
面向Java面试
2019-11-13 13:42:37 3 举报AI智能生成
Java资料整理
java
面试
资料
模板推荐
作者其他创作
大纲/内容
JavaSE
容器
1. Collection:Collection是集合List、Set、Queue的最基本的接口。 <br>2. Iterator:迭代器,可以通过迭代器遍历集合中的数据 <br>3. Map:是映射表的基础接口
Collection
List
ArrayList 底层以数组实现 扩容机制:每次扩容1.5倍
排列有序,可重复
底层使用数组
查询速度快,增删慢
线程不安全
当容量不够时,ArrayList是当前容量*1.5
ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,<br>因为这个数组是动态扩展的,并不是所有的空间都被使用,<br>因此就不需要所有的内容都被序列化。<br>通过重写序列化和反序列化方法(readObject、writeObject),<br>使得可以只序列化数组中有内容的那部分数据。<br><br>private transient Object[] elementData;
Vector 线程安全的ArrayList 所有方法都加了synchronized 关键字
排列有序,可重复
底层使用数组
查询速度快,增删慢
线程安全,效率低
当容量不够时,Vector默认扩展一倍容量
LinkedList 底层以链表实现
排列有序,可重复
底层使用双向循环链表数据结构
查询速度慢,增删快,add()和remove()方法快
线程不安全
Set
HashSet 基于HashMap的key实现
排列无序,不可重复
底层使用HashMap实现
存取速度快
TreeSet 元素有序的Set
排列有序,不可重复
底层使用红黑树实现
排序存储
内部TreeMap的SortedSet
Integer和String对象都可以进行默认的TreeSet排序,<br>而自定义类的对象是不可以的,<br>自 己定义的类必须实现Comparable接口,<br>并且覆写相应的compareTo()函数,<br>才可以正常使 用。
在覆写compare()函数时,<br>要返回相应的值才能使TreeSet按照一定的规则来排序
比较此对象与指定对象的顺序。<br>如果该对象小于、等于或大于指定对象,<br>则分别返回负整 数、零或正整数。
LinkedHashSet
采用HashMap存储,并用双向链表记录插入顺序
内部LinkedHashMap
继承 HashSet、又基于 LinkedHashMap 来实现的。 <br>LinkedHashSet 底层使用 LinkedHashMap 来保存所有元素,<br>它继承HashSet,其所有的方法 操作上又与HashSet相同,<br>因此LinkedHashSet 的实现上非常简单,<br>只提供了四个构造方法,并 通过传递一个标识参数,<br>调用父类的构造器,<br>底层构造一个 LinkedHashMap 来实现,<br>在相关操 作上与父类HashSet的操作相同,<br>直接调用父类HashSet的方法即可。
Queue
PriorityQueue 优先级队列
LinkedList FIFO
Deque 双端队列
Map
HashMap 以数组+链表实现,<font color="#00a650">Java8之后,当阈值到达8时,通过红黑树实现。</font> 允许key/value为空
HashMap根据键的hashCode值存储数据,<br>大多数情况下可以直接定位到它的值,<br>因而具有很快 的访问速度,<br>但遍历顺序却是不确定的。 <br>HashMap最多只允许一条记录的键为null,<br>允许多条记 录的值为 null。<br>HashMap 非线程安全,<br>即任一时刻可以有多个线程同时写 HashMap,<br>可能会导 致数据的不一致
hash函数<br>
很多操作都需要先确定一个键值对所在的桶下标。<br><br>int hash = hash(key);<br>int i = indexFor(hash, table.length);<br><br>计算 hash 值<br>final int hash(Object k) {<br> int h = hashSeed;<br> if (0 != h && k instanceof String) {<br> return sun.misc.Hashing.stringHash32((String) k);<br> }<br><br> h ^= k.hashCode();<br><br> // This function ensures that hashCodes that differ only by<br> // constant multiples at each bit position have a bounded<br> // number of collisions (approximately 8 at default load factor).<br> h ^= (h >>> 20) ^ (h >>> 12);<br> return h ^ (h >>> 7) ^ (h >>> 4);<br>}<br><br>public final int hashCode() {<br> return Objects.hashCode(key) ^ Objects.hashCode(value);<br>}<br><br>确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash % capacity,<br>如果能保证 capacity 为 2 的 n 次方,那么就可以将这个操作转换为位运算、优化执行效率。<br><br>static final int tableSizeFor(int cap) {<br> int n = cap - 1;<br> n |= n >>> 1;<br> n |= n >>> 2;<br> n |= n >>> 4;<br> n |= n >>> 8;<br> n |= n >>> 16;<br> return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;<br>}<br><br>static int indexFor(int h, int length) {<br> return h & (length - 1);<br>}<br><br>位运算的代价比求模运算小的多,因此在进行这种计算时用位运算的话能带来更高的性能(结果是等价的):<br><br>index = hash % length;<br>index = hash & (length - 1);<br>计算过程:令 x = 1 << 4,即 x 为 2 的 4 次方,它具有以下性质:<br><br>x : 00010000<br>x - 1 : 00001111<br>令一个数 y 与 x-1 做与运算,可以去除 y 位级表示的第 4 位以上数:<br><br>y : 10110010<br>x - 1 : 00001111<br>y & (x - 1) : 00000010<br>这个性质和 y 对 x 取模效果是一样的:<br><br>y : 10110010<br>x : 00010000<br>y % x : 00000010<br>
头插还是尾插
jdk1.8之前是插入头部
1.6源码
jdk1.6<br>put方法的代码如下:<br><br>public V put(K key, V value) {<br> if (key == null)<br> return putForNullKey(value);<br> int hash = hash(key.hashCode());<br> int i = indexFor(hash, table.length);<br> for (Entry<K,V> e = table[i]; e != null; e = e.next) {<br> Object k;<br> //如果发现key已经在链表中存在,则修改并返回旧的值<br> if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {<br> V oldValue = e.value;<br> e.value = value;<br> e.recordAccess(this);<br> return oldValue;<br> }<br> }<br> //如果遍历链表没发现这个key,则会调用以下代码<br> modCount++;<br> addEntry(hash, key, value, i);<br> return null;<br>}<br>阅读源码发现,如果遍历链表都没法发现相应的key值的话,<br>则会调用addEntry方法在链表添加一个Entry,<br>重点就在于addEntry方法是如何插入链表的,addEntry方法源码如下:<br><br>void addEntry(int hash, K key, V value, int bucketIndex) {<br> Entry<K,V> e = table[bucketIndex];<br> table[bucketIndex] = new Entry<K,V>(hash, key, value, e);<br> if (size++ >= threshold)<br> resize(2 * table.length);<br>}<br>这里构造了一个新的Entry对象(构造方法的最后一个参数传入了当前的Entry链表),<br>然后直接用这个新的Entry对象取代了旧的Entry链表,<br>可以猜测这应该是头插法,为了进一步确认这个想法,<br>我们再看一下Entry的构造方法:<br><br>Entry( int h, K k, V v, Entry<K,V> n) {<br> value = v;<br> next = n;<br> key = k;<br> hash = h;<br>}<br>从构造方法中的next=n可以看出确实是把原本的链表直接链在了新建的Entry对象的后边,<br>可以断定是插入头部。
jdk1.8中是插入尾部的
1.8源码
jdk1.8<br>put方法的代码如下:<br><br>public V put(K key, V value) {<br> return putVal(hash(key), key, value, false, true);<br>}<br>继续进入putVal方法(先不要着急去读它):<br><br>/**<br> * Implements Map.put and related methods<br> *<br> * @param hash hash for key<br> * @param key the key<br> * @param value the value to put<br> * @param onlyIfAbsent if true, don't change existing value<br> * @param evict if false, the table is in creation mode.<br> * @return previous value, or null if none<br> */<br>final V putVal(int hash, K key, V value, boolean onlyIfAbsent,<br> boolean evict) {<br> Node<K,V>[] tab; Node<K,V> p; int n, i;<br> if ((tab = table) == null || (n = tab.length) == 0)<br> n = (tab = resize()).length;<br> if ((p = tab[i = (n - 1) & hash]) == null)<br> tab[i] = newNode(hash, key, value, null);<br> else {<br> Node<K,V> e; K k;<br> if (p.hash == hash &&<br> ((k = p.key) == key || (key != null && key.equals(k))))<br> e = p;<br> else if (p instanceof TreeNode)<br> e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);<br> else {<br> for (int binCount = 0; ; ++binCount) {<br> if ((e = p.next) == null) {<br> p.next = newNode(hash, key, value, null);<br> if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st<br> treeifyBin(tab, hash);<br> break;<br> }<br> if (e.hash == hash &&<br> ((k = e.key) == key || (key != null && key.equals(k))))<br> break;<br> p = e;<br> }<br> }<br> if (e != null) { // existing mapping for key<br> V oldValue = e.value;<br> if (!onlyIfAbsent || oldValue == null)<br> e.value = value;<br> afterNodeAccess(e);<br> return oldValue;<br> }<br> }<br> ++modCount;<br> if (++size > threshold)<br> resize();<br> afterNodeInsertion(evict);<br> return null;<br>}<br>在jdk1.8中当链表长度大于8是会被转化成红黑树,<br>所以源码看起来比jdk1.6要复杂不少,<br>大量的if-else判断是为了处理红黑树的情况的,<br>与链表插入相关的核心代码只有如下几行:<br><br>for (int binCount = 0; ; ++binCount) {<br> //e是p的下一个节点<br> if ((e = p.next) == null) {<br> //插入链表的尾部<br> p.next = newNode(hash, key, value, null);<br> //如果插入后链表长度大于8则转化为红黑树<br> if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st<br> treeifyBin(tab, hash);<br> break;<br> }<br> //如果key在链表中已经存在,则退出循环<br> if (e.hash == hash &&<br> ((k = e.key) == key || (key != null && key.equals(k))))<br> break;<br> p = e;<br>}<br>//如果key在链表中已经存在,则修改其原先的key值,并且返回老的值<br>if (e != null) { // existing mapping for key<br> V oldValue = e.value;<br> if (!onlyIfAbsent || oldValue == null)<br> e.value = value;<br> afterNodeAccess(e);<br> return oldValue;<br>}<br>代码我一行行加了注释,其中链表插入的代码是:<br><br>//e是p的下一个节点<br>if ((e = p.next) == null) {<br> //插入链表的尾部<br> p.next = newNode(hash, key, value, null);<br> //如果插入后链表长度大于8则转化为红黑树<br> if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st<br> treeifyBin(tab, hash);<br> break;<br>}<br>从这段代码中可以很显然地看出当到达链表尾部(即p是链表的最后一个节点)时,<br>e被赋为null,会进入这个分支代码,<br>然后会用newNode方法建立一个新的节点插入尾部。 <br>结论:jdk1.8中是插入的是链表尾部
HashMap在jdk1.7中采用头插入法,在扩容时会改变链表中元素原本的顺序,<br>以至于在并发场景下导致链表成环的问题。<br>而在jdk1.8中采用尾插入法,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。<br>但没有解决死锁<br><br>https://juejin.im/post/5ba457a25188255c7b168023#heading-18<br>
死锁的原因<br>https://www.cnblogs.com/xrq730/p/5037299.html<br>
有二个线程T1、T2,HashMap容量为2,<br><br>T1线程放入key A、B、C、D、E。<br>在T1线程中A、B、C Hash值相同,<br>于是形成一个链接,假设为A->C->B,<br>而D、E Hash值不同,<br>于是容量不足,需要新建一个更大尺寸的hash表,<br>然后把数据从老的Hash表中,迁移到新的Hash表中<font color="#80bc42">(rehash)。</font><br><br>这时T2线程闯进来了,T1暂时挂起,T2进程也准备放入新的key,<br>这时也发现容量不足,<font color="#80bc42">也rehash一把。</font><br>rehash之后原来的链表结构假设为C->A,之后T1进程继续执行,<br>链接结构为A->C,这时就形成A.next=C,C.next=A的环形链表。<br><br>一旦取值进入这个环形链表就会陷入死循环。
Java7
Java8
TreeMap key是有序的
TreeMap 实现 SortedMap 接口,<br>能够把它保存的记录根据键排序,<br>默认是按键值的升序排序, <br>也可以指定排序的比较器,<br>当用Iterator遍历TreeMap时,得到的记录是排过序的。 <br><br>如果使用排序的映射,建议使用TreeMap。 <br><br>在使用 TreeMap 时,<br>key 必须实现 Comparable 接口<br>或者在构造 TreeMap 传入自定义的 Comparator,<br>否则会在运行时抛出java.lang.ClassCastException类型的异常。
HashTable 线程安全的 不允许key/value为空 数据结构上,通过数组和链表实现。
LinkedHashMap
LinkedHashMap 是 HashMap 的一个子类,<br>保存了记录的插入顺序,<br>在用 Iterator 遍历 LinkedHashMap时,<br>先得到的记录肯定是先插入的,<br>也可以在构造时带参数,按照访问次序排序。
线程安全的集合
Vector
HashTable
继承自 Dictionary 类<br>并且是线程安全的,<br>任一时间只有一个线程能写 Hashtable,<br>并发性不如 ConcurrentHashMap<br>
Collections.synchronized*[Map, List, Set, Collection]
ConcurrentHashMap 当阈值到达8时,通过红黑树实现。<br>JDK 1.6中,采用分离锁的方式,在读的时候,部分锁;写的时候,完全锁。<br>而在JDK 1.7、1.8中,读的时候不需要锁的,写的时候需要锁的。<br>并且JDK 1.8中在为了解决Hash冲突,采用红黑树解决。
ConcurrentHashMap分段锁
ConcurrentHashMap,<br>它内部细分了若干个小的 HashMap,<br>称之为段(Segment)。<br>默认情况下 一个ConcurrentHashMap被进一步细分为16个段,既就是锁的并发度。 <br><br>如果需要在 ConcurrentHashMap 中添加一个新的表项,<br>并不是将整个 HashMap 加锁,<br>而是首 先根据hashcode得到该表项应该存放在哪个段中,<br>然后对该段加锁,并完成put操作。<br>在多线程 环境中,如果多个线程同时进行put操作,<br>只要被加入的表项不存放在同一个段中,则线程间可以 做到真正的并行。
ConcurrentHashMap<br><br>是由 Segment数组结构和<br>HashEntry数组结构组成或者Node 数组,红黑树组成<br>
ConcurrentHashMap 是由 Segment 数组结构和HashEntry 数组结构组成。<br>Segment 继承了可 重入锁 ReentrantLock,<br>在 ConcurrentHashMap 里扮演锁的角色,<br>HashEntry 则用于存储键值 对数据。<br>一个 ConcurrentHashMap 里包含一个 Segment 数组,<br>Segment 的结构和 HashMap 类似,是一种数组和链表结构, <br>一个Segment里包含一个HashEntry 数组,<br>每个HashEntry是 一个链表结构的元素, <br>每个 Segment守护一个HashEntry数组里的元素,<br>当对HashEntry数组的 数据进行修改时,必须首先获得它对应的Segment锁。 <br>
Segment 段
ConcurrentHashMap 和 HashMap 思路是差不多的,<br>但是因为它支持并发操作,所以要复杂一 些。<br>整个 ConcurrentHashMap 由一个个 Segment 组成,<br>Segment 代表”部分“或”一段“的 意思,<br>所以很多地方都会将其描述为分段锁。<br>注意,行文中,我很多地方用了“槽”来代表一个 segment。 <br>
线程安全(Segment 继承 ReentrantLock 加锁)
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,<br>Segment 通过继承 ReentrantLock 来进行加锁,<br>所以每次需要加锁的操作锁住的是一个 segment,<br>这样只要保证每 个 Segment 是线程安全的,<br>也就实现了全局的线程安全。
map.computeIfAbsent("AaAa", mapFunction)在等待mapFunction.apply(key)的返回值,<br>而mapFunction:key -> map.computeIfAbsent("BBBB", key2 -> 42);<br>却进入了一个死循环,永远都不会返回。<br>因此整个代码的执行就被锁住了,<br>但是这算死锁吗?似乎和死锁的定义不太一样!<br><br>总之,为了避免这个问题,<br>在JDK1.8中使用ConcurrentHashMap时,<br>不要在computeIfAbsent的lambda函数中再去执行更新其它节点value的操作。<br><br>https://blog.csdn.net/lx1848/article/details/81256443<br>
并行度(默认 16)
concurrencyLevel:并行级别、并发数、Segment 数,<br>怎么翻译不重要,理解它。<br>默认是 16, 也就是说 ConcurrentHashMap 有 16 个 Segments,<br>所以理论上,这个时候,最多可以同时支 持 16 个线程并发写,<br>只要它们的操作分别分布在不同的 Segment 上。<br>这个值可以在初始化的时 候设置为其他值,<br>但是一旦初始化以后,它是不可以扩容的。<br>再具体到每个 Segment 内部,其实 每个 Segment 很像之前介绍的 HashMap,<br>不过它要保证线程安全,所以处理起来要麻烦些。
计算长度
每个 Segment 维护了一个 count 变量来统计该 Segment 中的键值对个数。<br><br>transient int count;<br>在执行 size 操作时,需要遍历所有 Segment 然后把 count 累计起来。<br>ConcurrentHashMap 在执行 size 操作时先尝试不加锁,<br>如果连续两次不加锁操作得到的结果一致,那么可以认为这个结果是正确的。<br>尝试次数使用 RETRIES_BEFORE_LOCK 定义,该值为 2,retries 初始值为 -1,因此尝试次数为 3。<br>如果尝试的次数超过 3 次,就需要对每个 Segment 加锁。<br><br>static final int RETRIES_BEFORE_LOCK = 2;<br>public int size() {<br>// Try a few times to get accurate count. On failure due to<br>// continuous async changes in table, resort to locking.<br>final Segment<K,V>[] segments = this.segments;<br>int size;<br>boolean overflow; // true if size overflows 32 bits<br>long sum; // sum of modCounts<br>long last = 0L; // previous sum<br>int retries = -1; // first iteration isn't retry<br>try {<br>for (;;) {<br>// 超过尝试次数,则对每个 Segment 加锁<br>if (retries++ == RETRIES_BEFORE_LOCK) {<br>for (int j = 0; j < segments.length; ++j)<br>ensureSegment(j).lock(); // force creation<br>}<br>sum = 0L;<br>size = 0;<br>overflow = false;<br>for (int j = 0; j < segments.length; ++j) {<br>Segment<K,V> seg = segmentAt(segments, j);<br>if (seg != null) {<br>sum += seg.modCount;<br>int c = seg.count;<br>if (c < 0 || (size += c) < 0)<br>overflow = true;<br>}<br>}<br><br> // 连续两次得到的结果一致,则认为这个结果是正确的<br>if (sum == last)<br>break;<br>last = sum;<br>}<br>} finally {<br>if (retries > RETRIES_BEFORE_LOCK) {<br>for (int j = 0; j < segments.length; ++j)<br>segmentAt(segments, j).unlock();<br>}<br>}<br>return overflow ? Integer.MAX_VALUE : size;<br>}
同步机制
Java1.8
总体结构上与 HashMap 类似,也是“数组 - 链表”的结构,但同步的粒度要更细致一些。<br><br>内部仍有 Segment,但只是保证序列化时的兼容性,已不具作用。由于不再使用 Segment,初始化操作简化为 lazy-load 形式;<br>数据存储利用 volatile 保证可见性;<br>使用 CAS 操作,在特定场景下进行无锁并发操作(高并发场景下性能一般);<br>使用 Unsafe、LongAdder 之类底层手段,进行极端情况的优化。<br>存储节点:key 定义为 final,val、next 都定义为 volatile 保证可见性。<br><br>static class Node<K,V> implements Map.Entry<K,V> {<br>final int hash;<br>final K key;<br>volatile V val;<br>volatile Node<K,V> next;<br>// … <br>}<br><br>对于 put 操作:<br>final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException();<br>int hash = spread(key.hashCode());<br>int binCount = 0;<br>for (Node<K,V>[] tab = table;;) {<br>Node<K,V> f; int n, i, fh; K fk; V fv;<br>if (tab == null || (n = tab.length) == 0)<br>tab = initTable();<br>else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {<br>// 利用 CAS 去进行无锁线程安全操作,如果 bin 是空的<br>if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))<br>break; <br>}<br>else if ((fh = f.hash) == MOVED)<br>tab = helpTransfer(tab, f);<br>else if (onlyIfAbsent // 不加锁,进行检查<br>&& fh == hash<br>&& ((fk = f.key) == key || (fk != null && key.equals(fk)))<br>&& (fv = f.val) != null)<br>return fv;<br>else {<br>V oldVal = null;<br>synchronized (f) {<br>// 细粒度的同步修改操作... <br>}<br>}<br>// Bin 超过阈值,进行树化<br>if (binCount != 0) {<br>if (binCount >= TREEIFY_THRESHOLD)<br>treeifyBin(tab, i);<br>if (oldVal != null)<br>return oldVal;<br>break;<br>}<br>}<br>}<br>addCount(1L, binCount);<br>return null;<br>}<br>对于初始化操作:<br>在一个 initTable 实现,利用 volatile 的 sizeCtl 作为互斥手段,<br>如果发生竞争性的初始化,就 spin (自旋锁)在哪里,等待条件回复;<br>否则利用 CAS 设置排他标志。如果成功则进行初始化,否则重试;<br>当 bin 为空时,同样是没有必要锁定,而以 CAS 操作放置;<br>同步逻辑上使用 synchronized(性能已被优化,且可以减少内存消耗);<br>更多细节实现通过 Unsafe 进行优化,如 tabAt 利用 getObjectAcquire 避免间接调用的开销。<br>private final Node<K,V>[] initTable() {<br>Node<K,V>[] tab; int sc;<br>while ((tab = table) == null || tab.length == 0) {<br>// 如果发现冲突,进行 spin 等待<br>if ((sc = sizeCtl) < 0)<br>Thread.yield(); <br>// CAS 成功返回 true,则进入真正的初始化逻辑<br>else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {<br>try {<br>if ((tab = table) == null || tab.length == 0) {<br>int n = (sc > 0) ? sc : DEFAULT_CAPACITY;<br>@SuppressWarnings("unchecked")<br>Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];<br>table = tab = nt;<br>sc = n - (n >>> 2);<br>}<br>} finally {<br>sizeCtl = sc;<br>}<br>break;<br>}<br>}<br>return tab;<br>}<br>对于 size 操作:<br>也是采用分治的方法进行计数,然后做求和处理:<br>求和处理是通过 CounterCell 实现,而 CounterCell 操作,是基于 LongAdder 进行的(略)。<br>final long sumCount() {<br>CounterCell[] as = counterCells; CounterCell a;<br>long sum = baseCount;<br>if (as != null) {<br>for (int i = 0; i < as.length; ++i) {<br>if ((a = as[i]) != null)<br>sum += a.value;<br>}<br>}<br>return sum;<br>}<br><br>static final class CounterCell {<br>volatile long value;<br>CounterCell(long x) { value = x; }<br>}
1.7
分段锁,在数据结构内部进行分段(Segment,默认16个),<br>内部使用 HashEntry 的数组,与 HashMap 类似,哈希值相同的值使用链表存放;<br><br>HashEntry 内部使用 volatile 修饰的值保证可见性,<br>也利用不可变对象的机制改进利用 Unsafe 提供的底层能力。<br>对于 get 操作,保证的是可见性,所以没有同步的逻辑。<br>public V get(Object key) {<br> Segment<K,V> s; // manually integrate access methods to reduce overhead<br>HashEntry<K,V>[] tab;<br>int h = hash(key.hashCode());<br>// 利用位操作替换普通数学运算<br>long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;<br>// 以 Segment 为单位,进行定位<br>// 利用 Unsafe 直接进行 volatile access<br>if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&<br>(tab = s.table) != null) {<br>// 省略<br>}<br>return null;<br>}<br><br>对于 put 操作,首先通过二次哈希避免冲突,<br>再以 Unsafe 调用方式直接获取的 Segment,进行线程安全的 put 操作:<br><br>获取重入锁:要确保数据一致性(Segment 本身是基于 ReentrantLock 的扩展实现),<br>在并发修改期间,相应的 Segment 是被锁定的;<br>重复性扫描:确定 Key 值是否已经存在于数组,进而决定执行更新或插入操作;<br>扩容:和 HashMap 类似,可能发生扩容问题,但也是针对 Segment 进行扩容。<br>final V put(K key, int hash, V value, boolean onlyIfAbsent) {<br>// scanAndLockForPut 会去查找是否有 key 相同 Node<br>// 无论如何,确保获取锁<br>HashEntry<K,V> node = tryLock() ? null :<br>scanAndLockForPut(key, hash, value);<br>V oldValue;<br>try {<br>HashEntry<K,V>[] tab = table;<br>int index = (tab.length - 1) & hash;<br>HashEntry<K,V> first = entryAt(tab, index);<br>for (HashEntry<K,V> e = first;;) {<br>if (e != null) {<br>K k;<br>// 更新已有 value...<br>}<br>else {<br>// 放置 HashEntry 到特定位置,如果超过阈值,进行 rehash<br>// ...<br>}<br>} finally {<br>unlock();<br>}<br>return oldValue;<br>}<br><br>对于 size 操作,则涉及分离锁的副作用,ConcurrentHashMap 则采用重试机制,<br>如没有监控到变化(modCount)则直接返回,<br>否则再获取锁(初始化操作也要锁定所有 Segment)。
LinkedBlockingQueue 链表结构;<br>有两个构造器,一个是(Integer.MAX_VALUE),无边界<br>另一个是(int capacity),有边界;
ArrayBlockingQueue 是数组结构;有边界。
LinkedTransferQueue java 7中提供的新接口,性能比LinkBlockingQUeue更优化。
CopyOnWriteArrayList
CopyOnWriteArraySet
ConcurrentSkipListSet
容器使用需要综合这些方面考虑:<br><br>数据存储特点(单个对象或键值对,是否需要排序、去重等)<br>是否保证线程安全,或安全的实现方式<br>底层数据结构及其空间占用情况<br>更新操作是否受元素位置影响<br>是否支持快速随机访问、效率如何<br>......<br>主要包括 Collection 和 Map 两种,Collection 存储对象的集合,Map 存储键值对的映射表:
接口
Java SE 7或更早版本
一个接口中只能只能定义如下两种:<br><br>常量<br>抽象方法
public interface JavaSeven{<br> String TYPE_NAME = "java seven interface";<br> int TYPE_AGE = 20;<br><br> void method01();<br> void method02(String arg);<br> void method03(String arg1,int arg2);<br> }
Java8中的接口
引入了一些新功能——默认方法和静态方法<br><br>常量<br>抽象方法<br>默认方法<br>静态方法<br>
public interface JavaEight{<br> String TYPE_NAME = "java seven interface";<br> int TYPE_AGE = 20;<br> String TYPE_DES = "java seven interface description";<br><br> default void method01(String msg){<br> //TODO<br> }<br> default void method02(){<br> //TODO<br> }<br><br> // Any other abstract methods<br> void method03();<br> void method04(String arg);<br> ...<br> String method05();<br> }
private interface DefaulableFactory {<br> // Interfaces now allow static methods<br> static Defaulable create(Supplier< Defaulable > supplier ) {<br> return supplier.get();<br> }<br>}<br>
默认方法允许我们在接口里添加新的方法,<br>而不会破坏实现这个接口的已有类的兼容性,<br>也就是说不会强迫实现接口的类实现默认方法。<br><br>默认方法和抽象方法的区别是抽象方法必须要被实现,默认方法不是。<br>作为替代方式,接口可以提供一个默认的方法实现,<br>所有这个接口的实现类都会通过继承得到这个方法
多重继承的冲突说明:<br><br>由于同一个方法可以从不同接口引入,自然而然的会有冲突的现象,规则如下:<br>1)一个声明在类里面的方法优先于任何默认方法<br>2)优先选取最具体的实现
为什么不能用默认方法来重载equals,hashCode和toString?
接口不能提供对Object类的任何方法的默认实现。<br>从接口里不能提供对equals,hashCode或toString的默认实现。<br>因为若可以会很难确定什么时候该调用接口默认的方法。<br><br>如果一个类实现了一个方法,那总是优先于默认的实现的。<br>一旦所有接口的实例都是Object的子类,<br>所有接口实例都已经有对equals/hashCode/toString等方法非默认 实现。<br>因此,一个在接口上的这些默认方法都是没用的,它也不会被编译。<br>(简单地讲,每一个java类都是Object的子类,<br>也都继承了它类中的equals/hashCode/toString方法,<br>那么在类的接口上包含这些默认方法是没有意义的,它们也从来不会被编译。)<br>
java 8中抽象类与接口的异同
相同点:<br>1)都是抽象类型;<br>2)都可以有实现方法(以前接口不行);<br>3)都可以不需要实现类或者继承者去实现所有方法,(以前不行,现在接口中默认方法不需要实现者实现)<br><br>不同点:<br>1)抽象类不可以多重继承,接口可以(无论是多重类型继承还是多重行为继承);<br>2)抽象类和接口所反映出的设计理念不同。<br> 其实抽象类表示的是"is-a"关系,接口表示的是"like-a"关系;<br>3)接口中定义的变量默认是public static final 型,且必须给其初值,<br> 所以实现类中不能重新定义,也不能改变其值;<br> 抽象类中的变量默认是 friendly 型,其值可以在子类中重新定义,也可以重新赋值。
friendly 型:<br><br>如果一个类、类属变量及方法不以public,protected,private这三种修饰符来修饰,<br>它就是friendly类型的,那么包内的任何类都可以访问它,<br>而包外的任何类都不能访问它(包括包外继承了此类的子类),<br>因此,这种类、类属变量及方法对包内的其他类是友好的,开放的,<br> 而对包外的其他类是关闭的。
Java9中的接口
在接口中使用private私有方法<br><br>常量<br>抽象方法<br>默认方法<br>静态方法<br>私有方法<br>私有静态方法<br>
public interface JavaNine{<br> String TYPE_NAME = "java seven interface";<br> int TYPE_AGE = 20;<br> String TYPE_DES = "java seven interface description";<br><br> default void method01(){<br> //TODO<br> }<br> default void method02(String message){<br> //TODO<br> }<br><br> private void method(){<br> //TODO <br> }<br><br> // Any other abstract methods<br> void method03();<br> void method04(String arg);<br> ...<br> String method05();<br> }
多态
编译时多态
方法的重载
运行时多态
程序中定义的对象引用所指向的具体类型在运行期间才确定。 <br>具体体现在重写(Override)、重载(Overload)、向上转型。
泛型
泛型的本 质是参数化类型,也就是说所操作的数据类型被指定为一个参数。<br><br>将类型由原来的具体的类型参数化<br><br>泛型的目的是实现Java的类型安全。<br><br>用于编译器在编译期进行类型检查,因此代码经过编译之后就不存在了。<br><br>消除强制类型转换,增强代码可读性,减少错误率。<br>
编译时检查<br><br><br>运行时擦除<br>
常见的如T、E、K、V等形式的参数常用于表示泛型形参,<br><br>在使用/调用时传入具体的类型(类型实参)<br><br>类型通配符上限通过形如Box<? extends Number><br><br>类型通配符下限为Box<? super Number><br>
泛型接口
泛型类
泛型类的声明和非泛型类的声明类似,<br>除了在类名后面添加了类型参数声明部分。<br>和泛型方法一 样,<br>泛型类的类型参数声明部分也包含一个或多个类型参数,<br>参数间用逗号隔开。<br>一个泛型参数, 也被称为一个类型变量,<br>是用于指定一个泛型类型名称的标识符。<br>因为他们接受一个或多个参数, <br>这些类被称为参数化的类或参数化的类型。
泛型方法
你可以写一个泛型方法,<br>该方法在调用时可以接收不同类型的参数。<br>根据传递给泛型方法的参数 类型,<br>编译器适当地处理每一个方法调用。
1. <? extends T>表示该通配符所代表的类型是T类型的子类。 <br>2. <? super T>表示该通配符所代表的类型是T类型的父类
类型通配符?
类型通配符一般是使用? <br>代 替 具 体 的 类 型 参 数 。 <br><br>例 如 List<?> 在逻辑上是 List<String>,<br>List<Integer> 等所有List<具体类型实参>的父类。
类型擦除
Java 中的泛型<br>基本上都是在编译器这个层次来实现的。<br>在生成的 Java 字节代码中是不包含泛 型中的类型信息的。<br>使用泛型的时候加上的类型参数,<br>会被编译器在编译的时候去掉。<br>这个过程就称为类型擦除。
反射
1.在反射中核心的方法是 <br>newInstance() 获取类实例,<br>getMethod(..) 获取方法,<br>使用 invoke(..) 进行方法调用,<br>通过 setAccessible 修改私有变量/方法的访问限制。<br><br><br>2.获取属性/方法的时候有无“Declared”的区别是,<br>带有 Declared 修饰的方法或属性,<br>可以获取本类的所有方法或属性(private 到 public),<br>但不能获取到父类的任何信息;<br>非 Declared 修饰的方法或属性,<br>只能获取 public 修饰的方法或属性,<br>并可以获取到父类的信息,比如 getMethod(..)和getDeclaredMethod(..)。
通过反射我们可以直接操作类或者对象<br>
比如获取某个对象的类定义<br>
通过forName() -> 示例:Class.forName("PeopleImpl")<br><br>通过getClass() -> 示例:new PeopleImpl().getClass()<br><br>直接获取.class -> 示例:PeopleImpl.class
获取类声明的属性和方法<br>
getName():获取类完整方法;<br><br>getSuperclass():获取类的父类;<br><br>newInstance():创建实例对象;<br><br>getFields():获取当前类和父类的public修饰的所有属性;<br><br>getDeclaredFields():获取当前类(不包含父类)的声明的所有属性;<br><br>getMethod():获取当前类和父类的public修饰的所有方法;<br><br>getDeclaredMethods():获取当前类(不包含父类)的声明的所有方法;
调用方法或者构造对象
反射要调用类中的方法,需要通过关键方法“invoke()”实现的,方法调用也分为三种
静态(static)方法调用
// 核心代码(省略了抛出异常的声明)<br>public static void main(String[] args) {<br> Class myClass = Class.forName("example.PeopleImpl");<br> // 调用静态(static)方法<br> Method getSex = <font color="#f15a23">myClass.getMethod</font>("getSex");<br><font color="#f15a23"> getSex.invoke</font>(myClass);<br>}<br>复制代码<br><br>静态方法的调用比较简单,<br>使用 getMethod(xx) 获取到对应的方法,<br>直接使用 invoke(xx)就可以了。
普通方法调用
//核心代码如下:<br>Class myClass = Class.forName("example.PeopleImpl");<br>Object object = myClass.<font color="#f15a23">newInstance()</font>;<br>Method method = <font color="#f15a23">myClass.getMethod</font>("sayHi",String.class);<br>method.<font color="#f15a23">invoke</font>(object,"老王");<br><br>普通非静态方法调用,需要先获取类实例,通过“newInstance()”方法获取,<br>getMethod 获取方法,可以声明需要传递的参数的类型。
私有方法调用
调用私有方法,必须使用“getDeclaredMethod(xx)”获取本类所有什么的方法,代码如下:<br><br>Class myClass = Class.forName("example.PeopleImpl");<br>Object object = myClass.<font color="#f15a23">newInstance()</font>;<br>Method privSayHi = myClass.<font color="#f15a23">getDeclaredMethod</font>("privSayHi");<br>privSayHi.<font color="#f15a23">setAccessible</font>(true); // 修改访问限制<br>privSayHi.<font color="#f15a23">invoke</font>(object);<br><br>除了“getDeclaredMethod(xx)”可以看出,<br>调用私有方法的关键是设置 setAccessible(true) 属性,<br>修改访问限制,这样设置之后就可以进行调用了。
甚至可以运行时修改类定义
创建对象的两种方法
使用 Class 对象的 newInstance()方法来创建该 Class 对象对应类的实例,<br>但是这种方法要求 该Class对象对应的类有默认的空构造器。
先使用Class对象获取指定的Constructor对象,<br>再调用Constructor对象的newInstance() 方法来创建 Class对象对应类的实例,<br>通过这种方法可以选定构造方法创建实例。
缺点
性能开销
因为反射涉及了动态类型的解析,<br>所以 JVM 无法对这些代码进行优化。<br>因此反射操作的效率要比那些非反射操作低得多。<br><br>应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
安全限制
使用反射技术要求程序必须在一个没有安全限制的环境中运行。<br>如果一个程序必须在有安全限制的环境中运行,<br>如 Applet,那么这就是个问题了。
内部暴露
由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),<br>所以使用反射可能会导致意料之外的副作用,<br>导致代码功能失调并破坏可移植性。<br>反射代码破坏了抽象性,<br>因此当平台发生改变的时候,<br>代码的行为就有可能也随着变化。
注解
注解(Annotation),也叫元数据。是一种代码级别的说明。
概念定义
注解
注解:提供一种为程序元素设置元数据的方法
基本原则:注解不能直接干扰程序代码的运行,无论增加或删除注解,代码都能够正常运行
注解分类
标注注解(marker annotation): 没有元素的注解
单值注解
完整注解
元数据
元数据(metadata)就是关于数据的数据
元数据作用
编写文档:通过代码里表示的元数据生成文档
代码分析:通过代码里表示的元数据对代码进行分析
编译检查:通过代码里表示的元数据让编译器能实现基本的编译检查
系统注解
标准注解
@Override
作用:保证编译时Override函数的声明正确性
@Deprecated
作用:对不应该再使用的方法添加注释,当使用这些方法的时候,将会在编译时显示提示信息
与javadoc里的@deprecated标记有相同的功能,准确的说它还不如javadoc @deprecated, 因为它不支持参数
@SuppressWarnings
作用:关闭特定的警告信息<br><br>参数:<br>deprecation: 使用了过时的类或方法时的警告<br>unchecked: 执行了未检查的转换时的警告<br>fallthrough: 当Switch程序块直接通往下一种情况而没有Break时的警告<br>path: 在类路径,源文件路径等中有不存在的路径时的警告<br>serial: 当在可序列化的类上缺少serialVersionUID定义时的警告<br>all: 关于以上所有情况的警告
@FunctionalInterface<br>(Java8新增)
供编译器检查,接口是否满足函数式接口条件
元注解
@Target
用于描述注解的使用范围(即:被描述的注解可以用在什么地方)
取值(ElementType)有: <br>1、CONSTRUCTOR:用于描述构造器<br><br>2、FIELD:用于描述字段<br><br>3、LOCAL_VARIABLE:用于描述局部变量<br><br>4、METHOD:用于描述方法<br><br>5、PACKAGE:用于描述包<br><br>6、PARAMETER:用于描述参数<br><br>7、TYPE:用于描述类、接口(包括注解类型) 或enum声明<br><br>如:@Target(ElementType.TYPE)
@Retention
用于描述注解的生命周期(即:被描述的注解在什么范围内有效)
取值(RetentionPoicy)有:<br>1、SOURCE:在源文件中有效(即源文件保留)<br><br>2、CLASS:在class文件中有效(即class保留)<br><br>3、RUNTIME:在运行时有效(即运行时保留)<br><br>如:@Retention(RetentionPolicy.RUNTIME)
@Documented
将此注解包含在 javadoc 中 ,它代表着此注解会被javadoc工具提取成文档。
@Inherited
允许子类继承父类的注解
@Repeatable<br>(Java8新增)
允许注解使用多次
注解元素数据类型
所有基本类型(int, float, boolean等)<br><br>String<br>Class<br>enum<br>Annotation<br>以上类型的数组
提取注解
java.lang.reflect.AnnotatedElement接口
已知实现类
Class<br>Constructor<br>Field<br>Method<br>Package
方法
getAnnotation: 返回该程序元素上存在的制定类型的注解。如果该类型的注解不存在, 则返回null<br><br>getAnnotations: 返回程序该元素上存在的所有注解<br><br>isAnnotationPresent: 判断该程序元素上是否包含制定类型的注解,存在返回true, 否则返回fase<br><br>getDeclaredAnnotations: 返回存在于此元素上的所有注解
自定义注解
区别于接口定义,使用@interface进行声明
/1:*** 定义注解*/ <br><br>@Target(ElementType.FIELD) <br>@Retention(RetentionPolicy.RUNTIME) <br>@Documented <br>public @interface FruitProvider { <br>/**供应商编号*/ <br>public int id() default -1; <br>/*** 供应商名称*/ <br>public String name() default ""; <br>/** * 供应商地址*/ <br>public String address() default ""; <br>} <br>
//2:注解使用 <br><br>public class Apple { <br>@FruitProvider(id = 1, name = "陕西红富士集团", address = "陕西省西安市延安路") <br>private String appleProvider; <br>public void setAppleProvider(String appleProvider) { <br>this.appleProvider = appleProvider; <br>} <br><br>public String getAppleProvider() { <br>return appleProvider; <br>} <br>} <br><br>
/3:*********** 注解处理器 ***************/ <br><br>public class FruitInfoUtil { <br>public static void getFruitInfo(Class<?> clazz) { <br>String strFruitProvicer = "供应商信息:"; <br>Field[] fields = clazz.getDeclaredFields();//通过反射获取处理注解 <br>for (Field field : fields) { <br>if (field.isAnnotationPresent(FruitProvider.class)) { <br>FruitProvider fruitProvider = (FruitProvider) field.getAnnotation(FruitProvider.class); <br>//注解信息的处理地方 <br>strFruitProvicer = " 供应商编号:" + fruitProvider.id() + " 供应商名称:" <br> + fruitProvider.name() + " 供应商地址:"+ fruitProvider.address(); <br>System.out.println(strFruitProvicer); <br>} <br>} <br>} <br>}
public class FruitRun { <br><br> public static void main(String[] args) { <br><br> FruitInfoUtil.getFruitInfo(Apple.class); <br><br> /***********输出结果***************/ <br><br>// 供应商编号:1 供应商名称:陕西红富士集团 供应商地址:陕西省西安市延 <br><br> } <br><br>}
JAVA序列化(创建可复用的 Java 对象)
保存 ( 持久化 ) 对象 及其状态到内存或者磁盘 <br>
序列化对象以字节数组保持 静态成员不保存 <br>
序列化用户远程对象传输 <br>
Serializable实现序列化 <br>
只要一个类实现了java.io.Serializable接口,那么它就可以被序列化
ObjectOutputStream<br>和 ObjectInputStream<br><br>对对象进行序列化及反序列化 <br>
writeObject 和 readObject<br>自定义序列化策略 <br>
序列化 ID
虚拟机是否允许反序列化,<br>不仅取决于类路径和功能代码是否一致,<br>一个非常重要的一点是两个 类的序列化 ID 是否一致<br>(就是 private static final long serialVersionUID)
序列化并不保存静态变量<br>序列化子父类说明 <br>
Transient 关键字 阻止该变量被序列化到文件中 <br>
在变量声明前加上Transient 关键字,<br>可以阻止该变量被序列化到文件中,<br>在被反序列 化后,transient 变量的值被设为初始值,<br>如 int 型的是 0,对象型的是 null
服务器端给客户端发送序列化对象数据,<br>对象中有一些数据是敏感的,<br>比如密码字符串 等,希望对该密码字段在序列化时,<br>进行加密,而客户端如果拥有解密的密钥,<br>只有在 客户端进行反序列化时,<br>才可以对密码进行读取,<br>这样可以一定程度保证序列化对象的 数据安全
序列化的方式
Java原生
通过实现 Serializable 接口(没有方法和字段,只起标识作用)实现类对象的序列化,<br>兼容性最好,但性能一般且不支持跨语言。<br><br>建议设置 serialVersionUID 字段值,<br>否则编译器编译器会根据类的内部实现 ,<br>包括类名、接口名、方法和属性等来自动生成 ,<br>源代码重新编译后可能会变化。<br><br>private static final long serialVersionUID = 362498820763181265L;<br>修改类时需要根据兼容性决定是否修改 serialVersionUID 的值,<br>只有在不兼容升级时才修改,避免反序列化混乱。
Hessian
支持动态类型、跨语言、基于对象传输的网络协议,具备以下特性:<br><br>自描述序列化类型。不依赖外部描述文件或接口定义 , <br>用一个字节表示常用基础类型,极大缩短二进制流。<br>语言无关,支持脚本语言。<br>协议简单,比 Java 原生序列化高效。<br>Hessian 会把复杂对象所有属性存储在一个 Map 中进行序列化。<br>所以在父类、子类存在同名成员变量的情况下,Hessian 序列化时,<br>先序列化子类,然后序列化父类,<br>因此反序列化结果会导致子类同名成员变量被父类的值覆盖。
json
将数据对象转换为 JSON 字符串,抛弃了类型信息,<br>在反序列化时需要重新提供。<br>但可读性更好,方便调试。
JAVA复制
直接赋值复制
在Java中,A a1 = a2,<br>我们需要理解的是这实际上复制的是引用,<br>也就是 说a1和a2指向的是同一个对象。<br>因此,当a1变化的时候,a2 里面的成员变量也会跟 着变化。
浅复制(复制引用但不复制引用的对象)
创建一个新对象,然后将当前对象的非静态字段复制到该新对象,<br>如果字段是值类型的, 那么对该字段执行复制;<br>如果该字段是引用类型的话,则复制引用但不复制引用的对象。 <br>因此,原始对象及其副本引用同一个对象。 <br>
深复制(复制对象和其应用对象)
深拷贝不仅复制对象本身,而且复制对象包含的引用指向的所有对象。
序列化(深clone一中实现)
在Java语言里深复制一个对象,<br>常常可以先使对象实现Serializable接口,<br>然后把对 象(实际上只是对象的一个拷贝)写到一个流里,<br>再从流里读出来,便可以重建对象。
JAVA 内部类
定义在类内部的类就被称为内部类。<br>根据定义的方式不同,<br>内部类分为静态内部类,<br>成员内部类,<br>局部内部类,<br>匿名内部类四种。
静态内部类
public class Out { <br>private static int a; <br>private int b; <br>public static class Inner { <br>public void print() { <br>System.out.println(a); <br>} <br>} <br>}
1. 静态内部类可以访问外部类所有的静态变量和方法,即使是private的也一样。 <br>2. 静态内部类和一般类一致,可以定义静态变量、方法,构造方法等。 <br>3. 其它类使用静态内部类需要使用“外部类.静态内部类”方式,<br> 如下所示:Out.Inner inner = new Out.Inner();inner.print(); <br>4. Java集合类HashMap内部就有一个静态内部类Entry。<br>Entry是HashMap存放元素的抽象, HashMap 内部维护 Entry 数组用了存放元素,<br>但是 Entry 对使用者是透明的。<br>像这种和外部 类关系密切的,且不依赖外部类实例的,<br>都可以使用静态内部类。
成员内部类
public class Out { <br> private static int a; <br> private int b; <br> public class Inner { <br> public void print() { <br> System.out.println(a); <br> System.out.println(b); <br> } <br> } <br>}
定义在类内部的非静态类,就是成员内部类。<br>成员内部类不能定义静态方法和变量(final 修饰的 除外)。<br>这是因为成员内部类是非静态的,<br>类初始化的时候先初始化静态成员,<br>如果允许成员内 部类定义静态变量,<br>那么成员内部类的静态变量初始化顺序是有歧义的。
局部内部类
public class Out { <br><br> private static int a; <br>private int b; <br>public void test(final int c) { <br>final int d = 1; <br>class Inner { <br>public void print() { <br>System.out.println(c); <br>} <br>} <br>} <br>}
定义在方法中的类,就是局部类。<br>如果一个类只在某个方法中使用,<br>则可以考虑使用局部类。
匿名内部类<br>(要继承一个父类或者实现一个接口、<br>直接使用 new 来生成一个对象的引用)
public abstract class Bird { <br>private String name; <br>public String getName() { <br>return name; <br>} <br>public void setName(String name) { <br>this.name = name; <br>} <br>public abstract int fly(); <br>} <br>public class Test { <br>public void test(Bird bird){ <br>System.out.println(bird.getName() + "能够飞 " + bird.fly() + "米"); <br>} <br>public static void main(String[] args) { <br>Test test = new Test(); <br>test.test(new Bird() { <br>public int fly() { <br>return 10000; <br>} <br>public String getName() { <br>return "大雁"; <br>} <br>}); <br>} <br>}
匿名内部类我们必须要继承一个父类或者实现一个接口,<br>当然也仅能只继承一个父类或者实现一 个接口。<br>同时它也是没有class关键字,<br>这是因为匿名内部类是直接使用new来生成一个对象的引 用。
public class OuterClass {<br><br> // 成员内部类<br>private class InstanceInnerClass {}<br><br> // 静态内部类<br>static class StaticInnerClass {}<br><br>public static void main(String[] args) {<br>// 匿名内部类<br>(new Thread() {}).start();<br>(new Thread() {}).start();<br><br> // 方法内部类<br>class MethodClass1 {}<br>class MethodClass2 {}<br>}<br><br>}
异常处理
分类
Throwable是 Java 语言中所有错误或异常的超类。下一层分为Error和Exception
自定义异常
继承Exception或RuntimeException
Error
Error类是指java运行时系统的内部错误和资源耗尽错误。<br>应用程序不会抛出该类对象。<br>如果 出现了这样的错误,除了告知用户,剩下的就是尽力使程序安全的终止。
Exception
运行时异常:RunTimeException类的子类
不需要显示的在程序中进行try...catch处理
如:<br>NullPointerException、<br>ConcurrentModificationException、<br>IndexOutOfBoundsException、<br>ClassCastException、<br>NoSuchElementException
受检异常CheckedException:非RuntimeException子类<br><br>一般是外部错误,这种异常都发生在编译阶段,<br>Java 编译器会强 制程序去捕获此类异常,<br>即会出现要求你把这段可能出现异常的程序进行 try catch,<br>该类异常一 般包括几个方面:<br>1. 试图在文件尾部读取数据 <br>2. 试图打开一个错误格式的URL <br>3. 试图根据给定的字符串查找class对象,而这个字符串表示的类并不存在<br>
必须在程序中显示进行异常捕获处理
如:IOException、SQLException、FileNotFoundException等
异常的处理方式
遇到问题不进行具体处理,而是继续抛给调用者( throw,throws ) <br>
一是throw,<br>一个throws,<br>还有一种系统自动抛异常
Throw和throws的区别
位置不同<br><br> 1. throws 用在函数上,后面跟的是异常类,可以跟多个;而 throw 用在函数内,后面跟的 是异常对象。
功能不同: <br>throws 用来声明异常,让调用者只知道该功能可能出现的问题,<br>可以给出预先的处理方 式;<br>throw抛出具体的问题对象,执行到throw,功能就已经结束了,<br>跳转到调用者,并 将具体的问题对象抛给调用者。<br>也就是说 throw 语句独立存在时,<br>下面不要定义其他语 句,因为执行不到。 <br>throws 表示出现异常的一种可能性,<br>并不一定会发生这些异常;<br>throw 则是抛出了异常, <br>执行throw则一定抛出了某种异常对象。 <br>两者都是消极处理异常的方式,<br>只是抛出或者可能抛出异常,<br>但是不会由函数去处理异 常,<br>真正的处理异常由函数的上层调用处理。 <br>
语法
try...catch、try..catch...finally、try...finally
throw、throws
io
BIO
同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
字符流 Writer、Reader
字节流 InputStream、OutputStream<br>
磁盘操作
File 类可以用于表示文件和目录的信息,但是它不表示文件的内容。<br>从 JDK 1.7 开始,可以使用 Paths 和 Files 代替 File。<br>递归地列出一个目录下的所有文件:<br><br>public static void listAllFiles(File dir) {<br>if (dir == null || !dir.exists()) {<br>return;<br>}<br>if (dir.isFile()) {<br>System.out.println(dir.getName());<br>return;<br>}<br>for (File file : dir.listFiles()) {<br>listAllFiles(file);<br>}<br>}
字节操作<br><br>使用 InputStream、OutputStream 读取或写入字节,如操作图片文件等。<br>
文件复制 <br><br>public static void copyFile(String src, String dist) throws IOException {<br>FileInputStream in = new FileInputStream(src);<br>FileOutputStream out = new FileOutputStream(dist);<br><br> byte[] buffer = new byte[20 * 1024];<br>int cnt;<br>// read() 最多读取 buffer.length 个字节<br>// 返回的是实际读取的个数<br>// 返回 -1 的时候表示读到 eof,即文件尾<br>while ((cnt = in.read(buffer, 0, buffer.length)) != -1) {<br>out.write(buffer, 0, cnt);<br>}<br><br>in.close();<br>out.close();<br>}<br>
装饰者模式<br><br>Java I/O 使用了装饰者模式来实现。以 InputStream 为例,<br>InputStream 是抽象组件;<br>FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;<br>FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。<br><br>实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。<br>FileInputStream fileInputStream = new FileInputStream(filePath);<br>BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);<br>DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。<br>
字符操作<br><br>使用 Reader、Writer 操作字符(如 1个 char = 8 bit),<br>增加了字符编码解码等功能,<br>适用于从文件中读取信息。<br>
编码与解码<br><br>编码就是把字符转换为字节,而解码是把字节重新组合成字符。<br>如果编码和解码过程使用不同的编码方式那么就出现了乱码。<br>GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;<br>UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;<br>UTF-16be 编码中,中文字符和英文字符都占 2 个字节。<br>UTF-16be 中的 be 指的是 Big Endian,也就是大端。<br>相应地也有 UTF-16le,le 指的是 Little Endian,也就是小端。<br><br>Java 的内存编码使用双字节编码 UTF-16be,这不是指 Java 只支持这一种编码方式,<br>而是说 char 这种类型使用 UTF-16be 进行编码。<br>char 类型占 16 位,也就是两个字节,<br>Java 使用这种双字节编码是为了让一个中文或者一个英文都能使用一个 char 来存储。<br>
String 的编码方式<br><br>String 可以看成一个字符序列,<br>可以指定一个编码方式将它编码为字节序列,<br>也可以指定一个编码方式将一个字节序列解码为 String。<br><br>String str1 = "中文";<br>byte[] bytes = str1.getBytes("UTF-8");<br>String str2 = new String(bytes, "UTF-8");<br>System.out.println(str2);<br>在调用无参数 getBytes() 方法时,<br>默认的编码方式不是 UTF-16be。<br>双字节编码的好处是可以使用一个 char 存储中文和英文,<br>而将 String 转为 bytes[] 字节数组就不再需要这个好处,<br>因此也就不再需要双字节编码。<br>getBytes() 的默认编码方式与平台有关,一般为 UTF-8。<br><br>byte[] bytes = str1.getBytes();<br>
Reader 与 Writer<br><br>不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符。<br>但是在程序中操作的通常是字符形式的数据,<br>因此需要提供对字符进行操作的方法。<br><br>InputStreamReader 实现从字节流解码成字符流;<br>OutputStreamWriter 实现字符流编码成为字节流。<br>public static void readFileContent(String filePath) throws IOException {<br>FileReader fileReader = new FileReader(filePath);<br>BufferedReader bufferedReader = new BufferedReader(fileReader);<br>String line;<br>while ((line = bufferedReader.readLine()) != null) {<br>System.out.println(line);<br>}<br><br>// 装饰者模式使得 BufferedReader 组合了一个 Reader 对象<br>// 在调用 BufferedReader 的 close() 方法时会去调用 Reader 的 close() 方法<br>// 因此只要一个 close() 调用即可<br>bufferedReader.close();<br>}<br>
网络操作<br><br>对于 Socket 服务端,在传统 IO 中,<br>给每个接入的客户端请求都创建一个线程处理会导致巨大的开销(线程频繁创建、切换),<br>尽管可以通过线程池来管理工作线程,<br>但当连接数急剧上升时这种方式也无法避免线程上下文切换的巨大开销:<br>
InetAddress<br><br>用于表示网络上的硬件资源,即 IP 地址;<br>没有公有的构造函数,只能通过静态方法来创建实例。<br>InetAddress.getByName(String host);<br>InetAddress.getByAddress(byte[] address);<br>
URL
Sockets
父主题
使用 TCP 协议实现网络通信。<br><br>ServerSocket:服务器端类<br>Socket:客户端类<br>服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。<br><br>一个简单的 Socket 服务器实现:<br><br>public class DemoServer extends Thread {<br>private ServerSocket serverSocket;<br>public int getPort() {<br>return serverSocket.getLocalPort();<br>}<br><br> public void run() {<br>try {<br>// 服务端启动 ServerSocket,自动绑定一个空闲端口<br>serverSocket = new ServerSocket(0);<br>while (true) {<br>// 调用 accept 方法,阻塞等待客户端连接<br>Socket socket = serverSocket.accept();<br>RequestHandler requestHandler = new RequestHandler(socket);<br>requestHandler.start();<br>}<br>} catch (IOException e) {<br>e.printStackTrace();<br>} finally {<br>if (serverSocket != null) {<br>try {<br>serverSocket.close();<br>} catch (IOException e) {<br>e.printStackTrace();<br>};<br>}<br>}<br>}<br><br> public static void main(String[] args) throws IOException {<br>DemoServer server = new DemoServer();<br>server.start();<br>// 利用 Socket 模拟一个客户端,只进行连接、读取和打印 <br>try (Socket client = new Socket(InetAddress.getLocalHost(), server.getPort())) {<br>BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(client.getInputStream()));<br>bufferedReader.lines().forEach(s -> System.out.println(s));<br>}<br>}<br>}<br><br>// 简化实现,不做读取,直接发送字符串<br>class RequestHandler extends Thread {<br>private Socket socket;<br>RequestHandler(Socket socket) {<br>this.socket = socket;<br>}<br><br>@Override<br>public void run() {<br>try (PrintWriter out = new PrintWriter(socket.getOutputStream());) {<br>out.println("Hello world!");<br>out.flush();<br>} catch (Exception e) {<br>e.printStackTrace();<br>}<br>}<br>}
Datagram<br><br>Datagram:使用 UDP 协议实现网络通信,其中:<br>DatagramSocket:通信类<br>DatagramPacket:数据包类<br>
NIO<br><br>NIO 在 JDK 1.4 引入,是多路复用、同步非阻塞 IO:<br><br>新的输入/输出 (NIO) 库是在 JDK 1.4 中引入的,弥补了原来的 I/O 的不足,提供了高速的、面向块的 I/O;<br>NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。<br>
同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
块:Block
I/O 与 NIO 最重要的区别是数据打包和传输的方式,<br>I/O 以流的方式处理数据,<br>而 NIO 以块的方式处理数据。<br><br>面向流:一次处理一个字节数据。<br>为流式数据创建过滤器非常容易,链接几个过滤器,<br>以便每个过滤器只负责复杂处理机制的一部分。<br>缺点是 I/O 通常相当慢;<br><br>面向块:一次处理一个数据块,<br>按块处理数据比按流处理数据要快得多。<br>但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。<br><br>java.io.* 已经以 NIO 为基础重新实现,<br>可以利用 NIO 的一些特性。<br>例如 java.io.* 包中的一些类包含以块的形式读写数据的方法,<br>这使得即使在面向流的系统中,处理速度也会更快。
字符集:Charset
提供 Unicode 字符串定义,NIO 也提供了相应的编码解码器,如:<br><br>Charset.defaultCharset().encode("Hello world!"));
通道:Channel<br><br>类似 Linux 系统的文件描述符(FileDescriptor),<br>是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。<br><br>与流的不同之处在于,<br>流只能在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类),<br>而通道是双向的,可以用于读、写或者同时用于读写。<br>
FileChannel 从文件中读写数据。<br><br>DatagramChannel 通过 UDP 读写网络中数据。<br><br>SocketChannel 通过 TCP 读写网络中数据。<br><br>ServerSocketChannel 可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
缓冲区:Buffer<br><br>高效的数据容器,<br>数据进出通道都需要经过缓冲区。<br>本质上是一个数组,<br>但提供了对数据的结构化访问,<br>而且还可以跟踪系统的读/写进程。<br>除了布尔类型,<br>所有原始类型都提供了相应的 Buffer 实现(XxxBuffer)。<br>
读写过程
选择器:Selector<br><br>NIO 实现了 IO 多路复用中的 Reactor 模型,<br>一个线程 Thread 使用一个选择器 Selector 通过轮询的方式去监听多个通道 Channel 上的事件,<br>从而让一个线程就可以处理多个事件。<br><br>通过配置监听的通道 Channel 为非阻塞,<br>那么当 Channel 上的 IO 事件还未到达时,<br>就不会进入阻塞状态一直等待,<br>而是继续轮询其它 Channel,<br>找到 IO 事件已经到达的 Channel 执行;<br><br>因为创建和切换线程的开销很大,<br>因此使用一个线程来处理多个事件而不是一个线程处理一个事件,<br>对于 IO 密集型的应用具有很好地性能。<br>
NIO 操作
文件操作
使用 NIO 快速复制文件:<br><br>public static void fastCopy(String src, String dist) throws IOException {<br>/* 获得源文件的输入字节流 */<br>FileInputStream fin = new FileInputStream(src);<br>/* 获取输入字节流的文件通道 */<br>FileChannel fcin = fin.getChannel();<br>/* 获取目标文件的输出字节流 */<br>FileOutputStream fout = new FileOutputStream(dist);<br>/* 获取输出字节流的文件通道 */<br>FileChannel fcout = fout.getChannel();<br>/* 为缓冲区分配 1024 个字节 */<br>ByteBuffer buffer = ByteBuffer.allocateDirect(1024);<br>while (true) {<br>/* 从输入通道中读取数据到缓冲区中 */<br>int r = fcin.read(buffer);<br>/* read() 返回 -1 表示 EOF */<br>if (r == -1) {<br>break;<br>}<br><br>/* 切换读写 */<br>buffer.flip();<br>/* 把缓冲区的内容写入输出文件中 */<br>fcout.write(buffer);<br>/* 清空缓冲区 */<br>buffer.clear();<br>}<br>}<br><br>或者利用 transferTo 或 transferFrom 方法实现(可能更快,更能利用操作系底层细节,避免不必要的拷贝和上下文切换):<br>public static void copyFileByChannel(File source, File dest) throws IOException {<br>try (<br>FileChannel sourceChannel = new FileInputStream(source).getChannel();<br>FileChannel targetChannel = new FileOutputStream(dest).getChannel();<br>){<br>for (long count = sourceChannel.size() ;count>0 ;) {<br>long transferred = sourceChannel.transferTo(sourceChannel.position(), count, targetChannel);<br>sourceChannel.position(sourceChannel.position() + transferred);<br>count -= transferred;<br>}<br>}<br>}
套接字操作
1. 创建选择器<br>
创建 Selector,充当类似调度员的角色。<br><br>Selector selector = Selector.open();
2. 通道注册到选择器
创建通道必须配置为非阻塞模式,<br>否则使用选择器就没有任何意义了,<br>因为如果通道在某个事件上被阻塞,<br>那么服务器就不能响应其它事件,<br>必须等待这个事件处理完毕才能去处理其它事件<br>(而且注册也不允许,会抛出 ILLegalBlockingModeException 异常)。<br><br>ServerSocketChannel ssChannel = ServerSocketChannel.open();<br>ssChannel.configureBlocking(false);<br>ssChannel.register(selector, SelectionKey.OP_ACCEPT); // 请求接入<br>在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:<br><br>SelectionKey.OP_CONNECT<br>SelectionKey.OP_ACCEPT<br>SelectionKey.OP_READ<br>SelectionKey.OP_WRITE<br><br>它们在 SelectionKey 的定义如下:<br><br>public static final int OP_READ = 1 << 0;<br>public static final int OP_WRITE = 1 << 2;<br>public static final int OP_CONNECT = 1 << 3;<br>public static final int OP_ACCEPT = 1 << 4;<br><br><br><br>// 可以看出每个事件可以被当成一个位域,从而组成事件集整数,例如:<br>// int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
3. 监听事件
使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。<br><br>int num = selector.select();
4. 获取到达的事件
Set<SelectionKey> keys = selector.selectedKeys();<br>Iterator<SelectionKey> keyIterator = keys.iterator();<br>while (keyIterator.hasNext()) {<br>SelectionKey key = keyIterator.next();<br>if (key.isAcceptable()) {<br>// ...<br>} else if (key.isReadable()) {<br>// ...<br>}<br>keyIterator.remove();<br>}
5. 事件循环
因为一次 select() 调用不能处理完所有的事件,<br>并且服务器端有可能需要一直监听事件,<br>因此服务器端处理事件的代码一般会放在一个死循环内。<br><br>while (true) {<br>int num = selector.select();<br>Set<SelectionKey> keys = selector.selectedKeys();<br>Iterator<SelectionKey> keyIterator = keys.iterator();<br>while (keyIterator.hasNext()) {<br>SelectionKey key = keyIterator.next();<br>if (key.isAcceptable()) {<br>// ...<br>} else if (key.isReadable()) {<br>// ...<br>}<br>keyIterator.remove();<br>}<br>}
demo
采用单线程轮询事件的机制,通过高效地定位就绪 Channel 来决定工作,<br>只有在 select 阶段是阻塞的(等待至少一个客户端请求接入),<br>可避免大量客户端连接时频繁线程切换的问题。<br><br><br><br>public class NIOServer {<br> public static void main(String[] args) throws IOException {<br>Selector selector = Selector.open();<br>ServerSocketChannel ssChannel = ServerSocketChannel.open();<br>ssChannel.configureBlocking(false);<br>ssChannel.register(selector, SelectionKey.OP_ACCEPT);<br>ServerSocket serverSocket = ssChannel.socket();<br>InetSocketAddress address = new InetSocketAddress("127.0.0.1", 8888);<br>serverSocket.bind(address);<br>while (true) {<br>selector.select();<br>Set<SelectionKey> keys = selector.selectedKeys();<br>Iterator<SelectionKey> keyIterator = keys.iterator();<br>while (keyIterator.hasNext()) {<br>SelectionKey key = keyIterator.next();<br>if (key.isAcceptable()) {<br>ServerSocketChannel ssChannel1 = (ServerSocketChannel) key.channel();<br>// 服务器会为每个新连接创建一个 SocketChannel<br>SocketChannel sChannel = ssChannel1.accept();<br>sChannel.configureBlocking(false);<br>// 这个新连接主要用于从客户端读取数据<br>sChannel.register(selector, SelectionKey.OP_READ);<br>} else if (key.isReadable()) {<br>SocketChannel sChannel = (SocketChannel) key.channel();<br>System.out.println(readDataFromSocketChannel(sChannel));<br>sChannel.close();<br>}<br>keyIterator.remove();<br>}<br>}<br>}<br><br>private static String readDataFromSocketChannel(SocketChannel sChannel) throws IOException {<br>ByteBuffer buffer = ByteBuffer.allocate(1024);<br>StringBuilder data = new StringBuilder();<br>while (true) {<br>buffer.clear();<br>int n = sChannel.read(buffer);<br>if (n == -1) {<br>break;<br>}<br>buffer.flip();<br>int limit = buffer.limit();<br>char[] dst = new char[limit];<br>for (int i = 0; i < limit; i++) {<br>dst[i] = (char) buffer.get(i);<br>}<br>data.append(dst);<br>buffer.clear();<br>}<br>return data.toString();<br>}<br>}<br><br>public class NIOClient {<br>public static void main(String[] args) throws IOException {<br>Socket socket = new Socket("127.0.0.1", 8888);<br>OutputStream out = socket.getOutputStream();<br>String s = "hello world";<br>out.write(s.getBytes());<br>out.close();<br>}<br>}
NIO2
异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
AIO 即 NIO 2,是异步非阻塞 IO,JDK 1.7 对 NIO 进行了重大改进:<br><br>提供全面的异步文件 IO 和文件系统访问支持(java.nio.file);<br>基于异步 Channel 的 IO(java.nio.channels);<br>在 Windows 上通过 IOCP、在 Linux 上通过 epoll 实现。<br>AsynchronousServerSocketChannel serverSock = AsynchronousServerSocketChannel.open().bind(sockAddr);<br>// 为异步操作指定 CompletionHandler 回调函数<br>serverSock.accept(serverSock, new CompletionHandler<>() { <br>@Override<br>public void completed(AsynchronousSocketChannel sockChannel, AsynchronousServerSocketChannel serverSock) {<br>serverSock.accept(serverSock, this);<br>// 另外一个 write(sock,CompletionHandler{})<br>sayHelloWorld(sockChannel, Charset.defaultCharset().encode<br>("Hello World!"));<br>}<br>// 省略其他路径处理方法...<br>});
内存映射文件
内存映射文件 I/O 是一种读和写文件数据的方法,<br>它可以比常规的基于流或者基于通道的 I/O 快得多。<br><br>向内存映射文件写入可能是危险的,<br>只是改变数组的单个元素这样的简单操作,<br>就可能会直接修改磁盘上的文件。<br>修改数据与将数据保存到磁盘是没有分开的。<br><br>下面代码行将文件的前 1024 个字节映射到内存中,<br>map() 方法返回一个 MappedByteBuffer,它是 ByteBuffer 的子类。<br>因此,可以像使用其他任何 ByteBuffer 一样使用新映射的缓冲区,<br>操作系统会在需要时负责执行映射。<br><br>MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
IO原理
同步和异步
同步:可靠有序的运行机制,进行同步操作时,后续任务是等待当前调用返回才执行;<br><br>异步:不等待当前调用返回,而通过事件、回调等机制实现任务间的次序关系。
阻塞和非阻塞
阻塞:进行操作时,当前线程处于等待状态,无法从事其他任务,直到条件就绪才能继续;<br><br>非阻塞:不过 IO 操作是否结束,直接返回,相应操作在后台继续处理。
Base64 转换文件
public static String encryptToBase64(String filePath) {<br> if (filePath == null) {<br> return null;<br> }<br> try {<br> byte[] b = Files.readAllBytes(Paths.get(filePath));<br> return Base64.getEncoder().encodeToString(b);<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br><br> return null;<br> }<br><br> public static String decryptByBase64(String base64, String filePath) {<br> if (base64 == null && filePath == null) {<br> return "生成文件失败,请给出相应的数据。";<br> }<br> try {<br> Files.write(Paths.get(filePath), Base64.getDecoder().decode(base64), StandardOpenOption.CREATE);<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br> return "success";<br> }
Java7易忽略的新特性
try-with-resources语句:简化资源的关闭操作,会自动在语句结束后将每个资源正确关闭。 <br>注:该资源类必须要直接或间接实现 java.lang.AutoCloseable 接口,该接口只包含一个close方法 <br>
switch语句支持String类型
单个catch捕获多个异常,如 catch(IOException | SQLException | FileNotFoundException ex)
泛型实例化类型自动推断,如List<Integer> list = new ArrayList<>();
数值可以使用下划线分隔,如 int n = 1_000_000表示1000000
多核并行计算支持: fork/join 框架
Java8新特性
介绍
函数式编程
函数式编程是相对于命令式编程而言的,常见的面向对象、面向过程编程都属于命令式编程。 <br><b>函数式编程关心数据的映射,命令式编程关心解决问题的步骤。</b>
高阶函数
简言之,就是该函数的参数可以是函数,类似于C语言中的函数指针
语法
函数式接口
定义
只含有一个抽象方法的接口,<br>或使用@FunctionalInterface注解的接口。<br>@FunctionalInterface注解和@Override用法类似,<br>都是在编译期进行检查
lambda表达式的类型就是函数式接口
内置函数接口
位于java.util.function包中
分类
Supplier<T>
数据提供,T表示 get 方法的返回类型
Consumer<T>
数据消费,T表示 accept 方法的参数类型
Function<T, R>
数据转换,T和R分别表示 apply 方法的参数和返回值类型
Predicate<T>
条件测试,T表示 test 方法的参数类型,返回值为boolean类型
用法
通常作为方法参数来使用(也可作为返回值): <br>Stream 的 map 方法接受Function<T, R> 作为参数,<br>filter 使用Predicate<T>作为参数,<br>forEach 使用Consumer<T>作为参数。
自定义函数接口
满足函数式接口的要求(只有一个抽象方法的接口),<br>在IDE中可以使用 @FunctionalInterface 注解来验证该要求是否满足
lambda表达式
lambda表达式体现了数据输入(方法参数)与输出(返回结果)的对应关系,实际就是一个回调函数
语法:()->{}:分别表示“参数->方法体”,只有函数式接口(Functional Interface)能写成此形式
可用于替代匿名内部类,它与匿名内部类的区别: <br>① this关键字指向不同:匿名类中this指代当前匿名类对象,<br>而lambda表达式中this指向包含它的类的对象。<br><br>② 编译方式不同:Java编译器将lambda表达式编译成类的私有方法,<br>使用了Java 7的 invokedynamic 字节码指令来动态绑定这个方法。
接口的默认方法default和静态方法static
方法引用
可用来替代传递lambda表达式,省略参数传递的表示,使代码更简洁和更具可读性
分类
构造器引用,如Integer::new
静态方法引用,如Integer::parseInt
特定类的任意对象的方法引用,语法是ClassName::method
特定对象的方法引用,语法是instance::method
变量类型推断机制,仅适用于lambda表达式中的参数类型推断
扩展注解的支持
重复注解
重复注解,允许一个注解同时出现多次。 <br>注意:重复注解机制本身必须用@Repeatable注解。
@Repeatable:允许在同一声明类型(类,属性,或方法)上多次使用同一个注解
类型注解
为@Target元注解的ElementType枚举类型<br>增加了TYPE_PARAMETER、TYPE_USE两个枚举值,<br>扩展了注解的使用范围
编译器
运行时方法参数名字,可通过反射API与Parameter.getName()方法获取
类库
Stream API
java.util.stream.Stream接口
支持集合元素的串、并行聚合操作
Stream 操作分为中间操作或者最终操作两种。 <br>最终操作返回一特定类型的计算结果,<br>而中间操作返回Stream本身,<br>这样就可以将多个操作依次串起来,形成链式调用。
注意:一旦执行终止操作后就不能再使用了
java.util.stream.Collectors工具类
Collectors.toList()、<br>Collectors.toSet()、<br>Collectors.groupingBy()(分组)、<br>Collectors.partitioningBy()(可替代if...else语句,进行条件划分)等方法
其它接口
如:<br>IntStream、FloatStream、<br>LongStream、DoubleStream等,<br>其中包括 range、rangeClosed、iterate 和 limit等方法
位于集合框架Collection接口的API中,<br>可用来简化foreach循环代码,<br>以及处理集合元素的计算、排序与统计等操作。
集合以表示数据为主,Stream流以计算为主
包括stream(创建串行流对象)、<br>parallelStream(创建并行流对象)、<br>filter(过滤元素)、<br>map(映射)、<br>reduce、<br>collect(收集)、<br>count(计数)等方法
新的Date/Time API (JSR 310)
包括LocalDate、LocalTime、LocalDateTime等
LocalDate
LocalDate是一个不可变的类,<br>它表示默认格式(yyyy-MM-dd)的日期,<br>我们可以使用now()方法得到当前时间,<br>也可以提供输入年份、月份和日期的输入参数来创建一个LocalDate实例。<br>该类为now()方法提供了重载方法,我们可以传入ZoneId来获得指定时区的日期。
@Test<br>public void testLocalDate() {<br> //Current Date<br> LocalDate today = LocalDate.now();<br> System.out.println("Current Date=" + today);<br><br> //Creating LocalDate by providing input arguments<br> LocalDate firstDay_2014 = LocalDate.of(2014, Month.JANUARY, 1);<br> System.out.println("Specific Date=" + firstDay_2014);<br><br> //Try creating date by providing invalid inputs<br> //LocalDate feb29_2014 = LocalDate.of(2014, Month.FEBRUARY, 29);<br> //Exception in thread "main" java.time.DateTimeException:<br> //Invalid date 'February 29' as '2014' is not a leap year<br><br> //Current date in "Asia/Kolkata", you can get it from ZoneId javadoc<br> LocalDate todayKolkata = LocalDate.now(ZoneId.of("Asia/Kolkata"));<br> System.out.println("Current Date in IST=" + todayKolkata);<br><br> //java.time.zone.ZoneRulesException: Unknown time-zone ID: IST<br> //LocalDate todayIST = LocalDate.now(ZoneId.of("IST"));<br><br> //Getting date from the base date i.e 01/01/1970<br> LocalDate dateFromBase = LocalDate.ofEpochDay(365);<br> System.out.println("365th day from base date= " + dateFromBase);<br><br> LocalDate hundredDay2014 = LocalDate.ofYearDay(2014, 100);<br> System.out.println("100th day of 2014=" + hundredDay2014);<br>}
<b><font color="#c41230">output:</font></b><br><br>Current Date=2018-05-29<br>Specific Date=2014-01-01<br>Current Date in IST=2018-05-29<br>365th day from base date= 1971-01-01<br>100th day of 2014=2014-04-10
LocalTime
LocalTime是一个不可变的类<br>它的实例代表一个符合人类可读格式的时间,<br>默认格式是hh:mm:ss.zzz。像LocalDate一样,<br>该类也提供了时区支持,<br>同时也可以传入小时、分钟和秒等输入参数创建实例<br>
@Test<br>public void testLocalTime() {<br> //Current Time<br> LocalTime time = LocalTime.now();<br> System.out.println("Current Time=" + time);<br><br> //Creating LocalTime by providing input arguments<br> LocalTime specificTime = LocalTime.of(12, 20, 25, 40);<br> System.out.println("Specific Time of Day=" + specificTime);<br><br> //Try creating time by providing invalid inputs<br> //LocalTime invalidTime = LocalTime.of(25,20);<br> //Exception in thread "main" java.time.DateTimeException:<br> //Invalid value for HourOfDay (valid values 0 - 23): 25<br><br> //Current date in "Asia/Kolkata", you can get it from ZoneId javadoc<br> LocalTime timeKolkata = LocalTime.now(ZoneId.of("Asia/Kolkata"));<br> System.out.println("Current Time in IST=" + timeKolkata);<br><br> //java.time.zone.ZoneRulesException: Unknown time-zone ID: IST<br> //LocalTime todayIST = LocalTime.now(ZoneId.of("IST"));<br><br> //Getting date from the base date i.e 01/01/1970<br> LocalTime specificSecondTime = LocalTime.ofSecondOfDay(10000);<br> System.out.println("10000th second time= " + specificSecondTime);<br>}
<b><font color="#c41230">Output:</font></b><br><br>Current Time=19:09:39.656<br>Specific Time of Day=12:20:25.000000040<br>Current Time in IST=16:39:39.657<br>10000th second time= 02:46:40
LocalDateTime
LocalDateTime是一个不可变的日期-时间对象,<br>它表示一组日期-时间,默认格式是yyyy-MM-dd-HH-mm-ss.zzz。<br>它提供了一个工厂方法,<br>接收LocalDate和LocalTime输入参数,<br>创建LocalDateTime实例。
@Test<br>public void testLocalDateTime() {<br> //Current Date<br> LocalDateTime today = LocalDateTime.now();<br> System.out.println("Current DateTime=" + today);<br><br> //Current Date using LocalDate and LocalTime<br> today = LocalDateTime.of(LocalDate.now(), LocalTime.now());<br> System.out.println("Current DateTime=" + today);<br><br> //Creating LocalDateTime by providing input arguments<br> LocalDateTime specificDate = LocalDateTime.of(2014, Month.JANUARY, 1, 10, 10, 30);<br> System.out.println("Specific Date=" + specificDate);<br><br> //Try creating date by providing invalid inputs<br> //LocalDateTime feb29_2014 = LocalDateTime.of(2014, Month.FEBRUARY, 28, 25,1,1);<br> //Exception in thread "main" java.time.DateTimeException:<br> //Invalid value for HourOfDay (valid values 0 - 23): 25<br><br> //Current date in "Asia/Kolkata", you can get it from ZoneId javadoc<br> LocalDateTime todayKolkata = LocalDateTime.now(ZoneId.of("Asia/Kolkata"));<br> System.out.println("Current Date in IST=" + todayKolkata);<br><br> //java.time.zone.ZoneRulesException: Unknown time-zone ID: IST<br> //LocalDateTime todayIST = LocalDateTime.now(ZoneId.of("IST"));<br><br> //Getting date from the base date i.e 01/01/1970<br> LocalDateTime dateFromBase = LocalDateTime.ofEpochSecond(10000, 0, ZoneOffset.UTC);<br> System.out.println("10000th second time from 01/01/1970= " + dateFromBase);<br>}
<b><font color="#c41230">Output:</font></b><br><br>Current DateTime=2018-05-29T19:10:00.353<br>Current DateTime=2018-05-29T19:10:00.353<br>Specific Date=2014-01-01T10:10:30<br>Current Date in IST=2018-05-29T16:40:00.353<br>10000th second time from 01/01/1970= 1970-01-01T02:46:40
java.time.Instant
Instant类是用在机器可读的时间格式上的,<br>它以Unix时间戳的形式存储日期时间
@Test<br>public void testTimestampForInstant() {<br> //Current timestamp<br> Instant timestamp = Instant.now();<br> System.out.println("Current Timestamp = " + timestamp);<br><br> //Instant from timestamp<br> Instant specificTime = Instant.ofEpochMilli(timestamp.toEpochMilli());<br> System.out.println("Specific Time = " + specificTime);<br><br> //Duration example<br> Duration thirtyDay = Duration.ofDays(30);<br> System.out.println(thirtyDay);<br>}
日期API工具
大多数日期/时间API类都实现了一系列工具方法,<br>如:加/减天数、周数、月份数,等等。<br>还有其他的工具方法能够使用TemporalAdjuster调整日期,<br>并计算两个日期间的周期。
@Test<br>public void testDateTool() {<br> LocalDate today = LocalDate.now();<br><br> //Get the Year, check if it's leap year<br> System.out.println("Year " + today.getYear() + " is Leap Year? " + today.isLeapYear());<br><br> //Compare two LocalDate for before and after<br> System.out<br> .println("Today is before 01/01/2015? " + today.isBefore(LocalDate.of(2015, 1, 1)));<br><br> //Create LocalDateTime from LocalDate<br> System.out.println("Current Time=" + today.atTime(LocalTime.now()));<br><br> //plus and minus operations<br> System.out.println("10 days after today will be " + today.plusDays(10));<br> System.out.println("3 weeks after today will be " + today.plusWeeks(3));<br> System.out.println("20 months after today will be " + today.plusMonths(20));<br><br> System.out.println("10 days before today will be " + today.minusDays(10));<br> System.out.println("3 weeks before today will be " + today.minusWeeks(3));<br> System.out.println("20 months before today will be " + today.minusMonths(20));<br><br> //Temporal adjusters for adjusting the dates<br> System.out.println(<br> "First date of this month= " + today.with(TemporalAdjusters.firstDayOfMonth()));<br> LocalDate lastDayOfYear = today.with(TemporalAdjusters.lastDayOfYear());<br> System.out.println("Last date of this year= " + lastDayOfYear);<br><br> Period period = today.until(lastDayOfYear);<br> System.out.println("Period Format= " + period);<br> System.out.println("Months remaining in the year= " + period.getMonths());<br>}
解析和格式化:将一个日期格式转换为不同的格式,<br>之后再解析一个字符串,得到日期时间对象,这些都是很常见的。
@Test<br>public void testFormat() {<br> //Format examples<br> LocalDate date = LocalDate.now();<br> //default format<br> System.out.println("Default format of LocalDate=" + date);<br> //specific format<br> System.out.println(date.format(DateTimeFormatter.ofPattern("d::MMM::uuuu")));<br> System.out.println(date.format(DateTimeFormatter.BASIC_ISO_DATE));<br><br> LocalDateTime dateTime = LocalDateTime.now();<br> //default format<br> System.out.println("Default format of LocalDateTime=" + dateTime);<br> //specific format<br> System.out.println(dateTime.format(DateTimeFormatter.ofPattern("d::MMM::uuuu HH::mm::ss")));<br> System.out.println(dateTime.format(DateTimeFormatter.BASIC_ISO_DATE));<br><br> Instant timestamp = Instant.now();<br> //default format<br> System.out.println("Default format of Instant=" + timestamp);<br><br> //Parse examples<br> LocalDateTime dt = LocalDateTime.parse("27::五月::2014 21::39::48",<br> DateTimeFormatter.ofPattern("d::MMM::uuuu HH::mm::ss"));<br> System.out.println("Default format after parsing = " + dt);<br>}
String类
新添加了一个新的join方法,该方法实现了字符串的拼接,可以把它看作split方法的逆操作
java.nio.file.Files类
为使用流读取文件行及访问目录项提供了一些简便的方法,如copy、list、walk、find等方法
JDBC增强
新增API
java.sql.DriverAction 接口
java.sql.SQLType 接口
java.sql.JDBCType 枚举
改变已有的接口
Optional类
用于防止NullPointerException的出现,避免null值判断。<br>可配合Lambda表达式使用,使代码更简洁美观,<br>包括(工厂方法of、ofNullable)、filter、map、orElse、get等方法
常用方法: <br><br>isPresent() :判断容器中是否有值。<br>ifPresent(Consume lambda) :容器若不为空则执行括号中的Lambda表达式。<br>T get() :获取容器中的元素,若容器为空则抛出NoSuchElement异常。<br>T orElse(T other) :获取容器中的元素,若容器为空则返回括号中的默认值
Base64类
提供原生Base64编码、解码支持,不需要再依赖第三方库
Base64.getEncoder().encodeToString(bytes)<br><br>Base64.getDecoder().decode(str)
并行(parallel)数组
Arrays类中增加对数组元素进行排序、过滤、分组相关并行操作API,比如parallelSort方法
java.util.concurrent 并发包
CompletionStage<T>接口
CompletableFuture类
函数式异步编程辅助类<br><br>实现了CompletionStage和Future接口
CompletionService
用于获取多个异步任务的执行结果
原理:将已经执行完成的任务保存在一个阻塞队列中,<br>使用take、poll方法从队列中取出任务获得执行结果
由于队列的特性,可以保证先执行完成的任务先拿到结果,因此可以减少等待时间
实现类:ExecutorCompletionService
使用Executor来执行任务
java.util.concurrent.atomic 子包
增加 DoubleAccumulator、DoubleAdder、LongAccumulator、 LongAdder四个类
LongAdder VS AtomicLong
原有的Atomic系列类通过CAS来保证并发时操作的原子性,<br>但是高并发也就意味着CAS的失败次数会增多,<br>失败次数的增多会引起更多线程的重试,<br>最后导致AtomicLong的效率降低。
低并发时两个类差不多,而高并发时使用LongAdder更高效
Java8 in action
第1章
新特性简介
特定类的任意对象的方法引用,语法是ClassName::method
你想要筛选一个目录中的所有隐藏文件。<br>你需要编写一个方法,然后给它一个File,<br>它就会告诉你文件是不是隐藏的。<br>幸好,File类里面有一个叫作isHidden的方法。<br>我们可以把它看作一个函数,<br>接受一个File,返回一个布尔值。<br>但要用它做筛选,你需要把它包在一个FileFilter对象里,<br>然后传递给File.listFiles方法
File[] hiddenFiles = new File(".").listFiles(new FileFilter() {<br> public boolean accept(File file) {<br> return file.isHidden();<br> }<br>});
子主题
你已经有了函数isHidden,<br>因此只需用Java 8的方法引用::语法<br>(即“把这个方法作为值”)将其传给listFiles方法
File[] hiddenFiles = new File(".").listFiles(File::isHidden);
与用对象引用传递对象类似(对象引用是用new创建的),<br>在Java 8里写下<br>File::isHidden的时候,你就创建了一个方法引用,你同样可以传递它
子主题
传递代码的一个例子<br>
假设你有一个Apple类<br>
before Java8
它有一个getColor方法,<br>还有一个变量inventory保存着一个Apples的列表。<br>你可能想要选出所有的绿苹果,并返回一个列表。<br><br>通常我们用筛选(filter)一词来表达这个概念。
public static List<apple> filterGreenApples(List<apple> inventory){<br> List<apple> result = new ArrayList<>();<br> for (Apple apple: inventory){<br> if ("green".equals(apple.getColor())) {<br> result.add(apple);<br> }<br> }<br> return result;<br>} </apple></apple></apple>
选出重的苹果,比如超过150克
public static List<apple> filterHeavyApples(List<apple> inventory){<br> List<apple> result = new ArrayList<>();<br> for (Apple apple: inventory){<br> if (apple.getWeight() > 150) {<br> result.add(apple);<br> }<br> }<br> return result;<br>} </apple></apple></apple>
Java8
Java 8会把条件代码作为参数传递进去,<br>这样可以避免filter方法出现重复的代码。
public static boolean isGreenApple(Apple apple) {<br> return "green".equals(apple.getColor());<br>}<br><br>public static boolean isHeavyApple(Apple apple) {<br> return apple.getWeight() > 150;<br>} <br>//Predicate 从库中import即可<br>public interface Predicate<t>{ <br> boolean test(T t); <br>} <br></t><br>static List<apple> filterApples(List<apple> inventory, Predicate<apple> p) {<br> List<apple> result = new ArrayList<>();<br> for (Apple apple: inventory){<br> if (p.test(apple)) { <br> result.add(apple);<br> }<br> }<br> return result;<br>} <br></apple></apple></apple></apple><br><br>filterApples(inventory, Apple::isGreenApple); <br><br>filterApples(inventory, Apple::isHeavyApple); <br><br>//引入Lambda<br>//代替isGreenApple(Apple apple)函数<br>filterApples(inventory, (Apple a) -> "green".equals(a.getColor()) );<br><br>//代替isHeavyApple(Apple apple)函数<br>filterApples(inventory, (Apple a) -> a.getWeight() > 150 ); <br>
流的例子
从一个列表中筛选金额较高的交易,然后按货币分组。
before Java8
子主题
Java8
子主题
用集合的话,你得自己去做迭代的过程。<br>你得用for-each循环一个个去迭代元素,然后再处理元素。<br>我们把这种数据迭代的方法称为外部迭代。<br>相反,有了Stream API,你根本用不着操心循环的事情。<br>数据处理完全是在库内部进行的。<br>我们把这种思想叫作内部迭代。
多线程
顺序处理
子主题
并行处理
子主题
子主题
接口中的默认方法
public interface List<e> extends Collection<e> {<br> <b><font color="#80bc42">default</font> </b>void sort(Comparator<!--? super E--> c) {<br> Object[] a = this.toArray();<br> Arrays.sort(a, (Comparator) c);<br> ListIterator<e> i = this.listIterator();<br> for (Object e : a) {<br> i.next();<br> i.set((E) e);<br> }<br> }</e><br>}</e></e>
Optional<t>类 避免NullPointer异常</t>
第2章
行为参数化
应对不断变化的需求
筛选绿苹果
初始方案
子主题
方案二:<br>把颜色作为参数
子主题
调用方法<br><br>List<apple> greenApples = filterApplesByColor(inventory, "green");<br>List<apple> redApples = filterApplesByColor(inventory, "red"); </apple></apple>
改变为筛选重量
子主题
每个属性做筛选
子主题
调用<br><br>List<apple> greenApples = filterApples(inventory, "green", 0, true); <br>List<apple> heavyApples = filterApples(inventory, "", 150, false); </apple><br></apple>
使用行为参数化之后
对你的选择标准建模:<br>你考虑的是苹果,需要根据Apple的某些属性<br>(比如它是绿色的吗?重量超过150克吗?)<br>来返回一个boolean值。<br>我们把它称为谓词(即一个返回boolean值的函数)。<br>让我们定义一个接口来对选择标准建模
public interface ApplePredicate{<br> boolean test (Apple apple);<br>}
用ApplePredicate的多个实现代表不同的选择标准
子主题
根据抽象条件筛选
子主题
找出所有重量超过150克的红苹果
子主题
filterApples方法的行为取决于你通过ApplePredicate对象传递的代码。<br>换句话说,你把filterApples方法的行为参数化了
唯一重要的代码是test方法的实现,正是它定义<br>了filterApples方法的新行为。
子主题
多种行为,一个参数
子主题
对付啰嗦
使用匿名类
子主题
使用 Lambda 表达式
子主题
将 List 类型抽象化
目前,filterApples方法还只适用于Apple。<br>你还可以将List类型抽象化,从而超越你眼前要处理的问题
子主题
子主题
真实的例子<br>
用 Comparator 来排序<br>
// java.util.Comparator<br>public interface Comparator<t> {<br> public int compare(T o1, T o2);<br>} </t>
可以随时创建Comparator的实现,<br>用sort方法表现出不同的行为。
匿名函数
Lambda表达式<br>inventory.sort(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight()) );
用 Runnable 执行代码块
// java.lang.Runnable<br>public interface Runnable{<br> public void run();<br>}
匿名函数<br><br>Thread t = new Thread(new Runnable() {<br> public void run(){<br> System.out.println("Hello world");<br> }<br>});
Lambda表达式<br><br>Thread t = new Thread(() -> System.out.println("Hello world"));
第3章
Lambda表达式
可以把Lambda表达式理解为<br>简洁地表示可传递的匿名函数的一种方式:<br>它没有名称,但它有<font color="#80bc42">参数列表、函数主体、返回类型</font>,可能还有一个<font color="#80bc42">可以抛出的异常列表</font>
匿名——我们说匿名,是因为它不像普通的方法那样有一个明确的名称:写得少而想得多!
