方法 Object.notify() / Object.notifyAll()<br>没有设置 Timeout 参数的 Thread.join() 方法 被调用的线程执行完毕<br>LockSupport.park() 方法 LockSupport.unpark(Thread)
限期等待(Timed Waiting):无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
进入方法 退出方法<br>Thread.sleep() 方法 时间结束<br>设置了 Timeout 参数的 Object.wait() 方法 时间结束 / Object.notify() / Object.notifyAll()<br>设置了 Timeout 参数的 Thread.join() 方法 时间结束 / 被调用的线程执行完毕<br>LockSupport.parkNanos() 方法 LockSupport.unpark(Thread)<br>LockSupport.parkUntil() 方法 LockSupport.unpark(Thread)
死亡(Terminated):可以是线程结束任务之后自己结束,或者产生了异常而结束。
二、使用线程
实现 Runnable 接口
1、实现Runnable的run()方法<br>2、通过 Thread 调用 start() 方法来启动线程。
实现 Callable 接口
1、实现Callable的call()方法<br>2、通过 Thread 调用 start() 方法来启动线程。
与 Runnable 相比,Callable 可以有返回值,返回值通过 FutureTask 进行封装。
继承 Thread 类
同样也是需要实现 run() 方法,因为 Thread 类也实现了 Runable 接口。
实现接口会更好一些,因为:<br>Java 不支持多重继承,因此继承了 Thread 类就无法继承其它类,但是可以实现多个接口;<br>类可能只要求可执行就行,继承整个 Thread 类开销过大。
三、基础线程机制
Executor
CachedThreadPool:一个任务创建一个线程;<br>FixedThreadPool:所有任务只能使用固定大小的线程;<br>SingleThreadExecutor:相当于大小为 1 的 FixedThreadPool。
守护进程(Daemon)
守护线程是程序运行时在后台提供服务的线程,不属于程序中不可或缺的部分。<br>当所有非守护线程结束时,程序也就终止,同时会杀死所有守护线程。<br>main() 属于非守护线程。<br>在线程启动之前使用 setDaemon() 方法可以将一个线程设置为守护线程。
sleep()
Thread.sleep(millisec) 方法会休眠当前正在执行的线程,millisec 单位为毫秒。<br>sleep() 可能会抛出 InterruptedException,因为异常不能跨线程传播回 main() 中,因此必须在本地进行处理。线程中抛出的其它异常也同样需要在本地进行处理。<br>
yield()
对静态方法 Thread.yield() 的调用声明了当前线程已经完成了生命周期中最重要的部分,可以切换给其它线程来执行。该方法只是对线程调度器的一个建议,而且也只是建议具有相同优先级的其它线程可以运行。
四、中断
InterruptedException
通过调用一个线程的 interrupt() 来中断该线程,如果该线程处于阻塞、限期等待或者无限期等待状态,那么就会抛出 InterruptedException,从而提前结束该线程。但是不能中断 I/O 阻塞和 synchronized 锁阻塞。
interrupted()
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt() 方法就无法使线程提前结束。
Executor 的中断操作
调用 Executor 的 shutdown() 方法会等待线程都执行完毕之后再关闭,但是如果调用的是 shutdownNow() 方法,则相当于调用每个线程的 interrupt() 方法。
五、互斥同步
第一个是 JVM 实现的 synchronized
同步一个代码块
它只作用于同一个对象,如果调用两个对象上的同步代码块,就不会进行同步。
同步一个方法
它和同步代码块一样,作用于同一个对象。
同步一个类
作用于整个类,也就是说两个线程调用同一个类的不同对象上的这种同步语句,也会进行同步。
同步一个静态方法
作用于整个类。
另一个是 JDK 实现的 ReentrantLock(可重入锁)
两种锁的比较
