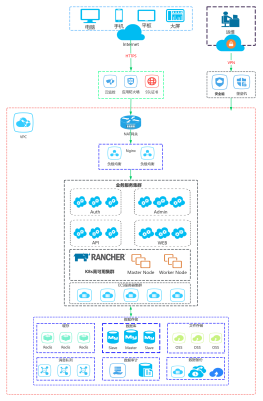
多实验田集群
分层
QueryRewrite:改写用户搜索词以期望得到更好的查询结果
Matching:根据用户搜索词,召回最符合用户意图的那些推广
Ranking:确定推广的输出顺序,需要兼顾用户体验和搜索平台的收益
优点
代码分为了基线和实验代码,实验代码对业务的侵入性比较小
实验田的流量和基线的流量从物理上严格分开,严格控制了实验对业务的影响
缺点
增加了运维的复杂性,运维需要维护多套环境
每套环境接入的流量都是由单个实验田集群的物理机器数量固定上限的,不能灵活地验证流量扩大的情景。这会导致对小流量实验效果很好的算法,在基线上有可能无法收到好的效果
实验的流量有限,导致实验的数量变少,而增大实验流量又会影响业务基线
Tesla
特点
一种高效便捷、能充分利用流量、并行多个实验的方法
也能支持系统的灰度发布
优点
提高并发:实现多实验并行迭代,加快迭代的速度
公平对比:做到实验效果公平、准确对比评估,即时停止不符预期的实验;随时扩大效果良好的实验的流量
降低门槛:提供实验管理工具,除算法以外,其他有实验需求的如产品、运营、前端等都可以独立申请发布实验
建立闭环:从想法、实验前线下评估、发布实验、实验进行、实验评估、最后实验总结,确保实验结果的质量
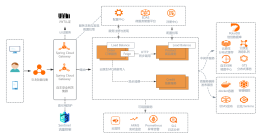
系统架构
实验配置管理发布系统
实验场景
实验分层和流量切分
实验分层的原则
相互之间有影响的实验分到同一层
保证同一请求不会去作两个互斥的实验
在线服务系统
接入方式
以 lib 库的方式接入在线服务系统
接入简单,不增加系统复杂性和运维的工作量
分流规则
由于不同层的实验之间毫无关系,为了保证实验效果绝对可信,需要做到不同层的流量正交
实验参数的处理
一个实验本质上是一堆抽象参数集合
为了保证系统的健壮性,如果一个请求缺少了某个实验参数的数值,系统应该设置一个抄底的值