函数——我们说它是函数,是因为Lambda函数不像方法那样属于某个特定的类。<br>但和方法一样,Lambda有参数列表、函数主体、返回类型,还可能有可以抛出的异常列表。
传递——Lambda表达式可以作为参数传递给方法或存储在变量中。
简洁——无需像匿名类那样写很多模板代码
子主题
Lambda表达式
有效表达式
1,2,3有效<br>4,5无效
子主题
在哪里以及如何使用 Lambda
函数式接口<br>
只定义一个抽象方法的接口
子主题
子主题
Lambda表达式允许直接以内联的形式为函数式接口的抽象方法提供实现,<br>并把整个表达式作为函数式接口的实例
Runnable是一个只定义了<br>一个抽象方法run的函数式接口
子主题
函数描述符
函数式接口的抽象方法的签名基本上就是Lambda表达式的签名。<br>我们将这种抽象方法叫作函数描述符。
Runnable接口可以看作一个什么也不接受什么也不返回(void)的函数的签名,<br>因为它只有一个叫作run的抽象方法,这个方法什么也不接受,什么也不返回(void)。
() -> void代表了参数列表为空,且返回void的函数。这正是Runnable接口所代表的
(Apple,Apple) -> int代表接受两个Apple作为参数且返回int的函数
子主题
Lambda表达式可以被赋给一个变量,或传递给一个接受函数式接口作为参数的方法<br><br>Lambda表达式的签名要和函数式接口的抽象方法一样<br>
可以直接把一个Lambda传给process方法
public void process(Runnable r){<br> r.run();<br>}<br>process( () -> System.out.println("This is awesome!!") ); <br><br>将打印“This is awesome!!”。<br>Lambda表达式 ()-> System.out.println("This is awesome!!")不接受参数且返回void<br>
@FunctionalInterface
函数式接口带有@FunctionalInterface的标注
注用于表示该接口会设计成一个函数式接口。<br>如果你用@FunctionalInterface定义了一个接口,<br>而它却不是函数式接口的话,编译器将返回一个提示原因的错误。
把 Lambda 付诸实践:环绕执行模式
环绕执行示例
子主题
第 1 步:记得行为参数化<br>
把行为传递给processFile,<br>以便它可以利用BufferedReader执行不同的行为
一次读两行
String result = processFile((BufferedReader br) -><br> br.readLine() + br.readLine()); <br>
第 2 步:使用函数式接口来传递行为
Lambda仅可用于上下文是函数式接口的情况。<br>你需要创建一个能匹配 BufferedReader -> String,<br>还可以抛出IOException异常的接口。<br>让我们把这一接口叫作 BufferedReaderProcessor
@FunctionalInterface<br>public interface BufferedReaderProcessor {<br> String process(BufferedReader b) throws IOException;<br>}
把这个接口作为新的processFile方法的参数
public static String processFile(BufferedReaderProcessor p) throws IOException {<br> …<br>}
第 3 步:执行一个行为
Lambda表达式允许你直接内联,<br>为函数式接口的抽象方法提供实现,<br>并且将整个表达式作为函数式接口的一个实例。
可以在processFile主体内,<br>对得到的BufferedReaderProcessor对象调用process方法执行处理
子主题
第 4 步:传递 Lambda
通过传递不同的Lambda重用processFile方法,<br>并以不同的方式处理文件
处理一行:<br>String oneLine = processFile((BufferedReader br) -> br.readLine());<br><br>处理两行:<br>String twoLines = processFile((BufferedReader br) -> br.readLine() + br.readLine());
总结
子主题
使用函数式接口
Predicate
java.util.function.Predicate<T><t>接口<br>定义了一个名叫test的抽象方法,<br>它接受泛型T对象,并返回一个boolean。<br><br>在需要表示一个涉及类型T的布尔表达式时,<br>就可以使用这个接口。<br></t>
定义一个接受String对象的Lambda表达式
Consumer
java.util.function.Consumer<T><br><t>定义了一个名叫accept的抽象方法,<br>它接受泛型T的对象,没有返回(void)。<br>你如果需要访问类型T的对象,<br>并对其执行某些操作,就可以使用这个接口。<br></t>
用它来创建一个forEach方法,接受一个Integers的列表,<br>并对其中每个元素执行操作。<br>使用这个forEach方法,并配合Lambda来打印列表中的所有元素。
Function
java.util.function.Function<T><t, r="">接口<br>定义了一个叫作apply的方法,<br>它接受一个泛型T的对象,<br>并返回一个泛型R的对象<br><br>如果你需要定义一个Lambda,<br>将输入对象的信息映射<br>到输出,<br>就可以使用这个接口<br>(比如提取苹果的重量,或把字符串映射为它的长度)<br></t,>
利用Function<T, R>来创建一个map方法,<br>以将一个String列表映射到包含每个String长度的Integer列表。
构造一个可以利用这些函数式接口的有效Lambda表达式
类型检查、类型推断以及限制
类型检查
Lambda的类型是从使用Lambda的上下文推断出来的。
上下文(比如,接受它传递的方法的参数,或接受它的值的局部变量)<br>中Lambda表达式需要的类型称为目标类型。
解读Lambda表达式的类型检查过程
首先,你要找出filter方法的声明。<br>第二,要求它是Predicate<apple>(目标类型)对象的第二个正式参数。<br>第三,Predicate<apple>是一个函数式接口,定义了一个叫作test的抽象方法。<br>第四,test方法描述了一个函数描述符,它可以接受一个Apple,并返回一个boolean。<br>最后,filter的任何实际参数都必须匹配这个要求。</apple></apple>
子主题
同样的 Lambda,不同的函数式接口
有了目标类型的概念,<br>同一个Lambda表达式就可以与不同的函数式接口联系起来,<br>只要它们的抽象方法签名能够兼容。
前面提到的Callable和PrivilegedAction,<br>这两个接口都代表着什么也不接受且返回一个泛型T的函数
两个赋值是有效的
//第一个赋值的目标类型是Callable<Integer><integer></integer><br>Callable<Integer><integer> c = () -> 42;<br><br>//第二个赋值的目标类型是PrivilegedAction<Integer><integer></integer><br>PrivilegedAction<Integer><integer> p = () -> 42;</integer></integer>
更多的例子
Comparator<Apple><apple> c1 = (Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());<br><br>ToIntBiFunction<Apple, Apple><apple, apple=""> c2 = (Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());<br><br>BiFunction<Apple, Apple, Integer><apple, apple,="" integer=""> c3 = (Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight()); </apple,></apple,></apple>
特殊的void兼容规则
如果一个Lambda的主体是一个语句表达式,<br>它就和一个返回void的函数描述符兼容(当然需要参数列表也兼容)。<br>例如,两行都是合法的,<br>尽管List的add方法返回了一个boolean,<br>而不是Consumer上下文(T -> void)所要求的void
// Predicate返回了一个boolean<br>Predicate<String><string> p = s -> list.add(s);<br>// Consumer返回了一个void<br>Consumer<String><string> b = s -> list.add(s); </string></string>
类型推断<br>
Java编译器会从上下文(目标类型)<br>推断出用什么函数式接口来配合Lambda表达式,<br>这意味着它也可以推断出适合Lambda的签名,<br>因为函数描述符可以通过目标类型来得到。<br>这样做的好处在于,<br>编译器可以了解Lambda表达式的参数类型,<br>这样就可以在Lambda语法中省去标注参数类型
Java编译器会推断Lambda的参数类型
Lambda表达式有多个参数,代码可读性的好处就更为明显。<br>例如,可以创建一个Comparator对象
子主题
使用局部变量
Lambda表达式也允许使用自由变量<br>(不是参数,而是在外层作用域中定义的变量),<br>就像匿名类一样。 它们被称作捕获Lambda。
Lambda捕获了portNumber变量
int portNumber = 1337;<br>Runnable r = () -> System.out.println(portNumber); <br>
Lambda可以没有限制地捕获(也就是在其主体中引用)实例变量和静态变量。<br>但局部变量必须显式声明为final,或事实上是final。<br>换句话说,Lambda表达式只能捕获指派给它们的局部变量一次。<br>(注:捕获实例变量可以被看作捕获最终局部变量this。)
子主题
对局部变量的限制
第一,实例变量和局部变量背后的实现有一个关键不同。<br>实例变量都存储在堆中,<br>而局部变量则保存在栈上。
如果Lambda可以直接访问局部变量,<br>而且Lambda是在一个线程中使用的,<br>则使用Lambda的线程,<br>可能会在分配该变量的线程将这个变量收回之后,去访问该变量。<br>因此,Java在访问自由局部变量时,<br>实际上是在访问它的副本,<br>而不是访问原始变量。<br>如果局部变量仅仅赋值一次那就没有什么区别了——因此就有了这个限制。
第二,这一限制不鼓励你使用改变外部变量的典型命令式编程模式<br>(这种模式会阻碍很容易做到的并行处理)。
方法引用
方法引用让你可以重复使用现有的方法定义,<br>并像Lambda一样传递它们。<br>在一些情况下,比起使用Lambda表达式,<br>它们似乎更易读,感觉也更自然。
用方法引用写的一个排序
子主题
方法引用可以被看作仅仅调用特定方法的Lambda的一种快捷写法。
基本思想是,<br>如果一个Lambda代表的只是“直接调用这个方法”,<br>那最好还是用名称来调用它,而不是去描述如何调用它。
方法引用就是让你根据已有的方法实现来创建Lambda表达式。<br>但是,显式地指明方法的名称,你的代码的可读性会更好。
当你需要使用方法引用时,目标引用放在分隔符::前,方法的名称放在后面
Apple::getWeight就是引用了Apple类中定义的方法getWeight
方法引用就是Lambda表达式 (Apple a) -> a.getWeight()的快捷写法
子主题
如何构建方法引用
(1) 指向静态方法的方法引用(例如Integer的parseInt方法,写作 Integer::parseInt)。
(2) 指 向 任意类型实例方法 的方法引用(例如 String 的 length 方法,写作 String::length)。
(3) 指向现有对象的实例方法的方法引用<br> (假设你有一个局部变量expensiveTransaction用于存放Transaction类型的对象,<br> 它支持实例方法getValue,那么你就可以写expensiveTransaction::getValue)。
类似于String::length的第二种方法引用的思想就是你在引用一个对象的方法,<br>而这个对象本身是Lambda的一个参数。<br>例如,Lambda表达式 (String s) -> s.toUppeCase()可以写作String::toUpperCase
第三种方法引用指的是,<br>你在Lambda中调用一个已经存在的外部对象中的方法。<br>例如,Lambda表达式 ()->expensiveTransaction.getValue()可以写作expensiveTransaction::getValue
子主题
还有针对构造函数、数组构造函数<br>和父类调用(super-call)的一些特殊形式的方法引用。
对一个字符串的List排序,忽略大小写。<br>List的sort方法需要一个Comparator作为参数。<br>Comparator描述了<br>一个具有(T, T) -> int签名的函数描述符。<br>你可以利用String类中的compareToIgnoreCase<br>方法定义一个Lambda表达式(注意compareToIgnoreCase是String类中预先定义的)<br>
List<string> str = Arrays.asList("a","b","A","B");<br><br>str.sort((s1, s2) -> s1.compareToIgnoreCase(s2)); </string>
Lambda表达式的签名与Comparator的函数描述符兼容。
List<string> str = Arrays.asList("a","b","A","B");<br><br>str.sort(String::compareToIgnoreCase); </string>
子主题
构造函数引用
对于一个现有构造函数,<br>你可以利用它的名称和关键字new来创建它的一个引用:<br>ClassName::new。它的功能与指向静态方法的引用类似。
假设有一个构造函数没有参数。<br>它适合Supplier的签名() -> Apple。可以这样做
子主题
等价于
子主题
如果构造函数的签名是Apple(Integer weight),<br>那么它就适合Function接口的签名,可以这样写
子主题
等价于
子主题
一个由Integer构成的List中的每个元素都通过我们前面定义的类似的<br>map方法传递给了Apple的构造函数,得到了一个具有不同重量苹果的List
子主题
有一个具有两个参数的构造函数Apple(String color, Integer weight),<br>那么它就适合BiFunction接口的签名,可以这样写
子主题
等价于
子主题
不将构造函数实例化却能够引用它
可以使用Map来将构造函数映射到字符串值。<br>可以创建一个giveMeFruit方法,<br>给它一个String和一个Integer,<br>它就可以创建出不同重量的各种水果
子主题
怎样才能对具有三个参数的构造函数,<br>比如Color(int, int, int),使用构造函数引用呢?
构造函数引用的语法是ClassName::new,<br>那么在这个例子里面就是Color::new。<br>但是需要与构造函数引用的签名匹配的函数式接口。<br>但是语言本身并没有提供这样的函数式接口,<br>可以自己创建一个<br>
public interface TriFunction<T, U, V, R><t, u,="" v,="" r="">{<br> R apply(T t, U u, V v);<br>} </t,>
可以像下面这样使用构造函数引用了:<br>TriFunction<Integer, Integer, Integer, Color><integer, integer,="" color=""> colorFactory = Color::new; </integer,>
Lambda 和方法引用实战
用不同的排序策略给一个Apple列表排序
最终解决方案是这样的:<br><br>inventory.sort(comparing(Apple::getWeight));<br>
第 1 步:传递代码
Java 8的API已经为你提供了一个List可用的sort方法,<br>sort方法的签名是这样的:<br>void sort(Comparator<!--? super E--> c)<br>
需要一个Comparator对象来比较两个Apple!<br>这就是在Java中传递策略的方式:<br>它们必须包裹在一个对象里。<br>我们说sort的行为被参数化了:<br>传递给它的排序策略不同,其行为也会不同。<br>
public class AppleComparator implements Comparator<apple> {<br> public int compare(Apple a1, Apple a2){<br> return a1.getWeight().compareTo(a2.getWeight());<br> }<br>}<br><br>inventory.sort(new AppleComparator());</apple>
第 2 步:使用匿名类
inventory.sort(new Comparator<apple>() {<br> public int compare(Apple a1, Apple a2){<br> return a1.getWeight().compareTo(a2.getWeight());<br> }<br>});</apple>
第 3 步:使用 Lambda 表达式
Lambda表达式提供了一种轻量级语法来实现相同的目标:传递代码。<br>在需要函数式接口的地方可以使用Lambda表达式。<br>我们回顾一下:函数式接口就是仅仅定义一个抽象方法的接口。<br>抽象方法的签名(称为函数描述符)描述了Lambda表达式的签名。
Comparator代表了函数描述符(T, T) -> int。<br>苹果具体代表的就是(Apple, Apple) -> int。
inventory.sort((Apple a1, Apple a2)<br> -> a1.getWeight().compareTo(a2.getWeight())<br> );
Java编译器可以根据Lambda出现的上下文来推断Lambda表达式参数的类型。
inventory.sort( (a1, a2) -> a1.getWeight().compareTo(a2.getWeight()) );
Comparator具有一个叫作comparing的静态辅助方法,<br>它可以接受一个Function来提取Comparable键值,并生成一个Comparator对象<br><br>现在传递的Lambda只有一个参数:Lambda说明了如何从苹果中提取需要比较的键值<br>
import static java.util.Comparator.comparing; <br><br>Comparator<apple> c = Comparator.comparing((Apple a) -> a.getWeight()); <br>inventory.sort(comparing((a) -> a.getWeight())); <br></apple>
第 4 步:使用方法引用
方法引用就是替代那些转发参数的Lambda表达式的语法糖。<br>可以用方法引用让代码更简洁(假设静态导入了java.util.Comparator.comparing)
inventory.sort(comparing(Apple::getWeight));
复合 Lambda 表达式的有用方法
可以把多个简单的Lambda复合成复杂的表达式。<br>比如,可以让两个谓词之间做一个or操作,组合成一个更大的谓词。<br>而且,还可以让一个函数的结果成为另一个函数的输入。
函数式接口中怎么可能有更多的方法呢?<br>(毕竟,这违背了函数式接口的定义啊!)<br>窍门在于,即将介绍的方法都是默认方法,<br>也就是说它们不是抽象方法。
比较器复合
以使用静态方法Comparator.comparing,<br>根据提取用于比较的键值的Function来返回一个Comparator,<br>如下所示:<br>Comparator<Apple><apple> c = Comparator.comparing(Apple::getWeight);</apple>
1. 逆序
对苹果按重量递减排序
用不着去建立另一个Comparator的实例。<br>接口有一个默认方法reversed可以使给定的比较器逆序。<br>因此仍然用开始的那个比较器,<br>只要修改一下前一个例子就可以对苹果按重量递减排序
inventory.sort( comparing(Apple::getWeight).reversed() );
2. 比较器链
如果发现有两个苹果一样重怎么办?<br>哪个苹果应该排在前面呢?<br>可能需要再提供一个Comparator来进一步定义这个比较。
在按重量比较两个苹果之后,<br>可能想要按原产国排序。<br>thenComparing方法就是做这个用的。<br>它接受一个函数作为参数(就像comparing方法一样),<br>如果两个对象用第一个Comparator比较之后是一样的,<br>就提供第二个Comparator。
子主题
谓词复合
谓词接口包括三个方法:negate、and和or,<br>可以重用已有的Predicate来创建更复杂的谓词。
使用negate方法来返回一个Predicate的非
苹果不是红的
子主题
把两个Lambda用and方法组合起来
一个苹果既是红色又比较重
子主题
进一步组合谓词
表达要么是重(150克以上)的红苹果,要么是绿苹果
子主题
请注意,and和or方法是按照在表达式链中的位置,<br>从左向右确定优先级的。因此,a.or(b).and(c)可以看作(a || b) && c
函数复合
可以把Function接口所代表的Lambda表达式复合起来<br><br>Function接口为此配了andThen和compose两个默认方法,<br>它们都会返回Function的一个实例<br>
andThen方法会返回一个函数,<br>它先对输入应用一个给定函数,<br>再对输出应用另一个函数
假设有一个函数f给数字加1 (x -> x + 1),<br>另一个函数g给数字乘2,<br>你可以将它们组合成一个函数h,先给数字加1,再给结果乘2
子主题
可以类似地使用compose方法,<br>先把给定的函数用作compose的参数里面给的那个函数,<br>然后再把函数本身用于结果<br>
在上一个例子里用compose的话,它将意味着f(g(x)),<br>而andThen则意味着g(f(x))
子主题
andThen和compose之间的区别
子主题
第4章
引入流
流是Java API的新成员,它允许你以声明性方式处理数据集合<br>(通过查询语句来表达,而不是临时编写一个实现)。
返回低热量的菜肴名称,<br>并按照卡路里排序
Java7
Java8
子主题
利用多核架构并行执行
子主题
流简介
流 就是“从支持数据处理操作的源生成的元素序列”
元素序列
像集合一样,流也提供了一个接口,<br>可以访问特定元素类型的一组有序值。
集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元<br>素(如ArrayList 与 LinkedList)。<br>
流的目的在于表达计算,比如你前面见到的<br>filter、sorted和map。<b><font color="#80bc42">集合讲的是数据,流讲的是计算</font></b>
源
流会使用一个提供数据的源,如集合、数组或输入/输出资源。 <br>请注意,从有序集合生成流时会保留原有的顺序。<br>由列表生成的流,其元素顺序与列表一致
数据处理操作
—流的数据处理功能支持类似于数据库的操作,<br>以及函数式编程语言中的常用操作,<br>如filter、map、reduce、find、match、sort等。<br>流操作可以顺序执行,也可并行执行。
流操作有两个重要的特点
流水线
很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线。<br><br>流水线的操作可以看作对数据源进行数据库式查询。
内部迭代
与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
例子
子主题
子主题
流与集合
集合与流之间的首要差异就在于什么时候进行计算。
集合是一个内存中的数据结构,<br>它包含数据结构中目前所有的值——集合中的每个元素都得先算出来才能添加到集合中。<br>(可以往集合里加东西或者删东西,但是不管什么时候,<br>集合中的每个元素都是放在内存里的,元素都得先算出来才能成为集合的一部分。)
集合则是急切创建的(供应商驱动:先把仓库装满,再开始卖,就像那些昙花一现的圣诞新玩意儿一样)。
流则是在概念上固定的数据结构(你不能添加或删除元素),其元素则是按需计算的。
流就像是一个延迟创建的集合:<br>只有在消费者要求的时候才会计算值<br>(用管理学的话说这就是需求驱动,甚至是实时制造)
只能遍历一次
和迭代器类似,流只能遍历一次。遍历完之后,我们就说这个流已经被消费掉了。<br>你可以从原始数据源那里再获得一个新的流来重新遍历一遍,就像迭代器一样<br>(这里假设它是集合之类的可重复的源,如果是I/O通道就没戏了)。
会抛出一个异常,说流已被消费掉了
子主题
外部迭代与内部迭代
集合和流的另一个关键区别在于它们遍历数据的方式。
使用Collection接口需要用户去做迭代(比如用for-each),这称为外部迭代。 <br>相反,Streams库使用内部迭代——它帮你把迭代做了,<br>还把得到的流值存在了某个地方,<br>你只要给出一个函数说要干什么就可以了。
集合:用for-each循环外部迭代
子主题
集合:用背后的迭代器做外部迭代
子主题
流:内部迭代
子主题
区别示意图
子主题
流操作
分为两大类
中间操作
可以连接起来的流操作
多个操作可以连接起来形成一个查询。<br>重要的是,除非流水线上触发一个终端操作,<br>否则中间操作不会执行任何处理——它们很懒。<br><br>这是因为中间操作一般都可以合并起来,<br>在终端操作时一次性全部处理。
终端操作
关闭流的操作
终端操作会从流的流水线生成结果。<br>其结果是任何不是流的值,比如List、Integer,甚至void。
forEach是一个返回void的终端操作,<br>它会对源中的每道菜应用一个Lambda。<br>把System.out.println传递给forEach,<br>并要求它打印出由menu生成的流中的每一个Dish
menu.stream().forEach(System.out::println);
使用流
流的使用一般包括三件事
一个数据源(如集合)来执行一个查询;<br>一个中间操作链,形成一条流的流水线;<br>一个终端操作,执行流水线,并能生成结果。
子主题
第5章
使用流
筛选和切片
用谓词筛选
Streams接口支持filter方法。<br>接受一个谓词(一个返回boolean的函数)作为参数,<br>并返回一个包括所有符合谓词的元素的流。
创建一张素食菜单
子主题
子主题
筛选各异的元素
distinct的方法,返回一个元素各异<br>(根据流所生成元素的hashCode和equals方法实现)的流
筛选出列表中所有的偶数,并确保没有重复
子主题
子主题
截短流<br>
limit(n)方法,会返回一个不超过给定长度的流。<br>所需的长度作为参数传递给limit。<br>如果流是有序的,则最多会返回前n个元素。
建立一个List,选出热量超过300卡路里的头三道菜
子主题
子主题
请注意limit也可以用在无序流上,比如源是一个Set。<br>这种情况下,limit的结果不会以任何顺序排列。
跳过元素
skip(n)方法,返回一个扔掉了前n个元素的流。<br>如果流中元素不足n个,则返回一个空流。<br><br>请注意,limit(n)和skip(n)是互补的!
跳过超过300卡路里的头两道菜,并返回剩下的
子主题
子主题
利用流来筛选前两个荤菜
List<dish> dishes =<br> menu.stream()<br> .filter(d -> d.getType() == Dish.Type.MEAT)<br> .limit(2)<br> .collect(toList()); </dish>
映射
常见的数据处理套路就是从某些对象中选择信息<br>Stream API也通过map和flatMap方法提供了类似的工具<br>
对流中每一个元素应用函数
map方法,接受一个函数作为参数。<br>这个函数会被应用到每个元素上,<br>并将其映射成一个新的元素<br>(使用映射一词,是因为它和转换类似,<br>但其中的细微差别在于它是“<b><font color="#80bc42">创建一个新版本</font></b>”而不是去“修改”)。
把方法引用Dish::getName传给map方法,<br>来提取流中菜肴的名称
List<string> dishNames = menu.stream()<br> .map(Dish::getName)<br> .collect(toList()); </string>
因为getName方法返回一个String,所以map方法输出的流的类型就是Stream<string></string>
给定一个单词列表,<br>你想要返回另一个列表,<br>显示每个单词中有几个字母。
对列表中的每个元素应用一个函数,用map方法去做!<br>应用的函数应该接受一个单词,并返回其长度。<br><br>给map传递一个方法引用String::length来解决这个问题<br>
List<string> words = Arrays.asList("Java 8", "Lambdas", "In", "Action");<br>List<integer> wordLengths = words.stream()<br> .map(String::length)<br> .collect(toList()); </integer></string>
找出每道菜的名称有多长
List<integer> dishNameLengths = menu.stream()<br> .map(Dish::getName)<br> .map(String::length)<br> .collect(toList());</integer>
流的扁平化
flatmap方法让你把一个流中的每个值都换成另一个流,然后把所有的流连接<br>起来成为一个流
对于一张单词表,如何返回一张列表,列出里面 各不相同的字符 呢?<br>例如,给定单词列表["Hello","World"],你想要返回列表["H","e","l", "o","W","r","d"]
第一个版本<br><br>把每个单词映射成一张字符表,<br>然后调用distinct来过滤重复的字符。<br>
words.stream()<br> .map(word -> word.split(""))<br> .distinct()<br> .collect(toList());
问题在于,传递给map方法的Lambda为每个单词返回了一个String[](String列表)。<br>因此,map返回的流实际上是Stream<String[]><string[]>类型的。<br>你真正想要的是用Stream<String><string>来表示一个字符流</string></string[]>
子主题
尝试使用map和Arrays.stream()
首先需要一个字符流,而不是数组流。<br>有一个叫作Arrays.stream()的方法可以接受<br>一个数组并产生一个流,
String[] arrayOfWords = {"Goodbye", "World"};<br>Stream<string> streamOfwords = Arrays.stream(arrayOfWords); </string>
用在前面的那个流水线里,看看会发生什么
子主题
得到的是一个流的列表(更准确地说是Stream<String><string>)!</string>
使用flatMap
子主题
使用flatMap方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。<br>所有使用map(Arrays::stream)时生成的单个流都被合并起来,即扁平化为一个流。
子主题
给定一个数字列表,如何返回一个由每个数的平方构成的列表呢?<br>例如,给定[1, 2, 3, 4,5],应该返回[1, 4, 9, 16, 25]。<br>
用map方法的Lambda,接受一个数字,<br>并返回该数字平方的Lambda来解决这个问题。<br>
List numbers = Arrays.asList(1, 2, 3, 4, 5);<br>List squares =<br> numbers.stream()<br> <b><font color="#80bc42">.map(n -> n * n)</font></b><br> .collect(toList());
给定两个数字列表,如何返回所有的数对<br><br>给定列表[1, 2, 3]和列表[3, 4],应该返回[(1, 3), (1, 4), (2, 3), (2, 4), (3, 3), (3, 4)]。<br>
使用两个map来迭代这两个列表,并生成数对。<br>但这样会返回一个Stream-<stream<integer[]>>。<br>你需要让生成的流扁平化,以得到一个Stream<integer[]>。<br>这正是flatMap所做的</integer[]></stream<integer[]>
List<Integer><integer> numbers1 = Arrays.asList(1, 2, 3);<br>List<Integer><integer> numbers2 = Arrays.asList(3, 4);<br>List<int[]><int[]> pairs =<br> numbers1.stream()<br> <b><font color="#80bc42"> .flatMap(i -> numbers2.stream()<br> .map(j -> new int[]{i, j})<br> )</font></b><br> .collect(toList());</int[]></integer></integer>
只返回总和能被3整除的数对呢?例如(2, 4)和(3, 3)
filter可以配合谓词使用来筛选流中的元素。<br>因为在flatMap操作后,你有了一个代表数对的int[]流,<br>所以只需要一个谓词来检查总和是否能被3整除就可以了
List<integer> numbers1 = Arrays.asList(1, 2, 3);<br>List<integer> numbers2 = Arrays.asList(3, 4);<br>List<int[]> pairs =<br> numbers1.stream()<br> .flatMap(i -><br> numbers2.stream()<br> <b><font color="#80bc42"> .filter(j -> (i + j) % 3 == 0)</font></b><br> .map(j -> new int[]{i, j})<br> )<br> .collect(toList());</int[]></integer></integer>
查找和匹配<br>
另一个常见的数据处理套路是看看数据集中的某些元素是否匹配一个给定的属性。<br>Stream API通过allMatch、anyMatch、noneMatch、findFirst和findAny方法提供了这样的工具
检查谓词是否至少匹配一个元素
anyMatch方法可以回答“流中是否有一个元素能匹配给定的谓词”
看看菜单里面是否有素食可选择
if(menu.stream().anyMatch(Dish::isVegetarian)){<br> System.out.println("The menu is (somewhat) vegetarian friendly!!");<br>}
anyMatch方法返回一个boolean,因此是一个终端操作
检查谓词是否匹配所有元素
allMatch方法的工作原理和anyMatch类似,<br>但它会看看流中的元素是否都能匹配给定的谓词
看看菜品是否有利健康(即所有菜的热量都低于1000卡路里)
boolean isHealthy = menu.stream()<br> .allMatch(d -> d.getCalories() < 1000);
流中没有任何元素与给定的谓词匹配
noneMatch
看看菜品是否有利健康(即所有菜的热量都低于1000卡路里)
boolean isHealthy = menu.stream()<br> .<b><font color="#80bc42">noneMatch</font></b>(d -> d.getCalories() <b style=""><font color="#80bc42">>=</font></b> 1000);
短路求值
短路
有些操作不需要处理整个流就能得到结果。<br>例如,假设你需要对一个用and连起来的大布尔表达式求值。<br>不管表达式有多长,你只需找到一个表达式为false,<br>就可以推断整个表达式将返回false,所以用不着计算整个表达式。
查找元素
findAny方法将返回当前流中的任意元素。它可以与其他流操作结合使用。
找到一道素食菜肴。<br>你可以结合使用filter和findAny方法来实现这个查询
Optional<Dish><dish> dish =<br> menu.stream()<br> .filter(Dish::isVegetarian)<br> .findAny();</dish>
Optional简介
Optional<T><t>类(java.util.Optional)是一个容器类,代表一个值存在或不存在。</t>
findAny可能什么元素都没找到。Java 8的库设计人员引入了Optional<T><t>,<br>这样就不用返回众所周知容易出问题的null了。</t>
isPresent()将在Optional包含值的时候返回true, 否则返回false
ifPresent(Consumer<t> block)会在值存在的时候执行给定的代码块。<br>我们在第3章介绍了Consumer函数式接口;<br>它让你传递一个接收T类型参数,<br>并返回void的Lambda表达式。</t>
T get()会在值存在时返回值,否则抛出一个NoSuchElement异常。
T orElse(T other)会在值存在时返回值,否则返回一个默认值。
在前面的代码中你需要显式地检查Optional对象中是否存在一道菜可以访问其名称
子主题
查找第一个元素
有些流有一个出现顺序(encounter order)来指定流中项目出现的逻辑顺序<br>(比如由List或排序好的数据列生成的流)。<br>对于这种流,你可能想要找到第一个元素。<br>为此有一个findFirst方法,它的工作方式类似于findany。
给定一个数字列表,找出第一个平方能被3整除的数
List<integer> someNumbers = Arrays.asList(1, 2, 3, 4, 5);<br>Optional<integer> firstSquareDivisibleByThree =<br> someNumbers.stream()<br> .map(x -> x * x)<br> .filter(x -> x % 3 == 0)<br> .findFirst(); // 9 </integer></integer>
归约<br>
把一个流中的元素组合起来,使用reduce操作来表达更复杂的查询<br><br>将流中所有元素反复结合起来,得到一个值,比如一个Integer。<br>这样的查询可以被归类为归约操作(将流归约成一个值)。<br><br>用函数式编程语言的术语来说,这称为折叠(fold),<br>因为你可以将这个操作看成把一张长长的纸(你的流)反复折叠成一个小方块,<br>而这就是折叠操作的结果。<br>
元素求和
for-each循环求和
numbers中的每个元素都<br>用加法运算符反复迭代来得到结果。<br>通过反复使用加法,<br>把一个数字列表归约成了一个数字。<br><br>int sum = 0;<br>for (int x : numbers) {<br> sum += x;<br>} <br>
有两个参数:<br> 总和变量的初始值,在这里是0;<br> 将列表中所有元素结合在一起的操作,在这里是+
要是还能把所有的数字相乘,而不必去复制粘贴这段代码<br>reduce操作对这种重复应用的模式做了抽象。<br>可以像下面这样对流中所有的元素求和
reduce
int sum = numbers.stream().reduce( <b><font color="#80bc42">0, (a, b) -> a + b</font></b> );<br>//起始值0很重要
reduce接受两个参数:<br>一个初始值,这里是0;<br>一个BinaryOperator<T><t>来将两个元素结合起来产生一个新值,<br> 这里我们用的是lambda (a, b) -> a + b。</t>
所有的元素相乘,只需要将另一个Lambda:(a, b) -> a * b传递给reduce操作
int product = numbers.stream().reduce( <b><font color="#80bc42">1, (a, b) -> a * b </font></b>);<br>//起始值1很重要
reduce操作是如何作用于一个流
Lambda反复结合每个元素,直到流被归约成一个值
子主题
使用方法引用让这段代码更简洁
int sum = numbers.stream().reduce( <b><font color="#80bc42">0</font></b>, Integer::sum ); <br>//起始值0很重要
无初始值
reduce还有一个重载的变体,它不接受初始值,但是会返回一个Optional对象
Optional<Integer><integer> sum = numbers.stream().reduce((a, b) -> (a + b))</integer>
考虑流中没有任何元素的情况。<br>reduce操作无法返回其和,<br>因为它没有初始值。<br>这就是为什么结果被包裹在一个Optional对象里,<br>以表明和可能不存在。
最大值和最小值
利用reduce来计算流中最大或最小的元素。<br>reduce接受两个参数:<br> 一个初始值<br> 一个Lambda来把两个流元素结合起来并产生一个新值<br><br>Lambda是一步步用加法运算符应用到流中每个元素上的,<br>需要给定两个元素能够返回最大值的Lambda,<br>reduce操作会考虑新值和流中下一个元素,<br>并产生一个新的最大值,直到整个流消耗完<br>
Optional<Integer><integer> max = numbers.stream().reduce(Integer::max); </integer>
子主题
计算最小值,你需要把Integer.min传给reduce来替换Integer.max
Optional<Integer><integer> min = numbers.stream().reduce(Integer::min);</integer>
可以写成Lambda (x, y) -> x < y ? x : y而不是Integer::min,不过后者比较易读。
计数
用map和reduce方法数一数流中有多少个菜呢
把流中每个元素都映射成数字1,然后用reduce求和。
int count = menu.stream()<br> .map(d -> 1)<br> .reduce(0, (a, b) -> a + b);
内置count方法可用来计算流中元素的个数
long count = menu.stream().count();
付诸实践
领域:交易员和交易
Traders
子主题
Transactions
子主题
子主题
问答
找出2011年的所有交易并按交易额排序(从低到高)<br>
子主题
交易员都在哪些不同的城市工作过
子主题
子主题
查找所有来自于剑桥的交易员,并按姓名排序
子主题
返回所有交易员的姓名字符串,按字母顺序排序
子主题
子主题
有没有交易员是在米兰工作的
子主题
打印生活在剑桥的交易员的所有交易额
子主题
所有交易中,最高的交易额是多少
子主题
找到交易额最小的交易
子主题
子主题
数值流
子主题
原始类型流特化
引入三个原始类型特化流接口来解决这个问题:<br>IntStream、DoubleStream和LongStream,<br>分别将流中的元素特化为int、long和double,<br>从而避免了暗含的装箱成本
1. 映射到数值流<br>
常用方法是mapToInt、mapToDouble和mapToLong。<br>这些方法和前面说的map方法的工作方式一样,<br>只是它们返回的是一个特化流,而不是Stream<T><t></t>
子主题
2. 转换回对象流
要把原始流转换成一般流<br>(每个int都会装箱成一个Integer),<br>可以使用boxed方法
子主题
3. 默认值OptionalInt
对于三种原始流特化,<br>也分别有一个Optional原始类型特化版本:<br>OptionalInt、OptionalDouble和OptionalLong
子主题
数值范围
和数字打交道时,有一个常用的东西就是数值范围。<br><br>两个可以用于IntStream和LongStream的静态方法,<br>帮助生成这种范围:<br>range和rangeClosed。<br>这两个方法都是第一个参数接受起始值,<br>第二个参数接受结束值。<br>但range是不包含结束值的,而rangeClosed则包含结束值。<br>
子主题
如果改用IntStream.range(1, 100),则结果将会是49个偶数,因为range是不包含结束值的
构建流
由值创建流
使用静态方法Stream.of,通过显式值创建一个流
子主题
使用empty得到一个空流<br>Stream<String><string> emptyStream = Stream.empty();</string>
由数组创建流
使用静态方法Arrays.stream从数组创建一个流。它接受一个数组作为参数
子主题
由文件生成流
java.nio.file.Files中的很多静态方法都会返回一个流。<br>例如,一个很有用的方法是Files.lines,它会返回一个由指定文件中的各行构成的字符串流
子主题
由函数生成流:创建无限流
Stream API提供了两个静态方法来从函数生成流:Stream.iterate和Stream.generate。<br>这两个操作可以创建所谓的无限流:不像从固定集合创建的流那样有固定大小的流。由iterate<br>和generate产生的流会用给定的函数按需创建值,因此可以无穷无尽地计算下去!一般来说,<br>应该使用limit(n)来对这种流加以限制,以避免打印无穷多个值。
1. 迭代
子主题
2. 生成
generate方法也可让你按需生成一个无限流。<br>但generate不是依次<br>对每个新生成的值应用函数的。<br>它接受一个Supplier<T><t>类型的Lambda提供新的值</t>
子主题
第6章
用流收集数据<br>
收集器简介
收集器用作高级归约
可以简洁而灵活地定义collect用来生成结果集合的标准<br><br>对流调用<br>collect方法将对流中的元素触发一个归约操作(由Collector来参数化)<br>
最直接和最常用的收集器是toList静态方法,它会把流中所有的元素收集到一个List中<br><br>List<Transaction><transaction> transactions = transactionStream.collect(Collectors.toList());</transaction><br>
预定义收集器
主要提供了三大功能
将流元素归约和汇总为一个值<br>元素分组<br>元素分区
归约和汇总
在需要将流项目重组成集合时,一般会使用收集器<br>但凡要把流中所有的项目合并成一个结果时就可以用。<br>这个结果可以是任何类型,<br> 可以复杂如代表一棵树的多级映射,<br> 或是简单如一个整数<br>
利用counting工厂方法返回的收集器,<br>数一数菜单里有多少种菜
long howManyDishes = menu.stream().collect(Collectors.counting());
long howManyDishes = menu.stream().count();
查找流中的最大值和最小值<br>
Collectors.maxBy和Collectors.minBy,<br>来计算流中的最大或最小值。<br>这两个收集器接收一个Comparator参数来比较流中的元素。
找出菜单中热量最高的菜
创建一个Comparator来根据所含热量对菜肴进行比较,<br>并把它传递给Collectors.maxBy
Comparator<Dish><dish> dishCaloriesComparator =<br> Comparator.comparingInt(Dish::getCalories);<br>Optional<Dish><dish> mostCalorieDish =<br> menu.stream()<br> .collect(maxBy(dishCaloriesComparator)); </dish></dish>
汇总
Collectors类专门为汇总提供了一个工厂方法:Collectors.summingInt。<br>它可接受一个把对象映射为求和所需int的函数,并返回一个收集器;<br>该收集器在传递给普通的collect方法后即执行我们需要的汇总操作
求出菜单列表的总热量
int totalCalories = menu.stream().collect(summingInt(Dish::getCalories));
Collectors.averagingInt 计算数值的平均数
double avgCalories = menu.stream().collect(averagingInt(Dish::getCalories));
得到两个或更多这样的结果,<br>而且希望只需一次操作就可以完成。<br>在这种情况下,可以使用summarizingInt工厂方法返回的收集器。
通过一次summarizing操作你可以就数出菜单中元素的个数,<br>并得到菜肴热量总和、平均值、最大值和最小值
IntSummaryStatistics menuStatistics =<br> menu.stream().collect(summarizingInt(Dish::getCalories));
这个收集器会把所有这些信息收集到一个叫作IntSummaryStatistics的类里,<br>它提供了方便的取值(getter)方法来访问结果。<br>打印menuStatisticobject会得到以下输出:<br> IntSummaryStatistics{count=9, sum=4300, min=120,<br> average=477.777778, max=800}
连接字符串
joining工厂方法返回的收集器会<br>把对流中每一个对象应用toString方法得到的所有字符串连接成一个字符串。<br><br>joining在内部使用了StringBuilder来把生成的字符串逐个追加起来<br>
把菜单中所有菜肴的名称连接起来
String shortMenu = menu.stream().map(Dish::getName).collect(joining());
如果Dish类有一个toString方法来返回菜肴的名称,<br>那你无需用提取每一道菜名称的函数来对原流做映射就能够得到相同的结果<br><br>String shortMenu = menu.stream().collect(joining()); <br>
二者均可产生以下字符串:<br><br>porkbeefchickenfrench friesriceseason fruitpizzaprawnssalmon <br>
joining工厂方法有一个重载版本可以接受元素之间的分界符
得到一个逗号分隔的菜肴名称列表
String shortMenu = menu.stream().map(Dish::getName).collect(joining(", "));
pork, beef, chicken, french fries, rice, season fruit, pizza, prawns, salmon
广义的归约汇总
分组
分组demo
把菜单中的菜按照类型进行分类
用Collectors.groupingBy工厂方法返回的收集器就可以轻松地完成这项任务<br><br>Map<<dish.type, list<dish="">Dish.Type, List<Dish><dish></dish>> dishesByType = menu.stream().collect(groupingBy(Dish::getType));</dish.type,>
结果:<br><br>{FISH=[prawns, salmon], OTHER=[french fries, rice, season fruit, pizza],<br>MEAT=[pork, beef, chicken]} <br>
给groupingBy方法传递了一个Function(以方法引用的形式),<br>它提取了流中每一道Dish的Dish.Type。<br>我们把这个Function叫作分类函数,<br>因为它用来把流中的元素分成不同的组。
把热量不到400卡路里的菜划分为“低热量”(diet),<br>热量400到700卡路里的菜划为“普通”(normal),<br>高于700卡路里的划为“高热量”(fat)。
子主题
多级分组
使用一个由双参数版本的Collectors.groupingBy工厂方法创建的收集器,<br>它除了普通的分类函数之外,还可以接受collector类型的第二个参数。<br>那么要进行二级分组的话,我们可以把一个内层groupingBy传递给外层groupingBy,<br>并定义一个为流中项目分类的二级标准
子主题
子主题
按子组收集数据<br>
把第二个groupingBy收集器传递给外层收集器来实现多级分组。<br>但进一步说,传递给第一个groupingBy的第二个收集器可以是任何类型,<br>而不一定是另一个groupingBy。<br><br>普通的单参数groupingBy(f)(其中f是分类函数)<br>实际上是groupingBy(f, toList())的简便写法<br>
要数一数菜单中每类菜有多少个,<br>可以传递counting收集器作为groupingBy收集器的第二个参数
Map<Dish.Type, Long><dish.type, long=""> typesCount = menu.stream().collect(<br> groupingBy(Dish::getType, counting()));</dish.type,>
结果是下面的Map:<br>{MEAT=3, FISH=2, OTHER=4}
把前面用于查找菜单中热量最高的菜肴的收集器改一改,<br>按照菜的类型分类
Map<<dish.type, optional<dish="">Dish.Type, Optional<Dish><dish></dish>> mostCaloricByType =<br> menu.stream()<br> .collect(groupingBy(Dish::getType,<br> maxBy(comparingInt(Dish::getCalories))));</dish.type,>
结果显然是一个map,以Dish的类型作为键,<br>以包装了该类型中热量最高的Dish的Optional<Dish><dish>作为值<br><br>{FISH=Optional[salmon], OTHER=Optional[pizza], MEAT=Optional[pork]} <br></dish>
把收集器的结果转换为另一种类型
使用Collectors.collectingAndThen工厂方法返回的收集器
子主题
这个工厂方法接受两个参数——要转换的收集器以及转换函数,并返回另一个收集器。<br>这个收集器相当于旧收集器的一个包装,collect操作的最后一步就是将返回值用转换函数做一个映射。<br>在这里,被包起来的收集器就是用maxBy建立的那个,<br>而转换函数Optional::get则把返回的Optional中的值提取出来。<br>前面已经说过,这个操作放在这里是安全的,<br>因为reducing收集器永远都不会返回Optional.empty()。
结果:<br>{FISH=salmon, OTHER=pizza, MEAT=pork}
与groupingBy联合使用的其他收集器的例子
通过groupingBy工厂方法的第二个参数传递的收集器<br>将会对分到同一组中的所有流元素执行进一步归约操作
重用求出所有菜肴热量总和的收集器,<br>不过这次是对每一组Dish求和
Map<Dish.Type, Integer><dish.type, integer=""> totalCaloriesByType =<br> menu.stream().collect(groupingBy(Dish::getType,<br> summingInt(Dish::getCalories))); </dish.type,>
常常和groupingBy联合使用的另一个收集器是mapping方法生成的。<br>这个方法接受两个参数:<br>一个函数对流中的元素做变换,<br>另一个则将变换的结果对象收集起来。<br>其目的是在累加之前对每个输入元素应用一个映射函数,<br>这样就可以让接受特定类型元素的收集器适应不同类型的对象。
对于每种类型的Dish,<br>菜单中都有哪些CaloricLevel
Map<<dish.type, set<caloriclevel="">Dish.Type, Set<CaloricLevel><caloriclevel></caloriclevel>> caloricLevelsByType =<br> menu.stream().collect(<br> groupingBy(Dish::getType, mapping(<br> dish -> { if (dish.getCalories() <= 400) return CaloricLevel.DIET;<br> else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;<br> else return CaloricLevel.FAT; },<br> toSet() ))); </dish.type,>
子主题
传递给映射方法的转换函数将Dish映射成了它的CaloricLevel:<br>生成的CaloricLevel流传递给一个toSet收集器,<br>它和toList类似,不过是把流中的元素累积到一个Set而不是List中,<br>以便仅保留各不相同的值<br><br>得到这样的Map结果<br>{OTHER=[DIET, NORMAL], MEAT=[DIET, NORMAL, FAT], FISH=[DIET, NORMAL]} <br>
通过使用toCollection,可以有更多的控制。<br>例如,你可以给它传递一个构造函数引用来要求HashSet
Map<<dish.type, set<caloriclevel="">Dish.Type, Set<CaloricLevel><caloriclevel></caloriclevel>> caloricLevelsByType =<br> menu.stream().collect(<br> groupingBy(Dish::getType, mapping(<br> dish -> { if (dish.getCalories() <= 400) return CaloricLevel.DIET;<br> else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;<br> else return CaloricLevel.FAT; },<br> toCollection(HashSet::new) ))); </dish.type,>
分区<br>
分区是分组的特殊情况:由一个谓词(返回一个布尔值的函数)作为分类函数,<br>它称分区函数。分区函数返回一个布尔值,这意味着得到的分组Map的键类型是Boolean,<br>于是它最多可以分为两组——true是一组,false是一组
把菜单按照素食和非素食分开
子主题
用同样的分区谓词,对菜单List创建的流作筛选,<br>然后把结果收集到另外一个List中也可以获得相同的结果
List<Dish><dish> vegetarianDishes =<br> menu.stream().filter(Dish::isVegetarian).collect(toList()); </dish>
分区的优势
分区的好处在于保留了分区函数返回true或false的两套流元素列表。
要得到非素食Dish的List,<br>你可以使用两个筛选操作来访问partitionedMenu这个Map中false键的值:<br>一个利用谓词,一个利用该谓词的非。
partitioningBy工厂方法有一个重载版本,<br>可以传递第二个收集器
子主题
重用前面的代码来找到素食和非素食中热量最高的菜
子主题
子主题
将数字按质数和非质数分区
写一个方法,它接受参数int n,并将前n个自然数分为质数和非质数。
首先,找出能够测试某一个待测数字是否是质数的谓词会很有帮助
子主题
一个简单的优化是仅测试小于等于待测数平方根的因子
public boolean isPrime(int candidate) {<br> int candidateRoot = (int) Math.sqrt((double) candidate);<br> return IntStream.rangeClosed(2, candidateRoot)<br> .noneMatch(i -> candidate % i == 0);<br>}
为了把前n个数字分为质数和非质数,<br>只要创建一个包含这n个数的流,<br>用刚刚写的isPrime方法作为谓词,<br>再给partitioningBy收集器归约
public Map<<boolean, list<integer="">Boolean, List<Integer><integer></integer>> partitionPrimes(int n) {<br> return IntStream.rangeClosed(2, n).boxed()<br> .collect(<br> partitioningBy(candidate -> isPrime(candidate)));<br>} </boolean,>
Collectors类的静态工厂方法
子主题
收集器接口
Collector接口包含了一系列方法,为实现具体的归约操作(即收集器)提供了范本
Collector接口的定义,它列出了接口的签名以及声明的五个方法
子主题
实现一个ToListCollector<T><t>类,<br>将Stream<T><t>中的所有元素收集到一个List<T><t>里</t></t></t>
public class ToListCollector<T><t> implements Collector<<t, list<t=""><t>T, List<T><t>, List<T><t></t></t>></t></t,></t>
理解 Collector 接口声明的方法
1. 建立新的结果容器:supplier方法
supplier方法必须返回一个结果为空的Supplier,<br>也就是一个无参数函数,<br>在调用时它会创建一个空的累加器实例,<br>供数据收集过程使用。
很明显,对于将累加器本身作为结果返回的收集器,<br>比如我们的ToListCollector,<br>在对空流执行操作的时候,<br>这个空的累加器也代表了收集过程的结果。<br>在我们的ToListCollector中,<br>supplier返回一个空的List
public Supplier<T<list<t>> supplier() {<br> return () -> new ArrayList<T><t>();<br>} </t></list<t>
也可以只传递一个构造函数引用<br>public Supplier<<list<t>List<T><t></t>> supplier() {<br> return ArrayList::new;<br>} </list<t><br>
2. 将元素添加到结果容器:accumulator方法
accumulator方法会返回执行归约操作的函数。<br>当遍历到流中第n个元素时,<br>这个函数执行时会有两个参数:<br>保存归约结果的累加器(已收集了流中的前 n1 个项目),<br>还有第n个元素本身。<br>该函数将返回void,因为累加器是原位更新,<br>即函数的执行改变了它的内部状态以体现遍历的元素的效果。
对于ToListCollector,<br>这个函数仅仅会把当前项目添加至已经遍历过的项目的列表
public BiConsumer<<list<t>List<T><t>, </t>T> accumulator() {<br> return (list, item) -> list.add(item);<br>}</list<t>
可以使用方法引用,这会更为简洁<br><br>public BiConsumer<List<T><list<t>, T> accumulator() {<br> return List::add;<br>} </list<t><br>
3. 对结果容器应用最终转换:finisher方法
finisher方法必须返回在累积过程的最后要调用的一个函数,<br>以便将累加器对象转换为整个集合操作的最终结果。
通常,就像ToListCollector的情况一样,<br>累加器对象恰好符合预期的最终结果,<br>因此无需进行转换。所以finisher方法只需返回identity函数
public Function<<list<t>List<T><t>,</t> List<T><t>> finisher() {<br> return Function.identity();<br>} </t></list<t>
这三个方法已经足以对流进行顺序归约,<br>至少从逻辑上看可以按图进行。<br>实践中的实现细节可能还要复杂一点,<br>一方面是因为流的延迟性质,<br>可能在collect操作之前还需要完成其他中间操作的流水线,<br>另一方面则是理论上可能要进行并行归约。
子主题
4. 合并两个结果容器:combiner方法
combiner方法会返回一个供归约操作使用的函数,<br>它定义了对流的各个子部分进行并行处理时,<br>各个子部分归约所得的累加器要如何合并。
对于toList而言, 这个方法的实现非常简单,<br>只要把从流的第二个部分收集到的项目列表加到遍历第一部分时得到 的列表后面就行了
public BinaryOperator<List<T><list<t>> combiner() {<br> return (list1, list2) -> {<br> list1.addAll(list2);<br> return list1; }<br>} </list<t>
有了这第四个方法,就可以对流进行并行归约了
用到Java 7中引入的分支/合并框架和Spliterator抽象
原始流会以递归方式拆分为子流,<br>直到定义流是否需要进一步拆分的一个条件为非<br>(如果分布式工作单位太小,<br>并行计算往往比顺序计算要慢,<br>而且要是生成的并行任务比处理器内核数多很多的话就毫无意义了)。
现在,所有的子流都可以并行处理,即对每个子流应用上图所示的顺序归约算法。
最后,使用收集器combiner方法返回的函数,<br>将所有的部分结果两两合并。<br>这时会把原始流每次拆分时得到的子流对应的结果合并起来。
子主题
5. characteristics方法
characteristics会返回一个不可变的Characteristics集合,<br>它定义了收集器的行为——尤其是关于流是否可以并行归约,<br>以及可以使用哪些优化的提示。<br>Characteristics是一个包含三个项目的枚举
UNORDERED——归约结果不受流中项目的遍历和累积顺序的影响。<br>
CONCURRENT——accumulator函数可以从多个线程同时调用,<br>且该收集器可以并行归约流。<br>如果收集器没有标为UNORDERED,那它仅在用于无序数据源时才可以并行归约。<br>
IDENTITY_FINISH——这表明完成器方法返回的函数是一个恒等函数,可以跳过。<br>这种情况下,累加器对象将会直接用作归约过程的最终结果。<br>这也意味着,将累加器A不加检查地转换为结果R是安全的
全部融合到一起<br>
子主题
Java9新特性
语法
增强@Deprecated注解
1、增加since版本标识属性 <br>2、增加forRemoval属性,表示是否会在未来版本移除,默认为false<br>
如@Deprecated(since = "1.1", forRemoval = true)
接口的 private 方法
在 Java 8 接口中增加 default 与 static 方法的基础上又增加了 private 方法
特殊标识符增加限制
Java 8 及之前版本中 String __ = "hello"; 这样的标识符是合法的,但是 Java 9 开始就用不了了。
改进 try-with-resources
无需在 try-with-resources 语句中声明一个新变量,直接使用即可;<br>如果有多个变量,则用分号隔开<br>
如: <br>InputStreamReader reader = new InputStreamReader(System.in); <br>OutputStreamWriter writer = new OutputStreamWriter(System.out); <br>try (reader ; writer) { <br>writer.write(reader.read()); <br>} catch (Exception e) { <br>e.printStackTrace(); <br>}
钻石操作符<>的升级
支持匿名内部类,如 new HashMap<>() {}
类库
引入HttpClient API
jdk.incubator.httpclient 的孵化器模块,<br>将会在以后的发布版本中用来替换旧的HttpURLConnection API。<br>其中不仅包含旧的 HttpURLConnection API 功能,<br>另外还加入了对 HTTP/2 和 WebSocket 的支持。
新增集合工厂方法
如List.of()、Set.of()、Map.of()方法创建不可变集合,也使集合初始化代码更简洁
改进 Optional 类
为 java.util.Optional 添加了很多新的有用方法,Optional 可以直接转为 stream
反应式流 ( Reactive Streams )
java.util.concurrent.Flow 类,<br>其中包含了 Flow.Publisher、Flow.Subscriber、Flow.Subscription 和 F low.Processor 4 个核心接口
进程API
新增 java.lang.ProcessHandle 接口,用于对原生进程进行管理
平台日志API
新增 java.lang.System.Logger 接口,其默认实现是 java.util.logging相关API
变量句柄 API
新增 java.lang.invoke.VarHandle 类,以作为 java.util.cocurrent.automic 包 和 sun.misc.Unsafe 类某些功能的替代方案。
改进的 Stream API
新增takeWhile(动态确定何时终止迭代)、dropWhile(跳过满足给定条件前的值)、ofNullable、iterate(新重载方法)方法
轻量级的 JSON API
内置了一个轻量级的JSON API
多分辨率图像 API
定义多分辨率图像API,开发者可以很容易的操作和展示不同分辨率的图像了
改进进程控制相关API
ProcessHandle类还可以监视进程的活跃性并破坏进程。<br>CompletableFuture 类的异步机制可以在 ProcessHandle.onExit 方法退出时执行操作
增加堆栈遍历 API
提供堆栈遍历API,允许轻松过滤和延迟访问堆栈跟踪中的信息。<br>见 java.lang.StackWalker 类
工具
jshell
Java语言的REPL,交互式命令行工具
1、简化简单程序的编写与运行,便于快速验证代码正确性。 <br>比如 System.out.println("Hello World") 仅仅一行代码就可以实现Hello World的输出 <br>
2、可执行单个jshell脚本文件。<br>将待执行的程序代码写到以.jsh为后缀名的文件中,<br>使用jshell [filename]命令执行
jlink
它是将 module 进行打包的工具,帮助目标机器的部署。打包后的文件将非常精简。
String底层存储结构的变更
由原来的 char 数组变成 byte 数组,<br>目的是为了更节省存储空间,提高性能。 <br>同样地,StringBuilder 和 StringBuffer 底层也进行了改变,<br>具体见 java.lang.AbstractStringBuilder 源码。
原理: 基于ISO/latin1/Utf-16编码,<br>latin1和ISO用一个byte标识,<br>UTF-16用两个byte标识。<br><br>Java 9会自动识别用哪个编码,<br>当数据用到1byte,就会使用iSO或者latin1编码,<br>当空间数据满足2byte的时候,自动使用utf-16编码,节省了很多空间。
多版本兼容jar
用于解决jar包版本冲突及兼容问题
JVM调优增强功能
统一JVM日志记录
使用G1作为默认的垃圾收集器,弃用CMS垃圾收集器
改进的Javadoc
1、Java 9中的Javadoc 支持在 API 文档中的进行搜索; <br>2、输出的Javadoc文档兼容 HTML5 标准; <br>3、每个 Javadoc 页面都包含有关 JDK 模块类或接口来源的信息。
国际化功能
properties文件默认以UTF-8编码加载,以前是ISO-8859-1
模块化系统Jigsaw
目标
使用模块(module)来清楚的描述组件之间的依赖关系,而不是jar; <br>使用新的module-path来解决类路径(classpath)管理的不足。<br><br>提供了更强大的代码封装性: <br>在Java 9 中,模块之间的关系被称为“可读性”(readability),<br>实际代码中一个类型对于另外一个类型的调用被称为“可访问性“(accessablity),<br>即private、默认、protected、public访问修饰符。<br><br>可访问性的前提是可读性。因此public访问修饰符不再意味着具有可访问性了。
模块声明:增加一个module-info.java文件描述模块信息。<br>模块声明中可以包含零个或多个模块语句。<br>包括以下五种类型:<br><br>1、(模块)导出语句(exports statement)<br>2、(模块)打开语句(opens statement)<br>3、(模块)导入语句(requires statement)<br>4、(服务)使用语句(uses statement)<br>5、(服务)提供语句(provides statement)
如 module test { <br>exports com.example.test; <br>requires main;<br>}
Java线程
Thread
状态
New<br><br>当程序使用new关键字创建了一个线程之后,<br>该线程就处于新建状态,<br>此时仅由JVM为其分配 内存,<br>并初始化其成员变量的值 <br>
Runnable<br>当线程对象调用了start()方法之后,<br>该线程处于就绪状态。<br>Java虚拟机会为其创建方法调用栈和 程序计数器,等待调度运行。
Blocked 进入EntrySet中<br><br>阻塞状态是指线程因为某种原因放弃了cpu 使用权,<br>也即让出了cpu timeslice,暂时停止运行。 <br>直到线程进入可运行(runnable)状态,<br>才有机会再次获得cpu timeslice 转到运行(running)状 态。<br>
阻塞的情况分三种
等待阻塞 ( o.wait-> 等待对列 )
运行(running)的线程执行o.wait()方法,<br>JVM会把该线程放入等待队列(waitting queue) 中。
同步阻塞 (lock-> 锁池 )
运行(running)的线程在获取对象的同步锁时,<br>若该同步锁被别的线程占用,<br>则JVM会把该线 程放入锁池(lock pool)中。
其他阻塞 (sleep/join)
运行(running)的线程<br>执行Thread.sleep(long ms)或t.join()方法,<br>或者发出了I/O请求时, <br>JVM会把该线程置为阻塞状态。<br>当sleep()状态超时、join()等待线程终止<br>或者超时、或者I/O 处理完毕时,<br>线程重新转入可运行(runnable)状态。
Waiting 处于waitSet中
Timed_Waiting
Terminated
终止线程 4 种方式
正常运行结束
使用退出标志退出线程
一般 run()方法执行完,线程就会正常结束,<br>然而,常常有些线程是伺服线程。<br>它们需要长时间的 运行,<br>只有在外部某些条件满足的情况下,<br>才能关闭这些线程。<br>使用一个变量来控制循环,<br>例如: 最直接的方法就是设一个boolean类型的标志,<br>并通过设置这个标志为true或false来控制while 循环是否退出
Interrupt 方法结束线程
使用interrupt()方法来中断线程有两种情况
线程处于阻塞状态:<br>如使用了 sleep,同步锁的 wait,socket 中的 receiver,accept 等方法时, <br>会使线程处于阻塞状态。<br><br>当调用线程的 interrupt()方法时,<br>会抛出 InterruptException 异常。 <br>阻塞中的那个方法抛出这个异常,<br>通过代码捕获该异常,然后 break 跳出循环状态,<br>从而让 我们有机会结束这个线程的执行。<br>通常很多人认为只要调用 interrupt 方法线程就会结束,<br>实 际上是错的, <br>一定要先捕获InterruptedException异常之后通过break来跳出循环,<br>才能正 常结束run方法。
线程未处于阻塞状态:<br>使用isInterrupted()判断线程的中断标志来退出循环。<br>当使用 interrupt()方法时,中断标志就会置true,<br>和使用自定义的标志来控制循环是一样的道理。
stop 方法终止线程(线程不安全)
程序中可以直接使用thread.stop()来强行终止线程,<br>但是stop方法是很危险的,就象突然关 闭计算机电源,<br>而不是按正常程序关机一样,可能会产生不可预料的结果,<br>不安全主要是: <br>thread.stop()调用之后,<br>创建子线程的线程就会抛出 ThreadDeath的错误,<br>并且会释放子 线程所持有的所有锁。<br>一般任何进行加锁的代码块,<br>都是为了保护数据的一致性,<br>如果在调用 thread.stop()后<br>导致了该线程所持有的所有锁的突然释放(不可控制),<br>那么被保护数据就有可能呈 现不一致性,<br>其他线程在使用这些被破坏的数据时,<br>有可能导致一些很奇怪的应用程序错误。<br>因 此,并不推荐使用stop方法来终止线程。
方法
Object.java的方法
线程等待(wait) <br>调用该方法的线程进入WAITING 状态,<br>只有等待另外线程的通知或被中断才会返回,<br>需要注意的 是调用wait()方法后,会释放对象的锁。<br>因此,wait方法一般用在同步方法或同步代码块中。
线程唤醒(notify) <br>Object 类中的 notify() 方法,<br>唤醒在此对象监视器上等待的单个线程,如果所有线程都在此对象 上等待,<br>则会选择唤醒其中一个线程,<br>选择是任意的,并在对实现做出决定时发生,<br>线程通过调 用其中一个 wait() 方法,<br>在对象的监视器上等待,直到当前的线程放弃此对象上的锁定,<br>才能继 续执行被唤醒的线程,<br>被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞 争。<br>类似的方法还有 notifyAll() ,唤醒在此监视器上等待的所有线程。
Thread.java的方法
线程睡眠(sleep) <br>sleep 导致当前线程休眠,<br>与 wait 方法不同的是 sleep 不会释放当前占有的锁,<br>sleep(long)会导致 线程进入TIMED-WATING状态,<br>而wait()方法会导致当前线程进入WATING状态
线程让步(yield) <br>yield 会使当前线程让出 CPU 执行时间片,<br>与其他线程一起重新竞争 CPU 时间片。<br>一般情况下, 优先级高的线程有更大的可能性成功竞争得到 CPU 时间片,<br>但这又不是绝对的,有的操作系统对 线程优先级并不敏感。
线程中断(interrupt) <br>中断一个线程,其本意是给这个线程一个通知信号,<br>会影响这个线程内部的一个中断标识位。这个线程本身并不会因此而改变状态(如阻塞,终止等)。 <br><br>1. 调用 interrupt()方法并不会中断一个正在运行的线程。<br>也就是说处于 Running 状态的线 程并不会因为被中断而被终止,<br>仅仅改变了内部维护的中断标识位而已。 <br>2. 若调用 sleep()而使线程处于 TIMED-WATING 状态,<br>这时调用 interrupt()方法,会抛出 InterruptedException,<br>从而使线程提前结束TIMED-WATING状态。 <br>3. 许多声明抛出InterruptedException的方法(如Thread.sleep(long mills方法)),<br>抛出异 常前,都会清除中断标识位,所以抛出异常后,<br>调用 isInterrupted()方法将会返回 false。 <br>4. 中断状态是线程固有的一个标识位,<br>可以通过此标识位安全的终止线程。<br>比如,你想终止 一个线程thread的时候,<br>可以调用thread.interrupt()方法,<br>在线程的run方法内部可以 根据thread.isInterrupted()的值来优雅的终止线程<br>
Join 等待其他线程终止 <br><br>在当前线程中调用一个线程的 join() 方法,<br>则当前线程转为阻塞 状态,<br>回到另一个线程结束,当前线程再由阻塞状态变为就绪状态,等待 cpu 的宠幸。
为什么要用 join()方法? <br>很多情况下,主线程生成并启动了子线程,<br>需要用到子线程返回的结果,<br>也就是需要主线程需要 在子线程结束后再结束,<br>这时候就要用到 join() 方法。 <br> System.out.println(Thread.currentThread().getName() + "线程运行开始!"); <br> Thread6 thread1 = new Thread6(); <br> thread1.setName("线程B"); <br> thread1.join(); <br> System.out.println("这时 thread1执行完毕之后才能执行主线程");
分类
守护线程(Daemon)
在程序运行的时候在后台提供一种通用服务的线程,<br>并且这个线程并不属于程序中不可或缺的部分。<br>因此,当所有的非后台线程结束时,程序也就终止了,<br>同时会杀死进程中的所有后台线程。反过来说, <br><br>只要有任何非后台线程还在运行,程序就不会终止。<br>必须在线程启动之前调用setDaemon()方法,才能把它设置为后台线程。
Finalizer守护进程、<br>引用处理守护进程、<br>GC守护进程、<br>服务守护进程、<br>编译守护进程、<br>windows下的监听Ctrl+break的守护进程<br>
用户线程(User)
判断虚拟机(JVM)何时离开,Daemon是为其他线程提供服务,<br>如果全部的User Thread已经撤离,<br>Daemon 没有可服务的线程,JVM撤离。
Object 的wait(), notify(), notifyAll() 需要先获得对象锁,然后才能wait, notify, notifyAll
Object#wait() 与Thread #sleep()区别
1. wait是Object的方法 <br> sleep是Thread的方法
2. wait需要获得对象锁,并且执行之后会释放对象 <br> sleep不需要释放获得锁,也不会释放对象
3. wait需要被notify/ notifyAll<br> sleep不需要被唤醒
sleep()方法导致了程序暂停执行指定的时间,<br>让出cpu该其他线程,但是他的监控状态依然 保持者,<br>当指定的时间到了又会自动恢复运行状态。
start 与 run 区别
1. start()方法来启动线程,真正实现了多线程运行。<br> 这时无需等待 run 方法体代码执行完毕, 可以直接继续执行下面的代码。
2. 通过调用 Thread 类的 start()方法来启动一个线程, <br>这时此线程是处于就绪状态, 并没有运 行。
3. 方法 run()称为线程体,它包含了要执行的这个线程的内容,<br>线程就进入了运行状态,<br>开始运 行run函数当中的代码。 <br>Run方法运行结束, 此线程终止。然后CPU再调度其它线程。
上下文切换
多线程会共同使用一组计算机上的CPU,<br>而线程数大于给程序分配的CPU数量时,<br>为了让各个线程都有执行的机会,就需要轮转使用CPU。<br>不同的线程切换使用CPU发生的切换数据等
巧妙地利用了时间片轮转的方式, <br>CPU 给每个任务都服务一定的时间,<br>然后把当前任务的状态保存 下来,<br>在加载下一任务的状态后,<br>继续服务下一任务,任务的状态保存及再加载, <br>这段过程就叫做 上下文切换。<br>时间片轮转的方式使多个任务在同一颗CPU上执行变成了可能。
上下文
某一时间点 CPU 寄存器和程序计数器的内容。
寄存器
CPU 内部的数量较少但是速度很快的内存(与之对应的是 CPU 外部相对较慢的 RAM 主内 存)。<br>寄存器通过对常用值(通常是运算的中间值)的快速访问来提高计算机程序运行的速 度。
程序计数器
一个专用的寄存器,<br>用于表明指令序列中 CPU 正在执行的位置,<br>存的值为正在执行的指令 的位置或者下一个将要被执行的指令的位置,<br>具体依赖于特定的系统。
PCB-“切换桢”
上下文切换可以认为是内核(操作系统的核心)<br>在 CPU 上对于进程(包括线程)进行切换,<br>上下 文切换过程中的信息是保存在进程控制块(PCB, process control block)中的。<br>PCB还经常被称 作“切换桢”(switchframe)。<br>信息会一直保存到CPU的内存中,直到他们被再次使用。
上下文切换的活动
1. 挂起一个进程,将这个进程在 CPU 中的状态(上下文)存储于内存中的某处。 <br>2. 在内存中检索下一个进程的上下文并将其在 CPU 的寄存器中恢复。 <br>3. 跳转到程序计数器所指向的位置(即跳转到进程被中断时的代码行),以恢复该进程在程序 中。
引起线程上下文切换的原因
1. 当前执行任务的时间片用完之后,系统CPU正常调度下一个任务; <br>2. 当前执行任务碰到 I/O阻塞,调度器将此任务挂起,继续下一任务; <br>3. 多个任务抢占锁资源,当前任务没有抢到锁资源,被调度器挂起,继续下一任务; <br>4. 用户代码挂起当前任务,让出CPU时间; <br>5. 硬件中断;
JAVA 锁
乐观锁
乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,<br>每次去拿数据的时候都认为 别人不会修改,所以不会上锁,<br>但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,<br>采取在写时先读出当前版本号,<br>然后加锁操作(比较跟上一次的版本号,如果一样则更新), <br>如果失败则要重复读-比较-写的操作。 <br><br>java 中的乐观锁基本都是通过 CAS 操作实现的,CAS 是一种更新的原子操作,<br>比较当前值跟传入 值是否一样,一样则更新,否则失败。
悲观锁
悲观锁是就是悲观思想,即认为写多,遇到并发写的可能性高,<br>每次去拿数据的时候都认为别人 会修改,<br>所以每次在读写数据的时候都会上锁,<br>这样别人想读写这个数据就会block直到拿到锁。 <br>java中的悲观锁就是Synchronized,<br>AQS框架下的锁则是先尝试cas乐观锁去获取锁,获取不到, <br>才会转换为悲观锁,如RetreenLock。
自旋锁
自旋锁原理非常简单,<br>如果持有锁的线程能在很短时间内释放锁资源,<br>那么那些等待竞争锁 的线程就不需要做内核态和用户态之间的切换进入阻塞挂起状态,<br>它们只需要等一等(自旋), <br>等持有锁的线程释放锁后即可立即获取锁,<br>这样就避免用户线程和内核的切换的消耗。 <br><br>线程自旋是需要消耗 cpu 的,说白了就是让 cpu 在做无用功,<br>如果一直获取不到锁,那线程 也不能一直占用cpu自旋做无用功,<br>所以需要设定一个自旋等待的最大时间。 <br><br>如果持有锁的线程执行的时间超过自旋等待的最大时间仍没有释放锁,<br>就会导致其它争用锁 的线程在最大等待时间内还是获取不到锁,<br>这时争用线程会停止自旋进入阻塞状态。 <br>
自旋锁的优缺点<br><br> 自旋锁尽可能的减少线程的阻塞,<br>这对于锁的竞争不激烈,<br>且占用锁时间非常短的代码块来说性能能大幅度的提升,<br>因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗,<br>这些操作会 导致线程发生两次上下文切换! <br><br>但是如果锁的竞争激烈,<br>或者持有锁的线程需要长时间占用锁执行同步块,<br>这时候就不适合 使用自旋锁了,<br>因为自旋锁在获取锁前一直都是占用 cpu 做无用功,<br>占着 XX 不 XX,同时有大量 线程在竞争一个锁,<br>会导致获取锁的时间很长,线程自旋的消耗大于线程阻塞挂起操作的消耗, <br>其它需要cpu的线程又不能获取到cpu,造成cpu的浪费。<br>所以这种情况下我们要关闭自旋锁;
自旋锁时间阈值 ( 1.6<br>引入了适应性自旋锁 )<br><br> 自旋锁的目的是为了占着 CPU 的资源不释放,等到获取到锁立即进行处理。<br>但是如何去选择 自旋的执行时间呢?如果自旋执行时间太长,<br>会有大量的线程处于自旋状态占用 CPU 资源,进而 会影响整体系统的性能。<br>因此自旋的周期选的格外重要! <br><br>JVM 对于自旋周期的选择,jdk1.5 这个限度是一定的写死的,<br>在 1.6 引入了适应性自旋锁,适应 性自旋锁意味着自旋的时间不在是固定的了,<br>而是由前一次在同一个锁上的自旋时间以及锁的拥 有者的状态来决定,<br>基本认为一个线程上下文切换的时间是最佳的一个时间,<br>同时 JVM 还针对当 前 CPU 的负荷情况做了较多的优化,<br>如果平均负载小于 CPUs 则一直自旋,如果有超过(CPUs/2) 个线程正在自旋,<br>则后来线程直接阻塞,<br>如果正在自旋的线程发现 Owner 发生了变化则延迟自旋 时间<br>(自旋计数)或进入阻塞,如果 CPU 处于节电模式则停止自旋,<br>自旋时间的最坏情况是 CPU 的存储延迟(CPU A存储了一个数据,到CPU B得知这个数据直接的时间差),<br>自旋时会适当放 弃线程优先级之间的差异。 <br><br>自旋锁的开启<br><br> JDK1.6中<br>-XX:+UseSpinning开启; <br>-XX:PreBlockSpin=10 为自旋次数; <br><br>JDK1.7后,去掉此参数,由jvm控制;
Synchronized 同步锁
synchronized 它可以把任意一个非 NULL 的对象当作锁。<br>他属于独占式的悲观锁,同时属于可重 入锁。 <br><br>Synchronized<br><br>作用范围<br><br> 1. 作用于方法时,锁住的是对象的实例(this); <br>2. 当作用于静态方法时,锁住的是Class实例,<br>又因为Class的相关数据存储在永久代PermGen (jdk1.8 则是 metaspace),<br>永久代是全局共享的,因此静态方法锁相当于类的一个全局锁, <br>会锁住所有调用该方法的线程; <br>3. synchronized 作用于一个对象实例时,<br>锁住的是所有以该对象为锁的代码块。<br>它有多个队列, 当多个线程一起访问某个对象监视器的时候,<br>对象监视器会将这些线程存储在不同的容器中。 <br><br>Synchronized<br><br>核心 组件<br><br> 1) Wait Set:调用wait方法被阻塞的线程被放置在这里; <br>2) Contention List:竞争队列,所有请求锁的线程首先被放在这个竞争队列中; <br>3) Entry List:Contention List中那些有资格成为候选资源的线程被移动到Entry List中; <br>4) OnDeck:任意时刻,最多只有一个线程正在竞争锁资源,该线程被成为OnDeck; <br>5) Owner:当前已经获取到所资源的线程被称为Owner; <br>6) !Owner:当前释放锁的线程。
1. JVM 每次从队列的尾部取出一个数据用于锁竞争候选者(OnDeck),<br> 但是并发情况下, ContentionList会被大量的并发线程进行CAS访问,<br> 为了降低对尾部元素的竞争,<br> JVM会将 一部分线程移动到EntryList中作为候选竞争线程。 <br>2. Owner 线程会在 unlock 时,<br> 将 ContentionList 中的部分线程迁移到 EntryList 中,<br> 并指定 EntryList中的某个线程为OnDeck线程(一般是最先进去的那个线程)。 <br>3. Owner 线程并不直接把锁传递给 OnDeck 线程,<br> 而是把锁竞争的权利交给 OnDeck, <br> OnDeck需要重新竞争锁。<br> 这样虽然牺牲了一些公平性,<br> 但是能极大的提升系统的吞吐量,<br> 在 JVM中,也把这种选择行为称之为“竞争切换”。 <br>4. OnDeck线程获取到锁资源后会变为Owner线程,<br> 而没有得到锁资源的仍然停留在EntryList 中。<br> 如果Owner线程被wait方法阻塞,<br> 则转移到WaitSet队列中,<br> 直到某个时刻通过notify 或者notifyAll唤醒,<br> 会重新进去EntryList中。 <br>5. 处于 ContentionList、EntryList、WaitSet 中的线程都处于阻塞状态,<br> 该阻塞是由操作系统 来完成的(Linux内核下采用pthread_mutex_lock内核函数实现的)。 <br>6. Synchronized是非公平锁。 <br> Synchronized在线程进入ContentionList时,<br> 等待的线程会先 尝试自旋获取锁,<br> 如果获取不到就进入 ContentionList,<br> 这明显对于已经进入队列的线程是不公平的,<br> 还有一个不公平的事情就是自旋获取锁的线程还可能直接抢占 OnDeck 线程的锁 资源。 <br> 参考:https://blog.csdn.net/zqz_zqz/article/details/70233767 <br>7. 每个对象都有个 monitor 对象,<br> 加锁就是在竞争 monitor 对象,<br> 代码块加锁是在前后分别加 上monitorenter和monitorexit指令来实现的,<br> 方法加锁是通过一个标记位ACC_SYNCHRONIZED来判断的 <br>8. synchronized 是一个重量级操作,<br> 需要调用操作系统相关接口,<br> 性能是低效的,有可能给线 程加锁消耗的时间比有用操作消耗的时间更多。 <br>9. Java1.6,synchronized进行了很多的优化,<br> 有适应自旋、锁消除、锁粗化、轻量级锁及偏向锁等,<br> 效率有了本质上的提高。<br> 在之后推出的 Java1.7 与 1.8 中,<br> 均对该关键字的实现机理做了优化。<br> 引入了偏向锁和轻量级锁。<br> 都是在对象头中有标记位,不需要经过操作系统加锁。 <br>10. 锁可以从偏向锁升级到轻量级锁,<br> 再升级到重量级锁。这种升级过程叫做锁膨胀; <br>11. JDK 1.6中默认是开启偏向锁和轻量级锁,<br> 可以通过-XX:-UseBiasedLocking来禁用偏向锁。
ReentrantLock
ReentantLock 继承接口 Lock 并实现了接口中定义的方法,<br>是一种可重入锁,除了能完 成 synchronized 所能完成的所有工作外,<br>还提供了<font color="#80bc42"><b>可响应中断锁、可轮询锁请求、定时锁</b></font>等 避免多线程死锁的方法。
Lock接口的主要 方法<br><br> 1. void lock(): <br> 执行此方法时, 如果锁处于空闲状态, 当前线程将获取到锁. <br> 相反, 如果锁已经 被其他线程持有, 将禁用当前线程, 直到当前线程获取到锁. <br>2. boolean tryLock():<br> 如果锁可用, 则获取锁, 并立即返回 true, 否则返回 false. <br> 该方法和 lock()的区别在于, tryLock()只是"试图"获取锁, <br> 如果锁不可用, 不会导致当前线程被禁用, <br> 当前线程仍然继续往下执行代码. <br> 而 lock()方法则是一定要获取到锁, <br> 如果锁不可用, 就一 直等待, 在未获得锁之前,<br> 当前线程并不继续向下执行. <br>3. void unlock():<br> 执行此方法时, 当前线程将释放持有的锁. <br> 锁只能由持有者释放, 如果线程 并不持有锁, 却执行该方法, <br> 可能导致异常的发生. <br>4. Condition newCondition():<br> 条件对象,获取等待通知组件。<br> 该组件和当前的锁绑定, 当前线程只有获取了锁,<br> 才能调用该组件的 await()方法,<br> 而调用后,当前线程将缩放锁。 <br>5. getHoldCount() :<br> 查询当前线程保持此锁的次数,<br> 也就是执行此线程执行lock方法的次 数。 <br>6. getQueueLength():<br> 返回正等待获取此锁的线程估计数,<br> 比如启动 10 个线程,1 个 线程获得锁,此时返回的是9 <br>7. getWaitQueueLength:<br> (Condition condition)返回等待与此锁相关的给定条件的线 程估计数。<br> 比如 10 个线程,用同一个 condition 对象,<br> 并且此时这 10 个线程都执行了 condition对象的 await方法,<br> 那么此时执行此方法返回10 <br>8. hasWaiters(Condition condition):<br> 查询是否有线程等待与此锁有关的给定条件 (condition),<br> 对于指定condition对象,有多少线程执行了condition.await方法 <br>9. hasQueuedThread(Thread thread):<br> 查询给定线程是否等待获取此锁 <br>10. hasQueuedThreads():<br> 是否有线程等待此锁 <br>11. isFair():<br> 该锁是否公平锁 <br>12. isHeldByCurrentThread(): <br> 当前线程是否保持锁锁定,<br> 线程的执行 lock 方法的前后分别是false和true <br>13. isLock():<br> 此锁是否有任意线程占用 <br>14. lockInterruptibly():<br> 如果当前线程未被中断,获取锁 <br>15. tryLock():<br> 尝试获得锁,仅在调用时锁未被线程占用,获得锁 <br>16. tryLock(long timeout TimeUnit unit):<br> 如果锁在给定等待时间内没有被另一个线程保持, 则获取该锁。
ReentrantLock 与 synchronized
1. ReentrantLock通过方法 lock()与unlock()来进行加锁与解锁操作,<br> 与synchronized会被 JVM 自动解锁机制不同,<br> ReentrantLock 加锁后需要手动进行解锁。<br> 为了避免程序出 现异常而无法正常解锁的情况,<br> 使用 ReentrantLock 必须在 finally 控制块中进行解锁操 作。 <br>2. ReentrantLock相比synchronized的优势是可中断、公平锁、多个锁。<br> 这种情况下需要 使用ReentrantLock。
Condition类和 Object类锁方法区别区别 <br>
1. Condition类的awiat方法和Object类的 wait方法等效 <br>2. Condition类的signal方法和Object类的 notify方法等效 <br>3. Condition类的signalAll方法和Object类的notifyAll方法等效 <br>4. ReentrantLock类可以唤醒指定条件的线程,而Object的唤醒是随机的
tryLock和 lock和 lockInterruptibly的区别 <br>
1. tryLock能获得锁就返回true,不能就立即返回false,<br> tryLock(long timeout,TimeUnit unit),可以增加时间限制,<br> 如果超过该时间段还没获得锁,返回false <br>2. lock能获得锁就返回true,不能的话一直等待获得锁 <br>3. lock 和 lockInterruptibly,如果两个线程分别执行这两个方法,<br> 但此时中断这两个线程, lock不会抛出异常,<br> 而lockInterruptibly会抛出异常。
非公平锁与公平锁
公平锁 <br>
加锁前检查是否有排队等待的线程,优先排队等待的线程,先来先得
公平锁指的是锁的分配机制是公平的,通常先对锁提出获取请求的线程会先被分配到锁, <br>ReentrantLock在构造函数中提供了是否公平锁的初始化方式来定义公平锁。
非公平锁 <br>
加锁时不考虑排队等待问题,直接尝试获取锁,获取不到自动到队尾等待
JVM 按随机、就近原则分配锁的机制则称为不公平锁,<br>ReentrantLock 在构造函数中提供了 是否公平锁的初始化方式,默认为非公平锁。<br>非公平锁实际执行的效率要远远超出公平锁,除非程序有特殊需要,否则最常用非公平锁的分配机制。
1. 非公平锁性能比公平锁高5~10倍,因为公平锁需要在多核的情况下维护一个队列 <br>2. Java中的synchronized是非公平锁,ReentrantLock 默认的lock()方法采用的是非公平锁
可重入锁(递归锁)
可重入锁,也叫 做递归锁,指的是同一线程 外层函数获得锁之后 ,<br>内层递归函数仍然有获取该锁的代码,但不受 影响。<br>在JAVA环境下 ReentrantLock 和synchronized 都是 可重入锁。
ReadWriteLock 读写锁
为了提高性能,Java 提供了读写锁,<br>在读的地方使用读锁,在写的地方使用写锁,灵活控制,<br>如 果没有写锁的情况下,读是无阻塞的,<br>在一定程度上提高了程序的执行效率。<br>读写锁分为读锁和写 锁,多个读锁不互斥,读锁与写锁互斥,<br>这是由jvm自己控制的,你只要上好相应的锁即可。 <br>
读锁 <br>如果你的代码只读数据,可以很多人同时读,但不能同时写,那就上读锁 <br><br>写锁 <br>如果你的代码修改数据,只能有一个人在写,且不能同时读取,那就上写锁。<br>总之,读的时候上 读锁,写的时候上写锁! <br><br>Java 中 读 写 锁 有 个 接 口 java.util.concurrent.locks.ReadWriteLock , <br>也 有 具 体 的 实 现 ReentrantReadWriteLock。
共享锁和独占锁
独占锁<br><br> 独占锁模式下,每次只能有一个线程能持有锁,<br>ReentrantLock 就是以独占方式实现的互斥锁。 <br>独占锁是一种悲观保守的加锁策略,<br>它避免了读/读冲突,<br>如果某个只读线程获取锁,<br>则其他读线 程都只能等待,<br>这种情况下就限制了不必要的并发性,<br>因为读操作并不会影响数据的一致性。
共享锁<br><br> 共享锁则允许多个线程同时获取锁,并发访问 共享资源,<br>如:ReadWriteLock。<br>共享锁则是一种 乐观锁,它放宽了加锁策略,<br>允许多个执行读操作的线程同时访问共享资源。 <br><br>1. AQS的内部类Node定义了两个常量SHARED和EXCLUSIVE,<br>他们分别标识 AQS队列中等 待线程的锁获取模式。 <br>2. java的并发包中提供了ReadWriteLock,读-写锁。<br>它允许一个资源可以被多个读操作访问, <br>或者被一个 写操作访问,但两者不能同时进行。
