
java面试学习路线图
2020-06-08 10:08:15 1 举报AI智能生成
Java中jvm,多线程,基础,io,框架整理
JVM
多线程
IO
Spring
分布式
软件开发
模板推荐
作者其他创作
大纲/内容
并发编程
lock
Lock锁
JDK5加入,与synchronized比较,显示定义,结构更灵活
void lock();上锁
void unlock();释放锁
boolean tryLock();//尝试获取锁
ReentrantLock
重入锁
最多持有2147483648把锁
JUC
线程安全的集合
Collections中的工具方法
以synchronized开头的方法
JDK1.2提供,接口统一、维护性高,但是性能没有提升,均以synchronized实现
CopyOnWriteArrayList
线程安全的ArrayList,加强版读写分离
写有锁,读无锁,读写之间不阻塞,优于读写锁
写入时,先copy一个容器副本,再添加新元素,最后替换引用
CopyOnWriteArraySet
底层是CopyOnWriteArrayList
在添加新元素时,使用addIfAbsent();添加,遍历数组
如果重复了,则抛弃掉副本(复制的数组)
ConcurrentHashMap
JDK1.7
初始容量16段(Segment),使用分段锁设计
不对整个Map加锁,而是对每个Segment加锁
当多个对象存入同一个Segment时,才需要互斥
最理想的状态为16个对象分别存入16个Segment,并行数量16个
JDK1.8
Queue 队列
FIFO(先进先出)
抛出异常的方法
返回特殊值的方法(推荐)
ConcurrentLinkedQueue
线程安全、可高效读写的队列,高并发下性能最好的队列
采用的是无锁、CAS比较交换算法
V:要更新的变量 E:预期值 N:新值
只用当V==E时,V=N,否则标识已被更新过,则取消当前操作
BlockingQueue 阻塞队列
put 阻塞添加
take 阻塞移除
可用于解决消费者、生产者的问题
ArrayBlockingQueue
数组结构实现,有界队列,手工固定上限
LinkedBlockingQueue
链表结构实现,无界队列(默认上限是Integer.MAX_VALUE)
CAS
AQS
进程
进程
真正运行时的程序,称之为进程
单核CPU下,在任何时间点上,只能运行一个程序
宏观并行,微观串行
多线程
synchronized
synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行
synchronized使用方式
修饰实例方法
被修饰的方法称为同步方法,作用的范围是整个方法,作用的对象是调用这个方法的对象
修饰静态方法
作用的范围是整个静态方法,作用的对象是这个类的所有对象
修饰代码块
被修饰的代码块称为同步代码块,作用的范围是大括号{}内的代码,作用的对象是调用这个代码块的对象
修饰类
作用的范围是synchronized后面括号括起来的部分,作用的对象是这个类的所有对象
sychronized修饰不加static的方法,锁是加在单个对象上,不同的对象没有竞争关系;修饰加了static的方法,锁是加在类上,这个类所有的对象竞争一把锁
sychronized缺陷
获取锁的线程由于等待IO或者sleep等被阻塞了,但是没有释放锁,影响其他线程执行
当一个线程在进行读操作时,其他线程只能等待无法进行读操作
volatile
作用
保证变量的可见性
防止指令重排序
详解
volatile的原理和实现机制
观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令
lock前缀指令实际上相当于一个内存屏障
它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成
它会强制将对缓存的修改操作立即写入主存
如果是写操作,它会导致其他CPU中对应的缓存行无效
synchronized关键字与volatile关键字的区别
volatile关键字是线程同步的轻量级实现,所以性能比synchronized关键字要好
volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块
多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞
volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证
volatile关键字主要用于解决变量在多个线程之间的可见性,而synchronized关键字解决的是多个线程之间访问资源的同步性
synchronized与Lock的区别
两者都是可重入锁
可重入锁指自己可以再次获取自己的内部锁
synchronized依赖于JVM,reenTrantLock依赖于API
reenTrantLock比synchronized增加了一些高级功能
新功能
等待可中断
ReenTrantLock可以通过 lock.lockInterruptibly()将正在等待的线程放弃,转而处理其他事情
可实现公平锁
synchronized只能是非公平锁
ReenTrantLock默认是非公平的,可以通过 ReenTrantLock(boolean fair) 构造方法来指定是否是公平的
可实现选择性通知(锁可以绑定多个条件)
synchronized关键字与 wait()和notify/notifyAll()方法结合可以实现等待/通知机制,但执行notifyAll()方法会通知所有处于等待状态的线程,从而造成很大的效率问题
ReenTrantLock借助于Condition接口和newCondition()方法,线程对象可以注册在指定的Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活
synchronized不需要用户手动释放锁,系统会把执行完的synchronized方法或者代码块的锁释放,而lock则必须用户手动释放锁
实现Runnable接口和Callable接口的区别
Callable规定的方法是call(),Runnable规定的方法是run()
Runnable接口不会返回结果但是Callable接口可以返回结果
call()方法可抛出异常,run()方法不能抛出异常
执行execute()方法和submit()方法的区别
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否
submit()用于提交需要返回值的任务,线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout, TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完
线程池
线程池提供了一种限制和管理资源。每个线程池还维护一些基本信息,例如已完成任务的数量
线程池的好处
降低资源消耗
通过重复利用已创建的线程降低线程创建和销毁造成的消耗
提高响应速度
当任务到达时,任务可以不需要等到线程创建就能立即执行
提高线程的可管理性
线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
如何创建线程池
ThreadPoolExecutor类的四个构造方法
newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待
newScheduledThreadPool
创建一个定长线程池,支持定时及周期性任务执行
newSingleThreadPool
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
弊端
newFixed 和newSingle 堆积的请求处理队列可能会耗费非常大的内存
newCached和newScheduled 线程数最大数是 Integer.MAX_VALUE 可能创建数量非常多的线程
线程池的参数
corePoolSize 线程池核心线程数量
maximumPoolSize 线程池最大线程数量
keepAliverTime 当活跃线程数大于核心线程数时,空闲的多余线程最大存活时间
unit 存活时间的单位
workQueue 存放任务的队列(阻塞队列),在任意时刻,不论并发有多高,永远只有一个线程能够进行入队或出队操作
handler 超出线程范围和队列容量的任务的处理程序
ThreadFactory 线程工厂
线程池的实现原理
提交一个任务到线程池,线程池判断线程池里的核心线程是否都在执行任务,如果不是,则创建一个新的工作线程来执行任务。如果核心线程都在执行任务,就进行下个流程
线程池判断工作队列是否已满,如果工作队列没有满,则将新提交的任务存储在这个工作队列里,如果工作队列满了,则进入下个流程
判断线程池里的线程是否都处于工作状态,如果没有,则创建一个新的工作线程来执行任务,如果已经满了,则交给饱和策略(直接抛出异常、只用调用所在的线程运行任务、丢弃队列里最近的一个任务,并执行当前任务、不处理,丢弃掉)来处理这个任务
线程池的关闭方式
shutdown()
shutdown()后线程池将变成shutdown状态,此时不接收新任务,但会处理正在运行的和在阻塞队列中等待处理的任务
shutdownNow()
shutdownNow()后线程池将变成stop状态,此时不接收新任务,不再处理在阻塞队列中等待的任务,还会尝试中断正在处理中的工作线程。
什么时候使用线程池
单个任务处理时间比较短
防止任务堆积
需要处理的任务数量很大
线程池里线程数量的确定
CPU密集型
任务需要大量的运算,需要将线程与核心对应,即取cpu核心数+1个线程
IO密集型
有大量的IO操作,如读取数据库,即会有线程阻塞,所以多个线程轮流,利用cpu资源,取CPU核数*2
java同步机制
synchronized
wait、notify
ThreadLocal机制
锁的相关概念
可重入锁
一个线程执行某个同步方法,该同步方法调用另一个同步方法,则该线程不需要再重新申请锁,而是直接执行另一个方法
可中断锁
synchronized是不可中断锁,lock是可中断锁
线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它
公平锁
尽量以请求锁的顺序来获取锁
如何减少线程上下文切换
无锁并发编程
多线程处理数据时,用一些办法避免使用锁,如将数据的ID按照Hash取模分段,不同的线程处理不同段的数据
CAS
Java的Atomic包使用CAS算法更新数据,而不需要加锁
控制线程数量
控制线程数量,避免创建不需要的线程,造成大量线程都处于等待状态
协程
在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换
进程的状态与切换
进程状态
新建
就绪
运行
阻塞
终止
状态切换
就绪态->运行态
得到处理机调度
运行态->就绪态
时间片用完;更高优先级的进程就绪时,可以调度优先级更高的程序执行
运行态->阻塞态
请求资源失败
阻塞态->就绪态
资源来了
一个进程由运行态到阻塞态是主动的行为,而阻塞态变成就绪态是被动行为,需要其他相关进程的协助
线程模型
用户线程(ULT)
由应用管理,应用提供创建,同步,调度等操作。不需要用户态/核心态切换
为什么有用户态到核心态的切换
内存分为用户空间和核心空间,当应用需要调用硬件时,需要内核线程调用
内核线程(KLT)
由操作系统管理
JVM在用户空间创建线程,通过库调度器,调用系统库创建内核线程。cpu通过调度算法调用内核线程
进程间通信的方式
共享内存
多个进程地址空间映射到同一块内存中
内存映射文件
管道
管道
用于连接一个读进程和一个写进程以实现它们之间通信的一个共享文件,只存在于内存中
写进程以字符流形式将大量的数据送入管道;读进程从管道中接收数据
只支持半双工通信(单向交替传输)
只能在亲源进程中使用
有名管道
去除了管道只能在父子进程中使用的限制
消息队列
消息队列是消息的链表,存放在内核中并由消息队列标识符表示,提供了一个从一个进程向另一个进程发送数据快的方法
特点
生命周期随内核,消息队列会一直存在,需要我们显示的调用接口删除或使用命令删除
消息队列可以双向通信
克服了管道只能承载无格式字节流的缺点
消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取
客户机-服务器系统通信
套接字(socket)
远程过程调用
通过RPC协议,允许运行于一台主机系统上的进程调用另一台主机系统的进程
信号量
是一个计数器,用于为多个进程提供共享数据对象的访问
它常作为一种锁的机制,防止某进程正在访问共享资源时,其他进程也访问该资源。主要作为不同进程或者同一进程之间不同线程之间同步的手段
进程同步
临界区
对临界资源进行访问的代码称为临界区
为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查
信号量
用于进程间传递信号的一个整数值
pv
管程
由若干个变量以及方法所组织成的一种特殊的结构
将分散在各个进程中的临界区集中起来进行统一控制和管理,并且将系统中的共享资源用数据结构抽象的描述出来,然后对临界区的访问通过管程进行统一管理
特性
互斥性
任何时刻只能最多一个进程进入管程活动,其他想进入必须等待
安全性
管程中的局部变量只能由管程的方法访问,其他进程或管程不能够对该局部变量进行直接访问
共享性
管程中的特定的方法可以被其他管程或进程访问,这样的方法有特殊说明
线程间通信的方式
加锁
synchronized加锁的线程中的 wait()/notify()
lock中condition类的await()/signal()
管道
管道流用于在不同线程间直接传送数据
一个线程发送数据到输出管道,另一个线程从输入管道读数据
wait() notify() notifyAll()的区别
wait: 线程自动释放其占有的对象锁,并等待notify()
notify: 唤醒一个正在wait当前对象锁的线程,并让它拿到对象锁
notifyAll:唤醒所有正在wait当前对象锁的线程
死锁
死锁的必要条件
互斥条件
不可抢占条件
请求和保持
环路等待
解决死锁的方法
死锁检测和死锁恢复
死锁预防
死锁避免
鸵鸟策略
进程和线程的区别
一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线
拥有资源:进程是资源分配的基本单位,线程几乎不拥有资源(只需要少量的资源(指令指针IP,寄存器,栈),线程可以访问隶属进程的资源
通信方面:线程间可以通过直接读写同一进程中的数据进行通信,但是进程通信需要借助IPC
调度:线程是独立调度的基本单位,在统一进程中,线程的切换不会引起进程切换,从一个进程中的线程切换到另一个进程中的线程会引起进程切换
系统开销:创建和销毁进程时,系统都要为之分配和回收资源,如内存空间、I/O设备等,所符出的开销远大于创建或撤销线程时的开销。类似的,在进行进程切换时,设计当前执行进程CPU环境的保存及新调度进程CPU环境的设置,而线程切换时只需保存和设置少量寄存器内容,开销很小
进程调度的基本方式
时间片轮转
优先级调度
多级反馈队列
进程同步和进程通信的区别
进程同步:控制多个进程按一定顺序执行
进程通信:进程间传输信息
sleep()和wait()的区别
当在一个Synchronized方法中调用sleep()时,线程虽然休眠了,但是对象的机锁没有被释放,其他线程任然不可以访问这个对象
wait()方法则会在线程休眠的同时释放掉机锁,其他线程可以访问该对象。
Yield()方法是停止当前线程,让同等优先权的线程运行。如果没有同等优先权的线程,那么Yield() 方法将不会起作用。
join()方法使当前线程停下来等待,直至另一个调用join方法的线程终止。
AQS
同步队列
一个虚拟双端队列,遵循FIFO原则,主要作用是用来存放在锁上阻塞的线程,当一个线程尝试获取锁时,如果已经被占用,那么当前线程就会被构造成一个Node节点加入到同步队列的尾部,队列的头节点是成功获取锁的节点,当头节点线程释放锁时,会唤醒后面的节点并释放当前头节点的引用
静态链接和动态链接
静态链接
在生成可执行程序的时候,把目标文件和静态库,使用Id连接器,链接生成一个可执行程序
动态链接
在生成可执行程序的时候,只是引用的未定义的符号作了标识,到加载到内存中的时候才进行符号重定位
守护线程
守护线程是程序运行时在后台提供服务的线程,不属于程序中不可或缺的部分
当所有非守护线程结束时,程序也就终止,同时会杀死所有守护线程
并行和并发的区别
并行是指两个或多个事件在同一时刻发生,并发是指两个或多个事件在同一时间间隔发生
并行是在不同实体上的多个事件,并发是在同一实体上的多个事件
在一台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务
fork()和exec()
fork()
Linux的进程都通过init进程或init进程的子进程fork出来的
fork()会产生一个和父进程完全相同的子进程(除了pid)
exec()
装载一个新的程序(可执行映像)覆盖当前进程内存空间中的映像,从而执行不同的任务
exec()系列函数在执行时会直接替换掉当前进程的地址空间
锁的膨胀
https://www.cnblogs.com/twoheads/p/10148598.html
并发工具类
CountDownLatch
CyclicBarrier
Semaphore
fork/join
网络编程
netty
socket
网络编程
网络
由点和线构成的,标识诸多对象间的相互联系
计算机网络
为实现资源共享和信息传递,通过通信线路连接起来的若干主机(Host)
互联网:点与点相连
万维网:端与端相连
物联网:物与物相连
网络编程:让计算机与计算机之间建立连接、进行通信
网络模型:OSI开放式系统互联
第一层:物理层(双绞线、光导纤维)
第二层:链路层(MAC)
第三层:网络层(IP地址)
第四层:传输层(TCP、UDP)
第五层:会话层(断点续传)
第六层:表示层(对数据转换以及加密)
第七层:应用层(HTTP、FTP、SMTP)
TCP/IP模型
一组用于实现网络互联的通信协议,分为了四层
第一层:网络接口层(以太网、ADSL)
第二层:网络层(分配地址、传送数据,IP协议)
第三层:传输层(文本数据,协议是TCP、UDP协议)
第四层:应用层(负责传送最终形态的数据,协议为HTTP、FTp)
TCP/UDP
TCP:传输控制协议 是一种面向连接、可靠的、基于字节流的传输层通信协议数据大小无限制
建立连接的过程需要三次握手
断开连接的过程需要四次挥手
UDP:用户数据报协议 是一种无连接的传输层协议,提供面向事务的简单、不可靠信息传送服务每个包的大小是64KB
IP
互联网协议/网际协议地址
分配给互联网设备的唯一数字标签(标识)
IPV4
4字节32位整数,分成4段8位的二进制数 255.255.255.255
IPV6
16字节128位整数,分成8段十六进制整数 FFFF:FFFF:FFFF:FFFF:FFFF:FFFF:FFFF:FF
回环地址
127.0.0.1 localhost
Port端口
在通信实体上进行网络通讯的程序的唯一标识
0~65535
常用端口
Mysql:3306
Oracle:1521
Tomcat:8080
Web服务器:80
FTP服务器:21
InetAddress
标识互联网协议(IP)地址对象。封装了与该IP地址对象相关的所有信息,并提供常用方法
无法直接创建对象,构造方法私有化。需要通过getXXX方法来获得
基于TCP的网络编程
Socket
是网络中的一个通信节点
分为客户端Socket和服务端ServerSocket
通信要求:IP地址+端口号
计算机网络
五层协议的体系结构
物理层
数据链路层
两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议
网络层
网络层负责为分组交换网上的不同主机提供通信服务。在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送
运输层(transport layer)
运输层的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务。应用进程利用该服务传送应用层报文
传输层协议
传输控制协议 TCP(Transmisson Control Protocol)
提供面向连接的,可靠的数据传输服务
TCP的主要特点
TCP是面向连接的
每一条TCP连接只能有两个端点,每一条TCP连接只能是点对点的(一对一)
TCP提供可靠支付的服务,通过TCP连接传送的数据,无差错、不丢失、不重复、并且按序到达
TCP提供全双工通信。TCP允许通信双方的应用进程在任何时候都能发送数据。TCP连接的两端都设有发送缓存和接收缓存,用来临时存放双方通信的数据
面向字节流。TCP中的“流”(stream)指的是流入进程或从进程流出的字节序列。“面向字节流”的含义是:虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序交下来的数据仅仅看成是一连串的无结构的字节流。
用户数据协议 UDP(User Datagram Protocol)
提供无连接的,尽最大努力的数据传输服务(不保证数据传输的可靠性)
UDP的主要特点
UDP是无连接的
UDP使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态
UDP是面向报文的
UDP没有阻塞控制,因此网络出现阻塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
UDP支持一对一、一对多、多对一和多对多的交互通信
UDP的首部开销小,只有8个字节,比TCP的20个字节的首部要短
为什么UDP有时比TCP更有优势
网速的提升给UDP的稳定性提供可靠网络保障,丢包率很低,如果使用应用层重传,能够确保传输的可靠性
TCP为了实现网络通信的可靠性,使用了复杂的拥塞控制算法,建立了繁琐的握手过程
TCP一旦发生丢包,TCP会将后续的包缓存起来,等前面的包重传并接收后再继续发送,延时会越来越大;UDP采用自定义重传机制,能够把丢包产生的延迟降到最低
