强化学习
2019-12-24 10:44:02 3 举报AI智能生成
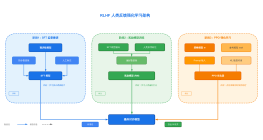
关于人工智能技术中强化学习的学习笔记
模板推荐
作者其他创作
大纲/内容





0 条评论
下一页