重量级锁(Mutex Lock)
Synchronized 是通过对象内部的一个叫做监视器锁(monitor)来实现的。<br>但是监视器锁本质又 是依赖于底层的操作系统的Mutex Lock来实现的。<br>而操作系统实现线程之间的切换这就需要从用 户态转换到核心态,<br>这个成本非常高,状态之间的转换需要相对比较长的时间,<br>这就是为什么 Synchronized 效率低的原因。<br>因此,这种依赖于操作系统 Mutex Lock 所实现的锁我们称之为 “重量级锁”。<br>JDK中对Synchronized做的种种优化,<br>其核心都是为了减少这种重量级锁的使用。 <br>JDK1.6 以后,为了减少获得锁和释放锁所带来的性能消耗,<br>提高性能,引入了“轻量级锁”和 “偏向锁”。
轻量级锁
锁的状态总共有四种:无锁状态、偏向锁、轻量级锁和重量级锁。 <br><br>锁升级<br><br> 随着锁的竞争,锁可以从偏向锁升级到轻量级锁,<br>再升级的重量级锁(但是锁的升级是单向的, 也就是说只能从低到高升级,不会出现锁的降级)。 <br><br>“轻量级”是相对于使用操作系统互斥量来实现的传统锁而言的。<br>但是,首先需要强调一点的是, 轻量级锁并不是用来代替重量级锁的,<br>它的本意是在没有多线程竞争的前提下,<br>减少传统的重量 级锁使用产生的性能消耗。<br>在解释轻量级锁的执行过程之前,先明白一点,<br>轻量级锁所适应的场 景是线程交替执行同步块的情况,<br>如果存在同一时间访问同一锁的情况,就会导致轻量级锁膨胀 为重量级锁。
偏向锁
Hotspot 的作者经过以往的研究发现大多数情况下锁不仅不存在多线程竞争,<br>而且总是由同一线 程多次获得。<br>偏向锁的目的是在某个线程获得锁之后,<br>消除这个线程锁重入(CAS)的开销,<br>看起 来让这个线程得到了偏护。<br>引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级 锁执行路径,<br>因为轻量级锁的获取及释放依赖多次 CAS 原子指令,<br>而偏向锁只需要在置换 ThreadID的时候依赖一次CAS原子指令<br>(由于一旦出现多线程竞争的情况就必须撤销偏向锁,<br>所 以偏向锁的撤销操作的性能损耗必须小于节省下来的 CAS 原子指令的性能消耗)。<br>上面说过,轻 量级锁是为了在线程交替执行同步块时提高性能,<br>而偏向锁则是在只有一个线程执行同步块时进 一步提高性能。 <br>
分段锁
分段锁也并非一种实际的锁,而是一种思想,ConcurrentHashMap是学习分段锁的最好实践
锁优化
减少锁持有时间<br><br> 只用在有线程安全要求的程序上加锁
减小锁粒度<br><br> 将大对象(这个对象可能会被很多线程访问),<br>拆成小对象,大大增加并行度,降低锁竞争。<br> 降低了锁的竞争,偏向锁,轻量级锁成功率才会提高。<br>最最典型的减小锁粒度的案例就是 ConcurrentHashMap。
锁分离<br><br> 最常见的锁分离就是读写锁ReadWriteLock,<br>根据功能进行分离成读锁和写锁,<br>这样读读不互 斥,读写互斥,写写互斥,即保证了线程安全,<br>又提高了性能,具体也请查看[高并发Java 五] JDK并发包。<br>读写分离思想可以延伸,只要操作互不影响,锁就可以分离。<br>比如 LinkedBlockingQueue 从头部取出,从尾部放数据
锁粗化<br><br> 通常情况下,为了保证多线程间的有效并发,<br>会要求每个线程持有锁的时间尽量短,<br>即在使用完 公共资源后,应该立即释放锁。<br>但是,凡事都有一个度,<br>如果对同一个锁不停的进行请求、同步 和释放,<br>其本身也会消耗系统宝贵的资源,反而不利于性能的优化 。
锁消除<br><br> 锁消除是在编译器级别的事情。<br>在即时编译器时,如果发现不可能被共享的对象,<br>则可以消除这 些对象的锁操作,多数是因为程序员编码不规范引起。
同步锁与死锁
同步锁
当多个线程同时访问同一个数据时,<br>很容易出现问题。<br>为了避免这种情况出现,<br>我们要保证线程 同步互斥,<br>就是指并发执行的多个线程,<br>在同一时间内只允许一个线程访问共享数据。 <br>Java 中可 以使用synchronized关键字来取得一个对象的同步锁。
死锁
何为死锁,就是多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。
多线程
线程创建和销毁所花时间,以及系统资源开销(线程池)<br><br>线程调度, 上下文切换 : 上下文切换过程并不廉价
多线程本质上是利用闲置的CPU资源,加快处理速度。
线程安全
Java多线程由于采用共享内存进行通信,<br>线程安全问题都是由共享变量(全局变量及静态变量)引起的。<br>共享变量的一致性和正确性。<br>多个线程访问共享变量,有线程安全问题。
如何在两个线程之间共享数据
JMM是一种规范,目的是解决由于多线程通过共享内存进行通信时,<br><br>存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。<br>需要关注原子性、可见性、有序性
原子性
可见性
有序性
Java 内存模型(JMM)解决了可见性和有序性的问题,<br>而锁解决了原子性的 问题,理想情况下我们希望做到“同步”和“互斥”。
常规实现方法
将数据抽象成一个类 ,并将数据的操作作为这个类的方法 <br>
将数据抽象成一个类,并将对这个数据的操作作为这个类的方法,<br>这么设计可以很容易做到 同步,只要在方法上加”synchronized“
code
Runnable对象作为 一个类的内部类 <br>
将Runnable对象作为一个类的内部类,<br>共享数据作为这个类的成员变量,<br>每个线程对共享数 据的操作方法也封装在外部类,<br>以便实现对数据的各个操作的同步和互斥,<br>作为内部类的各 个Runnable对象调用外部类的这些方法。
code
synchronized JVM层面保证线程同步
可以修饰方法 和代码块
修饰方法,是对类(this或者 .class对象)对象加锁使用ACC_SYNCHRONIZED指令
修饰代码块,是对给定的对象加锁 使用的是monitorenter 和 monitorexit指令
ReentrantLock Java API层面保证线程同步
只能用于修饰代码块
volatile <br>既有可见性又有原子性(非我及彼),可见性是一定的,原子性是看情况的。<br>对象类型和原生类型都是可见性,原生类型是原子性。<br><br>变量可见性、禁止重排序<br>
Java语言提供了一种稍弱的同步机制,即volatile变量,<br>用来确保将变量的更新操作通知到其他 线程。<br>volatile 变量具备两种特性,<br>volatile变量不会被缓存在寄存器或者对其他处理器不可见的 地方,<br>因此在读取volatile类型的变量时总会返回最新写入的值。
变量可见性 <br>其一是保证该变量对所有线程可见,<br>这里的可见性指的是当一个线程修改了变量的值,<br>那么新的 值对于其他线程是可以立即获取的。
禁止重排序 <br> volatile 禁止了指令重排。
比 sychronized<br>更轻量级的同步锁<br><br>在访问volatile变量时不会执行加锁操作,<br>因此也就不会使执行线程阻塞,<br>因此volatile变量是一 种比sychronized关键字更轻量级的同步机制。<br>volatile适合这种场景:一个变量被多个线程共 享,线程直接给这个变量赋值。
当对非 volatile 变量进行读写的时候,<br>每个线程先从内存拷贝变量到CPU缓存中。<br>如果计算机有 多个CPU,<br>每个线程可能在不同的CPU上被处理,<br>这意味着每个线程可以拷贝到不同的 CPU cache 中。<br>而声明变量是 volatile 的,<br>JVM 保证了每次读变量都从内存中读,<br>跳过 CPU cache 这一步。
适用场景<br><br> 值得说明的是对volatile变量的单次读/写操作可以保证原子性的,如long和double类型变量, <br>但是并不能保证i++这种操作的原子性,因为本质上i++是读、写两次操作。<br>在某些场景下可以 代替Synchronized。<br>但是 volatile不能完全取代Synchronized的位置,<br>只有在一些特殊的场景下,才能适用volatile。<br>总的来说,必须同时满足下面两个条件才能保证在并发环境的线程安 全: <br>(1)对变量的写操作不依赖于当前值(比如 i++),或者说是单纯的变量赋值(boolean flag = true)。 <br>(2)该变量没有包含在具有其他变量的不变式中,也就是说,不同的volatile变量之间,<br> 不 能互相依赖。只有在状态真正独立于程序内其他内容时才能使用 volatile。
ReentrantLock ReentrantReadWriteLock
ReentrantLock 是互斥锁
ReentrantReadWriteLock 是共享互斥的
一个是 ReadLock(共享,并行,强调数据一致性或者说可见性)<br>另一个是 WriteLock(互斥,串行)
线程池
内建的ExecutorService的实现
1.5:ThreadPoolExecutor、ScheduledThreadPoolExecutor<br><br>1.7:ForkJoinPool
Executors.newSingleThreadExecutor()<br>Executors.newCachedThreadPool()<br>Executors.newFixedThreadPool()<br>Executors.newScheduledThreadPool()<br>Executors.newWorkStealingPool(int parallelism):这是一个经常被人忽略的线程池,Java 8 才加入这个创建方法,其内部会构建ForkJoinPool,利用Work-Stealing算法,并行地处理任务,不保证处理顺序;<br>
public static ExecutorService newFixedThreadPool(int nThreads){<br> return new ThreadPoolExecutor(nThreads,nThreads,0L,TimeUnit.MILLISECONDS,<br> new LinkedBlockingQueue<Runnable>());<br>}<br>它是一种固定大小的线程池;<br>corePoolSize和maximunPoolSize都为用户设定的线程数量nThreads;<br>keepAliveTime为0,意味着一旦有多余的空闲线程,就会被立即停止掉;但这里keepAliveTime无效;<br>阻塞队列采用了LinkedBlockingQueue,它是一个无界队列;<br>由于阻塞队列是一个无界队列,因此永远不可能拒绝任务;<br>由于采用了无界队列,实际线程数量将永远维持在nThreads,因此maximumPoolSize和keepAliveTime将无效。 <br>
public static ExecutorService <font color="#80bc42">newCachedThreadPool()</font>{<br> return new ThreadPoolExecutor(0,Integer.MAX_VALUE,60L,TimeUnit.MILLISECONDS,<br> new SynchronousQueue<Runnable>());<br>}<br><br>它是一个可以无限扩大的线程池;<br>它比较适合处理执行时间比较小的任务;<br>corePoolSize为0,maximumPoolSize为无限大,意味着线程数量可以无限大;<br>keepAliveTime为60S,意味着线程空闲时间超过60S就会被杀死;<br>采用SynchronousQueue装等待的任务,这个阻塞队列没有存储空间,这意味着只要有请求到来,<br>就必须要找到一条工作线程处理他,如果当前没有空闲的线程,那么就会再创建一条新的线程。<br>
public static ExecutorService<font color="#80bc42"> newSingleThreadExecutor()</font>{<br> return new ThreadPoolExecutor(1,1,0L,TimeUnit.MILLISECONDS,<br> new LinkedBlockingQueue<Runnable>());<br>}<br><br>它只会创建一条工作线程处理任务;<br>采用的阻塞队列为LinkedBlockingQueue; <br>
public <font color="#80bc42">ScheduledThreadPoolExecutor</font>(int corePoolSize,ThreadFactory threadFactory,RejectedExecutionHandler handler) {<br> super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,<br> new DelayedWorkQueue(), threadFactory, handler);<br> }<br><br>它接收SchduledFutureTask类型的任务,有两种提交任务的方式:<br>scheduledAtFixedRate<br>scheduledWithFixedDelay<br>SchduledFutureTask接收的参数:<br>time:任务开始的时间<br>sequenceNumber:任务的序号<br>period:任务执行的时间间隔<br>它采用DelayQueue存储等待的任务<br>DelayQueue内部封装了一个PriorityQueue,它会根据time的先后时间排序,若time相同则根据sequenceNumber排序;<br>DelayQueue也是一个无界队列;<br>工作线程的执行过程:<br>工作线程会从DelayQueue取已经到期的任务去执行;<br>执行结束后重新设置任务的到期时间,再次放回DelayQueue<br>
public static ExecutorService newWorkStealingPool() {<br> return new ForkJoinPool<br> (Runtime.getRuntime().availableProcessors(),ForkJoinPool.defaultForkJoinWorkerThreadFactory,null, true);<br> }
ThreadPoolExecutor类是线程池中最核心的一个类
<b>构造函数</b> <br>public ThreadPoolExecutor( int corePoolSize,<br><br> int maximumPoolSize,<br><br> long keepAliveTime,<br><br> TimeUnit unit,<br><br> BlockingQueue<Runnable> workQueue,<br><br> ThreadFactory threadFactory,<br><br> RejectedExecutionHandler handler) <br>
corePoolSize<br><br>核心线程的数量,线程池初始化后,每接到一个任务就会创建一个线程来执行任务,直到当前的线程数目到达corePoolSize,此时新的任务将会进入queue中,只有当queue满了之后,maximunPoolSize才发挥作用<br><br>核心线程被保存在pool中,即使线程处于闲置状态也不会被回收,除非allowCoreThreadTimeOut被设置,从名字可以看出这是用来控制核心线程是否可以超时被回收的一个参数。<br><br>Ps核心线程可以理解为工厂的长工
maximumPoolSize<br><br>pool中所允许的最大线程数。线程池的queue满了之后,如果还有新的任务到来,此时如果线程数目小于maximumPoolSize,则会新建线程来执行任务。<br><br>Ps 非核心线程可以理解为工厂的短工 最大值=maximumPoolSize-corePoolSize
keepAliveTime<br><br>线程空闲的时间,默认情况该参数只针对”短工”有效(短工空闲太久就要被辞退),只有当配置allowCoreThreadTimeOut时该参数才对”长工”生效
unit<br><br>keepAliveTime的单位
workQueue<br><br>上文提到的queue,用来保存等待执行的任务的阻塞队列
ThreadFactory<br><br>线程工厂,可以用户自己配置,默认的ThreadFactory 1.给线程命名 2.将线程设置为非守护线程 3.优先级设置为NORM
handler<br><br>拒绝策略:当线程数=maximumPoolSize 且 queue已满 这时候新提交的任务会被拒绝(消费者已达到max,而待消费的任务也达到max)<br><br>1.AbortPolicy:直接抛出异常,默认策略;<br><br>2.CallerRunsPolicy:用调用者所在的线程来执行任务;<br><br>3.DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;<br><br>4.DiscardPolicy:直接丢弃任务;
事先创建若干个可执行的线程放入一个池(容器)中,<br>需要的时候从池中获取线程不用自行创建,<br>使用完毕不需要销毁线程而是放回池中,<br>从而减少创建和销毁线程对象的开销。<br><br>线程池做的工作主要是控制运行的线程的数量,<br>处理过程中将任务放入队列,<br>然后在线程创建后 启动这些任务,<br>如果线程数量超过了最大数量超出数量的线程排队等候,<br>等其它线程执行完毕, <br>再从队列中取出任务来执行。<br>他的主要特点为:线程复用;控制最大并发数;管理线程。 <br>
线程复用 <br>
每一个 Thread 的类都有一个 start 方法。 <br>当调用start启动线程时Java虚拟机会调用该类的 run 方法。 <br>那么该类的 run() 方法中就是调用了 Runnable 对象的 run() 方法。<br> 我们可以继承重写 Thread 类,<br>在其 start 方法中添加不断循环调用传递过来的 Runnable 对象。<br> 这就是线程池的实 现原理。<br>循环方法中不断获取 Runnable 是用 Queue 实现的,<br>在获取下一个 Runnable 之前可以 是阻塞的。
线程池的组成
1. 线程池管理器:用于创建并管理线程池 <br>2. 工作线程:线程池中的线程 <br>3. 任务接口:每个任务必须实现的接口,用于工作线程调度其运行 <br>4. 任务队列:用于存放待处理的任务,提供一种缓冲机制
Java 中的线程池是通过 Executor 框架实现的,<br>该框架中用到了 Executor,Executors, <br>ExecutorService,ThreadPoolExecutor ,<br>Callable和Future、FutureTask这几个类。
Java线程池工作过程
1. 线程池刚创建时,里面没有一个线程。<br> 任务队列是作为参数传进来的。<br> 不过,就算队列里面 有任务,线程池也不会马上执行它们。 <br>2. 当调用 execute() 方法添加一个任务时,<br> 线程池会做如下判断: <br> a) 如果正在运行的线程数量小于 corePoolSize,<br> 那么马上创建线程运行这个任务; <br> b) 如果正在运行的线程数量大于或等于 corePoolSize,<br> 那么将这个任务放入队列; <br> c) 如果这时候队列满了,<br> 而且正在运行的线程数量小于 maximumPoolSize,<br> 那么还是要 创建非核心线程立刻运行这个任务; <br> d) 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,<br> 那么线程池 会抛出异常RejectExecutionException。 <br>3. 当一个线程完成任务时,<br> 它会从队列中取下一个任务来执行。 <br>4. 当一个线程无事可做,<br> 超过一定的时间(keepAliveTime)时,<br> 线程池会判断,如果当前运 行的线程数大于 corePoolSize,<br> 那么这个线程就被停掉。<br> 所以线程池的所有任务完成后,<br> 它 最终会收缩到 corePoolSize 的大小。
JAVA阻塞队列原理
阻塞队列,关键字是阻塞,先理解阻塞的含义,<br>在阻塞队列中,线程阻塞有这样的两种情况
1. 当队列中没有数据的情况下,<br>消费者端的所有线程都会被自动阻塞(挂起),<br>直到有数据放 入队列。
2. 当队列中填满数据的情况下,<br>生产者端的所有线程都会被自动阻塞(挂起),<br>直到队列中有 空的位置,线程被自动唤醒。
Java中的阻塞队列
1. ArrayBlockingQueue :由数组结构组成的有界阻塞队列。 <br>2. LinkedBlockingQueue :由链表结构组成的有界阻塞队列。 <br>3. PriorityBlockingQueue :支持优先级排序的无界阻塞队列。 <br>4. DelayQueue:使用优先级队列实现的无界阻塞队列。 <br>5. SynchronousQueue:不存储元素的阻塞队列。 <br>6. LinkedTransferQueue:由链表结构组成的无界阻塞队列。 <br>7. LinkedBlockingDeque:由链表结构组成的双向阻塞队
ArrayBlockingQueue(公平、非公平) <br><br>用数组实现的有界阻塞队列。<br>此队列按照先进先出(FIFO)的原则对元素进行排序。<br>默认情况下 不保证访问者公平的访问队列,<br>所谓公平访问队列是指阻塞的所有生产者线程或消费者线程,<br>当 队列可用时,可以按照阻塞的先后顺序访问队列,<br>即先阻塞的生产者线程,可以先往队列里插入 元素,<br>先阻塞的消费者线程,可以先从队列里获取元素。<br>通常情况下为了保证公平性会降低吞吐 量。<br>我们可以使用以下代码创建一个公平的阻塞队列: <br><br>ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true); <br>
LinkedBlockingQueue(两个独立锁提高并发) <br><br>基于链表的阻塞队列,同ArrayListBlockingQueue类似,<br>此队列按照先进先出(FIFO)的原则对 元素进行排序。<br>而 LinkedBlockingQueue 之所以能够高效的处理并发数据,<br>还因为其对于生产者 端和消费者端分别采用了独立的锁来控制数据同步,<br>这也意味着在高并发的情况下生产者和消费 者可以并行地操作队列中的数据,<br>以此来提高整个队列的并发性能。 <br><br><br>LinkedBlockingQueue会默认一个类似无限大小的容量(Integer.MAX_VALUE)。
PriorityBlockingQueue(compareTo排序实现优先) <br><br>是一个支持优先级的无界队列。<br>默认情况下元素采取自然顺序升序排列。<br>可以自定义实现 compareTo()方法来指定元素进行排序规则,<br>或者初始化 PriorityBlockingQueue 时,<br>指定构造 参数Comparator来对元素进行排序。<br>需要注意的是不能保证同优先级元素的顺序。
DelayQueue(缓存失效、定时任务 ) <br><br>是一个支持延时获取元素的无界阻塞队列。<br>队列使用PriorityQueue来实现。队列中的元素必须实 现 Delayed 接口,<br>在创建元素时可以指定多久才能从队列中获取当前元素。<br>只有在延迟期满时才 能从队列中提取元素。<br>我们可以将DelayQueue运用在以下应用场景: <br><br>1. 缓存系统的设计:可以用 DelayQueue 保存缓存元素的有效期,<br> 使用一个线程循环查询 DelayQueue,<br> 一旦能从DelayQueue中获取元素时,表示缓存有效期到了。 <br>2. 定时任务调度:使用 DelayQueue 保存当天将会执行的任务和执行时间,<br> 一旦从 DelayQueue 中获取到任务就开始执行,<br> 从比如 TimerQueue 就是使用 DelayQueue 实现的。 <br>
SynchronousQueue(不存储数据、可用于传递数据) <br><br>是一个不存储元素的阻塞队列。<br>每一个 put 操作必须等待一个 take 操作,<br>否则不能继续添加元素。 <br>SynchronousQueue 可以看成是一个传球手,<br>负责把生产者线程处理的数据直接传递给消费者线 程。<br>队列本身并不存储任何元素,非常适合于传递性场景,<br>比如在一个线程中使用的数据,传递给 另 外 一 个 线 程 使 用 , <br>SynchronousQueue 的 吞 吐 量 高 于 LinkedBlockingQueue 和 ArrayBlockingQueue。
LinkedTransferQueue <br><br>是一个由链表结构组成的无界阻塞 TransferQueue 队列。<br>相对于其他阻塞队列, LinkedTransferQueue多了 tryTransfer和transfer方法。 <br><br>1. transfer 方法:<br> 如果当前有消费者正在等待接收元素(消费者使用 take()方法或带时间限制的 poll()方法时),<br> transfer 方法可以把生产者传入的元素立刻 transfer(传输)给消费者。<br> 如果没有消费者在等待接收元素,transfer 方法会将元素存放在队列的 tail 节点,<br> 并等到该元素 被消费者消费了才返回。 <br><br>2. tryTransfer 方法。则是用来试探下生产者传入的元素是否能直接传给消费者。<br> 如果没有消费 者等待接收元素,则返回 false。<br> 和 transfer 方法的区别是 tryTransfer 方法无论消费者是否 接收,方法立即返回。<br> 而transfer方法是必须等到消费者消费了才返回。 <br> 对于带有时间限制的tryTransfer(E e, long timeout, TimeUnit unit)方法,<br> 则是试图把生产者传 入的元素直接传给消费者,<br> 但是如果没有消费者消费该元素则等待指定的时间再返回,<br> 如果超时 还没消费元素,则返回false,<br> 如果在超时时间内消费了元素,则返回true。
LinkedBlockingDeque <br><br>是一个由链表结构组成的双向阻塞队列。<br>所谓双向队列指的你可以从队列的两端插入和移出元素。<br>双端队列因为多了一个操作队列的入口,<br>在多线程同时入队时,也就减少了一半的竞争。<br>相比其 他的阻塞队列,<br>LinkedBlockingDeque 多了 addFirst,addLast,offerFirst,offerLast, peekFirst,peekLast 等方法,<br>以 First 单词结尾的方法,表示插入,获取(peek)或移除双端队 列的第一个元素。<br>以 Last 单词结尾的方法,表示插入,获取或移除双端队列的最后一个元素。<br>另 外插入方法add等同于addLast,移除方法remove 等效于removeFirst。<br>但是take方法却等同 于takeFirst,不知道是不是Jdk的bug,<br>使用时还是用带有First和Last后缀的方法更清楚。 <br><br>在初始化 LinkedBlockingDeque 时可以设置容量防止其过渡膨胀。<br>另外双向阻塞队列可以运用在 “工作窃取”模式中。
线程池状态
并发工具
CyclicBarrier可以重复使用<br><br>可以实现让一组线程等待至某个状态之后再全部同时执行。<br>
CyclicBarrier中最重要的方法就是await方法
public int await():<br>用来挂起当前线程,<br>直至所有线程都到达 barrier 状态再同时执行后续任 务;
public int await(long timeout, TimeUnit unit):<br>让这些线程等待至一定的时间,<br>如果还有 线程没有到达barrier状态就直接让到达barrier的线程执行后续任务。
CountdownLatch不能重复使用<br><br>它可以实现类似计数器的功能。<br>
CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不 同;<br>CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;<br>而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时 执行;<br>另外,CountDownLatch是不能够重用的,而CyclicBarrier是可以重用的。
Semaphore(信号量/控制同时访问的线程个数)
Semaphore 和Lock类似,比Lock灵活。<br>其中有 acquire() 和 release() 两种方法,arg 都等于 1。<br>acquire() 会抛出 InterruptedException,同时从 sync.acquireSharedInterruptibly(arg:1)可以看出是读模式(shared); <br>release()中可以计数,可以控制数量,permits可以传递N个数量。<br>
Semaphore是一种基于计数的信号量。<br>它可以设定一个阈值,基于此,多个线程竞争获取许可信 号,<br>做完自己的申请后归还,超过阈值后,线程申请许可信号将会被阻塞。<br>Semaphore 可以用来 构建一些对象池,资源池之类的,比如数据库连接池 <br>
实现互斥锁(计数器为 1 ) <br>我们也可以创建计数为 1 的 Semaphore, <br>将其作为一种类似互斥锁的机制,这也叫二元信号量, 表示两种互斥状态。
Semaphore 与 ReentrantLock
Semaphore 基本能完成 ReentrantLock 的所有工作,<br>使用方法也与之类似,通过 acquire()与 release()方法来获得和释放临界资源。<br>经实测,Semaphone.acquire()方法默认为可响应中断锁, <br>与 ReentrantLock.lockInterruptibly()作用效果一致,<br>也就是说在等待临界资源的过程中可以被 Thread.interrupt()方法中断。 <br><br>此外,Semaphore也实现了可轮询的锁请求与定时锁的功能,<br>除了方法名tryAcquire 与tryLock 不同,其使用方法与ReentrantLock几乎一致。<br>Semaphore也提供了公平与非公平锁的机制,也 可在构造函数中进行设定。 <br><br>Semaphore的锁释放操作也由手动进行,<br>因此与ReentrantLock一样,<br>为避免线程因抛出异常而 无法正常释放锁的情况发生,<br>释放锁的操作也必须在finally代码块中完成。
原子操作
AtomicInteger
AtomicInteger,一个提供原子操作的 Integer 的类,<br>常见的还有 AtomicBoolean、AtomicInteger、AtomicLong、AtomicReference 等,<br>他们的实现原理相同, 区别在与运算对象类型的不同。<br>还可以通过 AtomicReference<V>将一个对象的所 有操作转化成原子操作。 <br><br>我们知道,在多线程程序中,诸如++i 或 i++等运算不具有原子性,是不安全的线程操作之一。 <br>通常我们会使用 synchronized 将该操作变成一个原子操作,<br>但 JVM 为此类操作特意提供了一些 同步类,使得使用更方便,<br>且使程序运行效率变得更高。<br>通过相关资料显示,通常AtomicInteger 的性能是ReentantLock的好几倍。
线程安全的集合类
ThreadLocal
为每个使用该变量的线程提供独立的变量副本,<br>所以每一个线程都可以独立地改变自己的副本,<br>而不会影响其它线程所对应的副本。<br><br>ThreadLocal 的经典使用场景是数据库连接和 session 管理等。
ThreadLocal 的作用 是提供线程内的局部变量,<br>这种变量在线程的生命周期内起作用,<br>减少同一个线程内多个函数或 者组件之间一些公共变量的传递的复杂度。
ThreadLocalMap (线程的一个属性)<br><br> 1. 每个线程中都有一个自己的 ThreadLocalMap 类对象,<br>可以将线程自己的对象保持到其中, <br>各管各的,线程可以正确的访问到自己的对象。 <br> 2. 将一个共用的 ThreadLocal 静态实例作为 key,<br>将不同对象的引用保存到不同线程的 ThreadLocalMap中,<br>然后在线程执行的各处通过这个静态ThreadLocal实例的get()方法取 得自己线程保存的那个对象,<br>避免了将这个对象作为参数传递的麻烦。 <br> 3. ThreadLocalMap其实就是线程里面的一个属性,<br>它在Thread类中定义 <br><br>ThreadLocal.ThreadLocalMap threadLocals = null;
同步
volatile
内存屏障,happen-before关系,防止重排序
内存可见性
synchronized
非公平锁
可重入锁
锁升级
偏向锁,只执行一次CAS,<br>下次同一线程访问同步区则偏向该线程,<br>无需再执行CAS操作。 单次CAS
轻量级锁(自旋锁)线程每次进入同步区之前,<br>都会执行CAS,若失败则膨胀为重量级锁。 <br>每次CAS
重量级锁,线程每次进入同步区之前,<br>都会执行CAS,若失败则阻塞。 <br>每次CAS+阻塞
ReentrantLock
可以指定是公平锁还是非公平锁
Condition(条件)类,<br>用来实现分组唤醒需要唤醒的线程们,<br>而不是像synchronized要么随机唤醒一个线程要么唤醒全部线程
提供了一种能够中断等待锁的线程的机制,<br>通过lock.lockInterruptibly()来实现这个机制。
JVM
类加载器(ClassLoader)<br>运行时数据区(Runtime Data Area)<br>执行引擎(Execution Engine)<br>本地库接口(Native Interface)<br>
先要把java代码转换成字节码(class文件),<br>jvm首先把字节码通过 类加载器(ClassLoader) <br>把文件加载到运行时数据区(Runtime Data Area) ,<br>而字节码文件是jvm的一套指令集规范,<br>并不能直接交个底层操作系统去执行,<br>因此需要 执行引擎(Execution Engine) <br>将字节码翻译成底层系统指令再交由CPU去执行,<br>而这个过程中需要调用本地库接口(Native Interface)来实现整个程序的功能,<br>这就是这4个主要组成部分的职责与功能。<br>
运行时数据区
数据
堆<br><br>存放的是对象实例本身以及数组<br>
这是被所有线程共享的一块内存区域,其中<font color="#80bc42">存放的是对象实例本身以及数组</font>(数组的引用在栈中)。 <br>
划分
年轻代/新生代(Young Generation)
年轻代用来存放新创建的Java对象。<br>对年轻代的垃圾回收称为“Minor GC”,采用的是复制清除算法、并行收集器。 <br>为使JVM更好的管理堆内存中对象的分配及回收,<br>年轻代又被分为三个区域:Eden、From Survivor、To Survivor。<br><br>注意:年轻代可用内存空间是Eden区+一个Survivor区,另一个Survivor区则保持空闲状态,<br>其中Eden区与一个Survivor区大小比例可以通过 -XX:SurvivorRatio参数进行设置,<br>默认为8,表示Eden区与一个Survivor区大小比值是8:1:1。<br>
MinorGC的过程(复制->清空->互换) <br>MinorGC采用复制算法。 <br>1 : 首先,把Eden和ServivorFrom区域中存活的对象复制到ServicorTo区域<br> (如果有对象的年龄以及达到了老年的标准,则复制到老年代区),<br> 同时把这些对象的年龄+1(如果 ServicorTo不够位置了就放到老年区); <br><br>2 : 然后,清空Eden和ServicorFrom中的对象; <br>3 : 最后,ServicorTo和ServicorFrom互换,原ServicorTo成为下一次GC时的ServicorFrom 区。 <br>
老年代(Tenured Generation)
年轻代中经过多次垃圾回收没有回收掉的对象将被Copy到老年代,<br>因此可以认为老年代中存放的都是生命周期较长的对象。<br>对老年代中对象的垃圾回收称为“Full GC”,采用的是标记-清除算法。 <br>
Major GC通常是跟full GC是等价的,收集整个GC堆。<br><br>老年代的对象比较稳定,所以 MajorGC 不会频繁执行。<br>在进行 MajorGC 前一般都先进行 了一次 MinorGC,<br>使得有新生代的对象晋身入老年代,导致空间不够用时才触发。<br>当无法找到足 够大的连续空间分配给新创建的较大对象时也会提前触发一次MajorGC进行垃圾回收腾出空间。 <br><br> MajorGC 采用标记清除算法:<br>首先扫描一次所有老年代,标记出存活的对象,然后回收没 有标记的对象。<br>MajorGC的耗时比较长,因为要扫描再回收。MajorGC 会产生内存碎片,为了减 少内存损耗,<br>我们一般需要进行合并或者标记出来方便下次直接分配。<br>当老年代也满了装不下的 时候,就会抛出OOM(Out of Memory)异常。
注: 1)其中年轻代和年老代位于堆内存,堆内存会从JVM启动参数(如-Xmx:3G表示最大堆内存为3G)指定的内存中分配;<br><br>2)Perm Gen不位于堆内存中,而是属于方法区,由虚拟机直接分配,但可以通过-XX:PermSize -XX:MaxPermSize 等参数调整其大小。
-Xmx最大堆大小<br><br>-Xms初始堆大小<br><br>-Xmn设置新生代大小<br><br>-Xss设置栈大小
方法区<br><br>存储已经被虚拟机加载的类、常量、静态变量、编译器编译后的字节码<br>
永久代(Permanent Generation)
简称Perm Gen,位于方法区。用于存放Class、Interface的元数据,<br>其大小跟项目的规模、类、方法的量有关。<br>永久代的对象垃圾回收发生在Full GC过程中。<br>
GC 不会在主程序运行期对永久区域进行清理。<br>所以这 也导致了永久代的区域会随着加载的Class的增多而胀满,最终抛出OOM异常。
注:Java 8 已经去掉了永久代,用 MetaSpace 予以替代
Java8中,永久代已经被移除,被一个称为“元数据区”(元空间)的区域所取代。<br>元空间 的本质和永久代类似,<br>元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用 本地内存。<br>因此,默认情况下,元空间的大小仅受本地内存限制。<br>类的元数据放入 native memory, <br>字符串池和类的静态变量放入 java 堆中,<br>这样可以加载多少类的元数据就不再由 MaxPermSize控制, 而由系统的实际可用空间来控制。
用于<font color="#80bc42">存储已经被虚拟机加载的类、常量、静态变量、编译器编译后的字节码</font>等数据信息。 <br><br>在方法区中还包含有运行时常量池,它是每一个类或接口的常量池的运行时表示形式,<br>在类和接口被加载到JVM后,对应的运行时常量池就被创建出来。<br>当然并非Class文件常量池中的内容才能进入运行时常量池,<br>在运行期间也可将新的常量放入运行时常量池中,比如String的intern方法
需要注意的是,虽然方法区逻辑上属于堆内存,但是在JVM规范中并没有强制要求对该区域进行垃圾回收。
运行时常量池
属于方法区。用于存储数值型常量
指令
程序计数器<br><br>用来标识执行的是哪条指令。<br>
也称作PC寄存器。它跟汇编语言中的程序计数器的功能在逻辑上是等同的,<br><font color="#80bc42">用来标识执行的是哪条指令。</font><br>每个线程都有自己独立的程序计数器,并且相互之间是独立的。
在JVM规范中规定: <br>1、如果线程执行的是非native方法,则程序计数器中保存的是当前需要执行的指令的地址;<br>2、如果线程执行的是native方法,则程序计数器中的值是undefined。
虚拟机栈<br><br><font color="#80bc42">存放:<br>局部变量表</font><br><font color="#80bc42">操作数栈<br>动态链接<br>方法出口</font><br><br>StackOverflowError、OutOfMemoryError<br>
其中存放的是一个个的栈帧,每个栈帧对应一个被调用的方法,<br>在栈帧中包括<br>局部变量表(Local Variables)、<br>操作数栈(Operand Stack)、<br>指向当前方法所属的类的运行时常量池(运行时常量池的概念在方法区部分会谈到)的引用(Reference to runtime constant pool)<br>以及方法返回地址(Return Address)。
本地方法栈
存放native方法信息,也就是由C/C++实现的方法
类加载机制
类加载器
BootstrapClassLoader
启动类加载器:负责加载java基础类,主要是 %JAVA_HOME/jre/lib/rt.jar中的类。<br>它是用C++语言写的。 由JVM启动,然后初始化sun.misc.Launcher,<br>sun.misc.Launcher初始化Extension ClassLoader、App ClassLoader。 <br>
ExtensionClassLoader
扩展类加载器:主要负责加载%JAVA_HOME%/jre/lib/ext/*.jar中的类 <br>
AppClassLoader
应用程序类加载器:主要负责加载应用中classpath目录下的类。 <br>
自定义ClassLoader
自定义ClassLoader需要继承ClassLoader抽象类,重写findClass方法,这个方法定义了ClassLoader查找class的方式。
加载过程
包括以下几个步骤: <br>1、加载:类加载器从类的.class文件读取二进制流到内存,并为之创建java.lang.Class对象,作为访问Class文件中的各种数据的入口,如反射机制。<br>2、连接:把类的二进制数据存储到虚拟机的各个内存区域中。<br>① 验证:目的是确保当前Class文件中的内容符合JVM规范的要求,并且不会危害虚拟机自身安全。主要包括文件格式验证、元数据验证、字节码验证、符号引用验证。<br>② 准备:为<b><font color="#00a650">静态变量</font></b>分配内存并设置类变量的默认值(如int、float的默认值是0,引用类型默认值是null。<br> 特别地,对于final修饰的静态变量,如final static int a = 20则在此阶段结束a的值为20)。<br>③ 解析:将常量池中的符号引用替换为直接引用。<br>3、初始化:为静态变量赋予正确的初始值。如对于代码 static int i = 20,准备阶段结束后i的值是0,此阶段结束后i的值才变为20。
加载
加载是类加载过程中的一个阶段,<br>这个阶段会在内存中生成一个代表这个类的java.lang.Class对象,<br>作为方法区这个类的各种数据的入口。<br>注意这里不一定非得要从一个Class文件获取,<br>这里既 可以从ZIP包中读取(比如从jar包和war包中读取),<br>也可以在运行时计算生成(动态代理), <br>也可以由其它文件生成(比如将JSP文件转换成对应的Class类)。
验证
为了确保Class文件的字节流中包含的信息是否符合当前虚拟机的要求,并 且不会危害虚拟机自身的安全。 <br><br>验证魔数 0xCAFEBABE<br>版本号<br>元数据验证<br>字节码是否安全<br>符号引用验证<br>
准备<br><br>为静态变量分配内存并设置静态变量的初始值<br>
准备阶段是正式为静态变量分配内存并设置静态变量的初始值阶段,<br>即在方法区中分配这些变量所使用的内存空间。<br>注意这里所说的初始值概念,比如一个类变量定义为: <br>public static int v = 8080; <br>实际上变量v在准备阶段过后的初始值为0而不是8080,<br>将v赋值为8080的 put static 指令是 程序被编译后,<br>存放于类构造器<client>方法之中。 但是注意如果声明为:<br>public static final int v = 8080; <br>在编译阶段会为v生成ConstantValue属性,<br>在准备阶段虚拟机会根据ConstantValue属性将v 赋值为8080。
解析<br><br>常量池中的符号引用替换为直接引用<br>
解析阶段是指虚拟机将常量池中的符号引用替换为直接引用的过程。<br>符号引用就是class文件中 的: <br>1. CONSTANT_Class_info <br>2. CONSTANT_Field_info <br>3. CONSTANT_Method_info <br>等类型的常量<br><br>invokedynamic每次都会重新引用,其他执行会缓存<br>
符号引用
符号引用与虚拟机实现的布局无关,<br>引用的目标并不一定要已经加载到内存中。<br>各种虚拟机实现的内存布局可以各不相同,<br>但是它们能接受的符号引用必须是一致的,<br>因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
直接引用
直接引用可以是指向目标的指针,<br>相对偏移量或是一个能间接定位到目标的句柄。<br>如果有了直接引用,那引用的目标必定已经在内存中存在。
初始化 <br>
初始化阶段是类加载最后一个阶段,前面的类加载阶段之后,<br>除了在加载阶段可以自定义类加载 器以外,<br>其它操作都由JVM主导。<br>到了初始阶段,才开始真正执行类中定义的Java程序代码。
类构造器<client>
初始化阶段是执行类构造器<client>方法的过程。<br><client>方法是由编译器自动收集类中的类变量的赋值操作和静态语句块中的语句合并而成的。<br>虚拟机会保证子<client>方法执行之前,父类 的<client>方法已经执行完毕,<br>如果一个类中没有对静态变量赋值也没有静态语句块,<br>那么编译 器可以不为这个类生成<client>()方法。
注意以下几种情况不会执行类初始化: <br><br>1. 通过子类引用父类的静态字段,只会触发父类的初始化,而不会触发子类的初始化。 <br>2. 定义对象数组,不会触发该类的初始化。 <br>3. 常量在编译期间会存入调用类的常量池中,本质上并没有直接引用定义常量的类,不会触 发定义常量所在的类。 <br>4. 通过类名获取Class对象,不会触发类的初始化。 <br>5. 通过Class.forName加载指定类时,如果指定参数initialize为false时,也不会触发类初始化,<br> 其实这个参数是告诉虚拟机,是否要对类进行初始化。 <br>6. 通过ClassLoader默认的loadClass方法,也不会触发初始化动作
使用
卸载
双亲委派模型
当加载一个类的时候会先委托给父类加载器去加载,当父类加载器无法加载的时候再尝试自己去加载,因此类的加载顺序是”自上而下“的。采用这种方式的好处: <br>1、主要是保证了安全性,避免用户自己编写的类动态替换Java的一些核心类,比如 java.lang.String;<br><br>2、避免了类的重复加载,因为在JVM中只有类名和加载类的ClassLoader都一样才认为是同一个类(即使是相同的class文件被不同的ClassLoader加载也被认为是不同的类)
由于双亲委托机制不是万能的,在某些情况下无法使用,因此可以通过重写类加载器的loadClass方法来避免双亲委托机制。
源码解析<br><br>java中的ClassLoader详解Java9 之前<br><br>https://blog.csdn.net/briblue/article/details/54973413<br>
JAVA类加载流程
Java语言系统自带有三个类加载器:<br><br>Bootstrap ClassLoader <br>最顶层的加载类,主要加载核心类库,<br>%JRE_HOME%\lib下的rt.jar、resources.jar、charsets.jar和class等。<br>另外需要注意的是可以通过启动jvm时指定-Xbootclasspath和路径来改变Bootstrap ClassLoader的加载目录。<br>比如java -Xbootclasspath/a:path被指定的文件追加到默认的bootstrap路径中。<br><br>Extention ClassLoader <br>扩展的类加载器,<br>加载目录%JRE_HOME%\lib\ext目录下的jar包和class文件。<br>还可以加载-D java.ext.dirs选项指定的目录。<br><br>Appclass Loader也称为SystemAppClass 加载当前应用的classpath的所有类。
加载顺序
我们看到了系统的3个类加载器,但我们可能不知道具体哪个先行呢?<br><br>我可以先告诉你答案<br><br>Bootstrap CLassloder<br>Extention ClassLoader<br>AppClassLoader
看sun.misc.Launcher,它是一个java虚拟机的入口应用。<br><br>public class Launcher {<br> private static Launcher launcher = new Launcher();<br> private static String bootClassPath =<br> System.getProperty("sun.boot.class.path");<br><br> public static Launcher getLauncher() {<br> return launcher;<br> }<br><br> private ClassLoader loader;<br><br> public Launcher() {<br> // Create the extension class loader<br> ClassLoader extcl;<br> try {<br> extcl = ExtClassLoader.getExtClassLoader();<br> } catch (IOException e) {<br> throw new InternalError(<br> "Could not create extension class loader", e);<br> }<br><br> // Now create the class loader to use to launch the application<br> try {<br> loader = AppClassLoader.getAppClassLoader(extcl);<br> } catch (IOException e) {<br> throw new InternalError(<br> "Could not create application class loader", e);<br> }<br><br> //设置AppClassLoader为线程上下文类加载器,这个文章后面部分讲解<br> Thread.currentThread().setContextClassLoader(loader);<br> }<br><br> /*<br> * Returns the class loader used to launch the main application.<br> */<br> public ClassLoader getClassLoader() {<br> return loader;<br> }<br> /*<br> * The class loader used for loading installed extensions.<br> */<br> static class ExtClassLoader extends URLClassLoader {}<br><br>/**<br> * The class loader used for loading from java.class.path.<br> * runs in a restricted security context.<br> */<br> static class AppClassLoader extends URLClassLoader {}<br>
源码有精简,我们可以得到相关的信息。<br><br>Launcher初始化了ExtClassLoader和AppClassLoader。<br>Launcher中并没有看见BootstrapClassLoader,但通过System.getProperty("sun.boot.class.path")得到了字符串bootClassPath,这个应该就是BootstrapClassLoader加载的jar包路径。
我们可以先代码测试一下sun.boot.class.path是什么内容。<br><br>System.out.println(System.getProperty("sun.boot.class.path"));<br><br>得到的结果是:<br><br>C:\Program Files\Java\jre1.8.0_91\lib\resources.jar;<br>C:\Program Files\Java\jre1.8.0_91\lib\rt.jar;<br>C:\Program Files\Java\jre1.8.0_91\lib\sunrsasign.jar;<br>C:\Program Files\Java\jre1.8.0_91\lib\jsse.jar;<br>C:\Program Files\Java\jre1.8.0_91\lib\jce.jar;<br>C:\Program Files\Java\jre1.8.0_91\lib\charsets.jar;<br>C:\Program Files\Java\jre1.8.0_91\lib\jfr.jar;<br>C:\Program Files\Java\jre1.8.0_91\classes<br><br>可以看到,这些全是JRE目录下的jar包或者是class文件。
ExtClassLoader源码
/*<br> * The class loader used for loading installed extensions.<br> */<br> static class ExtClassLoader extends URLClassLoader {<br><br> static {<br> ClassLoader.registerAsParallelCapable();<br> }<br><br> /**<br> * create an ExtClassLoader. The ExtClassLoader is created<br> * within a context that limits which files it can read<br> */<br> public static ExtClassLoader getExtClassLoader() throws IOException<br> {<br> final File[] dirs = getExtDirs();<br><br> try {<br> // Prior implementations of this doPrivileged() block supplied<br> // aa synthesized ACC via a call to the private method<br> // ExtClassLoader.getContext().<br><br> return AccessController.doPrivileged(<br> new PrivilegedExceptionAction<ExtClassLoader>() {<br> public ExtClassLoader run() throws IOException {<br> int len = dirs.length;<br> for (int i = 0; i < len; i++) {<br> MetaIndex.registerDirectory(dirs[i]);<br> }<br> return new ExtClassLoader(dirs);<br> }<br> });<br> } catch (java.security.PrivilegedActionException e) {<br> throw (IOException) e.getException();<br> }<br> }<br><br> private static File[] getExtDirs() {<br> String s = System.getProperty("java.ext.dirs");<br> File[] dirs;<br> if (s != null) {<br> StringTokenizer st =<br> new StringTokenizer(s, File.pathSeparator);<br> int count = st.countTokens();<br> dirs = new File[count];<br> for (int i = 0; i < count; i++) {<br> dirs[i] = new File(st.nextToken());<br> }<br> } else {<br> dirs = new File[0];<br> }<br> return dirs;<br> }<br> <br>......<br> }
我们先前的内容有说过,可以指定-D java.ext.dirs参数来添加和改变ExtClassLoader的加载路径。这里我们通过可以编写测试代码。<br><br>System.out.println(System.getProperty("java.ext.dirs"));<br><br>结果如下:<br><br>C:\Program Files\Java\jre1.8.0_91\lib\ext;C:\Windows\Sun\Java\lib\ext
AppClassLoader源码
/**<br> * The class loader used for loading from java.class.path.<br> * runs in a restricted security context.<br> */<br> static class AppClassLoader extends URLClassLoader {<br><br><br> public static ClassLoader getAppClassLoader(final ClassLoader extcl)<br> throws IOException<br> {<br> final String s = System.getProperty("java.class.path");<br> final File[] path = (s == null) ? new File[0] : getClassPath(s);<br><br> <br> return AccessController.doPrivileged(<br> new PrivilegedAction<AppClassLoader>() {<br> public AppClassLoader run() {<br> URL[] urls =<br> (s == null) ? new URL[0] : pathToURLs(path);<br> return new AppClassLoader(urls, extcl);<br> }<br> });<br> }<br><br> ......<br> }
可以看到AppClassLoader加载的就是java.class.path下的路径。我们同样打印它的值。<br><br>System.out.println(System.getProperty("java.class.path"));<br><br>结果:<br><br>D:\workspace\ClassLoaderDemo\bin<br><br>这个路径其实就是当前java工程目录bin,里面存放的是编译生成的class文件。
每个类加载器都有一个父加载器
每个类加载器都有一个父加载器,<br>比如加载Test.class是由AppClassLoader完成,<br>那么AppClassLoader也有一个父加载器,怎么样获取呢?<br>很简单,通过getParent方法。
ClassLoader cl = Test.class.getClassLoader();<br> <br>System.out.println("ClassLoader is:"+cl.toString());<br>System.out.println("ClassLoader\'s parent is:"+cl.getParent().toString());<br><br>运行结果如下:<br><br>ClassLoader is:sun.misc.Launcher$AppClassLoader@73d16e93<br>ClassLoader's parent is:sun.misc.Launcher$ExtClassLoader@15db9742<br><br>这个说明,AppClassLoader的父加载器是ExtClassLoader。那么ExtClassLoader的父加载器又是谁呢?<br><br>System.out.println("ClassLoader is:"+cl.toString());<br>System.out.println("ClassLoader\'s parent is:"+cl.getParent().toString());<br>System.out.println("ClassLoader\'s grand father is:"+cl.getParent().getParent().toString());<br><br>运行如果:<br><br>ClassLoader is:sun.misc.Launcher$AppClassLoader@73d16e93<br>Exception in thread "main" ClassLoader's parent is:sun.misc.Launcher$ExtClassLoader@15db9742<br>java.lang.NullPointerException<br> at ClassLoaderTest.main(ClassLoaderTest.java:13)
int.class的加载是由谁完成的呢?<br><br>cl = int.class.getClassLoader();<br> <br> System.out.println("ClassLoader is:"+cl.toString());<br><br>运行一下,却报错了<br>Exception in thread "main" java.lang.NullPointerException<br> at ClassLoaderTest.main(ClassLoaderTest.java:15)<br><br>提示的是空指针,意思是int.class这类基础类没有类加载器加载?<br><br>当然不是!<br>int.class是由Bootstrap ClassLoader加载的。
父加载器不是父类
由ExtClassLoader和AppClassLoader的代码。<br><br>static class ExtClassLoader extends URLClassLoader {}<br>static class AppClassLoader extends URLClassLoader {}<br><br>可以看见ExtClassLoader和AppClassLoader同样继承自URLClassLoader,<br>但上面一小节代码中,为什么调用AppClassLoader的getParent()代码会得到ExtClassLoader的实例呢?<br>先从URLClassLoader说起,这个类又是什么?<br>先上一张类的继承关系图
子主题
URLClassLoader的源码中并没有找到getParent()方法。这个方法在ClassLoader.java中。<br><br>public abstract class ClassLoader {<br><br>// The parent class loader for delegation<br>// Note: VM hardcoded the offset of this field, thus all new fields<br>// must be added *after* it.<br>private final ClassLoader parent;<br>// The class loader for the system<br> // @GuardedBy("ClassLoader.class")<br>private static ClassLoader scl;<br><br>private ClassLoader(Void unused, ClassLoader parent) {<br> this.parent = parent;<br> ...<br>}<br>protected ClassLoader(ClassLoader parent) {<br> this(checkCreateClassLoader(), parent);<br>}<br>protected ClassLoader() {<br> this(checkCreateClassLoader(), getSystemClassLoader());<br>}<br>public final ClassLoader getParent() {<br> if (parent == null)<br> return null;<br> return parent;<br>}<br>public static ClassLoader getSystemClassLoader() {<br> initSystemClassLoader();<br> if (scl == null) {<br> return null;<br> }<br> return scl;<br>}<br><br>private static synchronized void initSystemClassLoader() {<br> if (!sclSet) {<br> if (scl != null)<br> throw new IllegalStateException("recursive invocation");<br> sun.misc.Launcher l = sun.misc.Launcher.getLauncher();<br> if (l != null) {<br> Throwable oops = null;<br> //通过Launcher获取ClassLoader<br> scl = l.getClassLoader();<br> try {<br> scl = AccessController.doPrivileged(<br> new SystemClassLoaderAction(scl));<br> } catch (PrivilegedActionException pae) {<br> oops = pae.getCause();<br> if (oops instanceof InvocationTargetException) {<br> oops = oops.getCause();<br> }<br> }<br> if (oops != null) {<br> if (oops instanceof Error) {<br> throw (Error) oops;<br> } else {<br> // wrap the exception<br> throw new Error(oops);<br> }<br> }<br> }<br> sclSet = true;<br> }<br>}<br>}<br><br>我们可以看到getParent()实际上返回的就是一个ClassLoader对象parent,<br>parent的赋值是在ClassLoader对象的构造方法中,它有两个情况:<br><br>由外部类创建ClassLoader时直接指定一个ClassLoader为parent。<br>由getSystemClassLoader()方法生成,<br>也就是在sun.misc.Laucher通过getClassLoader()获取,<br>也就是AppClassLoader。直白的说,<br>一个ClassLoader创建时如果没有指定parent,<br>那么它的parent默认就是AppClassLoader。<br>我们主要研究的是ExtClassLoader与AppClassLoader的parent的来源,<br>正好它们与Launcher类有关,<br>我们上面已经粘贴过Launcher的部分代码。<br><br>public class Launcher {<br> private static URLStreamHandlerFactory factory = new Factory();<br> private static Launcher launcher = new Launcher();<br> private static String bootClassPath =<br> System.getProperty("sun.boot.class.path");<br><br> public static Launcher getLauncher() {<br> return launcher;<br> }<br><br> private ClassLoader loader;<br><br> public Launcher() {<br> // Create the extension class loader<br> ClassLoader extcl;<br> try {<br> extcl = ExtClassLoader.getExtClassLoader();<br> } catch (IOException e) {<br> throw new InternalError(<br> "Could not create extension class loader", e);<br> }<br><br> // Now create the class loader to use to launch the application<br> try {<br> //将ExtClassLoader对象实例传递进去<br> loader = AppClassLoader.getAppClassLoader(extcl);<br> } catch (IOException e) {<br> throw new InternalError(<br> "Could not create application class loader", e);<br> }<br><br>public ClassLoader getClassLoader() {<br> return loader;<br> }<br>static class ExtClassLoader extends URLClassLoader {<br><br> /**<br> * create an ExtClassLoader. The ExtClassLoader is created<br> * within a context that limits which files it can read<br> */<br> public static ExtClassLoader getExtClassLoader() throws IOException<br> {<br> final File[] dirs = getExtDirs();<br><br> try {<br> // Prior implementations of this doPrivileged() block supplied<br> // aa synthesized ACC via a call to the private method<br> // ExtClassLoader.getContext().<br><br> return AccessController.doPrivileged(<br> new PrivilegedExceptionAction<ExtClassLoader>() {<br> public ExtClassLoader run() throws IOException {<br> //ExtClassLoader在这里创建<br> return new ExtClassLoader(dirs);<br> }<br> });<br> } catch (java.security.PrivilegedActionException e) {<br> throw (IOException) e.getException();<br> }<br> }<br><br><br> /*<br> * Creates a new ExtClassLoader for the specified directories.<br> */<br> public ExtClassLoader(File[] dirs) throws IOException {<br> super(getExtURLs(dirs), null, factory);<br> <br> }<br> }<br> }<br><br>我们需要注意的是<br><br>ClassLoader extcl;<br> <br>extcl = ExtClassLoader.getExtClassLoader();<br><br>loader = AppClassLoader.getAppClassLoader(extcl);<br><br>代码已经说明了问题AppClassLoader的parent是一个ExtClassLoader实例。<br><br>ExtClassLoader并没有直接找到对parent的赋值。<br>它调用了它的父类也就是URLClassLoder的构造方法并传递了3个参数。<br><br>public ExtClassLoader(File[] dirs) throws IOException {<br> super(getExtURLs(dirs), null, factory); <br>}<br><br>对应的代码<br><br>public URLClassLoader(URL[] urls, ClassLoader parent,<br> URLStreamHandlerFactory factory) {<br> super(parent);<br>}<br><br>答案已经很明了了,ExtClassLoader的parent为null。<br><br>上面张贴这么多代码也是为了说明AppClassLoader的parent是ExtClassLoader,<br>ExtClassLoader的parent是null。这符合我们之前编写的测试代码。<br><br>不过,细心的同学发现,<br>还是有疑问的我们只看到ExtClassLoader和AppClassLoader的创建,<br>那么BootstrapClassLoader呢?<br><br>还有,ExtClassLoader的父加载器为null,<br>但是Bootstrap CLassLoader却可以当成它的父加载器这又是为何呢?<br><br>我们继续往下进行。
Bootstrap ClassLoader是由C++编写的
Bootstrap ClassLoader是由C/C++编写的,它本身是虚拟机的一部分,<br>所以它并不是一个JAVA类,也就是无法在java代码中获取它的引用,<br>JVM启动时通过Bootstrap类加载器加载rt.jar等核心jar包中的class文件,<br>之前的int.class,String.class都是由它加载。<br>然后呢,我们前面已经分析了,<br>JVM初始化sun.misc.Launcher并创建Extension ClassLoader和AppClassLoader实例。<br>并将ExtClassLoader设置为AppClassLoader的父加载器。<br>Bootstrap没有父加载器,但是它却可以作用一个ClassLoader的父加载器。<br>比如ExtClassLoader。<br>这也可以解释之前通过ExtClassLoader的getParent方法获取为Null的现象。<br>具体是什么原因,很快就知道答案了。
双亲委托
一个类加载器查找class和resource时,<br>是通过“委托模式”进行的,<br>它首先判断这个class是不是已经加载成功,<br>如果没有的话它并不是自己进行查找,<br>而是先通过父加载器,然后递归下去,<br>直到Bootstrap ClassLoader,<br>如果Bootstrap classloader找到了,<br>直接返回,如果没有找到,则一级一级返回,<br>最后到达自身去查找这些对象。这种机制就叫做双亲委托。
这张图是用时序图画出来的,不过画出来的结果我却自己都觉得不理想。<br><br>大家可以看到2根箭头,<br>蓝色的代表类加载器向上委托的方向,<br>如果当前的类加载器没有查询到这个class对象已经加载就请求父加载器(不一定是父类)进行操作,<br>然后以此类推。直到Bootstrap ClassLoader。<br>如果Bootstrap ClassLoader也没有加载过此class实例,<br>那么它就会从它指定的路径中去查找,<br>如果查找成功则返回,<br>如果没有查找成功则交给子类加载器,<br>也就是ExtClassLoader,这样类似操作直到终点,<br>也就是我上图中的红色箭头示例。<br>用序列描述一下:<br><br>一个AppClassLoader查找资源时,<br>先看看缓存是否有,缓存有从缓存中获取,<br>否则委托给父加载器。<br>递归,重复第1步的操作。<br>如果ExtClassLoader也没有加载过,<br>则由Bootstrap ClassLoader出面,<br>它首先查找缓存,如果没有找到的话,<br>就去找自己的规定的路径下,也就是sun.mic.boot.class下面的路径。<br>找到就返回,没有找到,让子加载器自己去找。<br>Bootstrap ClassLoader如果没有查找成功,<br>则ExtClassLoader自己在java.ext.dirs路径中去查找,<br>查找成功就返回,查找不成功,<br>再向下让子加载器找。<br>ExtClassLoader查找不成功,AppClassLoader就自己查找,<br>在java.class.path路径下查找。找到就返回。<br>如果没有找到就让子类找,如果没有子类会怎么样?抛出各种异常。<br>上面的序列,详细说明了双亲委托的加载流程。<br>我们可以发现委托是从下向上,<br>然后具体查找过程却是自上至下。
重要方法
loadClass()
JDK文档中是这样写的,通过指定的全限定类名加载class,它通过同名的loadClass(String,boolean)方法。<br><br>protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException
上面是方法原型,一般实现这个方法的步骤是<br><br>执行findLoadedClass(String)去检测这个class是不是已经加载过了。<br>执行父加载器的loadClass方法。<br>如果父加载器为null,则jvm内置的加载器去替代,也就是Bootstrap ClassLoader。<br>这也解释了ExtClassLoader的parent为null,但仍然说Bootstrap ClassLoader是它的父加载器。<br>如果向上委托父加载器没有加载成功,则通过findClass(String)查找。
如果class在上面的步骤中找到了,参数resolve又是true的话,<br>那么loadClass()又会调用resolveClass(Class)这个方法来生成最终的Class对象。 <br>我们可以从源代码看出这个步骤。
protected Class<?> loadClass(String name, boolean resolve)<br> throws ClassNotFoundException<br> {<br> synchronized (getClassLoadingLock(name)) {<br> // 首先,检测是否已经加载<br> Class<?> c = findLoadedClass(name);<br> if (c == null) {<br> long t0 = System.nanoTime();<br> try {<br> if (parent != null) {<br> //父加载器不为空则调用父加载器的loadClass<br> c = parent.loadClass(name, false);<br> } else {<br> //父加载器为空则调用Bootstrap Classloader<br> c = findBootstrapClassOrNull(name);<br> }<br> } catch (ClassNotFoundException e) {<br> // ClassNotFoundException thrown if class not found<br> // from the non-null parent class loader<br> }<br><br> if (c == null) {<br> // If still not found, then invoke findClass in order<br> // to find the class.<br> long t1 = System.nanoTime();<br> //父加载器没有找到,则调用findclass<br> c = findClass(name);<br><br> // this is the defining class loader; record the stats<br> sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);<br> sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);<br> sun.misc.PerfCounter.getFindClasses().increment();<br> }<br> }<br> if (resolve) {<br> //调用resolveClass()<br> resolveClass(c);<br> }<br> return c;<br> }<br> }
代码解释了双亲委托。
自定义ClassLoader
不管是Bootstrap ClassLoader还是ExtClassLoader等,<br>这些类加载器都只是加载指定的目录下的jar包或者资源。<br>如果在某种情况下,我们需要动态加载一些东西呢?<br>比如从D盘某个文件夹加载一个class文件,<br>或者从网络上下载class主内容然后再进行加载,这样可以吗?<br><br>如果要这样做的话,需要我们自定义一个classloader。
自定义步骤
编写一个类继承自ClassLoader抽象类。<br><br>复写它的findClass()方法。<br><br>在findClass()方法中调用defineClass()
defineClass()
这个方法在编写自定义classloader的时候非常重要,<br>它能将class二进制内容转换成Class对象,<br>如果不符合要求的会抛出各种异常。
注意点:
一个ClassLoader创建时如果没有指定parent,<br>那么它的parent默认就是AppClassLoader。 <br><br>上面说的是,如果自定义一个ClassLoader,<br>默认的parent父加载器是AppClassLoader,<br>因为这样就能够保证它能访问系统内置加载器加载成功的class文件。
自定义ClassLoader示例之DiskClassLoader
package com.frank.test;<br><br>public class Test {<br> public void say(){<br> System.out.println("Say Hello");<br>}<br>}<br><br>然后将它编译过年class文件Test.class放到D:\lib这个路径下<br>
DiskClassLoader<br>在findClass()方法中定义了查找class的方法,然后数据通过defineClass()生成了Class对象<br><br>import java.io.ByteArrayOutputStream;<br>import java.io.File;<br>import java.io.FileInputStream;<br>import java.io.FileNotFoundException;<br>import java.io.IOException;<br><br><br>public class DiskClassLoader extends ClassLoader {<br> <br> private String mLibPath;<br> <br> public DiskClassLoader(String path) {<br> // TODO Auto-generated constructor stub<br> mLibPath = path;<br> }<br><br> @Override<br> protected Class<?> findClass(String name) throws ClassNotFoundException {<br> // TODO Auto-generated method stub<br> <br> String fileName = getFileName(name);<br> <br> File file = new File(mLibPath,fileName);<br> <br> try {<br> FileInputStream is = new FileInputStream(file);<br> <br> ByteArrayOutputStream bos = new ByteArrayOutputStream();<br> int len = 0;<br> try {<br> while ((len = is.read()) != -1) {<br> bos.write(len);<br> }<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br> <br> byte[] data = bos.toByteArray();<br> is.close();<br> bos.close();<br> <br> return defineClass(name,data,0,data.length);<br> <br> } catch (IOException e) {<br> // TODO Auto-generated catch block<br> e.printStackTrace();<br> }<br> <br> return super.findClass(name);<br> }<br><br> //获取要加载 的class文件名<br> private String getFileName(String name) {<br> // TODO Auto-generated method stub<br> int index = name.lastIndexOf('.');<br> if(index == -1){ <br> return name+".class";<br> }else{<br> return name.substring(index+1)+".class";<br> }<br> }<br> <br>}
测试<br>import java.lang.reflect.InvocationTargetException;<br>import java.lang.reflect.Method;<br><br>public class ClassLoaderTest {<br><br> public static void main(String[] args) {<br> // TODO Auto-generated method stub<br> <br> //创建自定义classloader对象。<br> DiskClassLoader diskLoader = new DiskClassLoader("D:\\lib");<br> try {<br> //加载class文件<br> Class c = diskLoader.loadClass("com.frank.test.Test");<br> <br> if(c != null){<br> try {<br> Object obj = c.newInstance();<br> Method method = c.getDeclaredMethod("say",null);<br> //通过反射调用Test类的say方法<br> method.invoke(obj, null);<br> } catch (InstantiationException | IllegalAccessException <br> | NoSuchMethodException<br> | SecurityException | <br> IllegalArgumentException | <br> InvocationTargetException e) {<br> // TODO Auto-generated catch block<br> e.printStackTrace();<br> }<br> }<br> } catch (ClassNotFoundException e) {<br> // TODO Auto-generated catch block<br> e.printStackTrace();<br> }<br> <br> }<br><br>}<br>
关键字 <b><font color="#f15a23">路径</font></b>
从开篇的环境变量<br>到3个主要的JDK自带的类加载器<br>到自定义的ClassLoader<br><b><font color="#f15a23">它们的关联部分就是路径,也就是要加载的class或者是资源的路径。</font></b><br>BootStrap ClassLoader、ExtClassLoader、AppClassLoader都是加载指定路径下的jar包。<br>如果我们要突破这种限制,实现自己某些特殊的需求,我们就得自定义ClassLoader,<br>自已指定加载的路径,可以是磁盘、内存、网络或者其它。
Context ClassLoader 线程上下文类加载器
前面三个之所以放在前面讲,<br>是因为它们是真实存在的类,<br>而且遵从”双亲委托“的机制。<br>而ContextClassLoader其实只是一个概念。
查看Thread.java源码可以发现<br><br>public class Thread implements Runnable {<br><br>/* The context ClassLoader for this thread */<br> private ClassLoader contextClassLoader;<br> <br> public void setContextClassLoader(ClassLoader cl) {<br> SecurityManager sm = System.getSecurityManager();<br> if (sm != null) {<br> sm.checkPermission(new RuntimePermission("setContextClassLoader"));<br> }<br> contextClassLoader = cl;<br> }<br><br> public ClassLoader getContextClassLoader() {<br> if (contextClassLoader == null)<br> return null;<br> SecurityManager sm = System.getSecurityManager();<br> if (sm != null) {<br> ClassLoader.checkClassLoaderPermission(contextClassLoader,<br> Reflection.getCallerClass());<br> }<br> return contextClassLoader;<br> }<br>}<br><br>contextClassLoader只是一个成员变量,<br>通过setContextClassLoader()方法设置,<br>通过getContextClassLoader()设置。<br><br>每个Thread都有一个相关联的ClassLoader,默认是AppClassLoader。<br>并且子线程默认使用父线程的ClassLoader除非子线程特别设置。<br>
现在有2个SpeakTest.class文件,一个源码是<br><br>package com.frank.test;<br><br>public class SpeakTest implements ISpeak {<br><br> @Override<br> public void speak() {<br> // TODO Auto-generated method stub<br> System.out.println("Test");<br> }<br><br>}<br><br>它生成的SpeakTest.class文件放置在D:\\lib\\test目录下。<br>另外ISpeak.java代码<br><br> package com.frank.test;<br><br>public interface ISpeak {<br> public void speak();<br><br>}<br>然后,我们在这里还实现了一个SpeakTest.java<br><br>package com.frank.test;<br><br>public class SpeakTest implements ISpeak {<br><br> @Override<br> public void speak() {<br> // TODO Auto-generated method stub<br> System.out.println("I\' frank");<br> }<br><br>}<br>它生成的SpeakTest.class文件放置在D:\\lib目录下。<br><br>然后我们还要编写另外一个ClassLoader,<br>DiskClassLoader1.java这个ClassLoader的代码和DiskClassLoader.java代码一致,<br>我们要在DiskClassLoader1中加载位置于D:\\lib\\test中的SpeakTest.class文件。
测试代码:<br><br>DiskClassLoader1 diskLoader1 = new DiskClassLoader1("D:\\lib\\test");<br>Class cls1 = null;<br>try {<br>//加载class文件<br> cls1 = diskLoader1.loadClass("com.frank.test.SpeakTest");<br>System.out.println(cls1.getClassLoader().toString());<br>if(cls1 != null){<br> try {<br> Object obj = cls1.newInstance();<br> //SpeakTest1 speak = (SpeakTest1) obj;<br> //speak.speak();<br> Method method = cls1.getDeclaredMethod("speak",null);<br> //通过反射调用Test类的speak方法<br> method.invoke(obj, null);<br> } catch (InstantiationException | IllegalAccessException <br> | NoSuchMethodException<br> | SecurityException | <br> IllegalArgumentException | <br> InvocationTargetException e) {<br> // TODO Auto-generated catch block<br> e.printStackTrace();<br> }<br>}<br>} catch (ClassNotFoundException e) {<br>// TODO Auto-generated catch block<br>e.printStackTrace();<br>}<br> <br>DiskClassLoader diskLoader = new DiskClassLoader("D:\\lib");<br>System.out.println("Thread "+Thread.currentThread().getName()+" classloader: "+Thread.currentThread().getContextClassLoader().toString());<br>new Thread(new Runnable() {<br> <br> @Override<br> public void run() {<br> System.out.println("Thread "+Thread.currentThread().getName()+" classloader: "+Thread.currentThread().getContextClassLoader().toString());<br> <br> // TODO Auto-generated method stub<br> try {<br> //加载class文件<br> // Thread.currentThread().setContextClassLoader(diskLoader);<br> //Class c = diskLoader.loadClass("com.frank.test.SpeakTest");<br> ClassLoader cl = Thread.currentThread().getContextClassLoader();<br> Class c = cl.loadClass("com.frank.test.SpeakTest");<br> // Class c = Class.forName("com.frank.test.SpeakTest");<br> System.out.println(c.getClassLoader().toString());<br> if(c != null){<br> try {<br> Object obj = c.newInstance();<br> //SpeakTest1 speak = (SpeakTest1) obj;<br> //speak.speak();<br> Method method = c.getDeclaredMethod("speak",null);<br> //通过反射调用Test类的say方法<br> method.invoke(obj, null);<br> } catch (InstantiationException | IllegalAccessException <br> | NoSuchMethodException<br> | SecurityException | <br> IllegalArgumentException | <br> InvocationTargetException e) {<br> // TODO Auto-generated catch block<br> e.printStackTrace();<br> }<br> }<br> } catch (ClassNotFoundException e) {<br> // TODO Auto-generated catch block<br> e.printStackTrace();<br> }<br> }<br>}).start();<br><br><br>
结果<br><br>我们可以得到如下的信息:<br><br>DiskClassLoader1加载成功了SpeakTest.class文件并执行成功。<br>子线程的ContextClassLoader是AppClassLoader。<br>AppClassLoader加载不了父线程当中已经加载的SpeakTest.class内容。<br>
我们修改一下代码,在子线程开头处加上这么一句内容。<br><br>Thread.currentThread().setContextClassLoader(diskLoader1);
可以看到子线程的ContextClassLoader变成了DiskClassLoader。<br><br>继续改动代码:<br><br>Thread.currentThread().setContextClassLoader(diskLoader); <br>
可以看到DiskClassLoader1和DiskClassLoader<br>分别加载了自己路径下的SpeakTest.class文件,<br>并且它们的类名是一样的com.frank.test.SpeakTest,<br>但是执行结果不一样,因为它们的实际内容不一样。
总结
ClassLoader用来加载class文件的。<br>系统内置的ClassLoader通过双亲委托来加载指定路径下的class和资源。<br>可以自定义ClassLoader,一般覆盖findClass()方法。<br><b><font color="#80bc42">ContextClassLoader与线程相关,可以获取和设置,可以绕过双亲委托的机制。</font></b>
Java9之类加载
Java9带来了模块化系统,<br>同时类加载机制也进行了调整,<br>Java9中的类加载器,<br>变化仅仅是ExtClassLoader消失了且多了PlatformClassLoader,<br>JVM规范里5.3 Creation and Loading部分详细描述了类加载
规范里把类加载器分为两类,<br>一类是由虚拟机提供的启动类加载器,<br>另一类是由用户自定义的类加载器,<br>注意数组的创建不是类加载器创建的,<br>而是由虚拟机直接创建的。
加载又分为两种情况:defining loader和initiating loader<br>
defining loader只加载不初始化,<br><br>initiating loader是加载并初始化
在运行时一个类或接口是否唯一不是取决于其二进制名称,<br>而是二进制名称和defining其的类加载器的组合
其中JVM规范5.3.6 Modules and Layers有详细说明,<br>增加了Layer(层)的概念,<br>用Layer表示模块集,其实Layer和类加载器是对应的,<br>将启动类加载器加载的模块归一Layer,<br>用户自定义类加载器加载的模块归到另一Layer,<br>Layer也有委托的概念
类加载核心代码(参见jdk.internal.loader.BuiltinClassLoader#loadClassOrNull(java.lang.String, boolean)):
protected Class<?> loadClassOrNull(String cn, boolean resolve) {<br> synchronized (getClassLoadingLock(cn)) {<br> // check if already loaded<br> Class<?> c = findLoadedClass(cn);<br><br> if (c == null) {<br><br> // find the candidate module for this class<br> LoadedModule loadedModule = findLoadedModule(cn);<br> if (loadedModule != null) {<br><br> // package is in a module<br> BuiltinClassLoader loader = loadedModule.loader();<br> if (loader == this) {<br> if (VM.isModuleSystemInited()) {<br> c = findClassInModuleOrNull(loadedModule, cn);<br> }<br> } else {<br> // delegate to the other loader<br> c = loader.loadClassOrNull(cn);<br> }<br><br> } else {<br><br> // check parent<br> if (parent != null) {<br> c = parent.loadClassOrNull(cn);<br> }<br><br> // check class path<br> if (c == null && hasClassPath() && VM.isModuleSystemInited()) {<br> c = findClassOnClassPathOrNull(cn);<br> }<br> }<br><br> }<br><br> if (resolve && c != null)<br> resolveClass(c);<br><br> return c;<br> }<br> }