应用层(application layer)
应用层的任务是通过应用进程间的交互来完成特定网络应用。应用层协议定义的是应用进程间的通信和交互的规则。对于不同的网络需要不同的应用层协议
应用层协议
域名系统DNS(Domain Name System)
域名系统是因特网的一项核心服务,它作为可以将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网
超文本传输协议HTTP(HyperText Transfer Protocol)
超文本传输协议是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准
应用层交互的数据单元称为报文
TCP/IP的体系结构
网络接口层
网际层 IP
运输层 (TCP或UDP)
应用层(各种应用层协议,如TELNET,FTP,SMTP等)
TCP三次握手和四次分手
三次握手
第一次:客户端发送带有SYN=1,seq=x,标志的数据包给服务端,客户端进入SYN_SEND状态
第二次:服务端发送带有SYN=1,ACK=1,seq=y,ack=x+1,标志的数据包给客户端,服务端进入SYN_RCVD状态
第三次:客户端发送带有ACK=1,ack=y+1,标志的数据包给服务端,客户端进入ESTABLISHED状态,服务端接收到这个包后,也进入ESTABLISHED状态
四次分手
第一次:客户端发送一个FIN=1,seq=x,表示自己已经没有数据可以发送了,但是仍然可以接受数据,进入FIN_WAIT_1状态
第二次:服务器发回ACK=1,ack=x+1,表明自己收到客户端关闭连接的请求,但还没准备好关闭,进入CLOST_WAIT状态,客户端收到这个确认包后,进入FIN+WAIT_2状态
第三次:服务端发送 FIN=1,seq=y的报文,进入LAST_ACK状态,等待客户端的最后一个ACK
第四次:客户端接收到服务端的关闭请求,发回ACK=1,ack=y+1报文确认,进入TIME_WAIT状态,等待可能的重传ACK包,服务端接收到这个确认包后,关闭连接,进入CLOSED状态,客户端等待两个最大段生命周期,进入CLOSED状态
三次握手的原因
第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接
第三次握手失败怎么办
直接发送RTS报文段,进入CLOSED状态,这样做的目的是为了防止SYN泛洪攻击
四次挥手的原因
为了让服务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送 FIN 连接释放报文
TCP报文首部
源端口和目的端口
各占2个字节,分别写入源端口和目的端口
序号seq
占4个字节,TCP连接中传送的字节流中的每个字节都按顺序编号
确认号ack
占4个字节,是期望收到对方下一个报文的第一个数据字节的序号
数据偏移
占4位,它指出TCP报文的数据距离TCP报文段的起始处有多远
保留
占6位,保留今后使用
紧急URG
当URG=1,表明紧急指针字段有效。告诉系统此报文段中有紧急数据
确认ACK
仅当ACK=1时,确认号字段才有效。TCP规定,在连接建立后所有报文的传输都必须把ACK置1
推送PSH
当两个应用进程进行交互式通信时,有时在一端的应用进程希望在键入一个命令后立即就能收到对方的响应,这时候就PSH=1
复位RST
当RST=1,表明TCP连接中出现严重差错,必须释放连接,然后再重新建立连接
同步SYN
在连接建立时用来同步序号。当SYN=1,ACK=0,表明是连接请求报文,若同意连接,则响应报文中应该使SYN=1,ACK=1
终止FIN
用来释放连接。当FIN=1,表明此报文的发送方的数据已经发送完毕,并且要求释放
窗口
占2个字节,指的是通知接收方,发送本报文你需要有多大的空间来接受
检验和
占2个字节,校验首部和数据两部分
紧急指针
占2个字节,指出本报文段中的紧急数据的字节数
选项
长度可变,定义一些其他的可选的参数
IP数据报首部
版本
IPV4 和 IPV6两个版本
首部长度
区分服务
总长度
包括首部长度和数据部分长度
生存时间
防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当TTL为0时就丢弃
协议
指出携带的数据应该上交给哪个协议进行处理
首部检验和
因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包括数据部分可以减少计算的工作量
源地址
目的地址
标识
在数据报长度过长而发生分片的情况下,相同数据报的分片具有相同的标识符
片偏移
和标识符一起,用于发生分片的情况。片偏移的单位为8字节
TCP拥塞控制机制
原因
我们知道TCP通过一个定时器(timer)采样了RTT并计算RTO,但是,如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,然而重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这就导致了恶性循环,最终形成“网络风暴” —— TCP的拥塞控制机制就是用于应对这种情况
在某段时间,若对网络中某一个资源的需求超过了该资源所能提供的可用部分,网络的性能就会变坏,就是拥塞
拥塞窗口
在发送数据时,将拥塞窗口的大小与接收端ack的窗口的大小作比较,取较小者作为发送数据量的上限
拥塞控制算法
慢启动
刚刚加入网络的连接,一点一点的提速,不要一上来就把路占满,指数上升
拥塞避免
当拥塞窗口达到一个阈值时,窗口不再呈指数上升,而是以线性上升,避免增长过快导致网络拥塞
快重传
接收方在收到一个失序的报文段后就立即发出重复确认,而不要等到自己发送数据时捎带确认。发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必等待设置的重传时间
快恢复
慢开始只在TCP连接建立时和网络出现超时时才使用
当发送方连续收到三个重复确认时,就执行“乘法减小”算法,吧门限减半,但是不执行慢开始算法
拥塞控制与流量控制的区别
拥塞控制是防止过多的数据注入到网络中,可以使网络中的路由器或链路不致过载,是一个全局性的过程
流量控制是点对点通信量的控制,是一个端到端的问题,主要就是抑制发送端发送数据的速率,以便接收端来得及接收
滑动窗口
TCP滑动窗口技术通过动态改变窗口大小来调节两台主机间数据传输
状态码
1XX
信息性状态码
接收的请求正在处理
2XX
成功状态码
请求正常处理完毕
3XX
重定向状态码
需要进行附加操作以完成请求
301 永久性重定向
302 零时性重定向
4XX
客户端错误状态码
服务器无法处理请求
400 请求报文中存在语法错误
401 发送的请求需要有认证信息,若果之前已经进行过一次请求则标识用户认证失败
403 请求被拒绝
5XX
服务器错误状态码
服务器处理请求出错
session和cookie
cookie
cookie是由服务器发送给客户端的小量信息,以{key:value}的形式存在
原理
客户端请求服务器时,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。而客户端浏览器会把Cookie保存起来。当浏览器再请求 服务器时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器通过检查该Cookie来获取用户状态<br>
分类
会话期cookie
浏览器关闭之后会被自动删除,也就是仅在会话期内有效
持久性cookie
指定一个特定的过期时间或有效期之后就成为了持久性的cookie
session
session以服务端保存状态
原理
当客户端请求,服务端创建一个session,生成sessionID
服务端返回的响应报文的set-cookie首部字段包含这个sessionID,客户端将该Cookie值存入浏览器中
客户端再次请求时会包含该cookie,服务器收到之后提取出sessionID,取出用户信息
使用区别
登录信息等重要信息保存在session里
其他信息保存在cookie里
GET和POST的区别
对于RESTful规范来说,get用来获取数据,post用来提交数据
get是幂等的,post是非幂等的
post更安全,不会被缓存、保存在服务器日志以及浏览器记录中
get要快于post
HTTP1.0和2.0的区别
HTTP1.1
缓存处理
header里引入更多可供选择的缓存头来控制缓存策略
带宽优化及网络连接的使用
断点续传,请求头引入range头域,允许只请求资源的某个部分
错误通知的管理
新增24个错误状态响应码
Host头处理
支持虚拟主机
长连接
HTTP2.0
新的二进制格式
HTTP1.X解析是基于文本,HTTP2.0的协议解析采用二进制格式,方便且健壮
多路复用
连接共享,一个request对应一个id,一个连接上可以有多个request,每个连接的request可以随机的混杂在一起
header压缩
通讯双方各自cache一份header fields,避免重复header的传输,HTTP2.0 也使用哈夫曼编码对首部字段进行压缩
服务端推送
浏览器请求index.html,服务器把相应的style.css,example.png全部发送给浏览器,减少HTTP通信轮数
转发与重定向区别
转发在服务器端完成,重定向在客户端完成
转发速度快,重定速度慢
转发的是同一次请求,重定向是两次不同请求
转发地址栏没有变化,重定向地址栏有变化
TCP和UDP的特点
UDP是无连接的,尽最大可能交付,没有拥塞控制,面向报文,支持一对一,一对多,多对一,多对多的交互通信
TCP是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流,每一条TCP连接只能是一对一的
TCP和UDP的区别
TCP是面向连接的,UDP是无连接的
TCP提供可靠的服务,即通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
UDP具有较好的实时性,工作效率比TCP高,适用于高速传输和对实时性有较高的要求的通信或广播通信
每一条TCP连接只能是点到点的,UDP支持一对一,一对多,多对一,多对多的交互通信
TCP对系统资源要求较多,UDP对系统资源要求较少
使用代理服务器的原因
缓存
缓存一些公有资源
负载均衡
网络访问控制
访问日志记录
HTTPS
HTTP + 加密 + 身份认证 + 完整性保护
DNS
浏览器根据访问的域名找到其IP地址
DNS查找过程
浏览器缓存:浏览器会缓存DNS记录一段时间
系统缓存:浏览器会做一个系统调用,这样便可获得系统缓存中的记录
路由器缓存
向路由器发送查询请求,路由器一般会有自己的DNS缓存
ISP DNS缓存
请求缓存DNS的服务器
一个网页从开始请求到最终显示的完整过程
在浏览器中输入网址
发送至DNS服务器并获得域名对应的WEB服务器的IP地址
与WEB服务器通过三次握手建立TCP连接
浏览器向WEB服务器的IP地址发送相应的HTTP请求
WEB服务器响应请求并返回指定URL的数据,或错误信息,如果设定重定向,则重定向到新的URL地址
浏览器下载数据后解析HTML源文件,解析的过程中实现对页面的排版,解析完成后再浏览器中显示基础页面
分析页面中的超链接并显示在当前页面,重复以上过程直至无超链接需要发送,完成全部显示
IO模型
BIO(阻塞IO)
一个连接一个线程
现在服务端启动ServerSocket,然后在客户端启动Socket对服务端进行通信,默认情况下服务端需要对每个请求建立一堆线程等待请求,而客户端发送请求后,先咨询服务端是否有线程相应,如果没有则会一直等待或者遭到拒绝请求,如果有的话,客户端线程会等待请求结束后才继续执行
NIO(非阻塞IO)
一个请求一个线程
核心
Channel
Buffer
Selector
NIO基于Reactor,不是一个连接对应一个处理线程,而是一个有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。NIO最重要的地方是当一个连接创建后,不需要对应一个线程,这个连接会被注册到多路复用器上,所有的连接只需要一个线程就可以,当这个线程中的多路复用器进行轮询时,发现连接上有请求的话,才开启一个线程进行处理。
Reactor线程模型
Reactor 模式是处理并发 I/O 比较常见的一种模式,用于同步 I/O,中心思想是将所有要处理的IO事件注册到一个中心 I/O 多路复用器上,同时主线程/进程阻塞在多路复用器上;一旦有 I/O 事件到来或是准备就绪(文件描述符或 socket 可读、写),多路复用器返回并将事先注册的相应 I/O 事件分发到对应的处理器中
NIO服务端流程
创建ServerSocketChannel,绑定一个端口,并设置为非阻塞
生成一个selector对象
将ServerSocketChannel注册到selector上,并设置关心的事件为 OP_ACCEPT
循环等待客户端连接
如果selector对象调用select()没有事件发送,则返回
如果有事件发生,就获取到相关的 selectionKey集合,通过集合里的selectionKeys反向获取通道<br>
如果是 OP_ACCEPT事件, 调用serverSocketChannel.accept() 获得socketChannel,将该channel设置为非阻塞,并注册到selector对象中<br>
如果是OP_READ事件,通过selectionKeys获取对应通道,并读取他的buffer<br>
移除该 selectionKeys,防止多线程情况下重复处理
AIO(异步非阻塞IO)
一个有效请求一个线程
AIO需要一个连接注册读写事件和回调方法,当进行读写操作时,只须直接调用API的read或write方法即可。这两种方法均为异步的,对于读操作而言,当有流可读取时,操作系统会将可读的流传入read方法的缓冲区,并通知应用程序;对于写操作而言,当操作系统将write方法传递的流写入完毕时,操作系统主动通知应用程序。 即可以理解为,read/write方法都是异步的,完成后会主动调用回调函数
Netty简易
BossGroup维护一个selector,这个selector只处理client的accept事件
处理对应的accept事件,获得对应的socketChannel,封装成NIOSocketChannel,注册到WorkerGroup,并进行维护<br>
当worker线程接受到读写事件,就将这事件交给handler处理
框架,微服务
mybatis
个人笔记
docker
xxjob
spring
springBoot
个人笔记
springCloud
<b>SpringCloud <br>服务注册中心</b><br>
Eureka (目前停止更新)
Eureka 原理
Eureka 基本搭建
服务端(Server)环境配置
客户端环境配置
BUG
Eureka 集群环境搭建
修改系统配置
vim /etc/hosts
修改配置文件
127.0.0.1 eureka7001.com
127.0.0.1 eureka7002.com
YML 修改
启动参数
服务注册到 Eureka集群
YML 注册
服务的负载均衡
RestTemplate Bean 声明添加 @LoadBalanced
代码实例
修改请求地址
原始地址:http://localhost:8001
修改后地址:http://PAYMENT-SERVCIE
@LoadBalanced 默认采用轮询算法
actuator 微服务信息完善
显示主机名称
YML 配置
IP 配置
YML 配置
服务发现 Discovery
启动类
获取注册信息
Eureka 自我保护
自我保护的理论
禁用自我保护
某一时刻,不会自动删除服务
配置
Eureka Server YML 配置
Eureka Client YML 配置
Eureka 停止更新
Zookeeper
安装zk
docker 命令
添加 POM
YML
主启动类
Controller
注意:zk-discovery 中带的 zk 驱动版本和服务器上的 zk 版本是否一致
注册中心内容(基本信息)
zk 节点的划分
持久节点
临时节点
Consul
Consul 简介
是什么
能做什么
服务发现
提供HTTP 和 DNS 两种方式
健康检查
支持多种方式,HTTP,TCP,Docker。 Shell 脚本定制化
KV 存储
Key、Value 存储方式
多数据中心
Consul 支持多数据中心
可视化WEB管理
下载地址
安装步骤 :https://learn.hashicorp.com/consul/getting-started/install
与 spring-cloud 整合
安装并运行 Consul
服务提供者
POM
YML
启动类
业务代码
服务消费者(同服务提供者类似)
三个注册中心的异同
Eureka(java、AP、健康检查支持、HTTP、 集成Spring Cloud)
Consul(Go、CP、健康检查支持、HTTP/DNS 、集成Spring Cloud)
Zookeeper(java、CP、健康检查支持、客户端、集成 Spring Cloud)
CAP
C: Consistency(强一致性)
A: Availability (可用性)
P:Partitiontolerance(分区容错性)
CAP 理论关注细粒度是数据,而不是整体系统设计的
AP(Eureka)
CP (Consul/Zeekeeper)
<b>Spring Cloud Ribbon<br>负载均衡</b><br>
概述
是什么
官网
停止维护
替代方案 [Spring Cloud Loadbalancer]
功能
LB(负载均衡)
集中式 LB
进程内 LB
配置轮询(默认轮询)
Ribbon + RestTemplate
Ribbon 负载均衡演示
架构说明
POM
RestTemplate
(java doc)https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/client/RestTemplate.html
getForObject 方法/ getForEntity 方法
postForObject / postForEntity
GET 请求
POST 请求
Ribbon 核心组件 IRule
如何替换
注意事项
创建包
cn.edu.cqvie.myrule
添加自定义规则配置
启动类上添加 @RibbonClient
@RibbonClient(name="PAYMENT-SERVICE", configuration = MySelfRule.class)<br>
测试
IRule: 根据特定算法中从服务列表中选取一个要访问的服务
com.netflix.loadbalancer.RoundRobinRule
轮询
com.netflix.loadbalancer.RandomRule
随机
com.netflix.loadbalancer.RetryRule
先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会惊醒冲你是,获取可用的服务
WeightedResponseTimeRule
对RoundRobinRule 的拓展,响应速度越快的实例选择权重越大,越容易被选择
BestAvailableRule
会先过滤掉由于多次访问故障而处断路器跳闸状态的服务,然后选择一个并发量最小的服务
AvailabilityFilteringRule
先过滤掉故障实例,在选择并发较小的实例
ZoneAvoidanceRule
默认规则,符合判断Server 所在区域的性能和 Server 的可用性选择服务器
Ribbon 负载均衡算法
原理
RoundRobinRule 源码
自定义实现
SpringCloud OpenFeign<br>服务调用<br>
概述
feign 是一个声明式的Web服务客户端,让编写Web服务客户端变得非常容易,只需要创建一个接口并正在接口上添加注解即可。
GitHub
https://github.com/spring-cloud/spring-cloud-openfeign
fegin 能做什么
fegin 和 openfegin 区别
OpenFeign 使用步骤
接口 + 注解
微服务调用接口 + <font color="#c41230"><b>@FeignClient</b></font>
POM
YML
启动类
<font color="#c41230"><b>@EnableFeignClients</b></font>
微服务调用接口
<span style="font-size: inherit;">业务逻辑接口 + </span><font color="#c41230" style="font-size: inherit;"><b>@FeignClient 配置调用 Provider 服务</b></font><br>
<b><font color="#c41230">新建 PaymentFeignServer 接口</font></b> 并新增注解 @FeignClient
<b><font color="#c41230"> @FeignClient</font></b>
控制层 Controller
测试
小总结
OpenFeign 超时控制
YML 配置
OpenFeign 日志打印
日志级别
申明代码
YML 申明
SpringCloud Hystrix<br>服务降级/熔断/隔离<br>
Hystrix(目前停止更新)
服务降级
解决场景
服务超时(前台显示转圈)
出错(宕机或者程序运行出错)
解决
对方服务超时了,调用者不能一直死等,必须有服务降级
对方服务器 down 机了,调用者不能卡死等待,必须有服务降级
对方服务OK, 调用者自己出现故障(自己等待时间小于服务的超时时间,自己要求服务降级)
Hystrix 基本搭建
POM
主启动类
对方法添加降级
Hystrix 调用侧使用
POM
YML
主启动类
调用方法实例
Hystrix 统一的全局配置
配置方法代码
FeigClient
服务熔断
大神理论
https://martinfowler.com/bliki/CircuitBreaker.html
简单搭建
代码实例
总结
大神结论
熔断核心参数
断路器关闭的条件
当满足一定的阈值的到时候(默认10秒内超过20次请求)