1、锁的实现:synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
2、性能:新版本 Java 对 synchronized 进行了很多优化,例如自旋锁等,synchronized 与 ReentrantLock 大致相同。
3、等待可中断:当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。<br>ReentrantLock 可中断,而 synchronized 不行。
4、公平锁:公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。<br>synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
5、 锁绑定多个条件:一个 ReentrantLock 可以同时绑定多个 Condition 对象。
使用选择
除非需要使用 ReentrantLock 的高级功能,否则优先使用 synchronized。<br>这是因为 synchronized 是 JVM 实现的一种锁机制,JVM 原生地支持它,而 ReentrantLock 不是所有的 JDK 版本都支持。<br>并且使用 synchronized 不用担心没有释放锁而导致死锁问题,因为 JVM 会确保锁的释放。
六、线程之间的协作
join()
在线程中调用另一个线程的 join() 方法,会将当前线程挂起,而不是忙等待,直到目标线程结束。
忙碌等待:
wait() notify() notifyAll()
调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。<br>它们都属于 Object 的一部分,而不属于 Thread。<br>只能用在同步方法或者同步控制块中使用,否则会在运行时抛出 IllegalMonitorStateException。<br>使用 wait() 挂起期间,线程会释放锁。这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。<br>
wait() 和 sleep() 的区别
wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;<br>wait() 会释放锁,sleep() 不会。
await() signal() signalAll()
java.util.concurrent 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。
相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
使用 Lock 来获取一个 Condition 对象。
七、J.U.C - AQS
CountDownLatch
用来控制一个或者多个线程等待多个线程。
维护了一个计数器 cnt,每次调用 countDown() 方法会让计数器的值减 1,减到 0 的时候,那些因为调用 await() 方法而在等待的线程就会被唤醒。
CyclicBarrier(循环屏障)
用来控制多个线程互相等待,只有当多个线程都到达时,这些线程才会继续执行
和 CountdownLatch 相似,都是通过维护计数器来实现的。线程执行 await() 方法之后计数器会减 1,并进行等待,直到计数器为 0,所有调用 await() 方法而在等待的线程才能继续执行。
CyclicBarrier 和 CountdownLatch 的一个区别是,CyclicBarrier 的计数器通过调用 reset() 方法可以循环使用,所以它才叫做循环屏障。
CyclicBarrier 有两个构造函数,其中 parties 指示计数器的初始值,barrierAction 在所有线程都到达屏障的时候会执行一次。
Semaphore(信号量)
Semaphore 类似于操作系统中的信号量,可以控制对互斥资源的访问线程数。
八、J.U.C - 其它组件
FutureTask
在介绍 Callable 时我们知道它可以有返回值,返回值通过 Future 进行封装。<br>FutureTask 实现了 RunnableFuture 接口,该接口继承自 Runnable 和 Future 接口,这使得 FutureTask 既可以当做一个任务执行,也可以有返回值。
FutureTask 可用于异步获取执行结果或取消执行任务的场景。<br>当一个计算任务需要执行很长时间,那么就可以用 FutureTask 来封装这个任务,主线程在完成自己的任务之后再去获取结果。
BlockingQueue