这段代码可以看出,原有的双亲委派机制受到了模块化的影响,<br>首先如果当前类已经加载了则直接返回,<br>如果没加载,则根据名称找到对应的模块有没有加载,<br>如果对应模块没有加载,则委派给父加载器去加载。<br>如果对应模块已经加载了,则委派给对应模块的加载器去加载,<br>这里需要注意下,<br><font color="#80bc42">在模块里即使使用java.lang.Thread#setContextClassLoader方法改变当前上下文的类加载器,<br>或者在模块里直接使用非当前模块的类加载器去加载当前模块里的类,<br>最终使用的还是加载当前模块的类加载器。</font>
Java9虚拟机初始化系统类分成了3个阶段
阶段1<br>Initialize the system class. Called after thread initialization.<br>java.lang.System#initPhase1<br>阶段2<br>Invoked by VM. Phase 2 module system initialization.Only classes in java.base can be loaded in this phase.<br>java.lang.System#initPhase2<br>阶段3<br>Invoked by VM. Phase 3 is the final system initialization:<br>1. set security manager<br>2. set system class loader<br>3. set TCCL<br>java.lang.System#initPhase3
Java9之前的版本中没有模块化时只有一个初始化,<br>Java9中分成了3个阶段,<br>阶段2是模块化的初始化工作,<br>主要是boot layer的加载,<br>bootlayer里包含的是平台系统依赖的一些模块,<br>阶段3是访问控制设置,类加载器的状态变更等,<br>Java9里的获取系统类加载器时是根据不同的initLevel来做安全校验,<br>Level为4是表示系统初始化ok了,<br>应用调用此方法获取AppClassLoader时校验反射安全,<br>而虚拟机在0-2的状态里则不校验,<br>直接返回AppClassLoader。
initLevel从0到1的过程也就是上面说的阶段1,1到2的过程就是阶段2,2到3再到4是在阶段3里做的,3到4的过程如下:<br><br> // initializing the system class loader<br> VM.initLevel(3);<br><br> // system class loader initialized<br> ClassLoader scl = ClassLoader.initSystemClassLoader();<br><br> // set TCCL<br> Thread.currentThread().setContextClassLoader(scl);<br><br> // system is fully initialized<br> VM.initLevel(4);
Java7里的java.lang.ClassLoader#getSystemClassLoader的实现是:<br><br> public static ClassLoader getSystemClassLoader() {<br> initSystemClassLoader();<br> if (scl == null) {<br> return null;<br> }<br> SecurityManager sm = System.getSecurityManager();<br> if (sm != null) {<br> checkClassLoaderPermission(scl, Reflection.getCallerClass());<br> }<br> return scl;<br> }
Java9里的java.lang.ClassLoader#getSystemClassLoader的实现是:<br><br> public static ClassLoader getSystemClassLoader() {<br> switch (VM.initLevel()) {<br> case 0:<br> case 1:<br> case 2:<br> // the system class loader is the built-in app class loader during startup<br> return getBuiltinAppClassLoader();<br> case 3:<br> String msg = "getSystemClassLoader should only be called after VM booted";<br> throw new InternalError(msg);<br> case 4:<br> // system fully initialized<br> assert VM.isBooted() && scl != null;<br> SecurityManager sm = System.getSecurityManager();<br> if (sm != null) {<br> checkClassLoaderPermission(scl, Reflection.getCallerClass());<br> }<br> return scl;<br> default:<br> throw new InternalError("should not reach here");<br> }<br> }
BootClassLoader
启动类加载器,用于加载启动的基础模块类。
PlatformClassLoader
平台类加载器,用于加载一些平台相关的模块,双亲是BootClassLoader。
AppClassLoader
应用模块加载器,用于加载应用级别的模块,双亲是PlatformClassLoader。
packageToModule
全局的已经加载的boot layer的模块集记录Map,key是包名。
nameToModule<br><br>每个ClassLoader都有一个nameToModule,<br>是用于记录当前ClassLoader加载的模块,<br>一个模块里的类只会由一个ClassLoader来加载。<br>nameToModule是一个MAP,name是模块名,<br>和packageToModule不同。<br>
关于废弃的java.lang.Class#newInstance
Car类:<br><br>package test;<br><br>public class Car {<br><br> public Car(String brand) {<br> this.brand = brand;<br> }<br><br> private String brand;<br><br> public String getBrand() {<br> return brand;<br> }<br><br> public void setBrand(String brand) {<br> this.brand = brand;<br> }<br><br> public void run() {<br> System.out.println("run....");<br> }<br>}<br>
Java9之前和Java9使用ClassLoader的方式对比:<br><br>package test;<br><br>import java.lang.reflect.InvocationTargetException;<br><br>public class ClassLoaderTest {<br><br> public static void main(String[] args) {<br><br><br> ClassLoader loader = Thread.currentThread().getContextClassLoader();<br> try {<br> /** Java9之前的使用方式 */<br> Class clazz = loader.loadClass("test.Car");<br> Object obj = clazz.newInstance();<br> Car car = (Car) obj;<br> car.run();<br><br> } catch (ClassNotFoundException e) {<br> System.err.println(e);<br> } catch (InstantiationException e) {<br> System.err.println(e);<br> } catch (IllegalAccessException e) {<br> System.err.println(e);<br> }<br><br> try {<br> /** Java9的使用方式 */<br> Class clazz = loader.loadClass("test.Car");<br> Object obj = clazz.getDeclaredConstructor(String.class).newInstance("Benz");<br> Car car = (Car) obj;<br> car.run();<br><br> } catch (ClassNotFoundException e) {<br> System.err.println(e);<br> } catch (NoSuchMethodException e) {<br> System.err.println(e);<br> } catch (SecurityException e) {<br> System.err.println(e);<br> } catch (InstantiationException e) {<br> System.err.println(e);<br> } catch (IllegalAccessException e) {<br> System.err.println(e);<br> } catch (IllegalArgumentException e) {<br> System.err.println(e);<br> } catch (InvocationTargetException e) {<br> System.err.println(e);<br> }<br><br> }<br>}
注意,Car类没有参数为空的构造方式,只有一个带参的构造方法。<br><br>运行结果如下:<br>java.lang.InstantiationException: test.Car<br>run....<br><br>这种按构造方法实例化的方式应该是比较方便的技能了,<br>而且可以看出异常也更细分了。<br>如果Car类没有构造方法,两种方式都可以运行,<br>但明显Java9的这种方式更强大,<br>原先的方式自然会被申明废弃了。
GC
简单来说,垃圾回收机制就是由JVM中的垃圾收集器将不再使用的内存空间给释放掉,以便可以被程序再次利用。<br><br>主要包括两个步骤:<br>找到需要回收的目标(即无用的对象)<br>将该区域的内存空间释放掉<br>
垃圾回收的目标区域<br><br>由于JVM中的程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭,<br>栈帧随着方法的进入和退出做入栈和出栈操作,实现了自动的内存清理,<br>因此,内存垃圾回收主要集中于堆内存和方法区中。<br>
堆内存
方法区
主要包括对废弃的常量和无用的类进行回收
垃圾判断方法
四种引用类型和一个引用队列
强引用 <br>
把一个对象赋给一个引用变量,这个引用变量就是一个强引 用。<br>当一个对象被强引用变量引用时,它处于可达状态,<br>它是不可能被垃圾回收机制回收的,<br>即使该对象以后永远都不会被用到JVM也不会回收。<br>因此强引用是造成Java内存泄漏的主要原因之 一。
软引用
软引用需要用 SoftReference 类来实现,<br>对于只有软引用的对象来说,<br>当系统内存足够时它 不会被回收,<br>当系统内存空间不足时它会被回收。<br>软引用通常用在对内存敏感的程序中。
弱引用
弱引用需要用WeakReference 类来实现,<br>它比软引用的生存期更短,对于只有弱引用的对象 来说,<br>只要垃圾回收机制一运行,<br>不管JVM的内存空间是否足够,<br>总会回收该对象占用的内存。
虚引用
虚引用需要PhantomReference类来实现,<br>它不能单独使用,必须和引用队列联合使用。<br>虚引用的主要作用是跟踪对象被垃圾回收的状态。
引用队列
ReferenceQueue(引用队列)简介<br><br>当gc(垃圾回收线程)准备回收一个对象时,<br>如果发现它还仅有软引用(或弱引用,或虚引用)指向它,<br>就会在回收该对象之前,把这个软引用(或弱引用,或虚引用)加入到与之关联的引用队列(ReferenceQueue)中。<br>如果一个软引用(或弱引用,或虚引用)对象本身在引用队列中,就说明该引用对象所指向的对象被回收了。<br><br>当软引用(或弱引用,或虚引用)对象所指向的对象被回收了,<br>那么这个引用对象本身就没有价值了,<br>如果程序中存在大量的这类对象(注意,我们创建的软引用、弱引用、虚引用对象本身是个强引用,不会自动被gc回收),<br>就会浪费内存。因此我们这就可以手动回收位于引用队列中的引用对象本身。
WeakHashMap
原理简单来说就是HashMap里面的条目 Entry继承了 WeakReference,<br>那么当 Entry 的 key 不再被使用(即,引用对象不可达)且被 GC 后,<br>那么该 Entry 就会进入到 ReferenceQueue 中。<br>当我们调用WeakHashMap 的get和put方法会有一个副作用,<br>即清除无效key对应的Entry。<br>首先会从引用队列中取出一个Entry对象,<br>然后在HashMap中查找这个Entry对象的位置,<br>最后把这个 Entry 从 HashMap中删除,<br>这时key和value对象都被回收了。<br>重复这个过程直到队列为空。<br><br>最后说明一点,WeakHashMap是线程安全的。
引用计数法
每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计数为0时表示可以回收。
优缺点:此方法简单,但无法解决对象相互循环引用的问题。因此Java虚拟机未采用该种方法
可达性分析法
从GC Roots开始向下搜索,搜索所走过的路径称为引用链。<br>当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的。即为不可达对象,所以会被判定为是 可以回收的对象。
在Java中,GC Roots包括: <br>* 虚拟机栈(栈帧中的局部变量表)中引用的对象<br>* 方法区中类静态属性引用的对象<br>* 方法区中常量引用的对象<br>* 本地方法栈中JNI(即native方法)引用的对象
垃圾回收算法
标记-清除算法
复制算法
标记-整理算法
分代收集
指的是针对不同分代的内存区域,采用不同的垃圾回收算法
年轻代一般采用复制算法,老年代则一般采用标记-整理算法
垃圾收集器
新生代专用
复制算法
Serial收集器<br>
Serial(英文连续)是最基本垃圾收集器,使用复制算法。<br>Serial 是一个单线程的收集器,它不但只会使用一个 CPU 或一条线程去完成垃圾收集工作,<br>并且在进行垃圾收集的同时,必须暂停其他所有的工作线程,直到垃圾收集结束。 <br>Serial 垃圾收集器虽然在收集垃圾过程中需要暂停所有其他的工作线程,<br>但是它简单高效,对于限 定单个 CPU 环境来说,没有线程交互的开销,<br>可以获得最高的单线程垃圾收集效率,<br>因此 Serial 垃圾收集器依然是java虚拟机运行在Client模式下默认的新生代垃圾收集器。 <br>
ParNew收集器<br>
ParNew垃圾收集器其实是Serial收集器的多线程版本,也使用复制算法,<br>除了使用多线程进行垃圾收集之外,其余的行为和Serial收集器完全一样,<br>ParNew垃圾收集器在垃圾收集过程中同样也 要暂停所有其他的工作线程。 <br><br><br>ParNew 收集器默认开启和 CPU 数目相同的线程数,<br>可以通过-XX:ParallelGCThreads 参数来限 制垃圾收集器的线程数。<br>【Parallel:平行的】 ParNew虽然是除了多线程外和Serial收集器几乎完全一样,<br>但是ParNew垃圾收集器是很多java 虚拟机运行在Server模式下新生代的默认垃圾收集器。 <br>
参数<br><br>-XX:SurvivorRatio<br><br>-XX:PretenureSizeThreshold<br><br>-XX:HandlePromotionFailure<br><br>-XX:ParallelGCThreads
Parallel Scavenge 收集器<br>
Parallel Scavenge 收集器也是一个新生代垃圾收集器,同样使用复制算法,<br>也是一个多线程的垃 圾收集器,<br>它<font color="#80bc42">重点关注的是程序达到一个可控制的吞吐量</font><br>(Thoughput,CPU 用于运行用户代码 的时间/CPU 总消耗时间,<br>即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)),<br>高吞吐量可以最高效率地利用 CPU 时间,尽快地完成程序的运算任务,<br>主要适用于在后台运算而不需要太多交互的任务。<br>自适应调节策略也是 ParallelScavenge 收集器与 ParNew 收集器的一个重要区别
参数<br><br>-XX:MaxGCPauseMillis<br><br>-XX:GCTimeRatio<br><br>-XX:UseAdaptiveSizePolicy
老年代专用
标记-整理算法
Serial Old 收集器
Serial Old 是 Serial 垃圾收集器年老代版本,<br>它同样是个单线程的收集器,使用标记-整理算法, <br>这个收集器也主要是运行在Client模式的java虚拟机默认的年老代垃圾收集器。 <br><br>在Server模式下,主要有两个用途: <br>1. 在JDK1.5之前版本中与新生代的Parallel Scavenge收集器搭配使用。 <br>2. 作为年老代中使用CMS收集器的后备垃圾收集方案。
新生代Serial与年老代Serial Old搭配垃圾收集过程图
Scavenge/ParNew与年老代Serial Old搭配垃圾收集过程图
Parallel Old 收集器 <br>
Parallel Old收集器是Parallel Scavenge的年老代版本,<br>使用多线程的标记-整理算法,在JDK1.6 才开始提供。 <br>在 JDK1.6 之前,新生代使用 ParallelScavenge 收集器只能搭配年老代的 Serial Old 收集器,<br>只能保证新生代的吞吐量优先,无法保证整体的吞吐量,<br>Parallel Old 正是为了在年老代同样提供吞吐量优先的垃圾收集器,<br>如果系统对吞吐量要求比较高,<br>可以优先考虑新生代 Parallel Scavenge 和年老代Parallel Old收集器的搭配策略。
新生代Parallel Scavenge和年老代Parallel Old收集器搭配运行过程图
标记-清除算法
CMS收集器
Concurrent mark sweep(CMS)收集器是一种年老代垃圾收集器,<br>其最主要目标是获取最短垃圾回收停顿时间,<br><br>它使用多线程的标记-清除算法。 <br>最短的垃圾收集停顿时间可以为交互比较高的程序提高用户体验。
分为4个阶段
初始标记 只是标记一下GC Roots能直接关联的对象,速度很快,仍然需要暂停所有的工作线程。<br> <br>并发标记 进行GC Roots跟踪的过程,和用户线程一起工作,不需要暂停工作线程。 <br><br>重新标记 为了修正在并发标记期间,<br> 因用户程序继续运行而导致标记产生变动的那一部分对象的标记 记录,<br> 仍然需要暂停所有的工作线程。 <br><br>并发清除 清除GC Roots不可达对象,和用户线程一起工作,不需要暂停工作线程。<br> 由于耗时最长的并 发标记和并发清除过程中,<br> 垃圾收集线程可以和用户现在一起并发工作,<br> 所以总体上来看 CMS收集器的内存回收和用户线程是一起并发地执行。
CMS收集器工作过程
G1收集器
相比与CMS 收集器,<br>G1收集器两个最突出的改进是: <br>1. 基于标记-整理算法,不产生内存碎片。 <br>2. 可以非常精确控制停顿时间,在不牺牲吞吐量前提下,实现低停顿垃圾回收。 <br>G1 收集器避免全区域垃圾收集,它把堆内存划分为大小固定的几个独立区域,<br>并且跟踪这些区域 的垃圾收集进度,同时在后台维护一个优先级列表,<br>每次根据所允许的收集时间,优先回收垃圾 最多的区域。<br>区域划分和优先级区域回收机制,<br>确保 G1 收集器可以在有限时间获得最高的垃圾收集效率。
参数
-XX:UseSerialGC
Client端默认开启,Serial + Serial Old
-XX:UseParNewGC
默认关闭,打开后使用ParNew + Serial Old
-XX:UseConcMarkSweepGC
默认关闭,打开使用 Parnew + CMS + Serial Old
-XX:UseParallelGC
Server端默认开启,Parallel Scavenge + Serial old
-XX:UseParallelOldGC
默认关闭,打开使用Parallel Scavenge + Parallel Old
ClassLoader卸载Class
JVM中的Class只有满足三个条件,<br>才能被GC回收,<br>也就是该Class被卸载(unload)
1. 该类所有的实例都已经被GC<br>2. 加载该类的ClassLoader实例已经被GC<br>3. 该类的java.lang.Class对象没有在任何地方被引用
package testjvm.testclassloader;<br><br>public class TestClassUnLoad {<br> public static void main(String[] args) throws Exception {<br>SimpleURLClassLoader loader = new SimpleURLClassLoader();<br>// 用自定义的加载器加载A<br>Class clazzA = loader.load("testjvm.testclassloader.A");<br>Object a = clazzA.newInstance();<br>// 清除相关引用<br>a = null; //清除该类的实例<br>clazzA = null; //清除该class对象的引用<br>loader = null; //清楚该类的ClassLoader引用<br>// 执行一次gc垃圾回收<br>System.gc();<br>System.out.println("GC over");<br>}<br>}
类的生命周期<br>当Sample类被加载、连接和初始化后,它的生命周期就开始了。<br>当代表Sample类的Class对象不再被引用,即不可触及时,Class对象就会结束生命周期,<br>Sample类在方法区内的数据也会被卸载,从而结束Sample类的生命周期。<br>由此可见,一个类何时结束生命周期,取决于代表它的Class对象何时结束生命周期。
引用关系
加载器和Class对象
在类加载器的内部实现中,用一个Java集合来存放所加载类的引用。<br>另一方面,一个Class对象总是会引用它的类加载器。<br>调用Class对象的getClassLoader()方法,就能获得它的类加载器。<br>由此可见,Class实例和加载它的加载器之间为双向关联关系。
类、类的Class对象、类的实例对象
一个类的实例总是引用代表这个类的Class对象。<br>在Object类中定义了getClass()方法,<br>这个方法返回代表对象所属类的Class对象的引用。<br>此外,所有的Java类都有一个静态属性class,它引用代表这个类的Class对象。
类的卸载
由Java虚拟机自带的类加载器所加载的类,<br>在虚拟机的生命周期中,始终不会被卸载。<br><br>前面介绍过,<br>Java虚拟机自带的类加载器包括根类加载器、扩展类加载器和系统类加载器。<br><br>Java虚拟机本身会始终引用这些类加载器,<br>而这些类加载器则会始终引用它们所加载的类的Class对象,<br>因此这些Class对象始终是可触及的。<br><br>由用户自定义的类加载器加载的类是可以被卸载的。
子主题
loader1变量和obj变量间接应用代表Sample类的Class对象,<br>而objClass变量则直接引用它。<br><br>如果程序运行过程中,将上图左侧三个引用变量都置为null,<br>此时Sample对象结束生命周期,MyClassLoader对象结束生命周期,<br>代表Sample类的Class对象也结束生命周期,<br>Sample类在方法区内的二进制数据被卸载。<br><br>当再次有需要时,会检查Sample类的Class对象是否存在,<br>如果存在会直接使用,不再重新加载;<br>如果不存在Sample类会被重新加载,<br>在Java虚拟机的堆区会生成一个新的代表Sample类的Class实例<br>(可以通过哈希码查看是否是同一个实例)。
java内存诊断http://itfish.net/article/27446.html
GC日志
-XX:+PrintGC<br><br>-xx:+PrintGDDetails<br><br>-XX:+PrintGCTimeStamps<br><br>-XX:PrintGCApplicationStoppedTime
输出到文件
-verbose:gc,-XX:+PrintenuringDistribution<br><br>-Xloggc:gc.log
jps
-v:显示启动时jvm参数<br><br>-m 显示main函数参数
jstat
-class:类装载,卸载相关信息<br><br>-gc:监视java堆使用情况
jinfo
-flags 查看所有flag<br><br>-flag 查看/设置 flag
GC Portal GC内在预测
JConsole内存运行的状态
JVisualvm
vissualGC插件分析GC趋势
与JProfiler类似内存消耗 线程状态 以及cpu
jmap
jmap -heap [pid]<br><br>jamp -histo pid<br><br>jmap -dump:format=b,file=1.log pid<br><br>jmap -dump:live,format=b,file=xxx [pid]<br><br>-heap 显示java堆详细信息<br><br>-dump 生成堆快照 jmap -dump:format=b,file=test.bin 13940<br>
jstack
-F 强制输出堆栈<br><br>-l 出堆栈信息外,附加锁信息
jhat dump
jstat -gcutil pid interval
S0,S1 survivor使用率<br><br>E eden空间使用率<br><br>O 旧生代空间使用率<br><br>P持久代使用率<br><br>YGC monor GC执行次数<br><br>YGCT GC消耗时间<br><br>FGC full GC执行次数<br><br>FGCT full GC消耗时间<br><br>GCT Minor GC+FULL GC执行消耗的时间
MAT(RCLIPE memory analyzer)分析dump
http://blog.csdn.net/supera_li
client模式和server模式
区别<br>Client模式启动速度较快,<br>Server模式启动较慢;<br>但是启动进入稳定期长期运行之后Server模式的程序运行速度比Client要快很多。<br>这是因为Server模式启动的JVM采用的是重量级的虚拟机,对程序采用了更多的优化;<br>而Client模式启动的JVM采用的是轻量级的虚拟机。<br>所以Server启动慢,但稳定后速度比Client远远要快。
参数
-Xms设置堆的最小空间(初始)大小。<br>-Xmx设置堆的最大空间大小。<br><br>-XX:NewSize设置新生代最小空间大小。<br>-XX:MaxNewSize设置新生代最大空间大小。<br><br>-XX:PermSize设置永久代最小空间大小。<br>-XX:MaxPermSize设置永久代最大空间大小。<br><br>-Xss设置每个线程的堆栈大小。
GC日志分析<br><br>https://gceasy.io/<br>
Young GC回收日志:<br><br>2016-07-05T10:43:18.093+0800: 25.395: <br>[GC [PSYoungGen: 274931K->10738K(274944K)] 371093K->147186K(450048K), 0.0668480 secs] <br>[Times: user=0.17 sys=0.08, real=0.07 secs]<br><br>Full GC回收日志:<br><br>2016-07-05T10:43:18.160+0800: 25.462: <br>[Full GC <br> [PSYoungGen: 10738K->0K(274944K)] <br> [ParOldGen: 136447K->140379K(302592K)] 147186K->140379K(577536K) <br> [PSPermGen: 85411K->85376K(171008K)], 0.6763541 secs<br> ] <br> [Times: user=1.75 sys=0.02, real=0.68 secs] <br>
YoungGC
FullGC
GC日志中寻找FGC的命令以及结果(只贴出部分)<br><br>https://mp.weixin.qq.com/s/_9o4mcJ3Kqc6117KbTWpig<br>
2019-06-15T09:35:04.168-0800: <br>[Full GC (System.gc()) <br> [PSYoungGen: 6963K->0K(229376K)] <br> [ParOldGen: 8K->6793K(262144K)] 6971K->6793K(491520K), <br> [Metaspace: 5160K->5160K(1056768K)], 0.0085889 secs<br> ] <br> [Times: user=0.03 sys=0.01, real=0.01 secs]<br>2019-06-15T09:40:08.520-0800: <br>[Full GC (System.gc()) <br> [PSYoungGen: 5184K->0K(229376K)] <br> [ParOldGen: 6793K->6090K(262144K)] 11977K->6090K(491520K), <br> [Metaspace: 5168K->5168K(1056768K)], 0.0085573 secs<br> ] <br> [Times: user=0.01 sys=0.00, real=0.00 secs]<br>
根据这段GC日志就能非常肯定:是因为某些地方调用System.gc()触发的FGC。<br>最常见的方法还是借助btrace跟踪是哪里调用了System.gc()<br>
OOM 的 8 种原因、及解决办法
堆溢出
java.lang.OutOfMemoryError: <br>Java heap space
原因
1、代码中可能存在大对象分配<br>2、可能存在内存泄露,导致在多次GC之后,还是无法找到一块足够大的内存容纳当前对象。
解决方法
1、检查是否存在大对象的分配,最有可能的是大数组分配<br>2、通过jmap命令,把堆内存dump下来,使用mat工具分析一下,检查是否存在内存泄露的问题<br>3、如果没有找到明显的内存泄露,使用 -Xmx 加大堆内存<br>4、还有一点容易被忽略,检查是否有大量的自定义的 Finalizable 对象,也有可能是框架内部提供的,考虑其存在的必要性
永久代/元空间溢出
java.lang.OutOfMemoryError: PermGen space<br>java.lang.OutOfMemoryError: Metaspace
原因
永久代是 HotSot 虚拟机对方法区的具体实现,存放了被虚拟机加载的类信息、常量、静态变量、JIT编译后的代码等。<br>JDK8后,元空间替换了永久代,元空间使用的是本地内存,还有其它细节变化:<br><br>字符串常量由永久代转移到堆中<br>和永久代相关的JVM参数已移除<br><br>可能原因有如下几种:<br><br>1、在Java7之前,频繁的错误使用String.intern()方法<br>2、运行期间生成了大量的代理类,导致方法区被撑爆,无法卸载<br>3、应用长时间运行,没有重启<br><br>没有重启 JVM 进程一般发生在调试时,如下面 tomcat 官网的一个 FAQ:<br>Why does the memory usage increase when I redeploy a web application?<br><br>That is because your web application has a memory leak.<br><br>A common issue are “PermGen” memory leaks. <br>They happen because the Classloader (and the Class objects it loaded) cannot be recycled unless some requirements are met (). <br>They are stored in the permanent heap generation by the JVM, <br>and when you redeploy a new class loader is created, which loads another copy of all these classes. <br>This can cause OufOfMemoryErrors eventually.<br><br>(*) The requirement is that all classes loaded by this classloader should be able to be gc’ed at the same time.<br>
解决方法
1、检查是否永久代空间或者元空间设置的过小<br>2、检查代码中是否存在大量的反射操作<br>3、dump之后通过mat检查是否存在大量由于反射生成的代理类<br>4、放大招,重启JVM<br>
GC overhead limit exceeded
java.lang.OutOfMemoryError:GC overhead limit exceeded
原因
这个是JDK6新加的错误类型,一般都是堆太小导致的。<br>Sun 官方对此的定义:<br>超过98%的时间用来做GC并且回收了不到2%的堆内存时会抛出此异常。
解决方法
1、检查项目中是否有大量的死循环或有使用大内存的代码,优化代码。<br><br>2、添加参数 -XX:-UseGCOverheadLimit 禁用这个检查,<br>其实这个参数解决不了内存问题,<br>只是把错误的信息延后,<br>最终出现 java.lang.OutOfMemoryError: Java heap space。<br><br>3、dump内存,检查是否存在内存泄露,如果没有,加大内存。
方法栈溢出
java.lang.OutOfMemoryError: unable to create new native Thread
原因
出现这种异常,基本上都是创建的了大量的线程导致的,以前碰到过一次,通过jstack出来一共8000多个线程。
解决方法
1、通过 -Xss 降低的每个线程栈大小的容量<br><br>2、线程总数也受到系统空闲内存和操作系统的限制,检查是否该系统下有此限制:<br>/proc/sys/kernel/pid_max<br>/proc/sys/kernel/thread-max<br>maxuserprocess(ulimit -u)<br>/proc/sys/vm/maxmapcount
分配超大数组
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
这种情况一般是由于不合理的数组分配请求导致的,<br>在为数组分配内存之前,JVM 会执行一项检查。<br>要分配的数组在该平台是否可以寻址(addressable),<br>如果不能寻址(addressable)就会抛出这个错误。
解决方法就是检查你的代码中是否有创建超大数组的地方。
swap溢出
java.lang.OutOfMemoryError: Out of swap space
这种情况一般是操作系统导致的,可能的原因有:<br>1、swap 分区大小分配不足;<br><br>2、其他进程消耗了所有的内存。
解决方案:<br>1、其它服务进程可以选择性的拆分出去<br><br>2、加大swap分区大小,或者加大机器内存大小<br>
本地方法溢出
java.lang.OutOfMemoryError: stack_trace_with_native_method
本地方法在运行时出现了内存分配失败,<br>和之前的方法栈溢出不同,<br>方法栈溢出发生在 JVM 代码层面,<br>而本地方法溢出发生在JNI代码或本地方法处。
JavaEE
Spring
简介
spring boot就是一个大框架里面包含了许许多多的东西,其中spring Framework就是最核心的内容之一,当然就包含spring mvc。<br><br>spring mvc 是只是spring 处理web层请求的一个模块。<br><br>Spring 框架就像一个家族,有众多衍生产品例如 boot、security、jpa等等。<br><br>但他们的基础都是Spring Framework的 ioc和 aop。 <br>ioc 提供了依赖注入的容器。 aop 解决了面向横切面的编程,然后在此两者的基础上实现了其他延伸产品的高级功能。<br><br>Spring MVC是基于 Servlet 的一个 MVC 框架 主要解决 WEB 开发的问题,<br><br>因为 Spring 的配置非常复杂,各种XML、 JavaConfig 处理起来比较繁琐。<br>于是为了简化开发者的使用,从而创造性地推出了Spring boot,约定优于配置,简化了spring的配置流程。
Spring Framework
ContextLoaderListener监听器
是整个web Spring应用启动的关键
Spring启动过程大致如下: <br>1、在Servlet容器(Tomcat,Jetty。。。)启动后,会创建一个ServletContext(整个Web应用的上下文);<br>2、由于ContextLoaderListener实现了ServletContextListener,<br> 因此会在ServletContext创建完成后,其中的contextInitialized方法会自动被调用;<br> contextInitialized方法中将会通过ServletContext实例的getParameter()方法找到Spring配置文件位置,<br> 然后根据其中的内容为Spring创建一个根上下文(WebApplicationContext,即通常所说的IOC容器):<br>3、将WebApplicationContext作为ServletContext的一个属性放进去,<br> 名称是WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE
Ioc
WebApplicationContext: 即SpringIoc容器,由容器创建和管理Bean,使用时直接从容器中获取
好莱坞原则 <br><br>不用显式的创建对象,而是把创建对象的工作交给了Ioc容器,<br><br>在使用的时候,不用去new一个对象,而是从容器中直接拿
依赖注入
依赖注入的方式
构造器方式注入
<bean id="text" class="com.maven.Text" /><br><br><bean id="hello" class="com.maven.Hello"><constructor-arg ref="text" /></bean>
构造器依赖注入通过容器触发一个类的构造器来实现的,该类有一系列参数,每个参数代表一个对其他类的依赖。
注解自动注入(@autowire)
setter方法注入
例如:<bean id="hello" class="com.maven.Hello"><property name="text" ref="text" /></bean>
之所以叫setter方法注入,因为这是通过找到类的对应的setter方法,再进行相应的注入
Setter方法注入是容器通过调用无参构造器或无参static工厂 方法实例化bean之后,调用该bean的setter方法,即实现了基于setter的依赖注入。
最好的解决方案是用构造器参数实现强制依赖,setter方法实现可选依赖。
装配方式(依赖注入的具体行为)
基于注解的自动装配
实现方式
注解
@Autowired
优先byType
byName
@Resource
优先byName
byType
自动扫描(component-scan)
装配规则
基于XML配置的显式装配
(1)no:默认的方式是不进行自动装配的,通过手工设置ref属性来进行装配bean。
(2)byName:通过bean的名称进行自动装配,如果一个bean的 property 与另一bean 的name 相同,就进行自动装配。
(3)byType:通过参数的数据类型进行自动装配。
(4)constructor:利用构造函数进行装配,并且构造函数的参数通过byType进行装配。
(5)autodetect:自动探测,如果有构造方法,通过 construct的方式自动装配,否则使用 byType的方式自动装配。
基于Java配置的显式装配
能够在编译时就发现错误
循环依赖
构造器方式无法解决,只能抛出异常
因为加入singletonFactories三级缓存的前提是执行了构造器(因为要先构建出对象),所以构造器的循环依赖没法解决。
多例方式无法解决,只能抛出异常
因为Spring容器不缓存"prototype"作用域的bean,因此无法提前暴露一个创建中的bean。
单例模式可以解决
通过三级缓存+ 提前曝光 解决
在createBeanInstance()之后会调用addSingleton()方法将bean注册到singletonFactories中
通过提前暴露一个单例工厂方法,从而使其他bean能够引用到该bean/提前暴露一个正在创建中的bean
1.“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象<br><br>2.A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中(这步是关键)<br><br>3.A发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程<br><br>4.<br>B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),<br>尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),<br>尝试二级缓存earlySingletonObjects(也没有),<br>尝试三级缓存singletonFactories,<br>由于A通过ObjectFactory将自己提前曝光了,<br>所以B能够通过ObjectFactory.getObject拿到A对象<br><br>5.B拿到A对象后顺利完成了初始化阶段1、2、3,<br>完全初始化之后将自己放入到一级缓存singletonObjects中<br><br>6.返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,<br>最终A也完成了初始化,进去了一级缓存singletonObjects中<br><br>7.由于B拿到了A的对象引用,所以B类中的A对象完成了初始化。
Spring对于循环依赖的解决
Spring循环依赖的理论依据其实是Java基于值传递,传递引用,<br>当我们获取到对象的引用时,对象的field或者或属性是可以延后设置的。<br>
Spring单例对象的初始化其实可以分为三步
createBeanInstance, 实例化,<br>实际上就是调用对应的构造方法构造对象,<br>此时只是调用了构造方法,<br>spring xml中指定的property并没有进行populate
populateBean,填充属性,<br>这步对spring xml中指定的property进行populate
initializeBean,调用spring xml中指定的init方法,<br>或者AfterPropertiesSet方法<br><br>会发生循环依赖的步骤集中在第一步和第二步。
三级缓存
对于单例对象来说,在Spring的整个容器的生命周期内,<br>有且只存在一个对象,很容易想到这个对象应该存在Cache中,<br>Spring大量运用了Cache的手段,<br>在循环依赖问题的解决过程中甚至使用了“三级缓存”。
singletonObjects指单例对象的cache
earlySingletonObjects指提前曝光的单例对象的cache
singletonFactories指单例对象工厂的cache
解决方法
首先Spring会尝试从缓存中获取,这个缓存就是指<font color="#80bc42">singletonObjects<br><br></font>Spring首先从singletonObjects(一级缓存)中尝试获取,<br>如果获取不到并且对象在创建中,<br>则尝试从earlySingletonObjects(二级缓存)中获取,<br>如果还是获取不到并且允许从singletonFactories通过getObject获取,<br>则通过singletonFactory.getObject()(三级缓存)获取<font color="#80bc42"><br></font>
如果获取到了则移除对应的singletonFactory,<br>将singletonObject放入到earlySingletonObjects,<br>其实就是将三级缓存提升到二级缓存中!
解决循环依赖的诀窍就在于singletonFactories这个cache,这个cache中存的是类型为ObjectFactory
解决循环依赖的关键,<br>单例对象此时已经被创建出来的。<br>这个对象已经被生产出来了,<br>虽然还不完美(还没有进行初始化的第二步和第三步),<br>但是已经能被人认出来了(根据对象引用能定位到堆中的对象),<br>所以<font color="#f15a23">Spring此时将这个对象提前曝</font><font color="#f1753f">光</font>出来让大家认识,让大家使用。
Spring通过三级缓存加上“提前曝光”机制,<br>配合Java的对象引用原理,<br>比较完美地解决了某些情况下的循环依赖问题!
流程图
不用创建对象,而只需要描述它如何被创建,<br>不在代码里直接组装组件和服务,但是要在配置文件里描述哪些组件需要哪些服务,<br>之后一个容器(IOC容器)负责把他们组装起来。
Spring IoC容器的初始化过程
<span style="font-size: inherit;">启动是通过<font color="#80bc42">AbstractApplicationContext的refresh()方法</font>进行启动的,</span><br>这个方法标志IoC容器的正式启动.
第一个过程是Resource定位过程<br><br>指对BeanDefinition的资源定位过程。<br>通俗地讲,就是找到定义Javabean信息的XML文件,<br>并将其封装成Resource对象。<br>
这个Resource定位指的是BeanDefinition的资源定位,<br>它由ResourceLoader通过统一的Resource接口来完成,<br>这个Resource对各种形式的BeanDef-inition的使用都提供了统一接口。<br>对于这些BeanDefinition的存在形式,相信大家都不会感到陌生。<br>比如,<br>在文件系统中的Bean定义信息可以使用FileSystemResource来进行抽象;<br>在类路径中的Bean定义信息可以使用前面提到的ClassPathResource来使用,<br>等等。<br>这个定位过程类似于容器寻找数据的过程,就像用水桶装水先要把水找到一样。
第二个过程是BeanDefinition的载入<br><br>把用户定义好的Javabean表示为IoC容器内部的数据结构,<br>这个容器内部的数据结构就是BeanDefinition。<br>
这个载入过程是把用户定义好的Bean表示成IoC容器内部的数据结构,<br>而这个容器内部的数据结构就是BeanDefinition。<br>下面介绍这个数据结构的详细定义。<br>具体来说,<br>这个BeanDefinition实际上就是POJO对象在IoC容器中的抽象,<br>通过这个BeanDefinition定义的数据结构,<br>使IoC容器能够方便地对POJO对象也就是Bean进行管理。
第三个过程是向IoC容器注册这些BeanDefinition的过程
这个过程是通过调用BeanDefinitionRegistry接口的实现来完成的。<br>这个注册过程把载入过程中解析得到的BeanDefinition向IoC容器进行注册。<br>通过分析,我们可以看到,<br>在IoC容器内部将BeanDefinition注入到一个HashMap中去,<br>IoC容器就是通过这个HashMap来持有这些BeanDefinition数据的.
IoC容器初始化过程
一般不包含Bean依赖注入的实现。<br>在Spring IoC的设计中,<br>Bean定义的载入和依赖注入是两个独立的过程<br>
Spring IoC容器的初始化流程图
子主题
SpringIoc初始化-加载注册
子主题
Spring Ioc启动流程
流程图
子主题
Spring容器关闭过程
调用DisposableBean的destroy();
调用定制的destroy-method方法;
bean知识
bean的创建
1.进入<font color="#80bc42">AbstractBeanFactory.getBean()</font>方法
2.判断当前bean的作用域是否是单例,<br>如果是,则去对应缓存中查找,<br>没有查找到的话则新建实例并保存。<br>如果不是单例,则直接新建实例(createBeanInstance)
3.新建实例后再注入属性(populateBean),并处理回调
创建bean
找到@Autowired的对象
创建注入对象,并赋值
创建bean的主线
子主题
bean的生命周期
1.实例化Bean
2.设置Bean的属性
3.检查Aware相关接口并设置相关依赖
BeanNameAware
BeanFactoryAware
ApplicationContextAware
4.检查BeanPostProcessor接口并进行前置处理
5.检查Bean在Spring配置文件中配置的init-method属性并自动调用其配置的初始化方法。
由于这个是在Bean初始化结束时调用那个的方法,也可以被应用于内存或缓存技术;
6.检查BeanPostProcessor接口并进行后置处理
7.当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用那个其实现的destroy()方法;
8. 最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
bean的作用域
singleton<br>
Spring IoC容器中只会存在一个共享的Bean实例,无论有多少个Bean引用它,始终指向同一对象。
singleton是Bean的默认作用域
默认情况下是容器初始化的时候创建,但也可设定运行时再初始化bean
DefaultSingletonBeanRegistry类里的singletonObjects哈希表保存了单例对象。
Spring容器可以管理singleton作用域下bean的生命周期,在此作用域下,Spring能够精确地知道bean何时被创建,何时初始化完成,以及何时被销毁
prototype
每次通过Spring容器获取prototype定义的bean时,容器都将创建一个新的Bean实例,每个Bean实例都有自己的属性和状态
当容器创建了bean的实例后,bean的实例就交给了客户端的代码管理,Spring容器将不再跟踪其生命周期,并且不会管理那些被配置成prototype作用域的bean的生命周期。
对有状态的bean使用prototype作用域,而对无状态的bean使用singleton作用域。
request
在一次Http请求中,容器会返回该Bean的同一实例。而对不同的Http请求则会产生新的Bean,而且该bean仅在当前Http Request内有效。
session<br>
在一次Http Session中,容器会返回该Bean的同一实例。而对不同的Session请求则会创建新的实例,该bean实例仅在当前Session内有效。
global Session
在一个全局的Http Session中,容器会返回该Bean的同一个实例,仅在使用portlet context时有效。
application (Spring4)
为每个ServletContext创建一个实例。仅在Web相关的ApplicationContext中生效。
websocket(Spring5)
WebSocket的完整生命周期中将创建并提供一个实例。<br>Only valid in web-aware Spring ApplicationContext.
bean加载顺序,扫描bean顺序
单一Bean
装载
1. 实例化; <br>2. 设置属性值; <br>3. 如果实现了BeanNameAware接口,调用setBeanName设置Bean的ID或者Name; <br>4. 如果实现BeanFactoryAware接口,调用setBeanFactory 设置BeanFactory; <br>5. 如果实现ApplicationContextAware,调用setApplicationContext设置ApplicationContext <br>6. 调用BeanPostProcessor的预先初始化方法; <br>7. 调用InitializingBean的afterPropertiesSet()方法; <br>8. 调用定制init-method方法; <br>9. 调用BeanPostProcessor的后初始化方法;
多个Bean的先后顺序
优先加载BeanPostProcessor的实现Bean<br><br>按Bean文件和Bean的定义顺序按bean的装载顺序(即使加载多个spring文件时存在id覆盖)<br><br>“设置属性值”(第2步)时,遇到ref,则在“实例化”(第1步)之后先加载ref的id对应的bean<br><br>AbstractFactoryBean的子类,在第6步之后,会调用createInstance方法,之后会调用getObjectType方法<br><br>BeanFactoryUtils类也会改变Bean的加载顺序
Spring配置文件里bean,<br>究竟是按什么样的顺序加载呢?<br><br>Spring项目在部署时,<br>究竟创建了多少各beanFactory呢?<br>按什么顺序创建?<br>
Rule1:
首先读取WEB-INF/web.xml文件,<br>该文件内一般会配置spring-config和spring-mvc。<br>按顺序加载对应的xml文件。
Rule2:
若web.xml中还有除springmvc和默认的servlet之外的servlet(如servlet-test),<br>那么这些servlet会按照定义的顺序执行,<br>但一定是在默认servlet之后,springmvc之前执行,<br>并且,若这些servlet都会分别对应一个ApplicationContext,<br>当然也意味着分别拥有一个beanFactory。<br>这些ApplicationContext(包括springmvc的那个),<br>他们的parent ApplicationContext均是默认servlet对应的那个ApplicationContext(Root ApplicationContext)。<br>默认的servlet,是通过参数contextConfigLocation来指定一个xml文件。<br><br>因此,若springmvc里的某个Controller尝试通过auto wire注解来注入servlet-test里面的service,<br>那么在运行时会抛出”Could not autowire field …”异常,<br>因为spring从springmvc那个servlet中的beanFactory(包括其父beanFactory)中找不到对应的bean。
Rule3:
在加载某个包含bean的xml文件时,按照bean的类型<br>1)BeanFactoryPostProcessor类的bean;<br>2)BeanPostProcessor类的bean;<br>3)普通bean,包括import进来的(bean标签和scan标签指定的);的顺序进行加载。<br>同类型的bean按照定义顺序加载。<br>所有bean默认是单例的。<br><br>因此,对于BeanFactoryPostProcessor和BeanPostProcessor类型的bean,<br>即使被放置在最后面,也会先加载。
Rule4:
component-scan生成的<font color="#80bc42">bean的默认id是类名(首字母小写)</font>,例如testService1。<br><br><bean>标签生成的bean的默认id是:包名.类名#数字,例如qk.spring.beanFactory.service1.TestService1#0<br><br>如果component-scan和bean标签生成的bean有冲突(即bean的id相同),<br>并且都是单例(默认是单例),那么不会重复创建,<br>只保留最先创建出来的那个,同一个属性的话,<br>后续的会覆盖前面的。
Rule5:
创建BeanFactory时,按照如下顺序(beanpostprocessor不会处理beanFactory,虽然他也是个bean)):<br>见(org.springframework.context.support.AbstractApplicationContext)<br>(见AbstractAutowireCapableBeanFactory#initializeBean(…)。<br>里面分为<font color="#80bc42">AbstractAutowireCapableBeanFactory</font>#<font color="#f15a23">applyBeanPostProcessorsBeforeInitialization(…)</font><br>和<font color="#80bc42">AbstractAutowireCapableBeanFactory</font>#<font color="#f15a23">postProcessObjectFromFactoryBean(…))</font>
0)创建beanFactory,并尽可能初始化,此时普通bean还未创建;
1)创建spring的部分BeanPostProcessor;
2)创建并执行BeanFactoryPostProcessor(包括自定义的);
3)创建并注册剩余的内置BeanPostProcessor,<br>ApplicationContextAwareProcessor(见AbstractApplicationContext#prepareBeanFactory(…)),<br>ServletContextAwareProcessor见(AbstractRefreshableWebApplicationContext#postProcessBeanFactory(…));
4)创建并注册自定义的BeanPostProcessor(如aop代理,config)(AbstractApplicationContext#refresh());
5)创建普通bean(同时应用bean post processor)
Rule6:
单个bean加载过程
1)构造函数;<br><br>2)BeanPostProcessor#postProcessBeforeInitialization(…);<br><br>3)设置property;<br><br>4)InitializingBean#afterPropertiesSet();<br><br>5)BeanPostProcessor#postProcessAfterInitialization(…);<br><br>6)FactoryBean#getObject()的顺序构造bean实例。
Spring bean是如何加载的
加载bean的主要逻辑
在<font color="#80bc42">AbstractBeanFactory中<br>doGetBean对加载bean</font>的不同情况进行拆分处理,<br>并做了部分准备工作<br>
获取原始bean name
根据alia获取原始bean name
去除FactoryBean时的& [如果是需要获取FactoryBean自省,配置时需要在bean name前添加&]
尝试从缓存中获取实例
如果获取到实例,还要委托getObjectForBeanInstance解决FactoryBean的场景,就是调用getObject
判断原型场景的循环依赖问题,<br>如果是原型同时bean又正在创建,<br>说明是循环依赖,那直接抛异常,<br>spring不尝试解决原型的循环依赖
如果在本容器中没有定义该bean,需要去父容器查找
如果有参数,结合参数初始化
如果没有参数,需要结合类型初始化,<br>这边的调用是这个分支(当然这边一样没有类型)
如果不是类型检查,这边需要标记bean正在实例化
bean实例化的准备工作
合并父bean的定义,并转化GenericBeanDefinition为RootBeanDefinition
校验BeanDefinition,如果是抽象类或者非原型带参数抛异常[这边注释说的是只有原型才可以配置构造方法的参数]
解决bean的依赖
注册依赖的bean
递归调用getBean实例化依赖bean
创建单例的实例
为解决循环依赖问题,这边使用ObjectFactory在实例化前先暴露bean
老规矩,需要委托getObejctForBeanInstance解决FactoryBean的问题
创建原型实例
创建前的准备工作,使用prototypesCurrentlyInCreation标记bean正在实例化
委托createBean实例化bean
创建后的善后工作,从prototypesCurrentlyInCreation中删除标记
老规矩,委托getObjectForBeanInstance解决工厂方法的问题
创建其他scope的实例,这边的逻辑结合了单例跟原型的处理逻辑,<br>既使用解决循环依赖的ObjectFactory也使用prototypeCreation的标记
获取作用域scope,并校验是否已配置
使用ObjectFactory提早暴露实例
标记bean正在创建并委托createBean实例化
又是委托getObjectForBeanInstance解决工厂方法问题
最后需要对创建的实例进行类型校验,<br>如果不一致,<br>这边还需要委托TypeConverter进行类型装换
流程图
子主题
code
AbstractBeanFactory<br><br><br><br>@Override<br>public Object getBean(String name) throws BeansException {<br>return doGetBean(name, null, null, false);<br>}<br><br>protected <T> T doGetBean(<br>final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)<br>throws BeansException {<br>// 获取原始的bean name,去除&,解决alias问题<br>final String beanName = transformedBeanName(name);<br>Object bean;<br>// 尝试从缓存中获取bean<br>// Eagerly check singleton cache for manually registered singletons.<br>Object sharedInstance = getSingleton(beanName);<br>if (sharedInstance != null && args == null) {<br>if (logger.isDebugEnabled()) {<br>if (isSingletonCurrentlyInCreation(beanName)) {<br>// ...<br>}<br>else {<br>logger.debug("Returning cached instance of singleton bean '" + beanName + "'");<br>}<br>}<br><br> // 如果从缓存中或得bean,还需要判断是否是FactoryBean,并调用getObejct<br>bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);<br>}<br>else {<br>// 如果是原型scope,这边又是正在创建,说明有循环依赖,而原型的循环依赖Spring是不解决的<br>// Fail if we're already creating this bean instance:<br>// We're assumably within a circular reference.<br>if (isPrototypeCurrentlyInCreation(beanName)) {<br>throw new BeanCurrentlyInCreationException(beanName);<br>}<br>// 如果当前容器没有配置bean,那么去父容器查找<br>// Check if bean definition exists in this factory.<br>BeanFactory parentBeanFactory = getParentBeanFactory();<br>if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {<br>// Not found -> check parent.<br>String nameToLookup = originalBeanName(name);<br>if (args != null) {<br>// Delegation to parent with explicit args.<br>return (T) parentBeanFactory.getBean(nameToLookup, args);<br>}<br>else {<br>// No args -> delegate to standard getBean method.<br>return parentBeanFactory.getBean(nameToLookup, requiredType);<br>}<br>}<br><br> // 如果不是类型检查,这边需要标记类正在创建<br>if (!typeCheckOnly) {<br>markBeanAsCreated(beanName);<br>}<br>try {<br>// 实例化类之前,先去容器中获取配置的bean信息,这边需要将之前的GenericBeanDefinition转化为RootBeanDefinition<br>// 同时如果父bean的话,需要合并到子bean<br>final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);<br>checkMergedBeanDefinition(mbd, beanName, args);<br><br> // Guarantee initialization of beans that the current bean depends on.<br>String[] dependsOn = mbd.getDependsOn();<br>if (dependsOn != null) {<br>for (String dependsOnBean : dependsOn) {<br>if (isDependent(beanName, dependsOnBean)) {<br>throw new BeanCreationException(mbd.getResourceDescription(), beanName,<br>"Circular depends-on relationship between '" + beanName + "' and '" + dependsOnBean + "'");<br>}<br><br>// 解决依赖<br>registerDependentBean(dependsOnBean, beanName);<br>getBean(dependsOnBean);<br>}<br>}<br><br>// 创建单例的实例<br>// Create bean instance<br>if (mbd.isSingleton()) {<br>// 单例情况下,为解决循环依赖,在实例化之前,先新建一个ObjectFactory实例<br>sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {<br><br>@Override<br>public Object getObject() throws BeansException {<br>try {<br>return createBean(beanName, mbd, args);<br>}<br>catch (BeansException ex) {<br>// Explicitly remove instance from singleton cache: It might have been put there<br>// eagerly by the creation process, to allow for circular reference resolution.<br>// Also remove any beans that received a temporary reference to the bean.<br>destroySingleton(beanName);<br>throw ex;<br>}<br>}<br>});<br><br> bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);<br>}<br>// 创建原型实例<br>else if (mbd.isPrototype()) {<br>// It's a prototype -> create a new instance.<br>Object prototypeInstance = null;<br>try {<br>beforePrototypeCreation(beanName);<br>prototypeInstance = createBean(beanName, mbd, args);<br>}<br>finally {<br>afterPrototypeCreation(beanName);<br>}<br>bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);<br>}<br><br> // 创建其他scope的实例<br>else {<br>String scopeName = mbd.getScope();<br>final Scope scope = this.scopes.get(scopeName);<br>if (scope == null) {<br>throw new IllegalStateException("No Scope registered for scope '" + scopeName + "'");<br>}<br><br> try {<br>// 还是先创建ObejctFactory,只是这边没有处理<br>Object scopedInstance = scope.get(beanName, new ObjectFactory<Object>() {<br>@Override<br>public Object getObject() throws BeansException {<br>beforePrototypeCreation(beanName);<br>try {<br>return createBean(beanName, mbd, args);<br>}<br>finally {<br>afterPrototypeCreation(beanName);<br>}<br>}<br>});<br><br> bean = getObjectForBeanInstance(scopedInstance, name, beanName, mbd);<br>}<br>catch (IllegalStateException ex) {<br>throw new BeanCreationException(beanName,<br>"Scope '" + scopeName + "' is not active for the current thread; " +<br>"consider defining a scoped proxy for this bean if you intend to refer to it from a singleton",<br>ex);<br><br> }<br>}<br>}<br>catch (BeansException ex) {<br>cleanupAfterBeanCreationFailure(beanName);<br>throw ex;<br>}<br>}<br><br>// 这边需要对实例进行类型校验,如果与requiredType不一致,需要委托TypeConverter尝试类型转换<br>// Check if required type matches the type of the actual bean instance.<br>if (requiredType != null && bean != null && !requiredType.isAssignableFrom(bean.getClass())) {<br>try {<br>return getTypeConverter().convertIfNecessary(bean, requiredType);<br>}<br>catch (TypeMismatchException ex) {<br>if (logger.isDebugEnabled()) {<br>logger.debug("Failed to convert bean '" + name + "' to required type [" +<br>ClassUtils.getQualifiedName(requiredType) + "]", ex);<br>}<br>throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass());<br>}<br>}<br>return (T) bean;<br>}
Spring bean解析流程
流程图
子主题
bean实例的缓存分析
doGetBean首先尝试的是从缓存读取,分析下缓存具体是如何处理的.<br><br>逻辑是定义在<b><font color="#80bc42">DefaultSingletonBeanRegistry</font></b>中,<br>它是AbstractBeanFactory的父类,主要职责是共享实例的注册.<br><br>这边虽然定义的是singleton,但是实际使用的时候,处理prototype,<br>其他scope均使用了这边进行缓存.<br><br>这边主要是需要理解<br>singletonObjects,<br>earlySingletonObjects,<br>singletonFactories,<br>registeredSingletons这4个变量.
singletonObjects 缓存bean name ->实例
Cache of singleton objects: bean name --> bean instance<br><br>缓存的是实例
earlySingletonObjects 缓存提早暴露的实例 bean name -->bean instance<br>
Cache of early singleton objects: bean name --> bean instance <br><br>缓存的也是实例,只是这边的是为解决循环依赖而提早暴露出来的实例,其实是ObjectFactory
singletonFactories 缓存bean name -->ObjectFactory
Cache of singleton factories: bean name --> ObjectFactory<br><br>缓存的是为解决循环依赖而准备的ObjectFactory
registeredSingletons 已经注册的单例bean name<br><br>Set of registered singletons, containing the bean names in registration order<br>上面三个变量,任意一个添加了,这边都会添加bean name,标记已经注册
4个变量的关系如下
singletonObjects与earlySingletonObjects,singletonFactories是互斥的.<br>就是一个bean如果在其中任意一个变量中就,不会存在在另一变量中.这三个变量用于记录一个bean的不同状态.<br><br>如果bean已经添加到singletonObjects中,那么earlySinletonObjects和singltonFactories都不会考虑<br>singltonFactories中的bean 通过 ObjectFactory的getObject实例化后,添加到earlySingletonObjects(三级缓存升二级缓存)
code
DefaultSingletonBeanRegistry<br><br>/**<br>* 添加实例化的bean<br>* Add the given singleton object to the singleton cache of this factory.<br>* <p>To be called for eager registration of singletons.<br>* @param beanName the name of the bean<br>* @param singletonObject the singleton object<br>*/<br><br>protected void addSingleton(String beanName, Object singletonObject) {<br>synchronized (this.singletonObjects) {<br>this.singletonObjects.put(beanName, (singletonObject != null ? singletonObject : NULL_OBJECT));<br>this.singletonFactories.remove(beanName);<br>this.earlySingletonObjects.remove(beanName);<br>this.registeredSingletons.add(beanName);<br>}<br>}<br><br>/**<br>* 为解决单例的循环依赖,这边注册ObjectFactory<br>* Add the given singleton factory for building the specified singleton<br>* if necessary.<br>* <p>To be called for eager registration of singletons, e.g. to be able to<br>* resolve circular references.<br>* @param beanName the name of the bean<br>* @param singletonFactory the factory for the singleton object<br>*/<br>protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {<br>Assert.notNull(singletonFactory, "Singleton factory must not be null");<br>synchronized (this.singletonObjects) {<br>if (!this.singletonObjects.containsKey(beanName)) {<br>this.singletonFactories.put(beanName, singletonFactory);<br>this.earlySingletonObjects.remove(beanName);<br>this.registeredSingletons.add(beanName);<br>}<br>}<br>}<br><br>/**<br>* 清除实例<br>* Remove the bean with the given name from the singleton cache of this factory,<br>* to be able to clean up eager registration of a singleton if creation failed.<br>* @param beanName the name of the bean<br>* @see #getSingletonMutex()<br>*/<br>protected void removeSingleton(String beanName) {<br>synchronized (this.singletonObjects) {<br>this.singletonObjects.remove(beanName);<br>this.singletonFactories.remove(beanName);<br>this.earlySingletonObjects.remove(beanName);<br>this.registeredSingletons.remove(beanName);<br>}<br>}<br><br>/**<br>* 获取实例时,调用ObejctFactory的getObject 获取实例<br>* Return the (raw) singleton object registered under the given name.<br>* <p>Checks already instantiated singletons and also allows for an early<br>* reference to a currently created singleton (resolving a circular reference).<br>* @param beanName the name of the bean to look for<br>* @param allowEarlyReference whether early references should be created or not<br>* @return the registered singleton object, or {@code null} if none found<br>*/<br>protected Object getSingleton(String beanName, boolean allowEarlyReference) {<br>Object singletonObject = this.singletonObjects.get(beanName);<br>if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {<br>synchronized (this.singletonObjects) {<br>singletonObject = this.earlySingletonObjects.get(beanName);<br>if (singletonObject == null && allowEarlyReference) {<br>ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);<br>if (singletonFactory != null) {<br>singletonObject = singletonFactory.getObject();<br>this.earlySingletonObjects.put(beanName, singletonObject);<br>this.singletonFactories.remove(beanName);<br>}<br>}<br>}<br>}<br>return (singletonObject != NULL_OBJECT ? singletonObject : null);<br>}
Spring 中有两种类型的Bean
普通Bean
一般情况下,Spring通过反射机制利用<bean>的class属性指定实现类实例化Bean
工厂Bean 即 FactoryBean
FactoryBean跟普通Bean不同,<br>其返回的对象不是指定类的一个实例,<br>而是该FactoryBean的getObject方法所返回的对象。<br>创建出来的对象是否属于单例由isSingleton中的返回决定。
在某些情况下,实例化Bean过程比较复杂,如果按照传统的方式,<br>则需要在<bean>中提供大量的配置信息。<br>配置方式的灵活性是受限的,<br>这时采用编码的方式可能会得到一个简单的方案。<br>Spring为此提供了一个org.springframework.bean.factory.FactoryBean的工厂类接口,<br>用户可以通过实现该接口定制实例化Bean的逻辑。<br>FactoryBean接口对于Spring框架来说占有重要的地位,<br>Spring自身就提供了70多个FactoryBean的实现。
FactoryBean与BeanFactory
FactoryBean:是一个Java Bean,<br>但是它是一个能生产对象的工厂Bean,<br>它的实现和工厂模式及修饰器模式很像。
BeanFactory:这就是一个Factory,<br>是一个IOC容器或者叫对象工厂,<br>它里面存着很多的bean。
配置方式
XML方式
注解方式
基于Java类配置
通过 @Configuration 和 @Bean 这两个注解实现的
@Configuration 作用于类上,相当于一个xml配置文件;
@Bean 作用于方法上,相当于xml配置中的<bean>;
大致流程
1.首先根据配置文件找到对应的包,读取包中的类,,找到所有含有@bean,@service等注解的类,利用反射解析它们,包括解析构造器,方法,属性等等,然后封装成各种信息类放到container(其实是一个map)里(ioc容器初始化)
2.获取类时,首先从container中查找是否有这个类,如果没有,则报错,如果有,则通过构造器信息将这个类new出来
3.如果这个类含有其他需要注入的属性,则进行依赖注入,如果有则还是从container找对应的解析类,new出对象,并通过之前解析出来的信息类找到setter方法(setter方法注入),然后用该方法注入对象(这就是依赖注入)。如果其中有一个类container里没找到,则抛出异常
4.如果有嵌套bean的情况,则通过递归解析
5.如果bean的scope是singleton,则会重用这个bean不再重新创建,将这个bean放到一个map里,每次用都先从这个map里面找。如果scope是session,则该bean会放到session里面。
总结:通过解析 xml 文件,获取到bean的属性(id,name,class,scope,属性等等)里面的内容,利用反射原理创建配置文件里类的实例对象,存入到 Spring 的 bean 容器中
Aop 面向切面编程
基本概念<br>
面向切面编程就是指: 对很多功能都有的重复的代码抽取,再在运行的时候往业务方法上动态植入“切面类代码”。
核心业务功能和切面功能分别独立进行开发 ,然后把切面功能和核心业务功能 "编织" 在一起,这就叫AOP
让关注点代码与业务代码分离
应用场景:日志,事务管理,权限控制
在 AOP 中,以切面( Aspect )作为基本单元
什么是 Aspect
Aspect 由 PointCut 和 Advice 组成
它既包含了横切逻辑的定义,也包括了连接点的定义
Spring AOP 就是负责实施切面的框架,它将切面所定义的横切逻辑编织到切面所指定的连接点中
AOP 的工作重心
如何通过 PointCut 和 Advice 定位到特定的 JoinPoint 上
如何在 Advice 中编写切面代码
使用 @Aspect 注解的类就是切面
JoinPoint ,切点,程序运行中的一些时间点
比如:<br>一个方法的执行。<br>或者是一个异常的处理。
PointCut 是匹配 JoinPoint 的条件
关于 JoinPoint 和 PointCut 的区别
JoinPoint 和 PointCut 本质上就是两个不同纬度上的东西
在 Spring AOP 中,所有的方法执行都是 JoinPoint 。<br>而 PointCut 是一个描述信息,它修饰的是 JoinPoint ,通过 PointCut ,我们就可以确定哪些 JoinPoint 可以被织入 Advice
Advice 是在 JoinPoint 上执行的,而 PointCut 规定了哪些 JoinPoint 可以执行哪些 Advice
首先,Advice 通过 PointCut 查询需要被织入的 JoinPoint 。<br>然后,Advice 在查询到 JoinPoint 上执行逻辑。
什么是 Advice
Advice ,通知
特定 JoinPoint 处的 Aspect 所采取的动作称为 Advice 。<br>Spring AOP 使用一个 Advice 作为拦截器,在 JoinPoint “周围”维护一系列的拦截器。
有哪些类型的 Advice
Before - 这些类型的 Advice 在 JoinPoint 方法之前执行,并使用 @Before 注解标记进行配置。<br>After Returning - 这些类型的 Advice 在连接点方法正常执行后执行,并使用 @AfterReturning 注解标记进行配置。<br>After Throwing - 这些类型的 Advice 仅在 JoinPoint 方法通过抛出异常退出并使用 @AfterThrowing 注解标记配置时执行。<br>After Finally - 这些类型的 Advice 在连接点方法之后执行,无论方法退出是正常还是异常返回,并使用 @After 注解标记进行配置。<br>Around - 这些类型的 Advice 在连接点之前和之后执行,并使用 @Around 注解标记进行配置
什么是 Target
织入 Advice 的目标对象。<br>目标对象也被称为 Advised Object
因为 Spring AOP 使用运行时代理的方式来实现 Aspect ,因此 Advised Object 总是一个代理对象(Proxied Object) 。<br>注意, Advised Object 指的不是原来的对象,而是织入 Advice 后所产生的代理对象。<br>Advice + Target Object = Advised Object = Proxy
实现原理
静态代理 AspectJ
缺点
如果要代理一个接口的多个实现的话需要定义不同的代理类
代理类 和 被代理类 必须实现同样的接口,万一接口有变动,代理、被代理类都得修改
在编译的时候就直接生成代理类
动态代理 运行时生成代理类
jdk动态代理
主要通过Proxy.newProxyInstance()和InvocationHandler这两个类和方法实现
实现过程
创建代理类proxy实现Invocation接口,重写invoke()方法
调用被代理类方法时默认调用此方法
将被代理类作为构造函数的参数传入代理类proxy
调用Proxy.newProxyInsatnce(classloader,interfaces,handler)方法生成代理类
生成的代理类
$Proxy0 extends Proxy implements Person
类型为$Proxy0
因为已经继承了Proxy,所以jdk动态代理只能对接口进行代理
代理对象会实现用户提供的这组接口,因此可以将这个代理对象强制类型转化为这组接口中的任意一个
通过反射生成对象
总结: 代理类调用自己方法时,通过自身持有的中介类对象来调用中介类对象的invoke方法,从而达到代理执行被代理对象的方法。
JDK动态代理实现原理(jdk8)
JDK动态代理基于拦截器和反射来实现。<br><br>JDK代理是不需要第三方库支持的,<br>只需要JDK环境就可以进行代理,使用条件
1)必须实现InvocationHandler接口;<br>2)使用Proxy.newProxyInstance产生代理对象;<br>3)被代理的对象必须要实现接口;
code
使用JDK动态代理的五大步骤
1)通过实现InvocationHandler接口来自定义自己的InvocationHandler;<br><br>2)通过Proxy.getProxyClass获得动态代理类;<br><br>3)通过反射机制获得代理类的构造方法,方法签名为getConstructor(InvocationHandler.class);<br><br>4)通过构造函数获得代理对象并将自定义的InvocationHandler实例对象作为参数传入;<br><br>5)通过代理对象调用目标方法;
IHello接口
package com.lanhuigu.spring.proxy.jdk;<br><br>public interface IHello {<br> void sayHello();<br>}
HelloImpl接口实现
package com.lanhuigu.spring.proxy.jdk;<br> <br>public class HelloImpl implements IHello {<br> @Override<br> public void sayHello() {<br> System.out.println("Hello world!");<br> }<br>}
MyInvocationHandler(实现InvocationHandler接口)
package com.lanhuigu.spring.proxy.jdk;<br> <br>import java.lang.reflect.InvocationHandler;<br>import java.lang.reflect.Method;<br> <br>public class MyInvocationHandler implements <b><font color="#f1753f">InvocationHandler</font></b> {<br> <br> /** 目标对象 */<br> private Object target;<br> <br> public MyInvocationHandler(Object target){<br> this.target = target;<br> }<br> <br> @Override<br> public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {<br> System.out.println("------插入前置通知代码-------------");<br> // 执行相应的目标方法<br><font color="#80bc42"> Object rs = method.invoke(target,args);</font><br> System.out.println("------插入后置处理代码-------------");<br> return rs;<br> }<br>}
MyProxyTest(Client)
package com.lanhuigu.spring.proxy.jdk;<br> <br>import java.lang.reflect.Constructor;<br>import java.lang.reflect.InvocationHandler;<br>import java.lang.reflect.InvocationTargetException;<br>import java.lang.reflect.Proxy;<br> <br>/**<br> * 使用JDK动态代理的五大步骤:<br> * 1.通过实现InvocationHandler接口来自定义自己的InvocationHandler;<br> * 2.通过Proxy.getProxyClass获得动态代理类<br> * 3.通过反射机制获得代理类的构造方法,方法签名为getConstructor(InvocationHandler.class)<br> * 4.通过构造函数获得代理对象并将自定义的InvocationHandler实例对象传为参数传入<br> * 5.通过代理对象调用目标方法<br> */<br>public class MyProxyTest {<br> public static void main(String[] args)<br> throws NoSuchMethodException, IllegalAccessException, InstantiationException, InvocationTargetException {<br><font color="#f15a23"> // =========================第一种==========================</font><br><font color="#80bc42"> // 1、生成$Proxy0的class文件<br> System.getProperties().put("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");<br> // 2、获取动态代理类<br> Class proxyClazz = Proxy.getProxyClass(IHello.class.getClassLoader(),IHello.class);<br> // 3、获得代理类的构造函数,并传入参数类型InvocationHandler.class<br> Constructor constructor = proxyClazz.getConstructor(InvocationHandler.class);<br> // 4、通过构造函数来创建动态代理对象,将自定义的InvocationHandler实例传入<br> IHello iHello1 = (IHello) constructor.newInstance(new MyInvocationHandler(new HelloImpl()));<br> // 5、通过代理对象调用目标方法<br> iHello1.sayHello();</font><br> <br><font color="#f15a23"> // ==========================第二种=============================</font><br><font color="#80bc42"> /**<br> * Proxy类中还有个将2~4步骤封装好的简便方法来创建动态代理对象,<br> *其方法签名为:newProxyInstance(ClassLoader loader,Class<?>[] instance, InvocationHandler h)<br> */<br> IHello iHello2 = (IHello) Proxy.newProxyInstance(IHello.class.getClassLoader(), // 加载接口的类加载器<br> new Class[]{IHello.class}, // 一组接口<br> new MyInvocationHandler(new HelloImpl())); // 自定义的InvocationHandler<br> iHello2.sayHello();</font><br> }<br>}
深入源码分析
以Proxy.newProxyInstance()方法为切入点来剖析代理类的生成及代理方法的调用<br><br>newProxyInstance()方法帮我们执行了生成代理类----获取构造器----生成代理对象这三步;<br><br>生成代理类: Class<?> cl = getProxyClass0(loader, intfs);<br><br>获取构造器: final Constructor<?> cons = cl.getConstructor(constructorParams);<br><br>生成代理对象: cons.newInstance(new Object[]{h});<br>
@CallerSensitive<br> public static Object newProxyInstance(ClassLoader loader,<br> Class<?>[] interfaces,<br> InvocationHandler h)<br> throws IllegalArgumentException<br> {<br> // 如果h为空直接抛出空指针异常,之后所有的单纯的判断null并抛异常,都是此方法<br> Objects.requireNonNull(h);<br> // 拷贝类实现的所有接口<br> final Class<?>[] intfs = interfaces.clone();<br> // 获取当前系统安全接口<br> final SecurityManager sm = System.getSecurityManager();<br> if (sm != null) {<br> // Reflection.getCallerClass返回调用该方法的方法的调用类;loader:接口的类加载器<br> // 进行包访问权限、类加载器权限等检查<br> checkProxyAccess(Reflection.getCallerClass(), loader, intfs);<br> }<br> <br> /*<br> * Look up or generate the designated proxy class.<br> * 译: 查找或生成指定的代理类<br> */<br> Class<?> cl = getProxyClass0(loader, intfs);<br> <br> /*<br> * Invoke its constructor with the designated invocation handler.<br> * 译: 用指定的调用处理程序调用它的构造函数。<br> */<br> try {<br> if (sm != null) {<br> checkNewProxyPermission(Reflection.getCallerClass(), cl);<br> }<br> /*<br> * 获取代理类的构造函数对象。<br> * constructorParams是类常量,作为代理类构造函数的参数类型,常量定义如下:<br> * private static final Class<?>[] constructorParams = { InvocationHandler.class };<br> */<br> final Constructor<?> cons = cl.getConstructor(constructorParams);<br> final InvocationHandler ih = h;<br> if (!Modifier.isPublic(cl.getModifiers())) {<br> AccessController.doPrivileged(new PrivilegedAction<Void>() {<br> public Void run() {<br> cons.setAccessible(true);<br> return null;<br> }<br> });<br> }<br> // 根据代理类的构造函数对象来创建需要返回的代理类对象<br> return cons.newInstance(new Object[]{h});<br> } catch (IllegalAccessException|InstantiationException e) {<br> throw new InternalError(e.toString(), e);<br> } catch (InvocationTargetException e) {<br> Throwable t = e.getCause();<br> if (t instanceof RuntimeException) {<br> throw (RuntimeException) t;<br> } else {<br> throw new InternalError(t.toString(), t);<br> }<br> } catch (NoSuchMethodException e) {<br> throw new InternalError(e.toString(), e);<br> }<br> }
Proxy.getProxyClass0()如何生成代理类?