当失败率到达一定的时候,默认10秒内超过50%的请求失败
到达以上阈值,断路器将会开启
当开启的时候,所有的请求都不会进行转发
一段时间之后,(默认5秒),这个时候断路器是半开状态,会让其中一个请求进行转发。如果成功,断路器会挂壁,若失败,继续开始重复 4,5
断路器打开之后
服务限流在 (Alibaba - Sentiel 学习 )
服务监控
POM
启动类
访问端口
http://127.0.0.1:8001/hystrix
监控使用
注意事项
注意依赖
注意新版本 Hystrix 需要在启动类 中指定监控路径
Unable to connect to Command Metric Stream
404
启动类
测试地址
监控配置地址:http://127.0.0.1:8001/hystrix.stream
异常访问:http://127.0.0.1:8001/payment/payInfo/1
正常访问:
Spring Cloud Gateway<br>服务网关<br>
概述简介
是什么
一句话
SpringCloud Gateway 使用的 Webflux 中的 reactor-netty 响应式比亲车给你组件,底层采用了netty 通讯框架
源码架构
网关在架构中的位置
网关是在微服务访问的入口,对外是负载均衡 Nginx
zuul 和 gateway
我们为什选择 gateway
1. netflix 不靠谱,zuul2.0 一直跳票,迟迟不发布
2. springcloud gateway 具有如下特征
3. springcloud gateway 和 zuul 的区别<br>
zuul1.0 模型
gateway 模型
webflux
是什么
三大核心概念
Route (路由)
路由是构建网关的基本模块, 它由ID, 目标 URI , 一系列的断言和过滤器组成,如果断言为true 则匹配该路由
Predicate ( 断言)
参考 Java8 的 java.util.funcation.Predicate<br>开发从人员可以陪陪HTTP 请求中的所有内容(例如请求头或请求参数),<b><font color="#c41230">如果请求与断言适配类则进行路由</font></b>
Filter (过滤)
指的是Spring框架中的GateFilter 的实例, 使用过滤器, 可以在请求被路由前或者之后进行修改
总体
Gateway 工作流程
匹配路由转发
在执行转发的前后执行过滤链
入门配置
POM
YML
主启动类
路由映射
<b><font color="#c41230">YML 网关配置</font></b>
测试
添加网关之前:http://localhost:8501/payment/get/1
添加网关之后:http://localhost:8501/payment/get/1
<font color="#0076b3">YML 配置说明</font>
Gateway 网关路由有两种配置方式
在配置文件YML 中配置
见前面的步骤
代码中注入 RouteLoctor 的 Bean
自己实现
业务需求
通过网关转发百度新闻网址
config
http://news.baidu.com/guonei
通过微服务名实现动态路由
默认情况下 Gateway 会更具注册中心的服务列表<br>以注册中心上服务名为路径 <b><font color="#c41230">动态路由进行转发,从而实现动态路由的功能</font></b>
启动:
POM
YML
Predicate 的使用
1. After Route Predicate
2. Before Route Predicate
3. Between Route Predicate
4. Cookie Route Predicate
5. Header Route Predicate
6. Host Route Predicate
7. Method Route Predicate
8. Method Route Predicate
9. Query Route Predicate
10. 总结
Filter 的使用
是什么
Spring Cloud Gateway 的Filter
常用的 GatewayFilter
GatewayFilter
GlobalFilter
自定义过滤器
自定义全局过滤器
两个主要接口介绍
<b><font color="#0076b3">implements</font> GlobalFilter</b>
能做什么
全局日志记录
统一鉴权网关
案例代码
测试
<b>SpringCloud Config<br>服务配配置</b><br>
概述
解决了什么问题
是什么
能干什么
集中管理配置文件
不同环境的不同配置,动态化的配置更新,分环境部署比如:/dev/test/prod/beta/release
运行期间动态调整配置,不再需要在每个服务器部署的机器上编写配置文件,服务会向配置中心统一拉取配置自己的信息
当配置发生变动,服务不需要重启即可感知配置的并发并应用新的配置
将配置信息以REST接口的形式暴露
与GitHub整合配置
官网
Config 服务端配置与测试
github 创建仓库
ssm-laboratory-config
拉取远程仓库
git clone https://github.com/zhengsh/ssm-laboratory-config.git
添加配置(git)
表示多个环境的配置文件
config-dev.yml
config-test.yml
config-prod.yml
保存格式必须为 UTF-8
如果需要修改,此处模拟运维人员操作git 和 gitub
git add .
git commit -m 'init yml'
git push
POM
YML
主启动类
<b style="font-size: inherit;"><font color="#c41230">@EnableConfigServer</font></b><br>
修改本机 Host 映射
127.0.0.1 config3344.com
测试通过 Config 微服务是否可以从 GitHub 上面读取配置内容
启动 3344
http://127.0.0.1:3344/master/config-dev.yml
配置读取规则
官网
/{lable}/{applicaton}-{profile}.yml
master 分支
http://127.0.0.1:3344/master/config-dev.yml
http://127.0.0.1:3344/master/config-test.yml
http://127.0.0.1:3344/master/config-prod.yml
dev 分支
http://127.0.0.1:3344/dev/config-dev.yml
http://127.0.0.1:3344/dev/config-dev.yml
http://127.0.0.1:3344/dev/config-dev.yml
/{application}-{profile}.yml
http://127.0.0.1:3344/config-dev.yml
http://127.0.0.1:3344/config-test.yml
http://127.0.0.1:3344/config-prod.yml
http://127.0.0.1:3344/config-xx.yml
/{application}/{profile}[/{lable}]
http://127.0.0.1:3344/config/dev/master
http://127.0.0.1:3344/config/test/master
http://127.0.0.1:3344/config/prod/master
重要配置细节总结
<font color="#000000"><b>成功实现了通过 SpringCloud Config 从 GItHub 获取配置信息</b></font>
Config 客户端配置与测试
POM 配置
bootstrap.yml
YML 解释
主启动类
业务代码
测试
curl curl http://127.0.0.1:8001/configInfo
master branch,spring-cloud-config/config-dev.yml version=1
问题随之而来,分布式分配至的动态刷新问题
Linux 运维修改了GitHub 上的配置文件内容作出了调整
刷新 Config-Server, 发现 ConfigServer 配置中心立刻响应
刷新 Config-Client, 发现 ConfigClient 客户端没有任何响应
Config-Client 没有变化,除非自己重新启动或者重新加载
如果每次修改都需要重启画的 , 那将是一个非常复杂的操作
Config 客户端值动态刷新(手动版)
避免每次刷新配置都要重启客户端微服务
动态刷新
步骤
修改 Server-Client
POM 引入 actuator 监控
修改 YML , 暴露监控端口
<b><font color="#c41230">@RefeshScope</font></b> 业务类Controller 修改
此时 修改 GitHub -> Config-Server -> Config-Client
curl http://127.0.0.1:8001/configInfo
此时 Config-Client 依然没有生效 ??
How
需要发送 POST 请求到 Config-Client
必须是 POST 请求
curl -X POST "http://127.0.0.1:8001/actuator/refresh"
再次
curl http://127.0.0.1:8001/configInfo
成功将配置更新到 Config-Client
避免了服务器的重启
思考还有什么问题
如果有多个微服务客户端 config-client1、config-client2、config-client3
每个微服务都要执行一次 post 请求,手动刷新
是否可以官博,一处通知,处处生效?
我们需要大范围的自动刷新??
<b>SpringCloud Bus<br>消息总线</b><br>
概述
解决什么问题?
分布式自动刷新配置功能
可以结合 SpringCloud Config 实现自动刷新配置
是什么?
Bus 支持两种消息代理
RabbitMQ
Kafka
为什么被称作总线
RabbitMQ 环境配置(Mac)
安装:brew install rabbitmq
进入目录: cd /usr/local/Cellar/rabbitmq/3.8.2
启动 :brew services start rabbitmq
访问地址(可视化页面)
http://localhost:15672
输入账号密码:guest guest
SpringCloud Bus 动态刷新全局广播
必须具备 RabbitMQ 环境
广播效果,需要准备2个接受服务
设计思想
1)利用消息总线触发一个客户端 /bus/refresh, 而刷新所有客户端的配置
2)利用消息总线触发一个服务端 ConfigServer 的 bus/refresh 端点,而刷新所有客户端的配置
第二种方案更加合适,第一种方案不合适的原因
打破了微服务的职责单一性,因为微服务本省是业务模块,它本不应该承担配置刷新的职责
破坏了微服务各个节点的对等性
有一定的局限性,例如, 在微服务迁移时,它的网络地址常常会发生变化,如果此时时想自动属性,会增加更多的工作
配置中心添加消息支持
POM
YML
客户端添加消息支持
POM
YML
如果多个节点,需要对应配置
测试
运维工程师
修改 GitHub 上的配置
发送POST 请求
curl -X POST ”http://127.0.0.1:3344/actuator/bus-refresh“
一次发送,处处生效
配置中心
http://127.0.0.1:3344/dev/config-dev.yml
客户端
http://127.0.0.1:8001/configInfo
一次修改,广播通知处处生效
ok
SpringCloud Bus 动态属性定点通知
不想全部通知,只想定点通知
只通知 payment-8001
不通知 payment-8002
简单理解
指具体某一个实例生效而不是全部
公式:http://127.0.0.1:配置中心端口/actuator/bus-refresh/<font color="#c41230">{destination}</font>
/bus/refresh 请求不在发送到具体的服务实例上,而是发送给config server <br>通过 destination 参数指定需要更新配置的服务或实例<br>
案例
我们这里以刷新 payment-service 为例
只通知 payment-8001
不通知 payment-8002
curl -X POST "http://127.0.0.1:3344/actuator/bus-refresh/payment-service:8001"
通知总结All
Spring Cloud Stream<br>消息驱动<br>
消息驱动概述
是什么
一句话
屏蔽消息中间件的差异,降低切换恒本,统一的消息编程模型
官网
https://github.com/spring-cloud/spring-cloud-stream
https://cloud.spring.io/spring-cloud-static/spring-cloud-stream/3.0.3.RELEASE/reference/html/
中文资料
https://m.wang1314.com/doc/webapp/topic/20971999.html
设计思想
标准 MQ
生产者/消费者之间靠<font color="#c41230">消息</font>媒介传递内容
Message
消息必须走特定的<font color="#c41230">通道</font>
消息通道 MessageChannel
消息通道中的消息如何被消费, 谁来负责收发<font color="#c41230">处理</font>
消息通道 MesssageChannel 的子接口 SubscribableChannel , 由 MessageHandler 消息处理器所订阅
为什么用 Cloud Stream
Stream 为什么可以统一底层的差异
<b><font color="#c41230">Binder</font></b>
INPUT 对应于消费者
OUTPUT 对应于生产者
Stream 中的消息通讯方式遵循了发布-订阅模式
Topic 主题进行广播
在RabbitMQ 就是 Exchange
在Kafka中就是 Topic
Spring Cloud Stream 标准流程
Binder
很方便的连接中间件,屏蔽差异
Channel
通道,是队列 Queue 的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过channel 队列进行配置
Source 和 Sink
简单的理解为参照对象 Spring Cloud Stream 自身,<br>从 Steam 发布消息就是输出,接受消息就是输入
编码API 和 常用注解
Meddleware
中间件,目前只支持 RabbitMQ 和 Kafka
Binder
Binder 是应用消息中间件之间的封装, 目前实现了 Kafka 和 RabbitMQ 的Binder <br>通过 Binder 可以很方便的连接中间件,可以动态的改变消息类型(对于 Kafka 的 topic , rabbitmQ 的 exchange), <br>这些都可以通过配置文件来实现。
@Input
注解标识输入通道,通过该输入通道接收到的消息进入应用程序
@Output
注解标识输入通道,发布的消息将通过通道离开应用程序
@StramListener
监听队列,用于消费者的队列的消息接受
@EnableBinding
指信道 channel 和 exchange 绑定在一起。
案例说明
RbbitMQ 环境OK
工程模块
stream-provider
stream-consumer
消息驱动-生产者
POM
YML
主启动类
业务类
发送消息接口
发送下次接口实现类
Controller
测试
启动 Eureka
启动 RabbitMQ
启动 RabbitMQ-Provider
访问
消息驱动-消费者
POM
YML
主启动类
业务类
测试
curl http://127.0.0.1:8701/rabbit/send
消息发送端:=======> serial: b63ca8ce81ec4c2bb4429c5b9bff8bf8
消费者:8801, ------> 接受到的消息:b63ca8ce81ec4c2bb4429c5b9bff8bf8
分组消费与持久化
创建多个消费者服务
启动
RabbtMQ<br>
Eureka 服务注册
消息生产者
消息消费者-1
消息消费者-2
运行后的2个问题
有重复消费问题
消息持久化问题
消费
目前消费者-1、消费者-2都同时受到了,存在重复消费的问题
curl http://127.0.0.1:8701/rabbit/send
如何解决
<font color="#c41230"><b>分组和持久化属性 group </b></font>
重要
生产实际问题
分组
现状描述
故障现象是重复消费
导致现象是默认分组是不同的,组流水号不同,可以消费
自定义配置分组, 自定义配置分为同一个组,解决
重复消费问题
原理
微服务应用放置于同一个group 中, 就能保证消息只会被其中一个应用消费一次<br><b><font color="#c41230">不停的小组是可以消费的,同一个组内会发生竞争关系,只有其中一个可以消费</font></b>
消费者-1,消费者-2 都变成了<font color="#c41230"><b>不同组</b></font>,group 两个不同
group: atcqvie-01, atcqvie-02
消费者-1 修改 YML
消费者-2 修改 YML
自己的配置
结论
消费者-1,消费者-2 实现了轮询分组,每次只有一个消费者<br>发布者 模块发出的消息只能被 消费者-1,消费者-2 其中一个接收到,这样避免了重复消费的问题
<span style="font-size: inherit;">消费者-1,消费者-2 都变成了</span><b style="font-size: inherit;"><font color="#c41230">相同组</font></b><span style="font-size: inherit;">,group 两个相同</span><br>
group: atcqvie-01
消费者-1 修改 YML
消费者-2 修改 YML
持久化
通过上述,解决了重复消费问题,在看看持久化
停止 消费者-1,消费者-2, 并去掉 消费者-2 的 group
消费者-1 的 group: atcqvie-01 没有去掉
发布者先发布消息到 rabbitmq
启动消费者-2,无分组属性配置,后台没有打印出来消息
在启动消费者-1,有分组属性配置,后台打印出来了MQ上的消息
SpringCloud Sleuth<br>链路追踪 <br>
概述
为什么会出现这个技术?<br>需要解决那些问题?
问题
是什么
https://github.com/spring-cloud/spring-cloud-sleuth
Spring Cloud Sleuth 提供了一套完整的服务跟踪的解决方案。
在分布式系统中提供链路追踪解决方案并兼容支持了zipkin
解决
搭建链路监控步骤
1,zipkin
下载
Spring Cloud 从 F 版本过后已经不需要自己构建 Zipkin Server 了,只需要调用jar 即可
https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
zipkin-server-2.12.9-exec.jar
运行 jar
java -jar zipkin-server-2.12.9-exec.jar
运行控制台
访问控制台:http://localhost:9411/zipkin/
术语
完整的调用链路
子主题
理解调用链路设计
一条链路Trace ID 唯一标识, Span 标识发起的请求信息,各个 Span 通过 parent id 关联起来
名词解释
Trace : 类似于树结构的Span集合, 标识一条链路,存在唯一标识
Span: 标识调用链路来源,通俗的理解 span 就是一个请求信息
2. 服务提供者
POM
YML
启动类
业务类
3. 服务消费者(调用方)
POM
YML
启动类
业务类
4. 依次启动 eureka/ 8001 /8101
5. 打开浏览器访问:http://localhost:9411
<b>SpringCloud Alibaba<br>入门简介</b>
why 会出现 SpringCloud alibaba
Spring Cloud Netflix 项目进入维护模式
说明
Spring Cloud Netflix Projects Entering Maintenance Mode<br>
什么是维护模式
进入维护模式意味着什么呢
SpringCloud alibaba 带来了什么
是什么
能干什么
去哪里下
https://github.com/alibaba/spring-cloud-alibaba/blob/master/README-zh.md
怎么使用
官网
英文
https://github.com/alibaba/spring-cloud-alibaba
https://github.com/alibaba/spring-cloud-alibaba/tree/greenwich
中文
https://github.com/alibaba/spring-cloud-alibaba/blob/master/README-zh.md
SpringCloud alibaba 学习资料获取
SpringCloud Alibba<br>Nacos 服务注册中心
简介
为什么叫 Nacos
前面四个字母分别表示 Naming 和 Configuration 的前两个字母, 最后一个s 为 Service
是什么?
