深度学习整理
2021-05-06 11:11:44 3 举报AI智能生成
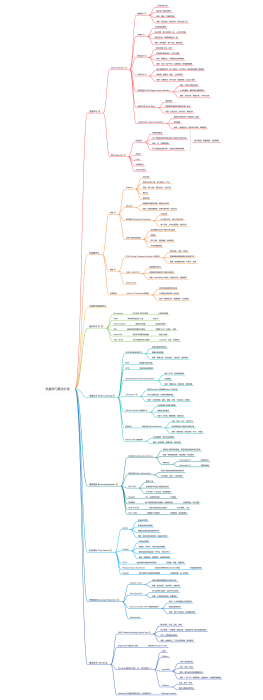
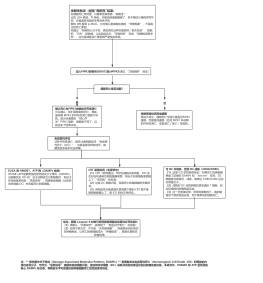
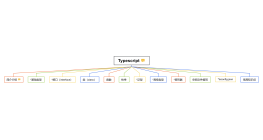
深度学习基础,神经网络原理、优化技巧及经典CV应用
模板推荐
作者其他创作
大纲/内容




0 条评论
下一页