private static Class<?> getProxyClass0(ClassLoader loader,<br> Class<?>... interfaces) {<br> // 接口数不得超过65535个,这么大,足够使用的了<br> if (interfaces.length > 65535) {<br> throw new IllegalArgumentException("interface limit exceeded");<br> }<br> <br> // If the proxy class defined by the given loader implementing<br> // the given interfaces exists, this will simply return the cached copy;<br> // otherwise, it will create the proxy class via the ProxyClassFactory<br> // 译: 如果缓存中有代理类了直接返回,否则将由代理类工厂ProxyClassFactory创建代理类<br> return proxyClassCache.get(loader, interfaces);<br> }
如果缓存中没有代理类,Proxy中的ProxyClassFactory如何创建代理类?从get()方法追踪进去看看。<br><br>get方法中Object subKey = Objects.requireNonNull(subKeyFactory.apply(key, parameter));<br><br>subKeyFactory调用apply,具体实现在ProxyClassFactory中完成。<br>
public V get(K key, P parameter) {// key:类加载器;parameter:接口数组<br> // 检查指定类型的对象引用不为空null。当参数为null时,抛出空指针异常。<br> Objects.requireNonNull(parameter);<br> // 清除已经被GC回收的弱引用<br> expungeStaleEntries();<br> // 将ClassLoader包装成CacheKey, 作为一级缓存的key<br> Object cacheKey = CacheKey.valueOf(key, refQueue);<br> <br> // lazily install the 2nd level valuesMap for the particular cacheKey<br> // 获取得到二级缓存<br> ConcurrentMap<Object, Supplier<V>> valuesMap = map.get(cacheKey);<br> // 没有获取到对应的值<br> if (valuesMap == null) {<br> ConcurrentMap<Object, Supplier<V>> oldValuesMap<br> = map.putIfAbsent(cacheKey,<br> valuesMap = new ConcurrentHashMap<>());<br> if (oldValuesMap != null) {<br> valuesMap = oldValuesMap;<br> }<br> }<br> <br> // create subKey and retrieve the possible Supplier<V> stored by that<br> // subKey from valuesMap<br> // 根据代理类实现的接口数组来生成二级缓存key<br> Object subKey = Objects.requireNonNull(subKeyFactory.apply(key, parameter));<br> // 通过subKey获取二级缓存值<br> Supplier<V> supplier = valuesMap.get(subKey);<br> Factory factory = null;<br> // 这个循环提供了轮询机制, 如果条件为假就继续重试直到条件为真为止<br> while (true) {<br> if (supplier != null) {<br> // supplier might be a Factory or a CacheValue<V> instance<br> // 在这里supplier可能是一个Factory也可能会是一个CacheValue<br> // 在这里不作判断, 而是在Supplier实现类的get方法里面进行验证<br> V value = supplier.get();<br> if (value != null) {<br> return value;<br> }<br> }<br> // else no supplier in cache<br> // or a supplier that returned null (could be a cleared CacheValue<br> // or a Factory that wasn't successful in installing the CacheValue)<br> <br> // lazily construct a Factory<br> if (factory == null) {<br> // 新建一个Factory实例作为subKey对应的值<br> factory = new Factory(key, parameter, subKey, valuesMap);<br> }<br> <br> if (supplier == null) {<br> // 到这里表明subKey没有对应的值, 就将factory作为subKey的值放入<br> supplier = valuesMap.putIfAbsent(subKey, factory);<br> if (supplier == null) {<br> // successfully installed Factory<br> // 到这里表明成功将factory放入缓存<br> supplier = factory;<br> }<br> // 否则, 可能期间有其他线程修改了值, 那么就不再继续给subKey赋值, 而是取出来直接用<br> // else retry with winning supplier<br> } else {<br> // 期间可能其他线程修改了值, 那么就将原先的值替换<br> if (valuesMap.replace(subKey, supplier, factory)) {<br> // successfully replaced<br> // cleared CacheEntry / unsuccessful Factory<br> // with our Factory<br> // 成功将factory替换成新的值<br> supplier = factory;<br> } else {<br> // retry with current supplier<br> // 替换失败, 继续使用原先的值<br> supplier = valuesMap.get(subKey);<br> }<br> }<br> }<br> }
ProxyClassFactory.apply()实现代理类创建。
private static final class ProxyClassFactory<br> implements BiFunction<ClassLoader, Class<?>[], Class<?>><br> {<br> // prefix for all proxy class names<br> // 统一代理类的前缀名都以$Proxy<br> private static final String proxyClassNamePrefix = "$Proxy";<br> <br> // next number to use for generation of unique proxy class names<br> // 使用唯一的编号给作为代理类名的一部分,如$Proxy0,$Proxy1等<br> private static final AtomicLong nextUniqueNumber = new AtomicLong();<br> <br> @Override<br> public Class<?> apply(ClassLoader loader, Class<?>[] interfaces) {<br> <br> Map<Class<?>, Boolean> interfaceSet = new IdentityHashMap<>(interfaces.length);<br> for (Class<?> intf : interfaces) {<br> /*<br> * Verify that the class loader resolves the name of this<br> * interface to the same Class object.<br> * 验证指定的类加载器(loader)加载接口所得到的Class对象(interfaceClass)是否与intf对象相同<br> */<br> Class<?> interfaceClass = null;<br> try {<br> interfaceClass = Class.forName(intf.getName(), false, loader);<br> } catch (ClassNotFoundException e) {<br> }<br> if (interfaceClass != intf) {<br> throw new IllegalArgumentException(<br> intf + " is not visible from class loader");<br> }<br> /*<br> * Verify that the Class object actually represents an<br> * interface.<br> * 验证该Class对象是不是接口<br> */<br> if (!interfaceClass.isInterface()) {<br> throw new IllegalArgumentException(<br> interfaceClass.getName() + " is not an interface");<br> }<br> /*<br> * Verify that this interface is not a duplicate.<br> * 验证该接口是否重复<br> */<br> if (interfaceSet.put(interfaceClass, Boolean.TRUE) != null) {<br> throw new IllegalArgumentException(<br> "repeated interface: " + interfaceClass.getName());<br> }<br> }<br> // 声明代理类所在包<br> String proxyPkg = null; // package to define proxy class in<br> int accessFlags = Modifier.PUBLIC | Modifier.FINAL;<br> <br> /*<br> * Record the package of a non-public proxy interface so that the<br> * proxy class will be defined in the same package. Verify that<br> * all non-public proxy interfaces are in the same package.<br> * 验证所有非公共的接口在同一个包内;公共的就无需处理<br> */<br> for (Class<?> intf : interfaces) {<br> int flags = intf.getModifiers();<br> if (!Modifier.isPublic(flags)) {<br> accessFlags = Modifier.FINAL;<br> String name = intf.getName();<br> int n = name.lastIndexOf('.');<br> // 截取完整包名<br> String pkg = ((n == -1) ? "" : name.substring(0, n + 1));<br> if (proxyPkg == null) {<br> proxyPkg = pkg;<br> } else if (!pkg.equals(proxyPkg)) {<br> throw new IllegalArgumentException(<br> "non-public interfaces from different packages");<br> }<br> }<br> }<br> <br> if (proxyPkg == null) {<br> // if no non-public proxy interfaces, use com.sun.proxy package<br> /*如果都是public接口,那么生成的代理类就在com.sun.proxy包下如果报java.io.FileNotFoundException: com\sun\proxy\$Proxy0.class <br> (系统找不到指定的路径。)的错误,就先在你项目中创建com.sun.proxy路径*/<br> proxyPkg = ReflectUtil.PROXY_PACKAGE + ".";<br> }<br> <br> /*<br> * Choose a name for the proxy class to generate.<br> * nextUniqueNumber 是一个原子类,确保多线程安全,防止类名重复,类似于:$Proxy0,$Proxy1......<br> */<br> long num = nextUniqueNumber.getAndIncrement();<br> // 代理类的完全限定名,如com.sun.proxy.$Proxy0.calss<br> String proxyName = proxyPkg + proxyClassNamePrefix + num;<br> <br> /*<br> * Generate the specified proxy class.<br> * 生成类字节码的方法(重点)<br> */<br> byte[] proxyClassFile = ProxyGenerator.generateProxyClass(<br> proxyName, interfaces, accessFlags);<br> try {<br> return defineClass0(loader, proxyName,<br> proxyClassFile, 0, proxyClassFile.length);<br> } catch (ClassFormatError e) {<br> /*<br> * A ClassFormatError here means that (barring bugs in the<br> * proxy class generation code) there was some other<br> * invalid aspect of the arguments supplied to the proxy<br> * class creation (such as virtual machine limitations<br> * exceeded).<br> */<br> throw new IllegalArgumentException(e.toString());<br> }<br> }<br> }
代理类创建真正在ProxyGenerator.generateProxyClass()方法中,方法签名如下:<br><br>byte[] proxyClassFile = ProxyGenerator.generateProxyClass(proxyName, interfaces, accessFlags);
public static byte[] generateProxyClass(final String name, Class<?>[] interfaces, int accessFlags) {<br> ProxyGenerator gen = new ProxyGenerator(name, interfaces, accessFlags);<br> // 真正生成字节码的方法<br> final byte[] classFile = gen.generateClassFile();<br> // 如果saveGeneratedFiles为true 则生成字节码文件,所以在开始我们要设置这个参数<br> // 当然,也可以通过返回的bytes自己输出<br> if (saveGeneratedFiles) {<br> java.security.AccessController.doPrivileged( new java.security.PrivilegedAction<Void>() {<br> public Void run() {<br> try {<br> int i = name.lastIndexOf('.');<br> Path path;<br> if (i > 0) {<br> Path dir = Paths.get(name.substring(0, i).replace('.', File.separatorChar));<br> Files.createDirectories(dir);<br> path = dir.resolve(name.substring(i+1, name.length()) + ".class");<br> } else {<br> path = Paths.get(name + ".class");<br> }<br> Files.write(path, classFile);<br> return null;<br> } catch (IOException e) {<br> throw new InternalError( "I/O exception saving generated file: " + e);<br> }<br> }<br> });<br> }<br> return classFile;<br> }
代理类生成的最终方法是ProxyGenerator.generateClassFile()
private byte[] generateClassFile() {<br> /* ============================================================<br> * Step 1: Assemble ProxyMethod objects for all methods to generate proxy dispatching code for.<br> * 步骤1:为所有方法生成代理调度代码,将代理方法对象集合起来。<br> */<br> //增加 hashcode、equals、toString方法<br> addProxyMethod(hashCodeMethod, Object.class);<br> addProxyMethod(equalsMethod, Object.class);<br> addProxyMethod(toStringMethod, Object.class);<br> // 获得所有接口中的所有方法,并将方法添加到代理方法中<br> for (Class<?> intf : interfaces) {<br> for (Method m : intf.getMethods()) {<br> addProxyMethod(m, intf);<br> }<br> }<br> <br> /*<br> * 验证方法签名相同的一组方法,返回值类型是否相同;意思就是重写方法要方法签名和返回值一样<br> */<br> for (List<ProxyMethod> sigmethods : proxyMethods.values()) {<br> checkReturnTypes(sigmethods);<br> }<br> <br> /* ============================================================<br> * Step 2: Assemble FieldInfo and MethodInfo structs for all of fields and methods in the class we are generating.<br> * 为类中的方法生成字段信息和方法信息<br> */<br> try {<br> // 生成代理类的构造函数<br> methods.add(generateConstructor());<br> for (List<ProxyMethod> sigmethods : proxyMethods.values()) {<br> for (ProxyMethod pm : sigmethods) {<br> // add static field for method's Method object<br> fields.add(new FieldInfo(pm.methodFieldName,<br> "Ljava/lang/reflect/Method;",<br> ACC_PRIVATE | ACC_STATIC));<br> // generate code for proxy method and add it<br> // 生成代理类的代理方法<br> methods.add(pm.generateMethod());<br> }<br> }<br> // 为代理类生成静态代码块,对一些字段进行初始化<br> methods.add(generateStaticInitializer());<br> } catch (IOException e) {<br> throw new InternalError("unexpected I/O Exception", e);<br> }<br> <br> if (methods.size() > 65535) {<br> throw new IllegalArgumentException("method limit exceeded");<br> }<br> if (fields.size() > 65535) {<br> throw new IllegalArgumentException("field limit exceeded");<br> }<br> <br> /* ============================================================<br> * Step 3: Write the final class file.<br> * 步骤3:编写最终类文件<br> */<br> /*<br> * Make sure that constant pool indexes are reserved for the following items before starting to write the final class file.<br> * 在开始编写最终类文件之前,确保为下面的项目保留常量池索引。<br> */<br> cp.getClass(dotToSlash(className));<br> cp.getClass(superclassName);<br> for (Class<?> intf: interfaces) {<br> cp.getClass(dotToSlash(intf.getName()));<br> }<br> <br> /*<br> * Disallow new constant pool additions beyond this point, since we are about to write the final constant pool table.<br> * 设置只读,在这之前不允许在常量池中增加信息,因为要写常量池表<br> */<br> cp.setReadOnly();<br> <br> ByteArrayOutputStream bout = new ByteArrayOutputStream();<br> DataOutputStream dout = new DataOutputStream(bout);<br> <br> try {<br> // u4 magic;<br> dout.writeInt(0xCAFEBABE);<br> // u2 次要版本;<br> dout.writeShort(CLASSFILE_MINOR_VERSION);<br> // u2 主版本<br> dout.writeShort(CLASSFILE_MAJOR_VERSION);<br> <br> cp.write(dout); // (write constant pool)<br> <br> // u2 访问标识;<br> dout.writeShort(accessFlags);<br> // u2 本类名;<br> dout.writeShort(cp.getClass(dotToSlash(className)));<br> // u2 父类名;<br> dout.writeShort(cp.getClass(superclassName));<br> // u2 接口;<br> dout.writeShort(interfaces.length);<br> // u2 interfaces[interfaces_count];<br> for (Class<?> intf : interfaces) {<br> dout.writeShort(cp.getClass(<br> dotToSlash(intf.getName())));<br> }<br> // u2 字段;<br> dout.writeShort(fields.size());<br> // field_info fields[fields_count];<br> for (FieldInfo f : fields) {<br> f.write(dout);<br> }<br> // u2 方法;<br> dout.writeShort(methods.size());<br> // method_info methods[methods_count];<br> for (MethodInfo m : methods) {<br> m.write(dout);<br> }<br> // u2 类文件属性:对于代理类来说没有类文件属性;<br> dout.writeShort(0); // (no ClassFile attributes for proxy classes)<br> <br> } catch (IOException e) {<br> throw new InternalError("unexpected I/O Exception", e);<br> }<br> <br> return bout.toByteArray();<br> }
通过addProxyMethod()添加hashcode、equals、toString方法。
private void addProxyMethod(Method var1, Class var2) {<br> String var3 = var1.getName(); //方法名<br> Class[] var4 = var1.getParameterTypes(); //方法参数类型数组<br> Class var5 = var1.getReturnType(); //返回值类型<br> Class[] var6 = var1.getExceptionTypes(); //异常类型<br> String var7 = var3 + getParameterDescriptors(var4); //方法签名<br> Object var8 = (List)this.proxyMethods.get(var7); //根据方法签名却获得proxyMethods的Value<br> if(var8 != null) { //处理多个代理接口中重复的方法的情况<br> Iterator var9 = ((List)var8).iterator();<br> while(var9.hasNext()) {<br> ProxyGenerator.ProxyMethod var10 = (ProxyGenerator.ProxyMethod)var9.next();<br> if(var5 == var10.returnType) {<br> /*归约异常类型以至于让重写的方法抛出合适的异常类型,我认为这里可能是多个接口中有相同的方法,而这些相同的方法抛出的异常类 型又不同,所以对这些相同方法抛出的异常进行了归约*/<br> ArrayList var11 = new ArrayList();<br> collectCompatibleTypes(var6, var10.exceptionTypes, var11);<br> collectCompatibleTypes(var10.exceptionTypes, var6, var11);<br> var10.exceptionTypes = new Class[var11.size()];<br> //将ArrayList转换为Class对象数组<br> var10.exceptionTypes = (Class[])var11.toArray(var10.exceptionTypes);<br> return;<br> }<br> }<br> } else {<br> var8 = new ArrayList(3);<br> this.proxyMethods.put(var7, var8);<br> } <br> ((List)var8).add(new ProxyGenerator.ProxyMethod(var3, var4, var5, var6, var2, null));<br> /*如果var8为空,就创建一个数组,并以方法签名为key,proxymethod对象数组为value添加到proxyMethods*/<br> }
生成的代理对象$Proxy0.class字节码反编译:
package com.sun.proxy;<br> <br>import com.lanhuigu.spring.proxy.jdk.IHello;<br>import java.lang.reflect.InvocationHandler;<br>import java.lang.reflect.Method;<br>import java.lang.reflect.Proxy;<br>import java.lang.reflect.UndeclaredThrowableException;<br> <br>public final class $Proxy0 extends Proxy<br> implements IHello // 继承了Proxy类和实现IHello接口<br>{<br> // 变量,都是private static Method XXX<br> private static Method m1;<br> private static Method m3;<br> private static Method m2;<br> private static Method m0;<br> <br> // 代理类的构造函数,其参数正是是InvocationHandler实例,Proxy.newInstance方法就是通过通过这个构造函数来创建代理实例的<br> public $Proxy0(InvocationHandler paramInvocationHandler)<br> throws <br> {<br> super(paramInvocationHandler);<br> }<br> <br> // 以下Object中的三个方法<br> public final boolean equals(Object paramObject)<br> throws <br> {<br> try<br> {<br> return ((Boolean)this.h.invoke(this, m1, new Object[] { paramObject })).booleanValue();<br> }<br> catch (RuntimeException localRuntimeException)<br> {<br> throw localRuntimeException;<br> }<br> catch (Throwable localThrowable)<br> {<br> throw new UndeclaredThrowableException(localThrowable);<br> }<br> }<br> <br> // 接口代理方法<br> public final void sayHello()<br> throws <br> {<br> try<br> {<br> this.h.invoke(this, m3, null);<br> return;<br> }<br> catch (RuntimeException localRuntimeException)<br> {<br> throw localRuntimeException;<br> }<br> catch (Throwable localThrowable)<br> {<br> throw new UndeclaredThrowableException(localThrowable);<br> }<br> }<br> <br> public final String toString()<br> throws <br> {<br> try<br> {<br> return ((String)this.h.invoke(this, m2, null));<br> }<br> catch (RuntimeException localRuntimeException)<br> {<br> throw localRuntimeException;<br> }<br> catch (Throwable localThrowable)<br> {<br> throw new UndeclaredThrowableException(localThrowable);<br> }<br> }<br> <br> public final int hashCode()<br> throws <br> {<br> try<br> {<br> return ((Integer)this.h.invoke(this, m0, null)).intValue();<br> }<br> catch (RuntimeException localRuntimeException)<br> {<br> throw localRuntimeException;<br> }<br> catch (Throwable localThrowable)<br> {<br> throw new UndeclaredThrowableException(localThrowable);<br> }<br> }<br> <br> // 静态代码块对变量进行一些初始化工作<br> static<br> {<br> try<br> {<br> // 这里每个方法对象 和类的实际方法绑定<br> m1 = Class.forName("java.lang.Object").getMethod("equals", new Class[] { Class.forName("java.lang.Object") });<br> m3 = Class.forName("com.lanhuigu.spring.proxy.jdk.IHello").getMethod("sayHello", new Class[0]);<br> m2 = Class.forName("java.lang.Object").getMethod("toString", new Class[0]);<br> m0 = Class.forName("java.lang.Object").getMethod("hashCode", new Class[0]);<br> return;<br> }<br> catch (NoSuchMethodException localNoSuchMethodException)<br> {<br> throw new NoSuchMethodError(localNoSuchMethodException.getMessage());<br> }<br> catch (ClassNotFoundException localClassNotFoundException)<br> {<br> throw new NoClassDefFoundError(localClassNotFoundException.getMessage());<br> }<br> }<br>}
当代理对象生成后,最后由InvocationHandler的invoke()方法调用目标方法:<br>在动态代理中InvocationHandler是核心,每个代理实例都具有一个关联的调用处理程序(InvocationHandler)。<br><br>对代理实例调用方法时,将对方法调用进行编码并将其指派到它的调用处理程序(InvocationHandler)的invoke()方法。<br><br>所以对代理方法的调用都是通InvocationHadler的invoke来实现中,而invoke方法根据传入的代理对象,<br><br>方法和参数来决定调用代理的哪个方法。<br><br>方法签名如下:<br><br>invoke(Object Proxy,Method method,Object[] args)<br><br>从反编译源码分析调用invoke()过程:<br><br>从反编译后的源码看$Proxy0类继承了Proxy类,同时实现了IHello接口,即代理类接口,<br><br>所以才能强制将代理对象转换为IHello接口,然后调用$Proxy0中的sayHello()方法。<br>
$Proxy0中sayHello()源码:
public final void sayHello()<br> throws <br> {<br> try<br> {<br> this.h.invoke(this, m3, null);<br> return;<br> }<br> catch (RuntimeException localRuntimeException)<br> {<br> throw localRuntimeException;<br> }<br> catch (Throwable localThrowable)<br> {<br> throw new UndeclaredThrowableException(localThrowable);<br> }<br> }
this.h.invoke(this, m3, null); <br><br>this就是$Proxy0对象;<br><br>m3就是m3 = Class.forName("com.lanhuigu.spring.proxy.jdk.IHello").getMethod("sayHello", new Class[0]);<br><br>即是通过全路径名,反射获取的目标对象中的真实方法加参数。<br><br>h就是Proxy类中的变量protected InvocationHandler h;<br><br>所以成功的调到了InvocationHandler中的invoke()方法,但是invoke()方法在我们自定义的MyInvocationHandler<br><br>中实现,MyInvocationHandler中的invoke()方法:
@Override<br> public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {<br> System.out.println("------插入前置通知代码-------------");<br> // 执行相应的目标方法<br> Object rs = method.invoke(target,args);<br> System.out.println("------插入后置处理代码-------------");<br> return rs;<br> }
所以,绕了半天,终于调用到了MyInvocationHandler中的invoke()方法,从上面的this.h.invoke(this, m3, null); <br><br>可以看出,MyInvocationHandler中invoke第一个参数为$Proxy0(代理对象),第二个参数为目标类的真实方法,<br><br>第三个参数为目标方法参数,因为sayHello()没有参数,所以是null。<br><br>到这里,我们真正的实现了通过代理调用目标对象的完全分析,至于InvocationHandler中的invoke()方法就是<br><br>最后执行了目标方法。到此完成了代理对象生成,目标方法调用。<br><br>所以,我们可以看到在打印目标方法调用输出结果前后所插入的前置和后置代码处理。
cglib
实现原理类似于 jdk 动态代理,<br>只是他在运行期间生成的代理对象是针对目标类扩展的子类
生成对象类型为Enhancer
CGLIB(Code Generation Library)是一个开源项目!是一个强大的,高性能,高质量的Code生成类库,<br><br>它可以在运行期扩展Java类与实现Java接口。Hibernate用它来实现PO(Persistent Object 持久化对象)字节码的动态生成。<br><br>CGLIB是一个强大的高性能的代码生成包。它广泛的被许多AOP的框架使用,例如Spring AOP为他们提供<br><br>方法的interception(拦截)。CGLIB包的底层是通过使用一个小而快的字节码处理框架ASM,来转换字节码并生成新的类。<br><br>除了CGLIB包,脚本语言例如Groovy和BeanShell,也是使用ASM来生成java的字节码。当然不鼓励直接使用ASM,<br><br>因为它要求你必须对JVM内部结构包括class文件的格式和指令集都很熟悉。
code
CGLIB动态代理实例
实现一个业务类,注意,这个业务类并没有实现任何接口:
package com.lanhuigu.spring.proxy.cglib;<br> <br>public class HelloService {<br> <br> public HelloService() {<br> System.out.println("HelloService构造");<br> }<br> <br> /**<br> * 该方法不能被子类覆盖,Cglib是无法代理final修饰的方法的<br> */<br> final public String sayOthers(String name) {<br> System.out.println("HelloService:sayOthers>>"+name);<br> return null;<br> }<br> <br> public void sayHello() {<br> System.out.println("HelloService:sayHello");<br> }<br>}
自定义MethodInterceptor:
package com.lanhuigu.spring.proxy.cglib;<br> <br>import net.sf.cglib.proxy.MethodInterceptor;<br>import net.sf.cglib.proxy.MethodProxy;<br> <br>import java.lang.reflect.Method;<br> <br>/**<br> * 自定义MethodInterceptor<br> */<br>public class MyMethodInterceptor implements MethodInterceptor{<br> <br> /**<br> * sub:cglib生成的代理对象<br> * method:被代理对象方法<br> * objects:方法入参<br> * methodProxy: 代理方法<br> */<br> @Override<br> public Object intercept(Object sub, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {<br> System.out.println("======插入前置通知======");<br> Object object = methodProxy.invokeSuper(sub, objects);<br> System.out.println("======插入后者通知======");<br> return object;<br> }<br>}
生成CGLIB代理对象调用目标方法:
package com.lanhuigu.spring.proxy.cglib;<br> <br>import net.sf.cglib.core.DebuggingClassWriter;<br>import net.sf.cglib.proxy.Enhancer;<br> <br>public class Client {<br> public static void main(String[] args) {<br> // 代理类class文件存入本地磁盘方便我们反编译查看源码<br> System.setProperty(DebuggingClassWriter.DEBUG_LOCATION_PROPERTY, "D:\\code");<br> // 通过CGLIB动态代理获取代理对象的过程<br> Enhancer enhancer = new Enhancer();<br> // 设置enhancer对象的父类<br> enhancer.setSuperclass(HelloService.class);<br> // 设置enhancer的回调对象<br> enhancer.setCallback(new MyMethodInterceptor());<br> // 创建代理对象<br> HelloService proxy= (HelloService)enhancer.create();<br> // 通过代理对象调用目标方法<br> proxy.sayHello();<br> }<br>}
CGLIB动态代理源码分析
实现CGLIB动态代理必须实现MethodInterceptor(方法拦截器)接口,源码如下:
/*<br> * Copyright 2002,2003 The Apache Software Foundation<br> *<br> * Licensed under the Apache License, Version 2.0 (the "License");<br> * you may not use this file except in compliance with the License.<br> * You may obtain a copy of the License at<br> *<br> * http://www.apache.org/licenses/LICENSE-2.0<br> *<br> * Unless required by applicable law or agreed to in writing, software<br> * distributed under the License is distributed on an "AS IS" BASIS,<br> * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.<br> * See the License for the specific language governing permissions and<br> * limitations under the License.<br> */<br>package net.sf.cglib.proxy;<br> <br>/**<br> * General-purpose {@link Enhancer} callback which provides for "around advice".<br> * @author Juozas Baliuka <a href="mailto:baliuka@mwm.lt">baliuka@mwm.lt</a><br> * @version $Id: MethodInterceptor.java,v 1.8 2004/06/24 21:15:20 herbyderby Exp $<br> */<br>public interface MethodInterceptor<br>extends Callback<br>{<br> /**<br> * All generated proxied methods call this method instead of the original method.<br> * The original method may either be invoked by normal reflection using the Method object,<br> * or by using the MethodProxy (faster).<br> * @param obj "this", the enhanced object<br> * @param method intercepted Method<br> * @param args argument array; primitive types are wrapped<br> * @param proxy used to invoke super (non-intercepted method); may be called<br> * as many times as needed<br> * @throws Throwable any exception may be thrown; if so, super method will not be invoked<br> * @return any value compatible with the signature of the proxied method. Method returning void will ignore this value.<br> * @see MethodProxy<br> */ <br> public Object intercept(Object obj, java.lang.reflect.Method method, Object[] args,<br> MethodProxy proxy) throws Throwable;<br> <br>}
这个接口只有一个intercept()方法,这个方法有4个参数:<br><br>1)obj表示增强的对象,即实现这个接口类的一个对象;<br><br>2)method表示要被拦截的方法;<br><br>3)args表示要被拦截方法的参数;<br><br>4)proxy表示要触发父类的方法对象;<br><br>在上面的Client代码中,通过Enhancer.create()方法创建代理对象,create()方法的源码
/**<br> * Generate a new class if necessary and uses the specified<br> * callbacks (if any) to create a new object instance.<br> * Uses the no-arg constructor of the superclass.<br> * @return a new instance<br> */<br> public Object create() {<br> classOnly = false;<br> argumentTypes = null;<br> return createHelper();<br> }
该方法含义就是如果有必要就创建一个新类,并且用指定的回调对象创建一个新的对象实例,<br><br>使用的父类的参数的构造方法来实例化父类的部分。核心内容在createHelper()中,源码如下
private Object createHelper() {<br> preValidate();<br> Object key = KEY_FACTORY.newInstance((superclass != null) ? superclass.getName() : null,<br> ReflectUtils.getNames(interfaces),<br> filter == ALL_ZERO ? null : new WeakCacheKey<CallbackFilter>(filter),<br> callbackTypes,<br> useFactory,<br> interceptDuringConstruction,<br> serialVersionUID);<br> this.currentKey = key;<br> Object result = super.create(key);<br> return result;<br> }
preValidate()方法校验callbackTypes、filter是否为空,以及为空时的处理。<br><br>通过newInstance()方法创建EnhancerKey对象,作为Enhancer父类AbstractClassGenerator.create()方法<br><br>创建代理对象的参数。
protected Object create(Object key) {<br> try {<br> ClassLoader loader = getClassLoader();<br> Map<ClassLoader, ClassLoaderData> cache = CACHE;<br> ClassLoaderData data = cache.get(loader);<br> if (data == null) {<br> synchronized (AbstractClassGenerator.class) {<br> cache = CACHE;<br> data = cache.get(loader);<br> if (data == null) {<br> Map<ClassLoader, ClassLoaderData> newCache = new WeakHashMap<ClassLoader, ClassLoaderData>(cache);<br> data = new ClassLoaderData(loader);<br> newCache.put(loader, data);<br> CACHE = newCache;<br> }<br> }<br> }<br> this.key = key;<br> Object obj = data.get(this, getUseCache());<br> if (obj instanceof Class) {<br> return firstInstance((Class) obj);<br> }<br> return nextInstance(obj);<br> } catch (RuntimeException e) {<br> throw e;<br> } catch (Error e) {<br> throw e;<br> } catch (Exception e) {<br> throw new CodeGenerationException(e);<br> }<br> }
真正创建代理对象方法在nextInstance()方法中,该方法为抽象类AbstractClassGenerator的一个方法,签名如下:<br><br>abstract protected Object nextInstance(Object instance) throws Exception;<br><br>在子类Enhancer中实现,实现源码如下:
protected Object nextInstance(Object instance) {<br> EnhancerFactoryData data = (EnhancerFactoryData) instance;<br> <br> if (classOnly) {<br> return data.generatedClass;<br> }<br> <br> Class[] argumentTypes = this.argumentTypes;<br> Object[] arguments = this.arguments;<br> if (argumentTypes == null) {<br> argumentTypes = Constants.EMPTY_CLASS_ARRAY;<br> arguments = null;<br> }<br> return data.newInstance(argumentTypes, arguments, callbacks);<br> }
看看data.newInstance(argumentTypes, arguments, callbacks)方法,<br><br>第一个参数为代理对象的构成器类型,第二个为代理对象构造方法参数,第三个为对应回调对象。<br><br>最后根据这些参数,通过反射生成代理对象,源码如下:
/**<br> * Creates proxy instance for given argument types, and assigns the callbacks.<br> * Ideally, for each proxy class, just one set of argument types should be used,<br> * otherwise it would have to spend time on constructor lookup.<br> * Technically, it is a re-implementation of {@link Enhancer#createUsingReflection(Class)},<br> * with "cache {@link #setThreadCallbacks} and {@link #primaryConstructor}"<br> *<br> * @see #createUsingReflection(Class)<br> * @param argumentTypes constructor argument types<br> * @param arguments constructor arguments<br> * @param callbacks callbacks to set for the new instance<br> * @return newly created proxy<br> */<br> public Object newInstance(Class[] argumentTypes, Object[] arguments, Callback[] callbacks) {<br> setThreadCallbacks(callbacks);<br> try {<br> // Explicit reference equality is added here just in case Arrays.equals does not have one<br> if (primaryConstructorArgTypes == argumentTypes ||<br> Arrays.equals(primaryConstructorArgTypes, argumentTypes)) {<br> // If we have relevant Constructor instance at hand, just call it<br> // This skips "get constructors" machinery<br> return ReflectUtils.newInstance(primaryConstructor, arguments);<br> }<br> // Take a slow path if observing unexpected argument types<br> return ReflectUtils.newInstance(generatedClass, argumentTypes, arguments);<br> } finally {<br> // clear thread callbacks to allow them to be gc'd<br> setThreadCallbacks(null);<br> }<br> <br> }
最后生成代理对象:<br>将其反编译后代码如下:<br>
package com.lanhuigu.spring.proxy.cglib;<br> <br>import java.lang.reflect.Method;<br>import net.sf.cglib.core.ReflectUtils;<br>import net.sf.cglib.core.Signature;<br>import net.sf.cglib.proxy.*;<br> <br>public class HelloService$$EnhancerByCGLIB$$4da4ebaf extends HelloService<br> implements Factory<br>{<br> <br> private boolean CGLIB$BOUND;<br> public static Object CGLIB$FACTORY_DATA;<br> private static final ThreadLocal CGLIB$THREAD_CALLBACKS;<br> private static final Callback CGLIB$STATIC_CALLBACKS[];<br> private MethodInterceptor CGLIB$CALLBACK_0; // 拦截器<br> private static Object CGLIB$CALLBACK_FILTER;<br> private static final Method CGLIB$sayHello$0$Method; // 被代理方法<br> private static final MethodProxy CGLIB$sayHello$0$Proxy; // 代理方法<br> private static final Object CGLIB$emptyArgs[];<br> private static final Method CGLIB$equals$1$Method;<br> private static final MethodProxy CGLIB$equals$1$Proxy;<br> private static final Method CGLIB$toString$2$Method;<br> private static final MethodProxy CGLIB$toString$2$Proxy;<br> private static final Method CGLIB$hashCode$3$Method;<br> private static final MethodProxy CGLIB$hashCode$3$Proxy;<br> private static final Method CGLIB$clone$4$Method;<br> private static final MethodProxy CGLIB$clone$4$Proxy;<br> <br> static void CGLIB$STATICHOOK1()<br> {<br> Method amethod[];<br> Method amethod1[];<br> CGLIB$THREAD_CALLBACKS = new ThreadLocal();<br> CGLIB$emptyArgs = new Object[0];<br> // 代理类<br> Class class1 = Class.forName("com.lanhuigu.spring.proxy.cglib.HelloService$$EnhancerByCGLIB$$4da4ebaf");<br> // 被代理类<br> Class class2;<br> amethod = ReflectUtils.findMethods(new String[] {<br> "equals", "(Ljava/lang/Object;)Z", "toString", "()Ljava/lang/String;", "hashCode", "()I", "clone", "()Ljava/lang/Object;"<br> }, (class2 = Class.forName("java.lang.Object")).getDeclaredMethods());<br> Method[] = amethod;<br> CGLIB$equals$1$Method = amethod[0];<br> CGLIB$equals$1$Proxy = MethodProxy.create(class2, class1, "(Ljava/lang/Object;)Z", "equals", "CGLIB$equals$1");<br> CGLIB$toString$2$Method = amethod[1];<br> CGLIB$toString$2$Proxy = MethodProxy.create(class2, class1, "()Ljava/lang/String;", "toString", "CGLIB$toString$2");<br> CGLIB$hashCode$3$Method = amethod[2];<br> CGLIB$hashCode$3$Proxy = MethodProxy.create(class2, class1, "()I", "hashCode", "CGLIB$hashCode$3");<br> CGLIB$clone$4$Method = amethod[3];<br> CGLIB$clone$4$Proxy = MethodProxy.create(class2, class1, "()Ljava/lang/Object;", "clone", "CGLIB$clone$4");<br> amethod1 = ReflectUtils.findMethods(new String[] {<br> "sayHello", "()V"<br> }, (class2 = Class.forName("com.lanhuigu.spring.proxy.cglib.HelloService")).getDeclaredMethods());<br> Method[] 1 = amethod1;<br> CGLIB$sayHello$0$Method = amethod1[0];<br> CGLIB$sayHello$0$Proxy = MethodProxy.create(class2, class1, "()V", "sayHello", "CGLIB$sayHello$0");<br> }<br> <br> final void CGLIB$sayHello$0()<br> {<br> super.sayHello();<br> }<br> <br> public final void sayHello()<br> {<br> MethodInterceptor var10000 = this.CGLIB$CALLBACK_0;<br> if(this.CGLIB$CALLBACK_0 == null) {<br> CGLIB$BIND_CALLBACKS(this);<br> var10000 = this.CGLIB$CALLBACK_0;<br> }<br> <br> if(var10000 != null) {<br> // 调用拦截器<br> var10000.intercept(this, CGLIB$setPerson$0$Method, CGLIB$emptyArgs, CGLIB$setPerson$0$Proxy);<br> } else {<br> super.sayHello();<br> }<br> }<br> ......<br> ......<br>}
从代理对象反编译源码可以知道,代理对象继承于HelloService,拦截器调用intercept()方法,<br><br>intercept()方法由自定义MyMethodInterceptor实现,所以,最后调用MyMethodInterceptor中<br><br>的intercept()方法,从而完成了由代理对象访问到目标对象的动态代理实现。
JDK动态代理和cglib的对比
CGLib所创建的动态代理对象在实际运行时候的性能要比JDK动态代理高
1.6和1.7的时候,CGLib更快
1.8的时候,jdk更快
CGLib在创建对象的时候所花费的时间却比JDK动态代理多
singleton的代理对象或者具有实例池的代理,因为无需频繁的创建代理对象,所以比较适合采用CGLib动态代理,反之,则适合用JDK动态代理
JDK动态代理是<b><font color="#80bc42">面向接口</font></b>的,CGLib动态代理是通过字节码底层继承<b><font color="#80bc42">代理类</font></b>来实现(如果被代理类被final关键字所修饰,那么会失败)
JDK生成的代理类类型是Proxy(因为继承的是Proxy),CGLIB生成的代理类类型是Enhancer类型
如果要被代理的对象是个实现类,那么Spring会使用JDK动态代理来完成操作(Spirng默认采用JDK动态代理实现机制);<br>如果要被代理的对象不是实现类,那么Spring会强制使用CGLib来实现动态代理。<br>
实战代码
定义一个注解
@Target(ElementType.METHOD)<br>@Retention(RetentionPolicy.RUNTIME)<br>@Documented<br>public @interface DataScope<br>{<br> /**<br> * 部门表的别名<br> */<br> public String deptAlias() default "";<br><br> /**<br> * 用户表的别名<br> */<br> public String userAlias() default "";<br>}<br>
定义一个Aspect
/**<br> * 数据过滤处理<br> * <br> * @author app<br> */<br>@Aspect<br>@Component<br>public class DataScopeAspect<br>{<br> /**<br> * 全部数据权限<br> */<br> public static final String DATA_SCOPE_ALL = "1";<br><br> /**<br> * 自定数据权限<br> */<br> public static final String DATA_SCOPE_CUSTOM = "2";<br><br> /**<br> * 部门数据权限<br> */<br> public static final String DATA_SCOPE_DEPT = "3";<br><br> /**<br> * 部门及以下数据权限<br> */<br> public static final String DATA_SCOPE_DEPT_AND_CHILD = "4";<br><br> /**<br> * 仅本人数据权限<br> */<br> public static final String DATA_SCOPE_SELF = "5";<br><br> // 配置织入点<br> @Pointcut("@annotation(com.app.framework.aspectj.lang.annotation.DataScope)")<br> public void dataScopePointCut()<br> {<br> }<br><br> @Before("dataScopePointCut()")<br> public void doBefore(JoinPoint point) throws Throwable<br> {<br> handleDataScope(point);<br> }<br><br> protected void handleDataScope(final JoinPoint joinPoint)<br> {<br> // 获得注解<br> DataScope controllerDataScope = getAnnotationLog(joinPoint);<br> if (controllerDataScope == null)<br> {<br> return;<br> }<br> // 获取当前的用户<br> LoginUser loginUser = SpringUtils.getBean(TokenService.class).getLoginUser(ServletUtils.getRequest());<br> SysUser currentUser = loginUser.getUser();<br> if (currentUser != null)<br> {<br> // 如果是超级管理员,则不过滤数据<br> if (!currentUser.isAdmin())<br> {<br> dataScopeFilter(joinPoint, currentUser, controllerDataScope.deptAlias(),<br> controllerDataScope.userAlias());<br> }<br> }<br> }<br><br> /**<br> * 数据范围过滤<br> * <br> * @param joinPoint 切点<br> * @param user 用户<br> * @param alias 别名<br> */<br> public static void dataScopeFilter(JoinPoint joinPoint, SysUser user, String deptAlias, String userAlias)<br> {<br> StringBuilder sqlString = new StringBuilder();<br><br> for (SysRole role : user.getRoles())<br> {<br> String dataScope = role.getDataScope();<br> if (DATA_SCOPE_ALL.equals(dataScope))<br> {<br> sqlString = new StringBuilder();<br> break;<br> }<br> else if (DATA_SCOPE_CUSTOM.equals(dataScope))<br> {<br> sqlString.append(StringUtils.format(<br> " OR {}.dept_id IN ( SELECT dept_id FROM sys_role_dept WHERE role_id = {} ) ", deptAlias,<br> role.getRoleId()));<br> }<br> else if (DATA_SCOPE_DEPT.equals(dataScope))<br> {<br> sqlString.append(StringUtils.format(" OR {}.dept_id = {} ", deptAlias, user.getDeptId()));<br> }<br> else if (DATA_SCOPE_DEPT_AND_CHILD.equals(dataScope))<br> {<br> sqlString.append(StringUtils.format(<br> " OR {}.dept_id IN ( SELECT dept_id FROM sys_dept WHERE dept_id = {} or find_in_set( {} , ancestors ) )",<br> deptAlias, user.getDeptId(), user.getDeptId()));<br> }<br> else if (DATA_SCOPE_SELF.equals(dataScope))<br> {<br> if (StringUtils.isNotBlank(userAlias))<br> {<br> sqlString.append(StringUtils.format(" OR {}.user_id = {} ", userAlias, user.getUserId()));<br> }<br> else<br> {<br> // 数据权限为仅本人且没有userAlias别名不查询任何数据<br> sqlString.append(" OR 1=0 ");<br> }<br> }<br> }<br><br> if (StringUtils.isNotBlank(sqlString.toString()))<br> {<br> BaseEntity baseEntity = (BaseEntity) joinPoint.getArgs()[0];<br> baseEntity.setDataScope(" AND (" + sqlString.substring(4) + ")");<br> }<br> }<br><br> /**<br> * 是否存在注解,如果存在就获取<br> */<br> private DataScope getAnnotationLog(JoinPoint joinPoint)<br> {<br> Signature signature = joinPoint.getSignature();<br> MethodSignature methodSignature = (MethodSignature) signature;<br> Method method = methodSignature.getMethod();<br><br> if (method != null)<br> {<br> return method.getAnnotation(DataScope.class);<br> }<br> return null;<br> }<br>}<br>
使用注解
@Override<br> @DataScope(deptAlias = "d", userAlias = "u")<br> public List<sysuser> selectUserList(SysUser user)<br> {<br> return userMapper.selectUserList(user);<br> }</sysuser>
事务管理<br><br>编程事务<br>声明事务
Spring 的声明式事务本质上是通过AOP来增强了类的功能
基本概念
如果需要某一组操作具有原子性,就用注解的方式开启事务,按照给定的事务规则来执行提交或者回滚操作
事务管理一般在Service层<br><br> 如果在dao层,回滚的时候只能回滚到当前方法,但一般我们的service层的方法都是由很多dao层的方法组成的<br><br> 如果在dao层,commit的次数会过多
ACID
Atomic<br><br>记录之前的版本,允许回滚<br>
一个事务包含多个操作,这些操作要么全部执行,要么全都不执行。<br>实现事务的原子性,要支持回滚操作,在某个操作失败后,回滚到事务执行之前的状态。
Consistency<br><br>事务开始和结束之间的中间状态不会被其他事务看到<br>
一致性是指事务使得系统从一个一致的状态转换到另一个一致状态。<br>事务的一致性决定了一个系统设计和实现的复杂度,也导致了事务的不同隔离级别。
强一致性:读操作可以立即读到提交的更新操作。
弱一致性:提交的更新操作,不一定立即会被读操作读到,<br>此种情况会存在一个不一致窗口,<br>指的是读操作可以读到最新值的一段时间。
最终一致性:是弱一致性的特例。<br>事务更新一份数据,最终一致性保证在没有其他事务更新同样的值的话,<br>最终所有的事务都会读到之前事务更新的最新值。<br>如果没有错误发生,不一致窗口的大小依赖于:通信延迟,系统负载等。
Isolation<br><br>适当的破坏一致性来提升性能与并行度 例如:最终一致~=读未提交。<br>
数据库隔离级别
TransactionDefinition.ISOLATION_DEFAULT: <br>使用后端数据库默认的隔离级别,<br>MySQL的默认隔离级别高于Oracle的默认隔离级别<br>Oracle 默认采用的 READ_COMMITTED隔离级别.<br>Mysql 默认采用的 REPEATABLE_READ隔离级别 。<br>
TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,<br>允许读取尚未提交的数据变更,可能会<font color="#00a650">导致脏读、幻读或不可重复读</font>
当两个事务同时进行时,即使事务没有提交,<br>所做的修改也会对事务内的查询做出影响,<br>这种级别显然很不安全。<br>但是在表对某行进行修改时,会对该行加上行共享锁
TransactionDefinition.ISOLATION_READ_COMMITTED: <br>允许读取并发事务已经提交的数据,<font color="#00a650">可以阻止脏读,但是幻读或不可重复读仍有可能发生</font>
当两个事务同时进行时,<br><font color="#f15a23">只有在事务提交后,才会对另一个事务产生影响,</font><br><br>并且在对表进行修改时,<br>会对表数据行加上行共享锁
TransactionDefinition.ISOLATION_REPEATABLE_READ: <br>对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,<br><font color="#00a650">可以阻止脏读和不可重复读,但幻读仍有可能发生。</font>
当两个事务同时进行时,<br>其中一个事务修改数据对另一个事务不会造成影响,<br><font color="#f15a23">即使修改的事务已经提交也不会对另一个事务造成影响。</font><br><br>在事务中对某条记录修改,<br>会对记录加上行共享锁,<br>直到事务结束才会释放。
TransactionDefinition.ISOLATION_SERIALIZABLE: <br>最高的隔离级别,完全服从ACID的隔离级别。<br>所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,<br>也就是说,该级别可以防止脏读、不可重复读以及幻读。<br>但是这将严重影响程序的性能。通常情况下也不会用到该级别。
在进行查询时就会对表或行加上共享锁,<br>其他事务对该表将只能进行读操作,<br>而不能进行写操作。
Durability<br><br>每一次的事务提交后就会保证不会丢失<br>
事务控制
Spring配置文件中关于事务配置总是由三个组成部分,<br>分别是<b><font color="#80bc42">DataSource</font></b>、<b><font color="#80bc42">TransactionManager</font></b>和<b><font color="#80bc42">代理机制</font></b>这三部分,<br>无论哪种配置方式,一般变化的只是代理机制这部分。<br><br> DataSource、TransactionManager这两部分只是会根据数据访问方式有所变化,<br>比如使用Hibernate进行数据访问时,<br>DataSource实际为SessionFactory,<br>TransactionManager的实现为HibernateTransactionManager。<br>
编程式事务控制
Spring提供两种方式的编程式事务管理
使用TransactionTemplate
采用TransactionTemplate和采用其他Spring模板,<br>如JdbcTempalte和HibernateTemplate是一样的方法。<br>它使用回调方法,把应用程序从处理取得和释放资源中解脱出来。<br>如同其他模板,TransactionTemplate是线程安全的。
TransactionTemplate tt = new TransactionTemplate(); // 新建一个TransactionTemplate<br><br>Object result = tt.execute(<br> new <b><font color="#80bc42">TransactionCallback</font></b>(){ <br> public Object doTransaction(TransactionStatus status){ <br> updateOperation(); <br> return resultOfUpdateOperation(); <br> } <br> }<br>); // 执行execute方法进行事务管理<br><br>使用TransactionCallback()可以返回一个值。<br>如果使用TransactionCallbackWithoutResult则没有返回值。<br>
使用PlatformTransactionManager
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(); <br>//定义一个某个框架平台的TransactionManager,如JDBC、Hibernate<br>dataSourceTransactionManager.setDataSource(this.getJdbcTemplate().getDataSource()); // 设置数据源<br>DefaultTransactionDefinition transDef = new DefaultTransactionDefinition(); // 定义事务属性<br>transDef.setPropagationBehavior(DefaultTransactionDefinition.PROPAGATION_REQUIRED); // 设置传播行为属性<br>TransactionStatus status = dataSourceTransactionManager.getTransaction(transDef); // 获得事务状态<br>try {<br>// 数据库操作<br>dataSourceTransactionManager.commit(status);// 提交<br>} catch (Exception e) {<br>dataSourceTransactionManager.rollback(status);// 回滚<br>}
声明式事务控制
Spring提供对事务的控制管理
XML方式<br>
注解方式
异常回滚
只会回滚RuntimException异常
事务属性
事务传播行为
required_new
如果当前方法有事务了,当前方法事务会挂起,在为加入的方法开启一个新的事务,直到新的事务执行完、当前方法的事务才开始
required(默认方法)
如果当前方法已经有事务了,加入当前方法事务
SUPPORTS
支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
MANDATORY
支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
NOT_SUPPORTED
以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
NEVER
以非事务方式执行,如果当前存在事务,则抛出异常。
NESTED
如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
事务超时属性
指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。
事务只读属性
对事务资源是否执行只读操作
回滚规则
定义了哪些异常会导致事务回滚而哪些不会。<br>默认情况下,事务只有遇到运行期异常时才会回滚,<br>而在遇到检查型异常时不会回滚,也可以由用户自己定义
Spring事务管理接口
PlatformTransactionManager
(平台)事务管理器
Spring并不直接管理事务,而是提供了多种事务管理器,<br>通过PlatformTransactionManager这个接口,<br>Spring为各个平台如JDBC、Hibernate等都提供了对应的事务管理器,<br>但是具体的实现就是各个平台自己的事情了。
TransactionDefinition
事务定义属性(事务隔离级别、传播行为、超时、只读、回滚规则)
TransactionStatus
事务运行状态
设计模式
(1)工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的实例;
(2)单例模式:Bean默认为单例模式。
(3)代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节码生成技术;
(4)模板方法:用来解决代码重复的问题。比如. RestTemplate, JmsTemplate, JpaTemplate。
(5)观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,<br> 所有依赖于它的对象都会得到通知被制动更新,如Spring中listener的实现--ApplicationListener。
Spring对一些Bean中非线程安全状态采用ThreadLocal进行处理,解决线程安全问题。
核心接口
BeanFactory Spring里面最底层的接口
包含了各种Bean的定义,<br>读取bean配置文档,<br>管理bean的加载、实例化,<br>控制bean的生命周期,<br>维护bean之间的依赖关系
采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。
ApplicationContext <br>除了提供BeanFactory所具有的功能外,<br>还提供了更完整的框架功能
①继承MessageSource,因此支持国际化。<br>②统一的资源文件访问方式。<br>③提供在监听器中注册bean的事件。<br>④同时加载多个配置文件。<br>⑤载入多个(有继承关系)上下文 ,<br> 使得每一个上下文都专注于一个特定的层次,比如应用的web层。
在容器启动时,一次性创建了所有的非延迟加载Bean。
定时任务调度 Spring Task
配置方式
XML配置<task:scheduler>标签
@Scheduled注解配置
Spring5新特性
兼容Java9
最低要求Java8,因为使用了Java8的一些新特性
响应式编程 WebFlux
即Spring-WebFlux模块,以Reactor库为基础,包含了对响应式HTTP、服务器推送事件(Server-sent Event)和WebSocket的客户端和服务器端的支持
基于Java注解编程模型
使用方式与Spring MVC基本一样,只是使用的类型不是普通的对象,而是响应式编程中的Mono、Flux对象
Mono对象
表示单个对象,如User,用法与Optional类似
Flux对象
表示一系列的对象,类似于List<User>
基于函数式编程模型
服务器端
HandlerFunction函数式接口
Mono<T extends ServerResponse> handle(ServerRequest request)方法用于处理客户端请求
RouterFunction路由接口
Mono<HandlerFunction<T extends ServerResponse>> route(ServerRequest request)方法用于选择处理对应请求的HandlerFunction对象并返回
只需要使用RouterFunctions.route方法创建RouterFunction类型的bean,就会被自动注册来处理请求并调用相应的HandlerFunction
客户端
使用WebClient.create方法创建客户端发起HTTP请求调用REST API和SSE(服务端推送)服务
使用WebSocketClient类的API访问WebSocket
测试
使用WebTestClient类进行测试
@Autowired写在变量上和构造器上的区别
@autowired可以写在变量和构造器上,注入bean,<br>但是有的时候写在变量上会报空指针异常NPE,<br>然后通过写在构造器上就解决了此问题
public class Test{<br> @Autowired<br> private A a;<br> private final String prefix = a.getExcelPrefix();<br> ........<br>}<br><br>这种方式会报错<br>
public class Test{<br> private final String prefix;<br> @Autowired<br> public Test(A a) {<br> this.prefix= a.getExcelPrefix();<br> }<br> ........<br>}<br><br>这样写就不报错了<br>
其实这两种方式都可以使用,<br>但报错的原因是加载顺序的问题,<br><font color="#80bc42">@autowired写在变量上的注入要等到类完全加载完,<br>才会将相应的bean注入,</font><br><font color="#80bc42">而变量是在加载类的时候按照相应顺序加载的,<br>所以变量的加载要早于@autowired变量的加载,<br>那么给变量prefix 赋值的时候所使用的a,其实还没有被注入,<br>所以报空指针,<br><br>而使用构造器就在加载类的时候将a加载了,<br>这样在内部使用a给prefix 赋值就完全没有问题。</font><br><br>如果不使用构造器,那么也可以不给prefix 赋值,<br>而是在接下来的代码使用的地方,<br>通过a.getExcelPrefix()进行赋值,<br>这时的对a的使用是在类完全加载之后,<br>即a被注入了,所以也是可以的。<br><br>@Autowired一定要等本类构造完成后,<br>才能从外部引用设置进来。<br>所以@Autowired的注入时间一定会晚于构造函数的执行时间。<br>但在初始化变量的时候就使用了还没注入的bean,所以导致了NPE。<br>如果在初始化其它变量时不使用这个要注入的bean,<br>而是在以后的方法调用的时候去赋值,是可以使用这个bean的,<br>因为那时类已初始化好,即已注入好了。
@autowired写在变量上的注入要等到类完全加载完,<br>才会将相应的bean注入,<br>而变量是在加载类的时候按照相应顺序加载的,<br>所以变量的加载要早于@autowired变量的加载,<br>那么给变量prefix 赋值的时候所使用的a,其实还没有被注入,<br>所以报空指针,<br><br>而使用构造器就在加载类的时候将a加载了,<br>这样在内部使用a给prefix 赋值就完全没有问题。
SpringMVC<br>
基于 Servlet 的一个 MVC 框架 主要解决 WEB 开发的问题<br>有利于分工 <br>复用<br>好扩展,好维护
Spring MVC启动分两个过程
ContextLoaderListener初始化,实例化IoC容器,并将此容器实例注册到ServletContext中
DispatcherServlet初始化
流程
(1) Http请求:客户端请求提交到DispatcherServlet。<br><br>(2) 寻找处理器:由DispatcherServlet控制器查询一个或多个HandlerMapping,找到处理请求的Controller。<br><br>(3) 调用处理器:DispatcherServlet将请求提交到Controller。<br><br>(4)(5)调用业务处理和返回结果:Controller调用业务逻辑处理后,返回ModelAndView。<br><br>(6)(7)处理视图映射并返回模型: DispatcherServlet查询一个或多个ViewResoler视图解析器,找到ModelAndView指定的视图。<br><br>(8) Http响应:视图负责将结果显示到客户端。
注解
@Controller
标记一个类是Controller
分发处理器将会扫描使用了该注解的类的方法,并检测该方法是否使用了@RequestMapping注解
可以把Request请求header部分的值绑定到方法的参数上
@RestController
相当于@Controller和@ResponseBody组合的效果
@RequestMapping
用来处理请求地址映射的注解,可用于类或方法上<br>用于类上,表示类中的所有响应请求都是以该地址作为父路径
@GetMapping
@PostMapping
@PutMapping
@DeleteMapping
@Autowired
可以对类成员变量,方法以及构造函数进行标注,完成自动装配的工作。<br>通过@Autowired消除set、get方法
@Component
泛指组件,当组件不好归类时,用该注解标注
@Repository
用于注解dao层,在daoImpl类上注解
@Service
用于标注业务层组件
@ResponseBody
异步请求
该注解用于将Controller的方法返回的对象,<br>通过适当的HttpMessageConverter转换为指定格式后,<br>写入到Response对象的body数据区
返回的数据不是html标签的页面,而是其他某种格式的数据时(json 、xml)使用
@PathVariable
用于将请求URL中的模板变量映射到功能处理方法的参数上,即取出url模板中的变量作为参数
@RequestParam
用于在SpringMVC后台控制层获取参数,类似一种是request.getParameter("name")
@RequestHandler
可以把Request请求header部分的值绑定到方法的参数上
@ModelAttribute
用于将请求参数或者方法的返回值绑定到Model对象
@EnableWebMvc
以编程的方式指定视图文件相关配置;
web.xml 加载过程
启动时,首先会去web.xml中读取<listener/> 和<context-param/>
创建一个ServletContext(application),这个web项目所有部分都将共享这个上下文
容器以<context-param/> 的name为键,value为值,将其转化为键值对,存入ServletContext
容器创建<listener/>中的类实例,根据配置的class类路径<listener-class>来创建监听器,<br>在监听中会有contextInitialized(ServletContextEvent args) 初始化方法,<br>启动Web应用时,系统调用Listener的该方法<br>在该方法中获得ServletContext application = ServletContextEvent.getServletContext();<br>context-param的值 = application.getInitParameter("context-param的键")<br>得到这个context-param的值之后,就可以有一些操作了
接着,容器会读取<filter/>,根据指定的类路径来实例化过滤器
servlet生命周期
1.加载和实例化
2.初始化
3.请求处理
4.服务终止
web.xml配置
contextConfigLocation
指定SpringIoC容器需要读取的XML文件路径
默认会去/WEB-INF/下加载applicationContext.xml
contextLoaderListener
Spring监听器
SpringMVC 在web容器中的启动器,读取applicaitonContext.xml 负责SpringIoC容器在Web上下文中的初始化
DispatchServlet
前端处理器,接受HTTP请求和转发请求
CharacterEncodingFilter
字符集过滤器
IntrospectorCleanupListener
防止spring内存溢出监听器
异常处理
HandlerExceptionResolver
可以实现全局异常控制
HandlerExceptionResolver接口中定义了一个resolverException方法<br>用于处理Controller中的异常,Exception ex参数即Controller抛出的异常<br>返回值类型是ModelAndView,可以通过这个返回值来设置异常时显示的页面
SimpleMappingExceptionResolver
Spring提供的一个默认的异常实现类
@ExceptionHandler
可以实现局部异常控制
如果@ExceptionHandler方法是在Controller内部定义的,<br>那么它会接受并处理由Controller(或其任何子类)中的@RequestMapping方法抛出的异常
web.xml的error-page标签
Http 4个动作的含义
GET
POST
PUT
DELETE
Spring Boot
实现自动配置,降低项目搭建的复杂度<br>简化应用配置,更容易使用spring。方便搭建项目或构建一个微服务。<br>简化配置:封装常用套件,比如mybatis、hibernate、redis、mongodb等<br>自动管理依赖。<br>部署简单:内嵌Web容器,如 Tomcat<br>缺点是集成度较高,使用过程中不太容易了解底层。
常见面试题
用于快速构建及开发Spring应用,可以看成是Spring框架的简化版
”约定优于配置“思想
使用约定的默认配置,减少配置文件编写
配置文件
properties文件
application.properties
yml文件
application.yml
Spring boot启动流程
流程图
开发环境和生产环境切换
在application.properties中定义<br>spring.profiles.active= dev<br>或者在启动时java -jar xxx.jar -D spring.profiles.active= prod<br><br>多个配置文件:<br>application-dev.properties<br>application-prod.properties<br>application-qas.properties<br>
基于注解配置
@SpringBootApplication注解的类
表示整个应用的入口,通常位于项目的顶层包
Spring原有的@Controller、@Service、@Component、@Bean、@Configuration等注解
properties配置文件读取
Spring原有的@Value
与@PropertySource配合使用读取指定配置属性值
缺点:<br>1、只支持单个属性值读取<br><br>2、只支持简单数据类型,如String、Boolean及数值类型
Spring Boot新增的@ConfigurationProperties
可以指定配置属性前缀,自动绑定属性值
比@Value功能更强大 <br>1、支持实体属性自动封装;<br><br>2、支持复杂数据类型的解析,比如数组、列表List
starter简化Maven配置
预先定义好需要的依赖并打包,需要时直接引入即可
所有Spring Boot项目公共的父依赖<br><br>spring-boot-starter-parent模块<br>
springboot常用的starter
spring-boot-starter spring core
spring-boot-starter-web 嵌入tomcat和web开发需要servlet与jsp支持
spring-boot-starter-data-jpa 数据库支持
spring-boot-starter-data-redis redis数据库支持
自动配置AutoConfigurer
为项目添加默认配置
application.properties/application.yml文件中定义的配置会覆盖默认配置
自带的spring-boot-autoconfigure模块
内置Servlet容器
Tomcat、Jetty、Undertow等
什么是SpringBoot?
1、用来简化spring初始搭建和开发过程使用特定的方式进行配置(properties或者yml文件)<br>2、创建独立的spring应用程序main方法运行<br>3、嵌入Tomcat无需部署war包,直接打成jar包nohup java -jar – & 启动就好<br>4、简化了maven的配置<br>4、自动配置spring添加对应的starter自动化配置
SpringBoot常用的starter
0、spring-boot-starter springcore<br>1、spring-boot-starter-web(嵌入Tomcat和web开发需要的servlet和jsp支持)<br>2、spring-boot-starter-data-jpa(数据库支持)<br>3、spring-boot-starter-data-Redis(Redis支持)<br>4、spring-boot-starter-data-solr(solr搜索应用框架支持)<br>5、mybatis-spring-boot-starter(第三方mybatis集成starter)
Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解<br><br>组合了 @SpringBootConfiguration 注解,实现<b><font color="#80bc42">配置文件的功能。</font></b><br> @EnableAutoConfiguration:<br> <b><font color="#80bc42">打开自动配置</font></b>的功能,也可以关闭某个自动配置的选项,<br> 如关闭数据源自动配置功能: <br> @SpringBootApplication<br> (exclude = { DataSourceAutoConfiguration.class })。<br> @ComponentScan:<b><font color="#80bc42">Spring组件扫描</font></b>。<br>@SpringBootApplication <br> = (默认属性)@@SpringBootConfiguration <br> + @EnableAutoConfiguration <br> + @ComponentScan。<br><br>@SpringBootApplication <br>public class ApplicationMain { <br> public static void main(String[] args) { <br> SpringApplication.run(Application.class, args); <br> } <br>}
@Configuration:<br>提到@Configuration就要提到他的搭档@Bean。<br>使用这两个注解就可以创建一个简单的spring配置类,<br>可以用来替代相应的xml配置文件。<br><br>@Configuration的注解类标识这个类可以使用Spring IoC容器作为bean定义的来源。<br>@Bean注解告诉Spring,一个带有@Bean的注解方法将返回一个对象,<br>该对象应该被注册为在Spring应用程序上下文中的bean。<br><br><beans> <br> <bean id = "car" class="com.test.Car"> <br> <property name="wheel" ref = "wheel"></property> <br> </bean> <br> <bean id = "wheel" class="com.test.Wheel"></bean> <br></beans> <br><br>@Configuration <br>public class Conf { <br> @Bean <br> public Car car() { <br> Car car = new Car(); <br> car.setWheel(wheel()); <br> return car; <br> } <br><br> @Bean <br> public Wheel wheel() { <br> return new Wheel(); <br> } <br>} <br>
@EnableAutoConfiguration:<br>能够自动配置spring的上下文,<br>试图猜测和配置你想要的bean类,<br>通常会自动根据你的类路径和你的bean定义自动配置。
@ComponentScan:<br>会自动扫描指定包下的全部标有@Component的类,并注册成bean,<br>当然包括@Component下的子注解@Service,@Repository,@Controller。
SpringBoot自动配置原理
1、@EnableAutoConfiguration这个注解会"猜"你将如何配置spring,<br> 前提是你已经添加了jar依赖项,<br> 如果spring-boot-starter-web已经添加Tomcat和SpringMVC,<br> 这个注释就会自动假设您在开发一个web应用程序并添加相应的spring配置,<br> 会自动去maven中读取每个starter中的spring.factories文件,<br> 该文件里配置了所有需要被创建spring容器中bean<br>2、在main方法中加上@SpringBootApplication和@EnableAutoConfiguration<br><br>Spring boot 的所有自动化配置的实现都在 spring-boot-autoconfigure 依赖中,<br>通过@EnableAutoConfiguration 核心注解初始化,<br>并扫描 ClassPath 目录中自动配置类对应依赖。<br>并对对应的组件依赖按一定规则获取默认配置并自动初始化所需要的 Bean。<br><br><br><br>先答为什么需要自动配置?<br><br>顾名思义,自动配置的意义是利用这种模式代替了配置 XML 繁琐模式。<br>以前使用 Spring MVC ,需要进行配置组件扫描、调度器、视图解析器等,<br>使用 Spring Boot 自动配置后,只需要添加 MVC 组件即可自动配置所需要的 Bean。<br>所有自动配置的实现都在 spring-boot-autoconfigure 依赖中,<br>包括 Spring MVC 、Data 和其它框架的自动配置。<br><br>接着答spring-boot-autoconfigure 依赖的工作原理?<br>spring-boot-autoconfigure 依赖的工作原理很简单,<br>通过 @EnableAutoConfiguration 核心注解初始化,<br>并扫描 ClassPath 目录中自动配置类对应依赖。<br>比如工程中有木有添加 Thymeleaf 的 Starter 组件依赖。<br>如果有,就按按一定规则获取默认配置并自动初始化所需要的 Bean。<br><br>ioc的思想最核心的地方在于,<br>资源不由使用资源的双方管理,<br>而由不使用资源的第三方管理,<br>这可以带来很多好处:<br>第一,资源集中管理,实现资源的可配置和易管理。<br>第二,降低了使用资源双方的依赖程度,也就是我们说的耦合度。<br><br>注解 @EnableAutoConfiguration, @Configuration, @ConditionalOnClass 就是自动配置的核心,<br>首先它得是一个配置文件,其次根据类路径下是否有这个类去自动配置。<br>
SpringBoot starter工作原理
1、SpringBoot在启动时扫描项目依赖的jar包,寻找包含spring.factories文件的jar<br>2、根据spring.factories配置加载AutoConfigure<br>3、根据@Conditional注解的条件,进行自动配置并将bean注入到Spring Context
SpringBoot的优点
1、减少开发、测试时间<br>2、使用JavaConfig有助于避免使用XML<br>3、避免大量的maven导入和各种版本冲突<br>4、通过提供默认值快速开始开发<br>5、没有单独的web服务器需要,这就意味着不再需要启动Tomcat、Glassfish或其他任何东西<br>6、需要更少的配置,因为没有web.xml文件。<br>只需添加用@Configuration注释的类,然后添加用@Bean注释的方法,<br>Spring将自动加载对象并像以前一样对其进行管理。<br>甚至可以将@Autowired添加到bean方法中,<br>以使用Spring自动装入需要的依赖关系中
Spring Boot 与 Spring Framework的区别
Spring Boot可以建立独立的Spring应用程序;<br>内嵌了如Tomcat,Jetty和Undertow这样的容器,也就是说可以直接跑起来,用不着再做部署工作了。<br>无需再像Spring那样搞一堆繁琐的xml文件的配置;<br>可以自动配置Spring;<br>提供了一些现有的功能,如度量工具,表单数据验证以及一些外部配置这样的一些第三方功能;<br>提供的POM可以简化Maven的配置;
springboot集成mybatis的过程
添加mybatis的starter maven依赖<br><br> <dependency><br><groupId>org.mybatis.spring.boot</groupId><br><artifactId>mybatis-spring-boot-starter</artifactId><br><version>1.2.0</version><br></dependency><br>在mybatis的接口中 添加@Mapper注解<br>在application.yml配置数据源信息
springboot如何添加【修改代码】自动重启功能
添加开发者工具集=====spring-boot-devtools<br><br><dependencies><br><dependency><br><groupId>org.springframework.boot</groupId><br><artifactId>spring-boot-devtools</artifactId><br><optional>true</optional><br></dependency><br></dependencies>
开启 Spring Boot 特性有哪几种方式?
1)继承spring-boot-starter-parent项目<br><br>2)导入spring-boot-dependencies项目依赖
Spring Boot 可以兼容老 Spring 项目吗,如何做?
可以兼容,使用 @ImportResource 注解导入老 Spring 项目配置文件。
Spring中基于Java的配置@Configuration和@Bean用法.代替xml配置文件
Spring中为了减少xml中配置,可以生命一个配置类(例如SpringConfig)来对bean进行配置。<br>一、首先,需要xml中进行少量的配置来启动Java配置:<br><br><?xml version="1.0" encoding="UTF-8"?> <br><beans xmlns="http://www.springframework.org/schema/beans" <br>xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" <br>xmlns:tx="http://www.springframework.org/schema/tx" xmlns:p="http://www.springframework.org/schema/p" <br>xmlns:context="http://www.springframework.org/schema/context" <br>xsi:schemaLocation=" <br>http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd <br>http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.2.xsd <br>http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.2.xsd <br>http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.2.xsd"> <br> <context:component-scan base-package="SpringStudy.Model"> <br> </context:component-scan> <br></beans> <br><br>二、定义一个配置类<br>用@Configuration注解该类,等价 与XML中配置beans;用@Bean标注方法等价于XML中配置bean。<br><br>package SpringStudy; <br>import org.springframework.context.annotation.Bean; <br>import org.springframework.context.annotation.Configuration; <br>import SpringStudy.Model.Counter; <br>import SpringStudy.Model.Piano; <br> <br><br>@Configuration <br>public class SpringConfig { <br> @Bean <br> public Piano piano(){ <br> return new Piano(); <br> } <br><br> @Bean(name = "counter") <br> public Counter counter(){ <br> return new Counter(12,"Shake it Off",piano()); <br> } <br>} <br>三、基础类代码<br><br>Counter:<br>package SpringStudy.Model; <br>public class Counter { <br> public Counter() { <br> } <br> public Counter(double multiplier, String song,Instrument instrument) { <br> this.multiplier = multiplier; <br> this.song = song; <br> this.instrument=instrument; <br> } <br><br> private double multiplier; <br> private String song; <br><br> @Resource <br> private Instrument instrument; <br> <br> public double getMultiplier() { <br> return multiplier; <br> } <br><br> public void setMultiplier(double multiplier) { <br> this.multiplier = multiplier; <br> } <br><br> public String getSong() { <br> return song; <br> } <br><br> public void setSong(String song) { <br> this.song = song; <br> } <br><br> public Instrument getInstrument() { <br> return instrument; <br> } <br><br> public void setInstrument(Instrument instrument) { <br> this.instrument = instrument; <br> } <br>} <br>Piano类<br><br>package SpringStudy.Model; <br><br><br>public class Piano { <br> private String name="Piano"; <br> private String sound; <br> public String getName() { <br> return name; <br><br> } <br><br> public void setName(String name) { <br> this.name = name; <br> } <br><br> public String getSound() { <br> return sound; <br> } <br><br> <br><br> public void setSound(String sound) { <br> this.sound = sound; <br> } <br><br>} <br><br><br>四、调用测试类<br><br><br>package webMyBatis; <br>import org.springframework.context.ApplicationContext; <br>import org.springframework.context.annotation.AnnotationConfigApplicationContext; <br>import SpringStudy.Model.Counter; <br><br>public class SpringTest { <br>public static void main(String[] args) { <br>//ApplicationContext ctx = new ClassPathXmlApplicationContext("spring/bean.xml");// 读取bean.xml中的内容 <br>ApplicationContext annotationContext = new AnnotationConfigApplicationContext("SpringStudy"); <br>Counter c = annotationContext.getBean("counter", Counter.class);// 创建bean的引用对象 <br>System.out.println(c.getMultiplier()); <br>System.out.println(c.isEquals()); <br>System.out.println(c.getSong()); <br>System.out.println(c.getInstrument().getName()); <br>} <br>} <br><br>注意:如果是在xml中配置beans和bean的话,或者使用自动扫描调用的话,代码为<br>ApplicationContext ctx = new ClassPathXmlApplicationContext("spring/bean.xml");// 读取bean.xml中的内容<br>Counter c = ctx.getBean("counter", Counter.class);// 创建bean的引用对象<br><br>五、运行结果<br><br>12.0<br>false<br>Shake it Off<br>Piano
优雅的关闭Springboot
Springboot 常用demo
结合netty
Server端
导入依赖
编写Netty服务端处理器
package com.example.demo.netty.server.demo;<br><br>import io.netty.channel.ChannelHandlerContext;<br>import io.netty.channel.ChannelInboundHandlerAdapter;<br>import lombok.extern.slf4j.Slf4j;<br><br>/**<br> * netty服务端处理器<br> **/<br>@Slf4j<br>public class NettyServerHandler extends ChannelInboundHandlerAdapter {<br> /**<br> * 客户端连接会触发<br> */<br> @Override<br> public void channelActive(ChannelHandlerContext ctx) throws Exception {<br> log.info("Channel active......");<br> }<br><br> /**<br> * 客户端发消息会触发<br> */<br> @Override<br> public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {<br> log.info("服务器收到消息: {}", msg.toString());<br> ctx.write("你也好哦");<br> ctx.flush();<br> }<br><br> /**<br> * 发生异常触发<br> */<br> @Override<br> public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {<br> cause.printStackTrace();<br> ctx.close();<br> }<br>}
编写Netty服务端初始化器
package com.example.demo.netty.server.demo;<br><br>import io.netty.channel.ChannelInitializer;<br>import io.netty.channel.socket.SocketChannel;<br>import io.netty.handler.codec.string.StringDecoder;<br>import io.netty.handler.codec.string.StringEncoder;<br>import io.netty.util.CharsetUtil;<br><br>/**<br> * netty服务初始化器<br> **/<br>public class ServerChannelInitializer extends ChannelInitializer<socketchannel> {<br> @Override<br> protected void initChannel(SocketChannel socketChannel) throws Exception {<br> //添加编解码<br> socketChannel.pipeline().addLast("decoder", new StringDecoder(CharsetUtil.UTF_8));<br> socketChannel.pipeline().addLast("encoder", new StringEncoder(CharsetUtil.UTF_8));<br> socketChannel.pipeline().addLast(new NettyServerHandler());<br> }<br>}</socketchannel>
编写Netty服务启动
package com.example.demo.netty.server.demo;<br><br>import io.netty.bootstrap.ServerBootstrap;<br>import io.netty.channel.ChannelFuture;<br>import io.netty.channel.ChannelOption;<br>import io.netty.channel.EventLoopGroup;<br>import io.netty.channel.nio.NioEventLoopGroup;<br>import io.netty.channel.socket.nio.NioServerSocketChannel;<br>import lombok.extern.slf4j.Slf4j;<br>import org.springframework.stereotype.Component;<br><br>import java.net.InetSocketAddress;<br><br>/**<br> * <p>* 服务启动监听器<br> **/<br>@Component<br>@Slf4j<br>public class NettyServer {<br><br> public void start(InetSocketAddress socketAddress) {<br> //new 一个主线程组<br> EventLoopGroup bossGroup = new NioEventLoopGroup(1);<br> //new 一个工作线程组<br> EventLoopGroup workGroup = new NioEventLoopGroup(200);<br> ServerBootstrap bootstrap = new ServerBootstrap()<br> .group(bossGroup, workGroup)<br> .channel(NioServerSocketChannel.class)<br> .childHandler(new ServerChannelInitializer())<br> .localAddress(socketAddress)<br> //设置队列大小<br> .option(ChannelOption.SO_BACKLOG, 1024)<br> // 两小时内没有数据的通信时,TCP会自动发送一个活动探测数据报文<br> .childOption(ChannelOption.SO_KEEPALIVE, true);<br> //绑定端口,开始接收进来的连接<br> try {<br> ChannelFuture future = bootstrap.bind(socketAddress).sync();<br> log.info("服务器启动开始监听端口: {}", socketAddress.getPort());<br> future.channel().closeFuture().sync();<br> } catch (InterruptedException e) {<br> e.printStackTrace();<br> } finally {<br> //关闭主线程组<br> bossGroup.shutdownGracefully();<br> //关闭工作线程组<br> workGroup.shutdownGracefully();<br> }<br> }<br>}</p>
启动类
package com.example.demo.netty.server;<br><br>import com.example.demo.netty.server.demo.NettyServer;<br>import org.springframework.boot.SpringApplication;<br>import org.springframework.boot.autoconfigure.SpringBootApplication;<br><br>import java.net.InetSocketAddress;<br><br>@SpringBootApplication<br>public class ServerApplication {<br><br> public static void main(String[] args) {<br> SpringApplication application = new SpringApplication(ServerApplication.class);<br> application.run(args);<br> //启动服务端<br> NettyServer nettyServer = new NettyServer();<br> nettyServer.start(new InetSocketAddress("127.0.0.1", 8090));<br> }<br><br><br>}
Client端
添加依赖
子主题
编写客户端处理器
package com.example.netty.client.demo;<br><br>import io.netty.channel.ChannelHandlerContext;<br>import io.netty.channel.ChannelInboundHandlerAdapter;<br>import lombok.extern.slf4j.Slf4j;<br><br>@Slf4j<br>public class NettyClientHandler extends ChannelInboundHandlerAdapter {<br> @Override<br> public void channelActive(ChannelHandlerContext ctx) throws Exception {<br> log.info("客户端Active .....");<br> }<br><br> @Override<br> public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {<br> log.info("客户端收到消息: {}", msg.toString());<br> }<br><br> @Override<br> public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {<br> cause.printStackTrace();<br> ctx.close();<br> }<br>}
编写客户端初始化器
package com.example.netty.client.demo;<br><br>import io.netty.channel.ChannelInitializer;<br>import io.netty.channel.socket.SocketChannel;<br>import io.netty.handler.codec.string.StringDecoder;<br>import io.netty.handler.codec.string.StringEncoder;<br><br>public class NettyClientInitializer extends ChannelInitializer<socketchannel> {<br> @Override<br> protected void initChannel(SocketChannel socketChannel) throws Exception {<br> socketChannel.pipeline().addLast("decoder", new StringDecoder());<br> socketChannel.pipeline().addLast("encoder", new StringEncoder());<br> socketChannel.pipeline().addLast(new NettyClientHandler());<br> }<br>} </socketchannel>
编写客户端
package com.example.netty.client.demo;<br><br>import io.netty.bootstrap.Bootstrap;<br>import io.netty.channel.ChannelFuture;<br>import io.netty.channel.ChannelOption;<br>import io.netty.channel.EventLoopGroup;<br>import io.netty.channel.nio.NioEventLoopGroup;<br>import io.netty.channel.socket.nio.NioSocketChannel;<br>import lombok.extern.slf4j.Slf4j;<br>import org.springframework.stereotype.Component;<br><br>@Component<br>@Slf4j<br>public class NettyClient {<br><br> public void start() {<br> EventLoopGroup group = new NioEventLoopGroup();<br> Bootstrap bootstrap = new Bootstrap()<br> .group(group)<br> //该参数的作用就是禁止使用Nagle算法,使用于小数据即时传输<br> .option(ChannelOption.TCP_NODELAY, true)<br> .channel(NioSocketChannel.class)<br> .handler(new NettyClientInitializer());<br><br> try {<br> ChannelFuture future = bootstrap.connect("127.0.0.1", 8090).sync();<br> log.info("客户端成功....");<br> //发送消息<br> future.channel().writeAndFlush("你好啊");<br> // 等待连接被关闭<br> future.channel().closeFuture().sync();<br> } catch (InterruptedException e) {<br> e.printStackTrace();<br> }finally {<br> group.shutdownGracefully();<br> }<br> }<br>}
启动类
package com.example.netty.client;<br><br>import com.example.netty.client.demo.NettyClient;<br>import org.springframework.boot.SpringApplication;<br>import org.springframework.boot.autoconfigure.SpringBootApplication;<br>import org.springframework.boot.web.embedded.tomcat.TomcatServletWebServerFactory;<br>import org.springframework.context.annotation.Bean;<br><br>import java.util.HashMap;<br>import java.util.Map;<br><br>@SpringBootApplication<br>public class ClientApplication {<br><br> public static void main(String[] args) {<br> SpringApplication application = new SpringApplication(ClientApplication.class);<br> application.run(args);<br> //启动netty客户端<br><br> NettyClient nettyClient = new NettyClient();<br> nettyClient.start();<br> }<br><br> @Bean<br> public TomcatServletWebServerFactory updatePort(){<br> return new TomcatServletWebServerFactory(8888);<br> }<br>}<br>
ChannelOption参数详解<br>
ChannelOption.SO_BACKLOG
ChannelOption.SO_BACKLOG对应的是tcp/ip协议listen函数中的backlog参数,<br>函数listen(int socketfd,int backlog)用来初始化服务端可连接队列,<br>服务端处理客户端连接请求是顺序处理的,<br>所以同一时间只能处理一个客户端连接,多个客户端来的时候,<br>服务端将不能处理的客户端连接请求放在队列中等待处理,<br>backlog参数指定了队列的大小
ChannelOption.SO_REUSEADDR
ChanneOption.SO_REUSEADDR对应于套接字选项中的SO_REUSEADDR,<br>这个参数表示允许重复使用本地地址和端口,<br>比如,某个服务器进程占用了TCP的80端口进行监听,<br>此时再次监听该端口就会返回错误,使用该参数就可以解决问题,<br>该参数允许共用该端口,这个在服务器程序中比较常使用,<br>比如某个进程非正常退出,<br>该程序占用的端口可能要被占用一段时间才能允许其他进程使用,<br>而且程序死掉以后,内核一需要一定的时间才能够释放此端口,<br>不设置SO_REUSEADDR就无法正常使用该端口。
ChannelOption.SO_KEEPALIVE
Channeloption.SO_KEEPALIVE参数对应于套接字选项中的SO_KEEPALIVE,<br>该参数用于设置TCP连接,当设置该选项以后,连接会测试链接的状态,<br>这个选项用于可能长时间没有数据交流的连接。<br>当设置该选项以后,如果在两小时内没有数据的通信时,<br>TCP会自动发送一个活动探测数据报文
ChannelOption.SO_SNDBUF和ChannelOption.SO_RCVBUF
ChannelOption.SO_SNDBUF参数对应于套接字选项中的SO_SNDBUF,<br>ChannelOption.SO_RCVBUF参数对应于套接字选项中的SO_RCVBUF<br>这两个参数用于操作接收缓冲区和发送缓冲区的大小,<br>接收缓冲区用于保存网络协议站内收到的数据,直到应用程序读取成功,<br>发送缓冲区用于保存发送数据,直到发送成功。
ChannelOption.SO_LINGER
ChannelOption.SO_LINGER参数对应于套接字选项中的SO_LINGER,<br>Linux内核默认的处理方式是当用户调用close()方法的时候,函数返回,<br>在可能的情况下,尽量发送数据,不一定保证会发生剩余的数据,<br>造成了数据的不确定性,使用SO_LINGER可以阻塞close()的调用时间,<br>直到数据完全发送
ChannelOption.TCP_NODELAY
ChannelOption.TCP_NODELAY参数对应于套接字选项中的TCP_NODELAY,<br>该参数的使用与Nagle算法有关,<br>Nagle算法是将小的数据包组装为更大的帧然后进行发送,<br>而不是输入一次发送一次,<br>因此在数据包不足的时候会等待其他数据的到了,<br>组装成大的数据包进行发送,虽然该方式有效提高网络的有效负载,但是却造成了延时,<br>而该参数的作用就是禁止使用Nagle算法,使用于小数据即时传输,<br>于TCP_NODELAY相对应的是TCP_CORK,<br>该选项是需要等到发送的数据量最大的时候,一次性发送数据,适用于文件传输。
IP_TOS
IP参数,设置IP头部的Type-of-Service字段,用于描述IP包的优先级和QoS选项。
ALLOW_HALF_CLOSURE
Netty参数,一个连接的远端关闭时本地端是否关闭,默认值为False。<br>值为False时,连接自动关闭;<br>为True时,触发ChannelInboundHandler的userEventTriggered()方法,<br>事件为ChannelInputShutdownEvent。
Netty的future.channel().closeFuture().sync();到底有什么用?