一个更易于构建云原生运用的动态服务发现、配置管理和服务管理平台
Nacos: Dynamic Naming and Configuration Service
Nacos 就是注册中心+ 配置中心
等价于
Nacos = Eureka + Config + Bus
能做什么
替代 Eureka 做服务注册中心
替代 Config 做服务配置中心
去哪里下载
https://github.com/alibaba/nacos
官方文档
https://nacos.io/en-us/
https://spring-cloud-alibaba-group.github.io/github-pages/greenwich/spring-cloud-alibaba.html
各个注册中心比较
运行 Nacos
下载地址:https://github.com/alibaba/nacos/releases
nacos-server-1.2.0.zip
创建数据库和导入SQL
创建数据库 nacos
导入数据: config/nacos-mysql.sql
修改配置
mysql 连接字符串(application.yml)
启动: ./bin/startup.sh -m standalone<br>
访问地址:http://127.0.0.1:8848/nacos
结果
作为服务中心演示
官方文档
https://spring-cloud-alibaba-group.github.io/github-pages/greenwich/spring-cloud-alibaba.html
基于 Nacos 的服务提供者
POM
YML
主启动类
业务类
测试
注册到 nacos
curl http://127.0.0.1:9002/payment/nacos/2
基于 Nacos 的服务消费者
POM
YML
主启动类
业务类
测试
启动 nacos
启动 payment-service、order-service
curl http://127.0.0.1:9101/consumer/payment/nacos/1
服务注册中心对比
各种注册中心的对比
Nacos 全景图所示
nacos 整体架构图
Nacos 和 CAP
切换
Nacos 支持 AP 和 CP模式的切换
作为服务配置中心演示
Nacos 作为配置中心 - 基础配置
POM
YML
bootstrap.yml
application.yml
主启动类
业务类
在 Nacos 中添加配置信息
Nacos 中的匹配规则
理论
cos 中的dataid 有的组成结构与 Spring boot 配置文件中的匹配规则
官网
实际操作
新增配置
Nacos 界面配置对应
设置DataId
公式
${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension}
prefix 默认为 spring.application.name 的值,也可以通过配置项 spring.cloud.nacos.config.prefix来配置。<br>
spring.profile.active 即为当前环境对应的 profile,详情可以参考 Spring Boot文档。 注意:当 spring.profile.active 为空时,对应的连接符 - 也将不存在,dataId 的拼接格式变成 ${prefix}.${file-extension}<br>
file-exetension 为配置内容的数据格式,可以通过配置项 spring.cloud.nacos.config.file-extension 来配置。目前只支持 properties 和 yaml 类型。<br>
小总结
历史配置
测试
curl http://127.0.0.1:9001/config/info
启动配置信息
自带动态刷新
修改下 Nacos 中的yaml 配置文件,再次调用查看配置的接口,就会发现配置已经刷新
Nacos 作为配置中心 - 分类配置
问题
多环境多项目管理
Nacos 的图形化管理界面
配置空间
命名空间
Namespace + Group + Data ID 三者之间的关系?为什么这样设计?
Case
三种方案加载配合
DataID 方案
指定 spring.profile.active 和配置文件的 DataID 来使不同环境读取不同的配置
默认空间+ 默认分组 + 新建 dev 和 test 两个 dataID
新建 dev DataID
新建 test DataID
通过 spring.profile.cative 属性就能惊醒多环境下配置文件的读取
测试
http://127.0.0.1:9001/config/info
配置环境是什么就加载什么
test
Group 方案
通过 Group 实现环境区分
新建 Group
在 Nacos 图形界面控制台上面新建配置文件 DataID
bootstrap + application
<b><font color="#c41230">在 config 下增加一条 group 的配置即可。<br>可配置为 DEV_GROUP 或 TEST_GROUP</font></b>
Namespace 方案
新建 dev/test 的Namespace
回到服务管理-服务列表查看
按照域名配置填写
YML
bootstrap.yml
集群和持久化配置
官网说明
https://nacos.io/zh-cn/docs/cluster-mode-quick-start.html
官网架构图
上图翻译真实情况
说明
持久化
按照上述,我们需要mysql 数据库
官网说明
Nacos 持久化配置解释
Nacos 默认自带的是嵌入式数据库 derby 。
https://github.com/alibaba/nacos/blob/develop/config/pom.xml
derby 到 mysql 切换配置步骤
nacos-server-version\nacos\conf 目录下找到 sql 脚本
nacos-mysql.sql
执行脚本
nacos-server-version\nacos\conf 目录下找到 application.properties
启动 Nacos , 可以看到一个全新的空界面, 以前是记录进 derby
Linux 版 Nacos + MySQL 生产环境配置
预计需要, 1 个 Nginx + 3个nacos 注册中心 + 1个 mysql
Nacos 下载 liunx 版本
https://github.com/alibaba/nacos/releases/tag/1.2.0
nacos-server-1.2.0.tar.gz<br>
解压后安装
集群配置步骤(重点)
1. Linunx 服务器上 mysql 数据库配置
SQL 脚本在哪里
SQL 语句源文件
nacos-mysql.sql
自己 Linunx 机器上的 MySQL 数据库
执行结果
2. apolication.properties 配置
位置
config/application.properties
内容
3. Linux 服务器上 nacos 集群配置 cluster.conf
梳理出3台 nacos 集群积极的不同服务器端口号
复制出cluster.conf
内容
<b><font color="#c41230">这个IP不能写 127.0.0.1. 必须是 <br>Linux 命令 hostname -i 能够识别的 IP</font></b>
4. 编辑Nacos 的启动脚本straup.sh, 使它能够接受不同的启动端口
/nacos/bin 目录下有一个 startup.sh
在什么地方,修改什么,怎么修改
思考
修改内容
执行方式
./startup.sh -p 3333
5. Nginx 的配置,由它作为负载均衡器
修改 Nginx 的配置文件
nginx.config
按照指定启动
查看启动 nacos 服务数量
ps -ef | grep nacos-server | grep -v grep| wc -l
启动 niginx
./nginx -c ../conf/nginx.conf
6. 截止到此处, 1 个 Nginx + 3个nacos 注册中心 + 1个 mysql
测试通过 nginx 访问 nacos
http://192.168.1.3:1111/nacos
记得开放端口,或者云服务器的安全组,如果使用阿里云服务器学生机或者 试用机,可能出现启动不了那么多台nacos 服务,此处我启动三台nacos, 但是实际只启动了2台,
新建一个配置测试
如图:可见config配置 已经持久化到mysql中
测试
微服务 启动注册进入 nacos 集群
查看服务注册情况
实现服务之间的相互调用
高可用小总结
<b>SpringCloud Alibaba<br>Sentinel 实现熔断与限流</b>
Sentinel
官网
https://github.com/alibaba/Sentinel
中文
https://github.com/alibaba/Sentinel/wiki/%E4%BB%8B%E7%BB%8D
是什么
一句话解释, 之前我们讲过的Hystrix
去哪下
https://github.com/alibaba/Sentinel/releases
能干什么
主要特征
怎么玩
安装 Sentinel
sentinel 组件由2部分组成
后台
前台8080
安装步骤
下载
https://github.com/alibaba/Sentinel/releases
下载到本地: sentinel-dashboard-1.7.1.jar
运行命令
前提
jdk 1.8
8080 端口不能被占用
命令
java -jar 下载到本地: sentinel-dashboard-1.7.1.jar
访问 sentinel 管理页面
http://127.0.0.1:8080
登录账号密码均为: sentinel
界面
初始化演示
启动 Nacos 8848
项目工程
POM
YML
主启动类
业务类
启动 Sentinel 8080
java -jar sentinel-dashboard-1.7.1.jar
启动微服务 9301
启动微服务 9301 微服务后查询看 sentienl 控制台
空空的什么东西都没有
sentienl 采用的是懒加载说明
服务访问
curl "http://127.0.0.1:9001/testA"
curl "http://127.0.0.1:9001/testB"
效果
结论
流控规则
基本介绍
流控规则
进一步说明
流控模式
直接(默认)
直接 -> 快速失败
系统默认
配置说明
测试
快速调用 : http://127.0.0.1:9001/testA
结果
<b><font color="#c41230">Blocked by Sentinel (flow limiting)</font></b>
思考???
直接调用默认报错信息,技术方面 OK<br>但是,是否应该有我们自己的后续处理?
累屎有个 fallback 的兜底方法
关联
关联是什么
当关联的资源达到阈值,时就限流自己
当A关联的资源B到达阈值后,就吸纳流自己
B热事情了,A挂了
配置 A
配置界面
postman 模式并发密集访问 testB
效果
运行后发现testA 挂了
curl "http://127.0.0.1:9001/testA"
<b><font color="#c41230">Blocked by Sentinel (flow limiting)</font></b>
链路
多个请求调用同一个微服务
自己试试
流控效果
直接 -> 快速失败(默认流控处理)
直接失败,抛出异常
<b><font color="#c41230">Blocked by Sentinel (flow limiting)</font></b>
源码
com.alibaba.csp.sentinel.slots.block.flow.controller.DefaultController
预热
说明
公式:阈值除以 coldFactor (默认值3), 经过预热时常后才会到达阈值
官网
https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6
https://github.com/alibaba/Sentinel/wiki/%E9%99%90%E6%B5%81---%E5%86%B7%E5%90%AF%E5%8A%A8
源码
com.alibaba.csp.sentinel.slots.block.flow.controller.WarmUpController
代码
WarmUp 配置
配置
多次点击 http://localhost:9001/testB
刚开始不行,后面慢慢OK
应用场景
排队等待
设置
设置效果
官网
https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6-%E5%8C%80%E9%80%9F%E6%8E%92%E9%98%9F%E6%A8%A1%E5%BC%8F
源码
com.alibaba.csp.sentinel.slots.block.flow.controller.RateLimiterController
测试
降级规则
官网
https://github.com/alibaba/Sentinel/wiki/%E7%86%94%E6%96%AD%E9%99%8D%E7%BA%A7
基本介绍
配置图示
进一步说明
<b>Sentinel 的断路器是<font color="#c41230">没有半开</font>状态的</b>
半开的状态系统自动去检测是否请求有异常,<br>没有异常就关闭断路器恢复使用,<br>有异常则继续打开断路器不可用。具体可以参考 Hystrix
复习 Hystrix
降级策略实战
RT
是什么
代码
jemter 压测
结论
异常比例
是什么
代码
配置
jemter 测试
总结
异常数
是什么
<b><font color="#c41230">异常数是按照分钟统计的</font></b>
测试
代码
配置
jemeter
热点key 限流
基本介绍
是什么
官网
https://github.com/alibaba/Sentinel/wiki/%E7%83%AD%E7%82%B9%E5%8F%82%E6%95%B0%E9%99%90%E6%B5%81
<b><font color="#0076b3">承上启下</font></b>
代码
com.alibab.csp.sentinel.slots.block.BlockException
配置
代码
sentinel 配置
配置
测试
curl http://127.0.0.1:9001/testHotKey\?p1\=1<br>
结论
➜ Downloads curl http://127.0.0.1:9001/testHotKey\?p1\=1<br>----- testHotKey% ➜ Downloads curl http://127.0.0.1:9001/testHotKey\?p1\=1<br>----- testHotKey% ➜ Downloads curl http://127.0.0.1:9001/testHotKey\?p1\=1<br>----- testHotKey% ➜ Downloads curl http://127.0.0.1:9001/testHotKey\?p1\=1<br>----- deal_testHotKey% ➜ Downloads curl http://127.0.0.1:9001/testHotKey\?p1\=1<br>----- testHotKey%
配置
1
@SentinelResource(value = "testHotKey"
异常达到了前台用户解决看到,不友好
2
@SentinelResource(value = "testHotKey", blockHandler = "deal_testHotKey")
方法 testHotKey 里面第一个参数只要 QPS 超过每秒1次, 马上降级处理
我们自定义的
测试
error
http://127.0.0.1:9001/testHotKey?p1=1
error
http://127.0.0.1:9001/testHotKey?p1=1&p2=2
right
http://127.0.0.1:9001/testHotKey?p2=2
参数例外项
上述案例演示了第一个参数 p1, 当QPS 超过1秒1次后立即马上被限流
特殊情况
普通
超过1秒钟一个后,达到阈值1后马上被限流了。
我们期望P1参数当它是某个特殊值时, 他的限流值和平时不一样
特例
加入当p1 的值等于5时,它的阈值可以达到 200
配置
子主题
测试
http://127.0.0.1:9001/testHotKey\?p1\=5
前提条件
其他
系统规则
是什么
官网
https://github.com/alibaba/Sentinel/wiki/%E7%B3%BB%E7%BB%9F%E8%87%AA%E9%80%82%E5%BA%94%E9%99%90%E6%B5%81
各个参数的配置
测试
curl http://127.0.0.1:9001/testA
是系统级别的限制,一揽子看姐
@SentinelResource
按资源名称 + 后续处理
启动 Nacos 成功
启动 Sentinel 成功
项目配置
POM
YML
业务 RateLimitController
主启动类
配置流控规则
配置步骤
配置
图形配置和代码关系
表示1秒钟内查询次数大于1 ,就跑到我们自定义的限流
测试
1秒钟点击1下,OK
超过上述,疯狂点击,返回了自定义的限流信息,限流发生
额外问题
关闭服务试试
Sentinel 控制台,流控规则消失了???
按 URL 地址限流 + 后续处理
通过访问的URL 来限流, 会返回Sentinel 自带默认的限流处理信息
业务类 RateLimitController
访问一次
http://127.0.0.1:9001/byResource
Sentinel 控制台配置
配置
测试
http://127.0.0.1:9001/byResource
结果
上面兜底方法面料的问题
客户自定义限流处理逻辑
创建 CustomerBlockHandler 类用于自定义限流处理逻辑
自定义限流处理类
CustomerBlockHandler <br>
RateLimitController
启动微服务后先调用一次
http://127.0.0.1:9001/rateLimit/customerBlockHandler
Seninel 控制台配置
测试我们自定义的出来了
进一步的说明
更多注解属性说明
多说一句
Snetinel 主要又三个核心 API
SphU 自定义资源
Tracer 定义统计
ContextUtil 定义了上下文
服务熔断功能
sentinel 整合 ribbon + openfeign + fallback
ribbon 系列
启动 Nacos 和 sentinel
提供者 9001/9002
POM
YML
主启动类
业务类
测试地址
消费者 9101
POM
YML
主启动类
业务类
AppConfig
<font color="#c41230"><b>CircleBreakerController</b></font>
修改后重启微服务
目的
fallback 管运行异常
blockHander 管配置违规
测试地址
http://127.0.0.1:9101/consumer/fallback/1
没有任何配置
给客户error页面不友好
只有 fallback
只配置 blockHandler
fallback 和 blockHandler 都配置
编码
结果
忽略属性 。。。。
<font color="#0076b3"><b>exceptionsToIgnore</b></font>
编码
结果
程序异常打印到了前台了,对用户不友好
Feign 系列
修改消费侧
消费侧提供者 9001/9002
Feign 组件一般是消费侧
POM
YML
业务类
<span style="font-size: inherit;">带 </span><font style="font-size: inherit;" color="#c41230">@FeignClient 注解的业务接口</font><br>
fallback = PaymentFallbackService.class
Controller
主启动类
访问
http://127.0.0.1:9101/paymentSQL/1
测试 9101 调用 9001 , 此时 <font color="#c41230">故意关闭 9001 微服务提供者</font>,看看消费侧自动降级
??? 遇到问题:com.alibaba.cloud.sentinel.feign.SentinelContractHolder.parseAndValidateMetadata
处理参考
处理方案
熔断框架比较
对比
规则持久化
是什么
一旦我们重启应用,sentinel 规则将消失,生产环境需要将配置规则进行持久化
怎么玩
将想留配置规则持久化经Nacos 保存, 只需要刷新 服务提供者的一个rest地址, sentinel 控制台的<br>流控规则就能看到, 只要Nacos 里面的配置不删除,针对服务提供者的 sentinel 上的控流规则
步骤
POM
YML
添加Nacos 数据源配置
添加Nacos业务规则配置
内容解析
内容
启动 9101 后<font color="#c41230">刷新 sentinel</font> 发现业务规则有了
快速访问测试接口
停止9101 再看 sentinel
重启 9101 再看 sentinel
默认无法加载流控规则
多次调用
http://127.0.0.1:9101/rateLimit/byUrl
重新配置出现,持久化验证通过
SpringCloud Alibaba<br> Seata 分布式事务 <br>
分布式事务问题
分布式前
单机没有问题
从 1:1 => 1:N => N:N
分布式之后
一句话
一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务
Steate 简介
是什么
Seata 是一款开源的分布式事务解决方案,致力于在微服务的分布式事务处理
https://seata.io/zh-cn
能干什么
一个典型的分布式事务过程
分布式事务处理过程的一个ID + 三个组件模型
Transaction ID XID
全局唯一的事务ID
3组件概念
Transaction Coordinator(TC)
事务协调者, 维护全局和分支事务的状态,驱动全局事务提交或回滚。<br>
Transaction Manager (TM)
事务管理器, 定义全局事务的范围:开始全局事务、提交或回滚全局事务。<br>
Resource Manager (RM)
资源管理器, 管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。<br>
处理过程
去哪里下载
https://seata.io/zh-cn/blog/download.html
怎么玩?