ForkJoin
九、线程不安全示例
如果多个线程对同一个共享数据进行访问而不采取同步操作的话,那么操作的结果是不一致的。<br>以下代码演示了 1000 个线程同时对 cnt 执行自增操作,操作结束之后它的值有可能小于 1000。
十、Java 内存模型(JMM)
主内存与工作内存
处理器上的寄存器的读写的速度比内存快几个数量级,为了解决这种速度矛盾,在它们之间加入了高速缓存。<br>加入高速缓存带来了一个新的问题:缓存一致性。如果多个缓存共享同一块主内存区域,那么多个缓存的数据可能会不一致,需要一些协议来解决这个问题。<br>所有的变量都存储在主内存中,每个线程还有自己的工作内存,工作内存存储在高速缓存或者寄存器中,保存了该线程使用的变量的主内存副本拷贝。<br>线程只能直接操作工作内存中的变量,不同线程之间的变量值传递需要通过主内存来完成<br>
内存间交互操作
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作。
read:把一个变量的值从主内存传输到工作内存中<br>load:在 read 之后执行,把 read 得到的值放入工作内存的变量副本中<br>use:把工作内存中一个变量的值传递给执行引擎<br>assign:把一个从执行引擎接收到的值赋给工作内存的变量<br>store:把工作内存的一个变量的值传送到主内存中<br>write:在 store 之后执行,把 store 得到的值放入主内存的变量中<br>lock:作用于主内存的变量<br>unlock
内存模型三大特性
1. 原子性
2. 可见性
可见性指当一个线程修改了共享变量的值,其它线程能够立即得知这个修改。
三种实现可见性的方式:
volatile<br>synchronized,对一个变量执行 unlock 操作之前,必须把变量值同步回主内存。<br>final,被 final 关键字修饰的字段在构造器中一旦初始化完成,并且没有发生 this 逃逸(其它线程通过 this 引用访问到初始化了一半的对象),那么其它线程就能看见 final 字段的值。
3. 有序性
有序性是指:在本线程内观察,所有操作都是有序的。<br>在一个线程观察另一个线程,所有操作都是无序的,无序是因为发生了指令重排序。
先行发生原则
1. 单一线程原则Single Thread rule
在一个线程内,在程序前面的操作先行发生于后面的操作。
2. 管程锁定规则Monitor Lock Rule
一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。
3. volatile 变量规则Volatile Variable Rule
对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。
4. 线程启动规则Thread Start Rule
Thread 对象的 start() 方法调用先行发生于此线程的每一个动作。
5. 线程加入规则Thread Join Rule
Thread 对象的结束先行发生于 join() 方法返回。
6. 线程中断规则Thread Interruption Rule
对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 interrupted() 方法检测到是否有中断发生。
7. 对象终结规则Finalizer Rule
一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize() 方法的开始。
8. 传递性Transitivity
如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那么操作 A 先行发生于操作 C。
十一、线程安全
实现方式
不可变
不可变(Immutable)的对象一定是线程安全的,不需要再采取任何的线程安全保障措施。<br>只要一个不可变的对象被正确地构建出来,永远也不会看到它在多个线程之中处于不一致的状态。<br>多线程环境下,应当尽量使对象成为不可变,来满足线程安全。
不可变的类型:
1、final 关键字修饰的基本数据类型<br>2、String<br>3、枚举类型<br>4、Number 部分子类,如 Long 和 Double 等数值包装类型,BigInteger 和 BigDecimal 等大数据类型。但同为 Number 的原子类 AtomicInteger 和 AtomicLong 则是可变的。<br>5、对于集合类型,可以使用 Collections.unmodifiableXXX() 方法来获取一个不可变的集合。
互斥同步
