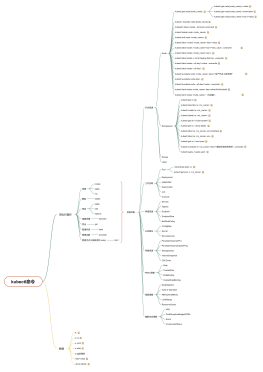
Collections(集合工具类)<br>
介绍
Collections工具类,主要就是操作集合的。<br>如果当操作集合的时候,发现集合的方法不够用了,<br>这时一定要先到Collections工具类中找有没有适合我们需求的功能。
常用方法<br>
public static <T> boolean addAll(Collection<T> c, T... elements):往集合中添加一些元素<br>
public static void shuffle(List<?> list) 打乱顺序:打乱集合顺序<br>
public static <T> void sort(List<T> list):将集合中元素按照默认规则排序<br>
public static <T> void sort(List<T> list,Comparator<? super T> ):将集合中元素按照指定规则排序
相关<br>
Comparator 比较器(用在排序中<自定义> 使用比较灵活)<br>
Comparable 比较器(用在排序中<自然排序>)
常用方法<br>
public int size() 返回集合中元素的个数<br>
public void clear() 清空集合中所有的元素<br>
public boolean add(E e) 把给定的对象添加到当前集合中<br>
public boolean isEmpty() 判断当前集合是否为空<br>
public boolean remove(E e) 把给定的对象在当前集合中删除<br>
public boolean contains(E e) 判断当前集合中是否包含给定的对象<br>
public Object[] toArray() 把集合中的元素,存储到数组中,可以间接对集合进行遍历<br>
public Iterator iterator() 获取集合对应的迭代器,用来遍历集合中的元素的