<b><font color="#0076b3">本地 @Transactional</font></b>
<b><font color="#c41230">全局 @GlobalTransactional</font></b>
SEATA 的分布式交易解决方案
Seata-Server 安装
1. 官网地址
https://seata.io/zh-cn
2. 下载版本
3. seata-server-1.0.0.zip 解压到指定目录并<br>修改conf 目录下的 file.conf 配置文件<br>
先备份
主要修改:自定义事务组名称 + 事务日志存储模式为db + 数据库链接信息
file.conf
service 模块
store 模块
完整文件
<font color="#f15a23">创建GC日志目录</font>
mkdir -p logs
4. mysql5.7 新建数据库 seata
5. 在seate 库中创建表
<font color="#c41230" style="">SQL 1.1.0 版本下载包中没有在此备份</font>
6. 修改 seata-server-1.0.0\seata\conf 目录下的 registry.conf 配置文件<br>
7. 先启动 Nacos 端口号 8848
8. 再启动 seata-server
订单/库存/账户业务数据库准备
以一下的演示都需要 先启动 <font color="#c41230">Nacos 后启动 Seata</font><font color="#381e11"> 确保两个都 OK</font>
Nacos
Seata
分布式事务说明
创建业务数据库
seata_order; 存储订单的数据库
seata_storage; 存储库存的数据库
seata_account; 存储账户信息的数据库
建库SQL
在上述的三个库创建对应的业务表
seata_order 库下创建 t_order 表
seata_storage 库下创建 t_storage 表
seata_account 库下创建 t_account 表
三个库的回滚日志表
订单-库存-账户3个库下都需要创建各自的回滚日志表
<span style="font-size: inherit;"><font color="#c41230">\seata\conf 目录下的 db_undo_log.sql (1.0.0 还是没有)</font></span><br>
建表SQL
最终结果
订单/库存/账户业务微服务准备
业务需求
下订单 -> 减库存 -> 库余额 -> 改 (订单)状态
新建订单 Order
1. seata-order-service
2. POM
3. YML
Nacos配置
4. file.conf
5. registry.conf
6. domain
7. Dao 接口以及实现
OrderDao
resources 文件夹下面 创建文件夹 mapper
8. Service 接口以及实现
<b>OrderService</b>
<b>AccountService</b>
<b>StorageService</b>
9. Controller
10. Config 配置
11. 主启动类
新建库存 Storage
参考订单
新建账户 Account
参考订单
Test
数据库初始情况
下单 -> 减库存 -> 扣余额 -> 改(订单)状态<br>
正常下单
http://127.0.0.1:2001/order/create?userId=1&productId=1&count=1&money=10
数据库情况
<b style=""><font color="#c41230">超时异常,没加 @GlobalTransactional</font></b>
<b>AccountServiceImpl 添加超时</b>
数据库情况
故障情况
当库存和账户金额扣减后,订单状态并没有设置为已经完成,没有从零改为1
而且由于feign 的重试机制,账户余额还有可能被多次扣减
<font color="#0076b3"><b>超时异常,添加 @GlobalTransactional</b></font>
<b>AccountServiceImpl 添加超时</b>
OrderServiceImpl @GlobalTransactional
下单后没有任何变化
补充部分
seata
2019 年 1 月份蚂蚁金服和阿里巴巴共同开源的一个分布式事务解决方案
Simple Extensible Autonomous Transaction Architecture ,简单刻拓展自治事务框架
2020开始,可以使用 1.0 以后版本
在看 TC/TM/RM 三大组件
TC ==> Seata 服务
TM => @GlobalTransactional 事务的发起方
RM 事务的参与方(数据库)
执行流程
TM 开启分布式事务 (TM 向 TC注册全局事务记录)
按业务场景,编排数据库,服务等事务内资源(RM 让TC 回报资源)
TM 结束分布式事务,事务一阶段结束(TM 同志 TC 提交/回滚分布式事务)
TC 汇总事务信息,决定分布式事务是提交还是回滚
TC 通知所有 RM 提交/回滚资源, 事务二阶段结束
AT 模式如何做到对业务的无侵入
https://seata.io/zh-cn/docs/overview/what-is-seata.html
一阶段加锁
二阶段提交
二阶段回滚
DEBUG
补充
Apache Doubbo<br>服务注册中心
概述
官网
http://dubbo.apache.org/zh-cn/index.html
是什么 ?
Apache Dubbo是一个高性能、基于Java的开源RPC框架<br>
分布式系统理论
是什么?
《分布式系统管理与规范》定义:<br>“分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统”,<br>分布式系统(distributed system)是建立在网络上的软件系统
总结
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已经无法应对,<br>分布式服务架构以及流动计算架构势在必行,需<font color="#c41230">一个治理系统</font>确保架构有一条不絮的演进。<br>
发展演变
演变过程
RPC
RPC 基本原理
能做什么
1. 面向接口代理的高性能 RPC 调用
提供高性能的基于代理的远程调用能力,服务以接口为粒度,为开发者屏蔽远程调用底层细节。<br>
2. 智能负载均衡
内置多种负载均衡策略,智能感知下游节点健康状况,显著减少调用延迟,提高系统吞吐量。<br>
3. 服务注册与发现
支持多种注册中心服务,服务实例上下线实时感知。<br>
4. 高度可拓展能力
遵循微内核+插件的设计原则,所有核心能力如Protocol、Transport、Serialization被设计为扩展点,平等对待内置实现和第三方实现。<br>
5. 运行期流量调度
内置条件、脚本等路由策略,通过配置不同的路由规则,轻松实现灰度发布,同机房优先等功能。<br>
6. 可视化服务治理和韵味
提供丰富服务治理、运维工具:随时查询服务元数据、服务健康状态及调用统计,实时下发路由策略、调整配置参数。<br>
技术架构
设计架构
环境搭建
1. zookeeper 注册中心
是什么?
Zookeeper 是 Apacahe Hadoop 的子项目,是一个树型的目录服务,支持变更推送,<br>适合作为 Dubbo 服务的注册中心,工业强度较高,可用于生产环境,并推荐使用。<br>
下载地址
http://zookeeper.apache.org/
安装
解压
tar -zxvf apache-zookeeper-3.6.0-bin.tar.gz
创建配置文件
cd conf && cp zoo_sample.cfg zoo.cfg
运行
./bin/zkServer.sh start
2. dubbo-admin
下载地址
https://github.com/apache/dubbo-admin
打包
mvn clean install
运行
java -Dserver.port=8081 -jar dubbo-admin-server-0.2.0.jar<br>
访问地址
http://127.0.0.1:8081
服务注册与发现
1. 服务提供者(dubbo-provider)
POM
YML
启动类
服务提供类
2. 服务调用者(dubbo-consumer)
POM
YML
启动类/服务调用类
4. 测试
1. 服务发布
准备工作
1. 启动 Zookeeper
2. 启动 dubbo-admin
启动服务发布端(dubbo-provider)
2. 服务消费
启动服务消费者(dubbo-consumer)
3. 服务消费方调用服务提供者的服务
查看服务生产者/消费者
小总结
1. 服务最佳化实践
http://dubbo.apache.org/zh-cn/docs/user/best-practice.html
Dubbo 配置
1. dubbo配置优先级
1. System Properties
-Ddubbo.registry.address=zookeeper://127.0.0.1:2181
2. Externalized Configuration
dubbo.registry.address=zookeeper://127.0.0.1:2181
3. Spring/API
RegistryConfig.setAddress("zookeeper://127.0.0.1:2181")
4. Local File
dubbo.registry.address=zookeeper://127.0.0.1:2181
2. 启动时检查
关闭某个服务的启动时检查 (没有提供者时报错):<br>
dubbo.reference.com.foo.BarService.check=false<br>dubbo.reference.check=false<br>
关闭所有服务的启动时检查 (没有提供者时报错):<br>
dubbo.consumer.check=false<br>
关闭注册中心启动时检查 (注册订阅失败时报错):<br>
dubbo.registry.check=false<br>
3. 超时配置
timeout = 1000ms
4. 重试次数
retries = 3
幂等操作
查询/修改/删除,不管查询多少次都是幂等的。
非幂等操作
数据库新增,比如超时了,就不能是幂等的。
5. 多版本(灰度发布)
服务提供者
声明服务 1.0.0
声明服务 2.0.0
服务消费者
6. 本地存根
本地存根实现
Dubbo 整合 Spring-Boot 的三种方式
1. 导入 dubbo-spring-boot-starter
开启 Dubbo 注解功能
@EnableDubbo
dubbo.scan.base-packages=cn.edu.cqvie
声明服务
@org.apache.dubbo.config.annotation.Service(version = "1.0.0")<br>public class UserServiceImpl implements UserService {<br> // other code<br>}<br>
调用服务
@Reference(version = "1.0.0")<br> private UserService userService;
YML 文件中配置
2. 保留 dubbo xml 配置文件
服务提供者
provider.xml 示例
服务调用者
consumer.xml 示例<br>
3. 使用注解的方式
@Service 申明配置
增加共享配置
配置文件
指定Spring扫描路径<br>
4. 基于 API 的方式
服务提供者
服务消费者
Dubbo 的高可用场景
1 zookeeper 宕机与dubbo 直连
现象: zookeeper 注册中心宕机,还可以消费 dubbo 暴露的服务
原因:
健壮性
监控中心宕机不影响使用,只是丢失部分采样数据
数据库宕机后,注册中心仍然能通过缓冲提供服务列表查询,但不能注册新服务
注册中心对等集群,任意一台宕机后,将自动切换到另一台
注册中心全部宕机后,服务提供者和服务消费者仍能通过本地缓存通讯
服务提供者无状态,任意一台宕掉后,不影响使用
服务提供者全部宕掉, 服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
高可用,通过设计,减少系统不能提供服务的时间。
直联方法
@Reference(version = "1.0.0", url ="dubbo://192.168.1.4:20881")
2. 负载均衡策略
随机:Random LoadBalance
轮询:RoundRobin LoadBalance
最少活跃调用数:LeastActive LoadBalance
一致性 Hash: ConsistentHash LoadBalance<br>
3. 服务降级
什么是服务降级?
当服务器压力剧增的情况下,根据实际业务情况以及流量,对一些服务和页面有策略的不处理<br>或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。<br>
服务降级配置
可以通过服务降级功能 [1] 临时屏蔽某个出错的非关键服务,并定义降级后的返回策略。<br><br>向注册中心写入动态配置覆盖规则:<br><br><font color="#c41230">RegistryFactory registryFactory = ExtensionLoader.getExtensionLoader(RegistryFactory.class).getAdaptiveExtension();<br>Registry registry = registryFactory.getRegistry(URL.valueOf("zookeeper://10.20.153.10:2181"));<br>registry.register(URL.valueOf("override://0.0.0.0/com.foo.BarService?category=configurators&dynamic=false&application=foo&mock=force:return+null"));</font><br>其中:<br><br>mock=force:return+null 表示消费方对该服务的方法调用都直接返回 null 值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。<br>还可以改为 mock=fail:return+null 表示消费方对该服务的方法调用在失败后,再返回 null 值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响。
4. 服务容错 & Hystrix
集群容错模式
Failover Cluster<br>
失败自动切换,当出现失败,重试其它服务器 [1]。通常用于读操作,<br>但重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)。<br>
Failfast Cluster<br>
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。<br>
Failsafe Cluster<br>
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。<br>
Failback Cluster<br>
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。<br>
Forking Cluster<br>
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。<br>可通过 forks="2" 来设置最大并行数。<br>
Broadcast Cluster<br>
广播调用所有提供者,逐个调用,任意一台报错则报错 [2]。通常用于通知所有提供者更新缓存或日志等本地资源信息。<br>
整合 Hystrix
5. Dubbo 原理
RPC & Netty 原理
RPC 原理
RPC 图解
RPC 通讯过程
Netty 原理
是什么?
Netty 是一个一步事件驱动的网络应用程序框架, <br>用于快速开发可维护的高性能协议服务其和客户端,<br>它极大的简化了 TCP 和 UDP 套戒指服务其等网络编程
BIO (Blocking IO)
NIO (Non-Blocking IO)
框架设计
标签解析
服务暴露流程
服务引用流程
服务调用流程
6. 总结
学海无涯,保持持续的学习状态
springData
spring Framework
spring
bean
bean
bean的作用域
singleton
prototype
request
session
globalSession
bean的实例化流程
实例化bean对象
设置对象属性
检查Aware相关接口并设置相关依赖
BeanPostProcessor前置处理
检查是否是InitializingBean以决定是否调用afterPropertiesSet方法
检查是否配置有自定义的init-method
BeanPostProcessor后置处理
注册必要的Destruction相关回调接口
使用
是否实现DisposableBean接口
是否配置有自定义的destroy方法
bean的生命周期
创建(调用构造函数)
set方法注入属性
BeanNameAware
BeanFactoryAware
ApplicationContextAware
BeanPostProcessor的before方法
InitalizingBean
自定义init方法
BeanPostProcessor的after方法
使用
容器的销毁
DisposableBean的destroy
自定义的销毁方法
AOP
实现原理
jdk动态代理
主要通过Proxy.newProxyInstance()和InvocationHandler这两个类和方法实现
实现过程
创建代理类proxy实现Invocation接口,重写invoke()方法
调用被代理类方法时默认调用此方法
将被代理类作为构造函数的参数传入代理类proxy
调用Proxy.newProxyInsatnce(classloader,interfaces,handler)方法生成代理类
生成的代理类
$Proxy0 extends Proxy implements Person
类型为$Proxy0
因为Proxy已经继承了Proxy,所以java动态代理只能对接口进行代理
代理对象会实现用户提供的这组接口,因此可以将这个代理对象强制类型转化为这组接口中的任意一个<br>
通过反射生成对象
总结: <b><font color="#c41230">代理类调用自己方法时,通过自身持有的中介类对象来调用中介类对象的invoke方法,从而达到代理执行被代理对象的方法</font></b>。
cglib
生成对象类型为Enhancer
实现原理类似于 jdk 动态代理,只是他在运行期间生成的代理对象是针<br>对目标类扩展的子类
Spring在运行期间通过CGlib继承要被动态代理的类,重写父类的方法,实现AOP面向切面编程。
静态代理
缺点
如果要代理一个接口的多个实现的话需要定义不同的代理类
代理类 和 被代理类 必须实现同样的接口,万一接口有变动,代理、被代理类都得修改,难以维护
在编译的时候就直接生成代理类
JDK动态代理和cglib的对比
CGLib所创建的动态代理对象在实际运行时候的性能要比JDK动态代理高
1.6和1.7的时候,CGLib更快
1.8的时候,jdk更快
CGLib在创建对象的时候所花费的时间却比JDK动态代理多
singleton的代理对象或者具有实例池的代理,因为<font color="#c41230"><b>无需频繁的创建代理对象</b></font>,所以比较适合采用CGLib动态代理,反之,则适合用JDK动态代理
JDK动态代理是面向接口的,CGLib动态代理是通过字节码底层继承代理类来实现(如果被代理类被final关键字所修饰,那么会失败)
JDK生成的代理类类型是Proxy(因为继承的是Proxy),CGLIB生成的代理类类型是Enhancer类型
如果要被代理的对象是个实现类,那么Spring会使用JDK动态代理来完成操作(Spirng默认采用JDK动态代理实现机制);<br>如果要被代理的对象不是实现类,那么Spring会强制使用CGLib来实现动态代理。 <br>
配置方式
XML方式
注解方式
基于Java类配置
通过 @Configuration 和 @Bean 这两个注解实现的
@Configuration 作用于类上,相当于一个xml配置文件;
@Bean 作用于方法上,相当于xml配置中的<bean>;
基本概念
核心业务功能和切面功能分别独立进行开发 ,然后把切面功能和核心业务功能 "编织" 在一起,这就叫AOP
让关注点代码与业务代码分离
面向切面编程就是指: 对很多功能都有的重复的代码抽取,再在运行的时候往业务方法上动态植入“切面类代码”。
应用场景:日志,事务管理,权限控制
IOC
依赖注入
装配方式(依赖注入的具体行为)
基于注解的自动装配
实现方式
注解
@Autowired
1.优先按照byType方式进行查找
2.如果查询的结果不止一个,而且没有设置名称的话,那么会报错。
3.否则@Autowired会按照byName方式来查找。
4.如果查询的结果为空,那么会抛出异常。可使用required=false解决
@Resource
1.默认按照byName方式进行装配,名称可以通过name属性进行指定
2. 如果没有指定name属性,当注解写在字段上时,默认取字段名进行按照名称查找,如果注解写在setter方法上默认取属性名进行装配。
3. 当找不到与名称匹配的bean时才通过byType进行装配。但是需要注意的是,如果name属性一旦指定,就只会按照名称进行装配。
4.只指定@Resource注解的type属性,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常。
自动扫描(component-scan)
标签将会开启Spring Beans的自动扫描,并可设置base-package属性,表示Spring将会扫描该目录以及子目录下所有被@Component标注修饰的类,对它们进行装配。 <br>
基于XML配置的显式装配
基于Java配置的显式装配
能够在编译时就发现错误
依赖注入的方式
构造器方式注入
<bean id="text" class="com.maven.Text" /><br><bean id="hello" class="com.maven.Hello"><b><font color="#c41230"><constructor-arg ref="text" /></font></b></bean>
构造器依赖注入通过容器触发一个类的构造器来实现的,该类有一系列参数,每个参数代表一个对其他类的依赖。
使用构造器注入的好处<br>
1.保证依赖不可变(final关键字)
2.保证依赖不为空
实例化Controller的时候,由于自己实现了有参数的构造函数,所以不会调用默认构造函数,那么就需要Spring容器传入所需要的参数,这样保证了依赖不为空
3.避免循环依赖
在构造器注入传入参数时,比如在A中注入B,在B中注入A。先初始化A,那么需要传入B,这个时候发现需要B没有初始化,那么就要初始化B,这个时候就出现了问题,会排除循环依赖错误,而使用filed注入方式则只能在运行时才会遇到这个问题<br>
setter方法注入
例如:<bean id="hello" class="com.maven.Hello"><b><font color="#c41230"><property name="text" ref="text" /></font></b></bean>
之所以叫setter方法注入,因为这是通过找到类的对应的setter方法,再进行相应的注入
Setter方法注入是容器通过调用无参构造器或无参static工厂方法实例化bean之后,调用该bean的setter方法,即实现了基于setter的依赖注入。