synchronized 和 ReentrantLock。
非阻塞同步
1. CAS
2. AtomicInteger
3. ABA
无同步方案
1. 栈封闭
2. 线程本地存储(Thread Local Storage)
3. 可重入代码(Reentrant Code)
十二、锁优化
自旋锁
锁消除
锁粗化
轻量级锁
偏向锁
十三、多线程开发良好的实践
给线程起个有意义的名字,这样可以方便找 Bug。<br>缩小同步范围,从而减少锁争用。例如对于 synchronized,应该尽量使用同步块而不是同步方法。<br>多用同步工具少用 wait() 和 notify()。首先,CountDownLatch, CyclicBarrier, Semaphore 和 Exchanger 这些同步类简化了编码操作,而用 wait() 和 notify() 很难实现复杂控制流;其次,这些同步类是由最好的企业编写和维护,在后续的 JDK 中还会不断优化和完善。<br>使用 BlockingQueue 实现生产者消费者问题。<br>多用并发集合少用同步集合,例如应该使用 ConcurrentHashMap 而不是 Hashtable。<br>使用本地变量和不可变类来保证线程安全。<br>使用线程池而不是直接创建线程,这是因为创建线程代价很高,线程池可以有效地利用有限的线程来启动任务。
java虚拟机
一、运行时数据区域
程序计数器
Java 虚拟机栈
-Xss
本地方法栈
堆
所有对象都在这里分配内存,是垃圾收集的主要区域("GC 堆")
现代的垃圾收集器基本都是采用分代收集算法,其主要的思想是针对不同类型的对象采取不同的垃圾回收算法
新生代(Young Generation)<br>
老年代(Old Generation)
-Xms 和 -Xmx
方法区
运行时常量池
直接内存
二、垃圾收集
判断一个对象是否可被回收
1. 引用计数算法<br>
为对象添加一个引用计数器,当对象增加一个引用时计数器加 1,引用失效时计数器减 1。引用计数为 0 的对象可被回收
在两个对象出现循环引用的情况下,此时引用计数器永远不为 0,导致无法对它们进行回收。正是因为循环引用的存在,因此 Java 虚拟机不使用引用计数算法。
2. 可达性分析算法
以 GC Roots 为起始点进行搜索,可达的对象都是存活的,不可达的对象可被回收。
子主题
三、内存分配与回收策略
四、类加载机制
加载(Loading)
链接
验证(Verification)<br>准备(Preparation)<br>解析(Resolution)
初始化(Initialization)
系统设计
系统设计基础
一、性能
性能指标
1. 响应时间
2. 吞吐量
单位时间内可以处理的请求数量,通常使用每秒的请求数来衡量。
3. 并发用户数
性能优化
1. 集群
将多台服务器组成集群,使用负载均衡将请求转发到集群中,避免单一服务器的负载压力过大导致性能降低。
2. 缓存
缓存能够提高性能的原因如下:<br><br>缓存数据通常位于内存等介质中,这种介质对于读操作特别快;<br>缓存数据可以位于靠近用户的地理位置上;<br>可以将计算结果进行缓存,从而避免重复计算。
3. 异步
某些流程可以将操作转换为消息,将消息发送到消息队列之后立即返回,之后这个操作会被异步处理。
二、伸缩性
伸缩性与性能
如果系统存在性能问题,那么单个用户的请求总是很慢的;<br>如果系统存在伸缩性问题,那么单个用户的请求可能会很快,但是在并发数很高的情况下系统会很慢
实现伸缩性
应用服务器只要不具有状态,那么就可以很容易地通过负载均衡器向集群中添加新的服务器。<br>关系型数据库的伸缩性通过 Sharding 来实现,将数据按一定的规则分布到不同的节点上,从而解决单台存储服务器的存储空间限制。<br>对于非关系型数据库,它们天生就是为海量数据而诞生,对伸缩性的支持特别好。
三、扩展性
实现可扩展主要有两种方式:<br><br>使用消息队列进行解耦,应用之间通过消息传递进行通信;<br>使用分布式服务将业务和可复用的服务分离开来,业务使用分布式服务框架调用可复用的服务。新增的产品可以通过调用可复用的服务来实现业务逻辑,对其它产品没有影响。
四、可用性
冗余
保证高可用的主要手段是使用冗余,当某个服务器故障时就请求其它服务器。<br>应用服务器的冗余比较容易实现,只要保证应用服务器不具有状态,那么某个应用服务器故障时,负载均衡器将该应用服务器原先的用户请求转发到另一个应用服务器上,不会对用户有任何影响。<br>存储服务器的冗余需要使用主从复制来实现,当主服务器故障时,需要提升从服务器为主服务器,这个过程称为切换。
监控
对 CPU、内存、磁盘、网络等系统负载信息进行监控,当某个信息达到一定阈值时通知运维人员,从而在系统发生故障之前及时发现问题。
