写并发越高,这里的同步延迟越大
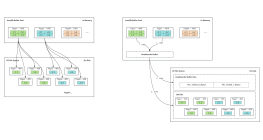
垂直拆分
count = n
事务B的ReadView
当前存活的事务
proxy
slave
Z值
client
连接池
磁盘文件
主从方案
4 写redolog
开始
roll_pointer
对于主索引来说,这个B+树的非叶子节点保存的是主键+指针,叶子节点保存的是数据行,所以如果主键过长导致单个节点保存指针过少,最后B+树深度加深。对于二级索引来说,这个B+树保存的是二级索引+指针,叶子节点保存的是主键,二级索引查询完必须去主索引拿数据,就叫回表,所以如果二级索引的索引项能包含所有要查询的字段,则不需要回表,则成为覆盖索引
解析器
free链表
只有执行到步骤8完毕事务才算提交成功 5-7宕机都算事务失败
db2t1
X值
db3
1.读取缓存数据
IO线程
负责BufferPool中页的适用频率,最近加载的数据放到头
trx_id=10
有空闲页就加入链表,要用就来这里拿
并行复制:从库可以有多个线程,重放不同库的日志
从库
事务B在RR级别下,第一次select时创建了一个readView。事务B只能看到小于min_trx_id的事务id和自己的id,所以此时无论事务A是否提交,B都只能沿着rollpointer回溯到undolog中trxid=30的Y值对于select快照读是走mvcc,把不可重复读,连带幻读都解决了对于udate,insert,delete是走当前读
6.redolog buffer刷入磁盘
BufferPool
master
事务B id = 52
半同步复制可以解决这里的复制延迟。打开后,主库必须等待从库写完relaylog后返回ack后才会认为写操作完成了
db3t2
LRU链表
produce db
结束
mysql
值B
page
db1t1
用户
id
Y值
sharding-jdbc
到步骤4为止还没有提交事务,这时宕机事务回滚
提交事务后写binlog
数据
按照hash分片,按照range分片
undo log
db2
BufferPool的结构
Mysql主从复制
2.写undolog用于回滚业务,和构建ReadView
如果写完binlog,但还没有写commit标记,宕机,恢复时也可以根据binlog自动提交这个事务
db1
一次加载一页 16k
水平拆分
解析sql
root
trx_id=20
事务C id = 30
hash(id) % 3
事务A id=49
执行器
db2t2
undolog
db3t1
5调用commit
redolog
值C
记录脏页,有脏页需要刷盘来这里拿
值A
sharding/proxy
BufferPool设置为机器大小的60%
9. buffer pool的脏页 后台随机刷回
data
trx_id=30
Sql线程
存储引擎
工作线程
7. 写入binlog
relaylog
db1t2
undo log的结构
事务A id=10
user db
优化器
NULL
redolog File
binlog
每个页描述符大概800字节,指向BufferPool中得一个page
优化执行计划
3. 更新内存数据
B+树的实现
主库
步骤5 innodb_flush_logs_at_trx_commit 这个如果设置为0 0 每秒一次刷盘设为1 每次提交刷盘设为2 不刷盘
price db
步骤7 同样有sync binlog配置控制刷盘
trx_id=49
事务B id=20
flush链表
指向脏页
mvcc原理
8.写入commit标记和binlog文件位置
用于回滚业务
还包含水平指针,便于顺序访问
driver