最好的解决方案是用构造器参数实现强制依赖,setter方法实现可选依赖。
循环依赖
构造器方式无法解决,只能抛出异常
因为加入singletonFactories三级缓存的前提是执行了构造器(因为要先构建出对象),所以构造器的循环依赖没法解决。
多例方式无法解决,只能抛出异常
因为Spring容器不缓存"prototype"作用域的bean,因此无法提前暴露一个创建中的bean。 <br>
单例模式可以解决
通过三级缓存解决
在createBeanInstance()之后会调用addSingleton()方法将bean注册到singletonFactories中
通过提前暴露一个单例工厂方法,从而使其他bean能够引用到该bean/提前暴露一个正在创建中的bean
举例
1.“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象
2.A首先完成了初始化的第一步,<b><font color="#c41230">并且将自己提前曝光到singletonFactories中(这步是关键)</font></b>
3.A发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程
4.B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象
5.B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中
6.返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中
7.由于B拿到了A的对象引用,所以B类中的A对象完成了初始化。
不用创建对象,而只需要描述它如何被创建,不在代码里直接组装组件和服务,但是要在配置文件里描述哪些组件需要哪些服务,之后一个容器(IOC容器)负责把他们组装起来。
容器的初始化过程
1.)Resource定位;指对BeanDefinition的资源定位过程。通俗地讲,就是找到定义Javabean信息的XML文件,并将其封装成Resource对象。
2.)BeanDefinition的载入;把用户定义好的Javabean表示为IoC容器内部的数据结构,这个容器内部的数据结构就是BeanDefinition。<br>
3.)向IoC容器注册这些BeanDefinition。
bean知识
bean的生命周期
1.实例化Bean
2.设置Bean的属性
3.检查Aware相关接口并设置相关依赖
BeanNameAware
spring将bean的id传给setBeanName()方法
BeanFactoryAware
会调用它实现的setBeanFactory(setBeanFactory(BeanFactory)传递的是Spring工厂自身(可以用这个方式来获取其它Bean,只需在Spring配置文件中配置一个普通的Bean就可以)
ApplicationContextAware
会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文
4.检查BeanPostProcessor接口并进行前置处理
调用postProcessBeforeInitialization(Object obj, String s)方法
5.检查Bean在Spring配置文件中配置的init-method属性并自动调用其配置的初始化方法。
由于这个是在Bean初始化结束时调用那个的方法,也可以被应用于内存或缓存技术;
6.检查BeanPostProcessor接口并进行后置处理
调用postProcessAfterInitialization(Object obj, String s)方法
7.当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用那个其实现的destroy()方法;
8. 最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
bean的作用域
singleton
Spring IoC容器中只会存在一个共享的Bean实例,无论有多少个Bean引用它,始终指向同一对象。
singleton是Bean的默认作用域
默认情况下是容器初始化的时候创建,但也可设定运行时再初始化bean
DefaultSingletonBeanRegistry类里的singletonObjects哈希表保存了单例对象。
Spring容器可以管理singleton作用域下bean的生命周期,在此作用域下,Spring能够精确地知道bean何时被创建,何时初始化完成,以及何时被销毁
prototype
每次通过Spring容器获取prototype定义的bean时,容器都将创建一个新的Bean实例,每个Bean实例都有自己的属性和状态
当容器创建了bean的实例后,bean的实例就交给了客户端的代码管理,Spring容器将不再跟踪其生命周期,并且不会管理那些被配置成prototype作用域的bean的生命周期。
对有状态的bean使用prototype作用域,而对无状态的bean使用singleton作用域。
request
在一次Http请求中,容器会返回该Bean的同一实例。而对不同的Http请求则会产生新的Bean,而且该bean仅在当前Http Request内有效。
session
在一次Http Session中,容器会返回该Bean的同一实例。而对不同的Session请求则会创建新的实例,该bean实例仅在当前Session内有效。
global Session
在一个全局的Http Session中,容器会返回该Bean的同一个实例,仅在使用portlet context时有效。
bean的创建过程
1.进入getBean()方法
2.判断当前bean的作用域是否是单例,如果是,则去对应缓存中查找,没有查找到的话则新建实例并保存。如果不是单例,则直接新建实例(createBeanInstance)
3.新建实例后再将注入属性(populateBean),并处理回调
创建bean
找到@Autowired的对象
创建注入对象,并赋值
大致流程
1.首先根据配置文件找到对应的包,读取包中的类,,找到所有含有@bean,@service等注解的类,利用反射解析它们,包括<b><font color="#c41230">解析构造器,方法,属性</font></b>等等,然后封装成各种信息类放到container(其实是一个map)里(<b><font color="#c41230">ioc容器初始化</font></b>)
2.获取类时,首先从container中查找是否有这个类,如果没有,则报错,如果有,则通过构造器信息将这个类new出来
3.<b><font color="#c41230">如果这个类含有其他需要注入的属性,则进行依赖注入,如果有则还是从container找对应的解析类,new出对象,并通过之前解析出来的信息类找到setter方法(setter方法注入),然后用该方法注入对象(这就是依赖注入)。如果其中有一个类container里没找到,则抛出异常</font></b>
4.如果有嵌套bean的情况,则通过递归解析
5.如果bean的scope是singleton,则会重用这个bean不再重新创建,将这个bean放到一个map里,每次用都先从这个map里面找。如果scope是session,则该bean会放到session里面。
总结:通过解析 xml 文件,获取到bean的属性(id,name,class,scope,属性等等)里面的内容,利用反射原理创建配置文件里类的实例对象,存入到 Spring 的 bean 容器中
事务管理
基本概念
如果需要某一组操作具有原子性,就用注解的方式开启事务,按照给定的事务规则来执行提交或者回滚操作
事务管理一般在Service层
事务控制
编程式事务控制
用户通过代码的形式手动控制事务
Conn.setAutoCommite(false); // 设置手动控制事务
粒度较细,比较灵活,但开发起来比较繁琐: 每次都要开启、提交、回滚
声明式事务控制
Spring提供对事务的控制管理
XML方式
注解方式
事务属性
事务传播行为
required_new
如果当前方法有事务了,当前方法事务会挂起,在为加入的方法开启一个新的事务,直到新的事务执行完、当前方法的事务才开始
required(默认方法)
如果当前方法已经有事务了,加入当前方法事务
其余五种方式(拓展学习)
事务传播行为用来描述由某一个事务传播行为修饰的方法被嵌套进另一个方法的时候事务如何传播。
数据库隔离级别
TransactionDefinition.ISOLATION_DEFAULT: 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.
TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
事务超时属性
指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。
事务只读属性
对事物资源是否执行只读操作
回滚规则
定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行期异常时才会回滚,而在遇到检查型异常时不会回滚,也可以用用户自己定义
Spring事务管理接口
PlatformTransactionManager
(平台)事务管理器
Spring并不直接管理事务,而是提供了多种事务管理器,通过PlatformTransactionManager这个接口,Spring为各个平台如JDBC、Hibernate等都提供了对应的事务管理器,但是具体的实现就是各个平台自己的事情了。
TransactionDefinition
事务定义属性(事务隔离级别、传播行为、超时、只读、回滚规则)
TransactionStatus
事务运行状态
事务管理一般在Service层
如果在dao层,回滚的时候只能回滚到当前方法,但一般我们的service层的方法都是由很多dao层的方法组成的
如果在dao层,commit的次数会过多
相关设计模式
1.单例模式
实现方式
Spring依赖注入Bean实例默认是单例的
2.工厂模式
实现方式
静态工厂
beanFactory
工厂模式
factoryBean
3.代理模式
实现方式
AOP中的JDK动态代理和CGLib
4.适配器模式
实现方式
SpringMVC中的适配器HandlerAdatper
实现原理
HandlerAdatper根据Handler规则执行不同的Handler
5.装饰器模式
实现方式
Spring中用到的包装器模式在类名上有两种表现:一种是类名中含有Wrapper,另一种是类名中含有Decorator。
7.观察者模式
实现方式
spring的事件驱动模型使用的是 观察者模式 ,Spring中Observer模式常用的地方是listener的实现
具体实现
事件机制的实现需要三个部分,事件源,事件,事件监听器
8.策略模式
实现方式
Spring框架的资源访问Resource接口 。该接口提供了更强的资源访问能力,Spring 框架本身大量使用了 Resource 接口来访问底层资源
9.模板方法模式
参考博客(写的很详细很棒)
https://blog.csdn.net/aa1215018028/article/details/81703900
SpringMVC
执行流程
1、 用户发送请求至前端控制器DispatcherServlet
2、 DispatcherServlet收到请求调用HandlerMapping处理器映射器。
3、 处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
4、 DispatcherServlet通过HandlerAdapter处理器适配器调用处理器
5、 执行处理器(Controller,也叫后端控制器)。
6、 Controller执行完成返回ModelAndView
7、 HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet
8、 DispatcherServlet将ModelAndView传给ViewReslover视图解析器
9、 ViewReslover解析后返回具体View
10、DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)。
11、DispatcherServlet响应用户
常用注解
@Compoent
@Controller
@Service
@Repository
在类定义之前添加@Component注解,它会被spring容器识别,并转为bean。
@RequestMapping
@RequestParam
@Autowired
@Resource
servlet生命周期
1.加载和实例化
2.初始化
3.请求处理
4.服务终止
ApplicationContext
FileSystemXmlApplicationContext
ClassPathXmlApplicationContext
WebXmlApplicationContext
spring-retry重试机制
nginx
分布式
ZK
zookeeper
主备模式
所有客户端写入数据都是写入到主进程(Leader),然后,由Leader复制到备份进程(Follower)中,从而保证数据一致性
zab协议
一种一致性协议
为分布式协调服务zookeeper专门设计的一种支持崩溃恢复和消息广播协议
消息广播(Leader正常)
对于客户端发送的写请求,全部由Leader接收,Leader将请求封装成一个事务Proposal,将其发送给所有Follower,然后根据所有Follower的反馈,如果超过半数成功响应,则执行commit操作(先提交自己,再发送commit给所有Follower)
细节
Leader在收到客户端请求之后,会将这个请求封装成一个事务,并给这个事务分配一个全局递增的唯一ID,称为事务ID,zab协议需要保证事务的顺序,因此将每个事务按照事务ID先排序再处理
再Leader和Follower之间还有一个消息队列,用来解耦他们之间的耦合,接触同步阻塞
zookeeper集群为保证任何所有进程能够有序的顺序执行,只能是Leader服务器接受写请求,即使是Follower服务器接受到客户端的请求,也会转发到Leader服务器进行处理
崩溃恢复(Leader崩溃)
两个原则
zab协议确保那些已经在Leader提交的事务最终会被所有服务器提交
新的 leader 与 follower 建立先进先出的队列, 先将自身有而 follower 没有的 proposal 发送给 follower,再将这些 proposal 的 COMMIT 命令发送给 follower,以保证所有的 follower 都保存了所有的 proposal、所有的 follower 都处理了所有的消息
zab协议确保丢弃那些只在Leader 提出/复制,但没有提交的事务
实现
通过选举算法(选举出来的Leader服务器拥有集群中事务ID最大的服务器),保证这个新选举出来的Leader一定具有所有已经提交的提案
数据同步
奔溃恢复之后,需要在正式工作之前(接受客户端请求),Leader服务器首先确认事务是否都已经被过半的Follower提交了,即是否完成了数据同步。
奔溃恢复之后,需要在正式工作之前(接受客户端请求),Leader服务器首先确认事务是否都已经被过半的Follower提交了,即是否完成了数据同步。
当完成Leader选举后,进行故障恢复的第二步就是数据同步: Leader服务器会为每一个Follower服务器准备一个队列,并将那些没有被各个Follower服务器同步的事务以Proposal的形式逐条发给各个Follower服务器,并在每一个Proposal后都紧跟一个commit消息,表示该事务已经被提交,当follower服务器将所有尚未同步的事务proposal都从leader服务器同步过来并成功应用到本地后,leader服务器就会将该follower加入到真正可用的follower列表中。(新选举周期,epoch已经更新了)
节点类型
持久节点
节点创建后,一直存在,直到主动删除了该节点
临时节点
生命周期和客户端会话绑定,一旦客户端会话失效,这个节点就会自动删除
序列节点
多个线程创建同一个顺序节点时,每个线程会得到一个带有编号的节点,节点编号是递增不重复的
脑裂
例如两个机房内的实例组成一个集群,如果两个机房间的网络出现问题,但机房内部通信没有问题,可能导致两个机房都选举出一个leader,一旦网络恢复,就存在脑裂问题
由于zk使用的是过半选举机制,所以不会出现脑裂问题
RPC通信
中间件
kafka
rabbitMQ
ActiveMQ
ES
个人笔记
Dubbo
分布式架构
负载均衡
随机,按照权重设置随机概率,可以动态调整权重
轮询,按公约后的权重设置轮询比率
最少活跃数,相同活跃数的随机,活跃数指调用前后计数差
一致性哈希
分布式锁
redis
通过setnx拿到key,然后通过expire对该key设置过期时间,将这两个操作通过加锁整合成原子性操作
zookeeper
多线程创建同一个临时节点,由于节点的唯一性,所以只会一个线程创建成功,其他线程watch这个节点。
羊群问题
当获得锁的线程释放锁后,所有等待的线程一起去抢这把锁,zk压力大。
每个线程都去创建一个顺序临时节点,相互监听,将非公平锁化为公平锁
zookeeper相对于redis有什么优势
redis当主拿到锁后,如果没有及时同步就宕机,可能导致锁失效
zk通过zab协议的限制,从而保证了只有超过半数实例拿到数据才算写成功,不会出现这个问题
分布式事务
TCC
lCN
nginx
分布式锁
全局唯一id生成
session共享
一致性算法
CPA/BASE理论
RPC
jvm常识
jvm组成
jvm内存模型
共享内存模型
jvm内存结构
类加载机制
类加载器
类加载过程原理
GC
收集器,调优
内存分配策略<br>
运行时数据区域
线程私有
程序计数器
字节码解释器通过改变程序计数器来一次读取指令,从而实现代码的流程控制
在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了
虚拟机栈
局部变量表
各种基本数据类型
对象引用
操作数栈
操作数的临时存放内存
动态链接
动态链接存储。在main方法中调用某个类的方法,该类的实例对象存在堆中,对象头记录着对应类元信息所在的方法区的指针。在调用这个方法的时候,会将该指针所存储的对应方法的字节码位置存入动态链接
方法出口
下一步main方法要执行的位置<br>
栈里每个方法都有自己的栈帧,用于存自己的局部变量表
本地方法栈
为虚拟机使用到的Native方法服务
线程共享
堆
存放对象实例
年轻代
伊甸园区
minor GC(将剩余存活对象移动到survivor区)
survivor区<br>
From区
minor GC(将剩余存活对象移动到To区,两者来回挪动,直到java分代年龄到15,移动到老年代)<br>
To区
老年代
方法区
存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
直接内存
避免Java堆和Native堆之间来回复制数据
对象创建过程
类加载检查
虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程
分配内存
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来
分配方式
指针碰撞
空闲列表
初始化零值
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值
设置对象头
初始化零值完成之后,虚拟机要对对象进行必要的设置,例如这个对象是那个类的实例、如何才能找到类的元数据信息、对象的哈希吗、对象的 GC 分代年龄等信息。 这些信息存放在对象头中。 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式
执行init方法
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,<init> 方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行 <init> 方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来
编程基础
数据结构
算法分析与设计
排序算法
选择排序
n平方
n平方
每一趟从待排序的记录中选出最小的元素,顺序放在已排好序的序列最后,直到全部记录排序完毕。
插入排序
n
n平方
从整个待排序列中选出一个元素插入到已经有序的子序列中去,得到一个有序的、元素加一的子序列,直到整个序列的待插入元素为0,则整个序列全部有序
冒泡排序
n
n平方
比较两个相邻的元素,将值大的元素交换至右端
希尔排序
n
n2
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
快速排序
nlgn
n2
堆排序
nlgn
nlgn
归并排序
nlgn
nlgn
设计模式
单例模式
单例模式可以保证系统中一个类只有一个实例
单例模式只能有一个实例
单例模式类必须自己创建自己的唯一实例
单例模式类必须给所有其他对象提供这一实例
分类
饿汉式
优点
实现简单,不存在多线程同步问题,避免了synchronized所造成的性能问题,是线程安全的(JVM保证线程安全)
JVM怎么保证线程安全
JVM以同步的形式完成类加载的整个过程
保证实例的唯一性
初始化过程只会执行一次
缺点
类加载的时候,静态变量被创建并分配内存空间。因此在特定条件下会耗费内存
实现
懒汉式
优点
实现简单,类加载的时候不会创建,当getInstance方法第一次被调用时,才初始化并分配内存
缺点
再并发环境下很可能出现多个实例
实现
饱汉式
优点
使用synchronized关键字避免多线程访问
缺点
同步方法频繁调用时,效率低
实现
双检锁
优点
避免了整个方法被锁,只需对需要锁的代码部分加锁,提高执行效率
实现
静态内部类
优点
不会在单例加载时就加载,而是在调用getInstance()方法时才进行加载,且是线程安全的
缺点
遇到序列化对象时,默认的方式运行得到的结果就是多例的
实现
内部枚举类
优点
自由序列化
保证只有一个实例
线程安全
实现
操作系统
tcp/Ip
Java编程基础
集合
date
collection
list
LinkedList
Vector
map
Hashtable
HashMap
WeakHashMap
vector
io
IO框架
流
内存与存储设备之间传输数据的通道
流的分类
按方向
输入流
将存储设备中的内容读入到内存中
输出流
将内存中的内容写入到存储设备中
按单位
字节流
以字节为单位,可以读写所有的数据
字符流
以字符为单位,只能读写文本数据
按功能
节点流
具有实际传输数据的读写功能
过滤流
在节点流的基础之上增强功能
字节流
InputStream 字节输入流
OutputStream 字节输出流
字节节点流
FileInputStream
FileOutputStream
字节过滤流
BufferedInputStream
BuffereOutpuStream
对象字节流
ObjectOutputStream
ObjectInputStream
使用对象字节流传输对象的过程,称为序列化、反序列化
必须实现Serializable接口
必须保证其属性均可序列化
transient修饰的属性为临时属性,不参与序列化
读取到文件末尾:java.io.EOFException
字符编码
UTF-8
针对Unicode可变长度字符编码
GB2312
简体中文
GBK
简体中文、扩展
当编码方式和解码方式不一致时,会出现乱码
字符流
Reader
Writer
字符节点流
FileWriter
FileReader
字符过滤流
BufferedWriter
BufferedReader
PrintWriter
桥转换流
InputStreamReader
OutputStreamWriter
可将字节流转换为字符流
可设置字符的编码方式
File类
代表了物理盘符中的一个文件或文件夹
FileFilter接口
