Block Nested-Loop Join
explain select * from t1 inner join t2 on t1.name = t2.name
优势
explain select * from t1 inner join t2 on t1.id = t2.id
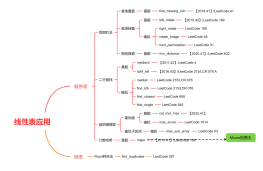
①mysql优化器会选择小表作为驱动表,当前模拟t1表10000条数据,t2表100条数据。②t1/t2表中字段id为主键,name为普通字段
①从表t2中读取一行数据(如果有查询条件的话,从过滤结果中选取一行数据)②从第1步中读取到的数据取出关联字段id去t1的聚簇索引中查询③取出表t1满足条件的行,和t2中获取的结果进行合并,存放到结果集中。④重复上面3步。
被驱动表的关联字段没索引为什么要选择使用 BNL 算法而不使用 Nested-Loop Join 呢?
Nested-Loop Join
①把驱动表t2的数据加载到join_buffer中②把被驱动表t1中每一行数据读取出来,和join_buffer中的数据进行对比③返回满足join条件的数据
关联字段为普通字段时,通过把驱动表的数据加载到join_buffer内存中,然后和被驱动表每一行进行比较。通过内存来比较,提升效率。
关联字段为主键字段时,通过聚簇索引来查找数据,效率更高。t2表查询100次,t1表也查询了100次,总查询次数为200次。
关联字段为普通字段时,如果采用NLJ算法,会全表扫描磁盘文件,没有了join_buffer内存比较,通过磁盘比较的话,效率大大降低,相当于进行了100X10000次的磁盘扫描,性能太低。
普通字段name
主键id