主线程执行到这里就 wait 子线程结束,<br>子线程才是真正监听和接受请求的,<br>closeFuture()是开启了一个channel的监听器,<br>负责监听channel是否关闭的状态,<br>如果监听到channel关闭了,子线程才会释放,<br>syncUninterruptibly()让主线程同步等待子线程结果
结合mybatis
Spring Cloud<br>
基于SpringBoot提供了一套微服务解决方案,<br>包括服务注册与发现,配置中心,全链路监控,服务网关,负载均衡,熔断器等组件。
架构设计
实战demo
服务注册
Config
Client
bootstrap.properties<br><br>spring.application.name=app_wechat_service #指定config server中配置的application名称<br>spring.cloud.config.uri=http://172.18.209.19:9088 #指定config server的地址<br>spring.cloud.config.profile=dev #指定当前运行的环境
Java代码中<br><br>@Scheduled(cron="${wx.token.sync.cron}") //从config server中配置的服务为 app_wechat_service,属性名为wx.token.sync.cron中读取数据<br>
安全认证方案
spring security -> 安全方案<br>oauth -> 授权框架, 用在使用第三方账号登录的情况(比如使用weibo, qq, github登录某个app)<br> -> 一定需要token,JWT是其中的一个<br> --> InMemoryTokenStore<br> --> JdbcTokenStore<br> --> JSON Web Token (JWT)<br>jwt <br> -> 认证协议, 基于Token的身份认证是无状态的,服务器或者Session中不会存储任何用户信息。<br> -> 用在前后端分离, 需要简单的对后台API进行保护时使用<br> -> 优点<br> -> 缺点 <br> -->不能很容易的撤销一个access token,<br> 因此一般用该方式存储的token的有效期很短,<br> 并且在刷新token的时候之前的token会被废除<br> -->token很长,<br> 因为它里面存了很多关于用户凭证的信息。<br> JwtTokenStore不会真的存储数据,<br> 它不持久化任何数据 <br>apache shiro
Spring security
为Java应用提供认证和授权管理。<br>它是一个强大的,高度自定义的认证和访问控制框架。
包括两个关键词:<br>Authentication(认证)<br>和 Authorization(授权,也叫访问控制)<br>
认证是验证用户身份的合法性<br>认证就是你是谁<br>
授权是控制你可以做什么<br>授权就是你可以做什么<br>
几个接口
AuthenticationProvider
用于认证的,可以通过实现这个接口来定制我们自己的认证逻辑,它的实现类有很多,默认的是JaasAuthenticationProvider
AccessDecisionManager
用于访问控制的,它决定用户是否可以访问某个资源,实现这个接口可以定制我们自己的授权逻辑。
AccessDecisionVoter<br>
投票器,在授权的时通过投票的方式来决定用户是否可以访问,这里涉及到投票规则
UserDetailsService<br>
用于加载特定用户信息的,它只有一个接口通过指定的用户名去查询用户。
UserDetails
代表用户信息,即主体,相当于Shiro中的Subject。User是它的一个实现。<br>
Spring Boot集成Spring Security<br>
为了定义我们自己的认证管理,我们可以添加UserDetailsService, AuthenticationProvider, or AuthenticationManager这种类型的Bean。
通过定义自己的UserDetailsService从数据库查询用户信息,至于认证的话就用默认的。<br>
pom依赖
子主题
Security配置
<br>@Configuration<br>@EnableWebSecurity<br>@EnableGlobalMethodSecurity(prePostEnabled = true) // 启用方法级别的权限认证<br>public class SecurityConfig extends WebSecurityConfigurerAdapter {<br><br> @Autowired<br> private MyUserDetailsService myUserDetailsService;<br><br><br> @Override<br> protected void configure(HttpSecurity http) throws Exception {<br> // 允许所有用户访问"/"和"/index.html"<br> http.authorizeRequests()<br> .antMatchers("/", "/index.html").permitAll()<br> .anyRequest().authenticated() // 其他地址的访问均需验证权限<br> .and()<br> .formLogin()<br> .loginPage("/login.html") // 登录页<br> .failureUrl("/login-error.html").permitAll()<br> .and()<br> .logout()<br> .logoutSuccessUrl("/index.html");<br> }<br><br> @Override<br> protected void configure(AuthenticationManagerBuilder auth) throws Exception {<br> auth.userDetailsService(myUserDetailsService).passwordEncoder(passwordEncoder());<br> }<br><br> @Bean<br> public PasswordEncoder passwordEncoder() {<br> return new BCryptPasswordEncoder();<br> }<br><br>}
MyUserDetailsService
@Service<br>public class MyUserDetailsService implements UserDetailsService {<br><br> @Autowired<br> private UserService userService;<br><br> /**<br> * 授权的时候是对角色授权,而认证的时候应该基于资源,而不是角色,因为资源是不变的,而用户的角色是会变的<br> */<br><br> @Override<br> public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {<br> SysUser sysUser = userService.getUserByName(username);<br> if (null == sysUser) {<br> throw new UsernameNotFoundException(username);<br> }<br> List<simplegrantedauthority> authorities = new ArrayList<>();<br> for (SysRole role : sysUser.getRoleList()) {<br> for (SysPermission permission : role.getPermissionList()) {<br> authorities.add(new SimpleGrantedAuthority(permission.getCode()));<br> }<br> }<br><br> return new User(sysUser.getUsername(), sysUser.getPassword(), authorities);<br> }<br>}</simplegrantedauthority>
权限分配
@Service<br>public class UserServiceImpl implements UserService {<br><br> @Autowired<br> private UserDao userDao;<br><br> @Cacheable(cacheNames = "authority", key = "#username")<br> @Override<br> public SysUser getUserByName(String username) {<br> return userDao.selectByName(username);<br> }<br>}
@Slf4j<br>@Repository<br>public class UserDao {<br><br> private SysRole admin = new SysRole("ADMIN", "管理员");<br> private SysRole developer = new SysRole("DEVELOPER", "开发者");<br><br> {<br> SysPermission p1 = new SysPermission();<br> p1.setCode("UserIndex");<br> p1.setName("个人中心");<br> p1.setUrl("/user/index.html");<br><br> SysPermission p2 = new SysPermission();<br> p2.setCode("BookList");<br> p2.setName("图书列表");<br> p2.setUrl("/book/list");<br><br> SysPermission p3 = new SysPermission();<br> p3.setCode("BookAdd");<br> p3.setName("添加图书");<br> p3.setUrl("/book/add");<br><br> SysPermission p4 = new SysPermission();<br> p4.setCode("BookDetail");<br> p4.setName("查看图书");<br> p4.setUrl("/book/detail");<br><br> admin.setPermissionList(Arrays.asList(p1, p2, p3, p4));<br> developer.setPermissionList(Arrays.asList(p1, p2));<br><br> }<br><br> public SysUser selectByName(String username) {<br> log.info("从数据库中查询用户");<br> if ("zhangsan".equals(username)) {<br> SysUser sysUser = new SysUser("zhangsan", "$2a$10$EIfFrWGINQzP.tmtdLd2hurtowwsIEQaPFR9iffw2uSKCOutHnQEm");<br> sysUser.setRoleList(Arrays.asList(admin, developer));<br> return sysUser;<br> }else if ("lisi".equals(username)) {<br> SysUser sysUser = new SysUser("lisi", "$2a$10$EIfFrWGINQzP.tmtdLd2hurtowwsIEQaPFR9iffw2uSKCOutHnQEm");<br> sysUser.setRoleList(Arrays.asList(developer));<br> return sysUser;<br> }<br> return null;<br> }<br><br>}
示例
用户登录成功以后跳到个人中心,然后用户可以可以进入图书列表查看。<br><br>用户zhangsan可以查看所有的,而lisi只能查看图书列表,不能添加不能查看详情。<br>
页面设计
LoginController.java
@Controller<br>public class LoginController {<br><br> // Login form<br> @RequestMapping("/login.html")<br> public String login() {<br> return "login.html";<br> }<br><br> // Login form with error<br> @RequestMapping("/login-error.html")<br> public String loginError(Model model) {<br> model.addAttribute("loginError", true);<br> return "login.html";<br> }<br><br>}
BookController.java
@Controller<br>@RequestMapping("/book")<br>public class BookController {<br><br> @PreAuthorize("hasAuthority('BookList')")<br> @GetMapping("/list.html")<br> public String list() {<br> return "book/list";<br> }<br><br> @PreAuthorize("hasAuthority('BookAdd')")<br> @GetMapping("/add.html")<br> public String add() {<br> return "book/add";<br> }<br><br> @PreAuthorize("hasAuthority('BookDetail')")<br> @GetMapping("/detail.html")<br> public String detail() {<br> return "book/detail";<br> }<br>}
UserController.java
@Controller<br>@RequestMapping("/user")<br>public class UserController {<br><br> @Autowired<br> private UserService userService;<br><br> /**<br> * 个人中心<br> */<br> @PreAuthorize("hasAuthority('UserIndex')")<br> @GetMapping("/index")<br> public String index() {<br> return "user/index";<br> }<br><br> @RequestMapping("/hi")<br> @ResponseBody<br> public String hi() {<br> SysUser sysUser = userService.getUserByName("zhangsan");<br> return sysUser.toString();<br> }<br><br>}
index.html
子主题
login.html
子主题
/user/index.html
子主题
/book/list.html
子主题
header.html
子主题
错误处理
ErrorController.java
<br>@Slf4j<br><b><font color="#80bc42">@ControllerAdvice</font></b><br>public class ErrorController {<br><br> @ExceptionHandler(Throwable.class)<br> @ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR)<br> public String exception(final Throwable throwable, final Model model) {<br> log.error("Exception during execution of SpringSecurity application", throwable);<br> String errorMessage = (throwable != null ? throwable.getMessage() : "Unknown error");<br> model.addAttribute("errorMessage", errorMessage);<br> return "error";<br> }<br><br>}
error.html
子主题
OAuth2
结合JWT
https://segmentfault.com/a/1190000009231329<br>//https://github.com/freew01f/securing-spring-boot-with-jwts<br>
创建一个Web 应用
@SpringBootApplication<br>@RestController<br>@EnableAutoConfiguration<br>public class DemoApplication {<br><br> // main函数,Spring Boot程序入口<br> public static void main(String[] args) {<br> SpringApplication.run(DemoApplication.class, args);<br> }<br><br> // 根目录映射 Get访问方式 直接返回一个字符串<br> @RequestMapping("/")<br> Map<string, string=""> hello() {<br> // 返回map会变成JSON key value方式<br> Map<string,string> map=new HashMap<string,string>();<br> map.put("content", "hello freewolf~");<br> return map;<br> }<br>}</string,string></string,string></string,>
访问http://localhost:8080/就能看到这个JSON的输出
{<br> "content": "hello freewolf~"<br>}
结果集处理方法类
package com.example.demo.demo.jwt;<br><br>import org.json.JSONObject;<br><br>public class JSONResult{<br> public static String fillResultString(Integer status, String message, Object result){<br> JSONObject jsonObject = new JSONObject(){{<br> put("status", status);<br> put("message", message);<br> put("result", result);<br> }};<br><br> return jsonObject.toString();<br> }<br>}
status - 返回状态码 0 代表正常返回,其他都是错误<br><br>message - 一般显示错误信息<br><br>result - 结果集
引入一个新的@RestController并返回一些简单的结果
@RestController<br>class UserController {<br><br> // 路由映射到/users<br> @RequestMapping(value = "/users", produces="application/json;charset=UTF-8")<br> public String usersList() {<br><br> ArrayList<string> users = new ArrayList<string>(){{<br> add("freewolf");<br> add("tom");<br> add("jerry");<br> }};<br><br> return JSONResult.fillResultString(0, "", users);<br> }<br><br> @RequestMapping(value = "/hello", produces="application/json;charset=UTF-8")<br> public String hello() {<br> ArrayList<string> users = new ArrayList<string>(){{ add("hello"); }};<br> return JSONResult.fillResultString(0, "", users);<br> }<br><br> @RequestMapping(value = "/world", produces="application/json;charset=UTF-8")<br> public String world() {<br> ArrayList<string> users = new ArrayList<string>(){{ add("world"); }};<br> return JSONResult.fillResultString(0, "", users);<br> }<br>}</string></string></string></string></string></string>
访问http://localhost:8080/users
{<br> "result": [<br> "freewolf",<br> "tom",<br> "jerry"<br> ],<br> "message": "",<br> "status": 0<br>}
使用JWT保护你的Spring Boot应用
对/users进行访问控制,<br>先通过申请一个JWT(JSON Web Token读jot),<br>然后通过这个访问/users,才能拿到数据。
JWT很大程度上还是个新技术,<br>通过使用HMAC(Hash-based Message Authentication Code)计算信息摘要,<br>也可以用RSA公私钥中的私钥进行签名。这个根据业务场景进行选择。
添加Spring Security
至此我们之前所有的路由都需要身份验证。<br>我们将引入一个安全设置类WebSecurityConfig,<br>这个类需要从WebSecurityConfigurerAdapter类继承。
package com.example.demo.demo.config;<br><br>import com.example.demo.demo.jwt.CustomAuthenticationProvider;<br>import com.example.demo.demo.jwt.JWTAuthenticationFilter;<br>import com.example.demo.demo.jwt.JWTLoginFilter;<br>import org.springframework.context.annotation.Configuration;<br>import org.springframework.http.HttpMethod;<br>import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder;<br>import org.springframework.security.config.annotation.web.builders.HttpSecurity;<br>import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;<br>import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;<br>import org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter;<br><br>@Configuration<br>@EnableWebSecurity<br>public class WebSecurityConfig extends WebSecurityConfigurerAdapter {<br><br> // 设置 HTTP 验证规则<br> @Override<br> protected void configure(HttpSecurity http) throws Exception {<br> // 关闭csrf验证<br> http.csrf().disable()<br> // 对请求进行认证<br> .authorizeRequests()<br> // 所有 / 的所有请求 都放行<br> .antMatchers("/").permitAll()<br> // 所有 /login 的POST请求 都放行<br> .antMatchers(HttpMethod.POST, "/login").permitAll()<br> // 添加权限检测<br> .antMatchers("/hello").hasAuthority("AUTH_WRITE")<br> // 角色检测<br> .antMatchers("/world").hasRole("ADMIN")<br> // 所有请求需要身份认证<br> .anyRequest().authenticated()<br> .and()<br> // 添加一个过滤器 所有访问 /login 的请求交给 JWTLoginFilter 来处理 这个类处理所有的JWT相关内容<br> .addFilterBefore(new JWTLoginFilter("/login", authenticationManager()),<br> UsernamePasswordAuthenticationFilter.class)<br> // 添加一个过滤器验证其他请求的Token是否合法<br> .addFilterBefore(new JWTAuthenticationFilter(),<br> UsernamePasswordAuthenticationFilter.class);<br> }<br><br> @Override<br> protected void configure(AuthenticationManagerBuilder auth) throws Exception {<br> // 使用自定义身份验证组件<br> auth.authenticationProvider(new CustomAuthenticationProvider());<br><br> }<br>}<br>
在上面的安全设置类中,<br>我们设置所有人都能访问/和POST方式访问/login,<br>其他的任何路由都需要进行认证。<br>然后将所有访问/login的请求,<br>都交给JWTLoginFilter过滤器来处理。
两个基本类,<br>一个负责存储用户名密码,<br>另一个是一个权限类型,负责存储权限和角色。
package com.example.demo.demo.jwt;<br><br>public class AccountCredentials {<br><br> private String username;<br> private String password;<br><br> public String getUsername() {<br> return username;<br> }<br><br> public void setUsername(String username) {<br> this.username = username;<br> }<br><br> public String getPassword() {<br> return password;<br> }<br><br> public void setPassword(String password) {<br> this.password = password;<br> }<br>}<br>
package com.example.demo.demo.jwt;<br><br>import org.springframework.security.core.GrantedAuthority;<br><br>public class GrantedAuthorityImpl implements GrantedAuthority {<br> private String authority;<br><br> public GrantedAuthorityImpl(String authority) {<br> this.authority = authority;<br> }<br><br> public void setAuthority(String authority) {<br> this.authority = authority;<br> }<br><br> @Override<br> public String getAuthority() {<br> return this.authority;<br> }<br>}
建立一个JWT生成,和验签的类
package com.example.demo.demo.jwt;<br><br>import com.example.demo.demo.jwt.JSONResult;<br>import io.jsonwebtoken.Claims;<br>import io.jsonwebtoken.Jwts;<br>import io.jsonwebtoken.SignatureAlgorithm;<br>import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;<br>import org.springframework.security.core.Authentication;<br>import org.springframework.security.core.GrantedAuthority;<br>import org.springframework.security.core.authority.AuthorityUtils;<br><br>import javax.servlet.http.HttpServletRequest;<br>import javax.servlet.http.HttpServletResponse;<br>import java.io.IOException;<br>import java.util.Date;<br>import java.util.List;<br><br>public class TokenAuthenticationService {<br> static final long EXPIRATIONTIME = 432_000_000; // 5天<br> static final String SECRET = "P@ssw02d"; // JWT密码<br> static final String TOKEN_PREFIX = "Bearer"; // Token前缀<br> static final String HEADER_STRING = "Authorization";// 存放Token的Header Key<br><br> static void addAuthentication(HttpServletResponse response, String username) {<br> // 生成JWT<br> String JWT = Jwts.builder()<br> // 保存权限(角色)<br> .claim("authorities", "ROLE_ADMIN,AUTH_WRITE")<br> // 用户名写入标题<br> .setSubject(username)<br> // 有效期设置<br> .setExpiration(new Date(System.currentTimeMillis() + EXPIRATIONTIME))<br> // 签名设置<br> .signWith(SignatureAlgorithm.HS512, SECRET)<br> .compact();<br><br> // 将 JWT 写入 body<br> try {<br> response.setContentType("application/json");<br> response.setStatus(HttpServletResponse.SC_OK);<br> response.getOutputStream().println(JSONResult.fillResultString(0, "", JWT));<br> } catch (IOException e) {<br> e.printStackTrace();<br> }<br> }<br><br> static Authentication getAuthentication(HttpServletRequest request) {<br> // 从Header中拿到token<br> String token = request.getHeader(HEADER_STRING);<br><br> if (token != null) {<br> // 解析 Token<br> Claims claims = Jwts.parser()<br> // 验签<br> .setSigningKey(SECRET)<br> // 去掉 Bearer<br> .parseClaimsJws(token.replace(TOKEN_PREFIX, ""))<br> .getBody();<br><br> // 拿用户名<br> String user = claims.getSubject();<br><br> // 得到 权限(角色)<br> List<grantedauthority> authorities = AuthorityUtils.commaSeparatedStringToAuthorityList((String) claims.get("authorities"));<br><br> // 返回验证令牌<br> return user != null ?<br> new UsernamePasswordAuthenticationToken(user, null, authorities) :<br> null;<br> }<br> return null;<br> }<br>} </grantedauthority>
两个static方法,一个负责生成JWT,一个负责认证JWT最后生成验证令牌。
自定义验证组件,<br><b><font color="#c41230">这里简单写了,这个类就是提供密码验证功能,<br>在实际使用时换成自己相应的验证逻辑,<br>从数据库中取出、比对、赋予用户相应权限。</font></b>
package com.example.demo.demo.jwt;<br><br>import org.springframework.security.authentication.AuthenticationProvider;<br>import org.springframework.security.authentication.BadCredentialsException;<br>import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;<br>import org.springframework.security.core.Authentication;<br>import org.springframework.security.core.AuthenticationException;<br>import org.springframework.security.core.GrantedAuthority;<br><br>import java.util.ArrayList;<br><br>// 自定义身份认证验证组件<br>public class CustomAuthenticationProvider implements AuthenticationProvider {<br><br> @Override<br> public Authentication authenticate(Authentication authentication) throws AuthenticationException {<br> // 获取认证的用户名 & 密码<br> String name = authentication.getName();<br> String password = authentication.getCredentials().toString();<br><br> // 认证逻辑<br> if (name.equals("admin") && password.equals("123456")) {<br><br> // 这里设置权限和角色<br> ArrayList<grantedauthority> authorities = new ArrayList<>();<br> authorities.add( new GrantedAuthorityImpl("ROLE_ADMIN") );<br> authorities.add( new GrantedAuthorityImpl("AUTH_WRITE") );<br> // 生成令牌<br> Authentication auth = new UsernamePasswordAuthenticationToken(name, password, authorities);<br> return auth;<br> }else {<br> throw new BadCredentialsException("密码错误~");<br> }<br> }<br><br> // 是否可以提供输入类型的认证服务<br> @Override<br> public boolean supports(Class<!--?--> authentication) {<br> return authentication.equals(UsernamePasswordAuthenticationToken.class);<br> }<br><br>} </grantedauthority>
实现JWTLoginFilter 这个Filter比较简单,除了构造函数需要重写三个方法。<br><br>attemptAuthentication - 登录时需要验证时候调用<br><br>successfulAuthentication - 验证成功后调用<br><br>unsuccessfulAuthentication - 验证失败后调用,这里直接灌入500错误返回,由于同一JSON返回,HTTP就都返回200了
package com.example.demo.demo.jwt;<br><br>import com.fasterxml.jackson.databind.ObjectMapper;<br>import org.json.JSONObject;<br>import org.springframework.security.authentication.AuthenticationManager;<br>import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;<br>import org.springframework.security.core.Authentication;<br>import org.springframework.security.core.AuthenticationException;<br>import org.springframework.security.web.authentication.AbstractAuthenticationProcessingFilter;<br>import org.springframework.security.web.util.matcher.AntPathRequestMatcher;<br><br>import javax.servlet.FilterChain;<br>import javax.servlet.ServletException;<br>import javax.servlet.http.HttpServletRequest;<br>import javax.servlet.http.HttpServletResponse;<br>import java.io.IOException;<br><br>public class JWTLoginFilter extends AbstractAuthenticationProcessingFilter {<br><br> public JWTLoginFilter(String url, AuthenticationManager authManager) {<br> super(new AntPathRequestMatcher(url));<br> setAuthenticationManager(authManager);<br> }<br><br> @Override<br> public Authentication attemptAuthentication(<br> HttpServletRequest req, HttpServletResponse res)<br> throws AuthenticationException, IOException, ServletException {<br><br> // JSON反序列化成 AccountCredentials<br> AccountCredentials creds = new ObjectMapper().readValue(req.getInputStream(), AccountCredentials.class);<br><br> // 返回一个验证令牌<br> return getAuthenticationManager().authenticate(<br> new UsernamePasswordAuthenticationToken(<br> creds.getUsername(),<br> creds.getPassword()<br> )<br> );<br> }<br><br> @Override<br> protected void successfulAuthentication(<br> HttpServletRequest req,<br> HttpServletResponse res, FilterChain chain,<br> Authentication auth) throws IOException, ServletException {<br> TokenAuthenticationService.addAuthentication(res, auth.getName());<br> }<br><br><br> @Override<br> protected void unsuccessfulAuthentication(HttpServletRequest request, HttpServletResponse response, AuthenticationException failed) throws IOException, ServletException {<br> response.setContentType("application/json");<br> response.setStatus(HttpServletResponse.SC_OK);<br> response.getOutputStream().println(JSONResult.fillResultString(500, "Internal Server Error!!!", JSONObject.NULL));<br> }<br>}<br>
JWTAuthenticationFilter,这也是个拦截器,<br>它拦截所有需要JWT的请求,<br>然后调用TokenAuthenticationService类的静态方法去做JWT验证
package com.example.demo.demo.jwt;<br><br>import org.springframework.security.core.Authentication;<br>import org.springframework.security.core.context.SecurityContextHolder;<br>import org.springframework.web.filter.GenericFilterBean;<br><br>import javax.servlet.FilterChain;<br>import javax.servlet.ServletException;<br>import javax.servlet.ServletRequest;<br>import javax.servlet.ServletResponse;<br>import javax.servlet.http.HttpServletRequest;<br>import java.io.IOException;<br><br>public class JWTAuthenticationFilter extends GenericFilterBean {<br><br> @Override<br> public void doFilter(ServletRequest request,<br> ServletResponse response,<br> FilterChain filterChain)<br> throws IOException, ServletException {<br> Authentication authentication = TokenAuthenticationService<br> .getAuthentication((HttpServletRequest)request);<br><br> SecurityContextHolder.getContext()<br> .setAuthentication(authentication);<br> filterChain.doFilter(request,response);<br> }<br>}<br><br>
进行测试
启动过程:<br><br>先程序启动 - main函数<br><br>注册验证组件 - WebSecurityConfig 类 configure(AuthenticationManagerBuilder auth)方法,这里我们注册了自定义验证组件<br><br>设置验证规则 - WebSecurityConfig 类 configure(HttpSecurity http)方法,这里设置了各种路由访问规则<br><br>初始化过滤组件 - JWTLoginFilter 和 JWTAuthenticationFilter 类会初始化
测试获取Token
curl -H "Content-Type: application/json" -X POST -d '{"username":"admin","password":"123456"}' http://127.0.0.1:8080/login
{<br> "result": "eyJhbGciOiJIUzUxMiJ9.eyJhdXRob3JpdGllcyI6IlJPTEVfQURNSU4sQVVUSF9XUklURSIsInN1YiI6ImFkbWluIiwiZXhwIjoxNDkzNzgyMjQwfQ.HNfV1CU2CdAnBTH682C5-KOfr2P71xr9PYLaLpDVhOw8KWWSJ0lBo0BCq4LoNwsK_Y3-W3avgbJb0jW9FNYDRQ",<br> "message": "",<br> "status": 0<br>}
这里我们得到了相关的JWT,反Base64之后,就是下面的内容,标准JWT。
{"alg":"HS512"}{"authorities":"ROLE_ADMIN,AUTH_WRITE","sub":"admin","exp":1493782240}
整个过程如下:
拿到传入JSON,解析用户名密码 - JWTLoginFilter 类 attemptAuthentication 方法<br><br>自定义身份认证验证组件,进行身份认证 - CustomAuthenticationProvider 类 authenticate 方法<br><br>验证成功 - JWTLoginFilter 类 successfulAuthentication 方法<br><br>生成JWT - TokenAuthenticationService 类 addAuthentication方法
测试一个访问资源
curl -H "Content-Type: application/json" -H "Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJhdXRob3JpdGllcyI6IlJPTEVfQURNSU4sQVVUSF9XUklURSIsInN1YiI6ImFkbWluIiwiZXhwIjoxNDkzNzgyMjQwfQ.HNfV1CU2CdAnBTH682C5-KOfr2P71xr9PYLaLpDVhOw8KWWSJ0lBo0BCq4LoNwsK_Y3-W3avgbJb0jW9FNYDRQ" http://127.0.0.1:8080/users
{<br> "result":["freewolf","tom","jerry"],<br> "message":"",<br> "status":0<br>}
处理流程:
接到请求进行拦截 - JWTAuthenticationFilter 中的方法<br><br>验证JWT - TokenAuthenticationService 类 getAuthentication 方法<br><br>访问Controller
在Spring Security中,<br>对于GrantedAuthority接口实现类来说是不区分是Role还是Authority,<br>二者区别就是如果是hasAuthority判断,就是判断整个字符串,判断hasRole时,<br>系统自动加上ROLE_到判断的Role字符串上,<br>也就是说hasRole("CREATE")和hasAuthority('ROLE_CREATE')是相同的。<br>利用这些可以搭建完整的RBAC体系。
ORM
Mybatis
Mybatis 面试题
主要组成
Configuration MyBatis配置信息
配置方式
XML文件
注解
SQLSession提供用户对数据库操作的API,完成增删改查
Executor由SQLSession调用执行数据库操作
StatementHandler对SQL语句进行操作
ParameterHandler将用户传递的参数转换成JDBC Statement所需要的参数
ResultSetHandler将JDBC返回的ResultSet结果集对象转换成List集合
TypeHandler负责java数据类型和jdbc数据类型之间的映射和转换
mybatis 在调用 connection 进行 sql 预编译之前,会对sql语句进行动态解析
占位符的处理
动态sql的处理
参数类型校验
动态SQL
通过标签的形式大大减少了条件查询时拼接SQL的难度,提高了SQL的准确率
常用标签
if、where、foreach
结果映射
resultMap
数据类型转换
插件机制
Interceptor接口
分页插件
缓存机制
一级缓存:Session级别的缓存,Executor对象会维护一个Cache缓存,默认开启
基于 PerpetualCache 的 HashMap 本地缓存,<br>其存储作用域为 Session,<br>当 Session flush 或 close 之后,<br>该 Session 中的所有 Cache 就将清空,<br>默认打开一级缓存。
二级缓存:Application级别的缓存,可以看作是作用于整个应用的全局缓存。<br> 一般通过自定义缓存Redis、Memcached等实现
二级缓存与一级缓存其机制相同,<br>默认也是采用 PerpetualCache,HashMap 存储,<br>不同在于其存储作用域为 Mapper(Namespace),<br>并且可自定义存储源,如 Ehcache,redis。<br>默认不打开二级缓存,要开启二级缓存,<br>使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),<br>在它的映射文件中配置<cache/>
Mybatis的二级缓存实现<br><br>https://juejin.im/post/592c08292f301e006c60cae2<br>
新建一个类实现org.apache.ibatis.cache.Cache接口<br><br>接口共有以下五个方法<br>
String getId():mybatis缓存操作对象的标识符。一个mapper对应一个mybatis的缓存操作对象。<br><br>void putObject(Object key, Object value):将查询结果塞入缓存。<br><br>Object getObject(Object key):从缓存中获取被缓存的查询结果。<br><br>Object removeObject(Object key):从缓存中删除对应的key、value。只有在回滚时触发。<br> 一般我们也可以不用实现,具体使用方式请参考:org.apache.ibatis.cache.decorators.TransactionalCache。<br><br>void clear():发生更新时,清除缓存。<br><br>int getSize():可选实现。返回缓存的数量。<br><br>ReadWriteLock getReadWriteLock():可选实现。用于实现原子性的缓存操作。
新建RedisCache类,实现Cache接口
public class RedisCache implements Cache {<br><br> private static final Logger logger = LoggerFactory.getLogger(RedisCache.class);<br><br> private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();<br><br> private final String id; // cache instance id<br><br> private RedisTemplate redisTemplate;<br><br> private static final long EXPIRE_TIME_IN_MINUTES = 30; // redis过期时间<br><br> public RedisCache(String id) {<br>if (id == null) {<br>throw new IllegalArgumentException("Cache instances require an ID");<br>}<br>this.id = id;<br>}<br><br> @Override<br>public String getId() {<br>return id;<br>}<br><br> /**<br>* Put query result to redis<br>*<br>* @param key<br>* @param value<br>*/<br>@Override<br>@SuppressWarnings("unchecked")<br>public void putObject(Object key, Object value) {<br>RedisTemplate redisTemplate = getRedisTemplate();<br>ValueOperations opsForValue = redisTemplate.opsForValue();<br>opsForValue.set(key, value, EXPIRE_TIME_IN_MINUTES, TimeUnit.MINUTES);<br>logger.debug("Put query result to redis");<br>}<br><br> /**<br>* Get cached query result from redis<br>*<br>* @param key<br>* @return<br>*/<br>@Override<br>public Object getObject(Object key) {<br>RedisTemplate redisTemplate = getRedisTemplate();<br>ValueOperations opsForValue = redisTemplate.opsForValue();<br>logger.debug("Get cached query result from redis");<br>return opsForValue.get(key);<br>}<br><br> /**<br>* Remove cached query result from redis<br>*<br>* @param key<br>* @return<br>*/<br>@Override<br>@SuppressWarnings("unchecked")<br>public Object removeObject(Object key) {<br>RedisTemplate redisTemplate = getRedisTemplate();<br>redisTemplate.delete(key);<br>logger.debug("Remove cached query result from redis");<br>return null;<br>}<br><br> /**<br>* Clears this cache instance<br>*/<br>@Override<br>public void clear() {<br>RedisTemplate redisTemplate = getRedisTemplate();<br>redisTemplate.execute((RedisCallback) connection -> {<br>connection.flushDb();<br>return null;<br>});<br>logger.debug("Clear all the cached query result from redis");<br>}<br><br> @Override<br>public int getSize() {<br>return 0;<br>}<br><br> @Override<br>public ReadWriteLock getReadWriteLock() {<br>return readWriteLock;<br>}<br><br> private RedisTemplate getRedisTemplate() {<br>if (redisTemplate == null) {<br>redisTemplate = ApplicationContextHolder.getBean("redisTemplate");<br>}<br>return redisTemplate;<br>}<br>}
关键点
1. 自己实现的二级缓存,必须要有一个带id的构造函数,否则会报错。<br><br>2.我们使用Spring封装的redisTemplate来操作Redis。<br> 网上所有介绍redis做二级缓存的文章都是直接用jedis库,但是笔者认为这样不够Spring Style,<br> 而且,redisTemplate封装了底层的实现,未来如果我们不用jedis了,我们可以直接更换底层的库,而不用修改上层的代码。<br> 更方便的是,使用redisTemplate,我们不用关心redis连接的释放问题,否则新手很容易忘记释放连接而导致应用卡死。<br><br>3. 需要注意的是,这里不能通过autowire的方式引用redisTemplate,<br> 因为RedisCache并不是Spring容器里的bean。所以我们需要手动地去调用容器的getBean方法来拿到这个bean。<br><br>4. 我们采用的redis序列化方式是默认的jdk序列化。所以数据库的查询对象(比如Product类)需要实现Serializable接口。
开启二级缓存
在ProductMapper.xml中开启二级缓存
<?xml version="1.0" encoding="UTF-8" ?><br><br><!DOCTYPE mapper<br>PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"<br>"http://mybatis.org/dtd/mybatis-3-mapper.dtd"><br><mapper namespace="com.wooyoo.learning.dao.mapper.ProductMapper"><br><!-- 开启基于redis的二级缓存 --><br><cache type="com.wooyoo.learning.util.RedisCache"/><br><select id="select" resultType="Product"><br>SELECT * FROM products WHERE id = #{id} LIMIT 1<br></select><br><br> <update id="update" parameterType="Product" flushCache="true"><br>UPDATE products SET name = #{name}, price = #{price} WHERE id = #{id} LIMIT 1<br></update><br></mapper>
<cache type="com.wooyoo.learning.util.RedisCache"/>表示开启基于redis的二级缓存,<br>并且在update语句中,我们设置flushCache为true,<br>这样在更新product信息时,能够自动失效缓存(本质上调用的是clear方法)。
# 与 $ 区别以及 sql 预编译
#{ } 解析为一个 JDBC 预编译语句(prepared statement)的参数标记符。<br>
${ } 仅仅为一个纯碎的 string 替换,在动态 SQL 解析阶段将会进行变量替换<br>
用法tips
1、能使用 #{ } 的地方就用 #{ }
首先这是为了性能考虑的,相同的预编译 sql 可以重复利用。
其次,${ } 在预编译之前已经被变量替换了,这会存在 sql 注入问题
2、表名作为变量时,必须使用 ${ }
sql预编译
JDBC 中使用对象 PreparedStatement 来抽象预编译语句
1、预编译阶段可以优化 sql 的执行。
2、预编译语句对象可以重复利用。
模糊查询like语句该怎么写
在Java代码中添加sql通配符
string wildcardname = “%smi%”;<br> list<name> names = mapper.selectlike(wildcardname);<br><br> <select id=”selectlike”><br>select * from foo where bar like #{value}<br></select>
在sql语句中拼接通配符,会引起sql注入
string wildcardname = “smi”;<br>list<name> names = mapper.selectlike(wildcardname);<br><br><select id=”selectlike”><br>select * from foo where bar like "%"#{value}"%"<br></select>
通常一个Xml映射文件,都会写一个Dao接口与之对应,<br>请问,这个Dao接口的工作原理是什么?<br>Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口即Mapper接口。<br>接口的全限名,就是映射文件中的namespace的值;<br>接口的方法名,就是映射文件中Mapper的Statement的id值;<br>接口方法内的参数,就是传递给sql的参数。<br><br><br>Mapper接口是没有实现类的,<br>当调用接口方法时,接口全限名+方法名拼接字符串作为key值,<br>可唯一定位一个MapperStatement。<br>在Mybatis中,每一个<select>、<insert>、<update>、<delete>标签,<br>都会被解析为一个MapperStatement对象。<br><br>举例:com.mybatis3.mappers.StudentDao.findStudentById,<br>可以唯一找到namespace为com.mybatis3.mappers.StudentDao<br>下面 id 为 findStudentById 的 MapperStatement。
Mapper接口里的方法,是不能重载的,<br>因为是使用 全限名+方法名 的保存和寻找策略。<br>Mapper 接口的工作原理是JDK动态代理,<br>Mybatis运行时会使用JDK动态代理为Mapper接口生成代理对象proxy,<br>代理对象会拦截接口方法,<br>转而执行MapperStatement所代表的sql,然后将sql执行结果返回。
Mybatis比IBatis比较大的几个改进是什么
a.有接口绑定,包括注解绑定sql和xml绑定Sql
b.动态sql由原来的节点配置变成OGNL表达式
c. 在一对一,一对多的时候引进了association,<br>在一对多的时候引入了collection节点,<br>不过都是在resultMap里面配置
接口绑定有几种实现方式,分别是怎么实现的?
一种是通过注解绑定,就是在接口的方法上面加上@Select@Update等注解里面包含Sql语句来绑定
另外一种就是通过xml里面写SQL来绑定,在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名.
Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,<br>它是针对ResultSet结果集执行的内存分页,而非物理分页,<br>可以在sql内直接书写带有物理分页的参数来完成物理分页功能,<br>也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,<br>实现自定义插件,在插件的拦截方法内拦截待执行的sql,<br>然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。<br><br>举例:select * from student,<br>拦截sql后重写为:select t.* from (select * from student)t limit 0,10
一对一、一对多的关联查询
一对一
<mapper namespace="com.lcb.mapping.userMapper"> <br><br> <!--association 一对一关联查询 --> <br><select id="getClass" parameterType="int" resultMap="<b><font color="#80bc42">ClassesResultMap</font></b>"> <br>select * from class c,teacher t where c.teacher_id=t.t_id and c.c_id=#{id} <br></select> <br><br><resultMap type="com.lcb.user.Classes" id="<b><font color="#80bc42">ClassesResultMap</font></b>"> <br><!-- 实体类的字段名和数据表的字段名映射 --> <br><id property="id" column="c_id"/> <br><result property="name" column="c_name"/> <br><b><font color="#80bc42"><association property="teacher" javaType="com.lcb.user.Teacher"> <br><id property="id" column="t_id"/> <br><result property="name" column="t_name"/> <br></association> </font></b><br></resultMap>
一对多
<!--collection 一对多关联查询 --> <br><select id="getClass2" parameterType="int" resultMap="ClassesResultMap2"> <br>select * from class c,teacher t,student s where c.teacher_id=t.t_id and c.c_id=s.class_id and c.c_id=#{id} <br></select> <br><br><<b><font color="#80bc42">resultMap</font></b> type="com.lcb.user.Classes" id="ClassesResultMap2"> <br><id property="id" column="c_id"/> <br><result property="name" column="c_name"/> <br><association property="teacher" javaType="com.lcb.user.Teacher"> <br><id property="id" column="t_id"/> <br><result property="name" column="t_name"/> <br></association> <br><br> <collection property="student" ofType="com.lcb.user.Student"> <br><id property="id" column="s_id"/> <br><result property="name" column="s_name"/> <br></collection> <br></<b><font color="#80bc42">resultMap</font></b>> <br></mapper>
MyBatis实现一对一有几种方式?具体怎么操作的?
联合查询
联合查询是几个表联合查询,只查询一次, <br>通过在resultMap里面配置association节点配置一对一的类就可以完成;
嵌套查询
嵌套查询是先查一个表,根据这个表里面的结果的 外键id,<br>去再另外一个表里面查询数据,也是通过association配置,<br>但另外一个表的查询通过select属性配置。
MyBatis实现一对多有几种方式,怎么操作的?
联合查询
联合查询是几个表联合查询,只查询一次,<br>通过在resultMap里面的collection节点配置一对多的类就可以完成;
嵌套查询
嵌套查询是先查一个表,根据这个表里面的 结果的外键id,<br>去再另外一个表里面查询数据,也是通过配置collection,<br>但另外一个表的查询通过select节点配置。
什么是MyBatis的接口绑定?有哪些实现方式?
接口绑定,就是在MyBatis中任意定义接口,<br>然后把接口里面的方法和SQL语句绑定, <br>我们直接调用接口方法就可以,<br>这样比起原来了SqlSession提供的方法我们可以有更加灵活的选择和设置。<br>
接口绑定有两种实现方式,<br>一种是通过注解绑定,<br>就是在接口的方法上面加上 @Select、@Update等注解,<br>里面包含Sql语句来绑定;<br><br>另外一种就是通过xml里面写SQL来绑定, <br>在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名。<br><br>当Sql语句比较简单时候,用注解绑定, <br>当SQL语句比较复杂时候,用xml绑定,一般用xml绑定的比较多。
简述Mybatis的插件运行原理,以及如何编写一个插件
Mybatis仅可以编写针对<br>ParameterHandler、<br>ResultSetHandler、<br>StatementHandler、<br>Executor这4种接口的插件,<br>Mybatis使用JDK的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,<br>每当执行这4种接口对象的方法时,就会进入拦截方法,<br>具体就是InvocationHandler的invoke()方法,<br>当然,只会拦截那些你指定需要拦截的方法。<br><br>实现Mybatis的Interceptor接口并复写intercept()方法,<br>然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,<br>association指的就是一对一,<br>collection指的就是一对多查询。<br>在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。<br><br>它的原理是,<br>使用CGLIB创建目标对象的代理对象,<br>当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),<br>拦截器invoke()方法发现a.getB()是null值,<br>那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,<br>然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。<br>这就是延迟加载的基本原理。<br><br>当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
Mybatis都有哪些Executor执行器?它们之间的区别是什么?
Mybatis有三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。<br>作用范围:Executor的这些特点,都严格限制在SqlSession生命周期范围内。<br><br>SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。<br><br>ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,<br>用完后,不关闭Statement对象,而是放置于Map<String, Statement>内,供下一次使用。<br>简言之,就是重复使用Statement对象。<br><br>BatchExecutor:执行update(没有select,JDBC批处理不支持select),<br>将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),<br>它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,<br>等待逐一执行executeBatch()批处理。与JDBC批处理相同。<br>
当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
第1种: 通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致<br><br><select id=”selectorder” parametertype=”int” resultetype=”me.gacl.domain.order”> <br><br> select <b><font color="#c1d18a">order_id id, order_no orderno ,order_price price</font></b> form orders where order_id=#{id}; <br><br> </select> <br>
第2种: 通过<resultMap>来映射字段名和实体类属性名的一一对应的关系<br><br> <select id="getOrder" parameterType="int" resultMap="orderresultmap"><br> select * from orders where order_id=#{id}<br> </select><br> <resultMap type=”me.gacl.domain.order” id=”orderresultmap”> <br> <!–用id属性来映射主键字段–> <br> <id property=”id” column=”order_id”> <br> <!–用result属性来映射非主键字段,property为实体类属性名,column为数据表中的属性–> <br> <result property = “orderno” column =”order_no”/> <br> <result property=”price” column=”order_price” /> <br> </reslutMap><br>
如何获取自动生成的(主)键值?
mysql:<br>通过LAST_INSERT_ID()获取刚插入记录的自增主键值,<br>在insert语句执行后,执行select LAST_INSERT_ID()就可以获取自增主键。<br><br><insert id="insertUser" parameterType="cn.itcast.mybatis.po.User"><br> <selectKey keyProperty="id" order="AFTER" resultType="int"><br> select LAST_INSERT_ID()<br> </selectKey><br> INSERT INTO USER(username,birthday,sex,address) VALUES(#{username},#{birthday},#{sex},#{address})<br></insert><br>
先查询序列得到主键,将主键设置到user对象中,将user对象插入数据库。<br><br><!-- oracle<br> 在执行insert之前执行select 序列.nextval() from dual取出序列最大值,将值设置到user对象 的id属性<br> --><br> <insert id="insertUser" parameterType="cn.itcast.mybatis.po.User"><br> <selectKey keyProperty="id" order="BEFORE" resultType="int"><br> select 序列.nextval() from dual<br> </selectKey><br> INSERT INTO USER(id,username,birthday,sex,address) VALUES( 序列.nextval(),#{username},#{birthday},#{sex},#{address})<br> </insert> <br>
在mapper中如何传递多个参数?
第一种:使用占位符的思想
在映射文件中使用#{0},#{1}代表传递进来的第几个参数<br><br>使用@param注解:来命名参数<br>public interface usermapper { <br> user selectuser(@param(“username”) string username, <br> @param(“hashedpassword”) string hashedpassword); <br><br> }<br><select id=”selectuser” resulttype=”user”> <br> select id, username, hashedpassword <br> from some_table where username = #{username} and hashedpassword = #{hashedpassword} <br> </select><br><br>#{0},#{1}方式<br>//对应的xml,#{0}代表接收的是dao层中的第一个参数,#{1}代表dao层中第二参数,更多参数一致往后加即可。<br><select id="selectUser"resultMap="BaseResultMap"> <br> select * fromuser_user_t whereuser_name = #{0} anduser_area=#{1} <br></select> <br>
第二种:使用Map集合作为参数来装载
try{<br><br> //映射文件的命名空间.SQL片段的ID,就可以调用对应的映射文件中的SQL<br>/**<br>* 由于我们的参数超过了两个,而方法中只有一个Object参数收集<br>* 因此我们使用Map集合来装载我们的参数<br>*/<br>Map<String, Object> map = new HashMap();<br>map.put("start", start);<br>map.put("end", end);<br>return sqlSession.selectList("StudentID.pagination", map);<br>}catch(Exception e){<br>e.printStackTrace();<br>sqlSession.rollback();<br>throw e;<br>}finally{<br>MybatisUtil.closeSqlSession();<br>}<br><br><!--分页查询--><br><select id="pagination" parameterType="map" resultMap="studentMap"><br>/*根据key自动找到对应Map集合的value*/<br>select * from students limit #{start},#{end};<br></select>
Mybatis动态sql是做什么的?<br>都有哪些动态sql?<br>能简述一下动态sql的执行原理不?
Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能。<br><br>Mybatis提供了9种动态sql标签:trim | where | set | foreach | if | choose | when | otherwise | bind。<br><br>其执行原理为,使用OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,以此来完成动态sql的功能。
Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
如果配置了namespace那么当然是可以重复的,因为我们的Statement实际上就是namespace+id<br><br>如果没有配置namespace的话,那么相同的id就会导致覆盖了。
为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。
而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。
通常一个Xml映射文件,都会写一个Dao接口与之对应,<br>请问,这个Dao接口的工作原理是什么?<br>Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口,就是人们常说的Mapper接口,<br>接口的全限名,就是映射文件中的namespace的值,<br>接口的方法名,就是映射文件中MappedStatement的id值,<br>接口方法内的参数,就是传递给sql的参数。
Mapper接口是没有实现类的,当调用接口方法时,<br>接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement
com.mybatis3.mappers.StudentDao.findStudentById,<br><br>可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。<br>在Mybatis中,每一个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement对象。
Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。<br>Dao接口的工作原理是JDK动态代理,<br>Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,<br>代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,<br>然后将sql执行结果返回。<br>
使用MyBatis的mapper接口调用时有哪些要求?
① Mapper接口方法名和mapper.xml中定义的每个sql的id相同;<br><br>② Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同;<br><br>③ Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同;<br><br>④ Mapper.xml文件中的namespace即是mapper接口的类路径。
Mapper编写有哪几种方式?
接口实现类继承SqlSessionDaoSupport:<br>使用此种方法需要编写mapper接口,mapper接口实现类、mapper.xml文件。
(1)在sqlMapConfig.xml中配置mapper.xml的位置<br><br><mappers><br> <mapper resource="mapper.xml文件的地址" /><br> <mapper resource="mapper.xml文件的地址" /><br></mappers>
(2)定义mapper接口<br><br>(3)实现类集成SqlSessionDaoSupport<br>mapper方法中可以this.getSqlSession()进行数据增删改查。<br><br>(4)spring 配置<br><bean id=" " class="mapper接口的实现"><br><property name="sqlSessionFactory" ref="sqlSessionFactory"></property><br></bean>
使用org.mybatis.spring.mapper.MapperFactoryBean
(1)在sqlMapConfig.xml中配置mapper.xml的位置,<br>如果mapper.xml和mappre接口的名称相同且在同一个目录,<br>这里可以不用配置<br><br><mappers><br><mapper resource="mapper.xml文件的地址" /><br><mapper resource="mapper.xml文件的地址" /><br></mappers>
(2)定义mapper接口:<br><br>①mapper.xml中的namespace为mapper接口的地址<br>②mapper接口中的方法名和mapper.xml中的定义的statement的id保持一致<br>③Spring中定义<br><bean id="" class="org.mybatis.spring.mapper.MapperFactoryBean"><br><property name="mapperInterface" value="mapper接口地址" /> <br><property name="sqlSessionFactory" ref="sqlSessionFactory" /> <br></bean>
使用mapper扫描器
(1)mapper.xml文件编写:<br><br>mapper.xml中的namespace为mapper接口的地址;<br>mapper接口中的方法名和mapper.xml中的定义的statement的id保持一致;<br>如果将mapper.xml和mapper接口的名称保持一致则不用在sqlMapConfig.xml中进行配置。
(2)定义mapper接口:<br>注意mapper.xml的文件名和mapper的接口名称保持一致,且放在同一个目录<br><br>(3)配置mapper扫描器:<br><bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><br><property name="basePackage" value="mapper接口包地址"></property><br><property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/> <br></bean><br><br>(4)使用扫描器后从spring容器中获取mapper的实现对象。
Mybatis3 注解编程
Springboot + Mybatis
@SpringBootApplication<br><b><font color="#c41230">@MapperScan("com.app.ghy.wechat.mapper")</font></b><br>public class AppWechatServiceApplication{<br> Logger logger = Logger.getLogger(AppWechatServiceApplication.class);<br><br> public static void main(String[] args) {<br> SpringApplication.run(AppWechatServiceApplication.class, args);<br> }<br>}
<b><font color="#c41230">package com.app.ghy.wechat.mapper;</font></b><br><br>import org.apache.ibatis.annotations.Mapper;<br>import org.apache.ibatis.annotations.Param;<br>import org.apache.ibatis.annotations.Select;<br><br>@Mapper<br>public interface BaseMapper {<br><br> @Select("SELECT FUNC_SYS_SEQ(#{keyname}) as keyid ")<br>//参数名为keyname, 使用数据库中定义的函数 FUNC_SYS_SEQ<br> public String createKeyIDByCustom(@Param("<b><font color="#c41230">keyname</font></b>") String keyname);<br> <br>}<br>
子主题
SQL答案整理
原始表及原始数据
--建表<br>--学生表<br>CREATE TABLE `Student`(<br>`s_id` VARCHAR(20),<br>`s_name` VARCHAR(20) NOT NULL DEFAULT '',<br>`s_birth` VARCHAR(20) NOT NULL DEFAULT '',<br>`s_sex` VARCHAR(10) NOT NULL DEFAULT '',<br>PRIMARY KEY(`s_id`)<br>);
--课程表<br>CREATE TABLE `Course`(<br>`c_id` VARCHAR(20),<br>`c_name` VARCHAR(20) NOT NULL DEFAULT '',<br>`t_id` VARCHAR(20) NOT NULL,<br>PRIMARY KEY(`c_id`)<br>);
--教师表<br>CREATE TABLE `Teacher`(<br>`t_id` VARCHAR(20),<br>`t_name` VARCHAR(20) NOT NULL DEFAULT '',<br>PRIMARY KEY(`t_id`)<br>);
--成绩表<br>CREATE TABLE `Score`(<br>`s_id` VARCHAR(20),<br>`c_id` VARCHAR(20),<br>`s_score` INT(3),<br>PRIMARY KEY(`s_id`,`c_id`)<br>);
--插入学生表测试数据<br>insert into Student values('01' , '赵雷' , '1990-01-01' , '男');<br>insert into Student values('02' , '钱电' , '1990-12-21' , '男');<br>insert into Student values('03' , '孙风' , '1990-05-20' , '男');<br>insert into Student values('04' , '李云' , '1990-08-06' , '男');<br>insert into Student values('05' , '周梅' , '1991-12-01' , '女');<br>insert into Student values('06' , '吴兰' , '1992-03-01' , '女');<br>insert into Student values('07' , '郑竹' , '1989-07-01' , '女');<br>insert into Student values('08' , '王菊' , '1990-01-20' , '女');<br>--课程表测试数据<br>insert into Course values('01' , '语文' , '02');<br>insert into Course values('02' , '数学' , '01');<br>insert into Course values('03' , '英语' , '03');<br><br>--教师表测试数据<br>insert into Teacher values('01' , '张三');<br>insert into Teacher values('02' , '李四');<br>insert into Teacher values('03' , '王五');<br><br>--成绩表测试数据<br>insert into Score values('01' , '01' , 80);<br>insert into Score values('01' , '02' , 90);<br>insert into Score values('01' , '03' , 99);<br>insert into Score values('02' , '01' , 70);<br>insert into Score values('02' , '02' , 60);<br>insert into Score values('02' , '03' , 80);<br>insert into Score values('03' , '01' , 80);<br>insert into Score values('03' , '02' , 80);<br>insert into Score values('03' , '03' , 80);<br>insert into Score values('04' , '01' , 50);<br>insert into Score values('04' , '02' , 30);<br>insert into Score values('04' , '03' , 20);<br>insert into Score values('05' , '01' , 76);<br>insert into Score values('05' , '02' , 87);<br>insert into Score values('06' , '01' , 31);<br>insert into Score values('06' , '03' , 34);<br>insert into Score values('07' , '02' , 89);<br>insert into Score values('07' , '03' , 98);
题目及答案
1、查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号。
-- 写法一:<br>select a.s_id<br>from Score a join Score b on a.s_id = b.s_id and a.s_score >b.s_score<br>where a.c_id = '01' and b.c_id= '02';
-- 写法二:<br>select a.s_id<br>from (select * from Score where c_id = '01') as a <br>join (select * from Score where c_id='02') as b<br>on a.s_id = b.s_id<br>where a.s_score > b.s_score;
2、查询平均成绩大于60分的学生的学号和平均成绩
select s_id, avg(s_score)<br>from Score<br>group by s_id<br>having avg(s_score)>60;
2、查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
select ROUND(t1.score,2) score ,t1.sid,t2.Sname from<br> (select avg(score) score , sid from sc GROUP BY sid)t1<br> left join student t2 on t1.sid = t2.sid<br> where t1.score >'60'
3、查询所有学生的学号、姓名、选课数、总成绩
select <br>student.s_id AS '学号', <br>student.s_name AS '姓名', <br>count(score.c_id) AS '选课数', <br>sum(score.s_score) AS '总成绩<br>from <br>student join score <br>on student.s_id = score.s_id <br>group by student.s_id, student.s_name
select t1.sid,t1.sname,count(t2.cid),sum(t2.score) from student t1 <br>left join sc t2 on t1.sid = t2.sid<br>GROUP BY t1.sid,t1.sname
4、查询姓“张”的老师的个数
select count(t_id)<br>from Teacher<br>where t_name like '张%';
select count(distinct(t_name))<br>from Teacher<br>where t_name like '张%';
5.查询没学过“张三”老师课的学生的学号、姓名(重点)
select s_id, s_name<br>from Student<br>where s_id not in <br>(<br>select s_id from Score join Course on Score.c_id = Course.c_id<br>join Teacher on Course.t_id = Teacher.t_id<br>where t_name = '张三'<br>);
6、查询学过“张三”老师所教课的同学的学号、姓名
写法一:<br>select s_id, s_name<br>from Student<br>where s_id in<br>(select s_id from Score join Course on Score.c_id = Course.c_id<br>join Teacher on Course.t_id = Teacher.t_id<br>where t_name = '张三');
写法二:<br>select Student.s_id, s_name<br>from <br>Student <br>JOIN Score on Student.s_id = Score.s_id<br>JOIN Course on Score.c_id = Course.c_id<br>JOIN Teacher on Teacher.t_id = Course.t_id<br>where t_name='张三';
select * from student where exists <br> (select 1 from<br> (select sid from course t1<br> left join sc t2 on t1.cid = t2.cid<br> where t1.tid = (select tid from teacher where tname = '张三'))t<br> where t.sid = student.sid)
7、查询学过编号为“01”的课程<br> 并且也学过编号为“02”的课程的学生的学号、姓名
--写法一:<br>select s_id, s_name<br>from Student<br>where s_id in<br>(select a.s_id from <br> (select s_id from Score where c_id = '01') as a<br>join (select s_id from Score where c_id ='02') as b<br>on a.s_id= b.s_id);
--写法二:<br>select s_id,s_name<br>from Student <br>where s_id in<br>(select s_id from Score where c_id = '01') <br>AND s_id in<br>(select s_id from Score where c_id = '02')
--写法三:<br>select a.s_id,a.s_name<br>from Student a JOIN Score b ON a.s_id=b.s_id<br>JOIN Score c ON a.s_id=c.s_id<br>where b.c_id='01' and c.c_id='02'<br>and b.s_id=c.s_id ;
8、查询课程编号为“02”的总成绩
select sum(s_score)<br>from Score<br>where c_id = '02';
9、查询所有课程成绩小于60分的学生的学号、姓名
select s_id, s_name<br>from Student <br>where s_id NOT IN (SELECT s_id FROM Score where s_score >=60)
10、查询没有学全所有课的学生的学号、姓名
写法一:<br>select Student.s_id, Student.s_name<br>from Student join Score on Score.s_id = Student.s_id<br>group by s_id, s_name<br>having count(Score.c_id) < (select count(c_id) from Course);
写法二:<br>select s_id, s_name<br>from Student <br>where s_id IN (SELECT s_id FROM Score group by s_id <br>having count(c_id)<(select count(c_id) from Course))
11、查询至少有一门课与学号为“01”的学生<br> 所学课程相同的学生的学号和姓名
select distinct a.s_id, a.s_name<br>from Student a join Score b on a.s_id= b.s_id<br>where c_id in<br>(select c_id from Score where s_id = '01')<br>and a.s_id<>'01';
12、查询和“01”号同学所学课程完全相同的其他同学的学号
select s_id<br>from Score<br>where c_id in<br>(select c_id from Score where s_id='01')<br>and s_id <> '01'<br>group by s_id<br>having count(c_id)=(select count(c_id) from Score where s_id='01');
13、把“SCORE”表中“张三”老师教的课的成绩都更改为此课程的平均成绩
update Score as a join <br>(select avg(s_score) as t, Score.c_id from Score <br>join Course on Score.c_id= Course.c_id<br>join Teacher on Teacher.t_id= Course.t_id<br>where t_name ='张三' group by c_id) as b#张三老师教的课与平均分<br>on a.c_id= b.c_id<br>set a.s_score= b.t;
14、查询和“02”号的同学学习的课程完全相同的其他同学学号和姓名(同12题)
select a.s_id,a.s_name <br>from Student a join Score b on a.s_id=b.s_id <br>where c_id in (select c_id from Score where s_id='02') <br>and a.s_id <> '02' <br>group by a.s_id <br>having count(c_id)=(select count(c_id) from Score where s_id='02');
15、删除学习“张三”老师课的SC表记录
delete from Score<br>where c_id in <br>(select c_id from Course join Teacher on Course.t_id=Teacher.t_id<br>where t_name ='张三');
17、按平均成绩从高到低显示所有学生的<br> “数据库”(c_id='04')、“企业管理”(c_id='01')、<br> “英语”(c_id='06')三门的课程成绩,<br> 按如下形式显示:<br> 学生ID,数据库,企业管理,英语,有效课程数,有效平均分
select s_id as '学生ID',<br>(case when c_id='04' then s_score else NULL end) as '数据库',<br>(case when c_id='01' then s_score else NULL end) as '企业管理',<br>(case when c_id='06' then s_score else NULL end) as '英语',<br>count(c_id) as 有效课程数,<br>avg(s_score) as 有效平均分<br>from Score<br>group by s_id<br>order by avg(s_score) DESC;
18、查询各科成绩最高和最低的分: 以如下的形式显示:课程ID,最高分,最低分
select c_id as 课程ID,<br>max(s_score) as 最高分,<br>min(s_score) as 最低分<br>from Score<br>group by c_id;
19、按各科平均成绩从低到高和及格率的百分数从高到低排列,以如下形式显示:课程号,课程名,平均成绩,及格百分数
select a.c_id as '课程号',c_name as '课程名',avg(s_score) as '平均成绩',<br>concat(<br>(select count(b.s_score) <br>from Score b where b.s_score>=60 <br>and a.c_id=b.c_id)/(select count(b.s_score) <br>from Score b where a.c_id=b.c_id)*100,'%'<br>) as '及格百分数'<br>from Score a join Course c<br>on a.c_id=c.c_id<br>group by a.c_id,c_name<br>order by 平均成绩, 及格百分数 DESC;
20、查询如下课程平均成绩和及格率的百分数(用1行显示),其中企业管理为001,马克思为002,UML为003,数据库为004
select sum(case when c_id = 01 then s_score else 0 end)/ <br> sum(case when c_id = 01 then 1 else 0 end), # 计算课程 01 的平均分<br><br> 100*<br> sum(case when c_id = 01 and s_score >= 60 then 1 else 0 end) / <br> sum(case when c_id = 01 then 1 else 0 end) # 计算课程 01 的及格率<br>from score;
21、查询不同老师所教不同课程平均分从高到低显示
select Teacher.t_id,Teacher.t_name,Course.c_name,avg(Score.s_score)<br>from Teacher <br>join Course on Teacher.t_id=Course.t_id<br>join Score on Course.c_id=Score.c_id<br>group by Teacher.t_id,Teacher.t_name,Course.c_name<br>order by avg(Score.s_score) DESC;
22、查询如下课程成绩第3名到第6名的学生成绩单,其中企业管理为001,马克思为002,UML为003,数据库为004,以如下形式显示: <br>学生ID学生姓名企业管理马克思UML数据库平均成绩
题目有问题,这道题不做
23、使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计各分数段人数:课程ID和课程名称
select a.c_id AS '课程ID',c_name '课程名称',<br>sum(case when s_score between 85 and 100 then 1 else 0 end) as '[100-85]',<br>sum(case when s_score >=70 and s_score<85 then 1 else 0 end) as '[85-70]',<br>sum(case when s_score>=60 and s_score<70 then 1 else 0 end) as '[70-60]',<br>sum(case when s_score<60 then 1 else 0 end) as '[<60]'<br>from Score a join Course b on a.c_id=b.c_id<br>group by a.c_id,c_name;
24、查询学生平均成绩及其名次
要点:算出在所有同学中有几个同学的平均分高于某个ID,然后+1,就是名次
#平均成绩 -> avgscore<br><br>SELECT s_id ,avgscore,<br> (SELECT COUNT(*) FROM<br> (SELECT s_id,AVG(s_score)AS avgscore FROM Score GROUP BY s_id)AS b <br> WHERE b.avgscore>a.avgscore)+1 as RANK<br>FROM (select s_id,avg(S_score) as avgscore from Score group by s_id)AS a<br>order by avgscore desc;
25、查询各科成绩前三名的记录(不考虑成绩并列情况)
要点:超过当前ID的人最多2人
SELECT c_id,s_id,s_score FROM Score a <br>WHERE (SELECT COUNT(*) FROM Score b WHERE a.c_id=b.c_id AND a.s_score
26、查询每门课程被选修的学生数
select c_id, count(s_id)<br>from Score<br>group by c_id;
27、查询出只选修了两门课程的全部学生的学号和姓名
写法一:<br>select Student.s_id,s_name, count(c_id)<br>from Student join Score on Student.s_id= Score.s_id<br>group by s_id,s_name<br>having count(c_id)=2;
写法二:<br>select s_id,s_name<br>from Student<br>WHERE s_id IN (SELECT s_id FROM Score GROUP BY s_id having count(c_id)=2)
28、查询男生、女生人数
select s_sex, count(*) from Student group by s_sex;
29、查询名字中含有“风”字的学生信息
select * <br>from Student<br>where s_name like '%风%';
30、查询同名同姓学生名单并统计同名人数
写法一:<br>select a.s_id, a.s_name,a.s_birth,a.s_sex<br>from Student AS a JOIN Student AS b<br>ON a.s_name=b.s_name<br>WHERE a.s_id<>b.s_id
写法二:<br>select s_name,count(*)<br>from Student<br>group by s_name<br>having count(*)>1
31、1990年出生的学生名单(注:Student表中s_birth列的类型是datetime)
-- 方法一<br>select s_name<br>from Student<br>where s_birth like '1990%';
-- 方法二<br>select s_name<br>from Student<br>where year(s_birth)=1990;
32、查询平均成绩大于85的所有学生的学号、姓名和平均成绩
select a.s_id as 学号, s_name as 姓名, avg(b.s_score) as 平均分<br>from Student a join Score b on a.s_id=b.s_id<br>group by a.s_id,s_name<br>having avg(b.s_score) >85;
33、查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
select c_id, avg(s_score) <br>from Score<br>group by c_id<br>order by avg(s_score),c_id DESC;
34、查询课程名称为“数学”且分数低于60的学生姓名和分数
select s_name as 学生姓名, s_score as 分数<br>from Student a join Score b on a.s_id=b.s_id<br>join Course c on c.c_id=b.c_id<br>where c_name='数学'<br>and s_score <60;
35、查询所有学生的选课情况
select a.s_id as 学号, s_name as 姓名 , c.c_id as 课程号,<br>c_name as 课程名称<br>from Student a join Score b on a.s_id=b.s_id<br>join Course c on b.c_id=c.c_id
36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
select s_name as 姓名,c_name as 课程名称,s_score as 分数<br>from Student a join Score b on at.s_id=b.s_id<br>join Course c on b.c_id=c.c_id<br>where s_score >70
37、查询不及格的课程并按课程号从大到小排列
select c_id as 课程号 ,s_score as 分数<br>from Score <br>where s_score<60<br>order by c_id;
38、查询课程编号为03且课程成绩在80分以上的学生的学号和姓名
写法一:<br>select a.s_id as 学号 ,s_name as 姓名<br>from Student a join Score b on a.s_id=b.s_id<br>where c_id='03'<br>and s_score>80;
写法二:<br>select s_id as 学号 ,s_name as 姓名<br>from Student <br>where s_id IN(SELECT s_id FROM Score WHERE c_id='03'<br>and s_score>80);
39、查询选了课程的学生人数
select count(DISTINCT s_id) as 学生人数 from Score
40、查询选修“张三”老师所授课程的学生中成绩最高的学生姓名及其成绩
select s_name as 学生姓名, s_score as 成绩<br>from Student a join Score b on a.s_id=b.s_id<br>join Course c on c.c_id=b.c_id<br>join Teacher d on d.t_id=c.t_id<br>where t_name='张三'<br>order by s_score DESC<br>limit 1;
41、查询各个课程及相应的选修人数
select a.c_id as 课程号,c_name as 课程名称, count(s_id)as 选修人数<br>from Score a join Course b on a.c_id=b.c_id<br>group by a.c_id;
42、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
select distinct a.s_id as 学生编号 ,a.c_id as 课程编号,a.s_score as 学生成绩<br>from Score a join Score b<br>on a.s_id=b.s_id and a.c_id<> b.c_id<br>where a.s_score=b.s_score;
43、查询每门课程成绩最好的前两名
SELECT a.c_id as 课程号,c_name as 课程名称,s_name as 姓名,b.s_score as chengji FROM <br>Course a join Score b on a.c_id=b.c_id<br>join Student c on c.s_id=b.s_id<br>WHERE (SELECT COUNT(*) FROM Score d WHERE a.c_id=d.c_id AND b.s_score
44、统计每门课程的学生选修人数(超过5人的课程才统计)。<br> 要求输出课程号和选修人数,<br> 查询结果按人数降序排序,<br> 若人数相同,按课程号升序排序
要点:分组,排序
select c_id as '课程号', count(s_id) as '选修人数'<br>from Score<br>group by c_id<br>having count(s_id)>5<br>order by count(s_id) DESC,c_id;
45、查询至少选修两门课程的学生学号
select s_id<br>from Score<br>group by s_id<br>having count(c_id)>=2;
46、查询选修了全部课程的学生信息
写法一:<br>select a.s_id, s_name,s_birth, s_sex<br>from Student a join Score b on a.s_id=b.s_id<br>group by a.s_id<br>having count(Score.c_id)=(select count(distinct c_id) from Score);
写法二:<br>select * from Student <br>where s_id in(select s_id from Score GROUP BY s_id <br>having count(c_id)=(select count(distinct c_id) from Score))
47、查询没学过“张三”老师讲授的任一门课程的学生姓名
select s_name from Student<br>where s_id not in <br>(select s_id from Score join Course on Score.c_id=Course.c_id<br>join Teacher on Teacher.t_id=Course.t_id<br>where t_name = '张三');
48、查询两门以上不及格课程的同学的学号及其平均成绩
select s_id as 学号, avg(s_score)as 平均成绩<br>from Score<br>where s_score <60<br>group by s_id<br>having count(c_id)>=2;
49、检索课程编号为“04”且分数小于60的学生学号,结果按按分数降序排列
select s_id<br>from Score<br>where c_id='04'<br>and s_score <60<br>order by s_score DESC;
50、删除学生编号为“02”的课程编号为“01”的成绩
delete from Score<br>where s_id='02'<br>and c_id='01';
查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数<br>
先查询01和02的sid和对应的分数组成两张中间表,利用left join连表<br> where加条件筛选,最后再利用sid和学生表join拿出所有信息
select t3.*,st.* from<br> (select t1.sid,s1,s2 from <br> (select Sid,score s1 from sc where Cid = '01')t1 <br> left join<br> (select Sid,score s2 from sc where Cid = '02')t2<br> on t1.sid = t2.sid<br> where t1.s1 > t2.s2 )t3<br> left join student st on st.sid = t3.sid
查询同时存在" 01 "课程和" 02 "课程的情况
要将01课程和02课程的信息全部筛出来<br> 然后令他们等于同一个人就行了,满足就select出来
select * from<br> (select * from sc where cid = '01')t1 <br> join (select * from sc where cid = '02')t2 <br> on t1.sid = t2.sid
查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显示为 null )
select * from<br> (select * from sc where cid = '01')t1 <br> left join (select * from sc where cid = '02')t2 <br> on t1.sid = t2.sid
查询不存在" 01 "课程但存在" 02 "课程的情况
查询出选了02课程下的选课信息,在其中筛选掉没选01课程的信息即可
select t1.* from sc t1 <br> where t1.cid = '02'<br> and<br> not exists (select 1 from sc where cid = '01' and sid = t1.sid)
时间相关函数
时间相减,要先转成秒time_to_sec() <br>再以秒相减
SELECT now(), date_format('2019-10-18 08:00:00','%Y-%m-%d %H:%i:%S' ), ( TIME_TO_SEC(NOW()) - TIME_TO_SEC(date_format('2019-10-18 08:00:00','%Y-%m-%d %H:%i:%S' ))) FROM DUAL
时间相加
SELECT NOW(), date_add(now(),interval 60 second) added FROM DUAL
零碎常见面试题
设计模式以及使用场景
策略模式<br><br>对于不同的bugStatus,使用不同的具体策略修改
单例模式<br><br>程序启动时加载配置
Builder模式<br>lombok<br><br>但要给对象赋值时,使用Builder模式,省去了setter()方法
单例模式的实现
懒汉模式(线程不安全)
public class SingletonDemo {<br> private static SingletonDemo instance;<br> private SingletonDemo(){<br> <br> }<br> public static SingletonDemo getInstance(){<br> if(instance==null){<br> instance=new SingletonDemo();<br> }<br> return instance;<br> }<br>}
线程安全的懒汉模式(线程安全)
public class SingletonDemo {<br> private static SingletonDemo instance;<br> private SingletonDemo(){<br> <br> }<br> public static synchronized SingletonDemo getInstance(){<br> if(instance==null){<br> instance=new SingletonDemo();<br> }<br> return instance;<br> }<br>}
饿汉模式(线程安全)
public class SingletonDemo {<br> private static SingletonDemo instance=new SingletonDemo();<br> private SingletonDemo(){<br> <br> }<br> public static SingletonDemo getInstance(){<br> return instance;<br> }<br>}<br>
静态类内部加载(线程安全)
public class SingletonDemo {<br> private static class SingletonHolder{<br> private static SingletonDemo instance=new SingletonDemo();<br> }<br> private SingletonDemo(){<br> System.out.println("Singleton has loaded");<br> }<br> public static SingletonDemo getInstance(){<br> return SingletonHolder.instance;<br> }<br>}
枚举方法(线程安全)
public enum SingletonDemo{<br> INSTANCE;<br> public void otherMethods(){<br> System.out.println("Something");<br> }<br>}
调用它的方法时
public class Hello {<br> public static void main(String[] args){<br> SingletonDemo.INSTANCE.otherMethods();<br> }<br>}
双重校验锁法(通常线程安全,低概率不安全)
public class SingletonDemo {<br> private static SingletonDemo instance;<br> private SingletonDemo(){<br> System.out.println("Singleton has loaded");<br> }<br> public static SingletonDemo getInstance(){<br> if(instance==null){<br> synchronized (SingletonDemo.class){<br> if(instance==null){<br> instance=new SingletonDemo();<br> }<br> }<br> }<br> return instance;<br> }<br>}
第七种终极版 (volatile)
public class Singleton{<br> private volatile static Singleton singleton = null;<br> private Singleton() { }<br><br> public static Singleton getInstance() {<br> if (singleton== null) {<br> synchronized (Singleton.class) {<br> if (singleton== null) {<br> singleton= new Singleton();<br> }<br> }<br> }<br> return singleton;<br> }<br>}
使用ThreadLocal实现单例模式(线程安全)
public class Singleton {<br> private static final ThreadLocal<singleton> tlSingleton =<br> new ThreadLocal<singleton>() {<br> @Override<br> protected Singleton initialValue() {<br> return new Singleton();<br> }<br> };<br> /**<br> * Get the focus finder for this thread.<br> */<br> public static Singleton getInstance() {<br> return tlSingleton.get();<br> }<br> // enforce thread local access<br> private Singleton() {}<br>}</singleton></singleton>
使用CAS锁实现(线程安全)
/**<br> * 更加优美的Singleton, 线程安全的<br> */<br>public class Singleton {<br> /** 利用AtomicReference */<br> private static final AtomicReference<singleton> INSTANCE = new AtomicReference<singleton>();<br> /**<br> * 私有化<br> */<br> private Singleton(){<br> }<br> /**<br> * 用CAS确保线程安全<br> */<br> public static final Singleton getInstance(){<br> for (;;) {<br> Singleton current = INSTANCE.get();<br> if (current != null) {<br> return current;<br> }<br> current = new Singleton();<br> if (INSTANCE.compareAndSet(null, current)) {<br> return current;<br> }<br> }<br> }<br> <br> public static void main(String[] args) {<br> Singleton singleton1 = Singleton.getInstance();<br> Singleton singleton2 = Singleton.getInstance();<br> System.out.println(singleton1 == singleton2);<br> }<br>}</singleton></singleton>
排序算法<br><br>https://www.jianshu.com/p/d243e1aa13ce<br>
子主题
冒泡排序<br><br>比较相邻的元素。如果第一个比第二个大,就交换他们两个。<br>对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。<br>针对所有的元素重复以上的步骤,除了最后一个。<br>持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。<br>
public static void bubbleSort(int[] data) {<br> for (int i = 0; i < data.length - 1; i++) {// 控制趟数<br> for (int j = 0; j < <font color="#f15a23" style=""><b>data.length - 1 -i</b></font>; j++) {<br> if (data[j] > data[j + 1]) {<br> int tmp = data[j];<br> data[j] = data[j + 1];<br> data[j + 1] = tmp;<br> }<br> }<br> }<br> }
选择排序<br><br>首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置<br>再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。<br>重复第二步,直到所有元素均排序完毕。<br>
public class SelectionSort {<br><br>public int[] sort(int[] sourceArray) throws Exception {<br> int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);<br><br> // 总共要经过 N-1 轮比较<br> for (int i = 0; i < arr.length - 1; i++) {<br> int min = i;<br> <br> // 每轮需要比较的次数 N-i<br> for (int j = i + 1; j < arr.length; j++) {<br> if (arr[j] < arr[min]) {<br> // 记录目前能找到的最小值元素的下标<br> min = j;<br> }<br> }<br><br> // 将找到的最小值和i位置所在的值进行交换<br> if (i != min) {<br> int tmp = arr[i];<br> arr[i] = arr[min];<br> arr[min] = tmp;<br> }<br><br> }<br> return arr;<br> }<br><br>}
插入排序<br><br>将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。<br>从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。<br>(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)<br>
public class InsertSort {<br><br> public int[] sort(int[] sourceArray) throws Exception {<br> // 对 arr 进行拷贝,不改变参数内容<br> int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);<br><br> // 从下标为1的元素开始选择合适的位置插入,因为下标为0的只有一个元素,默认是有序的<br> for (int i = 1; i < arr.length; i++) {<br><br> // 记录要插入的数据<br> int tmp = arr[i];<br> // 从已经排序的序列最右边的开始比较,找到比其小的数<br> int j = i;<br> while (j > 0 && tmp < arr[j - 1]) {<br> arr[j] = arr[j - 1];<br> j--;<br> }<br> // 存在比其小的数,插入<br> if (j != i) {<br> arr[j] = tmp;<br> }<br> }<br> return arr;<br> }<br><br>}
希尔排序<br><br>选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;<br>按增量序列个数 k,对序列进行 k 趟排序;<br>每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。<br>仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。<br>
public class ShellSort {<br><br> public int[] sort(int[] sourceArray) throws Exception {<br> // 对 arr 进行拷贝,不改变参数内容<br> int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);<br><br> int gap = 1;<br> while (gap < arr.length) {<br> gap = gap * 3 + 1;<br> }<br><br> while (gap > 0) {<br> for (int i = gap; i < arr.length; i++) {<br> int tmp = arr[i];<br> int j = i - gap;<br> while (j >= 0 && arr[j] > tmp) {<br> arr[j + gap] = arr[j];<br> j -= gap;<br> }<br> arr[j + gap] = tmp;<br> }<br> gap = (int) Math.floor(gap / 3);<br> }<br> return arr;<br> }<br><br>}
归并排序<br><br>申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;<br>设定两个指针,最初位置分别为两个已经排序序列的起始位置;<br>比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;<br>重复步骤 3 直到某一指针达到序列尾;<br>将另一序列剩下的所有元素直接复制到合并序列尾。<br>
public class MergeSort {<br><br> public int[] sort(int[] sourceArray) throws Exception {<br> // 对 arr 进行拷贝,不改变参数内容<br> int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);<br><br> if (arr.length < 2) {<br> return arr;<br> }<br> int middle = (int) Math.floor(arr.length / 2);<br><br> int[] left = Arrays.copyOfRange(arr, 0, middle);<br> int[] right = Arrays.copyOfRange(arr, middle, arr.length);<br><br> return merge(sort(left), sort(right));<br> }<br><br> protected int[] merge(int[] left, int[] right) {<br> int[] result = new int[left.length + right.length];<br> int i = 0;<br> while (left.length > 0 && right.length > 0) {<br> if (left[0] <= right[0]) {<br> result[i++] = left[0];<br> left = Arrays.copyOfRange(left, 1, left.length);<br> } else {<br> result[i++] = right[0];<br> right = Arrays.copyOfRange(right, 1, right.length);<br> }<br> }<br><br> while (left.length > 0) {<br> result[i++] = left[0];<br> left = Arrays.copyOfRange(left, 1, left.length);<br> }<br><br> while (right.length > 0) {<br> result[i++] = right[0];<br> right = Arrays.copyOfRange(right, 1, right.length);<br> }<br><br> return result;<br> }<br><br><br>}
快速排序<br><br>从数列中挑出一个元素,称为 “基准”(pivot);<br>重新排序数列,所有元素比基准值小的摆放在基准前面,<br>所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。<br>在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;<br><br>递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;<br>
public class QuickSort {<br><br> public int[] sort(int[] sourceArray) throws Exception {<br> // 对 arr 进行拷贝,不改变参数内容<br> int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);<br><br> return quickSort(arr, 0, arr.length - 1);<br> }<br><br> private int[] quickSort(int[] arr, int left, int right) {<br> if (left < right) {<br> int partitionIndex = partition(arr, left, right);<br> quickSort(arr, left, partitionIndex - 1);<br> quickSort(arr, partitionIndex + 1, right);<br> }<br> return arr;<br> }<br><br> private int partition(int[] arr, int left, int right) {<br> // 设定基准值(pivot)<br> int pivot = left;<br> int index = pivot + 1;<br> for (int i = index; i <= right; i++) {<br> if (arr[i] < arr[pivot]) {<br> swap(arr, i, index);<br> index++;<br> }<br> }<br> swap(arr, pivot, index - 1);<br> return index - 1;<br> }<br><br> private void swap(int[] arr, int i, int j) {<br> int temp = arr[i];<br> arr[i] = arr[j];<br> arr[j] = temp;<br> }<br><br>}
堆排序<br><br>创建一个堆 H[0……n-1];<br>把堆首(最大值)和堆尾互换;<br>把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;<br>重复步骤 2,直到堆的尺寸为 1。<br>
public class HeapSort {<br><br> public int[] sort(int[] sourceArray) throws Exception {<br> // 对 arr 进行拷贝,不改变参数内容<br> int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);<br><br> int len = arr.length;<br><br> buildMaxHeap(arr, len);<br><br> for (int i = len - 1; i > 0; i--) {<br> swap(arr, 0, i);<br> len--;<br> heapify(arr, 0, len);<br> }<br> return arr;<br> }<br><br> private void buildMaxHeap(int[] arr, int len) {<br> for (int i = (int) Math.floor(len / 2); i >= 0; i--) {<br> heapify(arr, i, len);<br> }<br> }<br><br> private void heapify(int[] arr, int i, int len) {<br> int left = 2 * i + 1;<br> int right = 2 * i + 2;<br> int largest = i;<br><br> if (left < len && arr[left] > arr[largest]) {<br> largest = left;<br> }<br><br> if (right < len && arr[right] > arr[largest]) {<br> largest = right;<br> }<br><br> if (largest != i) {<br> swap(arr, i, largest);<br> heapify(arr, largest, len);<br> }<br> }<br><br> private void swap(int[] arr, int i, int j) {<br> int temp = arr[i];<br> arr[i] = arr[j];<br> arr[j] = temp;<br> }<br><br>}<br>
计数排序<br><br>花O(n)的时间扫描一下整个序列 A,获取最小值 min 和最大值 max<br>开辟一块新的空间创建新的数组 B,长度为 ( max - min + 1)<br>数组 B 中 index 的元素记录的值是 A 中某元素出现的次数<br>最后输出目标整数序列,具体的逻辑是遍历数组 B,输出相应元素以及对应的个数<br>
public class CountingSort {<br><br> public int[] sort(int[] sourceArray) throws Exception {<br> // 对 arr 进行拷贝,不改变参数内容<br> int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);<br><br> int maxValue = getMaxValue(arr);<br><br> return countingSort(arr, maxValue);<br> }<br><br> private int[] countingSort(int[] arr, int maxValue) {<br> int bucketLen = maxValue + 1;<br> int[] bucket = new int[bucketLen];<br><br> for (int value : arr) {<br> bucket[value]++;<br> }<br><br> int sortedIndex = 0;<br> for (int j = 0; j < bucketLen; j++) {<br> while (bucket[j] > 0) {<br> arr[sortedIndex++] = j;<br> bucket[j]--;<br> }<br> }<br> return arr;<br> }<br><br> private int getMaxValue(int[] arr) {<br> int maxValue = arr[0];<br> for (int value : arr) {<br> if (maxValue < value) {<br> maxValue = value;<br> }<br> }<br> return maxValue;<br> }<br><br>}
桶排序<br><br>设置固定数量的空桶。<br>把数据放到对应的桶中。<br>对每个不为空的桶中数据进行排序。<br>拼接不为空的桶中数据,得到结果<br>
public class BucketSort {<br><br> private static final InsertSort insertSort = new InsertSort();<br><br> public int[] sort(int[] sourceArray) throws Exception {<br> // 对 arr 进行拷贝,不改变参数内容<br> int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);<br><br> return bucketSort(arr, 5);<br> }<br><br> private int[] bucketSort(int[] arr, int bucketSize) throws Exception {<br> if (arr.length == 0) {<br> return arr;<br> }<br><br> int minValue = arr[0];<br> int maxValue = arr[0];<br> for (int value : arr) {<br> if (value < minValue) {<br> minValue = value;<br> } else if (value > maxValue) {<br> maxValue = value;<br> }<br> }<br><br> int bucketCount = (int) Math.floor((maxValue - minValue) / bucketSize) + 1;<br> int[][] buckets = new int[bucketCount][0];<br><br> // 利用映射函数将数据分配到各个桶中<br> for (int i = 0; i < arr.length; i++) {<br> int index = (int) Math.floor((arr[i] - minValue) / bucketSize);<br> buckets[index] = arrAppend(buckets[index], arr[i]);<br> }<br><br> int arrIndex = 0;<br> for (int[] bucket : buckets) {<br> if (bucket.length <= 0) {<br> continue;<br> }<br> // 对每个桶进行排序,这里使用了插入排序<br> bucket = insertSort.sort(bucket);<br> for (int value : bucket) {<br> arr[arrIndex++] = value;<br> }<br> }<br><br> return arr;<br> }<br><br> /**<br> * 自动扩容,并保存数据<br> *<br> * @param arr<br> * @param value<br> */<br> private int[] arrAppend(int[] arr, int value) {<br> arr = Arrays.copyOf(arr, arr.length + 1);<br> arr[arr.length - 1] = value;<br> return arr;<br> }<br><br>}
基数排序<br><br>将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零<br>从最低位开始,依次进行一次排序<br>从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列<br>
public class RadixSort {<br><br> public int[] sort(int[] sourceArray) throws Exception {<br> // 对 arr 进行拷贝,不改变参数内容<br> int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);<br><br> int maxDigit = getMaxDigit(arr);<br> return radixSort(arr, maxDigit);<br> }<br><br> /**<br> * 获取最高位数<br> */<br> private int getMaxDigit(int[] arr) {<br> int maxValue = getMaxValue(arr);<br> return getNumLenght(maxValue);<br> }<br><br> private int getMaxValue(int[] arr) {<br> int maxValue = arr[0];<br> for (int value : arr) {<br> if (maxValue < value) {<br> maxValue = value;<br> }<br> }<br> return maxValue;<br> }<br><br> protected int getNumLenght(long num) {<br> if (num == 0) {<br> return 1;<br> }<br> int lenght = 0;<br> for (long temp = num; temp != 0; temp /= 10) {<br> lenght++;<br> }<br> return lenght;<br> }<br><br> private int[] radixSort(int[] arr, int maxDigit) {<br> int mod = 10;<br> int dev = 1;<br><br> for (int i = 0; i < maxDigit; i++, dev *= 10, mod *= 10) {<br> // 考虑负数的情况,这里扩展一倍队列数,其中 [0-9]对应负数,[10-19]对应正数 (bucket + 10)<br> int[][] counter = new int[mod * 2][0];<br><br> for (int j = 0; j < arr.length; j++) {<br> int bucket = ((arr[j] % mod) / dev) + mod;<br> counter[bucket] = arrayAppend(counter[bucket], arr[j]);<br> }<br><br> int pos = 0;<br> for (int[] bucket : counter) {<br> for (int value : bucket) {<br> arr[pos++] = value;<br> }<br> }<br> }<br><br> return arr;<br> }<br> private int[] arrayAppend(int[] arr, int value) {<br> arr = Arrays.copyOf(arr, arr.length + 1);<br> arr[arr.length - 1] = value;<br> return arr;<br> }<br><br>}
二叉树遍历
public class BinaryTreeNode {<br> private int data;<br> private BinaryTreeNode left;<br> private BinaryTreeNode right;<br>}
前序遍历
递归
public void preOrder(BinaryTreeNode root){<br> if(null!=root){<br> System.out.print(root.getData()+"\t");<br> preOrder(root.getLeft());<br> preOrder(root.getRight());<br> }<br> }
非递归
public void preOrderNonRecursive(BinaryTreeNode root){<br> Stack<binarytreenode> stack=new Stack<binarytreenode>();<br> while(true){<br> while(root!=null){<br> System.out.print(root.getData()+"\t");<br> stack.push(root);<br> root=root.getLeft();<br> }<br> if(stack.isEmpty()) break;<br> root=stack.pop();<br> root=root.getRight();<br> }<br> }</binarytreenode></binarytreenode>
中序遍历
递归
public void inOrder(BinaryTreeNode root){<br> if(null!=root){<br> inOrder(root.getLeft());<br> System.out.print(root.getData()+"\t");<br> inOrder(root.getRight());<br> }<br> }
非递归
public void inOrderNonRecursive(BinaryTreeNode root){<br> Stack<binarytreenode> stack=new Stack<binarytreenode>();<br> while(true){<br> while(root!=null){<br> stack.push(root);<br> root=root.getLeft();<br> }<br> if(stack.isEmpty())break;<br> root=stack.pop();<br> System.out.print(root.getData()+"\t");<br> root=root.getRight();<br> }<br> }</binarytreenode></binarytreenode>
iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii
递归
public void postOrder(BinaryTreeNode root){<br> if(root!=null){<br> postOrder(root.getLeft());<br> postOrder(root.getRight());<br> System.out.print(root.getData()+"\t");<br> }<br> }
非递归
public void postOrderNonRecursive(BinaryTreeNode root){<br> Stack<binarytreenode> stack=new Stack<binarytreenode>();<br> while(true){<br> if(root!=null){<br> stack.push(root);<br> root=root.getLeft();<br> }else{<br> if(stack.isEmpty()) return;<br> <br> if(null==stack.lastElement().getRight()){<br> root=stack.pop();<br> System.out.print(root.getData()+"\t");<br> while(root==stack.lastElement().getRight()){<br> System.out.print(stack.lastElement().getData()+"\t");<br> root=stack.pop();<br> if(stack.isEmpty()){<br> break;<br> }<br> }<br> }<br> <br> if(!stack.isEmpty())<br> root=stack.lastElement().getRight();<br> else<br> root=null;<br> }<br> }<br> }</binarytreenode></binarytreenode>
层序遍历
public void levelOrder(BinaryTreeNode root){<br> BinaryTreeNode temp;<br> Queue<binarytreenode> queue=new LinkedList<binarytreenode>();<br> queue.offer(root);<br> while(!queue.isEmpty()){<br> temp=queue.poll();<br> System.out.print(temp.getData()+"\t");<br> if(null!=temp.getLeft()) <br> queue.offer(temp.getLeft());<br> if(null!=temp.getRight()){<br> queue.offer(temp.getRight());<br> }<br> }<br>}</binarytreenode></binarytreenode>
Class.forName和classloader的区别
相同
class.forName()和classLoader都可用来对类进行加载
不同
class.forName()前者除了将类的.class文件加载到jvm中之外,还会<b><font color="#80bc42">对类进行解释,执行类中的static块</font></b>。
classLoader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
for-each remove
可以通过<br><br>List<String> list = new ArrayList<>();<br>list.add("F1");<br>list.add("F2");<br>list.add("F3");<br><br> for(int i = 0; i < 2; i++) {<br>list.remove(i);<br>}<br><br>for(int i = 0; i < 2; i ++) {<br> if(list.get(i).equals("F2")) {<br> list.remove(i);<br> }<br> }<br>
//抛出异常<br><br>List<String> list = new ArrayList<>();<br>list.add("F1");<br>list.add("F2");<br>list.add("F3");<br><br> for(String tmp : list) {<br> list.remove(tmp);<br>}
mysql索引最左匹配原则的理解
案例一及说明
创建表
create table test(<br> a int ,<br> b int,<br> c int,<br> d int,<br> key index_abc(a,b,c)<br>)engine=InnoDB default charset=utf8;
插入 10000 条数据
DROP PROCEDURE IF EXISTS proc_initData;<br>DELIMITER $<br>CREATE PROCEDURE proc_initData()<br>BEGIN<br>DECLARE i INT DEFAULT 1;<br>WHILE i<=10000 DO<br> INSERT INTO test(a,b,c,d) VALUES(i,i,i,i);<br> SET i = i+1;<br>END WHILE;<br>END $<br>CALL proc_initData();
建立了联合索引(a,b,c)
验证:
explain 指令详解可以查看
explain select * from test where a<10 ;
explain select * from test where a<10 and b <10;
explain select * from test where a<10 and b <10 and c<10;
能不能将 a,b出现顺序换一下,a,b,c出现顺序换一下
explain select * from test where b<10 and a <10;
explain select * from test where b<10 and a <10 and c<10;
不是最左匹配原则吗?
mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,<br>最后才生成真正的执行计划。<br>所以,当然是我们能尽量的利用到索引时的查询顺序效率最高咯,<br>所以mysql查询优化器会最终以这种顺序进行查询执行。
重点来了
explain select * from test where b<10 and c <10;<br>
explain select * from test where a<10 and c <10;
<b><font color="#80bc42">为什么 b<10 and c <10,没有用到索引?而 a<10 and c <10用到了?</font></b>
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,<br><b><font color="#80bc42">b+数是按照从左到右的顺序来建立搜索树的</font></b>,<br>比如当(张三,20,F)这样的数据来检索的时候,<br>b+树会优先比较name来确定下一步的所搜方向,<br>如果name相同再依次比较age和sex,最后得到检索的数据;<br>但当(20,F)这样的没有name的数据来的时候,<br>b+树就不知道下一步该查哪个节点,<br>因为建立搜索树的时候name就是第一个比较因子,<br>必须要先根据name来搜索才能知道下一步去哪里查询。<br>比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,<br>但下一个字段age的缺失,<br>所以只能把名字等于张三的数据都找到,<br>然后再匹配性别是F的数据了, <br>这个是非常重要的性质,<br><b><font color="#80bc42">即索引的最左匹配特性。</font></b><br>
案例二及说明
表
CREATE TABLE `user2` (<br> `userid` int(11) NOT NULL AUTO_INCREMENT,<br> `username` varchar(20) NOT NULL DEFAULT '',<br> `password` varchar(20) NOT NULL DEFAULT '',<br> `usertype` varchar(20) NOT NULL DEFAULT '',<br> PRIMARY KEY (`userid`),<br><b><font color="#f1753f"> KEY `a_b_c_index` (`username`,`password`,`usertype`)</font></b><br>) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
上表中有一个联合索引,<br>下面开始验证最左匹配原则
当存在username时会使用索引查询
explain select * from user2 where username = '1' and password = '1';
当没有username时,不会使用索引查询
explain select * from user2 where password = '1';
当有username,但顺序乱序时也可以使用索引
explain select * from user2 where password = '1' and username = '1';
最左匹配原则中,有如下说明
最左前缀匹配原则,非常重要的原则,<br>mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,<br>比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,<br>如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整<br>
=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,<br>mysql的查询优化器会帮你优化成索引可以识别的形式
Oracle , Mysql查询前N条数据
Oracle DB :SELECT column_name(s) FROM table_name WHERE ROWNUM <= number
MySQL:SELECT * FROM Persons LIMIT 5
synchronized 和 ReentrantLock 的区别
两者的共同点
1. 都是用来协调多线程对共享对象、变量的访问 <br>2. 都是可重入锁,同一线程可以多次获得同一个锁 <br>3. 都保证了可见性和互斥
两者的不同点
1. ReentrantLock显示的获得、释放锁,synchronized隐式获得释放锁 <br>2. ReentrantLock 可响应中断、可轮回,synchronized 是不可以响应中断的,为处理锁的 不可用性提供了更高的灵活性 <br>3. ReentrantLock是API级别的,synchronized是JVM级别的 <br>4. ReentrantLock可以实现公平锁 <br>5. ReentrantLock通过 Condition可以绑定多个条件 <br>6. 底层实现不一样, synchronized是同步阻塞,使用的是悲观并发策略,lock是同步非阻 塞,采用的是乐观并发策略 <br>7. Lock 是一个接口,而 synchronized 是 Java 中的关键字,synchronized 是内置的语言 实现。 <br>8. synchronized 在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生; 而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象, 因此使用Lock时需要在finally块中释放锁。 <br>9. Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时, 等待的线程会一直等待下去,不能够响应中断。 <br>10. 通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。 <br>11. Lock可以提高多个线程进行读操作的效率,既就是实现读写锁等。
什么是 CAS(比较并交换-乐观锁机制-锁自旋)
概念及特性 CAS(Compare And Swap/Set)比较并交换,<br>CAS 算法的过程是这样:它包含 3 个参数 CAS(V,E,N)。<br>V 表示要更新的变量(内存值),E 表示预期值(旧的),N 表示新值。<br>当且仅当 V 值等于 E 值时,才会将 V 的值设为 N,<br>如果 V 值和 E 值不同,则说明已经有其他线程做了更新,<br>则当 前线程什么都不做。最后,CAS返回当前V的真实值。 <br>CAS 操作是抱着乐观的态度进行的(乐观锁),<br>它总是认为自己可以成功完成操作。<br>当多个线程同时 使用 CAS 操作一个变量时,<br>只有一个会胜出,并成功更新,其余均会失败。<br>失败的线程不会被挂 起,仅是被告知失败,<br>并且允许再次尝试,当然也允许失败的线程放弃操作。<br>基于这样的原理, CAS操作即使没有锁,<br>也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
原子包 java.util.concurrent.atomic(锁自旋) <br>JDK1.5 的原子包:java.util.concurrent.atomic 这个包里面提供了一组原子类。<br>其基本的特性就 是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,<br>具有排他性,即当某个 线程进入方法,执行其中的指令时,<br>不会被其他线程打断,而别的线程就像自旋锁一样,<br>一直等 到该方法执行完成,才由 JVM 从等待队列中选择一个另一个线程进入,<br>这只是一种逻辑上的理解。 <br><br>相对于对于 synchronized 这种阻塞算法,<br>CAS 是非阻塞算法的一种常见实现。<br>由于一般 CPU 切 换时间比CPU指令集操作更加长,<br>所以J.U.C在性能上有了很大的提升。
ABA问题 <br><br>CAS 会导致“ABA 问题”。<br>CAS 算法实现一个重要前提需要取出内存中某时刻的数据,<br>而在下时 刻比较并替换,那么在这个时间差类会导致数据的变化。 <br><br>比如说一个线程 one 从内存位置 V 中取出 A,<br>这时候另一个线程 two 也从内存中取出 A,<br>并且 two进行了一些操作变成了B,<br>然后two又将V位置的数据变成A,<br>这时候线程one进行CAS操 作发现内存中仍然是A,然后one操作成功。<br>尽管线程one的CAS操作成功,<br>但是不代表这个过 程就是没有问题的。 <br><br>部分乐观锁的实现是通过版本号(version)的方式来解决ABA问题,<br>乐观锁每次在执行数据的修 改操作时,<br>都会带上一个版本号,<br>一旦版本号和数据的版本号一致就可以执行修改操作并对版本 号执行+1 操作,<br>否则就执行失败。<br>因为每次操作的版本号都会随之增加,<br>所以不会出现 ABA 问 题,<br>因为版本号只会增加不会减少。
概念及特性 CAS(Compare And Swap/Set)比较并交换,<br>CAS 算法的过程是这样:它包含 3 个参数 CAS(V,E,N)。<br>V 表示要更新的变量(内存值),E 表示预期值(旧的),N 表示新值。<br>当且仅当 V 值等于 E 值时,才会将 V 的值设为 N,<br>如果 V 值和 E 值不同,则说明已经有其他线程做了更新,<br>则当 前线程什么都不做。最后,CAS返回当前V的真实值。 <br>CAS 操作是抱着乐观的态度进行的(乐观锁),<br>它总是认为自己可以成功完成操作。<br>当多个线程同时 使用 CAS 操作一个变量时,<br>只有一个会胜出,并成功更新,其余均会失败。<br>失败的线程不会被挂 起,仅是被告知失败,<br>并且允许再次尝试,当然也允许失败的线程放弃操作。<br>基于这样的原理, CAS操作即使没有锁,<br>也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
什么是 AQS(抽象的队列同步器)
AbstractQueuedSynchronizer类如其名,抽象的队列式的同步器,<br>AQS定义了一套多线程访问 共享资源的同步器框架,<br>许多同步类实现都依赖于它,<br>如常用的 ReentrantLock/Semaphore/CountDownLatch。
两种资源共享方式
Exclusive<br><br>独占资源 -ReentrantLock Exclusive(独占,只有一个线程能执行,如ReentrantLock)
Share<br><br>共享资源 -Semaphore/CountDownLatch Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)。
AQS只是一个框架,具体资源的获取/释放方式交由自定义同步器去实现,<br>AQS这里只定义了一个 接口,<br>具体资源的获取交由自定义同步器去实现了(通过state的get/set/CAS)之所以没有定义成 abstract,<br>是因为独占模式下只用实现 tryAcquire-tryRelease,<br>而共享模式下只用实现 tryAcquireShared-tryReleaseShared。<br>如果都定义成abstract,<br>那么每个模式也要去实现另一模 式下的接口。<br>不同的自定义同步器争用共享资源的方式也不同。<br>自定义同步器在实现时只需要实 现共享资源 state 的获取与释放方式即可,<br>至于具体线程等待队列的维护(如获取资源失败入队/ 唤醒出队等),<br>AQS已经在顶层实现好了。自定义同步器实现时主要实现以下几种方法: <br><br>1. isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。 <br>2. tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。 <br>3. tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。 <br>4. tryAcquireShared(int):共享方式。尝试获取资源。<br> 负数表示失败;<br> 0 表示成功,但没有剩余 可用资源;<br> 正数表示成功,且有剩余资源。 <br>5. tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回 true,否则返回false。
同步器 的实现是 AQS核心( state资源状态计数) <br>
以ReentrantLock为例,<br>state初始化为0,表示未锁定状态。<br>A线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。<br>此后,其他线程再 tryAcquire()时就会失 败,<br>直到A线程unlock()到state=0(即释放锁)为止,<br>其它线程才有机会获取该锁。<br>当然,释放 锁之前,A 线程自己是可以重复获取此锁的(state 会累加),<br>这就是可重入的概念。<br>但要注意, 获取多少次就要释放多么次,<br>这样才能保证state是能回到零态的。
以CountDownLatch以例,<br>任务分为N个子线程去执行,<br>state也初始化为N(注意N要与 线程个数一致)。<br>这 N 个子线程是并行执行的,<br>每个子线程执行完后 countDown()一次,state 会CAS减1。<br>等到所有子线程都执行完后(即state=0),<br>会unpark()主调用线程,<br>然后主调用线程 就会从await()函数返回,<br>继续后余动作。
ReentrantReadWriteLock实现独占和共享两种 方式 <br>
一般来说,自定义同步器要么是独占方法,要么是共享方式,<br>他们也只需实现 tryAcquiretryRelease、<br>tryAcquireShared-tryReleaseShared 中的一种即可。<br>但 AQS 也支持自定义同步器 同时实现独占和共享两种方式,<br>如ReentrantReadWriteLock。
构造器注入和属性注入在初始化时区别
构造器注入前所有相关bean先实例化,<br>属性注入当某个属性对应的bean第一次被注入时才实例化。
泛型相比起 Object,泛型对象:<br><br>是类型安全的,会对参数做限制;<br>无须装箱和拆箱,类在实例化时按照传入的数据类型生成本地代码;<br>无须类型转换。
二维数组旋转<br>
public static int[][] rotateMatrixRight(int[][] matrix){<br><br> /* W and H are already swapped */<br>int w = matrix.length;<br>int h = matrix[0].length;<br>int[][] ret = new int[h][w];<br>for (int i = 0; i < h; ++i) {<br>for (int j = 0; j < w; ++j) {<br>ret[i][j] = matrix[w - j - 1][i];<br>}<br>}<br>return ret;<br>}
public int[][] rotateMatrixLeft(int[][] matrix){<br>/* W and H are already swapped */<br>int w = matrix.length;<br>int h = matrix[0].length; <br>int[][] ret = new int[h][w];<br>for (int i = 0; i < h; ++i) {<br>for (int j = 0; j < w; ++j) {<br>ret[i][j] = matrix[j][h - i - 1];<br>}<br>}<br>return ret;<br>}
Spring-MVC开发之全局异常捕获<br><br>https://www.cnblogs.com/afeng7882999/p/4318397.html<br>
定义服务器错误WEB.XML整合Spring MVC
web.xml
<error-page><br><br> <error-code>404</error-code><br><br> <location>/404</location><br><br></error-page><br><br><error-page><br><br> <error-code>500</error-code><br><br> <location>/500</location><br><br></error-page><br><br><br><br><!-- 未捕获的错误,同样可指定其它异常类,或自定义异常类 --><br><br><error-page><br><br> <exception-type>java.lang.Exception</exception-type><br><br> <location>/uncaughtException</location><br><br></error-page>
applicationContext.xml
<!-- 错误路径和错误页面,注意指定viewResolver --><br><br><mvc:view-controller path="/404" view-name="404"/><br><br><mvc:view-controller path="/500" view-name="500"/><br><br><mvc:view-controller path="/uncaughtException" view-name="uncaughtException"/>
Spring全局异常,Controller增强方式( Advising Controllers)
异常抛出
@Controller<br><br>public class MainController {<br><br> @ResponseBody<br><br> @RequestMapping("/")<br><br> public String main(){<br><br> throw new NullPointerException("NullPointerException Test!");<br><br> }<br><br>}
异常捕获
//注意使用注解@ControllerAdvice作用域是全局Controller范围,即必须与抛出异常的method在同一个controller<br><br>//可应用到所有@RequestMapping类或方法上的@ExceptionHandler、@InitBinder、@ModelAttribute,在这里是@ExceptionHandler<br><br>@ControllerAdvice<br><br>public class AControllerAdvice {<br><br> @ExceptionHandler(NullPointerException.class)<br> @ResponseStatus(HttpStatus.BAD_REQUEST)<br> @ResponseBody<br> public String handleIOException(NullPointerException ex) {<br> return ClassUtils.getShortName(ex.getClass()) + ex.getMessage();<br> }<br><br>}
为了确保@ResponseStatus标注的异常被Spring框架处理,<br>可以这样编写全局异常处理类:
@ControllerAdvice<br><br>class GlobalDefaultExceptionHandler {<br><br> public static final String DEFAULT_ERROR_VIEW = "error";<br><br>@ExceptionHandler(value = Exception.class)<br>public ModelAndView defaultErrorHandler(HttpServletRequest req, Exception e) throws Exception {<br>// If the exception is annotated with @ResponseStatus rethrow it and let<br>// the framework handle it - like the OrderNotFoundException example<br>// at the start of this post.<br>// AnnotationUtils is a Spring Framework utility class.<br>if (AnnotationUtils.findAnnotation(e.getClass(), ResponseStatus.class) != null)<br>throw e;<br><br> // Otherwise setup and send the user to a default error-view.<br>ModelAndView mav = new ModelAndView();<br>mav.addObject("exception", e);<br>mav.addObject("url", req.getRequestURL());<br>mav.setViewName(DEFAULT_ERROR_VIEW);<br>return mav;<br>}<br>}
@RestControllerAdvice<br>public class GlobalExceptionHandler{<br> /**<br> * 基础异常<br> */<br> @ExceptionHandler(BaseException.class)<br> public AjaxResult baseException(BaseException e){<br> return AjaxResult.error(e.getMessage());<br> }<br>}
Spirng全局异常,配置方式
异常抛出
异常捕获
<!-- 全局异常配置 --><br><bean id="exceptionResolver" class="org.springframework.web.servlet.handler.SimpleMappingExceptionResolver"><br><property name="exceptionMappings"><br><props><br><prop key="java.lang.Exception">errors/500</prop><br><prop key="java.lang.Throwable">errors/500</prop><br></props><br></property><br><property name="statusCodes"><br><props><br><prop key="errors/500">500</prop><br></props><br></property><br><br><!-- 设置日志输出级别,不定义则默认不输出警告等错误日志信息 --><br><property name="warnLogCategory" value="WARN"></property><br><!-- 默认错误页面,当找不到上面mappings中指定的异常对应视图时,使用本默认配置 --><br><property name="defaultErrorView" value="errors/500"></property><br><!-- 默认HTTP状态码 --><br><property name="defaultStatusCode" value="500"></property><br></bean>
对应500错误的view jsp页面
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%><br><br><%@taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%><br><br><!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"><br><br><html><br><br><head><br><br><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><br><br><title>500 Error</title><br><br></head><br><br><body><br><br> <% Exception ex = (Exception)request.getAttribute("exception"); %><br><br> <H2>Exception: <%= ex.getMessage()%></H2><br><br> <P/><br><br> <% ex.printStackTrace(new java.io.PrintWriter(out)); %><br><br></body><br><br></html>
Sping全局异常,自定义异常类和异常解析
自定义异常类
public class CustomException extends RuntimeException {<br><br>public CustomException(){<br>super();<br>}<br><br>public CustomException(String msg, Throwable cause){<br>super(msg, cause);<br>//Do something...<br>}<br>}
抛出异常
@ResponseBody<br>@RequestMapping("/ce")<br>public String ce(CustomException e){<br> throw new CustomException("msg",e);<br>}
实现异常捕获接口HandlerExceptionResolver
public class CustomHandlerExceptionResolver implements HandlerExceptionResolver{<br><br>@Override<br>public ModelAndView resolveException(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o, Exception e) {<br>Map<String, Object> model = new HashMap<String, Object>();<br>model.put("e", e);<br>//这里可根据不同异常引起类做不同处理方式,本例做不同返回页面。<br>String viewName = ClassUtils.getShortName(e.getClass());<br>return new ModelAndView(viewName, model);<br>}<br>}
新的的HandlerExceptionResolver实现类只需在配置文件中定义即可,<br>可以配置优先级。<br>DispatcherServlet初始化HandlerExceptionResolver的时候<br>会自动寻找容器中实现了HandlerExceptionResolver接口的类,<br>然后添加进来。配置Spring支持异常捕获
<bean class="cn.bg.controller.CustomHandlerExceptionResolver"/>
Errors and REST
使用Restful的Controller可以使用@ResponseBody处理错误,<br>首先定义一个错误
public class ErrorInfo {<br><br> public final String url;<br> public final String ex;<br><br> public ErrorInfo(String url, Exception ex) {<br>this.url = url;<br>this.ex = ex.getLocalizedMessage();<br>}<br><br>}
通过一个@ResponseBody返回一个错误实例
@ResponseStatus(HttpStatus.BAD_REQUEST)<br>@ExceptionHandler(MyBadDataException.class)<br>@ResponseBody <br>ErrorInfo handleBadRequest(HttpServletRequest req, Exception ex) {<br> return new ErrorInfo(req.getRequestURL(), ex);<br>}
数据库
数据库(关系型)设计原则
降低对数据库功能的依赖
功能应该由程序实现,数据库仅仅负责数据的存储,以达到最低的耦合。
三大范式
1NF是对<b><font color="#80bc42">属性(列)的原子性</font></b>,要求属性具有原子性,不可再分解;<br>符合1NF的关系中的每个属性都不可再分。
2NF是对<b><font color="#80bc42">记录的惟一性,要求记录有惟一标识,即实体的惟一性,即不存在部分依赖;</font></b><br>2NF在1NF的基础之上,<b><font color="#80bc42">确保表中的每列都和主键相关</font></b><br>一是表必须有一个主键;<br>二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
3NF是对字段的冗余性,<b><font color="#80bc42">确保每列都和主键列直接相关,而不是间接相关</font></b><br>
第二范式要把包含多个实体的不同属性分成多张表,<br>而第三范式是分表之后,每张表中都只能含有另一张表的id,<br>不能包含另一张表的其他属性。
反范式设计
主要是针对第一范式<br><br>位图(例如用途、用户中的管理员和vip)<br>逻辑齿解决稀疏矩阵 行列值
数据库优化
范式优化: 比如消除冗余(节省空间。。)
反范式优化:比如适当加冗余等(减少join)
拆分表: 分区将数据在物理上分隔开,不同分区的数据可以制定保存在处于不同磁盘上的数据文件里。
拆分其实又分垂直拆分和水平拆分
事务
事务的基本要素(ACID)
1、原子性(Atomicity)
事务开始后所有操作,要么全部做完,要么全部不做,<br>不可能停滞在中间环节。<br>事务执行过程中出错,会回滚到事务开始前的状态,<br>所有的操作就像没有发生一样。<br>也就是说事务是一个不可分割的整体,<br>就像化学中学过的原子,<br>是物质构成的基本单位。
2、一致性(Consistency)
事务开始前和结束后,<br>数据库的完整性约束没有被破坏 。<br>比如A向B转账,不可能A扣了钱,B却没收到。
3、隔离性(Isolation)
同一时间,只允许一个事务请求同一数据,<br>不同的事务之间彼此没有任何干扰。<br>比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
4、持久性(Durability)
事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
多版本并发控制(MVCC)
事务的并发问题
更新丢失:当两个或多个事务选择同一行,<br>然后基于最初选定的值更新该行时,<br>由于每个事务都不知道其他事务的存在,<br>就会发生丢失更新问题<br>
第一类丢失更新:<br>在没有事务隔离的情况下,<br>两个事务都同时更新一行数据,<br>但是第二个事务却中途失败退出, <br>导致对数据的两个修改都失效了。
1. 张三的工资为5000,事务A中获取工资为5000;<br>2. 事务B获取工资为5000,汇入100,并提交数据库,工资变为5100;<br>3. 事务A发生异常,回滚了,恢复张三的工资为5000;<br>END: 导致事务B的更新丢失。
第二类丢失更新:<br>不可重复读的特例。<br>有两个并发事务同时读取同一行数据,<br>然后其中一个对它进行修改提交,<br>而另一个也进行了修改提交。<br>这就会造成第一次写操作失效。
1. 事务A中,读取到张三的存款为5000,操作没有完成,事务还没提交。<br>2. 事务B,存储1000,把张三的存款改为6000,并提交了事务。<br>3. 在事务A中,存储500,把张三的存款改为5500,并提交了事务。<br>END:事务A的更新覆盖了事务B的更新。
脏读:<br>事务A读取了事务B更新的数据,<br>然后B回滚操作,<br>那么A读取到的数据是脏数据 <br>
1. 张三的工资为5000;事务A中把他的工资改为8000,但事务A尚未提交。<br>2. 事务B正在读取张三的工资,读取到张三的工资为8000。<br>3. 事务A发生异常,而回滚了事务。张三的工资又回滚为5000。<br>END: 事务B读取到的张三工资为8000的数据即为脏数据,事务B做了一次脏读。
不可重复读:<br>事务 A 多次读取同一数据,<br>事务 B 在事务A多次读取的过程中,<br>对数据作了更新并提交,<br>导致事务A多次读取同一数据时,结果不一致。 <br>
1. 事务A中,读取到张三的工资为5000,操作没有完成,事务还没提交。<br>2. 事务B把张三的工资改为8000,并提交了事务。<br>3. 事务A中,再次读取张三的工资,此时工资变为8000。<br>END:在一个事务中前后两次读取的结果并不致,导致了不可重复读。
幻读:<br>当事务不是独立执行时发生的一种现象,<br>例如第一个事务对一个表中的数据进行了修改,<br>这种修改涉及到表中的全部数据行。<br>同时,第二个事务也修改这个表中的数据,<br>这种修改是向表中插入一行新数据。<br>那么,以后第一个事务的用户再次读取时会发现表中还有没有修改的数据行,<br>就好象发生了幻觉一样。
1. 目前工资为5000的员工有10人,事务A读取所有工资为5000的人数为10人。<br>2. 事务B插入一条工资也为5000的记录。<br>END:事务A再次读取工资为5000的员工,记录为11人。此时产生了幻读。<br>不可重复读侧重于修改,幻读侧重于新增或删除。 解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
事务隔离级别
mysql中默认事务隔离级别是可重复读时并不会锁住读取到的行<br>
读未提交
事务最低的隔离级别,它充许另外一个事务可以看到这个事务未提交的数据。<br>写数据会锁住相应行<br>解决第一类丢失更新的问题,但仍存在脏读、不可重复读、第二类丢失更新的问题、幻读 。
不可重复读
保证一个事务修改的数据提交后才能被另外一个事务读取,即另外一个事务不能读取该事务未提交的数据。<br><br>解决第一类丢失更新和脏读的问题,但会出现不可重复读、第二类丢失更新的问题、幻读问题
可重复读
保证一个事务相同条件下前后两次获取的数据是一致的<br><br>解决第一类丢失更新,脏读、不可重复读、第二类丢失更新的问题,但会出幻读<br><br>事务隔离级别为可重复读时,如果有索引(包括主键索引)的时候,以索引列为条件更新数据,会存在间隙锁间隙锁、行锁、下一键锁的问题,从而锁住一些行;如果没有索引,更新数据时会锁住整张表
串行化
读写数据都会锁住整张表<br><br>事务被处理为顺序执行。
InnoDB实现MVCC
innodb存储的最基本row中包含一些额外的存储信息
DATA_TRX_ID
6字节的DATA_TRX_ID 标记了最新更新这条行记录的transaction id,<br>每处理一个事务,其值自动+1
DATA_ROLL_PTR
7字节的DATA_ROLL_PTR 指向当前记录项的rollback segment的undo log记录,<br>找之前版本的数据就是通过这个指针
DB_ROW_ID
6字节的DB_ROW_ID,<br>当由innodb自动产生聚集索引时,<br>聚集索引包括这个DB_ROW_ID的值,<br>否则聚集索引中不包括这个值,<br>这个用于索引当中
DELETE BIT
DELETE BIT位用于标识该记录是否被删除,<br>这里的不是真正的删除数据,<br>而是标志出来的删除。<br>真正意义的删除是在commit的时候
具体的执行过程
UPDATE的事务过程
begin->用排他锁锁定该行->记录redo log->记录undo log->修改当前行的值,<br>写事务编号,<br>回滚指针指向undo log中的修改前的行
insert的事务过程
undo log分insert和update undo log,<br>因为insert时,原始的数据并不存在,<br>所以回滚时把insert undo log丢弃即可,<br>而update undo log则必须遵守上述过程
依照事务的版本来检查每行的版本号
insert操作时 “创建时间”=DB_ROW_ID,这时,“删除时间 ”是未定义的;
update时,复制新增行的“创建时间”=DB_ROW_ID,<br>删除时间未定义,<br>旧数据行“创建时间”不变,删除时间=该事务的DB_ROW_ID;
delete操作,相应数据行的“创建时间”不变,<br>删除时间=该事务的DB_ROW_ID; <br>
select操作对两者都不修改,只读相应的数据
REPEATABLE READ 可重复读下的MVCC
SELECT
Innodb检查每行数据,确保他们符合两个标准:<br>
1.InnoDB只查找版本早于当前事务版本的数据行(也就是数据行的版本必须小于等于事务的版本),<br>这确保当前事务 读取的行都是事务之前已经存在的,<br>或者是由当前事务创建或修改的行
2.行的删除操作的版本一定是未定义的或者大于当前事务的版本号。<br>确定了当前事务开始之前,行没有被删除
符合了以上两点则返回查询结果。
INSERT
InnoDB为每个新增行记录当前系统版本号作为创建ID。
DELETE
InnoDB为每个删除行的记录当前系统版本号作为行的删除ID。
UPDATE
InnoDB复制了一行。这个新行的版本号使用了系统版本号。<br>它也把系统版本号作为了删除行的版本。
MVCC深入
理想的MVCC特点
每行数据都存在一个版本,每次数据更新时都更新该版本
修改时Copy出当前版本随意修改,各个事务之间无干扰
保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
就是每行都有版本号,保存时根据版本号决定是否成功,有点类似乐观锁
理想的MVCC是难以实现的,<br>当事务仅修改一行记录使用理想的MVCC模式是没有问题的,<br>可以通过比较版本号进行回滚;<br>但当事务影响到多行数据时,理想的MVCC据无能为力了。
如果Transaciton1执行理想的MVCC,修改Row1成功,而修改Row2失败,<br>此时需要回滚Row1,但因为Row1没有被锁定,<br>其数据可能又被Transaction2所修改,如果此时回滚Row1的内容,<br>则会破坏Transaction2的修改结果,导致Transaction2违反ACID。
修改两行数据,但为了保证其一致性,<br>与修改两个分布式系统中的数据并无区别,<br>而二提交是目前这种场景保证一致性的唯一手段。
Innodb的实现方式
事务以排他锁的形式修改原始数据
把修改前的数据存放于undo log,通过回滚指针与主数据关联
修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
同一般理解的MVCC特点的差别:当修改数据时是否要排他锁定
如果根据事务DB_TRX_ID去比较获取事务的话,<br>按道理在一个事务B(在事务A后,但A还没commit)select的话 B.<br>DB_TRX_ID>A.DB_TRX_ID则应该能返回A事务对数据的操作以及修改。<br>那不是和前面矛盾?其实不然。
InnoDB每个事务在开始的时候,<br>会将当前系统中的活跃事务列表(trx_sys->trx_list)创建一个副本(read view),<br>然后一致性读去比较记录的tx id的时候,<br>并不是根据当前事务的tx id,<br>而是根据read view最早一个事务的tx id(read view->up_limit_id)来做比较的,<br>这样就能确保在事务B之前没有提交的所有事务的变更,B事务都是看不到的。<br>
这里还有个小问题要处理一下,就是当前事务自身的变更还是需要看到的。
InnoDB引擎的锁机制
共享锁/排它锁
共享锁(S)读锁:允许一个事务去读一行,<br>阻止其他事务获得相同数据集的排他锁。<br>
即多个事务对于同一数据可以共享一把锁,<br>都能访问到数据,但是只能读不能修改。
排他锁(X)写锁:允许获得排他锁的事务更新数据,<br>阻止其他事务取得相同数据集的共享读锁和排他写锁。 <br>
不能与其他所并存,如一个事务获取了一个数据行的排他锁,<br>其他事务就不能再获取该行的其他锁,<br>包括共享锁和排他锁,但是获取排他锁的事务是可以对数据就行读取和修改。
锁关系
目的
InnoDB使用共享锁,可以提高读读并发
为了保证数据强一致,InnoDB使用强互斥锁,<br>保证同一行记录修改与删除的串行性;
意向锁
意向共享锁(IS):<br>事务打算给数据行加行共享锁,<br>事务在给一个数据行加共享锁前必须先取得该表的IS锁。
意向排他锁(IX):<br>事务打算给数据行加行排他锁,<br>事务在给一个数据行加排他锁前必须先取得该表的IX锁。
记录锁(Record Locks)
封锁指定的索引记录
比如where条件出的记录
select * from t where id =1 for update
间隙锁(Gap Locks)
当用范围条件而不是相等条件检索数据,<br>并请求共享或排他锁时,<br>InnoDB会给符合条件的已有数据记录的索引项加锁;<br>对于键值在条件范围内但并不存在的记录,<br>叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,<br>这种锁机制就是所谓 的间隙锁(Next-Key锁)。<br>
select * from t where id between 8 and 15 for update
InnoDB除了通过范围条件加锁时使用间隙锁外,<br>如果使用相等条件请求给一个不存在的记录加锁,<br>InnoDB也会使用间隙锁!<br>
目的
为了防止幻读,以满足相关隔离级别的要求,<br>对于上面的例子,要是不使用间隙锁,<br>如果其他事务插入了empid大于100的任何记录,<br>那么本事务如果再次执行上述语句,就会发生幻读;
为了防止其他事务在间隔中插入数据,以导致“不可重复读”。
临键锁(Next-key Locks)
概念
记录锁与间隙锁的组合<br><br>封锁范围既包含索引记录又包含索引区间
引申
临键锁会封锁索引记录本身,以及索引记录之前的区间。<br><br>如果一个会话占有了索引记录R的共享/排他锁,其他会话不能立刻在R之前的区间插入新的索引记录。
支主题
目的
临键锁的主要目的,也是为了避免幻读(Phantom Read)。<br>如果把事务的隔离级别降级为RC,临键锁则也会失效。
插入意向锁(Insert Intention Locks)
概念
是间隙锁(Gap Locks)的一种(所以,也是实施在索引上的),它是专门针对insert操作的。
用法
多个事务,在同一个索引,同一个范围区间插入记录时,如果插入的位置不冲突,不会阻塞彼此。
目的
InnoDB使用插入意向锁,可以提高插入并发
自增锁(Auto-inc Locks)
自增锁是一种特殊的表级别锁(table-level lock),<br>专门针对事务插入AUTO_INCREMENT类型的列。
https://blog.csdn.net/wufaliang003/article/details/81937410
SQL语句加锁
对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X)
对于普通SELECT语句,InnoDB不会加任何锁,<br>事务可以通过以下语句显示给记录集加共享锁或排他锁。
共享锁(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE。<br>
排他锁(X):SELECT * FROM table_name WHERE ... FOR UPDATE。
行锁的实现方式
InnoDB行锁是通过给索引上的索引项加锁来实现的
因此只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!<br>
由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,<br>所以虽然是访问不同行的记录,<br>但是如果是使用相同的索引键,是会出现锁冲突的。<br>
当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,<br>另外,不论是使用主键索引、唯一索引或普通索引,InnoDB都会使用行锁来对数据加锁。
相关文章
https://www.cnblogs.com/aipiaoborensheng/p/5767459.html
SQL优化
应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,<br>如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0
很多时候用 exists 代替 in 是一个好的选择
用Where子句替换HAVING 子句 因为HAVING 只会在检索出所有记录之后才对结果集进行过滤
使用like关键字模糊查询时,% 放在前面索引不起作用,只有“%”不在第一个位置,索引才会生效(like ‘%文’–索引不起作用),数据量巨大的模糊查询,可以考虑上 es。
如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则索引将会失效。
不在索引列上做任何操作,例如 计算、函数运算、(自动or手动)类型转换
尽量使用覆盖索引(只访问索引的查询(索引和查询列一致)),减少select*。
常见索引原则
1. 选择唯一性索引<br> 唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。 <br><br>2. 为经常需要排序、分组和联合操作的字段建立索引 :<br><br>3 .为常作为查询条件的字段建立 索引 。<br><br>4 .限制索引的数目:<br>越多的索引,会使更新表变得很浪费时间。 <br>尽量使用数据量少的索引<br><br> 6. 如果索引的值很长,那么查询的速度会受到影响。 <br>尽量使用前缀来索引<br><br> 7. 如果索引字段的值很长,最好使用值的前缀来索引。 <br>7 .删除不再使用或者很少使用的索引<br><br>8 . 最左前缀匹配原则,非常重要的原则。<br><br>10 . 尽量选择区分度高的列作为索引<br>区分度的公式是表示字段不重复的比例 <br><br>11 . 索引列不能参与计算,保持列“干净”:带函数的查询不参与索引。<br><br>12 . 尽量的扩展索引,不要新建索引。
最佳实践
https://blog.csdn.net/u011277123/article/details/78359016
表设计
合适的主键
自增主键有利于缩小二级索引所占空间
表宽度适度,避免宽表
个人理解:宽表如果数据分布在多页,需要跨页加载
避免太多关联
大字段建议分表存储,主键关联
大字段读取会导致:overflow跨页加载
索引列设置为非NULL
避免设置大小写不敏感
对比时需要实现转换为小写进行比较
varchar vs. char
由于CHAR是固定长度的,<br>所以它的处理速度比VARCHAR快得多,<br>但是其缺点是浪费存储空间,<br>程序需要对行尾空格进行处理,<br>所以对于那些长度变化不大并且对查询速度有较高要求的数据可以考虑使用CHAR类型来存储。<br>
InnoDB存储引擎:<br>建议使用VARCHAR类型。<br>对于InnoDB数据表,<br>内部的行存储格式没有区分固定长度和可变长度列<br>(所有数据行都使用指向数据列值的头指针),<br>因此在本质上,使用固定长度的CHAR列不一定比使用可变长度VARCHAR列性能要好。<br>因而,主要的性能因素是数据行使用的存储总量。<br>由于CHAR平均占用的空间多于VARCHAR,<br>因此使用VARCHAR来最小化需要处理的数据行的存储总量和磁盘I/O是比较好的。
SQL优化
不要在列上做运算
常见运算包括
覆盖索引
索引的最左原则
一个多列B-Tree索引中,<br>索引列的顺序意味着索引首先按照最左列进行排序,<br>其次是第二列...
索引可以按照升序或者降序进行扫描,<br>以满足精确符合列顺序的ORDER BY、GROUP BY和DISTINCT等子句的查询需求。<br>但要注意最左原则(参照字典查询单词的例子)
执行计划
explain
高级特性
字符集
character set
collation
stored program
存储过程(stored procedure)<br><br>函数(function)<br><br>触发器(trigger)<br><br>时间调度器(event)<br><br>show create …
视图
全文索引
partition
audit
复制
主从复制
主从复制流程图 <br>
https://www.cnblogs.com/zhoubaojian/articles/7866212.html
IO
IO模型
体系结构
MySQL体系结构
1. Connectors指的是不同语言中与SQL的交互。
2. Management Serveices & Utilities: 系统管理和控制工具。
3. Connection Pool: 连接池。管理缓冲用户连接,线程处理等需要缓存的需求。
4. SQL Interface: SQL接口。接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface。
5. Parser:解析器。<br>SQL命令传递到解析器的时候会被解析器验证和解析。<br>解析器是由Lex和YACC实现的,是一个很长的脚本。
将SQL语句分解成数据结构,<br>并将这个结构传递到后续步骤,<br>以后SQL语句的传递和处理就是基于这个结构的。<br>
如果在分解构成中遇到错误,<br>那么就说明这个sql语句是不合理的。
6. Optimizer: 查询优化器。
SQL语句在查询之前会使用查询优化器对查询进行优化。<br>他使用的是“选取-投影-联接”策略进行查询。<br>用一个例子就可以理解: select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,<br>而不是先将表全部查询出来以后再进行gender过滤。<br>这个select查询先根据uid和name进行属性投影,<br>而不是将属性全部取出以后再进行过滤,<br>将这两个查询条件联接起来生成最终查询结果。
7. Cache和Buffer: 查询缓存。
如果查询缓存有命中的查询结果,<br>查询语句就可以直接去查询缓存中取数据。<br>这个缓存机制是由一系列小缓存组成的。<br>比如表缓存,记录缓存,key缓存,权限缓存等。
8. Engine :存储引擎。
存储引擎是MySql中具体的与文件打交道的子系统。<br>
Mysql的存储引擎是插件式的。<br>它根据MySql AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)。<br>现在有很多种存储引擎,各个存储引擎的优势各不一样,最常用的InnoDB,MyISAM。
mysql 内存结构
内存结构示意
global_buffers ( 全局内存分配总和 )
all_thread_buffers (会话/线程级内存分配总和)
https://www.cnblogs.com/zhoubaojian/articles/7866292.html
MySQL
索引
底层结构
背景知识
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,<br>位于同一磁盘块中的数据会被一次性读取出来,而不是按需读取。
InnoDB 存储引擎使用页作为数据读取单位,<br>页是其磁盘管理的最小单位,默认 page 大小是 16k。
系统的一个磁盘块的存储空间往往没有这么大,<br>因此 InnoDB 每次申请磁盘空间时都会是若干地址连续磁盘块来达到页的大小 16KB。
BTree
数据结构图
模拟查找关键字 29 的过程:
1. 根据根节点找到磁盘块 1,读入内存。【磁盘 I/O 操作第 1 次】<br>
2. 比较关键字 29 在区间(17,35),找到磁盘块 1 的指针 P2。
3. 根据 P2 指针找到磁盘块 3,读入内存。【磁盘 I/O 操作第 2 次】
4. 比较关键字 29 在区间(26,30),找到磁盘块 3 的指针 P2。
5. 根据 P2 指针找到磁盘块 8,读入内存。【磁盘 I/O 操作第 3 次】
6. 在磁盘块 8 中的关键字列表中找到关键字 29。
特性
1、关键字集合分布在整颗树中;<br>
2、任何一个关键字出现且只出现在一个节点中;<br>
3、每个节点存储data和key;
4、搜索有可能在非叶子节点结束;
5、一个节点中的key从左到右非递减排列;
6、所有叶节点具有相同的深度,等于树高h。
每个节点占用一个盘块的磁盘空间,<br>一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,<br>指针存储的是子节点所在磁盘块的地址。
B+Tree(InnoDB举例)
设计初衷
InnoDB 存储引擎在设计时是将根节点常驻内存的,<br>力求达到树的深度不超过 3,<br>也就是说 I/O 不需要超过 3 次。
分析B-Tree的查找过程,发现需要3次磁盘 I/O 操作,<br>和3次内存查找操作。<br>由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。
在 B-Tree 中,每个节点中有 key,也有 data,<br>而每一个页的存储空间是有限的,<br>如果 data 数据较大时将会导致每个节点(即一个页)能存储的 key 的数量很小,<br>会导致 B-Tree 的深度较大,增大查询时的磁盘 I/O 次数,进而影响查询效率。。
数据结构图
B+Tree的检索过程
在B-Tree的基础上有两点变化:
数据是存在叶子节点中的;
数据节点之间是有指针指向的。
扁平的B+Tree
B+Tree尺度示意
Page结构
Page是整个InnoDB存储的最基本构件,<br>也是InnoDB磁盘管理的最小单位,<br>与数据库相关的所有内容都存储在这种Page结构里。
Page常见页类型
单个Page的大小是16K(编译宏UNIV_PAGE_SIZE控制),<br>每个Page使用一个32位的int值来唯一标识,<br>这也正好对应InnoDB最大64TB的存储容量(16Kib * 2^32 = 64Tib)。
Page的基本结构
头部结构示意图
Page的头部保存了两个指针,<br>分别指向前一个Page和后一个Page,<br>Page链接起来就是一个双向链表的结构。
主体内容
Page的主体内容中主要关注行数据和索引的存储,都位于Page的User Records部分在一个Page内部
InnoDB存在4种不同的Record,<br>它们分别是1主键索引树非叶节点 2主键索引树叶子节点 3辅助键索引树非叶节点 4辅助键索引树叶子节点。
User Record在Page内以单链表的形式存在,<br>最初数据是按照插入的先后顺序排列的,<br>但是随着新数据的插入和旧数据的删除,<br>数据物理顺序会变得混乱,<br>但他们依然保持着逻辑上的先后顺序。
UserRecord示意图
https://www.cnblogs.com/shijingxiang/articles/4743324.html
常见索引类型(逻辑分类)
主键索引
常规索引(非主键)
唯一索引
复合索引
由多列创建的索引称为符合索引
前缀索引
当索引的字符串列很大时,创建的索引也就变得很大,<br>为了减小索引体积,提高索引的扫描速度,<br>就用索引的前部分字串索引,<br>这样索引占用的空间就会大大减少,<br>并且索引的选择性也不会降低很多。<br>而且是对BLOB和TEXT列进行索引,<br>或者非常长的VARCHAR列,<br>就必须使用前缀索引,<br>因为MySQL不允许索引它们的全部长度。
全文索引
InnoDB引擎对FULLTEXT索引的支持是MySQL5.6新引入的特性,<br>之前只有MyISAM引擎支持FULLTEXT索引。<br>对于FULLTEXT索引的内容可以使用MATCH()…AGAINST语法进行查询。
MySQL 5.6以前版本
仅MyISAM引擎支持FULL TEXT索引,<br>可以使用MATCH()...AGAINST语法进行查询<br><br>
只支持英文。缘由是他从来都使用空格来作为分词的分隔符,<br>而对于中文来讲,显然用空格就不合适,需要针对中文语义进行分词。
MySQL 5.6
InnoDB支持FULL TEXT索引
MySQL 5.7以后版本
MyISAM、InnoDB均支持FULL TEXT索引<br>
支持中文索引
外键索引
它可以提高查询效率,外键会自动和对应的其他表的主键关联。<br>外键的主要作用是保证记录的一致性和完整性。<br>
不推荐使用外键,在应用层使用外键的思想来保证数据的一致性和完整性。
覆盖索引
使用覆盖索引扫描的查询可以直接使用节点页中的主键值。<br>(具体参照下图中的索引数据结构)
索引类型-叶子节点数据分类
聚簇索引
叶子节点中存放的是索引和数据记录行
聚簇索引的每一个叶子节点<br>都包含了主键值、事务ID、用于事务和MVCC(多版本控制)的回滚指针以及所有的剩余列。
优点
提高数据访问性能:聚簇索引把索引和数据都保存到同一棵B+树数据结构中,<br>并且同时将索引列与相关数据行保存在一起。<br>这意味着,当你访问同一数据页不同行记录时,<br>已经把页加载到了Buffer中,再次访问的时候,<br>会在内存中完成访问,不必访问磁盘。<br>
不同于MyISAM引擎(非聚簇索引),它将索引和数据没有放在一块,<br>放在不同的物理文件中,索引文件是缓存在key_buffer中,<br>索引对应的是磁盘位置,不得不通过磁盘位置访问磁盘数据。
缺点
基于聚簇索引的表在插入新行,或者主键被更新,<br>导致需要移动行的时候,可能面临“页分裂(page split)”的问题。<br>页分裂会导致表占用更多的磁盘空间。
建议在大量插入新行后,<br>选在负载较低的时间段,<br>通过OPTIMIZE TABLE优化表,<br>因为必须被移动的行数据可能造成碎片。<br>使用独享表空间可以弱化碎片
表如果使用UUId作为主键,使数据存储稀疏,<br>这就会出现聚簇索引有可能有比全表扫面更新
建议使用int的auto_increment作为主键
如果主键比较大的话,那辅助索引将会变的更大,<br>因为辅助索引的叶子存储的是主键值;<br>过长的主键值,会导致非叶子节点占用更多的物理空间
非聚簇索引(辅助索引)
叶子节点中存放的是索引以及对应的数据记录指针(或主键)
索引扫描方式
紧凑索引扫描(dense index)
为了定位数据需要做权表扫描,<br>为了提高扫描速度,<br>把索引键值单独放在独立的数据的数据块里,<br>并且每个键值都有个指向原数据块的指针,<br>因为索引比较小,扫描索引的速度就比扫描全表快,<br>这种需要扫描所有键值的方式就称为紧凑索引扫描
松散索引扫描(sparse index)
为了提高紧凑索引扫描效率,通过把索引排序和查找算法(B+trre),<br>发现只需要和每个数据块的第一行键值匹配,<br>就可以判断下一个数据块的位置或方向,<br>因此有效数据就是每个数据块的第一行数据,<br>如果把每个数据块的第一行数据创建索引,<br>这样在这个新创建的索引上折半查找,<br>数据定位速度将更快。这种索引扫描方式就称为松散索引扫描。
覆盖索引扫描(covering index)
包含所有满足查询需要的数据的索引称为覆盖索引,<br>即利用索引返回select列表中的字段,<br>而不必根据索引再次读取数据文件<br>
针对某种sql覆盖掉了某种操作
InnoDB
一级索引/主键索引/聚簇索引
数据结构<br>
聚簇索引中的每个叶子节点<br>包含主键值、事务ID、回滚指针(rollback pointer用于事务和MVCC)和余下的列(如col2)。 <br>
InnoDB默认创建聚簇索引
1) 有主键时,根据主键创建聚簇索引
2) 没有主键时,会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引
3) 如果以上两个都不满足那innodb自己创建一个虚拟的聚集索引
二级索引/非主键索引/非聚簇索引
数据结构
InnoDB的二级索引(非聚簇索引)的叶子节点中存储的不是“行指针”,而是主键值。
故通过二级索引查找数据时,会进行两次索引查找。<br>存储引擎需要先查找二级索引的叶子节点来获得对应的主键值,<br>然后根据这个主键值到聚簇索引中查找对应的数据行。
MYISAM
同InnoDB数据结构比较
分支主题
MyISAM的二级索引叶子节点存放的还是列值与行号的组合,<br>叶子节点中保存的是数据的物理地址。
MYISAM的主键索引和二级索引没有任何区别,<br>主键索引仅仅只是一个叫做PRIMARY的唯一、非空的索引,<br>且MYISAM引擎中可以不设主键。
MySQL如何实现ACID http://cloud.tencent.com/developer/article/1408793<br><br>MySQL的日志有很多种,<br>如二进制日志、错误日志、查询日志、慢查询日志等,<br>此外InnoDB存储引擎还提供了两种事务日志:<br>redo log(重做日志)和undo log(回滚日志)。<br>其中redo log用于保证事务持久性;<br>undo log则是事务原子性和隔离性实现的基础。<br>
原子性<br><br>undo log
InnoDB实现回滚,靠的是undo log:<br>当事务对数据库进行修改时,InnoDB会生成对应的undo log;<br><br>如果事务执行失败或调用了rollback,导致事务需要回滚,<br>便可以利用undo log中的信息将数据回滚到修改之前的样子。
持久性 redo log<br><br>持久性是指事务一旦提交,<br>它对数据库的改变就应该是永久性的。<br>
InnoDB作为MySQL的存储引擎,数据是存放在磁盘中的,但如果每次读写数据都需要磁盘IO,效率会很低。为此,InnoDB提供了缓存(Buffer Pool),Buffer Pool中包含了磁盘中部分数据页的映射,作为访问数据库的缓冲:当从数据库读取数据时,会首先从Buffer Pool中读取,如果Buffer Pool中没有,则从磁盘读取后放入Buffer Pool;当向数据库写入数据时,会首先写入Buffer Pool,Buffer Pool中修改的数据会定期刷新到磁盘中(这一过程称为刷脏)。<br><br>Buffer Pool的使用大大提高了读写数据的效率,但是也带了新的问题:如果MySQL宕机,而此时Buffer Pool中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性无法保证。<br><br>于是,redo log被引入来解决这个问题:当数据修改时,除了修改Buffer Pool中的数据,还会在redo log记录这次操作;当事务提交时,会调用fsync接口对redo log进行刷盘。如果MySQL宕机,重启时可以读取redo log中的数据,对数据库进行恢复。redo log采用的是WAL(Write-ahead logging,预写式日志),所有修改先写入日志,再更新到Buffer Pool,保证了数据不会因MySQL宕机而丢失,从而满足了持久性要求。<br><br>既然redo log也需要在事务提交时将日志写入磁盘,为什么它比直接将Buffer Pool中修改的数据写入磁盘(即刷脏)要快呢?主要有以下两方面的原因:<br><br>1、刷脏是随机IO,因为每次修改的数据位置随机,但写redo log是追加操作,属于顺序IO。<br><br>2、刷脏是以数据页(Page)为单位的,MySQL默认页大小是16KB,一个Page上一个小修改都要整页写入;而redo log中只包含真正需要写入的部分,无效IO大大减少。
redo log与binlog<br><br>我们知道,在MySQL中还存在binlog(二进制日志)也可以记录写操作并用于数据的恢复,但二者是有着根本的不同的:<br><br>1、作用不同:redo log是用于crash recovery的,保证MySQL宕机也不会影响持久性;<br>binlog是用于point-in-time recovery的,保证服务器可以基于时间点恢复数据,此外binlog还用于主从复制。<br><br>2、层次不同:redo log是InnoDB存储引擎实现的,<br>而binlog是MySQL的服务器层(可以参考文章前面对MySQL逻辑架构的介绍)实现的,同时支持InnoDB和其他存储引擎。<br><br>3、内容不同:redo log是物理日志,内容基于磁盘的Page;<br>binlog是逻辑日志,内容是一条条sql。<br><br>4、写入时机不同:binlog在事务提交时写入;<br>redo log的写入时机相对多元:<br><br>前面曾提到:当事务提交时会调用fsync对redo log进行刷盘;<br>这是默认情况下的策略,修改innodb_flush_log_at_trx_commit参数可以改变该策略,但事务的持久性将无法保证。<br><br>除了事务提交时,还有其他刷盘时机:如master thread每秒刷盘一次redo log等,这样的好处是不一定要等到commit时刷盘,commit速度大大加快。
隔离性<br><br>隔离性研究的是不同事务之间的相互影响。<br>隔离性是指,事务内部的操作与其他事务是隔离的,<br>并发执行的各个事务之间不能互相干扰。<br>
(一个事务)写操作对(另一个事务)写操作的影响:锁机制保证隔离性
隔离性要求同一时刻只能有一个事务对数据进行写操作,InnoDB通过锁机制来保证这一点。<br><br>事务在修改数据之前,需要先获得相应的锁;<br>获得锁之后,事务便可以修改数据;<br>该事务操作期间,这部分数据是锁定的,<br>其他事务如果需要修改数据,需要等待当前事务提交或回滚后释放锁。<br><br>锁可以分为表锁、行锁以及其他位于二者之间的锁。<br>表锁在操作数据时会锁定整张表,并发性能较差;<br>行锁则只锁定需要操作的数据,并发性能好。<br><br>但是由于加锁本身需要消耗资源(获得锁、检查锁、释放锁等都需要消耗资源),<br>因此在锁定数据较多情况下使用表锁可以节省大量资源。<br>MySQL中不同的存储引擎支持的锁是不一样的,例如MyIsam只支持表锁,而InnoDB同时支持表锁和行锁,且出于性能考虑,绝大多数情况下使用的都是行锁。<br>
(一个事务)写操作对(另一个事务)读操作的影响:MVCC保证隔离性
RR解决脏读、不可重复读、幻读等问题,使用的是MVCC:MVCC全称Multi-Version Concurrency Control,即多版本的并发控制协议。
为什么InnoDB能够保证原子性A?用的什么方式?<br><br>十万个为什么地址:<br>https://benjaminwhx.com/2018/04/25/<br>%E8%B0%88%E8%B0%88MySQL-InnoDB<br>%E5%AD%98%E5%82%A8%E5%BC%95%<br>E6%93%8E%E4%BA%8B%E5%8A%A1%E7<br>%9A%84ACID%E7%89%B9%E6%80%A7/
在事务里任何对数据的修改都会写一个Undo log,<br>然后进行数据的修改,如果出现错误或者用户需要回滚的时候可以利用Undo log的备份数据恢复到事务开始之前的状态。
为什么InnoDB能够保证持久性?用的什么方式?
在一个事务中的每一次SQL操作之后都会写入一个redo log到buffer中,<br>在最后COMMIT的时候,必须先将该事务的所有日志写入到redo log file进行持久化(这里的写入是顺序写的),<br>待事务的COMMIT操作完成才算完成。即使COMMIT后数据库有任何的问题,<br>在下次重启后依然能够通过redo log的checkpoint进行恢复。也就是crash recovery。
为什么InnoDB能够保证一致性?用的什么方式?
所谓一致性,指的是数据处于一种有意义的状态,这种状态是语义上的而不是语法上的。<br>最常见的例子是转帐。例如从帐户A转一笔钱到帐户B上,如果帐户A上的钱减少了,<br>而帐户B上的钱却没有增加,那么我们认为此时数据处于不一致的状态。<br><br>在数据库实现的场景中,一致性可以分为数据库外部的一致性和数据库内部的一致性。<br>前者由外部应用的编码来保证,即某个应用在执行转帐的数据库操作时,<br>必须在同一个事务内部调用对帐户A和帐户B的操作。<br>如果在这个层次出现错误,这不是数据库本身能够解决的,也不属于我们需要讨论的范围。<br>后者由数据库来保证,即在同一个事务内部的一组操作必须全部执行成功(或者全部失败)。<br>这就是事务处理的原子性。(上面说过了是用Undo log来保证的)<br><br>但是,原子性并不能完全保证一致性。<br>在多个事务并行进行的情况下,<br>即使保证了每一个事务的原子性,<br>仍然可能导致数据不一致的结果,<br>比如丢失更新问题。<br><br>为了保证并发情况下的一致性,引入了隔离性,<br>即保证每一个事务能够看到的数据总是一致的,<br>就好象其它并发事务并不存在一样。<br>用术语来说,就是多个事务并发执行后的状态,<br>\和它们串行执行后的状态是等价的。
为什么RU级别会发生脏读,而其他的隔离级别能够避免?
RU级别的操作其实就是对事务内的每一条更新语句对应的行记录加上读写锁来操作,而不把一个事务当成一个整体来加锁,所以会导致脏读。<br>但是RC和RR能够通过MVCC来保证记录只有在最后COMMIT后才会让别的事务看到。
为什么RC级别不能重复读,而RR级别能够避免?
MVCC的最后说到了,在RC事务隔离级别下,每次语句执行都关闭ReadView,然后重新创建一份ReadView。<br>而在RR下,事务开始后第一个读操作创建ReadView,一直到事务结束关闭。<br>
为什么InnoDB的RR级别能够防止幻读?
因为RR隔离级别使用了Next-key Lock这么个东东,也就是Gap Lock+Record Lock的方式来进行间隙锁定
sql题
mysql删除重复数据只保留id最大一条记录
DELETE FROM t_4g_phone WHERE id NOT IN (<br> SELECT id FROM ( SELECT max(b.id) AS id FROM t_4g_phone b <br> GROUP BY b.SERIAL_NUMBER ) b<br>)
Linux
文件目录
/bin:/usr/bin: 可执行二进制文件的目录
/boot: 放置linux系统启动时用到的一些文件。
/dev: 存放linux系统下的设备文件
/etc: 系统配置文件存放的目录
/home: 系统默认的用户家目录
/lib:/usr/lib:/usr/local/lib: 系统使用的函数库的目录
/lost+fount: 系统异常产生错误时,会将一些遗失的片段放置于此目录下
/mnt:/media: 光盘默认挂载点
/opt: 给主机额外安装软件所摆放的目录
/proc: 此目录的数据都在内存中
系统核心,外部设备,网络状态,<br>由于数据都存放于内存中,所以不占用磁盘空间,<br>比较重要的目录有/proc/cpuinfo、/proc/interrupts、/proc/dma、/proc/ioports、/proc/net/*等
/root: 系统管理员root的家目录
/sbin:/usr/sbin:/usr/local/sbin: 放置系统管理员使用的可执行命令
如fdisk、shutdown、mount等。与/bin不同的是,这几个目录是给系统管理员root使用的命令,一般用户只能"查看"而不能设置和使用。
/tmp: 一般用户或正在执行的程序临时存放文件的目录,任何人都可以访问,重要数据不可放置在此目录下
/srv: 服务启动之后需要访问的数据目录
/usr: 应用程序存放目录
vi
vim的几种工作模式
normal模式、编辑模式、命令模式
编辑模式
i <br>insert,光标当前字符前插入 <br><br>a <br>append, 光标当前字符后插入 <br><br>o <br>下一行插入 <br><br>s <br>不常用,删除当前字符并插入
退出、保存,在normal模式下使用冒号(:) 进入底线命令模式<br><br>:q <br>退出不保存 <br><br>:q! <br>强制退出不保存 <br><br>:wq <br>退出保存 <br><br>:wq! <br>强制退出保存
分割窗口【:split】
:%s/old/new/g # 全局替换,将old字符替换成new
:[n1],[n2]s/old/new/g # n1、n2为行号,意思是从第n1行到n2行。
网络
3种常见的计算机体系结构划分
OSI分层(7层):物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。
TCP/IP分层(4层):网络接口层、网际层、运输层、应用层。
五层协议(5层):物理层、数据链路层、网络层、运输层、应用层。
常见的网络协议
网络层
IP协议:网际协议<br><br>ICMP协议:Internet控制报文协议<br><br>ARP协议:地址解析协议<br><br>RARP协议:逆地址解析协议
传输层
UDP协议:用户数据报协议<br><br>TCP协议:传输控制协议
应用层
TCP对应的应用层协议<br><br>FTP:定义了文件传输协议,使用21端口。<br><br>Telenet:远程登录协议,23和22端口<br><br>POP3:邮局协议,用于接收邮件。通常情况下,POP3协议所用的是110端口。<br><br>HTTP协议<br><br>SMTP:简单邮件传送协议,25号端口<br>
UDP对应的应用层协议<br><br>DNS:用于域名解析服务,将域名地址转换为IP地址。DNS用的是53号端口。<br><br>SNMP:简单网络管理协议,使用161号端口,是用来管理网络设备的。由于网络设备很多,无连接的服务就体现出其优势。<br><br>TFTP(Trival File Transfer Protocal):简单文件传输协议,该协议在熟知端口69上使用UDP服务。
TCP连接的建立与终止过程
三次握手
第一次握手:客户端发送syn包(syn=x)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),<br>同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,<br>客户端和服务器进入ESTABLISHED状态,完成三次握手。
四次挥手
第一次挥手:主动关闭方发送一个FIN,<br>用来关闭主动方到被动关闭方的数据传送,<br>也就是主动关闭方告诉被动关闭方:<br>我已经不会再给你发数据了<br>(当然,在fin包之前发送出去的数据,如果没有收到对应的ack确认报文,<br>主动关闭方依然会重发这些数据),<br>但是,此时主动关闭方还可以接受数据。
第二次挥手:被动关闭方收到FIN包后,发送一个ACK给对方,<br>确认序号为收到序号+1。
第三次挥手:被动关闭方发送一个FIN,<br>用来关闭被动关闭方到主动关闭方的数据传送,<br>也就是告诉主动关闭方,我的数据也发送完了,不会再给你发数据了。<br>(与SYN相同,一个FIN占用一个序号)。
第四次挥手:主动关闭方收到FIN后,<br>发送一个ACK给被动关闭方,<br>确认序号为收到序号+1,至此,完成四次挥手。
TCP的半关闭
TCP提供了连接的一端在结束它的发送后还能接收来自另一端数据的能力,这就是半关闭。
网际协议IP
IP协议的特点
不可靠
无连接
IP首部
通的IP首部长20个字节(不包含选项字段),<br>包含协议版本号、首部长度、总长度、唯一标识、TTL、首部检验和、源IP地址和目的IP地址。
IP地址
A类地址:以0开头,第一个字节范围:0~127;<br><br>B类地址:以10开头,第一个字节范围:128~191;<br><br>C类地址:以110开头,第一个字节范围:192~223;<br><br>D类地址:以1110开头,第一个字节范围为224~239;
3个特殊的IP地址
255.255.255.255
受限的广播地址。
0.0.0.0
用于寻找自己的IP地址
127.0.0.1
回环地址,回环地址表示本机的地址
划分子网
如何正确地区分子网号和主机号是一个问题,<br>这可以通过子网掩码来确定。<br>将网络号和子网号全设为1的IP地址为子网掩码。
域名系统DNS
因特网的一项核心服务,<br>它作为可以将域名和IP地址相互映射的一个分布式数据库,<br>能够使人更方便的访问互联网,<br>而不用去记住能够被机器直接读取的IP数串。
当DNS客户机需要在程序中使用名称时,<br>它会查询DNS服务器来解析该名称。<br>客户机发送的每条查询信息包括三条信息:<br>包括:<br>指定的DNS域名,<br>指定的查询类型,<br>DNS域名的指定类别。<br>该应用一般不直接为用户使用,<br>而是为其他应用服务,<br>如HTTP,SMTP等在其中需要完成主机名到IP地址的转换。
域名服务器
根域名服务器:最高层次的,也是最重要的域名服务器。
顶级域名服务器:负责管理在该顶级域名服务器注册的二级域名。
权限域名服务器:负责一个“区”的域名服务器。
本地域名服务器:本地服务器不属于下图的域名服务器的层次结构,但是它对域名系统非常重要。
域名的解析过程
主机向本地域名服务器的查询一般都是采用递归查询。
递归查询就是:<br>如果主机所询问的本地域名服务器不知道被查询的域名的IP地址,<br>那么本地域名服务器就以DNS客户的身份,<br>向其它根域名服务器继续发出查询请求报文(即替主机继续查询),<br>而不是让主机自己进行下一步查询。
本地域名服务器向根域名服务器的查询的迭代查询。
迭代查询的特点:<br>当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,<br>要么给出所要查询的IP地址,要么告诉本地服务器:“你下一步应当向哪一个域名服务器进行查询”。<br>然后让本地服务器进行后续的查询。<br>根域名服务器通常是把自己知道的顶级域名服务器的IP地址告诉本地域名服务器,<br>让本地域名服务器再向顶级域名服务器查询。<br>顶级域名服务器在收到本地域名服务器的查询请求后,<br>要么给出所要查询的IP地址,<br>要么告诉本地服务器下一步应当向哪一个权限域名服务器进行查询。<br>最后,知道了所要解析的IP地址或报错,然后把这个结果返回给发起查询的主机。
假定域名为m.xyz.com的主机想知道另一个主机y.abc.com的IP地址
主机m.abc.com先向本地服务器dns.xyz.com进行递归查询。<br>本地服务器采用迭代查询。它先向一个根域名服务器查询。<br>根域名服务器告诉本地服务器,下一次应查询的顶级域名服务器dns.com的IP地址。<br>本地域名服务器向顶级域名服务器dns.com进行查询。<br>顶级域名服务器dns.com告诉本地域名服务器,下一步应查询的权限服务器dns.abc.com的IP地址。<br>本地域名服务器向权限域名服务器dns.abc.com进行查询。<br>权限域名服务器dns.abc.com告诉本地域名服务器,所查询的主机的IP地址。<br>本地域名服务器最后把查询结果告诉m.xyz.com。
整个查询过程共用到了8个UDP报文
面试题精选
TCP和UDP有什么区别
TCP是传输控制协议,<br>提供的是面向连接、可靠的字节流服务。<br>当客户和服务器批次交换数据前,<br>必须建立TCP连接之后才能传输数据。<br>TCP提供超时重传、丢弃重复数据、流量控制等功能,<br>保证数据能从一端传到另一端。
UDP是用户数据报协议,是一个简单的面向数据报的运输层协议。<br>UDP不提供可靠性,不保证数据能够到达目的地。<br>由于UDP在传输数据前不用在客户和服务器之间建立连接,<br>且没有超时重传等机制,故而传输速度很快。
TCP的可靠性如何保证
TCP的可靠性是通过顺序编号和确认(ACK)来实现的。
在浏览器中输入www.baidu.com后执行的全部过程
父主题
客户端浏览器通过DNS解析到www.baidu.com的IP地址220.181.27.48,<br>通过这个IP地址找到客户端到服务器的路径。<br>客户端浏览器发起一个HTTP会话到220.161.27.48,<br>然后通过TCP进行封装数据包,输入到网络层。<br><br>在客户端的传输层,把HTTP会话请求分成报文段,<br>添加源和目的端口,如服务器使用80端口监听客户端的请求,<br>客户端由系统随机选择一个端口如5000,与服务器进行交换,<br>服务器把相应的请求返回给客户端的5000端口。<br>然后使用IP层的IP地址查找目的端。<br><br>客户端的网络层不用关系应用层或者传输层的东西,<br>主要做的是通过查找路由表确定如何到达服务器,<br>期间可能经过多个路由器,这些都是由路由器来完成的工作,<br>通过查找路由表决定通过那个路径到达服务器。<br><br>客户端的链路层,包通过链路层发送到路由器,<br>通过邻居协议查找给定IP地址的MAC地址,<br>然后发送ARP请求查找目的地址,<br>如果得到回应后就可以使用ARP的请求应答交换的IP数据包现在就可以传输了,<br>然后发送IP数据包到达服务器的地址。
IP路由表包括哪几项内容?
子网掩码、目的网络地址、到目的网络路径上“下一个”路由器的地址。
高并发
概念
大量用户同时访问请求网站或系统,造成请求不能及时响应的现象 <br>
解决思路
负载均衡Load Balance
硬件
F5
软件
nginx
Linux服务器集群系统LVS (Linux Virtual Server)
HaProxy
服务器集群
服务器集群就是指将很多服务器集中起来一起进行同一种服务,在客户端看来就像是只有一个服务器。
常见集群
Tomcat服务器集群
Apache +Tomcat: 一台Apache服务器进行反向代理与请求分发,多台Tomcat服务器处理请求
Nginx + Tomcat:一台Nginx服务器进行反向代理与请求分发,多台Tomcat服务器处理请求
WebLogic服务器集群
数据库服务器集群
锁机制
分布式锁
基于数据库实现
锁表
创建一张锁表,当需要锁住某个方法或资源时,我们就在该表中增加一条相应的记录,想要释放锁的时候就删除该条记录
排他锁
在查询语句后面增加for update,数据库在查询过程中给数据库表增加排他锁,直到事务提交才会释放锁
基于缓存实现
如redis, memcached
基于zookeeper实现
Java中的锁
用于保证线程同步
同步锁synchronized关键字
Lock
CAS
数据库锁
已由数据库本身实现,只需调用相关语句即可
乐观锁
通常通过在表结构中增加一个版本号字段来解决,查询数据时将版本号一起查出来,需要更新数据时就将原有版本号加一
给数据库操作加版本号判断,满足条件才会执行,这就相当于给数据库操作加了一把锁
如update user set name = 'Tom', version = 2 where id = 1 and version = 1
悲观锁
共享锁
对于MySQL数据库,在查询语句后面加上lock in share mode, 数据库就会在查询过程中给数据库表增加共享锁
排他锁
也称独占锁。排他锁与共享锁相对应,就是指对于多个不同的事务,对同一个资源只能有一把锁
在查询语句后面增加for update,数据库会在查询过程中给数据库表指定行增加排他锁,直到事务提交才会释放锁
如 select * from user where name = '张三' for update
缓存技术
缓存主要是为了提高数据的读取速度。<br>因为服务器和应用客户端之间存在着流量的瓶颈,<br>所以读取大容量数据时,使用缓存来直接为客户端服务,<br>可以减少客户端与服务器端的数据交互,从而大大提高程序的性能。
要解决的问题
缓存一致性
缓存与数据库中的数据需要保证一致
缓存雪崩
缓存在同一时间大面积失效
缓存穿透
同一时间大量请求查询不存在的缓存,造成后端数据库压力增大
好处
减轻数据库压力
提高数据访问的速度
常用缓存中间件
redis
Redis的安装及配置(Linux环境下)
过期时间 expire
数据类型
String
最基本的存储结构
命令
get key
set key value
mget key1 key2
mset key1 key2
setnx key value
incr/decr key
Hash
key-value结构
命令
hget key field
hset key field value
hmset key field value1 field2 value2...
hmget key field1 field2...
List
双向链表结构,数据按从左到右的顺序存储
命令
lpush、rpush、lpop、rpop、lset key index value
Set
Set集合,不能有相同的值
命令
sadd key member1 member2<br>scard key<br>set key index value<br>sismember key member<br>smembers key
zset(sorted set)
有序集合,按照score排序
命令
zadd key score1 member1 score2 member2<br>zcard key<br>zrange key start stop[withscores]
存储
内存、磁盘、日志文件
持久化
RDB快照
Append-only file(缩写为AOF) 日志
发布/订阅
管道pipeline
可以一次性发生多条命令并在执行完成后一次性将结果返回
通过减少客户端与redis的通信次数来实现降低往返延时时间,而且其实现原理是队列,先进先出,因此可以保证数据的顺序性
事务
事务中的多条命令要么都执行成功,要么都失败
memcached
特点:<br>1、只支持key-value数据结构存储<br>2、缓存数据全部在内存中,不支持数据持久化
ehcache
CDN(Content Delivery Network, 内容分发网络) 缓存
服务降级
网页HTML静态化
数据库读写分离,分表分库
图片服务器分离
测试工具
主从与分库分表
主从
概述
主从复制过程,是异步复制<br>
三个线程,主io,从io,sql IO
类型
逻辑复制,基于sql的复,问题 日期和next-key等不好处理<br>
基于行的复制,binlog,5.0+支持 <br>
混合先sql,若无法精确采用行复制
复制过程
创建复制用户,可以选择那些表做主从<br>
master 记录binary log
slave 通过 i/o线程拷贝master的log到自己的中继日志(relay log) <br>
slave通过sql 线程 重做中继日志,是两者一致
复制是串行的,因此master的并行操作,在slave无法体现
配置过程
master建复制账号<br>
拷贝数据
冷拷贝
热拷贝,myiSAm 可通过mysqlhotcopy 命令 <br>
使用mysqldump
配置master 开启binlog
配置slaver 开启relaylog,设置只读
异常情况
从库提升到主库,reset slave all
其他
master master 结构
master,master,slaver 结构
分库分表
为什么要分库分表?
数据库的性能瓶颈
连接数
处理能力
存储容量
数据库的优化方案
SQL优化
批处理
索引
分区
缓存
主从复制<br><br>通过数据冗余实现高可用<br>
读写分离
主写
从读
集群<br><br>通过负载实现高性能<br>
向上扩展<br><br>扩展硬件<br>
分库分表
大数据 NoSQL
什么时候考虑切分
能不切分尽量不切分
数据量过大
单表行数 500万~1000万
单表存储 <2G
数据量增长过快
如商场活动期间订单爆炸增长
需要对某些字段进行切分
出于安全性和可用性考虑
切分的类型
垂直切分
垂直分库
垂直分表
业务相关表
一些字典共享表可缓存或者都复制一份
关联打断越多,影响join就多
根据活跃度来区别
冷数据适合做主从用myisam
热数据适合做master分表,用innoDB
更加活跃的数据考虑用缓存定时同步到DB <br>
考虑 字段大小和访问频度
水平切分
水平分表
类似于分区
水平分库分表
分区
Range<br><br>Hash<br><br>Key<br><br>List<br><br>Composite
分区or分表
优点
增删改索引消耗小<br><br>写操作的锁开销变小
数据切分后的问题以及解决方案
事务一致性问题
XA规范<br><br>两阶段提交<br><br>三阶段提交
跨节点的关联查询的问题
全局表
不会变化的公共表
字段冗余
ER分片(订单表、订单明细表)
数据组装
跨节点的排序、分页、函数的问题
结果汇总作二次计算
全局主键的问题
UUID
无序
数据表维护主键
并发性能低
开源的ID生成系统
snowflake<br>性能非常高, 缺点是如果时间回拨或者各个实例节点时间不一致, 容易出错<br>
美团开源的Leaf<br>支持多种不同模式的生成策略<br><br>1. 号段模式<br>该模式需要建DB表, 需要有专门的服务来提供获取id的接口, 存在网络延迟<br><br>2. Snowflake模式<br>为了追求更高的性能,需要通过RPC Server来部署Leaf 服务,那仅需要引入leaf-core的包,<br>把生成ID的API封装到指定的RPC框架中即可<br>
sharding-jdbc开源的主键生成组件<br>简单易用, 可以指定workerId或者不指定, 直接通过jar的方式引入即可<br>
百度开源的uid-generator<br>需要建DB表, 需要有专门的服务来提供获取id的接口, 存在网络延迟<br>
数据迁移、扩容的问题
分库分表中间件Mycat
术语
主机/实例<br><br>物理数据库<br><br>物理表<br><br>分片(切分)<br><br>分片节点<br><br>分片键<br><br>分片算法<br><br>逻辑表<br><br>逻辑数据库
配置文件
server.xml
用户、密码、权限
schema.xml
逻辑库、逻辑表
结构
schema
table1
dataNode 分布的节点
rule 分片的策略
table2
dataNode
name<br>
dataHost <br>
database
dataHost
heartbeat
writeHost
数据源配置
eadHost
rule.xml
分片策略
rang-long范围分片
mod-long取模分片
mod-long + ER分片
父表-子表(订单表-订单详情表)
确保关联的父表和子表的记录在同一个节点
范围取模算法(先范围再取模)
取模范围算法(先取模再范围)
结构
function
对应java接口
txt
策略配置
指定默认节点
性能优化
性能指标
硬件层面
软件层面
响应时间
系统对请求作出响应的时间,通常包括客户端响应时间、网络响应时间和服务端响应时间
吞吐量
并发用户数
性能测试
JMeter
硬件优化
CPU、内存、磁盘
数据库SQL优化
分析SQL执行计划
MySQL使用explain命令
如 explain select...
Oracle使用explain plan for命令
如explain plan for select...