对获取文件进行过滤,满足条件的文件或文件夹才能保存下来
awt
net
反射
反射
类的对象: 基于某个类new出来的对象,也称为实例对象
类对象
类加载的产物,封装了一个类的所有信息(类名、父类、接口、属性、方法、构造方法)
获取类对象的方法
通过类的对象,获取类对象
Person p = new Person(); Class c = p.getClass();
通过类名获取类对象
Class c = 类名.class;
通过静态方法获取类对象
Class c = Claa.forName(“包名.类名”);
常见方法
public String getName() //获取类对象名
public Package getPackage() //获取指定包名
public Class<? super T> getSupercalass() //获取父类Class对象
public Class<?>[] getInterfaces() //获取实现的接口
public Field[] getFields() //获取属性
public Method[] getMethods() //获取方法
public Constructor<?>[] getConstructors() //获取构造方法
public T newInstance() //获取对象
设计模式
工厂设计模式
开发中有一个非常重要的原则“开闭原则”,对拓展开放、对修改关闭
工厂模式主要负责对象创建的问题
可通过反射进行工厂模式的设计,完成动态的对象创建
工厂模式分类
创建对象工厂
创建对象并调用方法的工厂
单例设计模式
单例(Singleton): 只允许创建一个该类的对象
方式1: 饿汉式(类加载时创建,天生线程安全)
方式2: 懒汉式(使用时创建,线程不安全,加同步)
方式3: 懒汉式(使用时创建,线程安全)
面向对象设计原则
数据库
mysql
引擎
MyISAM和InnoDB
区别
count运算上的区别
因为MyISAM缓存有表meta-data(行数等),因此在做COUNT(*)时对于一个结构很好的查询是不需要消耗多少资源的。而对于InnoDB来说,则没有这种缓存
是否支持事务和崩溃后的安全恢复
MyISAM 强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。但是InnoDB 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表
是否支持外键
MyISAM不支持,而InnoDB支持
MyISAM更适合读密集的表,而InnoDB更适合写密集的的表。 在数据库做主从分离的情况下,经常选择MyISAM作为主库的存储引擎。<br>一般来说,如果需要事务支持,并且有较高的并发读取频率(MyISAM的表锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了),InnoDB是不错的选择。如果你的数据量很大(MyISAM支持压缩特性可以减少磁盘的空间占用),而且不需要支持事务时,MyISAM是最好的选择
MVCC
MVCC多版本并发控制
通过保存数据在某个时间点的快照来实现的。MVCC主要作用于事务性的,有行锁控制的数据库模型
InnoDB存储引擎MVCC实现策略
版本链
额外存储每次对某条聚簇索引记录进行修改的事务id和指向这条聚簇索引上一个版本的位置,上一版本的数据会保存在Undo日志中
ReadView
ReadView中有个列表存储系统中未提交的事务,通过这个列表来判断记录的某个版本是否对当前事务可见
当进行查询时,如果该行数据的版本号在列表记录前,就可以访问,在列表记录中和后,就不能访问
优化
步骤:<br>1.开启慢查询日志,设置阈值,比如超过5秒钟的就是慢SQL,并将它抓取出来;<br>2.EXPLAIN+慢SQL分析;<br>3.SHOW profile,查询SQL在MySQL服务器里面的执行细节和生命周期情况<br>4.具体优化
explain
语法explain select * from xxl_job_log l where l.job_id in (select id from xxl_job_info)
字段说明
id:表示查询中执行select子句或操作表的顺序
id相同,执行顺序由上至下;<br>id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行;<br>id相同不同,都存在
select_type:表示查询的类型,主要用于区别普通查询,联合查询,子查询等复杂查询<br>https://www.cnblogs.com/danhuangpai/p/8475458.html<br>
SIMPLE:简单的select查询,查询中不包括子查询或者UNION
PRIMARY:查询中若包括任何复杂的子部分,最外层查询则被标记为PRIMARY
SUBQUERY:在select或where列表中包含了子查询
DERIVED: 在FROM列表中,包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询,<br>把结果放在临时表里
UNION: 若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在FROM子句的子查询中,<br>外侧SELECT将被标记为 DERIVE
UNION RESULT: 从UNION表获取结果的SELECT
table:查询的表
type:在表中找到所需行的方式 ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
ALL:全部扫描,效率低
index:Full Index Scan,index与ALL区别为index类型只遍历索引树<br>explain select * from film; file中有name字段为索引<br>
range:只检索给定范围的行,使用一个索引来选择行<br>explain select * from employee where rec_id < 3其中rec_id为主键<br>
ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值<br>查找条件列使用了索引而且不为主键和unique。其实,意思就是虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。但它的好处是它并不需要扫全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内扫描。下面为了演示这种情形,给employee表中的name列添加一个普通的key(值允许重复)<br>explain select * from film where name = "film1" ref name是film中的普通索引<br>
eq_ref:类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件<br>eq_ref 与 ref相比牛的地方是,它知道这种类型的查找结果集只有一个?什么情况下结果集只有一个呢!那便是使用了主键或者唯一性索引进行查找的情况,比如根据学号查找某一学校的一名同学,在没有查找前我们就知道结果一定只有一个,所以当我们首次查找到这个学号,便立即停止了查询。这种连接类型每次都进行着精确查询,无需过多的扫描,因此查找效率更高,当然列的唯一性是需要根据实际情况决定的<br>explain select * from film_actor left join film on film_actor.film_id= film.id eq_ref 根据主键或唯一索引查询film<br>
const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system<br>select 1 from actor where id =1 const<br>explain extended select * from (select * from film where id =1) tmp 临时表中只有一条记录,system<br>
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成explain select min(id) from film id是主键
possible_keys:指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用(该查询可以利用的索引,如果没有任何索引显示 null),可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mys ql认为索引对此查询帮助不大,选择了全表查询
key:显示MySQL实际决定使用的键(索引)
key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,<br>并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)不损失精确性的情况下,长度越短越好<br>key_len计算规则如下:<br><br>字符串<br> char(n):n字节长度<br> varchar(n):2字节存储字符串长度,如果是utf-8,则长度3n + 2<br> 数值类型<br> tinyint:1字节<br> smallint:2字节<br> int:4字节<br> bigint:8字节 <br> 时间类型 <br> date:3字节timestamp:4字节<br> datetime:8字节如果字段允许为 NULL,需要1字节记录是否为 NULL<br>索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。<br>
ref:列与索引的比较,表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows:估算出结果集行数,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
filtered:一个半分比的值,rows * filtered/100 可以估算出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表)
Extra
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据,<br>这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤<br>
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ; order by;distinct
Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。<br>如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能<br>
Impossible where:这个值强调了where语句会导致没有符合条件的行(通过收集统计信息不可能存在结果)
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
No tables used:Query语句中使用from dual 或不含任何from子句
缺点:<br>• EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况<br>• EXPLAIN不考虑各种Cache<br>• EXPLAIN不能显示MySQL在执行查询时所作的优化工作<br>• 部分统计信息是估算的,并非精确值<br>• EXPLAIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划<br>
SHOW WARNINGS 在explain执行后执行,查看翻译后的sql
最佳左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列
索引优化规则
不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描<br>EXPLAIN SELECT * FROM employees WHERE name = 'LiLei'; 使用索引<br>EXPLAIN SELECT * FROM employees WHERE left(name,3) = 'LiLei'; 未使用索引<br>
存储引擎不能使用索引中范围条件右边的列<br>EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager'; 使用索引<br>EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age > 22 AND position ='manager'; 未使用索引<br>
尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少select *语句<br>EXPLAIN SELECT name,age FROM employees WHERE name= 'LiLei' AND age = 23 AND position ='manager'; 只查询索引不用查询具体的数据,效率更高<br>EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 23 AND position ='manager';<br>
mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
is null,is not null 也无法使用索引
like以通配符开头('$abc...')mysql索引失效会变成全表扫描操作
字符串不加单引号索引失效<br>EXPLAIN SELECT * FROM employees WHERE name = '1000';<br>EXPLAIN SELECT * FROM employees WHERE name = 1000;<br>
or 只有两边都有索引才走索引,如果都没有或者只有一个是不走索引的
in操作能避免则避免,若实在避免不了,需要仔细评估in后边的集合元素数量,控制在1000个之内
union all 不去重复,union去重复,union使用了临时表,应尽量避免使用临时表
order by如果根据多个值进行排序,那么排序方式必须保持一致,要么同时升续,要么同时降续,排序方式不一致不走索引
优化方式
优化数据库表结构的设计
字段的数据类型
不同的数据类型的存储和检索方式不同,对应的性能也不同,所以说要合理的选用字段的数据类型。比如人的年龄用无符号的unsigned tinyint即可,没必要用integer
数据类型的长度
数据库最终要写到磁盘上,所以字段的长度也会影响着磁盘的I/O操作,如果字段的长度很大,那么读取数据也需要更多的I/O, 所以合理的字段长度也能提升数据库的性能。比如用户的手机号11位长度,没必要用255个长度
表的存储引擎
分库分表
数据库参数配置优化
主从复制,读写分离
数据库编码: 采用utf8mb4而不使用utf8
字段名
MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写。因此,数据库名、 表名、字段名,都不允许出现任何大写字母,避免节外生枝。<br>一般所有表都要有id, id必为主键,类型为bigint unsigned,单表时自增、步长为1; 有些特殊场景下(如在高并发的情况下该字段的自增可能对效率有比价大的影响)id是通过程序计算出来的一个唯一值而不是通过数据库自增长来实现的。<br>一般情况下主键id和业务没关系的,例如订单号不是主键id,一般是订单表中的其他字段,一般订单号order_code为字符类型<br>一般情况下每张表都有着四个字段create_id,create_time,update_id,update_time, 其中create_id表示创建者id,create_time表示创建时间,update_id表示更新者id,update_time表示更是时间,这四个字段的作用是为了能够追踪数据的来源和修改<br>最好不要使用备用字段(个人观点), 禁用保留字,如 desc、range、match、delayed 等<br>表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint (1 表示是,0 表示否), 任何字段如果为非负数,必须是unsigned。表达逻辑删除的字段名 is_deleted,1 表示删除,0 表示未删除<br>如果某个值能通过其他字段能计算出来就不需要用个字段来存储,减少存储的数据<br>为了提高查询效率,可以适当的数据冗余,注意是适当<br>强烈建议不使用外键, 数据的完整性靠程序来保证<br>单条记录大小禁止超过8k, 一方面字段不要太多,有的都能上百,甚至几百个,另一方面字段的内容不易过大像文章内容等这种超长内容的需要单独存到另一张表<br>
字段类型
字符类型
不同存储引擎对char和varchar的使用原则不同,myisam:建议使用国定长度的数据列代替可变长度。<br>innodb:建议使用varchar,大部分表都是使用innodb,所以varchar的使用频率更高<br>
数值类型
金额类型的字段尽量使用long用分表示,尽量不要使用bigdecimal,严谨使用float和double因为计算时会丢失经度<br>如果需要使用小数严谨使用float,double,使用定点数decimal,decimal实际上是以字符串的形式存储的,所以更加精确,java中与之对应的数据类型为BigDecimal<br>如果值为非负数,一定要使用unsigned,无符号不仅能防止负数非法数据的保存,而且还能增大存储的范围<br>不建议使用ENUM、SET类型,使用TINYINT来代替<br>
日期类型
根据实际需要选择能够满足应用的最小存储日期类型。<br><br>如果应用只需要记录年份,那么仅用一个字节的year类型。<br>如果记录年月日用date类型, date占用4个字节,存储范围10000-01-01到9999-12-31<br>如果记录时间时分秒使用它time类型<br>如果记录年月日并且记录的年份比较久远选择datetime,而不要使用timestamp,因为timestamp表示的日期范围要比datetime短很多<br>如果记录的日期需要让不同时区的用户使用,那么最好使用timestamp, 因为日期类型值只有它能够和实际时区相对应<br>datetime默认存储年月日时分秒不存储毫秒fraction,如果需要存储毫秒需要定义它的宽度datetime(6)<br>timestamp与datetime<br><br>两者都可用来表示YYYY-MM-DD HH:MM:SS[.fraction]类型的日期。<br><br>都可以使用自动更新CURRENT_TIMESTAMP<br><br>对于TIMESTAMP,它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储。查询时,将其又转化为客户端当前时区进行返回。而对于DATETIME,不做任何改变,基本上是原样输入和输出。<br><br>timestamp占用4个字节:timestamp所能存储的时间范围为:’1970-01-01 00:00:01.000000’ 到 ‘2038-01-19 03:14:07.999999’<br>datetime占用8个字节 :datetime所能存储的时间范围为:’1000-01-01 00:00:00.000000’ 到 ‘9999-12-31 23:59:59.999999’<br><br>总结:TIMESTAMP和DATETIME除了存储范围和存储方式不一样,没有太大区别。如果需要使用到时区就必须使用timestamp,如果不使用时区就使用datetime因为datetime存储的时间范围更大<br><br>注意:<br><br>禁止使用字符串存储日期,一般来说日期类型比字符串类型占用的空间小,日期时间类型在进行查找过滤是可以利用日期进行对比,这比字符串对比高效多了,日期时间类型有丰富的处理函数,可以方便的对日期类型进行日期的计算<br>也尽量不要使用int来存储时间戳<br>
是否为null
MySQL字段属性应该尽量设置为NOT NULL,除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL 。<br><br>在MySql中NULL其实是占用空间的,“可空列需要更多的存储空间”:需要一个额外字节作为判断是否为NULL的标志位“需要mysql内部进行特殊处理”, 而空值”“是不占用空间的。<br><br>含有空值的列很难进行查询优化,而且对表索引时不会存储NULL值的,所以如果索引的字段可以为NULL,索引的效率会下降很多。因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替null。<br><br>联表查询的时候,例如SELECT user.username, info.introduction FROM tbl_user user LEFT JOIN tbl_userinfo info ON user.id = info.user_id; 如果tbl_userinfo.introduction设置的可以为null, 假如这条sql查询出了对应的记录,但是username有值,introduction没有值,那么就不是很清楚这个introduction是没有关联到对应的记录,还是关联上了而这个值为null,null意思表示不明确,有歧义<br><br>注意:NULL在数据库里是非常特殊的,任何数跟NULL进行运算都是NULL, 判断值是否等于NULL,不能简单用=,而要用IS NULL关键字。使用 ISNULL()来判断是否为 NULL 值,NULL 与任何值的直接比较都为 NULL。<br><br>1) NULL<>NULL的返回结果是NULL,而不是false。<br>2) NULL=NULL的返回结果是NULL,而不是true。<br>3) NULL<>1的返回结果是NULL,而不是true。<br>
实例
EXPLAIN SELECT * FROM tbl_user LIMIT 100000,2;<br>EXPLAIN SELECT * FROM tbl_user u INNER JOIN (SELECT id FROM tbl_user ORDER BY id ASC LIMIT 10000,2) temp ON u.id = temp.id;<br>id为主键,性能高于第一条全表扫描
where中如果有多个过滤条件,在没有索引的情况下将过滤多的写在前面,过滤少的写在后面
禁止使用select *,需要什么字段就去取哪些字段
不要使用count(列名)或 count(常量)来替代 count(),count()是SQL92定义的标准统计行数的语法,跟数据库无关,跟 NULL和非NULL无关。 说明:count(*)会统计值为NULL 的行,而count(列名)不会统计此列为NULL值的行
禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。避免使用存储过程、触发器
除了 IO 瓶颈之外,SQL优化中需要考虑的就是 CPU 运算量的优化了。order by, group by,distinct … 都是消耗 CPU 的大户(这些操作基本上都是 CPU 处理内存中的数据比较运算)。当我们的 IO 优化做到一定阶段之后,降低 CPU 计算也就成为了我们 SQL 优化的重要目标<br><br>
锁
分类
乐观锁和悲观锁
乐观锁
根据版本号控制
悲观锁
锁定表或者行,让其他数据操作等待
读锁(共享锁)
针对同一份数据,多个读操作可以同时进行而不会互相影响
不能进行写操作
写锁(排他锁)
当前写操作没有完成前,它会阻断其他写锁和读锁
表锁和行锁
表锁
表锁偏向MyISAM存储引擎,开销小,加锁快,无思索,锁定粒度大,发生锁冲突的概率最高,并发度最低<br>当前session对该表的增删改查都没有问题,其他session对该表的所有操作被阻塞 <br>