服务降级
服务降级是系统为了应对大量的请求,主动关闭部分功能,从而保证核心功能可用。
五、安全性
要求系统在应对各种攻击手段时能够有可靠的应对措施。
分布式
一、分布式锁
定义
在单机场景下,可以使用语言的内置锁来实现进程同步。但是在分布式场景下,需要同步的进程可能位于不同的节点上,那么就需要使用分布式锁。<br><br>阻塞锁通常使用互斥量来实现:<br>互斥量为 0 表示有其它进程在使用锁,此时处于锁定状态;<br>互斥量为 1 表示未锁定状态。<br>1 和 0 可以用一个整型值表示,也可以用某个数据是否存在表示。
实现方式
数据库的唯一索引
获得锁时向表中插入一条记录,释放锁时删除这条记录。唯一索引可以保证该记录只被插入一次,那么就可以用这个记录是否存在来判断是否存于锁定状态
存在以下几个问题:
锁没有失效时间,解锁失败的话其它进程无法再获得该锁。<br>只能是非阻塞锁,插入失败直接就报错了,无法重试。<br>不可重入,已经获得锁的进程也必须重新获取锁。
Redis 的 SETNX 指令
使用 SETNX(set if not exist)指令插入一个键值对,如果 Key 已经存在,那么会返回 False,否则插入成功并返回 True。
SETNX 指令和数据库的唯一索引类似,保证了只存在一个 Key 的键值对,那么可以用一个 Key 的键值对是否存在来判断是否存于锁定状态。
EXPIRE 指令可以为一个键值对设置一个过期时间,从而避免了数据库唯一索引实现方式中释放锁失败的问题。
Redis 的 RedLock 算法
使用了多个 Redis 实例来实现分布式锁,这是为了保证在发生单点故障时仍然可用。
尝试从 N 个互相独立 Redis 实例获取锁;<br>计算获取锁消耗的时间,只有当这个时间小于锁的过期时间,并且从大多数(N / 2 + 1)实例上获取了锁,那么就认为锁获取成功了;<br>如果锁获取失败,就到每个实例上释放锁。
Zookeeper 的有序节点
1. Zookeeper 抽象模型
Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节点为 /app1。
2. 节点类型
永久节点:不会因为会话结束或者超时而消失;<br>临时节点:如果会话结束或者超时就会消失;<br>有序节点:会在节点名的后面加一个数字后缀,并且是有序的,<br> 例如生成的有序节点为 /lock/node-0000000000,它的下一个有序节点则为 /lock/node-0000000001,以此类推。
3. 监听器
为一个节点注册监听器,在节点状态发生改变时,会给客户端发送消息。
4. 分布式锁实现
1、创建一个锁目录 /lock;<br>2、当一个客户端需要获取锁时,在 /lock 下创建临时的且有序的子节点;<br>3、客户端获取 /lock 下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁;否则监听自己的前一个子节点,获得子节点的变更通知后重复此步骤直至获得锁;<br>4、执行业务代码,完成后,删除对应的子节点。
5. 会话超时
如果一个已经获得锁的会话超时了,因为创建的是临时节点,所以该会话对应的临时节点会被删除,其它会话就可以获得锁了。可以看到,Zookeeper 分布式锁不会出现数据库的唯一索引实现的分布式锁释放锁失败问题。
6. 羊群效应
一个节点未获得锁,只需要监听自己的前一个子节点,这是因为如果监听所有的子节点,那么任意一个子节点状态改变,其它所有子节点都会收到通知(羊群效应),而我们只希望它的后一个子节点收到通知。
二、分布式事务
定义
指事务的操作位于不同的节点上,需要保证事务的 ACID 特性。
例如: 在下单场景下,库存和订单如果不在同一个节点上,就涉及分布式事务。
实现方式
两阶段提交(2PC) <br>
1. 运行过程
1.1 准备阶段
协调者询问参与者事务是否执行成功,参与者发回事务执行结果。
1.2 提交阶段
如果事务在每个参与者上都执行成功,事务协调者发送通知让参与者提交事务;否则,协调者发送通知让参与者回滚事务。
2. 存在的问题
2.1 同步阻塞
所有事务参与者在等待其它参与者响应的时候都处于同步阻塞状态,无法进行其它操作。
2.2 单点问题
协调者在 2PC 中起到非常大的作用,发生故障将会造成很大影响。特别是在阶段二发生故障,所有参与者会一直等待,无法完成其它操作。
2.3 数据不一致
在阶段二,如果协调者只发送了部分 Commit 消息,此时网络发生异常,那么只有部分参与者接收到 Commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。
