MGR插件
Write
一:主从复制原理1:Master将写操作记录到二进制日志(Bin Log)中。2:Master通过Dump Thread异步将Bin Log复制到Slave,Slave通过I/O Thread接收Master的Dump Thread发送的Bin Log,并写到自身中继日志(Relay Log)中。3:Slave通过SQL Thread读取Relay Log中的记录,并重做到Slave库。注:复制方式# 异步复制(默认):master使用dump线程异步将bin log复制到slave,不需要slave应答,直接提交事务。# 半同步复制(MySQL5.5开始通过插件方式支持):master使用dump线程异步将bin log复制到slave,slave使用IO线程将数据写入到relay log中,然后至少1个slave返回ACK应答给master,master再提交事务。# 全同步复制:master等所有slave返回ACK应答后,再提交事务。二:Slave的Thread设计I/O Thread和SQL Thread的设计能保证Master库和Slave库数据时延更小。三:存在的问题问题1:Master-Slave存在同步时延,可能会导致写入的数据,无法及时读取到。解决方式:关键性业务在Master库写读,非关键性业务在Slave库读。
Monitor
Slave
Replication
Master
Slave1
1:MySQL的一主多从架构
MySQL Router
Load Balancer
4:MySQL的MySQL InnoDB Cluster集群架构
Relay Log
2:MySQL的MHA(Master High Availability)主从复制架构
Slave2
Paxos
选举(单主模式)
Binary Log
Master2
Master1
一:架构说明:1:Master库负责写,2个Slave库负责读。2:通过使用Sharing-Jdbc来连接Master-Slave库,Sharding-Jdbc能自动对Slave库做负载均衡来读Slave库。二:架构的优缺点1:缺点:单点主库故障。Master库宕机后,Slave库无法自动接管为Master,导致所有的写操作失败,当前MySQL集群只支持读。三:适用场景:1:读多写少的场景。
集群1
2.2:Master-Slave级联集群架构图
1.1:主从复制原理
单体DB架构
业务代码
VIP 写入Write
Read
SQL优化以后的单体DB
Master3
4:水平拆分:单表数据量 > 500W行 或 2G (阿里巴巴开发手册提出的数据)
3:垂直拆分:大表拆分成小表到不同的数据库,且不同的表对应的数据库存于不同的数据库实例。建议:一个MySQL实例存储200个表
2.1:单Master-Slave架构图
一:MySQL高可用架构设计图
Keepalived
Send
MHA模式:日本人开源。一:架构说明:1:Master库负责写,2个Slave库负责读。2:MHA Manager Node管理Master-Slave集群。二:架构的优缺点优点:1:Master-Slave集群自动恢复,Master宕机后,Manager Node能监测到,然后提升其中1个Slave为Master,保证Master-Slave集群对外的读写能力。2:相比较1.2、1.3而言,一般会选用MHA架构,该方法比较成熟。缺点:1:需要安装第三方软件。三:适用场景:1:读多写少的场景。解决DB的访问压力。四:功能1:故障恢复时效性短,MHA能做到在0~30秒之内自动完成数据库的故障切换操作。2:数据一致性好,在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
一:架构说明(Master-Slave级联集群):1:1个MHA Manager Node管理多组Master-Slave集群,多组Master-Slave集群可以做数据分片。2:集群1、集群2、集群3可以对数据库表做数据分片,按水平拆分或者垂直拆分的方式。e.g:db表user表存了300条数据,则集群1可存储1~100的数据,集群2可存储101~200的数据,集群3存储201~300的数据,对涉及范围内的数据读写可以存储在不同的集群里面。二:适用场景:1:大数据量的读多写多的场景。解决DB的存储压力。
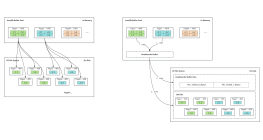
3:MySQL的MGR(MySQL Group Replication)集群架构
水平拆分
Sharding-Jdbc
垂直拆分
DB存储压力大
1.3:架构图
MHA单组Master-Slave架构
MHA多组Master-Slave架构
Data Changes
Dump Thread
一:架构说明1:MySQL InnoDB Cluster = MySQL Shell + MySQL Router + MySQL Group Replication二:MySQL InnoDB Cluster的限制1:存储引擎必须为Innodb。2:每个表必须提供主键。3:只支持ipv4,网络需求较高。4:一个组最多只能有9台服务器。5:不支持 Replication event checksums。6:不支持 Savepoints。7:多主模式不支持SERIALIZABLE事务隔离级别。8:多主模式不能完全支持级联外键约束。9:多主模式不支持在不同节点上对同一个数据库对象并发执行DDL(在不同节点上对同一行并发进行RW事务,后发起的事务会失败)。三:MySQL InnoDB Cluster和MySQL Group Replication的区别MySQL InnoDB Cluster:增加了MySQL Router层,业务代码直连MySQL Router,MySQL Router能帮助业务代码屏蔽底层的细节。MySQL Group Replication:业务代码直连群组集群中的MySQL实例,当故障重新选举后,业务代码需要更改连接信息进行重连。
集群2
1:业务场景:当前业务场景当并发上来后,对DB都是读远 >> 写。
2:业务场景:当数据量上来后,DB的存储压力大。
Query太慢
Manager Node
Replay
集群3
SQL Thread
一:架构说明1:MySQL5.7.17开始支持MGR插件。MGR支持单主模式(官方推荐)和多主模式。单主模式:集群中MySQL见通过Paxos协议进行选举,选出1个Master,其余为Slave,Master负责读写,Slave负责读。当Master宕机,集群能选举新的Master,达到自动恢复的效果。二:适用场景:1:对主从延迟比较敏感。2:希望对写服务提供高可用,又不想安装第三方软件。3:数据强一致的场景。二:MGR对比Master-Slave、MHA的优势1:MGR和Master-Slave:MGR:复制基本无延迟,延迟比异步的小很多;数据的强一致性,可以保证数据事务不丢失。Master-Slave:复制有延迟。2:MGR和MHAMGR:不需要第三方软件MHA:需要第三方管理软件,MHA Manager Node管理节点。
1:业务场景:当DB中数据比较多导致SQL查询慢,但不至于分表时,需要先进行SQL查询优化。
读 写
I/O Thread
一:架构说明:1:Master库负责写,2个Slave库负责读。2:通过使用Sharing-Jdbc来连接Master-Slave库,Sharding-Jdbc能自动对Slave库做负载均衡来读Slave库,通过Vip连接Master。二:架构的优缺点1:缺点:相比于1.2的架构而言,Master库做了冷备份,当1个Master宕机后,另1个Master能接管写,可用性比1.2高。三:适用场景:1:读多写少的场景。
1.2:架构图
二:生产环境MySQL架构演进