lock table表名称 read(write)<br>unlock tables<br>
MyISAM在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行增删改操作前,会自动给涉及的表加写锁。1、对MyISAM表的读操作(加读锁) ,不会阻寒其他进程对同一表的读请求,但会阻赛对同一表的写请求。只有当读锁释放后,才会执行其它进程的写操作。2、对MylSAM表的写操作(加写锁) ,会阻塞其他进程对同一表的读和写操作,只有当写锁释放后,才会执行其它进程的读写操作总结:简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁则会把读和写都阻塞<br>
行锁
行锁偏向InnoDB存储引擎,开销大,加锁慢,会出现死锁,锁定粒度最小,发生锁冲突的概率最低,并发度也最高。InnoDB与MYISAM的最大不同有两点:一是支持事务(TRANSACTION);二是采用了行级锁
行锁分析
show status like'innodb_row_lock%';
Innodb_row_ lock_current_wait
当前正在等待锁定的数量
Innodb_row_ lock_time
从系统启动到现在锁定总时间长度
Innodb_row_ lock_time_avg
每次等待所花平均时间
Innodb_row_ lock_time_max
从系统启动到现在等待最长的一次所花时间
Innodb_row_ lock_waits
系统启动后到现在总共等待的次数
死锁
Session _1执行:select *from account where i d= 1 for update;<br>Session _2执行:select *from account where i d= 2 for update;<br>Session _1执行:select *from account where i d= 2 for update;<br>Session _2执行:select *from account where i d= 1 for update;<br>查看近期死锁日志信息:show engine inno db statu s\G;<br>
ORACLE
PL/SQL
数据库优化的思路
选取最有效率的表名顺序
数据库的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表将被最先处理
如果三个表是完全 无关系的话,将记录和列名最少的表,写在最后,即选择记录条数最少的表放在最后
如果三个表是有关系的话,将引用最多的表,放在最后,即被其他表所引用的表放在最后
WHERE子句中的连接顺序
数据库采用自右向左的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之左,那些可以过滤掉最大数量记录的条件必须写在WHERE子句之右
SELECT子句中避免使用*号
*号可以获取表中全部的字段数据,但它是通过查询数据字典完成的,这意味着将耗费更多的时间
使用*号写出来的SQL语句也不够直观
使用TRUNCATE替代DELETE
对于删除表的全部记录,DELETE是逐条删除,Truncate是将整个表删除
多使用内部函数提高SQL效率
例如 : 使用mysql的concat()函数会比使用||来进行拼接快,因为concat()函数已经被sql优化过了
使用表或列的别名
一些简短的别名也能稍微提高一些SQL的性能
善用索引
索引就是为了提高我们的查询数据的速度的,当表的记录量非常大时,我们就可以使用索引了
SQL写大写
Oracle服务器总是先将小写字母转成大写后,才执行
避免在索引上使用NOT
Oracle服务器在遇到NOT后,他就会停止目前的工作,转而执行全表扫描
避免在索引列上使用计算
WHERE子句中,如果索引列是函数的一部分,优化器将不使用索引而使用全表扫描,这样会变慢
使用>=替代>
使用>会先定位到>的记录,然后扫描第一个大于的记录。>=会直接跳到第一个=的记录
使用IN替代OR
select * from emp where sal =100 or sal = 1000 or sal = 10;替换为 select * from emp where sal in (100,1000,10)
总是使用索引的第一个列
如果索引是建立在多个列上,只有在它的第一个列别WHERE子句引用时,优化器才会选择使用该索引
优化答题
先看慢日志,定位哪条语句慢,然后看语句的索引使用情况,是否使用到索引,索引是否失效。如果未建立索引,就建立索引。已经建立索引的话,就通过explain查看执行计划,通过type,key,rows,extra定位问题。type就是访问类型,ALL<index<range<ref<eq_ref。key就是具体使用的索引,rows是通过多少行拿到数据,extra常见Using filesort,出现在排序时索引失效,例如联合索引顺序有问题。extra还有Using temporary,使用临时表保存中间结果<br>
事务
什么是事务
满足ACID
事务特性
原子性
一致性
隔离性
持久性
事务隔离级别
Serializable
可避免脏读,不可重复读,虚读
Repeatable read
可避免脏读,不可重复读
Read committed
可避免脏读
Read uncommitted
级别最低,什么都避免不了
脏读、不可重复读、虚读(幻读)
脏读
脏读就是指当事务A对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务B也访问这个数据,然后使用了这个数据。
不可重复读
不可重复读是指在事务1内,读取了一个数据,事务1还没有结束时,事务2也访问了这个数据,修改了这个数据,并提交。紧接着,事务1又读这个数据。由于事务2的修改,那么事务1两次读到的的数据可能是不一样的,因此称为是不可重复读。
虚读
所谓幻读,指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻行。InnoDB存储引擎通过多版本并发控制(MVCC)解决了幻读的问题。
SQL约束有哪几种
NOT NULL
用于控制字段的内容一定不能为空
UNIQUE
控制字段内容不能重复,一个表允许有多个Unique约束
PRIMARY KEY
用于控制字段内容不能重复,一个表只允许出现一个
FOREIGN KEY
用于预防破环表之间连接的动作,也能防止非法数据插入外键列
CHECK
用于控制字段的值范围
三个范式
第一范式
数据库表中的字段都是单一属性的,不可再分
第二范式
满足第一范式,表中的字段必须完全依赖于全部主键而非部分主键
第三范式
满足第二范式,非主键外的所有字段必须互不依赖
锁
表锁
开销小,加锁快
不会出现死锁
锁定粒度大,发生锁冲突概率高,并发度最低
行锁
开销大,加锁慢
会出现死锁
锁定粒度小,发生锁冲突的概率低,并发度低
共享锁(读锁)
允许一个事务去读一行,阻止其他事务获得相同的排他锁
多个客户可以同时读取同一个资源,但不允许其他客户修改
排他锁(写锁)
允许获得排他锁的事务更新数据,组织其他事务取得相同数据集的共享读锁和排他写锁
写锁是排他的,写锁会阻塞其他的写锁和读锁
间隙锁GAP
间隙锁只在Repeatable read隔离级别下使用
在用范围条件检索数据并请求共享或排他锁,对于键值在条件范围内但并不存在的记录,也会加锁
作用:
防止幻读
满足恢复和复制的需要
在一个事务未提交前,其他并发事务不能插入满足其锁定条件的任何记录
死锁
避免死锁的方式
以固定的顺序访问表和行
大事务拆小
在同一事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率
降低隔离级别
为表添加合理的索引
不走索引将会为表的每一行记录添加上锁,死锁的概率大大增加
丢失更新
一个事务的更新覆盖了其他事务的更新结果
解决方法
使用Serializable隔离级别,事务是串行执行的
乐观锁
表中有一个版本字段,第一次读的时候,获取到这个字段。当更新时,再次查看该字段的值是否和第一次一样,如果一样更新,反之拒绝
实现方式
加version版本字段
悲观锁
悲观锁是数据库层面的加锁,每次操作都会阻塞去等待锁
实现方式
手动加行锁
例如:select * from xx for update
在select语句后面加了 for update 相当于加了排他锁,加了写锁以后,其他的事务就不能对它修改了,需要等待当前事务修改完之后
乐观锁和悲观锁的应用场景
乐观锁使用于多读场景(写比较少),即冲突很少发生的时候
悲观锁使用于多写场景,容易发生冲突的场景
for update
使用到索引
有数据
行锁
无数据
不加锁
没有使用到索引
有数据
表锁
无数据
不加锁
非关系型数据库
hive
MONGODB
redis
redis数据结构
Redis数据类型
String
存储的值
可以是字符串、整数或浮点,统称为元素
读写能力
对字符串操作,对整数类型加减
List
存储的值
一个有序序列集合且每个节点都包好了一个元素
读写能力
序列两端推入、或弹出元素、修剪、查改或移除元素
Set
存储的值
无序的方式,各不相同的元素
读写能力
从集合中插入或删除元素
Hash
存储的值
有key-valued的散列组,其中key是字符串,value是元素
读写能力
按照key进行增加删除
Sort Set
存储能力
带分数的score-value有序集合,其中score为浮点,value为元素
读写能力
集合插入,按照分数范围查找
String类型操作 [key|value(string/int/float)]
set
设置置顶key的值
set key value
get
获取指定key的值
get key
incr
将key中储存的数字值增一
incr key
decr key
将key中储存的数字值减一
decr key
incrby
key 所储存的值增加给定的减量值(decrement)
incrby key decrement
decrby
key 所储存的值减去给定的减量值(decrement)
decrby key decrement
append
如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。
append key value
setnx
只有在 key 不存在时设置 key 的值<br>
setnx key value
mget
获取所有(一个或多个)给定 key 的值。
mget key [key...]
mset
同时设置一个或多个 key-value 对
mget key value [key value ...]
getset
将给定 key 的值设为 value ,并返回 key 的旧值(old value)。
getset key value
setex
将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。
setex key seconds value
strlen
返回 key 所储存的字符串值的长度
strlen key
del
删除键
del key
List类型操作<br>[key => value1 | 自 <br> value2 | 左<br> value3 | 而<br> value4 | 右<br>]
push
lpush
将一个或多个值插入到列表头部
lpush key value1 [value2....]
rpush
将一个或多个值插入到列表尾部
rpush key value1 [value2....]
pop
lpop
移出并获取列表的第一个元素
lpop key
rpop
移出并获取列表的最后一个元素
rpop key
lrange
获取列表指定范围内的元素
lrange key start stop
llen
获取列表长度
llen key
lindex
通过索引获取列表中的元素
lindex key index
lrem
移除列表元素
lrem key count value
count > 0
从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT
count < 0
从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值
count = 0
移除表中所有与 VALUE 相等的值
lset key index value
通过索引设置列表元素的值<br>
lset key index value
Set类型操作<br>key->[ value1 <br> value2 <br> value3<br> value4<br> ]
sadd
向集合添加一个或多个成员(存在则返回0)
sdd key member1 [member2]
scard
获取集合的成员数
scard key
sinter
返回给定所有集合的交集
sinter key1 [key2]
sismember
判断 member 元素是否是集合 key 的成员
sismember key member
smembers
返回集合中的所有成员
smembers key
srandmember
返回集合中一个或多个随机数
srandmember key [count]
srem
移除集合中一个或多个成员
srem key member1 [member2]
Hash类型操作<br>key-> key1 value(string/int/float)<br> key2 value(string/int/float)<br> key3 value(string/int/float)<br> key4 value(string/int/float)
hset
将哈希表 key 中的字段 field 的值设为 value
srem key field value
hmset
同时将多个 field-value (域-值)对设置到哈希表 key 中
hmset key field1 value1 [field2 value2]
hsetnx
只有在字段 field 不存在时,设置哈希表字段的值
hsetnx key field value
hget
获取存储在哈希表中指定字段的值
hget key field
hmget
获取所有给定字段的值
hget key field1 [field2]
hgetall
获取在哈希表中指定 key 的所有字段和值
hgetall key
hvals
获取哈希表中所有值
hvals key
hlen
获取哈希表中字段的数量
hlen key
hkeys
获取所有哈希表中的字段
hkeys key
hdel
删除一个或多个哈希表字段
hdel key field1 [field2]
hexitst
查看哈希表 key 中,指定的字段是否存在
hexitst key field
Sorc Set类型操作<br>key-> score(10.1) value(string/int/float) rank:1<br> score(9.1) value(string/int/float) rank:0<br> score(11.2) value(string/int/float) rank:2
zadd
向有序集合添加一个或多个成员,或者更新已存在成员的分数
zadd key score1 member1 [score2 member2....]
zcard
获取有序集合的成员数
zcard key
zcount
计算在有序集合中指定区间分数的成员数
zcount key min max
zincrby
有序集合中对指定成员的分数加上增量 increment
zincrby key increment member
zrange
通过索引区间返回有序集合成指定区间内的成员
zrange key start stop [withscores]
zrank
返回有序集合中指定成员的索引
zrank key member
zrem
移除有序集合中的一个或多个成员
zrem key member1 [member2....]
zrevrange
返回有序集中指定区间内的成员,通过索引,分数从高到底
zrevrange key start stop [withscores]
zscore
返回有序集中,成员的分数值
zscore key member
redis分布式锁是怎么实现的
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间
setnx key value
将key的值设为value,当且仅当key不存在,若key存在,则不做任何动作
持久化
把内存的数据写到磁盘中,防止服务宕机内存数据丢失
方式
RDB(默认)
生成方式
SAVE
SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求
BGSAVE
BGSAVE命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求
AOF
存储结构
内容是redis通讯协议(RESP)格式的命令文本存储
AOF通过保存redis服务器所执行的写命令来记录数据库的数据的
持久化流程
写入AOF缓存区
服务器在执行完一个写命令之后,以协议格式将被执行的命令追加到aof_buf缓冲区的末尾中
考虑是否写入AOF文件
随后会调用flushAppendOnlyFile函数考虑是否需要将aof_buf缓冲区的内容写入到AOF文件中
考虑是否同步AOF文件
最后确定是否将AOF文件内容同步
如果两个都配置了,优先加载AOF
AOF文件的更新频率通常比RDB文件的更新频率高
对比
RDB
载入时恢复数据快,文件体积小
会一定程度上丢失数据
AOF
丢失数据少
恢复数据相对较慢,文件体积大
redis异步队列
使用list结构作为队列,rpush生产消息,lpop消费消息,当lpop没有消息的时候,适当sleep一会
redis存在的问题
缓存穿透
原因
恶意请求故意查询不存在的key,请求量很大,跳过缓存直接查询数据库
解决方法
对查询为空的情况也进行缓存,时间设置短一点,或者对该key有insert操作之后清理缓存
使用布隆过滤器过滤一定不存在的key
缓存雪崩
原因
当缓存服务器重启或者大量缓存集中在某个时间段失效,在失效的时候,会给后端系统带来很大压力
解决方法
保证缓存层服务高可用性
使用消息队列为后端限流
错开键的过期时间
主从复制相关
前置工作
从服务器设置主服务器的IP和端口
建立与主服务器的Socket连接
发送PING命令
身份验证
从服务器给主服务器发送端口的信息,主服务器记录监听的端口
完整重同步
从服务器向主服务器发送PSYNC命令
收到PSYNC命令的主服务器执行BGSAVE命令,在后台生成一个RDB文件。并用一个缓存区来记录从现在开始执行的所有写命令
当主服务器的BGSAVE命令执行完后,将生成的RDB文件发送给从服务器,从服务器接收和载入RBD文件将自己的数据库状态更新至与主服务器执行BGSAVE命令时的状态
主服务器将所有缓冲区的写命令发送给从服务器,从服务器执行这些写命令,达到数据最终一致性
部分重同步
模块
主从服务器的复制偏移量
执行复制的双方都会分别维护一个复制偏移量
主服务器每次传播N个字节,就将自己的复制偏移量加N,从服务器同理
通过对比主从复制的偏移量,判断主从服务器数据是否一致
主服务器的复制积压缓冲区
主服务器进行命令传播时,不仅会将命令发送给所有从服务器,还会将写命令入队到复制积压缓冲区里面。
如果复制积压缓冲区存在丢失的偏移量的数据,那就执行部分重同步,否则,执行完整重同步
服务器运行的ID(run ID)
服务器run ID用来比对ID是否相同,判断从服务器断线之前复制的主服务器和当前连接的主服务器是否是同一台服务器,不是则进行完整重同步
心跳检测
在命令传播阶段,从服务器默认会以每秒一次的频率,向主服务器发送命令
REPLCONF ACK <replication_offset>
replication_offset是从服务器当前的复制偏移量
检测主从服务器的网络连接状态
辅助实现min-slaves选项
检测命令丢失
哨兵机制
哨兵的含义就是监控redis系统的运行状态
监控所有节点数据库是否在正常运行。
master数据库出现故障时,可以自动通过投票机制,从slave节点中选举新的master,实现将从数据库转换为主数据库的自动切换
redis高并发和快速的原因
redis是基于内存的,内存的读写速度非常快
redis是单线程的,省去了很多上下文切换线程的时间
redis使用多路复用技术,可以处理并发的连接。
redis过期键处理
判断键是否过期
在redis中维护一个expires字典,保存数据库中所有设置了过期时间的键的过期时间。通过key去字典中获取key的过期毫秒时间戳,再减去当前时间戳,得到剩余生存时间
过期键删除策略
惰性删除策略(被动)
程序在取出键时才对key进行过期检查,若过期则删除,否则照常执行
优点
对CPU时间来说是最友好的:程序只会在取出键时才对键进行过期检查,这可以保证删除过期键的操作只会在非做不可的情况下进行,并且删除的目标仅限于当前处理的键,这个策略不会在删除其他无关的过期键上花费任何CPU时间<br>
缺点
对内存是最不友好的:如果一个键已经过期,而这个键又仍然保留在数据库中,那么只要这个过期键不被删除,它所占用的内存就不会释放
定期删除策略(主动)
每隔一段时间执行一次随机删除过期键的操作,并通过限制删除操作执行的时常和频率来减少删除操作对cpu时间的影响
通过定期删除过期键,定期删除策略有效地减少了因为过期键而带来的内存浪费
内存淘汰机制
定期删除漏掉很多过期key,且没及时执行惰性删除,大量过期key堆积在内存,导致redis内存块耗尽
volatile-lru
从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
volatile-ttl
从已设置过期时间的数据集中挑选将要过期的数据淘汰
volatile-random
从已设置过期时间的数据集中任意选择数据淘汰
allkeys-lru
从所有数据集中挑选最近最少使用的数据淘汰
allkeys-random
从所有数据集中任意选择数据进行淘汰
noeviction
禁止驱逐数据
一般场景
使用redis缓存数据时,为了提高缓存命中率,需要保证缓存数据都是热点数据。即将内存最大使用量设置为热点数据占用的内存量,然后启用allkeys-lru 淘汰策略,将最近最少使用的数据淘汰
持久化过程对过期键的处理
RDB
执行SAVE或者BGSAVE命令创建出的RDB文件,程序会对数据库中的过期键检查,已过期的键不会保存在RDB文件中
载入RDB文件时,程序同样会对RDB文件中的键进行检查,过期的键会被忽略
AOF
如果数据库的键已过期,但没被删除,AOF会保留该键,当过期的键被删除以后,会追加一条DEL命令来显示记录删除信息
重写AOF文件时,程序会对AOF文件中的键进行检查,过期的键会被忽略
主从复制
从在读到过期键的时候,不会删除,而是返回该值,只有在主显示删除改过期键时通知从才会删除该键,这样保证主从一致性
事务
Redis会将EXEC命令前的命令放入一个队列,当遇到EXEC时批量执行队列中的命令,但是Redis的事务不支持回滚
架构模式
单机
特点
简单
问题
内存容量有限
处理能力有限
无法高可用
主从复制
特点
数据相同,主服务器会把数据同步到从服务器
主服务器用来写,从服务器用来读
问题
无法保证高可用
没有解决master写的压力
哨兵
特征
监控 主服务器和从服务器是否运行正常
提醒 当被监控的redis服务器发现问题,可以通过api向管理员或者其他应用发送通知
自动故障迁移,将从服务器升级为主服务器
特点
保证高可用
监控各个节点
自动保障迁移
问题
没有解决master写的压力
切换主从模式需要时间丢数据
集群
代理集群
直连型集群
无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接
特点
所有的redis节点互联
节点的fail是通过集群中超过半数的节点检测失效时才生效
客户端与redis节点直连,不需要中间proxy层
个人笔记
项目管理
工具
idea
jenkins
mavem/gradle
tomcat
git/svn

收藏
立即使用


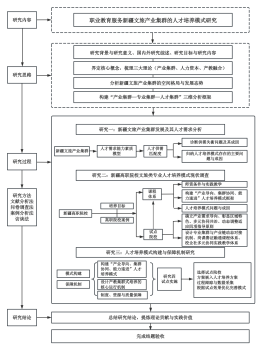
评论
0 条评论
下一页