2.4 太过保守
任意一个节点失败就会导致整个事务失败,没有完善的容错机制。
本地消息表
本地消息表与业务数据表处于同一个数据库中,这样就能利用本地事务来保证在对这两个表的操作满足事务特性,并且使用了消息队列来保证最终一致性。<br><br>1、在分布式事务操作的一方完成写业务数据的操作之后向本地消息表发送一个消息,本地事务能保证这个消息一定会被写入本地消息表中。<br>2、之后将本地消息表中的消息转发到消息队列中,如果转发成功则将消息从本地消息表中删除,否则继续重新转发。<br>3、在分布式事务操作的另一方从消息队列中读取一个消息,并执行消息中的操作。
三、CAP
一致性(C:Consistency)
一致性指的是多个数据副本是否能保持一致的特性,在一致性的条件下,系统在执行数据更新操作之后能够从一致性状态转移到另一个一致性状态。
对系统的一个数据更新成功之后,如果所有用户都能够读取到最新的值,该系统就被认为具有强一致性。
可用性(A:Availability)
可用性指分布式系统在面对各种异常时可以提供正常服务的能力,可以用系统可用时间占总时间的比值来衡量,4 个 9 的可用性表示系统 99.99% 的时间是可用的。
在可用性条件下,要求系统提供的服务一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
分区容错性(P:Partition Tolerance)
网络分区:指分布式系统中的节点被划分为多个区域,每个区域内部可以通信,但是区域之间无法通信。
在分区容错性条件下,分布式系统在遇到任何网络分区故障的时候,仍然需要能对外提供一致性和可用性的服务,除非是整个网络环境都发生了故障。
分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。<br>比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,对于用户而言并没有什么体验上的影响。
权衡
只能三取二
分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容忍性(P:Partition Tolerance),最多只能同时满足其中两项。
在分布式系统中,分区容忍性必不可少,因为需要总是假设网络是不可靠的。因此,CAP 理论实际上是要在可用性和一致性之间做权衡。<br><br>可用性和一致性往往是冲突的,很难使它们同时满足。在多个节点之间进行数据同步时,<br>为了保证一致性(CP),不能访问未同步完成的节点,也就失去了部分可用性;<br>为了保证可用性(AP),允许读取所有节点的数据,但是数据可能不一致。<br>
场景:银行
四、BASE
定义
BASE 是基本可用(Basically Available)、软状态(Soft State)和最终一致性(Eventually Consistent)三个短语的缩写。<br>BASE 理论是对 CAP 中一致性和可用性权衡的结果,它的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
基本可用
指分布式系统在出现故障的时候,保证核心可用,允许损失部分可用性。<br>
例如,电商在做促销时,为了保证购物系统的稳定性,部分消费者可能会被引导到一个降级的页面。
软状态
指允许系统中的数据存在中间状态,并认为该中间状态不会影响系统整体可用性,即允许系统不同节点的数据副本之间进行同步的过程存在时延。
最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能达到一致的状态。<br><br>ACID 要求强一致性,通常运用在传统的数据库系统上。而 BASE 要求最终一致性,通过牺牲强一致性来达到可用性,通常运用在大型分布式系统中。<br>在实际的分布式场景中,不同业务单元和组件对一致性的要求是不同的,因此 ACID 和 BASE 往往会结合在一起使用。
五、Paxos算法
用于达成共识性问题,即对多个节点产生的值,该算法能保证只选出唯一一个值。
六、Raft
Raft 也是分布式一致性协议,主要是用来竞选主节点。
集群
一、负载均衡
负载均衡算法
1. 轮询(Round Robin)
2. 加权轮询(Weighted Round Robbin)
3. 最少连接(least Connections)<br>
4. 加权最少连接(Weighted Least Connection)
5. 随机算法(Random)<br>
6. 源地址哈希法 (IP Hash)<br>
转发实现
1. HTTP 重定向
2. DNS 域名解析
3. 反向代理服务器
