行数据格式
varchar这种变长类型,在行的开头,有个变长字段的长度列表
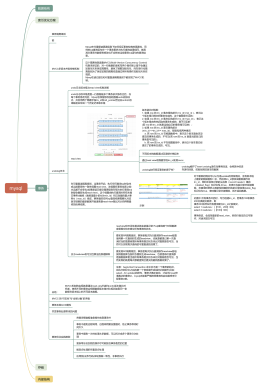
一行数据有VARCHAR(10) VARCHAR(5) VARCHAR(20) CHAR(1) CHAR(1),一共5个字段,假设数据是这样的:hello hi hao a a,则<br>实际存储:0x03 0x02 0x05 null值列表 头字段 hello hi hao a a<br>
针对可以为null的字段,每行都有一个null列表,每个字段占用1个bit,标识该行中,这个字段,是否为null
delete_mask:标识该行是否被删除
一行数据是“jack NULL m NULL xx_school”,真实存储如下所示:<br>0x09 0x04 00000101 0000000000000000000010000000000000011001 jack m xx_school<br>变长字段长度 null值列表 40bit的数据头 真实数据 <br>按字符集编码后:<br>0x09 0x04 00000101 0000000000000000000010000000000000011001 616161 636320 6262626262<br>
隐藏字段
DB_ROW_ID:行的唯一标识,没设主键的话,会自动用这个当成主键
DB_TRX_ID:当前事务id
DB_ROLL_PTR:回滚指针
最终结构:<br>0x09 0x04 00000101 0000000000000000000010000000000000011001 00000000094C(DB_ROW_ID)00000000032D(DB_TRX_ID) EA000010078E(DB_ROL_PTR) 616161 636320 6262626262<br>
行字段有text、blog这种时,在一行里放不下,产生行溢出问题。大字段的内容,会存放在其他数据页中,这边只存储指针
每次读表数据时,就去找到对应的组,区,数据页,然后把这一页(一个16kb的数据)读到内存buffer pool;<br>更新时,改过的页,会加入到flush list,后台线程再去flush list,把更新后的这一页,写回去<br>