SQL语句优化
建立及优化索引
JVM参数调优
内存泄漏
内存使用后未得到及时释放,而且不能被GC回收,导致虚拟机不能再次使用该内存,此时这段内存就泄漏了
内存溢出OOM
即OutOfMemoryError,当没有足够的空闲内存可供程序使用时出现
常见类型
Java Heap Space: Java 堆内存溢出
此种情况最常见,一般由于内存泄漏或者堆的大小设置不当引起<br>对于内存泄漏,需要通过内存监控软件(headdump)查找程序中的泄漏代码;而堆大小可通过设置JVM的参数-Xms、-Xmx来解决
PermGen Space:永久代内存溢出
即方法区内存溢出,如果程序加载的类过多,或者使用反射、gclib等这种动态代理生产类的技术,就可能导致该区发生内存溢出<br>此种情况可以通过更改方法区的大小来解决,设置-XX:PermSize=64m -XX:MaxPermSize=256m参数<br>另外,过多的常量尤其是字符串也会导致方法区溢出,因为常量池也位于方法区中
注:从Java8开始移除了Permgen Space,取而代之的是MetaSpace
StackOverflowError:栈溢出
即虚拟机栈或本地方法栈区域内存溢出
出现原因:程序中出现了死循环或递归次数过多;也可能是栈大小设置过小导致,可通过设置-Xss参数来调整栈大小
监控工具
JDK提供的工具,可帮助快速定位程序问题、性能瓶颈
jps:查看Java进程
jmap:查看JVM当前的堆内存快照(heapdump) <br>
jstack:查看JVM当前的线程快照,又称threaddump文件,它是JVM当前每一条线程正在执行的堆栈信息的集合 <br>
jinfo:实时查看JVM的参数信息 <br>
jstat:用于监控JVM的各种运行状态信息,如类的装载、内存、垃圾回收、JIT编译器等 <br>
jconsole:用于监控内存,线程、堆栈等信息 <br>
jprofile:类似于jconsole,比jconsole监控的信息更全面 <br>
程序优化
代码优化
JNI(Java本地接口)
Effective Java
创建和销毁对象
1. 用静态工厂方法代替构造器
2. 遇到多个构造器参数时要考虑使用Builder模式
3. 用私有构造器或者枚举类型强化Singleton属性
4. 通过私有构造器强化不可实例化的能力
5. 优先考虑依赖注入来引用资源
6. 避免创建不必要的对象
7. 消除过期对象引用
8. 避免使用终结方法和清除方法
9. try-with-resources优先于try-finally
对于所有对象都通用的方法
10. 覆盖equals时请遵守通用约定
11. 覆盖equals时总要覆盖hashCode
12. 始终要覆盖toString
13. 谨慎地覆盖clone
14. 考虑实现Comparable接口
类和方法
15. 使类和成员的可访问性最小化
16. 要在公有类而非公有域中使用访问方法
17. 是可变性最小化
18. 复合优先于继承
19. 要么设计继承并提供文档说明,要么禁止继承
20. 接口优于抽象类
21. 为后代设计接口
22. 接口只用于定义类型
23. 类层次优于标签类
24. 静态成员类优于非静态成员类
25. 限制源文件为单个顶级类
泛型
26. 请不要使用原生态类型
27. 消除非受检的警告
28. 列表优于数组
29. 优先考虑泛型
30. 优先考虑泛型方法
31. 利用有限制通配符来提升API的灵活性
32. 谨慎并用泛型和可变参数
33. 优先考虑类型安全的异构容器
枚举和注解
34. 用enum代替int常量
35. 用实例域代替序数
36. 用EnumSet代替位域
37. 用EnumMap代替序数索引
38. 用接口模拟可扩展的枚举
39. 注解优先于命名模式
40. 坚持使用Override注解
41. 用标记接口定义类型
Lambda和Stream
42. Lambda优先于匿名类
43. 方法引用优先于Lambda
44. 坚持使用标准的函数接口
45. 谨慎使用Stream
46. 优先选择Stream中无副作用的函数
47. Stream要优先用Collection作为返回类型
48. 谨慎使用Stream并行
方法
49. 检查参数的有效性
50. 必要时进场保护性拷贝
51. 谨慎设计方法签名
52. 慎用重载
53. 慎用可变参数
54. 返回零长度的数组或者集合,而不是null
55. 谨慎返回optional
56. 为所有导出的API元素编写文档注释
通用编程
57. 将局部变量的作用域最小化
58. for-each循环优先于传统的for循环
59. 了解和使用类库
60. 如果需要精确的答案,请避免使用float和double
61. 基本类型优先于装箱基本类型
62. 如果其他类型更适合,则尽量避免使用字符串
63. 了解字符串连接的性能
64. 通过接口引用对象
65. 接口优先于反射机制
66. 谨慎地使用本地方法
67. 谨慎地进行优化
68. 遵守普遍接受的命名惯例
异常
69. 只针对异常的情况才使用异常
70. 对可恢复的情况使用受检异常,对编程错误使用运行时异常
71. 避免不必要地使用受检异常
72. 优先使用标准的异常
73. 抛出与抽象对应的异常
74. 每个方法抛出的所有异常都要建立文档
75. 在细节消息中包含失败-捕获信息
76. 努力使失败保持原子性
77. 不要忽略异常
并发
78. 同步访问共享的可变数据
79. 避免过度同步
80. executor、task和stream优先于线程
81. 并发工具优先于wait和notify
82. 线程安全性的文档化
83. 慎用延迟初始化
84. 不要依赖于线程调度器
序列化
85. 其他方法优先于Java序列化
86. 谨慎地实现Serializable接口
87. 考虑使用自定义的序列化形式
88. 保护性地编写readObject方法
89. 对于实例控制,枚举类型优先于readResolve
90. 考虑用序列化代理代替序列化实例
DDIA
数据系统基础
第一章<br>可靠、可扩展、可维护的应用系统
父主题
数据密集型
数据库:用以存储数据,这样之后应用可以再次面问。<font color="#80bc42">集群/分库分表(垂直/水平)</font><br><br>高速缓存 : 缓存那些复杂或操作代价昂贵的结果,以加快下一次访问。<font color="#80bc42">缓存失效/雪崩</font><br><br>索引 : 用户可以按关键字搜索数据井支持各种过掳。<font color="#80bc42">elastic search/solr<br></font><br>流式处理:持续发送消息至另一个进程,处理采用异步方式。<font color="#80bc42">stream(spark streaming/ kafka streams)</font><br><br>批处理 : 定期处理大量的累积数据。<font color="#80bc42">hadoop/hive/hbase</font>
子主题
可靠性
能容错/弹性<br>硬件冗余<br>人为失误
最小出错方式设计系统
分离最容易出错的地方,容易引发故障的接口
充分测试
快速恢复机制
详细清晰的监控子系统
推行管理流程并培训
可扩展性
负载
Web服务器的每秒请求处理次数,<br>数据库中写入的比例,<br>聊天室的同时活动用户数量,<br>缓存命中率等。
性能
响应时间是客户端看到的 :<br>除了处理请求时间(服务时间, service time)外,<br>还包括来回网络延迟和各种排队延迟。 <br><br>延迟则是请求花费在处理上 的时间。
中位数指标非常适合描述多少用户需要等待多长时间: <br>一半的用户请求的服务时间少 于中位数响应时间,<br>另一半则多于中位数的时间。
应对负载增加的方法
针对特定级别负载而设计的架构不太可能应付超出预设目标10倍的实际负载。
如何在垂直扩展(即升级到更强大的机器)和水平扩展(即将负载 分布到多个更小的机器)之间做取舍。
某些系统具有弹性特征,它可以自动检测负载增加
无状态服务分布然后扩展至多台机器相对比较容易,<br>有状态服务从单个节点扩展 到分布式多机环境的复杂性会大大增加<br>
随着相关分布式系统专门组件和编程接口越来越好,<br> 至少对于某些应用类型来 讲,<br>上述通常做告或许会发生改变。<br>可以乐观设想 ,<br>即使应用可能并不会处理大量数 据或流量,<br>但未来分布式数据系统将成为标配。
Twitter的例子
将发送的新tweet插入到全局的tweet集合中。
当用户查看时间线肘,<br>首先查找所 有的关注对象,<br>列出这些人的所有tweet,<br>最后以时间为序来排序合井。
对每个用户的时间线维护一个缓存
类似每个用户一个tweet邮 箱。<br>当用户推送新tweet肘,<br>查询其关注者,<br>将tweet插入到每个关注者的时间线 缓存中。<br>因为已经预先将结果取出,<br>之后访问时间线性能非常快。 <br>
Twitter故事最后的结局是 : <br>方法2已经得到了稳定实现,Twitter正在转向结合两种方法。<br><br>大多数用户的tweet在发布时继续以一对多写入时间线,<br><br>但是少数具有超多关注者 (例如那些名人)的用户除外,<br>对这些用户采用类似方案1 ,<br> 其推文被单独提取,在 读取时才和用户的时间线主表合并。<br>这种混合方法能够提供始终如一的良好表现
可维护性
运维更轻松
提供对系统运行时行为和内部的可观测性,方便监控。<br><br>支持自动化, 与标准工具集成。<br><br>避免绑定特定的机器,这样在整个系统不间断运行的同时,允许机器停机维护。<br><br>提供良好的文档和易于理解的操作模式,诸如“如果我做了X,会发生Y”。<br><br>提供良好的默认配置,且允许管理员在需要时方便地修改默认值。<br><br>尝试自我修复,在需要时让管理员手动控制系统状态。<br><br>行为可预测,减少意外发生。 <br>
简化复杂度
把复杂性定义为一种“意外”
消除意外复杂性最好手段之一是抽象。 <br>一个好的设计抽象可以隐藏大量的实现细节, <br>并对外提供干净、易懂的接口。 <br>一个好的设计抽象可用于各种不同的应用程序。<br>这样,复用远比多次重复实现更有效率;<br>另一方面,也带来更高质量的软件,<br>而质量过硬的抽象组件所带来的好处,<br>可以使运行其上的所有应用轻松获益。 <br>
易于改变
当新产品推出,<br>或为了更好地理解用户需求,<br>或商业环境发生变化时,<br>就需要不断地添加或修改功能。<br>构建可适应变化的系统
第二章<br>数据模型与查询语言
子主题
模型
关系模型
SQL<br>数据被组织成关系,在SQL中称为表,每个关系都是元组的无序集合(SQL中称为行)
主要用于事务处理和批处理
如果数据存储在关系表中 , <br>那么应用层代码中的对象与表、行<br>和列的数据库模型之间需要一个笨拙的转换层(ORM)。
关系模型所做的则是定义了所有数据的格式:<br>关系(表)只是元组(行) 的集合 ,仅此而已。<br>没有复杂的嵌套结构, 也没有复杂的访问路径。<br>可以读取表中的任何一行或者所有行,<br>支持任意条件查询。<br>可以指定某些列作为键并匹配这些列来读取特定行。<br>可以在任何表中插入新行,<br>而不必担心与其他表之间的外键关系
在关系数据库中, 查询优化器自动决定以何种顺序执行查询 ,以及使用哪些索引。
如果想用新的方式查询数据,只需声明一个新的索引,查词会自动使用最合适的索 引。不需要更改查询即可利用新的索引
关系模型的一个核心要点是:<br>只需构建一次查询优化器,<br>然后使用该数据库的所有应用程序都可以从中受益。
文档模型
NoSQL
驱动因素
比关系数据库更好的扩展性需求,包括支持超大数据集或超高写入吞吐量<br>
普遍偏爱免费和开源软件而不是商业数据库产品
关系模型不能很好地支持一些特定的查询操作
对关系模式一些限制性感到沮丧,渴望更具动态和表达力的数据模型
文档数据库是某种方式的层次模型 : <br>即在其父记录中保存了嵌套记 录(一对多关系), 而不是存 储在单独的表中。
文档模型中的模式灵活性 <br>
大多数文档数据库,都不会对文档中的数据强制执行任何模式。<br>没有模式意味 着可以将任意的键值添加到文档中,<br>并且在读取时,客户端无陆保证文档可能包含哪些字段。 <br>
读时模式(数据的结构是隐式的,只有在读取时才解释)
写时模式(<font color="#80bc42">关系数据库的一种 传统方法</font>,模式是显式的,并且数据库确保数据写入时都必须遵循)
查询的数据局部性
通常建议文档应该尽量小且避免写入时增加文档大小。 <br>这些性能方面的不利因素大大限制了文档数据库的适用场景。 <br>
图模型
关系模型能够处理简单的多对多关系, <br>但是随着数据之间的关联越来越复杂,<br>将数据建模转化为图模型会更加自然。 <br>
图由两种对象组成:<br>顶点(也称为结点或实体)<br>和边(也称为关系或弧)。<br>很多数据 可以建模为图。
有很多著名的算法可以在这些图上运行。<br>例如,汽车导航系统搜索道路网中任意两点 之间的最短路径,<br>PageRank可以计算Web图上网页的流行度,从而确定搜索排名
图并不局限于这样的同构数据(图的顶点表示相同类型的事物),<br>图更为强大的用途在于,<br>提供了单个数 据存储区中保存完全不同类型对象的一致性方式。
构建和查询图中的数据的方法
模型
属性图模型
每个顶点包括<br>
唯一的标识符<br>
出边的集合
入边的集合
属性的集合 (键-值对)
每个边包括
唯一的标识符
边开始的顶点(尾部顶点)
边结束的顶点(头部顶点)
描述两个顶点间关系类型的标签
属性的集合 (键-值对)
可以将图存储看作由两个关系表组成,一个用于顶点, 另一个用于边
注意的地方<br>
任何顶点都可以连接到其他任何顶点。没有模式限制哪种事物可以或不可以关联<br>
给定某个顶点,可以高效地得到它的所有人边和出边,从而遍历图,即沿着这 些顶点链条一直向前或向后
通过对不同类型的关系使用不同的标签,可以在单个图中存储多种不同类型的信 息,同时仍然保持整洁的数据模型
图有利于演化:向应用程序添加功能时,图可以容易地扩展以适应数据结构的不断变化<br>
三元存储模型
所有信息都以非常简单的三部分形式存储(主体,谓语,客体)
三元组的主体相当于图中的顶点。 而客体则是以下两种之一: <br>
1. 原始数据类型中的值,如字符串或数字。<br>在这种情况下, 三元组的谓语和客体分别相当于主体(顶点) 属性中的键和值。 <br>例如, (Lucy, αge, 33 ) 就好比是顶 点lucy, 具有属性{"age”: 33}。 <br>
2. 图 中的另一个顶点。<br> 此时,谓语是图中的边 ,主体是尾部顶点 ,而客体是头部顶点。 <br>例如,在(Lucy , m.arriedTo, alain)中,主体Lucy和客体alain都是顶点 ,并且谓语marriedTo是连接二者的边的标签。 <br>
子主题
子主题
声明式图查询语言<br>
Cypher<br>一种用于属性图的声明式查询语言,最早为Neo4j图形数据库而创建<br>
子主题
子主题
MATCH语句中采用了相同的的箭头语义<br>(person) -[ : BORN_IN] - > ()来匹配这样的模式, <br>即所有顶点间带有标签BORN_IN 的边,<br>且尾部顶点对应于变量person ,而头部顶点则没有要求<br>
该查询的具体解读如下:<br><br>找到满足以下两个条件的任何顶点(顶点代表人,称其为person)<br>1. person有一个到其他顶点的出边BORN_IN。<br>从该顶点开始,可以沿着<font color="#80bc42">一系列出边WITHIN</font>,<br>直到最终到达类型为Location的顶点, name属性为”United States ” 。<br><br>2. 同一个person顶点也有一个出边LIVES_IN。<br>沿着这条边,然后是<font color="#80bc42">一系列出 边WITHIN </font>,<br>最终到达类型为Location的顶点, name属性为"Europe” 。 <br>
SPARQL<br>采用RDF数据模型的三元存储查询语言<br>
子主题
Datalog
Datalog的数据模型类似于三元存储模式 , 但更为通用一些。<br>它采用“谓语 (主体, 客体 )” 的表达方式而不是三元组 (主体,谓语 ,客体) 。
数据关系
一对多
在传统的SQL模型中, 最常见的规范化表示是将职位、教育 和联系信息放在单独的表中 , 并使用外键引用users表
之后的SQL标准增加了对结构化数据类型和XML数据的支持。<br>这允许将多值数据存储在单行内 ,并支持在这些文档中查询和索引。
第三个选项是将工作、教育和联系信息编码为JSON或XML文档,将<br>其存储在数据库的文本列中,并由应用程序解释其结构和内容。<br>对于此方法,通常不能使用数据库查询该编码列中的值。
对于像简历这样的数据结构,它主要是一个自包含的文档(document),<br>因此用 JSON表示非常合适, 参见示17tl2-l 。<br>与XML相比, JSON的吸引力在于它更简单。 <br>面向<font color="#80bc42">文档的数据库</font>(如MongoDB、RethinkDB、CouchDB和Espresso )都支持该数据模型。 <br>
一对多关系,意味着数据存在树状结 构,JSON表示将该树结构显式化
多对一
使用ID的好处是,<br>因为它对人类没有任何直接意义,<br>所以永远不需要直接改变 : 即使 ID标识的信息发生了变化, <br>它也可以保持不变。
数据规范化需要表达多对一的关系(许多人生活在同一地区, 许多人在同一 行业工作),这并不是很适合文档模型。
对于关系数据库,由于支持联结操作,可以 很方便地通过ID来引用其他表中的行。 <br>而在文档数据库中, 一对多的树状结构不需要 联结,支持联结通常也很弱
即使应用程序的初始版本非常适合采用无联结的文档模型 , <br>但随着应用支持越来越多 的功能,数据也变得更加互联一体化。
多对多
对比
在表示多对一和多对多的关系时,<br>关系数据库和文档数据库并没有根本的不 同 : <br>在这两种情况下,相关项都由唯一的标识符引用, <br>该标识符在关系模型中被称为 外键,<br>在文档模型中被称为文档引用。<br>标识符可以查询时通过联结操作或相关后续查询来解析。
关系数据库与文档数据库现状
支持文档数据模型的主要论点是模式灵活性,由于局部性而带来较好的性能 ,<br>对于某些应用来说,它更接近于应用程序所使用的数据结构。<br>
关系模型则强在联结操作、多 对一和多对多关系更简洁的表达上,与文档模型抗衡。
使用场景
应用数据具有类似文档的结构(即一对多关系树,通常一次加载整个树) , 那么 使用文档模型更为合适。
关系型模型则倾向于某种数据分解,它把文档结构分解为 多个表,有可能使得模式更 为笨重,以及不必要的应用代码复杂化。
查询语言
SQL
Web <br>
CSS选择器<br><br>XPath表达式
MapReduce
一种编程模型,用于在许多机器上批量处理海量数据
MongoDB对该模型的使用
MapReduce既不是声明式查询语言, 也不是一个完全命令式的查询API,<br>而是介于两 者之间: 查询的逻辑用代码片段来表示, 这些代码片段可以被处理框架重复地调用 。 <br>它主要基于许多函数式编程语言中的map和reduce函数
db.observations.mapReduce( <br> function map() { ②<br> var year = this. observationTimestamp.getFull Year(); <br> var month = this .observationTimestamp.getMonth() + 1; <br> emit (year +-”+ month, this.numAnimals); ③<br> }, <br> function reduce(key, values) { ④<br> return Array.sum(values); ⑤<br> },<br> {<br> query: { family:”Sharks" } , ①<br> out :”monthlySharkReport”⑥<br> }<br>);
① 过滤器声明式地指定皇室鱼种类(这是MongoDB对MapReduce的特有扩展)。<br><br>② 对于每个匹配查询的文档,都会调用一次JavaScript的map函数,并将其设置为文 档对象。<br><br>③ map函数发射一个键-值对,其中键是由年份和月份组成的字符串,如"2013-12” 或"2014-1”;值代表观察的动物数量。<br><br>④ map函数发射的键-值对按键分组。对于相同键(即相同的月份和年份)的所有键-值对,调用reduce函数。<br><br>⑤ reduce函数将特定月份内所有观察到的动物数量相加。<br><br>⑥ 最终的输出写入到monthlySharkReport集合中。 <br>
map和reduce函数对于可执行的操作有所限制。<br>它们必须是纯函数,这意味着只能使用传递进去的数据作为输入,<br>而不能执行额外的数据库查询, 也不能有任何副作用。
MapReduce的一个可用性问题是,<br>必须编写两个密切协调的JavaScript函数,<br>这通常 比编写单个查询更难。 <br>此外, 声明式查询语言为查询优化器提供了更多提高查询性 能的机会。<br>由于这些原因, MongoDB 2.2增加了称为聚合管道的声明式查询语言的支 持。
小结
文档数据库的目标用例是数据来自于自包含文挡,且一个文档与其他文档之间的 关联很少。
图数据库则针对相反的场景,目标用例是所有数据都可能会互相关联。 <br>
第三章<br>数据存储与检索
存储引擎
关系型
面向页的存储引擎<br>B-tree
NoSQL
日志结构的存储引擎
许多数据库内部都使用日志(log),<br>日志是一个仅支持追加式更新的 数据文件。
为了高效地查找数据库中特定键的值, <br>需要新的数据结构 : 索引
背后的基本想怯都是保留一些额外的元数 据,<br>这些元数据作为路标,帮助定位想要的数据。
由于每次写数据时,需要更新索引,<br>因此任何类型的 索引通常都会降低写的速度。<br><br>适当的索引可以加速读取查询,<br>但每个索引都会减慢写速度。 <br>
索引分类
hash索引
key-value存储与大多数编程语言所内置的字典结构非常相似,<br>通常采用hash map (或 者hash table,哈希表)来实现
假设数据存储全部采用追加式文件组成。 <br>那么最简单的索引策略 就是: <br>保存内存中的hash map,<br>把每个键一一映射到数据文件中特定的字节偏移量, <br>这样就可以找到每个值的位置
只要所有的key可以放入内存(因为hash map需要保存在内存中) 。 <br>而value数据量则可以超 过内存大小,<br>只需一次磁盘寻址,就可以将value从磁盘加载到内存。<br>如果那部分数据 文件已经在文件系统的缓存中,<br>则读取根本不需要任何的磁盘I/O。 <br>
只追加到一个文件,那么如何避免最终用尽磁盘空间? <br>一个好的解决方案 是将日志分解成一定大小的段,<br>当文件达到一定大小时就关闭它,井将后续写入到新 的段文件中。
压缩意味着在日志中丢 弃重复的键,并且只保留每个键最近的更新。 <br>
考虑的细节
文件格式
更快更简单的方法是使用二进制格式
删除记录
在数据文件中追加一个特殊的删除记录(有 时候称为墓碑)。<br>当合并日志段时, 一旦发现墓碑标记,则会丢弃这个己删除键 的所有值。 <br>
崩溃恢复
将每个段的hash map的快照存储在磁盘上,<br>可以更快地加载 到内存中,以此加快恢复速度。 <br>
部分写入的记录
并发控制
通常的实现选择是只有一个写线程。 <br>可以被多个线程同时读取。 <br>
追加式的设计非常不错,<br>主要原因有以下几个 : <br>
追加和分段合并主要是顺序写,它通常比随机写入快得多,特别是在旋转式磁 性硬盘上。
如果段文件是追加的或不可变的,则并发和崩溃恢复要简单得多
合并旧段可以避免随着时间的推移数据文件出现碎片化的问题。 <br>
哈希表索引也有其局限性
哈希表必须全部放入内存,所以如果有大量的键,就没那么幸运了。
区间查询效率不高。
SSTables和LSM-Tree<br>key-value对 按键排序
SSTables<br>排序字符串表
每个键在每个合并的段文件中只能出现一次
SSTab le相比哈希索引的日志段,具有以下优点:
合并段更加简单高效,即使文件大于可用内存<br>当多个段包含相同的键时,可以保留最新段的值,并丢弃旧段中的值<br>
在文件中查找特定的键时,<br>不再需要在内存中保存所有键的索引。
由于读请求往往需要扫描请求范围内的多个key-value对,<br>可以考虑将这些记录保存到一个块中并在写磁盘之前将其压缩<br>
构建和维护SSTables <br>
存储引擎的基本工作流程如下<br>
当写入时,将其添加到内存中的平衡树数据结构中({列如红黑树)。<br>这个内存中 的树有时被称为内存表。 <br>
当内存表大于某个阈值(通常为几兆字节)时,将其作为SSTable文件写入磁 盘。
为了处理读请求,首先尝试在内存表中查找键,<br>然后是最新的磁盘段文件,<br>接下 来是次新的磁盘段文件,以此类推,直到找到目标(或为空)。 <br>
后台进程周期性地执行段合并与压缩过程,<br>以合并多个段文件,并丢弃那些已被 覆盖或删除的值。 <br>
如果数据库崩溃,最近的写入(在 内存表中但尚未写入磁盘)将会丢失。<br>为了避免该问题,可以在磁盘上保留单独的日 志,每个写入都会立即追加到该日志。
不同的策略会影响甚至决定SSTables 压缩和合并时的具体顺序和时机
大小分级
HBase使用大小分级
较新的和较小的SSTables被连续合并到较旧和较大的SSTables
分层压缩
LevelDB和RocksDB使用分层压缩
键的范围分裂成多个更小的SSTables ,<br>旧数据被移动到单独的“层级”,<br>这样压缩可以逐步进行并节省磁盘空间。
Cassandra则同时支持这两种压缩
LSM-Tree <br>日志结构的合并树<br>
基于<font color="#80bc42">合并</font>和<font color="#80bc42">压缩</font>排序文件原理的存储引擎通常都被称为LSM存储引擎。
查找数据库中某个不存在的键时, <br>LSM-Tree算法可能很慢:在确定键不存在之前,<br> 必须先检查内存表,然后将段一直回溯访问到最旧的段文件<br><br>为了优化这种访问,存储引擎通常使用额外的布隆过滤器<br>
由于数据按排序存储,<br>因此可以有效地执行区间查询(从最小值到最大值扫描所有的 键),<br>并且由于磁盘是顺序写入的,<br>所以LSM-tree可以支持非常高的写入吞吐量。 <br>
B-trees
基本知识
几乎所有关系数据库中的标准索引实现,<br>许多非关系型 数据库也经常使用
B-tree保留按键排序的kek-value对,<br>这样可以实现高效的key-value查 找和区间查询。
B-tree将数据库分解成固定大小的块或页, <br>传统上大小为4 KB (有时更大),页是内部读/写的最小单元。<br><font color="#80bc42">这种设计更接近底层 硬件,因为磁盘也是以固定大小的块排列。</font>
每个页面都可以使用地址或位置进行标识,<br>这样可以让一个页面引用另一个页面,<br>类 似指针,不过是指向磁盘地址,而不是内存。
B-tree 中一个页所包含的子页引用数量称为分支因子。
要更新B-tree中现有键的值,<br>首先搜索包含该键的叶子页,更改该页的值,<br>并将页写回到磁盘(对该页的任何引用仍然有效)。<br><br>如果要添加新键,则需要找到其范围 包含新键的页,并将其添加到该页。<br><span style="font-size: inherit;">如果页中没有足够的可用空间来容纳新键,则将其<font color="#80bc42">分裂为两个半满的页</font>,</span><br>并且父页也需要更新以包含分裂之后的新的键范围,
使B-Tree可靠
支持磁盘上的额外的数据结 构 :<font color="#80bc42"> 预写日志( write-ahead log, WAL),也称为重做日志。</font><br>这是一个仅支持追加修改的文件,每个B-tree的修改必须先更新WAL然后再修改树本身的页。<br>当数据库在崩 愤后需要恢复时,该日志用于将B-tree恢复到最近一致的状态。 <br>
多个线程要同时访问B-tree, 则需要注意并发 控制,<br>否则线程可能会看到树处于不一致的状态。<br>通常使用锁存器(轻量级的锁)保 护树的数据结构来完成。
优化B-tree
一些数据库不使用覆盖页和维护WAL来进行崩愤恢复,而是使用 写时复制方案。
保存键的缩略信息,而不是完整的键,这样可以节省页空间。<b><font color="#80bc42">B+Tree</font></b>
尝试对树进行布局,以便相邻叶子页可以按顺序保存在磁盘上<br>
添加额外的指针到树中 。
B-tree的变体如分形树, 借鉴了一些 日志结构的想法来减少磁盘寻道
对比B-tree和LSM-tree <br>
LSM-tree通常对于写入更快,<br>B-tree被认为对于读取更快。<br><br>读取通常在LSM-tree上较慢,<br>因为它们必须在不同的压缩阶段检查多个不 同的数据结构和SSTable。 <br>
LSM-tree的优点 <br>
B tree索引必须至少写两次数据 : 一次写入预写日志, 一次写入树的页本身
对于大量写密集的应用程序,性能瓶颈很可能在于数据库写入磁盘的速率。<br>在这种情 况下, 写放大具有直接的性能成本 : <br>存储引擎写入磁盘的次数越多 ,<br>可用磁盘带宽中 每秒可以处理的写入越少。 <br>
LSM-tree通常能够承受比B-tree更高的写入吞吐量 , <br>部分是因为它们有时具有 较低的写放大,部分原因是它们以顺序 方式写入紧凑的SSTable文件, 而不必重写树中的多个页
LSM-tree可以支持更好地压缩,因此通常磁盘上的文件比B-tree小很多。<br><br>由于碎片, B-tree存储引擎使某些磁盘空间无法使用:<br>当页被分裂或当一行的内容不能适合现 有页时,<br>页中的某些空间无能使用。<br><br>由于LSM tree不是面向页的,<br>并且定期重写 SSTables,消除碎片化,<br>所以它们具有较低的存储开销,特别是在使用分层压缩时
LSM-tree的缺点 <br>
日志结构存储的缺点是压缩过程有时会干扰正在进行的读写操作<br>如果写入吞吐量很高并且压缩没有仔细配置,<br><br>那么就会发生压缩无法匹配新数据写入 速率的情况。<br>
B-tree的优点则是每个键都恰好唯一对应于索引 中的某个位置,<br>而日志结构的存储引 擎可能在不同的段中具有相同键的多个副本。<br>如果数据库希望提供强大的事务语义, <br>这方面B-tree显得更具有吸引力:<br>在许多关系数据库中, 事务隔离是通过键范围上的 锁来实现的,<br>并且在B-tree索引中,这些锁可以直接定义到树中
其他索引
key-value索引<br>
它们像关系模型中的主键(primary key )索 引。<br><br>主键唯一标识关系表中的一行,或文档数据库中的一个文档,<br><br>或图形数据库中的 一个顶点。<br><br>数据库中的其他记录可以通过其主键(或ID )来引用该行/文档/顶点,<br><br>该 索引用于解析此类引用 。
二级索引也很常见。
可以容易地基于key-value索引来构建。<br>主要区别在于它的键不是唯一的, <br>即可能有许多行(文档,顶点)具有相同键。<br>这可以通过两种方式解决:<br>使索引中的 每个值成为匹配行标识符的列表(像全文索引中的posting list),<br>或者追加一些行标 识符来使每个键变得唯一。<br>无论哪种方式, B-tree和日志结构索引都可以用作二级索引。 <br>
在索引中存储值 <br>
索引中的键是查询搜索的对象,<br>而值则可以是以下两类之一
上述的实际行 (文档,顶点)
对其他地方存储的行的引用
存储行的 具体位置被称为堆文件
堆文件方住比较常见, <br>这样当存在多个 二级索引时,<br>它可以避免复制数据,<br>即每个索引只引用堆文件中的位置信息,<br>实际数 据仍保存在一个位置。 <br>
当更新值而不更改键时,<br>堆文件方法会非常高效:
只要新值的字节数不大于旧值,记 录就可以直接覆盖。
如果新值较大,则情况会更复杂,<br>它可能需要移动数据以得到一 个足够大空间的新位置。<br>在这种情况下,所有索引都需要更新以指向记录的新的堆位 置 , <br>或者在旧堆位置保留一个间接指针
将索引行直接存储在索引中。这被称为聚集索引
MySQL InnoDB存储引擎中,<br>表的主键始终是聚集索引, <br>二级索引引用主键(而不是堆文件位置)<br>
聚集索引(在索引中直接保存行数据)<br>和非聚集索引(仅存储索引中的数据的引用) <br>之间有一种折中设计称为覆盖索 引或包含列的索引,<br>它在索 引中保存一些表的列 值。<br>它可以支持只通过索引即可回答某些简单查询<br>(在这种情况下,称索引覆盖了查询)
聚集和覆盖索引可以加快读取速度,<br>但是它们需要额外 的存储,<br>并且会增加写入的开销。 <br>此外,数据库还需要更多的工作来保证事务性,<br>这 样应用程序不会因为数据冗余而得到不一致的结果。 <br>
多列索引
最常见的多列索引类型称为级联索引, <br>它通过将一列追加到另一列,<br>将几个字段简单 地组合成一个键(索引的定义指定宇段连接的顺序 )
多维索引是更普遍的一次查询多列的方怯,<br>这对地理空间数据尤为重要。 <br>例如,餐馆 搜索网站可能有一个包含每个餐厅的纬度和经度的数据库。
标准B-tree或LSM-tree索引无诠高效地应对这种查询,<br>它只能提供一个纬度范围内 (但在任何经度)的所有餐馆,<br>或者所有经度范围内的每厅 (在北极和南极之间的任 何地方),<br>但不能同时满足。 <br>
一种选择是使用空格填充曲线将二维位置转换为单个数字,<br>然后使用常规的B-tree 索引。<br>更常见的是使用专门的空间索引,如R树。
全文搜索和模糊索引 <br>
全文搜索引擎通常支持对一个单词的所有同义词进行查询,<br>并忽略单词语法上的变体
为了处理文档或查询中的拼写错误, <br>Lucene能够在某个编辑距离内搜索 文本
Lucene对其词典使用类似SSTable的结构。<br>此 结构需要一个小的内存索引来告诉查询,<br>为了找到一个键,需要排序文件中的哪个偏 移量。
内存中的索引是键中的字符序列的有限状态自 动机,类似字典树
其他模糊搜索技术则沿着文档分类和机器学习的方向发展
在内存中保存所有内容
内存中的key-value存储(Memcached), 主要用于缓存
其他内存数据库旨在实现持久性
内存数据库的性能优势并不是因为它们不需要从磁盘读取。<br>如果有足够 的内存,即使是基于磁盘的存储引擎,<br>也可能永远不需要从磁盘读取,<br>因为操作系统 将最近使用的磁盘块缓存在内存中。
内存数据库可以更快,是因为它们避免使 用写磁盘的格式对内存数据结构编码的开销
内存数据库提供了基于磁盘索引难以实现 的某些数据模型。
Redis为各种数据结构(如优先级队列和集合)<br>都提供了类 似数据库的访问接口。<br>由于所有的数据都保存在内存中,所以实现可以比较简单。 <br>
OLTP/OLAP/数据仓库
OLTP<br>在线事务处理
事务主要指组成一个逻辑单元的一组读写操作。
OLAP<br>在线分析处理
OLTP与OLAP
数据仓库
将数据导入数据仓库的过程称为提取-转换-加载 (Extract-Transform-Load, ETL)
数据仓库与ETL
名称“星型模式”来源于当表关系可视化时 ,<br>事实表位于中间,被一系列维度表包 围;<br>这些表的连接就像星星的光芒。 <br>
列式存储
不要将一行中的所有值存储在一起,<br>而是将每列中的所有 值存储在一起。<br>如果每个列存储在一个单独的文件中,<br>查询只需要读取和解析在该查 询中使用的那些列,<br>这可以节省大量的工作
列压缩 <br>
在数据仓库中特别有效的一种技术是位 图编码
列存储中的排序 <br>
即使数据是按列存储的,它也需要一次排序整行
排序的另一个优点是它可以帮助进一步压缩列。<br>如果主排序列上没有很多不同的值,<br> 那么在排序之后,<br>它将出现一个非常长的序列, <br>其中相同的值在一行中重复多次
列存储的写操作
所有的写入首先进 入内存存储区,<br>将其添加到已排序的结构中,<br>接着再准备写入磁盘
执行查询时,<br>需要检查磁盘上的列数据和内存中最近的写入
聚合:数据立方体与物化视图
数据仓库的另一个值得一捷的是物化聚合。
在关系数据模型中,<br>它通常被定义为标准(虚 拟)视图:<br> 一个类似表的对象,其内容是一些查询的结果
物化视图是查 询结果的实际副本,<br>并被写到磁盘 ,<br>而虚拟视图只是用于编写查询的快捷方式。
当底层数据发生变化时,<br>物化视图也需要随之更新,<br>因为它是数据的非规范化副本。
第四章<br>数据编码与演化 <br>
子主题
应该构建可适应变化的系统<br>在大多数情况下,<br>更改应用程序功能时,<br>也需要更改其存储的数据 :<br>可能需要捕获新 的字段或记录类型,<br>或者需要以新的方式呈现已有数据。 <br>
数据模型
关系数据库通常假设数据 库中的所有数据都符合一种模式,<br>尽管该模式可以改变,<br>这样在任何一个给定时间点都只有一个有效的模式
读时模式 (“无模式”)数据库不强制执行模式,所以数据库包含了不同时间写入的新旧数据 的自合体
大 型应用系统,<br>代码更迭往往并非易事
对于服务器端应用程序,可能需要执行滚动升级<br>新版本部署无需服务暂停,从而支持更频繁的版本发布和更好的演化<br>
对于客户端应用程序,只能寄望于用户,<br>然而他们在一段时间内可能不会马上安 装更新。 <br>
新旧版本的代码,<br>以及新旧数据格式,<br>可能会同时在系统内共存。<br>为了使系 统继续顺利运行,<br>需要保持双向的兼容性
向后兼容
较新的代码可以读取由旧代码编写的数据。 <br>
作为新代码的作者,<br>清楚旧代码所编写的数据格式,<br>因此可 以比较明确地处理这些旧数据<br>(如果需要,只需保留 旧的代码来读取旧的数据)。
向前兼容
较旧的代码可以读取由新代码编写的数据。 <br>
需要旧代码忽略新版本的代码所做的添加。 <br>
数据编码格式 <br>
内存中
数据保存在对象、结构体、列表、 数组、哈希表和树等结构中。<br>这些 数据结构针对CPU的高效访问和操作进行了优化
将数据写入文件或通过网络发送时
必须将其编码为某种自包含的字节序列(例 如JSON文档)。
在这两种表示之间需要进行类型的转化。<br>从内存中的表示到字节序列的转化称 为编码(或序列化等),<br>相反的过程称为解码(或解析,反序列化)
语言特定的格式
许多编程语言都内置支持将内存中的对象编码为字节序列。<br>例如,Java有java.io.Serializable, Ruby有Marshal, Python有pickle等。<br>此外,还有许多第 三方库,例如用于Java 的Kryo。 <br>
一些深层次的问题 <br>
编码通常与特定的编程语言绑定在一起,<br>而用另一种语言访问数据就非常困难。 <br>不能将系统与其他组织(可能使用不同的语言)的系统方便地集成在 一起。 <br>
为了在相同的对象类型中恢复数据,<br>解码过程需要能够实例化任意的类<br><br>导致一些安全问题:<br>如果攻击者可以让应用程序解码任意的字节序列,<br>那么它们可以实例化任意的类,这通常意味着,<br>它们可以做些可怕的事情,比如远程执行任意代码<br>
向前和向后兼容性等问题被忽略<br>
效率(编码或fO平码花费的CPU时间, 以及编码结构的大小)通常也是次耍的。 <br>例 如, Java的内置序列化由于其糟糙的性能和臃肿的编码而广为诟病。 <br>
JSON 、 XML与二进制变体
文本格式,具有不错的可读性
XML经常被批评过于冗长和不必要的复杂 <br>
JSON受欢迎主要是由于它在Web浏览器中内置支持(因为是 JavaScript的一个子集)<br>以及相对于XML的简单性
csv是另一种流行的与语言无关 的格式,尽管功能较弱
一些微妙的问题 <br>
数字编码有很多模糊之处。
JSON和XML对Unicode字符串(即人类可读文本)有很好的支持 ,<br>但是它们不 支持二进制字符串(没有字符编码的字节序列)。
XML[ttJ和JSON[IZJ都有可选的模式支持。<br>这些模式语言相当强大,因此学习和 实现起来也比较复杂。
csv没有任何模式,因此应用程序需要定义每行和l每列的含义。
作为 数据交换格式(即将数据从一个组织发送到另一个组织),它们非常受欢迎。
二进制编码 <br>
Thrift
两种不同的二进制编码 格式
BinaryProtocol
子主题
每个字段都有一个类型注释(用于指示它是否是字符串 、整数 、列表 等) , <br>并且可以在需要时指定长度 (包括字符串的长度、列表中的项数)。 <br>与之前类 似,<br>数据中出现的字符串 ( “Martin”, “ daydreami ng”, “hacking”)<br>也被编码 为ASCII (或者更确切地说, UTF-8 )
最大的区别是没有字段名( userNam e 、 favoriteNumbe r和 int erest ) 。 <br>相反, 编码数据包含数字类型的字段标签 ( 1、 2和3 ) 。 <br>这些是模式定 义中出现的数字。<br>字段标签就像字段的别名,<br>用来指示当前的字段,但更为紧凑 ,可 以省去引用字段全名。 <br>
CompactProtocol
子主题
将相 同的信息打包成只有34字节。<br> 它通过将字段类型和标签号打包到单字节中,<br>并使用可 变长度整数来实现。<br>
Protocol Buffers
子主题
对相同的数据进行编码。 <br>它的位打包方式略有不同 ,<br>但与Thrift的CompactProtocol非常相似。 <br>Protocol Buffers只用33字节可以表示相同的记录。 <br>
在前面所示的模式中 ,<br>每个字段被标i己为required (必须) 或optional (可选) , <br>但这对宇段如何编码没有任何影响<br>(二进制数据中不会指示某 宇段是否必须)。<br>区别在于,如果字段设置了required ,但字段未填充,<br>则运行时检 查将出现失败, 这对于捕获错误非常有用。 <br>
都需要模式来编码任意的数据
字段标签和模式演化 <br>
一条编码记录只是一组编码字段的拼接。<br>每个字段 由其标签号 标识,<br>并使用数据类型(例如字符串或整数)进行注 释。<br>如果没有设置字段值,则将其从编码的记录中简单地忽略。<br>由此可以看出, 字段标签(field tag)对编码数据的含义至关重要。 <br>可以轻松更改模式中字段的名称,<br>而编码永远不直接引用字段名称。<br>但不能随便更改宇段的标签,<br>它会导致所有现有编码 数据无效。 <br>
可以添加新的字段到模式,<br>只要给每个字段一个新的标记号码。<br>如果旧的代码(不知道 添加的新标记号码)试图读取新代码写入的数据,<br>包括一个它不能识别的标记号码中新 的字段,<br>则它可以简单地忽略该字段。<br>实现时,通过数据类型的注释来通知解析器跳过 特定的字节数。<br>这样可以实现向前兼容性, 即旧代码可以读取由新代码编写的记录。 <br>
因为旧代码不会写入添加的新字段。<br>因此,为了 保持向后兼容性,<br>在模式的初始部署之后添加的每个字段都必须是可选的或具有默认 值。 <br>
只能删除可 选的字段(必填字段永远不能被删除),而且不能再次使用相同的标签号码
数据类型和模式演化
Avro
使用模式来指定编码的数据结构。<br>它有两种模式语言 : <br>一种(Avro IDL)用于 人工编辑,<br>另一种(基于JSON)更易于机器读取。 <br>
只有当读取数据的代码使用与写入数据的 代码完全相同的模式时,<br>才能正确解码二进制数据。<br>读和写的模式如果有任何不匹配 都将无法解码数据。 <br>
写模式
当应用程序想要对某些数据进行编码<br>(例如将其写入文件或数据库,以及 通过网络发送) 时 ,<br>它使用所知道的模式的任何版本来编码数据,<br>例如,可以编译到 应用程序中的模式。 <br>
读模式
当应用程序想要解码某些数据<br>(例如从文件或数据库读取数据,或者从网络接收数据 等)时,<br>它期望数据符合某个模式。
Avro的关键思想是, 写模式和读模式不必是完全一模一样,它们只需保持兼容。
模式演化规则
向前兼容意味着可以将新版本的模式作为writer,将旧版本的模式作为 reader
向后兼容意味着可以用新版本的模式作为reader,并用旧版本的模式作 为writer。 <br>
为了保持兼容性,只能添加或删除具有默认值的 字 段
如果 要允许字段为null ,则必须使用联合类型。<br> 例如 , union{ null, long, string}宇 段; <br>表示该宇段可以是数字、字符串或null。<br>只有当null是联合的分支之一时, 才可以 使用它作为默认值。
更改字段的名称也是可能的, 但有点棘手: <br>reader的模式可以包含字段名称的别名, <br>因此它可以将旧writer模式字段名称与别名进行匹配。<br>这意味着更改字段名称是向后兼容的,但不能向前兼容。<br>同样,向联合类型添加分支也是向后兼容的,但不能向前兼容。 <br>
reader如何知道特定的数据采用哪个writer的模 式编码的?
取决于Avro使用的上下文
有很多记录的大文件
该文件的writer可以仅在文件的开头包含writer的模式信 息。 <br>Avro通过指定一个文件格式(对象容器文件)来做到这一点。 <br>
具有单独写入记录的数据库
在每个编码记录的开 始处包含一个版本号,<br>并在数据库中保留一个模式版本列表。 <br>reader可以获取记 录,提取版本号,<br>然后从数据库中查询该版本号的writer模式。<br>使用该writer模 式,它可以解码记录的其余部分
通过网络连接发送记录
当两个进程通过双向网络连接进行通信肘,<br>他们可以在建立连接时协商模式版 本,<br>然后在连接的生命周期中使用该模式。
动态生成的模式 <br>
Avro对动态生成的模式更友好。
容易地根据关系模式生成 Avro模式,<br>并使用该模式对数据库内容进行编码,<br>然后将其全部转储到Avro对象容器 文件中。<br>可以为每个数据库的表生成对应的记录模式,<br>而每个列成为该记录中的一 个字段。<br>数据库中的列名称映射到Avro中的字段名称。 <br>
如果数据库模式发生变化(例如,表中添加了一列,删除了一列),<br>则可以从 更新的数据库模式生成新的Avro模式,<br>并用新的Avro模式导出数据。数据导出过程不 需要关注模式的改变,<br>每次运行时都可以简单地进行模式转换。<br>任何读取新数据文件 的人都会看到记录的字段已经改变,<br>但是由于字段是通过名字来标识的,<br>所以更新的writer模式仍然可以与旧的reader模式匹配。 <br>
代码生成和动态类型语言
模式的优点 <br>
许多数据系统也实现了一些专有的二进制编码。
基于模式的二 进制编码也是一个可行的选择。
它们可以比各种“二进制JSON”变体更紧凑,可以省略编码数据中的宇段名 称。
模式是一种有价值的文档形式,因为模式是解码所必需的,<br>所以可以确定它是最 新的(而手动维护的文档可能很容易偏离现实)。 <br>
模式数据库允许在部署任何内容之前检查模式更改的向前和向后兼容性。
对于静态类型编程语言的用户来说,<br>从模式生成代码的能力是有用的,<br>它能够在 编译时进行类型检查。 <br>
数据流模式 <br>
基于数据库的数据流 <br>
几个不同的进程同时访问数据库是很常见的。<br>这些进程可能是几个不同 的应用程序或服务, <br>也可能只是同一服务的几个实例
数据库中的值可以由较新版本的代码写入,<br>然后由仍在运行的旧版本代码读 取。<br>因此,数据库通常也需要向前兼容。 <br>
不同的时闯写入不同的值
归档存储
基于服务的数据流: REST和RPC
服务可以对客户端可以做什么和不能做什么施加细粒 度的限制。 <br>
面向服务/微服务体系结构的一个关键设计目标是,<br>通过使服务可独立部署和演化让应用程序更易于更改和维护
网络服务WebService
REST
一个基于HTTP原则的设计理念。<br>它强调简单的数据格 式,<br>使用URL来标识资源,<br>并使用HTTP功能进行缓存控制、身份验证和内容类型协商。
REST已经越来越受欢迎,<br>在跨组织服务集成的背景下, 经常与微服务相关联。<br>根据REST原则所设计的API称为RESTful<br>
RESTfu l的API倾向于更简单的方法,<br>通常涉及较少的代码生成和自动化工具。<br>定义 格式如OpenAPI,也称为Swagger,<br>可用于描述RESTful API并帮助生成文挡。 <br>
SOAP
一种基于XML的协议,<br>用于发出网络API请求的。<br>虽然它最常用 于HTTP,但其目的是独立于HTTP ,<br>并避免使用大多数HTTP功能。<br>相反,它带有庞大而复杂的多种相关标准,和 新增的各种功能。
SOAP Web服务的API使用被称为WSDL
远程过程调用( RPC ) <br>
RPC模型试图使向远程网络服务发出请求<br>看起来与在同一进程中调用编程语言中的函数或方法相同<br>(这种抽象称为位置透明)
网络请求与本地函数 调用非常不同 :
本地函数调用是可预测的<br><br>网络请求是 不可预测的<br>
本地函数调用要么返回一个结果,<br>要么抛出一个异常,<br>或者永远不会返回<br><br>网络请求有另一个可能的结果 : <br>由于超时,它返回时 可能没有结果。 <br>
如果重试失败的网络请求,<br>可能会发生请求实际上已经完成,<br>只是响应丢失的情 况。<br>在这种情况下,重试将导致该操作被执行多次,<br>除非在协议中建立重复数据 消除(幂等性)机制。
每次调用本地函数时,通常需要大致相同的时间来执行。<br><br>网络请求比函数调用要 慢得多,而且其延迟也有很大的变化
调用本地函数时,可以高效地将引用(指针)传递给本地内存中的对象。<br><br>当发出 网络请求时,<br>所有这些参数都需要被编码成可以通过网络发送的字节序列。<br>如果 参数是像数字或字符串这样的基本类型,<br>这没关系, 但是对于较大的对象很快就 会出现问题。 <br>
客户端和服务可以用不同的编程语言来实现,<br>所以RPC框架必须将数据类型从一 种语言转换成另一种语言
RPC的发展方向
新一代的RPC框架更加明确了远程请求与本地函数调用不同的事实。
Thrift和Avro带有RPC支持
gRPC是使用Protocol Buffers的RPC实 现
其中一些框架还提供了服务发现, <br>即允许客户端查询在哪个IP地址和端口号上获得特 定的服务
使用二进制编码格式的自定义RPC协议,<br>可以实现比诸如REST上的JSON之类的通用协议更好的性能。<br>
RESTful API还有其他一些显著的优点
有利于实验和调 试
支持所有的主流编程语言和平台
有一个庞大的工具生态系统
RPC的数据编码和演化
假定所有的服务器都先 被更新,<br>其次是所有的客户端
请求上具有向后兼容性
响应上 具有向前兼容性
Thrift、 gRPC (Protocol Buffers)和Avro RPC可以根据各自编码格式的兼容性规则进行演化。 <br>
在SOAP中,请求和响应是用XML模式指定的。这些都是可以由化的,但有一些 微妙的陷阱
RESTful API通常使用JSON (没有正式指定的模式)用于响应,<br>而请求则采用 JSON或URI编码/表单编码的请求参数。<br>为了保持兼容性,<br>通常考虑的更改包括 添加可边的请求参数和在响应中添加新的字段。 <br>
对于RESTful API,常用的方在是是在URL或HTTP Accept头中使用 版本号。
如果RPC经常用于跨组织边界的通信, 则服务的兼容性会变得更加困难,<br>服务的提供 者经常无法控制其客户,也不能强制他们升级
基于消息传递的数据流
客户端的请求(通常称为消息)以低延迟传递到另一个进程。
通过称为消息代 理(也称为消息队列,或面向消息的中间件)的中介发送的, 该中介会暂存消息。 <br>
消息代理有以下几个优点
如果接收方不可用或过载,它可以充当缓冲区,从而提高系统的可靠性。 <br>
可以自动将消息重新发送到崩愤的进程,从而防止消息丢失。 <br>
避免了发送方需要知道接收方的IP地址和端口 号
支持将一条消息发送给多个接收方
在逻辑上将发送方与接收方分离
消息传递通信通常是单向的<br>通信模式是异步的 <br>
消息代理 <br>
一个 进程向指定的队列或主题发送消息,<br>并且代理确保消息、被传递给队列或主题的一个或 多个消费者或订阅者。<br>在同一主题上可以有许多生产者和许多消费者。
主题只提供单向数据流。 但是,消费者本身可能会将消息发布到另一个主题<br>也可以发送到一个回复队 列,该队列由原始消息发送者来消费<br>
分布式Actor框架
Actor模型是用于单个进程中并发的编程模型<br>
逻辑被封装在Actor中,而不是直接 处理线程<br>每个Actor通常代表一个客户 端或实体,<br>它可能具有某些本地状态(不与其他任何Actor共享),<br>并且它通过发送 和接收异步消息与其他Actor通信。<br>不保证消息传送 : 在某些错误情况下,消息将丢 失。<br>由于每个Actor一次只处理一条消息,因此不需要担心线程,每个Actor都可以由框架独立调度。
在分布式Actor框架中,<br>这个编程模型被用来跨越多个节点来扩展应用程序。
无论发 送方和接收方是在同一个节点上还是在不同的节点上,<br>都使用相同的消息传递机制。 <br>如果它们位于不同的节点上,<br>则消息被透明地编码成字节序列,<br>通过网络发送,并在 另一端被解码。
位置透明性在Actor模型中更有效,<br>因为Actor模型已经假定消息可能会丢 失,<br>即使在单个进程中也是如此。<br>尽管网络上的延迟可能比同一个进程中的延迟更 高 ,<br>但是在使用Actor模型时,<br>本地和远程通信之间根本上的不匹配所发生的概率更小<br>
分布式的Actor框架实质上是将消息代理和Actor编程模型集成到单个框架中
对基于Actor的应用程序执行攘动升级,<br>则仍需担心向前和向后兼容性问题
A kka使用Java的内置序列化,<br>它不提供向前或向后兼容性。<br>但 是,可以用类似Protocol Buffers的东西替代它,<br>从而获得滚动升级的能力
Orleans使用不支持攘动升级部署的自定义数据编码格式:<br>要部署 新版本的应用程序,<br>需要建立一个新的集群,<br>将流量从旧集群导入到新集群,<br>然 后关闭旧集群。<br>像Akka一样, 也可以使用自定义序列化插件。 <br>
Erlang OTP中,很难对记录模式进行更改<br>(尽管系统具有许多为高可用性而设 计的功能) 。<br>滚动升级在技术上是可能的,但要求仔细规划
分布式数据系统
第五章<br>数据复制 <br>
子主题
通过数据复制方案,达到以下目的 :<br><br>使数据在地理位置上更接近用户,从而降低访问延迟。<br>当部分组件出现位障,系统依然可以继续工作,从而提高可用性。<br>扩展至多台机器以同时提供数据访问服务,从而提高读吞吐量。<br>
复制方法
主从复制
对于每一笔数据写入,所有副本都需要随之更新:<br>否则, 某些副本将出现不一致。<br>最常见的解决方案是基于主节点的复制
主从复制的工作原理
指定某一个副本为主副本 (或称为主节点)
其他副本则全部称为从副本(或称为从节点)。<br>主副本把新数据写入本地存 储后,<br>然后将数据更改作为复制的日志或更改流发送给所有从副本。<br>每个从副本 获得更改日志之后将其应用到本地,<br>且严格保持与主副本相同的写入顺序。<br>
客户端从数据库中读数据时,<br>可以在主副本或者从副本上执行查询。<br>再次强调, 只有主副本才可以接受写请求:<br>从客户端的角度来看,从副本都是只读的。<br>
PostgreSQL (9.0版本以后 )、 MySQL、 Oracle Data Guard<br>和SQL Server的AlwaysOn Availability Groups。<br>MongoDB、 RethinkDB和Espresso,Kafka和RabbitMQ
子主题
同步异步
复制非常重要的一个设计选项是<br>同步复制还是异步复制。<br>对于关系数据库系统,<br>同步 或异步通常是一个可配置的选项:<br>而其他系统则可能是硬性指定或者只能二选一。<br>
同步复制
优点
一旦向用户确认,<br>从节点可以明确保证完成了与主节点的更新同 步,<br>数据已经处于最新版本。<br>万一主节点发生故障,总是可以在从节点继续访问最新 数据。
缺点
缺点则是,如果同步的从节点无法完成确认<br>(例如由于从节点发生崩愤,或者 网络故障,或任何其他原因),<br>写入就不能视为成功。 <br>主节点会阻塞其后所有的写操作,直到同步副本确认完成。
半同步
实践中,如果数据库启用了同步复制, <br>通常意味着其中某一个从节点是同步的,<br>而其他节点则是异步模式。<br>万一同步的从节 点变得不可用或性能下降, <br>则将另一个异步的从节点提升为同步模式。<br>这样可以保证 至少有两个节点<br>(即主节点和一个同步从节点)拥有最新的数据副本。<br>这种配置有时 也称为半同步
异步复制
优点
不管从节点上数据多么滞后, <br>主节 点总是可以继续响应写请求,<br>系统的吞吐性能更好。
缺点
如果主节点发生失败且不可恢复 ,<br>则所有尚未复制到从节点的写请求都会丢失。<br>这意味着即使向客户端确认了写操作, <br>却无 法保证数据的持久化。<br>
异步模式这种弱化的持久性<br>听起来是一个非常不靠谱的折中设计,<br>但是异步复制还是 被广泛使用,<br>特别是那些从节点数量 巨大或者分布于广域地理环境。
子主题
配置新的从节点
增加副本数以提高容错能力,<br>替换失败的副本,增加新的从节点
步骤
在某个时间点对主节点的数据副本产生一个一致性快照,<br>这样避免长时间锁定整 个数据库。<br>目前大多数数据库都支持此功能,<br>快照也是系统备份所必需的。<br>而在 某些情况下,可能需要第三方工具, <br>如MySQL的innobackupex
将此快照拷贝到新的从节点
从节点连接到主节点并请求快照点之后所发生的数据更改日志。<br>因为在第一步创 建快照时,<br>快照与系统复制日志的某个确定位置相关联,<br>这个位置信息在不同的 系统有不同的称呼,<br>如PostgreSQL将其称为“log sequence number”(日志序列 号),<br>而MySQL将其称为“binlog coordinates” 。<br>
获得日志之后,从节点来应用这些快照点之后所有数据变更,<br>这个过程称之为追 赶。<br>接下来,它可以继续处理主节点上新的数据变化。<br>并重复步骤1~步骤4。<br>
处理节点失效<br>
从节点失效: 追赶式恢复
利用变更日志
主节点失效:节点切换
手动进行
自动方式进行
步骤
确认主节点失效
选举新的主节点
重新配置系统使新主节点生效
变数
异步复制,且失效之前,新的主节点并未收到原主节点的所有数据; <br>在选举之后,原主节点很快又重新上线并加入到集群,<br>接下来的写操作会发生什 么?新的主节点很可能会收到冲突的写请求,<br>这是因为原主节点未意识的角色变 化,<br>还会尝试同步其他从节点,<br>但其中的一个现在已经接管成为现任主节点。<br>
如果在数据库之外有其他系统依赖于数据库的内容并在一起协同使用,<br>丢弃数据 的方案就特别危险
在某些故障情况下,<br>可能会发生两个节点同时-都自认为是主节 点。<br>这种情况被称为脑裂,<br>它非常危险:两个主节点都可能接受写请求,<br>并且没 有很好解决冲突的办法,最后数据可 能会丢失或者破坏。
如何设置合适的超时来检测主节点失效呢? <br>主节点失效后,超时时间设置得越长 也意味着总体恢复时间就越长
节点失效、网络不可靠、副本一致性、持久性、<br>可用性与延迟之 间各种细微的权衡,<br>实际上正是分布式系统核心的基本问题
复制日志的实现
基于语句的复制
基于预写日志(WAL) 传输
基于行的逻辑日志复制
基于触发器的复制
复制滞后问题
主从复制要求所有写请求都经由主节点,<br>而任何副本只能接受只读查询
读自己的写
子主题
“写后读一致性”,<br>也称为读写一致性
方案
如果用户访问可能会被修改的内容,<br>从主节点读取 ; 否则 ,在从节点读取。
跟踪最近更新的时间 ,如果更新后一分钟 之内,<br>则总是在主节点读取;并监控从节点的复制滞后程度 ,<br>避免从那些滞后时 间超过一分钟的从节点读取。<br>
客户端还可以记住最近更新时的时间戳,<br>并附带在读请求中,据此信息,<br>系统可 以确保对该用户提供读服务时<br>都应该至少包含了该时间戳的更新。
副本分布在多数据中心<br>(例如考虑与用户的地理接近,以及高可用性),<br>情 况会更复杂些。<br>必须先把请求路由到主节点所在的数据中心<br>(该数据中心可能离 用户很远)
要提供跨设备的写后读一致性
元数据必须做到全局共享
如果副本分布在多数据中心, <br>无法保证来自不同设备的连接经过路由之后都到达<br>同一个数据中心<br>
单调读
子主题
单调读一致性可以确保不会发生这种异常。<br>这是一个比强一致性弱,但比最终一致 性强的保证。<br>当读取数据时,<br>单调读保证,<br>如果某个用户依次进行多次读取,<br>不会看到回滚现象
确保每个用户总是从固定的同一副本执行读取<br>(而不同的 用户可以从不同的副本读取)。<br>例如,基于用户ID的哈希的方法而不是随机选择副 本。<br>但如果该副本发生失效,则用户的查询必须重新路由到另一个副本。<br>
前缀一致读
子主题
对于一系列按照某 个顺序发生的写请求,<br>那么读取这些内容时也会按照当时写入的顺序。<br>
一个解决方案是确保任何具有因果顺序关系的写入都交给一个分区来完成,<br>但该方案 真实实现效率会大打折扣。<br>现在有一些新的算法来显式地追踪事件因果关系,<br>“Happened-before关系与并发”会继续该问题的探讨。<br>
复制滞后的解决方案
多主节点复制
适用场景
多数据中心
子主题
在每个数据中心都配置主节点。<br>在每个数据中心内,<br>采用常规的主从复制方案;<br>而在数据中心之间,<br>由各个数 据中心的主节点来<br>负责同其他数据中心的主节点进行数据的交换、更新。<br>
单主节点的主从复制方案<br>与多主复制方案之 间的差异
性能<br>
主从复制,每个写请求都必须经由广域网传送至主节点所在的数据中心。<br>这 会大大增加写入延迟,基本偏离了采用多数据中心的初衷
多主节点模型中,每个写操作都可以在本地数据中心快速响应,<br>然后采用异步 复制方式将变化同步到其他数据中心
容忍数据中心失效
主从复制,如果主节点所在的数据中心发生故障,<br>必须切换至另一个数据中 心,<br>将其中的一个从节点被提升为主节点。
多主节点模型中,<br>每个数据中心则 可以独立于其他数据中心继续运行,<br>发生故障的数据中心在恢复之后更新到最新 状态。
容忍网络问题
主从复制模型,由于写请求是同步操作,<br>对数据中心之间的网络性能和稳定 性等更加依赖。
多主节点模型则通常采用异步复制,<br>可以更好地容忍此类问题, <br>例如临时网络闪断不会妨碍写请求最终成功。<br>
离线客户端操作
应用在与网络断开后还需要继续工作
每个设备都有一个充当主节点的本地数据库<br>(用来接受写请求),<br>然后 在所有设备之间采用异步方式同步这些多主节点上的副本,<br>同步滞后可能是几小时或 者数天,<br>具体时间取决于设备何时可以再次联网。<br>
协作编辑
实时协作编辑应用程序允许多个用户同时编辑文档。
为了加快协作编辑的效率, 可编辑的粒度需要非常小
处理写冲突<br>
子主题
同步与异步冲突检测<br>
如果是主从复制数据库,<br>第二个写请求要么会被阻塞直到第一个写完成, <br>要么被中止 (用户必须重试) 。<br>然而在多主节点的复制模型下,<br>这两个写请求都是成功的,<br>并且 只能在稍后的时间点上才能异步检测到冲突,<br>那时再要求用户层来解决冲突为时已 晚。<br>
避免冲突
处理冲突最理想的策略是避免发生冲突 ,<br>即如果应用层可以保证对特定记录的写请求 总是通过同一个主节点,<br>这样就不会发生写冲突
收敛于一致状态
对干主从复制模型,<br>数据更新符合顺序性原则,<br>即如果同一个字段有多个更新,<br>则最 后一个写操作将决定该字段的最终值。<br>
实现方式
给每个写入分配唯一的ID ,<br>例如, 一个时间戳, 一个足够长的随机数,一个 UUID<br>或者一个基于键-值的哈希,挑选最高ID的写入作为胜利者,并将其他写入丢弃。<br>
为每个副本分配一个唯一的ID,并制定规则,<br>例如序号高的副本写入始终优先 于序号低的副本。<br>这种方法也可能会导致数据丢失。
以某种方式将这些值合并在一起。
利用预定义好的格式来记录和保留冲突相关的所有信息,<br>然后依靠应用层的逻 辑,事后解决冲突
自定义冲突解决逻辑
最合适的方式可能还是依靠应用层,<br>所以大多数多主节点复制模型都有工具 <br>来让用户编写应用代码来解决冲突
在写入时执行
只要数据库系统在复制变更日志时检测到冲突,<br>就会调用应用层的冲突处理程 序
在读取时执行
当检测到冲突时,<br>所有冲突写入值都会暂时保存下来。<br>下一次读取数据时,<br>会将 数据的多个版本读返回给应用层。<br>应用层可能会提示用户或自 动解决冲突, <br>并将 最后的结果返回到数据库。
什么是冲突?
拓扑结构<br>
子主题
全部-至-全部结构
每个主节点将其写入同步到其他 所有主节点。
全链接拓扑也存在一些自身的问题。<br>主要是存在某些网络链路比其他链 路更快的情况<br>(例如由于不同网络拥塞),<br>从而导致复制日志之间的覆盖
子主题
环形拓扑结构
默认情况下MySQL只支持
每个节点接收来自前序节点的写入,<br>并将这些写入(加上自 己的写入)转发给后序节点。
星形结构
一个指定的根节点将 写入转发给所有其他节点。<br>星形拓扑还可以推广到树状结构。<br>
环形和星形拓扑
写请求需要通过多个节点才能到达所有的副本,<br>即中间节点需 要转发从其他节点收到的数据变更。<br>为防止无限循环,每个节点需要赋予一个唯一的 标识符,<br>在复制 日志中的每个写请求都标记了已通过的节点标识符。<br>如果某个节点 收到了包含自身标识符的数据更改,<br>表明该请求已经被处理过,<br>因此会忽略此变更请 求,避免重复转发。
如果某一个节点发生了故障,<br>在修复之前,<br>会影响其他节 点之间复制日志的转发。<br>可以采用重新配置拓扑结构的方法暂时排除掉故障节点。<br>在 大多数部署中,这种重新配置必须手动完成。<br>而对于链接更密集的拓扑(如全部到全 部),<br>消息可以沿着不同的路径传播,避免了单点故障,<br>因而有更好的容错性。<br>
无主节点复制
选择放弃主节点,允许任何副本直接接受来自客户端的写请求。<br>
对于某些无主节点系统实现,<br>客户端直接将其写请求发送到多副本,<br>而在其他一些实 现中,<br>由一个协调者节点代表客户端进行写入,<br>但与主节点的数据库不同,<br>协调者井 不负责写入顺序的维护。
节点失效时写入数据库
父主题
用户 1234将写请求并行发送到三个副本,<br>有两个可用副本接受写请求,<br>而不可用的副本无 法处理该写请求。<br>如果假定三个副本中有两个成功确认写操作,<br>用户 1234收到两个 确认的回复之后,<br>即可认为写入成功。<br>客户完全可以忽略其中一个副本无法写入的情 况。<br>
子主题
当一个客户端从数据库中读取数据肘,<br>它不是向一个副本发送请 求,<br>而是并行地发送到多个副本。<br>客户端可能会得到不同节点的不同响应,<br>包括某些 节点的新值和某些节点的旧值。<br>可以采用版本号技术确定哪个值更新
读修复与反熵
读修复<br>
当客户端井行读取多个副本时,可以检测到过期的返回值。<br>例如,在图5-10中 , 用户2345从副本3获得的是版本6,<br>而从副本l和2得到的是版本7。 <br>客户端可以判 断副本3一个过期值,<br>然后将新值写入到该副本。<br>这种方怯主要适合那些被频繁 读取的场景。<br>
反熵过程
一些数据存储有后台进程不断查找副本之间数据的差异,<br>将任何缺少的数 据从一个副本复制到另一个副本。<br>与基于主节点复制的复制日志不同,<br>此反熵过 程并不保证以特定的顺序复制写入,<br>并且会引入明显的同步滞后。<br>
读写quorum<br>
有n个副本,<br>写入需要w个节点确认,<br>读取必须至少 查询r个节点, <br>则只要 w+r>n,读取的节点中一定会包含最新值。
一个常见的选择是设置n 为某奇数(通常为3或5), <br>w=r = (n + 1) /2 (向上舍入)。<br>也可以根据自己的需求灵 活调整这些配置。
仲裁条件w+r>n定义了系统可容忍的失效节点数
子主题
子主题
Quorum 一致性的局限性<br>
监控旧值
宽松的quorum与数据回传
多数据中心操作
检测并发写
最后写入者获胜(丢弃并发写入)
Happens-before关系和并发<br>
确定前后关系
合并同时写入的值
版本矢量
假设数据规模比较小,集群的每一台机器都可以保存数据集的完整副本。
第六章<br>数据分区
子主题
分区通常是这样定义的,<br>即每一条数据(或者每条记录,每行或每个文档)<br>只属于某 个特定分区。<br>每个分区都可以视为一 个完整的小型数据库,<br>虽然数据库可能存在一些跨分区的操作。<br>
数据分区与数据复制
分区通常与复制结合使用,<br>即每个分区在多个节点都存有副本。<br>这意味着某条记录属 于特定的分区 ,<br>而同样的内容会保存在不同的节点上以提高系统的容错性。<br>
子主题
键-值数据的分区<br><br>分区的主要 目标是<br>将数据和查询负载<br>均匀分布在所有节点上。<br><br>
基于关键字区间分区
为每个分区分配一段连续的关键字或者关键宇区间范围
如果知道关键字区间的上 下限,<br>就可以轻松确定哪个分区包含这些关键字。 <br>如果还知道哪个分区分配在哪个节 点,<br>就可以直接向该节点发出请求
关键字的区间段不一定非要均匀分布,<br>这主要是因为数据本身可能就不均匀。
分区边界可以由管理员手动确定,<br>或者由数据库自动选择
采用这种分区策略的系统<br>包括Bigtable, Bigtable的开源版本HBase , <br>RethinkDB和2.4版本之前MongoDB
区间查询
每个分区内可以按照关键字排序保存。<br>这 样可以轻松支持区间查询,<br>即将关键字作为一个拼接起来的索引项<br>从而一次查询得到 多个相关记录
基于关键字的区间分区的缺点是某些访问模式会导致热点。<br>如果关键字是时间 戳,则分区对应于一个时间范围,<br>例如每天一个分区。<br>然而,当测量数据从传感器写 入数据库时,<br>所有的写入操作都集中在同一个分区(即当天的分区),<br>这会导致该分 区在写入时负载过高,<br>而其他分区始终处于空闲状态
需要使用时间戳以外的其他内容作为关键字的第一项。<br>例如,可 以在时间戳前面加上传感器名称作为前缀,<br>这样首先由传感器名称,<br>然后按时间进行 分区。<br>假设同时有许多传感器处于活动状态,<br>则写入负载最终会比较均匀地分布在多 个节点上。<br>接下来,当需要获取一个时间范围内、多个传感器的数据时,<br>可以根据传 感器名称,各自执行区间查询。<br>
基于关键字哈希值分区<br>
对于数据倾斜与热点问题,<br>许多分布式系统采用了基于关键字哈希函数的方式来 分区。<br>
用于数据分区目的的哈希函数不需要在加密方面很强
Cassandra和MongoDB 使用MD5, Voldemort使用Fowler-Noll-Vo函数
Java的Object.hashCode和Ruby的Object#hash,同一个键在不同的进程中可能返回 不同的哈希值。<br>不适合分区<br>
可以很好地将关键字均匀地分配到多个分区中。<br>分区边界可以是均匀间隔,<br>也可以是伪随机选择(在这种情况下,该技术有时被称为一致性哈希)
区间查询
通过关键字哈希进行分区,<br>我们丧失了良好的区间查询特性。<br>即使关键字相 邻,<br>但经过哈希之后会分散在不同的分区中,<br>区间查询就失去了原有的有序相邻的特 性。
在MongoDB中,如果启用了基于哈希的分片模式,则区间查询会发送到所有的 分区上
Riak、 Couchbase 和 Voldemort干脆就不支持关键字上的区间查询。<br>
Cassandra则在两种分区策略之间做了一个折中。<br> Cassandra中的表可以声明为由 多个列组成的复合主键。<br>复合主键只有第一部分可用于哈希分区,<br>而其他列则用作组 合索引来对Cassandra SSTable中的数据进行排序<br>因此,它不支持在第一列上进行区 间查询,<br>但如果为第一列指定好了固定值,<br>可以对其他列执行高效的区间查询。 <br>
组合索引为一对多的关系提供了一个优雅的数据模型。
负载倾斜与热点
如果节点平均分担负 载,<br>那么理论上10个节点应该<br>能够处理10倍的数据量<br>和10倍于单个节点的读写吞吐量 <br><br>如果分区不均匀,<br>则会出现某些分区节点<br>比其他分区承担更多的<br>数据量或查询负 载,<br>称之为倾斜。
倾斜会导致分区效率严重下降,<br>在极端情况下,<br>所有的负载可能会 集中在一个分区节点上,<br>这就意味着10个节点9个空闲,<br>系统的瓶颈在最繁忙的那个 节点上。<br>这种负载严重不成比例的分区即成为系统热点。<br>
基于哈希的分区方能可以减轻热点,但无住做到完全避免。
只能通过应用层来减轻 倾斜程度。
如果某个关键字被确认为热点, <br>一个简单的技术就是在关键字的开 头或结尾处添加一个随机数。<br>只需一个两位数的十进制随机数<br>就可以将关键字的写操 作分布到100个不同的关键字上,<br>从而分配到不同的分区上。<br>
任何读取都需要些额外的工作,<br>必须从所有100个关键字中读取数据然后进行合并。<br>因此通常只对少量的热点关键字附加随机数才有意 义;<br>而对于写入吞吐量低的绝大多数关键字,<br>这些都意味着不必要的开销。<br>此外,还 需要额外的元数据来标记哪些关键字进行了特殊处理。<br>
分区与二级索引 <br><br>二级索引通常不能唯一标识一条记录,<br>而是用来加速特定值的查询<br>
二级索引是关系数据库的必备特性 ,<br>在文档数据库中应用也非常普遍。<br>但考虑到其 复杂性,许多键-值存储(HBase和Voldemort)并不支持二级索引;<br>但其他一些如 Riak则开始增加对二级索引的支持。 <br>此外, 二级索引技术也是Solr和Elasticsearch等全 文索引服务器存在之根本。<br>
基于文档分区的二级索引
图
子主题
每个分区完全独立,<br>各自维护自己的二级索引,<br>且只负责自己分 区内的文档而不关心其他分区中数据。<br>每当需要写数据库时,包括添加,删除或更新 文档等,<br>只需要处理包含目标文档ID的那一个分区。<br>因此文档分区索引也被称为本地 索引
如果想要搜索,就需要将查询发送到所有的分区,<br>然后合并所有 返回的结果。<br><br>查询分区数据库的方法有时也称为分散/聚集,<br>显然这种二级索引的查询代价高 昂。<br>即使采用了并行查询,也容易导致读延迟显著放大
基于词条的二级索引 分区
图
子主题
对所有的数据构建全局索引,<br>而不是每个分区维护自己的本地 索引。<br>
为避免成为瓶颈,<br>不能将全局索引存储在一个节点上,<br>否则就破坏了设计分区均衡的目标。<br>所以,全局索引也必须进行分区,<br>且可以与数据关键字采用不同 的分区策略。
词条分区,它以待查找的关键字本身作为索引。
可以直接通过关键词来全局划分索引,<br>或者对其取哈希值。 <br>直接分区的好处是可以支持高效的区间查询<br> 而采用哈希的方式则可以更均句的划分分区。<br>
优缺点
优点是读取更为高效
不利之处在于, 写入速度较慢且非常复 杂,<br>主要因为单个文档的更新时,<br>里面可能会涉及多个二级索引,<br>而二级索引的分区 又可能完全不同甚至在不同的节点上,<br>由此势必引人显著的写放大。<br>
实践中,对全局二级索引的更新往往都是异步的
分区再平衡<br>
随着时间的推移,<br>数据库可能总会出现某些变化:<br><br><span style="font-size: inherit;">查询压力增加,因此需要更多的CPU来处理负载。</span><br>数据规模增加,因此需要更多的磁盘和内存来存储数据。<br>节点可能出现故障,因此需要其他机器来接管失效的节点。<br>
分区再平衡通常至 少要满足 :<br><br>平衡之后,负载、数据存储、读写请求等应该在集群范围更均匀地分布。<br>再平衡执行过程中,数据库应该可以继续正常提供读写服务。<br>避免不必要的负载迁移,以加快动态再平衡,并尽量减少网络和磁盘I/O影响。<br>
动态再平衡的策略
不能取模<br><br>不直接使用mod <br>
如果节点数N发生了变化,<br>会导致很多关键字需要从现 有的节点迁移到另一个节点。
例如,假设hash(key) = 123456, 假定最初是10个节点, <br>那么这个关键字应该放在节点6 ( 123456 mod 10 = 6);<br>当节点数增加到11时,它需要移动到节点3 ( 123456 mod 11 = 3) ; <br>当继续增长到 12个节点时,又需要移动到节 点0 ( 123456 mod 12 = 0)。<br>这种频繁的迁移操作大大增加了再平衡的成本。<br>
固定数量的分区
子主题
创建远超实际节点数的分区数,<br>然后 为每个节点分配多个分区。
如果集群中添加了一个新节点,<br>该新节点可以从每个现有的节点上匀走几个 分区,<br>直到分区再次达到全局平衡
如果从集群中删除节点, <br>则采取相反的均衡措施。<br>
选中的整个分区会在节点之间迁移,<br>但分区的总数量仍维持不变,<br>也不会改变关键字 到分区的映射关系。<br>这里唯一要调整的是分区与节点的对应关系。<br>考虑到节点间通过 网络传输数据总是需要些时间 , <br>这样调整可以逐步完成,<br>在此期间, <br>旧的分区仍然可 以接收读写请求。<br>
原则上, 也可以将集群中的不同的硬件配置因素考虑进来,<br>即性能更强大的节点将分 配更多的分区,从而分担更多的负载。<br>
使用该策略时,分区的数量往往在数据库创建时就确定好,之后不会改变。
在初始化时,已经 充分考虑将来扩容增长的需求(未来可能拥有的最大节点数),<br>设置一个足够大的分 区数。<br>而每个分区也有些额外的管理开销,<br>选择过高的数字可能会有副作用。<br>
动态分区<br>
当分区的数据增 长超过一个可配的参数阈值(HBase上默认值是10GB ),<br>它就拆分为两个分区,每 个承担一半的数据量。<br>相反,如果大量数据被删除,<br>并且分区缩小到某个阈值以下,<br>则将其与相邻分区进行合并。该过程类似于B树的分裂操作
每个分区总是分配给一个节点,<br>而每个节点可以承载多个分区,<br>这点与固定数量的分 区一样。<br>当一个大的分区发生分裂之后,<br>可以将其中的一半转移到其他某节点以平衡 负载。
动态分区的一个优点是分区数量可以自动适配数据总量。<br>如果只有少量的数据,<br>少量 的分区就足够了,<br>这样系统开销很小;<br>如果有大量的数据,<br>每个分区的大小则被限制 在一个可配的最大值
对于一个空的数据库 , <br>因为没有任何先验知识可以帮助确定分 区的边界,<br>所以会从一个分区开始。<br>可能数据集很小,但直到达到第一个分裂点之 前,<br>所有的写入操作都必须由单个节点来处理, <br>而其他节点则处于空闲状态。<br>HBase和MongoDB允许在一个空的数据库上<br>配置一组初始分区(这 被称为预分裂)。<br>对于关键字区间分区,预分裂要求已经知道一些关键字的分布情况<br>
动态分区不仅适用于关键字区间分区, <br>也适用于基于哈希的分区策略。 <br>MongoDB从 版本2.4开始,同时支持二者,并且都可以动态分裂分区。<br>
按节点比例分区
使分区数与集群节点数成正比关系
Cassandra和Ketama采用
每个节点具有固定数量的分区
当节点数不变时,每个分区的大 小与数据集大小保持正比的增长关系 ;
当节点数增加时,分区则会调整变得更小。
较 大的数据量通常需要大量的节点来存储,<br>因此这种方陆也使每个分区大小保持稳定。<br>
当一个新节点加入集群时,<br>它随机选择固定数量的现有分区进行分裂,<br>然后拿走这 些分区的一半数据量,<br>将另一半数据留在原节点。
随机选择可能会带来不太公平的 分区分裂,<br>但是当平均分区数量较大时 ,<br>新节点最终会从现有节点中拿走相当数量的负载。
随机选择分区边界的前提要求采用基于哈希分区
自动与手动再平衡操作
请求路由<br><br>一类典型的服务发现问题,<br>服务发现并不限于数据库,<br>任何通过网络访问 的系统都有这样的需求,<br>尤其是当服务目标支持高可用时<br>
三种路由方式图
子主题
三种
允许客户端链接任意的节点(例如,采用循环式的负载均衡器)。<br>如果某节点恰 好拥有所请求的分区,<br>则直接处理该请求 :<br>否则,将请求转发到下一个合适的节 点,<br>接收答复,并将答复返回给客户端。
将所有客户端的请求都发送到一个路由层,<br>由后者负责将请求转发到对应的分区 节点上。<br>路由层本身不处理任何请求,<br>它仅充一个分区感知的负载均衡器。
客户端感知分区和节点分配关系。<br>此时,客户端可以直接连接到目标节点,而不 需要任何中介。
许多分布式数据系统依靠独立的协调服务(如ZooKeeper)跟踪集群范围内的元数 据
图
子主题
说明
每个节点都向ZooKeeper中注册自己, <br>ZooKeeper维护了分区到节 点的最终映射关系。<br>其他参与者(如路由层或分区感知的客户端)可以向ZooKeeper 订阅此信息。<br>一旦分区发生了改变,或者添加、 删除节点, <br>ZooKeeper就会主动通知 路由层,这样使路由信息保持最新状态。<br>
并行查询执行<br>
采用数据分区的主要目的是提高可扩展性。<br>不同的分区可以放在一个无共享集群的不同节点上。<br>一个大数据集可以分散在更多的磁盘上,<br>查询负载也随之分布到更多的处理器上。<br>
to be continue...
git
docker
mycat
netty
kotlin
https://www.processon.com/view/5d47a281e4b0bc1bbede91bf
https://www.processon.com/view/5cb3e3ade4b09ccab3588402

Collect
Get Started

Collect
Get Started

Collect
Get Started
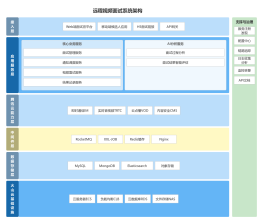
Collect
Get Started
评论
0 条评论
下一页