4. 网络层
5. 链路层
二、集群下的 Session 管理
Sticky Session
相同用户的请求都转发到一个服务器
Session Replication
每个服务器都保留session
Session Server
攻击技术
一、跨站脚本攻击
二、跨站请求伪造
三、SQL 注入攻击
四、拒绝服务攻击(洪水攻击)
缓存
一、缓存特征
命中率
最大空间
淘汰策略
FIFO(First In First Out)先进先出策略
LRU(Least Recently Used)最近最久未使用策略
LFU(Least Frequently Used)最不经常使用策略
二、LRU算法实现
三、缓存位置
浏览器
ISP(网络服务提供商)
反向代理
本地缓存
分布式缓存
数据库缓存
Java 内部的缓存
CPU 多级缓存
四、CDN
五、缓存问题
缓存穿透
缓存雪崩
缓存一致性
缓存 “无底洞” 现象
六、数据分布
哈希分布
顺序分布
七、一致性哈希
Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了克服传统哈希分布在服务器节点数量变化时大量数据迁移的问题。
实现原理:哈希环
消息队列
一、消息模型
点对点
发布/订阅
二、使用场景
应用解耦
异步处理
邮件、短信验证
流量削锋
三、可靠性
发送端的可靠性
发送端完成操作后一定能将消息成功发送到消息队列中。<br>
实现方法
在本地数据库建一张消息表,将消息数据与业务数据保存在同一数据库实例里,这样就可以利用本地数据库的事务机制。<br>事务提交成功后,将消息表中的消息转移到消息队列中,若转移消息成功则删除消息表中的数据,否则继续重传。
接收端的可靠性
接收端能够从消息队列成功消费一次消息。
两种实现方法
保证接收端处理消息的业务逻辑具有幂等性:只要具有幂等性,那么消费多少次消息,最后处理的结果都是一样的。
幂等性
保证消息具有唯一编号,并使用一张日志表来记录已经消费的消息编号。
数据库和缓存
redis
redis.conf
Redis支持的数据类型?
String(字符串)<br>Hash(哈希)<br>List(列表)<br>Set(集合)<br>zset(sorted set:有序集合)
什么是Redis持久化?Redis有哪几种持久化方式?优缺点是什么?
mysql
数据库引擎
同一个数据库也可以使用多种存储引擎的表。<br>如果一个表要求比较高的事务处理,可以选择InnoDB。<br>这个数据库中可以将查询要求比较高的表选择MyISAM存储。<br>如果该数据库需要一个用于查询的临时表,可以选择MEMORY存储引擎
缓存
缓存命中、缓存失效、缓存更新<br>
缓存穿透
解决办法:空值缓存、布隆过滤器<br>
缓存雪崩
解决办法:加锁队列、主从+哨兵、Ehcache本地缓存 + Hystrix限流&降级,避免MySQL被打死<br>
MQ
服务器搭建
环境
docker
Dockerfile文件
k8s
jenkins
rancher
Dubbo+zookeeper基础
四个节点
Provider(生产者): 暴露服务的服务提供方。<br>Consumer(消费者): 调用远程服务的服务消费方。<br>Registry(注册中心): 服务注册与发现的注册中心。dubbo推荐的是zookeeper.<br>Monitor: 统计服务的调用次调和调用时间的监控中心。<br>
过程
0 服务容器负责启动,加载,运行服务提供者。<br>1. 服务提供者(生产者)在启动时,向注册中心注册自己提供的服务。<br>2. 服务消费者在启动时,向注册中心订阅自己所需的服务。<br>3. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。<br>4. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。<br>5. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心
linux
shell
变量
变量类型
1) 局部变量:局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。<br>2) 环境变量:所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。<br>3) shell变量:shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
readonly:变量只读
unset:删除变量(不能删除只读)
菜狗子的单词本
面试题


评论
0 条评论
下一页

